
все способы. Часть 1 — SEO на vc.ru
Семантическое ядро – фундамент последующего продвижения сайта. Данная статья будет полезна как новичкам, так и практикующим специалистам, а также клиентам, стремящимся получше разобраться в вопросах поискового продвижения. Сложно и муторно в этой статье точно не будет – обещаем 🙂
5176 просмотров
Собрали целый массив структурированной информации: что такое семантика, как выглядит семантическое ядро; как собрать ядро для интернет-магазина или маркетплейса; способы кластеризации, а также анализ СЯ конкурента, и все способы сбора ключей.
Кстати, хорошие примеры семантического ядра есть у Rush Analytics.
Содержание:
1. Что такое семантика и как выглядит семантическое ядро
2. Как собрать семантическое ядро для интернет-магазина
2.1. С чего начать?
2.2. Используем готовый шаблон
2.3. Заполнение шаблона
3. База запросов
4. Подбираем запросы для СЯ
Что такое семантика и как выглядит семантическое ядро
Для совсем новичков приведем цитату из Википедии: семантическое ядро представляет собой упорядоченный набор слов, их морфологических форм и словосочетаний, характеризующих вид деятельности, товары и услуги, предлагаемые сайтом.
Страшно, сложно и непонятно.
Конкретизируем: семантическое ядро – структурированное описание сайта, учитывающее пользовательский спрос, интересы аудитории, специфику бизнеса и цели проекта. Таким образом, СЯ – это не просто список слов и словосочетаний.
К.О.
Стоит учитывать, что в ядро попадают запросы, вводимые пользователями в поисковую систему. Эти запросы называют ключевыми словами, иначе – ключами, благодаря которым вы можете узнать, что, как и для чего ищет ваша аудитория.
- Что ищут – какая информация, услуга, товар интересны пользователям.
- Как ищут – какими фразами они пользуются для поиска.
- Зачем ищут – цели получения информации. Например, сравнить цены, выбрать, купить и т.д.
Представим, что вы планируете открыть сервисный центр по ремонту телефонов и выйти в онлайн. Вам необходимо определиться, как составить семантическое ядро, какие услуги более всего интересуют ваших потенциальных клиентов.
Вордстат отражает, что вводят в поисковик люди, которым необходимо отремонтировать телефон.
А если кликнуть на запрос, то перейдем на следующий «уровень» с уточненными ключевыми словами.
«Починить телефон», «отремонтировать телефон» говорят нам о целях поиска. Сопутствующие основной фразе «самсунг», «iphone» и прочие отвечают на вопрос о том, что именно хотят починить пользователи.
Задачи семантического ядра не ограничиваются на описании тематики сайта:
- СЯ определяет структуру сайта – страницы, разделы, иерархичность. Это облегчает навигацию как для аудитории, так и для ПС.
- Благодаря семантическому ядру оптимизируем страницы под конкретные запросы — прописываем мета-теги, создаем релевантный контент.
- Создаем матрицу контента. Семантическое ядро дает нам основу для создания контент-плана — релевантные статьи (в том числе описания ассортимента), инфоблог и прочее.

- Оптимизированное ядро несложно использовать и для настройки контекстной рекламы.
- Благодаря СЯ мы грамотно линкуем страницы, чтобы корректно распределить ссылочный вес, а также для пользователей облегчить поиск необходимой информации.
- Актуализация ядра = достоверный анализ покупательского спроса. Отслеживая, чем интересуются пользователи, можно включать новые услуги, расширять ассортимент и прочее.

Таким образом, семантическое ядро – основа успешного продвижения ресурса в поисковых системах. Его составлением стоит заняться до создания сайта. Формирование семантического ядра до того, как создан ресурс, – это семантическое проектирование.
Для начала определяют тематику сайта, ключи должны наиболее полно описывать содержание. Далее запросы кластеризуют по разделам сайта. После – собранную семантику используют для постраничной оптимизации страниц.
Как собрать семантическое ядро для интернет-магазина
Как пользователи ищут товары и услуги в интернете?
- Если речь о технике, косметике, мебели, ищут по наименованию, а порой даже по артикулу.
- Если конкретики нет, то ищут по товарной категории.
- Часто вводят запросы, начинающиеся с «как…», «почему…», и в итоге находят, что им нужно купить, например, для удовлетворения той или иной потребности.

Чтобы собрать семантическое ядро для интернет-магазина, можно воспользоваться wordstat.yandex.ru, KeyCollector. Есть свои плюсы и минусы.
1. Wordstat бесплатен, предоставляет прекрасную возможность сориентироваться, насколько востребован конкретный запрос. Учитывается время, регион, порядок слов, статистика за месяц. Такой вариант подойдет для ручного сбора небольших семантических ядер. Не забудьте установить Yandex Wordstat Assistant, благодаря которому вы сможете сохранять и фразы, и их частотность в таблицах.
2. Парсер, например, Key Collector. Парсер это программа, сервис или скрипт, который собирает данные, анализирует и выдает в нужном формате. Чтобы было еще понятнее, условно определим парсер как сортировщик.
Key Collector 4 – новая версия известного парсера
С чего начать?
В первую очередь обозначим, что СЯ для страниц каталога и страниц товаров будут разными, раз мы говорим именно об интернет-магазине.
Рекомендуем начать с работы над страницами каталога, точнее, с его структуры. Почему это важно?
Продуманный каталог поможет не только собрать семантическое ядро, но и улучшать поведенческие факторы. Если структура удобна для пользователя, то и поисковая система «поднимет выше» сайт в выдаче.
Используем готовый шаблон
Чтобы подготовить каталог, воспользуйтесь готовым шаблоном –их можно найти в интернете. На скриншоте один из вариантов:
Таблица для подготовки семантического ядра интернет-магазина
Разумеется, это лишь пример, и ваша таблица может получить гораздо сложнее.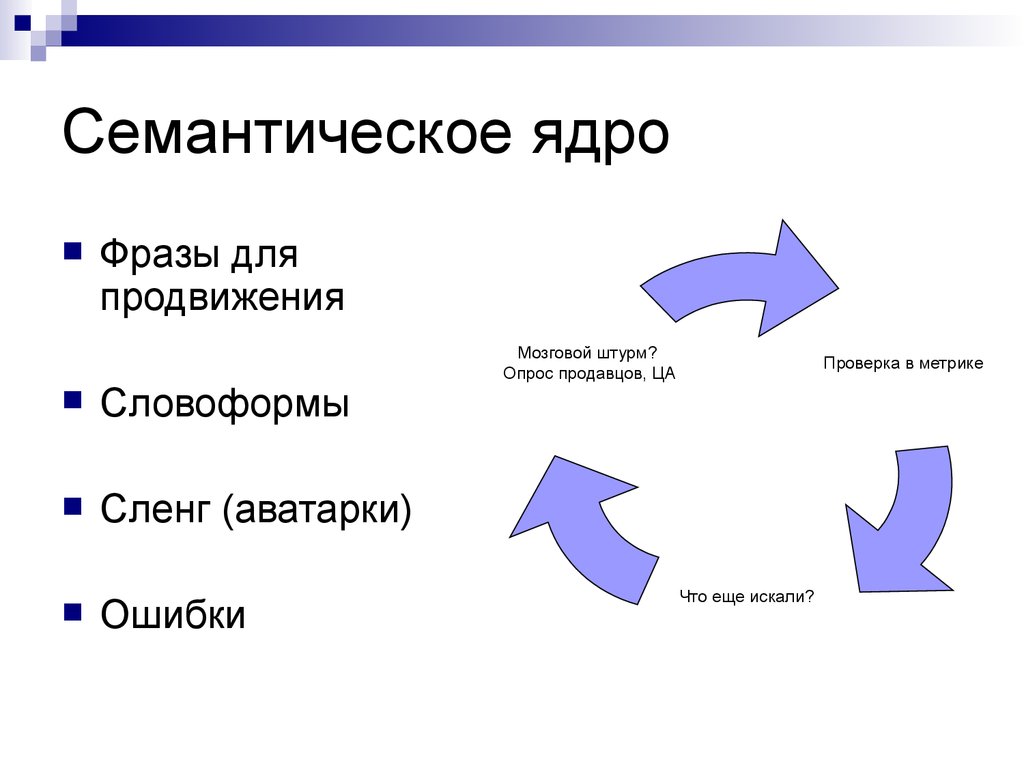 Главное – вы поняли принцип.
