
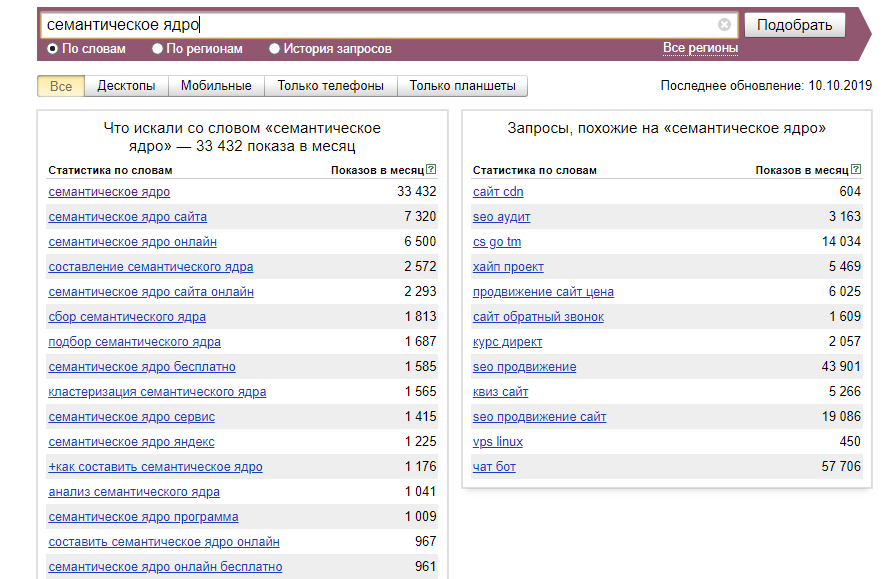
Семантическое ядро: парсинг, кластеризация с примерами
- 03.04.2020
- Екатерина Светцова
Перед тем как начать сбор семантического ядра нужно определиться со смысловыми группами для него. Когда сайт есть, группы формируются по разделам имеющегося сайта — каталог, карточки с товарами, услуги, подуслуги и т.д., также прорабатываются новые разделы (товары, бренды, категории). Если сайт находится на этапе проектирования, структура создается на основе того, что вы продаете и что вам наиболее выгодно продавать. В целом, это почти одно и тоже, разве что при наличии сайта есть куда подсмотреть.
Забегу немного вперед, после парсинга, вычитывая ключевые слова, у вас появятся новые идеи и инсайты о дополнительных разделах сайта.
Продолжим, например, у нас имеется магазин одежды. Какие группы мы можем выделить?
- Мужская одежда
- Женская одежда
- Детская одежда
Далее, составляем список словоформ и синонимов, например для фразы «мужская одежда» — это «одежда для мужчин», «одежда для мужиков»; для фразы «детская одежда» — «одежда для детей», «одежда для новорожденных», «одежда для подростков», «одежда для девочек, «одежда для мальчиков» и так далее; для фразы «женская одежда» — «одежда для женщин», «одежда для девушек», «одежда для дам» и т. д. Прошу обратить внимание что в наш шаблон при создании плана, структуры ядра не нужно вводить дополнительные слова к основной фразе, например: стильная женская одежда, верхняя мужская одежда, или крутая одежда для подростков. Слова: «верхняя» «крутая» и «стильная» подсоединятся к нашему шаблону (в данном случае шаблонами являются: «женская одежда», «мужская одежда» и «одежда для подростков») при парсинге. О парсинге данных позже.
д. Прошу обратить внимание что в наш шаблон при создании плана, структуры ядра не нужно вводить дополнительные слова к основной фразе, например: стильная женская одежда, верхняя мужская одежда, или крутая одежда для подростков. Слова: «верхняя» «крутая» и «стильная» подсоединятся к нашему шаблону (в данном случае шаблонами являются: «женская одежда», «мужская одежда» и «одежда для подростков») при парсинге. О парсинге данных позже.
То есть что мы делаем? Мы прорабатываем части речи, подбираем синонимы.
В данной тематике можно было начать создавать структуру с другого бока. А именно, задать главными разделами виды товара:
- Верхняя одежда
- Брюки
- Костюмы
- Обувь
- Нижнее белье
- И так далее
А уточнение пола (муж, жен) как бы входит в данные группы, и тогда в парсинг мы не добавляем слова: «мужчина», «женщина», «девочка», «мальчик», потому что в этом случае это будут дополнительные слова.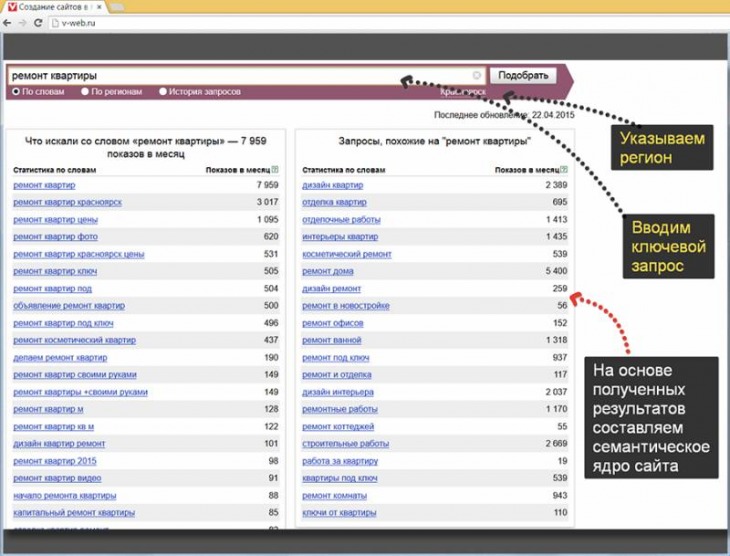 Для полноты семантического ядра, все же стоит прорабатывать семантику с разных сторон.
Для полноты семантического ядра, все же стоит прорабатывать семантику с разных сторон.
Но мы вернемся к первой группе.
У слова «одежда» синонимов как таковых нет. В данном случае это слово выступает как обобщенное понятие одежды в целом, т.е. в него входят: куртка, юбка, плащ, но эти слова, эти данные уходят дальше по структуре, углубляясь ниже, и это будет уже второй этап. Важно уяснить, что вначале нам нужно найти самые обобщенные группы.
