
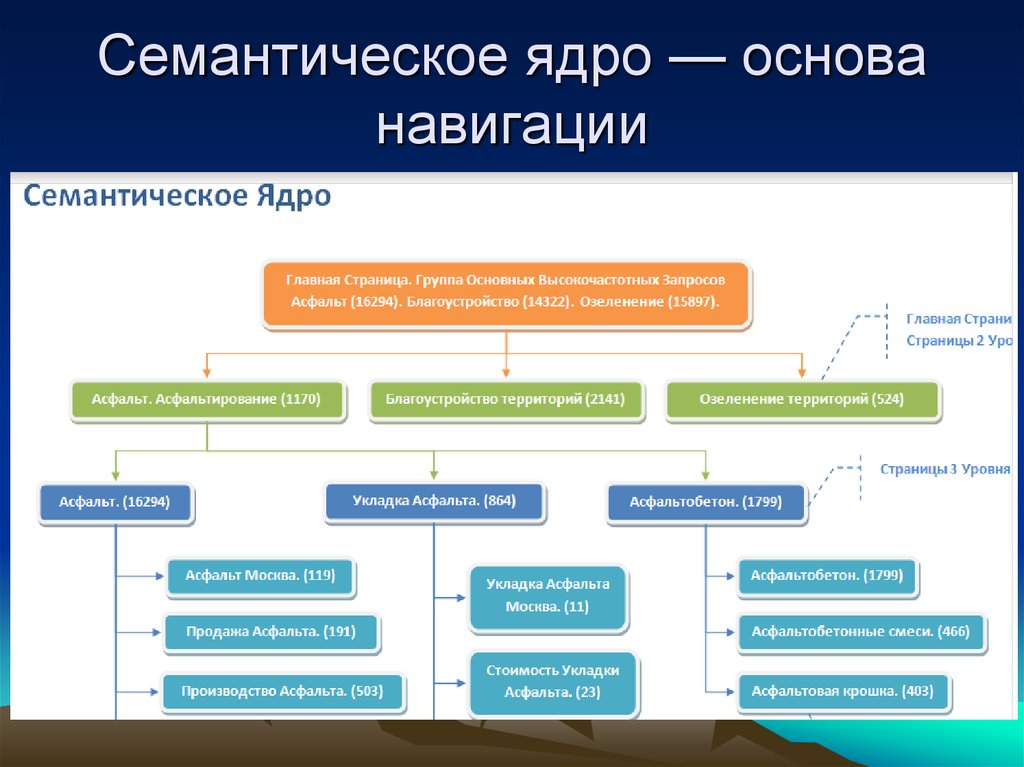
Семантическое ядро сайта: как составить. Пример.
В первой части нашей статьи мы рассказали, что такое семантическое ядро и дали общие рекомендации о том, как его составить.
Пришло время разобрать этот процесс в деталях, шаг за шагом создавая семантическое ядро для вашего сайта. Запаситесь карандашами и бумагой, а главное временем. И присоединяйтесь …
Составляем семантическое ядро для сайта
В качестве примера возьмем сайт http://promo.economsklad.ru/.
Сфера деятельности компании: складские услуги в Москве.
Сайт был разработан специалистами нашего сервиса 1PS.RU, и семантическое ядро сайта разрабатывалось поэтапно в 6 шагов:
Шаг 1. Составляем первичный список ключевых слов.
Проведя опрос нескольких потенциальных клиентов, изучив три сайта, близких нам по тематике и пораскинув собственными мозгами, мы составили несложный список ключевых слов, которые на наш взгляд отображают содержание нашего сайта: складской комплекс, аренда склада, услуги по хранению, логистика, аренда складских помещений, тёплые и холодные склады.
Задание 1: Просмотрите сайты конкурентов, посоветуйтесь с коллегами, проведите «мозговой штурм» и запишите все слова, которые, по вашему мнению, описывают ВАШ сайт.
Шаг 2. Расширение списка.
Воспользуемся сервисом http://wordstat.yandex.ru/. В строку поиска вписываем поочерёдно каждое из слов первичного списка:
Копируем уточнённые запросы из левого столбца в таблицу Excel, просматриваем ассоциативные запросы из правого столбца, выбираем среди них релевантные нашему сайту, так же заносим в таблицу.
Проведя анализ фразы «Аренда склада», мы получили список из 474 уточнённых и 2 ассоциативных запросов.
Проведя аналогичный анализ остальных слов из первичного списка, мы получили в общей сложности 4 698 уточнённых и ассоциативных запросов, которые вводили реальные пользователи в прошедшем месяце.
Задание 2: Соберите полный список запросов своего сайта, прогнав каждое из слов своего первичного списка через статистику запросов Яндекс.![]() Вордстат.
Вордстат.
Шаг 3. Зачистка
Во-первых, убираем все фразы с частотой показов ниже 50: «сколько стоит аренда склада» — 45 показов, «Аренда склада 200 м» — 35 показов и т.д.
Во-вторых, удаляем фразы, не имеющие отношения к нашему сайту, например, «Аренда склада в Санкт-Петербурге» или «Аренда склада в Екатеринбурге», так как наш склад находится в Москве.
Так же лишней будет фраза «договор аренды склада скачать» – данный образец может присутствовать на нашем сайте, но активно продвигаться по данному запросу нет смысла, так как, человек, который ищет образец договора, вряд ли станет клиентом. Скорее всего, он уже нашёл склад или сам является владельцем склада.
После того, как вы уберетё все лишние запросы, список значительно сократится. В нашем случае с «арендой склада» из 474 уточнённых запросов осталось 46 релевантных сайту.
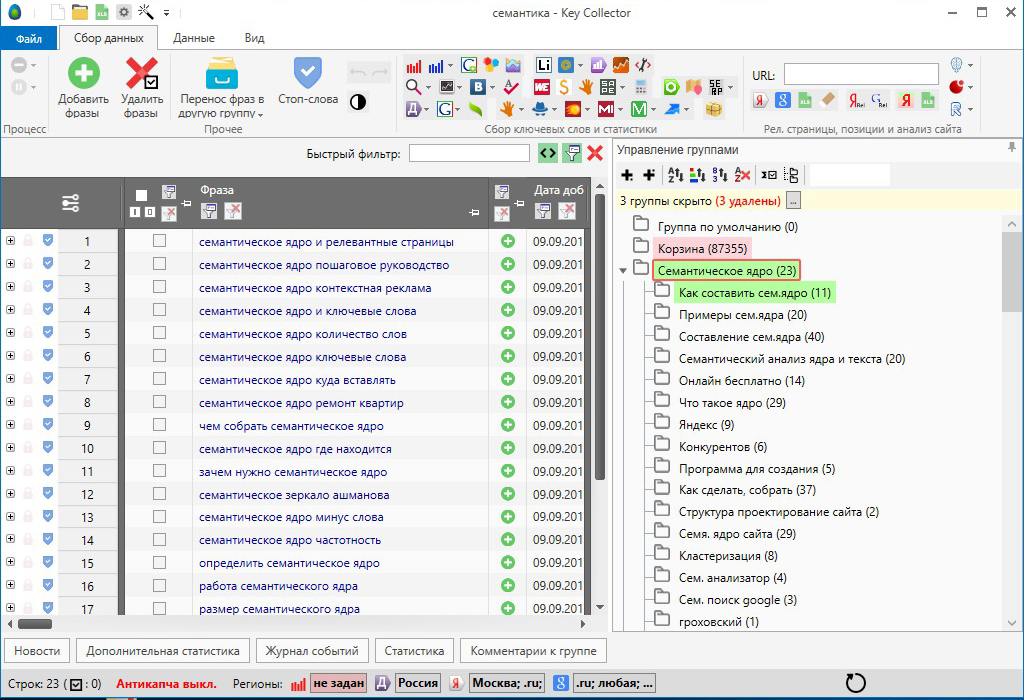
А когда мы почистили полный список уточнённых запросов (4 698 фраз), то получили Семантическое Ядро сайта, состоящее из 174 ключевых запросов.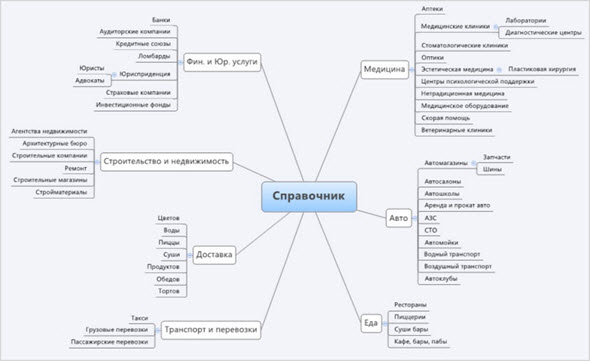
Задание 3: Почистите созданный ранее список уточнённых запросов, исключив из него низкочастоники с количеством показов меньше 50 и фразы, не относящиеся к вашему сайту.
