
все способы. Часть 1 — SEO на vc.ru
Семантическое ядро – фундамент последующего продвижения сайта. Данная статья будет полезна как новичкам, так и практикующим специалистам, а также клиентам, стремящимся получше разобраться в вопросах поискового продвижения. Сложно и муторно в этой статье точно не будет – обещаем 🙂
1969 просмотров
Собрали целый массив структурированной информации: что такое семантика, как выглядит семантическое ядро; как собрать ядро для интернет-магазина или маркетплейса; способы кластеризации, а также анализ СЯ конкурента, и все способы сбора ключей.
Кстати, хорошие примеры семантического ядра есть у Rush Analytics.
Содержание:
1. Что такое семантика и как выглядит семантическое ядро
2. Как собрать семантическое ядро для интернет-магазина
2.1. С чего начать?
2.2. Используем готовый шаблон
2.3. Заполнение шаблона
3. База запросов
4. Подбираем запросы для СЯ
Что такое семантика и как выглядит семантическое ядро
Для совсем новичков приведем цитату из Википедии: семантическое ядро представляет собой упорядоченный набор слов, их морфологических форм и словосочетаний, характеризующих вид деятельности, товары и услуги, предлагаемые сайтом.
Страшно, сложно и непонятно.
Конкретизируем: семантическое ядро – структурированное описание сайта, учитывающее пользовательский спрос, интересы аудитории, специфику бизнеса и цели проекта. Таким образом, СЯ – это не просто список слов и словосочетаний.
К.О.
Стоит учитывать, что в ядро попадают запросы, вводимые пользователями в поисковую систему. Эти запросы называют ключевыми словами, иначе – ключами, благодаря которым вы можете узнать, что, как и для чего ищет ваша аудитория.
- Что ищут – какая информация, услуга, товар интересны пользователям.
- Как ищут – какими фразами они пользуются для поиска.
- Зачем ищут – цели получения информации. Например, сравнить цены, выбрать, купить и т.д.
Представим, что вы планируете открыть сервисный центр по ремонту телефонов и выйти в онлайн. Вам необходимо определиться, как составить семантическое ядро, какие услуги более всего интересуют ваших потенциальных клиентов.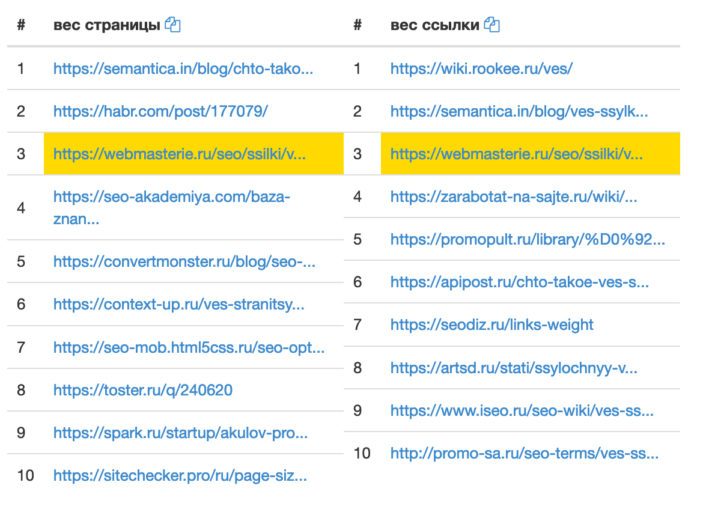
Вордстат отражает, что вводят в поисковик люди, которым необходимо отремонтировать телефон.
А если кликнуть на запрос, то перейдем на следующий «уровень» с уточненными ключевыми словами.
«Починить телефон», «отремонтировать телефон» говорят нам о целях поиска. Сопутствующие основной фразе «самсунг», «iphone» и прочие отвечают на вопрос о том, что именно хотят починить пользователи.
Задачи семантического ядра не ограничиваются на описании тематики сайта:
- СЯ определяет структуру сайта – страницы, разделы, иерархичность. Это облегчает навигацию как для аудитории, так и для ПС.
- Благодаря семантическому ядру оптимизируем страницы под конкретные запросы — прописываем мета-теги, создаем релевантный контент.
- Создаем матрицу контента. Семантическое ядро дает нам основу для создания контент-плана — релевантные статьи (в том числе описания ассортимента), инфоблог и прочее.

- Оптимизированное ядро несложно использовать и для настройки контекстной рекламы.
- Благодаря СЯ мы грамотно линкуем страницы, чтобы корректно распределить ссылочный вес, а также для пользователей облегчить поиск необходимой информации.
- Актуализация ядра = достоверный анализ покупательского спроса. Отслеживая, чем интересуются пользователи, можно включать новые услуги, расширять ассортимент и прочее.

Таким образом, семантическое ядро – основа успешного продвижения ресурса в поисковых системах. Его составлением стоит заняться до создания сайта. Формирование семантического ядра до того, как создан ресурс, – это семантическое проектирование.
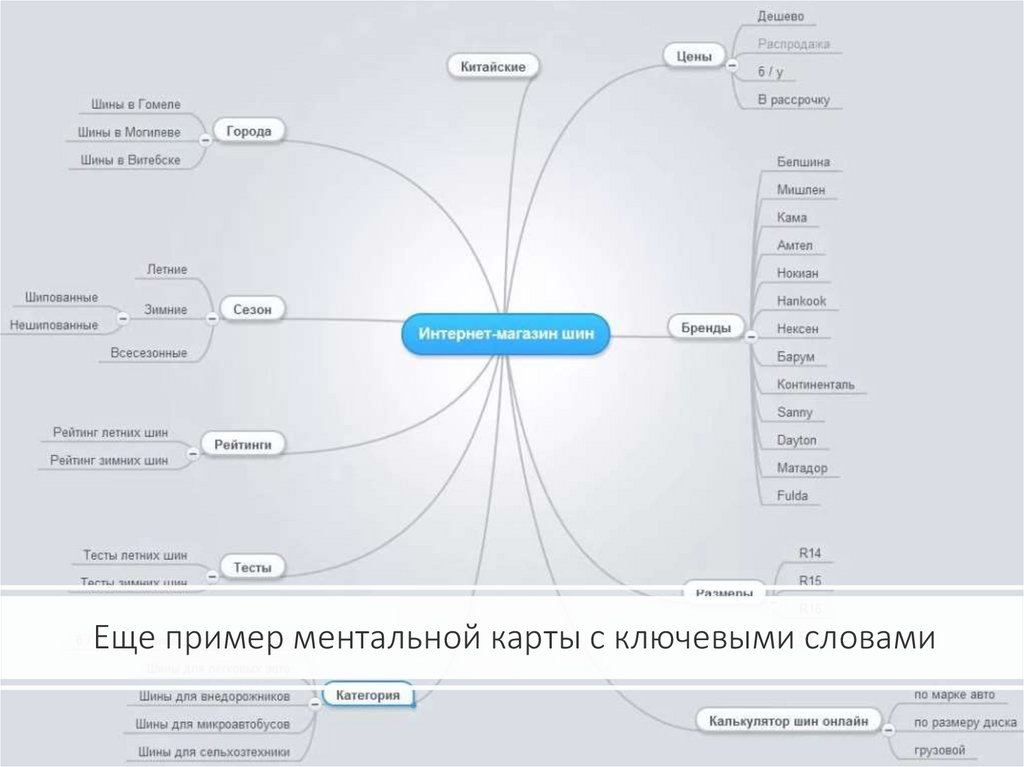
Для начала определяют тематику сайта, ключи должны наиболее полно описывать содержание. Далее запросы кластеризуют по разделам сайта. После – собранную семантику используют для постраничной оптимизации страниц.