Приведу другой пример, компания занимается юридическими услугами широкого спектра, это и банкротство юридических лиц, и банкротство физических лиц, брачные споры, сопровождение сделок, юристы по недвижимости, по наследству и так далее. Какая основная группа будет у этого сайта? Отвечаю: юридические услуги, юрист, адвокат, юридическая помощь, юридическое сопровождение и так далее. Стараемся найти всевозможные подсказки, всевозможные синонимы, меняем части речи – из прилагательного в существительное (юридические – юрист). После проработки общей группы, переходим к составлению более конкретных групп, в данной случае это конкретные услуги: юрист по банкротству, юрист по семейным делам и так далее. Здесь также ищем синонимы для каждой услуги. «Юрист по банкротству физ лиц» – это и:
Здесь также ищем синонимы для каждой услуги. «Юрист по банкротству физ лиц» – это и:
- Банкротство физических лиц
- Банкротство гражданина
- Юрист по банкротству физиков
- Адвокат банкротство физлиц
Ваш план с шаблонами фраз (иначе называется — маски) может быть очень большим, чем качественнее вы его прорабатываете, тем больше план и тем больше ключевых слов на выходе. Конечным семантическим ядром можно пользоваться при создании рекламной компании в Яндекс.Директе, в Google Ads, при SEO-продвижении. Это и был ответ на вопрос: зачем нужно семантическое ядро 🙂
Итак, мы создали план для парсинга. Теперь нам нужно спарсить всевозможные хвостики для всех шаблонов. Например, у нас шаблон: куртка женская, что спарсится:
- Куртка женская купить
- Куртка женская синяя
- Куртка женская зимняя
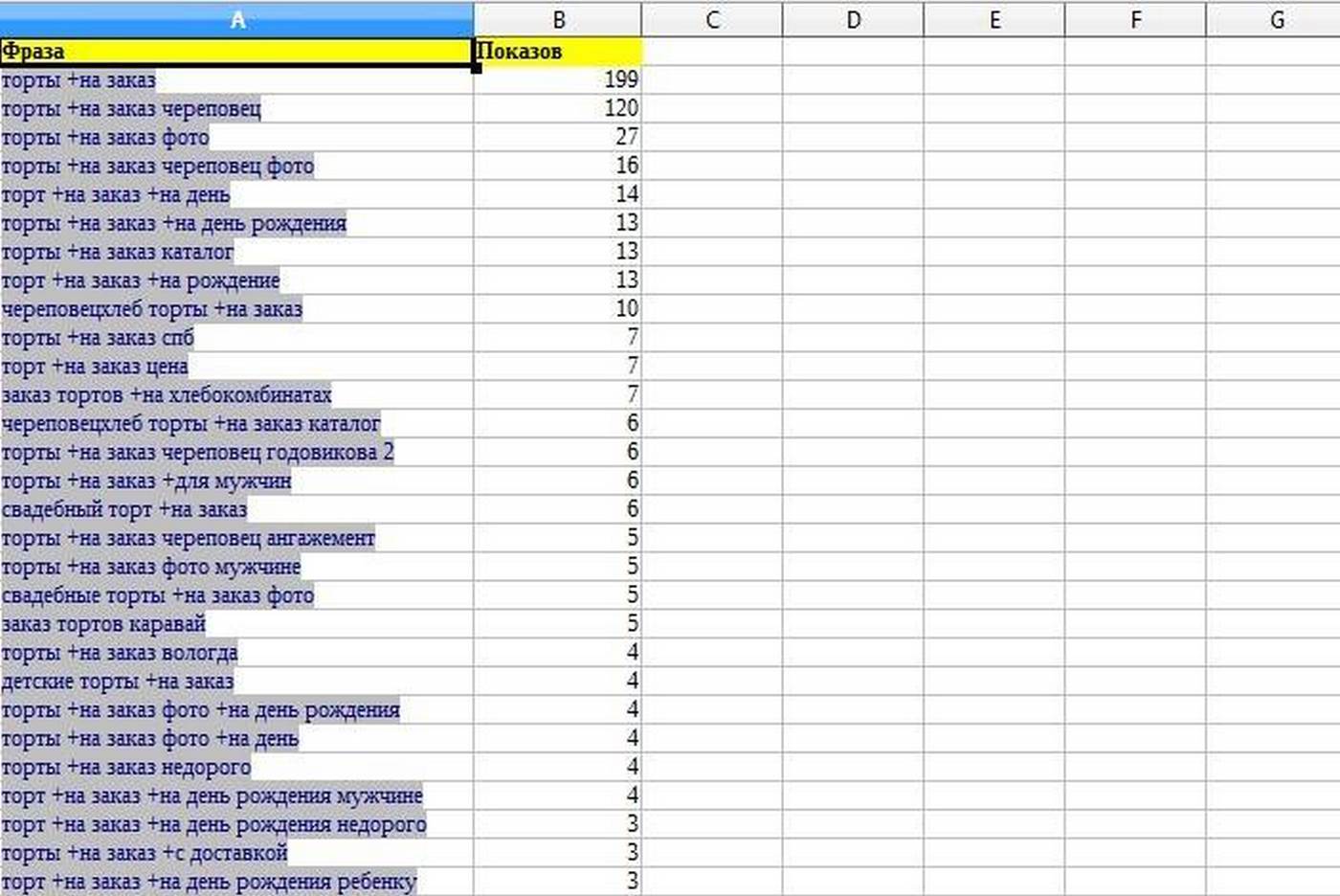
И так далее, для этого шаблона могут быть сотни, иногда тысячи фраз. Если у нас нет осенних курток и не предвидится, то перед парсином нужно определиться с минус словами для того, что не парсить лишнего, ведь потом нужно работать с вычиткой, класстеризаций.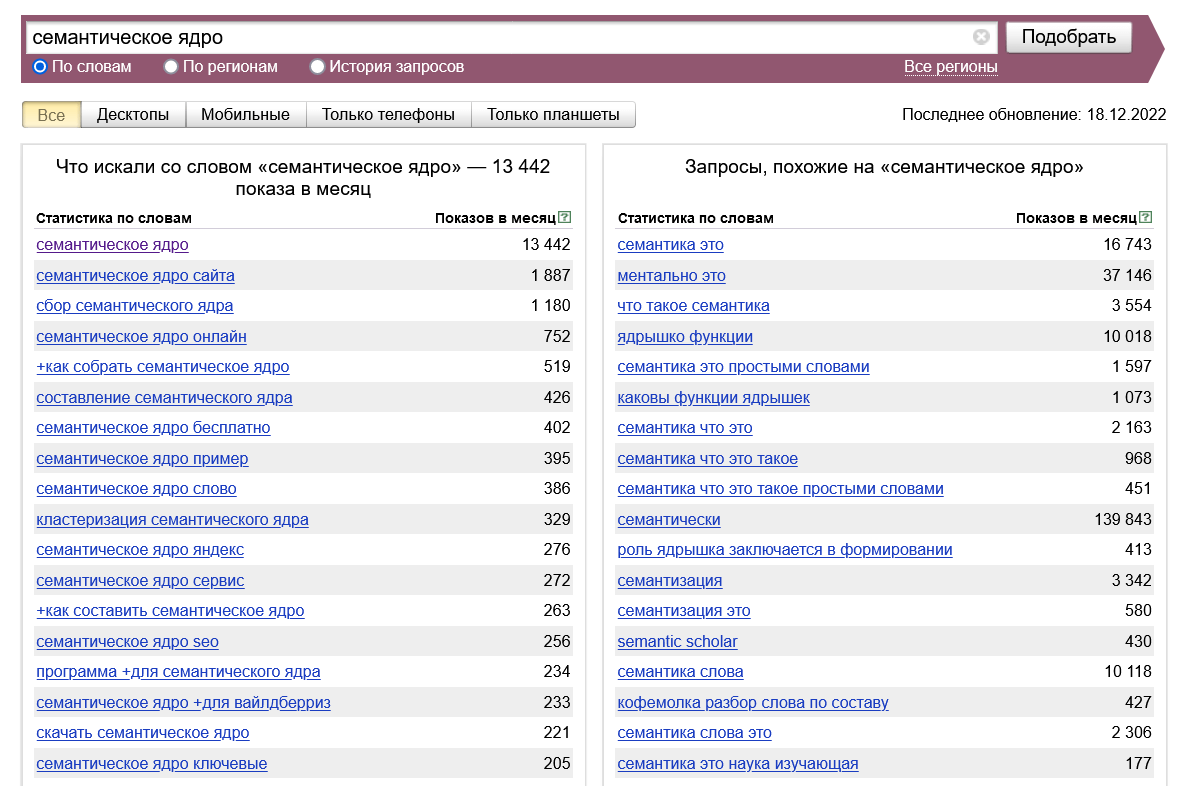
Пример масок для сайта по ремонту обуви, одежды, очков и др.