Шаг 4. Доработка
Поскольку на каждой странице можно использовать 3-5 различных ключевиков, то все 174 запроса нам не понадобятся.
Учитывая, что сам сайт небольшой (максимум 4 страницы), то из полного списка выбираем 20, которые на наш взгляд наиболее точно описывают услуги компании.
Вот они: аренда склада в Москве, аренда складских помещений, склад и логистика, таможенные услуги, склад ответственного хранения, логистика складская, логистические услуги, офис и склад аренда, ответственное хранение грузов и так далее….
Среди этих ключевых фраз есть низкочастотные, среднечастотные и высокочастотные запросы.
Заметьте, данный список существенно отличается от первичного, взятого из головы. И он однозначно более точен и эффективен.
Задание 4: Сократите список оставшихся слов до 50, оставив только те, которые по вашему опыту и мнению, наиболее оптимальны для вашего сайта. Не забудьте, что финальный список должен содержать запросы различной частоты.
Не забудьте, что финальный список должен содержать запросы различной частоты.
Заключение
Ваше семантическое ядро готово, теперь самое время применить его на практике:
- пересмотрите тексты вашего сайта, быть может, их стоит переписать.
- напишите несколько статей по вашей тематике, используя выбранные ключевые фразы, разместите статьи на сайте, а после того, как поисковики проиндексируют их, проведите регистрацию в каталогах статей. Читайте «Один необычный подход к статейному продвижению».
- обратите внимание на поисковую рекламу. Теперь, когда у вас есть семантическое ядро, эффект от рекламы будет значительно выше.
Продвигайтесь правильно, и пользователи вас обязательно найдут!
как подобрать семантическое ядро. Читайте на Cossa.ru
Начну с поисковых запросов — они лежат в основе взаимодействия пользователя с поисковой системой. Специалисты по продвижению всегда ориентируются на них. Совокупность этих запросов — и есть семантическое ядро.
К нам часто приходят клиенты со своими списками запросов, в которых много ошибок — как в указанных частотах, так и в самих фразах. В списке присутствуют запросы, по которым сайт не попадёт в топ, или наоборот будет в топе вне зависимости от работы оптимизатора.
Иногда подрядчик не объясняет клиенту некоторые важные моменты: почему выбраны именно эти запросы, что означают их частоты, почему список пересматривается или не меняется годами.
Поэтому мы решили рассказать, как мы в Sabit выбираем фразы. Для начала рассмотрим классы запросов с точки зрения обычного бизнеса. Наша классификация может отличаться от принятых поисковыми системами.
Навигационные
- Сложность вывода в топ не по своему бренду — высокая.
- Польза для бизнеса — практически отсутствует.
Навигационные запросы содержат название или адрес чего-либо, например, «ул. Мамедова-Шмайсера», «суши-бар „Алёнушка“», YouTube, www.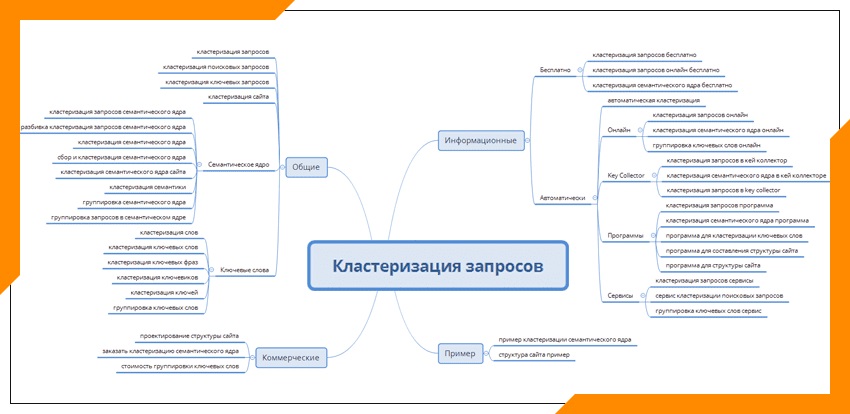
Переместите свои активности в email’е в российский сервис рассылок DashaMail
Удобный конструктор шаблонов, мощный функционал и хранение данных на российских серверах.
С 21 по 27 ноября в DashaMail проходит Чёрная Пятница! В рамках которой действует скидка 50% на все тарифы “За подписчиков” по промокоду BF2022.
Пожалуй, этой особой возможностью необходимо воспользоваться – получите комфортный инструмент для профессионального маркетинга по уютной цене.
Подробности→
Реклама. ООО «ПИСЬМО». ОГРН 1167847127909. ИНН 7811602601
Также продвижение в поисковых системах по своему бренду и адресу не требуется — ваш сайт будет в топе при грамотной базовой настройке.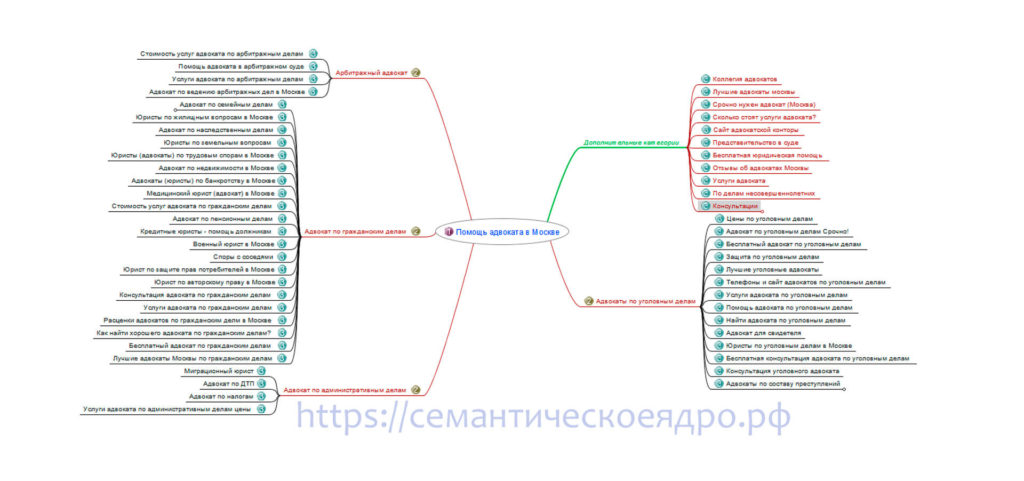
Пример. По запросу «Тануки» в Самаре первые пять мест в топе занимает сайт этой компании, а дальше идут различные каталоги и отзывы. Конкуренты не попадут в этот топ, поэтому дополнительное продвижение содержащих «Тануки» запросов не требуется.
