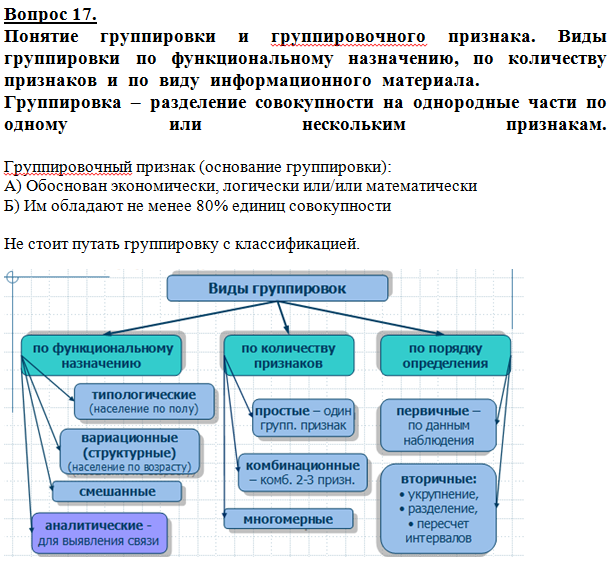
Группировка запросов онлайн — бесплатная кластеризация поисковых фраз из семантического ядра, разбивка ключевых слов на группы бесплатно в сервисе — Пиксель Тулс
Самая трудоемкая часть работы с семантическим ядром — это группировка запросов (кластеризация). Наш автоматический онлайн-кластеризатор делит ключевые слова на группы на основании анализа документов в ТОПе выдачи Яндекса и Google.
Зачем проводить кластеризацию запросов?
Семантическое ядро — это набор поисковых запросов, отражающих тематику и структуру сайта. Слова в ядре разделены на группы (кластеры).
Кластеризация помогает выстроить структуру, сформировать разделы сайта, составить контент-план. Каждая группа используется для оптимизации одной страницы сайта, чтобы продвинуть ее в органическом поиске.
Ручная группировка — долгая и кропотливая работа, из-за человеческого фактора высок риск ошибок. Она основана только на логике, не учитывает кластеризацию конкурентов — и это еще один существенный минус. Автоматическая кластеризация выполняется всего за несколько минут.
Автоматическая кластеризация выполняется всего за несколько минут.
Принцип работы онлайн-инструмента
Работа кластеризатора основана на анализе документов в поисковой выдаче:
-
1
Инструмент анализирует документы в ТОПе выдачи поисковых систем по запросу и вычленяет всю группу ключей, по которым продвигается страница.
-
2
На основании данных из ТОПа инструмент разбивает ключевые слова на кластеры.
-
3
Опционально собирает частоты и позиции продвигаемых страниц.
Как пользоваться инструментом
Выберите режим (турбо или большого ядра). Введите поисковые фразы (каждая с новой строки). Отметьте поисковую систему и регион. Выберите одну из 10 степеней группировки. 1 — самая мягкая группировка (в одну группу попадает наибольшее количество запросов), 10 — самая жесткая. Оптимальной считается 3 степень.
В режиме большого ядра можно выбрать метод группировки — со слабой, средней, сильной связью или алгоритм Пиксель Тулс (программа классифицирует запросы, отсеивая агрегаторы, обеспечивая наиболее точный результат).
Можно отметить в чекбоксах опции:
Получить результаты в виде CSV-файла.
Определить число главных страниц по запросу.
Собрать частоты.
Получить позиции.
В режиме турбо вы увидите группы и список конкурентов по каждой из них.
В режиме ядра (опционально) — общую и точную частотность, позицию сайта, количество главных страниц.
Кластеризатор запросов условно бесплатный, доступен на платных тарифах. За проверки списываются лимиты, в зависимости от количества ключевых фраз и отмеченных опций. 1 запрос = 2 лимита. Опция «Собрать частоты запросов» = +2 лимита за каждый запрос. Опция «Определить релевантные URL на сайте» = +1 лимит за каждый запрос.
Результат можно скачать в виде CSV-файла и использовать для формирования структуры и технических заданий на тексты.
Преимущества сервиса
Быстрый и удобный. Качественная альтернатива ручному способу кластеризации ядра.
Много дополнительных настроек (по регионам, поисковым системам, степеням группировки).
Есть полезные опции (определение частоты запросов, топовых конкурентов).
Сохраняются результаты предыдущих проверок.
Можно скачать данные в виде CSV-файла.
Дополнительные инструменты
Другие сервисы Пиксель Тулс, которые могут быть вам полезны:
Получение списка URL в ТОП выдачи Яндекс и Google. Инструмент бесплатно составляет список документов-лидеров по запросам в Google и Яндексе. Глубина сбора — от 10 до 200. Парсит Title и Description конкурентов.
Получение семантики по домену. Введите домен продвигаемого сайта, список конкурентов. Сервис соберет семантику, встречаемость у конкурентов, общую и точную частотность ключевых слов. Итоговый файл содержит до 100 тысяч слов. После чистки и разгруппировки их можно использовать как полноценное семантическое ядро для сайта.
Узнайте, как увеличить SEO‑трафик сайта в 3+ раза?
Укажите домен вашего сайта, приоритетные регионы продвижения и получите самый
полный список точек взрывного роста трафика и заявок с вашего сайта
Начать
Правила группировки фраз для семантического ядра сайта
Мы уже писали о сборе семантического ядра и его очистке в Key Collector. Но эта информация будет абсолютно бесполезна без знания правил группировки и кластеризации фраз.
Зачем группировать фразы?
