
Как собрать семантическое ядро сайта
Первая страница Яндекса недосягаема без грамотного SEO-продвижения. Эксперт Контур.Школы кратко и по делу рассказывает, с чего начать оптимизацию сайта
Что такое семантическое ядро и зачем оно сайту
Семантическое ядро (СЯ) — это набор слов и словосочетаний, которыми можно описать ваш сайт, и то, что вы на нем предлагаете пользователю.
Со сбора семантического ядра начинается работа над любым проектом. Без СЯ невозможно настроить эффективное SEO-продвижение и запустить контекстную рекламу. Грамотная структура сайта, построенная на основе СЯ, позволяет поисковым системам лучше ранжировать его и показывать целевым пользователям.
Чтобы сформировать СЯ, нужно собрать запросы, которые пользователи могут вводить в поисковиках. К примеру пользователь, интересующийся приобретением недвижимости, введет в поиске «купить квартиру». Если вы понимаете, что такой запрос подходит вашему продукту, добавьте его в список ключевых слов.
- Ключевые слова могут отражать не только тематику сайта, но и интересы аудитории, а также цели бизнеса.
Поисковые запросы
Поисковые запросы пользователей отражают, что, как и зачем
- Что — услуга, товар, информация: «жк телевизор», «химчистка», «банкротство».
- Как — какие ключевые фразы использует пользователь: «самсунг», «мытищи», «через мфц».
- Зачем — цель пользователя: «купить», «вызвать курьера», «смотреть онлайн бесплатно», «сравнить цены» и т.д.
Анализируя запросы, вы составляете обширный список ключевых слов, по которым потенциальный покупатель может искать именно ваш продукт.
Пользователь вводит запрос ⇒ Поисковик видит, что ваш сайт релевантен запросу ⇒ Выводит его в поисковой выдаче ⇒ Пользователь видит ваш сайт и переходит по ссылке
Запросы могут быть не только целевыми, вроде «ремонт холодильников», но и околоцелевыми.
подразумевают, что пользователь на момент поиска еще не задумывается о покупке услуги или товара, но чисто гипотетически может этим заинтересоваться. Примеры: «сломался холодильник», «холодильник перестал гудеть».Околоцелевые запросы
 Околоцелевые запросы
Околоцелевые запросыДопустим, вы создаете сайт для компании по ремонту телевизоров. Необходимо собрать семантическое ядро, чтобы пользователи могли найти сайт в поисковике.
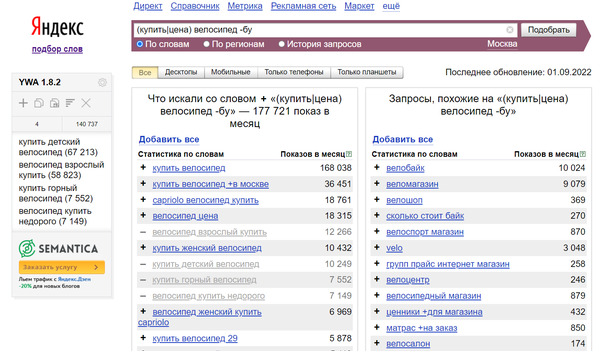
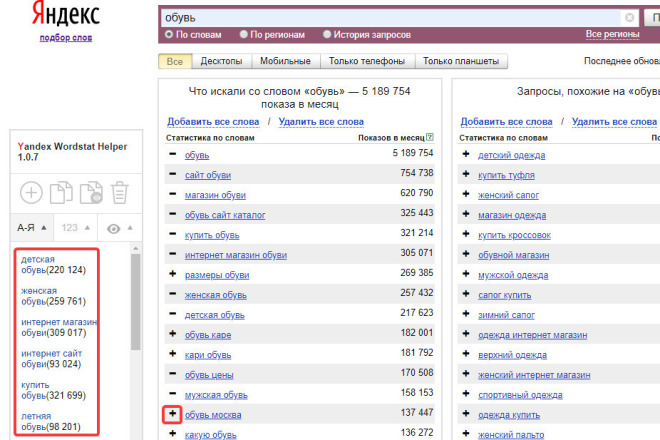
Воспользуемся бесплатным сервисом Яндекса Вордстат. При вводе запроса он выдает две таблицы:
- Таблица справа содержит запросы, схожие с фразой, которую вы ввели. Число напротив — количество показов в месяц.
- Таблица слева показывает, какие вариации вводят пользователи при поиске вашего продукта.
Вордстат выводит все ключевые слова, по которым люди могут искать услуги по ремонту телевизора:
Запрос «ремонт телевизора» говорит о самой цели поиска. Слова, сопутствующие основной фразе, — «самсунг», «на дому», «в москве» и прочие — конкретизируют, что именно, как и где пользователи хотят починить.
- Нужно учесть запросы со всеми уточнениями, чтобы у сайта было больше возможностей «поймать» пользователя в сети.
Важный нюанс: если вы продаете в определенном регионе, нужно выбрать его из списка. Это позволит учесть интересы жителей конкретного региона.
Виды поисковых запросов
Запросы классифицируют по частоте использования:
- Высокочастотные (ВЧ). Самые популярные поисковые запросы с частотой от 5000 и выше показов в месяц. Конкуренция по таким запросам очень высока, продвигаться по ним сложнее. Многие хотят «поймать» пользователя по запросам «туры в Турцию», «купить дом» или «ремонт квартир».
- Среднечастотные (СЧ). Это запросы частотностью от 500 до 5000 показов в месяц.
- Низкочастотные (НЧ) . Количество таких запросов не превышает 500 в месяц. Например, «торт кировский район» — всего около 300 запросов в месяц. По таким запросам низкая конкуренция, поэтому продвигать сайт по ним легко и быстро. Таким запросом выше вероятность «попасть» в заинтересованного пользователя здесь и сейчас. Зачастую по ним высокие показатели конверсии. Но нельзя остановиться только на НЧ: они привлекают очень мало пользователей, и вам будет сложно охватить всю целевую аудиторию и увеличить продажи.