Исключения. Если вы назовете фирму «Продажа дверей в Самаре» или заведёте сайт www.KupitDverivSamare.ru, то вам нужны мощные поисковые сигналы, чтобы поисковые системы связали бренд с таким запросом. В некоторых случаях системы посчитают такое название попыткой манипуляции поисковыми алгоритмами и наложат санкции на домен. Также у пользователя может сложиться недоверие к компании с таким именем или доменом.
Ещё важно не путать навигационные запросы с транзакционными запросами с названием производителя. Например, есть завод противопожарного оборудования «Гори дотла». Также есть несколько дилеров этого оборудования в регионе, среди которых и ваш бизнес. Тогда по запросам вида «противопожарное оборудование „Гори дотла“» сначала будет сайт завода, а уже потом дилеры.
Информационные
- Сложность вывода в топ — высокая.
- Польза для бизнеса — сомнительная.
Когда пользователь вводит информационный запрос, он собирает информацию, а не ищет товар или услугу. По смыслу эти запросы могут быть в тематике вашего бизнеса и казаться целевыми, но это не так. Выдача по таким запросам состоит из информационных сайтов: справочников, инструкций, форумов и так далее.
Коммерческие сайты по таким запросам редко встречаются в топе и добавляются технологией «Спектр» Яндекса. Часто информационные запросы геонезависимые, поскольку пользователю важна не меняющаяся от города к городу информация.
Пример. В топе по запросу «штукатурка для стен» будут только информационные сайты, которые не занимаются продажей штукатурки. Даже если у вас продающая штукатурку компания, такой запрос лучше не брать по нескольким причинам:
-
Пользователь не нуждается в товаре напрямую.
 Можно склонить посетителя к покупке, обещая самую дешёвую штукатурку, но конверсия будет стремиться к нулю.
Можно склонить посетителя к покупке, обещая самую дешёвую штукатурку, но конверсия будет стремиться к нулю. - Информационные запросы геонезависимы. Это значит, что трафик идёт со всей России. Если мы рассматриваем региональный бизнес, то посетители из других регионов ничего у вас не купят, потому что ваши магазины физически недоступны.
- Геонезависимость запросов повышает порог входа в топ. По информационным запросам в ранжировании участвуют все сайты России, а значит, придётся конкурировать с мощными информационными порталами с тысячами статей, видео и обзоров.
 Можно склонить посетителя к покупке, обещая самую дешёвую штукатурку, но конверсия будет стремиться к нулю.
Можно склонить посетителя к покупке, обещая самую дешёвую штукатурку, но конверсия будет стремиться к нулю.Исключения. Размещение информационных статей и обзоров на сайте положительно сказывается на доверии посетителя к компании, а также привлекает дополнительный низкочастотный трафик на сайт. В итоге этот трафик положительно скажется на ранжировании сайта по коммерческим запросам.
В некоторых тематиках можно успешно конвертировать посетителей по информационным запросам. Например, поставщику разливного пива и оборудования стоит создать цикл полезных статей про особенности бизнеса в регионе. Наличие топонима в статье позволит отсечь пользователей из нецелевых регионов, а также снизить конкуренцию.
Например, поставщику разливного пива и оборудования стоит создать цикл полезных статей про особенности бизнеса в регионе. Наличие топонима в статье позволит отсечь пользователей из нецелевых регионов, а также снизить конкуренцию.
Статьи должны быть написаны профессионалом, знакомым с тонкостями бизнеса в этом регионе, а также оперировать реальными цифрами, адресами и расчётами. Качественное исследование приведёт вам клиентов, но и ресурсов потребует немало. Введите популярный поисковый запрос и посмотрите, что в топе находятся объёмные статьи с графикой и видеоматериалами, а не переписанная чужая статья.
Google ценит новые материалы — стоит писать о том, о чём ещё никто не писал, а подобные исследования стоят дорого.
Делая упор в продвижении на информационные фразы, нужно понимать риски и быть готовым к отсутствию результатов в течение года и больше. В контекстной рекламе такие запросы работают хорошо, так как настройки этого инструмента значительно шире.
Медиа
- Сложность вывода в топ — высокая, но зависит от тематики.
- Польза для бизнеса — сомнительная.
Этот вид запросов направлен на поиск фото, видео или других файлов.
Пример. «Айфон х фото», «1с бухгалтерия скачать бесплатно без регистрации и смс», «настройка баяна видео».
Медиа запросы геонезависимы и не продвигаются без наличия соответствующего контента. Фото и видео продвигаются на специализированных ресурсах: YouTube, RuTube, Яндекс.Картинки и так далее. Для этого нужно создавать качественные видео, фотографии и рисовать инфографику.
Нечёткие
- Сложность вывода в топ — высокая.
- Польза для бизнеса — средняя.
Это запросы, по которым нельзя угадать потребности пользователя.
Пример. «Кроссовки найк», «генератор», «летние штаны». По таким запросам сложно понять, что хотел пользователь: узнать стоимость, купить, посмотреть фото, почитать отзывы или найти определение.
Подобные запросы могут присутствовать в семантическом ядре, но не стоит делать на них акцент и строить прогнозы на их основании.
Коммерческие
- Сложность вывода в топ — в зависимости от конкуренции.
- Польза для бизнеса — большая.
С помощью коммерческих запросов пользователь пытается получить услугу или товар. Этот тип запросов самый предпочтительный для продвижения. Подобными запросами пользователь напрямую сообщает вам о потребности.
Коммерческие запросы отличаются рядом важных характеристик:
Геозависимость
Если запрос геозависимый, то пользователю важно увидеть в результатах поиска сайты местных компаний. Поисковая система определяет регион пользователя и сначала выдаёт сайты этого региона, а затем сайты остальных регионов.
Для геозависимых запросов региональные сайты имеют весомое преимущество. Для местного бизнеса это хорошо, потому что приходится конкурировать только с сайтами аналогичной тематики своего региона, а не со всей Россией.
Для местного бизнеса это хорошо, потому что приходится конкурировать только с сайтами аналогичной тематики своего региона, а не со всей Россией.
Особый вид запросов — запросы с топонимом. Они явно содержат в себе название географического местоположения. С технической стороны они относятся к геонезависимым, потому что не зависят от местоположения пользователя.
Пример. Если пользователь из Воркуты набирает «купить сарай в Уфе», то в топе будут сайты из Уфы.
При этом запросы с топонимом показывают выдачу по региону из запроса, а значит, они полезны для продвижения товаров и услуг. Важно подбирать для продвижения геозависимые запросы или запросы с топонимом вашей целевой аудитории.
Есть и другой пример — «когда дадут отопление в Самаре». Топоним есть, но запрос информационный. Наличие топонима не значит, что запрос подходит для продвижения сайта.
Агрегированность
Перед тем как концентрировать усилия на определённых запросах, нужно оценить их вероятность выхода в топ. Кроме прямых конкурентов в топе есть сервисы самой поисковой системы (карты, торговые площадки), крупные федеральные проекты (Авито, LaModa), а также различные товарные агрегаторы и каталоги.
Кроме прямых конкурентов в топе есть сервисы самой поисковой системы (карты, торговые площадки), крупные федеральные проекты (Авито, LaModa), а также различные товарные агрегаторы и каталоги.
За счёт огромного количества страниц, мощной перелинковки, оптимизации и других факторов, эти сайты прочно находятся в топе и занять их место при разумных затратах невозможно. Получается, что места в топе для коммерческих сайтов становится меньше.
Пример. В топе по запросу «купить плащ» по Самаре всего два коммерческих сайта из региона, а остальные — агрегаторы и крупные федеральные площадки. Чтобы попасть в топ, нужно быть одним из двух лучших самарских сайтов по мнению поисковой системы. Соотношение сайтов в выдаче может быть различным, а также изменяться со временем.
