
Кластеризация семантического ядра + excel + автоматизация
Оглавление:
- Кластеризация и чистка семантического ядра в Excel
- Зачем все это нужно и почему все так сложно?
- Автоматизация кластеризации семантического ядра
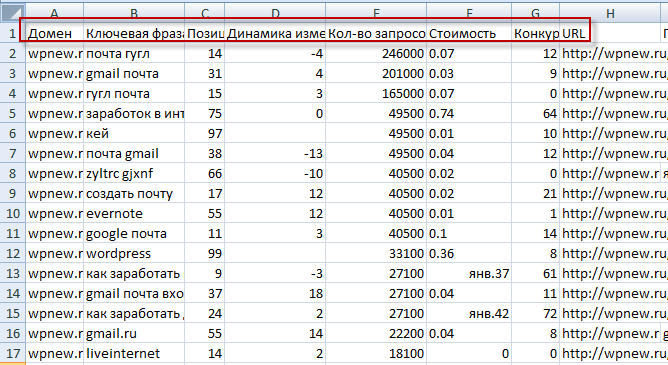
Здравствуйте, уважаемые читатели сайта Uspei.com. В этом уроке мы рассмотрим такие вещи как группировка запросов в рамках семантического ядра или кластеризация. Начнем мы с группировки поисковых запросов и чистки ядра. В прошлой статье мы посмотрели, как собирать статистику, какие инструменты для этого можно использовать, и все это почистили, удалив дубликаты. А также мы рассмотрели виды запросов.
У нас есть большой список запросов, из которого мы должны удалить оставшийся мусор и провести группировку. То есть у нас есть здоровенный список запросов. В некоторых тематиках он может доходить до 10 000. Наша задача сейчас разбить его на группы, каждая из которых будет содержать в себе только синонимы.
К примеру, если у нас есть запрос «купить ноутбук», то мы должны сделать группу, в которой будут только синонимы к запросу «купить ноутбук».
Под синонимом в SEO имеется в виду то, что в запросы, по которым люди ищут, вкладывается один и тот же смысл. К примеру, запросы «купить ноутбук» и «купить ноутбук apple» это НЕ синонимы и они будут входить в разные группы, потому что у них разное понятие. В первом случае человек ищет просто ноутбук и это может быть даже samsung, а совсем не apple. Во втором же случае человек ищет конкретно apple. Ну, еще один пример. Человек ищет «такси» и «междугороднее такси» — тут думаю тоже очевидно и понятно.
Таких групп в рамках большого семантического ядра может быть огромное количество, их может быть более нескольких сотен в редких случаях более тысячи.
И потом я вам дам ссылки на набор инструментов, который может существенно автоматизировать или ускорить эту группировку или кластеризацию, как это сейчас модно называть.
К оглавлению ↑
Кластеризация и чистка семантического ядра в Excel
Возвращаемся к нашему списку запросов и у нас достаточно простой алгоритм. У нас уже отсортированы все запросы по убыванию частотности, то есть от самых популярных до наименее популярных. Дубликаты мы удалили.
Мы берем каждый запрос и смотрим подходит он нам или нет. Например, у нас есть запрос «интернет-магазин», но если мы занимаемся только ноутбуками, то этот запрос без слова ноутбук нам не подходит. Значит запрос «интернет-магазин» мы удаляем — это не тематический запрос.
Дальше запрос «ноутбук». Да, в принципе это информационный запрос, но не совсем понятно, что человек вкладывает в этот запрос, когда вбивает его в поисковую строку. Ищет ли он информацию, картинку или он ищет товары или возможно что-то еще.
Если мы сомневаемся в смысле поискового запроса, логично его проверить. Как это делается? Мы копируем запрос и вбиваем его в новой вкладке в ту поисковую систему, с которой мы работаем. Например, Google.
Мы видим, что Google показывает нам набор интернет-магазинов. Мы видим точно, что это запрос коммерческий и если у нас интернет-магазин, мы его оставляем.
И мы добрались до первого подходящего нам запроса. Давайте выделим нашу первую группу запросов, в которую будут входить все слова с упоминанием слова «ноутбук». Для этого нужно включить фильтр и отфильтровать по текстовому условию «содержит». Но там могут быть словоформы запроса «ноутбук» поэтому мы просто напишем «ноут» и получаем список строк только с поисковыми запросами, в которых упоминается «ноут».
Каждую вкладку мы будем называть соответственно по тому слову, по которому мы произвели фильтрацию. В первой же вкладке мы вручную (!) выделяем все отфильтрованные ключи и удаляем. После чего очищаем фильтр.
Итак, в первой вкладке у нас остались все ключи, которые НЕ содержат «ноутбук», а мы переходим во вторую («ноутбук») и продолжаем работать теперь уже там.
Итак, следующее слово «ноутбук». Мы уже разобрались, что это коммерческий запрос и по нему также как и по запросу «купить ноутбук» показываются интернет-магазины, то есть это синонимы и мы оставляем их в одной группе.
«DNS ноутбуки» — как раз это тот самый навигационный запрос и можно предположить, что приставка «DNS» как популярный интернет-магазин будет часто встречаться в списке запросов про ноутбуки. Поэтому давайте сразу удалим все чужие навигационные запросы «DNS». Фильтр — выделяем вручную и удалить.
«Ноутбуки бу» — аналогично как с «dns» — удаляем, если только мы не продаем б/у ноубуки.
«Купить ноутбук Москва» — тут уже добавляется регион, а мы далеко не в Москве. По сути, запрос повторяет смысловую нагрузку запроса «купить ноутбук» или просто «ноутбук». Но поскольку добавляется регион, стоит проверить считает ли google эти поисковые запросы синонимами.
Мы берем запрос «купить ноутбук» вбиваем его в google и в другой вкладке вбиваем запрос «купить ноутбук Москва». И сравниваем результаты поиска на предмет повторения результатов, то есть именно конкретных страничек. Если хотя бы 4-5 страничек одинаковых, то мы можем считать, что это запросы синонимы и Google показывает по ним одинаковый смысл. Если же по этим запросам выдача разная, то «купить ноутбук Москва» навигационный запрос и он нам не нужен.
Идем дальше и таким образом проделываем ту же процедуру — удаляем мусор и создаем новые группы отличные по смыслу.
Очень рекомендую чистить семантику, используя фильтры, если чистить ручками, то есть большой шанс что-то пропустить.
Но когда мы фильтруем, надо быть аккуратным, чтобы не удалить какие-то важные слова случайно отфильтровав их. Например, если в фильтр вбить просто «бу» то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие «бу» — например, сам запрос «ноутБУк» — а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце » бу» и «бу «, а также через слэш «б/у». Помните это и будьте внимательны))))).
Например, если в фильтр вбить просто «бу» то он отфильтрует ВООБЩЕ ВСЕ слова, содержащие «бу» — например, сам запрос «ноутБУк» — а это уже крах))). Поэтому лучше вбить по очереди два варианта с пробелом вначале и вконце » бу» и «бу «, а также через слэш «б/у». Помните это и будьте внимательны))))).
И вот у нас запрос «ноутбук hp». Это уже не просто «ноутбук» — это уже более узкая тема, значит мы должны выделить ноутбуки hp в отдельную группу.
Производим фильтрацию «текст содержит» получаем набор запросов и переносим их в новую вкладку «ноутбуки hp». Из второй вкладки «ноутбук» перенесенные в 3 вкладку результаты удаляем.
Так мы будем повторять эту процедуру, пока в каждой вкладке не останутся только синонимы. То есть дальше мы должны перейти в 3 вкладку «ноутбуки hp» и здесь их разделить еще на более подробные группы. Мы видим, что здесь есть «ноутбук hp pavilion», » ноутбук hp compaq» и «ноутбук hp игровой». Таким образом, эта группа будет разбита еще на 3 группы.
Во вторую вкладку мы вернёмся, когда во всех следующих группах все слова будут синонимами и продолжим этот разбор. Продолжим до тех моментов, пока самая первая наша вкладка не будет разложена на группы, а в ней самой не останутся только нецелевые запросы или запросы, которые тоже будут синонимами.
В итоге наша задача создать файл, в котором у нас будет огромное количество вкладок. В разных темах по-разному — возможно в некоторых темах будет всего 5-6 вкладок, если тема очень маленькая, но основная задача, чтобы в рамках одной вкладки были только запросы синонимы.
Причем не просто слова синонимы в классическом понимании, а синонимы с точки зрения поисковой системы. Вот как из примера «купить ноутбук» и «ноутбук» это синонимы с точки зрения поисковой системы, поэтому они у нас остались в одной группе.
Если во вкладке 20 синонимов и один НЕ СИНОНИМ — выносим его одного в отельную вкладку. Это очень важный момент, так как каждая группа это отдельная страница, на которой эти запросы будут продвигаться, и чем больше будет ошибок и недоработок, тем менее чистой по смыслу станет страница, что скажется результатах поиска.
Повторю еще раз основную мысль — в каждой вкладке должны быть запросы подходящие по смыслу. Пример, если в текущей вкладке 5 запросов:
- «заработать в интернете»
- «как можно заработать в интернете»
- «где заработать через интернет»
- «как заработать деньги в интернете»
- «как заработать в интернете без обмана»
Первые три запроса останутся в текущей вкладке, так смысл у них один, а последние два уйдут каждый в свою группу-вкладку, так как они не совпадают по смыслу ни с первыми тремя, ни между собой — они более детализированы. В одном случае речь идет о деньгах ( а заработать в наши дни можно все что угодно — биткоины, баллы в играх и т.д.), а во-втором, речь идет о заработке без обмана.
Для понимания я в течение часа сварганил (правда не до конца) семантику по запросам, «заработок в интернете» «заработок в сети» «заработок онлайн». Первая вкладка — вся семантика, а далее по группам. Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Красные вкладки это основные, из которых идет разбор. Повторюсь, это полусырая заготовка, которую еще нужно дорабатывать.
Скачать пример семантического ядра в excele.
К оглавлению ↑
Зачем все это нужно и почему все так сложно?
Вы уже, наверное, поняли, как много времени вам придется уделить на сбор и кластеризацию семантического ядра, и часто люди спрашивают — зачем это все нужно? Какую практическую пользу это несет?
На самом деле, сейчас это не очевидно, но буквально через два-три этапа вы увидите, что вся поисковая оптимизация, абсолютно все seo, построено на основе правильно собранного семантического ядра. SEO — это не просто любительский способ сделать свой сайт лучше. Это, можно сказать наука, в которой все начинается с «атомов» и именно это приводит к результату.
SEO можно сравнить с большим спортом — боксом или сноубордом или любым другим. Если вы не освоите технику ПРОФЕССИОНАЛЬНЫХ ударов или элементов езды, то это скажется на скорости и выносливости и вы проиграете сопернику, кто этим не пренебрег. Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое — не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места — есть только первая страница и все.
Если вы не хотите делать этого, тогда это уже не SEO, а что-то другое — не такое эффективное. И в SEO, как и в спорте, нет 15 или 20 места — есть только первая страница и все.
Мы не можем начинать оптимизацию сайта, если мы не сделали семантику, не разбили ее на группы, не обработали и не почистили. И все что мы будем делать дальше, будет основано на семантике.
Приведу конкретный пример. Мы же понимаем, что по каждому запросу поисковик дает свой результат выдачи. Возьмем какую-то небольшую тематику по которой в семантике всего 100 запросов. И вот у одного владельца 100 страниц на сайте, в которых содержимое часто пересекается, структура сайта от этого расплывчатая, поисковик не понимает до конца, какие страницы релевантны запросу больше, а какие меньше. В итоге, кроме путаницы, эти 100 страниц содержат в своем «винегрете» ответы только на 30-40 запросов.
А у второго владельца сайта, благодаря полному собранному кластеризованному семантическому ядру, на каждый запрос есть соответствующая страница, строго релевантная только этому запросу. Поисковик и пользователи четко понимают структуру сайта, а также не страдают «дежавю», что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
Поисковик и пользователи четко понимают структуру сайта, а также не страдают «дежавю», что уже где-то несколько раз читали об этом на сайте. Внутренняя перелинковка четко структурирована, так как у владельца сайта не возникает вопросов на какую из 10 страниц поставить внутреннюю ссылку. Этот сайт поисковик покажет по ВСЕМ 100 запросам и соберет весь трафик.
К оглавлению ↑
Автоматизация кластеризации семантического ядра
Такая работа по группировке запросов по обработке всей этой статистики вручную занимает достаточно много времени. Особенно если человек делает это первый раз. Но я вам рекомендую, если вы хотите научиться работать запросами, работать с семантикой, хотя бы один раз проведите все это вручную в электронных таблицах. Тогда вы сможете прочувствовать и понять, как это работает.
Если же вы работаете в очень больших объемах, крайне рекомендую использовать профессиональные инструменты. Чаще всего они платные.
Один из самых популярных инструментов по работе с семантикой это инструмент «Key Collector», которая позволяет автоматизировать большинство процессов по сбору и обработке семантики. Как минимум, она умеет автоматически собирать ключевые слова из yandex wordstat, а также данные о частотности по запросам и другие рекомендации.
Если же у вас есть уже готовое отфильтрованное от мусора семантическое ядро, то вы можете прибегнуть к помощи дополнительных сервисов, которые производят автоматическую кластеризацию. Лидером сейчас на рынке является онлайн-сервис, который называется Rush analytics.
Расценки не очень высокие и в принципе, если у вас один сайт, вы владелец или вебмастер, то вы можете собрать семантику, почистить ее, после чего просто отдать на кластеризацию такому сервису.
Теги: AppleGoogleHPSamsungseoавтомобиливнутренние факторыинструментыинтернетконтентноутбукиопросочкисемантикассылкиструктура сайта
Мы в соцсетях:
Кластеризация поисковых запросов.
 Что это вообще такое и как правильно её сделать для SEO? / Хабр
Что это вообще такое и как правильно её сделать для SEO? / ХабрВсем привет! 🙋♀️ Когда-то я написала эту статью и опубликовала её на своем сайте, но решила уйти из SEO и сайт, соответственно, больше не нужен. Дабы не пропадать моей статье, решила перенести её на Хабр. Данная статья — туториал, который поможет разобраться как делать правильно кластеризацию или, простыми словами, группировать запросы для SEO-продвижения.
Кластеризация семантического ядра – это распределение ключевых запросов на группы, которые будут использоваться для оптимизации определенных страниц на сайте или добавления новых страниц.
Приступают к кластеризации после очищенного семантического ядра от неподходящих и «мусорных» запросов. Если этого не делать, могут быть проблемы со структурой сайта, особенно это касается интернет-магазинов и крупных сайтов (например, агрегаторы).\
Основная цель кластеризации – сделать удобный для пользователя сайт и дать релевантный ответ на запрос пользователя, показывая нужную страницу сайта.
Разбивка ключевых запросов необходима:
Для проработки будущей структуры сайта. Например, необходимо понять структуру будущего сайта компании, которая занимается полным циклом работ по котельным и котлам. Если семантическое ядро собрано с вхождениями «котельная» и «котел», то ядро будет состоять из множества кластеров, состоящих из коммерческих запросов по поиску товару («купить котел» и услуги («установка котельной цена»), информационных запросов («какой котел выбрать», «как установить котельную»), полукоммерческих или общих запросов («котел», «котельная»).
Для составления эффективной перелинковки между страницами. Например, необходимо добавить блок «Вам может быть интересно» на категорию товаров «Подгузники Huggies» в интернет-магазине. Но чтобы потенциальный покупатель не уходил сразу же с сайта, так как не нашел то, что нужно, в блок «Вам может быть интересно» добавляются те товары, которые также спрашивают в поиске и потенциально могут задержать пользователя на сайте и даже сделать покупку.

Для добавления новых страниц на сайт, которые будут приводить целевой трафик. Например, компания продает клеи для мебели, но, чтобы охватить больше трафика, необходимо создавать страницы под среднечастотные и низкочастотные запросы или более узкие запросы («клеи для мебельных щитов», «клеи для кромки»), при условии, что имеется ассортимент в этих категориях.

Что такое интент и почему он важен при кластеризации?
Интент или поисковый интент – это намерение или потребность человека, которая заключена в запросе. Интент важен в кластеризации, чтоб в кластерах не было лишних ключей, по которым страницы будут продвигаться.
Когда нужно понять интент, просто задайте вопрос: что именно ищет человек?
Пример:
Если ищут «ноутбук купить», логично предположить, что ищут ноутбуки с целью купить сейчас или в дальнейшем.
Если ищут «какой ноутбук купить», то вероятно ищут обзоры, рейтинг или инструкции по выбору ноутбука.
Если ищут просто «ноутбуки», то здесь уже не совсем ясно что нужно пользователю и необходимо анализировать выдачу.
Если ищут «ноутбуки москва», то здесь логично предположить, что ищут каталог ноутбуков с целью выбрать и приобрести сейчас или в дальнейшем.

Методы разбивки запросов по кластерам
Существуют несколько методов:
По интенту запросов
Кластеризация по интенту запросов проводиться на основе того, что собственно нужно пользователю. Это можно сказать точная кластеризация, так как группировка запросов по такому методу помогает грамотно распределять запросы по существующим или будущим страницам сайта.
Нельзя продвигать информационный ключ «какой корм для собак выбрать» на странице категории кормов для собак и логично, что «корм для собак купить» не пойдет в статью, которая продвигается по ключам «как выбрать корм для собак» или «какой выбрать корм для собак». Это грубая ошибка. Поэтому важно обращать внимание при группировке на поисковый интент.
Это грубая ошибка. Поэтому важно обращать внимание при группировке на поисковый интент.
Семантическая близость (схожесть) – это тоже про интент, но сюда подключается и морфология. Например, мы собрали семантическое ядро по теме «кастрация/стерилизация собаки» и в нем находятся такие запросы:
кастрация собаки;
стерилизация собаки;
кастрировать собаку;
стерилизовать собачку.
Все они имеют один и тот же интент (собственно, это самый главный критерий, по которому нужно ориентироваться при разбивке запросов), но морфологически немного отличаются:
Если не обращать внимание на интент, то схожие морфологически фразы из списка выше будут поделены на 2 группы:
Кастрация собаки: кастрация собаки, кастрировать собаку.
Стерилизация собаки: стерилизация собаки, стерилизовать собачку.
Но если мы обратим внимание на интент, то все запросы придется отнести в одну группу. По факту это вообще 2 разные процедуры, но люди привыкли под «стерилизацией» подразумевать «кастрацию». Поэтому важно не только морфологическую связь между словами и фразами учитывать, но и интент.
