
Разбираемся с ZFS — «Хакер»
Содержание статьи
В мире *nix-систем все более популярными становятся файловые системы ZFS и Btrfs. Популярность эта вполне заслуженна — в отличие от своих предшественников, они лишены некоторых проблем и имеют множество неоспоримых достоинств. А не так давно им присвоен статус стабильных. Все это и побудило написать данную статью.
WARNING!
Некоторые описываемые здесь команды способны необратимо уничтожить твои данные. Трижды проверяй введенное, прежде чем нажимать Enter.
Пожалуй, прежде чем перейти к практике, нужно дать некоторые пояснения, что собой представляют файловые системы нового поколения. Начну с ZFS. Эта ФС была разработана для Solaris и в настоящее время, поскольку Oracle закрыла исходный код, форкнута в версию OpenZFS. В дальнейшем под ZFS будет подразумеваться именно форк. Вот лишь некоторые из ключевых особенностей ZFS:
- огромный до невообразимости максимальный размер ФС;
- пулы хранения, которые позволяют объединять несколько разных устройств;
- контрольные суммы уровня файловой системы, при этом есть возможность выбирать алгоритм;
- основана на принципе COW — новые данные не перезаписывают старые, а размещаются в других блоках, что открывает такие возможности, как снапшоты и дедупликация данных;
- сжатие данных на лету — как и в случае с контрольными суммами, поддерживается несколько алгоритмов;
- возможность управлять файловой системой без перезагрузки.
Btrfs начала разрабатываться в пику ZFS компанией Oracle — еще до покупки Sun. Я не буду описывать ее особенности — они в ZFS и Btrfs, в общем-то, схожи. Отличия же от ZFS таковы:
- поддержка версий файлов (в терминологии Btrfs называемых поколениями) — есть возможность просмотреть список файлов, которые изменялись с момента создания снапшота;
- отсутствие поддержки zvol, виртуальных блочных устройств, на которых можно разместить, к примеру, раздел подкачки, — но данное отсутствие вполне компенсируется loopback-устройствами.
Далее будет описана как установка ZFSonLinux, так и некоторые интересные сценарии использования ZFS и Btrfs.
Для установки ZFSonLinux потребуется 64-разрядный процессор (можно и 32, но разработчики не обещают стабильности работы в таком случае) и, соответственно, 64-разрядный дистрибутив с ядром не ниже 2.6.26 — я использовал Ubuntu 13.10. Памяти тоже должно быть достаточно — не менее 2 Гб. Предполагается, что основные пакеты, необходимые для сборки и компиляции модулей и ядра, уже установлены. Накатываем дополнительные пакеты и качаем нужные тарболлы:
$ sudo apt-get install alien zlib1g-dev uuid-dev libblkid-dev libselinux-dev parted lsscsi wget
$ mkdir zfs && cd $_
$ wget http://bit.ly/18CpniI
$ wget http://bit.ly/1cEzO0V
Распаковываем оба архива, но сперва собираем SPL — слой совместимости с Solaris, а уж затем собственно ZFS. Отмечу, что, поскольку мы ставим свежайшую версию ZFSonLinux, DKMS (механизм, позволяющий автоматически перестраивать текущие модули ядра с драйверами устройств после обновления версии ядра) недоступен, и в случае обновления ядра придется собирать пакеты заново вручную.
$ tar -xzf spl-0.6.2.tar.gz
$ tar -xzf zfs-0.6.2.tar.gz
$ cd spl-0.6.2
$ ./configure
$ make deb-utils deb-kmod
Прежде чем компилировать ZFS, нужно поставить хидеры, заодно поставим и остальные свежесобранные пакеты:
$ sudo dpkg -i *.deb
Наконец, собираем и ставим ZFS:
$ cd ../zfs-0.6.2
$ ./configure
$ make deb-utils deb-kmod
$ sudo dpkg -i *.deb
Установку ZFS можно считать завершенной.
Установка нужных для компиляции ZFS пакетовСборка слоя совместимости с SolarisПредположим, ты хочешь получить безопасную, зашифрованную, но в то же время отказоустойчивую файловую систему. В случае с классическими ФС старого поколения тебе пришлось бы выбирать между шифрованием и отказоустойчивостью, поскольку эти вещи несколько несовместимы. В ZFS, однако, существует возможность «склеить» их между собой. Современная проприетарная реализация этой ФС поддерживает шифрование. Открытая реализация с версией пула 28 это не поддерживает — но ничто не мешает с помощью cryptsetup создать том (или несколько томов) LUKS и уже поверх них разворачивать пул. Что до отказоустойчивости ZFS, поддерживается создание мультидисковых массивов. Технология эта называется RAIDZ. Различные ее варианты позволяют пережить отказ от одного до трех дисков, и она, в силу некоторых особенностей ZFS, свободна от одного из фундаментальных недостатков традиционных stripe + parity RAID-массивов — write hole (ситуация с RAID 5 / RAID 6, когда при активных операциях записи и отключении питания данные на дисках в итоге отличаются).
INFO
Шифрование замедляет работу с данными. Не стоит его использовать на старых компьютерах.
Конечно, проще всего, если у тебя не стоит никакой системы — в этом случае заморачиваться придется меньше. Но живем мы не в идеальном мире, поэтому расскажу о том, как перенести уже установленную систему без раздела
Перво-наперво нужно создать сам этот раздел — без него перенос будет невозможен, поскольку система банально не загрузится. Предположим для простоты, что на диске имеется единственный раздел с Ubuntu, а хотим мы создать RAIDZ первого уровня (аналог RAID 5, для него требуется минимум три устройства, RAIDZ же больших уровней в домашних условиях смысла делать я не вижу). Создаем с помощью предпочитаемого редактора разделов два раздела — один размером 256–512 Мб, где и будет размещен /boot, и еще один, с размером не меньше текущего корневого, причем последнюю процедуру повторяем на всех трех жестких дисках. Перечитаем таблицу разделов командой
# partprobe /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309
# mke2fs -j /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part2 -L boot
Разумеется, в твоем случае идентификаторы жестких дисков будут другими. Вслед за этим нужно зашифровать раздел, на котором будет находиться том LUKS, и повторить эту процедуру для всех остальных разделов, на которых в конечном счете будет находиться массив RAIDZ:
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1
Чтобы не запутаться, рекомендую использовать один и тот же пароль. Но если твоя паранойя против — ничто не мешает использовать разные.
Подключаем зашифрованные тома:
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3 crypto0
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1 crypto1
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1 crypto2
И создаем пул ZFS:
# zpool create -o ashift=12 zroot raidz dm-name-crypto0 dm-name-crypto1 dm-name-crypto2
Следом создаем две вложенные друг в друга файловые системы:
# zfs create zroot/ROOT
# zfs create zroot/ROOT/ubuntu-1310-root
Отмонтируем все файловые системы ZFS и устанавливаем некоторые свойства ФС и пула:
# zfs umount -a
# zfs set mountpoint=/ zroot/ROOT/ubuntu-1310-root
# zpool set bootfs=zroot/ROOT/ubuntu-1310-root zroot
Наконец, экспортируем пул:
# zpool export zroot
/boot на нешифрованный раздел, чтобы следом установить туда загрузчик:# mkdir /mnt/boot
# mount /dev/disk/by-label/boot /mnt/boot
# cp -r /boot/* /mnt/boot/
# umount /mnt/boot
После этого перенесем grub на отдельный раздел /boot, для чего добавим в /etc/fstab cтрочку
# <...>
LABEL=boot /boot ext3 errors=remount-ro 0 0
Монтируем и перегенерируем конфиг grub:
# grub-mkconfig -o /boot/grub/grub.cfg
Для проверки перезагружаемся. Если все нормально, удаляем старое содержимое каталога /boot, не забыв предварительно отмонтировать раздел.
Пришло время клонировать Ubuntu. Весь процесс клонирования описан в полной версии статьи, которую можно найти на сайте ][, здесь же затрону некоторые тонкости, относящиеся к ZFS. Для нормальной загрузки с пула ZFS нужны некоторые скрипты initramfs. К счастью, изобретать их не нужно — они лежат на GitHub. Скачиваем репозиторий (все действия производим в chroot):
# git clone http://bit.ly/1esoc8i
И копируем файлы в необходимые места. Я внес единственную правку: вместо пула rpool поставил zroot. Теперь нужно записать hostid в файл /etc/hostid. Это нужно сделать из-за того, что ZFS портирована с Solaris, и слой совместимости требует его наличия:
# hostid >/etc/hostid
Наконец, нужно сгенерировать initramfs. Ни в коем случае не используй update-initramfs. Он перезаписывает существующий файл, и, если возникнут трудности, загрузиться с нормальной системы будет проблематично. Вместо него используй команду
# mkinitramfs -o /boot/initrd.img-$(uname -r)-crypto-zfs
Раздел /boot должен быть подмонтирован.
Затем нужно добавить пункт меню в grub. По причине достаточно хитрой конфигурации (еще бы: три криптотома, поверх которых расположена не совсем типичная для Linux файловая система) в chroot это сделать не получилось, поэтому выходим из него в основную (пока еще) систему и добавляем примерно такие строчки:
# vi /etc/grub.d/40_custom
menuentry "Ubuntu crypto ZFS" {
# <...>
linux /vmlinuz-3.11.0-14-generic boot=zfs rpool=zroot
initrd /initrd.img-3.11.0-14-generic-crypto-zfs
}
Запускаем update-grub, перезагружаемся, выбираем новый пункт меню и радуемся.
В большинстве случаев домашние пользователи не настраивают свои ФС. Однако параметры по умолчанию ZFS отнюдь не всегда подходят для применения в домашних условиях. Существуют также довольно интересные возможности, использование которых требует определенных навыков работы с данной файловой системой. Далее я опишу как тонкую подстройку ZFS под домашние нужды, так и эти возможности.
В случае же использования Btrfs никаких особых проблем не наблюдается. Тем не менее какие-то тонкости все же имеют место — в особенности если есть желание не просто «поставить и забыть», а задействовать новые возможности. О некоторых из них я и расскажу ниже.