Если вы решили взять агрегированные запросы на продвижение, то будьте готовы к трудностям и не ждите быстрых результатов. Со временем ситуация в топе может измениться как в лучшую сторону, так и наоборот.
Частотность
Фразы в системах статистики Wordstat и Keyword planner появляются не случайно. Их вводят пользователи. Частота запроса даёт предварительный прогноз числа показов в месяц. Вы получите число показов, выбрав этот запрос в качестве ключевого слова и продвинув его в топ. Это не переходы и не количество трафика на сайт, а только количество показов пользователю по данному запросу, если сайт будет в топ-10.
При этом пользователь может не выбрать ваш сайт из топ-10, потому что привлекательность сайта зависит от описания, заголовка, места, раскрученности бренда и множества других факторов. В некоторых тематиках пользователи заходят на сайт из топа почти каждый день. В других тематиках находят ответ на одном или на двух сайтах. В любом случае нельзя ассоциировать частоту с трафиком.
Частоты бывают трёх видов:
- общие — эта фраза встречается в окружении любых слов,
- «уточнённые» — только слова из фразы в любом склонении,
-
«!точные» — именно эти фразы с этим окончанием, но с любым порядком слов.
Мы используем уточнённые частоты с фиксированным количеством слов. Для крупных проектов в высококонкурентной тематике есть смысл брать точные запросы. Подробнее о частотах написано у Яндекса. Также частоты нужно собирать по региону, в котором идёт продвижение.
Фразы с большой частотой сложнее продвигать из-за высокой конкуренции. При этом важно понимать, что любая частота запроса непостоянна. Популярность запросов зависит от множества факторов: сезонности, изменений в экономике, развития технологий, трендов и так далее. При составлении ядра нужно учитывать эти изменения и следить за спросом в тематике.
Пример. О вейпах в начале 2016 года только начали говорить, поэтому запросов не было:
У кондиционеров и обогревателей строгая сезонность:
Частотность по шиномонтажу зависит от того, когда выпадет или растает снег. Из года в год это могут быть разные даты:
Максимально широкое и полное ядро можно собрать в разгар сезона.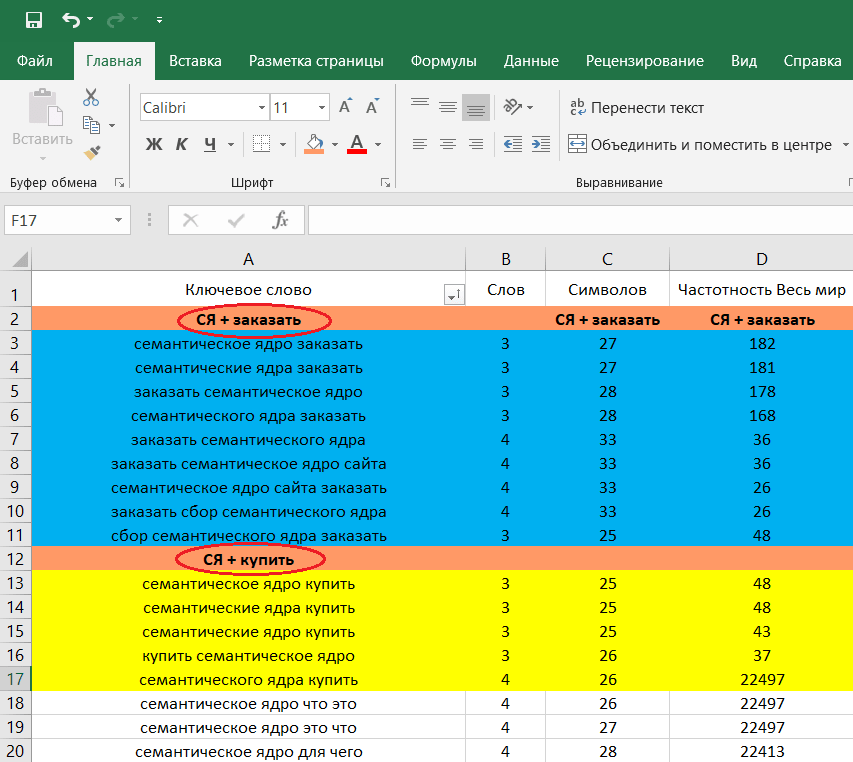 В другое время не стоит ожидать высокие частоты.
В другое время не стоит ожидать высокие частоты.
Целевые и нецелевые
При выборе запросов на продвижение нужно учитывать возможности своего бизнеса. В нашей практике было множество примеров продвижения запросов, по которым компания не оказывала услуги.
Пример. По запросу «водосточная система в Самаре» в топе находятся сайты, оказывающие услуги по расчёту, производству и установке водосточных систем. Если вы продаёте комплектующие для таких систем, то этот запрос для вас не целевой.
Наличие необходимой функциональности
При выборе запросов нужно отталкиваться от сайта и возможностей его доработки. В каждой конкурентной тематике есть свои наборы функциональных элементов, без которых трудно попасть в топ.
Пример. Для множества тематик с товарными предложениями нужен функционал интернет-магазина. Это предполагает наличие отдельных карточек товаров с описанием и возможностью купить или заказать.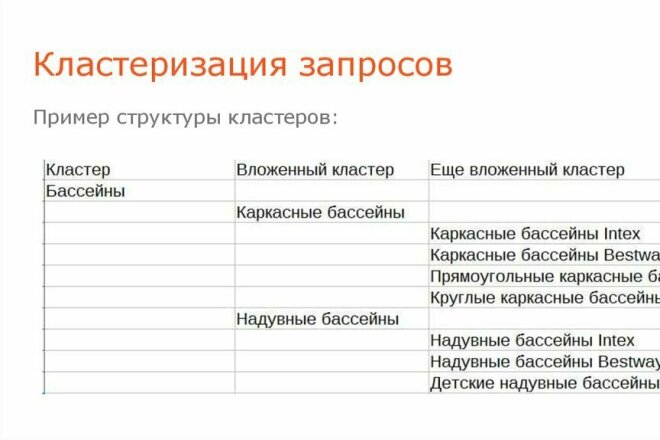 Если у вас есть только оптимизированный текст на странице, а у всех сайтов в топе обширный каталог, то ваши шансы попасть в топ снижаются.
Если у вас есть только оптимизированный текст на странице, а у всех сайтов в топе обширный каталог, то ваши шансы попасть в топ снижаются.
Для некоторых запросов необходимо наличие цен. Если в топе на всех сайтах они представлены, вам тоже стоит их указать. Если вы затрудняетесь предоставить цены или их диапазон, то такие запросы могут не пройти в топ.
В высококонкурентных тематиках появляются интерактивные элементы. Например, в натяжных потолках нужен калькулятор стоимости. Если на вашем сайте не хватает информации или функционала, и вы не готовы его реализовать, лучше сконцентрироваться на других запросах.
Определяем нужные запросы
Слова-маркеры: информационные и коммерческие
Информационные
Чтобы определить категорию запроса, можно использовать слова-маркеры. Для информационных запросов это будут вопросы: что, как, почему, чем, зачем и так далее. Практически все запросы с такими маркерами — информационные. При этом вопросы «где» и «сколько» не говорят об однозначной информационности запроса. Такие фразы нужно прорабатывать отдельно.
При этом вопросы «где» и «сколько» не говорят об однозначной информационности запроса. Такие фразы нужно прорабатывать отдельно.
Пример. «Как заправить принтер», «зачем штукатурка для стен», «что купить в подарок», «где вкусно поесть», «сколько нужно воды для варки риса» — это информационные запросы. «Где купить валенки», «сколько стоит линолеум» — коммерческие.
