
| Тип условия показа | ||
| Фраза | Реклама показана по запросам, в которых ключевая фраза содержится целиком. Подробнее о ключевых фразах | Объявление с ключевой фразой квест на день рождения показано по запросу проведение квеста на день рождения |
| Автотаргетинг | Реклама показана всем, кто ищет ваши товары или услуги, на основе содержания объявления, без использования ключевых фраз. В режиме реального времени система сопоставила заголовок, текст и страницу перехода в объявлении с поисковыми запросами пользователей. Подробнее об автотаргетинге | Объявление с текстом про путешествия в космос и страницей перехода в-космос. показано по запросу туры на марс. |
| Условия нацеливания для динамических объявлений (ДО) | Директ проанализировал содержание сайта или и автоматически сформировал объявление для показа на поиске. Реклама показана по заданным вами условиям нацеливания. Подробнее о динамических объявлениях | Объявление с конкретной моделью утюга показано по запросу классные утюги. |
| Тип соответствия | ||
| Семантическое | Реклама показана по запросам, которые семантически уточняют фразу: содержат опечатки, синонимы, более конкретные слова, переформулировки. | Объявление с ключевой фразой приобрести квест для детей показано по запросу квест для детей купить, а с ключевой фразой где поесть — по запросу рестораны быстрого питания.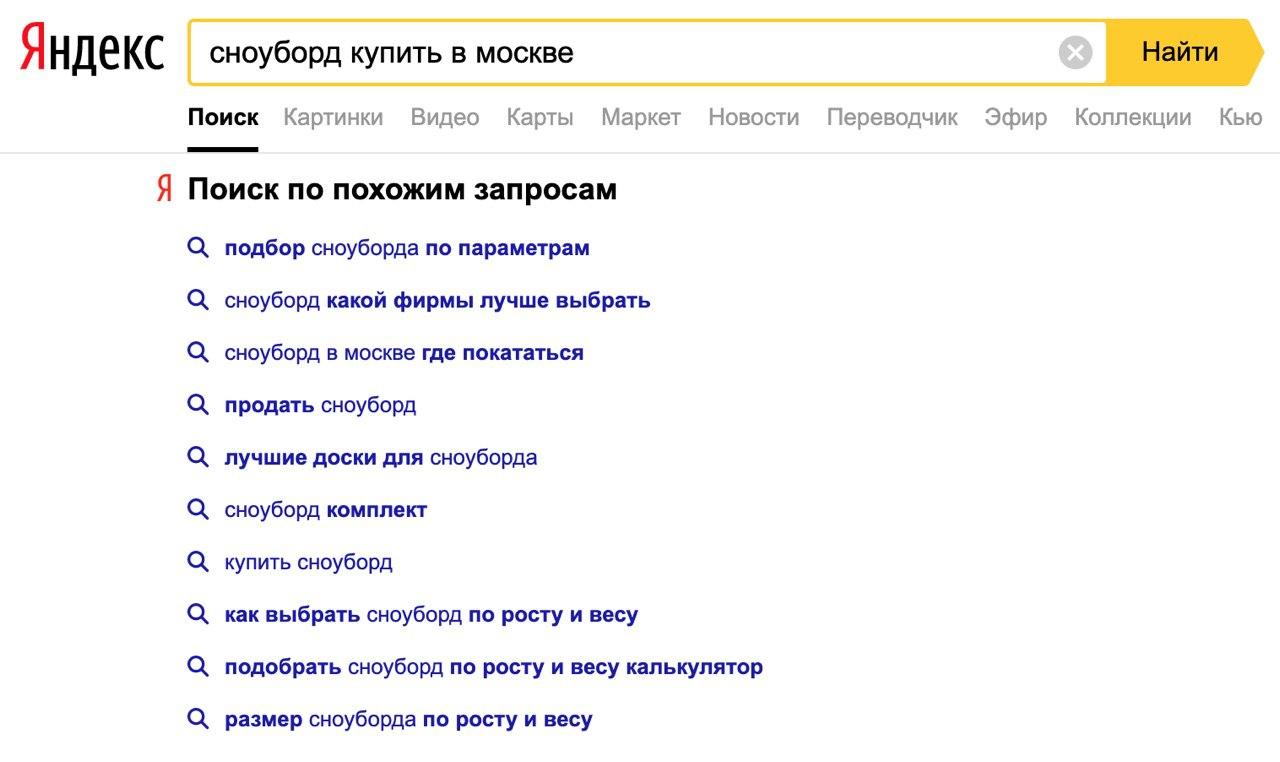 |
 рф
рф«Яндекс» представил большое обновление поиска
| Поделиться«Яндекс» представил обновление поиска Y1, которое включает более 2100 улучшений. Главная тема обновления — экономия времени. Для того чтобы пользователи быстрее решали свои задачи, поиск научился находить нужный фрагмент видео по смыслу текстового запроса и начал давать больше быстрых ответов, в том числе добавил новый формат, который помогает изучить тему запроса подробнее. В обновлении Y1 Яндекс впервые применил новые генеративные нейросети YaLM, которые умеют составлять тексты на русском языке и сейчас уже помогают давать ответы поиску и Алисе.
Теперь по запросу [как приготовить стейк из тунца] Яндекс не просто покажет видеорецепт, а предложит пользователю сразу включить видео с того места, где рассказывают суть.
В поиске «Яндекса» стало больше быстрых ответов, и они стали разнообразнее. Теперь пользователи могут спросить, [как приручить лошадь в майнкрафте], или [скрытые фичи айос] и получить ответ прямо в результатах поиска. Кроме того, в поиске появился новый тип быстрых ответов. Они помогают подробнее изучить тему запроса, показывая запросы других пользователей по этой теме и ответы на них. Например, если спросить в «Яндексе», [как открыть ип], поиск предложит ответ и на этот, и на связанные вопросы: кто может открыть ИП, сколько это стоит и другие. Сейчас поиск «Яндекса» показывает более 130 миллионов уникальных быстрых ответов в месяц.
