
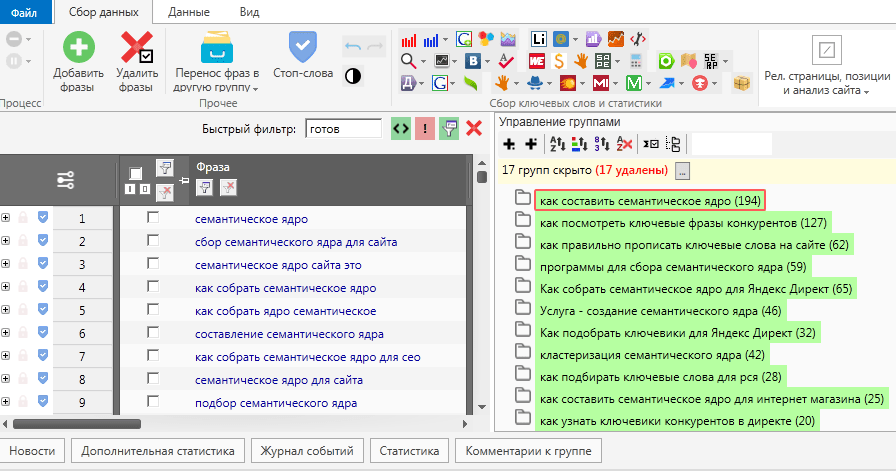
Программы для составления семантического ядра
Автоматизация составления семантического ядра
При работе с многотысячными ядрами не обойтись без автоматизации в с сборе, обработке и группировке фраз. Для этого используются решения:
- Профессиональные программы – Кей Коллектор, Олсабмиттер и т.д.
- Готовые базы фраз – Букварикс, Пастухов.
- Агрегаторы поисковых фраз конкурентов – СемРаш, СпайВордс.
- Сервисы обработки и группировки фраз – Семён ядрен, Джаст Маджик, КейАссорт.
- Сервисы анализа трафика конкурентов – Кейсо, СимиларВеб.
Профессиональные программы
Key Collector – незаменимая в работе профессионального оптимизатора программа, которая автоматизирует и упрощает процессы касающиеся семантики, планирования и контроля результатов.
Чем полезна программа в работе с семантическим ядром:
- Собирает фразы из Вордстат, поисковые подсказки, Метрика, Analytics, Adwords.
- Сбор частотности фраз – фразовой и точной.
 Подробнее здесь
Подробнее здесь - Кластеризация фраз по SERP, агрегатор слов для группировки по смыслу.
- Проверка запросов на сезонность, геозависимость и правильность словоформ.
- Подбор релевантных страниц с сайта для каждой фразы.
- Формирование из групп слов структуры сайта.
- Съем позиций по Яндекс и Google по выбранным запросам.
- Создание глобального списка минус слов, ускоряет чистку ядра от мусорных фраз.
- Выгрузка результатов в формате XSL, CSV.
 Подробнее здесь
Подробнее здесьЭтим функционалом программа не ограничивается. Проекты по поисковой оптимизации маркетологи студии DIUS ведут в КейКоллектор. Программа помогает контролировать этапы работы, видеть результаты, находить точки роста в развитии проектов.
AllSubmitter старейшая программа, которая использовалась для автоматической регистрации сайта в онлайн-каталогах. Позже появились функционалы съема позиций по запросам и сбор семантического ядра.
Полезна в работе с подбор поисковых запросов:
- Собирает данные с Вордстат, Adwords, поисковые подсказки.
- Подбирает релевантные страницы под запросы.
- Собирает частотность, сезонность, определяет геозависимость.
- Удобная работа с кластерами при помощи фильтров.
Готовые базы поисковых фраз
Букварикс онлайн база для подбора фраз, которая работает в 2-х режимах:
- Сбор фраз по направлению, например – «рольставни». Вводите слова и получаете фразы с их участием.
- Сбор фраз по доменному имени. Введите сайт конкуренты и получаете фразы по которым ранжируется конкурент.
Сервис удобен тем, что выдает фразы 2 вида частоты: общую и точную. При сборе информации по домену – также выдает позиции сайта по запросам. За 1 минуту можно получить десятки тысяч фраз для работы. Предусмотрена выгрузка данных в формате CSV.
Базы Пастухова – содержат 2 триллиона фраз. Информация собирается с сервисов Вордстат и Директ, поэтому помимо частоты запросов содержит информацию по ставкам в контекстной рекламе.
Поисковые запросы конкурентов
Для тех, кто решил скопировать чужой бизнес, полезно для работы получить поисковые фразы конкурентов. Таким образом быстро подбирается семантика, которая генерирует целевой поисковой трафик. Для работающих проектов при помощи сервисов анализа конкурентов подбираются новые точки роста и масштабирования.
Таким образом быстро подбирается семантика, которая генерирует целевой поисковой трафик. Для работающих проектов при помощи сервисов анализа конкурентов подбираются новые точки роста и масштабирования.
СемРаш – сервис, который собирает данные в поисковиках и систематизирует её для интернет-маркетологов. В режиме онлайн оперативно составляется семантическое ядро, разбитое на группы, отслеживаются позиции по словам. Также отображаются данные по конкурентам: фразы по которым они в ТОП-10, популярные запросы и страницы входа на сайт, обратные ссылки.
СпайВордс – похожий сервис за минусом технического аудита. Показывает фразы по направлениям и доменным именам. Отображает запросы конкурентов в органической выдачи, и по которым показывается контекстная реклама. Есть раздел «Битва доменов», где при введении 2-3 сайтов сравниваются пересечения по поисковым фразам. Используется для поиска новых направлений по каким привлекать поисковый трафик.
Сервисы по кластеризации семантики
ДжастМаджик – при помощи сервиса собирается и кластеризуется ядро. Также полезен при составлении технического задания для копирайтера. По фразам анализируются сайты из ТОП-10 и даются рекомендации по созданию контента.
