
Как правильно «готовить» искусственную семантику для рекламной кампании в Яндекс Директе — Маркетинг на vc.ru
1722 просмотров
Говорят, что искусственная семантика — это зло либо развод на деньги. Можно найти немало статей о печальном опыте применения искусственной семантики, более того — такой опыт есть и у нас! Но если подумать — окажется, что здесь все, как с картошкой.
Когда картофель завезли в Европу, он стал невероятно модным, но его никто не ел. Поначалу пробовали варить траву — редкая гадость! Тогда картофель стали воспринимать как декоративный цветок, и благородные дамы украшали им волосы и собирали пышные букеты. Клубни картофеля пугали народ, их считали не просто невкусными, но даже вредными и опасными.
Ученым и журналистам пришлось сильно потрудиться, чтобы убедить население употреблять в пищу клубни картофеля, а «вершки» оставить в покое. Эта рекламная кампания заняла около 100 лет. Надеюсь, современные технологии сэкономят нам время, и мы научимся применять метод искусственной семантики быстрее.
Коротко о том, что такое искусственная семантика
Искусственная семантика (далее — ИС) — это метод пересечения слов внутри ключевой фразы друг с другом так, чтобы получились уникальные длинные запросы.
Каждая ключевая фраза представляет собой некоторую синтаксическую конструкцию, в которой чаще всего мы имеем цепочку типа:
глагол _ объект поиска _ признак _ стоимость _ место
Например:
купить _ ванну _ белую _ недорого _ в Спб
Допустим, что в нашем магазине продаются не только ванны, но и раковины, душевые кабины и прочие биде. Не только белые, но и черные, красные, синие. Не только «недорого», но и «дешево», «цены», «стоимость». Продаем не только в «Спб», но и в Выборге.
Далее мы можем составить таблицу следующего вида:
*Яндекс.Директ понимает, что начальная форма и согласованная (нормальная) — это одно и то же. Поэтому можно писать всё в начальной форме — так быстрее. Порядок слов тоже не важен, если вы не используете оператор [ ]
Затем мы проводим мультиплексирование — то есть пересекаем все слова из таблицы друг с другом, чтобы получить все варианты ключевых фраз. Это делается автоматически через сервисы группировки слов.
Это делается автоматически через сервисы группировки слов.
Процедуру повторить, до тех пор пока не исчерпаем всю смысловую цепочку, ведь какой-нибудь компонент может быть упущен — с 3-его по 5-ый.
В итоге за довольно короткий срок и небольшие интеллектуальные усилия (надо-то заранее цепочки прописать один раз) можно получить несколько десятков тысяч низкочастотных ключевых фраз То есть это много дешевого трафика!
Круто же?! Почти.Теперь поговорим о проблемах ИС.
За что не любят искусственную семантику
Несколько десятков тысяч ключевых фраз — это уже проблема. С ними крайне тяжело работать, и Директ давится от такого количества.
Вторая проблема — количество показов. Если у ключевой фразы будет статус «Мало показов» (0-1 в месяц), ваши объявления не будут показываться вообще. Трафика не будет.
Третья беда — написание объявлений. Только если вы абстрагируетесь от «ключей» и напишете их просто в порыве вдохновения. Ранее популярный метод «один ключ — одно объявление» несовместим с искусственной семантикой и жизнью.
Четвертая — составление групп объявлений. Если вы не отфильтруете запросы по частотности и просто попытаетесь загрузить их в Директ, вам придется разделять их на группы по 200 ключевых фраз на каждую, согласно правилам Яндекс.Директа. Когда у вас тысячи похожих по смыслу запросов — поверьте, это может стать проблемой.
В итоге, радость от простой и удобной мультиплексации сменяется адским трудом, зависшим Excel и неприятно удивленным Яндекс.Директом. Вы потратили кучу времени и усилий, но в результате не получите ни трафика, ни дешевых кликов. Обидно. Но, как и с картошкой, вы начинаете есть ИС не с того конца.
Как правильно применять метод искусственной семантики
Искусственная семантика помогает сделать две вещи:
- перебрать все возможные сочетания слов внутри ключевой фразы и ничего не упустить;
- составить максимально эффективные объявления, в которых вы сможете учесть максимум ключевых слов.
В сумме это дает максимально возможное количество «съедобного» для Директа низкочастотного целевого трафика и дешевые клики. Однако метод искусственной семантики применим не для всех сфер бизнеса и всегда требует проверки на частотность. Разбираемся, когда ИС полезна и почему.
Однако метод искусственной семантики применим не для всех сфер бизнеса и всегда требует проверки на частотность. Разбираемся, когда ИС полезна и почему.
Искусственная семантика удобна для запросов с деталями
Искусственная семантика будет полезна, если вы продаете товар, где много уточнений. Например, вы продаете машины одной марки, но разных моделей. Или разных марок и моделей. Или вы продаете много запчастей для машин разных марок и моделей. Или вы продаете много запчастей для машин разных марок и моделей в разных городах по всей стране.
Искусственная семантика поможет быстро перебрать все сочетания марки и модели машины с основной частью ключевого запроса, вместо того чтобы искать такие «ключевики» по отдельности в вордстате.
Статистика вордстата показывает, что люди часто уточняют модель автомобиля
Еще одна область, в которой множество значимых уточнений, — недвижимость. Количество комнат, формы оплаты, новостройка или вторичное жилье, город и район города, — все это важно для потенциальных покупателей.
Для недвижимости будет типична цепочка вида:
купить _ количество комнат _ квартиру _ форма оплаты _ первичка/вторичка _ город
Данные Яндекс.Метрики показывают, что по этому запросу за месяц на сайт пришло 39 посетителей
В вордстате по запросу «купить квартиру от застройщика в рассрочку на 5 лет в спб» — всего 2 показа в месяц по России. Однако контекстная реклама и искусственная семантика — единственная возможность привести пользователей на сайт именно по этому ключевому слову.
