
Сервисы для сбора семантического ядра
В Интернете можно найти любую информацию: новости, описание товаров и услуг и отзывы о них, образовательные материалы, аналитический контент и т. д.
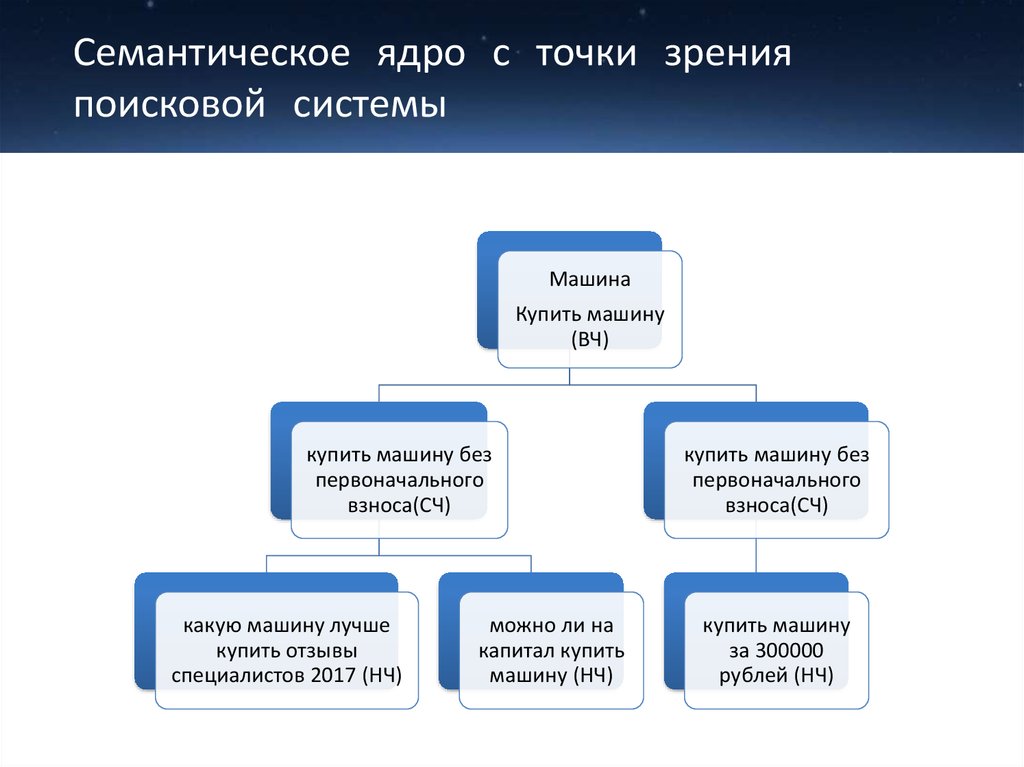
Необходимую информацию ищут с помощью поисковых запросов. Ключевые слова и фразы, которые люди вводят в поисковую строку браузера, формируют семантическое ядро (СЯ) сайта.
В этой статье мы расскажем, зачем нужно собирать семантику сайта и какие онлайн-сервисы можно использовать.
Photo from Pixabay
Подпишитесь на нас в Facebook, Telegram, Twitter или Instagram, чтобы ничего не пропустить!
Зачем собирают семантическое ядро?
Любой владелец бизнеса, интернет-маркетолог или блоггер заинтересован в том, чтобы его сайт получал трафик из Google или других поисковых систем.
Достичь этой цели поможет перечень правильных ключевых слов (ключей), которые нужно использовать для создания контента.
Первый шаг к формированию семантического ядра — понять, чем именно интересуются потенциальные клиенты.
Другими словами, необходимо найти ключи, которые уже использует ваша целевая аудитория при поиске аналогичных товаров и услуг.
Каждый поисковый запрос — это демонстрация потребностей, желаний и интересов интернет-пользователя.
Благодаря анализу запросов, касающихся конкретного бизнеса, можно улучшить свой продукт или сервис. Сделать его таким, чтобы он отвечал реальным потребностям ЦА.
Сервисы для составления семантического ядра помогают находить тысячи новых ключевых слов, улучшающих SEO-оптимизацию веб-ресурса, а следовательно, ускоряющих развитие бизнеса.
Когда начинать сбор семантического ядра?
На этапе прототипирования сайта.
Напомним, что прототип сайта — это упрощенный вариант будущего веб-ресурса. То есть это маркет, «черновик», в котором можно исправлять недостатки, менять набор функций еще до момента начала разработки основной версии сайта.
Работа над формированием семантического ядра помогает лучше понимать целевую аудиторию и правильно выстраивать структуру веб-ресурса.
Часто глубокий анализ ключей помогает изменить к лучшему не только сам сайт, но и сам продукт (товар или услугу), который вы предлагаете аудитории.
Где можно собрать семантическое ядро?
Для сбора семантики можно использовать Google Ads (старое название — Google AdWords) и другие подобные онлайн-сервисы:
- Serpstat;
- Keyword Shitter;
- Keyword Tool;
- Ahrefs Keywords Explorer и др.
Serpstat
Serpstat — инструмент для взрывного роста SEO, PPC и контент-маркетинга.
Сервис разработан в 2013 году как внутренний продукт, впоследствии превратившийся в многофункциональную SEO-платформу.
В базе данных Serpstat — более 5 млрд фраз. Сервисом пользуется более 200 тыс. пользователей со всего мира.
Компании, которые Serpstat с гордостью называет своими клиентами, — Rakuten Viber, Samsung, Uber, Philips, Shopify, Deloitte.
Этот онлайн-сервис используют представители малого и среднего бизнеса, агентства поискового маркетинга, SEO-специалисты штатных (in-house) или аутсорсинговых команд, а также специалисты, работающие над увеличением интернет-продаж.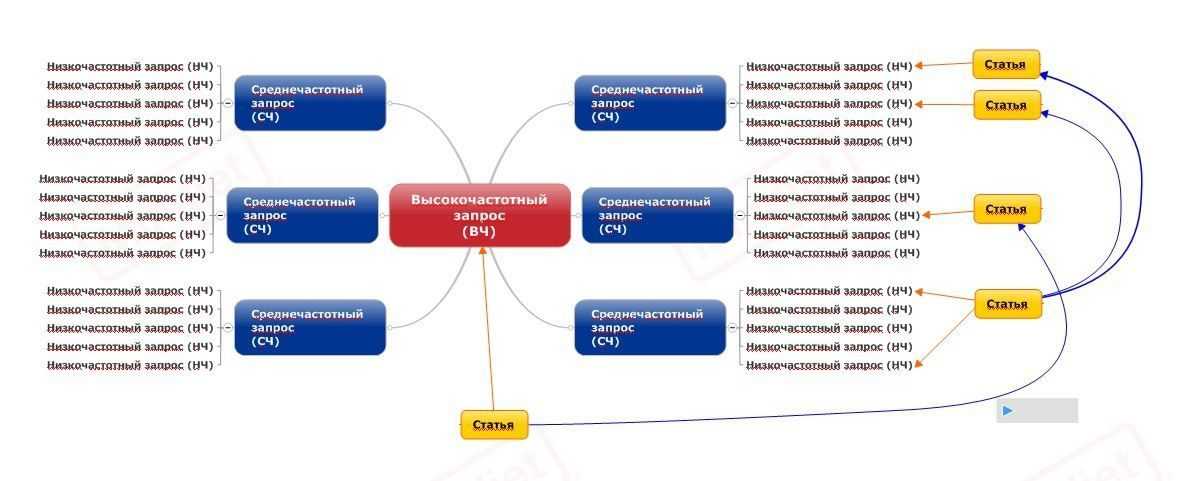
На многофункциональной платформе Serpstat можно выполнить:
- анализ ссылок;
- анализ ключевых фраз;
- аудит сайта;
- анализ конкурентов.
