
Что такое семантическое ядро (СЯ). Блог Web-студии РостСайт
- Что такое СЯ?
- Как составить СЯ?
- Как выбрать ключи для продвижения?
- Сколько нужно ключей на одну страницу сайта?
Правильное семантическое ядро представляет собой таблицу состоящую из:
- Списка ключевых запросов, по которым пользователи ищут сайт.
- Частоты запросов в месяц по каждому ключу.
- Текущей позиции сайта по каждому ключу.
Таблица по умолчанию должна быть отсортирована по убыванию частоты.
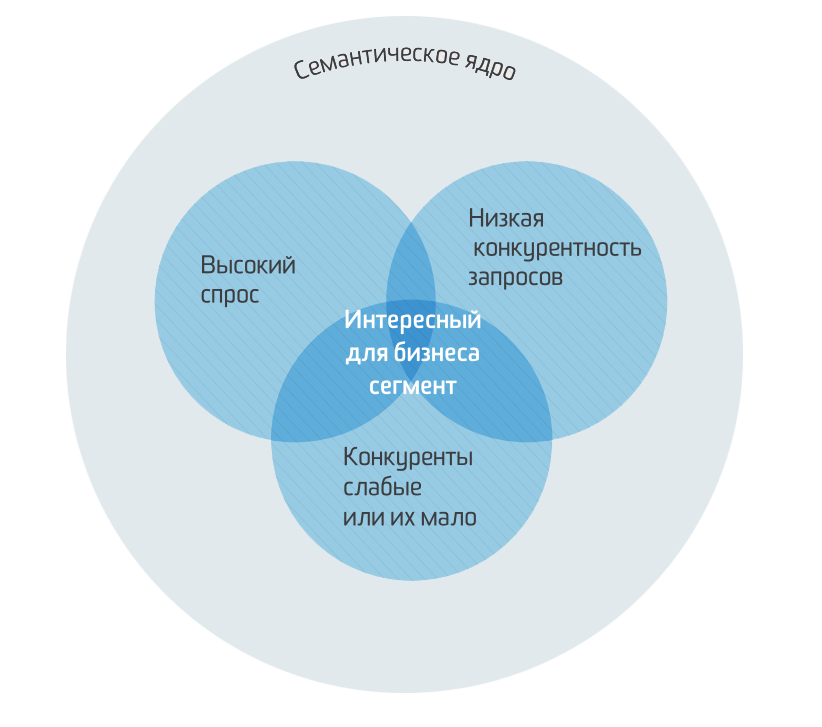
Семантическое ядро – это основа поискового продвижения сайта. Оно позволяет: определить популярность тематик, сгруппировать их и выстроить будущую структуру сайта, определить целесообразность направлений, составить грамотную описательную часть и так далее.
Итак на повестке вопрос: Как правильно составить СЯ? Как поделить СЯ по частотности и выбрать ключи для продвижения?
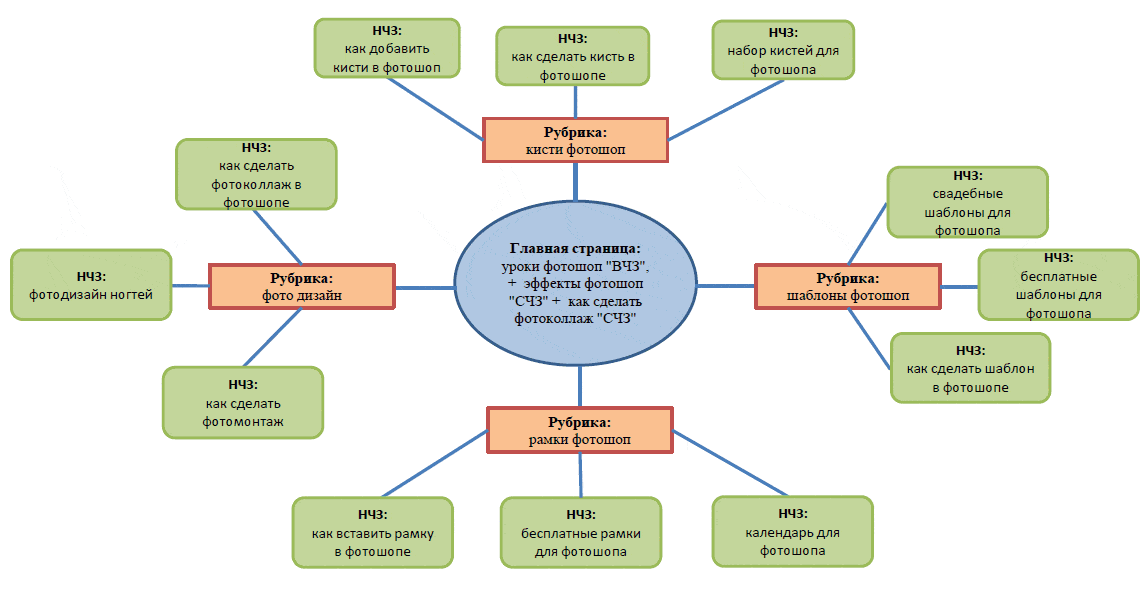
Определяем основные ключевые запросы. Например, для сайта продажи велосипедов это будет “велосипеды в Москве”, “купить велосипед” и т.д.