Коммерческие
Для коммерческих запросов также есть слова-маркеры: купить, заказать, цена, стоимость. Топоним в запросе тоже свидетельствует о коммерческом запросе.
Пример. «Купить зимние сапоги», «кухня на заказ», «проектирование дома цена» — коммерческие. «Как купить телевизор из Китая» — информационный.
Слова-маркеры нужно использовать аккуратно. Перед этим следует разобраться в терминологии и особенностях тематики, а также обладать некоторым опытом в составлении семантических ядер.
Поисковая выдача
Самый надёжный метод определения типа и пригодности запроса для продвижения — анализ выдачи поисковой системы. Для этого нужно ввести запрос в поисковую строку и посчитать количество коммерческих и информационных сайтов в топе и агрегаторов.
Для этого нужно ввести запрос в поисковую строку и посчитать количество коммерческих и информационных сайтов в топе и агрегаторов.
Для каждой поисковой системы значения будут разными. Может получиться так, что в Google запрос коммерческий, а в Яндексе — информационный, потому что у каждой поисковой системы свои алгоритмы.
Пересмотр семантического ядра
У запросов со временем меняется не только частотность, но и тип запроса, количество агрегатов в топе, геозависимость.
Пересмотр ядра, замена одних части запросов на другие — это нормальная практика. Как часто это стоит делать, зависит от конкретного бизнеса. Есть тематики, где годами актуально одно ядро, и наоборот.
Также бывают тематики, где нет большого списка целевых фраз. Нормально пересматривать ядро раз в полгода или при изменении в самой тематике (выход нового товара, изменения в услугах). Лучше собирать ядро через месяц после высокого сезона — так можно увидеть больше запросов. Если вы стартовали продвижение в «низкий» сезон, то пересматривать ядро нужно при первом всплеске активности в тематике.
Если вы стартовали продвижение в «низкий» сезон, то пересматривать ядро нужно при первом всплеске активности в тематике.
Узкие тематики без выраженного спроса
А если бизнес занимается непопулярными среди населения услугами и товарами? Как подбирать, если выбрать не из чего? Например, нефтегазовая отрасль, машиностроение, химическая промышленность и так далее.
Есть несколько вариантов:
-
Собирать запросы и частоты по всей России, а не только по своему региону, но без топонимов других регионов. Пользователи по стране задают примерно одинаковые запросы. Исследования Яндекса это подтверждают. Есть некоторые различия, например, бордюр и поребрик, файл и мультифора, но в основном названия одинаковые, особенно в узких нишах. Например, по запросу «теплотехнические испытания» в Самаре всего две фразы:
А вот по региону «Россия» уже больше:
-
Разобраться в специфике и терминологии тематики и смоделировать коммерческие запросы. Нужно собрать список названий и сокращений, используемых в отрасли и добавить к ним коммерческие слова-маркеры. Например, к запросу «теплотехнические испытания» добавляем коммерческие маркеры и получаем небольшое ядро по услуге:
- Использовать базы данных и системы статистики. В основном эти базы платные, поэтому нужно оценивать целесообразность их использования. Например, www.bukvarix.com и moab.pro.
- Анализ конкурентов. Если в вашей тематике есть конкуренты с оптимизированным сайтом и хорошим трафиком, можно посмотреть какие ключевые слова написаны в главных областях страниц: title и заголовках. Конкурентов можно смотреть по разным регионам, а также по России, добавляя соответствующие топонимы к запросам.
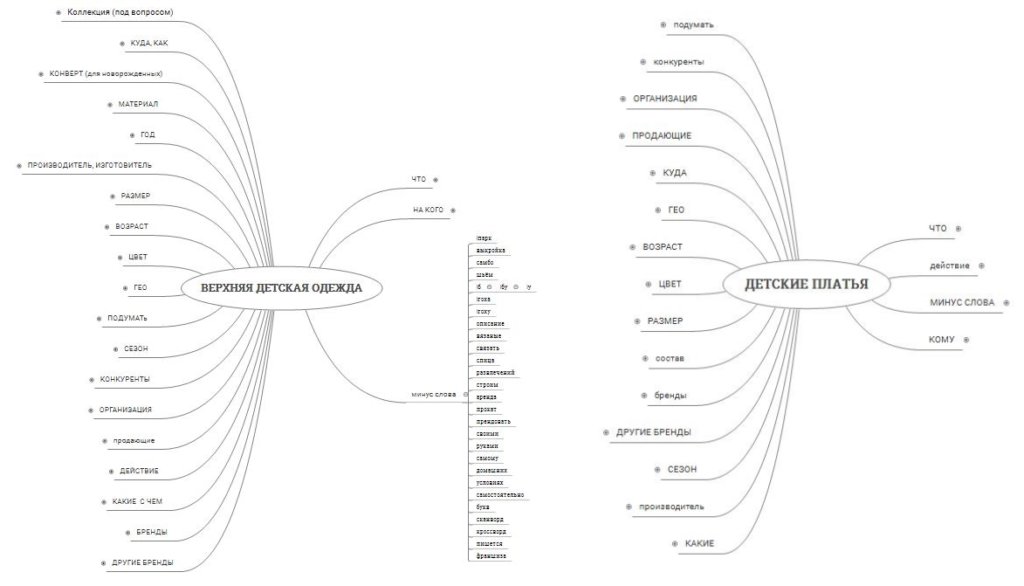 Нужно собрать список названий и сокращений, используемых в отрасли и добавить к ним коммерческие слова-маркеры. Например, к запросу «теплотехнические испытания» добавляем коммерческие маркеры и получаем небольшое ядро по услуге:
Нужно собрать список названий и сокращений, используемых в отрасли и добавить к ним коммерческие слова-маркеры. Например, к запросу «теплотехнические испытания» добавляем коммерческие маркеры и получаем небольшое ядро по услуге:Заключение
Мы советуем обращать внимание на коммерческие геозависимые запросы. Их нужно внимательно проверить на то, целевые они или нет. Можно использовать слова-маркеры, но надёжнее всего ввести запросы в поисковую строку и проверить на выдаче.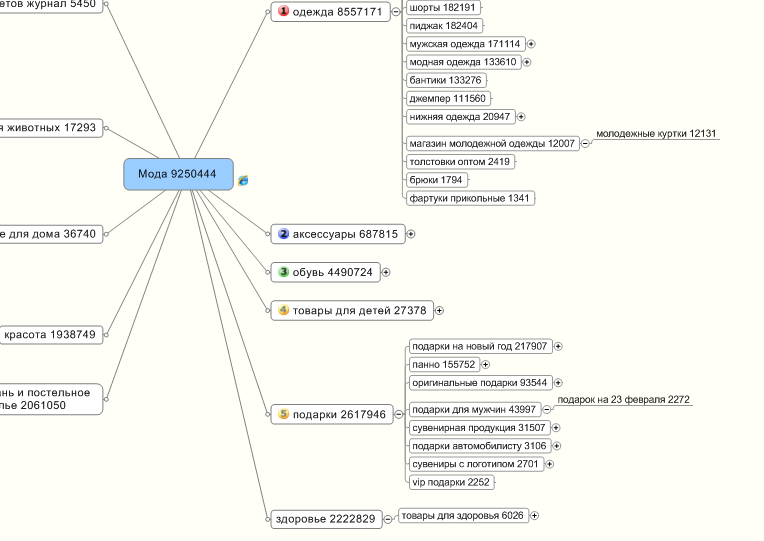 Если вы затрудняетесь самостоятельно проверить ядро, попросите своих специалистов по продвижению рассказать о запросах, по которым ведётся продвижение и почему выбраны именно они.
Если вы затрудняетесь самостоятельно проверить ядро, попросите своих специалистов по продвижению рассказать о запросах, по которым ведётся продвижение и почему выбраны именно они.
