
[X-Parser] Penguin Keywords Tools. Программа для быстрого составления, чистки семантического ядра
310.00р.
Цены в рублях, но мы принимаем и другие валюты
Курса пока нет в наличии
но в скором времени он у нас появится.
Рекомендуем вам подписаться на нашу группу в телеграмм, а так же зарегистрироваться на сайте, и добавить курс в избранное, чтобы не пропустить появление курса.
Скидки При покупке от трех курсов напишите нам Не нашли курс? Свяжитесь с нами, мы постараемся помочь Доступность Наши курсы вы с можете смотреть как с телефона так и с компьютера ЧАВО Ответы на часто задаваемые вопросы
Penguin [Keywords Tools]. Программа для быстрого составления чистки анализа и кластеризации семантического ядра.
Программа для быстрого составления чистки анализа и кластеризации семантического ядра.
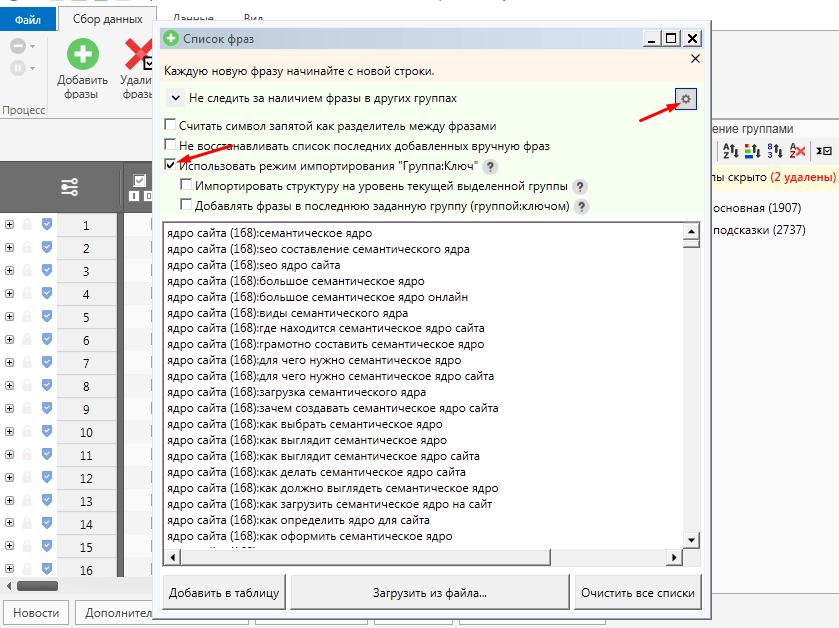
Программа работает с большими CSV-файлами, а так же с выгрузками Bukvarix, Ahrefs, SerpStat, KeySo, Majestic, SpyWords и любых других сервисов. Имеет самую быструю систему многоуровневой кластеризации и позволяет за минуты группировать миллионы поисковых запросов. Ускоряет работу с ключевыми словами в десятки раз!
Penguin [Keywords Tools] незаменим, если Вам нужно:
- Обрабатывать выгрузки из Bukvarix, Ahrefs, SerpStat, KeySo, Majestic и т.п. имея большой набор инструментов для этого.
- Быстро и без усилий составлять семантическое ядро для Ваших сайтов, интернет-магазинов, тегов для инстаграм каналов и т.п.
- Работать с большими базами ключевых слов, ссылок, аккаунтов размером в 1-100 гигабайт и более, как в текстовом, так и табличном формате.
- Очищать семантическое ядро от нерелевантных примесей других тематик, без необходимости самостоятельно составлять списки стоп-слов.

- Быстро группировать огромные списки поисковых запросов размером в миллионы строк.
- Иметь инструмент для обработки и анализа любых данных, хранящихся в txt, csv, xls, xslx, xml, sql и прочих файлов больших размеров.

Преимущества Penguin [Keywords Tools]:
- Автоматизация Сбор семантического ядра даже при использовании сервисов и программ никогда не был настолько автоматизированным, каким его делает Penguin [Keywords Tools]. Любые рутинные действия можно включить в сценарий и выполнять в 1 клик!
- Огромная скорость работы Penguin – самый быстрый софт для работы с семантикой. Обработка, чистка и кластеризация миллионов поисковых запросов с его помощью занимает минуты!
- Простота использования Penguin настолько прост в использовании, что Вам не нужно тратить ни минуты времени на его изучение. Запустив его впервые, Вы сразу же поймете, как с его помощью осуществить любое задуманное действие!
- Работа с большими данными Penguin [Keywords Tools] — лучший в мире редактор больших файлов, что позволяет Вам обрабатывать любые объемы поисковых запросов и не испытывать никаких затруднений!
- Экономия времени Составление семантического ядра всегда было рутинным и долгим процессом, но с Penguin этот процесс станет простым, приятным, быстрым и очень наглядным!
- Моментальная окупаемость Penguin настолько ускоряет работу с семантическим ядром, что за то время, которое раньше уходило на составление одного заказа, Вы будете выполнять 4-5 заказов, при этом тратя меньше времени и сил!
