Анализ страницы сайта онлайн: проверка SEO, ИКС, SSL
Проверка страниц сайта по 25 параметрам SEO оптимизации. Ключевые запросы в поисковиках, позиции в выдаче, внутренний анализ семантики, прогноз трафика, дубли страниц и другое!
395 285 страниц проверено
Анализ всех страниц сайта
⚡️⚡️️ Получайте позиции сайта раз в неделю в нашем телеграм боте @LiftwebPositionsBot бесплатно!
Генератор текста
Создать контент нейросетью
Пишет объемные уникальные осмысленные материалы за вас.
Очень быстро. Революция копирайтинга.
Генерировать
Инструменты анализа текста
Семантическое ядро текста
SEO анализ текста: тошнота, стоп-слова страницы
Проверка текста на воду
Проверить текст на водность, водные слова
Проверить переспам текста
Копировать текст страницы
Даже если есть защита от копирования
Транслит текста для SEO
Перевод URL на английскую раскладку
Количество символов
Проверить длину текста онлайн
Переходные слова
Проверить переходные слова в тексте
Технические инструменты
Возраст сайта
Проверить возраст домена и сроки его освобождения
Проверить whois
Информация о домене и его владельце
Код ответа сервера
Проверить статус-код любого URL сайта
Проверить сайт на дубли
Найти адреса, по которым страницы дублируются
Проверка сайта на вирусы
Проверить безопасность сайта в Яндекс и Google
Генератор фото людей
Генератор лиц ненастоящих людей
Проверить битые ссылки
Поиск нерабочих ссылок на сайте онлайн
Как проверить страницу сайта самому
Лучше один раз увидеть, чем 100 раз услышать.
Анализ страницы сайта онлайн — для чего?
В 2023 году важнейшую роль в ранжировании играет контент и его качество. Несложно оценить пользу сайта для людей. Но как проверить его SEO-оптимизацию для поисковиков?
С этой целью отлично справляется сервис онлайн анализа страницы сайта на портале Liftweb. Оптимизировав все параметры, вы поднимите свой ресурс в ТОПы выдачи поисковых систем. Много новых клиентов не заставят себя долго ждать, а с ними увеличатся продажи товаров и услуг.
Проверить страницу сайта
Мониторинг показателей страниц
Анализ страницы сайта онлайн обнаружит неявные недостатки, исправив которые вы получите новых посетителей из поисковиков. Следовательно, и увеличите продажи.
Следовательно, и увеличите продажи.
Что проверяет анализ страницы сайта Лифтвеб
01. Представление в поиске
Количество страниц в поисковой выдаче Яндекс и Google. А также региональная принадлежность ресурса.
02. Ключевые запросы сайта
Популярные ключевые запросы, по которым ресурс виден в поисковиках. И прогноз количества посетителей по каждому ключевику.
03. SSL сертификат
Инструмент Liftweb проверяет SSL сертификат сайта на работоспособность и срок годности. Обычно его нужно продлевать каждые 12 месяцев.
04. Проверка дублей сайта
Работа одинаковых страниц по разным адресам сводит на нет SEO продвижение. Кроме того, сервис проверяет атрибут Canonical — он препятствует появлению дубликатов.
05. Возраст домена
Для сравнения с конкурентами проверяется возраст сайта, дата создания домена и время истечения оплаты за него.
06. Анализ мета тегов
SEO оптимизация тегов Title, Description, Keywords на страницах.
07. Заголовки h2-h6
А также дубли заголовков страниц и их повторения с иными тегами.
08. Тексты на страницах
Например, проверка длины текста, затраты времени на его прочтение, кол-во символов, слов и предложений.
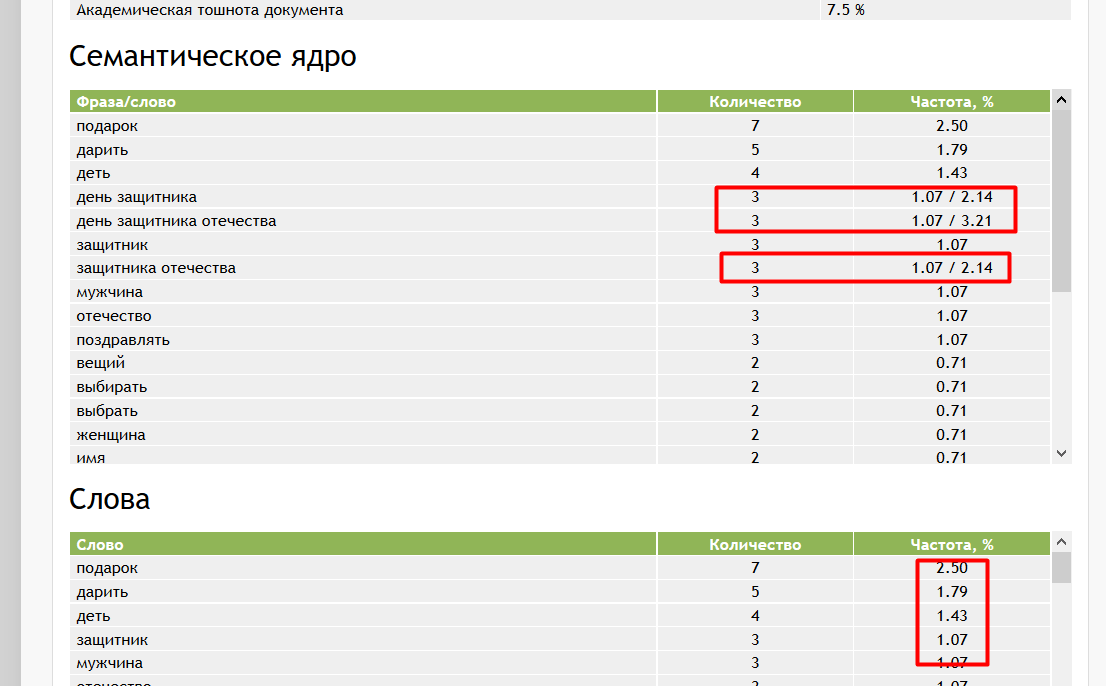
09. Анализ семантического ядра
Сервис проверяет сколько раз какие слова употребляются (с процентами). Кроме того, вы узнаете тошноту текста на странице.
