
Как почистить семантическое ядро от дублей и мусора
Для максимального охвата целевой аудитории в поиске необходимо собрать исчерпывающее семантическое ядро. Иногда это сотни, иногда тысячи, а иногда и десятки и сотни тысяч запросов — в зависимости от объема сайта и конкуренции в тематике.
Чтобы семантика полностью отражала спрос, нужно использовать разные источники — сервисы поисковых систем, поисковые подсказки, фразы-ассоциации и другие (подробно о сборе запросов мы писали в гайде).
При подборе ключевиков неизбежно прямое или косвенное их дублирование (например, «чай каталог» и «каталог чая»), попадание в список спецсимволов, лишних пробелов, слов с прописными буквами. Собрать полное семантическое ядро и удалить «мусорные» запросы вручную — задача рутинная, но нужная.
Мы покажем, как собрать и почистить семантическое ядро с помощью бесплатных автоматизированных инструментов PromoPult на примере чайного магазина.
Первоначальный сбор и расширение семантического ядра
Ручная очистка ядра от нерелевантных запросов
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Как чистить ядро с помощью «Нормализатора слов»
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Убирайте мусор вовремя
Первоначальный сбор и расширение семантического ядра
Сначала составляется базовый перечень фраз, описывающих бизнес. Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Это можно делать вручную при помощи Яндекс Вордстата или использовать бесплатные рекомендаторы SEO-модуля на шаге «Ключевые слова». Это следующий этап после заполнения основных данных проекта:
Переключаясь на вкладки, генерируйте запросы и подходящие добавляйте в опорный список для расширения.
Когда опорный список готов, переходите к расширению. Для этого понадобится раздел «Ручной подбор и расширение слов». Включите профессиональный режим:
Далее базовый список расширяйте в ширину с помощью правой колонки Вордстат (смежные по значению запросы) — кнопка «Показать ассоциации». Обязательно ознакомьтесь с рекомендациями по выбору числа страниц для парсинга (они будут во всплывающем окне после клика по ссылке «настройки»).
Найденные слова и фразы, которые отвечают тематике, добавляйте в опорный список к базовым запросам.
Затем опорный список расширяйте в глубину с помощью левой колонки Вордстат (другие фразы с вхождением ключа) – кнопка «Что искали со словами»:
Если слов очень много (более тысячи) и система начинает работать медленно, операцию можно проводить поэтапно.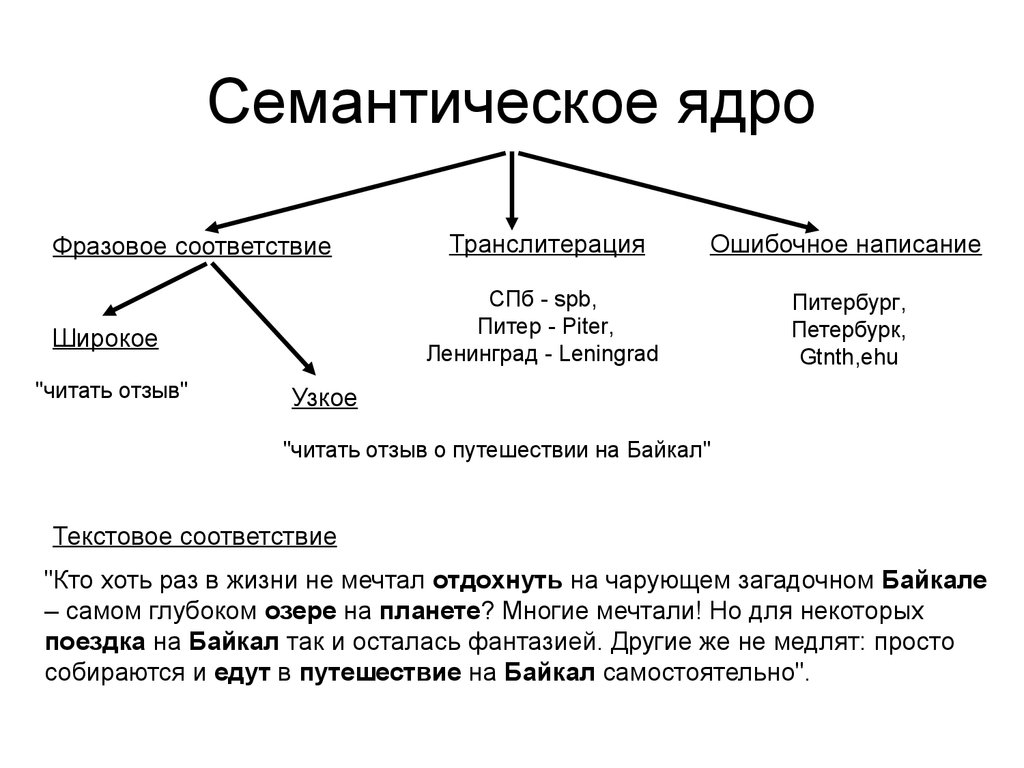 Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Подходящие слова из результатов расширения также добавляйте в опорный список, после чего экспортируйте его и скопируйте в файл Excel.