Возможности Keywords Tools:
- Быстрое составление семантического ядра
Penguin [Keywords Tools] – это самая быстрая программа для составления семантического ядра. Если Вы занимаетесь клиентским SEO, контекстной рекламой или создаете собственные сайты, то на сбор семантитки Вы тратите немало времени. А если речь идет о большом семантическом ядре, состоящем из миллионов поисковых запросов, то на его чистку от нерелевантных примесей могут уходить недели, ведь фактически приходится перечитать все строки, чтобы оставить только целевые фразы. Penguin же позволяет производить такую чистку за считанные минуты и моментально выделять только строго тематические ключевые слова, отсеивая весь нерелевантный мусор. Когда контекст очищен, Вам останется только лишь кластеризовать полученные ключевые слова в 1 клик, и Вы получите чистое структурированное ядро, готовое к применению. - Автоматическая кластеризация миллионов поисковых запросов
Penguin [Keywords Tools] обладает многоуровневой системой кластеризации и позволяет за считанные минуты кластеризовать миллионы ключей на всю глубину вложенности кластеров, что позволяет получить удобную древовидную структуру кластеров для выгрузки в Excel или KeyCollector. Вы можете легко управлять распределением фраз, указывая какие слова или словосочетания нужно считать приоритетными, какие нужно использовать неразрывно, какие слова игнорировать при построении кластеров, и какие словосочетания объединять в один кластер. Все это делается наглядно, легко и очень быстро. Благодаря таким объемам и скорости, Вы сможете моментально оценивать контекст любой выборки, что позволит быстро и детально анализировать семантическое ядро, выявляя и искореняя любой нерелевантный мусор не задумываясь о стоп-словах. - Быстрое составление списка стоп-слов для любой тематики
Когда Вы осуществляете подбор ключевых слов, все программы и сервисы предлагают единственный инструмент для фильтрации нерелевантных примесей – это стоп-слова или исключения. Это все хорошо, но сделав выгрузку по базовым маркерам, бывает так, что мы получаем до 70% нерелевантных фраз. Например, искали слово «Кольцо», желая найти бижутерию, а получили кольца для цилиндров двигателя авто, золотое кольцо России и много чего еще. И список стоп-слов в этом случае может составлять десяток тысяч фраз, и где же его брать? В итоге процесс чистки семантики превращается в сущий ад. Но если взять на вооружение Penguin [Keywords Tools], то об этой проблеме можно забыть раз и навсегда. С его помощью Вы сможете одновременно очистить контекст от нерелевантного мусора и собрать список стоп-слов для заданной тематики, не прилагая никаких усилий. - Удаление неявных дублей, оставляя самые правильные варианты
При сборе семантического ядра мы постоянно сталкиваемся с дублями поисковых запросов. Пользователи вводят свои запросы по разному и всегда существуют лучшие и худшие варианты написания поискового запроса. Как правило, нам нужен самый востребованный вариант. С Penguin [Keywords Tools] получить лучшие из неявных дублей очень просто: делаем выгрузку исходных поисковых запросов из привычного нам сервиса, например из Bukvarix, и открываем его в Penguin. Выбираем столбец с частотностью и сортируем список в порядке убывания частотности. Далее удаляем неявные дубли с учетом морфологии. В результате мы избавляемся от дублей, при этом получая самые востребованные варианты написания поисковых запросов. Также Penguin позволяет сгенерировать все варианты написания той или иной поисковой фразы, чтобы найти самый востребованный вариант ее написания. - Подбор ключевых слов из базы Пастухова, Букварикса и им подобным
Если Вы предпочитаете работать с локальными базами данных, такими как база Буквариса, Пастухова, или любой другой базы, хранящейся в большом текстовом файле, то Вы, безусловно, сталкивались с проблемой обработки таких баз. Penguin [Keywords Tools] — самый удобный инструмент для этого. Открыв с его помощью такую базу, Вы сразу увидите ее содержимое, что невозможно сделать с помощью других программ, особенно если база весит десятки гигабайт. Далее Вы сможете указать слова для осуществления первичной выборки и собрать все фразы, соответствующие Вашей тематике. Первичная выборка займет какое-то время, в зависимости от размера исходной базу, но получив в результате даже сотни миллионов строк, работа с ней станет очень быстрой, и Вы сможете за считанные минуты проанализировать их и отфильтровать, получив максимально качественный результат.
 Если Вы занимаетесь клиентским SEO, контекстной рекламой или создаете собственные сайты, то на сбор семантитки Вы тратите немало времени. А если речь идет о большом семантическом ядре, состоящем из миллионов поисковых запросов, то на его чистку от нерелевантных примесей могут уходить недели, ведь фактически приходится перечитать все строки, чтобы оставить только целевые фразы. Penguin же позволяет производить такую чистку за считанные минуты и моментально выделять только строго тематические ключевые слова, отсеивая весь нерелевантный мусор. Когда контекст очищен, Вам останется только лишь кластеризовать полученные ключевые слова в 1 клик, и Вы получите чистое структурированное ядро, готовое к применению.
Если Вы занимаетесь клиентским SEO, контекстной рекламой или создаете собственные сайты, то на сбор семантитки Вы тратите немало времени. А если речь идет о большом семантическом ядре, состоящем из миллионов поисковых запросов, то на его чистку от нерелевантных примесей могут уходить недели, ведь фактически приходится перечитать все строки, чтобы оставить только целевые фразы. Penguin же позволяет производить такую чистку за считанные минуты и моментально выделять только строго тематические ключевые слова, отсеивая весь нерелевантный мусор. Когда контекст очищен, Вам останется только лишь кластеризовать полученные ключевые слова в 1 клик, и Вы получите чистое структурированное ядро, готовое к применению. Вы можете легко управлять распределением фраз, указывая какие слова или словосочетания нужно считать приоритетными, какие нужно использовать неразрывно, какие слова игнорировать при построении кластеров, и какие словосочетания объединять в один кластер. Все это делается наглядно, легко и очень быстро. Благодаря таким объемам и скорости, Вы сможете моментально оценивать контекст любой выборки, что позволит быстро и детально анализировать семантическое ядро, выявляя и искореняя любой нерелевантный мусор не задумываясь о стоп-словах.
