
руководство для инди-студий — Gamedev на DTF
В статье описаны этапы сбора семантического ядра, составления фундамента всей текстовой ASO оптимизации и продвижения в поиске.
766 просмотров
На данный момент в Google Play более 11,4 млн., а в App Store более 4.4 млн. приложений.
Создавая и публикуя собственное приложение или игру в Google Play или App Store, вы задаетесь вопросом — как и по каким запросам пользователи найдут ваш проект? Как строить свое семантическое ядро для текстового ASO, чтобы приложение было заметно на фоне конкурентов и получало качественный органический трафик?
Чтобы ответить на эти вопросы, разберемся в терминах “ключевое слово” и “семантическое ядро”.
ASO терминология
Ключевые слова (поисковые запросы, ключи, ключевики, keywords) — это слова или фразы, которые включают интент (намерение,потребность) пользователя найти то или иное приложение или игру. Ключевые слова могут состоять из наименований жанров игры, категорий приложений, отдельных их функций или прямого описания.
Юзеры набирают ключи в строке поиска, ожидая найти наиболее подходящее их запросу приложение. Соответственно, разработчикам и ASO специалистам необходимо внедрять такие запросы в метаданные на страницах приложений, чтобы повысить поисковую видимость и конверсию.
Семантическое ядро (СЯ) — это все релевантные ключевые слова и фразы, описывающие ваше приложение. СЯ- это фундамент всей текстовой оптимизации и продвижения в поиске. От того насколько релевантны и ценны найденные вами ключевые слова и фразы зависит ваше ранжирование в поиске, а также появление в категориях и похожих (similar apps) в Google Play.
Важно не забывать, что семантическое ядро для Google Play и App Store отличается, так как это два разных не связанных между собой магазина приложений со своими уникальными алгоритмами.
При составлении СЯ необходимо собрать как можно больше ключевых слов, которые потенциально принесут установки вашему проекту.
Этап 1: Исследование
Как правило разработчики инди-студий и ASO специалисты могут быстро описать своё приложение на 15 — 20 слов без труда. А для расширения списка ключей понадобится помощь команды разработки. Вы можете устроить мозговой штурм или пустить в коллективе Google Форму, где каждый причастный к проекту поделится своими ассоциациями.
Обычно полученный список содержит большинство высокочастотных (ВЧ) и среднечастотных (СЧ) запросов, описывающих основные функции, жанр и задачи, которые решает ваше приложение.
Например, если это игра в жанре idle simulator, первыми запросами в списке скорее всего будут: idle simulator, idle simulation, simulator offline, idle simulation game. А если у вас брендовое приложение, список будет состоять из брендовых ключевых слов с общими запросами.
Добавьте их в свое стартовое семантическое ядро и переходите к следующему этапу.
Этап 2: Автоматические подсказки (Keyword Auto-Suggestions)
Воспользуйтесь инструментами ASO-сервисов и ASA для App Store и изучите, что ищут пользователи и что они находят по поисковым запросам.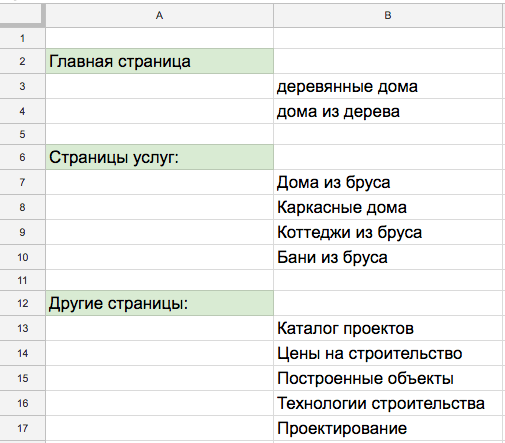 Потому что часто юзеры не вводят запрос целиком, а нажимают на поисковую подсказку, которую предлагает маркет.
Потому что часто юзеры не вводят запрос целиком, а нажимают на поисковую подсказку, которую предлагает маркет.
На этом этапе введите в поисковую строку релевантные запросы из своего стартового списка и вы получите ключи, которые ранее уже вводили юзеры. Они могут быть похожи на ваши, но с дополнительными словами, если они релевантны вашему приложению — добавьте их в свое семантическое ядро.
Для Google Play обращайте внимание на длинные запросы (long-tail keywords), они низкочастотные (НЧ) и конкуренция по ним низкая, более 60% поискового трафика приходится на long-tail запросы. И на старте вашего приложения long-tail ключи принесут вам первый целевой органический трафик.
При сборе семантики для App Store учитывайте показатель популярности запроса Search Ads Popularity (SAP). Apple маркирует им запросы при настройке рекламных кампаний в Apple Search Ads. И для App Store лучше не использовать и не вносить в ядро низкочастотные запросы, SAP которых меньше 5.
Автоматические сервисы помогут вам увеличить количество ключей в разы. Популярные ASO-сервисы с функцией автоматических подсказок по бесплатной пробной версии: AppFollow, ASO Desk, Checkaso, ASO Mobile.
Популярные ASO-сервисы с функцией автоматических подсказок по бесплатной пробной версии: AppFollow, ASO Desk, Checkaso, ASO Mobile.
Подсказки и запросы мы ищем в мобильном поиске (магазины приложений), а не в web поиске, так как это две абсолютно разных платформы размещения.
Этап 3: Анализ конкурентов
На этом этапе вам необходимо отобрать конкурентов, которые имеют сильные позиции на интересующих вас рынках. Воспользуйтесь вышеуказанными ASO-сервисами, добавьте конкурентов и оцените запросы, которые они используют, проверьте их на релевантность и добавьте в свое семантическое ядро.
Сбор семантического ядра при помощи конкурентов на примере Jumper Cat: Bouncing Kitten
Если же вы не знаете, кто ваш конкурент, введите запрос в строку и посмотрите, кто ранжируется по нему. Если приложения похожи на ваше, используйте этот запрос.
Также обращайте внимание на то, сколько приложений использует выбранный вами ключ. В случае, если ваше приложение пока не популярно, выйти в топ по ВЧ и СЧ запросам будет сложно и поэтому нужно ранжироваться по запросам с низкой конкуренцией. Чем меньше конкурентов на запрос, тем лучше.
В случае, если ваше приложение пока не популярно, выйти в топ по ВЧ и СЧ запросам будет сложно и поэтому нужно ранжироваться по запросам с низкой конкуренцией. Чем меньше конкурентов на запрос, тем лучше.
Этап 4: Чистка семантического ядра
На этом этапе вам необходимо очистить семантическое ядро от нерелевантных и низкочастотных запросов. Количество символов в метаданных ограничено, а значит включить в них все найденные запросы не получится. Нужно оставить именно те ключи, которые могут дать установки.
Следует оставлять только релевантные запросы, чтобы приложение находили только те юзеры, которым оно нужно. Иначе будут расти удаления, retention будет падать.
Для Google Play удаляйте запросы с ошибкой, по ним вы можете проиндексироваться, но использовать в метаданных их не следует.
Для App Store вы можете оставить запросы с ошибкой, их можно добавить поле ключевых слов и проиндексироваться по ним. Однако такие ключи следует проверять вручную, так как автокоррекция в IOS устройствах автоматически исправляет опечатки и такие ключи могут не дать трафика.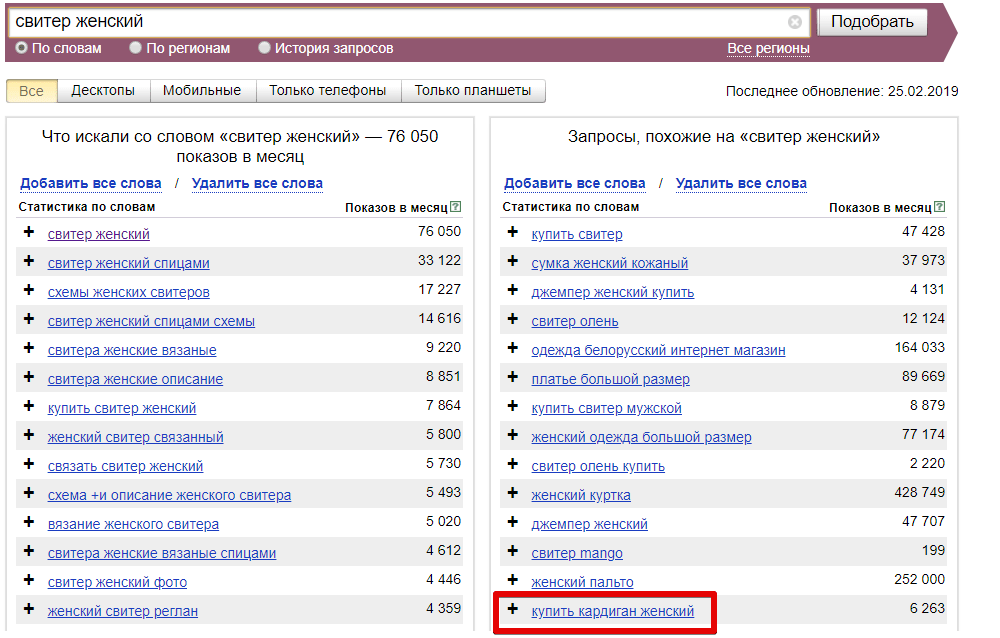
Если в вашем ASO-сервисе в списке с ключевыми фразами есть показатель Popularity и Difficulty, удаляйте слова с низким Popularity и высоким Difficulty. Вырасти в топе по таким ключам новому приложению будет невозможно.
Если вам необходимо собрать запросы для иностранных локализаций, переведите и проработайте СЯ на English. Такой способ даст понимание поведения пользователей и облегчит локализацию поисковых фраз.