Для «ширины» есть еще пара профессиональных инструментов PromoPult, для которых мы написали подробные инструкции:
- парсер поисковых подсказок;
- парсер фраз-ассоциаций (блок выдачи «вместе с запросом ищут»).
Прогоните через них базовый (начальный) список запросов и добавьте спарсенные слова в общий Excel-файл.
Собрать такой список — полдела.
В ядро могут попадать нерелевантные тематике фразы и мусор в виде дублей запросов, лишних символов, фраз с нулевой частотностью. Список обязательно нужно чистить.
Ручная очистка ядра от нерелевантных запросов
Нерелевантные запросы — это те, что не соответствуют тематике сайта. Например, чайной лавке из Тюмени не подойдут для продвижения такие запросы как «песня зеленый чай», «духи зеленый чай», «чайный гриб», «кафе кофе», «чай википедия» и т. д. В этом списке также могут быть фразы с указанием города, где нет представительства магазина, названия конкурирующих компаний.
Чтобы они заведомо не попали в список, при парсинге нужно указывать возможные минус-слова. В данном случае к ним относятся «песня», «духи», «гриб», «кафе», «википедия», «спб», «москва» и т. д.
Предусмотреть все минус-слова невозможно, поэтому после каждой операции по расширению ядра нужно визуально проверять список на наличие нерелевантных запросов и удалять их.
Обращайте внимание на фразы с неуточненным интентом и исключайте их из ядра. Например, ключевые слова «золотые брови», «красный халат» (такие сорта чая) применимы также к другим тематикам — продажа косметики, продажа текстиля. Дальнейшее расширение этих фраз спровоцирует появление множества запросов, не имеющих ничего общего с тематикой чая.
Автоматическая очистка ядра от дублей и лишних символов в «Нормализаторе слов»
Кроме нерелевантных фраз в списке неминуемо будут присутствовать повторяющиеся фразы и лишние символы. Это мусор, который провоцирует беспорядок в файле и требует удаления.
Опытные пользователи Excel убирают ненужные строки, символы и пробелы с помощью макросов, автозамен и формул. Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Наработать для себя набор таких приемов непросто и можно не учесть некоторые моменты, поэтому лучше использовать готовые инструменты — в частности, «Нормализатор слов» PromoPult.
Основные возможности инструмента:
- удаление дубликатов в точном вхождении;
- удаление дубликатов с перестановкой слов и учетом морфологии;
- удаление спецсимволов в начале и конце слова;
- удаление лишних пробелов между словами, в начале и конце строки;
- удаление табуляции в начале и конце строки;
- удаление пустых строк;
- преобразование слов в нижний регистр;
- замена ё на е.
Особенности сервиса:
- бесплатное использование;
- неограниченное количество запросов при проверке за один раз;
- работа онлайн — не требует установки софта;
- работа в фоне — не нужно держать страницу открытой;
- не требует разгадывания капчи;
- быстрая скорость обработки данных в облаке;
- результат обработки можно скачать в формате XLSX;
- бессрочное хранение выполненных задач в аккаунте PromoPult.

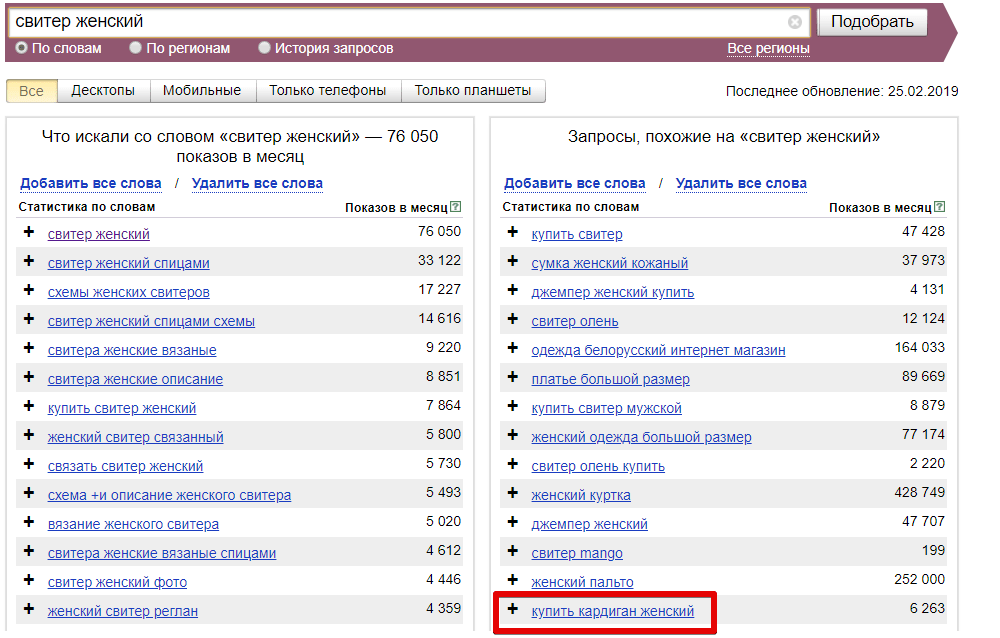
Как чистить ядро с помощью «Нормализатора слов»
Зарегистрируйтесь или авторизуйтесь в системе PromoPult — так все отчеты сохранятся в вашем личном кабинете.