Вы можете легко управлять распределением фраз, указывая какие слова или словосочетания нужно считать приоритетными, какие нужно использовать неразрывно, какие слова игнорировать при построении кластеров, и какие словосочетания объединять в один кластер. Все это делается наглядно, легко и очень быстро. Благодаря таким объемам и скорости, Вы сможете моментально оценивать контекст любой выборки, что позволит быстро и детально анализировать семантическое ядро, выявляя и искореняя любой нерелевантный мусор не задумываясь о стоп-словах.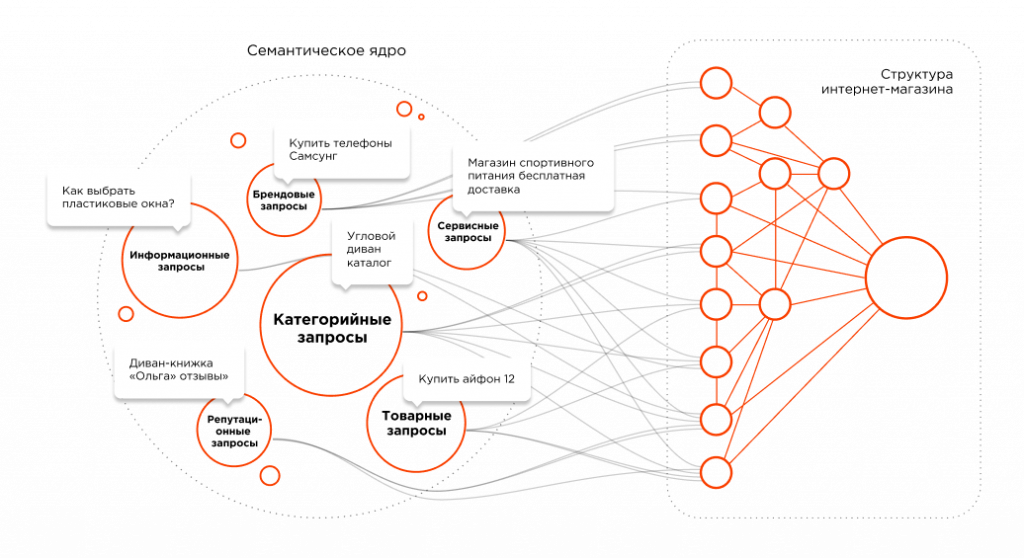 И список стоп-слов в этом случае может составлять десяток тысяч фраз, и где же его брать? В итоге процесс чистки семантики превращается в сущий ад. Но если взять на вооружение Penguin [Keywords Tools], то об этой проблеме можно забыть раз и навсегда. С его помощью Вы сможете одновременно очистить контекст от нерелевантного мусора и собрать список стоп-слов для заданной тематики, не прилагая никаких усилий.
И список стоп-слов в этом случае может составлять десяток тысяч фраз, и где же его брать? В итоге процесс чистки семантики превращается в сущий ад. Но если взять на вооружение Penguin [Keywords Tools], то об этой проблеме можно забыть раз и навсегда. С его помощью Вы сможете одновременно очистить контекст от нерелевантного мусора и собрать список стоп-слов для заданной тематики, не прилагая никаких усилий. Далее удаляем неявные дубли с учетом морфологии. В результате мы избавляемся от дублей, при этом получая самые востребованные варианты написания поисковых запросов. Также Penguin позволяет сгенерировать все варианты написания той или иной поисковой фразы, чтобы найти самый востребованный вариант ее написания.
Далее удаляем неявные дубли с учетом морфологии. В результате мы избавляемся от дублей, при этом получая самые востребованные варианты написания поисковых запросов. Также Penguin позволяет сгенерировать все варианты написания той или иной поисковой фразы, чтобы найти самый востребованный вариант ее написания.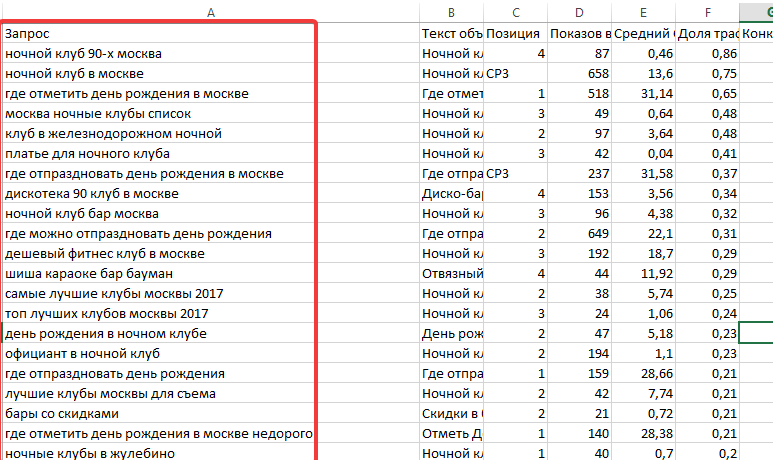
Отзывы
0/ 5
средний рейтинг товара
Нет отзывов о данном товаре. Станьте первым, оставьте свой отзыв.
Составление семантического ядра
Семантическое ядро – набор слов, фраз и словосочетаний, которые наиболее точно характеризуют предназначение сайта и суть информации на нем.
На первый взгляд составление семантического ядра – довольно простая процедура. Однако, если разобраться, есть множество тонкостей, не предусмотрев которые, можно загубить все продвижение в корне.
Программы по автоматической генерации семантического ядра
Существуют определенные программы, такие как key collector, с помощью которых можно быстро подобрать семантическое ядро. У таких программ есть свои плюсы и минусы. Главным плюсом программ для генерации является скорость. Если вы оптимизатор, работаете в веб-студии, и у вас просто гора проектов, то такие программы даже очень сократят время на подбор слов для СЯ. Но качество такого СЯ совсем не будет на высоте.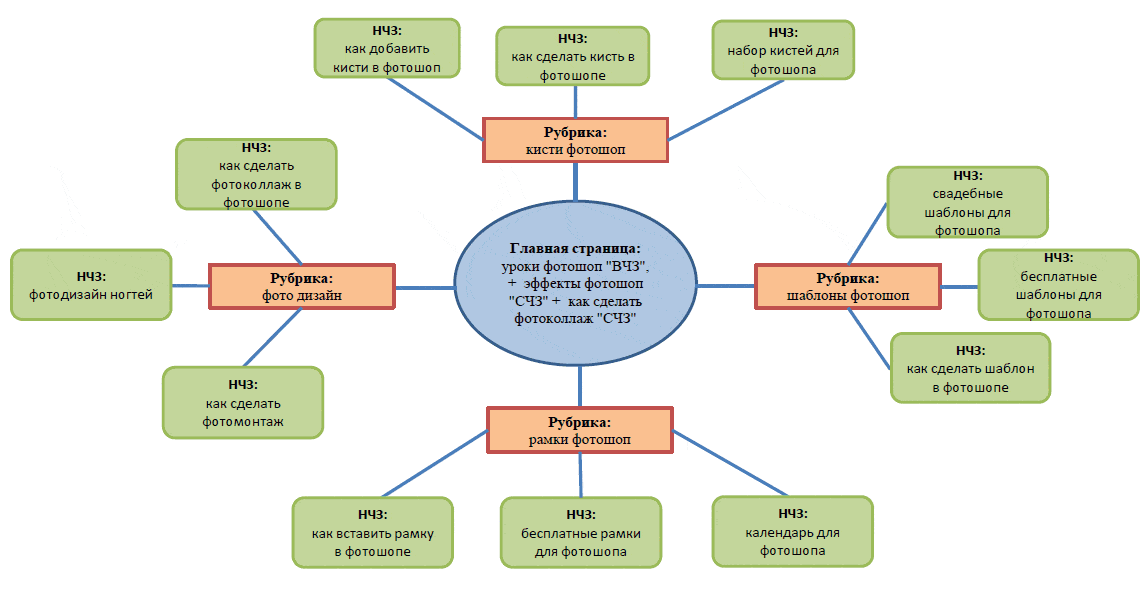 Нет ничего лучше и точнее ручного подбора слов.
