
Как быстро собрать ключевые слова в Яндекс Вордстат
iMacros — расширение для браузера, которое умеет выполнять однотипные действия в браузере. Все просто: жмете кнопку Play, открываете сайт, кликайте по нужным кнопкам, вводите текст в любые поля, нажимаете Stop и сохраняете записанный макрос. Спустя время можете запустить сохраненный скрипт для выполнения тех же действий. Это очень хорошо работает с WS.
Макрос можно создать и без записи действий. Откройте новый проект и пропишите нужный код. В нашем случае мы так и поступим, так как код уже написали.
Шаг 1
Установите WS Assistant в Chrome или Яндекс.Браузере.
Шаг 2
Установите iMacros в тот же браузер.
Шаг 3
Создайте новый макрос.
Зайдите на панель Record и кликните по кнопке Record Macro.
Потом нажмите на кнопку Stop.
У вас откроется окно с кодом. Неважно, что там написано, удалите все. После вставьте код, приведенный ниже:
VERSION BUILD=844 RECORDER=CR TAG POS=1 TYPE=B ATTR=TXT:Добавить<SP>все WAIT SECONDS=3 TAG POS=2 TYPE=SPAN ATTR=TXT:Добавить WAIT SECONDS=2 TAG POS=1 TYPE=A ATTR=TXT:далее WAIT SECONDS=2
Сохраните макрос.
Шаг 4
Проверяем работу макроса. Теперь в списке доступных макросов есть новый элемент.
Названия папок могут отличаться.
Заходим на страницу Вордстата и выполняем любой запрос.
Открываем iMacros, выбираем наш файл, устанавливаем число проходов и запускаем с повторами.
При этом в основном окне браузера вы должны оставаться на странице Вордстата, никуда не уходите. Во время работы макроса не пользуйтесь браузером.
После выполнения вы увидите, что собрано 150 запросов, соответствующих 3 страницам фраз. Если у вас всё так же, значит эта штуковина работает.
Разберем нюансы
- Пока работает макрос, пользоваться браузером нельзя, иначе ход выполнения действий собьется. Специально для сбора семантики таким способом рекомендуется установить отдельный браузер (Chrome или Яндекс) и ставить выполнение макроса в нем. При этом вы сможете спокойно работать в основном браузере.
- Для работы с WS залогиньтесь в новом аккаунте Яндекс.

- IMacros можно использовать и для любых других нужд, документация по ссылкам http://wiki.imacros.net/Main_Page, https://ru.wikipedia.org/wiki/IMacros.
- Вы можете использовать любые конструкции Вордстата при выполнении запросов.
- В любое время можно отредактировать созданный макрос. Если окно редактирования не запускается, то попробуйте запустить скрипт и тут же его остановить, затем еще раз попробовать отредактировать его.
- В коде есть 3 фрагмента типа WAIT SECONDS=3 – это периоды ожидания макроса после выполнения действий на странице Вордстата. Если у вас в запросе очень много минус-слов или объемная конструкция, то лучше увеличить эти периоды ожидания. Если же число символов в запросе невелико, то можете поставить небольшие значения. Во время своей работы макрос не ждет Вордстат, пока тот закончит выполнение запроса. Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.
- Для парсинга всех страниц WS установите в настройках Play Loop значение 42.
- iMacros имеет платную версию, но и бесплатной вполне хватает.
- Пока скрипт собирает семантику, вы занимаетесь другими делами и больше никогда не пролистываете страницы выдачи.

 Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.
Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.Будем рады вашим комментариям 💬
Яндекс.Вордстат — сервис для работы с семантикой » VADSTUDIO Молдова
29Для каждого интернет-маркетолога доступ к запросам пользователей и их частотности – незаменимый в работе инструмент, на котором можно построить стратегию текстового продвижения, использовать в формировании семантического ядра, узнать что сильнее интересует потребителей.