Разумеется это не все маски, а лишь отдельный кусочек.
Я собираю ключевые слова в программе КейКоллектор. Она платная, но цена вполне доступная. Если вам не хочется тратить денег или вы не собираетесь работать часто с семантическим ядром (у вас только один проект и больше проектов не предвидится), то можете попробовать бесплатный аналог с обрезанным функционалом и с похожим интерфейсом – Словоеб. Из названия программы мы можем явно увидеть всю радость работы с семантическим ядром 🙂
Как работать с KeyCollector
Так выглядит программа при запуске:
Для того чтобы запустить парсинг вам нужно зарегистрировать 2 -3 почты в Яндексе, свою действующую почту лучше не использовать, так как её могут заблокировать. При парсинге морфологической и точной частот начинает часто появляться капча, буквально каждую минуту, и отойти от программы нельзя, так как если вы не вводите данные — программа останавливается. Вы можете дать команду программе выключать из очереди закапчеванный аккаунт на определенное время. Поэтому лучше использовать минимум 2 аккаунта, а лучше 3. Также вы можете подключить прокси-серверы как платные, так и бесплатные от того же КейКоллектора. Но последние использовать не рекомендуется, так как они работают нестабильно — могут быть закапчиваны, например, и тольку от них в этом случае будет мало.
Вы можете дать команду программе выключать из очереди закапчеванный аккаунт на определенное время. Поэтому лучше использовать минимум 2 аккаунта, а лучше 3. Также вы можете подключить прокси-серверы как платные, так и бесплатные от того же КейКоллектора. Но последние использовать не рекомендуется, так как они работают нестабильно — могут быть закапчиваны, например, и тольку от них в этом случае будет мало.
Прокси выглядят примерно так:
- IP – 94.190.87.22;
- порт – 1489;
- логин – lala12;
- пароль – jhgh666aGGh
Когда вы получите прокси, вам нужно будет их добавить в КейКоллектор. Оформление похоже на настройку акканта для парсина, только добавляется пара переменных и символ собаки @:
94.190.87.22:1489@lala12:jhgh666aGGh
Первичная настройка аккаунта
Как я писала выше, вам необходимо зарегистрировать 2-3 почты на Яндексе. После того как вы это сделаете вам нужно внести эти данные в настройки программы. Для этого кликаем на значок шестеренки в левом верхнем углу:
Для этого кликаем на значок шестеренки в левом верхнем углу:
Парсинг данных
Шаг 1: добавление стоп-слов
Если у вас есть стоп-слова их лучше добавить перед парсингом сюда:
Кликаем. Появляется окошко:
 Неполную потому что КейКоллектор имеет лимит для парсинга — 40 страниц, и далее он не пойдет. Пример такого шаблона: «ручки оптом», хотя само количество фраз маленькое, тут есть интересные момент — ручки могут быть шариковые, а могут быть и дверные. Поэтому если вы продаете ручки от дверей, добавьте в стоп-лист слова: шариковые, гелиевые, пишущие. Так вы сэкономите часы своего труда. Иногда двойное значение слов появляется в самом неожиданном месте: вы продаете воду для кулера, и вводите такой шаблон. Но после паринга видите, что огромное количество фраз содержат значение «кулер для воды». И вы уже вместо производителей воды превратились в производителей кулера. Здесь, конечно, дело не в минус-словах, а в последовательности, которую вам нужно будет закрепить. Но это уже не в данном шаге.
Неполную потому что КейКоллектор имеет лимит для парсинга — 40 страниц, и далее он не пойдет. Пример такого шаблона: «ручки оптом», хотя само количество фраз маленькое, тут есть интересные момент — ручки могут быть шариковые, а могут быть и дверные. Поэтому если вы продаете ручки от дверей, добавьте в стоп-лист слова: шариковые, гелиевые, пишущие. Так вы сэкономите часы своего труда. Иногда двойное значение слов появляется в самом неожиданном месте: вы продаете воду для кулера, и вводите такой шаблон. Но после паринга видите, что огромное количество фраз содержат значение «кулер для воды». И вы уже вместо производителей воды превратились в производителей кулера. Здесь, конечно, дело не в минус-словах, а в последовательности, которую вам нужно будет закрепить. Но это уже не в данном шаге. Также стоит проработать стоп-слова когда ваши шаблоны могут иметь разные варианты продолжения. Например, вы продаете плитку для дома и выбрали такую простую фразу. Какое может быть продолжение? Как поведем себя данный шаблон:
Как товар:
Плитка для дома купить
Плитка для дома недорого
Как товар для внутреннего убранства:
Керамическая плитка для дома
Керамогранитная плитка для дома
Как товар, но для внешней отделки
Плитка для дома фасадная
Плитка для дома тротуарная
Как услуга:
Плитка для дома уложить
Плитка для дома демонтаж
Как бренд
Плитка для дома Kerama Marazzi
Плитка для дома Cersanit
Как бренды определенный геолокации
Плитка для дома Российская
Плитка для дома Испания
И так далее
Шаг 2: указание региона
Если не хотите собрать ключевые слова, которые вводят земляне, пользующиеся Яндексом, то вводите интересующий регион. Например, продавая товары москвичам выбирайте Москву и область, хотя некоторые города и округа МО можете убрать из парсинга. Выбирается здесь:
Например, продавая товары москвичам выбирайте Москву и область, хотя некоторые города и округа МО можете убрать из парсинга. Выбирается здесь:
Далее, нажимаем сюда:
Шаг 3: добавление масок
Теперь наш составленный план (маски) нужно загрузить в программу. Для этого создаем папки справа.
Теперь нажимаем на знак Wordstat:
В появившемся окне выбираем «Распределить по группам» (см. скриншот ниже). Справа появятся раннее созданные группы. Нужно из правой части перенести их в левую. Для этого кликаем по каждой группе двойным щелчком. В левые окошки вносим ключевые шаблоны (маски). И не забываем про стоп-слова (если есть) — ставим галочку на «Интегрировать стоп-слова при составлении запросов к Яндекс.Wordstat», выбираем название группы.