Пользователям бесплатного тарифа доступен полный набор функций Serpstat: можно исследовать семантику, анализировать сайты компаний-конкурентов и т. д.
Keyword Shitter
Это бесплатная программа для автоматического сбора семантического ядра. Онлайн-сервисом Keyword Shitter можно пользоваться даже без регистрации.
Преимущество перед другими аналогичными инструментами в том, что платформа поддерживает возможность выбора не только языка и страны, но даже региона (города).
Благодаря этой опции, сервис может предоставлять адаптированные данные на основе выбора международных пользователей.
Есть возможность загрузки данных в формате CSV. Также Keyword Shitter предоставляет данные о том, сколько раз слова искали в Google Trends, Yahoo!, Baidu, Google AdWords и по.
В Keyword Shitter есть функции, позволяющие находить связанные слова, просматривать ключи с низкой конкуренцией, проверять объем трафика и потенциальный рейтинг сайтов, использующих эти ключевые слова.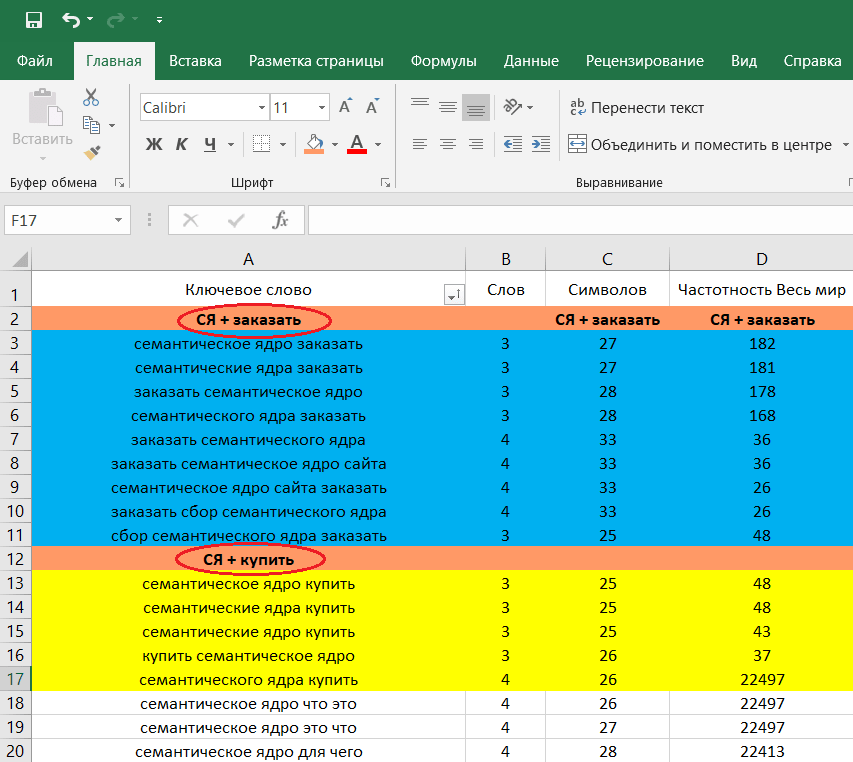
Keyword Tool
Еще одна популярная программа для подбора семантики. Есть две версии пользования онлайн-платформой Keyword Tool: без оплаты и с платной подпиской.
Бесплатная версия Keyword Tool генерирует до 750+ ключевых слов для каждого поискового запроса.
Сервис Keyword Tool, как и Keyword Shitter, можно использовать даже без создания учетной записи.
Keyword Tool считают лучшей альтернативой планировщику ключевых слов Google для поисковой оптимизации.
Этот инструмент не скрывает популярные ключи, которые могут быть использованы для создания контента.
Сервис предоставляет возможность использования функции автоматического заполнения Google для поиска ключей.
Также приложение «вытаскивает» поисковые подсказки Google и подает их в доступном формате.
Ahrefs Keywords Explorer
Онлайн-сервис Ahrefs Keywords Explorer также поможет вам собрать качественное семантическое ядро для своего сайта.
Инструмент подбирает ключи для Google и других платформ — Baidu, YouTube, Bing, Amazon и т. д.
д.
Программу можно использовать и для анализа других SEO-показателей — рейтинг возврата, клики за поиск, процент кликов (в том числе платных) и т. д.
Вывод
Семантическое ядро сайта — упорядоченный набор ключевых слов, их морфологических форм и словосочетаний, наиболее точно характеризующих вид деятельности компании, товар или услугу. Ключи — это эффективный инструмент продвижения веб-ресурса.
Семантическое ядро можно создать самостоятельно с помощью онлайн-сервисов. Или делегировать эту работу SEO-специалисту или digital-агентству.
Если вы только планируете создание собственного сайта, это можно сделать с помощью WordPress.
Важным фактором комфортного поиска вашего сайта является удачный домен. Надежность работы обеспечивает качественный хостинг. Эти услуги можно заказать на NIC.UA.
Также у нас можно купить SSL-сертификат и получить юридическую поддержку регистрации торговой марки.
▷ Як працює сервіс збору семантичного ядра? Інструкція з використання
Щоб сайт був видний в пошукових системах, а ще краще, щоб він займав лідируючі позиції у видачі, першим справу потрібно скласти семантичне ядро — набір слів і словосполучень, яким релевантний сайт.
Команда SEO-фахівців Inweb розробила і представила ще один інструмент в рамках проекту « Inweb Tools » — сервіс, який допоможе SEOшніку отримати семантику на основі аналізу посадкових сторінок конкурентів. Розповідаємо.
Зміст статті
- Для чого потрібен сервіс зі збору семантики?
- Що таке семантичне ядро?
- Для чого потрібно збирати семантичне ядро?
- Як працює інструмент для збору семантики?
- Помилки під час роботи з семантичним ядром
- З якими обмеженнями можна зіткнутися
Для чого потрібен сервіс зі збору семантики? h3>
Сервіс аналізує посадкові сторінки конкурентів, які знаходяться в ТОПі видачі, і на його підставі складає семантичне ядро. При цьому всі необхідні дані інструмент збирає з Serpstat .
Що таке семантичне ядро? h3>
Існує безліч визначень поняття « семантичне ядро » . Ми прочитали більшість з них, об’єднали головне, виділили особливості і ось що вийшло.
Семантичне ядро – загальний список пошукових запитів, ключових слів, різних форм словосполучень, завдяки яким визначається розуміння виду діяльності та перелік послуг сайту.
Завдяки цим словам зі списку сайт можна і потрібно просувати. Семантика, як правило, враховує бажання, інтереси користувачів і разом з цим відповідає цілям компанії.
Для чого потрібно збирати семантичне ядро? h3>
Збір семантичного ядра дає розуміння бізнесу, яка структура попиту і що люди шукають в принципі.
Очевидно, що продаючи електронну техніку, ви не будете « претендувати » на користувача, який шукає в інтернеті корм для домашніх вихованців.