 Таким запросом выше вероятность «попасть» в заинтересованного пользователя здесь и сейчас. Зачастую по ним высокие показатели конверсии. Но нельзя остановиться только на НЧ: они привлекают очень мало пользователей, и вам будет сложно охватить всю целевую аудиторию и увеличить продажи.
Таким запросом выше вероятность «попасть» в заинтересованного пользователя здесь и сейчас. Зачастую по ним высокие показатели конверсии. Но нельзя остановиться только на НЧ: они привлекают очень мало пользователей, и вам будет сложно охватить всю целевую аудиторию и увеличить продажи.Также запросы можно разделить по потребностям пользователя:
- Информационные запросы. Чаще всего по таким запросам пользователи ищут статьи, чтобы быстро узнать ответ на свой вопрос. К примеру, «что такое семантическое ядро», «как определить размер шляпы» и т.д.
- Транзакционные запросы. Пользователь стремится к какому-то действию. Например, чтобы отпраздновать день рождения, в поисковике вводят фразы «забронировать столик», «заказать ведущего», «купить шары» и др.
- Навигационные. Когда пользователь вводит конкретный домен, название сайта/компании, бренд. К примеру, сайт «Авито».
- Прочие запросы. Например, запрос «зимний костюм» — непонятно, хочет ли пользователь его купить, сшить, или просто посмотреть на картинках, какие бывают зимние костюмы.
 Например, запрос «зимний костюм» — непонятно, хочет ли пользователь его купить, сшить, или просто посмотреть на картинках, какие бывают зимние костюмы.
Например, запрос «зимний костюм» — непонятно, хочет ли пользователь его купить, сшить, или просто посмотреть на картинках, какие бывают зимние костюмы.При сборе семантического ядра не рекомендуется использовать ключевые слова с размытым смыслом. Выбирайте конкретные варианты — так вы не будете путать пользователя и сможете предложить именно то, что он ищет.
3 метода сбора семантического ядра
Мозговой штурм
Подумайте, какие проблемы есть у пользователя и как именно ваш продукт может их решить. Попробуйте ответить на вопросы:
- Какими словами можно называть ваш продукт? Используйте не только профессионализмы, но и жаргон, возможно, иностранные слова.
- Что может быть важно для пользователя? «Бесплатности», скорость доставки, акции и другое.
- Какие свойства продукта важны для потребителя?
- На какие условные составные части можно разделить продукт? К примеру, если вы предоставляете услуги тендерного сопровождения, это будут «поиск закупок», «сопровождение закупок», «анализ закупочной документации» и т. д.
 д.
д.Анализ конкурентов
Почитайте тексты на сайтах конкурентов и выпишите часто встречающиеся фразы. Для повышения эффективности поиска можно использовать сторонние сервисы: SEMrush, Serpstat или «Букварикс». Они покажут, по каким запросам покупатели находят сайты конкурентов.
- Как самостоятельно анализировать конкурентов и работать с отзывами об аналогичных продуктах, разбираем на бесплатном вебинаре.
Специальные сервисы
Собрать семантическое ядро сайта могут помочь бесплатные сервисы Яндекс.Вордстат, Google Keyword Planner.
Как отфильтровать семантическое ядро
Научитесь подбирать ключи к ЦА и настраивать рекламу
на курсе Контур.Школы «Интернет-маркетолог»
Смотреть программу
Готовый список ключевых слов необходимо почистить, так как не все они подойдут для вашего бизнеса.
Удалите из списка нерелевантные запросы:
- С указанием не вашего региона.
- Названия конкурентов.
- Со словами «дорого», «дешево» — если вам это не подходит. Ремонтируете квартиры премиум-класса? Ключ «ремонт квартир дешево» не принесет вам целевых клиентов.
- Информационные запросы — если речь идет о коммерческом ресурсе.
- Запросы с нулевой частотой, которые не имеют спроса. По данным Вордстат пользователи не вводят их в поисковик, и продвигаться по ним не имеет особого смысла.

Объем семантического ядра
Четкого ответа на вопрос, какой объем СЯ достаточен для сайта, не существует. Для каждого бизнеса количество ключей будет разным.
Однако есть правило рекомендательного характера: оптимизировать страницу под 1 высокочастотный запрос, 3–4 среднечастотных запроса и несколько низкочастотных. Говорит ли это о том, что вам придется создать несколько страниц под несколько высокочастотных запросов? Да! Чем релевантней страница запросу, тем легче поисковику ее найти, а пользователю — получить то, что ему нужно.
Следуйте этому правилу, создавая лендинги. Не стоит оптимизировать заголовки и текст страницы под множество ключевых фраз — это испортит вашу дружбу с поисковиком.
Не стоит оптимизировать заголовки и текст страницы под множество ключевых фраз — это испортит вашу дружбу с поисковиком.
Как использовать семантическое ядро
После того как вы соберете все ключевые запросы, их нужно разделить по страницам сайта. Этот процесс называется кластеризацией и чаще всего им занимается SEO-специалист. Запросы могут помочь вам при формировании структуры сайта: они подскажут, какие именно страницы понадобятся.
Если у вас нет сайта, ключевые запросы можно использовать в виде хештегов и в описаниях в социальных сетях.
- Также СЯ пригодится, чтобы настроить контекстную и таргетированную рекламу. Все это — компетенции интернет-маркетолога. Специфику этой профессии мы разбирали в статье «Что должен знать и делать интернет-маркетолог: навыки и требования».
Помните: недостаточно собрать ключевые слова и разместить их в текстах на сайте. Необходим комплексный подход и внимание ко всему: интерфейсу сайта, текстам и картинкам, качеству товара или услуги. Покажите пользователю, что именно ваш продукт решит его проблему и закроет его потребность, тогда клиент будет заинтересован в покупке.
Покажите пользователю, что именно ваш продукт решит его проблему и закроет его потребность, тогда клиент будет заинтересован в покупке.
Как составить семантическое ядро с помощью Яндекс.Вордстат
Краткое содержание статьи:
Семантическое ядро — это основа контента. По нему поисковые системы понимают, чему посвящен сайт. Также семантика помогает создать качественную удобную структуру. Можно сказать, что это одна из составляющих каркаса сайта.
