Что такое семантическое ядро сайта, зачем и как его собирать
Поисковое продвижение – залог присутствия вашего сайта в выдачах Яндекс или Google. Так вы получите потенциальных посетителей и клиентов. Чтобы это работало, сайту нужно семантическое ядро и страницы, содержащие запросы из него. Остановимся также на тонкостях и сервисах, помогающих в работе с ключевыми словами. Но обо всем по порядку.
Содержание
- Что такое семантическое ядро
- Какими бывают ключевые слова
- Из чего состоит поисковый запрос
- Как подбираются ключевые слова для семантического ядра
- Кластеризация запросов по смысловым группам
- Ошибки в работе с семантическим ядром
- Сервисы для упрощения работы с семантическим ядром
- Еще немного рекомендаций по работе с ключевыми словами
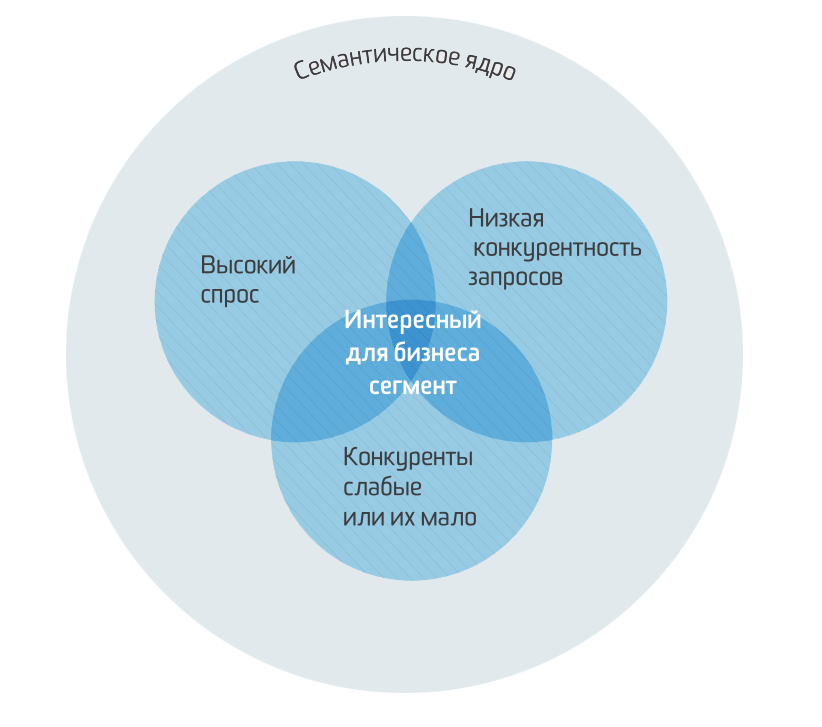
Что такое семантическое ядро
Семантическое ядро – это ключевые слова и словосочетания по тематике вашего проекта, которыми пользуется аудитория для поиска информации.
Результат сбора семантического ядра – это список ключевых слов, разделенный по группам для всех значимых страниц сайта – кластерам. В итоге у вас должен быть адрес страницы, перечень поисковых запросов для нее и необходимое количество их использований на странице.
Залог успешного продвижения – в том, чтобы люди вас находили в органических результатах поиска в Яндексе или Google. Будет ли ваш сайт там, зависит на первом этапе SEO-работ от того, насколько хорошо составлено семантическое ядро.
Что важно помнить:
- Семантическое ядро соответствует смысловому наполнению сайта. На страницах вашего ресурса пользователь должен находить ответ на свой вопрос.
- Клиентоориентированность важна не только в общении с покупателем, в сервисе или техподдержке.
 В поисковых запросах и заявленной пользе – тоже. Исходите из того, как информацию ищет большинство пользователей, а не из своего представления об этом.
В поисковых запросах и заявленной пользе – тоже. Исходите из того, как информацию ищет большинство пользователей, а не из своего представления об этом. - Весь набор ключевых слов и словосочетаний распределяется по страницам. Каждый раздел максимально релевантен кластеру. Это взаимосвязанные вещи.
 В поисковых запросах и заявленной пользе – тоже. Исходите из того, как информацию ищет большинство пользователей, а не из своего представления об этом.
В поисковых запросах и заявленной пользе – тоже. Исходите из того, как информацию ищет большинство пользователей, а не из своего представления об этом.Если вы планируете создание сайта, используйте анализ поисковых запросов еще на старте. Так ваш ресурс, его архитектура и иерархия будут определяться семантическим ядром.
Чаще сбор семантического ядра осуществляется для уже готового сайта. Тогда все множество ключевых слов будет распределено по готовой структуре с учетом имеющихся и планируемых страниц.
Поделимся соображениями на эту тему. Мы считаем, что первична именно структура сайта, а затем уже собирается семантическое ядро. На первом месте должно находиться то, что вы хотите донести, а на втором – как.
Если исходить из первичности семантического ядра, то структура сайта может оказаться далека от потребностей бизнеса и целевой аудитории. В этом случае сложнее меняться под динамичные условия среды, в которой вы работаете, вести конкурентную борьбу. Актуальность и эффективность ключевых фраз меняется и перекраивать в зависимости от этого весь сайт – трудозатратно. Проще подстроить семантику под ресурс.
В этом случае сложнее меняться под динамичные условия среды, в которой вы работаете, вести конкурентную борьбу. Актуальность и эффективность ключевых фраз меняется и перекраивать в зависимости от этого весь сайт – трудозатратно. Проще подстроить семантику под ресурс.
Определитесь, о чем вы будете говорить на своем сайте. Для этого изучайте своих конкурентов и нишу. Затем создайте примерную структуру сайта и перечень страниц, которые вам нужны. Далее, составляя семантическое ядро, вы поймете, как целевая аудитория ищет информацию о вас, и уточните список необходимых страниц.
В результате надо убедиться, что предложенный контент будет релевантным: он должен давать ответы на вопросы целевой аудитории по ключевым словам, которые вы определили для каждой страницы.
Какими бывают ключевые слова
Прежде чем начинать работу с семантическим ядром, рассмотрим виды запросов. Есть несколько классификаций, и все они важны.