Отключение изменения времени доступа к файлам и оптимизация для SSD-накопителей
Как известно, в *nix-системах каждый раз при обращении к файлам время доступа к ним меняется. Это всякий раз провоцирует запись на носитель. Если ты работаешь одновременно с множеством файлов или у тебя SSD-накопитель, это может оказаться неприемлемым. В классических файловых системах для отключения записи atime нужно было добавить параметр noatime в опции команды mount или в /etc/fstab. В ZFS же для отключения используется следующая команда (конечно, в твоем случае ФС может быть другой):
# zfs set atime=off zroot/ROOT/ubuntu-1310-root
В Btrfs, помимо вышеупомянутой опции noatime, имеется опция ssd и более оптимизирующая ssd_spread. Первая из них начиная с ядра 2.6.31, как правило, устанавливается автоматически, вторая предназначена для дешевых SSD-накопителей (ускоряет их работу).
ZFS — дублирование файлов
При работе с очень важными данными порой возникает пугающая мысль, что отключат электроэнергию или выйдет из строя один из жестких дисков. Первое в российских условиях очень даже возможно, а второе хоть и маловероятно, но тоже случается. К счастью, разработчики ZFS, по-видимому, сталкивались с подобным не раз и добавили опцию дублирования данных. Файлы при этом, если возможно, размещаются на независимых дисках. Предположим, у тебя есть ФС zroot/HOME/home-1310. Для установки флага дублирования набери следующую команду:
# zfs set copies=2 zroot/HOME/home-1310
Более того, если двух копий покажется недостаточно, можно указать цифру 3. В этом случае выполняется тройное резервирование и, если откажут два жестких диска из трех, на которых лежат эти копии, ZFS все равно восстановит их.
Отключение автомонтирования в ZFS
При подключении пула по умолчанию автоматом монтируются все вложенные файловые системы. Это может вызвать некоторый конфуз, поскольку, например, в случае с приведенной выше конфигурацией пользователю не нужен доступ ни к zroot, ни к zroot/ROOT. Существует возможность отключить автомонтирование с помощью двух следующих команд (для данного случая):
# zfs set canmount=noauto zroot/ROOT
# zfs set canmount=noauto zroot
Сжатие данных
ZFS поддерживает также и сжатие данных. На шифрованных томах это имеет смысл разве что для увеличения энтропии (и то не факт), но вообще для медленных носителей сжатие позволяет повысить производительность и может достаточно ощутимо сэкономить место на диске. В то же время сейчас, когда емкость винчестеров уже измеряется терабайтами, экономить место вряд ли кому-то особо нужно, а на производительности и расходе оперативной памяти это сказывается больше. Если же тебе это нужно, включить его можно следующим образом:
# zfs set compression=on zroot/ROOT/var-log
В Btrfs для включения сжатия нужно поставить опцию compress в /etc/fstab.
Автоматическое создание снапшотов в ZFS
Как известно, ZFS позволяет создавать снапшоты. Ручками, однако, их создавать лениво, да и есть вероятность попросту забыть об этом. В Solaris для автоматизации этой процедуры имеется служба Time Slider, но она — вот незадача! — хоть и использует функции ZFS, в ее состав не входит, поэтому в ZFSonLinux ее нет. Но огорчаться не стоит: имеется скрипт для автоматического их создания и для Linux. Скачаем его и установим нужные права:
# wget -O /usr/local/sbin/zfs-auto-snapshot.sh http://bit.ly/1hqcw3r
# chmod +x /usr/local/sbin/zfs-auto-snapshot.sh
Изменим сперва префикс для снапшотов, поскольку по умолчанию он не особо «говорящий». Для этого изменим в скрипте параметр opt_prefix с zfs-auto-snap на snapshot. Затем установим некоторые переменные файловой системы:
# zfs set com.sun:auto-snapshot=true zroot/ROOT/ubuntu-1310-root
# zfs set snapdir=visible zroot/ROOT/ubuntu-1310-root
Первый параметр нужен для скрипта, второй же открывает прямой доступ к снапшотам, что тоже нужно для скрипта.
Теперь можно уже создавать скрипт для cron (/etc/cron.daily/autosnap). Рассмотрим случай, когда нужно создавать снапшоты каждый день и хранить их в течение месяца:
#!/bin/bash
ZFS_FILESYS="zroot/ROOT/ubuntu-1310-root"
/usr/local/sbin/zfs-auto-snapshot.sh --quiet --syslog --label=daily --keep=31 "$ZFS_FILESYS"
Для просмотра созданных снапшотов используй команду zfs list -t snapshot, а для восстановления состояния — zfs rollback имя_снапшота.
ZFS — комплексный пример
Ниже будут приведены команды, создающие несколько ФС в пуле для разных целей и демонстрирующие гибкость ZFS.
# zfs create -o compression=on -o mountpoint=/usr zroot/ROOT/usr
# zfs create -o compression=on -o setuid=off -o mountpoint=/usr/local /zroot/ROOT/usr-local
# zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/crash zroot/ROOT/var-crash
# zfs create -o exec=off -o setuid=off -o mountpoint=/var/db zroot/ROOT/var-db
# zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/log zroot/ROOT/var-log
# zfs create -o compression=gzip -o exec=off -o setuid=off -o mountpoint=/var/mail zroot/ROOT/var-mail
# zfs create -o exec=off -o setuid=off -o mountpoint=/var/run zroot/ROOT/var-run
# zfs create -o exec=off -o setuid=off -o copies=2 -o mountpoint=/home zroot/HOME/home
# zfs create -o exec=off -o setuid=off -o copies=3 -o mountpoint=/home/rom zroot/HOME/home-rom
Дефрагментация Btrfs
Дефрагментация в Btrfs не столь уж необходима, но в отдельных случаях позволяет освободить занятое пространство. Она может быть проведена только на смонтированной системе. Замечу, что доступ к данным во время дефрагментации сохраняется — как на чтение, так и на запись. Для запуска процедуры дефрагментации используй следующую команду:
# btrfs filesystem defrag /
На старых ядрах эта процедура удаляла все COW-копии, такие как снапшоты и дедуплицированные данные, так что, если ты их используешь на ядрах старше 2.6.37, дефрагментация тебе только навредит.
RAID на Btrfs
Как и в случае с ZFS, Btrfs поддерживает многотомные массивы, но в отличие от ZFS называются они классически. На данный момент, однако, поддерживаются только RAID 0, RAID 1 и их комбинация, RAID 5 по-прежнему на этапе альфа-тестирования. Для создания нового массива RAID 10 попросту используй такую команду (с твоими устройствами):
# mkfs.btrfs /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
Ну а если нужно сконвертировать существующую ФС в RAID, то и для этого есть команды:
# btrfs device add /dev/sdb1 /dev/sdc1 /dev/sdd1 /
# btrfs balance start -dconvert=raid10 -mconvert=raid10 /
Первая команда добавляет устройства к файловой системе, вторая же как раз и перебалансирует все данные и метаданные для преобразования этого набора томов в массив RAID 10.
Снапшоты Btrfs
Естественно, Btrfs поддерживает снапшоты — причем помимо обычных снапшотов доступны снапшоты с возможностью записи (более того, они и создаются по умолчанию). Для создания снапшотов используется следующая команда:
# btrfs subvol snap -r / /.snapshots/2013-12-16-17-41
Подробнее о создании снапшотов, как ручном, так и автоматическом, можно прочитать в статье «Подушка безопасности», опубликованной в апрельском номере ][ за 2013 год. Здесь же я расскажу, как при наличии снапшота отследить, какие файлы изменились с момента его создания. Для этого в Btrfs есть так называемое поколение файлов. Возможность эта используется для внутренних целей, но есть команда, позволяющая смотреть список последних изменений — ею и воспользуемся. Сначала узнаем текущее поколение файлов:
# btrfs subvol find-new / 99999999
Если такого поколения нет (в чем можно практически не сомневаться), выведется последнее. Теперь эту же самую команду выполним над снапшотом:
# btrfs subvol find-new /.snapshots/2013-12-17-14-28 99999999
Если поколения будут отличаться, а они будут, то смотрим, какие же файлы изменялись со времени создания снапшота. В моем случае команда была следующей:
# btrfs subvol find-new / 96 | awk '{ print $17 }' | sort | uniq
NILFS2 — еще одна файловая система с поддержкой COW
Начиная с ядра 2.6.30 в Linux появилась поддержка еще одной ФС — NILFS2. Аббревиатура эта расшифровывается как new implementation of a log-structured file system. Основная особенность данной ФС заключается в том, что раз в несколько секунд в ней автоматически создаются чек-пойнты — примерный аналог снапшотов с одним отличием: спустя какое-то время они удаляются сборщиком мусора. Пользователь, тем не менее, может преобразовать как чек-пойнт в снапшот, в результате чего для сборщика мусора он становится невидимым, так и наоборот. Таким образом, NILFS2 можно рассматривать как своеобразную «Википедию», где фиксируются любые изменения. Из-за этой особенности — писать любые новые данные не поверх существующих, а в новые блоки — она прекрасно подходит для SSD-накопителей, где, как известно, перезапись данных не приветствуется.
Да, NILFS2 не настолько известна, как ZFS или Btrfs. Но в некоторых случаях ее применение будет более оправданным.
Может быть, я покажусь субъективным, но ZFS, если ее сравнивать с Btrfs, выигрывает. Во-первых, некоторые возможности Btrfs до сих пор находятся в зачаточном состоянии, несмотря на то, что ей уже более пяти лет. Во-вторых, ZFS, при прочих равных условиях, более обкатана. И в-третьих, как просто инструментов для работы с ZFS, так и ее возможностей больше.
С другой стороны, как бы ни была хороша ZFS, по лицензионным соображениям она вряд ли когда-нибудь будет включена в mainline kernel. Так что, если не появится какой-нибудь еще конкурент, придется пользоваться Btrfs.
Facebook и Btrfs
В ноябре 2013 года лидер команды разработчиков Btrfs Крис Мейсон перешел на работу в Facebook. Это же сделал и Джозеф Бацик, мейнтейнер ветки btrfs-next. Они вошли в состав отдела компании, специализирующегося на низкоуровневых разработках, где и занимаются ныне ядром Linux — в частности, работают над Btrfs. Разработчики заявили также, что Facebook заинтересована в развитии Btrfs, так что причин волноваться у сообщества нет решительно никаких.
Опубликовано в Хакере #181 (02.2014)
Файловая система ZFS | Losst
В наши дни все большей и большей популярности набирают файловые системы следующего поколения, которые имеют более широкую функциональность, чем в обычных файловых системах. Одни из таких файловых систем — это Btrfs и ZFS, Обе они уже стали достаточно стабильными и активно применяются пользователями. Для многих пользователей очень важна сохранность данных, и такие файловые системы могут обеспечить ее наилучшим образом.