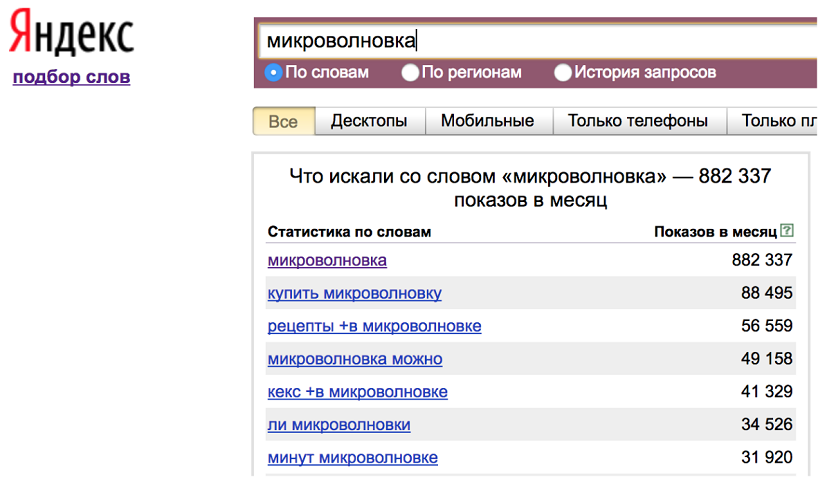
Яндекс.Вордстат — это сервис по подбору слов. Инструмент предоставляет информацию о поисковых запросах в Яндексе. Яндекс.Вордстат отслеживает и собирает наиболее распространенные запросы пользователей, и фразы схожие по тематике и смыслу.
Поиск товаров и услуг в Интернете, «связан» с ключевыми словами. Чтобы поисковик нашел тот или иной текст, товар или картинку, он должен обнаружить полное или частичное совпадение запроса пользователя с информацией, размещенной на ресурсе.
Работа с Яндекс.Вордстат
Интернет — это торговая площадка с миллиардами потенциальных покупателей. Задача команды VADSTUDIO — сделать так, чтобы покупатель и продавец встретились. Для этого специалисты VADSTUDIO проводят работу по подбору ключевых слов, которые являются своего рода указателями на пути от покупателя к продавцу. Важным инструментом в работе команды по SEO-оптимизации является сервис Яндекс.Вордстат. Возможности, которые открывает сервис специалистам:
- отбор ключевых фраз для составления семантического ядра сайта;
- получить обширную статистику частотности запросов;
- подобрать ключевые слова для конкретного товара или услуги;
- определить сезонность и географическую принадлежность наиболее распространенных поисковых запросов.
Как начать работать с Яндекс.Вордстат
Все что требуется для использования сервиса – зарегистрироваться и войти в свой аккаунт Яндекс.
Интерфейс предельно прост и понятен. В поисковую строку стартовой страницы необходимо ввести ключевой запрос, после нажать «Подобрать». Сервис выдаст перечень словоформ и фраз нужного слова и поисковые запросы, которые его включают.
Работа с Яндекс. Вордстатом предполагает наличие специальных познаний, позволяющих не просто подобрать наиболее распространенные семантические показатели поиска, но и правильно интегрировать ключевые слова в текстовое содержание сайта, дифференцировать источники трафика по ключевым словам.
Поделиться статьёй:
семантика, Яндекс, Яндекс.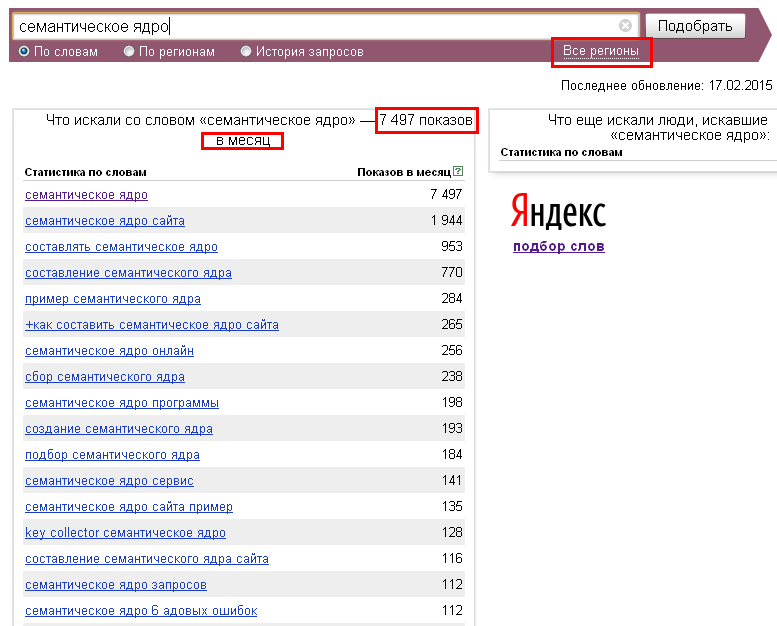 Вордстат
Вордстат
НОВЫЕ ФУНКЦИИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ WORDSTAT ДЛЯ МАЙНИНГА ТЕКСТОВ
Что нового в версии 8.0?