Главное – вы поняли принцип.
Заполнение шаблона
Ядро составляем на основе ассортимента интернет-магазина, но в первую очередь следует заняться категориями и подкатегориями. Непосредственно к карточкам товаров можно обратиться позже.
Как создать каталог?
- оценить, каким бы вы хотели видеть перечень, и составить его в соответствии с собственными предпочтениями и видением;
- опереться на прайсы поставщиков;
- позаимствовать у конкурентов из топа.
Так, например, будет выглядеть каталог для магазина растений и семян:
База запросов
Помимо этого, вы можете воспользоваться любой крупной базой ключевых слов. Например, у Keys.so база состоит более 120 млн слов из русскоязычного сегмента интернета и практически отсутствуют нулевые ключевые запросы. Вводите ключевое слово и выбираете регион:
Таким же образом вы можете взять сайт конкурента и проанализировать его, какие запросы он использует и какая видимость в поисковой выдаче:
Подбираем запросы
Категория должна быть релевантна своему запросу – это и есть основа оптимизации, благодаря которой мы привлекаем заинтересованных клиентов.
Как определить релевантность? Обратите внимание на частоту поиска фразы, которую вы проверяете в сервисе или программе. Если необходимо, ограничивайте по регионам.
Далее следует оптимизация страниц категорий и подкатегорий, начинающаяся с проработки Title, Description, h2, но это уже тема другой статьи.
Несколько советов касаемо сбора семантики :
- Сбор СЯ начинается с категорий и подкатегорий, если речь об интернет-магазине. Непосредственно к карточкам переходите после.
- При подборе проверяйте название и на русском, и на английском. Например, «Indesit» и «Индезит».
- Учитывайте, что поставщики формируют прайс так, как им удобно. Чтобы не ошибиться, формируйте категории все же на базе семантического ядра.
- Сбор начинайте с парсеров (в идеальном случае).
На этом пока завершим первую часть нашей статьи про семантическое ядро. В следующей части рассмотрим СЯ для сайта услуг; кластеризацию и детализацию запросов и как проанализировать семантическое ядро конкурентов.
как собрать семантику для полного охвата
Олександр Шараевський
SEO IM of Enterprise Department at Netpeak
Семантическое ядро — это неотъемлемая часть каждого сайта. Полнота и качество семантики определяют то, придут ли на ваш сайт целевые пользователи, и придут ли вовсе. Процесс сбора семантического ядра — трудоемкий, а иногда и бесконечный процесс, однако, зная некоторые важные приемы, можно его упростить и сэкономить время.
В данной статье я поэтапно расскажу о том, как быстро собрать семантическое ядро для сайта, кластеризовать его и расширить структуру сайта, используя комплекс инструментов. Поехали!
Содержание:
Семантическое ядро — мозг вашего сайта. Все его направления должны быть связаны с друг другом, но в то же время каждое отвечает за конкретное действие. Это сборник слов и словосочетаний, полностью охватывающий деятельность компании по разным направлениям.
Ядро состоит из ключевых фраз, по которым пользователь находит определенную страницу сайта в зависимости от своего запроса. На основании семантики составляется структура сайта, прописываются метатеги и основные заголовки страниц.
Каким должен быть размер семантического ядра
Вы не получите точный ответ на вопрос: сколько фраз нужно использовать в продвижении сайта? В узких нишах и специфических услугах это количество варьируется в пределах нескольких сотен. В обширном интернет-магазине их может быть пару сотен тысяч или миллион. На сайтах-агрегаторах используется несколько миллионов запросов.
Размер ядра напрямую зависит от типа сайта, его тематики и не определяется количеством существующих страниц. Структура сайта определяется исключительно после того, как будет завершен сбор семантического ядра.
Но как понять, сколько запросов может быть на вашем сайте, если он был недавно создан? Вам поможет сбор семантики конкурентов. Проанализируйте ключевые фразы конкурентов в топе поисковиков. У вас должно быть не меньше. Но копировать в точности чужую семантику не следует.
Проанализируйте ключевые фразы конкурентов в топе поисковиков. У вас должно быть не меньше. Но копировать в точности чужую семантику не следует.
Как сформировать первичную
структуру сайта
Первый этап работы над проектом — это составление первого (чернового) варианта структуры сайта. Она представляет собой костяк будущей структуры сайта и строится на основании маркерных запросов.
Маркерные запросы или маркеры — это ключевые фразы, которые определяют тематику ниши. Они должны четко отвечать тематике страницы (1 маркер — 1 страница). Зачастую маркерными запросами являются категории, разделы и рубрики на сайте. Отталкиваясь от маркерных запросов, можно расширять семантику.
Первичную структуру можно подготовить как для уже существующего сайта, так и для проекта в разработке. Но тут есть пара нюансов.
Для сайта, который еще в разработке:
Просим клиента предоставить данные об особенностях бизнеса.
Просим список всех товаров для будущего сайта в Google таблице или в формате .xls.
Анализируем данные и подготавливаем первичную структуру, учитывая также и технические страницы.
Для уже существующего сайта:
Переносим существующую структуру сайта в рабочую таблицу.
Изучаем ассортимент на сайте.
Анализируем поисковую выдачу по коммерческим маркерным запросам, которые характеризуют тематику.
Собираем список сайтов-конкурентов, которые занимаются этим направлением.
Просматриваем все сайты и набрасываем структуру сайта.
Переносим категории каждого из сайтов на таблицу и анализируем структуру каждой категории.
Обращаем внимание на фильтры, сортировки, тегирование и используем всю полезную информацию от конкурентов.
Это необходимо для максимально четкого разграничения категорий на сайте. Например, на одном из сайтов, над которым мы работаем, обнаружились разные типы товаров, находящиеся в одной категории.
Этого нужно избегать. Для этого мы доработали структуру и сформировали дополнительные категории под отдельные типы товаров. Получились такие категории:
москитные сетки;
спирали от комаров;
мухобойки;
липкие ленты;
ловушки;
палочки от комаров;
липкие листы.
Работая над расширением структуры, выделяем новые элементы другим цветом. Это помогает увидеть масштабы и объем работы при расширении, которые придется проделать.