По факту это вообще 2 разные процедуры, но люди привыкли под «стерилизацией» подразумевать «кастрацию». Поэтому важно не только морфологическую связь между словами и фразами учитывать, но и интент.
По выдаче ТОП-10
Кластеризация запросов проводиться на основе выдачи топ-10 и под регион, в котором собираетесь продвигать сайт. Программа или сам оптимизатор анализирует выдачу по определенным запросам и при пересечении определенного количества страниц создает для таких запросов группу (кластер).
Существуют 2 типа кластеризации по выдаче топ-10:
Soft. Все запросы сравниваются с самым высокочастотным ключом. Это не очень хорошо, так как одна группа может содержать слишком большое количество запросов, по которым нужно продвигать страницу. Подойдет для информационных проектов (сайты, содержащие только статьи), но и здесь спорно, так как многим таким проектам важно придерживаться SILO-структуры, чтоб продвигаться в поиске эффективно, а не так – зашел, прочитал статью и ушёл.
Также может подойти для коммерческих сайтов в небольших регионах, где конкуренции меньше.Hard. Все запросы сравниваются с высокочастотный ключом и между собой. Хорошо тем, что на выходе получается много групп с определенным интентом. Вероятность того, что человек попадет на нужную страницу по определенной группе запросов или по одному запросу из этой группы, гораздо выше, чем при кластеризации методом Soft. Подходит для всех сайтов, особенно для сайтов с высокой конкуренцией.
 Также может подойти для коммерческих сайтов в небольших регионах, где конкуренции меньше.
Также может подойти для коммерческих сайтов в небольших регионах, где конкуренции меньше.Способы группировки ключевых фраз
Ручная
Ручная кластеризация – это кластеризация без помощи специальных сервисов и программ. Медленно, но качественно. Подходит для семантических ядер, которые содержат менее 100 запросов. Бесплатно. Если запросов от 500, а то и от 1000, на кластеризацию вручную уйдет неделя с лишним.
Автоматическая
Автоматическая кластеризация — это кластеризация с помощью сервисов или программ. Быстро, но приходится доделывать вручную. Подходит для семантических ядер от 100 и выше. Этот способ гораздо эффективней, чем разбирать ключи при ручном способе. Большинство сервисов и программ – платные.
Быстро, но приходится доделывать вручную. Подходит для семантических ядер от 100 и выше. Этот способ гораздо эффективней, чем разбирать ключи при ручном способе. Большинство сервисов и программ – платные.
Эффективный способ кластеризации – совмещение автоматической и ручной кластеризации. Обязательно сначала кластеризовать автоматически, а потом уже доделать кластеризацию вручную. Наоборот – нет, это пустая трата времени.
Как разбить семантическое ядро по группам?
Ручная кластеризация (с сохранением частотности)
Возьмем тему — красные фиксаторы резьбы. Нужно разделить группы, под которые будут созданы новые подразделы и страницы.
Переходите по ссылке, чтоб скачать семантическое ядро по «красным фиксаторам резьбы». Если предпочитаете работать в Google Excel, создайте копию файла и начните работать с семантическим ядром.
1. Откройте список ключевых слов в Excel. Обязательно должно быть 2 столбца – Запрос и Частотность. Остальные – по желанию и при необходимости.
Остальные – по желанию и при необходимости.
2. Начните распределять по группам. Обратите внимание на интент запроса.
Если во фразах содержится слова «купить», «цена» и не указан конкретный бренд фиксатора, значит это общие коммерческие ключевые фразы. Выносим их в отдельную группу под названием «Купить красные фиксаторы». Для этой группы будет создана страница со всеми красными фиксаторами резьбы независимо от бренда.
Если во фразах содержатся слова «купить», «цена» и указан конкретный бренд, например, «abro», значит это коммерческие ключевые фразы по определенному бренду красного фиксатора. Выносим их в отдельную группу под названием «Купить красные фиксаторы Abro». Аналогично поступаем и с другими брендами.
Если во фразах содержаться вопросительные слова «сколько сохнет», «какой выбрать», «как использовать», а также фразы или слова, которые подразумевают поиск информации, например, «инструкция по применению» (может быть также коммерческим запросом), «виды», «состав», «время высыхания», значит они попадают в группу информационных запросов, по которым пишутся статья или несколько статей.

3. Посмотрите какие запросы остались некластеризованными. Если по интенту все ясно, определяете в свою группу. Если нет, необходимо посмотреть выдачу ТОП-10 по таким запросам по определенному региону, где будет продвигаться сайт. Другой вариант – проверка коммерциализации (показывает коммерциализацию в процентах).
Если вы видите, что чаще по запросу показываются статьи, значит запрос определенно стоит отнести к информационным запросам. Если примерно 50/50, то здесь вероятно тоже стоит отнести к информационным, если запрос совсем не похож на коммерческий. Например, такая ситуация может быть с общими фразами – «красные фиксаторы», «красные резьбовые фиксаторы».
Важно! Яндекс и Google имеют разную выдачу. Google, к примеру, по запросу «красные фиксаторы резьбы» показывает в основном коммерческие страницы, а вот Яндекс – часто статьи. Ориентируйтесь по той поисковой системе, которая для вас более приоритетна в продвижении.
4. Кластеризация закончена. Приступайте к добавлению новых страниц и их оптимизации или к оптимизации уже существующих страниц.
Приступайте к добавлению новых страниц и их оптимизации или к оптимизации уже существующих страниц.
Важно! По информационным запросам требуется дополнительный сбор семантики по всей стране, если вы реально хотите написать классную подробную статью на эту тему.
Инструкция – Автоматическая кластеризация
Возьмем эту же тему — красные фиксаторы резьбы. Нужно разделить группы, под которые будут созданы новые подразделы и страницы.
Переходите по ссылке, чтоб скачать семантическое ядро по «красным фиксаторам резьбы». Если предпочитаете работать в Google Excel, создайте копию файла и начните работать с семантическим ядром.
1. Откройте список ключевых слов в Excel. Обязательно должно быть 2 столбца – Запрос и Частотность. Остальные – по желанию и при необходимости.
2. Скопируйте список запросов (без частотности) и добавьте в любой сервис автоматической кластеризации. Большинство сервисов предлагают метод Soft или Hard.
3. Выберите метод Hard и запустите проверку.
4. По завершению выгрузите в Excel и откройте файл.
5. Перенесите частотность по формуле ВПР, проверьте группы и приведите таблицу в порядок, чтоб лучше видеть структуру.
6. Посмотрите какие запросы сервис не смог кластеризовать и распределите их по группам самостоятельно. Посмотрите выдачу ТОП-10 по нужному региону или процент коммерциализации, если есть сомнения куда отнести запрос.
7. Кластеризация закончена. Приступайте к добавлению новых страниц и их оптимизации или доработки существующих.
Резюме
Кластеризация – важный этап в поисковом продвижении.
Доступна ручная, автоматическая и комбинированная кластеризация запросов.(автоматическая + ручная).
Группировать запросы можно по выдаче ТОП-10, по интенту и семантической близости. По выдаче ТОП-10 доступны Soft- и Hard-метод.
Кластеризовать запросы может кто угодно: SEO-специалист, владелец сайта, интернет-маркетолог, специалист по контекстной рекламе и другие.
Главное, понимать принципы.Доверять кластеризацию лучше SEO-специалисту, так как именно этому человеку продумывать структуру сайта и продвигать ваш сайт в поиске.
 Главное, понимать принципы.
Главное, понимать принципы.✅ Семантическое ядро ЗДЕСЬ!
Этот сайт посвящен составлению семантических ядер и ниже написано что это такое. Здесь вы можете заказать семантическое ядро, а здесь задать интересующий вопрос.
Содержание:
- Как выглядит семантическое ядро?
- Ключевые слова – основа для продвижения
- Что дает семантическое ядро заказчику?
- Пример готового семантического ядра
- Как использовать собранное семантическое ядро?
- Применение ключевых слов конкурентов в своей контекстной рекламе
Семантическое ядро – набор ключевых слов и словосочетаний, которые наиболее релевантны тематике сайта или статье, в которых они используются. По своей сути — это запросы людей в поисковых системах, которые правильно сгруппированы в кластеры семантического ядра, которое, в свою очередь является базой для построения структуры сайта.
Семантическое ядро состоит из высокочастотных ключевых слов, среднечастотных и низкочастотных, иногда включают микронизкочастотные запросы.
Как выглядит семантическое ядро?
Выглядит оно как как файл Excel (обычно), в этом файле собраны ваши ключевые слова, которые сгруппированы (кластеризованы), у каждого слова есть своя частотность (базовая, фразовая, точная), + добавлены различные значения из Яндекс Директа, Google ADW, показатели KEI (конкуренция), другие показатели.
★ Примеры изображений семантического ядра ЗДЕСЬ
★ Скачать XLS файл пример
Ключевые слова — основа для продвижения
Сейчас наблюдаем следующие тенденции:
- основные механизмы поискового продвижения всем известны и практически исчерпаны,
- множество молодых сео оптимизаторов – специалисты с небольшим опытом,
- грамотных SEO специалистов надо целенаправленно искать, ведь кто из знакомых даст вам золотой номер телефона? А вдруг этот специалист будет меньше уделять времени ЕГО сайту?
Вывод: с каждым годом остается все меньше уникальных инструментов для продвижения сайтов и маркетинга. Только большие компании, с огромными бюджетами могут позволить себе огромные расходы на рекламу и качественное продвижение.
Только большие компании, с огромными бюджетами могут позволить себе огромные расходы на рекламу и качественное продвижение.
НО, все-таки, – семантика держится особняком, вопрос качественного сбора семантического ядра сайта полностью не закрыт и являет собой одну из немногих ниш, в которой есть не так уж много специалистов . Особенно в вопросе качества. А если и есть заявления о включении семантического ядра в структуру работ, то зачастую – это всего лишь сбор нескольких десятков слов и фраз вручную из Яндекс.Вордстат – не более.
Что дает семантическое ядро заказчику?
Само по себе семантическое ядро – лишь Excel файл с информацией. А вот содержащаяся в нем информация дает понимание – что делать и как делать. Не умозрительное понимание, а подтвержденное исследованием, каждый шаг которого можно отследить и проверить.
Для чего нужно СЯ по пунктам:
- Доработка сайтов уже существующего бизнеса,
- Анализ ниши, в которую вы предполагаете зайти,
- Планирование бюджета на рекламу, оптимизация рекламы.

Семантическое ядро по своей сути является картой, на которой видны пути развития вашего бизнеса или пути его создания. Главное – уделить ей время и изучить, я думаю, что те, кому важно развитие своего бизнеса сделают это во всей внимательностью. Особенное внимание надо уделять показателям частотности и конкуренции, но об этом написано несколько далее, а пока про использование и внедрение семантических ядер.
Правильно внедренное в проект семантическое ядро дает: гарантированный ТОП 10. Внедренное в рекламную кампанию это же ядро дает экономию рекламного бюджета: min от 10% и max до 70%.
*Небольшая ремарка – экономия 70% на контекстной рекламе это не предел, бывают и более поразительные результаты.
Пример готового семантического ядра
В данном примере показаны изображения семантического ядра,
собранного для адвоката, работающего в Москве, частотность собрана за месяц,
выгружены данные из Яндекс.Директа, собраны данные о конкуренции (KEI), рассчитаны уровни
конкуренции по формулам KEI.
Файл XLS Семантическое ядро (Пример)
В собранном семантическом ядре выявлены ключевые фразы с минимальной конкуренцией в РСЯ. Ключевые фразы были внедрены в РСЯ. По имеющейся информации сейчас заказчик семантического ядра – не справляется с объемами поступающих заявок и вынужден передавать заказы коллегам.
Заявка на сбор семантического ядра
Качество семантического ядра – это залог успеха
Исходя из написанного выше – остро стоит вопрос качественного сбора ядра и его проработки для каждого бизнеса. Именно от качества семантического ядра сайта зависит релевантная структура сайта, релевантность текстов, эффективность рекламы… А если в целом — перспективы бизнеса, которые вытекают из дальнейшей проработки и продвижения сайта.
И не только для продвижения – актуален так же вопрос составления качественной, таргетированой и экономной рекламной кампании, которая не жрет деньги с отдачей в 1%.
Поэтому заказать сбор ядра сайта нужно у специалистов. Заказать семантическое ядро можно и у нас. Качество и соответствие срокам исполнения гарантируем.
Размер семантического ядра
Размер семантического ядра зависит от ниши, для которой формируется. Чем больше и обширнее ниша или ассортимент оказываемых услуг / продаваемых товаров – тем больше и семантическое ядро.
Чем правильнее и полнее сформировано ядро сайта — тем больше работы у копирайтеров и разработчиков тем лучше перспективы развития сайта, больший охват аудитории и, следовательно – больше целевого трафика из органической выдачи.
Например, для крупных порталов, таких как Wildberries, DNS и других подобных крупных площадок СЯ может состоять из нескольких сотен тысяч или даже нескольких миллионов ключевых слов, а для среднего интернет-магазина обычно достаточно нескольких тысяч или десятков тысяч фраз. Тут все зависит от самой тематики и масштаба поиска.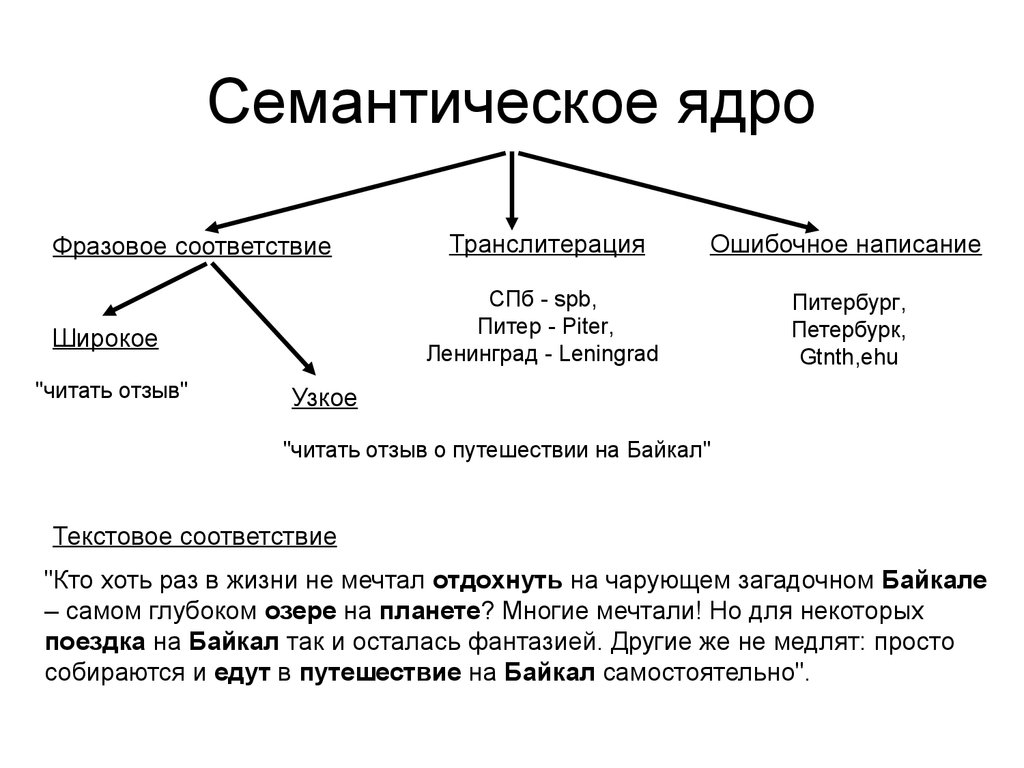
Считаю, что важно упомянуть так же и уникальные узкоспециализированные ниши.
Случай из нашей работы: Поступил заказ от небольшой компании на составление семантического ядра по их тематике, она не часто встречается, настолько не часто, что мы первый раз об этом слышали за всю свою жизнь! Начали собирать ядро, парсить слова, искать по сервисам (естественно платным)… а слов нет! Ну нет и все, никто таких слов в поиске не набирает! Что мы делаем – генерируем в Excel порядка 100.000 тематических и околотематических слов и словоформ на основании ТЗ заказчика и смотрим частотность этих ключей. Получаем около 200 тематических фраз с частотностью более 10, уже есть успех!)) В итоге заказ был выполнен – большими стараниями удалось найти целевых 1000 слов (примерно столько и оговаривалось) с приемлемой частотностью. В таких случаях мы берем в расчет и информационные запросы тоже.
Как использовать собранное семантическое ядро?
Теперь подробнее о применении СЯ. Семантическое ядро показывает ПЕРСПЕКТИВНОСТЬ ПУТЕЙ РАЗВИТИЯ и ПРОДВИЖЕНИЯ сайта, ВЫГОДНОСТЬ рекламной кампании. По большому счету от этих данных зависит эффективность и прибыльность вашего сайта или рекламы.
Семантическое ядро показывает ПЕРСПЕКТИВНОСТЬ ПУТЕЙ РАЗВИТИЯ и ПРОДВИЖЕНИЯ сайта, ВЫГОДНОСТЬ рекламной кампании. По большому счету от этих данных зависит эффективность и прибыльность вашего сайта или рекламы.
Далее будут рассмотрены варианты использования семантического ядра:
- Использование для оптимизации и продвижения сайта,
- Использование для контекстной рекламы,
- Комбинированное использование.
Использование семантического ядра для продвижения и оптимизации сайта
Семантическое ядро для продвиженияПравильно составленное ядро сайта – это кластеризованные (*сгруппированные) по определенным методикам целевые слова и фразы людей, эти ключевые слова, по сути, — должны быть основой для формирования или доработки структуры сайта, для создания релевантного контента сайта, для понимания интента (интент это запрос людей – т.е. чего они хотят на самом деле).
На основе сем. ядра готовятся исходные данные (ТЗ) для
подготовки материала (статей) или формирования рекламных кампаний.
Анализ ключевых слов:
- по частотности,
- по гео зависимости,
- по сезонности запросов,
- по релевантности,
- уровню конкуренции (показатели и формулы KEI),
- более детальное разделение на коммерческие запросы и информационные,
- выясняется конкуренция ключевых слов,
- позиции сайта по запросам.
Внедрение семантического ядра для продвижения:
- пишутся статьи, проспекты, презентации,
- или наоборот – не пишутся (либо пишутся, но чисто символически), это в случае огромной конкуренции (на основе анализа), когда просто не выгодно тратить ресурсы,
- соответствующим образом оформляются карточки товаров,
- дорабатывается структура сайта,
- удаляются или дорабатываются нерелевантные тексты,
- другие работы.