Как собрать семантическое ядро для интернет-магазина
Как пользователи ищут товары и услуги в интернете?
- Если речь о технике, косметике, мебели, ищут по наименованию, а порой даже по артикулу.
- Если конкретики нет, то ищут по товарной категории.
- Часто вводят запросы, начинающиеся с «как…», «почему…», и в итоге находят, что им нужно купить, например, для удовлетворения той или иной потребности.
Чтобы собрать семантическое ядро для интернет-магазина, можно воспользоваться wordstat.yandex.ru, KeyCollector. Есть свои плюсы и минусы.
1. Wordstat бесплатен, предоставляет прекрасную возможность сориентироваться, насколько востребован конкретный запрос. Учитывается время, регион, порядок слов, статистика за месяц. Такой вариант подойдет для ручного сбора небольших семантических ядер. Не забудьте установить Yandex Wordstat Assistant, благодаря которому вы сможете сохранять и фразы, и их частотность в таблицах.
2. Парсер, например, Key Collector. Парсер это программа, сервис или скрипт, который собирает данные, анализирует и выдает в нужном формате. Чтобы было еще понятнее, условно определим парсер как сортировщик.
Key Collector 4 – новая версия известного парсера
С чего начать?
В первую очередь обозначим, что СЯ для страниц каталога и страниц товаров будут разными, раз мы говорим именно об интернет-магазине.
Рекомендуем начать с работы над страницами каталога, точнее, с его структуры. Почему это важно?
Продуманный каталог поможет не только собрать семантическое ядро, но и улучшать поведенческие факторы. Если структура удобна для пользователя, то и поисковая система «поднимет выше» сайт в выдаче.
Используем готовый шаблон
Чтобы подготовить каталог, воспользуйтесь готовым шаблоном –их можно найти в интернете. На скриншоте один из вариантов:
Таблица для подготовки семантического ядра интернет-магазина
Разумеется, это лишь пример, и ваша таблица может получить гораздо сложнее.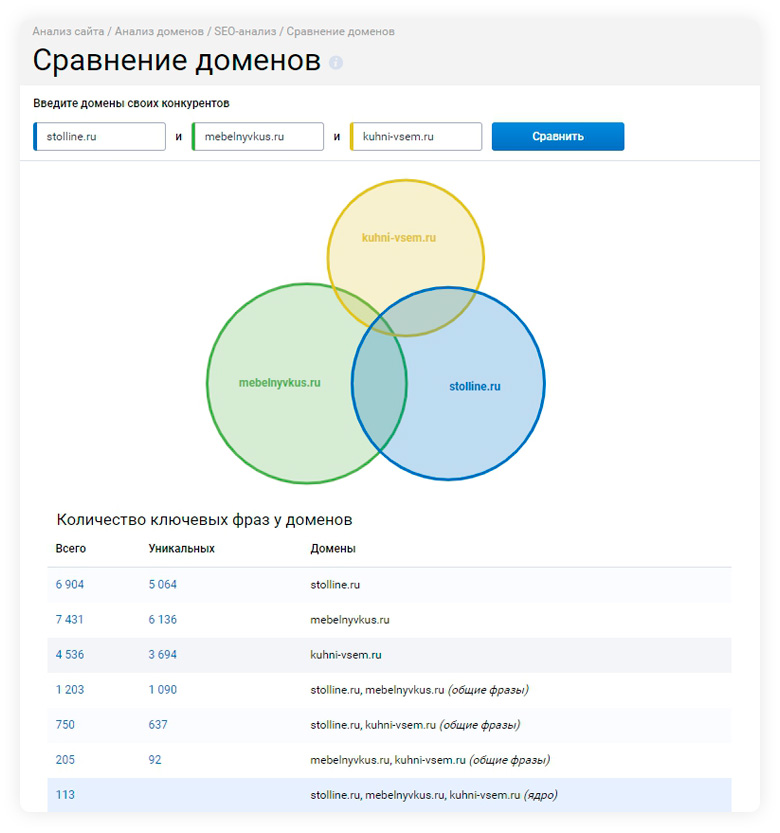 Главное – вы поняли принцип.
Главное – вы поняли принцип.
Заполнение шаблона
Ядро составляем на основе ассортимента интернет-магазина, но в первую очередь следует заняться категориями и подкатегориями. Непосредственно к карточкам товаров можно обратиться позже.
Как создать каталог?
- оценить, каким бы вы хотели видеть перечень, и составить его в соответствии с собственными предпочтениями и видением;
- опереться на прайсы поставщиков;
- позаимствовать у конкурентов из топа.
Так, например, будет выглядеть каталог для магазина растений и семян:
База запросов
Помимо этого, вы можете воспользоваться любой крупной базой ключевых слов. Например, у Keys.so база состоит более 120 млн слов из русскоязычного сегмента интернета и практически отсутствуют нулевые ключевые запросы. Вводите ключевое слово и выбираете регион:
Таким же образом вы можете взять сайт конкурента и проанализировать его, какие запросы он использует и какая видимость в поисковой выдаче:
Подбираем запросы
Категория должна быть релевантна своему запросу – это и есть основа оптимизации, благодаря которой мы привлекаем заинтересованных клиентов.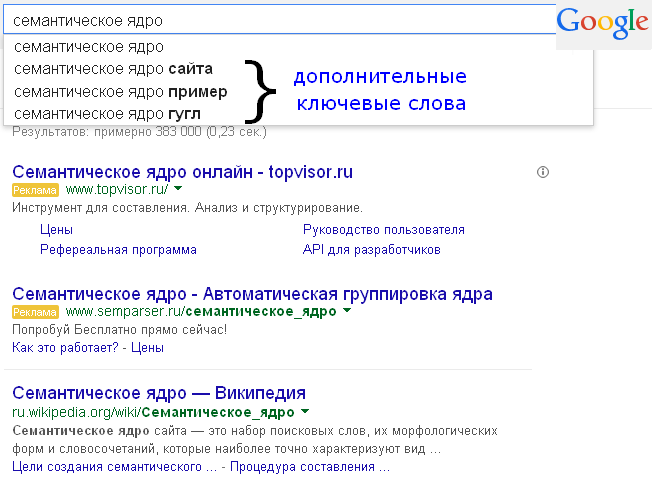
Как определить релевантность? Обратите внимание на частоту поиска фразы, которую вы проверяете в сервисе или программе. Если необходимо, ограничивайте по регионам.