Также полезен при составлении технического задания для копирайтера. По фразам анализируются сайты из ТОП-10 и даются рекомендации по созданию контента.
КейАссорт – программа по кластеризации семантического ядра по принципу поисковой выдачи (SERP). Создается проект, в который загружаются фразы. По ним производится съем выдачи в режиме XML от ТОП-5 до ТОП-50. Процесс группировки настраивается по нескольким параметрам, регулируется однородность кластеров. Программа создает многоуровневую структуру сайта на основе созданных групп. Результаты выгружаются в формате MS Excel.
Аналитические сервисы для сбор фраз конкурентов и расширения ядра
Keys.So – руссифицированный сервис, похож на СпайВордс. Выдает информацию по фразам: частотность, стоимость клика в контекстной рекламе, популярные сайты в органике, дополняющие фразы, историю частоты и стоимости. По доменному имени выдает: видимость сайта, охват запросов, трафик с поиска, индексация, запросы в ТОП-10, фразы в контекстной рекламе, конкуренты, история параметров сайта.
SimilarWeb – англоязычный сервис анализа конкурентов. Выдает информацию по доменному имени:
- источники трафика;
- популярные поисковые фразы;
- конкуренты домена;
- переходы с других ресурсов;
- популярность по странам и регионам.
Обсудим сотрудничество?
Какие задачи нужно решить:
Разработка сайта / интернет-магазина
Продвижение (SEO, Директ и т.п.)
Контент-маркетинг
Поддержка сайта (информационная, техническая)
Аудит сайта / интернет-магазина
Консультация
Программа для сбора семантического ядра сайта
Программа для сбора семантического ядра сайта позволяет собирать семантику. Сегодня рассмотрим, как с этой программой работать.
Здравствуйте, дорогие читатели! Я знаю, что многие из вас, если не все, стремятся к развитию своего сайта. Развивать его можно по-разному, но одним из основополагающих этапов становится составление семантического ядра. С этого нужно начинать в первую очередь.
Напомню, что семантическое ядро – это перечень ключевых слов, которые максимально полно характеризуют деятельность сайта. Так, правильно составленная семантика позволяет получать на ресурс целевых посетителей и увеличивать продажи.
Для составления семантики существует несколько методов. Можно отбирать ключевые слова вручную, а можно воспользоваться дополнительными инструментами, которые ускорят процесс. Таковым является программа Slovoeb.
Именно с помощью этого софта можно осуществить сбор подходящих фраз для сайта, отбросить мало эффективные и оставить те, которые принесут максимальную пользу.
Slovoeb представляет собой универсальный софт, благодаря которому легко подобрать ключевые слова, а затем обработать и отфильтровать их. Результатом этого станет готовый список фраз с большой эффективностью для продвижения.
Содержание Toggle
Программа для сбора семантического ядра сайта. Преимущества
Уникальный софт Slovoeb имеет множество достоинств:
- Сбор всех видов частотностей. Здесь можно собрать разные виды частотности для ключевых слов, значительно расширив их список;
- Информация о сезонности запроса. Сервис помогает выявить сезонность ключевой фразы, что может пригодиться некоторым видам бизнеса;
- Поиск дополнительных подсказок из поисковой выдачи. Небольшие подсказки из Яндекса, Гугла или Mail дополнят список фраз;
- Вычисление конкурентности ключевиков. Сервис проанализирует и выдаст информацию о конкурентности конкретных ключевых фраз, которые можно смело брать на вооружение.
 Здесь можно собрать разные виды частотности для ключевых слов, значительно расширив их список;
Здесь можно собрать разные виды частотности для ключевых слов, значительно расширив их список;Кроме того, сервис позволяет выявить релевантные страницы (то есть, те страницы, которые будут максимально полно отвечать на поисковый запрос пользователя).
И всё это в автоматизированном режиме. Согласитесь, что очень удобно? Ещё как.
Типы ключевых слов. Программа для сбора семантического ядра сайта
Прежде чем мы перейдём к детальной настройке программы и составлению семантики для сайта, мне бы хотелось напомнить вам о видах ключевиков. Эти знания помогут вам в процессе сбора семантики. Ключевики делятся на разные группы.
Эти знания помогут вам в процессе сбора семантики. Ключевики делятся на разные группы.
В зависимости от принадлежности и задач выделяют следующие виды:
- По частотности: высокочастотные, среднечастотные, низкочастотные.
- Принадлежности к региону.
- Цели: информационные и продающие (или коммерческие).
Так, высокочастотные запросы – это те, в которых число показов в месяц больше или равно 1000. Среднечастотные 500-700 показов в месяц. А низкочастотные до 100. Все эти обозначения условны и зависят от конкурентности ключевика, региона продвижения (если есть к нему привязка), сезонности предложения.
Информационные запросы характеризуются вопросительной интонацией. Пользователь интересуется тем, чего не знает, но очень хочет узнать.
Главными маркерами могут быть слова «как», «где», «сколько», «по чём». Например, «сколько стоит смартфон в 2018 году» — явно информационный запрос, цель которого – дать полезные сведения.

Цель коммерческого запроса – однозначно продажа. Запрос может содержать слова вроде «купить», «недорого», «заказать», «доставка», «цена». Например, «купить смартфон» — однозначно коммерческий запрос. Пользователю не просто интересно узнать про это, но он намеревается приобрести товар здесь и сейчас или во всяком случае в ближайшем будущем.
Скачивание программы. Программа для сбора семантического ядра сайта
Бесплатно скачать программу Slovoeb можно на сайте официального разработчика по ссылке
Программа не требует установки. Сразу после скачивания нужно извлечь все файлы из архива в отдельную папку на вашем ПК, после чего запустить файл Slovoeb.exe
Теперь программа готова к использованию.