Перейдите на страницу инструмента, нажмите «Добавить задачу» и укажите список запросов, который нужно почистить.
Загрузить запросы можно с помощью файла Excel (собираются данные с первого листа файла) или добавлением списка в окно сервиса (каждый запрос с новой строки).
Обратите внимание, что при загрузке XLSX-файла система считывает данные по принципу «одна ячейка — один запрос», поэтому добавляйте в файл только перечень запросов без другой служебной информации.
Далее необходимо поставить галочки — выбрать действия с ядром.
Удалить дубликаты слов
Система может удалить полностью идентичные строки (дубли словосочетаний) или строки, где слова в словосочетании имеют другой порядок и используются в других словоформах. Например, «виды китайского чая» и «китайский чай виды» будут считаться идентичными — в списке останется только тот запрос, что стоит выше.
Убрать спецсимволы
Иногда запросы для SEO могут мигрировать из контекстных рекламных кампаний и заимствовать спецсимволы. Или же попросту пользователи ставят при наборе запроса знаки препинания, которые вместе с фразами попадают в базы. Парсер поможет убрать их все одним кликом. По умолчанию заданы символы +-?: и при необходимости их можно дополнить.
Убрать лишние пробелы и табуляцию
При наличии лишних пробелов в начале текстовой строки, между словами во фразе и в конце строки система их обнаружит и удалит. Аналогично и с табуляцией — пустое пространство будет удалено в начале и в конце строки.
Удалить пустые строки
Строки без текста будут удалены.
Преобразовать слова в нижний регистр
Опция может быть полезна, когда список содержит спарсенные заголовки — часто слова в них бывают прописаны в верхнем регистре.
Заменить ё на е
На каждой площадке своя редполитика и свои правила написаний слов с буквой ё. Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Красоты ради собранный файл стоит унифицировать, заменив разом одну букву на другую.
Можно выставить сразу все галочки или только те, которые отвечают конкретной задаче. Ведь парсер полезен не только для чистки семантического ядра — он удобен для наведения порядка в любых списках.
По факту выполнения задачи будет доступен файл для скачивания. Задаче можно дать свое название, чтобы в будущем ее было проще идентифицировать.
В загруженном файле заполнен один лист с финальным списком запросов.
В нашем примере исходный список из 1103 запросов был обработан за 10 секунд. После чистки был удален мусор — дубликаты, занимающие порядка 11% ядра.
Автоматическая очистка ядра от нулевых запросов в парсере Wordstat
Отсеяв мусор и дубли, необходимо также почистить ядро от запросов, частотность которых стремится к нулю. Они не способны генерировать трафик, поэтому нет смысла тратить время и деньги на создание и оптимизацию посадочных страниц.
Собрать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Для ускорения работы существуют парсеры — в PromoPult есть и такой инструмент.
Убирайте мусор вовремя
Если раньше было достаточно оптимизировать сайт под сотню базовых запросов, то сегодня требуются тысячи НЧ и длиннохвостых запросов, которые вручную собрать невозможно. Благодаря парсерам эта задача решается быстро и просто, однако побочным эффектом выступает огромное наличие мусора.
Техническая чистка ядра — необходимая процедура, позволяющая исключить неэффективные для продвижения слова. Сделать проверку быстрой и точной можно с помощью инструментов PromoPult.
«Нормализатор слов» доступен бесплатно. Парсер Wordstat — от двух копеек за сбор частотностей для одного запроса. Первые 50 проверок — бесплатно.
Попробовать инструменты PromoPult
Как удалить из семантического ядра неэффективные запросы? Как и написать текст для «кривых» ключевых фраз?
Данный вопрос — приоритетный!