По частотности
Выделяют три основные группы:
- низкочастотные, НЧ – такие, которые имеют до 100-1000 показов в месяц, то есть пользователи ищут по этим словам не слишком часто;
- среднечастотные, СЧ – имеющие до 1000-5000 показов в месяц;
- высокочастотные, ВЧ – от 1000, 5000 или даже 10 000 показов в месяц.

Почему такой разбег по минимальному количеству показов в месяц? Все зависит от тематики, для которой составляется семантическое ядро. Частотность запроса «купить смартфон самсунг», например, велика. В нише электроники огромная конкуренция, потому что много запросов и продавцов:
Результаты Яндекс.Вордстат по ключу «купить смартфон самсунг» (вся Россия)
При этом ключ «купить доску евминова» по тому же региону и параметрам будет уже совсем другой и 1000 показов будет означать уже СЧ или ВЧ-запрос.
Результаты Яндекс.Вордстат по запросу «купить доску евминова» (вся Россия)
Важно:
- ⅔ запросов в семантическом ядре будут низкочастотными: по них легче продвигаться и они обычно дают лучшую конверсию.
- ВЧ и СЧ-запросы не отбрасываем. Важно все, но низкочастотные дадут вам максимум целевых пользователей.
По потребностям
- Транзакционные. «Купить ноутбук», «заказать такси», «скачать книгу» – это транзакционные вопросы, отражающие готовность пользователя к действию.
- Информационные. Все, что связано с поиском сведений на определенную тему: «как создать свой сайт», «как запустить таргетированную рекламу», «как избавиться от тараканов» и другие. Здесь нет желания купить – только найти информацию.
- Другие, где мотивация пользователя не ясна. Допустим, он пишет в строке поиска «рыба». Что ему нужно? Узнать, как ее приготовить или где купить? Возможно, его поиск связан с желанием узнать характеристики водных животных определенного вида или вовсе найти шаблоны документов.

Что дает понимание потребностей пользователя в запросах? Так мы узнаем, какой именно должна быть целевая страница, отвечающая на введенное словосочетание. Для информационного – статья, обзор или инструкция. Для транзакционного – страница с категорией или конкретным товаром.
Не забываем, что в транзакционные запросы входят коммерческие. Если у вас небольшой интернет-магазин, то по словосочетанию «купить ноутбук сяоми», вы будете соперничать с гигантами рынка в нише электроники. Поэтому ваше семантическое ядро должно основываться именно на средне- и низкочастотниках, чтобы не вести неравную борьбу с соперниками совершенно другого уровня.
Поэтому ваше семантическое ядро должно основываться именно на средне- и низкочастотниках, чтобы не вести неравную борьбу с соперниками совершенно другого уровня.
Как снижается частотность? Уточнениями в запросе. Например, ключ с указанием модели «купить ноутбук сяоми редми бук» имеет частотность ниже, чем ключевая фраза с упоминанием одного только бренда.
Из чего состоит поисковый запрос
В нем несколько составляющих: тело, спецификатор и хвост. Например, в ключе «купить цветы с доставкой» телом будет слово «цветы», спецификатором – «купить», а хвост – «с доставкой».
Тело
Запрос «цветы» не отражает намерений пользователя и является высокочастотным с выраженной конкуренцией в поисковой выдаче. Если использовать только его, получите много нецелевого трафика. Пользователи будут приходить с разными потребностями. Одна страница не способна соответствовать им всем одновременно. Это увеличит процент уходов со страницы – отказов, ухудшит поведенческие факторы сайта, а из-за этого ресурс может оказаться ниже в результатах поиска.
Ключевые слова, состоящие только из тела, всегда неспецифичны и высокочастотны.
Тело+спецификатор
Рассмотрим запрос «купить цветы». По спецификатору понятно – он транзакционный, а не информационный. Отличие от информационных запросов «букет цветов» или «комбинации цветов» очевидно.
Тело+спецификатор+хвост
В таком запросе хвост уточняет намерение пользователя или его потребность. Вариантов много: «купить цветы онлайн», «купить цветы в Самаре с доставкой», «купить живые цветы в Казани» и подобные. В каждом из них видим желание купить определенный товар, а в хвосте – уточнение, как, где или при каких условиях.
Что нам дает структура ключевых запросов?
На основе этого вы выделяете слова и понятия, связанные с вашим бизнесом, товаром/услугой, потребностями аудитории. Например, клиенты строительной компании ищут следующее: фундамент, отделка, строительство под ключ, блочный дом, деревянный дом и др.
После определения основных слов вы переходите к спецификаторам и хвостам по каждому из них. Так вы сделаете семантическое ядро приемлемо конкурентным для себя, одновременно увеличивая охват целевых пользователей, которые ищут именно то, что вы предлагаете.
Так вы сделаете семантическое ядро приемлемо конкурентным для себя, одновременно увеличивая охват целевых пользователей, которые ищут именно то, что вы предлагаете.
Как подбираются ключевые слова для семантического ядра
Сначала вы определяете базовые ключевые слова. Затем расширяете имеющееся семантическое ядро. В итоге удаляете те запросы, которые вам не нужны.
- Базовые поисковые слова пропишите в отдельном файле списком. Подключите к этому коллег. Записывайте все, что приходит в голову. На этом этапе у вас будут в основном высокочастотные запросы с низкой специфичностью. Для получения СЧ и НЧ расширяем ядро.
- Расширить семантическое ядро вам помогут дополнительные инструменты, например, Яндекс.Вордстат. Обратите внимание на географию и выбирайте регионы, актуальные для вашего бизнеса. Проверяйте в сервисе каждый записанный ключ и копируйте себе в таблицу ключевых слов всю левую колонку.
В правой колонке Яндекс.Вордстат будут запросы с теми словами, которые люди использовали с основным ключом. Копируйте подходящие в свою таблицу или весь список разом: так у каждого базового ключа появится список «дополнительных».
Копируйте подходящие в свою таблицу или весь список разом: так у каждого базового ключа появится список «дополнительных».