10. Вода в тексте
Инструмент анализирует процент воды в тексте и полный список употребленных стоп-слов.
11. Анализ картинок
Проверяются картинки и их ALT атрибуты. В том числе незаполненные и дубликаты среди них.
12. Размер HTML кода
В том числе скорость загрузки сайта и размер HTML файлов в килобайтах. Также вы узнаете соотношение кода к полезному тексту.
Также вы узнаете соотношение кода к полезному тексту.
13. Проверка вирусов
Сделав анализ страницы сайта, вы можете одним кликом проверить ее безопасность, наличие вирусов по мнению поисковиков Яндекс и Google.
14. Значение ИКС
Это индекс качества сайта, который рассчитывается Яндексом. Параметр может быть от нуля до нескольких тысяч, если речь про лидирующие площадки в отрасли.
15. Ссылки dofollow и nofollow
Анализатор страницы сайта проверяет открытые для индексации ссылки на внешние ресурсы. Ведь такой шаг может передать вес страницы там, где делать этого не следовало.
Проверка страниц по ключевым запросам
01. Позиция в яндексе
Основной запрос страниц определяется автоматически. Затем инструмент находит позицию ресурса в Яндексе, учитывая регион сайта.
02.
 Ключевые слова в тексте
Ключевые слова в тексте03. Ключевые слова в картинках
Это анализ повторов ключевых слов в атрибутах ALT картинок на странице.
Проверить страницу сайта
Полный анализ страницы с рекомендациями
Вы знакомы с параметрами SEO оптимизации или только начинаете изучение материала? В любом случае всегда полезно иметь под рукой рекомендации к каждому пункту проверки страницы во время ее анализа.
Мы составили описания к каждому критерию со ссылками на подробные статьи. А значит вам не понадобится искать и изучать терминологию в других источниках.
Проверить ключевые запросы сайта
При создании или доработке ресурса важно подобрать и использовать правильные ключевые запросы.
В соответствии с их популярными запросами и семантическим ядром формируйте и дополняйте свои материалы.
Позиции по поисковым запросам
Чтобы оптимизировать сайт в поисковых системах, важно знать его позиции по ключевым запросам. Для этого сделайте анализ страницы сайта онлайн на нашем сервисе. Просто введите ее адрес и нажмите «Проверить». Основное ключевое слово страницы будет распознано анализатором Liftweb. Кроме того, всегда можно уточнить его вручную.
Проверить страницу бесплатно
Проверка страницы сайта
Из итогов проверки можно одним кликом сделать анализ соседних страниц ресурса, ссылки на которые есть в проверяемом контенте. Поэтому ориентироваться по вашему сайту становится значительно проще.
СЕО анализ страницы сайта в динамике
Мы храним результаты проверок, чтобы вам было легко проследить динамику развития сайта онлайн. Поэтому вы можете посмотреть как текущий анализ, так и сохраненные ранее данные. Для этого есть кнопки со стрелками влево и вправо (← →).
Высокая скорость проверок
Команда Лифтвеб понимает, что никто не любит ждать. И поэтому наш бесплатный инструмент онлайн анализа страниц работает без задержек. Кроме того, мы не просим вас регистрироваться и указывать свои приватные данные. Все функции сайта доступны всем посетителям, в том числе — бесплатный анализ страницы сайта онлайн.
Актуальные записи
Смотреть больше →Что такое персональный поиск: влияние на SEO
Что такое SEO просто и понятно [2023]
SEO тренды в 2023 году
Как сделать семантический анализ текста
Здравтсвуйте!
Семантический анализ текста показывает, из каких слов и словосочетаний состоит контент и какие из них встречаются чаще всего. Преимущественно его используют для SEO-текстов с ключевыми словами и LSI-шлейфами: анализ позволяет примерно представить, как на контент отреагирует поисковая система.
Преимущественно его используют для SEO-текстов с ключевыми словами и LSI-шлейфами: анализ позволяет примерно представить, как на контент отреагирует поисковая система.
Но не всегда цифры бывают понятны, а результат правок по советам семантического анализа — хорошим. Мы расскажем, как сделать анализ, на что обратить внимание и что делать с показателями.
Онлайн-сервисы семантического и SEO-анализа текста
Advego.com. Семантический анализ от биржи контента Адвего — один из самых популярных сервисов у SEO-специалистов. Он бесплатен, доступен всем незарегистрированным и зарегистрированным пользователям.