Ось кілька застосувань семантичного ядра:
- Необхідність у створенні нових сторінок сайту. Семантика допомагає зрозуміти, що саме і як часто шукають користувачі. Можна зробити аналіз пошукової видачі, вивчити конкурентів і відповісти на питання, чи потрібно створювати нові сторінки або існуючих на сайті достатньо. У разі, якщо сторінки сайту втратили актуальність і ви прийняли рішення про створення нових, пам’ятайте: треба правильно прописати редіректи — перенаправлення користувача з одного URL на інший.
 Для цього рекомендуємо використовувати сервіс « Відстань Левенштейна » . div> li>
Для цього рекомендуємо використовувати сервіс « Відстань Левенштейна » . div> li> - Складання метатегів. Ядро допомагає зрозуміти, за допомогою яких слів і конструкцій користувач шукає той чи інший товар, послугу, і що дійсно його цікавить. Отримані дані потрібно використовувати для створення відповідної назви та опису сторінки. Якщо все виконати правильно, сторінка стане релевантною, що добре позначиться на видачу сайту в пошуковій системі.
- Контент на посадкових сторінках. Крім коректного, з точки зору оптимізації, опису сторінки, важливу роль відіграє наявність якісного тексту на сайті. Правильно написаний текст, з урахуванням всіх ключових слів і інших нюансів, допоможе зробити сторінки більш доречними для пошукових систем і привабливими для користувачів. Складайте технічне завдання для копірайтера в один клік за допомогою сервісу « Завдання для текстів » . Інструмент працює на основі аналізу сайту конкурентів. div> li>
- Статті на сайт. Постійне ведення блогу — важливий компонент в просуванні не тільки свого сайту, але і всього бізнесу. Інформаційні та / або комерційні статті, розміщені в окремому розділі, можуть допомогти в залученні потенційних клієнтів. li>
 Для цього рекомендуємо використовувати сервіс « Відстань Левенштейна » . div> li>
Для цього рекомендуємо використовувати сервіс « Відстань Левенштейна » . div> li> Постійне ведення блогу — важливий компонент в просуванні не тільки свого сайту, але і всього бізнесу. Інформаційні та / або комерційні статті, розміщені в окремому розділі, можуть допомогти в залученні потенційних клієнтів. li>
Постійне ведення блогу — важливий компонент в просуванні не тільки свого сайту, але і всього бізнесу. Інформаційні та / або комерційні статті, розміщені в окремому розділі, можуть допомогти в залученні потенційних клієнтів. li>Написання статей заради написання — ні до чого не приведе. Намагайтеся вибирати вузькоспрямовані теми, адже конкуренти можуть їх не зачіпати і ваш сайт буде потрапляти в ТОП видачі за цими пошуковими запитами.
Як працює інструмент для збору семантики? h3>
Сервіс містить в собі два методи збору семантичного ядра:
- за маркерними фразам; li>
- по URL-адресами конкурентів. Li>
Працюючи з маркерними фразами, інструмент отримує ТОП-10 по кожній фразі, бере URL-адреси з цього ТОПу і отримує їх список ключових фраз. Спираючись на вибрану кількість перетинів, видає підсумковий список загальних запитів за кожним маркерним словом.
У випадку з адресами конкурента, сервіс отримує список ключових фраз, за якими ранжуються сторінки, і далі працює аналогічно: виходячи з обраної кількості перетинів видає підсумковий список загальних запитів.
Збір даних за першим методом ґрунтується на конкурентів з пошукової видачі за високочастотними запитами, збирає фрази, за якими вони ранжуються в пошуковій видачі.
Маркерні запити — запити, які прямо відповідають просуває сторінці. Наприклад, для сторінки-категорії мобільних телефонів таким запитом буде & laquo; купити смартфон ».
Такий метод збору дає більш загальний і широкий набір ключових фраз, в порівнянні з другим методом. Найкраще підходить для швидкого збору семантичного ядра за декількома маркерним запитам в ніші, для якої існує велика кількість семантики. Наприклад, якщо вам необхідно зібрати семантику на сторінки інтернет-магазину з продажу електронної техніки.
Спосіб 1. Для збору семантики, використовуючи метод маркерних запитів, потрібно:
- Вказати пошукову сторінку і регіон: li>
- Вказати токен API Serpstat:
- Переконатися в тому, що лімітів досить. Для перегляду токена і кількості лімітів зайдіть у свій профіль в Serpstat: li>
- Ввести маркерні ключові слова. Нижче наведено приклад для магазину з продажу електронної техніки: li>
- Через кому можна ввести стоп-слова (фрази, які містять ці слова, не будуть включені в підсумковий список): li>
- Після всіх виконаних дій натискайте « Отримати семантичне ядро »: li>
 Нижче наведено приклад для магазину з продажу електронної техніки: li>
Нижче наведено приклад для магазину з продажу електронної техніки: li>На екрані з’явиться таблиця ключових фраз з їх частотністю. Для зручності ми передбачили можливість вивантаження даних в форматі .CSV.
Спосіб 2. За URL-адресами. Щоб зібрати семантичне ядро, потрібно:
- Вказати пошукову сторінку і регіон: li>
- Вказати токен API Serpstat: li>
- Переконатися в тому, що лімітів досить. Для перегляду токена і кількості лімітів зайдіть в свій профіль в Serpstat: li>
- Ввести для аналізу url-адреси конкурентів з пошукової видачі: li>
- Визначити кількість перетинів — кількість сайтів з такими ж ключами в семантиці. Ми рекомендуємо обирати 3 перетину для 5 сторінок конкурентів: li>
- Ввести стоп-слова, використавши кому: li>
- Натиснути кнопку « Отримати семантичне ядро »: li>
ol>Ви отримуєте таблицю ключових фраз з їх частотністю. Для зручності таблицю з результатами можна вивантажити в форматі .CSV.Помилки при роботі з семантичним ядром h3>
Як і в будь-якій справі, при роботі з семантичним ядром можна зіткнутися з деякими помилками.
Помилка 1: комерційні та інформаційні запити ведуть на одну сторінку strong>. Так ви ніколи не будете в ТОПі за запитом не того виду, оскільки у користувача інша суть питання і видача вже зайнята сторінками з найкращою відповіддю відповідного виду.
Як виправити: для таких запитів повинні бути зроблені окремі посадкові сторінки. Отже, запити « купити samsung galaxy s21 » і « samsung galaxy s21 розпакування » повинні вести на абсолютно різні сторінки.
Помилка 2: одна сторінка для регіональних представництв. Якщо у вас є представництва в різних регіонах, для просування в інших містах потрібно створювати окремі сторінки. Різні геозалежні запити показують різні результати, тому для кожного міста потрібна своя сторінка і відповідна інформація.
Як виправити: для кожного регіонального представництва потрібно створити окрему сторінку. Якщо сторінка відповідає магазину в Києві, то ні в якому разі не можна залишати для неї запити за типом « купити холодильник Харків » і навпаки. При такому розкладі ви не будете в ТОПі видачі.
Помилка 3. для всіх запитів – одна відповідь. До вас можуть потрапляти комерційні та інформаційні запити.
Як виправити: необхідно зробити перевірку — введіть ключову фразу в пошуковий рядок і поспостерігайте за результатом. Якщо більшість сторінок комерційні, значить користувачам необхідна комерційна відповідь, і навпаки: якщо 8 з 10 запитів інформаційні — варто підігнати інформацію під цей тип.