Этап 5: Кластеризация семантического ядра
Кластеризация как этап работы с семантикой в ASO оптимизации пришла к нам из SEO, где кластеризация запросов по Топу или семантическим когортам определяет пул запросов на посадочную страницу.
Кластеризация запросов по семантическим группам в ASO позволяет охватить большее количество запросов производных из одного ключа и проиндексировать их.
Выглядит кластеризация следующим образом, вы оцениваете свое семантическое ядро и выделяете отдельные кластеры по термам (подсловам), разбивая поисковые фразы и автоподсказки.
Кластеризация запросов в семантическом ядре на примере Samedi Manor: Idle Simulator
Метод поможет вам быстро отслеживать покрытие метаданных ключевыми фразами и выстроить поэтапно итеративную работу с текстовым ASO:
- сужать семантику и увеличивать ранжирование по выгодным кластерам из ТОП 5 — ТОП 20;
- увеличивать охват в рамках узкой семантической когорты;
- максимизировать установки, двигая ключевые слова из ТОП 50 в ТОП20; из ТОП 20 в ТОП 5 в рамках выбранного кластера.
Выводы
Чтобы собрать семантическое ядро, вам необходимо провести 5 этапов:
- Добавить все поисковые слова, которые ассоциируются с приложением у вас и вашей команды.
- Расширить семантическое ядро за счета автоматических подсказок ASO-сервисов и инструментов ASA.
- Проанализировать конкурентов и найти релевантные вам запросы, по которым они ранжируются.

- Очистить семантическое ядро от низкоконкурентных и нерелевантных запросов.
- Провести кластеризацию запросов для дальнейшей итеративной работы.

Учитывайте правила App Store и Google Play, подготовьте текстовые метаданные на основе вашей семантики.
Бонус! Вы можете скопировать Шаблон семантического ядра и распределения ключевых слов под метаданные для App Store и Google Play. В нем уже есть скрипт “Распред”, фильтрующий ключевые слова по кластерам для быстрой итеративной работы.
Работа с ключевыми словами — фундамент текстовой ASO оптимизации приложений. Собирая поэтапно семантическое ядро, вы найдете релевантные и ценные запросы, по которым пользователи найдут ваше приложение. Так вы сделаете ваше приложение более заметным на фоне конкурентов и получите качественный органический трафик.
Козловская Людмила
ASO Specialist /// Black Caviar Games
Подписывайтесь на официальный аккаунт Black Caviar Games на DTF, чтобы не пропустить новые интересные статьи! 😉
Мы также есть в YouTube, VK, Telegram, Яндекс. Дзен и TikTok.
Дзен и TikTok.
Собираем семантическое ядро самостоятельно с помощью Yandex.Wordstat
Все операторы и нюансы, которые нужно учитывать
Seo
Семантическое ядро — это основа оптимизации любого сайта. Именно сбор семантического ядра должен проводиться в первую очередь. Нередко после составления списка запросов для продвижения приходиться перекраивать структуру сайта, добавляя новые страницы или меняя вложенность страниц, их иерархическую последовательность.
Для сбора семантики можно использовать самые разные сервисы. Есть для этого и специальные программы как бесплатные (тот же «Словоеб»),так и платные. В последнем варианте наибольшей популярностью пользуется КейКоллектор.
Однако не следует сбрасывать со счетов и сервисы от самой поисковой системы, которые дают возможность совершенно бесплатно собрать хорошее семантическое ядро. Далее поговорим о том, как составить семантику при помощи всем известного и совершенно бесплатного сервиса «ЯндексВордстат».
Виды запросов
Прежде всего, давайте определимся с тем, какие бывают запросы по частотности. Здесь выделяют три группы:
Здесь выделяют три группы:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Точно по такому же принципу различают запросы и по конкуренции. Само собой разумеется, что продвигать сайт по высококонкурентным запросам сложно, особенно, если это молодой ресурс и оптимизация только началась. Можно потратить огромное количество средств и времени на такое продвижение и получить минимум трафика и пользователей. А вот продвижение по НЧ и СЧ запросам, как правило, дает очень хорошие результаты.
Сбор ключевых слов
Собирать ключевые запросы — это дело долгое и нудное, но очень важное. От того, насколько качественно будет произведена данная операция, зависит эффективность самого семантического ядра и оптимизации в целом.
Интерфейс Вордстата настолько простой, что запутаться в нем, даже при желании, просто невозможно. В окне вводим тематику, которая нас интересует. Далее можно выбрать географию показов — по всей стране, по отдельным регионам или городам. Яндекс выдаст вам все запросы, которые вводили пользователи за последний месяц, и покажет число показов. Обратите внимание, что вы можете выбрать статистику показов в соответствии с устройствами пользователя – все или только мобильные.
Яндекс выдаст вам все запросы, которые вводили пользователи за последний месяц, и покажет число показов. Обратите внимание, что вы можете выбрать статистику показов в соответствии с устройствами пользователя – все или только мобильные.
Именно число показов и даст нам возможность определить конкурентность запросов. Обратите внимание, что изначально сервис вам покажет количество не точных вхождений, а общее число запросов за месяц, в которых встречалась ваша фраза. Собственно, это хорошо видно на самой странице – « что искали со (слово запроса)».
В Вордстате присутствуют свои инструменты (так называемый инструментарий) — т.е. операторы, помогающие посмотреть различную статистику по каждому запросу. Ниже представлен список операторов, поддерживаемых вордстатом:
Основные операторы, которыми есть смысл пользоваться — это » » (заключение в кавычки) и оператор «!» (восклицательный знак).
Оператор Кавычки позволяют увидеть, сколько раз искали за последний месяц именно вашу фразу без добавления дополнительных слов, но с изменяемыми окончаниями.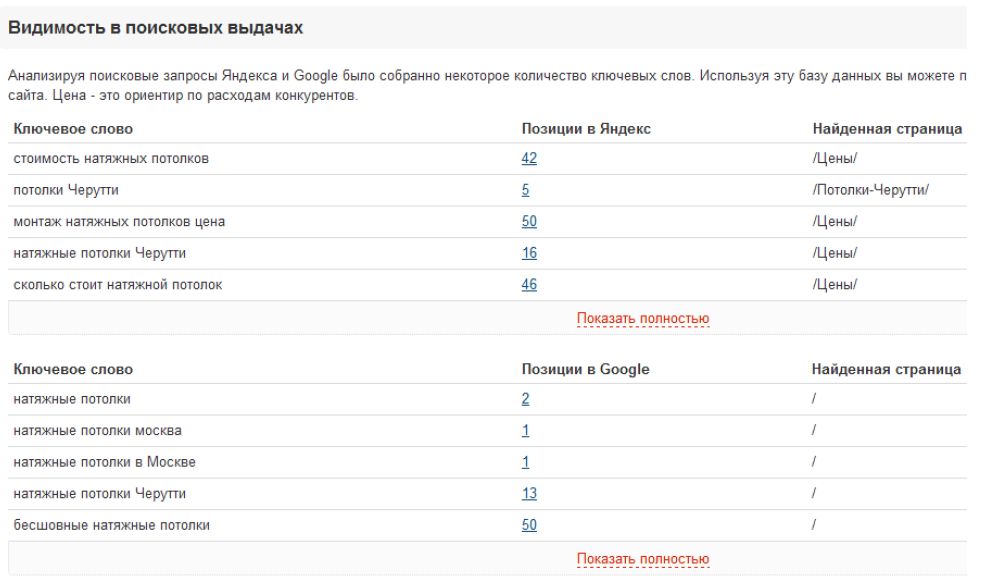
Для того чтобы отобрать точные вхождения, следует заключить запрос в кавычки и перед каждым словом проставить «!» — – «!продвижение !сайтов». Только в этом случае вы получите статистику именно по точным вхождениям.
Для наглядности сравним частотность запроса «продвижение сайтов» без операторов, в кавычках и с восклицательным знаком:
Как мы видим, общая частотность и точная частотность запроса «продвижение сайтов» разнится более чем в 10(!) раз.
Важность отбора целевых запросов
Из всех ключевых слов, которые получится отобрать, а их тысячи, следует оставить только те, которые точно отображают потребность вашего сайта. К примеру, если вы занимаетесь продажей сумок, то ключи типа «ремонт сумок», «пошить сумку своими руками», вам не подходят.
Нельзя забывать и про так называемые «Ассоциации» в Вордстате — правая колонка основного окна. Ассоциации показывают все похожие запросы, которые искали люди за последний месяц. Данный инструмент позволяет значительно расширить область вашего поиска и помогает найти максимальное количество различных формулировок одних и тех же запросов.
Операцию по отсеиванию лишнего нужно проводить до тех пор, пока не останутся только те ключи, которые максимально отражают представленность сайта в вашей нише.
Нужно изначально понимать, что составление нецелевых запросов просто не принесет вам заказов, не поможет продвинуть сайт и будет вести бесполезный трафик. Так, продвижение по запросу «как установить автомагнитолу» не поможет её продать, а только будет ухудшать поведенческие факторы при отсутствии соответствующих статей и форума.
Окончательный список ключей следует сгруппировать и распределить по конкретным страницам. Именно поэтому, нередко приходится добавлять новые страницы или менять структуру сайта.