Преимущества и недостатки продвижения сайта на основе семантического ядра
+ Преимущества: в результате получаете бесплатный трафик из
поисковых систем, все затраты полностью окупаются, количество заявок растет в
разы.
— Недостатки: долго, дорого, требуется взаимодействие со специалистами, которые будут проводить работы.
Использование семантического ядра в рекламной кампании
Cемантическое ядро в рекламной кампанииВ какой именно рекламной системе – не важно. В Яндекс.Директ, GoogleADS или других – не имеет большого значения т.к. правильное СЯ имеет собранные ключевые слова из всех основных поисковых систем. Итак, на основе анализа семантического ядра вы выбираете по каким словам рекламироваться, по каким не рекламироваться, где установить ставки побольше, где поменьше.
Анализ ключевых слов для контекста (Яндекс.Директ)
- оцениваем количество объявлений конкурентов по каждой фразе,
- оцениваем Среднюю стоимость клика (CPC), прогнозный бюджет,
- оцениваем кликабельность (CTR) количество показов и переходов.
Все эти данные будут выгружены в отчете.
Настройка РСЯ на основе полученных ключевых слов:
- добавляются в кампанию ключевые слова, которые ранее не были охвачены,
- удаляются не выгодные слова – на основании большой конкуренции,
- добавляются информационные ключевые запросы по минимальным ставкам,
- другие работы по настройке рекламы.
Преимущества и недостатки создания рекламной кампании на основе семантического ядра
+ Преимущества: сразу получаете целевой трафик из поисковых систем и соответственно выручку.
— Недостатки: 1) за рекламу, хоть и меньше, но все-таки надо платить, 2) ваш портал не развивается или развивается вслепую наощупь.
Комбинированное использование семантического ядра для рекламной кампании и для продвижения
На наш взгляд это наиболее правильная стратегия для работающего сайта, пока одни сотрудники приводят сайт в порядок – ваша реклама уже работает, требует и помогает окупать оплату услуг оптимизаторов и копирайтеров.
Применение ключевых слов конкурентов в своей контекстной рекламе
Запросы конкурентов как источник ключейМногие владельцы сайтов выбирают короткий путь получения ключевых слов для своего бизнеса. Вместо сбора полноценного семантического ядра – просто ищут ключевые слова конкурентов и не глядя, без анализа добавляют их в свою рекламную кампанию.
Во-первых – всех его слов, полностью, вы не получите, максимум – его же слова из контекстной рекламы. Возможно (есть минимальный шанс), что там будут низко конкурентные слова, где только вы и он будут конкурентами, но как показывает практика – такой подход приносит минимальную выгоду и, в принципе, с большой натяжкой сгодится на начальном этапе. При этом не забывайте – никакой речи об экономной рекламной кампании здесь не идет вообще.
Во-вторых – вы не развиваете свой сайт, просто получаете список его слов, без анализа, без данных о конкуренции, без структуры.
Вы скажете: «А что, если я выгружу слова у 10 или 20 конкурентов?» Теоретически идея имеет право на существование, но при одном условии: вы соберете частотность слов, получите аналитические данные об этих словах из поисковой системы, тогда, анализируя это самостоятельно вы, возможно, сможете выявить несколько относительно выгодных слов. И не забывайте, что другие могут делать тоже самое.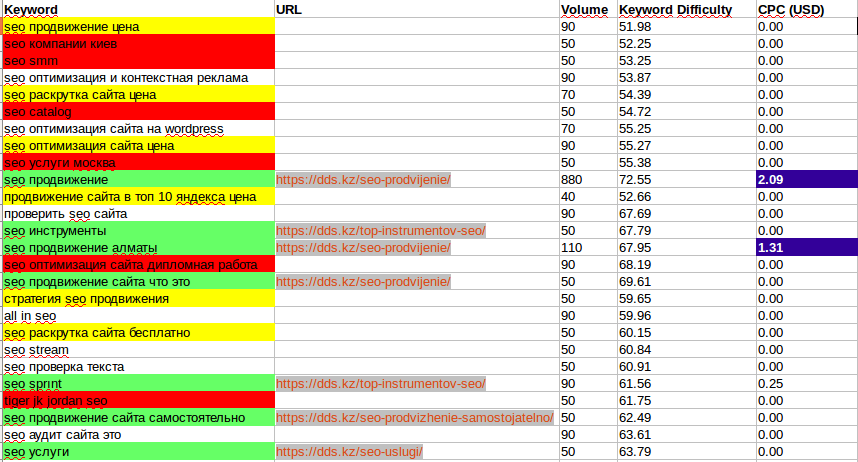
Заказать семантическое ядро
Как собрать семантическое ядро сайта в excel
Как составить семантическое ядро сайта
Часть 2 (практика)
В первой части нашей статьи мы рассказали, что такое семантическое ядро и дали общие рекомендации о том, как его составить.
Пришло время разобрать этот процесс в деталях, шаг за шагом создавая семантическое ядро для вашего сайта. Запаситесь карандашами и бумагой, а главное временем. И присоединяйтесь …
Составляем семантическое ядро для сайта
Сфера деятельности компании: складские услуги в Москве.
Сайт был разработан специалистами нашего сервиса 1PS.RU, и семантическое ядро сайта разрабатывалось поэтапно в 6 шагов:
Шаг 1. Составляем первичный список ключевых слов.
Проведя опрос нескольких потенциальных клиентов, изучив три сайта, близких нам по тематике и пораскинув собственными мозгами, мы составили несложный список ключевых слов, которые на наш взгляд отображают содержание нашего сайта: складской комплекс, аренда склада, услуги по хранению, логистика, аренда складских помещений, тёплые и холодные склады.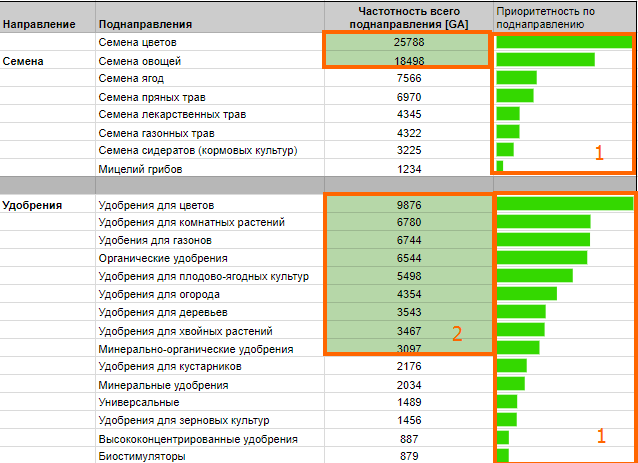
Задание 1: Просмотрите сайты конкурентов, посоветуйтесь с коллегами, проведите «мозговой штурм» и запишите все слова, которые, по вашему мнению, описывают ВАШ сайт.
Шаг 2. Расширение списка.
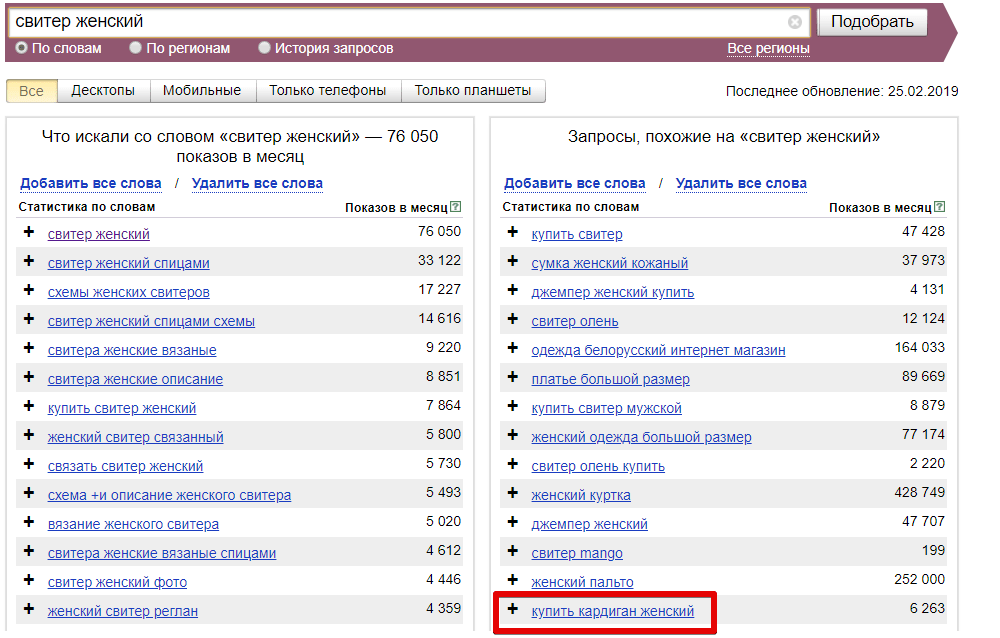
Воспользуемся сервисом http://wordstat.yandex.ru/. В строку поиска вписываем поочерёдно каждое из слов первичного списка:
Копируем уточнённые запросы из левого столбца в таблицу Excel, просматриваем ассоциативные запросы из правого столбца, выбираем среди них релевантные нашему сайту, так же заносим в таблицу.
Проведя анализ фразы «Аренда склада», мы получили список из 474 уточнённых и 2 ассоциативных запросов.
Проведя аналогичный анализ остальных слов из первичного списка, мы получили в общей сложности 4 698 уточнённых и ассоциативных запросов, которые вводили реальные пользователи в прошедшем месяце.
Задание 2: Соберите полный список запросов своего сайта, прогнав каждое из слов своего первичного списка через статистику запросов Яндекс. Вордстат.
Вордстат.
Шаг 3. Зачистка
Во-первых, убираем все фразы с частотой показов ниже 50: «сколько стоит аренда склада» — 45 показов, «Аренда склада 200 м» — 35 показов и т.д.
Во-вторых, удаляем фразы, не имеющие отношения к нашему сайту, например, «Аренда склада в Санкт-Петербурге» или «Аренда склада в Екатеринбурге», так как наш склад находится в Москве.
Так же лишней будет фраза «договор аренды склада скачать» – данный образец может присутствовать на нашем сайте, но активно продвигаться по данному запросу нет смысла, так как, человек, который ищет образец договора, вряд ли станет клиентом. Скорее всего, он уже нашёл склад или сам является владельцем склада.
После того, как вы уберетё все лишние запросы, список значительно сократится. В нашем случае с «арендой склада» из 474 уточнённых запросов осталось 46 релевантных сайту.
А когда мы почистили полный список уточнённых запросов (4 698 фраз), то получили Семантическое Ядро сайта, состоящее из 174 ключевых запросов.
Задание 3: Почистите созданный ранее список уточнённых запросов, исключив из него низкочастоники с количеством показов меньше 50 и фразы, не относящиеся к вашему сайту.
Шаг 4. Доработка
Поскольку на каждой странице можно использовать 3-5 различных ключевиков, то все 174 запроса нам не понадобятся.
Учитывая, что сам сайт небольшой (максимум 4 страницы), то из полного списка выбираем 20, которые на наш взгляд наиболее точно описывают услуги компании.
Вот они: аренда склада в Москве, аренда складских помещений, склад и логистика, таможенные услуги, склад ответственного хранения, логистика складская, логистические услуги, офис и склад аренда, ответственное хранение грузов и так далее….
Среди этих ключевых фраз есть низкочастотные, среднечастотные и высокочастотные запросы.
Заметьте, данный список существенно отличается от первичного, взятого из головы. И он однозначно более точен и эффективен.
Задание 4: Сократите список оставшихся слов до 50, оставив только те, которые по вашему опыту и мнению, наиболее оптимальны для вашего сайта. Не забудьте, что финальный список должен содержать запросы различной частоты.
Не забудьте, что финальный список должен содержать запросы различной частоты.
Заключение
Ваше семантическое ядро готово, теперь самое время применить его на практике:
- пересмотрите тексты вашего сайта, быть может, их стоит переписать.
- напишите несколько статей по вашей тематике, используя выбранные ключевые фразы, разместите статьи на сайте, а после того, как поисковики проиндексируют их, проведите регистрацию в каталогах статей. Читайте «Один необычный подход к статейному продвижению».
- обратите внимание на поисковую рекламу. Теперь, когда у вас есть семантическое ядро, эффект от рекламы будет значительно выше.
Как собрать семантическое ядро сайта в excel
Данный метод сбора семантического ядра актуален для небольших и средних интернет-магазинов. Он позволяет сократить время на подбор ключевых фраз и получить достаточно качественное семантическое ядро. Разберем суть метода на примере.
Допустим, ваш магазин продает три группы товаров: матрасы, подушки и одеяла.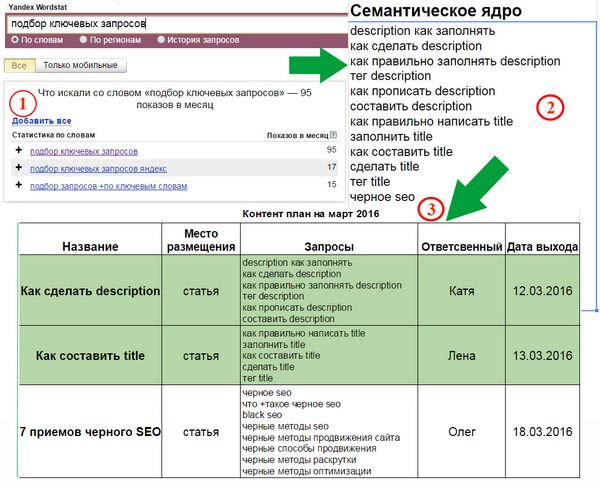 Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
Необходимо подобрать список запросов для продвижения раздела каталога с каждой группой товаров. Для этого нам нужно сгенерировать семантическое ядро, состоящее из запросов вида:
[ товарная категория ] + [ дополнительное продающее слово ]
Примеры продающих слов: купить, продажа, недорого, дешево, цена, стоимость, прайс. Соответственно, запросы для продвижения товарной категории «матрасы» будет выглядеть следующим образом:
матрасы купить
матрасы продажа
матрасы недорого
матрасы дешево
матрасы цена
матрасы стоимость
матрасы прайс
Что делать, если товарных категорий и товаров много, и вручную набивать все запросы будет долго? Воспользуемся файлом Excel, чтобы сгенерировать семантическое ядро в полуавтоматическом режиме.
Как пользоваться генератором
Файл состоит из листов. На листе «Вся семантика» автоматически собирается информация с других листов. Листы с номерами (от 1 до 5 в примере) обозначают отдельные страницы на сайте. Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
Чтобы сгенерировать семантическое ядро для конкретной страницы, необходимо открыть пустой лист и в столбце А добавить название товара или товарной категории. В примере ниже таким словом является «одеяло»:
В столбце С автоматически сформировалось семантическое ядро для страницы, а на листе «Вся семантика» скопировались данные из листа с примером:
Таким образом, вводя на страницах с номерами название товаров или товарных категорий, вы сможете сгенерировать семантику для всех страниц интернет-магазина.
Далее вам останется скопировать список запросов, который автоматически соберется на странице «Вся семантика», и при помощи специализированных программ или инструментов в https://direct.yandex.ru проверить список запросов на наличие «пустых» – после чего сформировать финальное семантическое ядро для продвижения интернет-магазина.
В файлике в примере есть 5 страниц для генерации семантики для конкретных страниц. При желании можно сделать файл на любое количество страниц, формулы в примере все открыты.
Как собрать семантическое ядро в Вордстат Яндекса
Без применения специализированных программ
Рассмотрим этапы формирования семантического ядра на основе сервиса Яндекс Вордстат (как им пользоваться). Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Возьмем направление «рольставни» для компании, которая занимается установкой защитных конструкций и их обслуживанием по Москве и области. В первую очередь актуальны запросы, которые формулируют люди, заинтересованные в покупке таких изделий или у которых возникли проблемы с эксплуатацией. Вводим маску в строку подбора, выбираем регион, например, Москва и область:
В колонке слева Wordstat показывает запросы пользователей, которые набирали со словом «рольставни». В правой колонке дополнительные запросы. Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.
Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.
Вордстат даёт 2000 запросов по одному направлению. На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:
Скачать файл Эксель-исходник
Группировка (кластеризация) запросов в семантическом ядре
После сбора запросов, группируем (кластеризируем). Для этого используют 3 вида кластеризации:
- по смыслу;
- по SERP;
- смешанный.
Разбивка «По смыслу» предполагает, что из запросов выделяется основной посыл, что хочет получить человек. В собранном перечне запросы делятся так:
- рольставни +в туалет
- рольставни +на окна
- сантехнические рольставни
- рольставни +в туалет купить
- рольставни +в санузел
- рольставни наружные
- рольставни +в туалет москва
- сантехнические рольставни +в туалет
- рольставни +на окна наружные
- рольставни +в туалет купить москва
- прозрачные рольставни
- рольставни сантехнические купить
- рольставни +в туалет цена
- рольставни +на окна цена
- рольставни +в санузел москва
- прозрачные рольставни +для веранды
Туалет: 1, 3, 4, 5, 7, 8, 10, 12, 13, 15.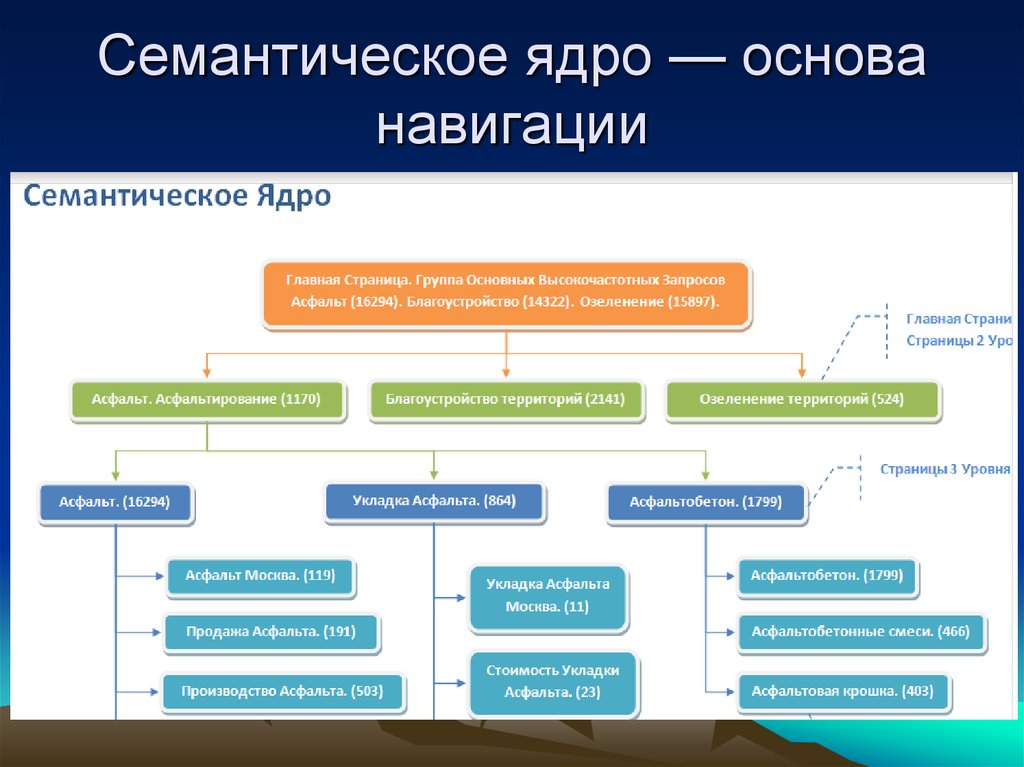 Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Окна: 2, 6, 9, 14. Установка на окна предполагает, что рольставни буду наружными (запрос №6).