В одной из предыдущих статей мы рассматривали файловую систему Btrfs. В нашей сегодняшней статье мы остановимся на ZFS, эти файловые системы похожи по своему применению и назначению, но имеют некоторые отличия. Мы рассмотрим как установить эту файловую систему в вашем дистрибутиве, настроить ее и использовать для решения повседневных задач.
Содержание статьи:
Что такое ZFS?
ZFS — это файловая система, объединенная с менеджером логических томов. Ее разработка началась в компании Sun Microsystems для ОСhttps://losst.ru/fajlovaya-sistema-btrfs Solaris. Файловая система выпускалась под открытой лицензией Common Development and Distribution License (CDDL). Она была предназначена для высокопроизводительных серверов, поэтому уже тогда поддерживала мгновенные снимки и клонирование данных. Но после покупки ее компанией Oracle, исходный код был закрыт, а сообщество создало форк последней доступной версии под именем OpenZFS. Именно эту файловую систему сейчас и можно установить и использовать.
Файловая система ZFS имеет обычные для таких файловых систем возможности. Это просто огромный размер одного раздела, и размер файла, поддерживается возможность хранения файлов на нескольких устройствах, проверка контрольных сумм для данных и шифрование на лету, а также запись новых данных в режиме COW, когда данные не переписываются, а пишутся в новое место, что позволяет делать мгновенные снапшоты.
Возможности очень похожи на Btrfs, но есть кое-какие отличия. В Btrfs можно посмотреть все файлы, измененные с момента последнего снапшота. Второе отличие, это отсутствие в Btrfs логических блоков zvol.
Установка ZFS
В последних версиях Ubuntu файловая система ZFS была добавлена в официальный репозиторий и в установочный диск. Поэтому для того, чтобы ее установить будет достаточно выполнить несколько команд:
sudo apt install -y zfs
В других дистрибутивах. например, CentOS или Fedora ситуация немного сложнее, сначала вам придется добавить официальный репозиторий, а затем установка zfs и самого набора утилит и модулей ядра:
sudo yum install http://download.zfsonlinux.org/epel/zfs-release.el7_3.noarch.rpm
$ sudo yum install zfs
Затем осталось включить загрузить модуль ядра с поддержкой этой файловой системы:
sudo modprobe zfs
Теперь файловая система установлена и готова к использованию. Дальше нам нужно выбрать разделы и создать на них файловые системы. Для настройки zfs используется утилита zpool, но для начала давайте рассмотрим ее синтаксис и возможности. Файловая система может быть расположена на нескольких разделах или жестких дисках, поэтому на уровне ядра формируется общий пул (куча), а к нему уже подключаются разделы. Тут можно провести аналогию с группой томов LVM.
Команда zpool
Это основной инструмент управления разделами и функциональными возможностями ZFS, поэтому вам важно его освоить. Общий синтаксис команды достаточно прост, но у нее есть множество подкоманд, которые имеют свой синтаксис и параметры:
$ zpool команда параметры опции устройства
Как я уже сказал, параметры и опции для каждой команды свои, а в качестве устройства может указываться пул или физический раздел на жестком диске. Теперь рассмотрим основные команды и их предназначение, чтобы вы могли немного ориентироваться, а более детальные параметры разберем уже на примерах:
- add — добавить раздел к существующему пулу;
- attach — добавить раздел или жесткий диск к пулу файловой системы;
- clean — очистить все ошибки дисков;
- create — создать новый пул из физического раздела, на котором будут размещены виртуальные диски;
- destroy — удалить пул разделов zfs;
- detach — отключить физический раздел от пула;
- events — посмотреть сообщения ядра, отправленные модулем zfs;
- export — экспортировать пул для переноса в другую систему;
- get — посмотреть параметры пула;
- set — установить значение переменной;
- history — отобразить историю команд zfs;
- import — импортировать пул;
- iostat — отобразить статистику ввода/вывода для выбранного пула zfs;
- list — вывести список всех пулов;
- offline/online — выключить/включить физическое устройство, данные на нем сохраняются, но их нельзя прочитать или изменить;
- remove — удалить устройство из пула;
- replace — перенести все данные со старого устройства не новое;
- scrub — проверка контрольных сумм для всех данных;
- status — вывести статус пула.
Это были все основные опции команды, которые мы будем использовать. Теперь рассмотрим примеры настройки zfs и управления разделами.
Как пользоваться ZFS
Настройка ZFS не очень сильно отличается от Btrfs, все базовые действия выполняются очень просто, вы сами в этом убедитесь.
Создание файловой системы
Сначала посмотрим есть ли уже созданные пулы ZFS. Для этого выполните такую команду:
sudo zpool list

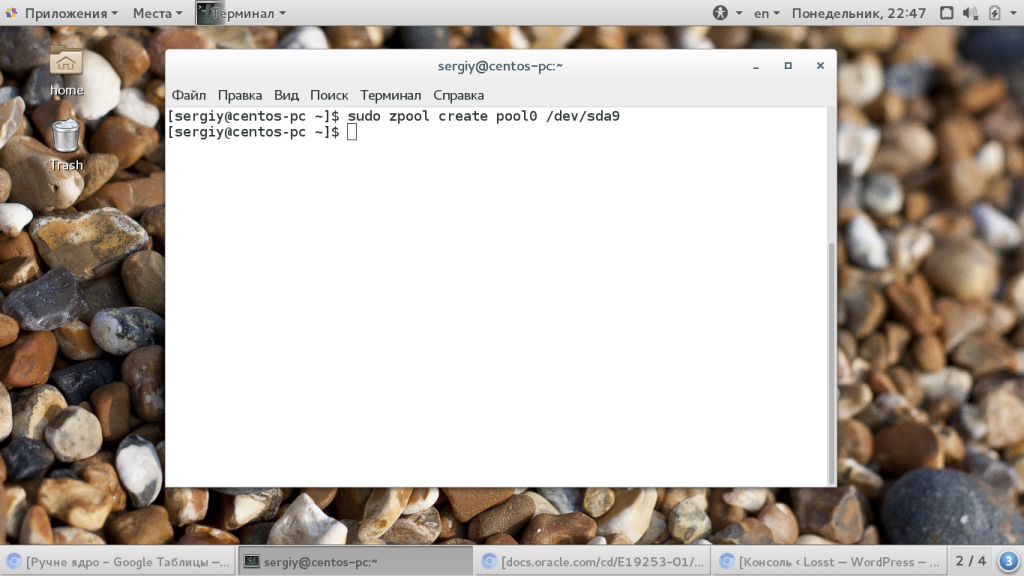
Если вы устанавливаете эту файловую систему в первый раз, то здесь будет пустой список. Теперь создадим пул на основе существующего раздела, мы будем использовать раздел /dev/sda6
sudo zpool create -f pool0 /dev/sda6
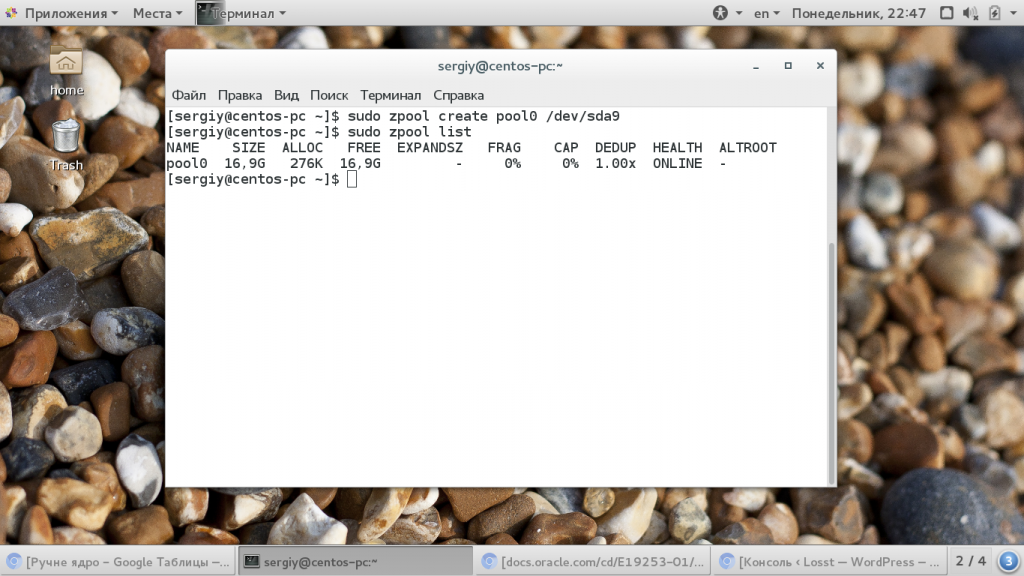
Хотя вы можете использовать не только раздел, а целый диск. Теперь смотрим еще раз список пулов:
sudo zpool list
Затем смотрим состояние нашего пула с помощью команды status, здесь выводится больше подробной информации. Если у вас есть несколько дисков, вы можете настроить RAID массив, чтобы данные хранились не на одном разделе, а синхронно копировались на несколько, это может в несколько раз увеличить производительность.
sudo zpool create pool0 zraid /dev/sda /dev/sdb /dev/sdc
Обратите внимание, что диски должны иметь одинаковый раздел. Если вам не нужен RAID, вы можете настроить обычное зеркалирование на второй диск. Это увеличивает надежность хранения данных:
sudo zpool create pool0 mirror sda sdb
Теперь данные будут писаться на оба диска. Такую же вещь можно проделать с разделами, но здесь нет смысла, поскольку если жесткий диск накроется, то данные вы потеряете, а прироста производительности не увидите. Вы можете использовать даже файлы, для создания файловых систем.