Показывает:
- Академическую тошноту;
- Классическую тошноту;
- Количество стоп-слов;
- Показатель «воды»;
- И другие менее значимые параметры.
Istio.com. Это — сервис, разработанный специально для семантического анализа текста. Доступен всем, регистрация не обязательна. Не требует оплаты подписки.
Не требует оплаты подписки.
Показывает:
- Показатель водности;
- Тошноту;
- Топ-10 самых используемых слов;
- Тематику текста;
- Другие параметры.
Miratext.ru. Это — еще один сервис от биржи копирайтинга. Тоже бесплатный, доступный зарегистрированным и незарегистрированным пользователям.
Показывает:
- Тошноту;
- «Водянистость»;
- Качество по закону Ципфа;
- Облако частотности слов;
- Другие менее значимые цифры.
Внимание! У каждого сервиса свой алгоритм, поэтому единых цифр, на которые стоит ориентироваться, нет. Например, наш текст показал тошноту 4,12/8,7%, 4,79% и 4,8% на трех разных сервисах. Цифры похожи, но не совпадают.
Поэтому обязательно читайте описание самого сервиса проверки и ориентируйтесь на рекомендованные им показатели.
Проверка текста на уникальность
Пример семантического анализа текста
Давайте разберем показатели на примере анализа текста по семантическому анализатору от Адвего. Первые несколько строк — количество знаков с пробелами и без, количество слов, уникальных и значимых слов — не так важны.
Первые несколько строк — количество знаков с пробелами и без, количество слов, уникальных и значимых слов — не так важны.
Важны следующие показатели:
- Вода — 67,7%;
- Классическая тошнота документа — 4,12%;
- Академическая тошнота документа — 8,7%;
- Семантическое ядро;
- Частота слов в семантическом ядре.
Давайте остановимся на каждом показателе подробнее.
Водность текста
Семантический анализатор Адвего показывает самую высокую водность — на других сервисах при проверке нашего текста она 44% и 5%. Показатель водности — это соотношение незначимых слов к общему количеству слов. Чем больше в тексте стоп-слов, не несущих смысловой нагрузки, тем выше процент воды.
Слова, которые сервис считает «водой», выводятся в отдельной таблице «Стоп-слова». Чаще всего в нее попадают предлоги и местоимения. Кстати, нормальный показатель, упомянутый в описании семантического анализа по Адвего — 55-75%. Значит, в нашем тексте уровень воды нормальный.
Значит, в нашем тексте уровень воды нормальный.
Классическая тошнота документа
Она рассчитывается по самому частотному слову, как квадратный корень из количества его вхождений. Другие сервисы проверки используют подобный алгоритм, поэтому их «тошноту» можно приравнять к показателю «классическая тошнота» на Адвего.
Определенные нормы по классической тошноте в описании анализатора не указаны.
Создатели лишь рассказали, что она зависит от длины текста — например, для статьи длиной в 20 000 символов тошнота 5% нормальная, а для заметки в 1 000 символов — слишком высокая. Многие агентства и SEO-специалисты придерживаются мнения, что тошнота не должна быть выше 4-6%.
Академическая тошнота текста
Она определяется как соотношение самых частотных и значимых слов ко всему тексту. Саму формулу подсчета не раскрывают.
В описании указано, что нормальный процент академической тошноты — 5-15%. Это косвенно подтверждено самим Яндексом: в его блоге привели пример переоптимизированного текста, и академическая тошнота этой заметки составила 19%.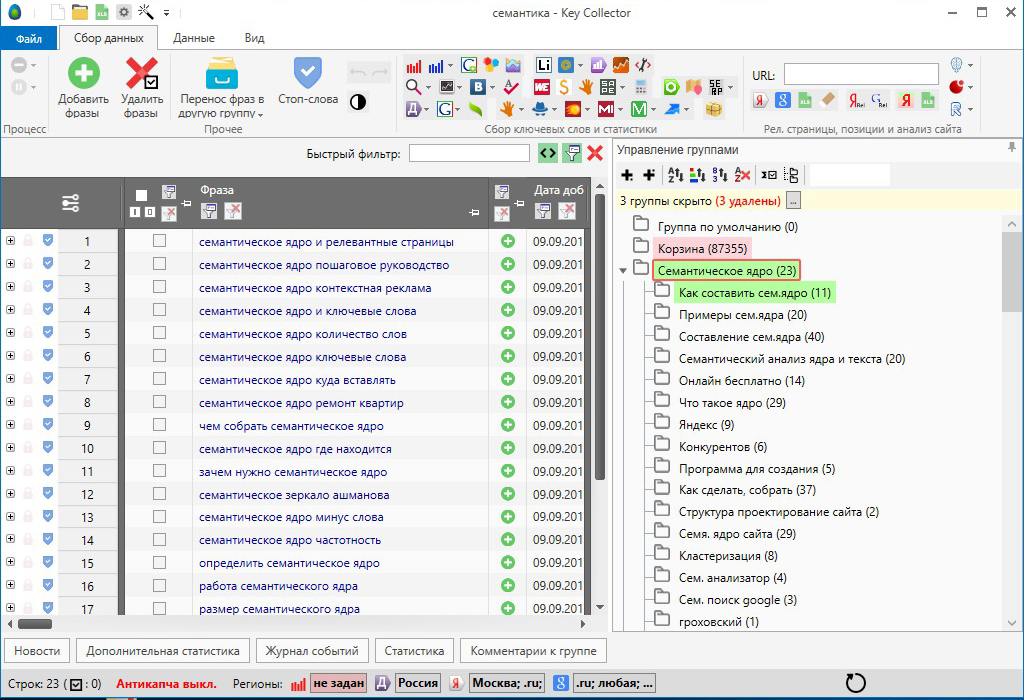 На практике многие SEO-специалисты требуют писать статьи с тошнотой не больше 10%.