Прозрачные: 11, 16.
Кластеризация по «SERP» предполагает использование специализированной программы или сервиса (например, keyassort.ru). Получается, что это автоматизированный процесс. SERP – это результат поисковой выдачи, проще говоря ТОП-10. Алгоритм действий здесь такой:
- Выбранные фразы добавляются в программу.
- По каждому запросу программа проверяет ТОП-10 или ТОП-20 в Яндекс (Гугл) и сохраняет результат в таблице.
- Далее программа анализирует сохраненные данные и соотносит страницы в выдаче и фразы. И запросы, по которым встречаются одни и те же страницы сайтов в выдаче, объединяет в одну группу.
Такой способ кластеризации подходит для многотысячной семантики и экономит время. По опыту студии, в результате разбивки качество получаемых ядер низкое и требует корректировок.
Смешанный метод – «SERP» и здравый смысл. Применение двух способов одновременно. Случается, что разбив ядро по смыслу, остаются фразы, назначение которых спорно и их сложно объединить в группы. В этом случае снимается СЕРП и на основе анализа разбиваются фразы.
Популярный вопрос «сколько фраз должно быть в одном кластере?». Ограничений нет, от одного запроса до нескольких сотен. Студия DIUS ведет проекты, где одна страница ранжируется по 200-300 запросам. Бывает наоборот, что первоначально добавили в кластер 100 запросов, но при оптимизации зашли только 50. Тогда детально и подробно изучаем оставшиеся фразы, делим по дополнительным признакам и создаем под них новые разделы или оптимизируем другие страницы.
Но такой подход требует опыта, т.к. поисковики негативно относятся, когда под похожие запросы создаются две страницы. В этом случае понижаются позиции по обеим страницам. В этом случае, внимательно изучайте конкурентов в выдаче, возможно на одну страницу следует добавить вхождений.
Для группировки ядра по направлению «Рольставни» воспользуемся методом «По смыслу», т.к. фраз всего 350 и группировка не займет много времени.
Делим фразы по: типу продукции, назначению, параметрам (цвет, материал) и т.д. И также нужно будет отбросить ненужные фразы, назовем эту группу «мусор». В неё попадают нецелевые фразы, которые содержат слова:
- леруа мерлен;
- своими руками;
- фото и видео;
- города не из Московской области;
- бу, схемы, инструкции.
Просмотрев и задав кластер для каждого запроса, получаются следующие группы:
Из 350 подобранных фраз получилось 85 мусорных, остальные распределились на 36 групп по типам и назначению изделия. В первой колонке группа, во второй сколько содержит слов из 350 подобранных:
| Группа | Количество фраз |
| основная | 63 |
| туалет | 61 |
| область | 35 |
| на окна | 28 |
| гараж | 7 |
| прозрачные | 6 |
| монтаж | 5 |
| электропривод | 5 |
| ремонт | 4 |
| шкаф | 4 |
| фотопечать | 4 |
| ванная | 3 |
| дача | 3 |
| комната | 3 |
| дверь | 3 |
| терраса | 2 |
| алютех | 2 |
| балкон | 2 |
| дорхан | 2 |
| перфорированные | 2 |
| торговые | 2 |
| встроенные | 2 |
| веранда | 2 |
| беседка | 2 |
| двери | 1 |
| проем | 1 |
| внутренние | 1 |
| управление | 1 |
| поликарбонат | 1 |
| защитные | 1 |
| мебельные | 1 |
| антивандальные | 1 |
| паркинг | 1 |
| противопожарные | 1 |
| стеклянные | 1 |
| квартира | 1 |
| утепленные | 1 |
| мусор | 85 |
Полученные кластеры в свою очередь группируем по смыслу и получаем структуру сайта для оптимизации:
- Рольставни:
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т. д.
- Назначение: окна, двери, квартира, проем, торговые, мебельные, туалет, гараж, паркинг и т.д.
- Профиль: алютех, дорхан.
- Опции: с электроприводом, с фотопечатью.
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т.
- Сервис
- Ремонт
- Монтаж
 д.
д.Из 2000 фраз, которые выдает Вордстат по заданному слову, получится составить структуру сайт гораздо шире, чем приведенная в примере. Естественно ориентируйтесь на ключевики, которые характеризуют продукцию или услуги компании. Если какой-то тип продукции или услуг компания не производит отправляйте их в раздел «мусор».
Расширение семантического ядра в Wordstat
Как подсказывает вордстат на скрине выше, некоторые называют рольставни другим словом – «роллеты». Поэтому для расширения ядра получения дополнительных фраз по ним также собираются фразы:
И:
Эти фразы добавляются в созданные группы или по ним создаются новые. Поисковики понимают, что «рольставни» и «роллеты» — это одно и тоже, поэтому совмещайте их в одних целевых кластерах.
Расширение ядра при помощи поисковых подсказок Yandex.ru
Дополнительным способом расширения семантики используют такой метод как «поисковые подсказки». Когда пользователь Яндекса вводит запрос в строку, поисковик предлагает варианты, исходя из статистики популярных запросов, дополняющие слова:
Видно, что на запрос «рольставни» поисковик предлагает запросы, которые уже были отобраны из сервиса Вордстат. Ориентируйтесь на фразы из 3-4 слов:
Тогда получится дополнить ядро. Вручную собирать подсказки трудозатратно, для этого целесообразно использовать профессиональные программы по сбору семантики или сервисы. РашАналитикс помогает собирать подсказки. На сервисе предусмотрена бесплатная регистрация, и сразу даётся 200 баллов.
Для сбора добавьте фразы из 3-4 слов из семантического ядра. Задайте популярные мусорные слова, чтобы сервис автоматически из убрал из результатов: своими руками, бу, леруа мерлен. В результате получаем такие дополнительные слова из подсказок:
Полученные фразы чистим от мусорных и проверяем частоту через Вордстат:
Сколько запросов собирать в ядро
По сути ограничений нет, чем больше фраз подобрано в семантическое ядро, тем лучше будет проработан сайт с точки зрения структуры и содержания.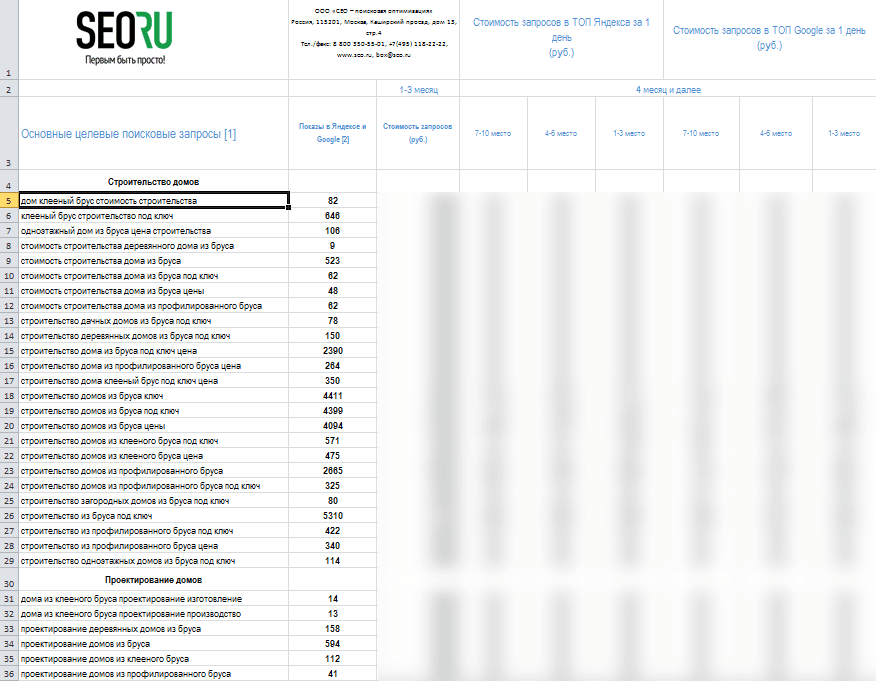 Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:
Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:
Ясно, что посетителей интересует:
- Цена такой конструкции.
- Варианты исполнения: с электроприводом или механические.
- Материалы изготовления: тканевые, металлические.
- Как устанавливают изделие.
- Для каких окон: квартиры, дачи, частный дом.
- Дополнительные функциональные свойства: защитные, антивандальные и т.д.
Каждый запрос в группе – это единица смысла, которую нужно отразить на созданной странице. Во-первых, это позволит употребить ключевые слова, что сделает сайт релевантным этому кластеру. Во-вторых, на странице будет опубликована полезная для посетителя информация.
Очистка семантики от мусора
При сборе многотысячного семантического ядра в список попадёт много нецелевых фраз:
- Тип продукции или схожий вид услуг, которыми компания не занимается. В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
- В запросах часто появляются названия фирм конкурентов, когда пользователь пишет товар или услугу, и указывает название компании.
- У людей, проживающих в Москве и имеющих коттедж в другом регионе, например, Твери, отразится это в запросах, когда они будут заказывать рольставни, ворота и т.д. Указывая город в сервисе, вы задаете географию пользователей, интересы которых могут лежать за пределами этого региона.
- Также убирайте из ядра ошибочные написания и опечатки. Если раньше под такие запросы создавались страницы, то сейчас поисковые алгоритмы обнаружив опечатку исправляют её и выдача формируется по корректной словоформе. И если появятся новые ошибки в названиях, это значит, что в ближайшее время алгоритм это учтет.
 В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.От нецелевых запросов следует избавляться по следующим причинам:
- Если пользователь зайдет на сайт и обнаружит, что компания из другого региона – он закроет страницу. Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
- Также это расценивается алгоритмами как поисковый спам, когда компания привлекает посетителей по запросам, задачи по которым она не решает.
- По некоторым запросам, типа «рейтинг компаний по рольставням», поисковики показывают сайты справочники, бизнес-каталоги, агрегаторы. По таким фразам не добраться до ТОП-10, если только не делать каталог организаций. Убрав их из ядра оптимизатор экономит время и ресурсы.
 Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.Как разбить семантическое ядро по типу запросов
Также стоит учесть разделение запросов по интенту пользователя:
- информационные;
- коммерческие.
Подробнее об этом в материале блога.
Для коммерческих запросов создаются разделы услуг, на которых предлагаются к продаже услуги и товары. Они называются коммерческими, т.к. предполагают, что у пользователя, при запросе прямое намерение купить или заказать продукцию, представленную на сайте. В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
Информационные запросы подразумевают, что пользователь хочет получить сведения о пользовании продукцией, инструкций и т.п. В таких запросах часто фигурируют вопросы: как, какой, зачем, что лучше, почему и т.д. Для таких групп создается раздел статей на сайте, который отвечают на популярные вопросы людей перед покупкой, например, по рольставняим: как выбрать, какой профиль лучше и т.д. Формируется дополнительное ядро запросов для написания полезных материалов. Его собирают из Вордстат, добавив к фразе конструкцию «+как»:
Также с «+где», «+когда» и т.д.
При этом информационные запросы геонезависимые, поэтому регион ставьте Россия. Грамотное использование инфозапросов даёт целевые переходы из поисковиков, которые также конвертятся в обращения и покупки. Для этого используйте «Лестницу Бена Ханта» — подробней в статье.
Предлагаем создание
семантического ядра для сайта
Узнать стоимость
Что делать с семантическим ядром после составления
Итак, семантика собрана, разбита на группы. Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Сначала еще раз посмотрите каждую группу, проверьте на соответствие ассортименту компании. На сколько формулировки соответствуют предлагаемым видам продукции или услуг.
Структура сайта на основе семантики
На основе семантического ядра разрабатываем структуру сайта:
- Главная страница под высокочастотные и прямые фразы. В случае с «Рольставни» — это: рольставни, рольставни купить / цена / заказать и т.д.
- Планируем разделы, в которые включаются виды продукции (услуг) и вспомогательные страницы (гарантии, отзывы, доставка, контактная информация, о компании) цель которых убедить посетителя в надежности представленной компании.
- Подразделы – группы запросов распределенные по видам, типам и т.д. В представленном примере «Рольставни» в разделе Профиль, будут 2 подраздела: Алютех и Дорхан, из которых производят изделия.
Содержание страниц
Как говорилось выше, семантика для маркетолога – это источник креатива и полезного контента. В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
Превратитесь на время в маркетолога, изучите каждую фразу под микроскопом. Что подразумевает человек в запросе. Какие у него опасения и как их развеять. В какой формате человек хочет получить решение проблемы и как показать, что компания выполнит желаемое. Какие факторы принятия решения влияют на него и как их усилить на странице? Таким образом составится уникальный контент, полезный для посетителя с коммерческим эффектом.
Вывод
Ручное составление семантического ядра при помощи Яндекс Вордстат трудозатратное мероприятие. Оно подходит для разовой работы и для небольших сайтов. При профессиональном продвижении сайтов целесообразно приобрести программу Кей Коллектор, которая упрощает работы и сокращает время по формирование семантики в разы. При этом она позволяет детально работать с группой и каждым словом. Пример сбора ядра в Key Collector можете посмотреть здесь.
Пример сбора ядра в Key Collector можете посмотреть здесь.
Сбор семантическое ядро: инструкция для начинающих
Алексей Шульгин
Старший специалист отдела продвижения компании SEO Интеллект
Основой успешного продвижения сайта в поисковых системах или запуска контекстной рекламы всегда являлось правильно собранное семантическое ядро. В данной статье показан весь процесс сбора и группировки запросов.
Мы разделили работу на три основных этапа:
- Сбор вариаций написания продукта и маркеров.
- Сбор и чистка семантического ядра в Key Collector.
- Кластеризация (группировка) семантического ядра.
Каждый этап мы разберем на примере группы товаров «Шлемы для мотоцикла», для которой и соберем семантическое ядро.
Чтение статьи займет у вас чуть больше 10 минут. Но если вы не очень любите читать, то можете потратить примерно то же время на просмотр ролика.
Этап 1. Сбор вариаций написания продукта и маркеров
Перед сбором запросов необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекса.
Методика
- Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».
- Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.
- Переносим все найденные варианты названия продукта в отдельный файл.
- На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.

Для выявления маркеров есть два пути:
1. Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
1.1. Плюс: Сбор всех существующих в спросе маркеров;
1.2. Минус: Долгий и трудозатратный процесс.
2. Поиск и анализ страниц конкурентов в ТОП 10, которые уже имеют страницы с нашим продуктом.
2.1. Плюс: Быстрый процесс;
2.2. Минус: Неполный сбор свойств, если они отсутствуют у конкурентов.
- Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП 10. Это возможно сделать вводом основного запроса прямо в поисковую систему или же воспользоваться инструментом полноценного поиска конкурентов по видимости их сайтов, как было рассказано в 4 пункте первого этапа данной статьи.
- На странице конкурента, нужно обратить внимание на структуру категории, то есть существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.
 В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.
В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.- Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
- Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в Microsoft Excel. В результате получим таблицу, аналогичную представленной ниже:
- Для пакетной (разовой) загрузки всех ключевых слов в KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:
 Итоговый список запросов в необходимом формате:
Итоговый список запросов в необходимом формате:Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:
После выбора региона можно приступать к сбору семантики.
Методика
- В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:
- В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:
- После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:
 Далее мы можем нажимать кнопку «Начать сбор»:
Далее мы можем нажимать кнопку «Начать сбор»:Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
- Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:
- Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
- Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
 Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
- Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
- Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:
Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.
- Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:
- После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».

После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
- Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Этап 3. Кластеризация (группировка) семантического ядра
Полученный список запросов нам нужно разбить на кластеры для последующей проработки посадочных страниц. Чтобы корректно выполнить эту задачу, нужно использовать сервисы кластеризации запросов, работающие на основе выдачи поисковых систем. Именно такой формат анализа, возможности продвижения тех или иных запросов на одной или разных страницах дает 70% успеха при дальнейшем продвижении сайта.
Популярные программные продукты:
1. KeyAssort – программа для кластеризации и структуризации семантического ядра.
2. Key Collector – функционал «Анализ групп» с типом группировки «По поисковой выдаче»).
Популярные онлайн-сервисы:
1. Engine Seointellect
2. Tools PixelPlus
3. Rush Analytics
Рассмотрим методику группировки запросов с помощью сервиса Engine Seointellect.
Методика
- Полученный список запросов, который мы выгрузили из программы Key Collector, содержит столбец с названием «Группа». Нам необходимо по очереди добавлять все запросы из каждой группы в кластеризатор.
- Заходим в сервис и выбираем в меню слева пункт «Кластеризация запросов». В открывшемся блоке мы видим кнопку «Новая группировка».
- Нажимаем на данную кнопку. На экране появятся следующие поля для заполнения:
1. Добавить запросы – в данный блок мы добавляем все запросы из первой анализируемой группы.
2. Вид группировки включает в себя три вида жесткости кластеризации:
2. 1.«Hard» – жесткая группировка.
1.«Hard» – жесткая группировка.
2.2.«Balance» – группировка средней жесткости.
2.3.«Soft» – группировка низкой жесткости.
Подробнее про различие работы методов группировки можно посмотреть в данном видео:
При группировке коммерческих запросов, как в нашем случае, следует изначально выбирать метод группировки «Hard», если запросы информационные, то рекомендуем пользоваться только методом «Soft».
3. Регион выбираем соответствующий регион продвижения.
4. Мой сайт не нужно указывать, так как эта функция нужна для определения запросов по уже существующим посадочным страницам указанного сайта.
- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа в правой части созданного задания вместо отображения процесса появится иконка «Глаз», на которую необходимо нажать.