Далее следует оптимизация страниц категорий и подкатегорий, начинающаяся с проработки Title, Description, h2, но это уже тема другой статьи.
Несколько советов касаемо сбора семантики :
- Сбор СЯ начинается с категорий и подкатегорий, если речь об интернет-магазине. Непосредственно к карточкам переходите после.
- При подборе проверяйте название и на русском, и на английском. Например, «Indesit» и «Индезит».
- Учитывайте, что поставщики формируют прайс так, как им удобно. Чтобы не ошибиться, формируйте категории все же на базе семантического ядра.
- Сбор начинайте с парсеров (в идеальном случае).
На этом пока завершим первую часть нашей статьи про семантическое ядро. В следующей части рассмотрим СЯ для сайта услуг; кластеризацию и детализацию запросов и как проанализировать семантическое ядро конкурентов.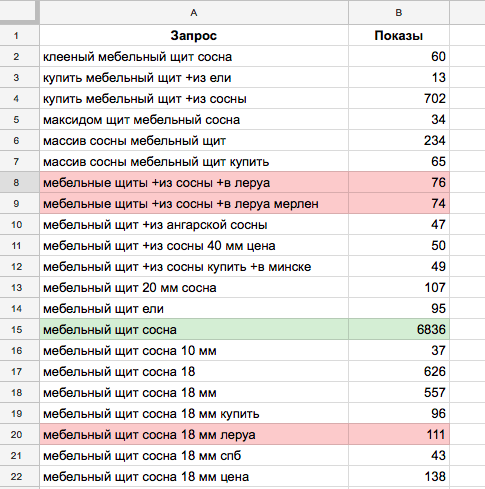
Как написать SEO статью. Читайте на Cossa.ru
В этом разделе материалы размещаются пользователями сайта и публикуются после одобрения модератором. Редакция не несет ответственности за орфографические и другие ошибки, хотя и старается исправлять их по мере возможности.
Добавить свою заметку вы можете на этой странице.
17 декабря 2015, 22:06
Давно не секрет, что хороший сайт пользуется спросом. Хорошим сайт становится при наличие качественного контента, так каким должен быть контент для того чтобы он пользовался популярностью.
Антон Щибря, uGrade
Поделиться
Поделиться
Как нам всем известно, трафик который приходит на сайт зачастую, считают поисковым. Это связано с тем, что большинство пользователей узнают о сайте с помощью поисковых машин. Хотя по статистике сайт, который успешный и имеет качественный и интересный контент, имеет ряд своих подписчиков, которые заходя через закладки или другими способами.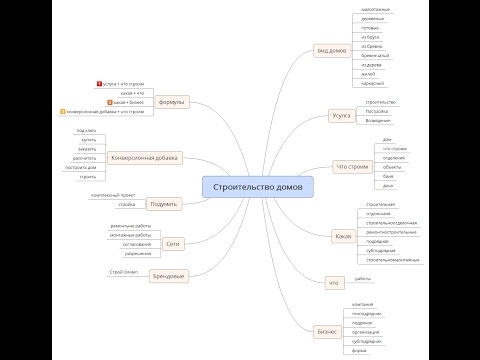
Понесло меня, сегодняшняя тема для обсуждения: «Написание seo статьи» или «Как написать seo статью». В данной теме, мы рассмотрим такие вопросы: составление ключевых слов, уникальность статьи, изображения и факторы ранжирования статьи.
1. Ключевые слова или составление семантического ядра
2. Уникальность статьи, проверка и написание.
3. Оптимизация изображений.
4. Как расположить ключевые слова.
5. Поведенческий фактор ранжирования.
1.Ключевые слова или составление семантического ядра
Семантическое ядро – это ядро статьи, а именно поисковые слова под которые заточена статья, чтобы привлечь посетителя для прочтения её или просмотра. Соответственно статья должна быть подготовлена в соответствие с тематикой сайта и под эти теги, которые использует сайт.
2.
 Уникальность статьи
Уникальность статьи
Поисковые системы твердят, что сайт должен быть уникальным. Делаем вывод, уникальная статья – это признак уникального сайта. То есть, я Вам советую не копировать текст непонятно откуда, да и вообще не копировать какой-либо текст. Пишите текст от себя, как вы думаете и как считаете. Уникальность статьи в идеале должна быть 100%, но если 90+ % это тоже хорошо. Хороший способ для проверки на уникальность онлайн ресурс — http://www.content-watch.ru/text.
3.Оптимизация изображений
Один текст, не вызывает интереса у посетителя. Для этого вносится разнообразие в виде изображений. Изображения воспринимаются поисковыми системами в двух аспектах, как изображение и как изображение в контексте. В первом варианте изображение индексируется отдельно, а во втором учитывается как единое целое статьи или страницы. Оптимизация изображений заключается в написание тегов title и alt, которые должны иметь ключевые слова, что и статья.
 Описана в другой статье нашего сайта.
Описана в другой статье нашего сайта.
4. Как расположить ключевые слова, плотность ключевых слов
Начнем с того что минимальное количество слов должно быть от 500-800 в зависимости от поисковика. Плотность ключевых слов должна быть не меньше 1%, но и не больше 8%. Одно можно сказать, что я стыкался с такими статьями, которые в топе выдачи и имеют 20% или вообще не иметь ключевых слов под которые оптимизированы. Такие поисковые аномалии встречаются, возможно это связано с тем, что сайт оптимизирован под этот ключ. Я советую, на этом не заострять внимание. А также ключевые слова, желательно выделять жирным шрифтом или брать в заголовки. Размещение считается самым благоприятным это первое и последнее предложение.
5. Поведенческий фактор
Данный пункт заключается в призыве действовать читателя, то есть куда-то перейти, что-то сделать. Мотивация может заключаться в банальном, дополните текст статьи Вашим способом оптимизации статьи, то есть просто призыв к комментированию статьи.
 Не забываем про перелинковку страниц, которая играет огромную роль в индексации сайта и статьи. Поведенческий фактор заключается в получение конверсии от пользователя, то есть какого-то рода исполнение действия.
Не забываем про перелинковку страниц, которая играет огромную роль в индексации сайта и статьи. Поведенческий фактор заключается в получение конверсии от пользователя, то есть какого-то рода исполнение действия.
А также, добавленное видео показывает авторитетность и тоже несет в себе поведенческий фактор ранжирования статьи, так как просмотр видео это тоже конверсия. Кстати, видео не должно быть уникальным, потому что это очень сложно, возьмите просто с ютуба.