Кликаем «Начать сбор» и ждем когда программа соберет фразы из Вордстата. Частотность соберется базовая, ещё я ее называю в данном контексте — первая колонка частотности. После того как будут спарсены фразы для первой колонки, нам нужно собрать частотности из двух других колонок: морфологическая или фиксирующая количество слов частота и точная частота.
Лирическое отступление: Как увидеть морфологическую частоту в Яндекс.Вордстате?
Ответ: взять ключевое слово в кавычки.
А как увидеть точную?
Ответ: Взять в кавычки ключевую фразу и перед каждый словом поставить по восклицательному знаку.
Продолжим. Чтобы собрать дополнительные виды частотностей нужно кликнуть на эту кнопку:
В появившемся окне обратите внимание на галочки: в первом чекбоксе галочки снимаем (мы уже собрали частотность для данного вида), в двух других — ставим.
Нажимаем на «Получить данные» и ждем. После того как все виды частотностей для всех групп будут собраны, вам нужно удалить нулевики т.е. те фразы у которых точная частотность имеет значение — 0. Для массового удаления в КейКоллекторе есть удобная фича — фильтр. Кликаем сюда:
В открывшемся окне ставим настройки как у меня на скриншоте:
После того как фильтр будет применен в выгрузке вы увидите те фразы, которые подходят под фильтр, в данном случае — ключи, у которых точная частотность нулевая. Теперь вам нужно их выделить и удалить. Далее, вернуться к фильтру и удалить выставленные значения.
Теперь вам нужно их выделить и удалить. Далее, вернуться к фильтру и удалить выставленные значения.
Шаг 4: вычитка ключевых слов
Самое времязатратное при создании семантического ядра — это вычитка и группировка большого количества фраз.
Поэтому лучше всего:
- Составлять минус-слова заранее перед парсингом
- Распределять парсинг в уже созданные группы и подгруппы.
Но даже после этого мы часто имеем очень много данных. Поэтому перед ручной вычиткой воспользуйтесь анализом групп в Кей Коллекторе. Ключевые фразы можно разбить по отдельным словам, по составу фраз, по поисковой выдаче и по составу фраз и поисковой выдаче. Мы остановимся на первом типе.
Если вы продаете декоративный кирпич, но не под камень, то отметьте слово «камень», а затем удалите все фразы, имеющие это слово. Так, пройдясь по всему списку слов, вы можете удалить большое количество ненужного. После прочитайте все фразы (уже не слова) и удалите лишнее.
Шаг 5: группировка
Итак, вы вычитали все слова, оставили только нужное, составили подгруппы при необходимости дополнительно в процессе вычитки и… это еще не все.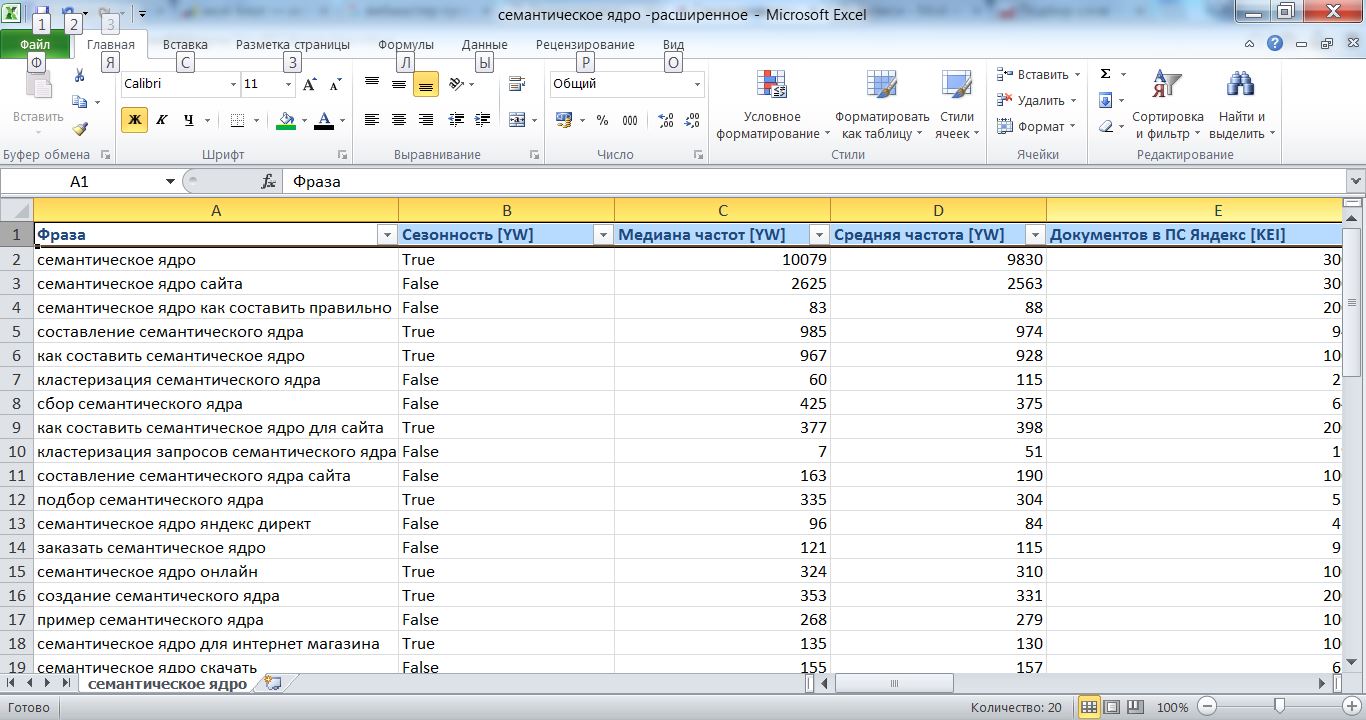 Далее вам нужно работать в Excel. Скачивайте группы, сохраняйте в отдельной папке.
Далее вам нужно работать в Excel. Скачивайте группы, сохраняйте в отдельной папке.
Например, вы скачали файл «Кирпич». Вам нужно распределить не только общие фразы по типу: купить кирпич, кирпич от производителя и кирпич Москва, но и другие параметры: цвет кирпича, место отделки кирпичом, материал из которого он изготовление, вид (лицевой, отделочный, рядовой, облицовочный и др), тип, формат (одинарный, двойной, фигурный и др), марка прочности и другое. Причем в этих группах могут быть и свои подгруппы, пример с группой: формат кирпича:
В идеале, одна маленькая группа равняется одной странице. Но не всегда такое возможно, особенно если это интернет-магазин и нет возможностей или смысла создавать такое большое количество страниц (подкаталогов).
И что делать дальше с этим прекрасным ядром?
Ну, а после мы делаем ТЗ для копирайтера. Но это тема уже другой статьи.
Надеюсь, у вас все получится и вы найдете верное применение собранной и сгруппированной семантики! А если вам нужна помощь, консультация или проработка вашего ядра — звоните или пишите нам!