Настройка программы
Перед тем как начать пользоваться софтом, необходимо произвести некоторые настройки. Это нужно для указания режима сбора, параметров открытия страниц, количества слов, которые используются при подборе. В комплексе правильные настройки повлияют на весь результат.
В комплексе правильные настройки повлияют на весь результат.
Подключение аккаунта Яндекса
Для начала работы вам следует подключить аккаунт от Яндекса, поэтому переходите на почту и регистрируйте почтовый ящик. После этого заходим в программу, нажимаем на иконку слева в верхней панели, далее переходим в «Настройки».
Переходим во вкладку «Парсинг» и «Yandex. Direct», указываем там логин, пароль через двоеточие без пробелов или прочих знаков.
Внимание! Лучше всего не использовать активный аккаунт или тот, которым вы пользуетесь во избежание бана от Яндекса.
Бдительная поисковая система не приветствует использование сторонних сервисов, а потому при распознавании похожих действий по сбору семантики, ваш аккаунт может быть заблокирован. Поэтому используйте только тот, который не жалко будет потерять.
На этом ещё не всё. Теперь нам предстоит выполнить дополнительные настройки. Для этого переходим к следующему шагу.
Теперь нам предстоит выполнить дополнительные настройки. Для этого переходим к следующему шагу.
Общие настройки. Программа для сбора семантического ядра сайта
Во вкладке «Общие» выставляем стандартные значения.
После чего переходим во вкладку «Yandex.Wordstat», выставляем следующие значения.
На этом настройку можно считать завершённой.
Работа с программой
Теперь давайте разберёмся как работать с самой программой. Здесь у вас вряд ли возникнут какие-либо сложности, так как интерфейс интуитивно понятен даже новичку.
Я буду пошагово описывать действия. Итак, поехали!
Шаг 1. Создание проекта
Для начала нам необходимо создать проект. Нажимаем на кнопку главного меню, которая находится сверху в левом углу. Жмём на «Создать проект». Пишем название проекта, простое и понятное. Сохраняем.
Шаг 2. Сбор ключевых слов
На этом этапе нам необходимо подобрать примерный список ключевиков для нашего сайта.
Это те фразы, которые может употребить ваш потенциальный клиент при поиске товара, услуги, продукции, предложения.
Допустим, у нас имеется интернет-магазин детской одежды.
Переходим во вкладку «Сбор ключевых слов и статистики», далее нажимаем «Пакетный сбор из левой колонки Yandex.Wordstat», после добавления нажимаем «Начать сбор». При необходимости задаём нужный регион.
Хочу отметить, что можно и даже нужно использовать разные виды ключевых фраз. Вовсе не возбраняется экспериментировать. Так, слова «купить», «недорого», «акции» имеют место быть особенно в сезон.
Дайте волю фантазии, экспериментируйте. Не забывайте о том, что вас будут искать реальные люди, а значит, нужно ориентироваться на их потребности.![]()
В результате у нас получится вот что:
Программа нашла 6443 фразы. Вот это результат! Теперь давайте дополним этот список подсказками.
Шаг 3. Использование подсказок
После того как основной список собран, мы воспользуемся подсказками.
Подсказки могут добавить некоторые интересные ключевики, до которых мы бы даже не додумались, но они могут быть интересны пользователям. Используем же возможности по максимуму.
Нажимаем на вкладку «Пакетный сбор поисковых подсказок».
В открывшемся окне вводим наши изначальные ключевики (см. шаг 2), отмечаем галочками нужные пункты. Это те сервисы, в которых будут искаться подсказки.
Рекомендую установить галочки напротив Яндекс, Google, mail.ru, на этом всё.
Получится вот такой результат:
Итак, у нас получилось 9640 ключевых фраз благодаря подсказкам.
Шаг 4. Выявление частотности запросов
Нажимаем на кнопку «Сбор частотности с Yandex. Wordstat», обязательно выбираем пункт «Собрать частотности «!».
Wordstat», обязательно выбираем пункт «Собрать частотности «!».
Ждём пока соберутся данные по частотности.
Шаг 5. Удаление пустых и ненужных запросов
На этом этапе чистим все ключевики, частотность которых меньше 10 или 0. Они не несут никакой пользы.
Те запросы, частотность которых больше этого значения, являются микрочастотными. Их можно использовать как дополнения к основным в разбавленной словоформе. Главное, не переусердствуйте с этим!
Выделяем строку, правой кнопкой мыши нажимаем «Удалить выделенные строки».
Можно пробежаться по списку, отметить галочками ненужные фразы. После этого уже удалить их все. В итоге наш список может слегка поредеть, но зато это будут точные ключевики, по которым уже можно продвигаться.
Шаг 6. Разделение ключевых фраз по видам
После всех произведённых действий у нас останется список ключевиков, который можно смело использовать для продвижения сайта.
Для удобства рекомендуется разделить фразы на «информационные» и «коммерческие». Это нужно для того, чтобы установить соответствие ключевика конкретным страницам на вашем сайте.
Например, в приведённом списке запрос «размеры детской одежды» является информационным, а «детская одежда оптом» уже коммерческий.
После всех произведённых действий можно экспортировать получившийся список в формате Excel.
Частые вопросы по теме. Программа для сбора семантического ядра сайта
Частые вопросы, которые могут возникнуть:
Почему ключевые фразы собираются только из левой колонки Яндекса? Для чего нужна правая колонка?
Ответ: По умолчанию лучше всего собирать список слов из левой колонки. Подобно тому, как мы это делаем без софта. Левая колонка отражает наиболее точные ключевики по тематике и частотность по ним. Правая же колонка отвечает за похожие запросы, которые будут дополнять те, что находятся в левой колонке.
Однако похожие запросы мы можем добавить через подсказки, а потому использование правой колонки может не пригодиться.
Как узнать сезонность запроса?
Ответ: Для этого в программе есть отдельная функция «Сбор данных сезонности» (в разных версиях может называть по-разному). Воспользовавшись ею, вы сможете увидеть наглядный график спада и роста позиций на сайте за прошедший месяц или неделю. Использовать сезонности можно только уже на готовом списке.