Если вы не можете часто пересматривать и пересогласовывать семантическое ядро, лучше выбирать схему работы, при которой оптимизаторы могут без согласования быстро менять списки запросов. Тогда специалисты по продвижению могут охватить больше направлений бизнеса и оперативно реагировать на изменения спроса в отрасли.
Составление грамотного семантического ядра — это задача специалистов по продвижению, а не менеджеров или клиента. Это долгий и трудоёмкий процесс, который не всегда можно успешно завершить на этапе заключения договора. В нашем агентстве ядро собирают специалисты по продвижению с учётом специфики бизнеса и тематики. Не бойтесь задавать вопросы по вашему ядру.
Источник тизера: TwitterView/Steven Ray Morris
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
Геоонтологический шаблон проектирования семантических траекторий
Альварес Л.О., Богорный В., Куйперс Б., Де Маседо Дж.А.Ф., Моэланс Б., Вайсман А.: Модель обогащения траекторий семантикой географическая информация. В: Самет, Х., Шахаби, К., Шнайдер, М. (ред.) Материалы 15-го Международного симпозиума ACM по географическим информационным системам, ACM-GIS 2007, Сиэтл, Вашингтон, США, 7-9 ноября. АКМ Пресс (2007)
Google ученый
Баттл, Р., Колас, Д.: Включение геопространственной семантической сети с Парламентом и GeoSPARQL. Semantic Web 3(4), 355–370 (2012)
Google ученый
Берг-Кросс Г., Круз И., Дин М., Финин Т., Гахеган М., Хитцлер П., Хуа Х., Янович К.
, Ли Н. , Мерфи, П., Нордгрен, Б., Обрст, Л., Шильдхауэр, М., Шет, А., Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.)Google ученый
Бизер, К., Хит, Т., Бернерс-Ли, Т.: Связанные данные – История до сих пор. Международный журнал Semantic Web and Information Systems 5(3), 1–22 (2009 г.)
CrossRef Google ученый
Богорный В., Куиджперс Б., Альварес Л.О.: ST-DMQL: язык запросов интеллектуального анализа данных семантической траектории. Международный журнал географической информатики 23(10), 1245–1276 (2009 г.).)
Перекрестная ссылка Google ученый
Бродарик, Б., Пробст, Ф.: Внедрение междисциплинарных электронных наук путем интеграции геолого-геофизических онтологий с Dolce. Интеллектуальные системы IEEE 24(1), 66–77 (2009 г.).)
Перекрестная ссылка Google ученый
Каррал, Д., Шайдер, С., Янович, К., Вардеман, К., Криснадхи, А.А., Хитцлер, П.: Шаблон проектирования онтологии для картографического масштабирования карты. В: Чимиано, П., Корчо, О., Пресутти, В., Холлинк, Л., Рудольф, С. (ред.) ESWC 2013. LNCS, vol. 7882, стр. 76–93. Springer, Heidelberg (2013)
CrossRef Google ученый
Чан, Л.-В., Чанг, Дж.-Р., Чен, Ю.-К., Кэ, К.-Н., Хсу, Дж., Чу, Х.-Х.: Сотрудничество локализация: улучшение оценки местоположения на основе Wi-Fi с соседними ссылками в кластерах. В: Фишкин, К.П., Шиле, Б., Никсон, П., Куигли, А. (ред.) PERVASIVE 2006. LNCS, vol. 3968, стр. 50–66. Springer, Heidelberg (2006)
CrossRef Google ученый
Chiou, Y., Wang, C., Yeh, S., Su, M.: Разработка адаптивной системы позиционирования на основе радиосигналов WiFi.
Компьютерные коммуникации 32(7), 1245–1254 (2009)CrossRef Google ученый
Комптон, М., Барнаги, П.М., Бермудес, Л., Гарсия-Кастро, Р., Корчо, О., Кокс, С., Грейбил, Дж., Хаусвирт, М., Хенсон, К.А., Герцог , А., Хуанг, В.А., Янович, К., Келси, В.Д., Фуок, Д.Л., Лефорт, Л., Легьери, М., Нейхаус, Х., Николов, А., Пейдж, К.Р., Пассант, А., Шет, А.П., Тейлор, К.: Онтология SSN группы инкубатора семантической сенсорной сети W3C. Журнал по веб-семантике 17, 25–32 (2012)
Перекрёстная ссылка Google ученый
Додж С., Вайбель Р., Лаутеншютц А.К.: На пути к таксономии моделей движения. Визуализация информации 7(3), 240–252 (2008)
CrossRef Google ученый
Гангеми, А.: Шаблоны проектирования онтологии для семантического веб-контента. В: Гил, Ю.
, Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005)Перекрёстная ссылка Google ученый
Гангеми, А., Фиссеха, Ф., Кейзер, Дж., Леманн, Дж., Лян, А., Петтман, И., Сини, М., Таконе, М.: Основная онтология рыболовства и его использование в проекте службы онтологии рыболовства. В: Первый международный семинар по основным онтологиям, конференция EKAW. CEUR-WS, том. 118 (2004)
Google ученый
Гангеми, А., Гуарино, Н., Мазоло, К., Олтрамари, А., Шнайдер, Л.: Подслащивание онтологий с помощью DOLCE. В: Гомес-Перес, А., Бенджаминс, В.Р. (ред.) EKAW 2002. LNCS (LNAI), том. 2473, стр. 166–181. Спрингер, Гейдельберг (2002)
Перекрёстная ссылка Google ученый
Грюнингер, М., Фокс, М.
С.: Роль вопросов компетентности в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994)Google ученый
Гутинг, Р.Х., Бёлен, М.Х., Эрвиг, М., Йенсен, К.С., Лоренцос, Н.А., Шнайдер, М., Вазиргианнис, М.: Основа для представления и запроса движущихся объектов. Транзакции ACM в системах баз данных (TODS) 25 (1), 1–42 (2000)
Перекрёстная ссылка Google ученый
Гутинг, Р., Де Алмейда, В., Дин, З.: Моделирование и запросы движущихся объектов в сетях. Журнал VLDB 15(2), 165–190 (2006)
CrossRef Google ученый
Гвон Ю., Джейн Р., Кавахара Т.: Надежная оценка местоположения стационарных и мобильных пользователей в помещении. В: Proceedings IEEE INFOCOM 2004, 23-я ежегодная совместная конференция IEEE Computer and Communications Societies, Гонконг, Китай, 7–11 марта, стр.
1032–1043. ИИЭР (2004)Google ученый
Ван Хаге В.Р., Малайз В., Сегерс Р.Х., Холлинк Л., Шрайбер Г.: Разработка и использование простой модели событий (SEM). Журнал по веб-семантике 9(2), 128–136 (2011)
CrossRef Google ученый
Хитцлер, П., Крётч, М., Рудольф, С.: Основы семантических веб-технологий. CRC Press (2010)
Google ученый
Хорн, Дж. С., Гартон, Э. О., Кроун, С. М., Льюис, Дж. С.: Анализ движений животных с использованием броуновских мостов. Экология 88, 2354–2363 (2007)
CrossRef Google ученый
Ху, Ю., Янович, К.: Улучшение управления личной информацией путем интеграции действий в физическом мире с семантическим рабочим столом. В: Круз, И.
Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012)Google ученый
Кейс, Р., Янсен, П.А., Кнехт, Э.М., Вохвинкель, Р., Викельски, М.: Влияние времени кормления на распространение семян виролы туканами, определенное с помощью GPS-трекинга и акселерометров. Acta Oecologica 37(6), 625–631 (2011)
CrossRef Google ученый
Кейс, Р., Янсен, П.А., Кнехт, Э.М., Вохвинкель, Р., Викельски, М.: Данные из: Влияние времени кормления на распространение семян виролы туканами, определенное с помощью GPS-трекинга и акселерометров. Хранилище данных Movebank (2012)
Google ученый
Маккензи Г., Адамс Б., Янович К.: Тематический подход к сходству пользователей, основанный на геосоциальных проверках. В: Материалы конференции AGILE 2013 г. (будет опубликовано в 2013 г.)