С уважением SEO-специалист и специалист по семантике Е. Светцова
Светцова
Семантическое ядро сайта: Как собрать и составить
- Что такое семантическое ядро
- Для чего нужно семантическое ядро
- Из чего состоит семантическое ядро
- Как создается семантическое ядро
- Советы по созданию семантики для сайта
- Семантическое ядро и контекстная реклама
- Неконвертируемые запросы
- Охват аудитории и укрепление бренда
- ЧаВо по семантическим ядрам
Что такое семантическое ядро.
Семантическое ядро — это пул (перечень) ключевых слов, их сочетаний, морфологических форм. Этот набор точно описывает специфику деятельности компании, предлагаемые услуги и товарные позиции, которые представлены на сайте, семантическое ядро которого составляется.
Для чего нужно семантическое ядро.

Цели создания семантического ядра сайта (страницы сайта) включают несколько направлений:
- Пул ключей формирует тематику веб-ресурса, которую учитывают поисковые машины.
- Правильно составленное ядро — это основа для построения оптимальной текстовой структуру веб-сайта.
- Составление набора ключевых слов позволяет грамотно выделить средства для раскрутки и продвижению сайта.
- Наличие семантического ядра даёт возможность точной оценки бюджета продвижения в поисковиках.
Из чего состоит семантическое ядро.
Набор ключей семантического ядра сайта должен содержать:
- URL-адреса конкретных страниц сайта.
- Заголовки страниц (текст, указанный в h2).
- Ключевые слова с их распределением по страницам, планируемым для продвижения в органической поисковой выдаче.
- Частотность. То количество раз, которое нужно использовать запрос для эффективной раскрутки.

Как создается семантическое ядро.
- Определяется список посадочных страниц, – точек входа на сайт. Как правило, сюда обязательно входит главная страничка и ещё 5-20 страниц, продвигаемых по отдельным ключам.
- Подбор тематических, релевантных, целевых запросов. Для этого задействуют специальные статистические сервисы, к примеру, Вордстат для Яндекса. SEO-оптимизатор выбирает несколько ключей. Основными ключевыми словами, как правило, являются самые частотные в перечне статистики.
- Подбор близких тематически, ассоциативных ключей. Это запросы, которые непосредственно связаны с основными. В сервисе Вордстат они указываются в разделе «Запросы похожие на …«. Под них иногда создаются дополнительные посадочные страницы.
Этапы составления семантического ядра
- Определение наиболее частых запросов на продвигаемом сайте и на сайтах его конкурентов.
- Сбор всех запросов, содержащих ключевые слова и их синонимы.
- Удаление нецелевых и бессмысленных ключевых слов из списка.
- Группировка ключевых слов по категориям.
- Создание новых целевых страниц в структуре сайта.
- Проверка рейтинга продвигаемого сайта и сайтов его конкурентов по ключевым словам.

На что влияет семантическое ядро сайта.
- Способ создания веб-сайта, а также категории и страницы, которые будут включены в список посадочных страниц.
- Внутренние ссылки, которые создаются для перелинковки и текст их привязки, который используется.
- Написание «продающих» информационных текстов, созданных с учетом семантического ядра сайта.
Частотность выбранных ключей семантического ядра.
Еще один важный критерий для группировки ключевых слов — это их частота:
- Высокочастотные ключи — это слова, которые наиболее кратко описывают тематику сайта. В основном они используются при поиске сайтов по этой теме. Поэтому они демонстрируют самую высокую рыночную конкуренцию.
- Ключевые слова среднего класса немного менее популярны, но остаются весьма востребованными.
- Низкочастотные ключи обычно состоят из нескольких слов и используются реже, чем предыдущие категории. Главное преимущество низкочастотных запросов в том, что они имеют более легкое продвижение в ТОП поисковой выдачи и возможность привлечь на ресурс «теплую» целевую аудиторию, которая знает, что ей нужно.
 В основном они используются при поиске сайтов по этой теме. Поэтому они демонстрируют самую высокую рыночную конкуренцию.
В основном они используются при поиске сайтов по этой теме. Поэтому они демонстрируют самую высокую рыночную конкуренцию.Советы по созданию семантики для сайта.
Кропотливая работа по правильному определению семантического ядра — это основа успешного SEO. Вот почему рекомендуется уделять достаточно времени настоящим маркетинговым исследованиям, а не механическому сбору слов и фраз.
При создании семантического ядра следует учитывать, что новые тенденции в поиске показывают то, что большую долю получают более длинные фразы, а не отдельные слова. Анализ ниши и выбор наиболее подходящих фраз поможет опередить конкурентов в поиске.
Анализ ниши и выбор наиболее подходящих фраз поможет опередить конкурентов в поиске.
После того, как семантическое ядро для сайта составлено, следует создать больше категорий, соответствующих выбранным ключевым словам. Контент должен иметь возможность «продавать», он должен быть информативным и понятным для посетителей, быть доступным и легким для поиска через хорошие внутренние ссылки, что облегчит пользователям получение необходимой информации.
Семантическое ядро и контекстная реклама.
Поисковое продвижение не единственный, хотя и безусловно главный, способ продвижения сайта в сети. Но разных этапах развития бизнеса в интернете необходимо комбинировать разные методы.
Контекстная реклама запускается для достижения одной из целей:
- Расширить охват аудитории.
- Повысить продажи.
- Улучшить узнаваемость бренда.
Независимо от главной поставленной цели для запуска и реализации успешной рекламной кампании необходимо запастись достаточным числом объявлений, правильным набором запросов, списком «минус слов».
Если для SEO семантическое ядро выступает базой под структуру сайта, то рекламной кампании этот аспект выполняет роль главного “зазывателя”. Соответственно нужны совсем другие запросы пользователей. Больше с коммерческим оттенком, отражающие не только ценовой диапазон и качество, но также брендовую составляющую.
Неконвертируемые запросы.
Те, кто занимается созданием рекламных объявлений научились отсекать ключевые слова, которые не будут приводить к продажам. В большинстве случаев это запросы + отвлекающие дополнения, например: своими руками, самостоятельно, бесплатно. Люди, вводящие такие поисковые фразы зачастую не входят в круг целевой аудитории для проектов, продающие товары и услуги. Чтобы не вести на сайт подобных псевдопокупателей, да еще за деньги из рекламного бюджета, надо максимально четко составить семантическое ядро и список минус-слов.
Избавление от неконвертируемых запросов дает следующее:
- Минимизация нецелевого платного трафика.
- Формирование максимально эффективных подборок ключевых слов (конкурентных и не дорогих).
- Повышение конверсии (меньше нецелевого трафика).
- Анализ рекламных кампаний работа по их большей эффективности в дальнейшем.

Охват аудитории и укрепление бренда.
Частотность используемых запросов не всегда влияет на качество и количество привлекаемого трафика. Для повышения числа продаж на сравнительно малом потоке пользователей можно ограничиться низкочастотными ключевыми словами. Если же стоит цель расширить охват целевой аудитории, то без высокочастотных запросов не обойтись.