WordStat 8 имеет новые функции и опции, повышающие гибкость и позволяющие использовать программное обеспечение как менее опытным, так и опытным пользователям.
Мы знаем, что вы получаете все больше и больше текстовых данных и ищете способы их анализа и классификации. Вам нужны инструменты, которые помогут вам быстро находить темы, контекст, важные понятия и смысл в больших объемах текстовых данных. Мы знаем, что это вызов для опытных специалистов по данным и менее опытных исследователей и аналитиков. Поиск способа поддержки этих групп был идеей WordStat 8. Мы хотели улучшить удобство использования и гибкость, одновременно повышая производительность и точность.
Мы считаем, что новый подход WordStat 8 достигает этих целей. Вы можете обрабатывать огромные объемы неструктурированных данных за считанные секунды с минимальным опытом или легко создавать свои собственные обширные словари категорий для точного измерения понятий.
1. Автономная платформа для анализа текста
Изучение нового программного обеспечения может оказаться непростой задачей. Особенно программное обеспечение со многими функциями, такими как WordStat. Раньше WordStat был дополнительным модулем QDA Miner. Это требовало от пользователей не только изучения WordStat, но и элементов QDA Miner для настройки своего проекта. WordStat 8 теперь является самостоятельным продуктом. Это снижает сложность и время обучения, поскольку теперь пользователи могут создавать свои проекты непосредственно в WordStat. Однако его по-прежнему можно запускать как надстройку для анализа контента QDA Miner, STATA или SimStat.
Теперь вы можете создать проект в самом WordStat из разных источников:
- Документы: MS Word, RTF, PDF, HTML и т.д.
- Файлы данных: Excel, CSV, Stata и т. д.
- Платформы веб-опросов: SurveyMonkey, Qualtrics, SurveyGizmo и т. д.
- Инструменты управления ссылками: Endnote, Zotero, Mendeley
- Социальные сети: Twitter, Facebook, Reddit, RSS-каналы, Youtube
- Платформы электронной почты: Outlook, Gmail, Hotmail, Mbox и формат EML
- Многие другие источники…
2.
 Новый режим проводника
Новый режим проводникаНовый режим проводника позволяет пользователям с небольшим опытом анализа текста быстро и легко извлекать смысл из больших объемов текстовых данных. Вы можете определить наиболее часто встречающиеся слова и фразы и выделить наиболее важные темы в своих документах с помощью улучшенного инструмента моделирования тем WordStat 8. В любой момент вы можете переключиться в экспертный режим, который дает вам доступ ко всем функциям WordStat, включая анализ контента. словари, кросс-таблицы и функции анализа совпадений.
3. Улучшенное тематическое моделирование
Существующая процедура тематического моделирования выигрывает от многочисленных улучшений, таких как дополнительный алгоритм извлечения (NNMF) для более быстрого извлечения тем, а также инновационный процесс обогащения тем. Этот метод позволяет выйти за рамки решения «мешка слов», типичного для традиционного тематического моделирования, путем автоматического выбора связанных фраз и предоставления предложений для дополнительных выражений, возможных исключений, а также исправлений правописания. Все эти инновации должны привести к более точному и всестороннему измерению основных тем в вашей текстовой коллекции.