- Удаляем лишние словосочетания:
- содержащие информацию о конкуренте;
- с упоминанием товаров/услуг, которые вы не продаете;
- демпингующие, включающие слова «дешево», «недорого» и подобные;
- дубли;
- геоключи с неподходящими регионами;
- запросы с ошибками и опечатками.
Даже при работе с сервисами по организации семантического ядра вам надо понимать, по какому принципу отбираются запросы, и контролировать качество всего списка и кластеров.
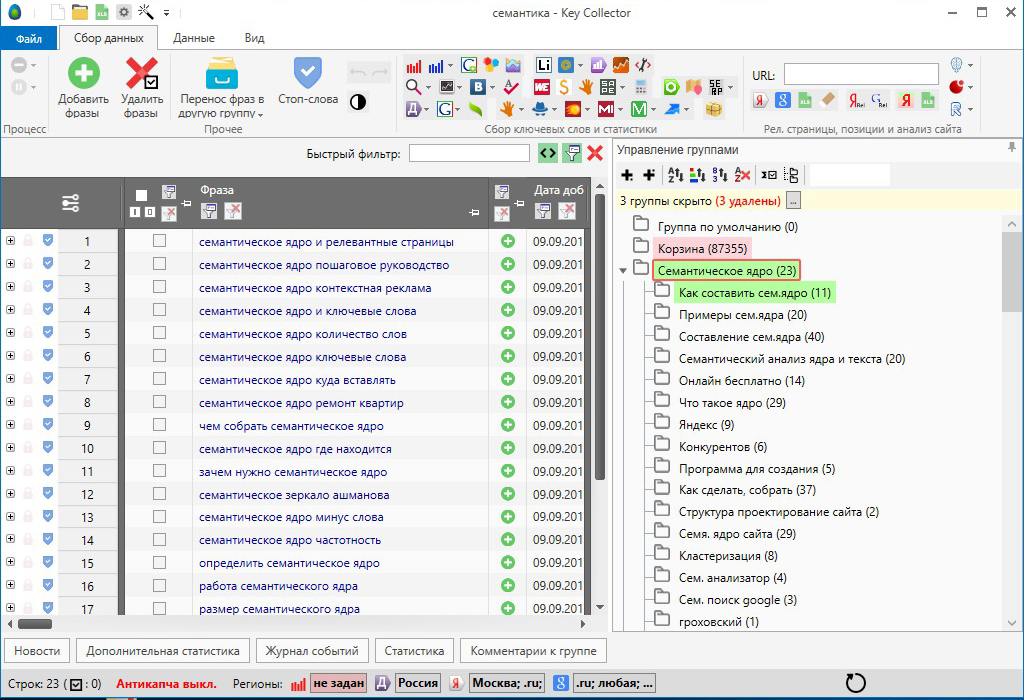
Яндекс.Вордстат – незаменимый инструмент для того, кто собирает семантическое ядро для небольшого сайта или отдельных страниц. Но если речь о многостраничном ресурсе или большом портале, рекомендуем обратиться за помощью к профессионалу. Специалист для подбора поисковых фраз использует инструменты другого уровня: KeyCollector, A-parser и подобные.
Когда работает SEO-специалист, вам не нужно контролировать процесс. Все автоматические и ручные операции он сделает за вас и представит уже готовый результат. Вы будете получать наглядные отчеты с динамикой роста трафика:
Пример отчета iTargency по поисковому продвижению сайта клиента
Кластеризация запросов по смысловым группам
Теперь время распределить весь список на тематические группы.
Кластер – это группы запросов, которые объединены по смыслу. Например, у интернет-магазина будет отдельный кластер поисковых словосочетаний для страницы о микроволновках и отдельный – для раздела об утюжках для волос. Не объединяйте такие запросы в один список, иначе страница перестанет быть релевантна запросу человека, которому нужны именно микроволновки.
Кластеры будут нескольких уровней, поскольку не все из них можно объединить в один. Все, что вы записали в начале, – это кластеры первого уровня. Они продиктованы структурой сайта в том числе. Дальше идет работа с кластерами второго уровня. «Идеи букетов» и «букеты на заказ» – это информационный и коммерческий запросы соответственно. Дополнительные поисковые фразы по ним подскажет Яндекс.Вордстат (левая и правая колонка). Дальше все ключи надо разделить по смыслу на кластеры и их распределить по страницам раздела «Букеты». Если подходящей страницы нет, ее нужно создать.
Все, что вы записали в начале, – это кластеры первого уровня. Они продиктованы структурой сайта в том числе. Дальше идет работа с кластерами второго уровня. «Идеи букетов» и «букеты на заказ» – это информационный и коммерческий запросы соответственно. Дополнительные поисковые фразы по ним подскажет Яндекс.Вордстат (левая и правая колонка). Дальше все ключи надо разделить по смыслу на кластеры и их распределить по страницам раздела «Букеты». Если подходящей страницы нет, ее нужно создать.
Например, если в нашем списке есть запрос «букет из гортензий», то в разделе «Букеты» надо создать такую страницу. Новый раздел включается в структуру сайта с названием, адресом и поисковыми фразами.
Отдельно посмотрите, как еще пользователи ищут букеты с гортензиями в поиске, используя Вордстат.
Когда в списке несколько тысяч ключевых запросов, помогают сервисы KeyAssort, SerpStat и другие. С ними кластеризация ключевых слов будет проще и быстрее.
Важно. Для страницы, которую вы хотите создать, нет кластера с запросами? Ничего страшного. Если у вас есть продукт, посмотрите, как его ищут. Используйте тот же Яндекс.Вордстат и ориентируйтесь на ключи, что есть в обеих колонках.
Если у вас есть продукт, посмотрите, как его ищут. Используйте тот же Яндекс.Вордстат и ориентируйтесь на ключи, что есть в обеих колонках.
Также после кластеризации могут остаться лишние ключи. Не удаляйте их. Возможно, они пригодятся для раздела «Статьи», где тематики шире.
Ошибки в работе с семантическим ядром
Рассказать о частых погрешностях бизнесменов и специалистов мы попросили Дмитрия Медведева, ведущего специалиста по SEO-продвижению iTargency:
«Главная ошибка – неправильная группировка ключей по целевым страницам. Порой информационный ключевик начинают продвигать на коммерческой странице. Идет неправильное объединение по интентам (намерениям пользователя).