Евгений:
Здравствуйте. В работе интернет-магазин и в данный момент подбирается семантическое ядро для одного из разделов.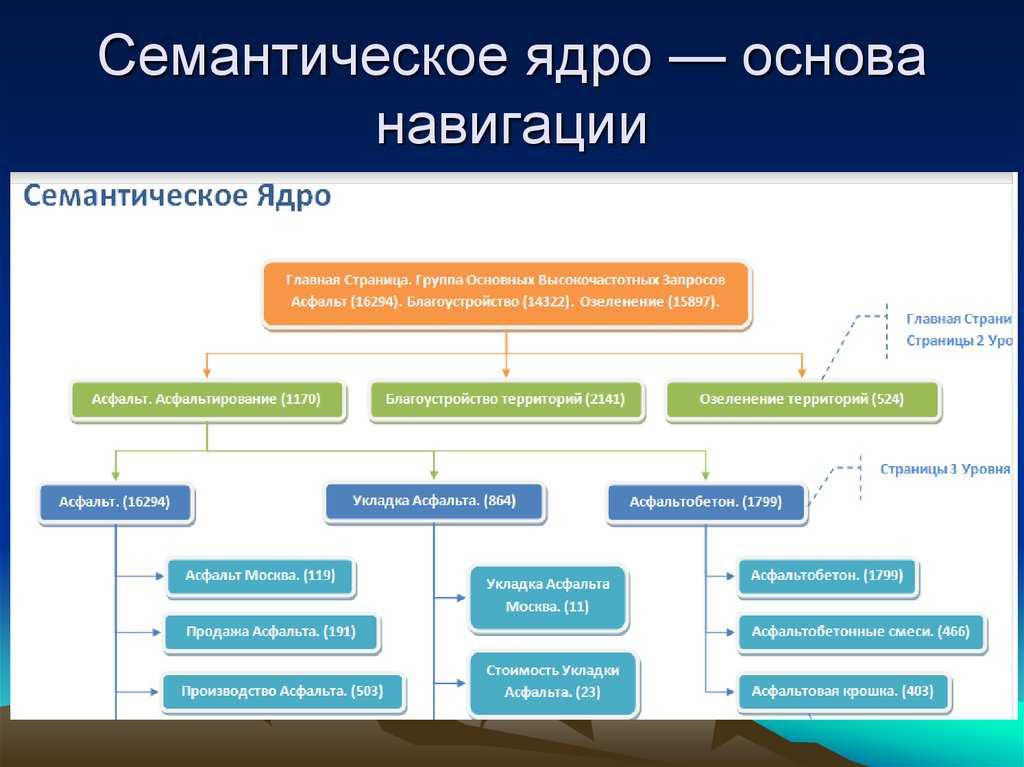
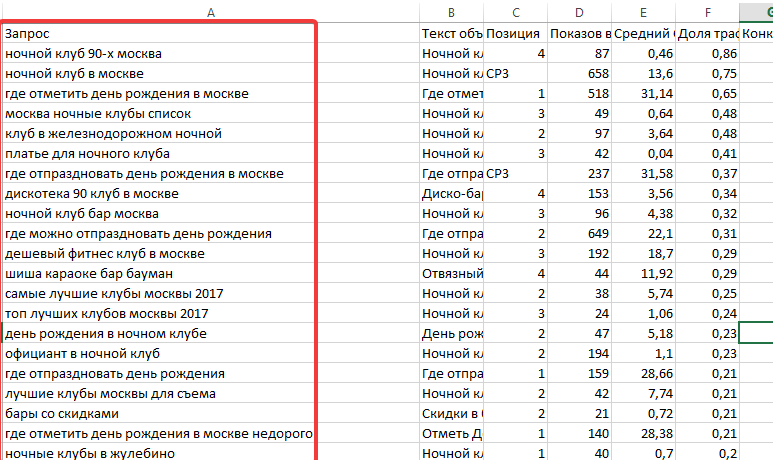
Собрано около 300 запросов после чистки: минимальная частота «!» не менее 30 (не видим смысла в разделах продвигать запросы которые даже спрашивают меньше 30 раз в месяц, после была чистка по формуле: [точная_частота/общая_частота < 0.05–0.07 (≈ 5%–7%)], после чистка на минус-слова и неподходящие).
Все запросы распределены по релевантным страницам, так же дополнительно будут созданы ещё страницы на различные комбинации фильтров релевантно запросам.
Но при этом, после распределения запросов, выходит ситуация, что на некоторых страницах по 30 или более фраз. Интересует, каким ещё методами (более автоматизированными) можно почистить семантическое ядро от неэффективных запросов, например, которые не принесут трафик вообще?
Делали попытку собрать данные (прогноз переходов) SeoPult, Rookee, ВебЭффектор и даже средние показатели. Но данные не внушают доверия, что бы им доверять, так как они слишком разные, в РАЗЫ!