Также при разработке первичной структуры, помимо категорий, учитываем типы и значения фильтров. Чем подробнее будет структура, тем проще и быстрее будет ее расширить.
Хотите при помощи Serpstat собрать семантику?
Активируйте триал и протестируйте платформу бесплатно в течение 7 дней!
| Зарегистрироваться! |
Как определить прямых конкурентов
Искать конкурентов можно двумя способами: вручную и автоматически, с помощью специализированных сервисов. Рассмотрим оба способа.
Рассмотрим оба способа.
Как найти конкурентов вручную
Чтобы искать прямых конкурентов вручную, необходимо иметь набор фраз, по которым вы хотите продвигаться. Когда у вас есть эти фразы, можно проверять, какие еще сайты ранжируются по этим фразам в поиске, и кто из них находится в топе.
Пробейте каждый запрос в поисковой системе и посмотрите, кто находится в выдаче по тем же фразам. Важно помнить, что поисковики часто персонализируют поиск и формируют SERP (страницу выдачи) на основе ваших прошлых запросов. Поэтому для большей точности используйте режим «Инкогнито»: в Google Chrome, Яндекс или Opera — комбинация клавиш Ctrl+Shift+N, в Mozilla — Ctrl+Shift+P.
Поочередно введите запросы в каждой поисковой системе, так как выдача в них отличается.
Создайте таблицу и внесите в нее сайты, которые ранжируются по нужным ключевикам. Вы получите общую картину по вашей нише и узнаете ближайших конкурентов. После чего можно начинать анализ.
После чего можно начинать анализ.
Просмотрев выдачу по всем ключевым фразам. Так вы соберете базу основных конкурентов и сможете продумать план дальнейших действий.
Однако поиск конкурентов вручную имеет ряд недостатков, которые следует учитывать:
большие временные затраты;
неточная картина по нише;
риск упустить важного конкурента или ключевой запрос;
сложно уследить за изменениями в нише и сохранять актуальность данных.
Как определить конкурентов с помощью Serpstat
Щоби пришвидчити пошук прямих конкурентів та отримати більш точні та актуальні дані, можна автоматизувати процес та використовувати спеціальні SEO-сервіси. Я покажу, як швидко зібрати базу конкуруючих сайтів за допомогою Serpstat.
Если сайт уже есть и по нему достаточно информации
Вводим адрес домена в поисковую строку→ выбираем необходимую базу данных→ нажимаем «Поиск». В Суммарном отчете видим график конкурентов.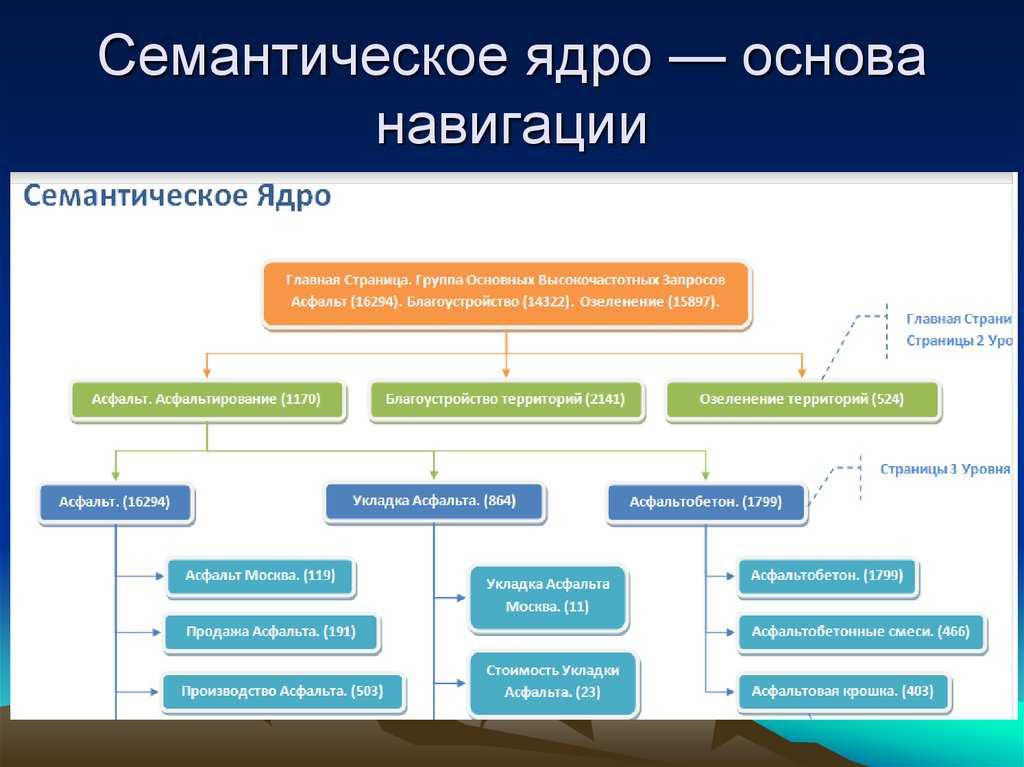
На нем показаны ближайшие конкуренты вашего домена на основе пересечения семантики. Анализируемый домен всегда будет в правом верхнем углу графика. Прямыми конкурентами являются те сайты, которые расположены ближе всего к нему на пересечении осей.
Чтобы получить полный список релевантных конкурентов, перейдите в раздел «Анализ сайта → Анализ доменов → SEO-анализ → Конкуренты».
Для дальнейшей работы выгружаем данные в удобном формате:
После выгрузки чистим список и оставляем только коммерческие сайты:
API Serpstat: конкуренты
Можно найти конкурентов с помощью API Serpstat, через дополнение для Google таблиц. API Serpstat экономит время и доступен на любом тарифе. Просто скопируйте домен(ы) в таблицу→ подключите дополнение→ выберите нужный метод→ получите результат! Подробнее об использовании читайте в инструкции.
УСТАНОВИТЬ ДОПОЛНЕНИЕ
Если сайт новый или по нему недостаточно данных
Если работа ведется над новым сайтом, либо по нему нет достаточного количества данных, можно прибегнуть к анализу отдельных категорий. Вводим в поисковую строку ключевую фразу (например, под категорию «Удобрения») и переходим в отчет «Анализ ключевых фраз→ SEO-анализ→ Конкуренты».
Вводим в поисковую строку ключевую фразу (например, под категорию «Удобрения») и переходим в отчет «Анализ ключевых фраз→ SEO-анализ→ Конкуренты».
Данные экспортируем и чистим по аналогии с предыдущим способом.
Анализ сайтов-конкурентов: масштабный путеводитель
| Читать |
API Serpstat: ключевые фразы
По аналогии с первым методом: вводим ключевые слова→ выбираем метод→ загружаем данные!
Получаем полный список конкурентов по фразам из топ-100 Google или топ-50 Яндекс:
Дополнение Serpstat Batch Analysis для Google Spreadsheets
| Читать |
Анализ структуры сайтов-конкурентов
На этапе анализа структуры, тщательно изучаем структуру сайтов-конкурентов, уделяем особое внимание категориям и фильтрам. Ищем интересные фишки и элементы, добавляем в структуру своего сайта для дальнейшей разработки.
Например, у одного из конкурентов мы нашли интересные фильтры в категории «Инсектициды»:
вредитель;
болезнь.