На практике многие SEO-специалисты требуют писать статьи с тошнотой не больше 10%.
Семантическое ядро
Блок семантического ядра показывает самые часто встречающиеся слова в тексте. Именно они задают тематику материала. Поэтому на первом месте должны быть слова, релевантные теме — иначе поисковая система не поймет, о чем вы пишете, и понизит сайт в выдаче или вообще не будет показывать страницу по нужным ключевым словосочетаниям.
В нашем примере в семантическом ядре на первом месте стоит слово «вебинар». Понятно, что статья о вебинарах — это подтверждают следующие позиции ядра из тематических слов.
Частота слов в семантическом ядре
Этот показатель рассчитывается по самым распространенным в тексте словам. Чем выше процент — тем чаще встречается слово. Этот показатель тесно связан с процентом самой тошноты.
В описании семантического анализа Адвего нет рекомендуемых параметров.
Многие SEO-специалисты и агентства требуют не превышать показатель в 3-4%.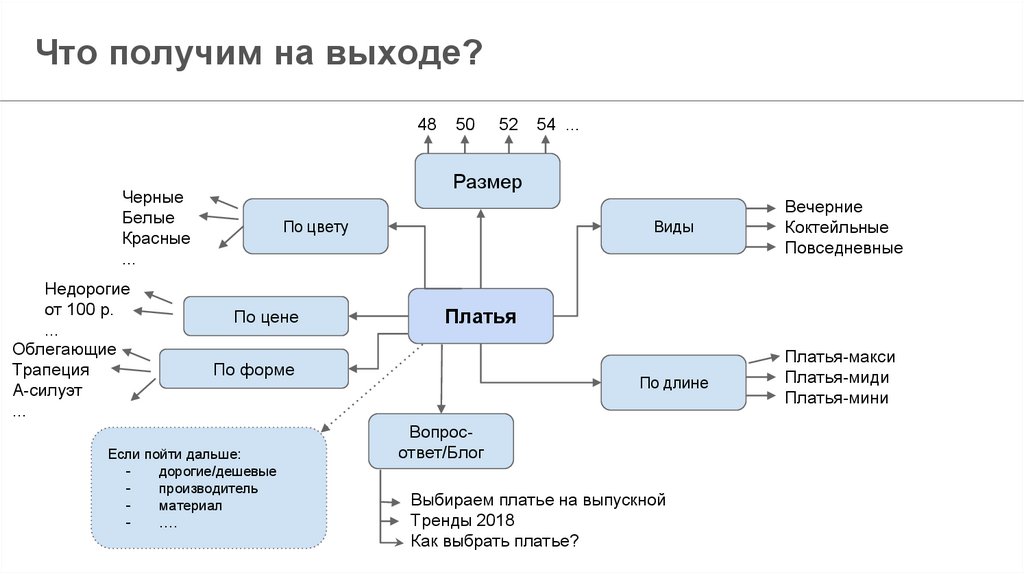 А в переоптимизированной заметке Яндекса максимальная частота слова в семантическом ядре превысила 8%.
А в переоптимизированной заметке Яндекса максимальная частота слова в семантическом ядре превысила 8%.
В Istio.com также показывают семантическое ядро, а в анализаторе Miratext.ru его заменяет облако слов. Самые часто встречающиеся слова написаны крупным шрифтом. Семантический анализ Miratext.ru такжп показывает качество текста по Ципфа. Точный алгоритм анализа по Ципфа неизвестен, но его создатели утверждают, что он проверяет «естественность» текста, а нормальный показатель начинается от 50%. Проверка нашего текста на анализаторе выдала показатель в 34%. А при проверке на самом сервисе Ципфа — 77%. Поэтому на эту строчку при проверке на Miratext.ru можно не обращать внимания — цифры не совпадают.
Как доработать текст
Если показатели вашего текста не совпадают с рекомендуемыми параметрами, его желательно доработать.
Сделать это просто, и мы подготовили небольшую шпаргалку:
- Если «вода» высокая, удалите малозначимые слова и словосочетания, переформулируйте предложения так, чтобы в них встречалось меньше предлогов; если показатель низкий, разбавьте текст или не трогайте его
- Если классическая тошнота высокая, удалите несколько вхождений самого часто встречающегося слова, если низкая — добавьте вхождения ключевых слов
- Если академическая тошнота текста высокая, удалите несколько вхождений ключевых слов, если низкая — добавьте вхождения главного ключа
- Если в семантическом ядре находятся нетематические слова, добавьте в текст вхождения ключей и других тематических слов
- Если частота слов в семантическом ядре слишком высокая, удалите несколько вхождений
Не забывайте о том, что в первую очередь текст должен нравиться людям. Поэтому не стоит воспринимать семантический анализ текста как истину в последней инстанции — даже далеко не идеальные в плане SEO статьи попадают в топ.
Поэтому не стоит воспринимать семантический анализ текста как истину в последней инстанции — даже далеко не идеальные в плане SEO статьи попадают в топ.