Напомню, семантическое ядро должно учитывать желания, интересы пользователей и соответствовать бизнес-целям проекта. Группировка фраз семантического ядра нужна для:
- создания структуры сайта — семантическое ядро помогает определить, в каком виде необходимо организовать меню сайта и внутренние связи страниц;
- маркетингового анализа — анализа текущего спроса на товары и услуги;
- создания контент-плана — подбора тем, интересующих пользователя, а также подбора запросов для оптимизации конкретных страниц сайта;
- создания грамотной перелинковки сайта;
- разделения запросов на коммерческие и информационные, чтобы запросы пользователей максимально соответствовали бизнес-целям сайта.


Грамотная группировка поисковых запросов позволяет максимально увеличить поисковой трафик.
Существует несколько способов группировки (кластеризации) ключевых фраз в семантическом ядре.
Группировка запросов по типам
Информационные запросы сразу же нужно выделить в отдельную группу. Когда человек вводит такой запрос, он хочет найти информацию для решения определенного вопроса. Такие запросы характерны для информационных порталов, новостников, в общем — для познавательных, научно-популярных, образовательных сайтов.
Читайте больше о скоростном методе подбора тем для информационных статей.
К информационным запросам относятся ключевые фразы с «что», «когда», «где», «как», а также «инструкция», «отзывы», «форум» и так далее.
Например:
лазерная липосакция отзывы
липосакция фото до и после
липосакция это
липосакция в домашних условиях
лазерная липосакция отзывы форум
Транзакционные (коммерческие) запросы помогают пользователю совершить какое-либо действие — скачать, купить, загрузить. Для интернет-магазинов именно транзакционные запросы приводят на сайт целевую и платежеспособную аудиторию.
Для интернет-магазинов именно транзакционные запросы приводят на сайт целевую и платежеспособную аудиторию.
Примеры:
липосакция цена
сколько стоит липосакция
липосакция стоимость
стоимость липосакции в украине
В отдельную группу выделяются геозависимые запросы. Это запросы, по которым пользователь ожидает увидеть местные или региональные сайты.
Например:
заказать массаж
визаж на дому
заказ парикмахера на дом
Общие или нечеткие запросы могут быть как информационными, так и транзакционными. В данном случае неясна цель пользователя. Конверсий по данному типу запросов значительно меньше, чем по транзакционным.
Примеры:
липосакция живота
лазерная липосакция
ультразвуковая липосакция
безоперационная липосакция
Продвигать сайт по данным запросам сложно, так как непонятно, что нужно пользователю: информация о «безоперационной липосакции» или заказ услуги.
Группировка запросов по смыслу
Отдельно можно выделить синонимичные запросы:
заказать уборку
заказать клининг
И профессионализмы:
smas-лифтинг цена
ультразвуковой лифтинг цена
Группировка по смыслу в первую очередь предназначена для удобства пользователя. Мы должны понять его уровень, требования к товару или услуге, и привести к цели.
Мы должны понять его уровень, требования к товару или услуге, и привести к цели.
Группировка запросов по типу страниц
Основные типы страниц:
- главная — слова и фразы, которые в целом дают характеристику сайту, например: клиника пластической хирургии Киев
- категории/подкатегории товаров и услуг — общие запросы под товары и услуги, например: липофилинг цена, липосакция киев;
- карточки товаров/услуг — группировка запросов, соответствующих конкретному товару или услуге, например: липофилинг губ, липофилинг слезных борозд;
- информационные страницы (блог/статьи) — страницы, которые будут отвечать на конкретный информационный запрос, например: что нельзя делать после инъекций ботокса;
- другие страницы сайта.
Правила группировки ключевых запросов
1. По одному маркерному запросу двигается одна страница сайта. Это не значит, что под каждый запрос на сайте должна быть отдельная страница. Просто под один и тот же запрос нельзя оптимизировать несколько страниц. Иначе на сайте будут плодиться похожие по смыслу страницы, что приведет к сложностям в навигации.
Это не значит, что под каждый запрос на сайте должна быть отдельная страница. Просто под один и тот же запрос нельзя оптимизировать несколько страниц. Иначе на сайте будут плодиться похожие по смыслу страницы, что приведет к сложностям в навигации.
2. Выбранная для ключевых запросов страница должна давать исчерпывающий ответ пользователю. Например, появление слова «купить» в запросе должно приводить к покупке товара на сайте. По запросу «цена» пользователь должен видеть прайс-лист.
3. Высокочастотные запросы должны находиться на расстоянии не далее одного-двух кликов от главной страницы, то есть в категориях.
4. На главную страницу рекомендуется вынести общие запросы, более конкретные запросы товаров, услуг необходимо распределить по страницам категорий и карточек товаров.
5. Недопустимо объединять на странице коммерческие и информационные запросы. Коммерческие запросы — каталоги товаров, прайс-листы, страницы услуг, информационные — статьи, новости, посты блога.
6. В одну группу лучше всего добавлять слова очень близкие по смыслу и структуре другим, входящим в запрос словам. Например, такими запросами могут быть «smas лифтинг», «ультразвуковой лифтинг», «безоперационный smas лифтинг» и «ультразвуковой smas лифтинг».
После грамотной группировки запросов можно даже поменять структуру сайта, как мы этом сделали при продвижении костюмерной Colombina.
Распространенные ошибки при группировке фраз
Не использовать низкочастотные запросы
Создание фильтра по низкочастотным запросам позволяет сделать страницу более полезной и удобной. Низкочастотные запросы являются более точными и указывают на конкретный товар или услугу, что ведет в свою очередь к дальнейшему совершению конверсии.
Например:
массажист для грудничка на дом
парикмахер визажист на свадьбу
Смешивать коммерческие и информационные запросы
Эти два типа запросов преследуют различные цели — привлечение готовых к покупке клиентов и расширение круга запросов, по которым могут обнаружить сайт.
Объединять разные группы на одной странице
Возвращаемся к тому, что для каждой группы запросов должна быть своя посадочная страница.
Например, не все запросы ниже нужно использовать на одной странице:
- липосакция живота цена
- липосакция живота стоимость
- липосакция подбородка цены
- сколько стоит липосакция бедер
- липосакция бедер стоимость
- липосакция лица цена
- липосакция рук цена
Первый и второй запрос стоит объединить в группу и разместить на одной целевой странице, четвертый и пятый — на другой. Каждый следующий запрос должен иметь свою целевую страницу. Так пользователь увидит страницы с нужной ему информацией.
Можно также использовать различные онлайн-сервисы для группировки фраз и не делать всю работу руками. С помощью инструмента Кластеризации в Serpstat можно самостоятельно задать нужные параметры группировки, а остальную работу сделает сервис. Получившиеся кластеры можно редактировать при необходимости.
Выводы
- Семантическое ядро должно полностью описывать тематику проекта.
- Группировка ключевых запросов нужна для многих целей — от маркетингового анализа товаров и услуг до создания оптимальной структуры сайта;
- При группировке запросов необходимо отталкиваться от бизнес целей проекта;
- Основные правила при группировке ключевых слов:
– одна группа поисковых запросов на одну посадочную страницу;
– целевые страницы должны быть релевантны запросам пользователя и давать исчерпывающий ответ;
– не стоит продвигать проект по общим запросам, а также смешивать в одну группу информационные и коммерческие запросы.
Группируйте запросы правильно и привлекайте максимум трафика из поисковых систем.
Семантика группировки в пользовательском интерфейсе Jetpack Compose | Атаул Муним | Google Developer Experts
Модификаторы семантики позволяют нам изменять аспекты дерева семантики в пользовательском интерфейсе Jetpack Compose — представление пользовательского интерфейса, полезное для служб специальных возможностей и среды тестирования.
Мы можем использовать эти модификаторы, чтобы сгруппировать несколько виджетов в один логический элемент, что ускорит навигацию по списку похожих элементов с помощью службы специальных возможностей, такой как TalkBack.
Например, в YouTube Music текущий список воспроизведения представлен в виде списка дорожек, каждая из которых содержит:
- название
- исполнитель
- длина трека
- действие воспроизведения/паузы
- увидеть больше/действие меню
- (и состояние — воспроизводится)
программы чтения с экрана, такие как TalkBack, будут иметь описание каждого элемента ( текст) или действие, что означает, что переход от одной дорожки к следующей будет стоить пользователям ~ 5 жестов.
Переписывание семантики
Мы можем переписать семантику дорожки так, чтобы она была представлена как один логический элемент:
Использование модификатора clearAndSetSemantics() необходимо ; в этом случае недостаточно использовать модификатор semantics() .
Modifier.clearAndSetSemantics()
Modifier.clearAndSetSemantics() очистит информацию о семантике для всех дочерних узлов и обновит текущий узел с заданными свойствами.
В документации к этой функции сказано:
это можно использовать для более удобного чтения с экрана: например, для очистки семантики группы крошечных кнопок и установки эквивалентных действий на карточке, содержащей их.
Это именно то, что нам нужно! Однако есть последствия для очистки семантики узлов-потомков:
- любые текстовые потомки больше не будут фокусироваться и не будут включены в описание содержимого. Наше описание контента должно быть точным описанием всей строки.
- Любые кликабельные потомки больше не будут фокусироваться. Вместо этого мы должны выставить эти действия (
customActions) в строке.
Модификатор.semantics()
Modifier.semantics() позволяет нам добавить семантическую информацию к текущему узлу. Нашей целью было упростить представление каждой дорожки до одного узла, поэтому здесь это не помогло бы.
Нашей целью было упростить представление каждой дорожки до одного узла, поэтому здесь это не помогло бы.
На самом деле, мы бы сделали еще хуже, сделав фокусируемой всю строку (в дополнение к тому, что у нас уже было).
Modifier.semantics(mergeDescendants = true)
Использование Modifier.semantics(mergeDescendants = true) немного полезнее, поскольку уменьшает количество фокусируемых элементов.
Установка MergedEscendants до True Will:
- Удалите все узлы потомков (если они также используют
MergedEscendants = True) - Попробуйте слияние свойств вместе, где это возможно
с элементами Clickable
с Clickable . модификатор не будет удален, потому что они используют mergeDescendants = true . В нашем случае это означает, что воспроизведение/пауза и действия меню по-прежнему будут сфокусированы.
Узлы названия, исполнителя и длины трека не кликабельны. Здесь будет попытка объединить семантическую информацию из этих узлов, что приведет к дублированию информации, потому что мы задаем описание контента вручную.
Здесь будет попытка объединить семантическую информацию из этих узлов, что приведет к дублированию информации, потому что мы задаем описание контента вручную.
Резюме
Modifier.clearAndSetSemantics() дает нам большой контроль над семантическим представлением узла и его потомков в пользовательском интерфейсе Compose. Хотя он мощнее, чем Modifier.semantics() , мы также должны быть более осторожны с ним.
Как правило, следует зарезервировать его использование для элементов коллекции (списков или сеток) и всегда проверять поведение.
Если вам понравился этот пост, у вас есть какие-либо вопросы, комментарии или исправления, пожалуйста, свяжитесь с нами через Twitter.
Семантика группирования дублирования в протоколе описания сеанса
RFC 7104: Семантика группирования дублирования в протоколе описания сеанса [Домашняя страница RFC] [ТЕКСТ|PDF|HTML] [Отслеживание] [ПИС] [Информационная страница] ПРЕДЛАГАЕМЫЙ СТАНДАРТ
Инженерная рабочая группа Интернета (IETF) А.Семантика, определенная в этом документе, должна использоваться с SDP. Структура группировки. Семантика группировки в источнике синхронизации (SSRC) также определены в этом документе для потоков RTP с использованием Мультиплексирование SSRC. Статус этого меморандума Это документ для отслеживания стандартов Интернета. Этот документ является продуктом Инженерной группы Интернета. (IETF). Он представляет собой консенсус сообщества IETF. Оно имеет получил общественное мнение и был одобрен для публикации Руководящая группа по разработке Интернет-технологий (IESG). Дополнительная информация о Интернет-стандарты доступны в разделе 2 RFC 5741. Информация о текущем статусе этого документа, любых опечатках, и как предоставить отзыв о нем можно получить на http://www.rfc-editor.org/info/rfc7104. Беген и др. Трек стандартов [Страница 1]
 Беген
Запрос комментариев: 7104 Cisco
Категория: Трек стандартов Y. Cai
ISSN: 2070-1721 Майкрософт
Х. Оу
Сиско
Январь 2014
Семантика группировки дублирования в протоколе описания сеанса
Абстрактный
Потеря пакетов нежелательна для сеансов мультимедиа в реальном времени, но это
может произойти из-за перегрузки или других незапланированных отключений сети. Этот
особенно актуально для многоадресных IP-сетей, где потеря пакетов
шаблоны могут сильно различаться между приемниками. Одна техника, которая может
использоваться для восстановления после потери пакетов без неограниченных задержек
для всех получателей — дублировать пакеты и отправлять их в
отдельные избыточные потоки. Этот документ определяет семантику для
группировка избыточных потоков в протоколе описания сеанса (SDP).
Беген
Запрос комментариев: 7104 Cisco
Категория: Трек стандартов Y. Cai
ISSN: 2070-1721 Майкрософт
Х. Оу
Сиско
Январь 2014
Семантика группировки дублирования в протоколе описания сеанса
Абстрактный
Потеря пакетов нежелательна для сеансов мультимедиа в реальном времени, но это
может произойти из-за перегрузки или других незапланированных отключений сети. Этот
особенно актуально для многоадресных IP-сетей, где потеря пакетов
шаблоны могут сильно различаться между приемниками. Одна техника, которая может
использоваться для восстановления после потери пакетов без неограниченных задержек
для всех получателей — дублировать пакеты и отправлять их в
отдельные избыточные потоки. Этот документ определяет семантику для
группировка избыточных потоков в протоколе описания сеанса (SDP).
RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г. Уведомление об авторских правах Copyright (c) 2014 IETF Trust и лица, указанные в качестве авторы документа.3. Соображения по поводу модели предложения/ответа SDP .................. 4 4. Примеры SDP ...................................................... ......5 4.1. Отдельные исходные адреса ......................................5 4.2. Отдельные адреса назначения ................................6 4.3. Временное резервирование ......................................7 5. Вопросы безопасности ......................................7 6. Соображения IANA ......................................................8 7. Благодарности ....................................................... ..8 8. Ссылки ....................................................... .......8 8.1. Нормативные ссылки ......................................................8 8.2. Информативные ссылки ......................................9Беген и др. Трек стандартов [Страница 2]
 Все права защищены.
Этот документ регулируется BCP 78 и юридическими документами IETF Trust.
Положения, касающиеся документов IETF
(http://trustee.ietf.org/license-info) действует на дату
публикации этого документа. Пожалуйста, ознакомьтесь с этими документами
внимательно, так как они описывают ваши права и ограничения в отношении
к этому документу. Компоненты кода, извлеченные из этого документа, должны
включить текст упрощенной лицензии BSD, как описано в Разделе 4.e
Доверительные юридические положения и предоставляются без гарантии, поскольку
описан в Упрощенной лицензии BSD.
Оглавление
1. Введение ............................................... .....2
2. Обозначение требований ......................................3
3. Группировка дубликатов ......................................3
3.1. Семантика группировки "DUP" ......................................3
3.2. Группировка дублирования для SSRC-мультиплексированных потоков RTP ......3
3.
Все права защищены.
Этот документ регулируется BCP 78 и юридическими документами IETF Trust.
Положения, касающиеся документов IETF
(http://trustee.ietf.org/license-info) действует на дату
публикации этого документа. Пожалуйста, ознакомьтесь с этими документами
внимательно, так как они описывают ваши права и ограничения в отношении
к этому документу. Компоненты кода, извлеченные из этого документа, должны
включить текст упрощенной лицензии BSD, как описано в Разделе 4.e
Доверительные юридические положения и предоставляются без гарантии, поскольку
описан в Упрощенной лицензии BSD.
Оглавление
1. Введение ............................................... .....2
2. Обозначение требований ......................................3
3. Группировка дубликатов ......................................3
3.1. Семантика группировки "DUP" ......................................3
3.2. Группировка дублирования для SSRC-мультиплексированных потоков RTP ......3
3.
RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г. 1. Введение В настоящее время широко используется транспортный протокол реального времени (RTP) [RFC3550].
 для доставки трафика IPTV и других мультимедийных сеансов в реальном времени.
Многие из этих приложений поддерживают очень большое количество приемников.
и полагаться на внутридоменную многоадресную рассылку UDP/IP для эффективного распределения
трафика внутри сети.
Хотя эта комбинация оказалась успешной, существует
слабость. Как отмечено в [RFC2354], потери пакетов нельзя избежать даже в
тщательно управляемая сеть. Эта потеря может быть связана с перегрузкой;
это также может быть результатом незапланированного отключения, вызванного
ссылка, сбой ссылки или интерфейса, программная ошибка или техническое обслуживание
человек случайно перерезал не то волокно. Поскольку потоки UDP/IP
не предоставлять никаких средств для обнаружения потери и повторной передачи пакетов,
это остается на уровне RTP и приложениях для обнаружения, и
оправиться от потери пакетов.
Один из методов восстановления после потери пакетов без неограниченных
задержка для всех получателей заключается в дублировании пакетов и отправке их
в отдельных избыточных потоках.
для доставки трафика IPTV и других мультимедийных сеансов в реальном времени.
Многие из этих приложений поддерживают очень большое количество приемников.
и полагаться на внутридоменную многоадресную рассылку UDP/IP для эффективного распределения
трафика внутри сети.
Хотя эта комбинация оказалась успешной, существует
слабость. Как отмечено в [RFC2354], потери пакетов нельзя избежать даже в
тщательно управляемая сеть. Эта потеря может быть связана с перегрузкой;
это также может быть результатом незапланированного отключения, вызванного
ссылка, сбой ссылки или интерфейса, программная ошибка или техническое обслуживание
человек случайно перерезал не то волокно. Поскольку потоки UDP/IP
не предоставлять никаких средств для обнаружения потери и повторной передачи пакетов,
это остается на уровне RTP и приложениях для обнаружения, и
оправиться от потери пакетов.
Один из методов восстановления после потери пакетов без неограниченных
задержка для всех получателей заключается в дублировании пакетов и отправке их
в отдельных избыточных потоках. Варианты этой идеи были
внедрена и развернута сегодня [IC2011]. [RTP-DUP] объясняет, как
дублирование может быть достигнуто для потоков RTP без нарушения RTP
и функции протокола управления RTP (RTCP). В этом документе мы
описать семантику, необходимую в протоколе описания сеанса
(SDP) [RFC4566] для поддержки этого метода.
2. Обозначение требований
Ключевые слова «ДОЛЖЕН», «НЕ ДОЛЖЕН», «ТРЕБУЕТСЯ», «ДОЛЖЕН», «НЕ ДОЛЖЕН»,
«СЛЕДУЕТ», «НЕ СЛЕДУЕТ», «РЕКОМЕНДУЕТСЯ», «НЕ РЕКОМЕНДУЕТСЯ», «МОЖЕТ» и
«НЕОБЯЗАТЕЛЬНО» в этом документе следует интерпретировать, как описано в
[RFC2119].
3. Группировка дубликатов
3.1. Семантика группировки "DUP"
Каждая строка «a=group» используется для обозначения ассоциативного отношения.
между избыточными потоками. Потоки, включенные в одну "a=group"
строки называются «группой дублирования».
Используя SDP Grouping Framework в [RFC5888], этот документ определяет
«DUP» как семантика группировки для избыточных потоков.
Беген и др.
Варианты этой идеи были
внедрена и развернута сегодня [IC2011]. [RTP-DUP] объясняет, как
дублирование может быть достигнуто для потоков RTP без нарушения RTP
и функции протокола управления RTP (RTCP). В этом документе мы
описать семантику, необходимую в протоколе описания сеанса
(SDP) [RFC4566] для поддержки этого метода.
2. Обозначение требований
Ключевые слова «ДОЛЖЕН», «НЕ ДОЛЖЕН», «ТРЕБУЕТСЯ», «ДОЛЖЕН», «НЕ ДОЛЖЕН»,
«СЛЕДУЕТ», «НЕ СЛЕДУЕТ», «РЕКОМЕНДУЕТСЯ», «НЕ РЕКОМЕНДУЕТСЯ», «МОЖЕТ» и
«НЕОБЯЗАТЕЛЬНО» в этом документе следует интерпретировать, как описано в
[RFC2119].
3. Группировка дубликатов
3.1. Семантика группировки "DUP"
Каждая строка «a=group» используется для обозначения ассоциативного отношения.
между избыточными потоками. Потоки, включенные в одну "a=group"
строки называются «группой дублирования».
Используя SDP Grouping Framework в [RFC5888], этот документ определяет
«DUP» как семантика группировки для избыточных потоков.
Беген и др. Трек стандартов [Страница 3]
Трек стандартов [Страница 3] RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г. Семантика "a=group:DUP" ДОЛЖНА использоваться для группировки избыточных потоки, за исключением случаев, когда потоки указаны в одном и том же медиа описание, т. е. в той же строке «m» (см. раздел 3.2). В "a=group:DUP" порядок перечисленных избыточных потоков не строго не указывать порядок передачи, хотя он РЕКОМЕНДУЕТСЯ, чтобы поток, указанный первым, был отправлен первым, с другой поток(и), являющийся дубликатом(ами) (с задержкой по времени). 3.2. Группировка дублирования для SSRC-мультиплексированных потоков RTP [RFC5576] определяет атрибут уровня мультимедиа SDP, называемый «ssrc-group». для группировки потоков RTP, которые мультиплексированы SSRC и передаются в тот же сеанс RTP. Группировка основана на идентификаторах SSRC. Поскольку потоки RTP, мультиплексированные SSRC, определяются в одной и той же строке «m», нельзя использовать атрибут "группа".
 В этом разделе объясняется, как дублирование используется с SSRC-мультиплексированием.
потоки с использованием атрибута «ssrc-group» [RFC5576].
Семантика «DUP» для атрибута «ssrc-group» такая же, как
тот, который определен для атрибута «группа», за исключением того, что SSRC
идентификаторы используются для обозначения группы дублирования
ассоциации: a=ssrc-group:DUP *(SP ssrc-id) [RFC5576]. Как указано выше,
а в строке "a=ssrc-group:DUP" порядок перечисленных
избыточные потоки не обязательно указывают порядок
передачи, но РЕКОМЕНДУЕТСЯ, чтобы поток, указанный первым, был
отправляется первым, а другие потоки являются (с задержкой по времени)
дубликаты).
3.3. Соображения по модели предложения/ответа SDP
При предложении группировки дублирования с использованием SDP в модели «предложение/ответ»
[RFC3264], применяются следующие соображения.
Узел, который получает предложение от отправителя, может или не может
понимать группировку строк. Возможно также, что узел
понимает группировку строк, но не понимает "DUP"
семантика.
В этом разделе объясняется, как дублирование используется с SSRC-мультиплексированием.
потоки с использованием атрибута «ssrc-group» [RFC5576].
Семантика «DUP» для атрибута «ssrc-group» такая же, как
тот, который определен для атрибута «группа», за исключением того, что SSRC
идентификаторы используются для обозначения группы дублирования
ассоциации: a=ssrc-group:DUP *(SP ssrc-id) [RFC5576]. Как указано выше,
а в строке "a=ssrc-group:DUP" порядок перечисленных
избыточные потоки не обязательно указывают порядок
передачи, но РЕКОМЕНДУЕТСЯ, чтобы поток, указанный первым, был
отправляется первым, а другие потоки являются (с задержкой по времени)
дубликаты).
3.3. Соображения по модели предложения/ответа SDP
При предложении группировки дублирования с использованием SDP в модели «предложение/ответ»
[RFC3264], применяются следующие соображения.
Узел, который получает предложение от отправителя, может или не может
понимать группировку строк. Возможно также, что узел
понимает группировку строк, но не понимает "DUP"
семантика. С точки зрения отправителя оферты, эти
случаи неразличимы.
Когда узлу предлагается сеанс с семантикой группировки "DUP"
но он не поддерживает группировку строк или группировку дублирования
семантике, согласно [RFC5888], узел отвечает на предложение либо
(1) с ответом, в котором отсутствует атрибут группировки, или (2) с
отказ на запрос (например, «488 здесь неприемлемо» или «606 не
Приемлемо в SIP").
Беген и др. Трек стандартов [Страница 4]
С точки зрения отправителя оферты, эти
случаи неразличимы.
Когда узлу предлагается сеанс с семантикой группировки "DUP"
но он не поддерживает группировку строк или группировку дублирования
семантике, согласно [RFC5888], узел отвечает на предложение либо
(1) с ответом, в котором отсутствует атрибут группировки, или (2) с
отказ на запрос (например, «488 здесь неприемлемо» или «606 не
Приемлемо в SIP").
Беген и др. Трек стандартов [Страница 4] RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г. В первом случае первоначальный отправитель предложения должен отправить новое предложение без дублирования группировки. Во втором случае, если отправитель предложения все еще желает установить сеанс, он должен повторите запрос с предложением без группировки дублирования. Это поведение указано в [RFC5888]. 4. Примеры SDP 4.1. Отдельные исходные адреса В этом примере избыточные потоки используют один и тот же IP-адрес назначения.a=ssrc:1000 cname:[email protected] a=ssrc:1010 cname:[email protected] a=ssrc-группа:DUP 1000 1010 а=середина:Ch2 Обратите внимание, что при фактическом использовании значения SSRC, которые являются случайными 32-битными числа, могут быть намного больше, чем те, которые показаны в этом примере. Также обратите внимание, что в этом описании SDP не используется атрибут delay" (определенный в [DELAYED-DUP]), так как отправитель не применять любую задержку между избыточными потоками при передаче.
 адрес (232.252.0.1), но они получены с разных адресов
(198.51.100.1 и 198.51.100.2). Таким образом, принимающий хост должен
присоединиться к обоим сеансам многоадресной рассылки (SSM) для конкретного источника по отдельности.
v=0
o=ali 1122334455 1122334466 В IP4 dup.example.com
s=Семантика группировки DUP
т=0 0
м=видео 30000 RTP/AVP 100
c=ВХОД IP4 233.252.0.1/127
a = исходный фильтр: вкл. IN IP4 233.252.0.1 198.51.100.1 198.51.100.2
a=rtpmap:100 MP2T/
адрес (232.252.0.1), но они получены с разных адресов
(198.51.100.1 и 198.51.100.2). Таким образом, принимающий хост должен
присоединиться к обоим сеансам многоадресной рассылки (SSM) для конкретного источника по отдельности.
v=0
o=ali 1122334455 1122334466 В IP4 dup.example.com
s=Семантика группировки DUP
т=0 0
м=видео 30000 RTP/AVP 100
c=ВХОД IP4 233.252.0.1/127
a = исходный фильтр: вкл. IN IP4 233.252.0.1 198.51.100.1 198.51.100.2
a=rtpmap:100 MP2T/ В качестве альтернативы МОЖНО явно вставить "a=duplication-delay:0"
строка перед строкой "a=mid:Ch2" для информационных целей.
Беген и др. Трек стандартов [Страница 5]
В качестве альтернативы МОЖНО явно вставить "a=duplication-delay:0"
строка перед строкой "a=mid:Ch2" для информационных целей.
Беген и др. Трек стандартов [Страница 5]
RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г.
4.2. Отдельные адреса назначения
В этом примере избыточные потоки имеют разные IP-адреса назначения.
адреса. В примере показан тот же номер порта UDP и источник IP.
адрес для каждого потока, но один или оба могут быть разными
для двух потоков.
v=0
o=ali 1122334455 1122334466 В IP4 dup.example.com
s=Семантика группировки DUP
т=0 0
а=группа:DUP S1a S1b
м=видео 30000 RTP/AVP 100
c=ВХОД IP4 233.252.0.1/127
a=фильтр-источника:вкл. IN IP4 233.252.0.1 198.51.100.1
a=rtpmap:100 MP2T/
а=середина:S1a
м=видео 30000 RTP/AVP 101
c=ВХОД IP4 233.252.0.2/127
a = исходный фильтр: вкл. IN IP4 233.252.0.2 198.51.100.1
a=rtpmap:101 MP2T/
а=середина:S1b
При желании можно быть более явным и вставить
Строка «a=duplication-delay:0» перед первой строкой «m».
Беген и др. Трек стандартов [Страница 6]
 Беген и др. Трек стандартов [Страница 6]
Беген и др. Трек стандартов [Страница 6]
RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г.
4.3. Временная избыточность
В этом примере избыточные потоки имеют один и тот же IP-источник и
адреса назначения (т. е. они передаются в одном и том же SSM
сессия). Из-за одинаковых адресов источника и получателя
пакеты в обоих потоках будут маршрутизироваться по одному и тому же пути. К
обеспечить устойчивость к потере пакетов, дубликат оригинала
пакет передается на 50 миллисекунд (мс) позже, как указано
Атрибут «задержка дублирования» (определен в [DELAYED-DUP]).
v=0
o=ali 1122334455 1122334466 В IP4 dup.example.com
s = отложенное дублирование
т=0 0
м=видео 30000 RTP/AVP 100
c=ВХОД IP4 233.252.0.1/127
a=фильтр-источника:вкл. IN IP4 233.252.0.1 198.51.100.1
a=rtpmap:100 MP2T/
a=ssrc:1000 cname:[email protected]
a=ssrc:1010 cname:[email protected]
a=ssrc-группа:DUP 1000 1010
а = задержка дублирования: 50
а=середина:Ch2
5.
Вопросы безопасности
В целом, к этому применимы соображения безопасности [RFC4566].
также документ.
Для получателя существует слабая угроза того, что группировка дублирования
могут быть изменены для указания отношений, которые не существуют. Такой
атаки могут привести к отказу механизмов дублирования и/или
неправильная обработка медиапотоков получателями.
Чтобы избежать атак такого рода, описание SDP должно
быть защищена целостностью и снабжена аутентификацией источника. Этот
может быть достигнуто, например, на сквозной основе с использованием S/MIME.
[RFC5652] [RFC5751], когда SDP используется в сигнальном пакете с использованием
Типы MIME (приложение/sdp). Альтернативно, HTTPS [RFC2818] или
метод аутентификации в протоколе оповещения о сеансе (SAP)
[RFC2974] тоже можно использовать. Что касается конфиденциальности, если она
желательно, может быть полезно использовать безопасный, зашифрованный транспорт
метод переноса описания SDP.
Беген и др. Трек стандартов [Страница 7]  Вопросы безопасности
В целом, к этому применимы соображения безопасности [RFC4566].
также документ.
Для получателя существует слабая угроза того, что группировка дублирования
могут быть изменены для указания отношений, которые не существуют. Такой
атаки могут привести к отказу механизмов дублирования и/или
неправильная обработка медиапотоков получателями.
Чтобы избежать атак такого рода, описание SDP должно
быть защищена целостностью и снабжена аутентификацией источника. Этот
может быть достигнуто, например, на сквозной основе с использованием S/MIME.
[RFC5652] [RFC5751], когда SDP используется в сигнальном пакете с использованием
Типы MIME (приложение/sdp). Альтернативно, HTTPS [RFC2818] или
метод аутентификации в протоколе оповещения о сеансе (SAP)
[RFC2974] тоже можно использовать. Что касается конфиденциальности, если она
желательно, может быть полезно использовать безопасный, зашифрованный транспорт
метод переноса описания SDP.
Беген и др.
Вопросы безопасности
В целом, к этому применимы соображения безопасности [RFC4566].
также документ.
Для получателя существует слабая угроза того, что группировка дублирования
могут быть изменены для указания отношений, которые не существуют. Такой
атаки могут привести к отказу механизмов дублирования и/или
неправильная обработка медиапотоков получателями.
Чтобы избежать атак такого рода, описание SDP должно
быть защищена целостностью и снабжена аутентификацией источника. Этот
может быть достигнуто, например, на сквозной основе с использованием S/MIME.
[RFC5652] [RFC5751], когда SDP используется в сигнальном пакете с использованием
Типы MIME (приложение/sdp). Альтернативно, HTTPS [RFC2818] или
метод аутентификации в протоколе оповещения о сеансе (SAP)
[RFC2974] тоже можно использовать. Что касается конфиденциальности, если она
желательно, может быть полезно использовать безопасный, зашифрованный транспорт
метод переноса описания SDP.
Беген и др. Трек стандартов [Страница 7]
Трек стандартов [Страница 7]
RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г.
6. Соображения IANA
Этот документ регистрирует следующую семантику в IANA в
"Семантика для подреестра "Группа" Атрибут SDP" (в разделе
Реестр «Параметры протокола описания сеанса (SDP)»:
Справочник по токену семантики
------------------------------------- ------ ------- --
Дублирование DUP [RFC7104]
Этот документ также регистрирует следующую семантику в IANA в
"Семантика для подреестра "ssrc-group" SDP Attribute" в
Реестр «Параметры протокола описания сеанса (SDP)»:
Справочник по семантике токенов
------- ----------------------------- ---------
Дублирование DUP [RFC7104]
7. Благодарности
Авторы благодарят Колина Перкинса, Билла Вера Стига, Дэйва
Oran и Toerless Eckert за их вклад и предложения.
8. Ссылки
8.1. Нормативные ссылки
[RFC2119] Брэднер, С., «Ключевые слова для использования в RFC для указания
Уровни требований», BCP 14, RFC 2119, март 1997 г.
[RFC3264] Розенберг, Дж. и Х. Шульцринн, «Модель предложения/ответа».
с протоколом описания сеанса (SDP)», RFC 3264, июнь
2002.
[RFC3550] Шульцринн Х., Каснер С., Фредерик Р. и В.
Джейкобсон, «RTP: транспортный протокол для реального времени».
Приложения», STD 64, RFC 3550, июль 2003 г.
[RFC4566] Хэндли, М., Якобсон, В., и К. Перкинс, "SDP: Session
Протокол описания», RFC 4566, июль 2006 г.
[RFC5576] Леннокс, Дж., Отт, Дж., и Т. Ширл, "Source-Specific
Атрибуты мультимедиа в протоколе описания сеанса
(SDP)», RFC 5576, июнь 2009 г..
[RFC5888] Камарильо, Г. и Х. Шульцринн, «Описание сеанса
Структура группировки протокола (SDP), RFC 5888, июнь 2010 г.
Беген и др. Трек стандартов [Страница 8]  [RFC3264] Розенберг, Дж. и Х. Шульцринн, «Модель предложения/ответа».
с протоколом описания сеанса (SDP)», RFC 3264, июнь
2002.
[RFC3550] Шульцринн Х., Каснер С., Фредерик Р. и В.
Джейкобсон, «RTP: транспортный протокол для реального времени».
Приложения», STD 64, RFC 3550, июль 2003 г.
[RFC4566] Хэндли, М., Якобсон, В., и К. Перкинс, "SDP: Session
Протокол описания», RFC 4566, июль 2006 г.
[RFC5576] Леннокс, Дж., Отт, Дж., и Т. Ширл, "Source-Specific
Атрибуты мультимедиа в протоколе описания сеанса
(SDP)», RFC 5576, июнь 2009 г..
[RFC5888] Камарильо, Г. и Х. Шульцринн, «Описание сеанса
Структура группировки протокола (SDP), RFC 5888, июнь 2010 г.
Беген и др. Трек стандартов [Страница 8]
[RFC3264] Розенберг, Дж. и Х. Шульцринн, «Модель предложения/ответа».
с протоколом описания сеанса (SDP)», RFC 3264, июнь
2002.
[RFC3550] Шульцринн Х., Каснер С., Фредерик Р. и В.
Джейкобсон, «RTP: транспортный протокол для реального времени».
Приложения», STD 64, RFC 3550, июль 2003 г.
[RFC4566] Хэндли, М., Якобсон, В., и К. Перкинс, "SDP: Session
Протокол описания», RFC 4566, июль 2006 г.
[RFC5576] Леннокс, Дж., Отт, Дж., и Т. Ширл, "Source-Specific
Атрибуты мультимедиа в протоколе описания сеанса
(SDP)», RFC 5576, июнь 2009 г..
[RFC5888] Камарильо, Г. и Х. Шульцринн, «Описание сеанса
Структура группировки протокола (SDP), RFC 5888, июнь 2010 г.
Беген и др. Трек стандартов [Страница 8] RFC 7104 Семантика группировки дублирования в SDP, январь 2014 г. 8.2. Информативные ссылки [ОТЛОЖЕННОЕ ДУБЛИРОВАНИЕ] Беген А., Цай Ю. и Х.
 Оу, "Отложенное дублирование
Атрибут в протоколе описания сеанса», Работа в
Прогресс, декабрь 2013 г.
[IC2011] Эванс, Дж., Беген, А., Гринграсс, Дж., и К. Филсфилс,
«На пути к передаче видео без потерь, IEEE Internet Computing,
об. 15/6, стр. 48-57", ноябрь 2011 г.
[RFC2354] Перкинс, К. и О. Ходсон, «Варианты ремонта
Потоковое мультимедиа», RFC 2354, 19 июня.98.
[RFC2818] Рескорла, Э., «HTTP через TLS», RFC 2818, май 2000 г.
[RFC2974] Хэндли, М., Перкинс, К., и Э. Уилан, "Session
Протокол объявлений», RFC 2974, октябрь 2000 г.
[RFC5652] Хаусли, Р., «Синтаксис криптографических сообщений (CMS)», STD 70,
RFC 5652, сентябрь 2009 г.
[RFC5751] Рамсделл, Б. и С. Тернер, "Безопасный/многоцелевой
Почтовые расширения (S/MIME) Версия 3.2 Сообщение
Спецификация», RFC 5751, январь 2010 г.
[RTP-DUP] Беген, А. и К. Перкинс, «Дублирование потоков RTP», Работа
в процессе, октябрь 2013 г.
Оу, "Отложенное дублирование
Атрибут в протоколе описания сеанса», Работа в
Прогресс, декабрь 2013 г.
[IC2011] Эванс, Дж., Беген, А., Гринграсс, Дж., и К. Филсфилс,
«На пути к передаче видео без потерь, IEEE Internet Computing,
об. 15/6, стр. 48-57", ноябрь 2011 г.
[RFC2354] Перкинс, К. и О. Ходсон, «Варианты ремонта
Потоковое мультимедиа», RFC 2354, 19 июня.98.
[RFC2818] Рескорла, Э., «HTTP через TLS», RFC 2818, май 2000 г.
[RFC2974] Хэндли, М., Перкинс, К., и Э. Уилан, "Session
Протокол объявлений», RFC 2974, октябрь 2000 г.
[RFC5652] Хаусли, Р., «Синтаксис криптографических сообщений (CMS)», STD 70,
RFC 5652, сентябрь 2009 г.
[RFC5751] Рамсделл, Б. и С. Тернер, "Безопасный/многоцелевой
Почтовые расширения (S/MIME) Версия 3.2 Сообщение
Спецификация», RFC 5751, январь 2010 г.
[RTP-DUP] Беген, А. и К. Перкинс, «Дублирование потоков RTP», Работа
в процессе, октябрь 2013 г.