Все эти инновации должны привести к более точному и всестороннему измерению основных тем в вашей текстовой коллекции.
4. Новые и улучшенные графические дисплеи
WordStat 8 имеет несколько новых графических дисплеев, которые помогут вам лучше понять результаты анализа данных. Мы улучшили интерактивные облака слов, кольцевые и радиолокационные диаграммы.
5. Таблица отклонений
Это совершенно новая функция, включенная в WordStat 8. Она была добавлена после выпуска, и вам необходимо загрузить WordStat 8.0.7 или более позднюю версию, чтобы иметь к ней доступ. Таблица отклонений позволяет увидеть, какие слова/фразы используются в большей или меньшей степени по сравнению с другими переменными. Сначала вам нужно активировать кнопку кросс-таблицы, чтобы увидеть значок. Вы можете щелкнуть правой кнопкой мыши, чтобы найти KWIC, удалить и сохранить в формате Tab Delimited, HTML или Bitmap. Чтобы узнать больше об этой специфической функции WordStat 8, щелкните следующую ссылку: таблица отклонений/
6.
 Экспорт результатов в Tableau Software
Экспорт результатов в Tableau SoftwareОдним щелчком мыши вы также можете экспортировать свои результаты в Tableau Software, чтобы использовать его передовые интерактивные инструменты визуализации данных.
7. Улучшенное построение словаря для контент-анализа
Несколько новых функций и улучшений были внесены в раздел словарей категоризации, чтобы помочь вам быть более точным при текстовом поиске и получать более точные результаты.
Записи с учетом регистра: словари категорий и список исключений теперь поддерживают записи с учетом регистра для устранения неоднозначности таких слов, как «Bill» и «bill», «Buck» и «buck» или «us» и «US».