Например, в первой в выдаче по запросу «что такое инфляция» статье показатель воды по Адвего приближается к верхней планке, составляет 72,6%.
А на странице со второго места показатель академической тошноты превышает рекомендованную многими SEO-специалистами отметку в 10%, а частота слова в семантическом ядре превысила 5%.
Если текст интересный, полезный, структурированный, но немного не соответствует рекомендуемым показателям, можете оставить все как есть.
А какими показателями при проверке руководствуетесь вы? Поделитесь своим мнением в комментариях!
До новых встреч!
тошнота и содержание воды, подсчет количества символов и частоты слов, все для белого SEO
Оценивает его насыщенность по ключевым словам, содержание воды, спам-контент. Обратите внимание: анализ корректно работает на английском, немецком, русском и украинском языках.
Язык текста: Автоопределение(только RU и EN)АнглийскийРусскийУкраинскийНемецкий
Морфология
Не требуется
Всего символов: 0
Без пробелов: 0
Морфология
Анализ семантического ядра текста оценивает его плотность ключевых слов, обводненность и заспамленность.
Семантический анализ текста Istio оценивает переполнение ключевыми словами, воду и спам. Поисковые системы определяют качество и релевантность текста по содержащимся в нем словам и фразам.
Если текст содержит соответствующее количество релевантных ключевых фраз, поисковые системы оценят его положительно. Водянистые статьи и статьи с недостаточным количеством ключевых слов не будут отображаться на первой странице результатов поиска. Тексты, перегруженные ключевыми словами, расцениваются как спам, и поисковые системы редко их показывают.
Что показывает семантический анализ текста
SEO-анализ текста позволяет оценить процент ключевых слов и количество стоп-слов. Сервис показывает:
Сервис показывает:
- Плотность ключевых слов и их соотношение к ядру текста
- Количество слов и символов с пробелами и без них
- Словарь по общему количеству статей и основных единиц
- Плотность слов с указанием 10 наиболее часто используемых слов
- Язык текста и примерная тематика
- Вода
Семантический анализ текста Istio автоматически подсчитывает количество символов и оценивает набивку и воду. Сервис выделяет ключевые слова и воду и рисует удобную частотную диаграмму.
Проверка наполнения ключевыми словами
Индекс чрезмерного количества спама показывает, насколько текст перенасыщен ключевыми словами. Чем больше ключевых слов, тем выше индекс. Поисковики оценят такие тексты как некачественные и не покажут их на первой странице.
Вставьте ключевые слова в поле «Выделить ключевые слова», чтобы оценить их плотность, и служба выделит их автоматически.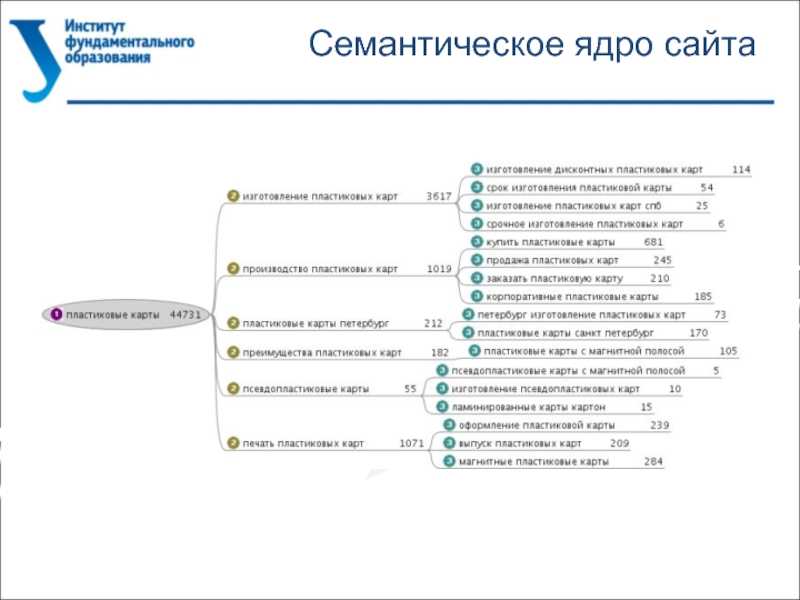
Количество ключевых слов и их соотношение к общему тексту и к его ядру будет показано внизу страницы.
Текстовая диаграмма покажет часто повторяющиеся единицы для визуальной оценки их распределения в тексте.
Вода
Анализ воды выявляет количество стоп-слов, просторечных выражений и избыточных конструкций. Их удаление не ухудшает смысла контента, вместо этого повышая его качество.
Служба выделяет избыточную лексику, используемую для увеличения значения, а также слова и фразы, не содержащие конкретной информации, рекомендуя выделенные единицы для удаления или замены.
Некоторое количество ненужного контента является естественным, но оно должно быть сведено к минимуму для создания высококачественного текста без воды.
Количество символов и плотность ключевых слов
В нижней части страницы показано количество символов со стоп-словами и без них, а также плотность отдельных единиц. Плотность ключевых слов отображается в отдельном поле с указанием их соотношения ко всему тексту и релевантным фразам.