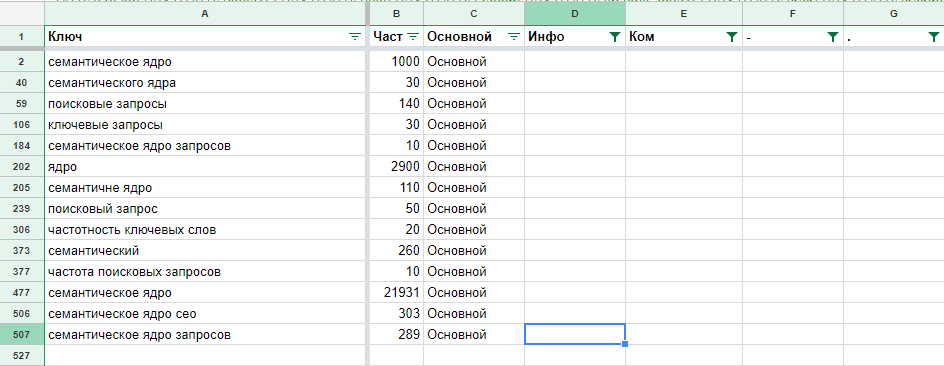
Заходим на сайт https://wordstat.yandex.ru/, выбираем основной регион сайта (в примере — Москва).
Далее в строку поиска вбиваем по очереди основные ключи и смотрим результаты поиска.
Список полученных запросов копируем в excel-таблицу, для более удобного редактирования. Далее в Вордстат вводим другой ключевой запрос и копируем новые результаты.
Редактирование полученной таблицы заключается в удалении знаков “+” из результатов выдачи, удалении дублирующихся запросов или запросов, которые не соответствуют тематике сайта (например, для магазина лишними будут ключи “велосипед даром” или “подарю велосипед”).
Окончательный результат сортируется по столбцу показов так, чтобы наиболее частые запросы находились вверху таблицы.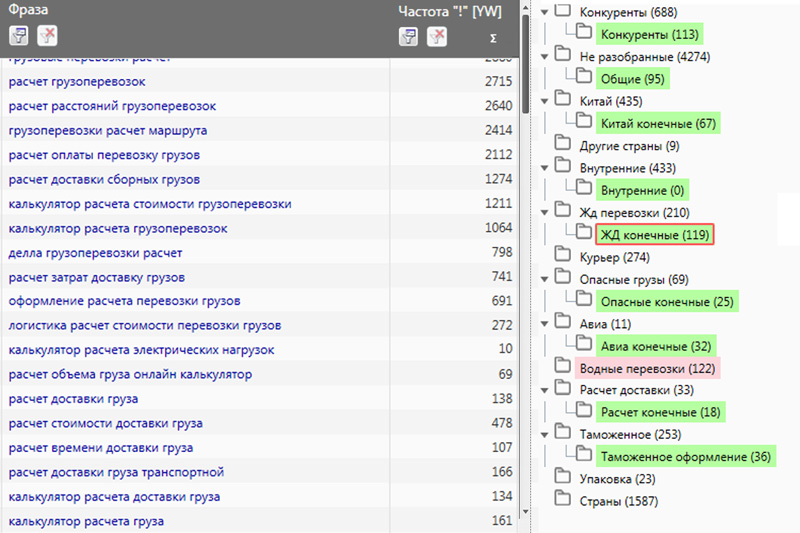
Конечный вариант СЯ должен выглядеть следующим образом:
Указывается номер запроса, сам запрос и частота его поиска пользователями.