Сразу же добавили их и в свою структуру:
Как собрать семантическое ядро
На этапе сбора семантического ядра необходимо максимально охватить нишу: собрать максимум фраз, кластеризовать их и распределить по категориям, доработать структуру, категории, фильтры.
Под каждую категорию собираем маркерные ключевые фразы в соответствии с названием категории. Отталкивая от этого, расширяем семантику с помощью синонимов.
Чтобы собрать синонимы, используем такие сервисы:
Serpstat
API Консоль и дополнение для Google таблиц
KeyCollector
Яндекс.Вордстат
Планировщик ключевых слов Google Рекламы
Когда предстоит работа с большим количеством ключевых фраз, для всех операций лучше использовать KeyCollector.
Настройка KeyCollector
Прежде чем начать работу с KeyCollector:
Подключаем прокси. Чтобы избежать бана в сервисах лучше использовать платные персональные прокси.
Подключаем аккаунт Яндекс.Директ и Google Ads. Нужно создать специальные аккаунты для KeyCollector, а не использовать основные, так как их могут забанить.
Подключаем API.
Указываем ключ для распознавания капчи.
Указываем регион для Яндекс.Вордстат и Директа.
Важно: чтобы сделать работу по сбору и кластеризации ключей в KeyCollector более удобной, мы создаем папку под каждую категорию, подкатегорию, фильтр. Такие группы упрощают дальнейшую работу с семантическим ядром.
Формирование базовых запросов
Анализируем каждую категорию и страницу и подбираем по несколько ключевых фраз, которые будут описывать их содержимое. Например, запросы для категории «Препараты защиты растений»:
препараты защиты растений;
средства для защиты растений.

Далее расширяем семантику. Для этого смотрим отчет Serpstat «Анализ ключевых фраз→ SEO-анализ→ Подбор фраз», в нем собраны все фразы, включающие анализируемую:
Также берем фразы из отчета «Анализ ключевых фраз→SEO-анализ→ Похожие фразы», в нем собраны ключевики из топ-20, семантически связанные с анализируемой фразой (синонимы, альтернативное название и т.д.):
Чтобы получить эти данные сразу в таблице, можно выгрузить из через API-дополнение, пользуясь аналогичными методами:
Далее заимствуем семантику конкурентов. Для этого в поисковую строку Serpstat вводим отдельные страницы конкурента и смотрим, по каким фразам они ранжируются в топ-100:
Чтобы получить еще больше данных, комбинируем результаты по нескольким регионам и поисковым системам. Переносим всю информацию в KeyCollector.
Кстати, чтобы не переносить фразы вручную, мы используем функционал, который позволяет собирать фразы по URL или домену напрямую из Serpstat. Можно указать несколько URL и добавить запросы в проект. Это экономит массу времени:
Можно указать несколько URL и добавить запросы в проект. Это экономит массу времени:
Как за 10 минут собрать семантическое ядро и еще 5 крутых SEO-кейсов
| Читать |
Поиск синонимов через дополнительные сервисы
Для расширения семантики также можно использовать правую колонку в Вордстат.
Также подходит планировщик ключевых слов в Google Ads. Для этого открываем Планировщик→ кликаем на «Поиск новых ключевых слов по фразе, сайту или категории»→ вписываем запросы→ выбираем язык и регион→ кликаем «Получить варианты».
В результате получаем список синонимов:
Как найти ключевые фразы, которых нет в Google Adwords?
| Читать |
Сбор поисковых запросов через разные источники
В качестве дополнительного источника семантики мы используем инструменты Яндекс, Вордстат, Serpstat, в KeyCollector. Также собираем поисковые подсказки, для этого подходит отчет «Поисковые подсказки» в интерфейсе Serpstat:
Также собираем поисковые подсказки, для этого подходит отчет «Поисковые подсказки» в интерфейсе Serpstat:
Или через API:
Такого инструментария будет вполне достаточно.
Как за 10 минут собрать семантическое ядро и еще 5 крутых SEO-кейсов
| Читать |
Сбор стоп-слов
Для составления качественного семантического ядра необходим также список стоп-слов. Он поможет избавиться от всех мусорных фраз и избежать двойной работы при обновлении семантического ядра в будущем.
В список стоп-слов включаем:
Приставки, характеризующие информационные запросы: что, это, как, фото, видео, смотреть, своими руками и т.д.
Топонимы, не соответствующие вашим целям.
Фразы, предполагающие бесплатное получение: дешево, недорого, бесплатно, скачать и т.д.
Названия популярных сайтов и брендов: розетка, olx, vk, шафа.
Субъективные понятия: самый качественный/ лучший и т.д.

Список стоп-слов будет постоянно расширяется по мере работы над семантическим ядром. Для работы с большим массивом стоп-слов подойдет специальный инструмент в KeyCollector:
Расширение семантики в Serpstat
Чтобы собрать расширения, в KeyCollector выбираем «Serpstat→ Сбор расширений ключевых фраз»:
Добавляем фразы и получаем список расширений:
Как собрать семантическое ядро самостоятельно с помощью Serpstat
| Читать |
Сбор расширений в Вордстат
Следующий этап — сбор расширений в Вордстат. Используем «Пакетный сбор» слов из левой колонки Yandex Wordstat:
Перед сбором применяем стоп-слова (список стоп-слов не должен превышать 7000 символов):
Так мы избавимся от лишних фраз. Если же ваш список свыше 7000 символов, этот шаг можно пропустить и вернуться к нему после сбора данных.
Сбор поисковых подсказок
Далее собираем поисковые подсказки из Google и Яндекс. Тут подойдет Serpstat (как уже упоминалось выше) и KeyCollector.
Собрать подсказки в Serpstat можно двумя способами.
Через интерфейс
Вводим ключевую фразу→ выбираем поисковую систему и регион→ переходим в отчет «Поисковые подсказки»→ скачиваем отчет.
Также можно воспользоваться пакетной выгрузкой:
Через API
Чтобы выгрузить подсказки через API, можно перейти в API Консоль — ее использование не требует знаний в программировании — и следуем инструкции:
Выбираем поисковую систему.
Выбираем API-метод.
Вводим запросы.
Загружаем данные.
Получаем отчет и экспортируем его.
Помимо API Консоли можно воспользоваться Дополнением для Google Таблиц «Serpstat Batch Analysis» на базе API Serpstat. Подробнее читайте в статье.
Подробнее читайте в статье.
Дополнение Serpstat Batch Analysis для Google Spreadsheets
| Читать |
Хотите узнать, как с помощью API Serpstat собрать семантическое ядро?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как почистить семантику
Далее чистим семантическое ядро от мусорных фраз, нерелевантных и низкоэффективных ключей.
Если на этапе сбора расширений ваш список стоп-слов превышал 7000 символов, и вы не воспользовались опцией чистки запросов, то на данном этапе нужно применить инструмент «Стоп-слова»:
Собираем частотность фраз: переходим в инструмент «Сбор статистики Яндекс.Директ»→ берем статистику за год, чтобы не привязываться к сезонности→ отмечаем чек-бокс «Целью запуска сбора…. » → нажимаем «Получить данные».
» → нажимаем «Получить данные».
Далее настраиваем инструмент «Анализ неявных дублей»:
Искать дубли во всех видимых группах.
Отметить все, кроме самых высокочастотных в каждой группе.