Чтобы проверить текст на содержание воды, плотность ключевых слов и частоту фраз:
- Выберите Анализ текста и вставьте его в поле
- Введите ключевые слова в Список ключевых слов, если необходимо
- Нажмите «Выделить ключевые слова», чтобы увидеть их расположение в тексте
- Выберите Диаграмму для службы, чтобы отображать наиболее часто обнаруживаемые единицы крупным шрифтом
- Щелкните Watery, чтобы выделить ненужные единицы
Istio доступен для использования без регистрации и авторизации и не устанавливает ограничений на количество символов для проверки.
Значение, технология и семантическая сеть
Значение, технология и семантическая сетьКарен Койл
Препринт. Опубликовано в Journal of Academic Librarianship , т. 34, н. 3, май 2008 г., стр. 263-264
Когда в начале 1990-х годов в ЦЕРН была разработана Всемирная паутина, она создала связанную сеть документов, расположенную поверх базовой сети Интернета. В Сети очень мало правил; текст почти любой полосы может быть размещен в Интернете, проиндексирован и извлечен. Тем не менее, тот факт, что элементы в Интернете по большей части состоят из неструктурированных данных, накладывает большие ограничения на то, что мы можем и не можем делать с точки зрения объединения ресурсов и предоставления услуг.
Цель семантической сети состоит в том, чтобы преобразовать сеть в сеть данных, а не в сеть документов. Веб-ресурсы должны перестать быть однообразными строками текста; вместо этого они должны быть в состоянии раскрыть смысл в тексте. Смысл, конечно, в данном случае такой: смысл в том, что машины могут обрабатывать. Для этого семантическая сеть должна создавать взаимодействия между идеями и фактами в веб-ресурсах.
В Сети очень мало правил; текст почти любой полосы может быть размещен в Интернете, проиндексирован и извлечен. Тем не менее, тот факт, что элементы в Интернете по большей части состоят из неструктурированных данных, накладывает большие ограничения на то, что мы можем и не можем делать с точки зрения объединения ресурсов и предоставления услуг.
Цель семантической сети состоит в том, чтобы преобразовать сеть в сеть данных, а не в сеть документов. Веб-ресурсы должны перестать быть однообразными строками текста; вместо этого они должны быть в состоянии раскрыть смысл в тексте. Смысл, конечно, в данном случае такой: смысл в том, что машины могут обрабатывать. Для этого семантическая сеть должна создавать взаимодействия между идеями и фактами в веб-ресурсах.
Впервые представленная как новая концепция на конференции World Wide Web в 1994 году, широкая публика узнала о Semantic Web из статьи в Scientific American в мае 2001 года [1], автором которой является отец сети, Тим Бернерс-Ли, и коллеги Джеймс Хендлер и Ора Лассила. В этой статье «описывается эволюция сети, состоящей в основном из документов, предназначенных для чтения людьми, до документа, включающего данные и информацию, которыми могут манипулировать компьютеры. семантическая паутина — это признание того, что большинство данных в сегодняшней паутине не закодированы и не дифференцированы; это текст на естественном языке. Любой, кто занимался обработкой данных, знает, что вы можете писать компьютерные программы только для данных, которые были закодированы по смыслу («почтовый индекс = 20001») и которые имеют определенные закономерности, которыми программа может воспользоваться. Простой текст, не представляющий проблемы для человека, может быть инертным перед инструкцией типа «Какая дата этого документа?» если эти данные не существуют в предсказуемой структуре и формате.
В этой статье «описывается эволюция сети, состоящей в основном из документов, предназначенных для чтения людьми, до документа, включающего данные и информацию, которыми могут манипулировать компьютеры. семантическая паутина — это признание того, что большинство данных в сегодняшней паутине не закодированы и не дифференцированы; это текст на естественном языке. Любой, кто занимался обработкой данных, знает, что вы можете писать компьютерные программы только для данных, которые были закодированы по смыслу («почтовый индекс = 20001») и которые имеют определенные закономерности, которыми программа может воспользоваться. Простой текст, не представляющий проблемы для человека, может быть инертным перед инструкцией типа «Какая дата этого документа?» если эти данные не существуют в предсказуемой структуре и формате.
Семантика как технология
Семантика Semantic Web не должна быть совершенно незнакома библиотекарям. Один очень простой пример семантического утверждения: «Герман Мелвилл написал книгу «Моби Дик» или «Моби Дик, написанный Германом Мелвиллом». Если вы хотите, чтобы компьютер использовал это, вы можете создать что-то вроде этого в формате MARC21:
Если вы хотите, чтобы компьютер использовал это, вы можете создать что-то вроде этого в формате MARC21:
100 $a Мелвилл, Герман 245 $ за Моби Дикили это в Dublin Core:
Создатель = Герман Мелвилл Название = Моби Дик
Очевидно, что помимо этих двух полей требуется нечто большее, но именно такое количество семантического кодирования определяет разницу между данными, на которые можно повлиять, и данными, на которые нельзя повлиять. С помощью этой кодировки можно задать вопрос: «Кто написал Моби Дика?» и, возможно, получить ответ. Это не мышление со стороны машин или какого-либо разума; просто обработка данных.