Вы можете добавить новый жесткий диск или раздел к пулу:
sudo zpool attach pool0 /dev/sdd
Или удалить устройство из пула:
sudo zpool detach pool0 /dev/sdd
Чтобы удалить пул используйте команду destroy:
sudo zpool destroy pool0
Для проверки раздела на ошибки используйте команду scrub:
sudo zpool scrub pool0

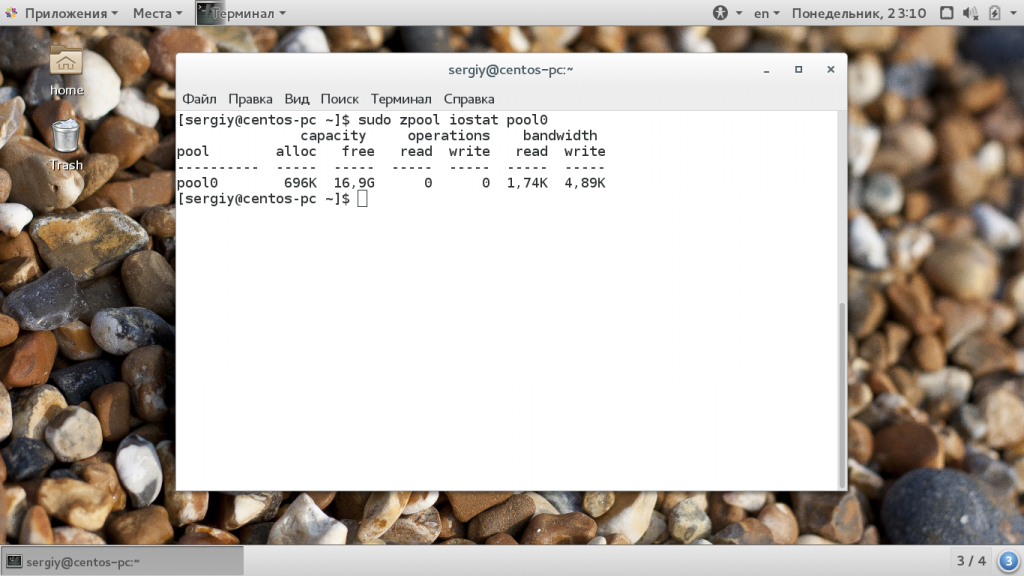
Статистику использования пула можно посмотреть с помощью команды iostat:
sudo zpool iostat pool0
Файловые системы ZFS
Теперь нужно создать файловые системы на только что созданном пуле. Создадим три файловые системы, data, files и media. Для этого используется команда zfs:
sudo zfs create pool0/data
$ sudo zfs create pool0/files
$ sudo zfs create pool0/media
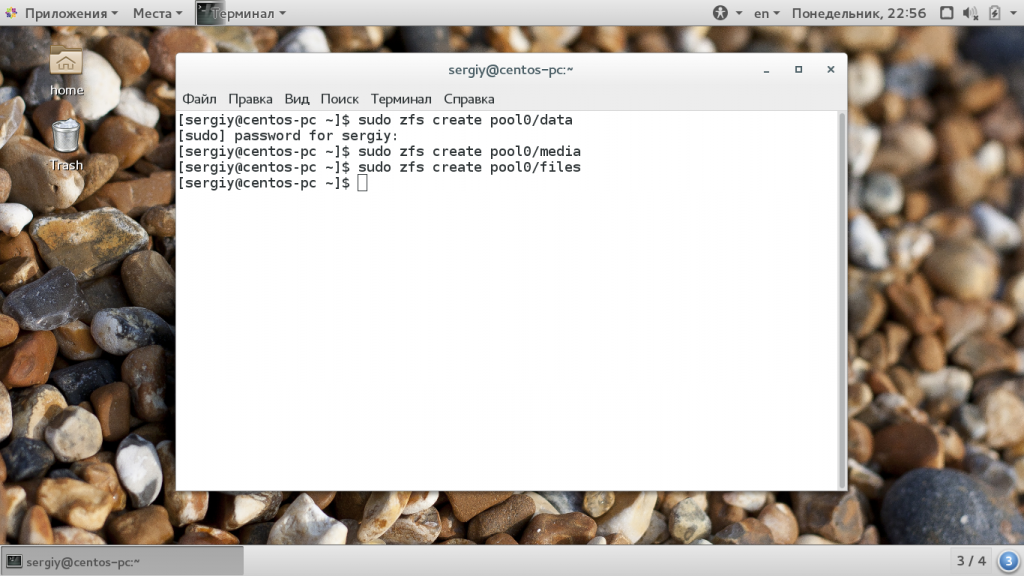
Файловые системы готовы, дальше рассмотрим монтирование zfs.

Монтирование ZFS
Точка монтирования для пула и для каждой созданной в нем файловой системы создается в корневом каталоге. Например, в нашем случае точки монтирования выглядят так:
ls -l /pool0
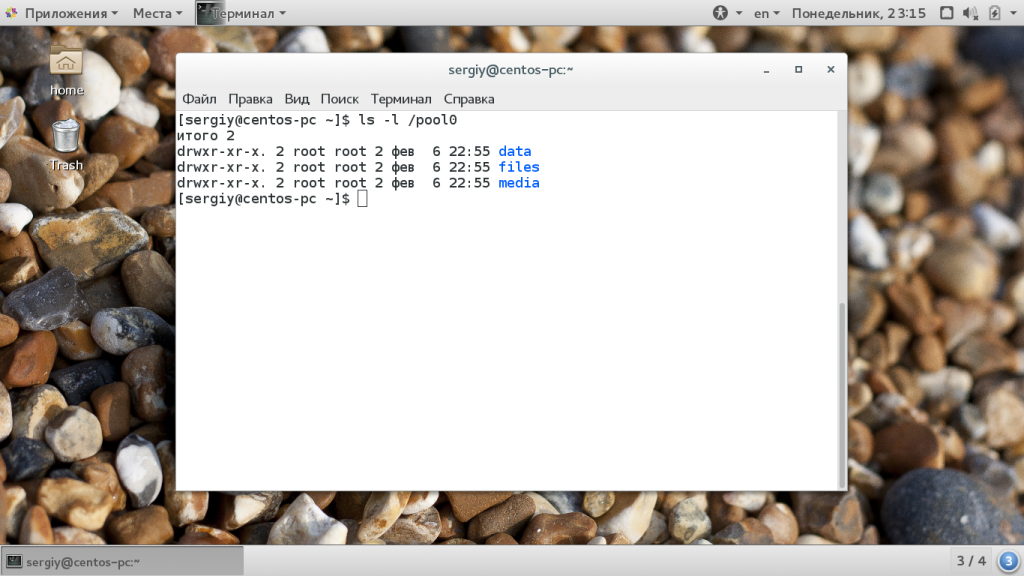
Или можно использовать такую команду:
sudo zfs mount

Чтобы размонтировать файловую систему для одного из созданных разделов используйте команду zfs umount:
sudo zfs umount /pool0/data
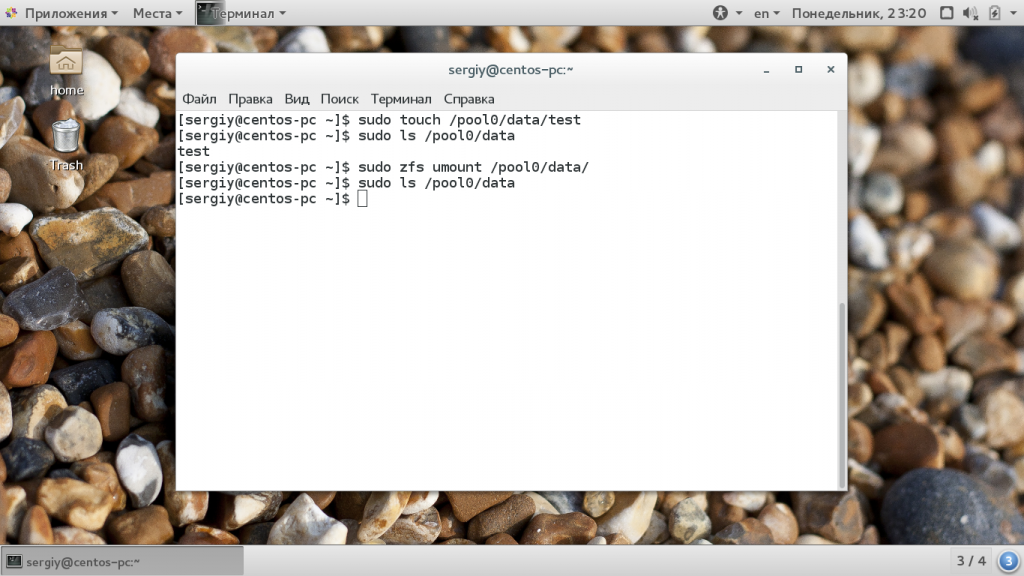
Затем можно ее обратно примонтировать:
sudo zfs mount pool0/data

Параметры файловой системы
Кроме всего прочего, вы можете настроить различные параметры файловой системы ZFS, например, можно изменить точку монтирования или способ сжатия. Вы можете посмотреть все текущие параметры для файловой системы или пула с помощью команды:
sudo zfs get all pool0/files

Сначала включим сжатие:
sudo zfs set compression=gzip pool0/files
Затем отключим проверку контрольных сумм:
sudo zfs set checksum=off pool0/files
Смотрим точку монтирования:
sudo zfs get mountpoint pool0/files
Затем установим свою:
sudo zfs set mountpoint=/mnt pool0/files

Теперь раздел будет монтироваться в /mnt, настройки можно изменить для каждого из разделов.
Снимки состояния ZFS
Снапшоты zfs или снимки состояния могут использоваться восстановления данных. Благодаря особенностям файловой системы снимки можно создавать мгновенно. Для создания снимка просто наберите:
sudo zfs snapshot pool0/files pool0/files@shot1
Для восстановления используйте:
sudo zfs rollback pool0/files@shot1
Посмотреть список снимков вы можете командой:
sudo zfs list -t snapshot
А удалить ненужный снимок:
sudo zfs destory pool0/files@shot1
Выводы
В этой статье мы рассмотрели как работает файловая система zfs, как выполняется настройка zfs и как ее использовать. Это очень перспективная файловая система, с огромным набором функций, которая способна сравняться, а в некоторых областях и обойти Btrfs. Надеюсь, эта информация была полезной для вас, если у вас остались вопросы, спрашивайте в комментариях!
ZFS — лучшая файловая система (пока) / Habr
ZFS должна быть классной, но меня немного бесит, что она словно застряла в прошлом — даже до того, как её признали крутой и лучшей файловой системой. Она негибкая, ей не хватает современной интеграции с флеш-памятью и она не поддерживается напрямую большинством операционных систем. Но я храню все свои ценные данные на ZFS, поскольку именно она обеспечивает наилучший уровень защиты для условий SOHO (малый офис/домашний офис). И вот почему.Первая директива систем хранения: не возвращать неправильные данные!Революция ZFS. Около 2006 года
В своих статьях о FreeNAS я настойчиво повторял, что «ZFS — самая лучшая файловая система», но если вы посмотрите мои сообщения в социальных медиа, то станет ясно, что мне она на самом деле не совсем нравится. Я пришёл к выводу, что такое противоречие требует объяснения и контекста, так что рискнём потревожить фанатов ZFS и сделаем это.