Пам’ятайте про потреби користувача, адже запит може бути не повністю комерційним або інформаційним, а на 70% або 80%.
Помилка 4: не відповідають мовній версії запиту. Не залишайте запити, які не відповідають мовній версії сторінки.
Як виправити: для просування на інших мовах доведеться створити окремі лендінги.
В іншому випадку ваш сайт не зможе бути в ТОПі видачі.Помилка 5: нехтування створенням нових посадкових сторінок. Визначення в потрібності нових посадкових – одна з цілей створення семантичного ядра. Якщо існує безліч запитів, відмінних від вихідного, є сенс задуматися про створення посадкової сторінки.
Як виправити: щоб перевірити необхідність створення окремої посадкової сторінки, введіть запит подібного виду в видачу і перевірте її. Якщо на верхніх рядках з’являються сторінки конкурентів з такими сторінками – робіть окрему посадкову сторінку на своєму сайті. Якщо з’являються тільки картки товарів – окремо створювати посадкову не треба.
З яким обмеженнями можна зіткнутися h3>
З огляду на нюанси сервісу зі збору семантичного ядра, ви зможете убезпечити себе від помилок. По-перше, переконайтеся, що токен для доступу до API Serpstat робочий і містить достатню кількість лімітів. По-друге, запам’ятайте, що запит для пошуку знаходиться в базі Serpstat.
І, по-третє, – чим більше вкажете перетинів, тим релевантні і чистіше буде список пошукових запитів.Знаючи всі нюанси й використавши наш сервіс зі збору семантичного ядра, ви зможете обійти конкурентів і отримати максимум конверсії.
 Для зручності таблицю з результатами можна вивантажити в форматі .CSV.
Для зручності таблицю з результатами можна вивантажити в форматі .CSV.
 В іншому випадку ваш сайт не зможе бути в ТОПі видачі.
В іншому випадку ваш сайт не зможе бути в ТОПі видачі. І, по-третє, – чим більше вкажете перетинів, тим релевантні і чистіше буде список пошукових запитів.
І, по-третє, – чим більше вкажете перетинів, тим релевантні і чистіше буде список пошукових запитів.Семантическое ядро с ручной кластеризацией за 50$, фрилансер Юлия (SEO-1) — Kwork
Неограниченное количество бесплатных доработок в рамках начального объема вашего заказа. Вы будете платить только за изменения, которые превышают ваши первоначальные требования. Узнать больше
К сожалению, продавец приостановил продажу данного кворка.
Найдите похожие услуги в категории «Анализ ключевых слов».
SEO-1
- 4.9
- (55)
К сожалению, продавец приостановил продажу данного кворка.
Найдите похожие услуги в категории «Анализ ключевых слов».
Кворк Обзор
Предлагаю услугу по составлению семантического ядра для готового или нового сайта.
Семантическое ядро — это набор слов и словосочетаний, которые пользователи вводят для поиска необходимой им информации.
Что даст семантика вашему сайту?
Пользователи будут приходить на ваш сайт по предложенным словам. Google подскажет нам эти слова. Моя задача правильно собрать семантику и распределить ее по разделам и страницам сайта.
Тогда ваш сайт сможет получить максимальное количество трафика от Google.
Что входит в кворк?
- Сбор всех ключевых слов по вашей теме (до 1000 ключевых слов).
- очистка неактуальных запросов, пустышек и дубликатов, вы платите только за уникальные и полезные ключи.
- ручная группировка ключей (кластеризация).
- Группировка ключевых слов и фраз основана на логике и значении. Вы получите максимальное целевое ядро, сгруппированное в кластеры по смысловой составляющей (включая все интенты).
Мой опыт
Большой опыт, более 10 лет в SEO.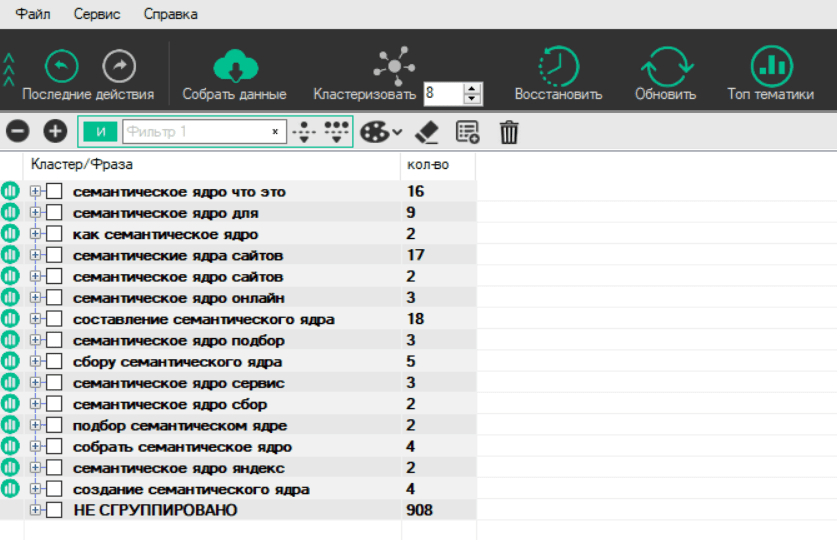 Индивидуальный подход к каждому проекту, согласование всех нюансов.
Индивидуальный подход к каждому проекту, согласование всех нюансов.
Предлагаю услугу по составлению семантического ядра для готового или нового сайта.
Семантическое ядро — это набор слов и словосочетаний, которые пользователи вводят для поиска нужной им информации.
Что даст семантика вашему сайту?
Пользователи будут приходить на ваш сайт по предложенным словам. Google подскажет нам эти слова. Моя задача правильно собрать семантику и распределить ее по разделам и страницам сайта.
Тогда ваш сайт сможет получить максимальный объем трафика от Google.
Что входит в кворк?
- сбор всех ключевых слов по вашей теме (до 1000 ключевых слов) .
- очищая неактуальные запросы, пустышки и дубликаты, вы платите только за уникальные и полезные ключи.
- ручная группировка ключей (кластеризация).
- Группировка ключевых слов и фраз основана на логике и значении. Вы получите максимальное целевое ядро, сгруппированное в кластеры по смысловой составляющей (включая все интенты).
 Вы получите максимальное целевое ядро, сгруппированное в кластеры по смысловой составляющей (включая все интенты).
Вы получите максимальное целевое ядро, сгруппированное в кластеры по смысловой составляющей (включая все интенты).Мой опыт
Большой опыт, более 10 лет в SEO. Индивидуальный подход к каждому проекту, согласование всех нюансов.
Целевой язык:
Объем этого kwork: 1 000 ключевых слов
Раскрыть Скрыть
Гарантия возврата денег
Мы обещаем отличный опыт заказа или
ваши деньги обратно. Как это работает?