Google ученый
Мика П., Оберле Д., Гангеми А., Сабоу М.: Основы сервисных онтологий: согласование OWL-S с Dolce. В: Материалы 13-й конференции World Wide Web, стр. 563–572. АКМ (2004)
Google ученый
Муза, К., Риго, П.: Модели подвижности. GeoInformatica 9(4), 297–319 (2005)
CrossRef Google ученый
Приянта, Н.: Система определения местоположения в помещении для игры в крикет. Кандидат наук. диссертация, Массачусетский технологический институт (2005 г.)
Google ученый
Шмид Ф., Рихтер К.-Ф., Лаубе П.: Сжатие семантической траектории. В: Мамулис, Н., Зайдл, Т., Педерсен, Т.Б., Торп, К., Ассент, И. (ред.) SSTD 2009. LNCS, том. 5644, стр. 411–416. Springer, Heidelberg (2009)
CrossRef Google ученый
Спаккапьетра, С., Парент, К., Дамиани, М., Де Маседо, Дж., Порто, Ф., Ванженот, К.: Концептуальный взгляд на траектории. Инженерия данных и знаний 65(1), 126–146 (2008)
CrossRef Google ученый
Виллемс, Н., ван Хаге, В.Р., де Врис, Г., Янссенс, Дж.Х.М., Малайз, В.: Интегрированный подход к визуальному анализу базы знаний о движущихся объектах из нескольких источников. Международный журнал географической информатики 24(10), 1543–1558 (2010)
CrossRef Google ученый
Ян, З., Маседо, Дж., Пэрент, К., Спаккапьетра, С.: Траекторные онтологии и запросы. Транзакции в ГИС 12, 75–91 (2008)
Перекрёстная ссылка Google ученый
Ян З.: На пути к семантическому анализу траекторных данных: концептуальный и вычислительный подход.
В: Риго, П., Сенелларт, П. (ред.) Материалы семинара докторантуры VLDB 2009. Совместно с 35-й Международной конференцией по очень большим базам данных (VLDB 2009), Лион, Франция, 24 августа. Фонд VLDB (2009)Google ученый
Ин, Дж.Дж.К., Лу, Э.Х.К., Ли, В.К., Венг, Т.С., Ценг, В.С.: Добыча сходства пользователей на основе семантических траекторий. В: Материалы 2-го международного семинара ACM SIGSPATIAL по социальным сетям на основе местоположения, стр. 19–26. АКМ (2010)
Google ученый
 , Ли Н. , Мерфи, П., Нордгрен, Б., Обрст, Л., Шильдхауэр, М., Шет, А., Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.)
, Ли Н. , Мерфи, П., Нордгрен, Б., Обрст, Л., Шильдхауэр, М., Шет, А., Синха, К., Тессен, А., Виганд, Н., Заславский, И.: Семантика и онтологии для ЗемляКуб. В: Материалы семинара 2012 г. по ГИСауке в эпоху больших данных, совместно с Седьмой международной конференцией по географической информатике 2012 г. (ГИСаенс 2012), Колумбус, Огайо, США, 18 сентября (2012 г.) «>
«>Бракатсулас, С., Пфосер, Д., Трифона, Н.: Моделирование, хранение и анализ баз данных движущихся объектов. В: 8-й Международный симпозиум по разработке баз данных и приложений (IDEAS 2004), Коимбра, Португалия, 7–9 июля, стр. 68–77. Компьютерное общество IEEE (2004)
Google ученый
 «>
«>Карраль, Д., Янович, К., Хитцлер, П.: Логический шаблон проектирования геоонтологии для количественной оценки типов. В: Круз, И.Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 239–248. АКМ (2012)
Google ученый
 Компьютерные коммуникации 32(7), 1245–1254 (2009)
Компьютерные коммуникации 32(7), 1245–1254 (2009)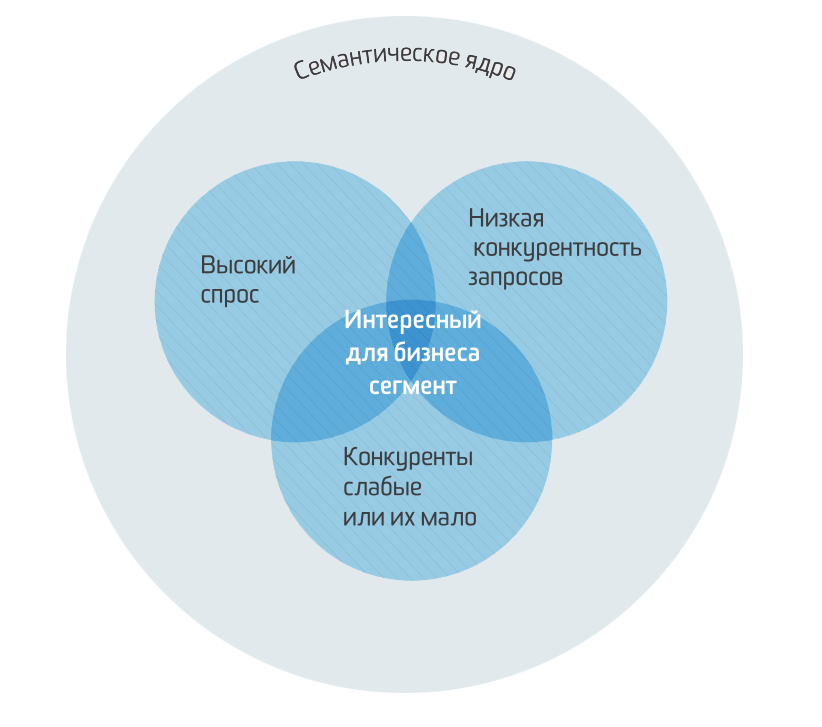 , Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005)
, Мотта, Э., Бенджаминс, В.Р., Мусен, М.А. (ред.) ISWC 2005. LNCS, vol. 3729, стр. 262–276. Спрингер, Гейдельберг (2005) С.: Роль вопросов компетентности в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994)
С.: Роль вопросов компетентности в проектировании предприятия. В: Труды IFIP WG5, vol. 7, стр. 212–221 (1994) 1032–1043. ИИЭР (2004)
1032–1043. ИИЭР (2004) Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012)
Ф., Ноблок, К., Крегер, П., Танин, Э., Видмайер, П. (ред.) SIGSPATIAL 2012 Международная конференция по достижениям в области географических информационных систем (ранее известная как ГИС), SIGSPATIAL 2012, Редондо Бич, Калифорния, США, 7-9 ноября, стр. 578–581. АКМ (2012) «>
«>Li, X., Claramunt, C., Ray, C., Lin, H.: семантический подход к представлению данных о траекториях, ограниченных сетью. В: Ридл, А., Кайнц, В., Элмс, Г.А. (ред.) Прогресс в обработке пространственных данных, стр. 451–464. Спрингер (2006)
Google ученый
 «>
«>Ни, Л., Лю, Ю., Лау, Ю., Патил, А.: LANDMARC: определение местоположения в помещении с использованием активной RFID. Беспроводные сети 10(6), 701–710 (2004 г.)