Если искать такие запросы в вордстате — гарантированно что-то упустите. Составлять их руками — легче застрелиться. Искусственная семантика позволяет собрать все возможные сочетания, примерно, за час работы вашего мозга.
Искусственная семантика применима там, где есть значимые для пользователя уточнения: по цвету, размеру или габаритам, геолокации, количеству (мест в палатке или хостеле, комнат в квартире), материала и т. д.
Искусственная семантика помогает составить эффективные объявления
Собрав все возможные сочетания основного слова со значимыми для пользователей уточнениями, нужно выполнить группировку и прогнать их через сервис проверки частотности.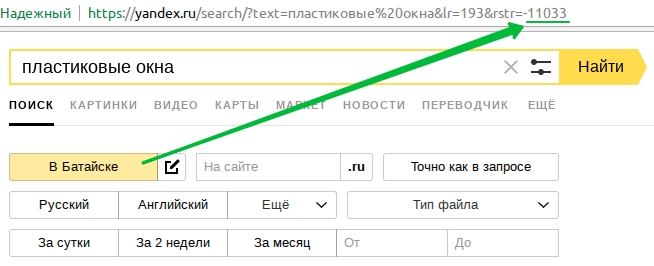 Все «0» — отметаем.
Все «0» — отметаем.
«Ватрушка» и «бублик» — абсолютные синонимы, их лучше разделить на разные группы, чтобы писать точные заголовки
Видя все уточнения сразу, несложно составить заголовки объявлений, в которых органически будет учтены всё: «Бублик для катания с горки, цена», «Ватрушка детская для катания с горки по снегу» (есть водные ватрушки, поэтому пишем «по снегу»).
В результате вы получаете объявление с высоким показателем эффективности Директа — это хорошо сказывается на показах, и Яндекс будет дополнительно подсвечивать совпавшие с запросом пользователя слова в выдаче.
Вставлять много ключей в заголовки и тексты объявлений, конечно, непросто и важно писать их «по-человечески», но не стоит это переоценивать. Просто понаблюдайте за собой: вот вы набрали запрос, кликнули по одной из верхних ссылок в выдаче, попали на сайт… Вы помните, что именно было написано в заголовке этой ссылки? Нет, не помните. Зато вы помните запрос, который вбили в поисковик, что-то вроде: «купить шины летние р15 хакапелита».
Не используйте искусственную семантику для брендовых запросов — для них лучше подойдет оператор Яндекс.Директа ( | )
По аналогии с моделями, марками, радиусами и прочим, многие пытаются использовать искусственную семантику для брендовых запросов. Не надо!
Более экономичным решением для формирования группы брендовых запросов (как своих, так и чужих) является не искусственная семантика, а оператор яндекса ( | )
Этот оператор позволяет указать несколько взаимозаменяемых слов через вертикальную черту и показывать их объявления из группы к любому из них. Например, мы делаем рекламу для Банка SIAB по брендовым запросам. Нам неважно, как пользователь напишет название компании — во всех объявлениях мы укажем правильный вариант.
С помощью этого оператора вы получите, например, такую группу ключевых фраз:
рко (банк сиаб | сиаб | siab | банк siab | санкт-петербургский индустриальный акционерный банк)
Или, если вы формируете группу ключевых фраз, чтобы показываться по запросам с упоминанием конкурентов, такую:
рко (альфа | альфа-банк | альфа банк | втб | сбер | ак барс | уралсиб)
Таким образом, вам нужно будет загрузить в Директ не 7 ключевых фраз, а всего одну с 7 вариантами через ( | ) — это гораздо быстрее и проще, чем делать то же самое методом искусственной семантики.
Использовать оператор ( | ) для абсолютных синонимов — плохая идея.
Непонятно, какой из синонимов писать в заголовке объявления. Если написать общую фразу, это снизит качество объявления — и ваш CTR уменьшится. Вы не сможете понять, какой из синонимов спрашивают чаще и какой из них лучше конвертирует.
Важные рекомендации
Ниже — выжимка основной части статьи и ряд правил, о которых нельзя забывать, какую бы рекламную кампании вы не настраивали.
- Всегда сначала смотрите естественную семантику. Она позволит вам найти синонимы и понять, какие стандартные элементы цепочки характерны для вашей области. Для некоторых сфер бизнеса не типичны длинные запросы.Составьте один длинный запрос и обратитесь к вордстату. Если там 0 показов — начните уменьшать «хвост» запроса по одному слову, пока не увидите нормальную частотность. Далее — пересекайте в рамках получившейся цепочки.Так, например, про город спрашивают реже, чем про районы города: все уже привыкли, что поисковики умеют определять геолокацию.

- Не составляйте слишком длинные цепочки и фразы: они должны умещаться в 7 слов и 4096 символов, включая минус-слова. Фразы с бо̀льшим количеством слов или символов Директ не понимает и «режет» по эти самые первые семь слов;
- Не загружайте фразы с «нулевой» частотностью. Очень хорошая частотность — от 10 показов в месяц по Яндекс вордстату;
- В каждой группе не должно быть более 200 ключевых фраз и 50 объявлений;
- Искусственная семантика хорошо работает для областей, где много уточнений, значимых для покупателя: марки и модели, габариты и размеры, цвета, формы оплаты и цены, локации и т. д. В сферах бизнеса, которые обслуживают потребности «здесь и сейчас» (такси, доставка пиццы, салоны красоты и т. д.) не только не поможет, но и навредит.

Семантика Яндекс Директ | Как собрать ключевые слова
Тема этой статьи — семантика Яндекс Директ, или как собрать ключевые слова.
Когда из ВШТ мне предложили написать серию статей о рекламе в Яндекс Директ, я задумался о глубине.
Дело в том, что я занырнул в контекст не так давно — учусь и усиленно погружаюсь, но вижу, что впереди еще глубина. И там еще кораллы, кракены и всякие формы жизни, которых создали алгоритмы природы.