Например, наш опыт показывает, что запрос «смартфоны» коммерческий, а «смартфон» — информационный. Различие неочевидно. Да, есть сервисы, которые показывают, коммерческий он или нет. Например, мы используем Пиксель Тулс. Для запросов по смартфонам мы видим следующее:
К сожалению, разница очевидней не стала.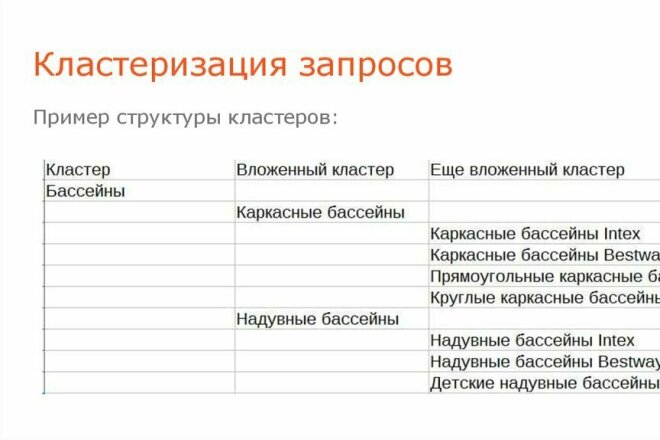 Поэтому дальше мы вынуждены проверять выдачу Яндекса вручную. Здесь видим, что на один запрос нам предлагаются информационные материалы, а на другой — коммерческие. Приходится вручную разбираться, какой запрос перед нами».
Поэтому дальше мы вынуждены проверять выдачу Яндекса вручную. Здесь видим, что на один запрос нам предлагаются информационные материалы, а на другой — коммерческие. Приходится вручную разбираться, какой запрос перед нами».
Сервисы для упрощения работы с семантическим ядром
При составлении семантического ядра для сайта пользуются и системами аналитики: Яндекс.Метрикой и Google Analytics. Они помогут вам определить фразы, по которым аудитория приходит на сайт.
Выглядит это так:
Пример статистики в Яндекс.Метрике поисковых запросов, по которым пользователи приходят на сайт
В сборе семантического ядра вам помогут автоматические инструменты. Например: KeyCollector, A-parser, Word-Keeper, SpyWords. Последний помогает анализировать домены в топе выдачи, а также расширять и дополнять семантическое ядро.
Подбор ключевых слов в KeyCollector
Анализируйте сайты конкурентов по ключевым запросам. Так вы не упустите важную семантику. Для этого пригодится SpyWords и подобные.
Для этого пригодится SpyWords и подобные.
Еще немного рекомендаций по работе с ключевыми словами
Это полезно знать каждому бизнесмену и специалисту. Прочтите перед началом работы с семантическим ядром:
- Не выбрасывайте ключевые запросы просто так. Ориентируйтесь на высококонкурентные, но не ставьте цели безусловно попасть в топ.
- Активно работайте с низкочастотными ключами. Они приведут ваш целевой трафик. В случае больших сайтов лучше обратиться за помощью к SEO-специалистам.
- Ключевые запросы работают с разной эффективностью. Это нормально.
- Полностью автоматизировать работу с семантическим ядром невозможно. Его должен оценивать живой специалист, который будет контролировать список и кластеры вручную. Сервисы несовершенны.
- Не ставьте себе цели на старте собрать абсолютно все ключевые слова. Большая часть придет сразу. Остальные по анализу конкурентов или другими способами получите позже, когда будете искать новые идеи и расширять семантическое ядро.

Этим и завершим наш материал. Будем рады помочь в составлении семантического ядра и комплексном SEO-продвижении вашего проекта!
что это и как составлять (+ видеоинструкция)
Навигация:
- Что такое семантическое ядро для сайта
- Как собрать семантическое ядро (текстовая инструкция)
- Как собрать семантическое ядро (видеоинструкция)
Что такое семантическое ядро
Семантическое ядро – это упорядоченный список слов, который выглядит как запросы пользователей в поисковых системах (Яндекс, Google, Bing, Поиск Mail.ru).
У профессиональных SEO-специалистов семантическое ядро содержит более 1000 слов. Все слова – это ключевые запросы, которые пользователи вбивают в поисковые системы, ожидая увидеть какой-то интересующих их ответ.
SEO-специалист не придумывает все ключевые слова, все они доступны в сервисе Яндекс Вордстат. Специалист лишь берет их оттуда. Чуть ниже, в практической части, мы познакомимся с этим сервисом.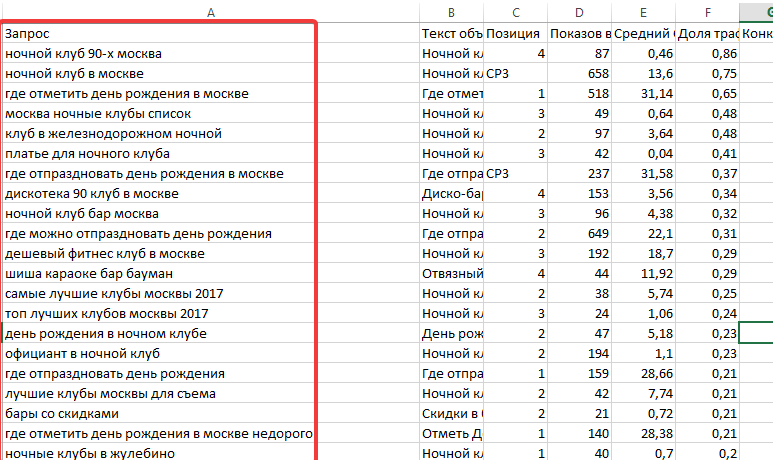
Еще важное понятие – кластеризация. Это процесс группировки ключевых слов в семантическом ядре по какому-либо принципу. Например, постранично (скриншот ниже).
Каждый такой сгруппированный мини-список называют кластером. В идеальном случае семантическое ядро состоит из десятков кластеров, которые бережно собраны SEO-специалистом.