Нет ничего лучше и точнее ручного подбора слов.
Создание семантического ядра самостоятельно
Для того, чтобы подобрать слова, очень просто воспользоваться сервисом Яндекса для подбора yandex.wordstat. Перед тем, как создавать семантическое ядро для своего сайта, необходимо выделить основные направления, которым он должен отвечать. Если ваш сайт посвящен продаже оборудования для общепита, то надо разделить это оборудование на категории. Например: холодильное, тепловое, нейтральное. И обратим внимание на свод правил составления СЯ.
1. Разумная пропорция ВЧ, СЧ и НЧ запросов
Все ядро должно состоять из нескольких ВЧ-запросов (около 10%), чуть больше СЧ-запросов (около 30%) и большого пула НЧ запросов (около 60%). Если собрать в СЯ только высокачастотники, то шансов выйти такому сайту в ТОП-10 фактически нет, особенно, если сайт молодой.
2. Концентрация ключевиков на странице
Известный факт, что на одну посадочную страницу не должно идти большого количества запросов неважно какой частотности. На одной странице должно быть расположено не более 2-3 ключевиков.
На одной странице должно быть расположено не более 2-3 ключевиков.
Пример неправильного подбора:
алкогольная лицензия |
алкогольная лицензия для магазина |
выдача лицензии на алкоголь |
госпошлина на лицензию на алкоголь |
Документы для лицензии на алкоголь |
Лицензия на алкоголь для ип |
лицензия на алкоголь для кафе |
лицензия на алкоголь розничный |
Лицензия на алкоголь Екатеринбург |
Все ключевые слова из этого списка по логике должны идти на одну посадочную страницу. Но невозможно уместить все эти слова в Title. Тошнота получится с очень высоким процентом, что уже переспам.
Но невозможно уместить все эти слова в Title. Тошнота получится с очень высоким процентом, что уже переспам.
3. Только целевые и «нужные» запросы
Не стоит замусоривать сайт ненужными запросами. Если у вас коммерческий сайт, то не надо подбирать информационные запросы. Исключение составляет, если есть блок с новостями, и информационные запросы можно конвертировать в коммерческие. Также, не стоит выделять обобщенные слова в отдельные ключевики. Например, если ваш сайт посвящен холодильному оборудованию, то не нужно продвигать его по слову «оборудование». Нужно в качестве ключевика взять целую фразу: «холодильное оборудование».
4. Тематика запросов
Все запросы должны быть объединены одной общей тематикой. На сайте не должно быть запросов по продаже туристических путевок и строительству одновременно. По таким тематикам нужны раздельные сайты с отдельными ядрами.
5. Количество запросов
Количество ключевых слов в ядре – чем больше, тем лучше. По пяти ключевым словам двигать сайт бессмысленно. Нужно собирать всегда максимально возможное количество слов, которое адекватно тематике сайта. У крупных ресурсов ядро может составлять до 1000 слов.
По пяти ключевым словам двигать сайт бессмысленно. Нужно собирать всегда максимально возможное количество слов, которое адекватно тематике сайта. У крупных ресурсов ядро может составлять до 1000 слов.
6. Распределение по группам
Поскольку СЯ делится по направлениям в зависимости от тематики сайта, значит нужно верно определить все запросы, подходящие к конкретному направлению.
ВЕРНО |
холодильное оборудование |
барные холодильники |
лари морозильные |
моноблоки |
НЕВЕРНО |
холодильное оборудование |
барные холодильники |
лари морозильные |
жарочные поверхности |
Резюмируем.
Если у вас есть выбор – подбирать СЯ самостоятельно или генератором, то с ручной подборкой никто и ничто не сможет сравниться. Если же вы все-таки не уверены в собственных силах, то смело обращайтесь к нам, и мы с удовольствием составим для вашего сайта семантическое ядро!
Доказуемо надежный семантический стек для многоядерного системного программирования с потоками ядра title={Доказуемо надежный семантический стек для многоядерного системного программирования с потоками ядра}, автор={Артем Алехин}, год = {2016} }
- Алехин А.
- Опубликовано в 2016 г.
- Информатика
Операционные системы и гипервизоры (например, Microsoft Hyper-V) для многоядерных процессорных архитектур обычно реализуются на высокоуровневых языках программирования на основе стека, интегрированных с механизмы многопоточного выполнения задач, а также доступ к низкоуровневым аппаратным функциям. Гарантия функциональной корректности таких систем считается сложной задачей в области формальной верификации, поскольку для этого требуется надежная параллельная вычислительная модель, включающая программирование…
Просмотр через Publisher
d-nb. info
info
На пути к всеобъемлющей формальной верификации многоядерных операционных систем и гипервизоров, реализованных на языке C
- Сабина Шмальц
Информатика 9009 90 4 90 104 9001 007
Эта диссертация обеспечивает операционная семантика для довольно простого промежуточного языка для C, а также расширение этой семантики со спецификационным (фантомным) состоянием и кодом, которые могут служить основанием для аргументации правильности VCC.
Рассуждения о реализации абстракций параллелизма на x86-TSO
- Скотт Оуэнс
Информатика
ECOOP
- 2010
- Цыбань А.
Информатика
- 2009
- Шадрин А.