Алгоритмы рекламных систем понятнее, но всегда можно напороться на (морского ежа) ряд тонкостей.
Я уже проходил подобное с таргетом пару лет назад, поэтому осознаю процесс погружения — приборы работают исправно))
И сейчас я на глубине исследователя. Это не гуру и не эксперт, но накапливать и систематизировать опыт это мое.
Будет полезно начинающим директологам, владельцам бизнеса, а также таргетологам, которые хотят уметь в контекст))
И в первой статье мы рассмотрим такую тему, как семантика Яндекс Директ — основная сложность была в ней.
1. Начинаем с азов. Мы хотим настраиваться по ключевым запросам, а какие они вообще бывают?Брендовые (по названию кампании)
Горячие (коммерческие) — со словами купить, цена и т.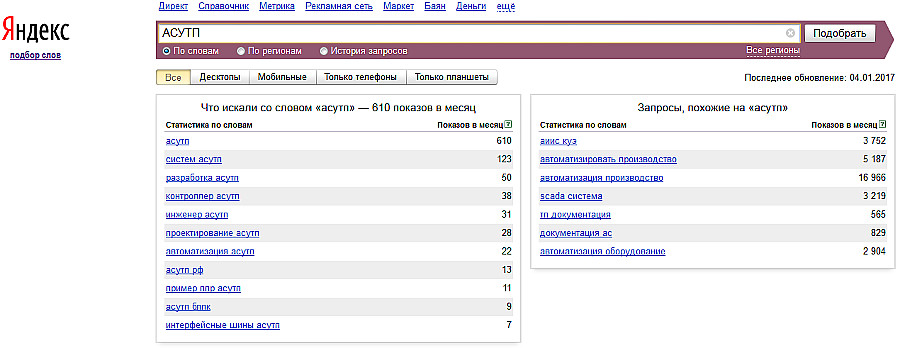 п. Например, «шелковое платье купить».
п. Например, «шелковое платье купить».
Внимание — с этими словами могут быть и информационные запросы, если цена периодически меняется — «золото цена сегодня». Такие запросы не всегда строго коммерческие, поэтому лучше их выносить в отдельную группу и тестировать.
Теплые (широкие тематические) — платье из шелка
Холодные (информационные) — как выбрать платье из шелка
Околоцелевые (косвенные) — туфли/аксессуары под вечернее платье. И т.п.
Ввели основной запрос в Вордстате
2. С какой частотой брать запросыВсе слова по частоте запросов делятся на 3 категории, в зависимости от того, как часто пользователи вводят их в поисковую строку:
А) Высокочастотные — ВЧ
Б) Среднечастотные — СЧ
В) Низкочастотные — НЧ
Частотность для каждой ниши и продукта определяется индивидуально, где-то это тысячи запросов, а где-то сотни или даже десятки.
В любом случае, как я понял, выгоднее брать ВЧ — по ним больше показов и в них входят и СЧ и в НЧ. Получается, в выдаче по ним мы можем быть не на 1 месте, а на 2-3, но количественно это гораздо выгоднее, чем быть на 1 по НЧ — раз их не ищут.
3. Хорошо, теперь как нам определить наши запросы и как вообще их сгруппировать?Здесь все зависит от нашего ассортимента и вариантов применения продукта.
Если у нас несколько категорий — по каждой будем собирать ключи отдельно. Например, мы продаем и платья и туфли — собираем отдельно.
Опять же, платья могут быть разные — вечерние, свадебные и т.д. Т.е. здесь уже смотрим и если направления сильно отличаются — разделяем и ключи.
Дальше. Мы определили направления, в которых будем собирать ключи. Эти направления называются маски и они, по сути, являются названиями целых категорий (платья, туфли и т.д.)
И просто в широком виде они включают в себя вообще все возможные словосочетания с нашими ключами, поэтому так мы их в большинстве случаев не берем.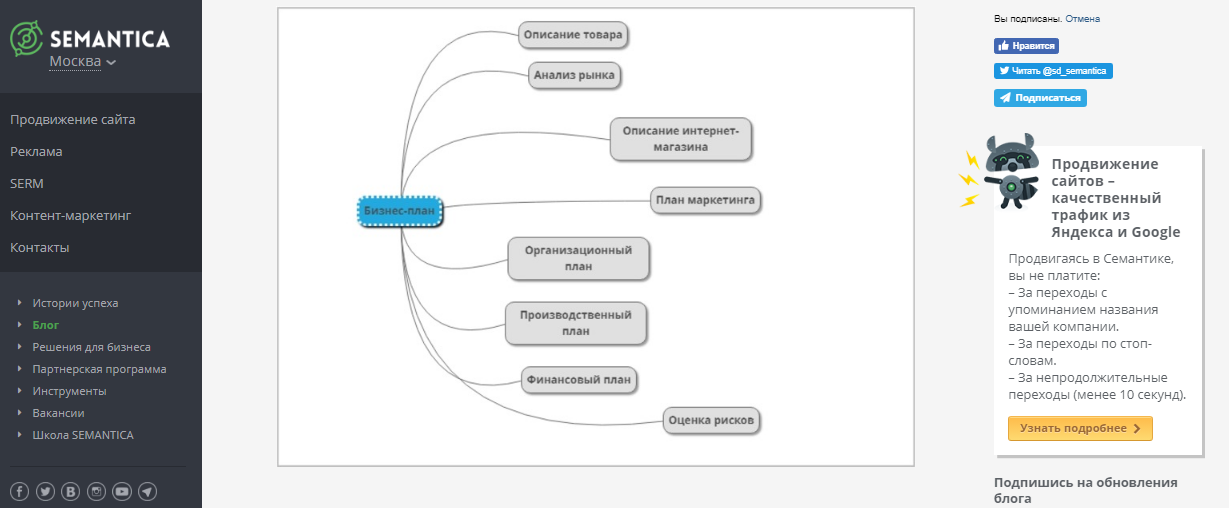
Мы идем в сервис Вордстат или Прогноз бюджета в Яндекс Директе и смотрим, что входит в запросы с этими масками и уже внутри будем собирать ключевые слова.