Поделиться в социальных сетях
Семантическое управление веб-сервисами с использованием базовой онтологии сервисов
Семантическое управление веб-сервисами с использованием базовой онтологии сервисов Различные стандарты веб-служб, такие как WSDL, WS-Security, WS-Policy и т. д., далее именуемые WS*, делят задачи управления веб-службами на различные аспекты, такие как ввод/вывод, рабочий процесс или безопасность. Преимущества WS* многочисленны и уже достигли промышленного значения. Описания WS* взаимозаменяемы, и разработчики могут использовать разные реализации для одного и того же описания веб-службы. Недостатки WS*, однако, также очевидны: хотя разные стандарты дополняют друг друга, они должны перекрываться, и можно создавать модели, составленные из разных описаний WS*, которые несовместимы друг с другом, но причины несоответствий не ясны. легко определяется. Это происходит потому, что не существует согласованной концептуальной модели WS*, т. е. термины с эквивалентной семантикой вводятся по-разному в соответствующих XML-DTD. Таким образом, невозможно требовать выводов, полученных в результате объединения различных описаний WS*. Следовательно, обнаружение таких проблем управления веб-службой или запрос других подобных выводов, полученных в результате интеграции описаний WS*, остается чисто ручной задачей, которую должны выполнять разработчики программного обеспечения, практически не используя формального механизма.
Описания WS* взаимозаменяемы, и разработчики могут использовать разные реализации для одного и того же описания веб-службы. Недостатки WS*, однако, также очевидны: хотя разные стандарты дополняют друг друга, они должны перекрываться, и можно создавать модели, составленные из разных описаний WS*, которые несовместимы друг с другом, но причины несоответствий не ясны. легко определяется. Это происходит потому, что не существует согласованной концептуальной модели WS*, т. е. термины с эквивалентной семантикой вводятся по-разному в соответствующих XML-DTD. Таким образом, невозможно требовать выводов, полученных в результате объединения различных описаний WS*. Следовательно, обнаружение таких проблем управления веб-службой или запрос других подобных выводов, полученных в результате интеграции описаний WS*, остается чисто ручной задачей, которую должны выполнять разработчики программного обеспечения, практически не используя формального механизма.
Исследователи, изучающие семантические веб-сервисы, четко сформулировали эти недостатки стандартизации WS* и представили подходы к устранению некоторых из них [6]. Суть их предложений заключается в создании семантических стандартов, их основной целью является далеко идущая формализация, позволяющая полностью автоматизировать задачи управления веб-сервисами, такие как обнаружение и составление. Опять же, потенциальные преимущества очевидны; недостатки, однако, также очевидны: неясно, какой мощный механизм мог бы составить семантическую модель, допускающую полную автоматизацию, и действительно, такая полная автоматизация, похоже, выходит за рамки реальных программных приложений в обозримом будущем.
Суть их предложений заключается в создании семантических стандартов, их основной целью является далеко идущая формализация, позволяющая полностью автоматизировать задачи управления веб-сервисами, такие как обнаружение и составление. Опять же, потенциальные преимущества очевидны; недостатки, однако, также очевидны: неясно, какой мощный механизм мог бы составить семантическую модель, допускающую полную автоматизацию, и действительно, такая полная автоматизация, похоже, выходит за рамки реальных программных приложений в обозримом будущем.
Таким образом, мы постулируем, что семантическое управление веб-службами не должно стремиться к полной автоматизации всех задач управления веб-службами в качестве своей цели, поскольку это требует слишком глубокого понимания мира, чтобы его можно было моделировать в явном виде. Вместо этого мы предвидим более пассивную роль семантического управления веб-сервисами. Тот, который обусловлен потребностями разработчиков, которые должны справляться со сложностью интеграции веб-сервисов и описаниями WS*. Они могли бы использовать ценные инструменты для интеграции ранее разделенных аспектов. Таким образом, семантическое управление веб-службами также использовалось в качестве примера для примечания W3C Целевой группы по разработке программного обеспечения.
Они могли бы использовать ценные инструменты для интеграции ранее разделенных аспектов. Таким образом, семантическое управление веб-службами также использовалось в качестве примера для примечания W3C Целевой группы по разработке программного обеспечения.
Цели, к которым должно стремиться это семантическое управление, ограничены компромиссом между затратами усилий на управление веб-службами и затратами усилий на семантическое моделирование веб-служб. Компромисс качественно показан на рис. 1. Цель полной автоматизации с помощью семантического моделирования потребует очень мелкозернистого, подробного моделирования всех аспектов веб-сервисов — практически всего, что должен знать интеллектуальный человек. Таким образом, усилия по моделированию резко возрастают в конце мелкозернистого моделирования. С другой стороны, там, где моделирование очень грубое и слабое моделирование облегчает управление, усилия по управлению распределенными системами резко возрастают, как показывает опыт прошлого.
Мы реализуем наш подход с помощью комплексной онтологии для моделирования сервисов и задач управления сервисами, Core Ontology of Services (CoS), основанной на основополагающей онтологии DOLCE [11]. Мы не рассматриваем CoS как стандарт, но понимаем его как чистую справочную онтологию для устранения неоднозначности перегруженных терминов, таких как веб-служба.
Оставшаяся часть этого документа состоит из разделов, содержащих обсуждение вариантов использования, некоторые замечания о CoS, описание прототипа, связанную работу и выводы.
Чтобы воспользоваться преимуществами компромисса, показанного на рис. 1, потенциальные варианты приложений должны приблизиться к точке минимальных общих усилий. Мы определили и проанализировали ряд вариантов использования, которые можно ожидать от семантического управления с использованием нашего подхода. Они также позволяют нам отличить семантическое управление от других задач, связанных с разработкой веб-сервисов, и от полной автоматизации, как постулируется семантическими веб-сервисами. Подробное изложение нашего анализа дано в [9].], а мы ограничимся кратким обсуждением нескольких примеров.
1, потенциальные варианты приложений должны приблизиться к точке минимальных общих усилий. Мы определили и проанализировали ряд вариантов использования, которые можно ожидать от семантического управления с использованием нашего подхода. Они также позволяют нам отличить семантическое управление от других задач, связанных с разработкой веб-сервисов, и от полной автоматизации, как постулируется семантическими веб-сервисами. Подробное изложение нашего анализа дано в [9].], а мы ограничимся кратким обсуждением нескольких примеров.
Обнаружение циклов в цепочке вызовов
Приложения на основе веб-служб обычно используют асинхронный обмен сообщениями, что приводит к возникновению сложных протоколов взаимодействия между деловыми партнерами. Существующие инструментальные средства проектирования рабочих процессов только визуализируют локальный поток и оставляют согласование сообщений с деловыми партнерами на усмотрение разработчика. Мы считаем, что в машиночитаемом формате доступно достаточно информации, чтобы инструмент мог помочь разработчику в оценке глобального потока. Например, структура локального потока может быть объединена с общедоступными абстрактными потоками партнеров для обнаружения петель в цепочке вызовов, которые могут привести к незавершению работы системы.
Например, структура локального потока может быть объединена с общедоступными абстрактными потоками партнеров для обнаружения петель в цепочке вызовов, которые могут привести к незавершению работы системы.Несовместимые входы и выходы
Проверка типов уже не так проста, если использовать слабосвязанные сервисы, которыми управляет большое количество организаций. Кроме того, интерпретация термина B2B, такого как «цена», может быть различной, даже если синтаксически он относится к согласованному типу XML-схемы. Например, у разных партнеров могут быть разные предположения о валюте и деталях налогообложения. Система, которая автоматически сравнивает входы и выходы связи в соответствии с более подробной моделью, поможет предотвратить неожиданное поведение в системе.Управление изменениями
Система, которая больше не находится под жестким контролем одного организационного подразделения, определенно будет подвержена проблемам с версиями служб. Обновление одного компонента уже требует тесного сотрудничества между участвующими сторонами, и это, без сомнения, будет намного сложнее в приложениях на основе веб-сервисов.