Информатика
- 2012
- Михаил Ковалев
Информатика
- 2013
- Христо Пенчев
Информатика
- 2016
- Чжун Шао
Информатика
- 2015
- Дирк Лейненбах, В. Пол, Елена Петрова
Информатика
SEFM
- 2005
- А. Малкис, А. Подельский, А. Рыбальченко
Информатика
SAS
- 2007
- Томас Ин дер Риден, А. Цибан
Информатика
SSV
- 2008
9003 рассуждения о предыдущих программах сборки о новых программах x-6 Модель памяти TSO разработан и используется для анализа пяти реализаций абстракции параллелизма: двух спин-блокировок; неблокирующий протокол записи; идиома блокировки с двойной проверкой; и Паркер из java.
util.concurrent.Формальная верификация фреймворка для программистов микроядра
моделируются выполнением модели архитектуры набора инструкций VAMP, чередующейся с устройствами.
Смешанная семантика языков программирования низкого и высокого уровня и автоматическая проверка небольшого гипервизора
Представлена смешанная семантика C и макросборки, которая может обрабатывать смешанные языковые реализации, где контекст выполнения изменяется вызовом внешней функции с ассемблера на C и наоборот, а теорема пошагового моделирования — это состояние между смешанными программами и скомпилированным и собранным кодом.
Виртуализация TLB в контексте проверки гипервизора
Введено расширение семантики C, которое учитывает возможное MMU и гостевое взаимодействие с памятью программы, и утверждает, что расширенная семантика C имитирует аппаратная машина, которая выполняет скомпилированный код гипервизора, при условии, что компилятор правильный.
Звуковая семантика языка высокого уровня с межпроцессорными прерываниями
В этой диссертации представлен подход к интеграции межпроцессорных прерываний, обеспечиваемых многоядерными архитектурами, при всеобъемлющей проверке системного программного обеспечения, написанного на C, и определяется расширение семантики язык высокого уровня, учитывающий межпроцессорные прерывания.
Расширенная разработка сертифицированных ядер ОС
Ядро гипервизора CertiKOS с чистого листа, которое работает на многоядерных платформах и поддерживает приложения Linux и ROS, новые сертифицированные методологии и инструменты программирования, которые могут проверять контекстуальную правильность, живучесть и свойства безопасности в унифицированных настройках, и новый язык помощника по корректуре VeriML и библиотеки Coq Ltac.
На пути к формальной верификации компилятора C0: правильность генерации кода и реализации
Операционная семантика малых шагов для C0, формализованная в Isabelle/HOL, и реализация компилятора в C0, а также формальное доказательство того, что реализация производит тот же код, что и Спецификация.
Precise Thread-Modular Verification
Предлагается новый алгоритм абстракции для верификации модулей нитей, который предлагает как высокую точность, так и полиномиальную сложность, основанный на новой области абстракции, которая сочетает декартову абстракцию с наборами исключений, что позволяет точно обрабатывать определенные взаимодействия потоков.
CVM — проверенная среда для программистов микроядер
java — ОШИБКА! исключение на этапе «семантического анализа»
У меня есть приложение с весенней загрузкой 1.1.7, использующее Gradle 1.10 и jdk1.8. Я использую Groovy/Spock для тестирования. Он имеет две зависимости: jar-файлы, созданные с помощью Apache Maven 3.1.1 и jdk 1.8. Я создаю банки и копирую их в каталог /lib. Затем я пытаюсь построить с помощью «чистой сборки gradle».
Вот часть моего файла gradle:
применить плагин: «java» применить плагин: 'groovy' применить плагин: 'идея' применить плагин: «весенняя загрузка» применить плагин: 'jacoco' применить плагин: 'maven' проект.ext { springBootVersion = '1.1.7.RELEASE' } зависимости { скомпилировать дерево файлов (каталог: 'libs', включить: ['*.jar']) } скрипт сборки { репозитории { плоскийКаталог { каталоги "$rootProject. projectDir/libs"
}
maven { URL-адрес 'https://oss.sonatype.org/content/repositories/snapshots/'}
maven { URL-адрес "http://repo.spring.io/libs-milestone"}
maven { URL-адрес "http://repo.spring.io/libs-snapshot"}
mavenLocal()
mavenCentral()
}
зависимости {
путь к классам ("org.springframework.boot: spring-boot-gradle-plugin: 1.2.5.RELEASE")
testCompile('org.spockframework:spock-core:1.0-groovy-2.0') {
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile('org.spockframework:spock-spring:1.0-groovy-2.0') {
группа исключения: 'org.spockframework', модуль: 'spock-core'
исключить группу: «org.spockframework», модуль: «пружинные бобы»
исключить группу: «org.spockframework», модуль: «весенний тест»
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile("org.springframework.boot:spring-boot-starter-test:$springBootVersion")
testCompile('org.codehaus.groovy. modules.http-builder:http-builder:0.7+')
testCompile("Юнит:Юнит")
}
}
jacocoTestReport {
группа = "Отчетность"
description = "Создавать отчеты о покрытии Jacoco после выполнения тестов."
}
оболочка задачи (тип: оболочка) {
градлеверсион = '1.11'
}
Независимо от сборки из командной строки или IntelliJ я получаю следующую ошибку:
Выполнение org.gradle.api.internal.tasks.compile.ApiGroovyCompiler@5474aad4 в демоне компилятора. Исключение при выполнении org.gradle.api.internal.tasks.compile.ApiGroovyCompiler@5474aad4 в демоне компилятора: ОШИБКА! исключение на этапе «семантический анализ» в исходном модуле «/Users/David/projects/.../controller/AboutControllerTest.groovy» sun.reflect.annotation.TypeNotPresentExceptionProxy. :compileTestGroovy НЕ ПРОШЕЛ
Вот трассировка стека:
org.gradle.api.tasks.TaskExecutionException: не удалось выполнить задачу ':compileTestGroovy'. в org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.