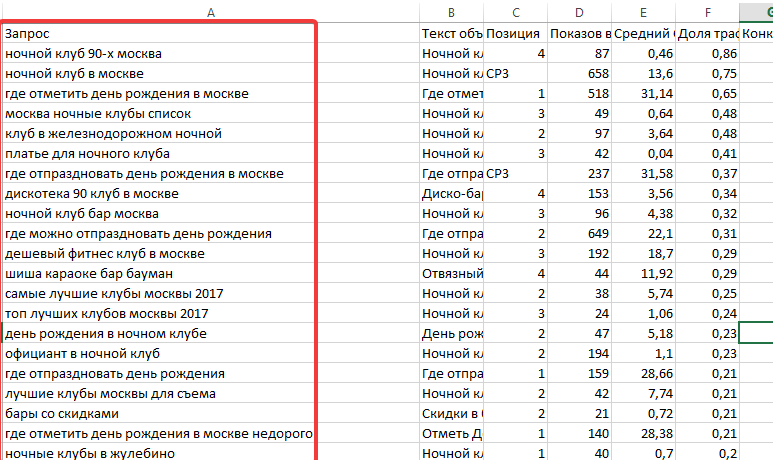
- Мы попадаем на страницу результата группировки и можем проанализировать данные:
1. Мы видим, что все наши запросы, кроме одного, попали в одну группу (отмечено зеленым), а значит их можно продвигать вместе на одной посадочной странице.
2. Также присутствует нераспределенный запрос (отмечено синим), это значит, что по данному запросу результаты выдачи сильно отличаются от результатов других запросов. В таком случае следует сделать вывод, что под этот запрос нужно создавать отдельную посадочную страницу бренда Ataki.
3. Справа от группы есть функционал «Показать список URL», нажав на который откроется блок со ссылками на страницы из ТОП 10, по которым была проведена кластеризация.
- Если бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можно продвигать в готовых группах. Можно просто увидеть эти запросы и перенести в нужную группу, но если фраз много, то их следует отправить на группировку по методу «Soft». Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
- Проведя данные действия с каждой группой из нашего файла, мы получим готовый список разделенных запросов, для последующей проработки страниц.
 Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».Финальная версия файла семантического ядра
Итоговый файл с семантическим ядром должен представлять собой таблицу, включающую следующие столбцы с данными:
1. Запрос
2. Группа
3. Базовая частотность
4. Уточненная частотность
5. Посадочная страница
Все группы мы рекомендуем отделять чертой друг от друга, чтобы впоследствии с таким файлом было легче работать:
Выводы
Теперь вы знаете, насколько трудозатратным является процесс сбора и группировки семантического ядра для продвижения сайта или настройки контекстной рекламы.
Это лишь базовая инструкция, которая не охватывает многих нюансов, возникающих в процессе, но именно эта работа является основой успешного достижения целей продвижения, а значит выполнять ее некачественно равносильно бездействию, так как вы не добьетесь никаких результатов без «построенного фундамента».
Семантическая кластеризация ключевых слов для более чем 10 000 ключевых слов [со сценарием]
Семантическая кластеризация ключевых слов может помочь вывести исследование ключевых слов на новый уровень.
В этой статье вы узнаете, как использовать лист Google Colaboratory, доступный исключительно для читателей журнала Search Engine.
Эта статья расскажет вам об использовании листа Google Colab, подробном обзоре того, как он работает внутри, и о том, как внести коррективы в соответствии с вашими потребностями.
Но, во-первых, зачем вообще группировать ключевые слова?
Распространенные варианты использования кластеризации ключевых слов
Вот несколько вариантов использования кластеризации ключевых слов.
Faster Keyword Research:
- Отфильтруйте фирменные ключевые слова или ключевые слова, не имеющие коммерческой ценности.
- Сгруппируйте связанные ключевые слова вместе, чтобы создать более подробные статьи.
- Сгруппируйте связанные вопросы и ответы для создания часто задаваемых вопросов.

Платные поисковые кампании:
- Быстрее создавайте списки минус-слов для объявлений с использованием больших наборов данных — перестаньте тратить деньги на ненужные ключевые слова!
- Сгруппируйте похожие ключевые слова в варианты рекламных кампаний.
Вот пример скрипта, объединяющего похожие вопросы вместе, идеально подходит для подробной статьи!
Скриншот из Microsoft Excel, февраль 2022 г.
Проблемы с более ранними версиями этого инструмента
Если вы следите за моей работой в Твиттере, то знаете, что я уже некоторое время экспериментирую с кластеризацией ключевых слов.
Более ранние версии этого скрипта были основаны на превосходной библиотеке PolyFuzz, использующей сопоставление TF-IDF.
В то время как это делало работу, всегда были некоторые головокружительные кластеры, которые я чувствовал, что первоначальный результат мог быть улучшен.
Слова с одинаковым набором букв будут сгруппированы, даже если они не связаны семантически.
Например, не удалось сгруппировать такие слова, как «Велосипед» с «Велосипед».
В более ранних версиях скрипта также были другие проблемы:
- Он плохо работал на других языках, кроме английского.
- Было создано большое количество групп, которые невозможно было сгруппировать.
- Не было большого контроля над тем, как создавались кластеры.
- Сценарий был ограничен примерно 10 000 строк, прежде чем истекло время ожидания из-за нехватки ресурсов.
Семантическая кластеризация ключевых слов с использованием глубокого обучения обработки естественного языка (NLP)
Перенесемся на четыре месяца вперед к последнему выпуску, который был полностью переписан для использования самых современных встроенных предложений глубокого обучения.
Взгляните на некоторые из этих удивительных семантических кластеров!
Заметили, что «горячий», «термический» и «теплый» содержатся в одном и том же кластере ключевых слов?
Скриншот из Microsoft Excel, февраль 2022 г.
Или как насчет оптом и оптом?
Скриншот из Microsoft Excel, февраль 2022 г.
Собака и такса, Рождество и Рождество?
Скриншот из Microsoft Excel, февраль 2022 г.
Он даже может объединять ключевые слова на более чем ста разных языках!
Снимок экрана из Microsoft Excel, февраль 2022 г.
Особенности нового скрипта по сравнению с более ранними версиями
В дополнение к семантической группировке ключевых слов в последнюю версию этого скрипта были добавлены следующие улучшения.
- Поддержка кластеризации более 10 000 ключевых слов одновременно.
- Уменьшено число кластерных групп.
- Возможность выбора разных предварительно обученных моделей (хотя модель по умолчанию работает нормально!).
- Возможность выбирать, насколько тесно должны быть связаны кластеры.
- Выбор минимального количества ключевых слов для использования в кластере.
- Автоматическое определение кодировки символов и разделителей CSV.
- Многоязычная кластеризация.
- Готово работает со многими стандартными экспортами ключевых слов. (Данные Search Console, AdWords или сторонние инструменты подсказки ключевых слов, такие как Ahrefs и Semrush).
- Работает с любым файлом CSV со столбцом «Ключевое слово».
- Простой в использовании (сценарий работает путем вставки нового столбца с именем «Имя кластера» в любой список загруженных ключевых слов).
Как использовать скрипт за пять шагов (быстрый старт)
Чтобы начать работу, вам нужно щелкнуть эту ссылку, а затем выбрать параметр «Открыть в Colab», как показано ниже.
Скриншот из Google Colaboratory, февраль 2022 г.
Измените тип среды выполнения на GPU, выбрав Runtime > Change Runtime Type .
Скриншот из Google Colaboratory, февраль 2022 г.
Выберите Время выполнения > Запустите all из верхней навигации Google Colaboratory (или просто нажмите Ctrl+F9).
Скриншот Google Colaboratory, февраль 2022 г.
Скриншот из Google Colaboratory, февраль 2022 г.
Кластеризация должна быть довольно быстрой, но в конечном итоге она зависит от количества ключевых слов и используемой модели.
Вообще говоря, вы должны быть хороши для 50 000 ключевых слов.
Если вы видите ошибку Cuda Out of Memory Error, вы пытаетесь объединить слишком много ключевых слов одновременно!
(Стоит отметить, что этот скрипт можно легко адаптировать для запуска на локальном компьютере без ограничений Google Colaboratory.)
Выходные данные скрипта
Скрипт запустится и добавит кластеры к исходному файлу в новый столбец с именем Имя кластера.
Имена кластеров назначаются с использованием самого короткого ключевого слова в кластере.
Например, имя кластера для следующей группы ключевых слов было задано как «alpaca socks», поскольку это самое короткое ключевое слово в кластере.
Скриншот из Microsoft Excel, февраль 2022 г.
После завершения кластеризации автоматически сохраняется новый файл с добавлением кластеризованного в новый столбец к исходному файлу.
Как работает ключевой инструмент кластеризации
Этот сценарий основан на алгоритме быстрой кластеризации и использует модели, которые были предварительно обучены в больших объемах данных.
Это позволяет легко вычислять семантические отношения между ключевыми словами, используя готовые модели.
(Вам не нужно быть специалистом по данным, чтобы использовать его!)
На самом деле, хотя я сделал его настраиваемым для тех, кто любит возиться и экспериментировать, я выбрал несколько сбалансированных значений по умолчанию, которые должны быть разумными. для большинства случаев использования людей.
Различные модели могут быть заменены в скрипте и из него в зависимости от требований (более быстрая кластеризация, лучшая многоязычная поддержка, лучшая семантическая производительность и т. д.).
После долгих испытаний я нашел идеальный баланс скорости и точности, используя трансформатор all-MiniLM-L6-v2, который обеспечил отличный баланс между скоростью и точностью.
Если вы предпочитаете использовать свои собственные, вы можете просто поэкспериментировать, вы можете заменить существующую предварительно обученную модель любой из моделей, перечисленных здесь или в разделе Hugging Face Model Hub.
Обмен в предварительно обученных моделях
Обмен в моделях так же прост, как замена переменной именем предпочитаемого преобразователя.
Например, вы можете изменить модель по умолчанию all-miniLM-L6-v2 на all-mpnet-base-v2, отредактировав:
transform = ‘all-miniLM-L6-v2’ 9От 0003
до
трансформатор = ‘ all-mpnet-base-v2 ’
Здесь вы должны отредактировать его на листе Google Colaboratory.
Скриншот из Google Colaboratory, февраль 2022 г.
Компромисс между точностью кластеризации и отсутствием кластерных групп
Распространенная жалоба на предыдущие версии этого скрипта заключается в том, что он приводил к большому количеству некластеризованных результатов.
К сожалению, всегда будет баланс между точностью кластера и количеством кластеров.
Более высокая точность кластеризации приведет к большему количеству некластеризованных результатов.
Существуют две переменные, которые могут напрямую влиять на размер и точность всех кластеров:
min_cluster_size
и
точность кластера
Я установил значение по умолчанию 85 (/100) для точности кластера минимальный размер кластера 2.
При тестировании я обнаружил, что это лучший вариант, но не стесняйтесь экспериментировать!
Здесь можно установить эти переменные в скрипте.
Скриншот Google Colaboratory, февраль 2022 г.
Вот и все! Я надеюсь, что этот скрипт кластеризации ключевых слов будет полезен для вашей работы.
Дополнительные ресурсы:
- Введение в Python и машинное обучение для технического SEO
- 6 задач SEO для автоматизации с помощью Python
- Продвинутое техническое SEO: полное руководство
Рекомендуемое изображение: Графическая сетка/Shutterstock
Категория SEO
Шаблон исследования ключевых слов и пошаговое руководство пользователя
В этой статье рассказывается, как использовать приведенный ниже бесплатный шаблон для исследования, классификации и определения приоритетов целевых ключевых слов.
SEO и исследование ключевых слов резко изменились, и я своими глазами видел, насколько за последние несколько лет стало сложнее исследовать ключевые слова.
Как мы выяснили в недавней статье о ключевых словах с латентным семантическим индексированием (LSI), стратегии контента должны уйти от старой модели таргетинга на одно ключевое слово на страницу с некачественным или некачественным контентом (посредственный контент тоже не подойдет).
При насыщении контентом почти по всем мыслимым темам, бренды, которые хотят победить в поисковых рейтингах, должны не только создавать уникально ценный контент, но и быть уникальным всесторонним .
Почему? Потому что люди (и Google) любят подробные ответы на свои вопросы. Анализ миллиона поисковой выдачи показал, что среднее количество слов на первой странице в Google составляет 1890.
*Примечание : я не говорю, что контент должен намеренно растягиваться дольше, чем это необходимо. Содержание должно быть как можно более кратким, но настолько подробным, насколько это необходимо для полного ответа на все аспекты данного вопроса.
Таким образом, если целью нашего контента является качество и полнота, мы можем использовать исследование ключевых слов для поддержки нашей стратегии контента:0018
Но для этого нам нужна довольно продвинутая электронная таблица — обычный статический шаблон Excel, который вы видите в Интернете, просто не справится с этой задачей. Нам нужны все навороты, свистки, формулы и фильтры. К счастью, мы построили один.
На этом мы представляем шаблон исследования ключевых слов, который мы используем для разработки стратегий SEO и контента наших клиентов.
👉
Получите доступ к бесплатному шаблону исследования ключевых слов здесь 👈
Пошаговое руководство по использованию этого шаблона читайте дальше.
Шаг 1. Создайте мастер-список ключевых слов
Это фаза мозгового штурма. Начните с перечисления всех возможных ключевых слов, которые вы, ваша команда и/или ваш клиент можете придумать и которые могут иметь отношение к вашему продукту или услуге, в столбце А.
Цель состоит в том, чтобы быстро составить как можно больший список, так что пока не беспокойтесь об их анализе. Просто получите список ключевых слов. Обычно мы начинаем с ~ 200-500 в зависимости от объема и размера веб-сайта клиента, но это число может варьироваться в зависимости от вашего проекта.
При составлении списка постоянно подсчитывайте потенциальные категории высокого уровня, в которые похожие ключевые слова могут быть сгруппированы в столбце C. предложить и др.). Чтобы получить дополнительные советы по исследованию ключевых слов, ознакомьтесь с нашей публикацией о ключевых словах LSI.
Шаг 2. Создайте и импортируйте данные о ключевых словах для определения спроса и конкуренции
Когда у вас будет большой список ключевых слов, импортируйте их в выбранный вами инструмент (мы используем Moz и SEMRush), чтобы получить приблизительные ежемесячные данные о поиске и конкуренции .
Как только вы сможете экспортировать данные из инструмента подсказки ключевых слов, вставьте их на вкладку электронной таблицы с надписью «Отфильтрованные данные ключевых слов» и убедитесь, что правильно выровняли данные в столбцах с B по E. На данный момент столбцы A и F должны быть пустым.
Если у вас более 500 ключевых слов, вам нужно просто добавить столько строк, сколько необходимо, над итоговой строкой в строке 500.
Шаг 3. Назначьте темы ключевых слов вручную
Со всеми вашими ключевыми словами данные на месте, пришло время просмотреть и вручную назначить тему каждому ключевому слову в столбце А. Крайне важно, чтобы все темы были написаны одинаково. По этой причине мы используем функцию проверки данных для создания раскрывающегося списка.
Чтобы отредактировать это раскрывающееся меню со своими собственными темами, выделите все ячейки в столбце A, перейдите в «Данные» > «Проверка данных» и измените свои входные данные в поле «Критерии».
** Совет для профессионалов. Вы увидите условное форматирование для быстрого определения ключевых слов с низкой конкуренцией. Обычно я использую фильтр в ячейке A7 для выбора определенных тем, а затем использую фильтр в ячейке C7 для сортировки по объему поиска от наибольшего до наименьшего. **
При назначении тем вы увидите, что агрегированные тематические данные динамически отображаются на вкладке «Тематический обзор». Эта вкладка полностью заполнена вкладкой «Отфильтрованные данные ключевых слов», поэтому нет необходимости настраивать здесь какие-либо данные.
Шаг 4. Определите темы высокого уровня с наибольшими возможностями
Теперь, когда ваши целевые ключевые слова организованы по темам, должно быть совершенно очевидно, в чем заключаются возможности.
Приоритет следует отдавать темам с наибольшим объемом поиска и наименьшей конкуренцией.
Шаг 5. Создание и повторение Но помните, этот шаблон задуман как живой и дышащий документ, который следует обновлять по мере создания контента и открытия новых идей.
В столбце «Отфильтрованные данные ключевых слов» используйте столбец F, чтобы определить ключевые слова, для которых вы создали контент. В идеале вы используете такой инструмент, как Moz или AHrefs, для отслеживания вашего рейтинга, чтобы вы могли видеть, насколько эффективно контент ранжируется по заданному термину с течением времени.
** Совет для профессионалов. Если вы используете платформу анализа продаж и маркетинга, такую как HubSpot, вы даже можете отслеживать, как каждый кластер контента привлекает новых потенциальных клиентов и/или доход. **
Дополнительный кредит! Оцените существующий контент с помощью автоматизированного аудита контента
Прежде чем начинать какие-либо новые кампании, контент или веб-сайты, я настоятельно рекомендую начать с аудита и оценки вашего существующего контента. Мы обнаружили, что значительные результаты можно получить, просто обновив существующий контент — вам не всегда нужно создавать что-то совершенно новое.
В любом случае, этот аудит даст вам количественную оценку всех веб-страниц в домене, а предоставит представление о содержании, которое приносит результаты вашему бизнесу и какие страницы могут вас сдерживать.
👉
Получите доступ к бесплатному руководству по аудиту контента здесь
Семантический уровень — данные для всех
В своем первом блоге из этой серии «Семантика семантического уровня» я изложил семь основных возможностей семантического уровня. В этом блоге я углублюсь в то, как семантический слой связывает данные с людьми , где бы они ни находились и какой бы инструмент они ни предпочли использовать.
Напоминаем, что на следующей диаграмме показаны семь основных возможностей платформы семантического уровня. Этот блог будет посвящен «Интеграции потребления», выделенной красным цветом:
Чтобы семантический уровень был по-настоящему универсальным, он должен поддерживать «живые» соединения запросов для всех пользователей и для всех популярных инструментов запросов и программных интерфейсов.
Больше, чем просто BI
Универсальный уровень данных полезен не только для бизнес-аналитиков и бизнес-аналитиков пользователей. Семантический уровень также должен удовлетворять потребности специалиста по данным и разработчика приложений .
Начнем с человека, занимающегося наукой о данных. Как и бизнес-аналитикам, специалистам по данным также необходим доступ к согласованным, удобным для бизнеса данным для построения и обучения своих моделей машинного обучения. В дополнение к возможности читать (или потреблять) семантический слой, специалистам по данным также необходимо записывать свои прогнозы и функции обратно в семантический слой. Поддерживая как чтение, так и запись, семантический слой и лежащая в его основе семантическая модель становятся мостом, соединяющим традиционные хранилища бизнес-аналитики и науки о данных. На изображении ниже показано, как семантический уровень объединяет рабочие процессы бизнес-аналитика и специалистов по обработке и анализу данных:
Помимо бизнес-аналитиков и специалистов по данным, разработчикам приложений нужны простые интерфейсы для работы с данными для создания приложений, управляемых данными.