Поделиться
Поделиться
⚡ Телеграм Коссы — здесь самый быстрый диджитал и самые честные обсуждения: @cossaru
📬 Письма Коссы — рассылка о маркетинге и бизнесе в интернете. Раз в неделю, без инфошума: cossa.pulse.is
Как это работает и для кого это
Для простых пользовательских запросов поисковая система может надежно найти правильный контент, используя только сопоставление ключевых слов.
Запрос «красный тостер» извлекает все продукты со словом «тостер» в заголовке или описании и красным цветом в атрибуте цвета.
Добавьте синонимы, например темно-бордовый к красному, и вы сможете найти еще больше тостеров.
Но все становится намного сложнее: вы должны добавить эти синонимы самостоятельно, и ваш поиск также выдаст тостеры.
Здесь на помощь приходит семантический поиск.
Семантический поиск пытается применить намерение пользователя и значение (или семантику) слов и фраз для поиска нужного контента.
Он выходит за рамки сопоставления ключевых слов, используя информацию, которая может не присутствовать непосредственно в тексте (сами ключевые слова), но тесно связана с тем, что хочет искатель.
Например, найти свитер по запросу «свитер» или даже «слаще» не составит труда для поиска по ключевым словам, а запросы «теплая одежда» или «как согреться зимой?» лучше обслуживаются семантическим поиском.
Как вы можете себе представить, попытка выйти за пределы информации поверхностного уровня, встроенной в текст, является сложной задачей.
Его пробовали многие, и он включает множество различных компонентов.
Кроме того, как и все, что подает большие надежды, семантический поиск — это термин, который иногда используется для поиска, который на самом деле не соответствует названию.
Чтобы понять, применим ли семантический поиск к вашему бизнесу и как лучше всего воспользоваться преимуществами, полезно понять, как он работает, и компоненты, входящие в состав семантического поиска.
Что такое элементы семантического поиска?
Семантический поиск применяет намерение пользователя, контекст и концептуальные значения для сопоставления запроса пользователя с соответствующим содержимым.
Он использует векторный поиск и машинное обучение для возврата результатов, которые должны соответствовать запросу пользователя, даже если нет совпадений слов.
Эти компоненты совместно извлекают и ранжируют результаты на основе их значения.
Одним из самых фундаментальных элементов является контекст.
Контекст
Контекст, в котором происходит поиск, важен для понимания того, что ищущий пытается найти.
Контекст может быть таким же простым, как место действия (американец, ищущий слово «футбол», хочет чего-то другого, чем британец, ищущий то же самое), или гораздо более сложным.
Интеллектуальная поисковая система будет использовать контекст как на личном, так и на групповом уровне.
Воздействие на результаты на личностном уровне вполне уместно называется персонализацией.
Персонализация будет использовать сходство этого отдельного искателя, предыдущие поиски и предыдущие взаимодействия, чтобы вернуть контент, который лучше всего подходит для текущего запроса.
Он применим ко всем видам поиска, но семантический поиск может пойти еще дальше.
На групповом уровне поисковая система может повторно ранжировать результаты, используя информацию о том, как все пользователи взаимодействуют с результатами поиска, например, какие результаты чаще всего нажимаются или даже сезонность, когда одни результаты более популярны, чем другие.
Опять же, это показывает, как семантический поиск может привнести интеллект в поиск, в данном случае интеллект через поведение пользователя.
Семантический поиск также может использовать контекст в тексте.
Мы уже обсуждали, что синонимы полезны во всех видах поиска и могут улучшить поиск по ключевым словам, расширяя соответствие запросов к связанному контенту.
Но мы также знаем, что синонимы не универсальны – иногда два слова эквивалентны в одном контексте, а не в другом.
Когда кто-то ищет «футболисты», какие результаты будут правильными?
Ответ в Кенте, штат Огайо, будет другим, чем в графстве Кент, Великобритания.
Запрос типа «футболисты тампа-бэй», однако, вероятно, не должен знать, где находится искатель.
Добавление общего синонима, который сделал бы футбол и футбол эквивалентными, привело бы к плохому опыту, когда этот искатель увидел бы футбольный клуб Tampa Bay Rowdies рядом с Роном Гронковски.
(Конечно, если мы знаем, что искатель предпочел бы увидеть Tampa Bay Rowdies, поисковая система может принять это во внимание!)
Это пример понимания запроса с помощью семантического поиска.
Намерение пользователя
Конечной целью любой поисковой системы является помощь пользователю в успешном выполнении задачи.
Этой задачей может быть чтение новостных статей, покупка одежды или поиск документа.
Поисковая система должна выяснить, что пользователь хочет сделать или что пользователь намерение есть.
Мы можем увидеть это при поиске на веб-сайте электронной коммерции.
Когда пользователь вводит запрос «Jordan», поиск автоматически фильтруется по категории «Обувь».
Предполагается, что целью пользователя является поиск обуви, а не иорданского миндаля (который будет в категории «Еда и закуски»).
Опередив намерения пользователя, поисковая система может возвращать наиболее релевантные результаты и не отвлекать пользователя элементами, которые совпадают по тексту, но не релевантно.
Это может быть еще более уместно, если применить сортировку в верхней части поиска, например, цену от самой низкой до самой высокой.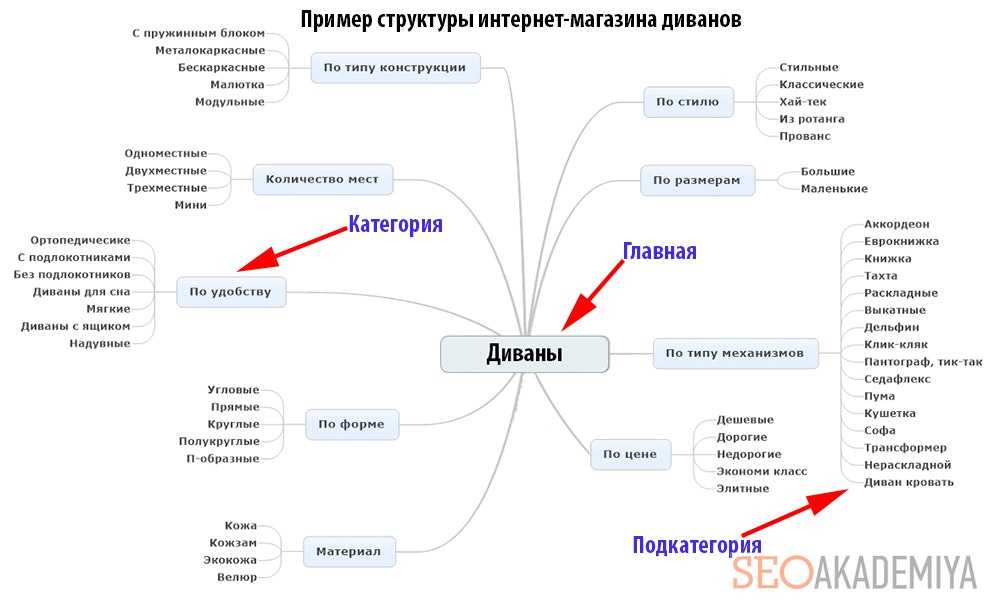
Это пример классификации запроса .