Агрегирование служебной информации
Службы часто будут реализованы на основе других служб. Поставщик услуг публикует информацию о своих услугах. Сюда могут входить соглашения об уровне обслуживания с указанием гарантированного времени отклика в наихудшем случае, стоимости услуги или средних показателей доступности. Запрашивающая услуга, в данном случае разрабатываемая составная услуга, может собирать эту информацию от соответствующих поставщиков услуг. В свою очередь, он предлагает услугу и должен публиковать аналогичные номера. Мы предполагаем инструмент, который поможет администратору предоставить первую часть этих данных путем агрегирования данных, собранных от внешних поставщиков.Другие варианты использования
которые подробно описаны в [9], включают анализ контекстов сообщений, выбор функциональных возможностей и политик обслуживания, сопоставление параметров связи и анализ качества обслуживания. Только что рассмотренные варианты использования показывают, что мы хотим облегчить выполнение задач управления, охватывающих широкий спектр аспектов. Таким образом, лежащая в основе онтология должна обеспечивать возможность моделирования таких разнообразных аспектов, как профили услуг, таксономии услуг, политики, информация о рабочих процессах, описания интерфейсов и информация о качестве услуг. Мы также стремимся согласовать неявные, но достаточно схожие концептуальные модели, лежащие в основе всех усилий по WS*.
Только что рассмотренные варианты использования показывают, что мы хотим облегчить выполнение задач управления, охватывающих широкий спектр аспектов. Таким образом, лежащая в основе онтология должна обеспечивать возможность моделирования таких разнообразных аспектов, как профили услуг, таксономии услуг, политики, информация о рабочих процессах, описания интерфейсов и информация о качестве услуг. Мы также стремимся согласовать неявные, но достаточно схожие концептуальные модели, лежащие в основе всех усилий по WS*.
На рис. 2 показан тщательно продуманный набор онтологий, которые мы повторно использовали и создали соответственно. Он состоит из базовой онтологии DOLCE [11], онтологических модулей для контекстного моделирования (Descriptions & Situations [3]) и планов (Ontology of Plans [2]). Все три используются для формулирования основной онтологии услуг 2 , который моделирует услуги и их взаимосвязи независимым от домена способом. Наконец, онтологии предметной области специализируют концепции, ассоциации и аксиомы в конкретных условиях. За подробностями читатель вновь отсылается к [9].
Роль базовой онтологии сервисов по отношению к существующим усилиям, таким как OWL-S [13] или WSMO [1], где предполагаемое значение терминов часто неоднозначно, заключается в обоснованном наименьшем общем знаменателе. Существующие усилия могут быть приведены в соответствие с этой онтологией и, таким образом, согласованы.
Наш подход использует инфраструктуру веб-служб и онтологий KAON SERVER в качестве основы для семантического управления веб-службами. Существующие описания WS* по-прежнему передаются в соответствующие механизмы для обеспечения безопасности, транзакций или рабочего процесса. Разработчику еще необходимо ознакомиться и работать с описаниями WS*.
Однако мы берем описания WS* за основу, т. е. анализируем их, извлекаем соответствующую информацию и интегрируем их как экземпляры в нашу онтологию. Аналогичным образом можно использовать уже используемые программный код и инструменты моделирования. В результате разработчик может запросить и обосновать согласованную концептуальную модель, охватывающую несколько аспектов (рис. 3).
В качестве примера вывода, полученного из описания BPEL и WS-Policy, рассмотрим следующий случай. Предположим, что интернет-магазин реализован с внутренними и внешними веб-сервисами, составленными и управляемыми механизмом BPEL.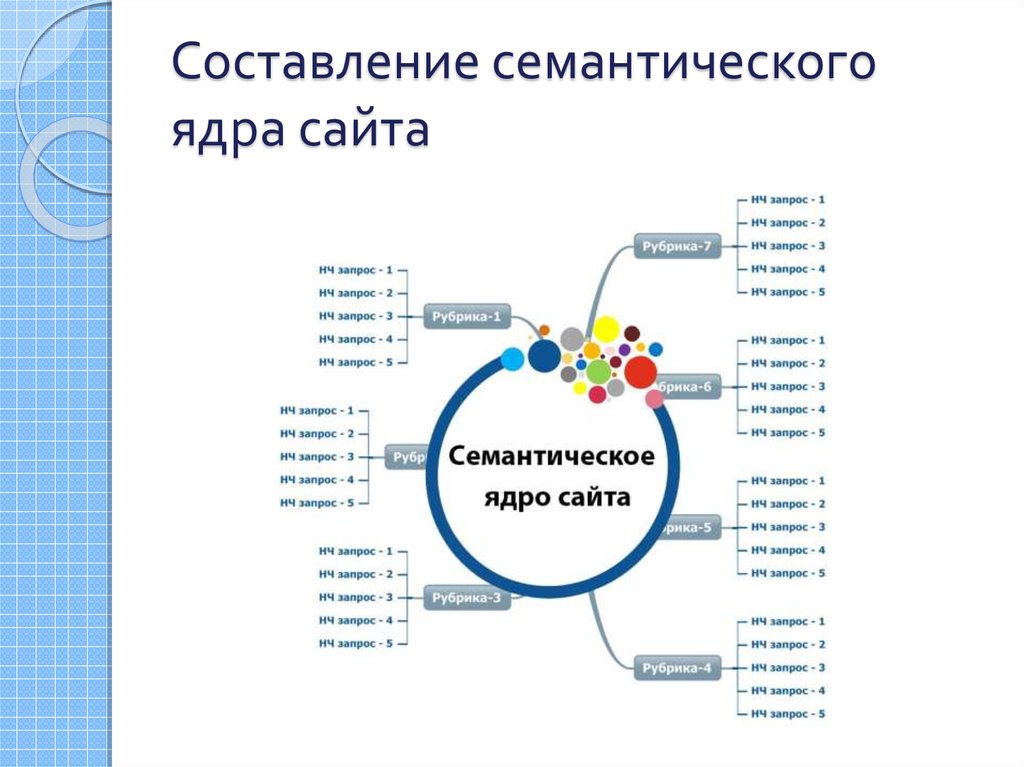 После отправки заказа процесс BPEL проверяет кредитную карту клиента на действительность в зависимости от типа кредитной карты (VISA, MasterCard и т. д.). Мы предполагаем, что поставщики кредитных карт предлагают эту функцию через веб-службы. Таким образом, соответствующий BPEL-процесс checkAccount вызывает одну из веб-служб провайдера в зависимости от кредитной карты клиента.
После отправки заказа процесс BPEL проверяет кредитную карту клиента на действительность в зависимости от типа кредитной карты (VISA, MasterCard и т. д.). Мы предполагаем, что поставщики кредитных карт предлагают эту функцию через веб-службы. Таким образом, соответствующий BPEL-процесс checkAccount вызывает одну из веб-служб провайдера в зависимости от кредитной карты клиента.
Теперь предположим, что веб-служба одного поставщика кредитных карт, скажем, MasterCard, принимает только аутентифицированные вызовы, соответствующие Kerberos или X509. Такие политики указаны в соответствующем документе WS-Policy. Вызов завершится ошибкой, если разработчик не обеспечит соблюдение политик. Это означает, что разработчик должен проверять политики вручную во время разработки или должен реализовать эту функцию, чтобы реагировать на политики во время выполнения.