Высокочастотные запросы следует использовать для продвижения главной страницы. Следует отметить, что если в семантическом ядре есть ключевые запросы, которые вам подходят, но нет контентной страницы, следует ее создать. Продвижение по средне- и низкочастотным запросам дает хороший трафик.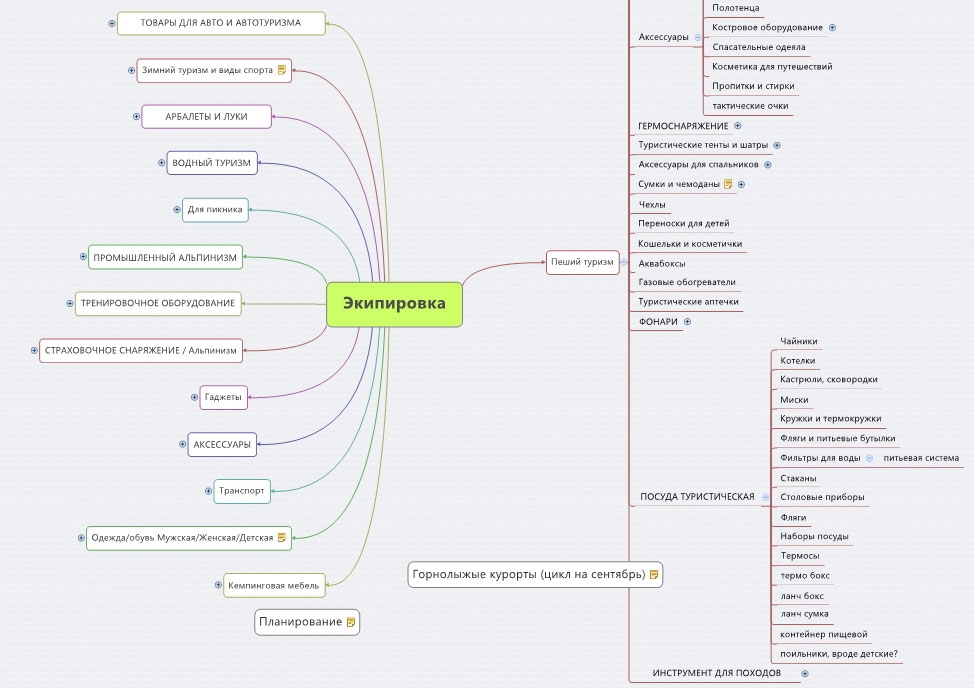 Главное, не лепить все на одну страницу, в противном случае результата не получится никакого. Так, можно ли на вывеске магазина на улице поместить всё: продажу вешалок, туалетной бумаги, сантехники и эксклюзивных ёршиков и какой от этого будет результат? Так же и здесь. Лучше сделать несколько отдельных «вывесок» — в этом случае люди гарантированно увидят каждую из них.
Главное, не лепить все на одну страницу, в противном случае результата не получится никакого. Так, можно ли на вывеске магазина на улице поместить всё: продажу вешалок, туалетной бумаги, сантехники и эксклюзивных ёршиков и какой от этого будет результат? Так же и здесь. Лучше сделать несколько отдельных «вывесок» — в этом случае люди гарантированно увидят каждую из них.
Понять, какие из запросов есть смысл заключать в одну логическую группу можно исходя из анализа своих конкурентов, находящихся в ТОПе. Если они ранжируются высоко — значит поисковику такое распределение нравится и значит на них можно ориентироваться.
Группировка должна быть прежде всего логичной. Не нужно создавать 10 страниц под подобные ключи типа «пластиковые окна недорого», «заказать пластиковые окна», «пластиковые окна дешево» и т.п. — это будет явный переспам и в результате может повлечь негативные последствия.
Ручной процесс составления семантического ядра довольно длительный. Однако, это фундамент дальнейшей оптимизации и эффективности сайта. И не забывайте, что на сайте — важно прежде всего наличие хорошего контента, который будет действительно читаться и использоваться людьми. Откровенные SEO-тексты и переоптимизация никогда не смогут дать долговрочного результата.
Однако, это фундамент дальнейшей оптимизации и эффективности сайта. И не забывайте, что на сайте — важно прежде всего наличие хорошего контента, который будет действительно читаться и использоваться людьми. Откровенные SEO-тексты и переоптимизация никогда не смогут дать долговрочного результата.
Семантические шаблоны – nsm-approach.net
(2008) NSM — Эмоции и двуязычие
Опубликовано 15 января 2022 г. Последнее обновление 15 января 2022 г.
Вежбицкая, Анна. (2008). Концептуальная основа для исследования эмоций и двуязычия. Билингвизм: язык и познание 11 (2), 193–195. doi:10.1017/S1366728908003362
Исследование, проведенное одним или несколькими опытными практикующими специалистами NSM
Теги: (E) злой, (E) разочарование
(2011) Английский — Сверхъестественные существа
Опубликовано 12 мая 2017 г. Последнее обновление 25 июля 2020 г.
Хабиб, Сэнди (2011). призраков , фей , эльфов и нимф : к семантическому шаблону для нечеловеческих понятий.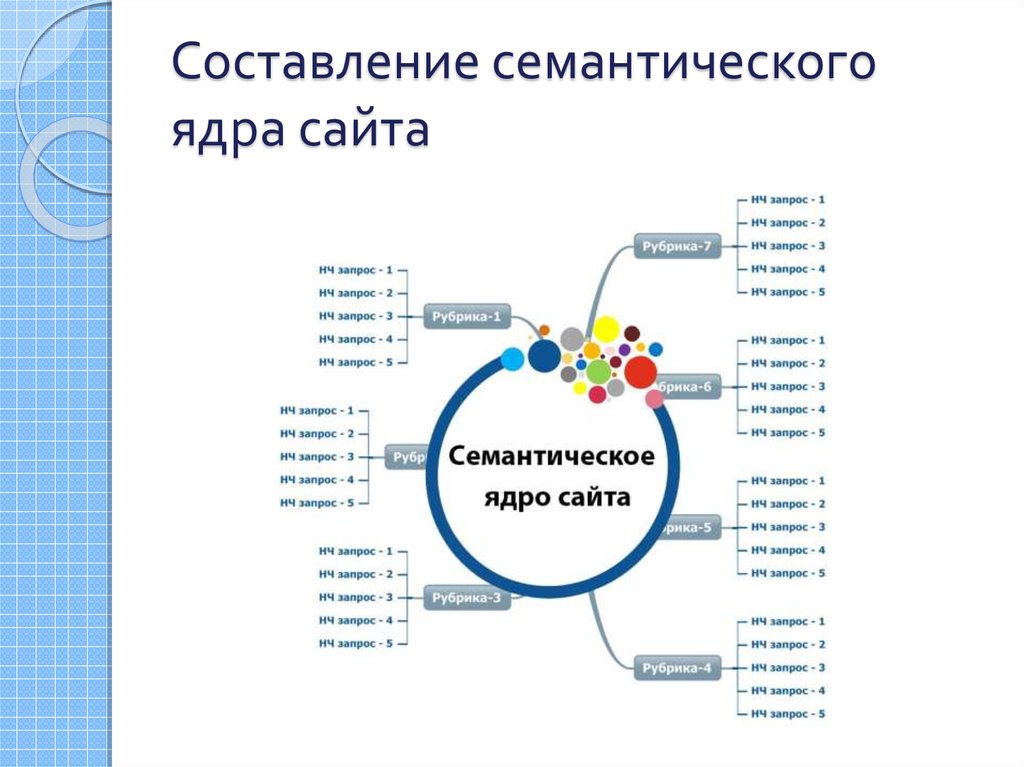 Австралийский журнал лингвистики, 31 (4), 411-443.
Австралийский журнал лингвистики, 31 (4), 411-443.
DOI: https://doi.org/10.1080/07268602.2012.625599
Аннотация:
Целью данного исследования было разработать семантический шаблон для терминов, не относящихся к человеку. Для достижения этой цели были проанализированы четыре понятия, не относящиеся к человеку, и для каждого понятия была построена экспликация. Сравнение экспликаций дало семантический шаблон из девяти частей. Полезность этого семантического шаблона тройная. Во-первых, это упрощает задачу объяснения нечеловеческих понятий, потому что части шаблона могут служить ориентирами, которым нужно следовать при построении объяснений. Во-вторых, это облегчает сравнение между родственными нечеловеческими понятиями из разных языков. В-третьих, он выявляет приемы, воплощенные в структуре нечеловеческих понятий и позволяющие людям без труда пользоваться этими сложными понятиями.
Рейтинг:
Исследование, проведенное в консультации или под наблюдением одного или нескольких опытных специалистов-практиков НСМ
Теги: (E) эльф, (E) фея, (E) призрак, (E) нимфа
(2012) Простые числа NSM, семантические молекулы, семантические шаблоны
Опубликовано 12 мая 2017 г. Последнее обновление 23 мая 2019 г.
Последнее обновление 23 мая 2019 г.
Годдард, Клифф (2012). Семантические простые числа, семантические молекулы, семантические шаблоны: ключевые понятия в подходе NSM к лексической типологии. Лингвистика, 50 (3), 711-743 .
DOI: 10.1515/ling-2012-0022
Abstract:
Подход NSM имеет большой опыт в кросс-лингвистической лексической семантике. Поэтому неудивительно, что она имеет четкую теоретическую позицию по ключевым вопросам лексико-семантической типологии и развитый набор аналитических приемов.