Как узнать релевантность страницы, для чего это нужно?
Ответ: Воспользоваться разделом «Релевантные страницы и позиции». Ввести ссылку на свой сайт, после чего сервис вычислит наиболее подходящие страницы для вашего сайта. Это нужно прежде всего для повышения лояльности пользователей, а также для уменьшения отказов при просмотре страниц.
Проще говоря, пользователь, переходя из поисковиков по определённому запросу, должен попадать на страницу, которая отвечает на этот вопрос.
 В противном случае он просто уйдёт, и это негативно отразится на доверии.
В противном случае он просто уйдёт, и это негативно отразится на доверии.Заключение
Пожалуй, это вся информация, которой мне хотелось бы поделиться с вами. Изучайте постепенно, внедряйте и получайте свои результаты от проделанной работы. Я уверен, что у вас всё обязательно получится. До встречи!
Список популярных инструментов исследования ключевых слов
26 июля 2019 г.
Одним из основных компонентов поисковой оптимизации является KWR. Исследуя ключевые слова, вы уточняете свою целевую аудиторию и поисковые запросы, которые они вводят в поле поиска. Чтобы получить основу для оптимизации веб-сайта, необходимо создать сильное семантическое ядро. Имея его, вы сможете читать мысли целевых клиентов.
Основной принцип подбора ключевых слов заключается в том, чтобы знать, какие слова и фразы вводят ваши потенциальные пользователи в поля поиска. На основе этой информации вы можете оптимизировать содержание своего веб-сайта и продвигать свои продукты или услуги во всемирной паутине. Но прежде чем собирать семантическое ядро, вам также необходимо проверить позиции вашего сайта в самых популярных поисковых системах.
Но прежде чем собирать семантическое ядро, вам также необходимо проверить позиции вашего сайта в самых популярных поисковых системах.
Чтобы провести исследование релевантных ключевых слов, вам нужны инструменты проверки релевантных ключевых слов, а с помощью программы проверки ключевых слов Google вы можете увеличить не только количество посетителей вашего сайта, но и рейтинг вашего сайта в поисковых системах. Более того, вы легко сравниваете веб-рейтинги своих конкурентов со своими.
Служба SpySERP
Этот инструмент ранжирования SERP является идеальным помощником в проверке позиций вашего сайта в Google, Bing и других поисковых системах. На основе этого анализа вы получите «удобный для поисковых систем» сайт. С его помощью вы можете получать аналитические данные не только о своем сайте, но и о сайтах ваших конкурентов.
Он также имеет функцию инструмента группировки ключевых слов и улучшенный процесс кластеризации. С его помощью можно создать наиболее релевантную по семантике группировку ключевых слов, а также группировку поисковых запросов и ряд других преимуществ.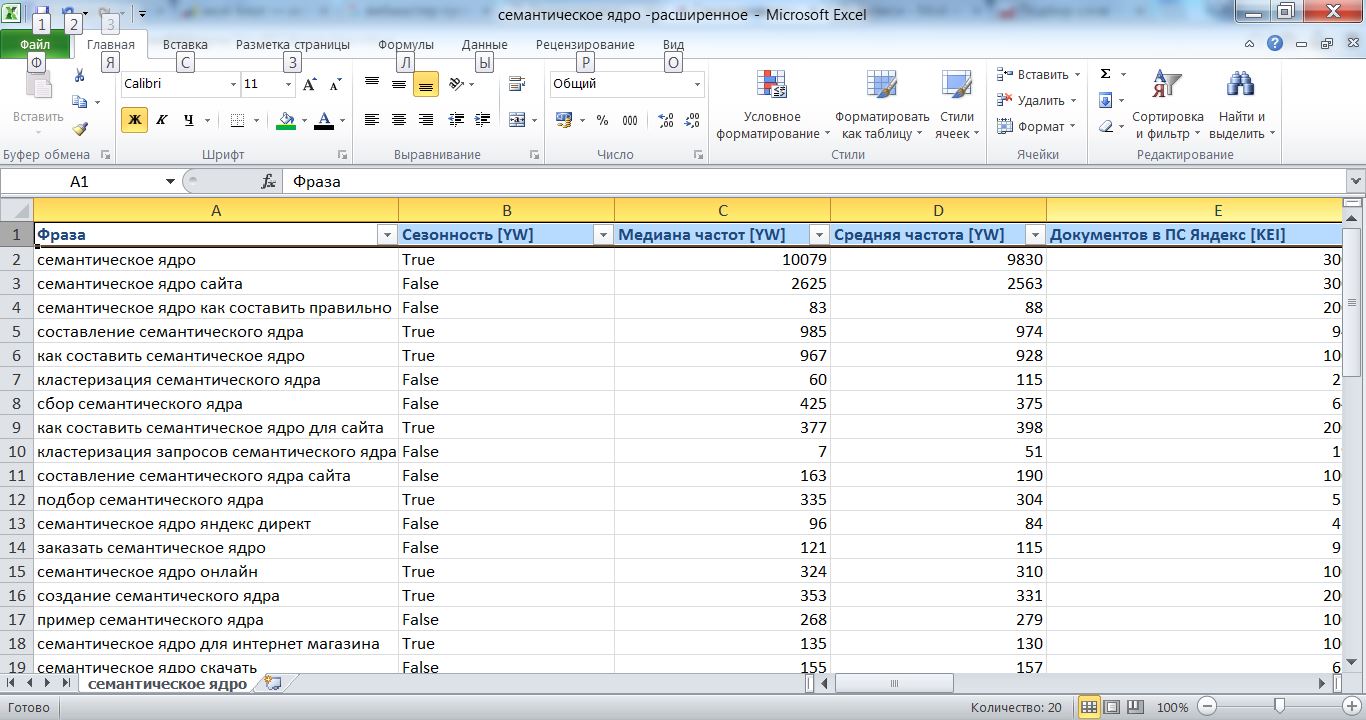
Google Search Console
Это нетипичный инструмент для исследования ключевых слов. Используя его, вы можете собрать множество «Ключевых слов возможностей». Одной из самых интересных функций является отчет об эффективности. Благодаря этому отчету вы получите страницы вашего сайта, на которые приходится наибольшее количество кликов пользователей. Более того, вы также получите ключевые слова и фразы, которые пользователи вводят в поле поиска Google, а затем посещают ваш сайт по этим ключевым словам. Итак, если вы собираетесь исследовать ключевые слова с помощью бесплатных инструментов, примите во внимание Google Search Console. Он дает вам не только ключевые слова, но и самые популярные веб-страницы вашего сайта с наибольшим количеством посетителей.