Категоризация запроса и ограничение набора результатов гарантируют отображение только релевантных результатов.
Разница между поиском по ключевому слову и семантическим поиском
Мы уже видели, как семантический поиск является интеллектуальным, но стоит подробнее рассмотреть, чем он отличается от поиска по ключевым словам.
Хотя поисковые системы по ключевым словам также вводят обработку естественного языка для улучшения этого сопоставления слов — с помощью таких методов, как использование синонимов, удаление стоп-слов, игнорирование множественного числа — эта обработка по-прежнему зависит от сопоставления слов со словами.
Но семантический поиск может возвращать результаты, в которых нет совпадающего текста, но любой, кто знаком с предметной областью, может увидеть, что есть явно хорошие совпадения.
Это связано с большой разницей между поиском по ключевым словам и семантическим поиском, которая заключается в том, как происходит сопоставление между запросом и записями.
Чтобы упростить некоторые вещи, поиск по ключевым словам происходит путем сопоставления текста.
«Soap» всегда будет соответствовать «soap» или «soapy» из-за перекрытия текстового качества.
Более конкретно, имеется достаточно совпадающих букв (или символов ), чтобы сообщить движку, что пользователь, ищущий одно, захочет другое.
Это же соответствие сообщит движку, что запрос мыла более вероятно соответствует слову «суп», чем слову «моющее средство».
Если только владелец поисковой системы не сообщил машине заранее, что мыло и моющее средство являются эквивалентами, в этом случае поисковая система будет «притворяться», что моющее средство на самом деле является мылом, когда определяет сходство.
Поисковые системы на основе ключевых слов также могут использовать такие инструменты, как синонимы, альтернативы или удаление слова из запроса — все типы расширения и ослабления запроса — для облегчения этой задачи поиска информации.
Инструменты NLP и NLU, такие как устойчивость к опечаткам, токенизация и нормализация, также улучшают поиск.
Хотя все это помогает улучшить результаты, они могут потерпеть неудачу из-за более интеллектуального сопоставления и сопоставления концепций.
Семантический поиск соответствует понятиям
Поскольку семантический поиск соответствует понятиям, поисковая система больше не может определять релевантность записей на основе того, сколько символов разделяет два слова.
Опять же, подумайте о «мыле», «супе» и «моющем средстве».
Или более сложные запросы, такие как «чистка прачечной», «удаление пятен с одежды» или «как вывести пятна от травы с джинсовой ткани?»
Вы даже можете включить поиск изображений!
Реальной аналогией этого может быть клиент, спрашивающий сотрудника, где находится «чистый туалет».
Сотрудник, который понимает запрос только на уровне ключевых слов, не выполнит его, если только магазин прямо не называет свои плунжеры, очистители стоков и шнеки для унитазов «средствами для прочистки унитазов».
Но, хотелось бы надеяться, у сотрудника хватит ума, чтобы связать разные термины и направить покупателя в нужный отдел.
(Возможно, сотрудник знает различные термины или синонимы, которые клиент может использовать для любого продукта).
Кратко подытоживая то, что делает семантический поиск, можно сказать, что семантический поиск повышает интеллект, чтобы сопоставлять больше понятий, чем слов, за счет использования векторного поиска.
С таким интеллектом семантический поиск может выполняться более по-человечески, подобно тому, как искатель находит платья и костюмы при поиске модных вещей, но в поле зрения нет джинсов.
Чем не является семантический поиск?
К настоящему моменту семантический поиск должен стать мощным методом повышения качества поиска.
Таким образом, вы не должны удивляться, узнав, что значение семантического поиска применяется все шире и шире.
Часто такие возможности поиска не всегда оправдывают название.
И хотя официального определения семантического поиска не существует, мы можем сказать, что это поиск, выходящий за рамки традиционного поиска по ключевым словам.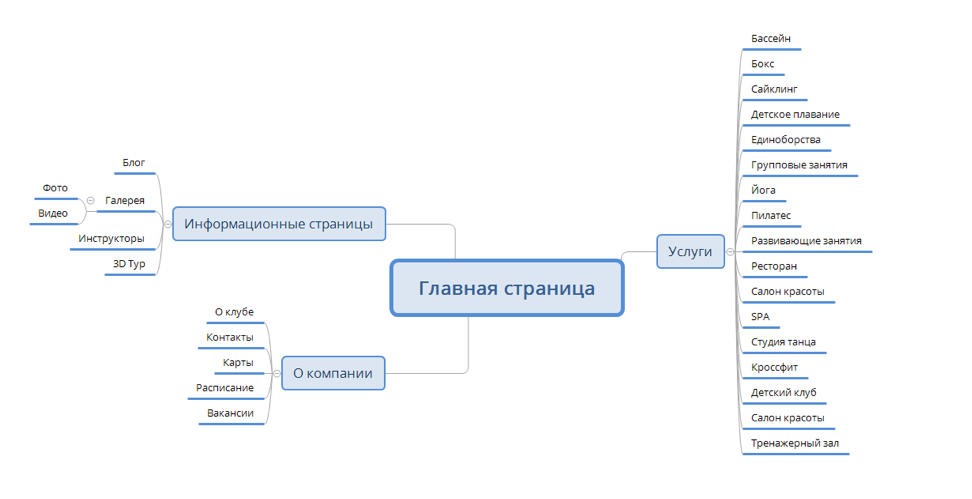
Он делает это, используя знания из реального мира для определения намерений пользователя на основе значения запросов и контента.
Это приводит к выводу, что семантический поиск — это не просто применение НЛП и добавление синонимов в индекс.
Это правда, токенизация требует некоторых реальных знаний о конструкции языка, а синонимы применяют понимание концептуальных соответствий.
Однако в большинстве случаев им не хватает искусственного интеллекта, необходимого для того, чтобы поиск поднялся до уровня семантического.
Powered By Vector Search
Именно этот последний элемент делает семантический поиск одновременно мощным и сложным.
Как правило, с термином семантический поиск подразумевается некоторый уровень машинного обучения.
Почти так же часто это также включает векторный поиск .
Векторный поиск работает путем кодирования сведений об элементе в векторы и последующего сравнения векторов, чтобы определить, какие из них наиболее похожи.
Опять же, может помочь даже простой пример.
Возьмите два словосочетания: «Тойота Приус» и «стейк».
А теперь давайте сравним их с «гибридом».
Какие из первых двух больше похожи?
Ни один из них не соответствует тексту, но вы, вероятно, скажете, что «Toyota Prius» больше похожа на них.
Вы можете сказать это, потому что знаете, что «Prius» — это тип гибридного транспортного средства, потому что вы видели «Toyota Prius» в том же контексте, что и слово «гибрид», например, «Toyota Prius — это гибрид, заслуживающий внимания», или «гибридные автомобили, такие как Toyota Prius».