Принципы составления семантического ядра
Семантика собирается не по принципу “мне понравилась эта фраза, использую ее”, а так, чтобы было удобно продвигать сайт.
- Хорошая структура сайта, составленная на основе семантического ядра, позволяет увеличить статический вес определенных страниц. Для увеличения веса лучше выбрать основные страницы — главную, основные разделы или категории. На таких страницах лучше использовать высокочастотные запросы.
- На внутренних
страницах эффективно использовать низкочастотные запросы. По ним хоть и редко
ищут информацию, зато у страниц с такими ключами очень низкая конкуренция и их
можно продвинуть без лишних затрат.
- Уровень частотности определяется не в количестве запросов за месяц, а исходя из темы, города продвижения. Например, ключ “купить козловой кран” в Воронеже просто не может превысить нескольких десятков запросов в месяц, потому что это слишком нишевый товар.
 По ним хоть и редко
ищут информацию, зато у страниц с такими ключами очень низкая конкуренция и их
можно продвинуть без лишних затрат.
По ним хоть и редко
ищут информацию, зато у страниц с такими ключами очень низкая конкуренция и их
можно продвинуть без лишних затрат. Но также обратите внимание на то, что в очень конкурентных тематиках даже низкочастотные запросы могут стоить очень дорого, так как конкуренты бьются за каждого клиента. Посмотрите, сколько сайтов-конкурентов по ключу “seo продвижение”, и все они борются за клиентов:
Чтобы собрать семантику для контекстной рекламы или seo-продвижения, есть множество инструментов: СловоЕб, KeyCollector, Semrush и прочие. Но самый простой, доступный и бесплатный инструмент — Яндекс.Вордстат.
Семантическое ядро в Вордстате: что учесть при сборе?
Вордстат — очень просто инструмент с интуитивно
понятным интерфейсом.
Чтобы успешно использовать Вордстат и любой другой инструмент сбора семантики, нужно понимать, что:
- Чтобы получать хороший трафик на сайт, он должен находиться хотя бы в ТОП-10, а лучше в ТОП-3. Если это запросы для контекстной рекламы, она должны показываться на первых четырех местах рекламной выдачи. При этом нужно помнить, что конкурентов очень много и все хотят попасть в ТОП, потому семантика — это не все, что нужно для успешной раскрутки.
- Поисковые системы формируют индивидуальную выдачу для пользователей. При ее формировании Гугл и Яндекс учитывают интересы, историю поиска, регион проживания. Поэтому позиции сайта, можно сказать, относительные. Чтобы видеть реальную картину, нужно пользоваться режимом Инкогнито.
- Даже если
получится попасть на первые места выдачи, переходов все равно может быть
немного. Например, у сайтов на первом и десятом месте в ТОПе количество
переходов будет существенно разниться. Также переходы зависят от
привлекательности сниппетов.
- Собранные для продвижения ключи могут оказаться бесполезными. По ним не будет ни показов, ни переходов. Со временем их нужно отсеивать.
- Есть ключевики, по которым статистика накручивается. Если продвигать интернет-ресурс по ним, результата не будет.
- При сборе семантики уточняйте регион продвижения.
- Также нужно учитывать сезонность. Ее можно посмотреть в “Истории запросов” в Вордстате. Это нужно, чтобы правильно оценивать приток трафика. Например, у турагентств приток клиентов обычно бывает летом, а в остальное время их немного, соответственно и запросов, и переходов на сайт немного.
- Легко и удобно в Вордстате собирать небольшое количество запросов, а потом это становится рутиной, которая занимает много времени. Поэтому нужно пользоваться плагинами для Вордстата, например, Wordstat Helper, и уметь работать с формулами и функциями Excel.
- Операторы Вордстата повышают эффективность продвижения в разы.
Что нужно понимать для использования семантического ядра?
Семантическое ядро — инструмент для SEO и
контекстной рекламы.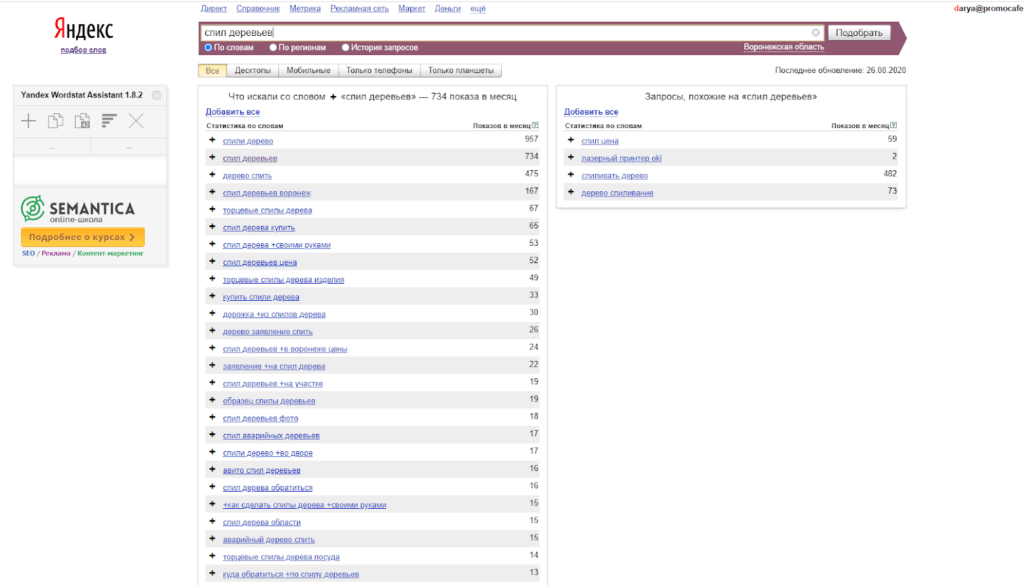 В зависимости от цели сбора семантики, оно используется
по-разному.
В зависимости от цели сбора семантики, оно используется
по-разному.
SEO:
- Сначала собирается семантика, потом на ее основе создается структура сайта, а не наоборот. Так получится полезный сайт с полной информацией о товаре или услуге.
- Вместе с ключами нужно записывать количество запросов и учитывать, что не всегда высокочастотные приводят больше клиентов — по ним бывает высокая конкуренция. Эффективнее использовать все запросы: ВЧ, СЧ, НЧ.