Снять отметку со всех неявных дублей.
Отметить все, кроме 1 элемента в каждой группе.
Задать частотность, но основе которой будут анализироваться неявные дубли.
Нажимаем на «Выполнить поиск дублей повторно» и получаем дубли, которые нужно удалить:
Далее переходим к инструменту «Анализ групп»:
Удаляем оставшиеся неподходящие фразы, отмечая ненужные группы. В меню выбираем «Отправить все слова из определений групп, в которых хотя бы одна фраза отмечена, в окно стоп-слов»:
Переносим все неподходящие фразы в список стоп-слов.
Чистим фразы, у которых частотность («») за год ниже 10 (однако, для разных тематик этот показатель может отличаться). Такие ключевики несут информационный шум, поэтому стоит от них избавить с помощью фильтров в KeyCollector:
Кластеризация ключевых фраз
Сгруппировать фразы можно как вручную, так и автоматически. Для автоматической группировки можно использовать Кластеризацию Serpstat или группировку в KeyCollector.
Для автоматической группировки можно использовать Кластеризацию Serpstat или группировку в KeyCollector.
Чтобы кластеризовать фразы в Serpstat:
Перейдите в раздел «Инструменты» и кликните кнопку «Открыть» в ячейке «Кластеризация и текстовая аналитика».
Нажмите кнопку «Создать проект».
Введите в полученной ячейке название проекта и домен (если собираетесь проводить текстовую аналитику по конкретному домену) нажмите «Далее».
Задайте список фраз или загрузите их в окошко в файле CSV или TXT.
Добавьте поисковую систему, страну, регион и город.
Выберите силу связи, тип кластеризации и нажмите «Готово».
Чтобы сгруппировать фразы в KeyCollector:
Переходим в раздел «Вычисление KEI» и выбираем «Получить данные для ПС Google».
Чтобы не попасть в бан вам потребуется много платных прокси.
Используем инструмент «Анализ групп» и настраиваем группировку как на скриншоте:
Вручную обрабатываем все группы запросов и «доводим ее до ума». После ручной проработки получается практически готовая семантика.
После ручной проработки получается практически готовая семантика.
Как автоматизировать и ускорить SEO-задачи с помощью API Serpstat — инструкция от Flatfy
| Читать |
Как сформировать структуру сайта
Когда собраны и кластеризованы все ключевые фразы, приступаем к формированию структуры сайта. Здесь мы уже окончательно оформляем категории, подкатегории, сортировки и фильтры.
Все данные анализируем и переносим в таблицу. Вот небольшая часть того, что должно получиться:
Подробнее о том, как составить структуру, читайте в статье.
Как создать структуру сайта на основе семантики
| Читать |
Бонус: распространенные ошибки при составлении семантического ядра
При составлении семантического ядра может быть допущена масса ошибок. Вот основные из них:
Соединение разных по смыслу ключей на одной странице.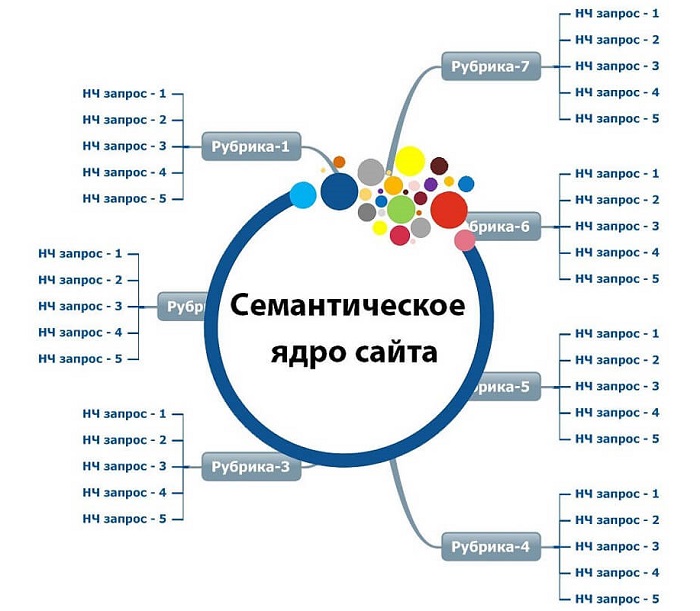
Игнорирование синонимов и смежных по смыслу слов.
Отсутствие страниц геолокации (например, продажа скутеров в Екатеринбурге), если вы продаете в разных городах.
Комбинация информационных и коммерческих запросов на одной странице.
Игнорирование последовательности слов во фразах. Например, «купить автомобиль» и «автомобиль купить» дают разный итог в выдаче.
Отсутствие низкочастотных запросов. Лучше продвинуть сто страниц по словам с запросами менее 10 показов в месяц, чем использовать только 10 страниц с запросами более 1000 показов в месяц.
Полное исключение странных на первый взгляд комбинаций ключевых фраз. Например, если вы продаете одежду, то запрос «куртка с тигром» может быть очень полезен для вашего сайта.
Полное копирование семантики у конкурентов. Вместе с запросами вы можете скопировать и их ошибки.
Добавление новых поисковых фраз на существующие страницы.
Пять адовых ошибок при работе с семантическим ядром
| Читать |
Заключение
Для составления семантического ядра нужно использовать все доступные каналы подбора ключевых фраз. После сбора семантик, вам потребуется удалить минус-слова, мусорные сочетания, добавить названия городов (если есть потребность) и провести группировку по релевантным страницам.
После сбора семантик, вам потребуется удалить минус-слова, мусорные сочетания, добавить названия городов (если есть потребность) и провести группировку по релевантным страницам.
Посмотрите, сколько всего фраз у конкурентов. Проанализируйте их структуру и процент показов. Из имеющихся запросов проведите грамотную кластеризацию по принципу «один запрос = одна страница». Обратите внимание на последовательность слов во фразах, не путайте информационные запросы с коммерческими.
Учтите тот факт, что люди в процессе поиска находятся на разных стадиях. Ваша задача — учесть все возможные запросы на каждой из этих стадий. Не забывайте о низкочастотных запросах, которые помогут вам быстрее выбраться в топ. Размещайте их во вложенных страницах, а в описаниях разделов и категорий применяйте более частотные фразы. Регулярно расширяйте семантику на вашем сайте.