С теоретической точки зрения основной вопрос касается сравнения tertium . Каковы оптимальные концепции и категории для поддержки систематического исследования лексиконов и лексикологических явлений в языках мира? Ответ NSM на этот вопрос заключается в том, что необходимые концепты могут — и должны — основываться на общем лексико-понятийном ядре всех языков, которое исследователи NSM, как утверждают, обнаружили в ходе тридцатипятилетней программы эмпирических перекрестных исследований.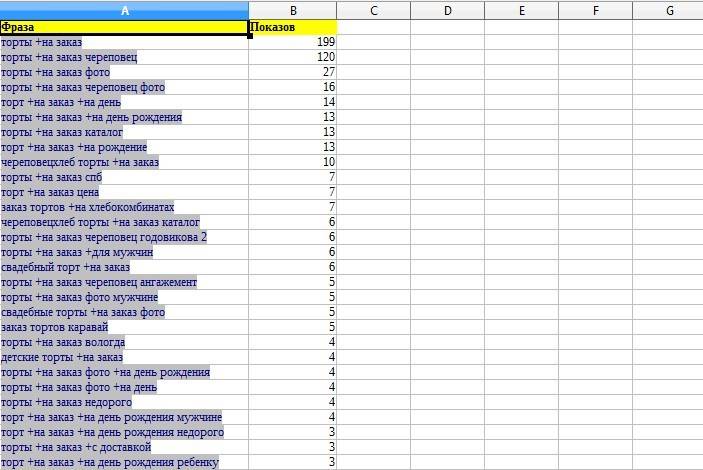 лингвистическая семантика. Это общее лексико-концептуальное ядро представляет собой мини-язык семантических простых чисел и связанной с ними грамматики.
лингвистическая семантика. Это общее лексико-концептуальное ядро представляет собой мини-язык семантических простых чисел и связанной с ними грамматики.
Кроме того, исследователи NSM разработали некоторые оригинальные аналитические конструкции, которые обещают повысить эффективность и систематичность подхода: в частности, понятия семантических молекул и семантических шаблонов. Эта статья призвана объяснить и проиллюстрировать эти понятия, сообщить о некоторых ключевых аналитических выводах (во многих случаях обновленных из ранее опубликованных отчетов) и экстраполировать их значение для дальнейшего развития лексической типологии.
Эта статья содержит подробные объяснения английского глагола drink и его ближайший каламский аналог –b ‘есть/пить’, а также английского глагола cut и его японского аналога 切る kiru .
Рейтинг:
Исследование, проведенное одним или несколькими опытными специалистами NSM
Теги: (Д) дети, (Д) резать, (Д) пить, (Д) руки, (Д) голова, (Д) киру 切る, (Д) ноги, (Д) длинные, (Д) ñb, (Э) ) женщины, (Т) японка, (Т) русская, (Т) смысловые молекулы, (Т) испанская
(2015) Английский – Глаголы физической активности
Опубликовано 12 мая 2017 г. Последнее обновление 17 февраля 2019 г.
Последнее обновление 17 февраля 2019 г.
Годдард, Клифф (2015). Классы глаголов и чередование валентности (подход NSM) с особой ссылкой на английские глаголы физической активности. В Andrej Malchukov & Bernard Comrie (Eds.), Классы валентности в языках мира , vol. 2 (стр. 1671-1701). Берлин: де Грюйтер Мутон. DOI: 10.1515/9783110429343-020
В этом исследовании рассматриваются пять английских глаголов физической активности ( есть , наливать , копать , нести , резать ) и, используя специальный семантический шаблон, предлагается подробное семантическое объяснение основной активности в жизни. прогресс значения этих глаголов. Затем с помощью другого шаблона показано, как эти базовые значения могут быть преобразованы в совершенное употребление. В исследовании исследуются и эксплицируются 11 чередований (специализированных конструкций) с участием пяти глаголов, показывая в каждом случае, как именно чередования связаны с базовой семантикой глагола. В своей демонстрации автор опирается на концепцию производная база , которая является новой концепцией в исследованиях NSM.
В своей демонстрации автор опирается на концепцию производная база , которая является новой концепцией в исследованиях NSM.
Общая картина такова, что специализированные конструкции носят квазидеривационный характер: первичное или семантически основное значение глагола встраивается в более сложную конфигурацию, содержащую дополнительный смысловой материал. Часто большая часть этого дополнительного материала моделируется семантикой глаголов, принадлежащих к разным семантическим типам (лексико-синтаксическое смешение), но может быть отчасти идиосинкразической или непредсказуемой. Каждая специализированная конструкция представляет собой своего рода полисемию «слово в конструкции».
Исследование, проведенное одним или несколькими опытными специалистами-практиками НСМ
Теги: (Е) нести, (Е) резать, (Е) копать, (Е) есть, (Е) насыпать
(2016) Английский – Глаголы «делать и происходить»
Опубликовано 12 мая 2017 г. Последнее обновление 5 сентября 2018 г.
Годдард, Клифф и Вежбицкая, Анна (2016). Объяснение английского слова «делать и происходит». Функции языка, 23 (2), 214-256. DOI: 10.1075/fol.23.2.03god
В этом исследовании предлагаются семантические объяснения NSM для поперечного сечения английской словесной лексики «делать и происходить». Двадцать пять глаголов взяты примерно из дюжины классов глаголов, включая глаголы для нетипичных движений ( ползать , плавать , летать ), других непереходных действий ( играть , петь ), манипулировать ( держать ), действия, влияющие на целостность материала ( резать , шлифовать , копать ), создание/производство ( сделать , построить , вырезать ), действия, которые воздействуют на людей или вещи ( ударить , пнуть , убить ) или вызвать изменение местоположения ( подобрать , POT , Throw , Push ), телесные реакции на чувства ( Смех , CRY ), Смещение ( Осень , SING ) и погода. .
.
Хотя объясненные глаголы являются специфически английскими глаголами, они были выбраны с учетом их отношения к лексической типологии и кросс-лингвистической семантике (многие взяты из списка значений глаголов проекта Leipzig Valency Patterns), и есть надежда, что аналитическая стратегия и методология, представленные в этом исследовании, могут быть полезной моделью для исследования других языков. Исследование демонстрирует применение концепции семантических шаблонов NSM, которые обеспечивают четкую «скелетную» структуру для экспликаций значительной внутренней сложности и помогают учитывать общие семантические и грамматические свойства глаголов данного подкласса.
Исследование, проведенное одним или несколькими опытными специалистами-практиками НСМ
Теги: (E) строить, (E) вырезать, (E) ползти, (E) плакать, (E) резать, (E) копать, (E) падать, (E) летать, (E) точить, (E) ударить, (Д) держать, (Д) пинать, (Д) убивать, (Д) смеяться, (Д) заставлять, (Д) поднимать, (Д) играть, (Д) толкать, (Д) класть, (Д) ) дождь, (Э) петь, (Э) тонуть, (Э) снег, (Э) плавать, (Э) бросать, (Т) английский язык, (Т) семантические молекулы
(2017) Датский — Этнопсихология и личность
Опубликовано 12 мая 2017 г. Последнее обновление 18 июня 2019 г.
Последнее обновление 18 июня 2019 г.
Левизен, Карстен (2017). Конструкции личности в языке и мышлении: новые данные из Дании. В Zhengdao Ye (Ed.), Семантика существительных (стр. 120-146). Оксфорд: Издательство Оксфордского университета.
DOI: https://doi.org/10.1093/oso/9780198736721.003.0005
Abstract:
В этой главе анализируются конструкции личности, особый тип существительных, части которых концептуализируют невидимую личность. Значение конструктов личности берет свое начало в культурных дискурсах, и они могут значительно различаться в разных языковых сообществах. Они отражают господствующие в обществе этнопсихологические идеи и развиваются вместе с историческими изменениями в дискурсе. Опираясь на результаты предыдущих исследований, разрабатывается семантическая модель, учитывающая как различия, так и сходства в личностных построениях. С помощью подробного тематического исследования датских конструктов личности эта глава тестирует шаблон датской концепции 9, устойчивой к переводу. 0144 sind вместе с двумя другими датскими существительными: sjæl «душа» и ånd «дух». Тематическое исследование представляет собой модель того, как конструкции личности могут быть эмпирически исследованы с помощью инструментов лингвистической семантики.
0144 sind вместе с двумя другими датскими существительными: sjæl «душа» и ånd «дух». Тематическое исследование представляет собой модель того, как конструкции личности могут быть эмпирически исследованы с помощью инструментов лингвистической семантики.
Рейтинг:
Исследование, проведенное одним или несколькими опытными специалистами NSM
Метки: (E) ånd, (E) душа душа, (E) maum 몸, (E) разум, (E) sind, (E) sjæl, (S) бессмертие, (S) духовность
(2018) английский, иврит, арабский — народные религиозные представления
Опубликовано 27 мая 2019 г. Последнее обновление 25 июля 2020 г.
Хабиб, Сэнди (2018). Heaven и hell : кросс-лингвистический семантический шаблон для сверхъестественных мест. РАСК, 48 , 1–34.
Открытый доступ
Резюме:
Целью данного исследования было разработать кросс-лингвистический семантический шаблон для терминов сверхъестественного места. Для достижения этой цели были проанализированы шесть концепций сверхъестественных мест, и для каждой концепции была построена экспликация. Сравнение экспликаций дало семантический шаблон из семи частей. Полезность этого семантического шаблона тройная. Во-первых, это упрощает задачу объяснения концепций сверхъестественных мест, потому что части шаблона могут служить ориентирами, которым нужно следовать при построении объяснений. Во-вторых, это облегчает сравнение связанных концепций сверхъестественных мест из разных языков. В-третьих, он раскрывает приемы, воплощенные в структуре понятий сверхъестественного места и позволяющие людям без труда использовать эти сложные понятия.
Для достижения этой цели были проанализированы шесть концепций сверхъестественных мест, и для каждой концепции была построена экспликация. Сравнение экспликаций дало семантический шаблон из семи частей. Полезность этого семантического шаблона тройная. Во-первых, это упрощает задачу объяснения концепций сверхъестественных мест, потому что части шаблона могут служить ориентирами, которым нужно следовать при построении объяснений. Во-вторых, это облегчает сравнение связанных концепций сверхъестественных мест из разных языков. В-третьих, он раскрывает приемы, воплощенные в структуре понятий сверхъестественного места и позволяющие людям без труда использовать эти сложные понятия.