executeActions(ExecuteActionsTaskExecuter.java:69)
в org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.execute(ExecuteActionsTaskExecuter.java:46)
в org.gradle.api.internal.tasks.execution.PostExecutionAnalysisTaskExecuter.execute(PostExecutionAnalysisTaskExecuter.java:35)
в org.gradle.api.internal.tasks.execution.SkipUpToDateTaskExecuter.execute(SkipUpToDateTaskExecuter.java:64)
в org.gradle.api.internal.tasks.execution.ValidatingTaskExecuter.execute(ValidatingTaskExecuter.java:58)
в org.gradle.api.internal.tasks.execution.SkipEmptySourceFilesTaskExecuter.execute(SkipEmptySourceFilesTaskExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipTaskWithNoActionsExecuter.execute(SkipTaskWithNoActionsExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipOnlyIfTaskExecuter.execute(SkipOnlyIfTaskExecuter.java:53)
в org.gradle.api.internal.tasks.execution.ExecuteAtMostOnceTaskExecuter.execute(ExecuteAtMostOnceTaskExecuter. java:43)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:203)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:185)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.processTask(AbstractTaskPlanExecutor.java:62)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.run(AbstractTaskPlanExecutor.java:50)
в org.gradle.execution.taskgraph.DefaultTaskPlanExecutor.process(DefaultTaskPlanExecutor.java:25)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter.execute(DefaultTaskGraphExecuter.java:110)
в org.gradle.execution.SelectedTaskExecutionAction.execute(SelectedTaskExecutionAction.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.access$000(DefaultBuildExecuter. java:23)
в org.gradle.execution.DefaultBuildExecuter$1.proceed(DefaultBuildExecuter.java:43)
в org.gradle.execution.DryRunBuildExecutionAction.execute(DryRunBuildExecutionAction.java:32)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:30)
в org.gradle.initialization.DefaultGradleLauncher$4.run(DefaultGradleLauncher.java:158)
в org.gradle.internal.Factory$1.create(Factory.java:22)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:52)
в org.gradle.initialization.DefaultGradleLauncher.doBuildStages(DefaultGradleLauncher.java:155)
в org.gradle.initialization.DefaultGradleLauncher.access $ 200 (DefaultGradleLauncher.java: 36)
в org.gradle.initialization. DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:103)
в org.gradle.initialization.DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:97)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:62)
в org.gradle.initialization.DefaultGradleLauncher.doBuild(DefaultGradleLauncher.java:97)
в org.gradle.initialization.DefaultGradleLauncher.run(DefaultGradleLauncher.java:86)
в org.gradle.launcher.exec.InProcessBuildActionExecuter$DefaultBuildController.run(InProcessBuildActionExecuter.java:102)
в org.gradle.tooling.internal.provider.ExecuteBuildActionRunner.run(ExecuteBuildActionRunner.java:28)
в org.gradle.launcher.exec.ChainingBuildActionRunner.run(ChainingBuildActionRunner.java:35)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter. java:47)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter.java:32)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:77)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:47)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:51)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:28)
на org.gradle.launcher.cli.RunBuildAction.run(RunBuildAction.java:43)
в org.gradle.internal.Actions$RunnableActionAdapter.execute(Actions.java:170)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory.java:237)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory. java:210)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:35)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:24)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:206)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:169)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:33)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:22)
в org.gradle.launcher.Main.doAction(Main.java:33)
на org.gradle.launcher.bootstrap.EntryPoint.run(EntryPoint.java:45)
в org.gradle.launcher.bootstrap.ProcessBootstrap.runNoExit(ProcessBootstrap.java:54)
на org.gradle.launcher.bootstrap.ProcessBootstrap.run(ProcessBootstrap.java:35)
на org.gradle.launcher.GradleMain. main(GradleMain.java:23)
Причина: ОШИБКА! исключение на этапе «семантический анализ» в исходном модуле «/Users/David/projects/.../src/test/groovy/.../controller/AboutControllerTest.groovy» sun.reflect.annotation.TypeNotPresentExceptionProxy
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:152)
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:51)
в org.gradle.api.internal.tasks.compile.daemon.CompilerDaemonServer.execute(CompilerDaemonServer.java:53)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
в org.gradle.messaging.remote.internal.hub.MessageHub$Handler.run(MessageHub.java:360)
в org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:54)
в org.gradle.internal.concurrent.StoppableExecutorImpl$1.
 util.concurrent.
util.concurrent.


 projectDir/libs"
}
maven { URL-адрес 'https://oss.sonatype.org/content/repositories/snapshots/'}
maven { URL-адрес "http://repo.spring.io/libs-milestone"}
maven { URL-адрес "http://repo.spring.io/libs-snapshot"}
mavenLocal()
mavenCentral()
}
зависимости {
путь к классам ("org.springframework.boot: spring-boot-gradle-plugin: 1.2.5.RELEASE")
testCompile('org.spockframework:spock-core:1.0-groovy-2.0') {
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile('org.spockframework:spock-spring:1.0-groovy-2.0') {
группа исключения: 'org.spockframework', модуль: 'spock-core'
исключить группу: «org.spockframework», модуль: «пружинные бобы»
исключить группу: «org.spockframework», модуль: «весенний тест»
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile("org.springframework.boot:spring-boot-starter-test:$springBootVersion")
testCompile('org.codehaus.groovy.