4. Сколько масок (направлений) брать?Опять же, зависит от номенклатуры. На старте оптимально 3-6, но может быть и 20-30. Естественно, чем больше направлений — тем больше объем работы и тем больше требуется бюджета.
На этапе теста вообще можно начать с одного самого главного направления и дальше уже углубляться.
Потенциальные маски
5. Какие брать дополнительные слова к основным ключам? И как определить, что запрос нам не подходит?В принципе, здесь все просто — берем все, которые подходят. Но очень важно — берем только 100% релевантные запросы! Чем точнее, тем прицельнее настроимся и тем выше будет конверсия.
Если сомневаемся в запросе — можем забить его в поиск и посмотреть, что там выходит.
Это могут быть сразу сайты с возможностью купить — «купить шелковое платье» (значит запрос коммерческий и он нам подходит)
Просто статьи — «как выбрать шелковое платье» (информационный запрос, можно вынести в отдельную группу, но скорее всего лучше не брать вообще)
Смешанная информация — и предложения о покупке и просто разного рода информация
— «пошив шелковых платьев на заказ» (и не понятно, хотят заказать платье или заняться пошивом на заказ)
— «сколько стоит шелковое платье» (выглядит как коммерческий, но далеко не факт — здесь либо действительно хотят купить платье либо это просто любопытство или далеко отложенный спрос. А может хотят продать).
6. Сколько брать ключей по основному запросу?Здесь нужно понимать, что все собранные ключи мы будем распределять по группам объявлений. Как правило, на одну маску мы делаем одну группу объявлений.
Т.е. Маска “платья из шелка” = группа объявлений “платья из шелка”. А вот сколько ключей должно получиться в одной группе?
Здесь все индивидуально. Это может быть и 5 запросов, и 30 и даже 100+. Но, в среднем, 10 — 30 запросов считается нормальным.
7. Тонкость. Если продаем несколько очень похожих позиций или товар один, но несколько названий — все ключи в одну группу?Здесь 2 пути — делать по каждому товару/названию свою группу или же собрать все в одну.
Так дробить или нет, от чего зависит?
А) Восприятие товара покупателями — если использовать разные названия не критично — можно сгруппировать.
Б) Удобство работы — индивидуально. Кому-то удобнее дробить, кому-то группировать. В любом случае, если сгруппируем — система сама уберет пересечения и на настройку это не повлияет.
В) Достаточное количество показов — важно, чтобы по каждой группе их набиралось хотя бы больше 100 в месяц.
Г) Бюджет — чем сильнее дробим, тем больше нужно бюджета.
Вывод — на старте, скорее всего, лучше не дробить, а максимально группировать все, что можно.
Разные группы объявлений с похожими названиями в одной рекламной кампании
8. Еще момент. Мы имеем несколько главных ключей — каждый будем прогонять через Вордстат и/или Прогноз бюджета?Да. Это позволяет качественно добрать семантику, а заодно и сразу насобирать максимум минус-фраз.
При чем Вордстат выдает 40 страниц по 50 запросов и нужно пролистать все. Кажется, что много, но на самом деле это всего 2000 фраз и этого может быть недостаточно. В особых случаях требуется еще использовать дополнительный софр — парсеры.
Первая страница Вордстата — таких нужно пролистать 40
9. И вишенка на торте — а как вообще понять, достаточно ли у меня сейчас ключей?Если мы собрали все маски по направлениям и прошерстили прогноз бюджета и Вордстат — то собрали все, сколько есть. Для надежности и если недостаточно можно пропарсить.
Также можно расширять семантику за счет околоцелевых, косвенных запросов и т.д.
10. Отлично, и напоследок — как расширять семантику?Лайфхак. Идем к заказчику и его продажникам и уточняем, что еще может искать наша ЦА (целевая аудитория) и для чего еще можно использовать наш продукт, с чем он “соприкасается” тематически.
Также еще раз изучаем сайт и сайты конкурентов, возвращаемся к анализу целевой аудитории.
В общем, ищем новые направления и идеи.
При этом, расширяя семантику, мы можем:
А) Добавить новые ключи в действующую группу, если они подходят по смыслу и группа не получается не слишком громоздкой.
Б) Создать новые группы и работать с ними.
*********************************************************************************
Посмотрите внимательно на эти 10 вопросов — теперь, если они возникнут у вас — вы знаете, что делать!
И пусть эта статья будет полезной для вас. Ответы реально выстраданы — я кропотливо заносил в майнд-карту возникающие вопросы, а потом сломя голову вписывал ответы, как только удавалось их найти. Нашел все)
А вот так выглядит фрагмент моей майнд-карты с вопросами.
Не хуже пиратской карты сокровищ, ведь помогает приводить клиентов с золотыми монетами))
Напоследок добавлю, что маркетинговая часть по рекламе в Яндекс Директе у меня хорошо ложится на базу таргетолога — как по рельсам, а вот техническая часть мало похожа на настройку таргета. Разве что тем, что в рекламном кабинете ВК тоже есть настройка по ключевым словами, но она отличается. В общем, местами приходится не легко.
Но как-бы-то ни было, я рад, что этот эффективный инструмент встал в строй и пополнил мой маркетинговый арсенал.
Считаю, что таргетологу вполне по силам овладеть контекстом и наоборот, так что если задумываетесь, но боитесь — смелее, дорогу осилит идущий!
Автор статьи: Игорь Брагин — интернет-маркетолог, создатель сообщества Дельный SMM, подписывайтесь!