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе.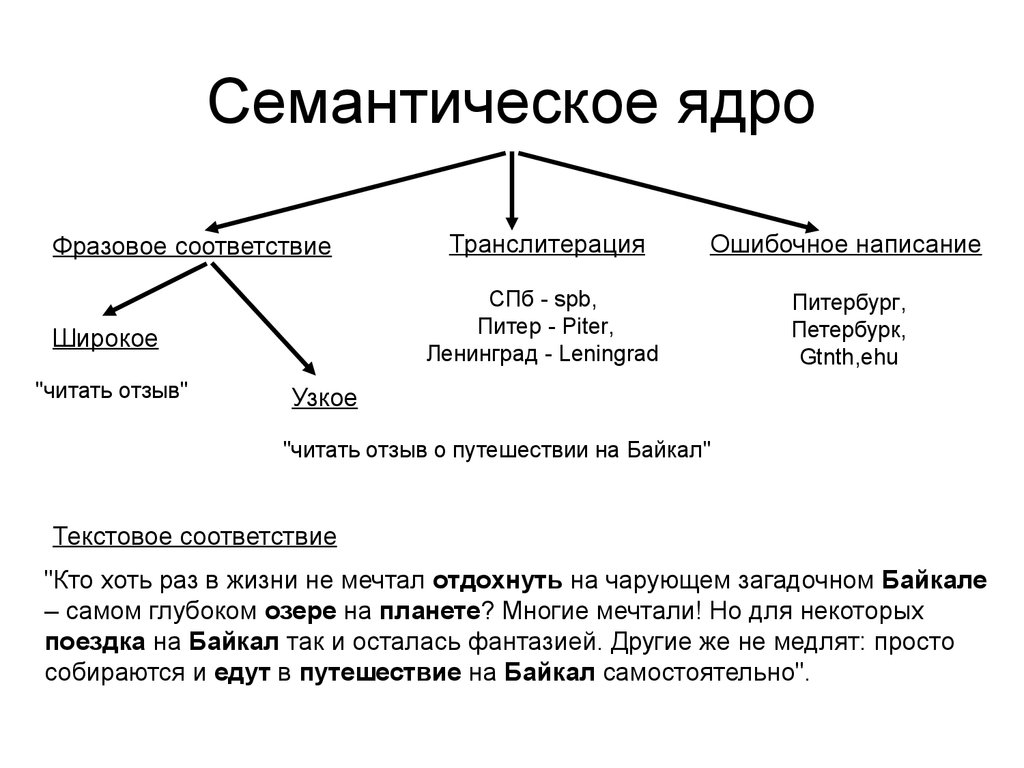 Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Понимание необходимости базовой семантической модели
Чтобы прочитать предыдущую статью из этой серии от группы [A] Semantics для получения более подробной информации, щелкните здесь.
Мотивация необходимости базовой семантической модели: вызов
Многие организации, по крайней мере, все больше осознают необходимость использования семантики для контроля терминов организации. Таксономии и системы тегов существуют даже в небольших организациях и изолированных отделах. Однако лишь немногие обладают достаточным опытом для преобразования существующих словарей и таксономий в связную семантическую систему, которую можно использовать в нескольких группах на предприятии. Базовая модель контента — это важный компонент анализа контента, являющийся мощным инструментом для определения структуры ресурсов контента организации. Но сам по себе СКК не передает никакой информации о значении или контексте содержания организации. Другими словами, информации не хватает семантической интерпретации.
Но сам по себе СКК не передает никакой информации о значении или контексте содержания организации. Другими словами, информации не хватает семантической интерпретации.
Без семантической интерпретации CCM является просто моделью чистой структуры ресурсов контента организации. С точки зрения цепочки поставок контента, система управления контентом играет решающую роль в отправке контента по различным каналам, которые организация использует для доставки контента. Без семантического уровня для интерпретации контента организации система управления контентом не может эффективно доставлять контент по нужному каналу или сборке потребления.
Во многих организациях ранние семантические формы встречаются в «тегах» в отделах маркетинга или поддержки. Теги важны для отслеживания маркетинговых атрибуций или тем поддержки, но они также важны для таргетинга контента для динамической сборки. Все теги должны работать вместе, а семантическая ткань объединяет теги с другими семантическими источниками в базовой семантической модели.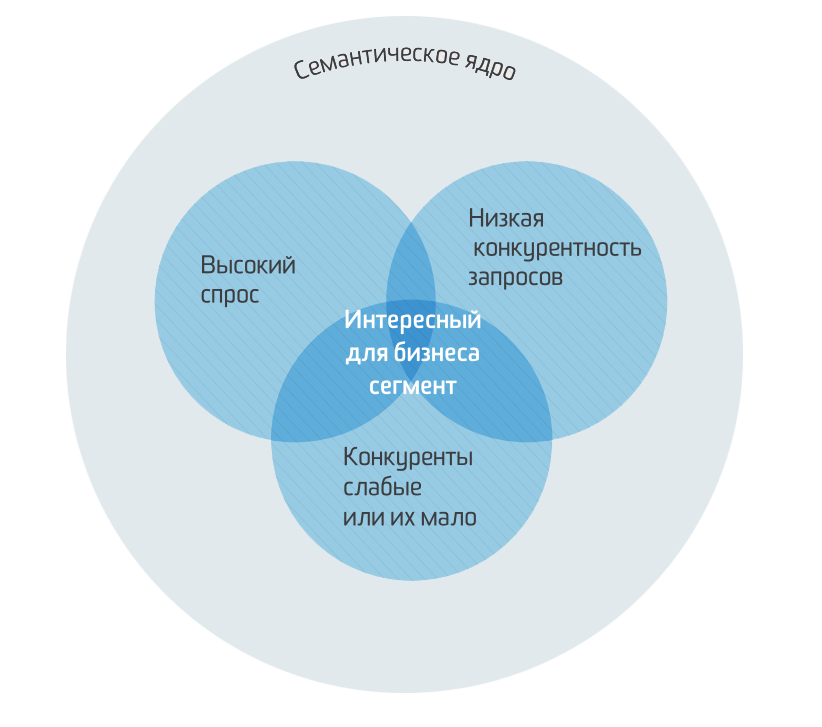
Конечно, авторы, редакторы и издатели организации привносят в содержание свое собственное значение и интерпретацию. Это нормальная часть создания смысла между контентом и людьми.
Но если каждый раз требуется 100% субъективная человеческая интерпретация, чтобы придать содержанию смысл, то само по себе содержание не является разумным. Это приводит к неоднозначному контенту, который трудно найти и к которому трудно получить доступ в рамках всей организации. В результате многие организации оказались в ситуации, когда создание контента обходится дорого, но его ценность не используется в полной мере. Другими словами, возможности команд по всей компании использовать существующий контент сильно ограничены, что приводит либо к дорогостоящему копированию контента, либо к командам, действующим без контента, необходимого им для работы на максимально эффективном уровне.
Кроме того, если авторы контента, редакторы и издатели просто используют свою собственную интерпретацию, они будут склонны маркировать и маркировать контент непоследовательным образом.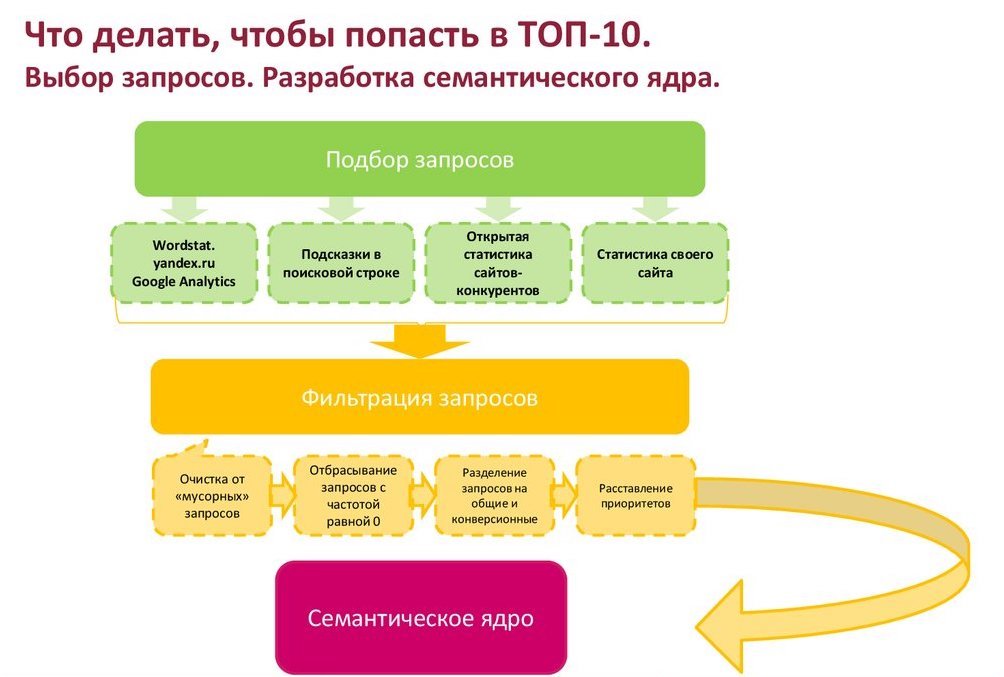 Это приводит к замешательству клиентов и разочарованию сотрудников, которые не знают, как найти или интерпретировать контент организации, что приводит к потере продаж и снижению эффективности. Чтобы в полной мере реализовать инвестиции в контент, его необходимо дополнить семантикой.