Рейтинг:
Исследование, проведенное одним или несколькими опытными специалистами NSM
Метки: (E) альжанна, (E) ган эден, (E) гейхином, (E) рай, (E) ад, (E) джаханнам
(2019) Эмоции
Опубликовано 15 января 2022 г. Последнее обновление 15 января 2022 г.
Е, Чжэндао. (2019). Семантика эмоций: от теории к эмпирическому анализу. Притцкер, Соня.Э., Фенигсен, Янина., и Уилс, Джеймс.М. (Ред.). Справочник Routledge по языку и эмоциям (1-е изд.). Рутледж. https://doi.org/10.4324/9780367855093
Abstract
В этой главе представлен систематический отчет о подходе Естественно-семантического метаязыка (НСМ) к эмоциям и «аффективной науке», особенно о том, как он решает три методологических вопроса: ( а) как эмоциональное значение может быть объяснено в терминах, которые психологически реальны для людей; (б) как культурно-специфические значения могут быть аутентично переданы другому лингвокультурному сообществу, чтобы важные нюансы в концептуализации эмоций могли быть оценены культурными аутсайдерами; и (в) как общие черты и различия в человеческом опыте могут быть выявлены и сформулированы? Глава опирается на широкий выбор работ NSM на многих языках, включая бислама, английский, мбула (PNG) и китайский.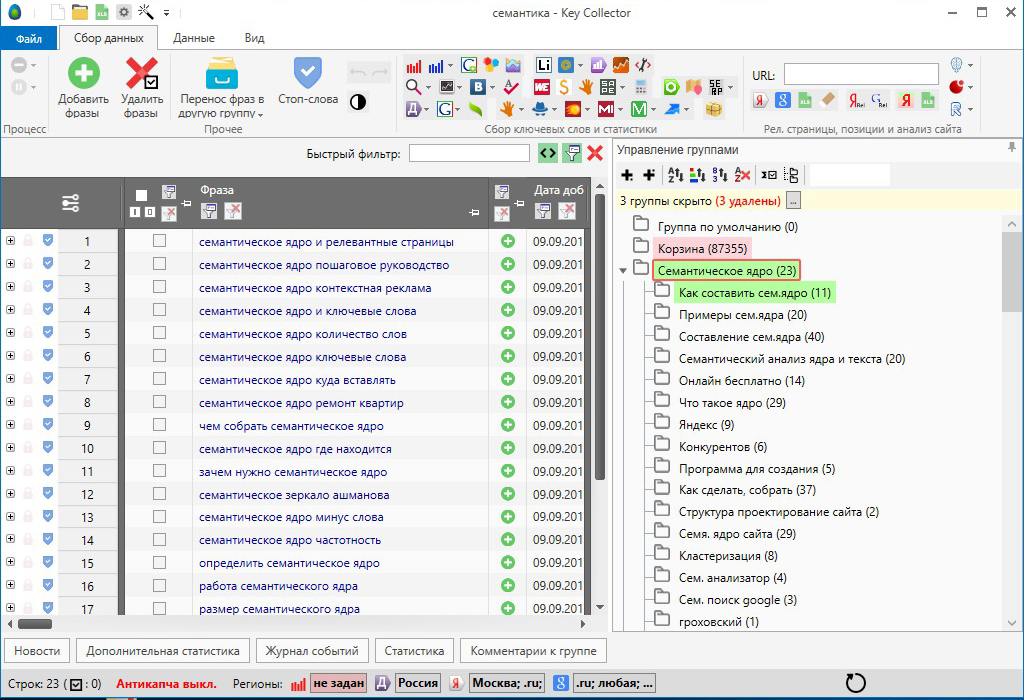
Исследование, проведенное одним или несколькими опытными специалистами NSM
Теги: (E) фаго, (E) в ужасе, (E) леле имбай па, (E) любовь, (E) мата-ийойу па, (E) Mi kros, (E) Mi les, (E) окаменевший, ( E) qian cháng guà dù 牵肠挂肚, (E) téng/téng’ài, (E) испуганный, (E) va ŋu/ŋú, (E) xìngfú 幸福, (E) xīnlǐ hén kŭ, (T) английский
(2019) Английский – Оценочные прилагательные
Опубликовано 12 мая 2017 г. Последнее обновление 11 января 2022 г.
Годдард, Клифф, Майте Табоада и Радослава Трнавац (в печати). Семантика оценочных прилагательных: перспективы естественного семантического метаязыка и оценки. Функции языка, 26 (3), 308-342.
DOI: https://doi.org/10.1075/fol.00029.god
Abstract:
результаты с изображением, разработанным в рамках оценки (Martin & White 2005). Анализ проводится на основе корпуса, примеры взяты в основном из обзоров фильмов и книг и поддерживаются словосочетаниями и статистической информацией из WordBanks Online.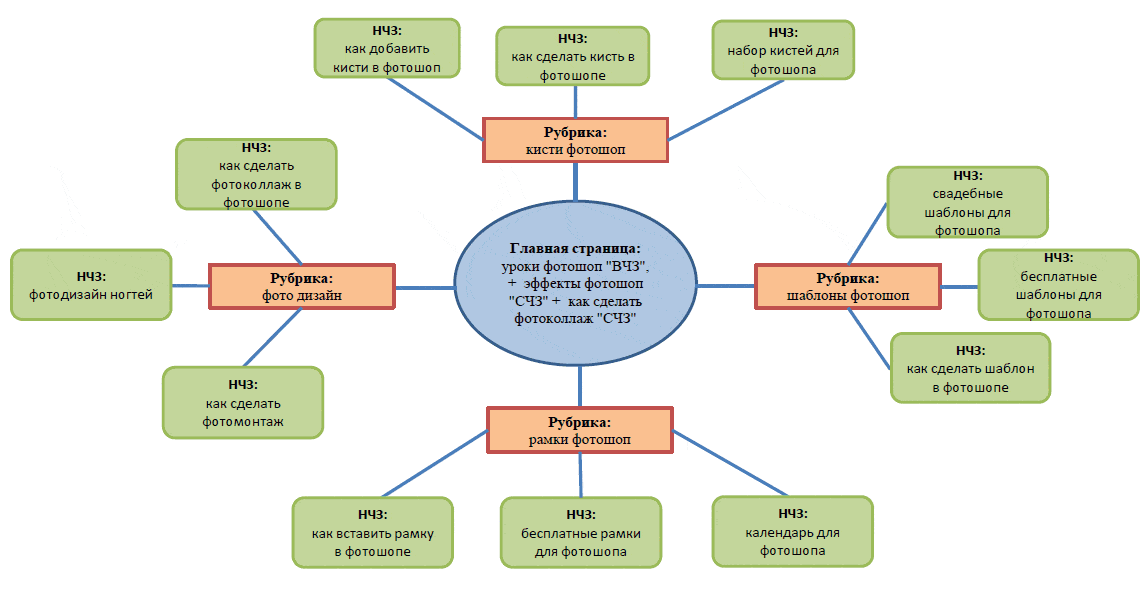 Мы предлагаем экспликации НСМ для 15 оценочных прилагательных, утверждая, что они делятся на пять групп, каждая из которых соответствует отдельному семантическому шаблону. Группы можно набросать следующим образом: «мысль от первого лица плюс аффект», т.е. замечательный ; «Экспериментальный», т.е. развлекательный ; «Опыт с телесной реакцией», например. захват ; «Длительное воздействие», т.е. памятный ; «Когнитивная оценка», т.е. сложный, отличный . Эти группировки и семантические шаблоны сравниваются с классификациями в системе оценки Оценки. Кроме того, нас особенно интересует анализ настроений, автоматическая идентификация оценки и субъективности в тексте. Мы обсуждаем актуальность двух фреймворков для анализа настроений и других приложений языковых технологий.
Мы предлагаем экспликации НСМ для 15 оценочных прилагательных, утверждая, что они делятся на пять групп, каждая из которых соответствует отдельному семантическому шаблону. Группы можно набросать следующим образом: «мысль от первого лица плюс аффект», т.е. замечательный ; «Экспериментальный», т.е. развлекательный ; «Опыт с телесной реакцией», например. захват ; «Длительное воздействие», т.е. памятный ; «Когнитивная оценка», т.е. сложный, отличный . Эти группировки и семантические шаблоны сравниваются с классификациями в системе оценки Оценки. Кроме того, нас особенно интересует анализ настроений, автоматическая идентификация оценки и субъективности в тексте. Мы обсуждаем актуальность двух фреймворков для анализа настроений и других приложений языковых технологий.
Рейтинг:
Исследование, проведенное одним или несколькими опытными специалистами NSM
Теги: (E) блестящий, (E) сложный, (E) восхитительный, (E) занимательный, (E) отличный, (E) захватывающий, (E) отличный, (E) захватывающий, (E) впечатляющий, (E) запоминающийся, (E) выдающийся, (E) мощный, (E) потрясающий, (E) замечательный
(2020) Английский — Оценочные прилагательные
Опубликовано 15 января 2022 г. Последнее обновление 15 января 2022 г.
Последнее обновление 15 января 2022 г.
Трнавац, Радослава и Табоада, Майте. (2020). Положительная оценка в комментариях к онлайн-новостям. В Керри Муллан, Берт Питерс и Лорен Садоу (ред.), Исследования по этнопрагматике, культурной семантике и межкультурной коммуникации: Том. 1. Этнопрагматика и семантический анализ (стр. 185–206). Сингапур: Спрингер.