Обращаясь ко всем трем персонам, семантический уровень может предоставить все четыре разновидности аналитики, от описательной и диагностической (бизнес-аналитики) до предиктивной (специалист по данным) и предписывающей (специалист по данным, разработчик приложений) , став объединяющей нитью, лежащей в основе всего спектра анализа и персон.
Ключевой вывод: Семантический уровень должен поддерживать несколько типов потребителей, включая бизнес-аналитиков, специалистов по данным и разработчиков приложений, чтобы обеспечить полный спектр доступа к данным и их анализ.
Больше, чем просто SQL
SQL стал находкой для программистов баз данных, поскольку он стал стандартом доступа к структурированным данным для различных платформ данных. Поскольку существует семантический уровень, обеспечивающий доступ к данным всем, , а не только программистам и инженерам данных, доступ только на основе SQL ограничивает пользователей инструментами, говорящими на SQL, или теми, кто может писать на SQL.
Хотя большинство инструментов говорят на SQL, некоторые инструменты, такие как Excel (самый популярный инструмент бизнес-аналитики на планете) и Power BI, плохо работают с SQL. Скорее, эти инструменты предпочитают говорить на своих родных многомерных диалектах, используя MDX (Excel) и DAX (Power BI). Специалисты по данным предпочитают обращаться к своим данным с помощью Python и фреймов данных, в то время как разработчики приложений могут предпочесть использовать интерфейсы REST, JDBC или ODBC.
Например, все следующие запросы отвечают на один и тот же вопрос «сколько бутылок с водой я продал по штатам в США?»:
SQL (из Tableau)
ВЫБЕРИТЕ «Интернет-продажи». ` AS `state`,
SUM(`Интернет-продажи`.`orderquantity1`) AS `sum_orderquantity1_ok`
ОТ `анализ продаж – снежинка`.`Интернет-продажи` `Интернет-продажи`
ГДЕ ((`Интернет-продажи` .`CountryCity` = ‘США’) И (`Интернет-продажи`.`Название продукта` = ‘Бутылка для воды – 30 унций’))
GROUP BY 1,
2,
3
MDX (From Excel)
SELECT
NON EMPTY Hierarchize(
DrilldownMember(
{ { DrilldownLevel(
{ [Geography Dimension]. [ Географический город]. [All]} ,
включил_CALC_MEMBERS
)}},
{[Географический измерение]. [Географический город].0003
)
) Свойства измерения Parent_unique_name,
Hierarchy_unique_name на столбцах
из
(
Select
(
{[Deafure Geography]. [География Город География].
) на столбцах
от
[Интернет -продажи]
)
, где
(
[Dimension]. [Размер продукта]. [Линия продукта]. & [S]. & [S] [28].& [477],
[Измерения].
1001,
CalculateTateable (
AddColumns (
Keepfilters (
AddColumns (
Keepfilters (
Filter (
Keepfilters (
Summarize (
значения («измерение географии»),
«Измерение географии» [City.Key0],
«Размер географии» [City.Key1],
‘География. ]
)
),
NOT(ISBLANK(‘CubeMeasures’ [количество заказа1]))
900 02 0003),
“orderquantity1_City_Key0”,
‘CubeMeasures’ [orderquantity1]
)
),
“orderquantity1”,
[orderquantity1_City_Key0]
),
KEEPFILTERS(
FILTER(
KEEPFILTERS(
VALUES(‘Географическое измерение’ [CountryCity. Key0])
),
‘Географическое измерение’ [CountryCity.Key0] = «США»
)
)
),
[orderquantity1_city_key0],
0,
‘География Damension’ [City],
1,
‘География.
‘Географическое измерение’ [city.key1],
1
)
Порядок на
[Orderquantity1_city_key0] DESC,
‘География Demension’ [City],
‘Dimension’ [City.Key0]. ,
‘Geography Dimension’ [City.Key1]
Как видите, хотя вопросы и ответы одинаковы, эти инструменты выдают совершенно разные запросы на своем родном диалекте. Семантический уровень должен обрабатывать все эти диалекты (и многое другое), обеспечивать одинаковую производительность запросов менее секунды, применять одни и те же фильтры управления и, конечно же, возвращать одинаковые результаты. Чтобы семантический уровень был универсальным , он должен передавать данные своим потребителям, а это означает говорить на родном языке инструмента, который предпочитает конечный пользователь, будь то бизнес-аналитик, специалист по данным или разработчик приложений.
Ключевой вывод: Семантический уровень должен поддерживать несколько входящих языков, чтобы поддерживать широкий круг потребителей данных, использующих предпочитаемые ими протоколы. Решения семантического уровня, поддерживающие только SQL или Javascript, не подходят для использования в качестве конечных точек для различных популярных инструментов потребления.
Zero Footprint
Семантический уровень не может раскрыть весь свой потенциал, если он не доступен и не может использоваться всеми . Чтобы охватить наибольшее количество пользователей, семантический уровень не должен требовать дополнительного клиентского программного обеспечения для своей работы. Это сложнее, чем кажется, потому что для работы инструментов запросов и приложений с большинством платформ данных обычно требуются специальные драйверы или подключаемые модули.
Хорошо спроектированный семантический уровень будет использовать встроенные возможности подключения каждого инструмента запроса для доступа к семантическому уровню. Например, AtScale использует встроенные драйверы служб SQL Server Analysis Services (SSAS) в Excel и Power BI для подключения к семантическому уровню AtScale. Это означает, что любой, у кого есть Excel, может подключиться «вживую» к семантическому уровню AtScale без каких-либо дополнительных требований к программному обеспечению.
Ключевой вывод: Семантический уровень не должен требовать от ИТ-специалистов установки дополнительного клиентского программного обеспечения на машинах потребителей запросов.
Данные для всех
Помимо того, что семантический уровень служит центром метрик, он обеспечивает удобный для бизнеса интерфейс к данным для всех типов пользователей, инструментов и диалектов. Семантический уровень действительно демократизирует доступ к данным, превращая всех в лиц, принимающих решения на основе данных. В моем следующем посте, части третьей из восьми, мы углубимся в модель семантических данных семантического уровня для сопоставления ваших цифровых активов с бизнесом. А пока, если вы хотите пропустить вперед, загрузите технический документ «Семантика семантического слоя». Он подробно описывает 7 ключевых требований и делится десятилетним опытом работы с реальными, требовательными корпоративными клиентами.
Semantic Web Tools — Semantic Web и связанные данные
Похоже, вы используете Internet Explorer 11 или более раннюю версию. Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge. Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
Домашний
Добро пожаловать!
Семантическая паутина представляет собой новое поколение веб-технологий, задуманное Тимом Бернерсом-Ли и возглавляемое Консорциумом всемирной паутины (W3C). Эта сеть данных позволяет связывать наборы данных между хранилищами данных в Интернете, обеспечивая связь между машинами с помощью связанных данных. В этом руководстве представлены ресурсы для использования и внедрения этой технологии.
Дом
ПРИМЕЧАНИЕ.
The UCLA Semantic Web LibGuide был скомпилирован и написан Рондой Супер. Это началось как страница данных на домашней странице личного ресурса г-жи Супер. За двадцать лет он превратился в отдельный LibGuide, который служил всеобъемлющим ресурсом для сообщества Semantic Web и Linked Data, предоставляя ссылки на инструменты, лучшие стандарты, учебные материалы, варианты использования, словари и многое другое.
Руководство постоянно обновлялось до августа 2022 года с использованием платформы SpringShare LibGuide, настроенной библиотекой Калифорнийского университета в Лос-Анджелесе. Многие из его ресурсов предоставляют исторический взгляд на развитие связанных данных.
Г-жа Супер имеет степень магистра коммуникаций Университета Огайо и степень MLIS Государственного университета Сан-Хосе со специализацией в области архивов, редких книг и академических библиотек. Она получила сертификат по системам XML и RDF в Library Juice Academy. Г-жа Супер работала в библиотеке Калифорнийского университета в Лос-Анджелесе с 2007 г. до выхода на пенсию в 2022 г.
Последняя версия Руководства была размещена в хранилище электронных стипендий Калифорнийского университета, поэтому сообщество связанных данных может продолжать использовать его в качестве ресурса.
Если вы цитируете ресурсы из этого Руководства, пожалуйста, проверьте исходный ресурс на соответствие требованиям к авторскому праву и цитированию.
Содержание
Прокрутите страницу вниз, чтобы получить доступ к темам, перечисленным ниже.
- Дом
- Передовой опыт, стандарты и профили приложений метаданных (MAPS)
- Блоги, серверы рассылок и вики
- Книги
- Наборы данных
- Учебные ресурсы
- Журналы, статьи и документы
- Семантические веб-службы
- Семантические веб-инструменты
- СПАРКЛ
- словарей, онтологий и фреймворков
- Онтологии и платформы
- Реестры, порталы и органы
- Схемы
- Словари
- Викибаза и Викиданные
- ВикиПроекты
- Свойства Викиданных
- Инструменты Викиданных
- Мастерские и проекты
- Примеры использования
О семантической сети
Semantic Web предоставляет возможность семантически связывать отношения между веб-ресурсами, ресурсами реального мира и концепциями посредством использования связанных данных, поддерживаемых платформой описания ресурсов (RDF). RDF использует простой оператор субъект-предикат-объект, известный как тройка, в качестве основного строительного блока. Это обеспечивает гораздо более полное исследование веб-ресурсов и ресурсов реального мира, чем веб-документы, к которым мы привыкли.
СВЯЗАННЫЕ ОТКРЫТЫЕ ДАННЫЕ (LOD) ОБЛАКО
Об облаке LOD
Диаграмма на этой странице представляет собой визуализацию связанных открытых наборов данных, опубликованных в формате связанных данных по состоянию на апрель 2014 г. Большой круг в центре — это Dbpedia, версия Википедии со связанными данными. Нажмите на диаграмму, чтобы узнать больше о диаграмме, лицензированных и открытых связанных данных, статистике о наборах данных на диаграмме и последней версии LOD Cloud. По состоянию на июнь 2018 года вы можете просматривать Sub-Clouds по предметным областям.
Диаграмма Linking Open Data cloud 2014, Макс Шмахтенберг, Кристиан Бизер, Аня Дженцш и Ричард Цыганиак.
Содержание
Рекомендации, стандарты и профили приложений метаданных (MAP)
5-звездочные правила открытых данных
5 звезд Открытые данные
Нажмите на изображение кружки и откройте ссылку, чтобы получить дополнительную информацию.
Документация по словарям Getty
Словари Getty см. на странице «Реестры, порталы и органы» в разделе «Словари, онтологии и структуры».
Передовая практика и стандарты
Доверие является основным компонентом Semantic Web. Это требует предоставления точной информации при публикации экземпляра связанных данных. Консорциум World Wide Web (W3C), состоящий из представителей международного сообщества, разрабатывает веб-стандарты и передовой опыт. Кроме того, авторитеты в предметных дисциплинах устанавливают, администрируют и поддерживают стандарты в своих дисциплинах, которые соответствуют лучшим практикам W3C.
Эта страница предоставляет доступ к информации о передовом опыте и стандартах, относящихся к технологии Semantic Web, разработанной W3C и другими авторитетными организациями. Контролируемые словари, онтологии и т. д. см. на странице Словари, онтологии и Fameworks.
Дополнительные ресурсы о стандартах
Профили приложений метаданных (MAP)
Профиль приложения метаданных (MAP) — это набор записанных решений об общем приложении или службе метаданных, будь то хранилище данных, репозиторий, система управления, уровень индексации обнаружения или другое, для данного сообщества. MAP определяют, какие типы сущностей будут описаны и как они соотносятся друг с другом (модель), какие контролируемые словари используются, какие поля являются обязательными и какие поля имеют ограничение на количество раз, которое они могут использовать, типы данных для строковые значения, а также направляющие примечания к тексту/областям для последовательного использования полей/свойств.
MAP может быть многочастной спецификацией с удобочитаемым и машиночитаемым аспектами, иногда в одном файле, иногда в нескольких файлах (например, удобочитаемый файл, который может включать правила ввода, машиночитаемый словарь, и схему проверки).
Функция MAP состоит в том, чтобы прояснить ожидания от метаданных, принимаемых, обрабатываемых, управляемых и предоставляемых приложением или службой, и документировать общие модели и стандарты сообщества, а также отмечать, где реализации могут отличаться от стандартов сообщества.
Библиотека Корнельского университета. (2018, 23 октября). Профили приложений метаданных CUL. Загружено в январе 2020 г. из
Библиотеки Конгресса. (2019, 30 апреля). Целевая группа PCC по профилям приложений метаданных. Загружено 19 июля 2022 г. с https://confluence.cornell.edu/display/mwgweb/CUL+Metadata+Application+Profiles
Блоги, серверы рассылок и вики
Блоги, серверы списков и вики
Книги
Книги
Ниже приведен список книг, дающих хорошее введение в семантическую паутину. Элементы, заголовки которых выделены синим цветом, ссылаются либо на запись библиотеки Калифорнийского университета в Лос-Анджелесе для этого заголовка, если плитка хранится в библиотеке, либо на онлайн-копию, если она доступна. Используйте ссылку Safari Books Online для поиска дополнительных ресурсов.
Наборы данных
Наборы данных
На этой странице представлен краткий список наборов данных и порталов данных. Чтобы изучить глобальную сеть наборов данных, подключенных к Интернету, щелкните Linked Open Data Cloud на главной странице.
Учебные ресурсы
Учебные ресурсы
Существует множество ресурсов, которые помогут вам узнать о Semantic Web и связанных данных. Эта страница предоставляет доступ к нескольким учебным ресурсам по темам, связанным со связанными данными, в различных форматах. См. страницу SPARQL для учебных ресурсов, связанных с SPARQL.
Журналы, статьи и документы
Журналы, статьи и документы
Статьи и документы
Семантические веб-службы
Семантические веб-службы
На этой странице перечислены сервисы Semantic Web, представляющие интерес для специалистов по информации, библиотек, музеев и культурных организаций.
Инструменты семантической сети
Инструменты семантической сети
Технология Semantic Web использует множество инструментов. На этой странице перечислены инструменты преобразования, инструменты управления данными, глоссарии, платформы для построения онтологий и словарей, семантические веб-браузеры, валидаторы, редакторы XML и инструменты XPath.
Инструменты оценки
Авторские инструменты
Инструменты BIBFRAME
Инструменты преобразования
Средства управления данными
Интерфейсы обнаруженияРедакторы
Генераторы
Глоссарии
Платформы и инструменты для построения онтологии/лексики
Инструменты запросов, поисковые системы и надстройки для браузера
серверов
Инструменты тройного магазина
Валидаторы
Средства визуализации
Инструменты XPath
Разное
Учебные ресурсы для семантических инструментов
СПАРКЛ
СПАРКЛ
SPARQL служит поисковой системой для RDF. Это набор спецификаций, рекомендованных Рекомендацией W3C, которые предоставляют языки и протоколы для запроса и управления содержимым графа RDF в Интернете или в тройном хранилище RDF.
Документация SPARQL
GeoSpatial SPARQL
В дополнение к документам W3c SPARQL имеется документация для языка запросов Geospatial SPARQL.
Конечные точки SPARQL
В этом поле содержатся ссылки на некоторые конечные точки SPARQL, полезные для исследователей и являющиеся хорошими примерами наборов данных для практики использования запросов SPARQL. Набор данных Europeana используется в учебнике SPARQL для гуманитариев слева.
Инструменты SPARQL
Этот ящик содержит инструменты SPARQL.
Учебные ресурсы SPARQL
Словари, онтологии и рамки
Словари, онтологии и основы
Контролируемые словари, онтологии, схемы, тезаурусы и синтаксисы — это стандартные блоки, используемые платформой описания ресурсов (RDF) для семантического структурирования данных, идентификации ресурсов и отображения взаимосвязей между ресурсами в связанных данных. Библиотеки и учреждения культуры принадлежат к одной из многих областей организации знаний, использующих контролируемые органы. На этих страницах особое внимание уделяется словарям и компьютерным языкам, которые используются в информационном ландшафте библиотек и учреждений культурного наследия.
Стандарты видения: визуализация вселенной метаданных
О стандартах зрения
Беккер, Девин и Дженн Л. Райли. (2010). Стандарты видения: визуализация вселенной метаданных . Нажмите на диаграмму, чтобы открыть PDF-версию и Глоссарий стандартов метаданных.
О словарях
Онтологии и каркасы
Онтологии и фреймворки
International Image Interoperability Framework (IIIF)
IIIF — это платформа для доставки изображений, разработанная сообществом ведущих исследовательских библиотек и репозиториев изображений. Цели состоят в том, чтобы обеспечить доступ к беспрецедентному уровню единообразного и богатого доступа к ресурсам на основе изображений, размещенным по всему миру, определить набор общих интерфейсов прикладного программирования, поддерживающих взаимодействие между репозиториями изображений, разрабатывать, развивать и документировать общие технологии, такие как изображения серверы и веб-клиенты для обеспечения просмотра, сравнения, обработки и комментирования изображений.
Два основных API для Framework:
- IIIF Image API 3.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. В этом документе описывается спецификация API доставки изображений для веб-службы , которая возвращает изображение в ответ на стандартный запрос HTTP или HTTPS . URI может указывать регион, размер, поворот, характеристики качества и формат запрошенного изображения, а также может запрашивать базовую техническую информацию об изображении для поддержки клиентских приложений.
- IIIF Презентация API 3.0.
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. IIF Presentation API предоставляет информацию, необходимую пользователям-людям, чтобы обеспечить богатую онлайн-среду просмотра сложных цифровых объектов. Он позволяет отображать оцифрованные изображения, видео, аудио и другие типы контента, связанные с конкретным физическим или изначально цифровым объектом, обеспечивает навигацию между несколькими представлениями или временными экстентами объекта, последовательно или иерархически, отображает описательную информацию об объекте. , представления или структуры навигации, а также предоставляет общую среду, в которой издатели и пользователи могут снабжать объект и его содержимое дополнительной информацией.
- Презентация поваренной книги рецептов IIIF
The Cookbook предоставляет типы ресурсов и свойства спецификации Presentation и для визуализации средствами просмотра и другими программными клиентами. Приведены примеры, чтобы побудить издателей принять общие шаблоны при моделировании классов сложных объектов, дать возможность разработчикам клиентского программного обеспечения поддерживать эти шаблоны для единообразия взаимодействия с пользователем и продемонстрировать применимость IIIF в широком диапазоне вариантов использования.