Когда ZFS впервые появилась в 2005 году, она была абсолютно своевременной, но она застряла там до сих пор. Разработчики ZFS сделали много правильных вещей, объединив лучшие функции диспетчера томов с файловой системой «зеттабайтного масштаба» в Solaris 10:
- ZFS достигла такого уровня масштабируемости, который должна иметь каждая современная файловая система, практически без ограничений на количество данных и метаданных и размер файлов.
- ZFS проверяет контрольные суммы всех данных и метаданных для обнаружения повреждений, это совершенно необходимая функция для долговременного крупномасштабного хранения данных.
- Когда ZFS выявляет ошибку, то может автоматически восстановить данные с зеркал, блоков чётности или альтернативных мест хранения.
- В систему встроены зеркалирование и RAID-Z, за счёт чего многочисленные накопители органично объединяются в один логический том.
- ZFS имеет надёжные функции для подготовки снапшотов и зеркал, в том числе возможность пошагово обновлять данные на других томах.
- Данные можно сжимать на лету, также поддерживается дедупликация.
Когда появилась ZFS, это была революционная система, по сравнению со старыми диспетчерами томов и файловыми системами. И Sun открыла бóльшую часть исходного кода ZFS, позволив портировать её на другие операционные системы. Как любимая игрушка всей индустрии, ZFS быстро появилась на Linux и FreeBSD, и даже Apple начала внедрять её как часть файловой системы следующего поколения в Mac OS X! Будущее казалось таким светлым!
Контрольные суммы для пользовательских данных необходимы, иначе вы неизбежно потеряете данные: «Почему в больших дисках требуется проверка целостности данных» и «Первая директива систем хранения: не терять данные»
С 2007 по 2010-й: ZFS пошла под откос
Но что-то ужасное случилось с ZFS на пути к её триумфу: судебные иски, проблемы с лицензиями и FUD — тактика психологической манипуляции от недоброжелателей.
Первые тучи появились в 2007 году, когда NetApp подала иск к Sun на основании того, что ZFS нарушает их патенты на WAFL. Sun ответила встречным иском в том же году — и юридические тяжбы затянулись. Хотя в ZFS определённо не было кода NetApp, но механизм копирования при записи в снапшоты был похож на WAFL, и некоторые из нас в индустрии обеспокоились, что иск NetApp повлияет на доступность открытых исходников ZFS. Этих рисков оказалось достаточно для Apple, чтобы отказаться от поддержки ZFS в Mac OS X 10.6 “Snow Leopard” прямо перед выпуском этой ОС.
Вот отличный блог о ZFS и Apple от Адама Левенталя, который работал над этим проектом в компании: ZFS: Apple’s New Filesystem That Wasn’t
Тогда Sun переживала трудные времена, и Oracle воспользовалась моментом для покупки компании. Это посеяло новые сомнения о будущем ZFS, поскольку Oracle известна как не большой любитель широкой общественной поддержки свободных проектов. А лицензия CDDL, которую Oracle применила к коду ZFS, признана несовместимой с GPLv2, которая используется в Linux, что делает невозможным использование ZFS в самой популярной в мире ОС для серверов.
Хотя проект OpenSolaris продолжился и после приобретения Oracle, а ZFS включили во FreeBSD, но это было в значительной степени за пределами корпоративного сектора. Конечно, NexentaStor и GreenBytes помогли продвинуть ZFS в корпоративном секторе, но недостаток поддержки серверов Sun со стороны Oracle тоже начал влиять на ситуацию.
Какие проблемы у ZFS сейчас?
OpenZFS практически не отличается от той файловой системы, что была десять лет назад.
Многие продолжают скептически относиться к дедупликации, которая требует много дорогой памяти. И я действительно имею в виду дорогой: практически каждый ZFS FAQ однозначно требует наличия памяти только ECC и минимум 8 ГБ. По моему собственному опыту с FreeNAS, для активного маленького сервера с ZFS подойдёт 32 ГБ, а это стоит $200-300 даже по сегодняшним ценам.
И ZFS так и по-настоящему не приспособился к флеш-памяти, которая сейчас используется повсеместно. Хотя флеш можно использовать для кэшей ZIL и L2ARC, это сомнительное преимущество для систем с достаточным количеством RAM, и у ZFS нет настоящей функции гибридного хранилища данных. Смехотворно, что в документации ZFS повсеместно упоминаются несколько гигабайт флеш-памяти SLC, когда на рынке уже есть многотерабайтные диски 3D NAND. И никто не говорит о NVMe, хотя это стандарт для высокопроизводительых ПК.
И есть ещё вопрос гибкости, точнее, её отсутствия. Если вы создали том ZFS, то он практически зафиксирован на всю жизнь. Есть только три способа расширить пул хранения:
- Заменить абсолютно все диски в пуле на диски большей ёмкости (что классно, но дорого).
- Создать дисковую последовательность с другим набором дисков (что может привести к несбалансированной производительности, избыточности и куче других потенциально глупых ошибок).
- Построить новый пул и перенести туда наборы данных командой
zfs send(так поступаю я, хотя тут свои хитрости).
Кроме третьего способа, у вас нет возможности уменьшить пул ZFS. Хуже того, вы не можете изменить тип защиты данных без пересборки всего пула, в том числе добавить второй и третий диски чётности. FreeNAS добросовестно тратит огромное количество времени, пытаясь отговорить новичков от использования RAID-Z1[1], и жалуется, если они всё равно выбирают такую схему.
Всё это может показаться мелкими, незначительными придирками, но в совокупности они субъективно отправляют ZFS в средние века, после использования Drobo, Synology или современных облачных систем хранения. С ZFS вам нужно «купить диски, много памяти, создать RAID-массив и никогда его больше трогать», что не совсем соответствует современному использованию систем хранения[2].
Какие варианты?
Наверное, я представил ZFS не совсем в выгодном свете. Когда-то она была революционной, но сейчас начинает проявлять ограничения и выпадать из контекста современного мира с флеш-хранением данных. Так есть ли альтернативы?
В Linux несколько приличных диспетчеров томов и файловых систем, а большинство используют LVM или MD и ext4. Спецов по файловым системам очень порадовала Btrfs, которая сочетает в себе функции диспетчера томов и файловой системы в стиле ZFS, но с дополнительной гибкостью за пределами того, на чём шлёпнулась ReiserFS. И Btrfs действительно могла бы стать «ZFS для Linux», но не так давно разработка споткнулась, после ужасного прошлогоднего бага с потерей данных с рейдах RAID 5 и 6, и больше о них почти ничего не слышно. Но я по-прежнему думаю, что через пять лет буду рекомендовать пользователям Linux использовать Btrfs, особенно с её мощным потенциалом для применения в контейнерах[3].
Для Windows компания Microsoft тоже выкатывает собственную файловую систему нового поколения ReFS с использованием деревьев B+ (похоже на Btrfs), с сумасшедшим масштабированием и функциями стойкости и защиты данных[4]. В сочетании со Storage Spaces, у Microsoft будет жизнеспособная система хранения следующего поколения для Windows Server, которая может даже использовать SSD и 3D-XPoint как уровень или кэш.
И есть ещё Apple, которая по слухам несколько раз меняла систему хранения, до того как остановиться на APFS, которая вышла в этом году в macOS High Sierra. APFS во многом похожа на Btrfs и ReFS, хотя реализована совершенно иначе, с большей ориентацией на пользователя. Уступая в некоторых сферах (пользовательские данные не проверяются контрольной суммой и не поддерживается сжатие), APFS — именно та система, которая нужна для iOS и macOS. И APFS — это последний гвоздь в гроб идеи «ZFS на Mac OS X».
В каждой из трёх основных ОС теперь есть файловая система нового поколения (и диспетчер томов). В Linux есть Btrfs, в Windows — ReFS и Storage Spaces, а в macOS есть APFS. FreeBSD вроде бы сохранила приверженность ZFS, но это незначительная часть рынка. И каждая система корпоративного уровня уже продвинулась намного дальше того, что может делать ZFS и системы корпоративного уровня на базе ZFS от Sun, Nexenta и iXsystems.
Но ZFS по-прежнему намного превосходит старые файловые системы для домашнего пользователя. Из-за отсутствия проверки целостности, избыточности и восстановления после ошибок NTFS (Windows), HFS+ (macOS) и ext3/4 (Linux) абсолютно не подходят для долговременного хранения данных. И даже ReFS и APFS из-за отсутствия проверки целостности не подходят там, где потеря данных неприемлема.
Позиция автора: используйте ZFS (пока)
Грустно это признавать, но на 2017 год ZFS — лучшая файловая система для долговременного широкомасштабного хранения данных. Хотя иногда и сложно с ней работать (кроме FreeBSD, Solaris и специализированных устройств), но надёжность и проверенность делают ZFS единственным заслуживающим доверия инструментом для хранения данных за пределами корпоративных систем хранения. В конце концов, надёжное хранение данных — это единственное, что действительно должна делать файловая система. Все мои важные данные сразу идут в ZFS, от фотографий до музыки, от фильмов до офисных файлов. Ещё нескоро я доверюсь чему-нибудь кроме ZFS!
Сноски
1. Для современных больших дисков предпочтительнее RAID-Z2 и RAID-Z3 с большей избыточностью.↑
2. Странно, хотя множественные пулы и съёмные диски отлично работают на ZFS, почти никто не говорит о таком варианте использования. Всегда речь идёт об одном пуле под названием “tank”, который включает в себя все диски в системе.↑
3. Одна вещь, которой по-настоящему не хватает в Btrfs — это поддержки флеш, и особенно гибридных систем хранения. Но лично я бы предпочёл, чтобы они сначала реализовали поддержку RAID-6.↑
4. Хотя контрольные суммы для данных в ReFS по-прежнему отключены по умолчанию.↑
Что такое ZFS? И почему люди от неё без ума? / Habr
Сейчас мы обсудим ZFS, продвинутую файловою систему. Мы обсудим как она появилась, что из себя представляет, и почему так популярна в технических кругах и предприятиях.Хотя я из США, я предпочитаю произносить ZedFS вместо ZeeFS, потому что это звучит круче. Вы же можете выбрать вариант произношения для себя.