Поскольку информацию о процессах и политиках можно разобрать, проанализировать и интегрировать в нашу онтологию, проверка существования внешних политик сводится к простому запросу. Без нашего подхода разработчику пришлось бы собирать и проверять эту информацию вручную, анализируя документы BPEL и WS-Policy. Как мы можем понять из этого небольшого примера, желательно запросить систему для семантического управления, а не вручную проверять сложный набор определений процессов. Мы можем придумать более сложные примеры, когда мы запрашиваем определенные ограничения политики или когда у нас есть большие косвенные каскады процессов.
Без нашего подхода разработчику пришлось бы собирать и проверять эту информацию вручную, анализируя документы BPEL и WS-Policy. Как мы можем понять из этого небольшого примера, желательно запросить систему для семантического управления, а не вручную проверять сложный набор определений процессов. Мы можем придумать более сложные примеры, когда мы запрашиваем определенные ограничения политики или когда у нас есть большие косвенные каскады процессов.
Разработчикам приходится сталкиваться с множеством спецификаций WS*, таких как WSDL, WS-Policy, WS-Coordinate, WS-Transaction или BPEL. Из-за их огромного количества и разрозненности управление веб-службами с помощью WS* требует от разработчика значительных усилий по управлению. Не существует согласованной формальной модели WS* и нет средств запрашивать, возможно, нежелательные выводы, возникающие в результате интеграции нескольких описаний WS*.
Тем не менее, в настоящее время возникает несколько семантических стандартов в области исследований, которую часто называют «семантической веб-службой» [6].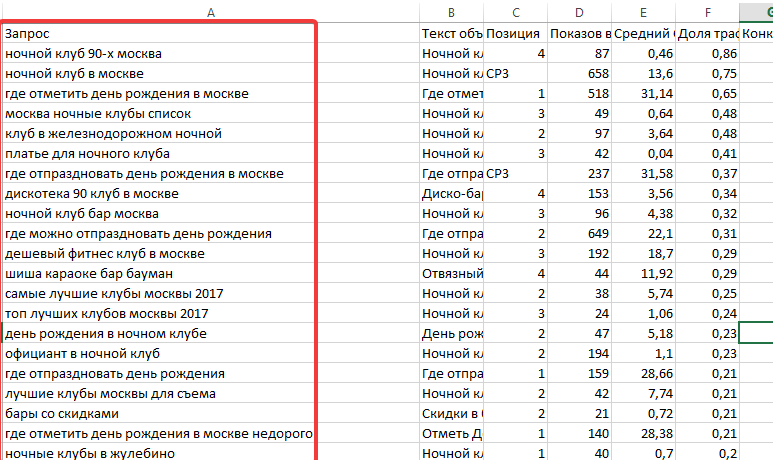 В отличие от нашего подхода, они нацелены на полную автоматизацию вызова, обнаружения и составления веб-сервисов. Однако общие языки онтологии обычно недостаточно выразительны для достижения этих целей. Например. [6] использует логику описания, расширенную Golog для автоматизации задач планирования. Golog — это язык программирования высокого уровня, основанный на ситуационном исчислении. Кроме того, цель полной автоматизации с помощью семантического моделирования потребует очень мелкозернистого, детального моделирования всех аспектов веб-сервисов, что приведет к высоким затратам на моделирование. Наш подход находится между двумя крайностями WS* и семантическими стандартами и находит хороший компромисс между затратами на моделирование и управление. В следующем абзаце обсуждаются некоторые семантические усилия.
В отличие от нашего подхода, они нацелены на полную автоматизацию вызова, обнаружения и составления веб-сервисов. Однако общие языки онтологии обычно недостаточно выразительны для достижения этих целей. Например. [6] использует логику описания, расширенную Golog для автоматизации задач планирования. Golog — это язык программирования высокого уровня, основанный на ситуационном исчислении. Кроме того, цель полной автоматизации с помощью семантического моделирования потребует очень мелкозернистого, детального моделирования всех аспектов веб-сервисов, что приведет к высоким затратам на моделирование. Наш подход находится между двумя крайностями WS* и семантическими стандартами и находит хороший компромисс между затратами на моделирование и управление. В следующем абзаце обсуждаются некоторые семантические усилия.
Например, два подхода пытаются внедрить семантическую технологию в UDDI. Первый, [14], предлагает таксономическую поддержку семантики в реестре. Основная цель состоит в том, чтобы обеспечить лучшее обнаружение и сопоставление за счет использования семантических описаний. Второй пытается достичь аналогичных целей путем включения профилей OWL-S в реестр UDDI [12]. OWL-S 5 — одна из первых основных онтологий, явно нацеленных на автоматическое обнаружение, автоматический вызов, автоматическую композицию и взаимодействие, а также автоматическое выполнение веб-сервисов. Онтология моделирования веб-сервисов (WSMO) [1] имеет цели, аналогичные OWL-S. Однако он дополнительно определяет среду выполнения (WSMX) для динамического обнаружения, выбора, посредничества, вызова и взаимодействия семантических веб-служб. [5] принимают во внимание, что большая часть семантических усилий была оторвана от появляющихся стандартов WS*. Следовательно, они предлагают восходящий подход к обогащению BPEL семантикой. Однако они также пытаются включить автоматическое обнаружение, настройку и семантический перевод служб.
Второй пытается достичь аналогичных целей путем включения профилей OWL-S в реестр UDDI [12]. OWL-S 5 — одна из первых основных онтологий, явно нацеленных на автоматическое обнаружение, автоматический вызов, автоматическую композицию и взаимодействие, а также автоматическое выполнение веб-сервисов. Онтология моделирования веб-сервисов (WSMO) [1] имеет цели, аналогичные OWL-S. Однако он дополнительно определяет среду выполнения (WSMX) для динамического обнаружения, выбора, посредничества, вызова и взаимодействия семантических веб-служб. [5] принимают во внимание, что большая часть семантических усилий была оторвана от появляющихся стандартов WS*. Следовательно, они предлагают восходящий подход к обогащению BPEL семантикой. Однако они также пытаются включить автоматическое обнаружение, настройку и семантический перевод служб.
В определенном смысле наш подход похож на то, как решается задача в инженерии, управляемой моделями (MDE), а именно. абстрагируя моделирование некоторых частей архитектуры, сохраняя при этом полный контроль за инженером-программистом. Однако MDE/MDA 6 и семантическое управление различаются, поскольку последнее представляет собой точную, формальную исполняемую модель, которую можно использовать не только во время компиляции (как MDE/MDA), но также для горячего развертывания или во время выполнения. Действительно, основная идея MDA состоит в том, чтобы отделить концептуальные проблемы, например, какой компонент использует какой другой компонент, от проблем, связанных с реализацией, таких как какая версия интерфейса приложения требует каких версий библиотек Windows. MDA достигает этого разделения, разлагая две задачи на множители, указывая их отдельно и компилируя их в исполняемый файл. Несмотря на то, что MDA уже обеспечивает концептуальное моделирование для улучшения управления сложными системами, MDA имеет два недостатка. Во-первых, MDA требует этапа компиляции, предотвращающего изменения во время выполнения, которые характерны для программного обеспечения сервера приложений. Во-вторых, сам MDA не может подвергаться сомнению или анализу.