- Наполнение статей огромным количеством ключевиков уже не работает — стоит использовать не больше 2-3 ключей на один текст, вписывать их максимально естественно. Контент должен быть полезным для людей.
- Ключи вписываются не только в тело статьи, но и в заголовки, title.
- Для сайтов, продающих товары, лучше использовать коммерческие ключи.
- Со временем семантику нужно обновлять, так как появляются новые запросы.
Контекстная реклама:
- Чем более
популярный запрос, тем выше по нему конкуренция, тем выше стоимость клика по
объявлению с ним.
- Нужно использовать минус-слова. Они сэкономят бюджет, так как интернет-пользователи не будут кликать по объявлению по мусорным запросам.
- Для экономии бюджета и более эффективной рекламы также стоит использовать операторы Вордстата. Показов будет меньше, но они будут более точными.
- Собранная семантика делится по группам на ключи с похожими словами. “Деревянные лестницы” и “Лестницы из дерева” должны быть в разных группах, по ним совсем разная выдача. А “Деревянные лестницы” и “Деревянные лестницы в Воронеже” можно поместить в одну группу.

Подбор ключевых слов в Яндекс.Вордстат
В первую очередь нужно провести мозговой штурм: подумать, по каким запросам люди могут искать сайт, синонимы, похожие слова. Можно проанализировать конкурентов.
После сбора основной семантики, можно начать собирать расширенную семантику с помощью Вордстата.
- В строку вбить придуманный запрос. Предположим,
продвигается сайт с косметикой Натура Сиберика в Екатеринбурге. Основной ключ,
который первым приходит в голову будет Natura Siberica. Получаем выдачу:
 Основной ключ,
который первым приходит в голову будет Natura Siberica. Получаем выдачу:
Основной ключ,
который первым приходит в голову будет Natura Siberica. Получаем выдачу:- Далее выбираем регион продвижения. Если это интернет-магазин, который продвигается по всей России, нужно выбрать страну Россия, а не выбирать регионы по отдельности. У нас в примере магазин работает только в Екатеринбурге, потому выбираем Екатеринбург. Количество запросов в месяц существенно снизилось:
- Статистика по регионам нас не очень сильно интересует, так как магазин продвигается только в одном регионе. Но можно из любопытства или на будущее посмотреть статистику в других регионах. Больше 100% означает, что спрос очень большой:
- Сезонность нам тоже не так интересна, так как
Natura Siberica производит косметику, которая подходит для любого сезона,
любого возраста и тип кожи. Но можно примерно понять по графику, в какие месяцы
трафика будет меньше или больше. Например, в декабре спрос растет, так как
скоро Новый год и люди закупают косметику в подарок.

- Чтобы было удобнее и быстрее пользоваться Вордстатом, а не выгружать все запросы в Эксель, а потом тратить время на сортировку, можно пользоваться плагинами: Yandex Wordstat Assistant или Wordstat Helper. В них можно добавлять только нужные ключи и легко исключать, если они не подходят:
- Яндекс Вордстат по умолчанию показывает количество запросов в месяц по общим запросам со всеми окончаниями, без ограничения слов и прочее. Операторы могут уменьшить количество запросов, но за счет того, что они будут более точными, продвигаться по ним получится эффективнее.
Оператор ! фиксирует падеж, число, время слова. Например, “купить крем натура сиберика !екатеринбург” будет показываться по запросу “купить крем натура сиберика екатеринбург”, но не будет по “купить крем натура сиберика в екатеринбурге”.
Оператор + фиксирует предлоги, местоимения и
другие слова без смысла. “Крем +с ежевикой” будет показываться по запросу “крем
с ежевикой”, но не “крем из ежевики”.
Оператор “ “ фиксирует количество слов в ключе. “”Купить крем Натура Сиберика”” покажется по запросу “Купить крем Natura Siberica”, но не покажется по “Купить крем Натура Сиберика в Екатеринбурге”.
Оператор [ ] фиксирует порядок слов. “[Крем с ежевикой] Натура Сиберика” покажется по запросу “Крем с ежевикой Натура Сиберика”, но не покажется по “Крем детский с ежевикой Натура Сиберика”.
- После того, как собрана семантика по одному запросу, пора переходить к другому. Можно использовать слова-подсказки из правого столбика:
Это похожие запросы. Здесь можно найти еще варианты для сбора семантики. Тут это “Натура сиберика” русскими буквами. Вбиваем “Натура Сиберика” и получаем совершенно иные возможные ключи:
Таким образом можно собрать максимально полное семантическое ядро.
- Для контекстной рекламы важны минус-слова.
Добавлять минус слова лучше сразу при сборе ключей. Чтобы сделать это, в запрос
нужно вписать “-слово”. Например, “Натура сиберика — отзывы”, чтобы объявления
не показывались по запросам, через которые ищут отзывы о косметике.

Рассказать друзьям:
Что такое семантическое ядро?
Интро
Составление семантического ядра — важнейшая и фундаментальная часть любого продвижения сайта. Умение правильно ее собрать — полезный навык, а понять, что делать с полученной информацией — уже искусство.
Эта статья создана для людей, не имеющих профессиональных навыков или специализированных автоматизированных сервисов. Его цель – сформировать у читателя целостное представление о том, зачем нужно семантическое ядро, как его собрать и что с ним делать в дальнейшем. Материала много, заваривай чай.
Зачем нужно семантическое ядро и как с ним работать
Многие заказчики и начинающие сео-специалисты просто не понимают реальной значимости процедуры сбора семантики в процессе SEO-продвижения. Однако при правильном подходе к обработке данных из ядра мы получаем мощный инструмент для самых разных задач. Мы постарались выделить наиболее важные направления:
Аналитика
Семантическое ядро — чрезвычайно гибкое понятие. В зависимости от уровня требований и поставленной задачи он может сильно варьироваться в конечном виде.
В зависимости от уровня требований и поставленной задачи он может сильно варьироваться в конечном виде.
Обязательный минимум — наличие только поискового запроса.