Семантика — Rush Analytics
Семантика
Категории статей
- SEO-оптимизация
- Семантика
Типы поисковых запросов
Под поисковым запросом понимается фраза или слово, которое пользователь, желающий найти определенную информацию, указывает в Google, Yandex или другой поисковой системе. «Купить ноутбук», «приготовить окрошку» – виды поисковых запросов многочисленны. После их обработки система формирует список сайтов, страниц, содержимое которых содержит максимум полезных сведений по обозначенной теме.
- Юлия Туловская
- 03 июня 2022
- 10 мин.
- Семантика
- SEO-оптимизация
- Интервью
- Обучение
Чистим семантическое ядро от мусора в два клика
Все, кто собирает семантику, сталкивается с проблемой – не целевые (мусорные) слова, которые очень муторно вычищать, чтобы получить финальный список ключевых слов, пригодный для работы.
- Олег Шестаков
- 16 декабря 2021
Как использовать Google Keyword Planner
Хотите получать больше трафика из Google? Тогда первым делом вам нужно провести поиск и анализ ключевых слов, чтобы понять, что действительно люди ищут в сети.
- Дмитрий Цытрош
- 14 декабря 2021
- Семантика
Парсим поисковые подсказки из Youtube в Rush Analytics
Впервые эта технология начала применяться в Google еще в далеком 2004 году, затем она была реализована во многих других сервисах компании, включая Google Labs, Google Toolbar, Maps и, конечно, YouTube.
- Дмитрий Цытрош
- 14 декабря 2021
- Семантика
- SEO-оптимизация
Операторы Wordstat — как работать с ними эффективно
Сегодня мы в Rush Analytics до конца реализовали поддержку всех операторов Wordstat. Зачастую Вордстат может сильно облегчить задачу сбора семантики, особенно на начальном этапе, поэтому грамотное использование операторов на старте обязательно.
- Антон Жиронкин
- 10 декабря 2021
- Семантика
- SEO-оптимизация
- Обучение
Низкочастотные запросы
Обычно такие запросы вводят люди, которые точно знают, что ищут. Продвижение по низкочастотным запросам — это недорогой способ получения целевого трафика — правило касается как SEO, так и контекстной рекламы.
- Дмитрий Цытрош
- 10 декабря 2021
- Семантика
- SEO-оптимизация
- Инструкция
Аналитика источников семантики
Каждый SEO-специалист знает, что успешное продвижение сайта в поиске невозможно без качественного семантического ядра, включающего в себя по возможности все поисковые запросы (или ключевые слова, маркерные запросы) в нужной ему тематике.
- Валентин Батрак
- 09 декабря 2021
- Семантика
- SEO-оптимизация
- Инструкция
- Обучение
HARD-кластеризация в Rush Analytics
Не все семантически похожие запросы выражают одно и то же желание пользователя, например, вводя запрос «купить ноутбук», пользователь явно хочет увидеть весь ассортимент ноутбуков и выбрать из него самостоятельно,
- Валентин Батрак
- 08 декабря 2021
Здесь вы можете собрать поисковые подсказки из Яндекс, Google или YouTube
Зарегистрироваться
Искусственный интеллект и семантика через призму структурного, постструктурного и трансцендентального подходов
. 2016 декабрь; 50 (4): 704-743.
doi: 10.1007/s12124-016-9344-8.
Диана Гаспарян 1
принадлежность
- 1 Национальный исследовательский университет «Высшая школа экономики», Москва, Россия. [email protected].
- PMID: 26975762
- DOI: 10.1007/с12124-016-9344-8
Диана Гаспарян. Integr Psychol Behav Sci. 2016 Декабрь
. 2016 декабрь; 50 (4): 704-743.
дои: 10. 1007/s12124-016-9344-8.
Автор
Диана Гаспарян 1
принадлежность
- 1 Национальный исследовательский университет «Высшая школа экономики», Москва, Россия. [email protected].
- PMID: 26975762
- DOI: 10.1007/с12124-016-9344-8
Абстрактный
Существует проблема, связанная с современными исследованиями философии сознания, в которых основное внимание уделяется отождествлению и сближению человеческого и машинного интеллекта. Это проблема машинной эмуляции смысла. В настоящем исследовании анализ этой проблемы осуществляется на основе концепций структурного и постструктурного подходов, которые практически полностью игнорируются современной философией сознания. Если обратиться к базовым определениям «знака» и «значения», встречающимся в структурализме и постструктурализме, то мы увидим принципиальную разницу между возможностями машины и человеческого мозга, занятого обработкой знака. Это исследование продемонстрирует и предоставит дополнительные доказательства в поддержку различий между синтаксическими и семантическими аспектами интеллекта, вопрос, широко обсуждаемый адептами современной философии сознания. Исследование продемонстрирует, что некоторые аспекты ряда идей, предложенных в отношении семантики и семиозиса в структурализме и постструктурализме, аналогичны тем, которые мы находим в современных аналитических исследованиях, связанных с теорией и философией искусственного интеллекта. В заключительной части статьи предлагается интерпретация проблемы формализации смысла, связанная с его метафизическими (трансцендентальными) свойствами.
Ключевые слова: Искусственный интеллект; Когнитивная лингвистика; Значение; Постструктурная семантика; постструктурализм; Ссылка; Семантика; семиозис; Смысл; структурная лингвистика; Структурная семантика; Структурализм; Синтаксис.
Похожие статьи
[Биологический против искусственного интеллекта: критический подход].
Санвито WL. Санвито ВЛ. Арк Нейропсиквиатр. 1995 г., сен; 53 (3-A): 361-8. Арк Нейропсиквиатр. 1995. PMID: 8540808 Португальский.
Заземление символов: мост от искусственной жизни к искусственному интеллекту.
Томпсон Э. Томпсон Э. Познание мозга 1997 г., июнь; 34 (1): 48–71. doi: 10.
1006/brcg.1997.0906.
Познание мозга 1997.