Это приводит к замешательству клиентов и разочарованию сотрудников, которые не знают, как найти или интерпретировать контент организации, что приводит к потере продаж и снижению эффективности. Чтобы в полной мере реализовать инвестиции в контент, его необходимо дополнить семантикой.
Поисковая оптимизация (SEO) полностью зависит от семантики, но недостаток семантики часто восполняется за счет использования неуклюжих и непоследовательных «ключевых слов» или «тегов» на специальной постраничной основе. Генерация структурированных данных для поисковых систем часто является ручным и утомительным процессом, не интегрированным с семантическими или структурными системами.
Таким образом, все компании нуждаются в улучшении семантики контента, хотя у большинства из них нет плана или в штате есть специалисты, которые могут стратегически и тактически планировать интеграцию семантики. Большинству компаний сегодня также не хватает инфраструктуры для управления и контроля семантики их контента.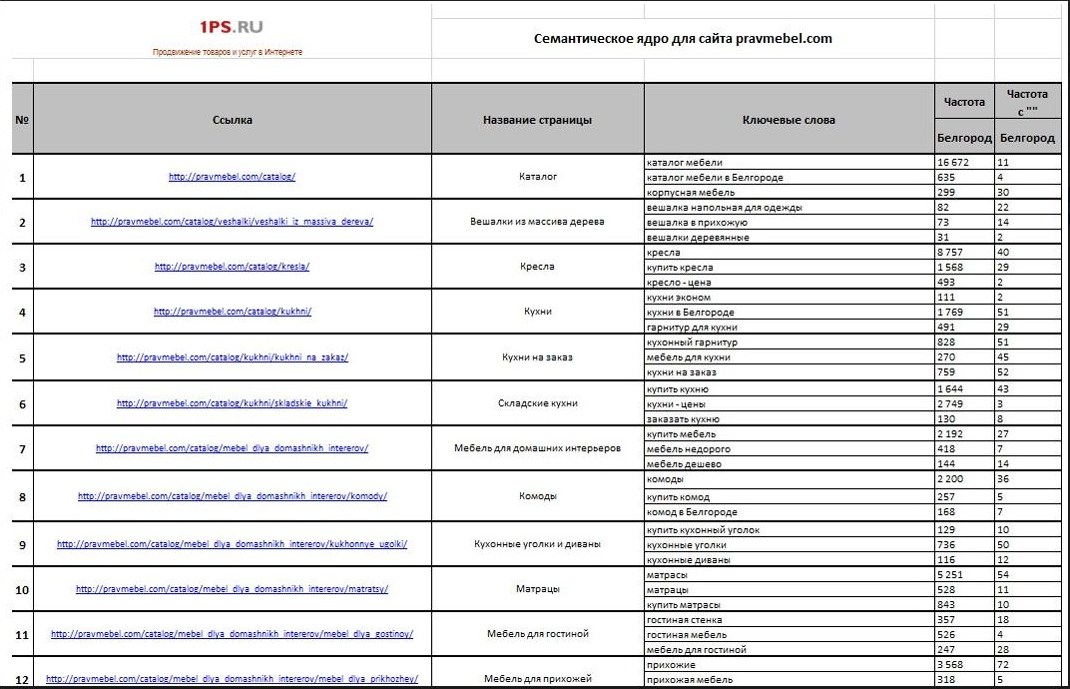 Семантика облегчает жизнь множеству разных людей в организации, но, поскольку сегодня это невидимая функция, семантика игнорируется и недофинансируется. Это изменится, потому что это необходимо для создания интеллектуальных систем.
Семантика облегчает жизнь множеству разных людей в организации, но, поскольку сегодня это невидимая функция, семантика игнорируется и недофинансируется. Это изменится, потому что это необходимо для создания интеллектуальных систем.
Решение
Решение состоит в построении семантической карты смысловой территории. Нам необходимо построить формальную модель смысла и контекста содержания организации. Таким образом, помимо построения и поддержания модели, семантическая интерпретация содержания организации больше не зависит исключительно от человеческого вмешательства. Именно здесь вступает в действие Базовая семантическая модель, действующая как комплексная и интегрированная модель семантики, лежащей в основе активов контента организации.
Добавление семантики к существующим структурам контента значительно расширяет возможности доставки контента нескольким пользователям по нескольким каналам. Семантика облегчает эту доставку, упрощая поиск ресурсов контента и доступ к ним в разных доменах и системах.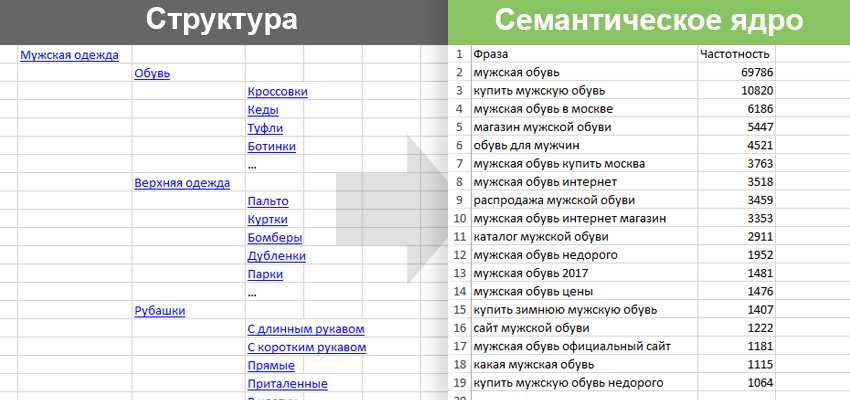
CSM достигает этого, внедряя согласованную систему тегов и меток, чтобы навигация и доступ к содержимому были максимально плавными и автоматическими. Использование существующих таксономий обеспечивает быстрый старт для создания семантического решения в дополнение к интеграции существующих структур контента , таких как существующие маркировки и навигация , в семантический «уровень».
Базовая семантическая модель устанавливает надежную и совместно используемую основу для маркировки содержимого и данных. Будучи встроенным в программную платформу семантики, CSM становится «источником истины» для всей семантики, предоставляя теги и темы, которые аннотируются как к модульным объектам контента, так и к данным клиентов.