Работа с сервисами по созданию семантического ядра для контекстной рекламы существенно не отличается. Но есть важные стратегические моменты, которые следует учитывать. Например, выбранный тип рекламы способствует охвату целевой аудитории по брендовым запросам. Больше пользователей узнают о компании, что впоследствии опосредованно повлияет на приток покупателей, уже ищущих товары конкретного производителя или продавца.
ЧаВо по семантическим ядрам.
Семантическое ядро надо составлять только один раз вначале продвижения сайта?
Нет, семантическое ядро необходимо периодически обновлять и даже расширять. Со временем запросы пользователей меняются, а также обновляется информация на сайте. Если этого не делать, то продвижение не будет эффективным.
Какую частоту ключей необходимо использовать для продвижения малобюджетных сайтов?
Частоту ключей необходимо выбирать, исходя из многих факторов: бюджет, цель, способ продвижения и многое другое. Важно четко определиться с тем, какой результат требуется получить на выходе.
Может ли обычный копирайтер написать ключи для семантического ядра?
Нет, потому что составление семантического ядра — это не только написание ключевых слов, а также детальный анализ сайта, который не сможет сделать неквалифицированный специалист.
Может ли неправильно составленное семантическое ядро навредить продвижению сайта?
Да, потому что семантическое ядро — это «основа основ», то что закладывает всю концепцию развития сайта и его последующее существование. Без правильно составленных ключей компания может понести убытки.
Без правильно составленных ключей компания может понести убытки.
Заберите ссылку на статью к себе, чтобы потом легко её найти!
Раз уж досюда дочитали, то может может есть желание рассказать об этом месте своим друзьям, знакомым и просто мимо проходящим?
Не надо себя сдерживать! 😉
[PDF] Yago: ядро семантических знаний 07ЯгоАС, title={Яго: ядро семантических знаний}, автор = {Фабиан М. Суханек, Гьерджи Каснечи и Герхард Вейкум}, booktitle={Веб-конференция}, год = {2007} }
- Фабиан М. Суханек, Г. Каснечи, Г. Вейкум
- Опубликовано на веб-конференции 8 мая 2007 г.
- Информатика
Просмотр на ACM
hal.archives-ouvertes.frYAGO: Большая онтология из Википедии и WordNet
- Фабиан М.
- 2008
 Суханек, Г. Каснечи, Г. Вейкум
Суханек, Г. Каснечи, Г. ВейкумИнформатика
J. Web Semant.
UNIpedia: унифицированная платформа онтологических знаний для тегирования семантического контента и поиска
- Мурат Календер, Цзянбо Данг, Сюзан Ускюдарли
- 2010
- 2013
- 2015
- 2009
- 2010
- 2010
- 2009
- 2008
- 2004
- 2006
- 2004
- 2006
- 2006
- 2000
- 2000
- 2006
Альварес Л.О., Богорный В., Куйперс Б., Де Маседо Дж.А.Ф., Моэланс Б., Вайсман А.: Модель обогащения траекторий с помощью семантическая географическая информация. В: Самет, Х., Шахаби, К., Шнайдер, М. (ред.) Материалы 15-го Международного симпозиума ACM по географическим информационным системам, ACM-GIS 2007, Сиэтл, Вашингтон, США, 7-9 ноября.. АКМ Пресс (2007)
Google Scholar
Баттл, Р., Колас, Д.: Включение геопространственной семантической сети с Парламентом и GeoSPARQL. Semantic Web 3(4), 355–370 (2012)
Google Scholar
Берг-Кросс Г., Круз И., Дин М., Финин Т., Гахеган М., Хитцлер П., Хуа Х., Янович К., Ли Н. , Мерфи, П., Нордгрен, Б., Обрст, Л., Шильдхауэр, М., Шет, А.
, Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.)Google Scholar
Бизер, К., Хит, Т., Бернерс-Ли, Т.: Связанные данные – История до сих пор. Международный журнал Semantic Web and Information Systems 5(3), 1–22 (2009 г.)
CrossRef Google Scholar
Богорный В., Куиджперс Б., Альварес Л.О.: ST-DMQL: язык запросов интеллектуального анализа данных семантической траектории. Международный журнал географической информатики 23(10), 1245–1276 (2009 г.).)
Перекрестная ссылка Google Scholar
Бракатсулас, С.
, Пфосер, Д., Трифона, Н.: Моделирование, хранение и анализ баз данных движущихся объектов. В: 8-й Международный симпозиум по разработке баз данных и приложений (IDEAS 2004), Коимбра, Португалия, 7–9 июля, стр. 68–77. Компьютерное общество IEEE (2004)Google Scholar
Бродарик, Б., Пробст, Ф.: Внедрение междисциплинарных электронных наук путем интеграции геолого-геофизических онтологий с Dolce. Интеллектуальные системы IEEE 24(1), 66–77 (2009 г.).)
Перекрестная ссылка Google Scholar
Каррал, Д., Шайдер, С., Янович, К., Вардеман, К., Криснадхи, А.А., Хитцлер, П.: Шаблон проектирования онтологии для картографического масштабирования карты. В: Чимиано, П., Корчо, О., Пресутти, В., Холлинк, Л., Рудольф, С. (ред.) ESWC 2013. LNCS, vol. 7882, стр. 76–93. Springer, Гейдельберг (2013)
CrossRef Google Scholar
Чан, Л.-В., Чанг, Дж.-Р., Чен, Ю.-К., Кэ, К.-Н., Хсу, Дж., Чу, Х.-Х.: Сотрудничество локализация: улучшение оценки местоположения на основе Wi-Fi с соседними ссылками в кластерах. В: Фишкин, К.П., Шиле, Б., Никсон, П., Куигли, А. (ред.) PERVASIVE 2006. LNCS, vol. 3968, стр. 50–66. Springer, Heidelberg (2006)
CrossRef Google Scholar
Chiou, Y., Wang, C., Yeh, S., Su, M.: Разработка адаптивной системы позиционирования на основе радиосигналов WiFi.
Компьютерные коммуникации 32(7), 1245–1254 (2009)CrossRef Google Scholar
Комптон, М., Барнаги, П.М., Бермудес, Л., Гарсия-Кастро, Р., Корчо, О., Кокс, С., Грейбил, Дж., Хаусвирт, М., Хенсон, К.А., Херцог , А., Хуанг, В.А., Янович, К., Келси, В.Д., Фуок, Д.Л., Лефорт, Л., Легьери, М., Нейхаус, Х., Николов, А., Пейдж, К.Р., Пассант, А., Шет, А.П., Тейлор, К.: Онтология SSN группы инкубатора семантической сенсорной сети W3C. Журнал по веб-семантике 17, 25–32 (2012)
Перекрёстная ссылка Google Scholar
Додж С., Вайбель Р., Лаутеншютц А.К.: На пути к таксономии моделей движения. Визуализация информации 7(3), 240–252 (2008)
CrossRef Google Scholar
Гангеми, А.: Шаблоны проектирования онтологии для семантического веб-контента. В: Гил, Ю.
, Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005)Перекрёстная ссылка Google Scholar
Гангеми, А., Фиссеха, Ф., Кейзер, Дж., Леманн, Дж., Лян, А., Петтман, И., Сини, М., Таконе, М.: Основная онтология рыболовства и его использование в проекте службы онтологии рыболовства. В: Первый международный семинар по основным онтологиям, конференция EKAW. CEUR-WS, том. 118 (2004)
Google Scholar
Гангеми, А., Гуарино, Н., Мазоло, К., Олтрамари, А., Шнайдер, Л.: Подслащивание онтологий с помощью DOLCE. В: Гомес-Перес, А., Бенджаминс, В.Р. (ред.) EKAW 2002. LNCS (LNAI), vol. 2473, стр. 166–181. Спрингер, Гейдельберг (2002)
Перекрёстная ссылка Google Scholar
Грюнингер, М.
, Фокс, М.С.: Роль вопросов о компетенциях в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994)Google Scholar
Гутинг, Р. Х., Бёлен, М. Х., Эрвиг, М., Йенсен, К. С., Лоренцос, Н. А., Шнайдер, М., Вазиргианнис, М.: Основа для представления и запроса движущихся объектов. Транзакции ACM в системах баз данных (TODS) 25 (1), 1–42 (2000)
Перекрёстная ссылка Google Scholar
Гутинг, Р., Де Алмейда, В., Дин, З.: Моделирование и запросы движущихся объектов в сетях. Журнал VLDB 15(2), 165–190 (2006)
CrossRef Google Scholar
Гвон Ю., Джейн Р., Кавахара Т.: Надежная оценка местоположения стационарных и мобильных пользователей в помещении. В: Proceedings IEEE INFOCOM 2004, 23-я ежегодная совместная конференция IEEE Computer and Communications Societies, Гонконг, Китай, 7–11 марта, стр.
1032–1043. ИИЭР (2004)Google Scholar
ван Хаге, В.Р., Малайз, В., Сегерс, Р.Х., Холлинк, Л., Шрайбер, Г.: Разработка и использование простой модели событий (SEM). Журнал по веб-семантике 9(2), 128–136 (2011)
CrossRef Google Scholar
Хитцлер, П., Крётч, М., Рудольф, С.: Основы семантических веб-технологий. CRC Press (2010)
Google Scholar
Хорн, Дж. С., Гартон, Э. О., Кроун, С. М., Льюис, Дж. С.: Анализ движений животных с использованием броуновских мостов. Экология 88, 2354–2363 (2007)
CrossRef Google Scholar
Ху, Ю., Янович, К.: Улучшение управления личной информацией путем интеграции действий в физическом мире с семантическим рабочим столом.
В: Круз, И.Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012)Google Scholar
Кейс, Р., Янсен, П.А., Кнехт, Э.М., Вохвинкель, Р., Викельски, М.: Влияние времени кормления на распространение семян виролы туканами, определенное с помощью GPS-трекинга и акселерометров. Acta Oecologica 37(6), 625–631 (2011)
CrossRef Google Scholar
Кейс, Р., Янсен, П.А., Кнехт, Э.М., Вохвинкель, Р., Викельски, М.: Данные из: Влияние времени кормления на распространение семян виролы туканами, определенное с помощью GPS-трекинга и акселерометров. Хранилище данных Movebank (2012)
Google Scholar
Маккензи Г., Адамс Б., Янович К.: Тематический подход к сходству пользователей, основанный на геосоциальных проверках. В: Материалы конференции AGILE 2013 г. (будет опубликовано в 2013 г.)
Google Scholar
Мика П., Оберле Д., Гангеми А., Сабоу М.: Основы сервисных онтологий: согласование OWL-S с Dolce. В: Материалы 13-й конференции World Wide Web, стр. 563–572. АКМ (2004)
Google Scholar
Муза, К., Риго, П.: Модели подвижности. GeoInformatica 9(4), 297–319 (2005)
CrossRef Google Scholar
Приянта, Н.: Система определения местоположения в помещении для игры в крикет. Кандидат наук. диссертация, Массачусетский технологический институт (2005 г.)
Google Scholar
Шмид Ф., Рихтер К.-Ф., Лаубе П.: Сжатие семантической траектории. В: Мамулис, Н., Зайдл, Т., Педерсен, Т.Б., Торп, К., Ассент, И. (ред.) SSTD 2009. LNCS, том. 5644, стр. 411–416. Springer, Heidelberg (2009)
CrossRef Google Scholar
Спаккапьетра, С., Парент, К., Дамиани, М., Де Маседо, Дж., Порто, Ф., Вангенот, К.: Концептуальный взгляд на траектории. Инженерия данных и знаний 65(1), 126–146 (2008)
CrossRef Google Scholar
Виллемс, Н., ван Хаге, В.Р., де Врис, Г., Янссенс, Дж.Х.М., Малайз, В.: Интегрированный подход к визуальному анализу базы знаний о движущихся объектах из нескольких источников. Международный журнал географической информатики 24(10), 1543–1558 (2010)
CrossRef Google Scholar
Ян, З., Маседо, Дж., Пэрент, К., Спаккапьетра, С.: Траекторные онтологии и запросы. Транзакции в ГИС 12, 75–91 (2008)
Перекрестная ссылка Google Scholar
Ян З.: К семантическому анализу траекторных данных: концептуальный и вычислительный подход.
Информатика
Четвертая международная конференция IEEE по семантическим… их экземпляры как концепции WordNet и их отображение алгоритмы используют эвристики, основанные на правилах, извлеченные из онтологических и статистических характеристик концепции и экземпляров.
Изучение семантических N-арных отношений из Википедии
- М. Банек, Дамир Юрич, З. Скоцир
Информатика
DEXA
Предложение Изучение семантики WikiTables
- Чандра Бхагаватула
Информатика
 из таблиц Википедии чтобы лучше понять семантику таблиц Википедии.
из таблиц Википедии чтобы лучше понять семантику таблиц Википедии.Обогащение структурированных знаний открытой информацией
- Арнаб Датта, Кристиан Мейлике, Х. Штукеншмидт
Информатика
WWW
Подход YAGO-NAGA к открытию знаний
- G. Kasneci, Maya Ramanath, Fabian M. Sulanek, G. Weikum
Компьютерный науки
SGMD
Поддержка обработки естественного языка с помощью фоновых знаний: Кейс разрешения кореферентности
- Ольга Брыль, К. Джулиано, Л.
 Серафини, К. Тимошенко
Серафини, К. ТимошенкоИнформатика
SEMWEB
Использование фоновых знаний для поддержки решения Coreference
- Ольга Брыль, К. Джулиано, Л. Серафини, К. Тимошенко
Информатика
ECAI
Горное дело Значение из Википедии
- Елена Меделян, К. Легг, Дэвид Н. Милн, И. Виттен
Информатика
Междунар. Дж. Хам. вычисл. Стад.
Автоматическое уточнение онтологии инфобокса Википедии
- Fei Wu, Daniel S. Weld
Информатика
WWW

Индукция семантической таксономии на основе гетерогенных данных
- Р. Сноу, Дэн Джурафски, А. Нг tic таксономии, которые гибко включают данные из нескольких классификаторов по гетерогенные отношения для оптимизации всей структуры таксономии, используя знание терминов координат слова, чтобы помочь в определении его гипернимов, и наоборот.