Как собрать семантическое ядро (текстовая инструкция)
Все довольно просто, но не без подводных камней. Поэтому давайте по-порядку.
Теория
Перед сбором семантического ядра для сайта важно понимать, что ВСЕ ключевые слова имеют частотность употребления. Поэтому ключевые слова делятся SEO-специалистами на 3 группы.
Высокочастотные – слова, которые ежедневно запрашивают пользователи тысячи раз в день. Например, “купить телевизор”.
Среднечастотные – слова, которые ежедневно запрашивают пользователи сотни раз в день. Например, “купить телевизор LG в Екатеринбурге”
Например, “купить телевизор LG в Екатеринбурге”
Низкочастотные – слова, которые ежедневно запрашивают пользователи десятки раз в день. Например, “купить телевизор LG 43uk6300plb”
Что делать с этой информацией?
Для начала запомнить.
Во-первых, SEO-специалисты иногда кластеризируют свое семантическое ядро для сайта по этому признаку.
Во-вторых, чем запрос высокочастотней, тем его сложнее продвигать из-за конкуренции. Низкочастотные запросы могут “продвинуться сами”, им лишь нужна хорошая техническая оптимизация сайта.
В-третьих, из-за таких особенностей низкочастотные запросы добавляют в товары сайта (максимально конкретная модель телевизора), среднечастотные располагают в родительских категориях (страница с телевизорами LG), а самые высокочастотные – на главной (страница с общим списком телевизоров всех марок).
Поэтому перед сбором семантического ядра определитесь, куда будете “сажать” свои ключевые запросы.
Практика (пример на любимых телевизорах)
В примере ниже, при сборе своего семантического ядра для сайта, мы будем отталкиваться от всех вышеописанных критериев. И еще, в примере мы будем использовать браузер Google Chrome и плагин Wordstat Assistant к нему. Вы можете все собирать вручную или тоже установить данный плагин бесплатно, и ускорить процесс сборки.
1.Заходим в Яндекс Wordstat. Надеемся, Вы уже определились, на какую страницу будете собирать семантическое ядро. Мы же будем показывать все на уже типичных для нас “телевизорах”. Представим, нам нужно собрать семантику для страницы, где располагаются все телевизоры бренда LG.
2. Вбиваем запросы “купить телевизор LG”. И начинаем выбирать запросы. “Плюсик” добавляет запросы к Вам в список, который одним кликом можно скопировать в буфер обмена и перенести в удобное место.
Как видите, мы выбрали 8 запросов. Первый – это наш основной, поэтому по остальным 7 давайте мы обоснуем наш выбор.
“купить телевизор lg в Москве” – допустим, наш интернет-магазин имеет магазин/склад в этом городе.
“телевизор lg смарт тв купить” – допустим, в нашем интернет-магазине, именно на этой странице, есть смарт телевизоры LG.
“купить lg телевизор цены” – потому что на данной странице сайта есть цены.
“купить телевизор lg 55 дюймов” – допустим, в нашем интернет-магазине, именно на этой странице, есть телевизоры LG 55 дюймов.
“купить телевизор lg 4k ultra hd” – допустим, в нашем интернет-магазине, именно на этой странице, есть 4K телевизоры LG.
“купить хороший телевизор lg” – просто потому, что наши телевизоры LG хорошие.
“купить 3d телевизор lg” – допустим, в нашем интернет-магазине, именно на этой странице, есть 3D телевизоры LG.
Далее жмем на “два листочка бумаги” (где панель плагина слева, рядом с большим плюсом), копируем все, что у нас получилось и сохраняем в документе. На этом все, Вы собрали первый кластер. Продолжайте в том же духе, через пару часов семантическое ядро будет куда больших размеров, чем сейчас. Если есть еще вопросы, посмотрите видео инструкцию.
Как собрать семантическое ядро (видеоинструкция)
Для тех, кому проще один раз увидеть чем сто раз услышать (или прочитать).
Понимание компонентов семантического уровня dbt
TLDR: семантический уровень состоит из комбинации предложений с открытым исходным кодом и SaaS и изменит то, как ваша команда определяет и использует метрики.
На прошлогоднем Coalesce Дрю показал нам будущее 1 — видение того, как могут выглядеть показатели в dbt. С тех пор мы создаем инфраструктуру, чтобы воплотить это видение в реальность. Мы хотели поделиться с вами тем, где мы находимся сегодня и как это вписывается в более широкую картину того, куда мы идем.
Для тех, кто не следил за этой сагой с таким вниманием, как кто-то следит за своими инвестициями на рынке криптовалют, мы запускаем этот новый ресурс, чтобы помочь вам лучше понять семантический уровень dbt и предоставить разъяснения по следующим вещам:
- Что такое семантический слой dbt?
- Как его использовать?
- Что сейчас общедоступно?
- Что еще находится в разработке?
Итак, приступим!
Некоторые из вас, возможно, были рядом, когда это изначально называлось уровнем показателей.
 Когда мы оценили долгосрочные планы того, чем должна была стать эта часть dbt, мы поняли, что название «Семантический слой» лучше отражает его возможности и то, где мы планируем его использовать.
Когда мы оценили долгосрочные планы того, чем должна была стать эта часть dbt, мы поняли, что название «Семантический слой» лучше отражает его возможности и то, где мы планируем его использовать.Семантический уровень dbt — это новая часть dbt, помогающая повысить точность и согласованность при одновременном расширении гибкости и возможностей современного стека данных. Наш маэстро метрик, Дрю Банин, опубликовал запись в блоге, в которой подробно изложил свое видение того, куда мы идем. Первый вариант использования, который мы рассматриваем, — это тот, который большинство практиков 9Заинтересованные стороны 0029 и знакомы с метриками. Далее в этом посте мы рассмотрим, как это выглядит на практике.
Под капотом семантический уровень dbt представляет собой набор нескольких компонентов — некоторые из них являются частью dbt Core, некоторые частью dbt Cloud, а некоторые представляют собой новые функциональные возможности. Все они объединяются вместе, как Voltron, чтобы создать единый интерфейс, с помощью которого бизнес-пользователи могут запрашивать данные в контексте наиболее знакомой им метрики. И самое приятное то, что они могут делать это в системах, которые им уже удобно использовать.