DOI: https://doi.org/10.1007/978-981-32-9983-2_10
Abstract
В этой главе исследуется лингвистическое выражение положительной оценки в английском языке и описывается предварительная типология используемых языковых средств. за положительную оценку. Используя корпусный анализ, мы классифицируем некоторые ресурсы, играющие роль в выражении положительной оценки, на явления в лексикограмматике и явления, относящиеся к дискурсивной семантике, и сравниваем эти ресурсы с теми, которые задействованы для отрицательной оценки (см. отрицательная оценка у Табоады и др. в Corpus Pragmat, 1:57–76, 2017). Эта общая классификация оценочных устройств пересекается с планами выражения в системной функциональной лингвистике. Наши данные получены из коллекции авторских статей и комментариев, связанных с ними (Kolhatkar et al., в Корпусе мнений и комментариев SFU: корпус для анализа комментариев к онлайн-новостям, находится на рассмотрении). Мы используем набор из 1000 комментариев, ранее аннотированных для оценки (Мартин и Уайт на языке оценки. Пэлгрейв, Нью-Йорк, 2005 г.), включая ярлыки отношения (аффект, суждение, признательность) и полярность (положительный, отрицательный, нейтральный). Центральным компонентом главы является анализ ресурсов, используемых комментаторами для выражения положительной оценки. Мы исследуем, используют ли они риторические фигуры, продолжая нашу работу с Клиффом Годдардом по использованию риторических фигур в выражении отрицательной оценки (Taboada et al. in Corpus Pragmat, 1:57–76, 2017). Затем мы анализируем семантику оценочных прилагательных, используя подход естественного семантического метаязыка, и следуем нашей предыдущей работе над шаблонами, которые охватывают различные типы прилагательных и делятся на пять групп (Goddard et al.
Эта общая классификация оценочных устройств пересекается с планами выражения в системной функциональной лингвистике. Наши данные получены из коллекции авторских статей и комментариев, связанных с ними (Kolhatkar et al., в Корпусе мнений и комментариев SFU: корпус для анализа комментариев к онлайн-новостям, находится на рассмотрении). Мы используем набор из 1000 комментариев, ранее аннотированных для оценки (Мартин и Уайт на языке оценки. Пэлгрейв, Нью-Йорк, 2005 г.), включая ярлыки отношения (аффект, суждение, признательность) и полярность (положительный, отрицательный, нейтральный). Центральным компонентом главы является анализ ресурсов, используемых комментаторами для выражения положительной оценки. Мы исследуем, используют ли они риторические фигуры, продолжая нашу работу с Клиффом Годдардом по использованию риторических фигур в выражении отрицательной оценки (Taboada et al. in Corpus Pragmat, 1:57–76, 2017). Затем мы анализируем семантику оценочных прилагательных, используя подход естественного семантического метаязыка, и следуем нашей предыдущей работе над шаблонами, которые охватывают различные типы прилагательных и делятся на пять групп (Goddard et al. , в Funct Lang 26, 2019 г.).). Хотя наш корпусный анализ ограничен и включает в себя только определенный тип данных (комментарии к онлайн-новостям), явления, которые мы обсуждаем, присутствуют в разных жанрах текстов. В то время как наша предыдущая работа была сосредоточена на том, как выразить отрицательную оценку, в этой главе мы попытаемся воздать должное Клиффу Годдарду и его положительному влиянию, изучая, как позитивность реализуется в языке.
, в Funct Lang 26, 2019 г.).). Хотя наш корпусный анализ ограничен и включает в себя только определенный тип данных (комментарии к онлайн-новостям), явления, которые мы обсуждаем, присутствуют в разных жанрах текстов. В то время как наша предыдущая работа была сосредоточена на том, как выразить отрицательную оценку, в этой главе мы попытаемся воздать должное Клиффу Годдарду и его положительному влиянию, изучая, как позитивность реализуется в языке.
Исследование, проведенное одним или несколькими опытными специалистами НСМ
Метки: (E) удивительно, (E) удобно, (E) критично, (E) весело, (E) с чувством юмора, (E) вдохновляюще, (E) благородно, (E) приятно, (E) освежающе, (E) с облегчением, (E) благодарен
(2020) Английский, английский язык австралийских аборигенов, Бислама — Позор
Опубликовано 22 ноября 2020 г. Последнее обновление 22 ноября 2020 г.
Питерс, Берт (2020). Язык имеет значение: преодоление барьера стыда. Люблинские исследования современного языка и литературы , 44(1), 27-37.
DOI: https://doi.org/10.17951/lsmll.2020.44.1.27-37 (Открытый доступ)
Резюме:
Эта статья выступает против реификации стыда и использования англоцентристского жаргона. чтобы объяснить, что это влечет за собой. Он показывает, как можно использовать естественный семантический метаязык для определения стыда и выделения его из родственных понятий в английском языке австралийских аборигенов и в бисламе, английском креольском языке, на котором говорят в Вануату.
Рейтинг:
Исследование, проведенное одним или несколькими опытными специалистами NSM
Теги: (E) стыдно, (E) мужчина сем, (E) стыд, (T) стыд
Как создать семантическую модель с помощью шаблонов базы данных Synapse Analytics | конец
Барри Смарт Консультант
TLDR; в этой второй из четырех частей серии блогов мы исследуем различные методы, доступные для создания семантической модели с использованием шаблонов базы данных в Azure Synapse Analytics.
В этом блоге мы будем использовать реальный сценарий, чтобы проиллюстрировать, как можно использовать шаблоны базы данных для разработки семантической модели в качестве основного компонента в современном конвейере данных и аналитики.
Сценарий связан с предоставлением аналитики компании по строительству жилья, которая позволит ей выбрать оптимальные места для строительства новых домов, чтобы она могла прибыльно развивать бизнес.
Сценарий запускается в точке жизненного цикла после завершения целевого, ориентированного на личность процесса Insight Discovery. Другими словами, бизнес-ориентированный анализ был завершен, чтобы определить действенную информацию и данные, которые необходимо предоставить для ее поддержки.
Этот блог посвящен следующему этапу процесса: он касается разработки семантической модели , которая позволит предоставить практическую информацию. Представление семантической модели высокого уровня было набросано следующим образом, в котором используется шаблон схемы «звезда» в качестве модели данных, оптимальной для последующих отчетов в Power BI:
.
Мы находимся в той точке процесса, когда нам нужно превратить концептуальный проект высокого уровня выше в конкретную схему для семантической модели (таблицы, столбцы и отношения). Мы обратимся к новым шаблонам базы данных в аналитике Azure Synapse, чтобы завершить эту задачу.
Преимущества такого подхода к разработке семантической модели:
Интегрированные инструменты — Шаблоны баз данных интегрированы в Azure Synapse Analytics, что устраняет риск расхождения дизайна и реализации
Совместная работа — Шаблоны баз данных обеспечивают единый источник достоверной информации, вокруг которого широкий круг людей в организации может сотрудничать для определения семантических моделей
Применение схемы — Шаблоны базы данных инкапсулируют целевую схему для вашей семантической модели, что позволяет использовать ее во время разработки и применять во время выполнения
Интеграция в DevOps (или DataOps) — если вы синхронизируете свою среду Synapse с системой управления исходным кодом Azure DevOps, шаблоны базы данных хранятся (и имеют версии) в виде файлов JSON вместе со всеми другими артефактами Synapse, что упрощает управление текущими изменениями
Мы изучим пять различных различных методов, доступных для этого:
- Метод 1 — создание пользовательского шаблона базы данных с помощью пользовательского интерфейса
- Метод 2 — создание шаблона базы данных из отраслевых шаблонов
- Способ 3. Создание пользовательского шаблона базы данных из файлов в озере данных
- Метод 4. Создание пользовательского шаблона базы данных с помощью Pyspark
- Метод 5 — создание шаблонов базы данных с помощью Synapse REST API
 Создание пользовательского шаблона базы данных из файлов в озере данных
Создание пользовательского шаблона базы данных из файлов в озере данныхЗатем округляем до:
- Извлеченные уроки
- Выводы
Метод 1 — создание пользовательского шаблона базы данных с помощью пользовательского интерфейса
Шаг 1 — создание новой базы данных озера
Для начала необходимо создать новую базу данных Lake следующим образом:
- Войдите в Azure Synapse Studio
- Перейдите в меню данных
- Выберите значок + и выберите Lake Database
- Теперь вы можете настроить новую базу данных следующим образом:
Обратите внимание, что в настоящее время доступны только два варианта формата данных: с разделителями (CSV) и паркет. Было бы хорошо, если бы в качестве опции была добавлена дельта!
Шаг 2 — добавьте определение таблицы
После создания базы данных вы теперь можете использовать новые функции шаблонов баз данных для добавления пользовательских определений таблиц.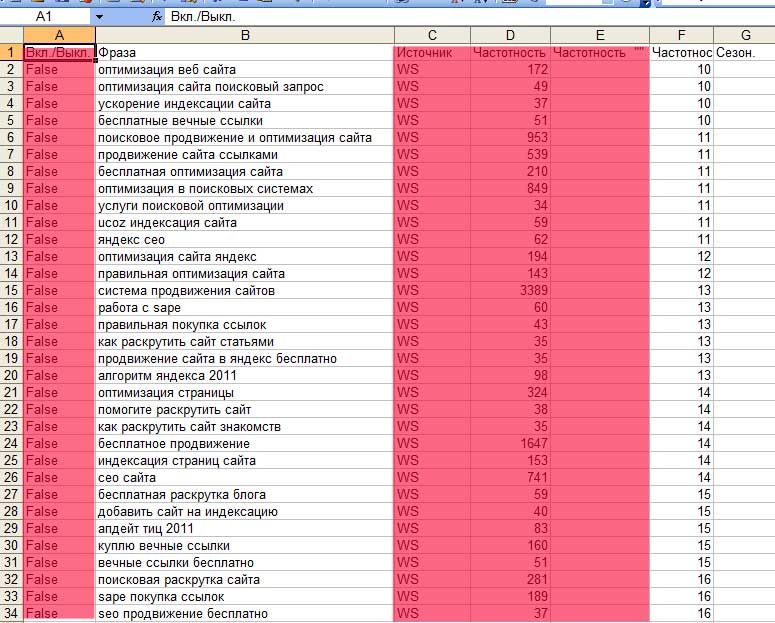 Для этого:
Для этого:
- Выберите меню + Таблица
- Выберите параметр Custom
- Задайте имя и предоставьте описание таблицы следующим образом:
Шаг 3 — добавьте определения столбцов в таблицу
Теперь, когда таблица создана, вы можете выбрать вкладку Столбцы и начать добавлять столбцы.