projectDir/libs"
}
maven { URL-адрес 'https://oss.sonatype.org/content/repositories/snapshots/'}
maven { URL-адрес "http://repo.spring.io/libs-milestone"}
maven { URL-адрес "http://repo.spring.io/libs-snapshot"}
mavenLocal()
mavenCentral()
}
зависимости {
путь к классам ("org.springframework.boot: spring-boot-gradle-plugin: 1.2.5.RELEASE")
testCompile('org.spockframework:spock-core:1.0-groovy-2.0') {
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile('org.spockframework:spock-spring:1.0-groovy-2.0') {
группа исключения: 'org.spockframework', модуль: 'spock-core'
исключить группу: «org.spockframework», модуль: «пружинные бобы»
исключить группу: «org.spockframework», модуль: «весенний тест»
группа исключения: 'org.codehaus.groovy', модуль: 'groovy-all'
}
testCompile("org.springframework.boot:spring-boot-starter-test:$springBootVersion")
testCompile('org.codehaus.groovy.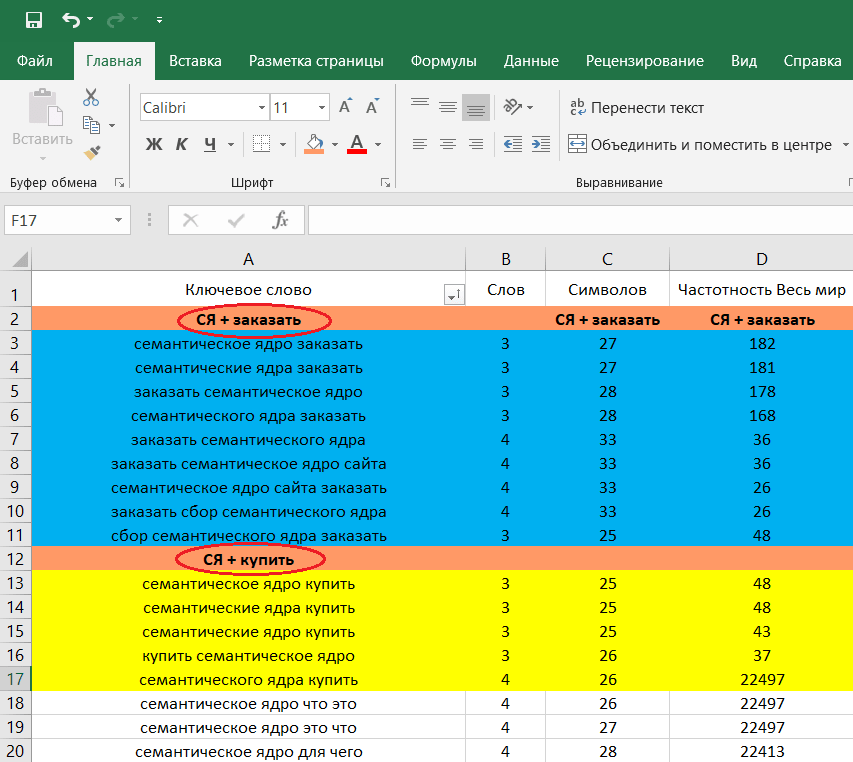 modules.http-builder:http-builder:0.7+')
testCompile("Юнит:Юнит")
}
}
jacocoTestReport {
группа = "Отчетность"
description = "Создавать отчеты о покрытии Jacoco после выполнения тестов."
}
оболочка задачи (тип: оболочка) {
градлеверсион = '1.11'
}
modules.http-builder:http-builder:0.7+')
testCompile("Юнит:Юнит")
}
}
jacocoTestReport {
группа = "Отчетность"
description = "Создавать отчеты о покрытии Jacoco после выполнения тестов."
}
оболочка задачи (тип: оболочка) {
градлеверсион = '1.11'
}
 executeActions(ExecuteActionsTaskExecuter.java:69)
в org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.execute(ExecuteActionsTaskExecuter.java:46)
в org.gradle.api.internal.tasks.execution.PostExecutionAnalysisTaskExecuter.execute(PostExecutionAnalysisTaskExecuter.java:35)
в org.gradle.api.internal.tasks.execution.SkipUpToDateTaskExecuter.execute(SkipUpToDateTaskExecuter.java:64)
в org.gradle.api.internal.tasks.execution.ValidatingTaskExecuter.execute(ValidatingTaskExecuter.java:58)
в org.gradle.api.internal.tasks.execution.SkipEmptySourceFilesTaskExecuter.execute(SkipEmptySourceFilesTaskExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipTaskWithNoActionsExecuter.execute(SkipTaskWithNoActionsExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipOnlyIfTaskExecuter.execute(SkipOnlyIfTaskExecuter.java:53)
в org.gradle.api.internal.tasks.execution.ExecuteAtMostOnceTaskExecuter.execute(ExecuteAtMostOnceTaskExecuter.
executeActions(ExecuteActionsTaskExecuter.java:69)
в org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.execute(ExecuteActionsTaskExecuter.java:46)
в org.gradle.api.internal.tasks.execution.PostExecutionAnalysisTaskExecuter.execute(PostExecutionAnalysisTaskExecuter.java:35)
в org.gradle.api.internal.tasks.execution.SkipUpToDateTaskExecuter.execute(SkipUpToDateTaskExecuter.java:64)
в org.gradle.api.internal.tasks.execution.ValidatingTaskExecuter.execute(ValidatingTaskExecuter.java:58)
в org.gradle.api.internal.tasks.execution.SkipEmptySourceFilesTaskExecuter.execute(SkipEmptySourceFilesTaskExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipTaskWithNoActionsExecuter.execute(SkipTaskWithNoActionsExecuter.java:52)
в org.gradle.api.internal.tasks.execution.SkipOnlyIfTaskExecuter.execute(SkipOnlyIfTaskExecuter.java:53)
в org.gradle.api.internal.tasks.execution.ExecuteAtMostOnceTaskExecuter.execute(ExecuteAtMostOnceTaskExecuter. java:43)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:203)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:185)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.processTask(AbstractTaskPlanExecutor.java:62)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.run(AbstractTaskPlanExecutor.java:50)
в org.gradle.execution.taskgraph.DefaultTaskPlanExecutor.process(DefaultTaskPlanExecutor.java:25)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter.execute(DefaultTaskGraphExecuter.java:110)
в org.gradle.execution.SelectedTaskExecutionAction.execute(SelectedTaskExecutionAction.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.access$000(DefaultBuildExecuter.
java:43)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:203)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter$EventFiringTaskWorker.execute(DefaultTaskGraphExecuter.java:185)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.processTask(AbstractTaskPlanExecutor.java:62)
в org.gradle.execution.taskgraph.AbstractTaskPlanExecutor$TaskExecutorWorker.run(AbstractTaskPlanExecutor.java:50)
в org.gradle.execution.taskgraph.DefaultTaskPlanExecutor.process(DefaultTaskPlanExecutor.java:25)
в org.gradle.execution.taskgraph.DefaultTaskGraphExecuter.execute(DefaultTaskGraphExecuter.java:110)
в org.gradle.execution.SelectedTaskExecutionAction.execute(SelectedTaskExecutionAction.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.access$000(DefaultBuildExecuter. java:23)
в org.gradle.execution.DefaultBuildExecuter$1.proceed(DefaultBuildExecuter.java:43)
в org.gradle.execution.DryRunBuildExecutionAction.execute(DryRunBuildExecutionAction.java:32)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:30)
в org.gradle.initialization.DefaultGradleLauncher$4.run(DefaultGradleLauncher.java:158)
в org.gradle.internal.Factory$1.create(Factory.java:22)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:52)
в org.gradle.initialization.DefaultGradleLauncher.doBuildStages(DefaultGradleLauncher.java:155)
в org.gradle.initialization.DefaultGradleLauncher.access $ 200 (DefaultGradleLauncher.java: 36)
в org.gradle.initialization.