Семантическая сеть управляет значением с помощью машинных действий, выражая все понятия как «тройки» — субъект, предикат и объект. Эта тройка похожа на очень простое предложение, и в самой упрощенной форме наше утверждение будет звучать так:
субъект (Герман Мелвилл) предикат (автор) объект (Моби Дик)
Реальные семантические веб-выражения намного сложнее, чем это под капотом. Они используют структуру описания ресурсов (RDF) [3] и часто кодируются в XML. Они широко используют унифицированные идентификаторы ресурсов (URI), которые необходимы для машинной обработки, но очень неудобны для человека. Из Википедии [4] вот RDF-выражение утверждения «почтовый индекс Нью-Йорка — NY»:
Они используют структуру описания ресурсов (RDF) [3] и часто кодируются в XML. Они широко используют унифицированные идентификаторы ресурсов (URI), которые необходимы для машинной обработки, но очень неудобны для человека. Из Википедии [4] вот RDF-выражение утверждения «почтовый индекс Нью-Йорка — NY»:
Нью-Йорк Это компьютерный код, не предназначенный для чтения человеком. Тем не менее, он показывает, что с помощью этой техники можно сделать концепты пригодными для машинных действий. Что нам нужно представить, так это информационные услуги, которые могли бы быть предложены, если бы информация, содержащаяся во многих документах во всемирной паутине, могла быть использована осмысленным образом.
Определение смысла
Одно из распространенных возражений против идеи семантической паутины состоит в том, что просто невозможно рассматривать семантическое кодирование многих миллиардов элементов в паутине.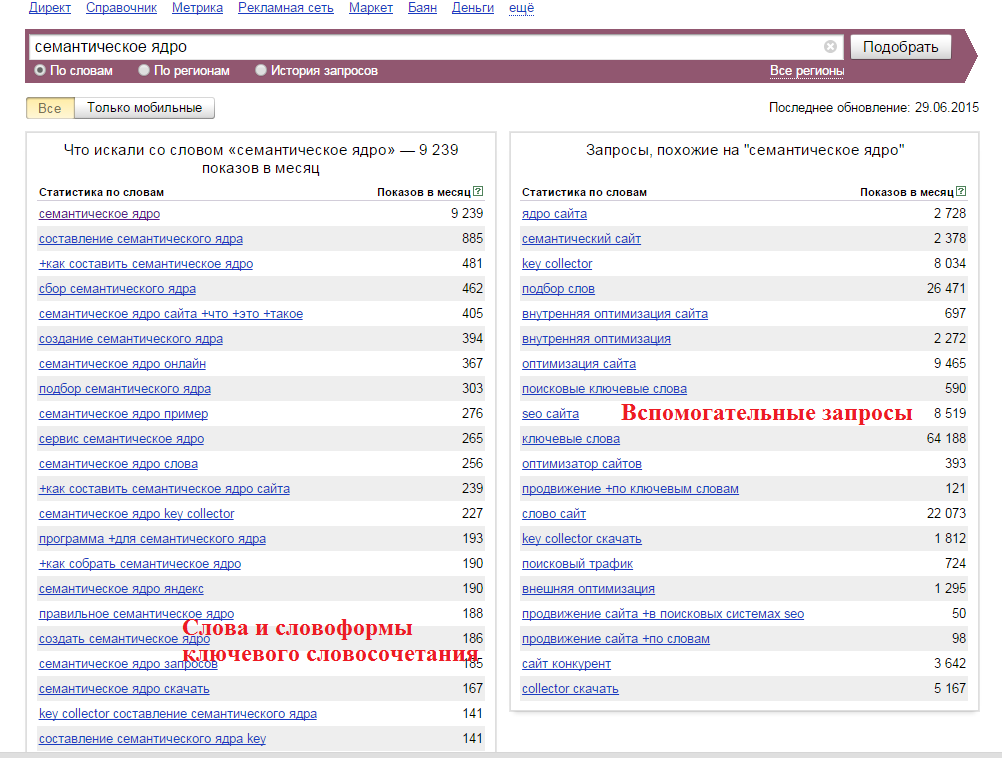 Это не второстепенный момент. Если реализация Semantic Web зависит от ручного кодирования всех прошлых, текущих и будущих текстов, она обречена на провал. Вместо этого можно воспользоваться регулярностью некоторых шаблонов данных. Кроме того, выводы могут быть сделаны на основе сходства между закодированными данными и открытыми текстами.
Это не второстепенный момент. Если реализация Semantic Web зависит от ручного кодирования всех прошлых, текущих и будущих текстов, она обречена на провал. Вместо этого можно воспользоваться регулярностью некоторых шаблонов данных. Кроме того, выводы могут быть сделаны на основе сходства между закодированными данными и открытыми текстами.
Использование шаблонов для добавления семантики к тексту уже существует в некоторых программах. Например, Microsoft Office обнаруживает шаблоны, указывающие на адреса, даты, географические названия и имена людей. Когда программа встречает строку, которая может быть личным именем, она может предложить найти это имя в адресной книге электронной почты пользователя и открыть пустую форму электронной почты, адресованную этому человеку. Возможное географическое название может быть сверено с географическим справочником в сети, и могут быть предложены карты, направления или соответствующие фотографии.
Автоматическому присвоению значения текстам или частям текстов может способствовать существование закодированных словарей или «онтологий» (структурированных словарей, таких как тезаурусы). Таким образом, если в Интернете существует машиночитаемый словарь, в котором говорится, что «собака» является подвидом «млекопитающего», тогда программное обеспечение может сделать вывод, что тексты с термином «собака» могут быть релевантны поиску по слову «млекопитающие». .» С течением времени, подобно тому, как ценность Сети возрастает по мере увеличения количества ресурсов, следует ожидать качественного увеличения ценности по мере добавления большего количества семантических связей.