Путем моделирования важных семантических отношений между терминами можно настроить цепочку поставок контента, чтобы обеспечить немедленный доступ к соответствующему контенту для клиентов и сотрудников. Например, путем моделирования того факта, что два продукта обычно используются друг с другом, когда покупатель покупает один продукт, релевантная информация о другом продукте может быть легко доступна этому покупателю.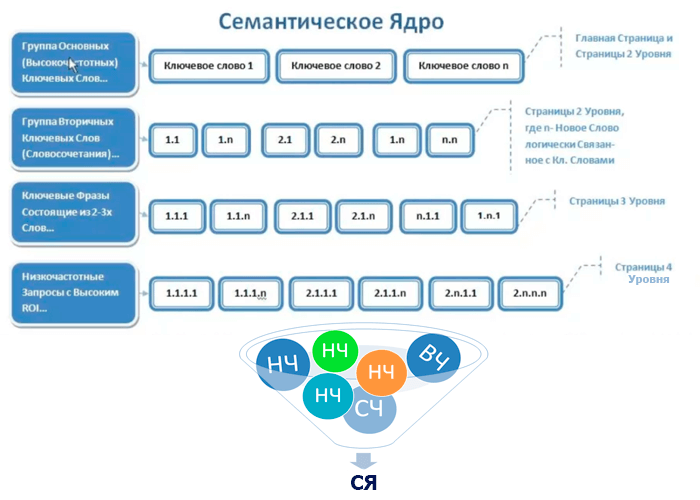
Программный стек маркетинговых технологий (Martech) почти всегда включает в себя предоставление ориентированного на контент обслуживания клиентов, основанного на таксономии тегов. Иногда их называют «категориями», «переменными атрибуции» или просто «тегами». Независимо от формы или имени, семантика необходима для соответствия контента намерениям клиента.
Со временем CSM становится все более комплексным и интегрированным, как и любая картографическая система. Подумайте о процессе перехода от отсутствия карт к рудиментарным, к комплексным плоским картам и атласам, к цифровым многослойным картам, к интерактивным картам, основанным на интеллекте. Это та же самая территория, которая становится все более доступной для людей и машин благодаря постоянному улучшению карт.
Первый шаг к интеллекту начинается с создания хотя бы простой отправной точки для семантической модели предметной области.
Узнайте больше об услугах семантического моделирования [A] или позвоните по телефону
, чтобы получить бесплатную консультацию.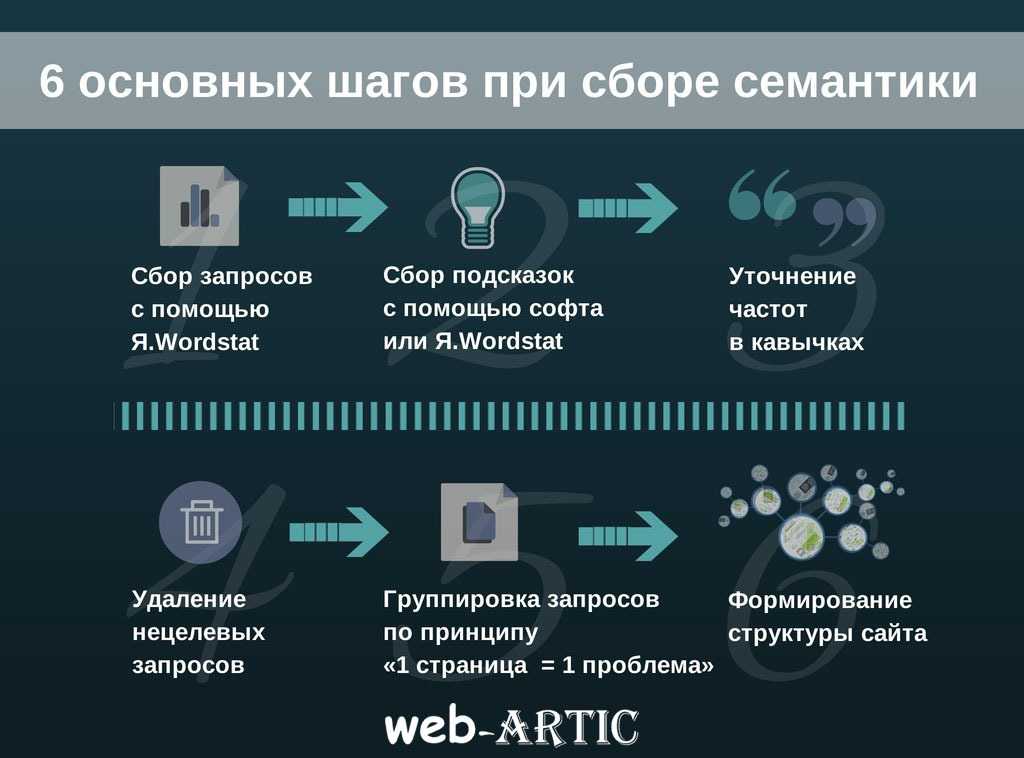
Ready to Talk
Как самостоятельно составить семантическое ядро? — Команда веб-разработки Loveitgroup
Если вы хотите сами собирать свои запросы, мы покажем вам, как это сделать бесплатными способами:
- используйте подсказки поисковых систем (те самые выпадающие подсказки, когда вы только начинаете вводить запрос в поиске). Например, у вас есть интернет-магазин одежды, есть категория вечерние платья, начинаем набирать в строке поиска — купить вечернее.. и получаем массу вариантов.
- используйте поле под результатами поиска «Вместе с … часто ищет». Также получите варианты того, как люди ищут ваш продукт или услугу
- воспользуйтесь сервисом подбора ключевых слов в контекстной рекламе для Яндекса — Wordstat, для Google Keyword Planner (Совет — в Wordstat можно найти гораздо большее количество низкочастотных запросов, Google выдает более обобщенную статистику)
- если повезет, у конкурентов может быть открытый счетчик LiveInternet, но это везение граничит с фантастикой
- собственные данные по запросам, по которым были переходы на сайт (если сайт существует какое-то время и на нем установлена какая-либо система аналитики трафика)
Совет №1
Не зацикливайтесь на точном вхождении словосочетаний — если в семантическом ядре у вас есть словосочетание — «купить платье Харьков» — это не значит, что нужно так писать на Вашем сайте.
Это означает, что слова купить, одеть и Харьков должны быть на оптимизированной под такой запрос странице, но этого должно быть достаточно. Например, у вас в тексте есть словосочетание «купить платье», а на странице есть блок «Доставляем в города…» и здесь вполне логично впишется слово Харьков.
Совет №2
Чем детальнее вы разделите свое семантическое ядро на группы, тем проще будет оптимизировать страницу. Согласитесь, красиво использовать в одном предложении, которое будет звучать и в названии, и в описании, и в тексте, все слова из группы легче, когда слов в группе меньше. Для ориентировки – 10-15 фраз будет достаточно.
Однако при делении списка запросов (семантического ядра) на группы все же следует руководствоваться логикой и здравым смыслом, а не количественными показателями. Если вам кажется, что в группе много фраз — подумайте, может, они имеют логические отличия и лучше разбить группу на несколько, чтобы потом оптимизировать свою страницу под каждую группу.