Чтобы получить больший эффект, вы можете использовать Google Analytics, а также Google Search Console.
Анализ ключевых слов с помощью Ahrefs
В Ahrefs есть функция «Проводник ключевых слов». С его помощью вы можете получить подробную информацию по всем ключевым словам. Вы получаете гораздо больше данных, чем просто объем поиска. Такая функция, как сложность ключевых слов, анализируется настолько глубоко, насколько это возможно, и веб-мастер даже знает, сколько обратных ссылок нужно добавить на веб-страницу, чтобы попасть на первую страницу Google!
С его помощью вы можете получить подробную информацию по всем ключевым словам. Вы получаете гораздо больше данных, чем просто объем поиска. Такая функция, как сложность ключевых слов, анализируется настолько глубоко, насколько это возможно, и веб-мастер даже знает, сколько обратных ссылок нужно добавить на веб-страницу, чтобы попасть на первую страницу Google!
Планировщик ключевых слов Google
Этот инструмент предлагает вам обширную базу данных ключевых слов. Одним из его преимуществ является точность, ведь GKP берет данные именно из Google. Пожалуй, самая оригинальная его особенность — ставка вверху страницы. Эта функция необходима тем, кто увеличивает платный трафик, но Google Keyword Planner также очень полезен для увеличения органического трафика. Исследуйте ключевое слово в Google и получите мощный поток аудитории из самой популярной поисковой системы.
SEMRush
SEMrush показывает вам ключевые слова, по которым ранжируются ваши конкуренты. Вы не должны работать со списками предлагаемых ключевых слов, которые вам могут предложить многие другие инструменты. Эта особенность нетипична и дает дополнительные преимущества. Вебмастер получает ключи, которые стандартные инструменты ему не предлагают.
Вы не должны работать со списками предлагаемых ключевых слов, которые вам могут предложить многие другие инструменты. Эта особенность нетипична и дает дополнительные преимущества. Вебмастер получает ключи, которые стандартные инструменты ему не предлагают.
Кстати, SEMrush ранжирует сайт по оценке его органического трафика.
Как оптимизировать контент вокруг ваших ключевых слов?
Квалифицированные SEO-специалисты могут оптимизировать свой контент по всем выбранным ключевым словам и разместить свои веб-ресурсы на первых страницах Google, Bing, Yahoo и т.д. В результате владелец сайта получает сильный поток посетителей сайта. Дополнительным преимуществом этого является то, что большинство из них будут целевыми клиентами, потому что оптимизация вашего контента будет соответствовать поисковым запросам пользователей.
Передовой опыт показывает, что глубокий анализ ключевых слов конкурентов является эффективным способом сбора релевантных KWR. Чтобы быть впереди других, вы должны понимать их стратегии и ориентироваться на их смысловое ядро.
Значение каждого ключевого слова неоценимо. Вы должны точно подобрать семантическое ядро, чтобы убедиться, что ваш контент соотносится с теми ключевыми словами, которые пользователи вводят в поисковые окна.
Как ключевые слова работают для SEO?
Исследуя ключевые слова для SEO, вы должны быть уверены в их эффективности. Попробуйте комбинировать длинные фразы и короткие ключи. Но их подбор — это только половина дела. Получив их, вы должны сделать вторую часть этой работы — вставить их в свой контент, включая заголовок, подзаголовок, другие теги и тело статьи.
Поисковые системы должны быть вашими хорошими друзьями, но учтите, что вашими лучшими друзьями являются посетители сайта. Создавая свой контент, ориентируйтесь на своих читателей. Они должны получить ответы на свои вопросы; найти то, что искали. Только если ваш контент будет соответствовать поисковым запросам пользователей, ваш сайт получит сильный поток трафика.
В заключение
Новейшие технологии и многофункциональное программное обеспечение открывают широкие возможности перед веб-мастерами и оптимизаторами. Они могут отобрать все частые запросы целевой аудитории и собрать максимально точное семантическое ядро на свои сайты. Каждую ключевую фразу и слово можно выделить в отдельную группу, категорию по своим особенностям. Процесс кластеризации также является необходимой функцией для веб-мастеров, чтобы делать KWR и создавать контент на его основе.
Они могут отобрать все частые запросы целевой аудитории и собрать максимально точное семантическое ядро на свои сайты. Каждую ключевую фразу и слово можно выделить в отдельную группу, категорию по своим особенностям. Процесс кластеризации также является необходимой функцией для веб-мастеров, чтобы делать KWR и создавать контент на его основе.
У нас есть все инструменты, чтобы сделать наши сайты привлекательными как для целевых клиентов, так и для поисковых систем. Для стабильного потока трафика и высоких позиций сайта нужно быть в тренде и следить за всеми изменениями в алгоритмах Google, Bing и т.д. Но как показывает практика, все алгоритмы мощных поисковых систем ориентируются на качество контента и обращают на это внимание. черт слишком много. Итак, оптимизация контента — это ваша основа продвижения в сети.