Однако большие проекты, над которыми работают целые группы SEO-специалистов, рекламщиков и прочих маркетологов всех мастей, требуют гораздо большего усердия при сборе ядра.
Простейшим примером аналитики, доступной на уровне коллекции семантического ядра, является анализ сезонности запросов. Вот как выглядит такое дополнение к семантическому ядру:
В этом представлении мы хорошо видим, где сезон идет на спад (красные клетки слева), а в какие месяцы начинается рост (желтые и зеленые) .
Если вам нужно проанализировать массив нишевой информационной тематики для роста тренда, для работы с блогом, то отлично подойдет дополнение в виде графика или диаграммы:
Вот пример другой версии расширенное семантическое ядро:
В дальнейшем, возможно, мы напишем отдельную статью, в которой разберем назначение каждого отдельного параметра, но в данной теме мы просто посмотрим на них поверхностно.![]()
Отдельно хотелось бы остановиться на таком важном нюансе работы с семантикой, как принадлежность ключевых запросов к коммерческому или информационному сегменту. Я часто нахожу в Интернете статьи, где специалисты очень просто различают ключи по условным признакам.
Например, если запрос содержит слова типа:
- «цена»
- «стоимость»
- «заказ»
- «купить»
это обязательно коммерческие ключи, которые необходимо использовать для продвижения соответствующих страниц.
Если ключевые слова имеют вопросительную структуру и включают соответствующие местоимения, например:
- «как»
- «почему»
- «сколько»
- «где»
, то их следует считать «информационными».
В большинстве случаев это так, но бывают крайне неоднозначные исключения. Например:
Запрос «виндовс лучшие цены» на первый взгляд кажется чисто коммерческим, но если изучить результаты поиска, то можно увидеть, что большая часть результатов — это сайты-агрегаторы.
В то же время поисковая фраза «сколько стоит установка windows» предложит нам гораздо более целенаправленные результаты поиска, несмотря на наличие вопроса и соответствующего местоимения.
Это неудивительно, так как поисковые системы совершенствуются и учитывают не только оформление поискового запроса, но и результаты, которые большинство пользователей выбрали как релевантные, с аналогичным доступом. В связи с этим предлагаю следовать самому проверенному правилу:
Если вы не уверены в принадлежности запроса, просто обратитесь в поисковик. Он точно знает!
Планирование
1. Структура
Уже сгруппировав семантику, мы начинаем проектировать структуру сайта. Если у вас есть базовая разветвленная структура, вы можете попробовать масштабировать ее, создав страницы для менее частотных запросов.
Даже несмотря на обилие низкочастотной семантики, не всегда нужно увеличивать количество страниц до максимума, хотя бы для сохранения логики в архитектуре сайта.
В нашей практике мы ориентируемся на показатель частоты запроса маркера кластера не менее 100, в точном соответствии.
Маркерные ключи — это запросы, наиболее точно соответствующие продвигаемой странице или кластеру (группе) ключевых слов в ядре. Обычно они влекут за собой ряд подобных вариаций.
Пример:
«Смартфон смартфон xiaomi redmi note 10 pro» — запрос маркера соответствующей страницы.
Смартфон смартфон xiaomi redmi note 10 pro цена
Смартфон смартфон xiaomi redmi note 10 pro купить
xiaomi redmi note 10 pro смартфон отзывы ia это вспомогательные клавиши Киев
Смартфон смартфон xiaomi redmi note 10 pro заказ
2. Метаданные и текстовый контент на коммерческих страницах
Важно помнить, что при работе с метаданными в Google порядок записи ключей имеет гораздо большее значение, чем в Яндексе.
На основе семантики каждого отдельного кластера составляются уникальные метаданные и задание копирайтеру на написание текстового контента.
В связи с этим можно допустить существенную ошибку при написании заголовка, просто перепутав запросы, например, используя ключ «велосипеды для детей» (с частотой 400), левее, чем «велосипеды для детей (при частоте 3500)
Написание технического задания для копирайтера — отдельная тема. Просто у нас есть хорошая статья на эту тему, предлагаю и вам ее прочитать: https://wedex.com.ua/blog/kak-pravilno-pisat-teksty-dlya-sajtov-v-2021-godu/
3. Возвращаясь к сезонности
Имея перед собой наглядную статистику динамики роста и падения спроса в Интернете на отдельные услуги и товары, мы сможем более точно расставить приоритеты контекстной рекламы, вплоть до отдельных страниц – когда и на какие страницы лучше ориентироваться.
В некоторых случаях можно попробовать поэкспериментировать с метаданными, обновив некоторые из них в соответствии с сезонностью.
4. Планирование статьи
Как я уже говорил выше, потребность в написании информационных статей формируется исходя из динамики частотности по конкретной теме.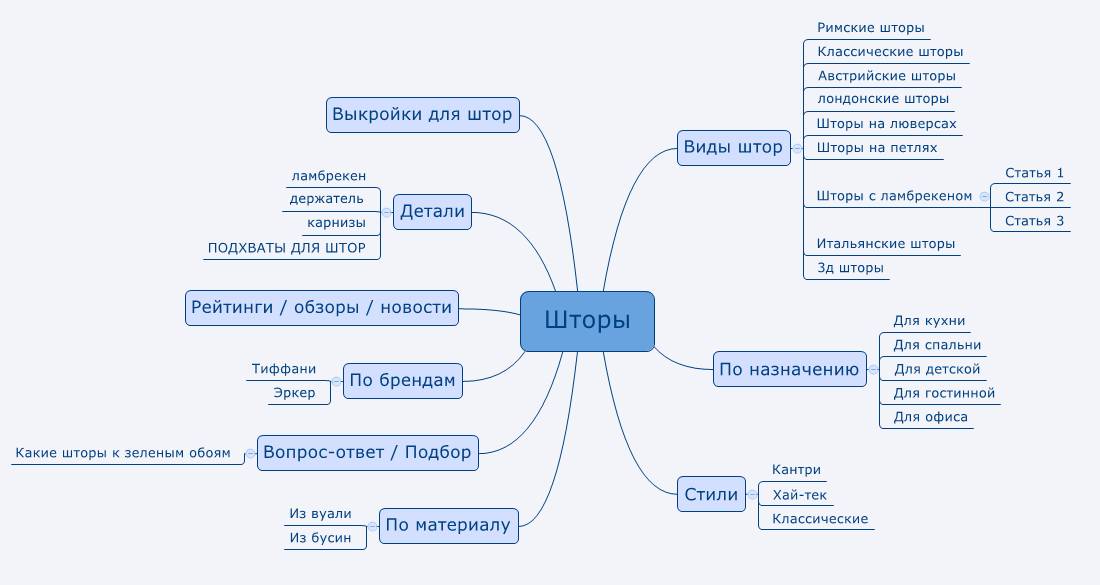
Например, если специалист наблюдает устойчивый рост интереса к теме со стороны пользователей, вот так (частота за последние 9 месяцев):
Как составить семантическое ядро
Составление семантического ядра достаточно индивидуальный процесс. Не стоит думать, что все SEO-специалисты строго следуют одному и тому же алгоритму. Наоборот, каждый работает исходя из своего опыта, вовлеченности в проект и свободного времени.