Частотность запросов
В стандартном виде СЯ должно представлять собой таблицу, отсортированную по убыванию частоты запросов и содержащую не менее 100 запросов. Примерная схема определения частотности представлена ниже в таблице:
| Частотность запроса | Условие 1 | Условие 2 |
|---|---|---|
| Высокочастотные (ВЧ) | Первые 15% из всего списка | Больше 1 000 запросов в месяц |
| Среднечастотные (СЧ) | Следующие 25% из всего списка | От 100 до 1 000 запросов в месяц |
| Низкочастотные (НЧ) | Последние 60% из всего списка | От 0 до 100 запросов в месяц |
Цель SEO – получить максимальное количество заинтересованного поискового трафика в минимальный срок. Поэтому мы рекомендуем начинать seo- продвижение только с ВЧ запросов. В таком случае распределение ключей на структуру сайта должно происходить следующем образом:
Поэтому мы рекомендуем начинать seo- продвижение только с ВЧ запросов. В таком случае распределение ключей на структуру сайта должно происходить следующем образом:
- Главная (ВЧ — запросы)
- 1 уровень. Каталог или Услуги (ВЧ и СЧ — запросы)
- 2 уровень. Товар или Услуга (СЧ и НЧ — запросы)
- 3 уровень. Детальное описание (НЧ — запросы)
В зависимости от конкуренции и региональности запросов вывести в ТОП ВЧ запрос не всегда представляется возможным. В таких случаях необходимо прорабатывать более низкочастотные запросы, развивая и улучшая структуру и наполнения сайта, как следствие ВЧ запросы начинают подтягиваться.
Мы рекомендуем использовать не более 5 ключевых запросов для одной страницы. Это наиболее эффективно, так как сужает тематическое перенасыщение сайта.
Сбор семантического ядра для сайта
Семантическое ядро — это таблица ключевых запросов, которые описывают структуру Вашего бизнеса — вашего каталога товаров, и поисковые запросы пользователей, по которым они могут искать страницы вашего сайта
Семантическое ядро — это списки поисковых запросов, которые задают пользователи в поисковой системе, когда ищут информацию. Они могут искать статьи, товары, услуги, контент.
Они могут искать статьи, товары, услуги, контент.
В семантике все запросы сгруппированы по кластерам и распределены по потенциальным страницам.
Как использовать семантическое ядро?
Семантическое ядро сайта необходимо для вашего сайта При помощи правильно собранной семантики вы сможете:
Создать контент
Подготовить информацию для написания текстов копирайтером. Прописать правильные Title и Description для ваших страниц сайта.
Оптимизировать сайт
Равномерно распределить вес страниц согласно запросам. Выявить проблемы переспама и каннибализации (повтора ключевых слов).
Настроить контекст
Сгруппировать запросы по страницам. На основе собранных ключевых слов конкурентов изучить структуру, ассортимент товаров и услуг вашего сайта. Кластеризовать семантику по страницам, сформировать ключи для блога. Собрать ключевые слова для контекстной рекламы Google AdWords (Ads).
При сборке семантического ядра мы используем следующие сервисы:
Примеры сайтов для сбора семантического ядра
Количество страниц
от 1 до 15
- Сбор ключевых запросов
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для страниц сайта
Количество страниц
от 20 до 50
- Сбор ключевых запросов
- Кластеризация инфозапросов
- Структура сайта
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для раздела услуг
- ТЗ копирайтеру для блога
Количество страниц
от 100 до 1000+
- Сбор ключевых запросов
- Подбор запросов для посадочных страниц
- Подбор тегов для фильтров по трафику
- Структура каталога для сайта
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для блога
- ТЗ программисту для каталога сайта
Семантическое ядро должно быть удобным — для SEO и контекстной рекламы.