Так же интересует понимание правильных словоформ и порядка слов.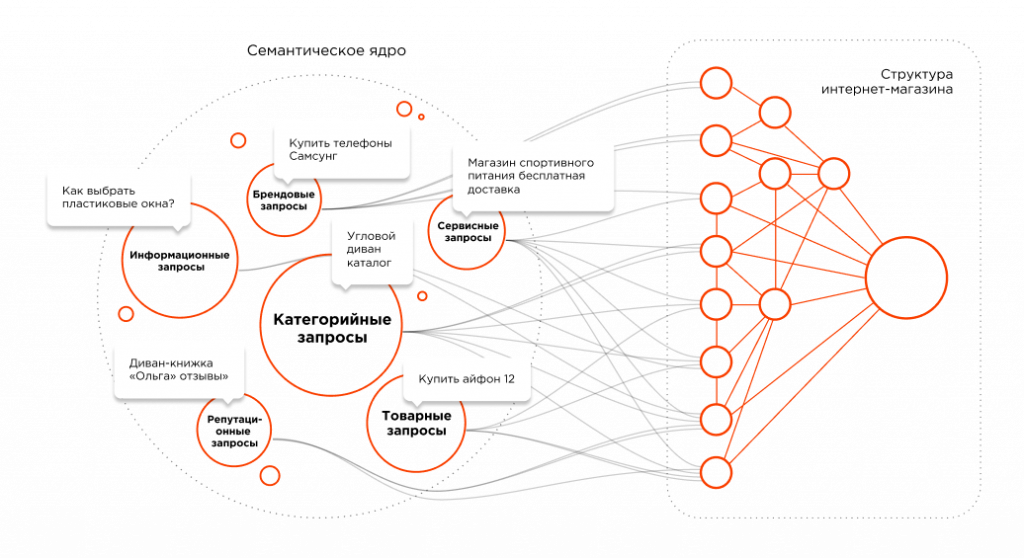 Как быть в случае, если запрос звучит явно не так как он мог бы быть использован в тексте (SEO)?
Как быть в случае, если запрос звучит явно не так как он мог бы быть использован в тексте (SEO)?
Например: [офисное кресло купить в москве], хотя логичнее если запрос в тексте будет [купить офисное кресло в москве], возможно не самый лучший пример, но всё же главная загвоздка в том, что не всегда ключи выглядят достаточно хорошо, что бы входить в содержание сайта и возникает ощущение, что так не ищут и незачем такой запрос продвигать?
Работа проводится в Key Collector.
Евгений, приветствую! Если резюмировать, то у вас три вопроса:
Как удалить из семантического ядра неэффективные запросы?
Как сгруппировать фразы? Можно ли продвинуть условные 30 запросов на документе?
Как правильно написать текст, если исходная фраза звучит «криво»?
Разберём их в этом порядке.
1. Неэффективные фразы
Давайте называть эффективной не ту фразу, которая имеет точную частоту более 30, а ту, которая удовлетворяет следующим критериям:
Она целевая.
То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.Стоимость совершения целевого действия по которой — является рентабельной для проекта.
 То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.
То есть, та, по которой интент пользователя преимущественно совпадает с тем, который вы можете удовлетворить на документе.Как правило, рассчитать CPA по фразе на этапе сбора семантики — сложно и следует опираться на стоимость одного показа, метрика CPV = Стоимость продвижения / Точная частота в регионе.
Если вы достаточно хорошо умеете оценивать стоимость продвижения, то опираться лучше именно на это соотношение, а не на точную частоту. Число показов может быть и менее 30, но если они вам не будут почти ничего стоить и будут целевыми, то это эффективные фразы.