В этой статье мы опустим варианты работы через платные автоматизированные сервисы, такие как KeyCollector, и остановимся подробнее на всех нюансах ручной сборки, которые обычно упускают авторы подобных статей.
Сбор запросов маркеров. Zoom
Как указано выше, маркерные запросы (далее – маркеры) являются своего рода ориентирами для соответствующих групп базовых ключевых фраз. То есть именно маркеры позволяют понять основную канву семантики.
На схеме это будет выглядеть так:
Желтым маркером я выделил запросы, а все остальное тематические запросы.
Для ручного подбора маркеров используются Яндекс Вордстат и Планировщик ключевых слов Google Ads для Яндекса и Google соответственно.
Начнем со службы Google. Вот пример его интерфейса:
Важно отметить, что этот инструмент больше ориентирован на работу с поисковой рекламой. Не очень подходит для получения точных данных о частоте запросов; скорее, он дает понимание «набросков» этих ценностей. Google просто не публикует точную информацию по этому параметру.
Кроме того, сервис может пропускать низкочастотные ключи, которые не фигурируют в действующих рекламных кампаниях, что еще больше усложняет работу.
Яндекс Вордстат удобнее для ручного сбора семантики в этом плане.
Помимо точной информации о частоте поисковых запросов и сохранения статистики по ней, сервис позволяет подключить дополнительный плагин для браузера — Яндекс Вордстат Помощник, добавляющий вспомогательные элементы интерфейса (выделены красным на изображении), что значительно упрощает ручной сбор.
Так как же выделить маркерные запросы? Вариантов много, но мы предпочитаем самый проверенный — ручной. Особенно когда речь идет о незнакомых темах.
Принцип отбора достаточно прост: ищем варианты, способные масштабировать исходный запрос, но не конфликтующие с ним на логическом уровне.
Если рассматривать пример выше, то маркерными (помимо основного «купить кровать») будут следующие запросы:
При формировании первого уровня маркерных запросов будет возможно дальнейшее масштабировать их. Для запроса «купить детскую кроватку» это будет выглядеть так:
Очень важно помнить следующее:
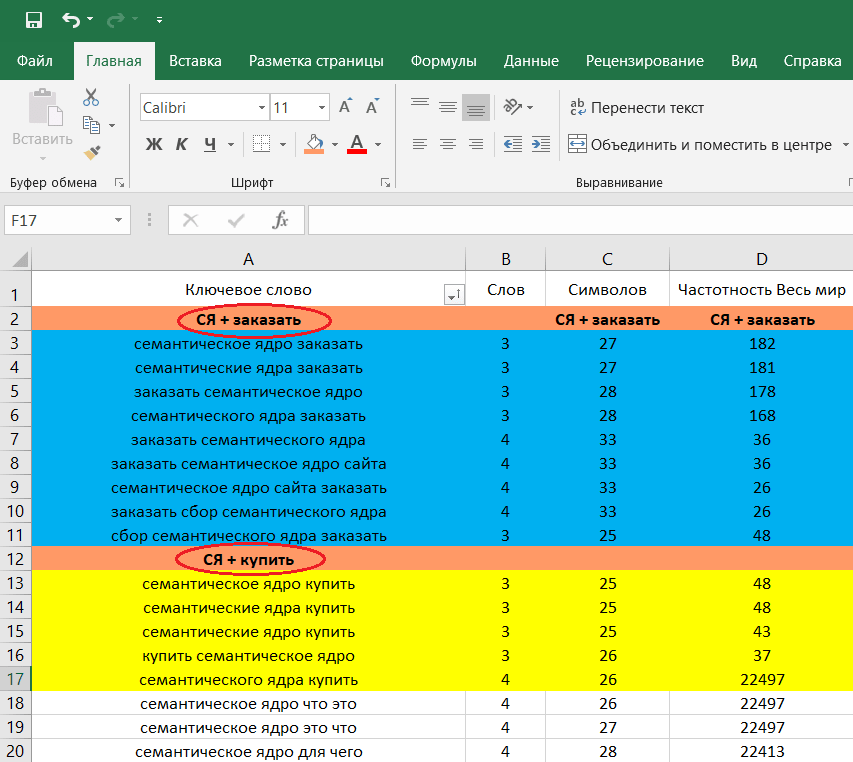
В правом столбце указана общая частота всех запросов в кластере, а не запрос по отдельности
Например, если ключ «купить детскую кроватку» имеет частоту 83495 , это значит, что учитывалась сумма запросов «купить детскую кроватку недорого», «купить детскую кроватку с бортиком» и т.д.
Если вы хотите просмотреть конкретную частоту определенного ключа, вы должны использовать оператор «». Пример:
Пример:
Это желаемое значение.
Всех остальных операторов можно найти в этой статье: https://test.wedex.com.ua/blog/operatory-poiska-v-google-i-yandeks/
Небольшие советы по сбору семантики
Использовать групповой поиск по ключам
Очень часто пользователи ищут один и тот же сервис совершенно разными способами. Так как нам нужны абсолютно все варианты поисковых запросов, а поиск в порядке приоритета довольно медленный, рекомендуем использовать массивы. Например:
Есть ключевая фраза «автомобиль Mitsubishi». Чтобы правильно собрать семантику для этого запроса, нам будет недостаточно просто выгрузить все ключи для него, потому что мы пропустим огромное количество дополнительных записей. Для этого нужно подключить свое воображение и продумать все возможные варианты, которые может придумать пользователь.