PMID: 9209755
Обзор.Новый подход к устранению неоднозначности смысла слов, основанный на тематических и семантических ассоциациях.
Ван Х, Цзо В, Ван Ю. Ван Х и др. Журнал «Научный мир». 2013 31 октября; 2013: 586327. дои: 10.1155/2013/586327. Электронная коллекция 2013. Журнал «Научный мир». 2013. PMID: 24294131 Бесплатная статья ЧВК.
Лакан и постструктурализм.
Марта Дж. Марта Дж. Am J Психоанал. 1987 Весна; 47 (1): 51-7. дои: 10.1007/BF01252332. Am J Психоанал. 1987. PMID: 2437811 Аннотация недоступна.
О происхождении мысленных представлений.
Бени Мэриленд. Бени MD. Биосистемы. 2019 окт.; 184:103995. doi: 10.1016/j.biosystems.2019.103995. Epub 2019 19 июля. Биосистемы. 2019. PMID: 31330174
Посмотреть все похожие статьи
использованная литература
- Тенденции Cogn Sci. 2003 март;7(3):113-118 — пабмед
- наук Ам. 1990 января; 262 (1): 32-7 — пабмед
- PLoS Comput Biol. 2013;9(8):e1003167
—
пабмед
- PLoS Comput Biol.
- Annu Rev Neurosci. 1996;19:577-621 — пабмед
термины MeSH
Рынок семантических знаний. Определение возможностей роста в будущем. Перспективы на 2022–2028 годы
Глобальный исследовательский отчет Semantic Knowledge Graphing Market за 2022 год содержит базовый обзор отрасли, включая определения, классификации, приложения и структуру отраслевой цепочки. Отчет о рынке семантических знаний предоставляет информацию о размере рынка, доле, тенденциях, росте, структуре затрат, глобальной рыночной конъюнктуре, движущих силах рынка, проблемах и возможностях, емкости, доходах и прогнозе на 2028 год. Ожидается, что среднегодовой темп роста составит 15,4% в течение прогнозируемого периода.
В отчете представлен всесторонний обзор важнейших элементов рынка, таких как движущие силы, текущие тенденции прошлого и настоящего, сценарий надзора и технологический рост. Этот отчет также включает общее и всестороннее исследование рынка Графические семантические знания со всеми его аспектами, влияющими на рост рынка. Этот отчет представляет собой исчерпывающий количественный анализ отрасли Industrial Semantic Knowledge Graphing и предоставляет данные для разработки стратегий, направленных на повышение роста и эффективности рынка.
Объем отчета:
В отчете оцениваются темпы роста и рыночная стоимость на основе динамики рынка, факторов, способствующих росту. Полная информация основана на последних новостях отрасли, возможностях и тенденциях.
Получите образец PDF-файла (включая полное оглавление, таблицы и рисунки) документа Semantic Knowledge Graphing Market
https://www. infinitybusinessinsights.com/request_sample.php?id=815867&mode=V087
В отчете представлена конкурентная среда на рынке и соответствующий подробный анализ основных поставщиков/ключевых игроков на рынке.
Ведущие компании на мировом рынке графического представления семантических знаний
Microsoft, Яндекс, LinkedIn, Google, Franz, Semantic Web Company, Baidu, Wolfram Alpha и приложения
В этом отчете сегментируется рынок семантических знаний на основе Типы : —
Текстовый дисплей
Фото -презентация
Глубокое чтение
Другие
На основе Применения , рынок графы семантического знания сегментируется на: —
Семантический поиск
Вопрос и ответ и ответ. Машина
Поиск информации
Электронное чтение
Онлайн-обучение
Региональный обзор : Регионы, охваченные в отчетах Semantic Knowledge Graphing Market,
Северная Америка (США, Канада, Мексика)
Европа (Германия, Великобритания, Франция, Италия, Россия, Испания и т. д.)
Азиатско-Тихоокеанский регион (Китай, Индия, Япония, Юго-Восточная Азия и т. д.)
Южная Америка (Бразилия, Аргентина и т. д.)
Ближний Восток и Африка (Саудовская Аравия, Южная Африка и т. д.)
Купить эксклюзивный отчет
https://www.infinitybusinessinsights.com/checkout?id=815867&price=&mode=V087
Влияние Semantic Knowledge Graphing Обзор рынка
– Всесторонняя оценка всех возможностей и рисков на рынке Semantic Knowledge Graphing.
– Последние инновации и основные события рынка семантических знаний.
– Подробное исследование бизнес-стратегий для роста ведущих игроков на рынке Семантическая графика знаний.
– Итоговое исследование графика роста рынка семантических знаний на ближайшие годы.
— Глубокое понимание рынка семантических графических знаний — конкретных факторов, ограничений и основных микрорынков.
– Благоприятное впечатление от жизненно важных технологических и последних тенденций рынка, отраженных в отчете о рынке.
Какие рыночные факторы объясняются в отчете?
– Ключевые стратегические разработки: исследование также включает ключевые стратегические разработки на рынке, включая исследования и разработки, запуск новых продуктов, слияния и поглощения, соглашения, сотрудничество, партнерство, совместные предприятия и региональный рост ведущих конкурентов, работающих на рынке на глобальном и региональном масштабе.
— Основные характеристики рынка: в отчете оцениваются ключевые характеристики рынка, включая выручку, цену, мощность, коэффициент использования мощностей, валовую прибыль, производство, производительность, потребление, импорт/экспорт, спрос/предложение, стоимость, долю рынка, CAGR и валовая прибыль. Кроме того, исследование предлагает всестороннее изучение динамики ключевых рынков и их последних тенденций, а также соответствующих сегментов и подсегментов рынка.