Можно прокачать формулу оценки и добавить к числу показов (точная частота) множитель, который отвечает за долю целевых показов. Если рассматривать коммерческий проект, то в данным коэффициентом будет степень коммерциализации выдачи по «Пиксель Тулс». Ниже приведена оценка, после выгрузки из инструмента.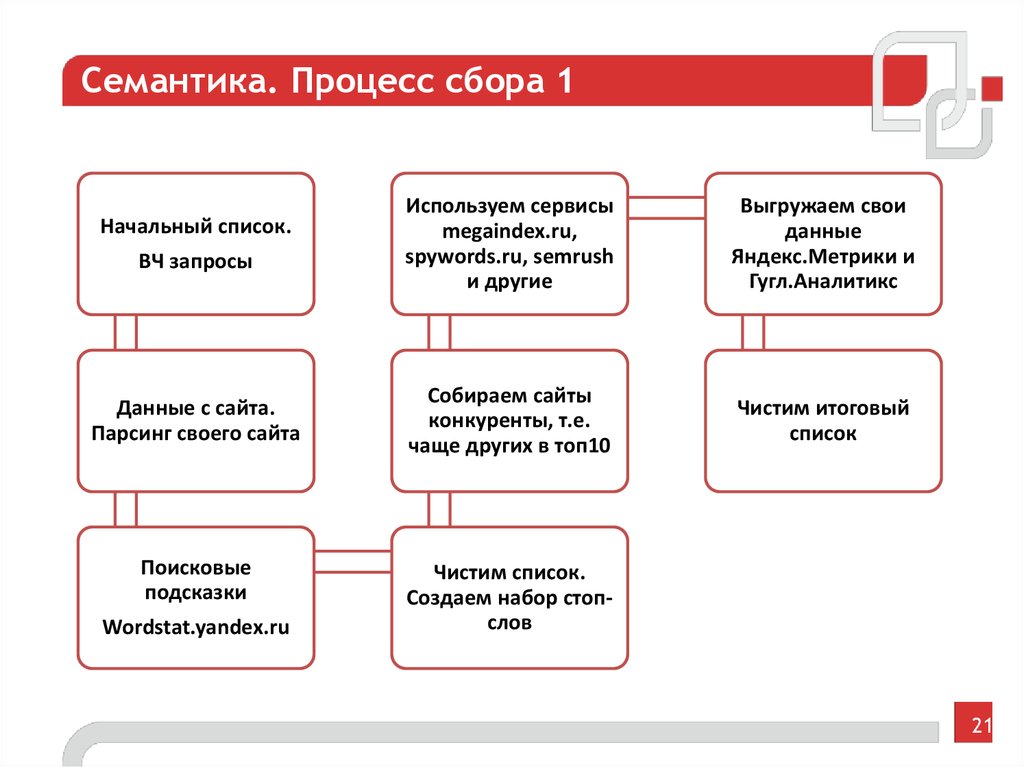
Следует ориентироваться на соотношение: стоимость продвижения / эффективные показы.
Дополнительно лучше оценить, что запрос входит / есть в поисковых подсказках и она не сгенерирована, это позволит очистить ядро от накрученных запросов.
2. Группировка и финальная чистка
Финальную чистку семантического ядра рекомендуется производить уже после его группировки и распределения по посадочным страницам. Почему это важно? Это связано с тем, что решение удалять или не удалять запрос будет зависеть от того, если ли у вас в группе на URL другие фразы.
Поясним: если на URL ведёт всего 1 запрос, то лучше оставить его (если он целевой) и наоборот, можно удалить запрос с высоким значением CPV, если в группе много других, более эффективных фраз.
Первичную группировку/кластеризацию лучше производить с помощью инструментов автоматизации — «Онлайн кластеризация семантического ядра сайта». Сервис поможет в пару кликов определить частоты фраз, релевантные URL и текущую позицию сайта, а также, что самое важное, опираясь на ТОП-10 скомпонует запросы так, как их можно будет продвинуть.
Если после кластеризации и оценки CPV у вас остались эффективные фразы, которые нормально продвинутся на одном URL, то их может быть и 10-15 и 30 штук (редко, но такое бывает, да). Бояться этого не стоит, переходите к этапу внутренней оптимизации.
ТОП — не врёт!
3. Работа с «кривыми» ключами
Да, часто запросы звучат не так, как их можно использовать в тексте. Самый базовый пример: [мебель москва].
Совет очень простой: используйте в тексте наиболее приближенные фразы, корректные с точки зрения русского языка. Несколько примеров:
- [мебель москва] -> …мебель в Москве…
- [мебель цена] -> …цена на мебель…
- [офисное кресло купить в москве] -> …купить офисное кресло в Москве…
Это позволит удовлетворить большинство текстовых факторов ранжирования и не попасть под санкции за переоптимизацию. Стоить также избегать точных вхождений в тексте для очень длинных фраз, они, в последнее время, не очень хорошо воспринимаются поисковой системой Яндекс. Разбейте запрос на 2 более коротких фрагмента с частичным вхождением.
Разбейте запрос на 2 более коротких фрагмента с частичным вхождением.
Итоговая последовательность действия
Если резюмировать, то итоговая последовательность действий следующая:
Проверяете точную частоту фраз.
Удаляете запросы, которые не подходят вам по интенту / потребности.
Удаляете запросы, которые отсутствуют в поисковых подсказках или подсказки автосгенерированные.
Определяете стоимость продвижения.
Определяете коммерциализацию выдачи (коммерческий проект).
Вычисляете CPV по эффективным показам = Стоимость продвижения / (Точная частота × Степень коммерциализации).
Группируете запросы и распределяете их по посадочным URL.
Удаляете фразы с завышенным значением CPV, если в группе уже достаточное число запросов (5-10).
Для технических заданий на тексты и тегов — приводите фразы к корректному написанию с точки зрения русского языка.
Проводите оптимизацию. В помощь — критерии, которым требуется удовлетворить.

Видео с чек-листом чистки фраз
Удачи в самостоятельном продвижении в ТОП!