Дополнительные API для платформы:
- API аутентификации IIF 1.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. Спецификация аутентификации описывает набор рабочих процессов для проведения пользователя через существующую систему контроля доступа . Он предоставляет ссылку на пользовательский интерфейс для входа в систему и службы, которые предоставляют учетные данные, смоделированные по образцу элементов рабочего процесса OAuth3, выступающих в качестве моста к системе управления доступом, используемой на сервере, при этом клиенту не требуется знание этой системы.
- API поиска контента IIIF 1.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. Спецификация Content Search устанавливает механизм взаимодействия для выполнения поиска среди различных типов контента из разных источников. Областью применения спецификации является поиск содержимого аннотаций в пределах одного ресурса IIIF , такого как манифест, диапазон или коллекция.
Связанное искусство
Linked Art — это модель данных, которая предоставляет профиль приложения, используемый для описания ресурсов культурного наследия с упором на произведения искусства и музейную деятельность. Основываясь на реальных данных и вариантах использования, он определяет общие шаблоны и термины, используемые в его концептуальной модели, онтологиях и словаре. Linked Art следует существующим стандартам и рекомендациям, включая CIDOC-CRM, словари Getty и JSON-LD 1. 1 в качестве основного формата сериализации.
OWL 2
Онтологии представляют собой формализованные словари терминов, часто охватывающие определенную область. Они определяют определения терминов, описывая их отношения с другими терминами в онтологии. OWL 2 — это язык веб-онтологий, предназначенный для облегчения разработки онтологий и обмена ими через Интернет. Он предоставляет классы, свойства, отдельных лиц и значения данных, которые хранятся в виде документов Semantic Web. В качестве словаря RDF OWL можно использовать в сочетании со схемой RDF.
VOWL : Визуальная нотация для онтологий OWL
Негру, Стефан, Ломанн, Сеффан и Хааг, Флориан. (2014, 7 апреля). Спецификация версии 2.0. VOWL определяет визуальный язык для ориентированного на пользователя представления онтологий. Язык предоставляет графические изображения для элементов OWL, которые объединены в силовой макет графа, визуализирующий онтологию. Он фокусируется на визуализации классов, свойств и типов данных, иногда называемых TBox, а также включает рекомендации о том, как изображать людей и значения данных, ABox. Для понимания этой спецификации требуется знакомство с OWL и другими технологиями Semantic Web.
PRESSoo
RDF 1.1
Структура описания ресурсов (RDF) представляет собой структуру для представления информации в сети данных. Он включает набор стандартов и спецификаций, документация по которым приведена ниже.
RDF 1.1 Сериализации
Существует ряд форматов сериализации RDF для реализации RDF. Первым форматом был XML/RDF. Последующие форматы сериализации были разработаны и могут больше подходить для конкретных сред.
SKOS (Простая система организации знаний)
SKOS — это модель данных W3C, определенная как полная онтология OWL для использования с системами организации знаний, включая тезаурусы, схемы классификации, системы предметных рубрик и таксономии. Многие словари Semanatic Web включают модель SKOS. Предметные рубрики Библиотеки Конгресса и словари Гетти являются примерами словарей, опубликованных как словари SKOS.
Разработка онтологии
Реестры, порталы и органы власти
Открытые связанные словари (LOV)
Нажмите на изображение LOV, чтобы получить доступ к словарям, выбранным на основе требований к качеству и лучших практик публикации.
Нажмите на словарь. Найдите обведенный эллипс в правом верхнем углу, нажмите на него и получайте удовольствие, играя с инструментами для словарей. Исследуйте немного больше и найдите полезную информацию о выбранной вами лексике.
Реестры, порталы и органы
Словари Гетти
Схемы
Схемы
Схема использует формальный язык для описания системы баз данных и относится к тому, как построена организация данных в базе данных. В этом поле перечислены несколько схем, адресованных различным доменным областям. Прокрутите вниз до поля Dublin Core, чтобы получить доступ к информации о схеме и инструментах Dublin Core.
Дублинское ядро
Юридические схемы
СВЯЗАННЫЕ РЕСУРСЫ
Словари
Словари
Словарь взаимосвязанных наборов данных (VoID)
Примечания
Словари Getty см. на странице «Реестры, порталы и органы».
Викибаза и Викиданные
Викибаза и Викиданные
Викибаза — это платформа, на которой строятся Викиданные, проект Викимедиа. Это позволяет использовать многоязычные экземпляры. Сценарии использования Wikibase см. в поле «Случаи использования Wikibase» в нижней части страницы «Случаи использования».
Движение Викимедиа
Викимедиа — это глобальное движение, которое стремится предоставить миру бесплатное образование с помощью веб-сайтов, известных как проекты Викимедиа. Проекты Викимедиа размещаются Фондом Викимедиа. Некоторые из этих проектов перечислены ниже. Получите доступ ко всему семейству проектов Викимедиа здесь.
Викибаза
Ресурсы Викибазы
Предупреждение Викиданных
Викиданные
Викиданные — это бесплатное многоязычное программное приложение для совместной работы, созданное из компонентов Викибазы, которые могут читать и редактировать люди и машины. Он собирает структурированные данные для поддержки проектов Викимедиа, включая Википедию, Викисклад, Википутешествие, Викисловарь, Викиресурс и другие. Содержимое Викиданных доступно по бесплатной лицензии, экспортируется с использованием стандартных форматов и может быть связано с другими наборами открытых данных в сети связанных данных.
Статьи, планы развития и отчеты
Ресурсы, связанные с Викиданными
WikiProjects
Университеты WikiProject
ВикиПроекты
Свойства Викиданных
Свойства Викиданных
Викиданные/Инструменты Викимедиа
Викиданные/Инструменты Викимедиа
Для работы с Викиданными разработано множество инструментов, многие из которых перечислены на странице Инструменты Викиданных, указанной ниже. Общие инструменты, полезные для редактирования и добавления элементов в Викиданные, перечислены здесь.
Мастерские и проекты
Мастерские и проекты
Эта страница обеспечивает доступ к документам и отчетам, связанным с семинарами, учреждениями, организациями или другими субъектами, которые содержат ценную информацию или описывают инициативы или проекты, касающиеся Semantic Web или связанных данных.
Основные моменты
Варианты использования
Варианты использования
На этой странице представлены ссылки на примеры используемых в настоящее время связанных данных.
Примеры использования Wikibase
Эдинбургский университет Wikimedian in Residence Projects
XML RDF
❮ Предыдущий Далее ❯
Пример документа RDF
0″?>
xmlns:si= «https://www.w3schools.com/rdf/»>
Что такое RDF?
- RDF означает R esource D описание F каркас
- RDF — это структура для описания ресурсов в Интернете
- RDF предназначен для чтения и понимания компьютерами
- RDF не предназначен для показа людям
- RDF написан на XML
- RDF является частью Semantic Web Activity W3C.
- RDF является рекомендацией W3C от 10 февраля 2004 г.
RDF — примеры использования
- Описание свойств товаров для покупок, таких как цена и доступность
- Описание расписания веб-событий
- Описание информации о веб-страницах (содержание, автор, дата создания и изменения)
- Описание содержания и рейтинг веб-изображений
- Описание контента для поисковых систем
- Описание электронных библиотек
RDF предназначен для чтения компьютерами
RDF был разработан, чтобы обеспечить общий способ описания информации, чтобы ее можно было
читается и понимается компьютерными приложениями.
Описания RDF не предназначены для отображения в Интернете.
RDF написан на XML
Документы RDF написаны на XML. Язык XML, используемый RDF, называется RDF/XML.
Используя XML, можно легко обмениваться информацией RDF между различными типами компьютеров с различными типами операционных систем и приложений языки.
RDF и «Семантическая сеть»
Язык RDF является частью Семантическая веб-активность W3C. «Semantic Web Vision» W3C — это будущее, в котором:
- Веб-информация имеет точное значение
- Веб-информация может быть понята и обработана компьютерами
- Компьютеры могут интегрировать информацию из Интернета
RDF использует веб-идентификаторы (URI) для идентификации ресурсов.
RDF описывает ресурсы со свойствами и значениями свойств.
Ресурс RDF, свойство и значение свойства
RDF идентифицирует объекты с помощью веб-идентификаторов (URI) и описывает ресурсы со свойствами и значениями свойств.
Объяснение ресурса, свойства и значения свойства:
- Ресурс — это все, что может иметь URI, например «https://www.w3schools.com/rdf»
- Свойство – это ресурс с именем, например «автор» или «домашняя страница» .
- A Значение свойства — это значение свойства, например «Jan Egil Refsnes» или «https://www.w3schools.com» (обратите внимание, что значением свойства может быть другой ресурс)
Следующий RDF-документ мог бы описать ресурс «https://www.w3schools.com/rdf»:
<Описание about="https://www.w3schools.com/rdf">
<домашняя страница>https://www.w3schools.com
Приведенный выше пример упрощен. Пространства имен опущены.
Операторы RDF
Комбинация ресурсов, свойств и значений свойств образует Заявление (известное как субъект , предикат и объект заявления).
Давайте рассмотрим несколько примеров утверждений, чтобы лучше понять:
Заявление: «Автор https://www.w3schools.com/rdf — Ян Эгил Рефснес».
- Тема заявления выше: https://www.w3schools.com/rdf
- Предикат: автор
- Объект: Ян Эгиль Рефснес
Заявление: «Домашней страницей https://www.w3schools.com/rdf является https://www.w3schools.com».
- Тема заявления выше: https://www.w3schools.com/rdf
- Предикат: домашняя страница
- Объект: https://www.w3schools.com
Пример RDF
Вот две записи из CD-листа:
| Название | Художник | Страна | Компания | Цена | Год |
|---|---|---|---|---|---|
| Империя Бурлеск | Боб Дилан | США | Колумбия | 10,90 | 1985 |
| Спрячь свое сердце | Бонни Тайлер | Великобритания | CBS отчеты | 9,90 | 1988 |
Ниже приведены несколько строк из документа RDF:
0″?>
xmlns:cd= «http://www.recshop.fake/cd#»>
.
.
.
Первая строка документа RDF представляет собой объявление XML. За объявлением XML следует корневой элемент документов RDF:
Пространство имен xmlns:rdf указывает, что элементы с префиксом rdf взяты из пространства имен «http://www. w3.org/19″.99/02/22-rdf-syntax-ns#».
Пространство имен xmlns:cd указывает, что элементы с префиксом cd взяты из пространства имен «http://www.recshop.fake/cd#».
Элемент
Элементы:
RDF Online Validator
Служба проверки RDF W3C полезна при изучении RDF. Здесь вы можете поэкспериментировать с файлами RDF.
Онлайн-валидатор RDF анализирует ваш RDF-документ, проверяет синтаксис и создает табличное и графическое представление вашего RDF-документа.
Скопируйте и вставьте приведенный ниже пример в средство проверки RDF W3C:
xmlns:si= «https://www.w3schools.com/rdf/»>
w3schools.com»>
При анализе приведенного выше примера результат будет выглядеть примерно так.
Элементы RDF
Основными элементами RDF являются корневой элемент
Элемент
.
… Здесь идет описание…
Элемент
Элемент
Элемент
0″?>
xmlns:cd= «http://www.recshop.fake/cd#»>
Элементы, исполнитель, страна, компания, цена и год определены в http://www.recshop.fake/cd# пространство имен. Это пространство имен находится за пределами RDF (и не является частью RDF). RDF определяет только рамки. Элементы, исполнитель, страна, компания, цена и год должны быть определены кем-то другим (компания, организация, лицо и др.).
Свойства как атрибуты
Элементы свойств также могут быть определены как атрибуты (вместо элементов):
w3.org/1999/02/22-rdf-syntax-ns#»
xmlns:cd= «http://www.recshop.fake/cd#»>
cd:artist=»Боб Дилан » cd:country=»США»
cd:company=»Колумбия» cd:price=»10,90″
cd:year=»1985″ />
Свойства как ресурсы
Элементы свойств также могут быть определены как ресурсы:
xmlns:cd= «http://www.recshop.fake/cd#»>
…
…
В приведенном выше примере свойство artist имеет не значение, а ссылку на ресурс, содержащий информацию об исполнителе.
Контейнеры RDF
Контейнеры RDF используются для описания группы вещей.
Для описания групп используются следующие элементы RDF:
Элемент
Элемент
Элемент
Пример
xmlns:cd= «http://www.recshop.fake/cd#»>
Элемент
Элемент
Элемент
Пример
xmlns:cd= «http://www.recshop.fake/cd#»>
<кд:исполнитель>
Элемент
Элемент
Пример
xmlns:cd=»http://www.recshop.fake/cd#»>
recshop.fake/cd/Битлз»>
<кд:формат>
Термины RDF
В приведенных выше примерах мы говорили о «списке значений» при описании элементы контейнера. В RDF эти «списки значений» называются элементами.
Итак, имеем следующее:
- Контейнер — это ресурс, который содержит вещи
- Содержащиеся вещи называются членами (не списком значений)
Коллекции RDF
Коллекции RDF описывают группы, которые могут содержать ТОЛЬКО указанные элементы.
Атрибут rdf:parseType=»Collection»
Как видно из предыдущей главы, контейнер сообщает, что содержащиеся в нем ресурсы являются членами, а не говорит что другие участники не допускаются.
Коллекции RDF используются для описания групп, которые могут содержать ТОЛЬКО указанные элементы.
Коллекция описывается атрибутом rdf:parseType=»Collection».
Пример
xmlns:cd=»http://recshop.fake/cd#»>
Схема RDF и классы приложений
Схема RDF (RDFS) является расширением RDF.
RDF описывает ресурсы с классами, свойствами и значениями.
Кроме того, RDF также нуждается в способе определения классов и свойств, специфичных для приложения. Специфичные для приложения классы и свойства должны быть определены с помощью расширений RDF.
Одним из таких расширений является схема RDF.
Схема RDF (RDFS)
Схема RDF не предоставляет реальных классов и свойств, специфичных для приложения.
Вместо этого схема RDF обеспечивает структуру для описания классов и свойств, специфичных для приложения.
Классы в схеме RDF очень похожи на классы в объектно-ориентированных языках программирования. Это позволяет определять ресурсы как экземпляры классов и подклассы классов.
Пример RDFS
Следующий пример демонстрирует некоторые возможности RDFS:
xmlns:rdfs= «http://www.w3.org/2000/01/rdf-schema#»
xml:base=»http://www.animals.fake/animals#»>
w3.org/2000/01/rdf-schema#Class»/>
В приведенном выше примере ресурс «лошадь» является подклассом класса «животное».
Сокращенный пример
Поскольку класс RDFS является ресурсом RDF, мы можем сократить приведенный выше пример следующим образом: используя rdfs:Class вместо rdf:Description, и удалите информацию rdf:type:
xmlns:rdfs=»http://www.w3.org/2000/01/rdf-schema#»
xml:base=»http://www. animals.fake/animals#»>
Вот оно!
The Dublin Core
Инициатива метаданных Dublin Core (DCMI) создала несколько
предопределенные свойства для описания документов.
RDF — это метаданные (данные о данных). RDF используется для описания информационных ресурсов.
Dublin Core — это набор предопределенных свойств для описания документов.
Первые свойства Dublin Core были определены на семинаре по метаданным . в Дублине, штат Огайо, , в 1995 году и в настоящее время поддерживается Инициатива Дублинского ядра по метаданным.
| Собственность | Определение |
|---|---|
| Участник | Субъект, ответственный за внесение вклада в содержание ресурс |
| Покрытие | Степень или объем содержимого ресурса |
| Создатель | Субъект, в первую очередь ответственный за создание содержимого ресурса |
| Формат | Физическое или цифровое воплощение ресурса |
| Дата | Дата события в жизненном цикле ресурса |
| Описание | Аккаунт содержания ресурса |
| Идентификатор | Однозначная ссылка на ресурс в заданном контексте |
| Язык | Язык интеллектуального содержания ресурса |
| Издатель | Объект, ответственный за предоставление ресурса |
| Связь | Ссылка на связанный ресурс |
| Права | Информация о правах на ресурс |
| Источник | A Ссылка на ресурс, из которого получен текущий ресурс |
| Субъект | Тема содержания ресурса |
| Титул | Имя, присвоенное ресурсу |
| Тип | Характер или жанр содержания ресурса |
Беглый взгляд на приведенную выше таблицу показывает, что RDF идеально подходит для представления информации Dublin Core.
Пример RDF
Следующий пример демонстрирует использование некоторых свойства в документе RDF:
xmlns:dc= «http://purl.org/dc/elements/1.1/»>
Ссылка RDF
Пространство имен RDF (xmlns:rdf): http://www.w3.org/1999/02/22-rdf-syntax-ns#
Пространство имен RDFS (xmlns:rdfs): http://www.w3.org/2000/01/rdf-schema#
Рекомендуемое расширение файла RDF: .rdf . Тем не менее
расширение . xml есть
часто используется для обеспечения совместимости со старыми парсерами xml.
Тип MIME должен быть «application/rdf+xml» .