Вы получите готовую семантику в легкочитаемом для Вас формате:
Таблица с ключевыми словами
Каждой странице соответствует группа ключевых слов
Ключевые слова содержат необходимые метрики
Подобраны рекомендации для Title и Description
Представлена структура ключевых слов в Mind карте
Документ с семантическим ядром Онлайн
Как правильно собирать семантическое ядро?
Условно существует три этапа по созданию семантики:
Анализируем конкурентов
Первоначально мы проводим выборку Ваших конкурентов в поиске.
Внимательно изучаем нишу вашего бизнеса.
Затем собираем все ключевые слова и трафик по ним и сравниваем позиции, уровень конкуренции.
Собираем поисковые запросы
На основе собранных ключевых слов конкурентов изучается структура, ассортимент товаров и услуг вашего сайта.
Группируем запросы по страницам
На основе собранных ключевых слов конкурентов изучается структура, ассортимент товаров и услуг вашего сайта.

Кластеризируем семантику по страницам, формируем ключи для блога

Часто задаваемые вопросы по составлению семантического ядра
Зачем нужно собирать семантическое ядро
Семантическое ядро нужно для определения структуры сайта, подбора оптимальных заголовков для страницы и мета-тега Title. Также семантическое ядро применяется для оптимизации контента на странице контент-менеджером и копирайтером. Без семантического ядра сложно определить те запросы, под которые нужно подбирать анкоры страницы для перелинковки.
Сколько будет ключевых слов?
Мы не можем это спрогнозировать. Точное количество ключевых слов может быть вычислено только после сбора семантики до конца: некоторые страницы могут априори не иметь большого количества поисковых фраз, тогда как некоторые страницы лучше разбивать на несколько из-за разноплановой семантики
Что нужно учитывать при сборе семантического ядра?
Семантическое ядро содержит все релевантные запросы для конкретных страниц.
Ключевым показателем является отсутствие дублей, кластеризация, разделение ключевых слов по трафику – Высокочастотные, среднечастотные и низкочастотные запросы.Могу ли я купить уже готовое семантическое ядро дешево?
Да, вы можете заказать семантику дешевле, но не факт, что она будет отражать реальную картину ключевых слов для вашего сайта. Для глубокой проработки нужно опираться на все страницы на вашем сайте – учитывать реальный трафик в вебмастерах и обновлять актуальные данные согласно свежей статистики.
У меня на сайте мало страниц. Нужно ли мне создавать новые?
Чаще всего оказывается, что большая часть контента лежит в поле информационных ключей.
Но им не место на основной странице – так как они могут собрать больше трафика. Тогда такие ключи обычно используются для раздела блогов и вопросов и ответов.
У меня есть KeyCollector. Вы сможете предоставить мне семантику в виде файла?
Да, конечно, готовый файл может быть выслан для вас
Вы можете предоставить пример семантического ядра перед заказом?
Мы можем предоставить временные ключевые слова на основе ваших конкурентов и дать представления о популярных ключевых словах у них.
Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвиженияЧем отличается семантика для интернет-магазина?
Семантика для интернет магазина содержит огромное количество низкочастотных комбинаций ключевых слов, связанных с категориями продаваемых товаров, брендами производителей, характеристиками и материалами. Каждый раздел нужно проверить на популярность запросов и расположить в правильной очередности для создания правильного технического задания для метаданных страниц данных фильтров.
 Ключевым показателем является отсутствие дублей, кластеризация, разделение ключевых слов по трафику – Высокочастотные, среднечастотные и низкочастотные запросы.
Ключевым показателем является отсутствие дублей, кластеризация, разделение ключевых слов по трафику – Высокочастотные, среднечастотные и низкочастотные запросы. Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвижения
Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвиженияПродвижение видео на YouTube в поиске (Секрет по оптимизации)
Продвижение видео на YouTube в поиске (Секрет по оптимизации)
Реклама в YouTube: Настройка серий видеообъявлений в AdWords
Реклама в YouTube: Настройка серий видеообъявлений в AdWords
наверх

 Кроме того, основная часть сопоставления дистрибутивов довольно ограничена по объему и также требует много ручного труда. Я бы даже сказал, что это доходит до того, что в первую очередь потребуются экземпляры для фактического создания профилей.