Для этого подготавливаем сложную структуру:
автомобиль (Mitsubishi|Mitsubishi|Mitsubishi|Mitsubishi|Mitsubishi)
И смотрим как часто эту марку ищут по тому или иному варианту:
Если изучить результаты, то скорее всего можно найти информацию по каждому из вариантов группы.
Комбинировать группы
Для удобства можно создавать комбинации групп запросов, например:
(натяжные|навесные) потолки (ткань|ткань) (Клипсо|Клипсо) (купить|цена|заказать|стоимость )
Этот массив поможет набрать частоту на тканевых натяжных потолках Clipso, при этом использовать вторичный «шарнирный» ключ, который некоторые пользователи ошибочно применяют к натяжным потолкам.
Использовать минус-слова
Если нам не нужны абсолютно все запросы, то можно избавиться от отдельного мусора на этапе сбора. Для этого после построения необходимо добавить исключения со знаком минус. Пример:
Работа с подсказками
Еще одним важным преимуществом Яндекс Вордстата является наличие поисковых подсказок. Кстати, этим функционалом можно пользоваться даже при поиске дополнительных опций под гуглом, т.к. более 95% русскоязычных запросов идентичны для обоих поисковых систем.
Эти ключи можно увидеть в правой колонке Яндекс Вордстат:
В некоторых случаях сервис предлагает очень интересные варианты, которые даже самый опытный специалист может упустить из виду.
Выгрузка и изучение семантики конкурентов
Одним из финальных аккордов масштабирования ядра является выгрузка сайтов-конкурентов и изучение их семантики. Этот этап не стоит игнорировать, потому что, зачастую, ресурсы конкурентов из ТОП поисковой выдачи имеют полный список вхождений ключевых слов. В том числе и те, которые вы могли пропустить.
Для этих целей мы используем платный сервис Serpstat. Имеет максимально удобный интерфейс и подходящий набор инструментов для работы с семантикой конкурентов.
Пример загруженной семантики, по которой ранжируется сайт:
Всю информацию можно сохранить в виде таблицы Excel, где вам будет удобнее продолжать работу.
Кластеризация запросов
После того как маркерные запросы собраны и масштабированы с использованием поисковых подсказок и семантики конкурентов, пришло время их кластеризовать. Если не игнорировать этап подбора маркеров, то процесс распределения их по группам будет достаточно простым.
Самый простой способ выполнить кластеризацию — создать проект в Excel и отсортировать его с помощью фильтров. Лучше даже иметь отдельные вкладки, особенно для тех групп, которые могут иметь одинаковые вторичные ключи (например, марки велосипедов). Это значительно облегчит работу с фильтром.
Одной из важнейших задач кластеризации является объединение запросов по логической составляющей, а не только по смысловой.
Пример двух семантически разных групп, логически идентичных:
ВАЖНО! В данном случае «трюк» относится исключительно к велосипедам «bmx» и только к ним. Если бы существовала другая группа товаров, которая соответствовала бы этому признаку, то объединение не нужно было бы производить.
При кластеризации полезно сразу определять тип каждого отдельного запроса, как уже было сказано здесь. При необходимости можно выделить все инфо-ключи и агрегаторы в отдельные вкладки.
Резюме
Подбор семантики – этап работы, в который следует вкладывать душу, как ни в чем другом. Информация, которую мы получаем на выходе, является важнейшим источником данных, которые можно использовать для решения совершенно разных задач.
Информация, которую мы получаем на выходе, является важнейшим источником данных, которые можно использовать для решения совершенно разных задач.
Процесс сбора информации не должен полностью доверяться автоматизированным службам; как минимум требуется проверка ручного управления.
В сложных нишах не грех прибегнуть к регулярным консультациям с заказчиками, особенно если последние хорошо разбираются в вопросе.
Усердно работайте, набирайтесь опыта и делитесь им!
Александр Байчук SEO-специалист
Узнайте, как мы можем помочь развитию вашего бизнеса
Свяжитесь с нами!
похожие статьи
подписываться:
# Полезные подсказки 29 ноября 2021
# Полезные подсказки 17 декабря 2021
# Полезные подсказки 4 Февраля 2022
Комментарии
Как мы убрали Яндекс Штраф «Баден-Баден» из шинного интернет-магазина
Начало истории
В нашу компанию обратился клиент, занимающийся продажей дисков и шин для автомобилей. Его сайт попал под фильтр Баден-Баден в Яндексе. До 2017 года сайт продвигали
другой SEO-компанией, а позже и самим клиентом. Наша цель состояла в том, чтобы удалить фильтр и
сделать сайт выше в поисковой выдаче к октябрю — сезону продаж зимних шин. Это было
Также большое значение имеет не потерять свои позиции в Google. Если бы результаты были неблагоприятными,
бизнес клиента остался бы без крупного дохода до весны. Наши специалисты знали
что необходимо будет в короткие сроки сделать редизайн всего сайта интернет-магазина,
но клиент доверился нам, так как хорошо действовать самостоятельно, но настоящие профессионалы справились бы с этим намного лучше.
Его сайт попал под фильтр Баден-Баден в Яндексе. До 2017 года сайт продвигали
другой SEO-компанией, а позже и самим клиентом. Наша цель состояла в том, чтобы удалить фильтр и
сделать сайт выше в поисковой выдаче к октябрю — сезону продаж зимних шин. Это было
Также большое значение имеет не потерять свои позиции в Google. Если бы результаты были неблагоприятными,
бизнес клиента остался бы без крупного дохода до весны. Наши специалисты знали
что необходимо будет в короткие сроки сделать редизайн всего сайта интернет-магазина,
но клиент доверился нам, так как хорошо действовать самостоятельно, но настоящие профессионалы справились бы с этим намного лучше.