И самое приятное то, что они могут делать это в системах, которые им уже удобно использовать.
Как это будет выглядеть для моих потребителей данных и заинтересованных сторон?
В конечном итоге это выглядит так, что люди могут взаимодействовать с надежными наборами данных в удобных для них инструментах (и, в конечном итоге, в новых инструментах, разработанных специально для метрик).
Примером, который мы нашли полезным, является ARR. Критическая для бизнеса метрика для SaaS-компаний, ARR может быть сложным расчетом, чтобы обеспечить согласованность для всех инструментов, используемых в бизнесе. С семантическим уровнем dbt это определение будет жить в dbt, и логика создания набора данных для этой метрики будет единой для всех различных способов потребления. Лучше всего то, что изменения определения будут отражаться в нижестоящих инструментах, поэтому вам больше не нужно вручную искать и обновлять каждую нижестоящую зависимость. Каллум трехлетней давности прыгает от радости.
Это хорошо и все такое, но как это выглядит для практикующих?
Семантический слой DBT состоит из следующих компонентов 2 :
Доступно сегодня
-
МетрикаNode в DBT Core: , схоже намоделиили. Истота DBT: ,моделиили. конкретный тип узла в dbt Core. Это определение агрегации временных рядов по таблице, которая поддерживает ноль или более измерений. Полученный узел сохраняется вmanifest.jsonточно так же, какмоделируети упоминается в DAG. -
Пакет dbt_metrics: Этот пакет содержит макросы, которые объединяют определение метрики с контролем версии и параметры времени запроса (такие как измерения, временной интервал и вторичные вычисления) для создания SQL-запроса, который вычисляет значение метрики. - API облачных метаданных dbt: API GraphQL, который поддерживает произвольные запросы к метаданным, созданным облачными заданиями dbt. Содержит метаданные, связанные с точностью, актуальностью, конфигурацией и структурой представлений и таблиц в хранилище, а также многое другое.
 Содержит метаданные, связанные с точностью, актуальностью, конфигурацией и структурой представлений и таблиц в хранилище, а также многое другое.
Содержит метаданные, связанные с точностью, актуальностью, конфигурацией и структурой представлений и таблиц в хранилище, а также многое другое.Новый
- Сервер dbt: этот компонент упаковывает ядро dbt в постоянный сервер, который отвечает за обработку запросов RESTful API для операций dbt. Это тонкий интерфейс, который в первую очередь отвечает за производительность и надежность в производственных средах.
- Прокси-сервер dbt Cloud: этот компонент позволяет dbt Cloud динамически переписывать запросы к хранилищу данных и компилировать dbt-SQL в необработанный SQL, понятный базе данных. Затем он возвращает набор данных, созданный необработанным SQL, на платформу, которая его отправила.
Понимание того, как и когда использовать метрики?
Давайте рассмотрим пример того, как вы можете использовать вышеперечисленные компоненты, чтобы начать работу с нашим старым другом — магазином Jaffle Shop.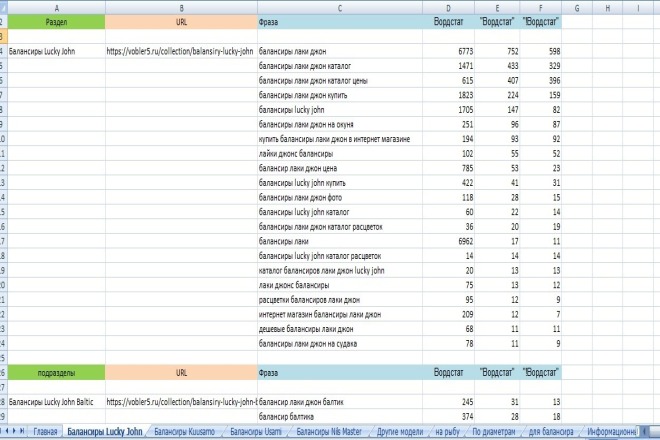 Мы рассмотрим, как вы можете начать определять и тестировать метрики сегодня, а также как вы будете взаимодействовать с ними после выпуска новых компонентов.
Мы рассмотрим, как вы можете начать определять и тестировать метрики сегодня, а также как вы будете взаимодействовать с ними после выпуска новых компонентов.
Когда использовать метрики
Первый вопрос, который вам нужно задать: Должны ли мы использовать метрики?
Мы считаем, что метрики не являются универсальным решением. Они предназначены для основных бизнес-показателей, где согласованность и точность имеют ключевое значение, а не для исследовательских вариантов использования или специального анализа. Наш сокращенный способ определить, должна ли метрика быть определена в dbt, был - , это то, о чем должны сообщать наши команды?
Итак, предположим, финансовый директор нашего Jaffle приходит к нам в понедельник утром и приказывает группе данных пересмотреть то, как мы отчитываемся о доходах. Наш региональный менеджер Джим и директор по продажам Пэм 3 давали ему разные отчеты! Прямо сейчас это беспорядок инструментов и несоответствий - числа Джима определены в Таблице и говорят одно, Пэм в Хексе и говорят другое! Финансовый директор недоволен этим и хочет, чтобы во всей компании была слаженная работа, где у всех были бы одинаковые цифры дохода. Он проходит тест отчета, это важная бизнес-метрика; понеслось!
Он проходит тест отчета, это важная бизнес-метрика; понеслось!
Определение метрики с помощью узла метрики
В этом примере мы скажем, что и Джим, и Пэм извлекают данные из таблицы, созданной dbt, с именем orders . В настоящее время он содержит поля для суммы и всех различных методов payment_amounts, таких как кредитные карты или подарочные карты. Джим вычислял доход, суммируя поля Credit_card_amount и gift_card_amount , так как он забыл обновить свое определение, когда компания добавила купоны и платежи банковским переводом. Между тем, Пэм правильно суммирует сумма поле, но не учитываются заказы на возврат, которые не должны учитываться!