Заметка: В этой статье вы увидите, что ZFS повторяется очень много раз. Когда я буду говорить об особенностях и установке, я имею в виду OpenZFS. Пути ZFS (разработанная Oracle) и OpenZFS разошлись, с того момента как Oracle закрыла проект OpenSolaris. (Подробнее дальше в статье.)
История ZFS
Файловая система Z (ZFS) была создана Меттью Ареном и Джефом Бонвиком в 2001. ZFS была разработана, для того чтобы стать следующим поколением файловых систем OpenSolaris от Sun Microsystems. В 2008 ZFS была портирована на FreeBSD. В этом же году началось портирование ZFS на Linux. Однако, с того момента как ZFS начала выпускаться под лицензией CDDL, которая несовместима с GNU GPL, она не может быть добавлена к ядру Linux. Что бы обойти это ограничение, большинство дистрибутивов предлагают методы установки ZFS.
В скоре после того, как Oracle купила Sun Microsystems, код OpenSolaris стал закрыт. Вся последующая разработка ZFS стала закрытой тоже. Большое количество разработчиков ZFS разочаровалось из-за таких изменений. Две трети важных разработчиков ZFS, включая Аренса и Бонвика, покинули Oracle вследствие этого решения. Они присоединились к другим компаниям и создали проект OpenZFS в сентябре 2013. Проект возглавил открытую разработку ZFS.
Вернемся же к проблеме с лицензиями упомянутой выше. С того момента как OpenZFS отделился от Oracle, кому-то может быть интересно, почему они не изменили лицензию совместимую с GPL, так, чтобы включить файловую систему в ядро Linux. Согласно сайту OpenZFS, изменение лицензии влечёт за собой контакт разработчиков которые вносили изменения в релиз OpenZFS (включая тех, кто начал этот проект и код ZFS до OpenSolaris) и получить их разрешение. Это уже почти невозможно (возможно кто-то из них уже умер или их не так легко найти), они решили оставить все как есть.
Что такое ZFS? Чем она особенна?
Как я сказал ранее, ZFS это продвинутая файловая система. Как таковая, она имеет некоторые интересные особенности. Такие, как:
- Объединённое хранилище (Pooled storage)
- Copy-on-write
- Снапшоты
- Проверка цельности информации и автоматическая починка
- RAID-Z
- Максимальный размер файла в 16 Эксабайт (Прим. переводчика: 10^18 байт)
- Максимальный размер хранилища в 256 квадрильонов Зеттабайт (Прим. переводчика: Квадрильон — миллион^4; Зеттабайт — 10^21 байт)
Разберемся же в некоторых из них.
Объединённое хранилище
В отличие от других файловых систем, ZFS совмещает возможности файловой системы и менеджера дисков. Это означает что ZFS может создать файловую систему охватив все диски. Но не только это, можно также добавить хранилище в систему дисков. ZFS займется разделением и форматированием дисков.
Copy-on-write
Copy-on-write это другая интересная особенность. Но большинстве файловых систем, если информация перезаписана, она утрачена навсегда. В ZFS новая информация записывается в отдельный блок. Как только запись завершена, метаданные файловой системы обновляются к точке новой информации. Это гарантирует что если файловая система сломается (или случится что-либо подобное) во время записи, старая информация будет фиксирована. Это означает что системе не нужно запускать fsck после сбоя.
Снапшоты
Copy-on-write приводит к другой интересной вещи в ZFS: снапшоты. ZFS использует снимки, для того чтобы следить за изменениями в файловой системе. Снимок хранит оригинальную версию файловой системы и текущую, в которой все изменения с момента создания снимка. Никакого дополнительного места не используется. Как только новая информация записывается в текущую файловую систему, новые блоки распределяются для её хранения. Если же файл был удален, упоминание о нём из снимка исчезает. Снимки разработаны для слежки за изменениями, но не являются дополнением и не создают файлов.
Снимки могут быть смонтированы в формате read-only для восстановления старой версии файла. Также можно откатить систему к предыдущему снимку. Все изменения сделанные после снимка будут утрачены.
Проверка цельности информации и автоматическая починка
Всякий раз когда новая информация записывается в ZFS, создается чек-сумма (контрольная сумма) для этой информации. Когда информация прочитана, чек-сумма подтверждается. Если чек-суммы не совпадают, ZFS замечает ошибку и попытается её исправить.
RAID-Z
ZFS может поднять RAID без вспомогательного софта. Не удивительно, что ZFS предоставляет свою реализацию RAID: RAID-Z. RAID-Z это по сути вариация RAID-5. Тем не менее RAID-Z разработан так, что бы превзойти RAID-5 в плане ошибки, «все данные и информация о контроле по чётности становится несовместимой после непредвиденной перезагрузки.» Чтобы использовать базовый уровень (RAID-Z1) вам необходимо минимум два диска для хранения и один для контроля по чётности. RAID-Z2 нужно как минимум два диска для хранения и два для контроля по чётности. RAID-Z3 требует два диска для хранения и три для контроля по чётности. Как только диски добавлены к группам RAID-Z они должны быть кратны двум.
Огромные возможности хранилища
Когда ZFS была создана, она была спроектирована, чтобы стать лучшей в своем роде. Во время когда большинство файловых систем были 64-битными, создатели ZFS решили сделать её 128-битной, для будущего подтверждения этого. Это означает, что ZFS предоставляет емкость 16 миллионов миллионов 32 или 64-битных систем. К тому же, Джеф Бонвик (один из создателей) сказал что энергоснабжение полностью заполненного 128-битного пула памяти будет буквально требовать больше энергии чем для вскипания океанов.
Как установить ZFS
Если вы хотите использовать ZFS из коробки, то необходимо установить либо FreeBSD, либо ОС, которая использует illumos-ядро. Illumos это форк ядра OpenSolaris.
На самом деле, поддержка ZFS и для ZFS это главный аспект, почему некоторые опытные пользователи Linux останавливают свой выбор на BSD.
Если вы хотите использовать ZFS на Linux, вы сможете её использовать как файловую систему только для хранения. Насколько мне известно, никакой из дистрибутивов не даёт возможности установить ZFS, так, чтобы она работала сразу. Если вы заинтересованы и хотите попробовать, есть проект ZFS on Linux, который предоставляет несколько туториалов.
Напоследок
В этой статье я рассказал о плюсах ZFS. И сейчас о маленькой проблеме. Использование RAID-Z может дорого обойтись из-за количества дисков нужных для него.
А вы когда-то использовали ZFS? И как она вам? Расскажите об этом в комментариях.
Послесловие переводчика
Спасибо за то, что прочитали. Удачи вам.
disk-encryption — Насколько надежно шифрование ZFS?
Я бы сказал «очень», так как файлы зашифрованы с помощью AES в режиме CCM (по умолчанию). Однако AES как таковая не является гарантией, многое зависит от того, как она реализована.
И в документации есть это предложение, которое заставляет меня задуматься:
При использовании свойств сжатия, дедупликации и шифрования ZFS выполните следующие действия:
When a file is written, the data is compressed, encrypted, and the checksum is verified. Then, the data is deduplicated, if possible. When a file is read, the checksum is verified and the data is decrypted. Then, the data is decompressed, if required.
Насколько я понимаю, для дедупликации данных после шифрования должно быть так, что два файла (или два блока данных) идентичны. Но с блоками, зашифрованными с помощью AES, это имеет либо крайне малую вероятность быть истинным (2 -128 для значения по умолчанию aes-128-ccm), и, следовательно, время, затрачиваемое на проверки дедупликации, может быть также полностью сэкономлено, или же означает, что два идентичных файла будут зашифрованы в идентичные зашифрованные файлы, что возможно только при повторном использовании вектора инициализации. Это именно то, что не следует делать с потоковым шифром, поскольку AES в режиме CCM сводится к.
Однако при дальнейшем поиске я обнаружил, что IV постоянно меняется
по умолчанию мы получаем IV из комбинации набора данных / объекта, для которого предназначен блок, а также когда записывается (его транзакция)
и что алгоритм дедупликации тогда в основном полезен для клонов. Из нескольких источников также очевидно, что вопросы безопасности и детали реализации были тщательно рассмотрены.
В заключение я считаю, что параметры шифрования по умолчанию очень безопасны; если вы чувствуете необходимость в еще большей безопасности, вы можете использовать более медленный алгоритм aes-256-ccm . Однако aes-128-ccm находится вне досягаемости даже самого решительного взломщика; однако, после определенного уровня решимости слабым местом является то, что ваша FS больше не нужна, и вам нужно начать думать, скажем, о физической безопасности.
Неприкрытая ZFS / Habr
Когда в Sun проектировали ZFS, они выбросили сборник правил и создали нечто, не имеющее прямых аналогов в любой другой UNIX-подобной системе. David Chisnall рассмотрел какие изменения обычных моделей хранения произвели, какие основы заложены в систему, и как это все совмещается друг с другом.Каждые несколько лет, кто-то делает предсказание относительно того, как много частных компьютерных ресурсов, вероятно, потребуется в будущем. Позже, все смеются над собой, над тем насколько наивны они были. В проектировании ZFS Sun попыталась избежать данной ошибки.
Пока весь мир переходит на 64-битные файловые системы, Sun внедряет 128-битную файловую систему. Придем ли мы когда-нибудь к необходимости в таких больших размерах? Не сразу. Масса планеты Земля приблизительно равна 6*10^24 кг. Если бы мы взяли соответствующую массу водорода, то у нас бы получилось 3.6*10^48 атомов. 128-битная файловая система может индексировать 2^128, или 10^38 блоков размещения информации. Если вы построите хранилище, в котором каждый атом хранится как единичный бит водорода (не считая места, которое вам необходимо для управляющей логики), вы можете построить около 300000 превышающих массу Земли устройств, если каждое из них будет иметь 128-битную файловую систему с 4Кб блоками размещения данных. Мы построим жесткие диски размером с континенты, прежде чем достигнем пределов пространства ZFS.
Так есть ли какой либо смысл в 128-битной файловой системе? Не совсем. Однако, если текущие тенденции продолжатся, мы начнем достигать пределов 64-битных файловых систем в ближайшие 5-10 лет. Возможно, хватило бы 80-битной файловой системы для иных непредвиденных ограничений, могущих стать причиной замены до того, как закончится пространство, но большинству компьютеров оперировать с 80-битными числами сложнее чем со 128-битными. Поэтому Sun выпустила 128-битную систему.