Для каждого столбца вы определяете следующее:
- Имя — вы можете использовать только прописные и строчные буквы и знаки подчеркивания. Было бы предпочтительнее использовать пробелы в именах столбцов для отражения бизнес-терминологии, но это, скорее всего, ограничение используемой базовой технологии.
- Ключи — указывает, является ли поле первичным ключом (это блокирует параметр, допускающий значение NULL, как False)
- Описание — укажите полезный контекст для столбца, включая несколько примеров
- Nullability — указывает, может ли столбец содержать
значений NULLили нет - Тип данных — тип данных для столбца, есть обширный список доступных опций
- Формат/длина (актуально только для типов строки и даты) — используется для определения длины столбца строки или формата столбца даты
Использование этого подхода приводит к следующему дизайну таблицы HousePrices:
Возникает досадная ошибка при использовании пользовательского интерфейса для создания новых столбцов.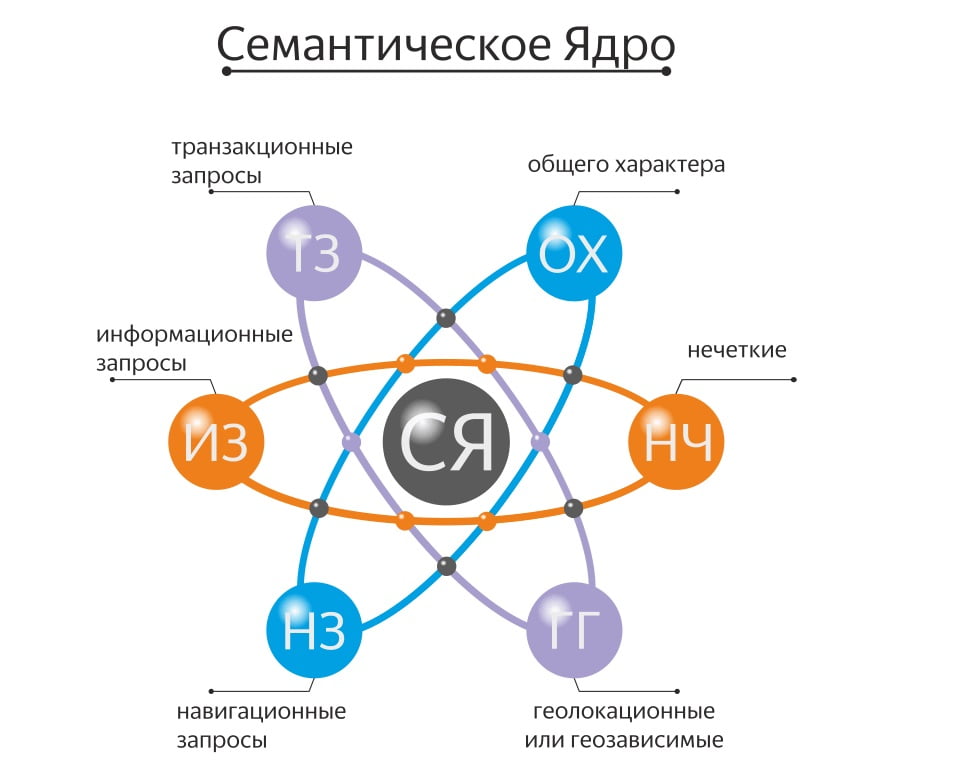 Кажется, что он срабатывает, когда вы печатаете быстро, и это приводит к тому, что фокус сбрасывается с поля имени столбца, так что дальнейшие нажатия клавиш не фиксируются. Надеюсь, Microsoft скоро решит эту проблему!
Кажется, что он срабатывает, когда вы печатаете быстро, и это приводит к тому, что фокус сбрасывается с поля имени столбца, так что дальнейшие нажатия клавиш не фиксируются. Надеюсь, Microsoft скоро решит эту проблему!
Шаг 4 — создание отношений
Повторите шаги 2 и 3 выше, чтобы создать дополнительные таблицы по мере необходимости.
Если в вашей базе данных имеется более одной таблицы, вы можете начать добавлять отношения следующим образом:
Терминология основана на словах «от» и «до». Лучший способ представить это так: сторона «от» представляет собой таблицу с первичным ключом (таблица измерений в этом примере), а сторона «кому» — это таблица с внешним ключом (таблица фактов в этом примере). . Похоже, что они ограничены только отношениями «1 ко многим», вы не можете указать другие типы отношений, такие как «1 к 1» или «многие ко многим».
После того, как вы добавите все таблицы, столбцы и связи, вы сможете увидеть окончательную модель в Synapse:
Шаг 5 — проверьте артефакты в системе управления версиями
Еще одной важной особенностью работы в Synapse является то, что всеми артефактами, будь то записные книжки, SQL-скрипты или конвейеры, можно управлять как кодом с помощью Git.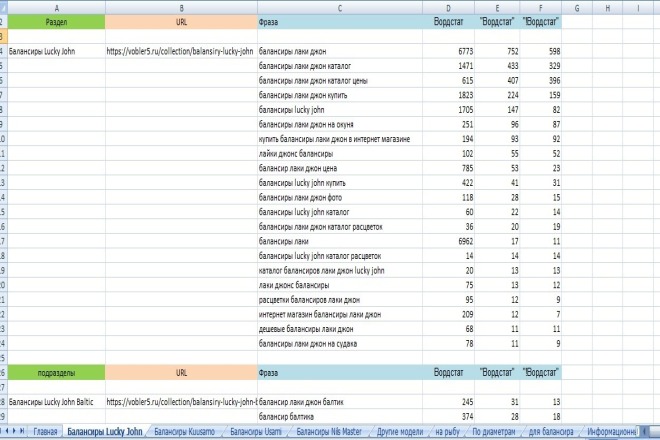
Шаблоны баз данных ничем не отличаются. При синхронизации с репозиторием Git мы ясно видим, что конфигурация базы данных Lake хранится в формате JSON в стандартном расположении 9.0518 ./database/<имя базы данных озера> , где две подпапки отношения и таблицы используются для захвата определения шаблона базы данных:
Файлы JSON имеют проприетарный формат, но их легко открывать, читать и редактировать по мере необходимости.
Это дает возможность использовать преимущества функций Git, таких как ветки и запросы на вытягивание, для управления жизненным циклом шаблонов базы данных наряду со всеми другими вышестоящими и нижестоящими артефактами, которые имеют зависимость. Уже одно это является значительным шагом вперед, поскольку позволяет управлять дизайном целевой семантической модели вместе с конвейерами Synapse, сценариями SQL, записными книжками Spark, API данных и отчетами Power BI, с которыми она связана. Это позволяет распространять проект как первоклассный гражданин в конвейерах DevOps посредством разработки, тестирования, приемки и запуска в производство (жизненный цикл DTAP).
Метод 2 — создание шаблона базы данных из отраслевых шаблонов
В пользовательском интерфейсе шаблонов базы данных выберите меню + Таблица и из него выберите Из шаблона :
Эти отраслевые модели были подготовлены на основе опыта, накопленного во многих проектах в ряде общих отраслевых вертикалей. Они носят всеобъемлющий и абстрактный характер. Например, Страхование имущества и от несчастных случаев Модель кажется наиболее подходящей для конкретного сценария, с которым мы работаем, поскольку она включает таблицы, предназначенные для хранения данных о свойствах. Эта отраслевая модель содержит более 3000 таблиц. Глядя на таблицу Property , мы видим, что она была разработана для обеспечения высокой степени гибкости, чтобы ее можно было использовать для моделирования многих различных типов свойств:
В этом конкретном примере эти шаблоны кажутся тяжелыми. Мы не хотим втягиваться в выяснение того, как мы можем адаптировать его для решения этой конкретной проблемы. Мы концентрируемся на конкретной действенной информации и хотим предоставить семантическую модель, которая будет ее поддерживать. Таким образом, в этом сценарии мы не используем подход, основанный на шаблонах.
Мы концентрируемся на конкретной действенной информации и хотим предоставить семантическую модель, которая будет ее поддерживать. Таким образом, в этом сценарии мы не используем подход, основанный на шаблонах.
Как объяснялось в первом блоге этой серии, наши консультанты предпочитают думать об этих отраслевых шаблонах как о чем-то, во что организации могут «вырасти», когда они накопит критическую массу действенных идей по своим данным и лучше поймут стратегические проблемы, с которыми они сталкиваются в таких темах, как основные данные и управление.
Дополнительную информацию об этих шаблонах см. в документации Microsoft. Практическое руководство. Создайте базу данных озера из шаблонов базы данных.
Метод 3. Создание пользовательского шаблона базы данных из файлов в озере данных
Этот подход реконструирует шаблон базы данных из файлов, которые уже существуют в озере данных. Это не решение, соответствующее рассматриваемому нами сценарию. Здесь мы разрабатываем «справа налево», определяя семантическую модель, которая необходима для поддержки практического понимания, основанного на бизнес-целях.