Регулярные выражения (регулярные выражения) Поиски: мы создали редактор регулярных выражений, в котором вы можете создавать свои собственные формулы регулярных выражений, чтобы быстро извлекать определенную информацию из ваших текстовых данных, таких как адреса электронной почты или почтовые индексы.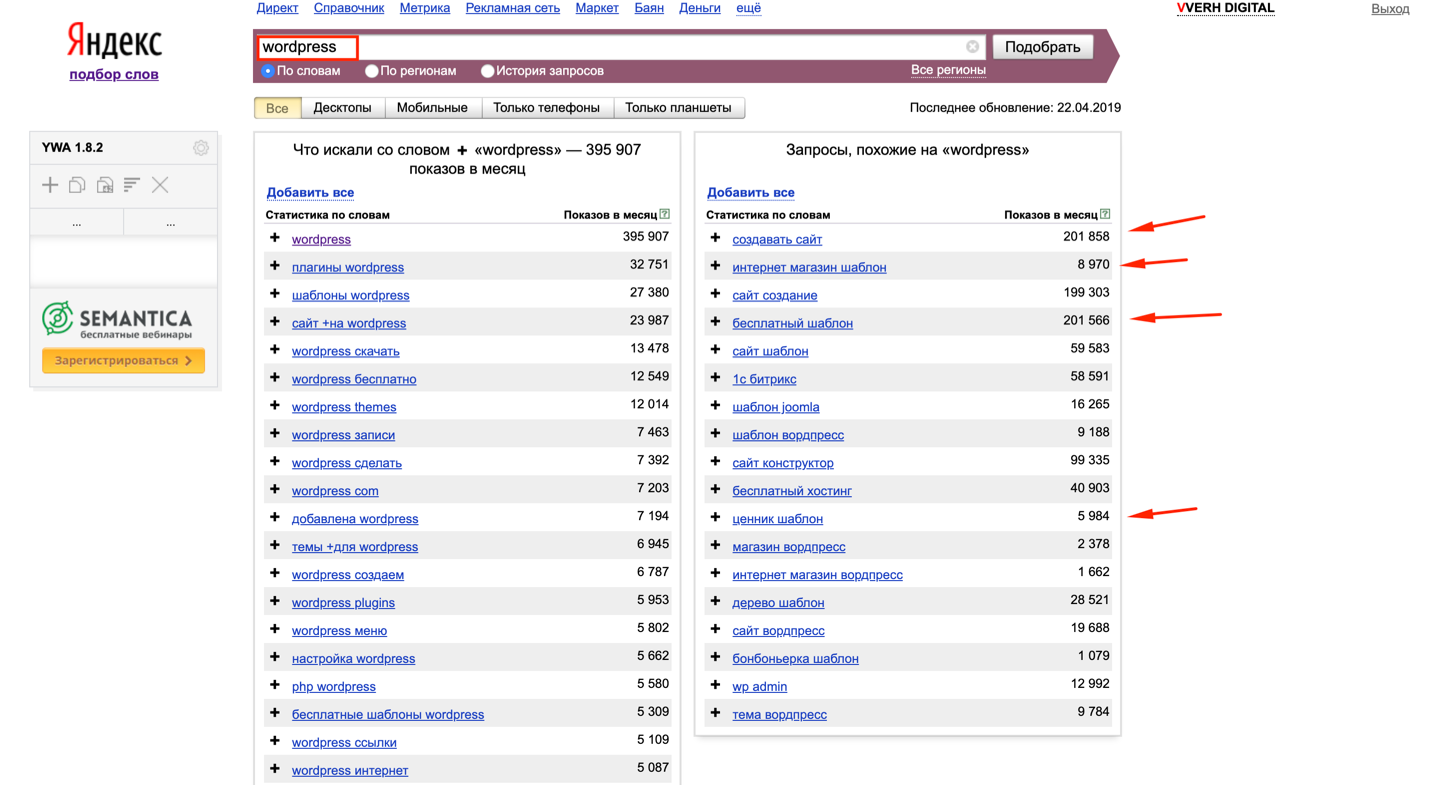
Новый процесс замены: w e мы улучшили процесс замены, разделив его на две части. Отделив его от нашего процесса лемматизации, вы можете легко отслеживать замены и не допускать ошибок в словаре вашего контента.
Списки исключений и замен вместе со словарем категоризации теперь можно сохранять в файл модели категоризации. Этот файл можно использовать в других проектах WordStat, а также в QDA Miner, WordStat Document Explorer или в нашем SDK.
8. Улучшенный интерфейс
Улучшенный интерфейс позволяет быстро получать доступ к результатам и сравнивать их, благодаря чему вы можете извлечь ценную информацию за несколько секунд.
WordStat 7
WordStat 8
9. Преобразование текста с помощью скриптов Python
WordStat 8 открывает специалистам по обработке и анализу данных возможность использовать скрипт Python и полный спектр его библиотек с открытым исходным кодом для предварительной обработки или преобразования текстовых документов для анализа в WordStat. Эта новая функция повышает гибкость WordStat и позволяет пользователям использовать свои навыки программирования на Python.
Эта новая функция повышает гибкость WordStat и позволяет пользователям использовать свои навыки программирования на Python.
10. Числовое преобразование
Новое диалоговое окно числового преобразования позволяет вычислять числовые переменные из других переменных с использованием до 50 функций преобразования, включая тригонометрические, статистические функции и функции случайных чисел. Условное преобразование также может быть выполнено с использованием логической структуры IF-THEN-ELSE.