Таким образом, если в Интернете существует машиночитаемый словарь, в котором говорится, что «собака» является подвидом «млекопитающего», тогда программное обеспечение может сделать вывод, что тексты с термином «собака» могут быть релевантны поиску по слову «млекопитающие». .» С течением времени, подобно тому, как ценность Сети возрастает по мере увеличения количества ресурсов, следует ожидать качественного увеличения ценности по мере добавления большего количества семантических связей.
Адаптация семантической сети
К сожалению, Semantic Web не появился так быстро, как хотелось бы. Консорциум World Wide Web осуществляет значительную деятельность по разработке стандартов, но фактическое использование методов Semantic Web происходит редко. Часть проблемы заключается в сложности базовой модели и в том факте, что пока у нас нет приложений, которые в достаточной степени скрывают эту сложность. Другая часть проблемы, однако, заключается в том, что сама разработка семантической паутины не отличается удобством для пользователя.
Начнем с того, что семантическая паутина выражается на языке, который часто уникален для деятельности семантической паутины; таким образом, использование термина «онтологии» (который в философии означает «изучение бытия») для обозначения того, что более известно как тезаурусы. Чтобы язык семантической сети оставался нейтральным с точки зрения типов данных, вместо того, чтобы говорить о «статьях», «авторах» или «изображениях», в документах семантической сети используются термины «ресурс» или «сущность» для всего, что может быть определено. целевой. Эти понятия настолько абстрактны в некоторых контекстах, что может быть трудно понять, что они означают.
Семантическая сеть в значительной степени полагается на формальные идентификаторы элементов своих значимых утверждений. Таким образом, термин, подобный «заголовку» Dublin Core, становится «http://purl.org/dc/elements/1.1/title», а ролевой термин MARC21 «переводчик» становится «http://www.loc.gov/loc.terms». /отношения/TRL. » Значение этих полей не меняется, но основной формат, который должен быть скрыт от глаз за удобным для человека интерфейсом, для большинства совершенно чужд. Это затрудняет чтение и понимание документов стандартов Semantic Web. Возможно, из-за этой кривой обучения библиотеки не были более вовлечены в разработку семантического веба, даже несмотря на то, что мы храним данные, которые могли бы обеспечить очень полезную основу для многих действий семантического веба.
Понятно, что Semantic Web несколько застрял в «инженерном режиме». Документы на сайте Semantic Web разрабатывают концепции, устанавливают правила и иллюстрируют код. Но даже в самом базовом пояснительном документе RDF Primer [6] отсутствуют примеры того, какие услуги могут быть предоставлены и как это может выглядеть для пользователя Semantic Web.
» Значение этих полей не меняется, но основной формат, который должен быть скрыт от глаз за удобным для человека интерфейсом, для большинства совершенно чужд. Это затрудняет чтение и понимание документов стандартов Semantic Web. Возможно, из-за этой кривой обучения библиотеки не были более вовлечены в разработку семантического веба, даже несмотря на то, что мы храним данные, которые могли бы обеспечить очень полезную основу для многих действий семантического веба.
Понятно, что Semantic Web несколько застрял в «инженерном режиме». Документы на сайте Semantic Web разрабатывают концепции, устанавливают правила и иллюстрируют код. Но даже в самом базовом пояснительном документе RDF Primer [6] отсутствуют примеры того, какие услуги могут быть предоставлены и как это может выглядеть для пользователя Semantic Web.
Семантическая сеть и библиотеки
Какое отношение Semantic Web имеет к библиотекам? Библиотеки находятся в уникальном положении, позволяющем воспользоваться преимуществами Semantic Web; у них есть огромный запас семантически закодированной общедоступной информации в каталогах их библиотек. Чтобы стать частью зарождающейся семантической сети, библиотечное сообщество должно сделать две вещи. Во-первых, библиографические данные библиотек необходимо преобразовать из их текущей машиночитаемой структуры в формат, совместимый с Semantic Web. Во-вторых, данные библиотеки больше не должны храниться в базах данных, а должны находиться в Интернете, где они могут взаимодействовать с другими веб-ресурсами. Это требует существенного изменения формы и хранения библиотечных данных. Ведется работа по созданию первой семантической веб-интерпретации стандартных элементов данных библиотеки [7] в рамках совместных усилий Объединенного руководящего комитета RDA [8] и Инициативы по метаданным Dublin Core [9].]
Чтобы стать частью зарождающейся семантической сети, библиотечное сообщество должно сделать две вещи. Во-первых, библиографические данные библиотек необходимо преобразовать из их текущей машиночитаемой структуры в формат, совместимый с Semantic Web. Во-вторых, данные библиотеки больше не должны храниться в базах данных, а должны находиться в Интернете, где они могут взаимодействовать с другими веб-ресурсами. Это требует существенного изменения формы и хранения библиотечных данных. Ведется работа по созданию первой семантической веб-интерпретации стандартных элементов данных библиотеки [7] в рамках совместных усилий Объединенного руководящего комитета RDA [8] и Инициативы по метаданным Dublin Core [9].]
Несмотря на то, что семантическая паутина сегодня не в состоянии использовать преимущества библиотечных данных, доступность этих данных в совместимой форме может стать стимулом для разработки удобных приложений семантической паутины на основе очень распространенного и популярного формата: книга.