– Аналитические инструменты: Отчет о глобальном рынке графических семантических знаний включает в себя тщательно изученные и оцененные данные о ключевых игроках отрасли и их масштабах на рынке с помощью ряда аналитических инструментов. Для анализа использовались такие аналитические инструменты, как анализ пяти сил Портера, SWOT-анализ, технико-экономическое обоснование и анализ доходности инвестиций.
У вас есть вопросы или конкретные требования? Спросите нашего отраслевого эксперта по телефону
https://www.infinitybusinessinsights.com/enquiry_before_buying.php?id=815867&mode=V087
Настройка отчета: Этот отчет можно настроить в соответствии с вашими потребностями для дополнительных данных до 3 компаний или странах или 40 часов аналитика.
О нас:
Infinity Business Insights — это компания, занимающаяся исследованиями рынка, которая предлагает аналитические исследования рынка и бизнеса по всему миру. Мы специализируемся на предоставлении услуг в различных отраслевых вертикалях, чтобы распознать их наиболее ценный шанс, решить их самые аналитические проблемы и изменить их работу.
Contact Us:
Amit Jain
Sales Coordinator
– +1 518 300 357
inquiry@infinitybusinessinsights. com
https://www.infinitybusinessinsights. com
Семантика в веб-разработке
Что мы подразумеваем под фразами «Семантический код», «Семантическая разметка» и «Семантическая сеть»? Ну… это вопрос семантики.
Веб-разработчики занимаются коммуникацией, передавая смысл от одного объекта к другому. Метод, который мы используем, — это язык, человеческий язык для людей и язык программирования для компьютеров.
Семантика — это изучение «значения», передаваемого с помощью этих языков.
Люди стремятся найти смысл во всем, поэтому область семантики огромна!
Поэтому неудивительно, что термин «Семантика» может означать много разных вещей. В этой статье я выявлю и объясню некоторые из наиболее распространенных примеров в нашей отрасли.
Ключевые элементы семантики
Мы часто слышим фразы; что-то «семантически неверно» или «вопрос семантики». Что мы «подразумеваем» под этими фразами в контексте веб-разработки?
Давайте рассмотрим три ключевых элемента, определяющих семантику в веб-разработке:
- Намерение
- Содержание
- Контекст
Намерение
Когда мы создаем контент, который мы хотим сообщить, есть два намерения; наша предполагаемая аудитория (цифровая или человеческая) и наше предполагаемое значение , иногда наши намерения терпят неудачу.
Мы создаем контент, чтобы передать предполагаемое значение предполагаемому получателю, но иногда дорога к неудаче вымощена благими намерениями
Предполагаемая аудитория
Предполагаемая аудитория — это форма контекста.
Мы все случайно отправили электронное письмо не тому человеку, обычно когда у них одинаковое имя, и мы не замечаем, что непреднамеренный получатель был добавлен автозаполнением.
Правильное содержание, неправильный контекст.
Предполагаемый смысл
Часто мы пишем что-то, что, по нашему мнению, очень ясно, когда предполагаемый получатель видит или слышит что-то совершенно другое. В коде мы получаем сообщение об ошибке, в реальной жизни мы можем получить нежелательные непредвиденные последствия.
Контент
Коммуникация требует контента, будь то визуальное, письменное слово или компьютерный код. В веб-разработке мы часто комбинируем потребляемый контент, предназначенный для получателя-человека, с учебным контентом в виде кода для цифрового получателя.
Содержание маркировки также очень важно, т.е. садовники часто наклеивают этикетки на горшки с растениями, чтобы напомнить им, что в них содержится.
Всегда сразу маркируйте пакеты с семенами. Хранить в прохладном, сухом месте до посева.
— Monty Don
Давайте рассмотрим пример простой веб-страницы о лаванде на веб-сайте садового центра с семантически названным доменным именем:
- umbraco-gardencenter.co.uk
Еще до того, как мы начнем обсуждать сематический код, сематическую разметку или семантическую паутину, вот наш первый пример кода, который имеет смысл как для людей, которые могут его читать, так и для компьютеров, использующих DNS, которые могут направлять пользователей в нужное веб-приложение.
Точно так же, как мы можем использовать имена файлов для описания содержимого, наша сиреневая страница может быть плохо названа:
- страница-07.html
Если гиперссылки ведут на эту страницу, технически это работает для компьютеров, но это не имеет никакого значения для людей, кроме того, что это может быть страница номер 7 в серии веб-страниц.
В SEO-сообществе ведутся споры о том, учитывают ли алгоритмы популярных поисковых систем имена файлов, но это также может быть примером использования семантики для передачи значения компьютерам в целях поиска.
Чтобы придать этой странице смысл для людей, лучшим названием было бы:
- лаванда.html
То же самое относится к файлу изображения. Если вы загрузите несколько изображений с веб-сайта и найдете их через несколько недель без предварительного просмотра изображений, поймете ли вы, что на самом деле изображено на этом изображении:
- g5ds5sdf4sdf.jpg
Конечно, было бы лучше, если бы изображения назывались:
- lavender.jpg
- роза.jpg
- жимолость.jpg
Итак, вы поняли, насколько важно содержание имен. В некотором смысле осмысленное именование файлов на самом деле является формой метаданных (или данных о данных), т. е. имя файла сообщает нам, какой контент содержится в этом файле, будь то изображение или веб-страница.
Итак, теперь у нас есть веб-страница, посвященная «Лаванде», которая находится по следующему веб-адресу:
- umbraco-gardencenter.co.uk/lavender.html .
Это совершенно логично в «контексте» веб-сайта садового центра, который точно выводит нас в контекст.
Контекст
Иногда простого именования недостаточно. Если ваша целевая аудитория не распознает название, тогда контекст моей помощи.
Контент — король, контекст — королева, и вместе они правят.
Представьте, что у нас есть список растений, использующих их латинские названия, и они сгруппированы по тому, любят ли они солнце или тень.
Мы можем создавать осмысленные URL-адреса, используя только HTML и разумно используя структуру папок и имена файлов.