В пользовательском интерфейсе шаблонов базы данных выберите меню + Таблица и из него выберите Из озера данных .
Это позволяет перейти через связанную службу к файлам данных, которые уже существуют в озере. Первый шаг — найти файл (или папку), который вы хотите, чтобы Synapse сканировал, чтобы обнаружить схему:
.После сканирования файла вы можете изменить параметры файла и визуализировать данные:
Если вы довольны результатами, вы можете выбрать Создать , и таблица будет добавлена в шаблон базы данных:
Примечание. По умолчанию эта таблица поддерживается файлом или папкой озера данных, которые вы использовали для обнаружения схемы. Вы можете оставить эту конфигурацию, и в этом случае она останется внешней таблицей .
Однако вы также можете изменить местоположение следующим образом:
Если вы выберете Наследовать от базы данных по умолчанию , это создаст пустую схему базы данных обратно в базе данных озера, в расположении и с использованием параметров хранения, которые вы выбрали при создании базы данных озера.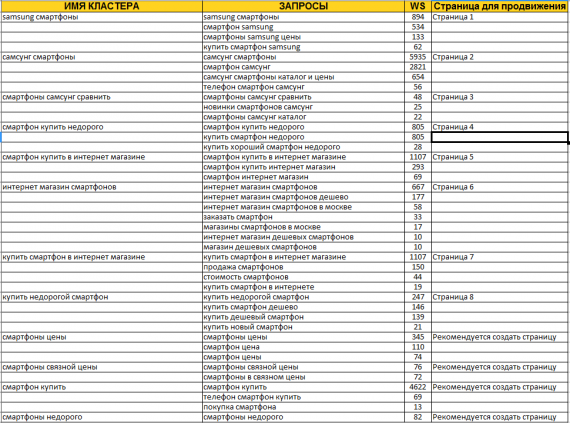
Это изящный трюк для создания нового пустого шаблона базы данных из файлов-образцов , которые вы, возможно, создали в качестве прототипов. Это создает полезный ярлык для получения ключевой информации о новых таблицах шаблона базы данных в Synapse Analytics.
Способ 4. Создание пользовательского шаблона базы данных с помощью Pyspark
Вы можете создать шаблон базы данных из блокнота Synapse, используя метод saveAsTable для кадра данных следующим образом:
# Создать простой фрейм данных с 3 столбцами и 5 строками данных
property_types = spark.createDataFrame(
[
(«Ф», «Плоский», 1),
(«Т», «Террасный», 2),
(«Д», «Отдельностоящий», 4),
(«О», «Коммерческий», 5),
(«S», «Сдвоенный», 3),
],
["PropertyTypeCode", "PropertyTypeName", "PropertyTypeOrder"]
)
# Записываем кадр данных в озеро в виде таблицы
property_types.write.saveAsTable("HousePriceData.PropertyTypeFromPyspark", mode="overwrite")
# Теперь читаем результаты обратно из таблицы
spark. read.table("HousePriceData.PropertyTypeFromPyspark").show()
 read.table("HousePriceData.PropertyTypeFromPyspark").show()
read.table("HousePriceData.PropertyTypeFromPyspark").show()
Это приводит к следующему результату:
+----------------+----------------+----------------------------- ---+ |PropertyTypeCode|PropertyTypeName|PropertyTypeOrder| +----------------+----------------+------------------------------ --+ | С| Полуотдельный| 3| | О| Коммерческий| 5| | Д| Частный| 4| | Т| Терраса| 2| | Ф| Квартира| 1| +----------------+----------------+------------------------------ --+
Вы также можете наблюдать результат команд Pyspark выше, проверив озеро данных — данные, которые мы записали в таблицу, создаются в озере в ожидаемом месте:
Однако, как показано стрелкой выше, новая таблица не отображается в пользовательском интерфейсе Synapse.
Было бы неплохо решить эту проблему, потому что было бы очень полезно иметь возможность создавать таблицы в базах данных озера, созданных с помощью новых функций шаблонов баз данных в Synapse.
Метод 5 — создание шаблонов базы данных с помощью Synapse REST API
Последний метод, который мы исследовали для создания шаблонов баз данных, — это REST API Azure Analytics. В настоящее время мы широко используем этот API для наложения процессов DevSecOps на Azure Analytics. REST API имеет мощный набор конечных точек для управления всеми артефактами Azure Synapse, такими как записные книжки, сценарии SQL и конвейеры. К сожалению, на момент написания этого блога конечная точка для шаблонов баз данных не была доступна. Итак, мы не смогли исследовать это дальше.
В настоящее время мы широко используем этот API для наложения процессов DevSecOps на Azure Analytics. REST API имеет мощный набор конечных точек для управления всеми артефактами Azure Synapse, такими как записные книжки, сценарии SQL и конвейеры. К сожалению, на момент написания этого блога конечная точка для шаблонов баз данных не была доступна. Итак, мы не смогли исследовать это дальше.
Извлеченные уроки
Изучая эти различные методы создания семантической модели с использованием шаблонов базы данных Synapse Analytics, мы извлекли несколько важных уроков, которые мы опишем более подробно ниже, но вкратце таковы:
- Имена таблиц и столбцов не допускают пробелов
- Система управления версиями использует специальную схему JSON
- Таблицы Pyspark не отображаются в Synapse
- Дельта-таблицы еще не поддерживаются
- Разочаровывающие сбои в пользовательском интерфейсе шаблонов базы данных
- Нет конечной точки шаблонов базы данных в REST API
Имена таблиц и столбцов не допускают пробелов
Одним из ограничений шаблонов баз данных является то, что имена таблиц и столбцов НЕ МОГУТ содержать пробелы. Вероятно, это связано с ограничениями базового формата паркета, используемого для хранения данных.
Вероятно, это связано с ограничениями базового формата паркета, используемого для хранения данных.
Это означает, что вам может потребоваться добавить дополнительный уровень абстракции ниже по течению в таких инструментах, как Power BI, чтобы получить настоящую «семантическую модель», которую ищут конечные пользователи. Например, переименование столбца «PropertyTypeCode» в «Код типа свойства», чтобы его было легче использовать в отчетах, созданных на основе данных.
Мы рекомендуем вам принять четкое соглашение для имен таблиц и столбцов. В этом блоге мы использовали Pascal Case в качестве стандарта, но может быть более уместно использовать символы подчеркивания для разделения слов, так как их легче разобрать на пробелы.
Система управления версиями использует специальную схему JSON
Шаблоны базы данных возвращаются в систему управления версиями в формате JSON. Это использует собственный синтаксис, а не более широко распространенный язык определения схемы.
JSON определения шаблона базы данных также содержит другие метаданные, а это означает, что вам нужно просмотреть много вспомогательной информации в исходном файле, чтобы добраться до основного определения схемы базы данных.
Это также препятствует возможности подключения других сторонних инструментов и пакетов поверх шаблона базы данных.
Таблицы Pyspark не отображаются в Synapse
Мы обнаружили, что можно создать новую таблицу в базе данных озера, которая была создана с помощью новой функции шаблонов базы данных с использованием .write.saveAsTable() Метод Pyspark. Однако эта таблица не отображается в интерфейсе шаблонов базы данных Synapse.
Примечание: если мы используем тот же метод для создания таблицы в базе данных озера по умолчанию, она ДЕЙСТВИТЕЛЬНО появится в Synapse. Это кажется странным несоответствием в поведении.
Если это технически возможно, было бы неплохо решить эту проблему. Было бы полезно иметь возможность программно создавать новые таблицы с помощью Pyspark и отображать их в новом пользовательском интерфейсе шаблонов баз данных в Synapse.
Было бы полезно иметь возможность программно создавать новые таблицы с помощью Pyspark и отображать их в новом пользовательском интерфейсе шаблонов баз данных в Synapse.
Дельта-таблицы еще не поддерживаются
В настоящее время таблицы, созданные с помощью шаблонов баз данных, можно создавать только в формате с разделителями (CSV) или в формате паркета. Мы надеемся, что формат Delta будет поддерживаться в ближайшем будущем.
Разочаровывающие сбои в пользовательском интерфейсе
При создании новых строк в пользовательских таблицах с помощью пользовательского интерфейса шаблонов базы данных поле, используемое для указания имени столбца, имеет «глюк», означающий, что оно теряет фокус при вводе имени столбца. Похоже, это связано с логикой на стороне клиента, которая проверяет имя столбца при вводе.
Это неприятный сбой, когда вы пытаетесь настроить новую таблицу с большим количеством столбцов, потому что вам постоянно приходится останавливаться и щелкать мышью, чтобы вернуть фокус в поле.
Надеюсь, Microsoft быстро решит эту проблему.
Нет конечной точки шаблонов базы данных в REST API
В отличие от других артефактов, таких как записные книжки, сценарии SQL и конвейеры, в Synapse REST API нет конечной точки для управления шаблонами базы данных.
Это значительное упущение. Этот API является мощной функцией Synapse, поскольку он дает пользователям возможность создавать свои собственные рабочие процессы. Это означает, что шаблоны баз данных не могут использовать тот же жизненный цикл DevSecOps, что и другие артефакты в Synapse.
Выводы
Мы продемонстрировали, что шаблоны баз данных обладают всеми функциями, необходимыми для использования Synapse Analytics для разработки новых семантических моделей. При этом мы выделили некоторые преимущества такого подхода:
- Встроенный инструмент
- Сотрудничество
- Применение схемы
- Интеграция в DevOps (или DataOps)
Это большой шаг вперед для организаций, стремящихся оптимизировать свои процессы создания и управления современными конвейерами данных с помощью Synapse Analytics.