java:23)
в org.gradle.execution.DefaultBuildExecuter$1.proceed(DefaultBuildExecuter.java:43)
в org.gradle.execution.DryRunBuildExecutionAction.execute(DryRunBuildExecutionAction.java:32)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:37)
в org.gradle.execution.DefaultBuildExecuter.execute(DefaultBuildExecuter.java:30)
в org.gradle.initialization.DefaultGradleLauncher$4.run(DefaultGradleLauncher.java:158)
в org.gradle.internal.Factory$1.create(Factory.java:22)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:52)
в org.gradle.initialization.DefaultGradleLauncher.doBuildStages(DefaultGradleLauncher.java:155)
в org.gradle.initialization.DefaultGradleLauncher.access $ 200 (DefaultGradleLauncher.java: 36)
в org.gradle.initialization. DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:103)
в org.gradle.initialization.DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:97)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:62)
в org.gradle.initialization.DefaultGradleLauncher.doBuild(DefaultGradleLauncher.java:97)
в org.gradle.initialization.DefaultGradleLauncher.run(DefaultGradleLauncher.java:86)
в org.gradle.launcher.exec.InProcessBuildActionExecuter$DefaultBuildController.run(InProcessBuildActionExecuter.java:102)
в org.gradle.tooling.internal.provider.ExecuteBuildActionRunner.run(ExecuteBuildActionRunner.java:28)
в org.gradle.launcher.exec.ChainingBuildActionRunner.run(ChainingBuildActionRunner.java:35)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter.
DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:103)
в org.gradle.initialization.DefaultGradleLauncher$1.create(DefaultGradleLauncher.java:97)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
в org.gradle.internal.progress.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:62)
в org.gradle.initialization.DefaultGradleLauncher.doBuild(DefaultGradleLauncher.java:97)
в org.gradle.initialization.DefaultGradleLauncher.run(DefaultGradleLauncher.java:86)
в org.gradle.launcher.exec.InProcessBuildActionExecuter$DefaultBuildController.run(InProcessBuildActionExecuter.java:102)
в org.gradle.tooling.internal.provider.ExecuteBuildActionRunner.run(ExecuteBuildActionRunner.java:28)
в org.gradle.launcher.exec.ChainingBuildActionRunner.run(ChainingBuildActionRunner.java:35)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter. java:47)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter.java:32)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:77)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:47)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:51)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:28)
на org.gradle.launcher.cli.RunBuildAction.run(RunBuildAction.java:43)
в org.gradle.internal.Actions$RunnableActionAdapter.execute(Actions.java:170)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory.java:237)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory.
java:47)
в org.gradle.launcher.exec.InProcessBuildActionExecuter.execute(InProcessBuildActionExecuter.java:32)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:77)
в org.gradle.launcher.exec.ContinuousBuildActionExecuter.execute(ContinuousBuildActionExecuter.java:47)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:51)
в org.gradle.launcher.exec.DaemonUsageSuggestingBuildActionExecuter.execute(DaemonUsageSuggestingBuildActionExecuter.java:28)
на org.gradle.launcher.cli.RunBuildAction.run(RunBuildAction.java:43)
в org.gradle.internal.Actions$RunnableActionAdapter.execute(Actions.java:170)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory.java:237)
в org.gradle.launcher.cli.CommandLineActionFactory$ParseAndBuildAction.execute(CommandLineActionFactory. java:210)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:35)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:24)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:206)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:169)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:33)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:22)
в org.gradle.launcher.Main.doAction(Main.java:33)
на org.gradle.launcher.bootstrap.EntryPoint.run(EntryPoint.java:45)
в org.gradle.launcher.bootstrap.ProcessBootstrap.runNoExit(ProcessBootstrap.java:54)
на org.gradle.launcher.bootstrap.ProcessBootstrap.run(ProcessBootstrap.java:35)
на org.gradle.launcher.GradleMain.
java:210)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:35)
в org.gradle.launcher.cli.JavaRuntimeValidationAction.execute(JavaRuntimeValidationAction.java:24)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:206)
в org.gradle.launcher.cli.CommandLineActionFactory$WithLogging.execute(CommandLineActionFactory.java:169)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:33)
в org.gradle.launcher.cli.ExceptionReportingAction.execute(ExceptionReportingAction.java:22)
в org.gradle.launcher.Main.doAction(Main.java:33)
на org.gradle.launcher.bootstrap.EntryPoint.run(EntryPoint.java:45)
в org.gradle.launcher.bootstrap.ProcessBootstrap.runNoExit(ProcessBootstrap.java:54)
на org.gradle.launcher.bootstrap.ProcessBootstrap.run(ProcessBootstrap.java:35)
на org.gradle.launcher.GradleMain. main(GradleMain.java:23)
Причина: ОШИБКА! исключение на этапе «семантический анализ» в исходном модуле «/Users/David/projects/.../src/test/groovy/.../controller/AboutControllerTest.groovy» sun.reflect.annotation.TypeNotPresentExceptionProxy
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:152)
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:51)
в org.gradle.api.internal.tasks.compile.daemon.CompilerDaemonServer.execute(CompilerDaemonServer.java:53)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
в org.gradle.messaging.remote.internal.hub.MessageHub$Handler.run(MessageHub.java:360)
в org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:54)
в org.gradle.internal.concurrent.StoppableExecutorImpl$1.
main(GradleMain.java:23)
Причина: ОШИБКА! исключение на этапе «семантический анализ» в исходном модуле «/Users/David/projects/.../src/test/groovy/.../controller/AboutControllerTest.groovy» sun.reflect.annotation.TypeNotPresentExceptionProxy
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:152)
в org.gradle.api.internal.tasks.compile.ApiGroovyCompiler.execute(ApiGroovyCompiler.java:51)
в org.gradle.api.internal.tasks.compile.daemon.CompilerDaemonServer.execute(CompilerDaemonServer.java:53)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
в org.gradle.messaging.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
в org.gradle.messaging.remote.internal.hub.MessageHub$Handler.run(MessageHub.java:360)
в org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:54)
в org.gradle.internal.concurrent.StoppableExecutorImpl$1.