Просто вложив HTML-файлы с именами по умолчанию, такими как index.html, в папки, мы можем создать URL-адреса, такие как:
- umbraco-gardencenter.co.uk/sunny/
- umbraco-gardencenter. co.uk/shady/
Теперь, когда мы помещаем соответствующие файлы в правильные папки, мы генерируем осмысленные URL-адреса, которые описывают структуру, например:
- umbraco-gardencenter.co.uk/sunny/lavender.html
Конечно, большинство современных серверных языков теперь могут делать это с маршрутизацией. На самом деле мы могли бы сделать так, чтобы lavender.html отображался в:
- солнечный/лиловый
- фиолетовый/лавандовый
- ароматизированный/лавандовый
И используйте осмысленный для описания адреса по умолчанию для Lavender.
Независимо от используемого метода, все это является частью семантики в современной веб-разработке, мы дали «контенту» некоторый «контекст».
Семантический код
В нашем разговорном языке мы кодируем значение. Слушатель должен знать этот язык, чтобы расшифровать (или декодировать) «смысл», чтобы понять это значение между двумя языками, нам нужен переводчик.
Мы наводняем людей информацией. Нам нужно пропустить его через процессор. Человек должен превратить информацию в интеллект или знания. Мы склонны забывать, что ни один компьютер никогда не задаст новый вопрос.
— Грейс Хоппер
Когда мы даем инструкции компьютеру в виде кода, они также должны передаваться на языке программирования, понятном компьютеру. Но мы можем написать инструкции на совершенно другом языке программирования и перевести их с помощью транспилятора (или транскомпилятора).
Точно так же, как люди могут описывать одни и те же вещи на нескольких языках, мы можем делать то же самое с компьютерами на разных языках программирования. Фактически, термины в языках программирования часто могут использоваться по-разному в зависимости от «контекста», в котором они используются.
Человекочитаемый код
Компьютеры оценивают код, используя синтаксис и контекст, и хотя некоторые языки программирования могут быть синтаксически правильными, это означает, что код имеет смысл только для компьютеров.
В веб-разработке контент, который мы создаем, часто должен иметь «значение» как для людей, так и для машин, т. е. человекочитаемый код.
В современных языках программирования синтаксис часто легко выучить, и он имеет смысл для людей. Фактически, написание хорошего кода часто включает в себя возможность передачи его другому разработчику.
Хорошим примером того, как сделать код понятным для человека, может быть система БЭМ, разработанная Яндексом.
Примечание. Семантические имена классов не влияют на доступность, т. е. синтаксис БЭМ является сематическим для разработчиков, но не вспомогательных технологий.
Разработчики Яндекса обнаружили, что их CSS становится слишком сложным, когда они делились им, и поэтому предложили соглашение об именах, чтобы упростить задачу.
Эта система стала известна как БЭМ или Блок, Элемент, Модификатор, используя следующий синтаксис:
- имя-блока_имя-модификатора
- имя-блока__имя-элемента_имя-модификатора
Вот простой пример от Яндекса, показывающий использование БЭМ:
<форма>
<ввод>
Методология БЭМ нашла применение во многих других языках программирования, включая CSS и JavaScript, и даже в именовании файлов и структуре проекта.
Вы можете узнать больше о БЭМ здесь:
https://en.bem.info/methodology/
Мы, конечно, можем просто использовать хорошие комментарии, но еще лучше мы можем написать самодокументирующийся код.
Семантическая разметка
Семантическая разметка — это форма семантического кода, которая чаще всего используется в веб-разработке в HTML.
Мы все видели примеры вещей, которые выглядят как кнопки, которые на самом деле представляют собой 5 или 6 вложенных элементовс неразрывным пробелом посередине. Затем, чтобы это работало правильно в невизуальных браузерах, вы должны поместить на него индекс вкладок, чтобы убедиться, что его можно вставлять, потому что в браузерах по умолчанию могут быть вкладки только ссылки и элементы формы. Затем вам нужно добавить немного JavaScript сверху, чтобы обрабатывать клики. Тогда вам, вероятно, придется использовать некоторый CSS и при наведении или фокусе изменить указатель курсора, чтобы он выглядел как маленькая рука, указывающая.на самом деле выполняет роль кнопки. Или вы можете просто использовать элемент кнопки, для чего он там и есть, и все это вам дается. Мне кажется, это неспроста.
— Брюс Лоусон (Семантика HTML с Брюсом Лоусоном | The Web Ahead)Самые ранние версии HTML включали инструкции для пользовательского агента, обычно веб-браузера, о структуре документа, а также инструкции по форматированию, такие как цвета и шрифты. .
По мере того, как требования к веб-приложениям становились все более сложными, вскоре стало ясно, что требуется разделение задач, и аспектом форматирования HTML стали каскадные таблицы стилей (CSS).
Так что же мы подразумеваем под семантической разметкой в HTML?
HTML — Несемантический
Давайте сразу обратимся к слону в комнате, некоторые HTML не являются семантическими и, к сожалению, это тип, который используется чаще всего и неправильно. Да я про вас
и .Все это,
Все это,
Эй, ты знал, что эта <кнопка> является?
— ср. ‘Everything’s A Drum’Часто на целых HTML-страницах каждый элемент помечен как
; только потому, что вы можете, это не значит, что вы должны.Элементов
и не было в исходном черновике HTML, но они появились в спецификациях примерно в 1997 году. Первоначальное намерение состояло в том, чтобы решить проблему добавления языковых атрибутов в середине абзацев и, следовательно, это встроенный элемент:
Я не очень хорошо говорю на 日本語< /p>
Элемент
(сокращение от Division), с другой стороны, является блочным элементом и был введен для предоставления общего контейнера, который не имел значения или стиля макета (кроме того, что они располагаются один над другим, как и любой другой блочный элемент). ).Элементследует использовать только тогда, когда никакой другой семантический элемент (например,или