Выяснили, что основная проблема заключалась в большом количестве автогенерируемых неуникальных текстов. На сайте было
сотни страниц с шинами стандартных размеров, которые отличались диаметром колеса, шириной и
высота шины. Чтобы не писать тексты для каждой страницы такого типа, клиент создал
текстовый шаблон с простым изменением стандартного размера.
Качество уникальных текстов также оставляло желать лучшего. Они содержали большие ряд фраз, которые странно звучали в живой речи, выдавали в них SEO-тексты, были неинформативны и заспамлены.
Это доказало сообщение в Вебмастере:
Ни один из 5000 выбранных поисковых запросов не попал в топ-10:
Исходный процент ключей в топ-10:
• Google: 57%
• Яндекс: 0%
Посещаемость сайта с Яндекса значительно снизилась, при этом сайт не потерял своих позиций в Google:
1.
1. За первый месяц (май) нам удалось собрать полное семантическое ядро более более 5000 запросов. Позже наша команда проверила качество всех текстов на сайте и составила для них контент-план. Анализировались как технические показатели (спам, избыточность, уникальность), так и полезность текста для пользователя.
Мы также нашли логические дубликаты страниц, которые привлекли одну и ту же группу запросов. Например, для шин одного бренда было сделано 2 лендинга.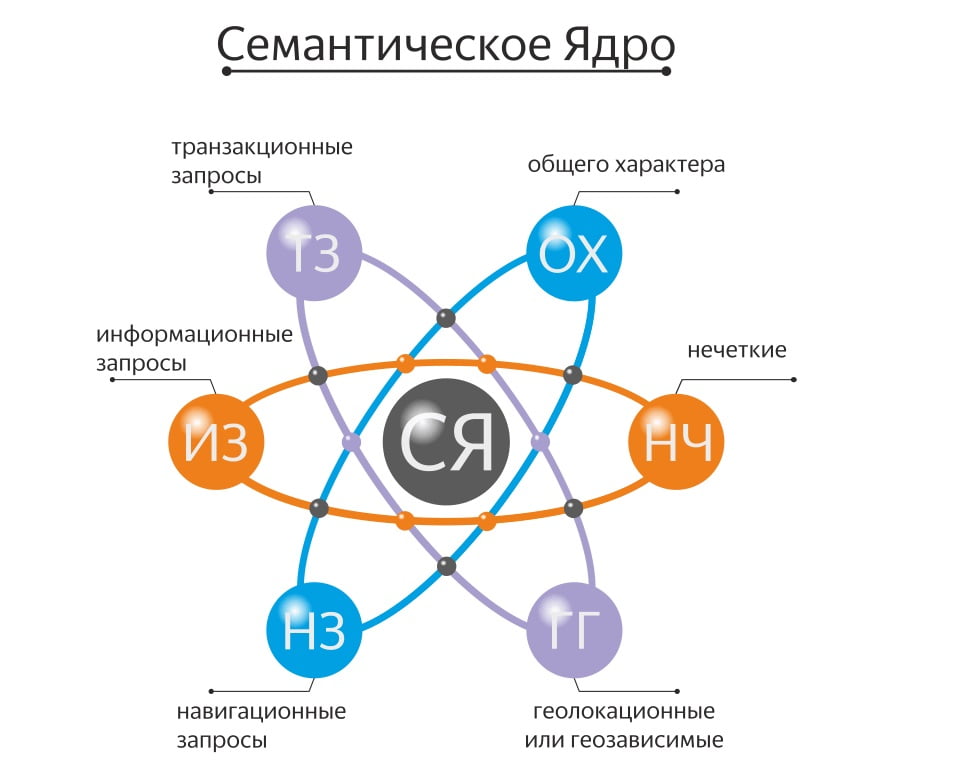 Итак, наша команда настроила 301 редирект с дублирующих страниц на основные.
Итак, наша команда настроила 301 редирект с дублирующих страниц на основные.
2.
2. С июня по август нашими специалистами обработано 160 страниц с текстами. Эти тексты были отредактированы, дополнены и написаны с нуля. Это представляло собой сложную задачу, так как требовалось создать уникальный качественный контент для стандартных страниц, заполненных товарами с практически полностью идентичными характеристиками. Мы также исправили метатеги.
В сентябре, пятого месяца, мы отправили запрос через Вебмастера на удаление фильтра. Позже фильтр был успешно удален.
Фильтр снят, сайт поднялся выше в поисковой выдаче:
3.
3. Также наши специалисты провели полный технический аудит сайта и дали рекомендации по устранению ошибок. Удалось исправить:
Большое количество внутренних ссылок, дающих 301 и 404 коды ответа.
Такие ссылки опасны тем, что можно получить статус дорвея, который не имеет никакого другого смысла, кроме перенаправления пользователя на какой-то другой. А код 404 просто говорит, что страницы не существует.
А код 404 просто говорит, что страницы не существует.
Скрытие скриптов, файлов стилей и изображений в robots.txt.
Этот недостаток скрывает от поисковой системы стили, формирующие внешний вид страницы. Без их распознавания страница будет выглядеть грязной, незаконченной.
Ошибки в файле sitemap.xml.
Этот файл представляет собой список страниц сайта для поисковой системы. Облегчает обход робота, сообщает о дате изменения страницы, поэтому файл имеет существенное значение для такого крупного сайта, как proshina.by.
Проблемы с дублированием страниц из-за записи URL в разные регистры.
Дубликаты — это страницы, доступные по разным URL-адресам, но содержащие одинаковый или похожий контент. Они конкурируют друг с другом в результатах поиска, нанося ущерб рейтингу сайта.
Проблемы с пагинацией страниц, которым система добавляла различные параметры, что приводило к многочисленным дублям и другим недостаткам.
При снятии сайта с фильтра в связи с улучшением качества текстов процент ключей в топе Google увеличился с 57% до 71%:
В итоге к октябрю процент ключей в Яндекс топ 10 составил 39% (на момент снятия фильтра):
Благодаря комплексной работе над сайтом (улучшение качества тегов, тексты и техническое состояние) сняли фильтр Баден-Баден, заняли выгодные позиции в Яндексе и даже улучшили позиции в Гугле.