Однако MDE/MDA 6 и семантическое управление различаются, поскольку последнее представляет собой точную, формальную исполняемую модель, которую можно использовать не только во время компиляции (как MDE/MDA), но также для горячего развертывания или во время выполнения. Действительно, основная идея MDA состоит в том, чтобы отделить концептуальные проблемы, например, какой компонент использует какой другой компонент, от проблем, связанных с реализацией, таких как какая версия интерфейса приложения требует каких версий библиотек Windows. MDA достигает этого разделения, разлагая две задачи на множители, указывая их отдельно и компилируя их в исполняемый файл. Несмотря на то, что MDA уже обеспечивает концептуальное моделирование для улучшения управления сложными системами, MDA имеет два недостатка. Во-первых, MDA требует этапа компиляции, предотвращающего изменения во время выполнения, которые характерны для программного обеспечения сервера приложений. Во-вторых, сам MDA не может подвергаться сомнению или анализу. Следовательно, нет возможности спросить систему, действительна ли какая-то конфигурация или нужны ли дополнительные компоненты.
Следовательно, нет возможности спросить систему, действительна ли какая-то конфигурация или нужны ли дополнительные компоненты.
Наш подход также дополняет возникающие в настоящее время спецификации управления в сообществе веб-сервисов. Во-первых, OASIS работает над распределенным управлением веб-сервисами 7 . Во-вторых, WS-Management от IBM и других компаний представляет собой конкурирующую спецификацию с аналогичными целями. Оба варианта использования частично совпадают с нашим подходом, но они могут значительно выиграть от семантической технологии.
Мы показали, какой вклад семантическое управление веб-службами может внести в общее управление веб-службами. Мы описали варианты использования для семантического управления веб-службами, которые могут быть реализованы с помощью существующих технологий и которые обеспечивают немедленную пользу их целевым группам, то есть разработчикам программного обеспечения и администраторам, которые имеют дело с веб-службами. Варианты использования показали, что семантические описания могут играть плодотворную роль в поддержке интегрированного представления определений веб-служб в WS*. В основу интеграции мы положили Core Ontology of Services.
Варианты использования показали, что семантические описания могут играть плодотворную роль в поддержке интегрированного представления определений веб-служб в WS*. В основу интеграции мы положили Core Ontology of Services.
Несмотря на то, что мы внедрили прототип в качестве доказательства концепции нашего подхода, в долгосрочной перспективе жизнеспособность и успех семантических описаний будут проявляться только в их успешном использовании в интегрированных средах разработки и выполнения. Разработка соответствующей парадигмы семантического управления веб-сервисами посредством вариантов использования, онтологий, прототипов и примеров является важным шагом в этом направлении.
Версия этого документа в формате pdf доступна на веб-страницах авторов по адресу http://www.aifb.uni-karlsruhe.de/WBS/dob/pubs/icws2005.pdf. Статья основана главным образом на [9]. Базовая онтология сервисов доступна по адресу http://cos.ontoware.org. Реализация прототипа доступна на http://kaon. semanticweb.org/server.
semanticweb.org/server.
- 1
- Дитер Фензель и Кристоф Басслер.
Платформа моделирования веб-служб WSMF.
Электронная коммерция: исследования и приложения , 1:113-137, 2002. - 2
- Альдо Гангеми, Стефано Борго, Карола Катеначчи и Джос Леманн.
Таксономии задач для содержания знаний.
Поставка Metokis d07, июнь 2004 г. - 3
- Альдо Гангеми и Питер Мика.
Понимание семантической сети через описания и ситуации.
В DOA/CoopIS/ODBASE 2003 Proceedings , LNCS. Спрингер, 2003. - 4
- Альдо Гангеми, Питер Мика, Марта Сабу и Даниэль Оберле.
Онтология сервисов и описания сервисов.
Технический отчет, Лаборатория прикладной онтологии (ISTC-CNR), Viale Marx, 15, 00137 Roma, 2003. - 5
- Дэниел Дж. Манделл и Шейла Макилрайт.
Адаптация BPEL4WS для семантической сети: восходящий подход к взаимодействию веб-сервисов.
В 2-й межд. Semantic Web Conference , том 2870 из LNCS , страницы 227-247. Спрингер, 2003. - 6
- Шейла А. Макилрайт, Тран Цао Сон и Хунлей Цзэн.
Семантические веб-сервисы.
Интеллектуальные системы IEEE , 16(2):46-53, март 2001 г. - 7
- Питер Мика, Даниэль Оберле, Альдо Гангеми и Марта Сабу.
Основы сервисных онтологий: согласование OWL-S с DOLCE.
В Материалы 13-й Международной конференции по всемирной паутине , страницы 563-572. АКМ, май 2004 г. - 8
- Даниэль Оберле, Андреас Эберхарт, Штеффен Стааб и Рафаэль Фольц.
Разработка и управление программными компонентами на сервере приложений на основе онтологий.
В 5-й Международной конференции по промежуточному программному обеспечению , LNCS. Спрингер, 2004. - 9
- Даниэль Оберле, Штеффен Лампартер, Андреас Эберхарт и Штеффен Стааб.
Семантическое управление веб-сервисами.
Технический отчет, Университет Карлсруэ, 2005 г.
http://www.aifb.uni-karlsruhe.de/WBS/dob/icws2005.pdf. - 10
- Даниэль Оберле, Штеффен Стааб, Руди Штудер и Рафаэль Фольц.
Поддержка разработки приложений в семантической сети.
ACM Transactions on Internet Technology (TOIT) , 4(4), ноябрь 2004 г. - 11
- А. Олтрамари, А. Гангеми, Н. Гуарино и К. Мазоло.
Подсластить онтологии с помощью DOLCE.
В Ontologies and the Semantic Web, 13th Int. Конференция, EKAW 2002, Труды , 2002. - 12
- Массимо Паолуччи, Такахиро Кавамура, Терри Р. Пейн и Катя П. Сикара.
Импорт Semantic Web в UDDI.
В CAiSE 2002 International Workshop, WES 2002 , страницы 225-236, 2002. - 13
- Коалиция служб DAML.
Черновой выпуск OWL-S 1.0.
http://www.daml.org/services/owl-s/1.0/, декабрь 2003 г. - 14
- Макс Воскоб.
Требование UDDI Spec TC V4 — поддержка таксономии для семантики.
OASIS, 2004.
http://www.oasis-open.org.



Сноски
- Даниэль Оберле получает поддержку Федерального министерства образования и исследований Германии (BMBF) в рамках проекта SmartWeb.
- Штеффен Лампартер поддерживается Немецким исследовательским фондом в Высшей школе управления информацией и рыночной инженерии (грант DFG № GRK 89).5).
- Судхир Агарвал работает при поддержке Федерального министерства образования и исследований Германии (BMBF) в рамках интернет-экономического проекта SESAM.
- Stephan Grimm поддерживается Европейским Союзом в рамках проекта IST DIP (№ FP6 — 507483).
- # Паскаль Хитцлер поддерживается Федеральным министерством образования и исследований Германии (BMBF) в рамках проекта SmartWeb и Европейским союзом в рамках сети передового опыта KnowledgeWeb.
- 1 http://www.w3.org/2001/ws/BestPractices/SE/ODA/
- 2 Поддерживается на http://cos.
- Штеффен Лампартер поддерживается Немецким исследовательским фондом в Высшей школе управления информацией и рыночной инженерии (грант DFG № GRK 89).5).