Первым шагом является создание единого определения дохода. Для этого мы создадим следующее определение yml в нашем репозитории dbt:
версия: 2метрики:
- имя: доход
метка: доход
модель: ref('orders')
описание: "Всего выручка от нашего джеффл-бизнеса"тип: сумма
sql: суммаметка времени: order_date
time_grains: [день, неделя, месяц, год]размеры:
- customer_status
- has_coupon_payment
- has_bank_transfer_payment
- has_credit_card_payment
- has_gift_card_paymentoperator:
:
- field: status:
'completed'"
Этот показатель теперь определен в метаданных dbt и его можно увидеть в DAG!
Запуск пакета метрик Расчет метрики
Чтобы убедиться, что и Джим, и Пэм получают одни и те же числа для своей метрики, нам нужно, чтобы они оба выполнили запрос метрики для вычисления . В этом примере нас не интересуют конкретные типы платежей, а мы хотим увидеть доход, разделенный на
В этом примере нас не интересуют конкретные типы платежей, а мы хотим увидеть доход, разделенный на неделю и customer_status .
выберите *
из {{ metrics.calculate(
метрика('доход'),
зернистость='неделя',
размеры=['customer_status']
) }}
This would return a dataset that looks like this:
| date_week | customer_status | revenue |
|---|---|---|
| 2018-01-01 | Churn Risk | 43 |
| 2018-01-01 | Churned | 0 |
| 2018-01-01 | Healthy | 26 |
| 2018-01-08 | Churn Risk | 27 |
Jim and Pam would then be able to ссылка на столбец дохода во вновь созданном наборе данных, и вам никогда больше не придется беспокоиться о расчете дохода 4 ! Мир совершенен, и баланс восстановлен.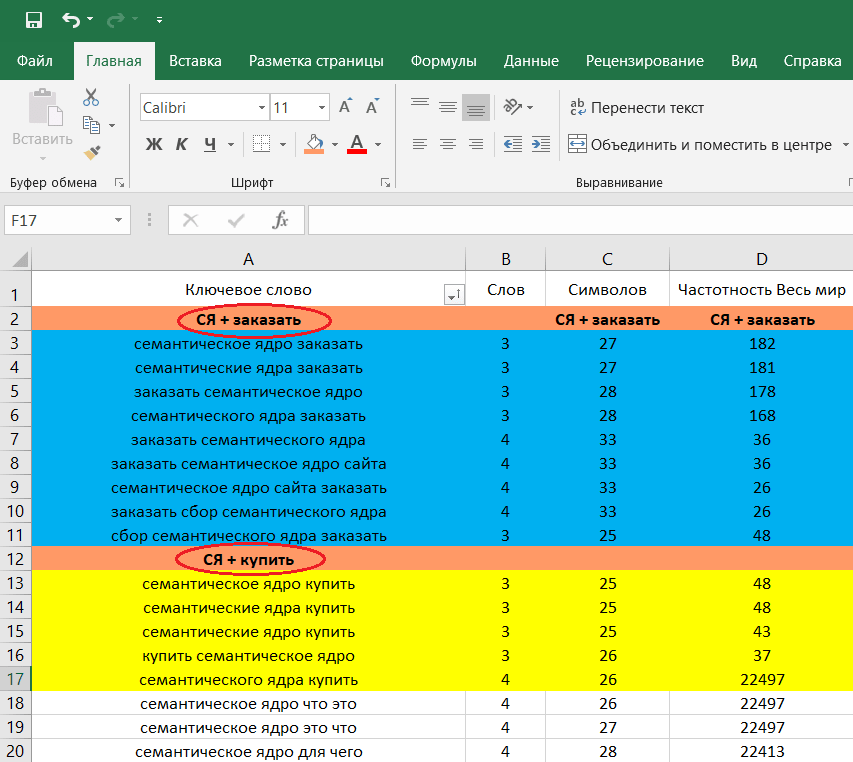
В ближайшем будущем с dbt Server
Когда dbt Server будет выпущен позднее в этом году, порядок использования метрик значительно изменится. Вашей организации больше не нужно материализовывать каждую метрику в модели, чтобы воспользоваться преимуществом определения метрики. Вместо этого вы сможете напрямую запросить сервер dbt с предоставленным кодом метрики и получить правильный набор данных, возвращенный выбранному вами инструменту BI.
Кроме того, партнеры по интеграции наработают опыт работы с метриками с помощью API метаданных, чтобы создать уникальные и творческие способы для потребителей получать данные метрик, абстрагируясь от сложности. Например, поле, которое позволяет пользователю выбирать из списка показатели, интервалы времени, измерения и вторичные вычисления, а затем получать правильную информацию независимо от выбора!
Итак, что сейчас общедоступно?
На данный момент два основных общедоступных компонента с открытым исходным0061 metric узел в dbt Core и пакет dbt_metrics . Вместе эти два компонента могут работать на вводном семантическом уровне, позволяя инженерам-аналитикам определять метрики, а затем запрашивать эти метрики через пакет метрик.
Вместе эти два компонента могут работать на вводном семантическом уровне, позволяя инженерам-аналитикам определять метрики, а затем запрашивать эти метрики через пакет метрик.
Эти два компонента представляют собой статический интерфейс, который необходимо определить в проекте dbt (поскольку выбранные измерения определяются при создании модели), но они полезны для тех, кто хочет обеспечить согласованность показателей во всех инструментах бизнес-аналитики. Если вы идентифицируете себя с любым из следующих условий, вы можете хорошо подойти для реализации этого в том виде, в каком он существует сегодня:
- Вы хотите подготовить свою организацию к полному запуску семантического уровня.
- В вашей организации есть как минимум несколько ключевых метрик
- В вашей организации используется 1 или несколько инструментов бизнес-аналитики
- В вашей организации иногда возникают проблемы, связанные с расчетом различных метрик
- Вашей организации требуется централизованное расположение для всех метрик, чтобы все в бизнесе знали, где посмотреть
Все это отличные причины, чтобы приступить к изучению внедрения метрик в ваш проект dbt! Если вам интересно, как может выглядеть реализация этого, мы рекомендуем обратиться к репозиторию jaffle_shop_metrics!
Что еще находится в разработке?