Автоматическое извлечение семантических связей для WordNet с помощью изучения шаблонов из Википедии 8 Автоматический подход к идентификации лексических моделей, представляющих семантические отношения между понятиями из онлайновой энциклопедии, и эти шаблоны могут применяться для расширения существующих онтологий или семантических сетей новыми отношениями.
Извлечение информации в веб-масштабе в Knowitall: (предварительные результаты)
- Oren Etzioni, Michael J. Cafarella, A. Yates
Computer Science
WWW ’04

Сочетание лингвистического и статистического анализа для извлечения связей из веб-документов
- Фабиан М. Суханек, Джорджиана Ифрим, Г. Вейкум
Информатика
KDD ’06
Использование словарей при извлечении именованных сущностей: сочетание полумарковских процессов извлечения и методов интеграции данных
- Уильям В. Коэн, Сунита Сараваги
Информатика
KDD

Еще более неотразимый SROIQ
- Ян Хоррокс, О. Куц, У. Сэттлер
Информатика
KR
Эспрессо: использование общих шаблонов для автоматического сбора семантических отношений
- П. Пантел, М. Пенначчиотти
Информатика
ACL
WordNet: электронная лексическая база данных
- C.
 Fellbaum
FellbaumИнформатика
Snowball: извлечение соотношений из больших коллекций открытого текста
- Eugene Agichtein, L. Gravano
Computer Science
DL ’00
ЛЕЙЛА: Обучение извлечению информации с помощью лингвистического анализа
- Фабиан М. Суханек, Джорджиана Ифрим, Г. Вейкум
Компьютерная наука
Онтологический ослепитель@coling/acl
Геоонтологический шаблон проектирования семантических траекторий
 , Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.)
, Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.) , Пфосер, Д., Трифона, Н.: Моделирование, хранение и анализ баз данных движущихся объектов. В: 8-й Международный симпозиум по разработке баз данных и приложений (IDEAS 2004), Коимбра, Португалия, 7–9 июля, стр. 68–77. Компьютерное общество IEEE (2004)
, Пфосер, Д., Трифона, Н.: Моделирование, хранение и анализ баз данных движущихся объектов. В: 8-й Международный симпозиум по разработке баз данных и приложений (IDEAS 2004), Коимбра, Португалия, 7–9 июля, стр. 68–77. Компьютерное общество IEEE (2004) «>
«>Карраль, Д., Янович, К., Хитцлер, П.: Логический шаблон проектирования геоонтологии для количественной оценки типов. В: Круз, И.Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 239–248. АКМ (2012)
Google Scholar
 Компьютерные коммуникации 32(7), 1245–1254 (2009)
Компьютерные коммуникации 32(7), 1245–1254 (2009) , Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005)
, Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005) , Фокс, М.С.: Роль вопросов о компетенциях в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994)
, Фокс, М.С.: Роль вопросов о компетенциях в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994)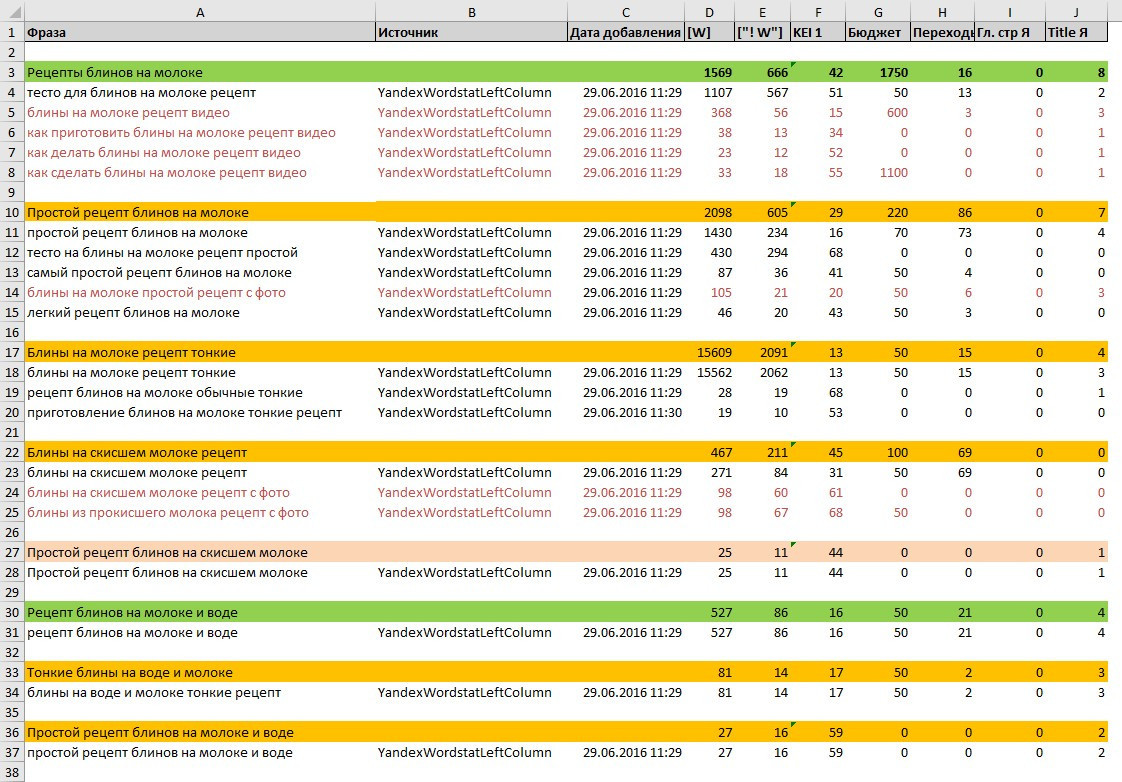 1032–1043. ИИЭР (2004)
1032–1043. ИИЭР (2004) В: Круз, И.Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012)
В: Круз, И.Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012) «>
«>Li, X., Claramunt, C., Ray, C., Lin, H.: семантический подход к представлению данных о траекториях, ограниченных сетью. В: Ридл, А., Кайнц, В., Элмс, Г.А. (ред.) Прогресс в обработке пространственных данных, стр. 451–464. Спрингер (2006)
Google Scholar
 «>
«>Ни, Л., Лю, Ю., Лау, Ю., Патил, А.: LANDMARC: определение местоположения в помещении с использованием активной RFID. Беспроводные сети 10(6), 701–710 (2004 г.)
CrossRef Google Scholar
 «>
«>Вазиргианнис М., Вольфсон О.: Пространственно-временная модель и язык для перемещения объектов по дорожным сетям. В: Дженсен, К.С., Шнайдер, М., Сигер, Б., Цотрас, В.Дж. (ред.) SSTD 2001. LNCS, vol. 2121, стр. 20–35. Спрингер, Гейдельберг (2001)
Перекрёстная ссылка Google Scholar