Дата ответа:
Автор ответа:
Дмитрий Севальнев
Рисунок 6. Компиляция Haskell в JavaScript с помощью ядра Clean
- Идентификатор корпуса: 55242607
title={Компиляция Haskell в JavaScript через ядро Clean},
автор = {L {\ 'a} szl {\ 'o} Домошлай и Ринус Пласмейер},
год = {2012}
} - L. Domoszlai, R. Plasmeijer
- Опубликовано в 2012 г.
- Информатика

Преодоление границ языков, позволяющее им сотрудничать на уровне исходного кода, имеет огромные преимущества, поскольку разные языки имеют различные языковые функции и полезные библиотеки для совместного использования . Это особенно верно для мира функционального программирования, где языки находятся в постоянном развитии и являются объектом активных исследований. Уже существует обоюдоострый внешний интерфейс компилятора для ленивых функциональных языков Haskell и Clean, который обеспечивает взаимодействие функций обоих…
Портативная платформа реализации на основе виртуальных машин для нестрогих языков функционального программирования
- Дж. М. Янсен, Джон Х. Г. ван Гронинген
Информатика
IFL 2016
30009- 0046 В этом документе представлена виртуальная машина, которая способный к эффективному выполнению байт-кода, сгенерированного компилятором для нестрогого промежуточного функционального языка, и получает переносимую платформу выполнения для нестрогих функциональных языков с лучшей производительностью на стороне клиента, чем существующие платформы выполнения на стороне клиента.
Люк в крыше: монадический DSL для генерации JavaScript ll-hosted для конкретного домена Язык для генерации JavaScript с использованием монадической реификации и генерации JavaScript из глубокого внедрения монады JavaScript.
Материалы 30-го симпозиума по внедрению и применению функциональных языков
- О. Читил, Мэн Ванг, Аарон Стамп, Джастин Бейли, Теодор Р. Купер
Информатика
IFL
- 2018
Целенаправленное программирование и Интернет вещей
- Mart Lubbers, P. Koopman, M. J. Plasmeijer
Computer Science
IFL
- 2018 Task
, что позволяет определять на высоком уровне абстракции произвольное сотрудничество между людьми, большими системами, а теперь и устройствами IoT.
Обмен исходными кодами между clean и Haskell: обоюдоострый интерфейс для чистого компилятора
- John H.G. van Groningen, T.V. Noort, P. Achten, P. Koopman, M.J. Plasmeijer
Информатика
Haskell ’10 ged
- 2010 A
4 реализовано для существующей очистки компилятор в качестве отправной точки, и это позволяет обоим языкам легко использовать многие языковые функции друг друга, которые раньше были чужды друг другу.
Эффективная интерпретация путем преобразования типов данных и шаблонов в функции
Представлено пошаговое построение эффективного интерпретатора для ленивых языков функционального программирования, таких как Haskell и Clean, который оказывается очень конкурентоспособным в сравнении с другими интерпретаторами, такими как Hugs, Helium, GHCi и Amanda, по ряду тестов.
Реализация ленивых функциональных языков на стандартном оборудовании: Spineless Tagless G-machine
Суть компиляции с продолжениями
- К. Фланаган, А. Сабри, Б. Дуба, М. Фелейзен
Информатика
PLDI ’93
- 1994 900 Комбинированный эффект из трех фаз эквивалентно преобразованию источника в источник, которое имитирует фазу сжатия, и полностью разработанным компиляторам CPS не нужно использовать преобразование CPS, но они могут достичь тех же результатов с помощью простого преобразования на уровне исходного кода.
Редуктор реконфигурирован
- Мэтью Нейлор, К. Рансимен
Информатика
ICFP ’10
- 2010
который реализован с использованием готового реконфигурируемого оборудования и подчеркивает низкоуровневый параллелизм, присутствующий в последовательном сокращении графа.
Реализация нестрогого чисто функционального языка в JavaScript
- E. Bru, J. M. Jansen
Информатика
- 2011
В этой статье описывается реализация нестрогого чисто функционального языка в JavaScript на основе перевода функционального языка высокого уровня, такого как Haskell. или Очистить в JavaScript через промежуточный функциональный язык Sapl, который опирается на использование функции оценки для эмуляции нестрогой семантики этих языков.
Реализация языков функционального программирования (Международная серия Prentice-hall по компьютерным наукам)
- С. Джонс
Информатика
- 1987
Компилятор Glasgow Haskell: технический обзор Jones
Информатика
- 1993
Дан обзор компилятора Glasgow Haskell, особое внимание уделено тому, как компилятор смог использовать богатую теорию функциональных языков для получения очень практических улучшений в компиляторе.