Вы уверены, однако, что никогда не видели «стейк» и «гибрид» в таком тесном пространстве.
Построение векторов для поиска подобия
Обычно поиск векторов работает так же.
Модель машинного обучения берет тысячи или миллионы примеров из Интернета, книг или других источников и использует эту информацию, чтобы делать прогнозы.
Конечно, модели не могут сравниваться по отдельности («Часто ли Toyota Prius и гибрид видят вместе? Как насчет гибрида и стейка?»), поэтому вместо этого происходит то, что модели кодировать шаблоны , которые он замечает по разным фразам.
Это похоже на то, как вы смотрите на фразу и говорите: «это положительное» или «тот содержит цвет».
За исключением машинного обучения, языковая модель не работает так прозрачно (вот почему языковые модели могут быть трудны для отладки).
Эти кодировки хранятся в виде вектора или длинного списка числовых значений.
Затем векторный поиск использует математику для расчета степени сходства различных векторов.
Еще один способ представить измерения подобия, которые выполняет векторный поиск, — представить построенные векторы.
Это невероятно сложно, если вы попытаетесь представить себе вектор, представленный в сотнях измерений.
Если вы вместо этого представите вектор, построенный в трех измерениях, принцип тот же.
Эти векторы образуют линию при построении графика, и возникает вопрос: какие из этих линий ближе всего друг к другу?
Строки для «стейк» и «говядина» будут ближе, чем строки для «стейк» и «машина», и поэтому они более похожи.
Этот принцип называется векторным или косинусным сходством.
Сходство векторов имеет множество применений.
Он может давать рекомендации на основе ранее приобретенных продуктов, находить наиболее похожие изображения и определять, какие элементы лучше всего соответствуют семантически по сравнению с запросом пользователя.
Заключение
Семантический поиск — это мощный инструмент для поисковых приложений, который вышел на передний план с появлением мощных моделей глубокого обучения и оборудования для их поддержки.
Хотя мы затронули здесь ряд различных распространенных приложений, существует еще больше, использующих векторный поиск и ИИ.
Под семантический поиск может подпадать даже поиск изображений или извлечение метаданных из изображений.
Нас ждут захватывающие времена!
И, тем не менее, его применение еще рано, и его известная сила может привести к неправильному присвоению термина.
Конвейер семантического поиска состоит из множества компонентов, и важно правильно определить каждый из них.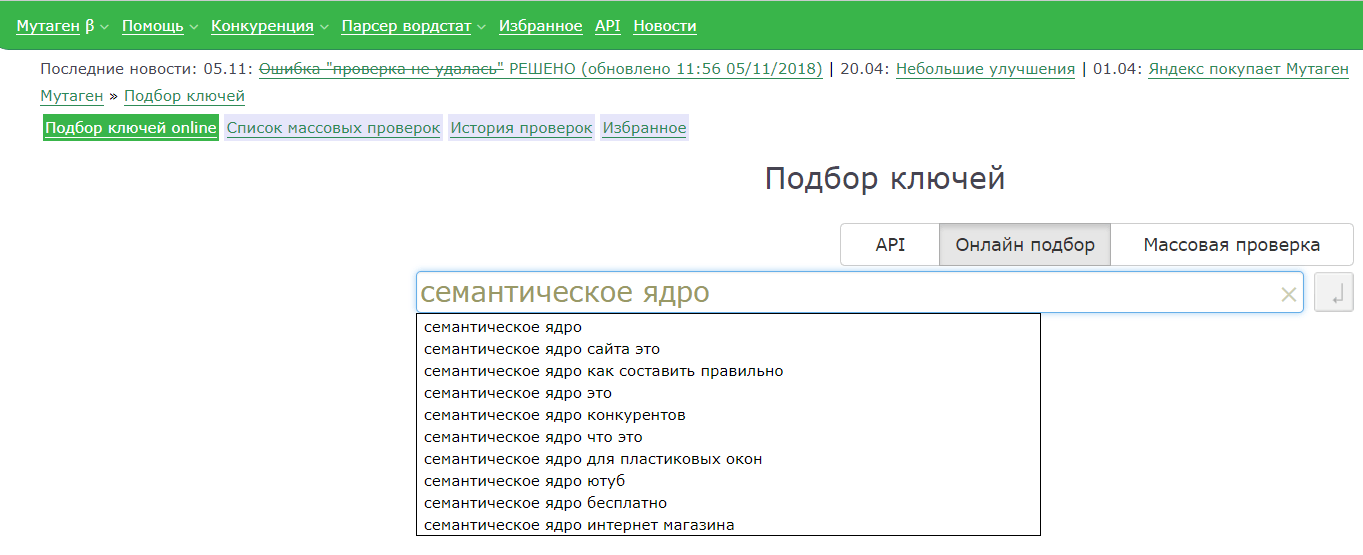
Если все сделано правильно, семантический поиск будет использовать реальные знания, особенно с помощью машинного обучения и подобия векторов, чтобы сопоставить запрос пользователя с соответствующим контентом.
Дополнительные ресурсы:
- Патент раскрывает, как Google может интерпретировать запросы на основе информации о сущности
- Семантическая кластеризация ключевых слов для более чем 10 000 ключевых слов [со сценарием]
- Как провести исследование ключевых слов для SEO: полное руководство
Рекомендуемое изображение: волшебные картинки/Shutterstock
Категория SEO
Что такое основная семантическая модель и как она строится?
Чтобы прочитать предыдущую запись в этой серии от команды [A] Semantics для получения дополнительной информации, щелкните здесь.
Что такое основная семантическая модель?