Лучшее программное обеспечение Linux Semantic Web с открытым исходным кодом 2023
Просмотрите бесплатное программное обеспечение и проекты Semantic Web с открытым исходным кодом для Linux ниже.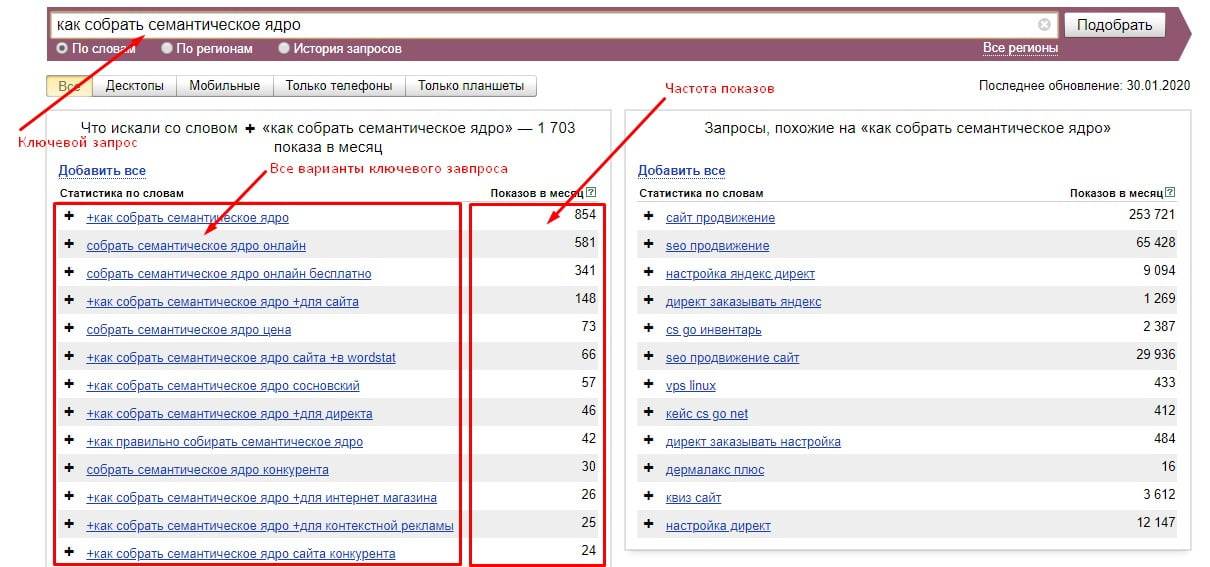 Используйте переключатели слева для фильтрации программного обеспечения Semantic Web с открытым исходным кодом по ОС, лицензии, языку, языку программирования и статусу проекта.
Используйте переключатели слева для фильтрации программного обеспечения Semantic Web с открытым исходным кодом по ОС, лицензии, языку, языку программирования и статусу проекта.
- Профессиональная платформа для поставщиков услуг тайных покупателей и исследователей CX/VoC
Checker предлагает интегрированную платформу для исследования рынка, позволяющую эффективно проводить исследования Mystery Shopping, CX/VoC и VoE.
Платформа, основанная в 2005 году, экспоненциально выросла благодаря более продвинутым функциям, которые сочетают в себе функцию «Тайный покупатель» с управлением качеством обслуживания клиентов за счет многоканального сбора данных, полного рабочего процесса и унифицированных инструментов отчетности.
Узнать больше
- Quaeris: GPT Driven Action Platform
Генеративный ИИ для ваших данных. Мгновенное понимание, действуйте, сотрудничайте и сообщайте.
Исследуйте данные и получайте мгновенную информацию, выполняя поиск в корпоративных данных — например, Google для ваших данных! Персонализированный, основанный на ваших интересах, роли и истории. Закрепляйте эти идеи, чтобы создавать персональные доски/панели мониторинга, делиться своими идеями и совместно работать над ними, а также стать по-настоящему управляемыми данными.
Узнать больше
- 1
Кунжут
Java RDF-фреймворк
Этот проект больше не поддерживается. На смену ему приходит проект Eclipse RDF4J, который можно найти на GitHub и http://www.rdf4j.org/. Sesame — это де-факто стандартная структура для обработки данных RDF. Это включает синтаксический анализ, масштабируемое хранилище, рассуждение и полную поддержку запросов/обновлений SPARQL 1.1. Sesame предлагает полностью модульный инструментарий и простой в использовании Java API, который можно подключить ко всем ведущим решениям для хранения RDF.
- 2
рдф2рдф
Этот инструмент Java преобразует данные RDF из любого формата RDF в любой другой.
Этот инструмент Java преобразует файлы RDF из любого формата RDF в любой другой формат. Он основан на проекте openRDF.org Sesame и упакован в один JAR-файл для простоты использования.
- 3
MRCube
Управление метамоделями на основе RDF Revision Reflection
MRCube — это инструмент графического редактирования содержимого на основе RDF, разработанный для управления отношениями между содержимым RDF и RDFS.
- 4
Семантическая МедиаВики
Позволяет хранить и запрашивать данные на страницах вики.
Semantic MediaWiki — это расширение программного обеспечения MediaWiki (на основе Википедии), которое расширяет Wiki идеями из Semantic Web.
Мы ориентируемся на удобство использования и тесную интеграцию.
См. веб-сайт для получения дополнительной информации и GitHub по адресу https://github.com/SemanticMediaWiki/SemanticMediaWiki/releases для выпуска файлов! (начиная с версии 2.4.0). LibreOffice — это бесплатный и мощный офисный пакет. Текстовый процессор, электронные таблицы, презентации, диаграммы, базы данных, редакторы формул, диаграммы и многое другое. Совместимость с Windows, Mac и Linux.
Загрузить сейчас
- 5
EulerGUI
Облегченная IDE для искусственного интеллекта. Запущен как графический интерфейс для механизма рассуждений Эйлера. Источниками могут быть N3, RDF, OWL, UML, eCore, обычный XML или XSD, файлы или URL-адреса. Обертывает Drools (или CWM, FuXi) как движки правил N3. Приложение на основе модели. поколение.