.Reduceron: расширение узкого места фон Неймана для сокращения графов с использованием ПЛИС узкое место фон Неймана с помощью исследуется специальная машина для сокращения графов с большой параллельной памятью, а прототип машины — Reduceron — реализован с использованием FPGA и основан на простом оценщике создания экземпляров шаблона.
Серверная часть Haskell для JavaScript http://utrechthaskellcompiler.wordpress.com/2010/10/18/ haskell-to-javascript-backend
- 2010
Веб-сайты семантического ядра и архитектуры
Сбор и кластеризация СЕМАНТИЧЕСКОГО ЯДРА
. АРХИТЕКТУРА САЙТА КОНСТРУКЦИЯ
01
СБОР КЛЮЧЕВЫХ СЛОВ ДЛЯ ОПРЕДЕЛЕННОЙ НИШИ
из результатов органического поиска, сайтов конкурентов, мировых баз данных ключей, из собственных баз данных — 800 миллионов ключей в США и 1,2 миллиарда ключей по всему миру
02
Мы выполняем чистящую, структурирующую и ручную группировку семантического ядра
на основе требований клиента
03
Мы строим структуру сайта
, основанные на результатах кластера Semantic Core.
— формируем новую или улучшаем старую04
СОЗДАЕМ КАРТУ РЕЛЕВАНТНОСТИ
по ключевым словам
05
ПРОЕКТИРУЕМ АВТОМАТИЧЕСКИЕ УНИКАЛЬНЫЕ ШАБЛОНЫ
для документов сайта0017
06
СОСТАВЛЯЕМ ПРОФЕССИОНАЛЬНЫЕ ТЕХНИЧЕСКИЕ ЗАДАНИЯ ДЛЯ КОПИРАЙТЕРОВ
на основе групп и ядра, обращая внимание на БИС
07
ФОРМИМ ОСНОВНЫЕ МЕТАДАННЫЕ
9004 на базе которых формируется: Название, h2, описание. При формировании учитываются все детали и требования поисковых систем (учитывается более 17 правил формирования)08
ОСУЩЕСТВЛЯЕМ ВНУТРЕННЮЮ ССЫЛКУ НА САЙТ.
На базе готового ядра
09
РАЗРАБАТЫВАЕМ АРХИТЕКТУРУ САЙТА
на основании состояния семантического ядра и исходных данных клиента (полная структура и навигация)
Что вы получаете на финале и какие возможности дает
СЕМАНТИЧЕСКОЕ ЯДРО САЙТА:
Современная автоматизация разработки семантического ядра для сайта является одной из наших основных услуг, и мы делаем эту услугу как субподрядчики для многих других SEO-компаний.
Основные 4 цели правильного семантического ядра: «рост сайта в ТОП 10 по целевым запросам» >> «лиды и заказы» >> «продажи» >> «получение прибыли».
Просто доверьте Webcorelab всю рутинную работу по кластеризации ключевых слов и сосредоточьтесь на своих основных ежедневных задачах. От вас требуется лишь заполнить наш бриф, а все остальное мы берем на себя.
1
Возможна разработка и формирование четкой и понятной структуры сайта
2
Максимальная верность ПК структуре и содержанию сайта (выписано на основе семантического ядра).
3
Высокая скорость индексации страниц сайта и высокие позиции веб-ресурса в поисковых системах.
4
Все документы сайта написаны на основе технических заданий по семантическому ядру.
Это с высокой вероятностью выведет сайт на первые места в поисковой выдаче, даже без дополнительной стимуляции.Для каких проектов
НЕОБХОДИМО ГРУППОВУЮ СЕМАНТИКУ?
01
Интернет-магазины и порталы
02
Компании, оказывающие некоторые услуги
03
Контекстные проекты
04
2010904 Арбитраж трафика04
2010904 9Для контекстной рекламы
05
Для продвижения мероприятий
Статистика сервиса:
Создано семантических ядер:
Большие семантические ядра:
Довольных клиентов:
Заказов в день:
Средний размер СК (ключей):
НЕ ПЛАТИТЕ ДЕНЬГИ ЗА ПРОЦЕСС
ПОЛУЧИТЕ ГАРАНТИРОВАННО РЕЗУЛЬТАТ!
заказ услуг
Услуга: «Аудит семантического ядра»:
Деловое предложение для владельцев бизнеса и топ-менеджеров:
— если у вас есть сайт и вы продвигаетесь много лет, то задайте себе очень простой вопрос: насколько эффективно его выполняет собственная команда, фрилансер или SEO-компания.


 Bru, J. M. Jansen
Bru, J. M. Jansen .
. — формируем новую или улучшаем старую
— формируем новую или улучшаем старую
 Это с высокой вероятностью выведет сайт на первые места в поисковой выдаче, даже без дополнительной стимуляции.
Это с высокой вероятностью выведет сайт на первые места в поисковой выдаче, даже без дополнительной стимуляции.