[A] определяет Базовую семантическую модель как комплексную модель, которая определяет термины и терминологию организации, а также их отношения, чтобы обеспечить идентификацию этих терминов в предметной области и в разных системах.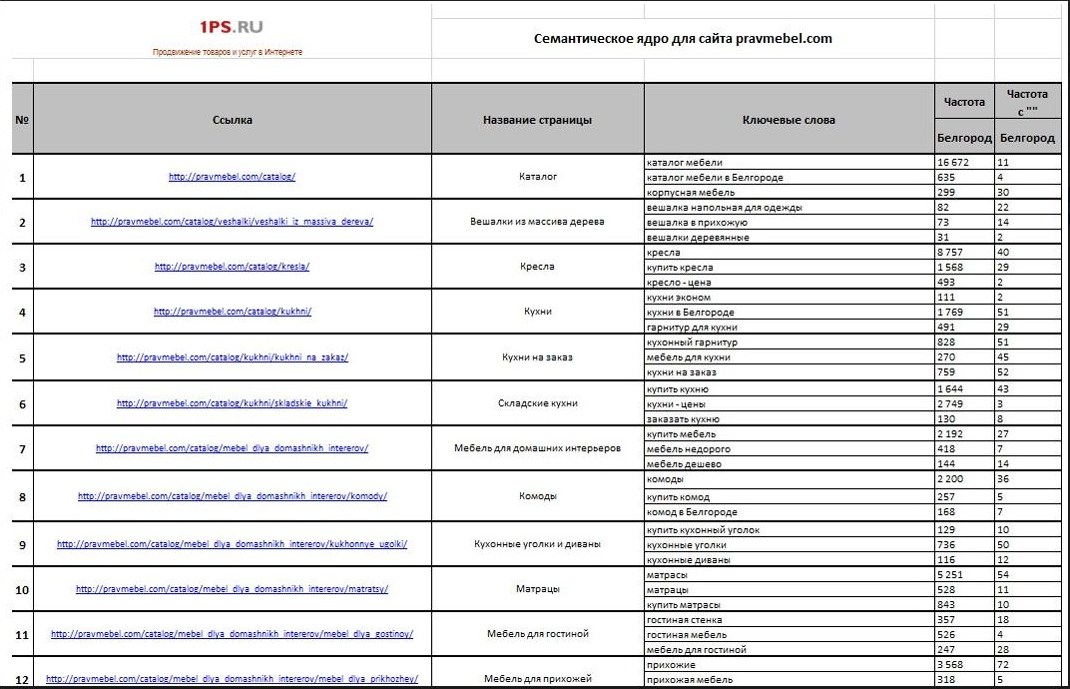 CSM применяет эти определения к содержимому с помощью основной записи метаданных (CMR), компонента CCM, ориентированного на метаданные ресурса содержимого.
CSM применяет эти определения к содержимому с помощью основной записи метаданных (CMR), компонента CCM, ориентированного на метаданные ресурса содержимого.
Это определение состоит из четырех ключевых компонентов:
- Семантические определения — Основная семантическая модель включает канонические определения всех ключевых терминов для контроля использования этих терминов в организации. Эти определения могут исходить из таксономий предприятия и определений глоссария.
- Отношения между терминами — Основная семантическая модель использует принятые стандарты, такие как Простая система организации знаний (SKOS), для моделирования семантических отношений между терминами в машиночитаемом виде. Эти отношения можно использовать, например, для расширения возможностей контента для многоканальной доставки.
- Облегчает идентификацию терминов в предметной области и в разных системах. — Семантический уровень, представленный базовой семантической моделью, позволяет системе определять, какие термины означают одно и то же, и доставлять правильный термин по нужному каналу.
- Интеграция с CMR в CCM — CSM выполняет важную функцию в сочетании с CCM. CCM обеспечивает структуру контента, а CSM обеспечивает значение и интерпретацию этого контента. Говоря более формально, CSM интегрируется с CCM, связывая содержащиеся в нем семантические определения и отношения в виде метаданных, определенных в компоненте CMR CCM.

Компоненты базовой семантической модели
Из чего состоит основная семантическая модель? Создание интерпретируемой компьютером карты значения, безусловно, нуждается в логической основе для ее построения. Вот компоненты, которые [A] включает в CSM: Таксономии и SKOS.
Таксономии и СКОС
CSM начинается с существующих таксономий организации. Скорее всего, они уже разработаны, чтобы облегчить маркировку и навигацию по контенту организации или улучшить использование поисковых систем в организации. После завершения аудита таксономий организации при необходимости создаются дополнительные таксономии, чтобы охватить все активы контента, которые выиграют от семантического уровня.
После завершения аудита таксономий организации при необходимости создаются дополнительные таксономии, чтобы охватить все активы контента, которые выиграют от семантического уровня.
Таксономия включает иерархические отношения между ее терминами. Он указывает, какие термины шире или уже, чем другие термины. Например, у организации может быть категория товаров кухонные столовые приборы. Эта категория может быть классифицирована как более узкая, чем категория кухонных инструментов, а также более широкая, чем категория кухонных ножей. Но чтобы быть полностью функциональной и полезной во всех наборах, Базовая семантическая модель должна пойти дальше и включить моделирующие отношения из широко применяемого стандарта для простой системы организации знаний (SKOS).
В частности, модели потребуется способность определять, когда разные термины означают одно и то же, определять, какие термины семантически связаны друг с другом, и идентифицировать существенные наборы терминов. Продолжая наш пример с кухонными столовыми приборами, расширив нашу модель, включив в нее отношения SKOS, мы можем включить дополнительную ключевую информацию.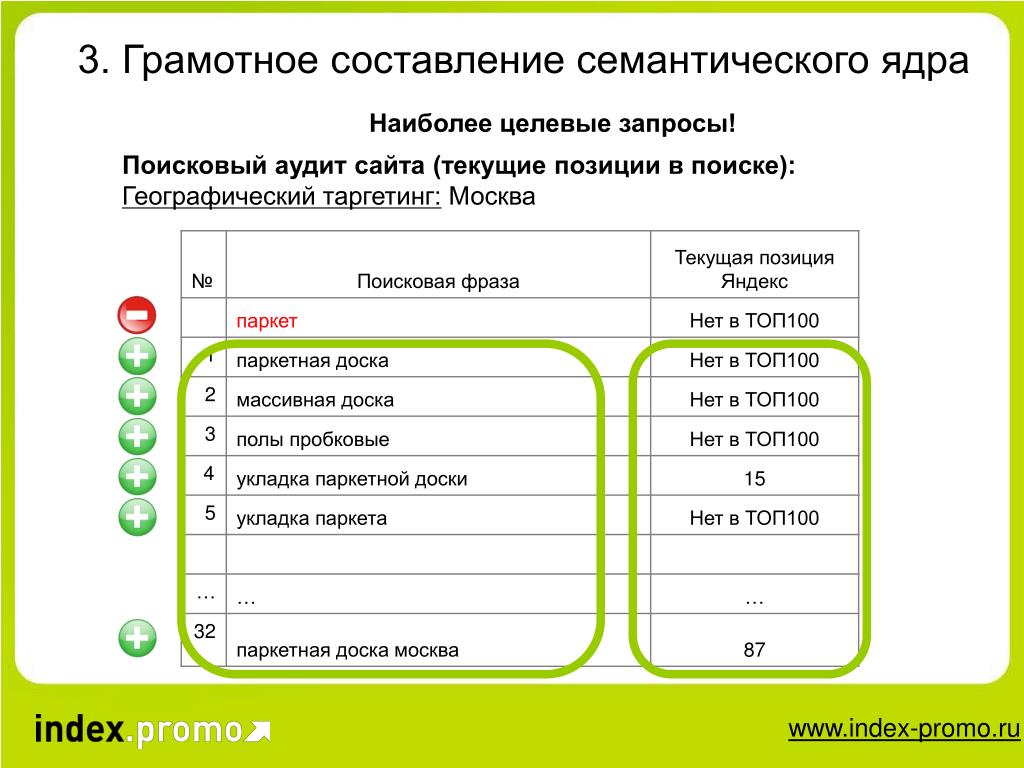 Мы можем смоделировать тот факт, что термин «серебряная посуда» является распространенным альтернативным термином для «кухонных столовых приборов». Поскольку клиенты, покупающие кухонные ножи, скорее всего, будут заинтересованы в покупке разделочной доски, мы также можем отметить, что кухонные ножи связаны с разделочными досками. Наконец, мы могли бы отметить, что кухонные ножи требуют предосторожности при использовании, и сделать это, собирая кухонные ножи с другими продуктами, требующими предосторожности.