CrossRef Google ученый
 «>
«>Вазиргианнис М., Вольфсон О.: Пространственно-временная модель и язык для перемещения объектов по дорожным сетям. В: Дженсен, К.С., Шнайдер, М., Сигер, Б., Цотрас, В.Дж. (ред.) SSTD 2001. LNCS, vol. 2121, стр. 20–35. Спрингер, Гейдельберг (2001)
Перекрёстная ссылка Google ученый
 В: Риго, П., Сенелларт, П. (ред.) Материалы семинара докторантуры VLDB 2009. Совместно с 35-й Международной конференцией по очень большим базам данных (VLDB 2009), Лион, Франция, 24 августа. Фонд VLDB (2009)
В: Риго, П., Сенелларт, П. (ред.) Материалы семинара докторантуры VLDB 2009. Совместно с 35-й Международной конференцией по очень большим базам данных (VLDB 2009), Лион, Франция, 24 августа. Фонд VLDB (2009)Скачать ссылки
Шаблоны зависимостей сложных предложений и семантическое устранение неоднозначности для разбора представления абстрактного значения
Юки Ямамото, Юдзи Мацумото, Taro Watanabe
Abstract
Abstract Meaning Representation (AMR) — это представление значения на уровне предложения, основанное на структуре аргумента предиката. Одна из проблем, с которыми мы сталкиваемся при синтаксическом анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные модели сложных предложений и соответствующие описания УПП будут обнародованы.
Одна из проблем, с которыми мы сталкиваемся при синтаксическом анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные модели сложных предложений и соответствующие описания УПП будут обнародованы.- Anthology ID:
- 2021.starsem-1.20
- Volume:
- Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics
- Month:
- August
- Year:
- 2021
- Адрес:
- онлайн
- Место проведения:
- *SEM
- SIG:
- SIGSEM
- Издатель:
- Ассоциация для вычислительной лингвистики
- :
- . 0251
- 212–221
- .
- Процитируйте (ACL):
- Юки Ямамото, Юдзи Мацумото и Таро Ватанабэ. 2021. Шаблоны зависимостей сложных предложений и семантическое устранение неоднозначности для анализа представления абстрактного значения. In Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics , страницы 212–221, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициальный):
- Шаблоны зависимостей сложных предложений и семантическое устранение неоднозначности для разбора представления абстрактного значения (Ямамото и др., *SEM 2021)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2021.starsem-1.20.pdf
 0251
0251PDF Процитировать Поиск
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированная
@inproceedings{yamamoto-etal-2021-dependency,
title = "Шаблоны зависимостей сложных предложений и семантическое устранение неоднозначности для анализа {A}абстрактного {M}значения {R}представления",
автор = "Ямамото, Юки и
Мацумото, Юдзи и
Ватанабэ, Таро».
booktitle = "Материалы *SEM 2021: Десятая совместная конференция по лексической и вычислительной семантике",
месяц = август,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.starsem-1.20",
doi = "10.18653/v1/2021.starsem-1.20",
страницы = "212--221",
abstract = "Abstract Meaning Representation (AMR) – это представление значения на уровне предложения, основанное на структуре аргумента предиката. Одна из проблем, с которыми мы сталкиваемся при анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части В такой задаче может быть полезно заранее изучить структуру предложения. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления шаблонов все вхождения конструкций сложных предложений извлекаются из входное предложение. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ.Разработанные сложные шаблоны предложений и соответствующие описания AMR будут быть обнародованы.»,
}
 booktitle = "Материалы *SEM 2021: Десятая совместная конференция по лексической и вычислительной семантике",
месяц = август,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.starsem-1.20",
doi = "10.18653/v1/2021.starsem-1.20",
страницы = "212--221",
abstract = "Abstract Meaning Representation (AMR) – это представление значения на уровне предложения, основанное на структуре аргумента предиката. Одна из проблем, с которыми мы сталкиваемся при анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части В такой задаче может быть полезно заранее изучить структуру предложения. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления шаблонов все вхождения конструкций сложных предложений извлекаются из входное предложение.
booktitle = "Материалы *SEM 2021: Десятая совместная конференция по лексической и вычислительной семантике",
месяц = август,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.starsem-1.20",
doi = "10.18653/v1/2021.starsem-1.20",
страницы = "212--221",
abstract = "Abstract Meaning Representation (AMR) – это представление значения на уровне предложения, основанное на структуре аргумента предиката. Одна из проблем, с которыми мы сталкиваемся при анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части В такой задаче может быть полезно заранее изучить структуру предложения. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления шаблонов все вхождения конструкций сложных предложений извлекаются из входное предложение. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ.Разработанные сложные шаблоны предложений и соответствующие описания AMR будут быть обнародованы.»,
}
Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ.Разработанные сложные шаблоны предложений и соответствующие описания AMR будут быть обнародованы.»,
}
<моды> <информация о заголовке> Шаблоны зависимостей сложных предложений и семантическое устранение неоднозначности для синтаксического анализа представления абстрактного значения <название типа="личное">Юки Ямамото <роль>автор <название типа="личное">Юдзи Мацумото <роль>автор <название типа="личное">Таро Ватанабэ <роль>автор <информация о происхождении>2021-08 текст <информация о заголовке> Материалы *SEM 2021: Десятая объединенная конференция по лексической и вычислительной семантике <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Абстрактное представление значения (AMR) — это представление значения на уровне предложения, основанное на структуре аргумента-предиката. yamamoto-etal-2021-dependency 10. <местоположение>https://aclanthology.org/2021.starsem-1.20 <часть> <дата>2021-08 <единица экстента="страница">212 <конец>221
 Одна из проблем, с которыми мы сталкиваемся при синтаксическом анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные шаблоны сложных предложений и соответствующие им описания УПП будут обнародованы.
Одна из проблем, с которыми мы сталкиваемся при синтаксическом анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами. Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные шаблоны сложных предложений и соответствующие им описания УПП будут обнародованы. 18653/v1/2021.starsem-1.20
18653/v1/2021.starsem-1.20%0 Материалы конференции Шаблоны зависимостей %T сложных предложений и семантическое устранение неоднозначности для синтаксического анализа представления абстрактного значения %A Ямамото, Юки %A Мацумото, Юдзи %A Ватанабэ, Таро %S Материалы *SEM 2021: Десятая совместная конференция по лексической и вычислительной семантике %D 2021 %8 августа %I Ассоциация компьютерной лингвистики %С онлайн %F yamamoto-etal-2021-зависимость %X Представление абстрактного значения (AMR) — это представление значения на уровне предложения, основанное на структуре аргумента предиката. Одна из проблем, с которыми мы сталкиваемся при синтаксическом анализе AMR, заключается в том, чтобы зафиксировать структуру сложных предложений, которая выражает отношение между предикатами.
 Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные модели сложных предложений и соответствующие описания УПП будут обнародованы.
%R 10.18653/v1/2021.starsem-1.20
%U https://aclanthology.org/2021.starsem-1.20
%U https://doi.org/10.18653/v1/2021.starsem-1.20
%Р 212-221
Знание основной части структуры предложения заранее может быть полезным в такой задаче. В этой статье мы представляем список шаблонов зависимостей для конструкций сложных предложений английского языка, предназначенных для разбора AMR. С помощью специального средства сопоставления с образцом все вхождения сложных конструкций предложений извлекаются из входного предложения. Хотя некоторые из подчиненных имеют семантическую неоднозначность, мы решаем эту проблему путем обучения моделей классификации на данных, полученных из AMR и корпуса Википедии, устанавливая новую основу для будущих работ. Разработанные модели сложных предложений и соответствующие описания УПП будут обнародованы.
%R 10.18653/v1/2021.starsem-1.20
%U https://aclanthology.org/2021.starsem-1.20
%U https://doi.org/10.18653/v1/2021.starsem-1.20
%Р 212-221
Markdown (неофициальный)
[Шаблоны зависимости сложных предложений и семантическое устранение неоднозначности для анализа представления абстрактного значения] (https://aclanthology.