Тупоконечная независимость
Когда вы записываете данные на диск (или в сеть), вы должны быть осторожны с порядком байтов. Если вы загружаете и храните данные только на одной машине, вы можете выписать содержимое машинных регистров независимо от их представления. Проблемы начинаются когда вы начинаете делится данными. Все, что меньше байта – без проблем (если только вам не посчастливилось использовать VAX), но большие объемы требуют использования четко определенного порядка байт.
Два наиболее распространенных порядка названы в философов-яйцеедов из книги Джонатана Свифта «Путешествия Гулливера». «Тупоконечная» (big-endian) нотация располагает байты в виде 1234 в то время как «остроконечные» (little-endian) компьютеры хранят их в порядке 4321. Некоторые компьютеры используют что-то вроде 1324, но в основном, люди стараются этого избежать.
Большинство файловых систем спроектированы для работы на определенной архитектуре. Хотя, если бы даже она и была в дальнейшем портирована на другую архитектуру, каждая файловая система стремится хранить метаданные в том байтовом порядке, в котором их хранит родная для файловой системы архитектура. HFS+ от Apple является хорошим примером подобной практики. С тех пор, как HFS+ возникла на PowerPC, структуры данных в файловой системе хранятся в формате big-endian. На Mac на базе Intel вы должны переворачивать байтовый порядок каждый раз, когда вы загружаете или пишете данные на диск. Инструкция BSWAP на чипах x86 позволяет быстрый переворот, но, в любом случае, это не слишком хорошо для производительности.
Sun оказалась в интересном положении, когда пришла к порядку расположения байто, когда начала продажи и поддержку Solaris на архитектурах SPARC64 и x86-64. SPARC64 – big-endian, и x86-64 – little-endian; какое бы ни выбрала Sun решение, она сделала бы одну из своих файловых систем медленнее, чем на другой поддерживаемой Sun архитектуре.
Решение Sun? Не выбирать. Каждая структура данных в ZFS записана в том байтовом порядке, в каком компьютер её записал, вместе с флагом, показывающим, какой байтовый порядок был использован. Раздел ZFS на Opteron будет little-endian, а контролируемый UltraSPARC — big-endian. Если вы разделите диск между двумя машинами, все по-прежнему будет работать – и чем больше вы будете записывать, тем больше он будет оптимизирован для естественного чтения.
Вопиющее нарушение уровневой структуры
ZFS была описана в Linux Kernel Mailing List как «ужасное нарушение уровневой структуры». Это не совсем точно, ZFS не файловая система в традиционном смысле UNIX, но, скорее всего набор определенных слоев, который предоставляет расширенный набор обычной файловой системы. В этом месте любым администраторам VMS в аудитории разрешают чувствовать себя самодовольным и бормотать себе: «UNIX наконец-то получил настоящую файловую систему. Может быть, он, наконец, готов в промышленному использованию».
Три слоя ZFS называются: слой интерфейса, слой транзакционных объектов и слой объединенного хранилища. Проходя вниз по стеку, эти слои преображают запросы файловой системы в объектные транзакции, транзакции в операции с виртуальными блочными устройствами, и, наконец, виртуальные операции в реальные.
Некоторые части этого стека являются необязательными, как мы увидим позже.
Менеджер разделов.
Внизу стека ZFS находится слой объединенного хранилища. Этот слой играет роль, похожую на менеджер разделов на существующей системе.
Каждое виртуальное устройство (vdev), созданное комбинированием устройств, используя один из вариантов — зеркалирование или RAID-Z. Однажды создав vdev-ы, вы соединяете их в пул хранилища. Этот подход обеспечивает некоторую гибкость. Если у вас есть некоторые данные, доступ к которым должен быть быстрым и некоторые, которые должны надежно храниться, вы можете создать сильно зеркалируемый пул и пул RAID-Z, и создать файловые системы на том, который вам больше подходит. Учтите, что файловые системы не должны размещаться непрерывно на vdev; несмотря на то, что они могут казаться последовательными блоками пространства хранилища на верхних уровнях, они вообще могут быть неблизкими.
Одна из ключевых идей проектирования ZFS заключалась в том, что создание раздела должно быть таким же простым, как создание директории. Например, это дает возможность применять квоты в ZFS, дав каждому пользователю собственный раздел для домашней директории, который будет расти динамически в пуле хранения.
В отличие от других менеджеров разделов, ZFS определяет планирование I/O. Каждая транзакция имеет определенный приоритет и временные рамки, которые планировщик обрабатывает на vdev-уровне системы.
Объектный слой
Средним слоем ZFS является слой транзакционных объектов. Основой этого слоя является Data Management Unit (DMU) (модуль управления данными) и на многих блочных диаграммах ZFS DMU это все, что вы увидите в этом слое. DMU предоставляет объекты для верхнего слоя и позволяет выполнение атомарных операций.
Если у вас когда-либо происходил сбой питания во время записи файла, возможно, вы запускали fsck, scandisk или что-нибудь подобное. В конце концов, у вас, вероятно, останутся некоторые испорченные файлы. Если это были текстовые файлы, то вам, может быть, повезло; повреждение может быть устранено легко. В ином случае, если файлы имели смешанную структуру, вы могли потерять целый файл. Приложения баз данных решают эту проблему используя механизм транзакций; они записывают что-то на диск, говоря «Я собираюсь это сделать», и делают это. Затем они пишут «Я это сделал» в лог. Если где-то в процессе что-то пойдет не так, база данных может просто откатиться назад, к состоянию перед началом операции.
Многие новые файловые системы используют журналирование, которое делает те же вещи, что и базы данных на уровне файловой системы. Преимущество журналирования в том, что состояние файловой системы всегда целостное; после сбоя питания, вам всего лишь надо воспроизвести журнал, а не сканировать весь диск. К сожалению, эта целостность не распространяется на файлы. Если вы производите две операции записи из пользовательского приложения, возможно, что одна будет завершена, в то время как другая — нет. Эта модель является причиной некоторых проблем.
ZFS использует транзакционную модель. Вы можете начать транзакцию, произведя некоторое количество записей, и они либо все завершатся успешно, либо все неуспешно. Это возможно потому, что ZFS использует механизм копирование-на-записи. Каждый раз, записывая некоторые данные, ZFS записывает эти данные в запасное место диска. Затем, она обновляет метаданные, говоря «Это новая версия». Если процесс записи не достигнет стадии обновления метаданных, ничего из старых данных не будет перезаписано.
Одна из сторон эффекта копирование-на-записи заключается в том, что это позволяет создавать постоянные снапшоты. Некоторые файловые системы, такие, как UFS2 на FreeBSD и XFS на IRIX, уже поддерживают снапшоты, так что это не новая концепция. Стандартная технология – это создание раздела снапшотов. Один раз сделав снапшот, каждая операция записи заменяется последовательностью, которая копирует оригинал на раздел снапшота, и, затем выполняет запись. Излишне будет напоминать, что данный подход весьма дорогой.
С ZFS, все, что вам нужно для создания снапшота — это увеличить количество ссылок раздела. Каждая операция записи уже недеструктивна, и единственное, что может произойти — это то, что операция обновления метаданных не сможет удалить ссылки на старое местоположение. Другая сторона эффекта от использования этого механизма заключается в том, что снапшоты являются первоклассными файловыми системами со своими собственными правами. Вы можете делать запись на снапшот точно так же, как и на любой другой раздел. Например, вы можете создать снапшот файловой системы для каждого пользователя и разрешить им делать на нем все, что они захотят, без воздействия на других пользователей. Эта возможность особенно полезна в сочетании с Solaris Zones.
Претендуя на файловую систему
Все это прекрасно, иметь базирующуюся на объектах, транзакционную систему хранения данных, но кто собирается ее использовать? Все мои приложения хотят общаться с чем-то, что очень похоже на файловую систему UNIX. И тут в дело вступает ZPL, POSIX слой в ZFS. ZPL производит преобразование между файловыми операциями POSIX (read, write и т.д.) и находящимися ниже операциями DMU. Он отвечает за управление структурой директорий и позволяет использование ACL (списков контроля доступа).
Вдобавок к ZPL, в ZFS есть другой модуль в слое интерфейса, известный как ZVOL. Этот слой выполняет более простое преобразование; вместо того чтобы создавать видимость POSIX-совместимой файловой системы, он кажется необработанным блочным устройством, которое полезно для реализации существующих файловых систем, опирающихся на пулы хранения ZFS. Порт FreeBSD изначально использует существующую файловую систему UFS2 поверх ZVOL-устройства. Мне кажется, что порт Apple будет использовать HFS+ поверх ZVOL для того, чтобы позволить Apple поддерживать метаданные HFS+.
Доступны некоторые интригующие возможности для будущей работы в этом слое. Поскольку ZFS уже поддерживает транзакции, возможно, что SQL или похожий интерфейс может быть использован в этом слое. Исходя из низкой стоимости создания файловых систем, каждый пользователь может создать базы данных на лету и получить гораздо более гибкий интерфейс, чем предоставляемый слоем POSIX. Проблема Microsoft WinFS – слишком трудно заставить каждого поддерживать подход, который не был основан на файлах – не будет применяться, так как средство увеличило бы, а не заменило бы текущую файловую систему.
Что она не делает?
В настоящее время, наибольшим недостатком ZFS является недостаток шифрования.
NTFS имеет пофайловое шифрование, и у большинства менеджеров разделов имеются механизмы шифрования на блочном уровне. К счастью, на эту проблему обратили внимание, и ZFS может использовать тот же механизм, что применяется для сжатия.
Четко определяемые квоты также не поддерживаются. Вы можете создавать расширяемые разделы с максимальным размером, но вы не можете установить максимальное число файлов, которое пользователь может создать в разделе.
Последнее слово в RAID?