Мы можем смоделировать тот факт, что термин «серебряная посуда» является распространенным альтернативным термином для «кухонных столовых приборов». Поскольку клиенты, покупающие кухонные ножи, скорее всего, будут заинтересованы в покупке разделочной доски, мы также можем отметить, что кухонные ножи связаны с разделочными досками. Наконец, мы могли бы отметить, что кухонные ножи требуют предосторожности при использовании, и сделать это, собирая кухонные ножи с другими продуктами, требующими предосторожности.
Определения семантической модели
Следующим компонентом CSM является канонический контролируемый список определений для всех семантически релевантных терминов. Это связано с базовой моделью контента, предоставляя разработчикам контента возможность понять интегрированную взаимосвязь между двумя моделями.
Отношения между терминами
Для большей функциональности CSM со временем будет расширяться для моделирования более сложных семантических отношений. Выходя за пределы отношений, представленных в таксономии или модели SKOS, CSM в конечном итоге разовьется в полную онтологию, то есть машиночитаемую формальную модель домена терминов с более широким набором отношений, чем в модели таксономии или SKOS. . С помощью онтологии у нас есть машиночитаемый способ выражения почти любого отношения между терминами, которое мы пожелаем. Возвращаясь к нашему примеру с кухонными ножами, в нашей семантической модели SKOS мы могли бы смоделировать, что кухонные ножи связаны с разделочными досками. Но если мы расширим используемые нами отношения, мы сможем быть более конкретными. Мы могли бы использовать более конкретное отношение, например, используемые вместе: кухонные ножи и разделочные доски используются вместе. Используя эту более конкретную связь между кухонными ножами и разделочными досками, можно затем увеличить продажи кухонных ножей, ориентируясь на клиентов, которые покупают разделочные доски.
Выходя за пределы отношений, представленных в таксономии или модели SKOS, CSM в конечном итоге разовьется в полную онтологию, то есть машиночитаемую формальную модель домена терминов с более широким набором отношений, чем в модели таксономии или SKOS. . С помощью онтологии у нас есть машиночитаемый способ выражения почти любого отношения между терминами, которое мы пожелаем. Возвращаясь к нашему примеру с кухонными ножами, в нашей семантической модели SKOS мы могли бы смоделировать, что кухонные ножи связаны с разделочными досками. Но если мы расширим используемые нами отношения, мы сможем быть более конкретными. Мы могли бы использовать более конкретное отношение, например, используемые вместе: кухонные ножи и разделочные доски используются вместе. Используя эту более конкретную связь между кухонными ножами и разделочными досками, можно затем увеличить продажи кухонных ножей, ориентируясь на клиентов, которые покупают разделочные доски.
Как строится основная семантическая модель?
Оценка существующих таксономий и источников семантической достоверности
Во многих организациях уже есть таксономии, наборы тегов, словари терминов, руководства по поисковой оптимизации, системы управления терминологией, метаданные с информацией о продуктах и множество других источников семантической достоверности, которые могут быть получены из существующих ресурсов контента. Таким образом, первый шаг к построению CSM включает в себя аудит этих существующих таксономий и других семантических источников. Эти аудиты предоставляют начальный набор терминов, используемых для начала моделирования их отношений с полями метаданных в базовой модели содержимого. Эти таксономии составят начальную основу нашего CSM.
Таким образом, первый шаг к построению CSM включает в себя аудит этих существующих таксономий и других семантических источников. Эти аудиты предоставляют начальный набор терминов, используемых для начала моделирования их отношений с полями метаданных в базовой модели содержимого. Эти таксономии составят начальную основу нашего CSM.
Интеграция с моделью основного содержимого
После того, как был проведен аудит существующих таксономий организации, мы можем обратиться к CCM ресурсов контента организации в качестве руководства по построению CSM. Это обеспечит правильную интеграцию CSM с CCM, что является ключом к обеспечению интеллектуального взаимодействия с клиентами. Интеграцию CSM с CCM можно выполнить, выполнив следующие действия:
- Инвентаризация активов контента: мы отвечаем на следующие вопросы:
- Какие активы моделируются в CCM?
- Какие активы имеют наибольшее семантическое значение?
- Как они используются?
- Как они доставляются?
- Где они созданы?
- Семантический анализ
После проведения инвентаризации ресурсов контента мы можем приступить к семантическому анализу. Именно здесь мы определяем важную семантическую информацию, которую мы в конечном итоге хотим смоделировать в нашем CSM, отвечая на следующие вопросы:
Именно здесь мы определяем важную семантическую информацию, которую мы в конечном итоге хотим смоделировать в нашем CSM, отвечая на следующие вопросы:
- Какие термины вместе образуют естественную категорию?
- Какие виды отношений существуют между терминами?
- Какие термины взаимозаменяемо используются организацией?
- Дизайн семантической модели
После завершения анализа мы можем приступить к построению самой семантической модели. Сюда входит построение таксономии всех семантически релевантных терминов с указанием иерархических отношений между терминами. Это также включает в себя моделирование того, какие термины уже или шире, чем другие термины.
Это также включает другие семантически релевантные отношения между терминами, такие как отношения SKOS, рассмотренные выше, или более конкретные отношения, составляющие онтологию. Как упоминалось ранее, крайне важно, чтобы модель CSM соответствовала установленным отраслевым стандартам. SKOS является одним из таких стандартов. По мере того, как модель превращается в онтологию, разработчики моделей должны быть внимательны к другим соответствующим стандартам, таким как RDF или OWL.
SKOS является одним из таких стандартов. По мере того, как модель превращается в онтологию, разработчики моделей должны быть внимательны к другим соответствующим стандартам, таким как RDF или OWL.
Наконец, модель также включает контролируемый список канонических семантических определений всех терминов.
Часто эта работа включает сотрудничество с различными заинтересованными сторонами для достижения общих семантических конструкций. Не каждая группа должна соглашаться. Тезаурусы могут отображать вместе то, что нужно каждой группе, чтобы называть вещи для своих целей. Но сущность смыслов нуждается в общей основе в согласованной истине; и эта общая истина — это то, что мы кодифицируем в семантической модели.
Демонстрация семантической модели
Ценность CSM должна быть осязаема посредством демонстрации. Таким образом, следующим шагом является создание парадигмы использования семантической модели. Например, окончательная таксономия может использоваться для облегчения доступа к активам контента или навигации по ним, или может использоваться модель альтернативных меток для терминов, чтобы обеспечить согласованность маркировки контента.