И облачный прокси-сервер dbt, и сервер dbt в настоящее время находятся в разработке, релиз запланирован на конец этого года.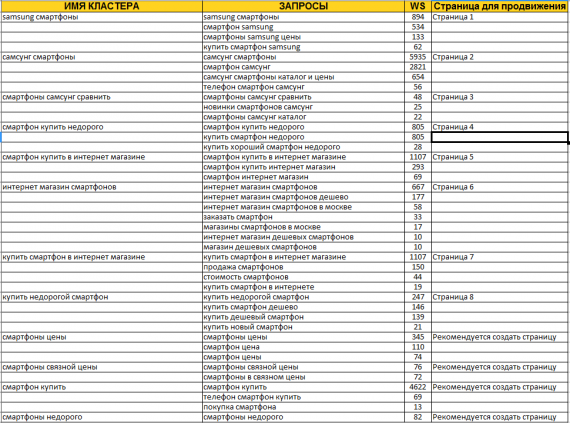 Если вам интересно протестировать их после их выпуска, мы рекомендуем следить за объявлениями о наших продуктах, а затем обращаться к ним, как только они станут общедоступными!
Если вам интересно протестировать их после их выпуска, мы рекомендуем следить за объявлениями о наших продуктах, а затем обращаться к ним, как только они станут общедоступными!
Что делать, если у меня есть вопросы?
Если у вас есть какие-либо вопросы об этих компонентах или метриках в целом, пожалуйста, не стесняйтесь размещать сообщения в канале #dbt-metrics-and-server на dbt Slack! Я слоняюсь там и всегда готов пообщаться с метриками!
Сноски
- В этом будущем, возможно, не упоминались роботы, но я держусь за утреннюю машину в стиле Джетсона, чтобы помочь мне собраться утром. ↩
- Мы специально призываем к лицензированию, потому что в сообществе много путаницы по поводу того, что является открытым исходным кодом, а что нет. Это становится только сложнее с введением лицензирования BSL, которое гарантирует, что пользователи могут запускать свой собственный сервер, но его нельзя продавать как облачный сервис. Для получения дополнительной информации о том, почему были выбраны эти типы лицензирования, мы рекомендуем блог Тристана о лицензировании dbt. Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩
- Полная прозрачность, я никогда не видел Офис. Неуклюжий юмор заставляет меня чувствовать себя так неловко, что я вынужден выключить телевизор. Извините, если названия персонажей неверны.↩
- Псих! Они определенно заинтересованы в расчете ARR. На самом деле, они не очень доверяют числам , если не понимают, как они вычисляются. Именно здесь они могут использовать API метаданных, чтобы запросить всю информацию о метрике, такую как определение, время выполнения, допустимые размеры и т. д. Сейчас Джиму и Пэм нужно будет запрашивать API напрямую, но в будущем мы ожидайте, что будет несколько различных способов получить эту информацию, начиная от прямой интеграции с инструментом BI и заканчивая материализацией этой информации в информационной схеме dbt! Для текущих табличных альтернатив есть несколько интересных макросов в недавно выпущенном пакете dbt-project-evaluator. Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩
 Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩
Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩ Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩
Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩Связанные данные и семантическая сеть — метаданные и обнаружение @ Pitt
Связанные открытые данные (LOD)
Связанные данные, выпущенные под открытой лицензией, которая не препятствует их бесплатному повторному использованию. — Тим Бернерс-Ли, Связанные данные.
Примеры больших связанных наборов открытых данных включают DBpedia и Wikidata.
Структура описания ресурсов (RDF)
Набор стандартов семантической сети, разработанный консорциумом Worldwide Web (W3C). Эти стандарты создают структуру для создания простых утверждений о ресурсах, чтобы машины могли интерпретировать отношения. Эти операторы называются триплетами, которые представляют собой операторы субъект-предикат-объект, используемые для описания отношений между сущностями в среде связанных данных.
Ресурсы: RDF 1.1 Primer
Схема
Набор элементов для структурирования данных (например, MARC, MODS, EAD, RDFS).
URI
URI или унифицированный идентификатор ресурса — это уникальный контролируемый термин, используемый для идентификации чего-либо.
Одним из типов URI является URN или универсальное имя ресурса, которое представляет собой установленную стандартизированную метку для конкретного объекта. Другой тип URI — это URL-адрес, который указывает местоположение ресурса в Интернете. Машинно интерпретируемые URI обычно имеют форму URL. Эти URL-адреса могут привести пользователей к дополнительной информации об этих ресурсах, но не все URI должны указывать на удобочитаемую веб-страницу.
Примером URI неподвижного изображения (изображения, карты и т. д.) из словаря типов Dublin Core является http://purl.org/dc/dcmitype/StillImage. Другой пример дает URI для американского автора по имени Марк Твен как https://viaf.org/viaf/50566653.
Тройки
Тройки, также известные как семантические тройки, представляют собой операторы субъект-предикат-объект, используемые для описания отношений между сущностями в среде связанных данных. Они являются строительными блоками связанных данных. Например, для описания книги под названием «Какая-то книга», написанной автором по имени Джейн Доу, тройка может быть чем-то вроде Джейн Доу — автора «Какой-то книги». В Semantic Web каждый компонент триплета обычно задается в URI.
Они являются строительными блоками связанных данных. Например, для описания книги под названием «Какая-то книга», написанной автором по имени Джейн Доу, тройка может быть чем-то вроде Джейн Доу — автора «Какой-то книги». В Semantic Web каждый компонент триплета обычно задается в URI.
Семантическая сеть
Считающаяся следующей стадией развития после Всемирной паутины, Семантическая сеть представляет собой представление Всемирной паутины связанных данных. В семантической сети все данные в сети структурированы и машиночитаемы. Это позволяет компьютерам делать выводы о взаимосвязях между ресурсами, расширяя возможности человека для открытия новых областей знаний. Одним из современных предшественников Semantic Web является панель знаний Google, которая объединяет данные из многих источников в компактное и простое информационное окно.
Turtle
Тройной язык Terse RDF (более известный как Turtle) — это синтаксис и формат для хранения и представления данных в модели Resource Description Framework (RDF).