Классы RDFS/RDF
| Элемент | Класс | Подкласс |
|---|---|---|
| rdfs: класс | Все классы | |
| rdfs: тип данных | Типы данных | Класс |
| rdfs:Ресурс | Все ресурсы | Класс |
| rdfs:контейнер | Контейнеры | Ресурс |
| rdfs: литерал | Буквенные значения (текст и числа) | Ресурс |
| rdf:Список | Списки | Ресурс |
| rdf: Собственность | Свойства | Ресурс |
| rdf:Заявление | Заявления | Ресурс |
| рдф: Альт | Альтернативные контейнеры | Контейнер |
| rdf:Сумка | Неупорядоченные контейнеры | Контейнер |
| rdf:Seq | Заказные контейнеры | Контейнер |
| rdfs:ContainerMembershipProperty | Свойства членства в контейнере | Свойство |
| rdf:XMLLiteral | Литеральные значения XML | Буквальный |
Свойства RDFS / RDF
| Элемент | Домен | Диапазон | Описание |
|---|---|---|---|
| rdfs:домен | Свойство | Класс | Домен ресурса |
| rdfs:диапазон | Свойство | Класс | Ассортимент ресурса |
| rdfs: subPropertyOf | Свойство | Свойство | Свойство является подсвойством свойства |
| rdfs:subClassOf | Класс | Класс | Ресурс является подклассом класса |
| rdfs:комментарий | Ресурс | Буквальный | Человекочитаемое описание ресурса |
| rdfs:этикетка | Ресурс | Буквальный | Читаемая человеком метка (имя) ресурса |
| rdfs:isDefinedBy | Ресурс | Ресурс | Определение ресурса |
| rdfs: см. также | Ресурс | Ресурс | Дополнительная информация о ресурсе |
| rdfs:член | Ресурс | Ресурс | Участник ресурса |
| рдф: первый | Список | Ресурс | |
| рдф:остальные | Список | Список | |
| рдф:тема | ЗаявлениеРесурс | Тема ресурса в заявлении RDF | |
| rdf:предикат | ЗаявлениеРесурс | Предикат ресурса в операторе RDF | |
| рдф:объект | ЗаявлениеРесурс | Объект ресурса в операторе RDF | |
| rdf:значение | Ресурс | Ресурс | Свойство, используемое для значений |
| рдф:тип | Ресурс | Класс | Ресурс является экземпляром класса |
Атрибуты RDF
| Атрибут | Описание |
|---|---|
| рдф: около | Определяет описываемый ресурс |
| rdf:Описание | Контейнер для описания ресурса |
| рдф:ресурс | Определяет ресурс для идентификации свойства |
| rdf:тип данных | Определяет тип данных элемента |
| рдф:ID | Определяет идентификатор элемента |
| рдф:ли | Определяет список |
| rdf:_ n | Определяет узел |
| рдф: идентификатор узла | Определяет идентификатор узла элемента |
| rdf:parseType | Определяет, как должен анализироваться элемент |
| рдф:рдф | Корень документа RDF |
| XML: база | Определяет базу XML |
| xml:язык | Определяет язык содержимого элемента |
❮ Предыдущий Следующая ❯
Как использовать Python для НЛП и семантического SEO
2 февраля 2022 г. |
Сообщение от
Марко Джордано
В настоящее время в SEO наблюдается рост таких концепций, как семантическая поисковая оптимизация, обработка естественного языка (NLP) и языки программирования. Говоря об этом, Python очень помогает в оптимизации и большинстве скучных задач, которые вы, возможно, захотите выполнять во время работы. Не волнуйтесь, сначала кодирование может показаться сложным, но благодаря некоторым специализированным библиотекам оно намного проще, чем вы думаете.
Мы уже обсуждали семантический поиск, а также тематические авторитеты, и Python — это хорошее решение для изучения новых идей и более быстрых вычислений по сравнению с обычным рабочим процессом Excel.
Не секрет, что Google во многом полагается на NLP для получения результатов, и это основная причина, по которой мы заинтересованы в изучении естественного языка Google, чтобы получить больше подсказок о том, как мы можем улучшить наш контент.
В этом посте я уточняю:
- Основные семантические задачи SEO, которые вы можете выполнять в Python
- Фрагменты кода о том, как их реализовать
- Краткие практические примеры для начала работы
- Варианты использования и мотивация
- Ловушки и ловушки слепого копирования кода для принятия решений
Осторожно, это руководство предназначено для того, чтобы показать, как использовать Python для нетехнической аудитории. Поэтому мы не будем подробно останавливаться на каждой технике, так как это отнимет много времени.
Приведенные примеры — это только часть множества приемов, которые можно реализовать в языке программирования. Я просто перечисляю то, что считаю наиболее актуальным для людей, которые только начинают и интересуются SEO.
Цель состоит в том, чтобы продемонстрировать преимущества добавления Python в ваш рабочий процесс, чтобы получить преимущество в задачах Semantic SEO, таких как извлечение сущностей, анализ предложений или оптимизация контента.
Никаких специальных знаний Python не требуется, за исключением некоторых основных понятий. Примеры будут показаны по этой ссылке Google Colab, так как ее легко и быстро использовать.
НЛП и задачи семантического SEO в Python
Существует множество языков программирования, которые вы можете изучить, Javascript и Python являются наиболее подходящими для специалистов по SEO. Некоторые из вас могут спросить, почему мы предпочитаем Python, а не R, популярную альтернативу науке о данных.
Основная причина кроется в сообществе SEO, которое более комфортно чувствует себя с Python, идеальным языком для написания сценариев, автоматизации и задач NLP. Вы можете выбрать все, что вам нравится, хотя в этом руководстве мы покажем только Python.
Распознавание именованных объектов (NER)
Одной из наиболее важных концепций для поисковой оптимизации является способность распознавать объекты в тексте, т. е. распознавание именованных объектов (NER). Вы можете спросить себя, зачем вам этот метод, если Google уже использует его.
Идея состоит в том, чтобы узнать, какие объекты наиболее распространены на данной странице, чтобы понять, что следует включить в собственный текст.
Для этой задачи вы можете использовать spaCy или Google NLP API. Оба имеют свои преимущества и недостатки, хотя в этом примере вы увидите spaCy, очень популярную библиотеку для NLP, идеально подходящую для NER.
импортное пространство
от смещения импорта
#загрузить конвейер на английском языке
nlp = spacy. load (‘en_core_web_sm’)
text = ’18 января Microsoft купила Activision за 68,7 миллиарда долларов’
т = нлп (текст)
#давайте визуализируем объекты в блокноте
displacey.render(t,style=»ent»,jupyter=True)
Как вы можете видеть в записной книжке, ваш текст теперь помечен сущностями, и это очень удобно для понимания того, что используют ваши конкуренты. В идеале вы можете комбинировать это с очисткой, чтобы извлечь значимую часть текста и перечислить все объекты.
Это также можно распространить на всю поисковую выдачу, чтобы получить наиболее полезные объекты и понять, что включить в вашу копию. Однако есть еще одно полезное приложение: вы можете очистить страницу Википедии, чтобы получить список сущностей, а затем создать карту тем на основе того, что вы нашли.
Он очень хорошо работает с длинными страницами Википедии и на англоязычных рынках, я тестировал его на других языках, но обычно Википедия не такая полная.
NER — это базовая техника с интересными приложениями, и я могу гарантировать, что при правильном использовании она изменит правила игры. Идеально подходит для тех сценариев, когда вы не знаете, какие сущности добавить во вступление и вам нужно это выяснить, или для планирования тематических карт.
Маркировка части речи (маркировка POS)
Semantic SEO проявляет особый интерес к частям речи, которые термины имеют в предложениях. Как некоторые из вас, возможно, уже догадались, положение слова может изменить его важность при извлечении сущностей.
Маркировка POS удобна при анализе конкурентов или вашего собственного веб-сайта, чтобы понять структуру определений избранных фрагментов или получить более подробные сведения об идеальном порядке предложений. Python предлагает большую поддержку для этой задачи, снова в виде библиотеки spaCy, вашего лучшего друга для большинства ваших задач НЛП.
Подводя итог, можно сказать, что теги POS — это мощная идея, позволяющая понять, как вы можете улучшить свои предложения на основе существующего материала или того, как это делают другие люди.
displacy. render(t, jupyter=True)
Запрос к сети знаний
Как уже говорилось в другой статье о сети знаний, вам должно быть удобно работать с сущностями и устанавливать связи. Говоря об этом, очень полезно знать, как делать запросы к Графику знаний Google, и это довольно просто.
Библиотека advertools предлагает простую функцию, которая позволяет вам сделать это, взяв в качестве входных данных ваш ключ API. Результатом является фрейм данных, содержащий некоторые объекты, связанные с вашим запросом (если таковые имеются), а также показатель достоверности, который вам не нужно интерпретировать.
Полезный урок здесь состоит в том, чтобы получить определения и связанные сущности, если таковые имеются. График знаний — это одна большая база данных, в которой хранятся объекты и их отношения, это способ Google понять связи и корень семантического SEO. По сути, это одна из предпосылок достижения актуального авторитета в долгосрочной стратегии.
Иногда одной сети знаний недостаточно, поэтому я собираюсь показать вам еще один API, который хорошо работает в паре.
%%захват !pip установить рекламные инструменты из рекламных инструментов импортаknowledge_graph импортировать панд как pd #увеличить ширину столбца для лучшей визуализации pd.set_option(‘display.max_colwidth’, 300) key = ‘вставьте сюда свой ключ’
kg_df =knowledge_graph(key=key, query=»cat», languages = ‘en’) kg_df.head()
Query Google Trends (неофициальный) API
Google Trends может быть частью вашей контент-стратегии, позволяющей выявлять новые тенденции или оценивать, стоит ли обсуждать определенную тему, в которой вы не уверены. Допустим, вы хотите расширить свою сеть контекстной рекламы новыми идеями, но не уверены, что Google Trends может помочь вам в принятии решения.
Хотя официального API Google нет, мы можем использовать неофициальный, который охватывает то, что нам нужно. Ключевым моментом здесь является предоставление списка ключевых слов, выбор временных рамок и местоположения.
Самые популярные и набирающие популярность ключевые слова отлично подходят для понимания того, что нам нужно для нашей контент-стратегии. Рост относится к новым тенденциям и запросам, за которыми вы должны следить, иногда вы можете найти золотые возможности, особенно если вы сосредоточены на новостном SEO.
Наоборот, Топовые ключевые слова более постоянны и стабильны во времени, они в большинстве случаев дают вам подсказки о ваших тематических картах.
Я рекомендую поиграть с этим API, если вы также работаете в мире электронной коммерции из-за сезонных распродаж. Google Trends — это огромное преимущество для новостей и сезонного контента, API может только улучшить ваш опыт.
%%захват !pip установить pytrends из pytrends.request импортировать TrendReq pytrends = TrendReq() kw_list=[‘SEO’, ‘маркетинг’, ‘Python’, ‘Лингвистика’] #вы можете изменить время и место pytrends.build_payload(kw_list, timeframe=’today 1-m’, geo=’US’)
Тематическое моделирование (скрытое распределение Дирихле — LDA)
Одним из наиболее интересных приложений НЛП является тематическое моделирование, то есть распознавание тем. из набора слов. Это хороший способ увидеть, о чем говорится на большой странице, и можно ли выделить подтемы. Этот алгоритм можно запустить на всем веб-сайте, хотя это приведет к непомерным вычислительным затратам и выходит за рамки данного руководства.
Я покажу вам короткий пример с алгоритмом LDA, реализованным через библиотеку Bertopic, чтобы упростить наш рабочий процесс:
%%capture !pip установить бертопик от bertopic импорт BERTopic из sklearn.datasets импортировать fetch_20newsgroups #загружаем образец набора данных, чтобы показать вам, как это делается docs = fetch_20newsgroups(subset=’all’, remove=(‘headers’, ‘footers’, ‘quotes’))[‘data’] тема_модель = BERTopic () темы, проблемы = тема_модель.фит_трансформ (документы)
Тематическое моделирование — очень недооцененный метод оценки сети контекстной рекламы или даже разделов определенного веб-сайта, и именно поэтому вам следует потратить довольно много времени на более глубокое изучение LDA!
Подводя итог, можно сказать, что LDA — это один из способов оценить весь веб-сайт или некоторые его разделы. Поэтому его можно рассматривать как способ понять содержание конкурентов в вашей нише, при условии, что у вас достаточно вычислительных мощностей.
N-граммы
N-грамму можно рассматривать как непрерывную последовательность слов, слогов или букв. Я покажу вам, как создавать n-граммы из корпуса на Python, не вдаваясь в подробности. Поэтому нашей единицей будут слова, так как нам интересно знать, какие сочетания слов наиболее распространены в корпусе.
N-граммы, состоящие из двух слов, называются биграммами (триграммами, если их три) и так далее. Вы можете проверить блокнот Colab, чтобы получить представление о том, что мы пытаемся получить.
импортировать панд как pd
импортировать нлтк
#стоп-слова, такие как статьи или союзы, бесполезны и создают шум для моделей
nltk.download(‘стоп-слова’)
из nltk.corpus импортировать стоп-слова
из sklearn.feature_extraction.text импортировать CountVectorizer
из sklearn.datasets импортировать fetch_20newsgroups двадцать_поезд = fetch_20групп новостей (подмножество = ‘все’)
стоп-лист = стоп-слова. слова(‘английский’)
c_vec = CountVectorizer (stop_words = стоп-лист, ngram_range = (2,2))
# матрица энграмм
ngrams = c_vec.fit_transform(twenty_train.data[:100])
count_values = ngrams.toarray().sum(ось=0) df_ngram = pd.DataFrame(sorted([(count_values[i],k) для k,i в c_vec.vocabulary_.items()], reverse=True)
).rename(columns={0: ‘частота’, 1: ‘биграмма’}) df_ngram.head()
Теперь у вас есть четкое представление о наиболее частых сочетаниях в тексте, и вы готовы оптимизировать свой контент. Вы также можете попробовать разные комбинации, например, 4 грамма или 5 граммов. Поскольку Google полагается на индексирование на основе фраз, более выгодно рассматривать предложения, а не ключевые слова, когда речь идет о поисковой оптимизации на странице.
Это еще одна причина, по которой вы никогда не должны думать с точки зрения отдельных ключевых слов, а должны понимать, что ваш текст должен быть удобен для чтения человеком. И что может быть лучше, чем оптимизировать целые предложения, а не отдельные термины?
N-граммы — повторяющаяся концепция в НЛП, и на то есть веская причина. Протестируйте скрипт с некоторыми страницами и протестируйте различные комбинации, цель здесь — найти ценную информацию.
Генерация текста
Нынешняя шумиха вокруг поисковой оптимизации вращается вокруг генерируемого контента. Существует множество онлайн-инструментов, позволяющих автоматически создавать текст. Это не так просто, как кажется на самом деле, и материал по-прежнему требует исправления перед выходом в эфир.
Python способен генерировать контент или даже короткие фрагменты, но если вам нужен простой способ, настоятельно рекомендуется полагаться на инструменты.
Я покажу вам простой пример с библиотекой openai, шаги по созданию учетной записи находятся в Google Colab.
Как видите, код тут довольно простой и особо комментировать нечего. Возможно, вы захотите поиграть с некоторыми параметрами, чтобы проверить разницу в результатах, но если вы хотите генерировать контент, существуют сервисы, не требующие кодирования.
На самом деле вам нужно будет платить за использование Open AI, поэтому, если вы хотите выполнить работу, лучше выбрать другие платные услуги.
Кластеризация
Очень полезное приложение в поисковой оптимизации, один из самых важных методов повышения ценности вашего рабочего процесса. Если у вас мало времени, сначала сосредоточьтесь на этом, поскольку он достаточно надежен для электронной коммерции и является находкой для обнаружения новых категорий продуктов.
Кластеризация создает группы чего-то, чтобы выделить то, что вы не можете видеть обычно. Это мощный набор техник, и с их помощью не так просто добиться значимых результатов. По этой причине я приведу краткий пример, призванный показать код одного алгоритма и возможные недостатки его неправильного применения.
Кластеризация контента — это тема, для использования которой определенно требуется отдельный учебник, так как довольно сложно получить некоторые концепции.
Вы можете либо использовать данные отслеживания рейтинга Rank Ranger, либо данные Google Search Console, это вообще не имеет значения. Важно то, что вы экономите время и получаете новую информацию, даже если у вас нет знаний о веб-сайте.
Существует множество сценариев Python, блокнотов и даже приложений Streamlit, доступных в Интернете, этот раздел предназначен только для того, чтобы научить вас основам.
из sklearn.cluster импортировать DBSCAN На этот раз #беру больше рядов! X = vectorizer.fit_transform(twenty_train.data[:10000]) кластеризация = DBSCAN().fit(X) кластеры = clustering.labels_.tolist() df_new = pd.DataFrame(twenty_train.data[:10000]) #прикрепляем метки (группы) к нашему набору данных, чтобы понять, какие тексты к какой группе относятся df_new[‘DBSCAN_labels’]= clustering.labels_
Можно сказать, что это лучшее оружие в вашем арсенале, когда дело доходит до электронной коммерции или для поиска неизведанных тем на вашем веб-сайте. Кластеризацию легко спутать с тематическим моделированием, поскольку оба они приводят к одинаковым результатам. Однако напомним, что для кластеризации речь идет о группировке ключевых слов, а не текста, это ключевое отличие.
Кластеризация чрезвычайно полезна для тех, кто работает со страницами категорий и для всех, кто пытается найти новые возможности для контента. Возможности здесь почти безграничны, и у вас также есть несколько вариантов, давайте углубимся в некоторые алгоритмы:
- Kmeans
- БДскан
- Использование графиков
- Расстояние Word Mover
Если вы только начинаете, лучший совет — начать с Kmeans или DBscan. Последний не требует поиска оптимального количества кластеров и по этой причине больше подходит для использования по принципу plug-and-play.
Использование графов — это метод фиксации семантических отношений, а также отличный способ начать мыслить в терминах графов знаний. Другие методы, такие как расстояние Word Mover, превосходны, но сложны и требуют слишком много усилий для более простых задач.
Преимущества использования Python для семантического SEO
Python не является обязательным для всех, это зависит от вашего опыта и от того, кем вы хотите быть. Семантическое SEO — лучший подход, который вы можете использовать прямо сейчас, и знание основ кодирования может вам очень помочь, особенно для изучения некоторых концепций.
Есть несколько инструментов, подходящих для этих задач, которые могут сэкономить вам много времени и сил. Тем не менее, внедрение кода с нуля и решение проблем являются желательными навыками, которые могут стать еще более ценными по мере того, как SEO переходит к более технической реальности.
Более того, для выполнения определенных задач вам обязательно понадобится кодирование, так как альтернативы нет.
Можно резюмировать преимущества Python для семантического SEO следующим образом:
- Лучшее понимание теоретических концепций (например, лингвистики, вычислений и логики)
- Возможность изучения алгоритмов на практике
- Автоматизация невыполнимых задач
- Новые идеи и разные взгляды на SEO
То, что перечислено выше, может быть применено к любому другому языку программирования, мы упоминаем Python, потому что на данный момент он является самым популярным в SEO-сообществе.
Сколько времени это займет?
На этот вопрос нет точного ответа, все зависит от вашей последовательности и опыта. Я предлагаю делать что-нибудь понемногу каждый день, пока не почувствуете себя комфортно. В Интернете есть много хороших ресурсов, поэтому нет никаких оправданий, чтобы начать практиковать.
Тем не менее, изучение Python — это одно, а изучение NLP и Semantic SEO — совсем другое. Настоятельно рекомендуется сначала понять основную теорию, сохраняя ее в форме с помощью надлежащей практики.
Самые полезные библиотеки Python для семантического SEO
Некоторые из них не рассматривались в этом руководстве, так как они включали бы более сложные концепции, требующие отдельных статей. Более того, почти все они также используются для общих задач НЛП.
С этими библиотеками тесно связан веб-скрапинг, который можно легко выполнить с помощью таких библиотек, как BeautifulSoup, Requests и Scrapy.