11. Объединение в группы
Функцию объединения теперь можно использовать для преобразования непрерывных значений в меньшее количество отдельных категорий. Его можно использовать для уменьшения влияния числовых выбросов, аномальных распределений или преобразования непрерывной числовой переменной в порядковую. Это особенно полезно для создания графических отображений сравнений, когда количество различных значений в числовой переменной слишком велико. используется для представления объекта, выражения идеи или чувства или добавления нюанса к письменному сообщению.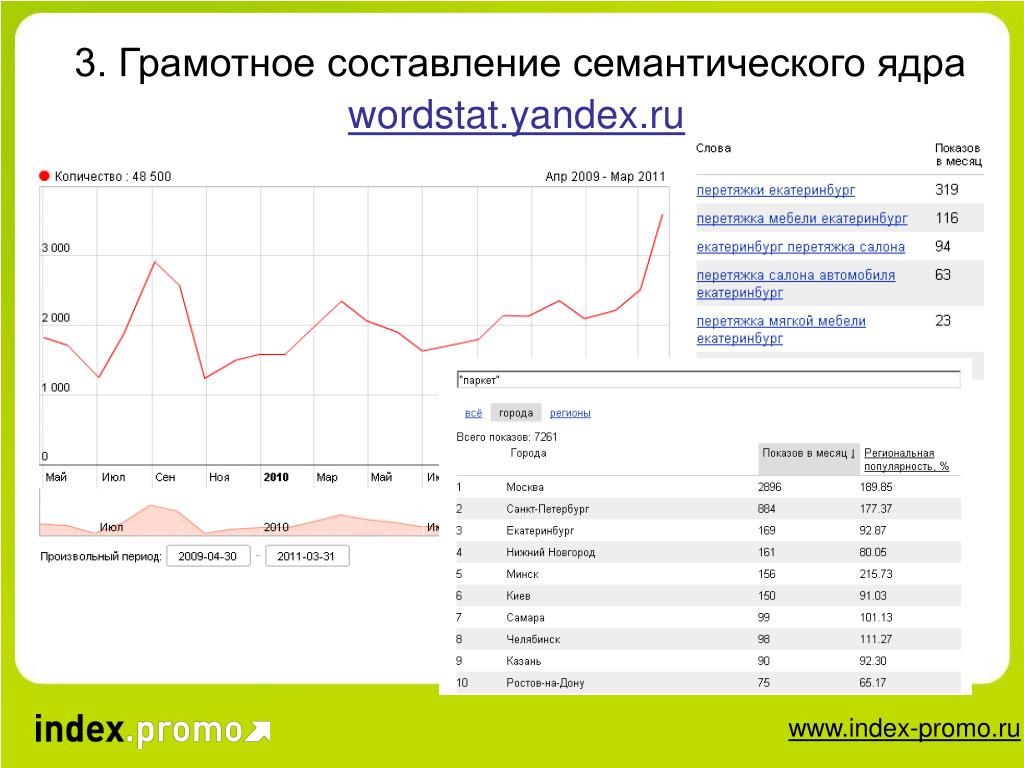 Они часто являются неотъемлемой частью сообщения и вряд ли могут быть проигнорированы. WordStat 8.0 может преобразовывать эмодзи в их текстовое представление, что позволяет анализировать их либо отдельно, либо как часть всего сообщения.
Они часто являются неотъемлемой частью сообщения и вряд ли могут быть проигнорированы. WordStat 8.0 может преобразовывать эмодзи в их текстовое представление, что позволяет анализировать их либо отдельно, либо как часть всего сообщения.
13. Исследуйте свои документы из проводника Windows
Новый инструмент проводника документов позволяет пользователям быстро просматривать содержимое своих документов из проводника Windows без необходимости импортировать документы или создавать проект. Вам просто нужно выбрать документы, которые вы хотите изучить, или папку, содержащую их, щелкнуть правой кнопкой мыши и выбрать «Исследовать», чтобы быстро определить наиболее часто встречающиеся слова и фразы и их местонахождение в ваших документах. С помощью простого щелчка правой кнопкой мыши вы также можете выполнить семантический поиск в ваших документах, используя существующий словарь категоризации, или классифицировать документы, используя модель прогнозирования в WordStat.
Новые возможности WordStat 7 можно посмотреть здесь
STAT Semantics
На прошлой неделе скептически настроенный коллега почувствовал необходимость связаться со мной и высказать свое мнение: больница, которую он обслуживает, сделала «Super-STAT» официальной частью своего рабочего процесса.
Этот термин, вероятно, знаком любому читателю, работающему в сфере здравоохранения уже некоторое время. На первый взгляд, думаю, у большинства такая же реакция на это: «Какой в этом смысл?»
STAT означает, что что-то должно произойти немедленно. На самом деле я никогда не понимал, почему люди чувствуют необходимость писать с большой буквы все слово. Это не аббревиатура, это сокращение от statim, что в переводе с латыни означает «немедленно». Тем не менее, все остальные пишут все заглавными буквами, так кто я такой, чтобы отличаться? СТАТ это.