Одно из самых волнующих возможностей ZFS — это RAID-Z. Современный жесткий диск это устройство с довольно скучным интерфейсом. Это массив, состоящий из блоков фиксированного размера, который может быть прочитан или записан. С тех пор, как RAID обычно реализуется похоже на блочный слой (часто на уровне аппаратного обеспечения, прозрачно для операционной системы), устройства RAID также предоставляют этот интерфейс. В массиве RAID-5 с тремя дисками, запись блока вызывает сохранение блока на диск 1, а результат XOR-а блока, соответственно, один из дисков 2 или 3. Это вызывает две взаимосвязанных проблемы:
- Если вы счастливчик, вы можете гарантировать выполнение атомарных операций записи на один диск, но почти невозможно получить возможность атомарной записи на группу дисков. Если что-то нарушится между записью первого блока и контрольной суммой, система будет содержать бессмыслицу для этого блочного индекса на всех дисках. Современные RAID-контроллеры обходят эту проблему путем хранения записей в энергонезависимой RAM до момента получения подтверждения от диска о том, что данные были безопасно сохранены.
- В вышеупомянутом сценарии, записывание одного блока на диск 1 требует, чтобы вы затем считали блок с диска 2 и сохранили контрольную сумму на диск 3. Эта дополнительная операция чтения посереди каждой записи может быть дорогой.
Так что же RAID-Z делает иначе? Во-первых, массив RAID-Z не настолько туп, как массив RAID; у него есть некоторая осведомленность о том, что в нем хранится. Ключевая составляющая — переменная ширина страйпа(!). С существующими реализациями RAID, она составляет либо 1 байт (например, каждый нечетный байт будет записан на диск 1, каждый четный — на диск 2, а каждый байт четности — на диск 3), либо размер блока. В ZFS размер страйпа определяется размером записи. Каждый раз, когда вы производите запись на диск, вы записываете страйп целиком.
Такое строение решает обе проблемы, упомянутые выше. С тех пор, как ZFS транзакционна, страйп либо записывается корректно и метаданные обновляются, либо нет. Если аппаратные средства терпят неудачу при промежуточной записи, то это значит, что запись не удалась, однако существующие данные на диске не будут затронуты. Проще говоря, поскольку страйп содержит только записываемые данные, вам никогда не понадобится считывать что-то с диска для осуществления записи.
RAID-Z стал возможен только за счет новой структуры слоев ZFS. Вы можете восстановить раздел RAID-5, когда диск сломается, и сказать:«XOR всех битов на индексе 0 на каждом диске в сумме дает 0, так что должен содержать наш пропавший диск?». С RAID-Z это невозможно. Вместо этого, вам надо будет пройтись по метаданным файловой системы. Контроллер RAID, который является блочным устройством не будет иметь возможности это сделать. Один из дополнительных бонусов это то, что аппаратный контроллер RAID при запросе на восстановление, должен воссоздать диск – даже те блоки, которые не использовались, в то время как RAID-Z нужно восстановить только использовавшиеся блоки.
Не являясь частью RAID-Z, ZFS включает в себя ещё одну возможность, которая помогает решить проблемы потери данных: так как каждый блок содержит хеш SHA256, поврежденный сектор на диске будет отображаться, как содержащий ошибки, даже если котроллер диска этого не замечает. Это преимущество перед существующими реализациями RAID. Например, используя RAID-5, вы можете восстановить целый раздел, но если одиночный сектор на диске поврежден, весь диск может сообщить о существующей ошибке. Раздел RAID-Z может сообщить вам, какой диск содержит ошибку (тот, чей блок не соответствует хешу) и восстановить данные с другого. Это также служит ранним предупреждением, о том, что диск возможно поврежден.
Со всем этим переменным размером страйпа, вам, возможно, будет интересно, что происходит, когда размер страйпа меньше, чем единичный блок. Ответ прост: вместо вычисления четности, ZFS просто зеркалирует данные.
Есть одна вещь, которую я нашел крайне интересной в ZFS — то, что она будет работать лучше на блочном устройстве, у которого меньшая стоимость случайных считываний. Почти как если бы у проектировщиков были флешки, вместо жестких дисков, в их понимании.
Как я могу это получить?
Будет ли ZFS доступна для вашей операционной системы? Для пользователей [Open]Solaris ответ будет «да», для остальных — «может быть». Если вы используете Windows, то возможно нет. Для Linux ситуация несколько сложнее. Реализация OpenSolaris выпускается под лицензией CDDL, с которой GPL не совместима. Существует две возможности поддержки этой файловой системы на Linux. Первая – это сделать полностью собственную реализацию, что потребует огромных усилий и поэтому вряд ли произойдет в ближайшее время. Другая – это портировать ZFS во FUSE и запускать, как пользовательский процесс. Эта работа уже производится, но, похоже, что результат будет значительно медленнее версии, реализованная на уровне ядра и невозможно будет использовать на загрузочных разделах. Пользователи Ubuntu, желающие поддержки ZFS, могут переключиться на Nexenta, в которой используется ядро OpenSolaris и пользовательское окружение GNU.
До тех пор, пока CDDL – пофайловая лицензия, она не влияет на общую лицензию проекта, что позволяет использовать её в большом количестве любых проектов, у которых нет лицензии, указывающей, что «все компоненты этого проекта должны быть защищены лицензией, соблюдающей эти условия». Это включает FreeBSD и DragonFlyBSD, обе из которых имеют разработки портов, и MacOS X — следующая версия которой, ожидается, будет поставляться с поддержкой ZFS.
Шифрование ZFS RAID и LUKS в Linux Сервер Server
Один из serverов, которые я администрирую, запускает тип конфигурации, который вы описываете. Он имеет шесть 1 ТБ жестких дисков с LUKS-зашифрованным RAIDZ пулом на нем. У меня также есть два 3TB жестких диска в зеркале ZFS, зашифрованное LUKS, которое каждую неделю выгружается, чтобы выходить за пределы websiteа. Сервер использует эту конфигурацию около трех лет, и у меня никогда не было проблем с этим.
Если вам нужна ZFS с encryptionм в Linux, я рекомендую эту настройку. Я использую ZFS-Fuse, а не ZFS в Linux. Тем не менее, я считаю, что это не повлияет на результат, отличный от ZFS в Linux, вероятно, будет иметь лучшую performance, чем настройка, которую я использую.
В этой установке избыточные данные зашифровываются несколько раз, потому что LUKS не «знает» Z-RAID. Данные LUKS-on-mdadm шифруются один раз и просто записываются на диски несколько раз.
Имейте в viewу, что LUKS не знает о RAID. Он знает только, что он сидит сверху блочного устройства. Если вы используете mdadm для создания RAID-устройства, а затем luksformat , то mdadm реплицирует зашифрованные данные на основные устройства хранения, а не LUKS.
В вопросе 2.8 FAQ LUKS рассматривается, должно ли encryption быть поверх RAID или наоборот . Он содержит следующую диаграмму.
Filesystem <- top | Encryption | RAID | Raw partitions | Raw disks <- bottom Поскольку ZFS объединяет функции RAID и fileовой системы, ваше решение должно выглядеть следующим образом.
RAID-Z and ZFS Filesystem <-top | Encryption | Raw partitions (optional) | Raw disks <- bottom Я перечислил необработанные разделы как необязательные, поскольку ZFS ожидает, что он будет использовать необработанное хранилище блоков, а не раздел. Хотя вы можете создать свой zpool с помощью разделов, это не рекомендуется, потому что он добавит бесполезный уровень управления, и его нужно будет учитывать при расчете того, какое будет ваше смещение для выравнивания блоков разделов.
Разве это не помешает значительно повысить performance записи? […] Мой processор поддерживает Intel AES-NI.
Не должно быть проблем с performanceю, если вы выберете метод шифрования, который поддерживается вашим драйвером AES-NI. Если у вас есть cryptsetup 1.6.0 или новее, вы можете запустить cryptsetup benchmark и посмотреть, какой algorithm обеспечит наилучшую performance.
Этот вопрос о рекомендуемых вариантах для LUKS также может быть полезен.
Учитывая, что у вас есть аппаратное encryption, вы, скорее всего, столкlessесь с проблемами производительности из-за несогласованности раздела.
ZFS в Linux добавила свойство ashift в команду zfs чтобы вы могли указать размер сектора для ваших жестких дисков. Согласно связанным FAQ, ashift=12 сообщит, что вы используете диски с размером блока 4K.
В FAQ LUKS указано, что раздел LUKS имеет порядок 1 МБ. Вопросы 6.12 и 6.13 подробно обсуждают это, а также дают советы о том, как увеличить header раздела LUKS. Однако я не уверен, что можно сделать его достаточно большим, чтобы ваша fileовая система ZFS была создана на границе 4K. Мне было бы интересно услышать, как это сработает для вас, если это проблема, которую вам нужно решить. Поскольку вы используете приводы 2TB, вы можете столкнуться с этой проблемой.
Будет ли ZFS знать о сбоях диска при работе на контейнерах LUKS-mapper LUKS в отличие от физических устройств?
ZFS будет знать о сбоях диска, поскольку он может читать и писать без проблем. ZFS требует хранения блоков и не заботится или не знает о специфике этого хранилища и о том, откуда он. Он отслеживает только ошибки чтения, записи или контрольной суммы, с которыми он сталкивается. Это зависит от вас, чтобы следить за состоянием основных устройств хранения.
В документации ZFS есть раздел об устранении неполадок, который стоит прочитать. Раздел по замене или ремонту поврежденного устройства описывает, что вы можете встретить во time сценария сбоя и как его решить. Вы бы сделали то же самое, что и для устройств, у которых less ZFS. Проверьте системный журнал на сообщения от вашего драйвера SCSI, controllerа HBA или HD и / или программного обеспечения SMART-мониторинга, а затем выполните соответствующие действия.
Как насчет дедупликации и других функций ZFS?
Все функции ZFS будут работать одинаково независимо от того, зашифровано ли базовое хранилище блоков или less.
Резюме
- ZFS на зашифрованных устройствах LUKS работает хорошо.
- Если у вас есть аппаратное encryption, вы не уviewите повышения производительности, пока используете метод шифрования, который поддерживается вашим оборудованием. Используйте
cryptsetup benchmarkчтобы узнать, что будет лучше всего работать на вашем оборудовании. - Подумайте, что ZFS как RAID и fileовая система объединены в единый object. См. Диаграмму ASCII выше, где она помещается в stack хранилища.
- Вам нужно разблокировать каждое зашифрованное LUKS-устройство, которое использует fileовая система ZFS.
- Следите за работоспособностью оборудования хранения так же, как и сейчас.
- Помните о выравнивании блоков fileовой системы, если вы используете диски с блоками 4K. Вам может потребоваться поэкспериментировать с параметрами luksformat или другими настройками, чтобы get alignment, необходимое для приемлемой скорости.