Кроме того, основная часть сопоставления дистрибутивов довольно ограничена по объему и также требует много ручного труда. Я бы даже сказал, что это доходит до того, что в первую очередь потребуются экземпляры для фактического создания профилей. 12011.pdf https://arxiv.org/pdf/2105.07624.pdf и https://arxiv.org/pdf/2005.08314.pdf
12011.pdf https://arxiv.org/pdf/2105.07624.pdf и https://arxiv.org/pdf/2005.08314.pdf
 Например, если встречается строковое значение «Париж», вы не сопоставите его с , вместо этого вы сопоставите его с некоторым литеральным значением на графике.
Например, если встречается строковое значение «Париж», вы не сопоставите его с , вместо этого вы сопоставите его с некоторым литеральным значением на графике. Таким образом, утечка все еще может произойти. Возможно, этот последний пункт все еще вызывает у меня серьезную озабоченность. Насколько вы уверены в отсутствии проблем с утечкой данных для разных наборов данных?
Таким образом, утечка все еще может произойти. Возможно, этот последний пункт все еще вызывает у меня серьезную озабоченность. Насколько вы уверены в отсутствии проблем с утечкой данных для разных наборов данных? Пожалуйста, разъясните это лучше. Кроме того, было бы разумно сделать выбор типа данных зависимым от других столбцов, а не изолированно.
Пожалуйста, разъясните это лучше. Кроме того, было бы разумно сделать выбор типа данных зависимым от других столбцов, а не изолированно.Семантический анализ и таблицы символов
Семантический анализ
На этом этапе мы говорили о лексировании и разборе. Лексический анализ преобразовал входной поток символов в токены, а синтаксический анализ (парсинг) преобразовал поток токенов в абстрактное синтаксическое дерево. Следующий этап компилятора — семантический. анализ, который проверяет, что AST представляет собой действительную, правильно сформированную программу.
Каждый из этих первых трех этапов может обнаружить какую-либо ошибку в программе. Лексический анализ
выявляет лексические ошибки (неверно сформированные токены), синтаксический анализ выявляет синтаксические ошибки и
семантический анализ обнаруживает семантические ошибки, такие как ошибки статического типа, неопределенные переменные,
и неинициализированные переменные. После завершения семантического анализа программа
должна быть легальной программой на языке программирования; больше ошибок в программе быть не должно
быть сообщено компилятором.
В дополнение к проверке того, что AST является действительной программой, семантический анализ может также вычислить дополнительную информацию, которая полезна для остальных процесс компиляции: например, типы выражений, структура памяти структур данных или представлений классов и модулей, отличных от AST. Таким образом, результатом успешного семантического анализа является декорированных AST, в которых AST был дополнен этой дополнительной информацией.
Проверка типа
Для многих языков статическая проверка типов является основной задачей семантического анализа. Это обычно реализуется как рекурсивный обход AST. Чтобы увидеть, как это работает, рассмотрим проблему проверки типов с использованием оператора +. С тех пор разделяет многие функции с другими бинарными операторами в объектно-ориентированной среде, такой как Java. естественно определить класс который фиксирует общие черты всех бинарных операторов, таких как левый и правые операнды:
класс BinaryExpr расширяет Expr {
Выражение влево, вправо;
. ..
}
 ..
}
..
}
Предположим, что наша проверка типов предназначена для записи типа каждого выражения.
узел в АСТ. Это украшение может быть выражено добавлением переменной экземпляра к
общий суперкласс Expr :
код
Переменная типа является украшением, которое необходимо заполнить семантическим анализом.
с реальным типом. Метод typeCheck() используется для реализации проверки типов,
с каждым классом узлов, обеспечивающим логику для проверки типов описываемых им выражений;
это естественно для typeCheck() как рекурсивный метод. Обратите внимание, что без аргументов
даны для typeCheck() ; вскоре мы увидим, что необходим хотя бы один аргумент.
Теперь попробуем написать код для добавления проверки типов на Java. Вот
упрощенная версия этого кода с некоторыми недостающими частями. Предполагая, что у нас есть
существующее представление типов int и String ,
мы могли бы написать код, подобный следующему, используя вызовы рекурсивных методов для проверки типов. поддеревья
поддеревья слева и справа :
код
Контексты ввода
То, что чего-то все еще не хватает, можно увидеть, если мы рассмотрим, как проверить тип идентификатора.