Если STAT означает «немедленно», разумный человек может задаться вопросом, как «супер-STAT» может быть быстрее. Пока кто-нибудь не поймет, как манипулировать течением времени, STAT по определению работает настолько быстро, насколько это возможно.
Пока кто-нибудь не поймет, как манипулировать течением времени, STAT по определению работает настолько быстро, насколько это возможно.
Определение, которое, к сожалению, недолговечно при контакте с реальным миром. Говорите о срочности сколько угодно, но ресурсы ограничены. Люди и предметы могут двигаться только с определенной скоростью и делать так много.
Для получения дополнительной информации, основанной на мнениях и исследованиях отраслевых экспертов, подпишитесь на электронный информационный бюллетень по диагностической визуализации здесь.
Таким образом, группа направляющих врачей заявляет, что их заказы на визуализацию являются STAT, но последний общий путь — доставка пациентов к оборудованию для визуализации, вход и выход из него — является узким местом. Как и интерпретация этих исследований после их завершения. В этой цепочке событий только STAT-декларация является мгновенной, легкой и без отпора или другого сопротивления.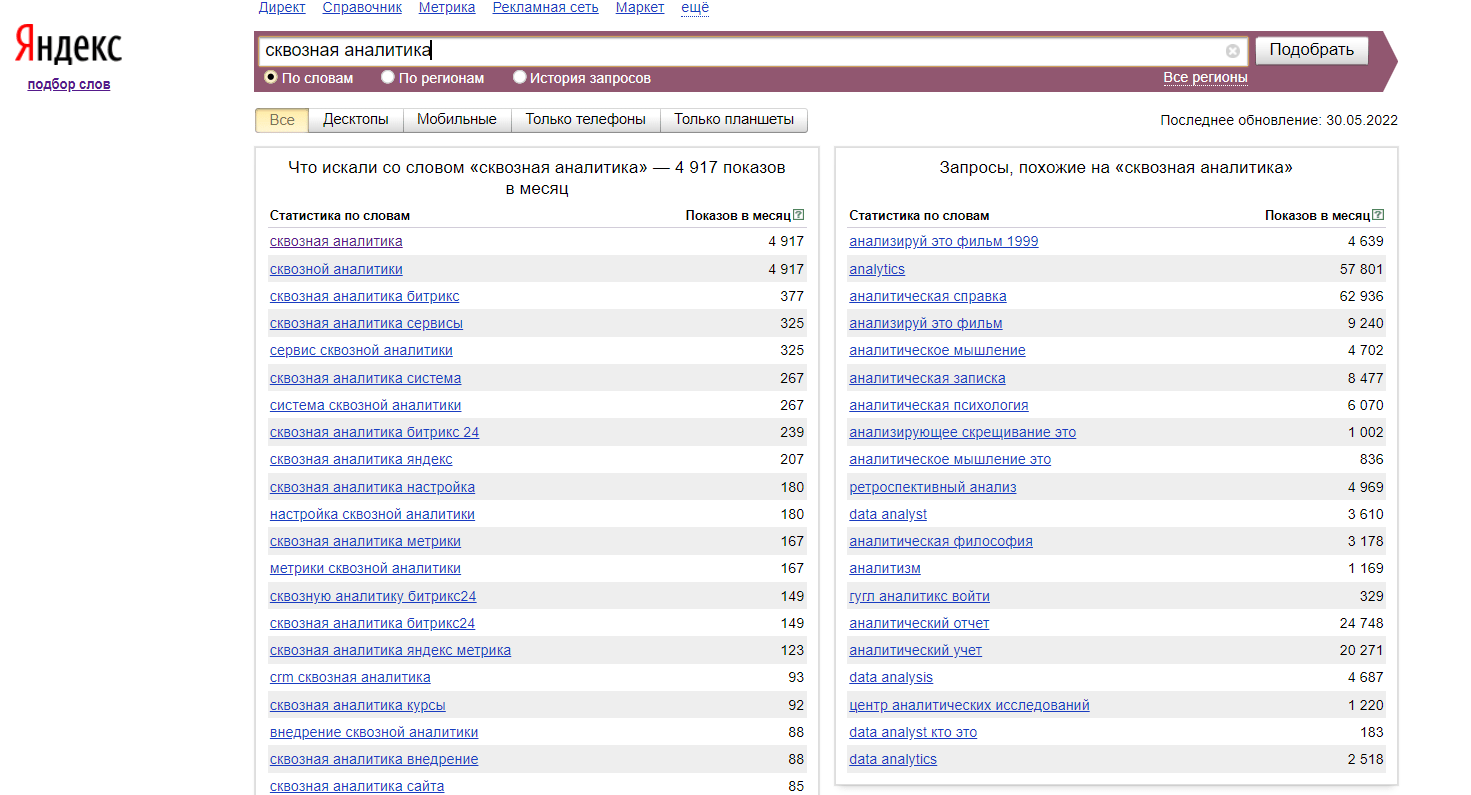
По сути, единственная причина, по которой заказ
В таком случае неудивительно, что мы оказываемся в вечной пробке STAT, которую необходимо выполнить. Но знаете, что происходит, когда все должны ходить первыми? Никто не делает. STAT становится новой процедурой. Все остальные категории, которые могут быть у объекта — экстренные, срочные, рутинные… все они борются за то, чтобы остаться последними, независимо от того, как они называются.
Итак, в какой-то момент врачу приходит в голову блестящая идея: Вот этот пациент — «настоящий» STAT. Не так, как все те другие STAT кричащих волков, которые засоряют медицинский ландшафт. И, устно или фактически в письменной форме, он/она объявляет случай «Super-STAT». Каким-то образом это должно заставить все остальные STAT отойти в сторону.
И, устно или фактически в письменной форме, он/она объявляет случай «Super-STAT». Каким-то образом это должно заставить все остальные STAT отойти в сторону.
Чистая семантика. Любой другой клиницист, осведомленный о ситуации, мог бы немедленно ответить: «О, да? Ну, эти 18 моих пациентов STAT? Они все тоже суперСТАТ». И действительно, трюк с заказом супер-СТАТа прижился.
Бедные рентгенологи и клерки не имеют права что-либо делать с этим. Что они собираются делать, высовывать головы и спорить с реферерами? Проще и безопаснее пойти по пути наименьшего сопротивления и делать то, что им говорят. «Конечно, док, вы говорите, что у вашего пациента больше STAT, чем у всех остальных, так что вперед и приведите его».
Я вижу учреждение, чувствующее потребность в официальной политике, регулирующей этот материал. Но меня удивляет, что этот выбор подлил масла в огонь и сделал «Супер-СТАТ» новой приоритетной категорией. Неужели кто-то действительно думает, что это исправит ситуацию? Сколько времени потребуется, чтобы рефереры «Если я закажу это, это будет STAT» превратиться в рефереров «Если я закажу это, это будет супер-STAT»? Как только новый термин станет популярным, кто будет беспокоиться об обычном STAT? Все, что нужно сделать, это убедиться, что ваши пациенты находятся в первых рядах в конце очереди.
Когда я оцениваю проблему, я сосредотачиваюсь на том, что требует наименьшего количества времени, усилий, ресурсов и т. д. для решения. В данном случае я вижу два рычага, которые можно двигать. Приток (способность направляющих делать STAT-заказы, когда им заблагорассудится) и отток (способность рентгенологического отделения получать изображения пациентов, а затем интерпретировать эти изображения).
Чтобы «исправить» отток, можно попробовать найти более эффективные решения… но давайте будем честными, эта лошадь была забита почти до смерти за эти годы. Департаменты, пытающиеся не отставать от сокращения возмещения расходов и тому подобного, уже сделали все, что могли придумать. На этом этапе дальнейшее улучшение обычно связано с дорогостоящими вещами, такими как покупка большего количества сканеров, наем большего количества персонала, передача некоторых операций чтения по контракту и т. д.
Или мы могли бы исправить приток и наложить ограничения на то, как рефереры перебрасывают слово STAT.