- 7
CDM_Core
Онтология CDM-Core (модель данных CREMA — основной модуль) представляет собой производственную онтологию, специализирующуюся на двух прикладных поддоменах: 1) производство выхлопных автомобилей и 2) обслуживание металлических прессов Онтология CDM-Core была разработана: Доктор Лука Маццола, Msc. Патрик Капанке, Марко Вуйич и приват-доцент доктор Матиас Клуш в Немецком исследовательском центре искусственного интеллекта DFKI GmbH (http://www.
dfki.de) в Саарбрюккене, Германия. Авторские права: DFKI, 2016, лицензия CC BY-SA см. http://creativecommons.org/licenses/by-sa/3.0/ Для сообщений об ошибках, технических проблем и запросов функций, пожалуйста, обращайтесь: Лука Маццола: [email protected] или [email protected] Патрик Капанке: [email protected] - 8
XLWrap
Оболочка электронных таблиц в RDF, способная преобразовывать электронные таблицы в произвольные графики RDF; поддерживает язык сопоставления с мощными выражениями формул, как вы знаете из Excel, локальный/удаленный Excel/ODF/CSV, сервис SPARQL — источник доступен на https://github.com/theandyl/xlwrap
- 9
MapPSO
- Программное обеспечение для управления проектами ProWorkflow
Тратьте меньше времени на мысленное управление процессом. ProWorkflow позволяет с легкостью назначать сотрудников, отслеживать время или переносить проекты.
Если вы хотите с легкостью управлять своими проектами и командами, обратитесь к ProWorkflow. Программное обеспечение для управления проектами через Интернет для фрилансеров, стартапов и предприятий. ProWorkflow поставляется с рядом мощных инструментов, помогающих пользователям выполнять свою работу. ProWorkflow предлагает функции для назначения задач, отслеживания времени или изменения расписания проектов. Он также предлагает простые инструменты цитирования и выставления счетов.
Узнать больше
- 10
RDFConvert
преобразователь синтаксиса командной строки для RDF
RDFConvert — это простой инструмент командной строки для преобразования файлов RDF между различными форматами синтаксиса.
Он основан на наборе инструментов парсера OpenRDF Rio и в настоящее время поддерживает RDF/XML, Trig, Trix, Turtle, N3, N-Triples, RDF/JSON, JSON-LD, Sesame Binary RDF и N-Quads. - 11
Преобразователь XML в RDF xml2rdf.xsl
Общий преобразователь XML в RDF
Это общий преобразователь XML в RDF, который использует преобразования XSLT для преобразования любого XML-документа в формат RDF. Преобразование использует процессор XSLT, такой как xsltproc. Командная строка для оболочки Bash: xsltproc xml2rdf3.xsl документ.xml >
- 13
ASIBsync
Агент синхронизации ASI для Smart-M3 SIB
- 14
AnnoCultor
AnnoCultor: перенос культурных репозиториев в Semantic Web.
- 15
Arastreju
Arastreju — это Java-движок для управления информацией на основе онтологий.
- 16
Семантический и онтологический раздел
Семантический и онтологический раздел: está compuesto de distintas partes Programas en Diferentes lenguajes: а. Фихерос PHP б. Ficheros на JavaScript (AJAX) в. Ходжас де Эстило CSS д. Необходимо установить сервер APACHE и TomCat для корректной работы. е. Краткое описание функций: средство передачи данных PHP, построенное по формулам, которые восстанавливают информацию и перемещают переменные POST и GET, действуя в соединении с файлами данных в JavaScript (AJAX) и подключаясь к серверу SOLR.
- 17
Common Lisp Reasoner
Common Lisp Reasoner расширяет объектную систему Common Lisp (CLOS) и включает в себя мощный язык правил, подходящий для всех видов задач рассуждений, стандартные интерфейсы XML и RDF/XML, а также поддержку различных AI- связанные приложения, такие как планирование, планирование и диагностика.
- 18
Преобразователь RDF в OWL
Преобразователь файлов в формат этикетки, исходящий из формата этикетки назначения: анализатор, позволяющий преобразовать файлы формата в другой, который создан для преобразования форматов в файл R ДФ: DC в формате OWL для использования в Protègè. Posee ип система де configuración де etiquetas origen y etiquetas destino, siendo posible la conversion de múltiples formatos diferentes. Эль-программа реализована на языке JAVA.
- 19
DB2RDF
DB2RDF — это программный инструмент, который преобразует данные из реляционной модели данных в семантическую модель данных (в форме RDF и RDFS). Конечная точка SPARQL для запроса преобразованных данных. Для запроса семантических данных используется язык запросов SPARQL.
- 21
DynamiCoS
DynamiCoS — это платформа для поддержки ориентированной на пользователя композиции услуг. Он использует методы семантической сети для описания и обнаружения услуг, которые затем используются в композициях, направленных на удовлетворение целей пользователя. Текущая версия по-прежнему является альфа-версией. Дальнейшие разработки должны быть опубликованы в ближайшее время.
- 22
ExiFlow
Набор инструментов (командная строка и графический интерфейс) для обеспечения полного рабочего процесса работы с цифровыми фотографиями для Unix.


 Мы ориентируемся на удобство использования и тесную интеграцию.
См. веб-сайт для получения дополнительной информации и GitHub по адресу https://github.com/SemanticMediaWiki/SemanticMediaWiki/releases для выпуска файлов! (начиная с версии 2.4.0).
Мы ориентируемся на удобство использования и тесную интеграцию.