выражение (например, локальная переменная). Тело метода typeCheck() :
невозможно реализовать, потому что у нас нет возможности узнать, какой идентификатор типа имя следует ассоциировать с.
код
В общем, при семантическом анализе какой-либо части программы нам нужен описание окружающих контекст , в котором находится этот фрагмент программы. Для обработки идентификаторов проверки типов контекст должен включать среду . который сопоставляет имена идентификаторов с типами. В настройках компиляторов эта среда известна как таблица символов . Простой контекст ввода может выглядеть следующим образом:
код
Затем мы модифицируем подпись typeCheck , чтобы принять Context как
Аргумент. Реализация
Реализация Id.typeCheck становится проще:
код
Однако изменение подписи typeCheck означает, что контекст должен проходить через все рекурсивные вызовы. Например,
соответственно обновляется метод Plus.typeCheck :
код
Формализация контекстов ввода
Мы представляем среды более формально как отображение \(Г\) из идентификаторов \(х\) в типы \(t\). Окружение \(Γ\) записывается как \(Γ = x_1:t_1, x_2:t_2, \dots x_n:t_n\), что означает, что каждый идентификатор \(x_i\) отображается в соответствующий тип \(t_i\).
Используя эту нотацию, давайте рассмотрим следующий пример, предполагая, что первоначальный ввод контекст не имеет переменных в области видимости: \(Γ=∅\).
{ // Г=∅
инт я, н; // Г=i:целое, n:целое
для (я = 0; я
Как мы видим, контекст ввода меняется по мере того, как мы сталкиваемся с объявлениями переменных и
выход на просторы. Например, мы можем реализовать проверку типов для объявлений переменных.
следующим образом, добавив объявленную переменную в контекст:
код
Эта реализация разработана в предположении, что операторы в данном блоке
проверяются последовательно, что позволяет накапливать новые объявления путем простого изменения
текущая среда.
код
Однако, как показывает приведенный выше пример, блоки создают еще одну проблему: переменные должны
вне сферы действия. Один из способов реализации этого показан в блоке . Контекст
поддерживает стек сред, так что c.push() сохраняет текущую среду
и c.pop() восстанавливает последнюю сохраненную среду, которая не была восстановлена.
Реализация контекстов ввода
Языки программирования, как правило, имеют множество механизмов для введения новых областей видимости. Например,
в Java у нас есть блоки, методы, классы (включая вложенные классы) и пакеты.
Контекст ввода должен иметь возможность отслеживать, какие идентификаторы связаны во всех этих
масштабы.
Стек хеш-таблиц. Традиционная реализация представляет собой таблицу символов, реализованную в виде стека хэш-таблиц.
Таблица символов обязательно обновляется во время проверки типов. При входе в новую сферу, новый,
пустая хеш-таблица помещается в стек, что занимает \(O(1)\) времени. При выходе из области видимости
верхняя хеш-таблица извлекается из стека, что занимает \(O(1)\) времени. Добавление нового идентификатора
в контексте просто требуется добавить сопоставление в верхнюю хеш-таблицу за время \(O(1)\). Однако,
поиск идентификатора требует, как правило, обхода стека, проверки каждой хеш-таблицы.
Для идентификатора на глубине \(d\) это занимает \(O(d)\) времени. Конечно, значение \(d\) мало в
большинство программ.
Неизменяемое дерево поиска. Второй способ реализации контекста типизации — использование постоянной (неразрушающей) структуры данных,
Например, бинарное дерево поиска. Двоичное дерево поиска может быть обновлено за время \(O(\lg n)\) для получения
новое бинарное дерево поиска, не затрагивая исходное. Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно.
Хэш-таблица с повторяющимися записями и журналом. Если изменяемая реализация приемлема, асимпотически оптимальные данные
структура представляет собой единую связанную хеш-таблицу, в которой мы допускаем дублирование ключей для
появляются в том же ведре. Кроме того, контекст отслеживает журнал
обновленные ключи, которые могут быть реализованы в виде связанного списка. Идентификатор
искал, используя хэш-таблицу напрямую, и брал самое раннее совпадение
отображение в своем ведре, занимая время \(O(1)\).
 следующим образом, добавив объявленную переменную в контекст:
следующим образом, добавив объявленную переменную в контекст:
 Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно.
Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно.