
Как почистить семантическое ядро от дублей и мусора
Для максимального охвата целевой аудитории в поиске необходимо собрать исчерпывающее семантическое ядро. Иногда это сотни, иногда тысячи, а иногда и десятки и сотни тысяч запросов — в зависимости от объема сайта и конкуренции в тематике.
Чтобы семантика полностью отражала спрос, нужно использовать разные источники — сервисы поисковых систем, поисковые подсказки, фразы-ассоциации и другие (подробно о сборе запросов мы писали в гайде).
При подборе ключевиков неизбежно прямое или косвенное их дублирование (например, «чай каталог» и «каталог чая»), попадание в список спецсимволов, лишних пробелов, слов с прописными буквами. Собрать полное семантическое ядро и удалить «мусорные» запросы вручную — задача рутинная, но нужная.
Мы покажем, как собрать и почистить семантическое ядро с помощью бесплатных автоматизированных инструментов PromoPult на примере чайного магазина.
Первоначальный сбор и расширение семантического ядра
Ручная очистка ядра от нерелевантных запросов
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Как чистить ядро с помощью «Нормализатора слов»
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Убирайте мусор вовремя
Первоначальный сбор и расширение семантического ядра
Сначала составляется базовый перечень фраз, описывающих бизнес. Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Переключаясь на вкладки, генерируйте запросы и подходящие добавляйте в опорный список для расширения.
Когда опорный список готов, переходите к расширению. Для этого понадобится раздел «Ручной подбор и расширение слов». Включите профессиональный режим:
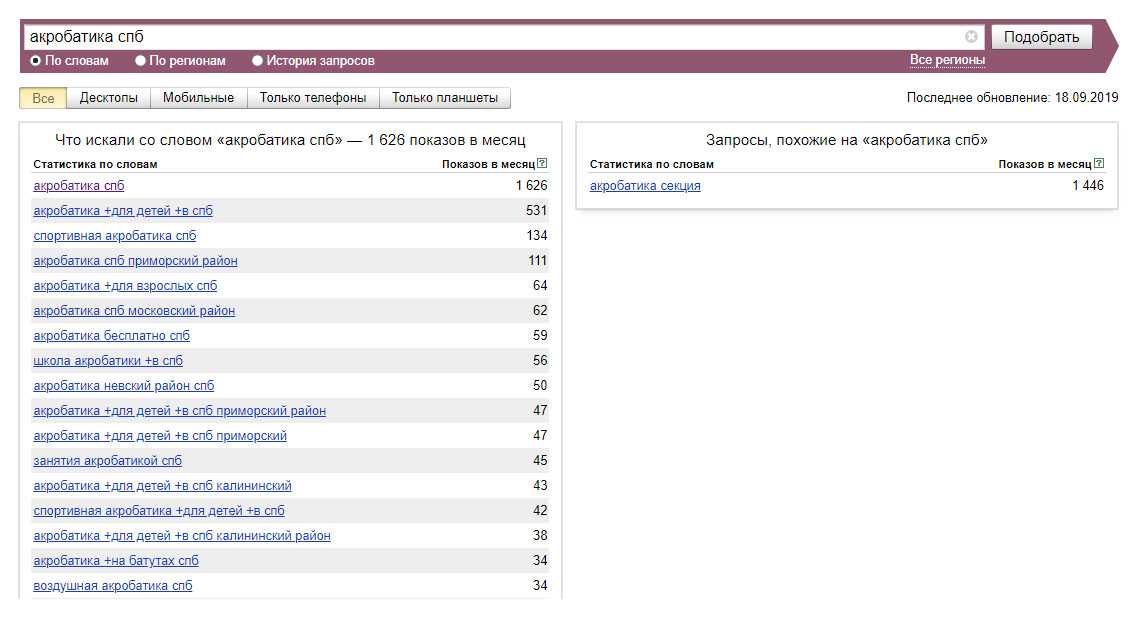
Далее базовый список расширяйте в ширину с помощью правой колонки Вордстат (смежные по значению запросы) — кнопка «Показать ассоциации». Обязательно ознакомьтесь с рекомендациями по выбору числа страниц для парсинга (они будут во всплывающем окне после клика по ссылке «настройки»).
Найденные слова и фразы, которые отвечают тематике, добавляйте в опорный список к базовым запросам.
Затем опорный список расширяйте в глубину с помощью левой колонки Вордстат (другие фразы с вхождением ключа) – кнопка «Что искали со словами»:
Если слов очень много (более тысячи) и система начинает работать медленно, операцию можно проводить поэтапно. Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Для «ширины» есть еще пара профессиональных инструментов PromoPult, для которых мы написали подробные инструкции:
- парсер поисковых подсказок;
- парсер фраз-ассоциаций (блок выдачи «вместе с запросом ищут»).
Прогоните через них базовый (начальный) список запросов и добавьте спарсенные слова в общий Excel-файл.
Собрать такой список — полдела.
В ядро могут попадать нерелевантные тематике фразы и мусор в виде дублей запросов, лишних символов, фраз с нулевой частотностью. Список обязательно нужно чистить.
Ручная очистка ядра от нерелевантных запросов
Нерелевантные запросы — это те, что не соответствуют тематике сайта. Например, чайной лавке из Тюмени не подойдут для продвижения такие запросы как «песня зеленый чай», «духи зеленый чай», «чайный гриб», «кафе кофе», «чай википедия» и т. д. В этом списке также могут быть фразы с указанием города, где нет представительства магазина, названия конкурирующих компаний.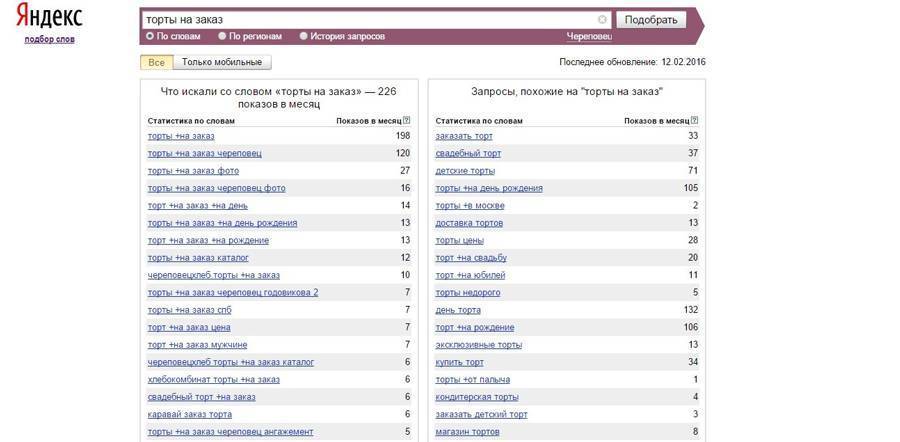
Чтобы они заведомо не попали в список, при парсинге нужно указывать возможные минус-слова. В данном случае к ним относятся «песня», «духи», «гриб», «кафе», «википедия», «спб», «москва» и т. д.
Предусмотреть все минус-слова невозможно, поэтому после каждой операции по расширению ядра нужно визуально проверять список на наличие нерелевантных запросов и удалять их.
Обращайте внимание на фразы с неуточненным интентом и исключайте их из ядра. Например, ключевые слова «золотые брови», «красный халат» (такие сорта чая) применимы также к другим тематикам — продажа косметики, продажа текстиля. Дальнейшее расширение этих фраз спровоцирует появление множества запросов, не имеющих ничего общего с тематикой чая.
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Кроме нерелевантных фраз в списке неминуемо будут присутствовать повторяющиеся фразы и лишние символы. Это мусор, который провоцирует беспорядок в файле и требует удаления.
Опытные пользователи Excel убирают ненужные строки, символы и пробелы с помощью макросов, автозамен и формул.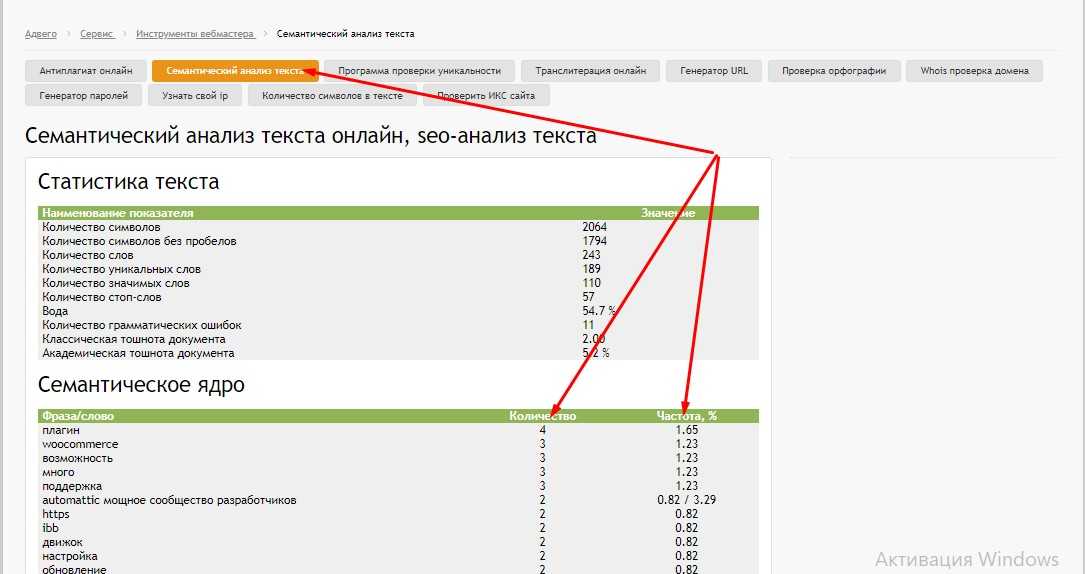 Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Основные возможности инструмента:
- удаление дубликатов в точном вхождении;
- удаление дубликатов с перестановкой слов и учетом морфологии;
- удаление спецсимволов в начале и конце слова;
- удаление лишних пробелов между словами, в начале и конце строки;
- удаление табуляции в начале и конце строки;
- удаление пустых строк;
- преобразование слов в нижний регистр;
- замена ё на е.
Особенности сервиса:
- бесплатное использование;
- неограниченное количество запросов при проверке за один раз;
- работа онлайн — не требует установки софта;
- работа в фоне — не нужно держать страницу открытой;
- не требует разгадывания капчи;
- быстрая скорость обработки данных в облаке;
- результат обработки можно скачать в формате XLSX;
- бессрочное хранение выполненных задач в аккаунте PromoPult.


Как чистить ядро с помощью «Нормализатора слов»
Зарегистрируйтесь или авторизуйтесь в системе PromoPult — так все отчеты сохранятся в вашем личном кабинете.
Перейдите на страницу инструмента, нажмите «Добавить задачу» и укажите список запросов, который нужно почистить.
Загрузить запросы можно с помощью файла Excel (собираются данные с первого листа файла) или добавлением списка в окно сервиса (каждый запрос с новой строки).
Обратите внимание, что при загрузке XLSX-файла система считывает данные по принципу «одна ячейка — один запрос», поэтому добавляйте в файл только перечень запросов без другой служебной информации.
Далее необходимо поставить галочки — выбрать действия с ядром.
Удалить дубликаты слов
Система может удалить полностью идентичные строки (дубли словосочетаний) или строки, где слова в словосочетании имеют другой порядок и используются в других словоформах. Например, «виды китайского чая» и «китайский чай виды» будут считаться идентичными — в списке останется только тот запрос, что стоит выше.
Убрать спецсимволы
Иногда запросы для SEO могут мигрировать из контекстных рекламных кампаний и заимствовать спецсимволы. Или же попросту пользователи ставят при наборе запроса знаки препинания, которые вместе с фразами попадают в базы. Парсер поможет убрать их все одним кликом. По умолчанию заданы символы +-?: и при необходимости их можно дополнить.
Убрать лишние пробелы и табуляцию
При наличии лишних пробелов в начале текстовой строки, между словами во фразе и в конце строки система их обнаружит и удалит. Аналогично и с табуляцией — пустое пространство будет удалено в начале и в конце строки.
Удалить пустые строки
Строки без текста будут удалены.
Преобразовать слова в нижний регистр
Опция может быть полезна, когда список содержит спарсенные заголовки — часто слова в них бывают прописаны в верхнем регистре.
Заменить ё на е
На каждой площадке своя редполитика и свои правила написаний слов с буквой ё. Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Можно выставить сразу все галочки или только те, которые отвечают конкретной задаче. Ведь парсер полезен не только для чистки семантического ядра — он удобен для наведения порядка в любых списках.
По факту выполнения задачи будет доступен файл для скачивания. Задаче можно дать свое название, чтобы в будущем ее было проще идентифицировать.
В загруженном файле заполнен один лист с финальным списком запросов.
В нашем примере исходный список из 1103 запросов был обработан за 10 секунд. После чистки был удален мусор — дубликаты, занимающие порядка 11% ядра.
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Отсеяв мусор и дубли, необходимо также почистить ядро от запросов, частотность которых стремится к нулю. Они не способны генерировать трафик, поэтому нет смысла тратить время и деньги на создание и оптимизацию посадочных страниц.
Собрать частотности Wordstat можно вручную, но это долго и неудобно.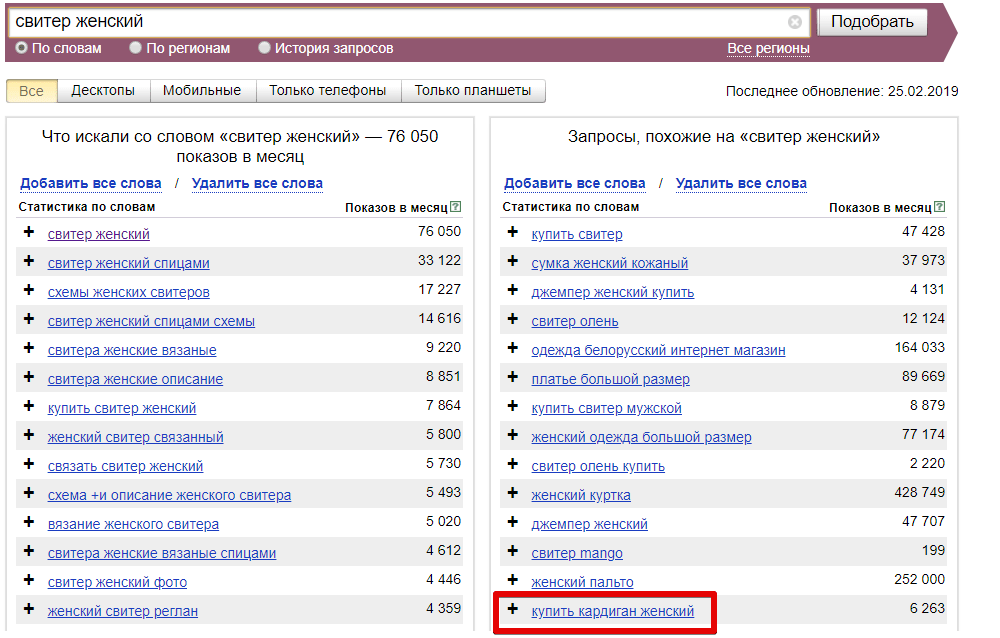 Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Убирайте мусор вовремя
Если раньше было достаточно оптимизировать сайт под сотню базовых запросов, то сегодня требуются тысячи НЧ и длиннохвостых запросов, которые вручную собрать невозможно. Благодаря парсерам эта задача решается быстро и просто, однако побочным эффектом выступает огромное наличие мусора.
Техническая чистка ядра — необходимая процедура, позволяющая исключить неэффективные для продвижения слова. Сделать проверку быстрой и точной можно с помощью инструментов PromoPult.
«Нормализатор слов» доступен бесплатно. Парсер Wordstat — от двух копеек за сбор частотностей для одного запроса. Первые 50 проверок — бесплатно.
Попробовать инструменты PromoPult
метод «Муравейника». Читайте на Cossa.ru
07 февраля 2018, 14:40
О своём методе рассказывает Андрей Буйлов из агентства «Муравейник».
Андрей Буйлов, Агентство Муравейник
Поделиться
Поделиться
Один из первых шагов при продвижении сайта — создание семантического ядра (списка ключевых слов) или доработка существующего.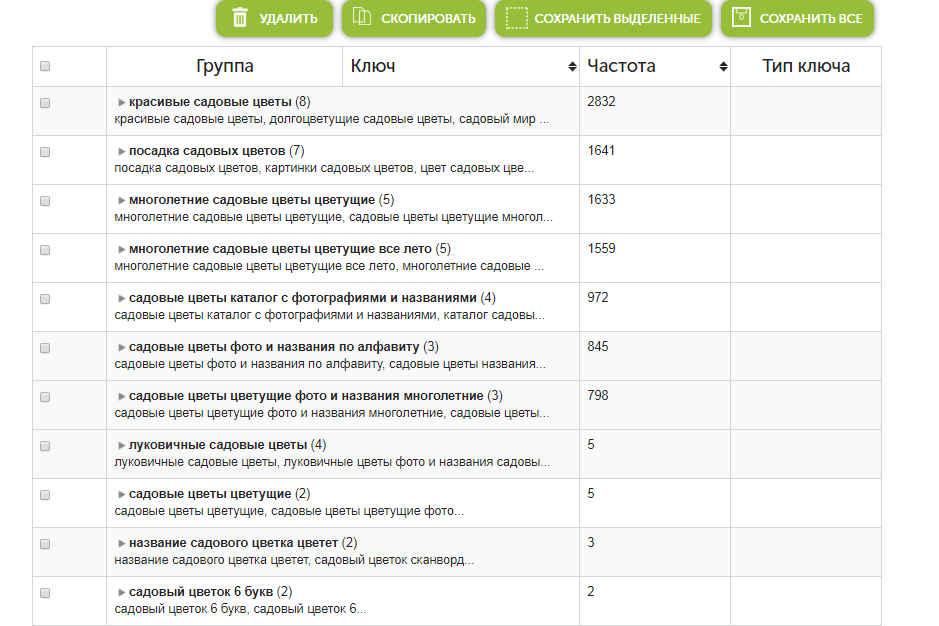
SEO-специалисты подходят к этому процессу с разных сторон.
Одни начинают с проработки mindmap-карты со всеми возможными комбинациями ключевых слов. Потом проверяют по частоте все варианты и получившийся список берут в работу.
Другие собирают семантику конкурентов (Serpstat, Spywords), статистику систем контекстной рекламы (Яндекс.Директ, Google AdWords), поисковые подсказки, запросы из счётчиков статистики, базы ключевых слов (Moab, «Букварикс»).
Всё это собирают вместе и начинают многочасовую фильтрацию в ручном режиме с применением некоторой автоматизации.
Мы обычно применяем оба этих способа, но к фильтрации у нас свой подход. О нём в том числе и расскажу в этой статье.
Есть разные метода сбора семантики.
Метод первый. Полностью вручную
Нереально трудоёмкий и неэффективный процесс. Останавливаться на нём не будем. Не надо так.
Не надо так.
Метод второй. С использованием инструментов
Часто используется Key Collector.
|
|
Фильтры в Key Collector | Группы в Key Collector | Неявные дубли в Key Collector |
|
|---|---|---|---|---|
|
|
|
В нём же фильтруются запросы с нулевой частотой и проводится фильтрация с помощью подгрузки списка стоп-слов.
Применяется ещё ряд методик облегчающих процесс фильтрации, но после этого всё равно приходится часами проверять оставшиеся запросы вручную.
Наш подход
Мы много лет применяли вышеописанный подход. Но не покидало ощущение, что можно сделать это проще и быстрее.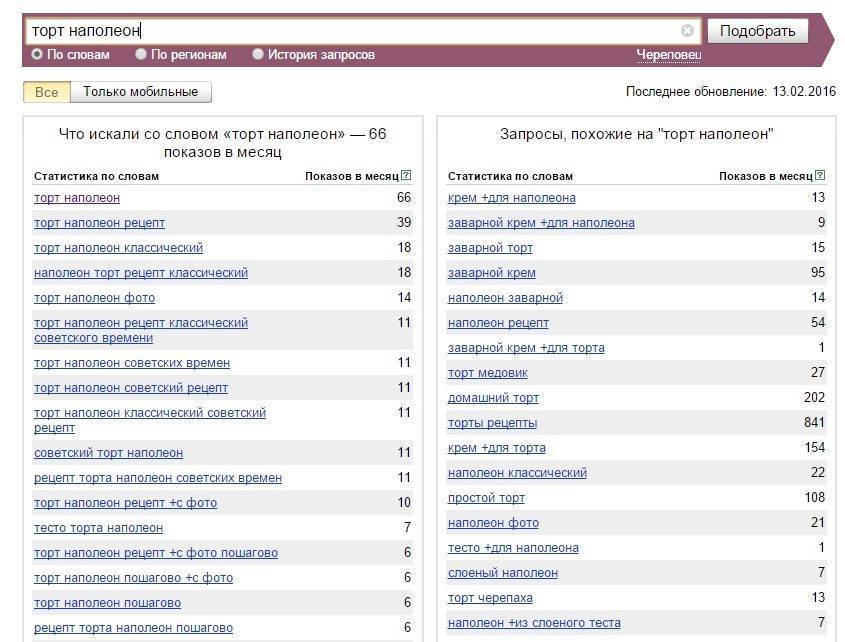
Стали искать варианты. Причём искали не только метод фильтрации, но и выявления вероятности продвижения конкретного сайта по этому запросу. И среди прочих методик выбрали ту, которая давала наибольшее качество и скорость. Это определение «похожести» сайтов из первой десятки на продвигаемый сайт.
Логика простая: если в топе по запросу нет сайтов похожих на нас и много непохожих, то алгоритм поисковой системы и нас туда редко будет пропускать.
Позже к этому мы стали добавлять к оценке параметры конкурирующих сайтов и выводить параметр на их основе (в западных сервисах это часто называется Keyword difficulty), чтобы среди «похожих» выявить более лёгкие и сложные запросы.
Например, если на первой странице только сайты агрегаторы, то сайт конкретной организации по нему будет продвинуть маловероятно. Или если только информационные сайты, то продвинуть по такому запросу коммерческий сайт (даже его информационной страницей) также затруднительно.
Сначала мы применяли этот подход практически в ручном режиме, потом написали скрипт, который автоматизировал этот процесс.
В нём на вход подаётся:
- список запросов;
- целевой поисковик;
- регион;
- несколько похожих сайтов конкурентов.
На выходе:
- похожесть топа;
- среднее значение параметров по топам (возраста конкурентов, число их страниц в индексе, их ссылочные параметры…).
Примеры применения
Пришёл клиент — интернет-магазин лакокрасочных материалов. От прошлого подрядчика остались 705 запросов. На первый взгляд, неплохо подобранные. Основная часть инструмента была к тому моменту готова и активно тестировалась. Сразу загрузили в него, и итог отсортировали по убыванию похожести.
В итоге в верху списка оказались сайты, у которых много похожих и мало непохожих.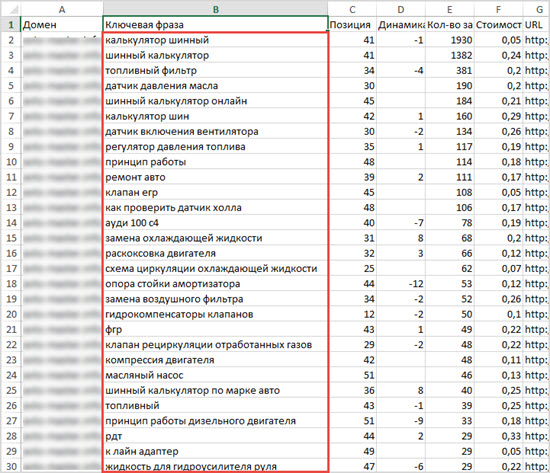
Внизу — мало похожих, много непохожих.
Видно, что уже сейчас самый верх списка имеет много хороших позиций, а внизу их практически нет.
Что мы сделали дальше? Через 15 минут после получения списка запросов вернули клиенту проанализированный список запросов с прозрачной аргументацией, почему треть запросов из его списка в ближайшем будущем практически не имеют шансов выхода в топ и на них не нужно тратить время и деньги.
Ещё один пример чистого списка запросов.
Тематика: маникюрный интернет-магазин.
До внедрения методики мои ребята подобрали 2000 запросов. Как и в прошлом случае проверку «на глазок» запросы проходят.
Здесь мы уже добавили подгрузку дополнительных параметров. Аналогично отсортировали по убыванию суммарной похожести в Яндексе и Google.
Верх списка:
Середина:
Низ:
Мы проверили динамику позиций запросов и опасения подтвердились. Запросы с высокой похожестью за время продвижения заметно выросли. С низкой — даже немного просели.
Запросы с высокой похожестью за время продвижения заметно выросли. С низкой — даже немного просели.
В результате мы отсеяли треть запросов.
И на этом этапе ввели в работу коэффициент сложности запроса Keyword Difficulty, рассчитанный на основе дополнительных параметров без учёта похожести.
Оставшиеся 2/3 запросов объединили в кластера и отсортировали кластера по сочетанию средней похожести, Keyword Dificulty и частоты и продолжили работу продвигаясь по кластерам, начиная с наиболее полезных.
Как мы это сейчас используем
- Фильтрация грязной семантики.
- Фильтрация чистой семантики.
- Выявление запросов «в зоне риска».
- Приоритизация запросов и кластеров.
- Анализ проседания из-за смены интента запроса/кластера.
Про запросы «в зоне риска» хочется сказать отдельно. Это очень важно в клиентском SEO. Когда запускаем продвижение, часто сайт клиента находится в топе по многим запросам, где он не должен находиться и где он один. Например, когда в топе по запросу только информационные сайты и наш клиент — один коммерческий среди них. Положение по такому запросу довольно шаткое и скорее всего сайт рано или поздно по этому запросу вылетит.
Когда запускаем продвижение, часто сайт клиента находится в топе по многим запросам, где он не должен находиться и где он один. Например, когда в топе по запросу только информационные сайты и наш клиент — один коммерческий среди них. Положение по такому запросу довольно шаткое и скорее всего сайт рано или поздно по этому запросу вылетит.
И здесь важно аргументированно предупредить клиента об этом, чтобы клиент имел некоторый прогноз как в целом по продвижению, так и по группам запросов.
Мы выложили этот инструмент на поддомен своего сайта, назвали его «Муравейник Tools».
Для тех, кто дочитал до этого места и хочет обкатать эту методику, есть промокод на 5000 лимитов.
Регистрация
Промо-код: cossa
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
Поделиться
Поделиться
⚡ Телеграм Коссы — здесь самый быстрый диджитал и самые честные обсуждения: @cossaru
📬 Письма Коссы — рассылка о маркетинге и бизнесе в интернете.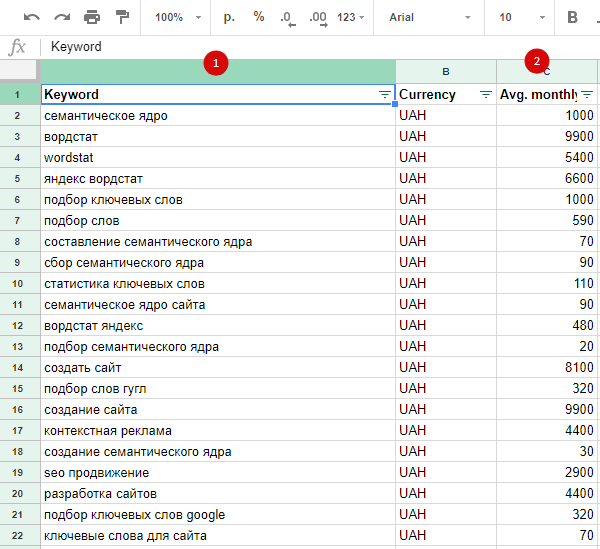 Раз в неделю, без инфошума: cossa.pulse.is
Раз в неделю, без инфошума: cossa.pulse.is
Анализ и чистка семантического ядра. Приоритезация запросов
Как уже упоминалось ранее, после первоначального сбора в вашем списке окажутся десятки и сотни тысяч ключевых слов. Из них необходимо отобрать целевые запросы, то есть те запросы, продвижение по которым коммерчески оправданно.
Это простая, но очень трудозатратная работа, поэтому хотя бы ее часть желательно выполнять в автоматическом или полуавтоматическом режиме. В этом вам помогут онлайн-сервисы или специальные программы.
Фильтровать запросы нужно итерациями, причем таким образом, чтобы в процессе не собирать лишние данные. Например: лучше сначала удалить запросы со стоп-словами, а потом собирать частотность. В противном случае вам придется собирать частотность в том числе и у неподходящих ключевых слов.
Порядок действий зависит от конкретного проекта и приоритетности характеристик поисковых запросов. Ниже мы рассмотрим общий алгоритм, который легко адаптировать под конкретную задачу.
Мусорные запросы
На первом этапе из списка нужно удалить весь мусор, в том числе:
- Запросы со стоп-словами:
— упоминанием конкурирующих брендов,
— ненужными спецификаторами (например, «бесплатно», «рецепт», «скачать»),
— ошибками и опечатками,
— со слишком длинным хвостом (5 и более слов), - Запросы-дубли. Так как запросы собираются из разных источников, в общем списке они неизбежно будут дублироваться. Из группы повторяющихся запросов надо оставить один ключевик в правильной словоформе. Например, из двух запросов «купить живые морепродукты» и «живые морепродукты купить» надо оставить первый, так как именно в такой форме его набирают пользователи согласно данным сервиса Яндекс.Вордстат .
- Товары и услуги, которые вы не продаете.
- Запросы с упоминанием ненужных регионов.
- Zero-click запросы. С ними можно работать, но проще сосредоточиться на более понятных с коммерческой точки зрения направлениях.
- Нецелевые запросы, то есть запросы на темы, которые на вашем сайте не освещены.
- Случайные запросы, не относящиеся к вашей тематике (к сожалению, их будет немало).

Частотность запросов
Для всех оставшихся запросов необходимо собрать показатели из сервиса Яндекс.Вордстат, в том числе базовую (запрос), фразовую (запрос в кавычках) и точную (запрос в кавычках и с восклицательным знаком перед каждым словом) частотность.
Далее можно рассчитать, какой процент фразовая частотность составляет от общей (получится так называемая «полнота запроса» ). Для этого нужна следующая формула:
Полнота запроса = (фразовая частотность)/(общая частотность)*100%
Чем выше полученный коэффициент — тем больше трафика можно получить по запросу и тем он перспективнее в плане поискового продвижения. Чем ниже полнота, тем более общим и многозначным является запрос. Брать такие ключевые слова в продвижение как правило нецелесообразно, так как конкуренция по ним велика, а трафик невысокий.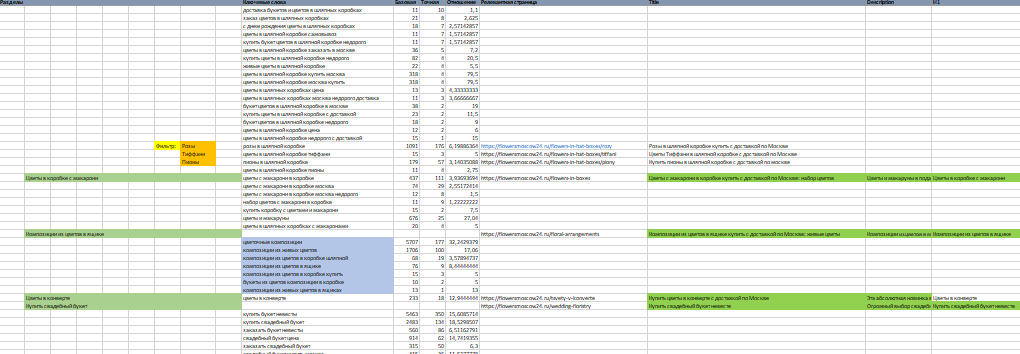 Также можно обратить внимание на точную частотность — если она маленькая или равна нулю, возможно, такой запрос не даст трафика.
Также можно обратить внимание на точную частотность — если она маленькая или равна нулю, возможно, такой запрос не даст трафика.
Это базовые правила отбора, однако при принятии решений об исключении запросов из списка надо учитывать ряд нюансов, которые зависят от конкретного проекта.
Например, в ходе анализа вы видите, что запрос имеет низкую или даже нулевую точную частотность. Такой ключевик все еще можно включить в семантическое ядро, если:
- по нему есть трафик на ваш сайт или сайт ваших конкурентов (согласно системам веб-статистики),
- он присутствует в подсказках,
- по запросу продвигаются конкуренты (хотя сперва надо понять, зачем они это делают),
- запрос является имиджевым,
- запрос имеет сезонность («подарки на Новый год» ищут только в предновогодний период),
- запрос есть в системах статистики других поисковиков (Google, Mail.ru) или сторонних базах,
- запрос появился недавно и по нему еще нет статистики (новостной инфоповод, новый бренд).

Также необходимо учитывать маркетинговую стратегию сайта.
При продвижении сайта часто возникают противоречия между оптимизаторами и маркетологами. Корни разногласий лежат в разности подходов к построению структуры сайта.
Оптимизаторы считают, что надо отталкиваться от спроса. То есть найти и сгруппировать нужные запросы, а затем построить структуру сайта таким образом, чтобы она максимально соответствовали сегодняшним потребностям целевой аудитории.У маркетологов свой взгляд. Они вдохновляются успешными примерами вывода на рынок новых продуктов (вспомним историю «айфона» Стива Джобса) и справедливо полагают, что пользователи часто сами не понимают, чего хотят. А поэтому нужно разработать хорошую архитектуру сайта самостоятельно, до анализа поисковых запросов, а затем предложить ее пользователям.
Оба подхода имеют плюсы и минусы. В первом случае вы подстраиваетесь под существующие потребности, но становитесь реактивным и следуете за потребителем.
Во втором случае вы остаётесь проактивным и сами выбираете, что показывать потенциальным клиентам. Но такой подход требует затрат для глубокой проработки потребностей рынка и времени на проектирование сайта. К тому же всегда есть риск, что вы ошибетесь и сайт будет неудобным. В таком случае отбить затраты будет сложно, а созданная площадка потребует дополнительных инвестиций для проведения доработок.
 На практике такой подход часто приводит к перегибам, а сайты создаются не для людей, а для поисковых роботов и получения трафика. В среде оптимизаторов даже появился специальный термин — СДЛ («сайт для людей», то есть ресурс, который СЕО-шник пытается сделать полезным для конечный пользователей).
На практике такой подход часто приводит к перегибам, а сайты создаются не для людей, а для поисковых роботов и получения трафика. В среде оптимизаторов даже появился специальный термин — СДЛ («сайт для людей», то есть ресурс, который СЕО-шник пытается сделать полезным для конечный пользователей).Если опираться только на «технические» показатели (например, частотность), можно необоснованно отсеять часть перспективных запросов. Например, вы продвигаете сайт стоматологической клиники в Рязани. В тематике «установка брекетов» вы нашли запрос «невидимые брекеты», но Яндекс. Вордстат показал, что он имеет всего 4 запроса в месяц.
Вордстат показал, что он имеет всего 4 запроса в месяц.
Если вы решите, что частотность слишком маленькая и запрос стоит отсеять — это будет ошибкой. Ведь любой маркетолог сразу поймет, что многие пациенты захотят установить именно такие брекеты, так как они не видны окружающим.
Приоритезация запросов
Для всех оставшихся после анализа частотности запросов надо определить, являются они коммерческими или информационными.
Для сайтов, которые продают товары или услуги, нужно брать в работу коммерческие запросы; для ресурсов, ориентированных на привлечение трафика — информационные.
Однако не спешите удалять «неподходящие» запросы. Разделение на коммерческие и информационные ключевые слова условное, и скорее влияет на приоритет запросов, чем служит инструментом отбора. Ведь всегда можно придумать варианты, при которых ваш ресурс сможет помочь пользователю удовлетворить его потребность.
Рассмотрим пример. Интернет-магазин отверток в первую очередь продвигается по коммерческому запросу «купить отвертку», но в своем блоге привлекает дополнительный трафик по информационным запросам «виды отверток» и «как пользоваться отверткой». Понятно, что этот дополнительный трафик магазин пытается монетизировать: показывает карточки товаров, дает ссылки на нужные категории и описывает преимущества своей продукции.
Понятно, что этот дополнительный трафик магазин пытается монетизировать: показывает карточки товаров, дает ссылки на нужные категории и описывает преимущества своей продукции.
Также необходимо рассчитать показатели конкурентности. Как уже упоминалось выше, в первую очередь в работу в надо брать запросы с высокими показателями частотности и умеренной (а в идеале — низкой) конкуренцией. Это поможет добиться результатов в обозримой перспективе и вывести процесс продвижения на самоокупаемость.
Отметим, что на практике бывает сложно определить целесообразность продвижения по конкретному запросу, так как для принятия решения нужно в условиях частичной неопределенности оценить сразу множество параметров. Совет здесь простой: не жалейте времени на анализ рынка и погружение в тему. Так вы сформируете то глубокое понимание предметной области, которое в совокупности со здравым смыслом поможет вам сделать правильный выбор в каждом отдельном случае.
Больше информации:
- продвижение сайтов
- создание продающих сайтов
Очистка база данных ключевых слов SerpStat от Junk запросов
112911 6 3
| Обновления SerpStat | — 8 мин. |
Прочтите позднее
Yuliia Zadachenkova
. столкнулись с ситуацией при сборе семантики, увидели в отчете много ключевых слов с ошибками, а то и всю первую страницу «мусорных» ключевых слов , были вынуждены применить фильтр и очистить от них экспортированный отчет? Такие клавиши часто могут похвастаться высокой частотой, но Google уже знает, как их заменить. Следовательно, t эй бесполезны .
Вы больше никогда не будете делать двойную работу, так как наша команда очистила базы данных от таких ключевых слов. Подробнее об очищенных базах!
Содержание
- Что представлял собой процесс очистки и зачем он был нужен?
- Какие результаты принесла чистка?
- Подведем итоги
Что представлял собой процесс очистки и зачем он был нужен?
Все мы можем забыть переключить раскладку и ввести поисковую фразу с ошибками. Это фраз, которые являются «мусорными». Не стоит ориентироваться на них при сборе семантики, но обратите внимание на правильно написанные ключевые слова .
Это фраз, которые являются «мусорными». Не стоит ориентироваться на них при сборе семантики, но обратите внимание на правильно написанные ключевые слова .
Возможно, вы знаете, что Google Ads объединяет частоту часто используемых фраз с их синонимами с ошибками . Например, частота фраз «facevook» и «facebook» будет одинаково высокой. Поэтому добавлять фразу «facevook» на свой сайт бесполезно .
Google объединяет эти фразы вместе, потому что когда пользователь вводит ключевое слово «facevook» в поисковую систему, он все равно получает результаты на «facebook». Таким образом, под словосочетанием с ошибкой Google подразумевает правильное высокочастотное ключевое слово и показывает его частотность для всех «мусорных» синонимов, но фактическая частотность таких «мусорных» словосочетаний невелика.
Вот наглядная ситуация при поиске «facevook»:
К высокочастотной фразе может прилипнуть целая группа однотипных «неявных синонимов», и все они будут иметь одинаковые частотные показатели:
Мы научились отличать высокочастотные фразы от фраз с неправильным написанием . Мы разработали алгоритм, с помощью которого очищаем базы ключевых слов от «неявных синонимов». В результате очистки в отчетах остались только те фразы, которые пользователи хотели ввести в строку поиска Google, но по каким-то причинам ошиблись при вводе.
Мы разработали алгоритм, с помощью которого очищаем базы ключевых слов от «неявных синонимов». В результате очистки в отчетах остались только те фразы, которые пользователи хотели ввести в строку поиска Google, но по каким-то причинам ошиблись при вводе.
Вот несколько скриншотов отчетов «Подбор ключевых слов» в модуле «Исследование ключевых слов» для сравнения результатов до и после очистки:
На данный момент мы провели первую очистку базы данных:
- Google AU (Австралия)
- Google CA (Канада)
- Google DE (Германия)
- Google ES (Испания)
- Google IT (Италия)
- Google SE (Швеция)
- Google UK (Великобритания)
- Google US (90) США)
- Google RU (Россия)
- Google UA (Украина)
- Google KZ (Казахстан)
А наша команда продолжает работу с остальными базами и будет очищать каждый из «мусорных» запросов. Очищенные базы сразу попадут в список выше.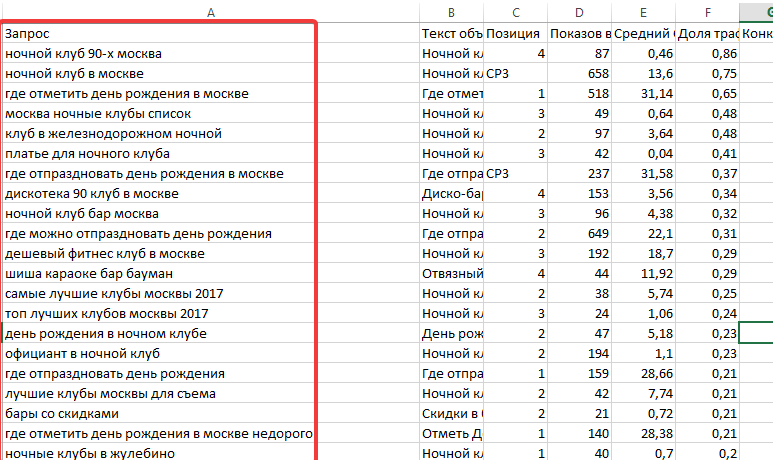
Узнать о возможностях сервиса бесплатно
Какие результаты принесла чистка?
Улучшен алгоритм подсчета трафика по доменам. Он стал ближе к реальным показателям и больше не учитывает «мусорные» запросы;
Лучший выбор фраз в отчетах;
Увеличена скорость загрузки отчетов;
Более быстрая работа фильтра.
Хотите узнать, как расширить семантическое ядро с помощью Serpstat?
Закажите бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут!
| Запросить демонстрацию |
Подведем итоги
- Мы попытались ответить на важный вопрос: «Нужно ли добавлять ключевые слова с ошибками?» . Больше никаких «мусорных» запросов вас не введут в заблуждение!
- Некоторые наши базы данных уже избавлены от ненужных запросов , и работа еще продолжается.
- У вас уже есть возможность работать с готовыми базами в Поисковой аналитике и сравнивать разницу, не тратя время на ручное удаление таких ключей.
Если у вас есть вопросы о наших 5 модулях, не стесняйтесь задавать их в комментариях под этой статьей или обращаться в нашу команду по работе с клиентами .
Присоединяйтесь к нам на Facebook и Twitter, чтобы следить за обновлениями нашего сервиса и новыми сообщениями в блоге 🙂
Узнайте, как получить максимальную отдачу от Serpstat
Хотите получить личную демонстрацию, пробный период или множество успешных вариантов использования?
Отправьте заявку и наш специалист свяжется с Вами 😉
Оцените статью по пятибалльной шкале
Статью уже оценили 927 человек в среднем 3,43 из 5
Нашли ошибку? Выберите его и нажмите Ctrl + Enter, чтобы сообщить нам
Рекомендованные посты
Обновления Serpstat +1
Юлия Задаченкова
Анализ обратных ссылок: доработка интерфейса, фильтры и сортировка API
Как проверить позиции сайта в любое подходящее время
Обновления Serpstat
Стейси Майн
Режим управления командой Serpstat: Один аккаунт для управления вашей командой
Кейсы, лайфхаки, исследования и полезные статьи
Нет времени следить за новостями? Без проблем! Наш редактор подберет статьи, которые обязательно помогут вам в работе. Присоединяйтесь к нашему уютному сообществу 🙂
Присоединяйтесь к нашему уютному сообществу 🙂
Нажимая на кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Поделитесь этой статьей с друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылки.
Отчет A BUG
Отмена
[PDF] NADEEF: A A A A A A A A Somplecty Data System
- DOI: 10.1145/2463676.2465327
- CORPUS ID: 207202965
6262626262626262626262626 FRPURSPROUS. title={NADEEF: система очистки данных о товарах}, автор = {Мишель Даллакиеза, Амр Эбайд, Ахмед Эльдави, Ахмед К. Эльмагармид, Ихаб Ф. Ильяс, Мурад Уззани и Нан Танг}, booktitle={SIGMOD ’13}, год = {2013} }
- Michele Dallachiesa, Amr Ebaid, N. Tang
- Опубликовано в SIGMOD ’13 22 июня 2013 г.
- Информатика
 Tang
TangНесмотря на растущую важность качества данных и богатый теоретический и практический вклад во все аспекты очистки данных, не существует единого комплексного готового решения для (полу)автоматизации обнаружения и исправления нарушений w.r.t. набор разнородных и специальных ограничений качества. Короче говоря, не существует общедоступной платформы, подобной СУБД общего назначения, которую можно было бы легко настроить и развернуть для решения проблем с качеством данных, характерных для конкретных приложений. В этой статье…
Посмотреть на ACM
www-users.cs.umn.eduNADEEF: Обобщенная система очистки данных
- Амр Эбайд, А. Эльмагармид, Си Инь
Информатика
Proc. ВЛДБ Эндоу.
- 2013
NADEEF проводит различие между программным интерфейсом и ядром для достижения универсальности и расширяемости, расширяемой, универсальной и простой в развертывании системы очистки данных.
Тенденции очистки реляционных данных: непротиворечивость и дедупликация
Предлагается классификация современных методов обнаружения аномалий, включая типы ошибок, автоматизация процесса обнаружения и распространение ошибок, и делается вывод о текущих тенденциях в очистке «больших данных».
Картирование и очистка: путь LLUNATIC
- Флорис Гертс, Г. Мекка, Паоло Папотти, Донателло Санторо
Информатика
- 2014 9002 для сопоставления схем и восстановления данных разработан алгоритм, основанный на поиске, для вычисления решений.
- Э. Резиг, М. Уззани, Валид Г. Ареф, А. Эльмагармид, Ахмед Р. Махмуд, М. Стоунбрейкер
Информатика
Proc. ВЛДБ Эндоу.
- 2021
- Зухаир Хайят, И. Ильяс, Си Инь
Информатика
Конференция SIGMOD
- 2015
- Донателло Санторо
Информатика
- 2014
- Dong Deng, R. Fernandez, N. Tang
Компьютерные науки
CIDR
- 2017
- Floris Geerts, G. Mecca, Paolo Papotti, Donatello Santoro
- . предложение обрабатывать сопоставления схем и восстановление данных единым образом и основано на интуитивном понимании того, что преобразование и очистку данных можно рассматривать как разные аспекты одной и той же проблемы, объединенные их декларативным характером.
ПОКАЗАНЫ 1–10 ИЗ 37 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Декларативная очистка данных: язык, модель и алгоритмы
Информатика
VLDB
- 2001
- Виджайшанкар Раман, Дж. Хеллерштейн
Информатика
VLDB
- 2001
- G. Cong, W. Fan, Floris Geerts, X. Jia, Shuai Ma
Computer Science
VLDB
- 2007
- Омар Бенджеллун, Х. Гарсия-Молина, Дэвид Менестрина, Ци Су, Стивен Юджонг Ванг, Дж. Видом
Информатика
The VLDB Journal
- 2008
- W. Fan, Jianzhong Li, Shuai Ma, N. Tang, Wenyuan Yu
Информатика
JDIQ
- 2014
- В. Фан, Флорис Гиртс, X. Цзя, Анастасиос Кементсиедис
Информатика
TODS
- 2008
- W. Fan, Jianzhong Li, Shuai Ma, N. Tang, Wenyuan Yu
Информатика
Журнал VLDB
- 2011
- Крис Мэйфилд, Дженнифер Невилл, С. Прабхакар
Информатика
Конференция SIGMOD
- 2010
- Xu Chu
Computer Science, Psychology
Encyclopedia of Machine Learning and Data Mining
- 2017
- М. Бергман, Т. Майло, Слава Новгородов, В. Тан
Информатика
Proc. ВЛДБ Эндоу.
- 2015
- М. Бергман, Т. Майло, Слава Новгородов, В. Тан
Информатика
-ориентированную систему очистки данных с помощью оракулов и показывает, что задача определения минимальных взаимодействий с оракулами для получения правок базы данных для удаления (добавления) некорректных кортежей в результат запроса в общем случае является NP-трудной.
Автоматизированные рассуждения о целостности больших данных в возможностном SQL
- И. Литвиненко
Информатика
- 2020
пропозициональную логику Хорна, и, следовательно, может применять линейное разрешение, чтобы рассуждать о них, и этот основной вклад состоит в том, чтобы вооружить SQL возможностями рассуждений о семантике больших данных, которые могут характеризоваться измерениями объема, разнообразия и достоверности.
Очистка данных
- Сюй Чу
Информатика
- 2018
Разработка эффективных и действенных решений по очистке данных является сложной задачей и сопряжена с глубокими теоретическими и инженерными проблемами.
Очистка веб-скрейпинга данных с помощью Python
- Tasnuva Tarannum
Информатика
- 2019
Тестовая работа в рекомендации подтвердила пояснение, что нет очевидной лучшей структуры информации, и показывает, что, например, пропорция набора данных, скорость ошибок в наборах данных, тип строк в наборе данных и даже тип синтаксического контроля в строке будут иметь основное влияние на выполнение выбранных фреймворков.
Изучение основанного на ограничениях подхода к качеству данных в информационных системах
- О. Пробст
Информатика
- 2013
Реализация структуры управления качеством данных на основе запроса спецификации Java (9Jean 9BSR3) Валидация 1.
1) с использованием единой модели ограничений, которая позволяет избежать несоответствий и избыточности в рамках спецификации ограничений и процесса проверки.Частичная ссылочная целостность в базах данных SQL
- Можган Мемари
Информатика
- 2016
частичная ссылочная целостность для основных задач обработки данных, таких как запросы, обновления и исправления.
Качественная очистка неопределенных данных
- Хеннинг Кёлер, С. Ссылка
Информатика
CIKM
- 2016
В этой работе используются степени вероятности и определенности для разработки специального алгоритма с фиксированным параметром, поддающегося обработке в размере качественного покрытия вершин, и показано, что он быстрее, чем решатели классической задачи вершинного покрытия на несколько порядков, а производительность улучшается с увеличением числа степеней неопределенности.
Борьба с грязными данными с помощью виртуализации данных
Ясность данных, используемая вместе с виртуализацией данных, обеспечивает исключительное решение этих проблем, обрабатывая сложные рабочие нагрузки данных в отношении разнородных данных и разрозненных источников данных, а также обеспечивает целостное представление данных для бизнес-организации.
ПОКАЗАНЫ 1-10 ИЗ 16 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантность Наиболее влиятельные документыНедавность
Расширяемая платформа для очистки данных
Основное новшество работы заключается в том, что структура позволяет следующие оптимизации производительности, которые предназначены для приложений очистки данных: смешанная оценка , хеш-соединение по соседству, преобразование решения и ускоренное вычисление.
An automatic blocking mechanism for large-scale de-duplication tasks
- A. Sarma, Ankur Jain, Ashwin Machanavajjhala, P. Bohannon
Computer Science
CIKM
- 2012
CBLOCK learns hash functions automatically из атрибутивных доменов и помеченного набора данных, состоящего из дубликатов, и выражает функции блокировки с использованием иерархической древовидной структуры, состоящей из атомарных хеш-функций, которая управляет процессом автоматической блокировки на основе архитектурных ограничений.
Обзор методов индексирования для масштабируемого связывания записей и дедупликации
Обзор 12 вариантов 6 методов индексирования для связывания и дедупликации записей, направленный на сокращение количества пар записей, подлежащих сравнению в процессе сопоставления, путем удаления явно несовпадающих пар, при этом сохраняется высокое качество согласования.
Динамические ограничения для сопоставления записей
- W. Fan, Hong Gao, X. Jia, Jianzhong Li, Shuai Ma
Информатика
The VLDB Journal
- 2010
Экспериментально подтверждено, что алгоритмы помогают инструментам сопоставления эффективно идентифицировать ключи во время компиляции для сопоставления, блокировки или работы с окнами, и, кроме того, методы на основе md эффективно повысить качество и эффективность различных методов сопоставления записей.
Крупномасштабная дедупликация с ограничениями с использованием Dedupalog
В этой работе представлена декларативная структура для коллективной дедупликации ссылок на объекты при наличии ограничений, основанная на простом языке в стиле декларативного журнала данных с точной семантикой, и показано, что его алгоритмы имеют точную семантику. теоретические гарантии для большого подкласса фреймворка.
Приблизительные соединения строк в базе данных (почти) бесплатно
- Л. Гравано, Панайотис Г. Ипейротис, Х. Джагадиш, Н. Кудас, С. Мутукришнан, Д. Шривастава
Компьютерные науки
2 VLDB
- 2001
В этой статье разрабатывается метод создания возможностей приблизительного соединения строк поверх коммерческих баз данных с использованием уже имеющихся в них средств и экспериментально демонстрируются преимущества этого метода по сравнению с прямым использованием пользовательских функций.
Адаптивная блокировка: обучение масштабированию связывания записей
В этом документе представлена адаптивная структура для автоматического обучения функциям блокировки, которые являются эффективными и точными, и описаны две формулировки обучаемых функций блокировки на основе предикатов и представлены алгоритмы обучения для их обучения.
Теория связывания записей
Резюме Разработана математическая модель, обеспечивающая теоретическую основу для компьютерно-ориентированного решения проблемы распознавания тех записей в двух файлах, которые представляют собой идентичные…
Интеграция данных с помощью повторного использования преобразования в проекте Morpheus
- Tiffany Dohzen, Mujde Pamuk, Seok-Won Seong, J. Hammer, M. Stonebrak Morpheus мотивирован целью повторного использования (частей) ранее написанных преобразований для решения проблем интеграции данных путем поиска соответствующих преобразований в репозитории и последующего изменения их для повторного использования.
Horizon: Масштабируемая очистка данных на основе зависимостей
Представлен Horizon — комплексная система восстановления FD, решающая две ключевые задачи: точность и масштабируемость.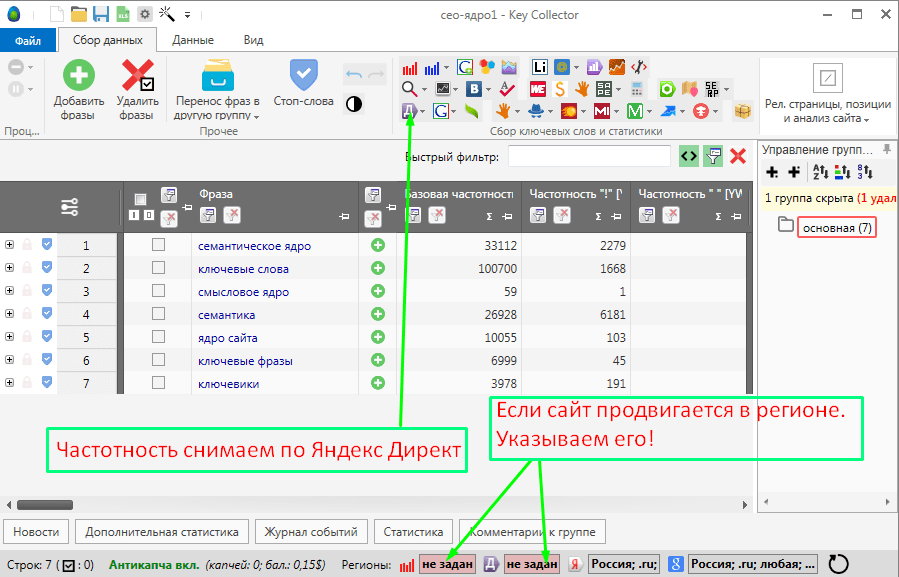
BigDansing: система очистки больших данных
Экспериментальные результаты как на синтетических, так и на реальных наборах данных показывают, что BigDansing превосходит существующие базовые системы более чем на два порядка без ущерба для качества, обеспечиваемого алгоритмами восстановления.
Передовые методы картирования и очистки
Разработана новая семантика для этих сценариев, которая представляет собой консервативное расширение предыдущей семантики для сопоставления схем и восстановления данных, а также представлен основанный на преследовании алгоритм для вычисления решений.
Сопоставление и очистка
Разработана новая семантика для этих сценариев, которая представляет собой консервативное расширение предыдущей семантики для сопоставления схем и восстановления данных, а также представлен основанный на преследовании алгоритм для вычисления решений.
Подход к очистке данных на основе плотности для дедупликации с согласованностью и точностью данных
Представлена единая структура и алгоритмы для интеграции дедупликации данных с восстановлением несогласованных данных и обнаружением точных значений в данных, а также представлена весовая модель для присвоения оценок достоверности, основанных на плотности данных.
Система цивилизации данных
Первоначальный положительный опыт показывают, что даны даны даты гражданских данных. усилия, необходимые для поиска, подготовки и анализа данных.
Обзор системы Llunatic

В этом документе представлены язык, модель выполнения и алгоритмы, которые позволяют пользователям декларативно выражать спецификации очистки данных и эффективно выполнять очистку, а экспериментальные результаты оценивают предлагаемые фреймворк для очистки данных.
Реальные данные грязные: очистка данных и проблема слияния/очистки
В этом документе разрабатывается система для выполнения этой задачи очистки данных и демонстрируется ее использование для очистки списков имен потенциальных клиентов в приложениях прямого маркетинга и отчеты об успешном внедрении реальной базы данных, которая убедительно подтверждает результаты, ранее достигнутые для статистически сгенерированных данных.
Гончарный круг: интерактивная система очистки данных
Представляем гончарный круг, интерактивную систему очистки данных, которая постепенно объединяет обнаружение, преобразование и диск. обнаруживаются несоответствия и очищают данные без написания сложных программ и длительных задержек.
Повышение качества данных: непротиворечивость и точность
заданный набор CFD, а другой — для поэтапного поиска исправления в ответ на обновления чистой базы данных.
Swoosh: общий подход к разрешению объектов
Эта работа формализует общую проблему ER, рассматривая функции сравнения и слияния записей как черные ящики, и определяет четыре важных свойства, которые, если они удовлетворяются соответствием и функции слияния позволяют использовать гораздо более эффективные алгоритмы ER.
Взаимодействие между сопоставлением записей и восстановлением данных
В этой статье представлена единая структура, которая органично объединяет операции восстановления и сопоставления для очистки базы данных на основе ограничений целостности, правил сопоставления и основных данных, а также предлагает эффективные алгоритмы для очистки данные как путем сопоставления, так и восстановления.
Условные функциональные зависимости для выявления несоответствий данных
В этой работе предлагается класс ограничений целостности для реляционных баз данных, называемых условными функциональными зависимостями (CFD), и предоставляется система вывода, аналогичная аксиомам Армстронга для FD, и показывает, что проблема импликации является coNP-полной для CFD, в отличие от линейно-временной сложности для их традиционного аналога.
К некоторым исправлениям с правилами редактирования и основными данными
Основная структура и алгоритм поиска определенных исправлений данных , представлено понятие определенных областей и класс правил редактирования путем взаимодействия с пользователями, чтобы убедиться, что одна из определенных областей верна.
ERACER: база данных для статистического вывода и очистки данных
Реальные базы данных часто содержат современные синтаксические и семантические ошибки в ограничениях целостности, несмотря на встроенные меры безопасности СУБД. Мы представляем ERACER, итеративную…
TAILOR: набор инструментов для связывания записей
Результаты показывают, что предложенные модели связывания записей на основе машинного обучения превосходят существующие как по точности, так и по производительности.
Очистка данных: практический взгляд title={Очистка данных: практическая перспектива}, автор={Венкатеш Ганти и Аниш Дас Сарма}, booktitle={Очистка данных: практический взгляд}, год = {2013} }
Хранилища данных объединяют различные виды деятельности бизнеса и часто образуют основу для создания отчетов, поддерживающих важные бизнес-решения. Ошибки в данных имеют тенденцию появляться по разным причинам. Некоторые из этих причин включают ошибки при сборе входных данных и ошибки при объединении данных, собранных независимо из разных баз данных. Эти ошибки в хранилищах данных часто приводят к ошибочным исходящим отчетам и могут негативно повлиять на бизнес-решения. Поэтому один…
View via Publisher
link.springer.com
Data Cleaning
QOCO: A Query Oriented Data Система очистки с оракулами
 Бергман, Т. Майло, Слава Новгородов, В. Тан
Бергман, Т. Майло, Слава Новгородов, В. ТанПредставлен QOCO, новая система очистки, ориентированная на запросы, которая использует материализованные представления, определенные пользовательскими запросами, в качестве триггера для выявления оставшейся неверной/отсутствующей информации в базе данных.

 1) с использованием единой модели ограничений, которая позволяет избежать несоответствий и избыточности в рамках спецификации ограничений и процесса проверки.
1) с использованием единой модели ограничений, которая позволяет избежать несоответствий и избыточности в рамках спецификации ограничений и процесса проверки.
 Bohannon
Bohannon