См. веб-сайт для получения дополнительной информации и GitHub по адресу https://github.com/SemanticMediaWiki/SemanticMediaWiki/releases для выпуска файлов! (начиная с версии 2.4.0). org/ListItem»>
6
org/ListItem»>
6RDBToOnto
RDBToOnto позволяет автоматически генерировать точно настроенные онтологии OWL из реляционных баз данных. Главной особенностью этого полноценного инструмента является возможность создания структурированных онтологий с более глубокой иерархией за счет использования как схемы базы данных, так и хранимых данных. RDBToOnto можно использовать для создания связанных данных RDF. Его также можно использовать для создания высокоточных правил сопоставления RDB-RDF (для D2RQ Server и Triplify).

 Алгоритм массивно параллелен и естественным образом адаптируется к параллельным архитектурам.
Алгоритм массивно параллелен и естественным образом адаптируется к параллельным архитектурам.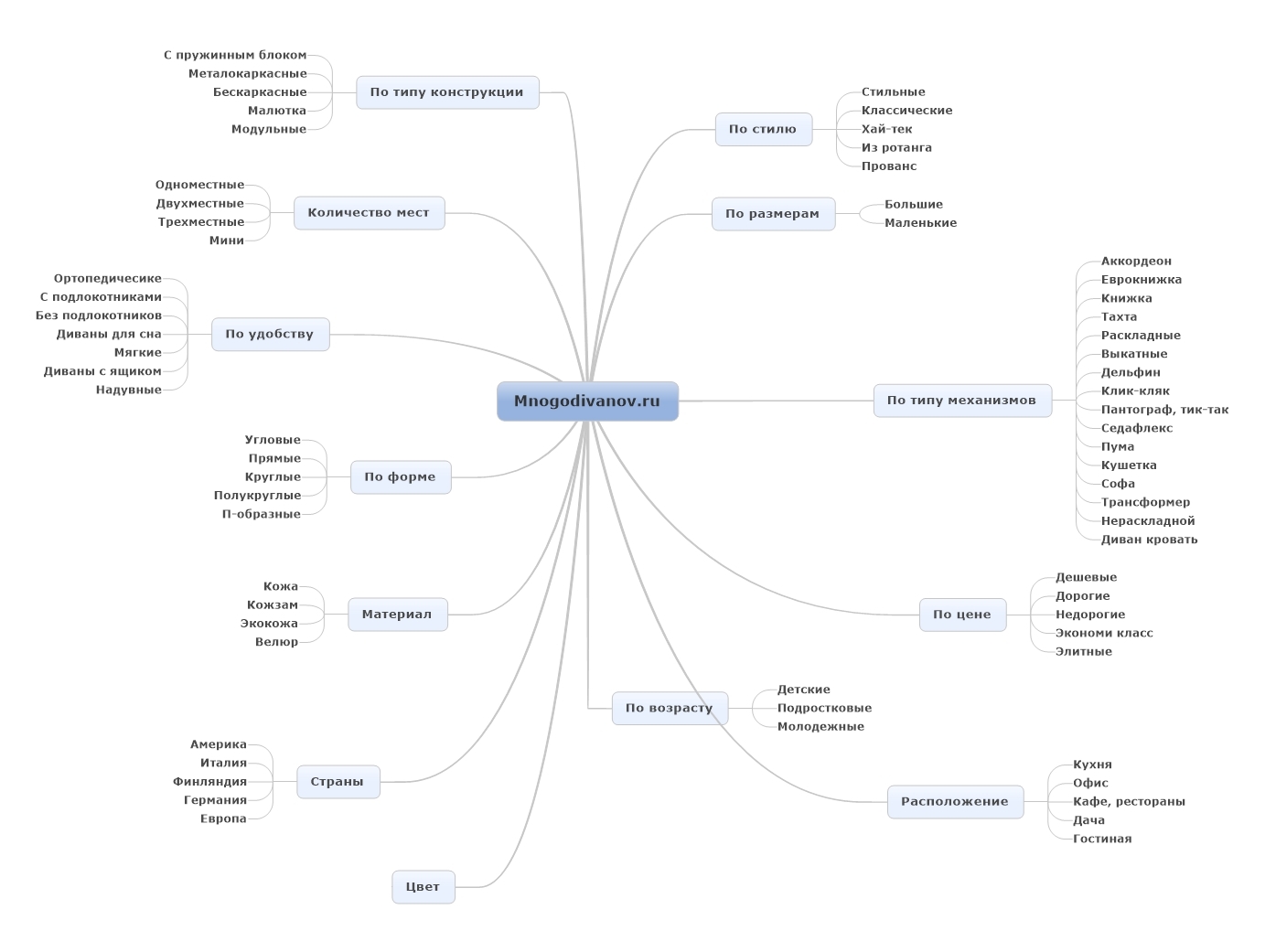 Он основан на наборе инструментов парсера OpenRDF Rio и в настоящее время поддерживает RDF/XML, Trig, Trix, Turtle, N3, N-Triples, RDF/JSON, JSON-LD, Sesame Binary RDF и N-Quads.
Он основан на наборе инструментов парсера OpenRDF Rio и в настоящее время поддерживает RDF/XML, Trig, Trix, Turtle, N3, N-Triples, RDF/JSON, JSON-LD, Sesame Binary RDF и N-Quads. org/ListItem»>
12
org/ListItem»>
12XMLtoRDF
Программа для преобразования любого документа XML в документ RDF.
Некоторые сценарии нейроинформатических экспериментов сохраняются в стандартном XML-документе. Эта программа должна быть в состоянии проанализировать почти любой сценарий, чтобы создать полноценный RDF-файл, где каждая часть сценария имеет свой собственный URI. Этот проект из Университета Западной Богемии в Чешской Республике требуется для Основ программной инженерии (KIV/ZSWI).


 org/ListItem»>
20
org/ListItem»>
20ДОДДЛ-СОВА
Среда быстрой разработки предметной онтологии – расширение OWL
DODDLE-OWL — инструмент разработки онтологий предметной области для Semantic Web. DODDLE-OWL повторно использует существующие онтологии и поддерживает полуавтоматическое построение таксономических и других отношений в онтологиях предметной области из документов.