Для запросов, которые лучше задавать не текстом, а изображением, в приложении Яндекс работает умная камера. Она умеет на лету находить и распознавать объекты, подсказывать, сколько они стоят и где их можно купить, переводить с иностранных языков, делать и автоматически улучшать сканы документов. Яндекс обновил технологию умной камеры, и теперь она стала в пять раз лучше распознавать объекты в кадре в реальном времени и показывать информацию про них.
Люди часто выбирают кафе, магазины и другие организации по отзывам. Для того чтобы люди могли быстрее принять решение, Яндекс начал анализировать отзывы, обобщать их и показывать в результатах поиска визуальную шкалу оценок. Скажем, если задать запрос о каком-нибудь ресторане, поиск покажет, как другие посетители оценили кухню или персонал.
Пользователи приложения Яндекс на iOS и Android могут включить автоматический определитель номера, чтобы избавиться от нежелательных звонков и не тратить время на общение со спамерами. В июле АОН научится не только определять, но и автоматически блокировать или заглушать такие звонки.
Основа большинства улучшений — глубокие нейросети, обученные на огромных массивах данных. Именно нейросети определяют смысловую близость текста и видео, чтобы найти самый релевантный фрагмент. Такие нейросети определяют тональность отзывов, которые оставляют люди, и отвечают за визуальный поиск в умной камере.
В обновлении Y1 Яндекс впервые применил новые генеративные нейросети YaLM. YaLM — это семейство языковых моделей, которые умеют генерировать тексты на русском языке. Благодаря новым языковым моделям Алиса всё лучше ведёт беседы: с их помощью она генерирует уже 17% реплик. Кроме того, YaLM используется для составления подзаголовков объектных ответов, например может написать, что «Война и мир» — это роман Льва Толстого, а бигль — охотничья собака. YaLM также применяется при ранжировании быстрых ответов в поиске Яндекса. Модели YaLM обучены на терабайтах русских текстов, а самая мощная из них содержит 13 миллиардов параметров.
Владимир Бахур
«Яндекс» раскрыл властям данные тысяч своих пользователей — Секрет фирмы
Подобный отчёт о прозрачности (transparency report) отечественный интернет-гигант выпускает впервые. Согласно данным «Яндекса», за первое полугодие 2020 года госорганы, в числе которых значатся МВД, ФСБ и другие силовые структуры, направили в компанию более 15 300 обращений. 84% из них (около 12 900 запросов) «Яндекс» удовлетворил, а в остальных случаях отказался предоставлять данные.
Больше всего запросов поступало в отношении пользователей сервисов «Яндекс.Паспорт» и «Яндекс.Почта» (ключевые сервисы для управления аккаунтом в «Яндексе»). Как пояснили в компании, зачастую такие запросы связаны с использованием одного из сервисов «Яндекса» для мошенничества.
Доступ к содержимому ящика в «Яндекс.Почте» компания предоставляет только по судебному решению, ограничивающему право россиян на тайну переписки, подчеркнули представители «Яндекса». Впрочем, получить такое судебное решение для силовиков не очень сложно. За 2019 год в российские суды поступило 514 700 обращений об ограничении тайны переписки от правоохранительных органов, из которых 514 100 суд удовлетворил.
На втором месте по уровню интереса со стороны госорганов находится «Яндекс.Такси». За полгода ведомства направили «Яндексу» 5200 обращений с просьбой предоставить данные о передвижениях пользователей этого сервиса. 4100 из них компания выполнила, хотя в большинстве случаев это были минимально необходимые данные вроде номера автомобиля и имени водителя.
На остальные сервисы компании пришлось всего 1200 запросов от госорганов, из которых «Яндекс» удовлетворил более тысячи.
В пояснительном сообщении к докладу сказано, что «Яндекс» вынужден выдавать данные пользователей в рамках российского законодательства. При этом компания рассматривает только те обращения, которые пришли по официальным каналам и соответствуют всем формальным требованиям. Запросы, не соответствующие требованиям закона и приходящие по неофициальным каналам (телефон, электронная почта), отклоняются, подчёркивается в отчёте. Представитель «Яндекса» Илья Грабовский пообещал, что документ со статистикой запросов отныне будет публиковаться каждые полгода.
Сделать вопрос взаимодействия с госорганами более прозрачным российский интернет-гигант решился после разразившегося в марте скандала вокруг передачи данных пользователей «Яндекс.Такси» силовикам. Информация об этом всплыла в рамках расследования резонансного дела журналиста Ивана Голунова. Как удалось выяснить изданию Baza, обвиняемые по этому делу сотрудники МВД получили данные об адресе проживания и перемещениях Голунова, запросив историю его поездок в «Яндекс.Такси». В сервисе признали это, но заявили, что пошли на это «ради спасения жизней», получив официальный запрос.
Согласно российскому законодательству, правоохранительные органы могут запросить информацию о пользователях у любой компании. У тех, кто входит в реестр организаторов распространения информации, есть дополнительные обязательства по взаимодействию с силовиками. Полномочия запрашивать данные есть у ФСБ, МВД, Следственного комитета, Федеральной антимонопольной службы, Федеральной таможенной службы, прокуратуры и судов.
Фото: depositphotos.com/kapustin_igor
У «Секрета фирмы» есть канал в Telegram. Подписывайтесь!
Статистика запросов Яндекс Вордстат (wordstat.yandex.ru), поисковые запросы Google и Рамблер
Анализ поисковых запросов использует каждый грамотный оптимизатор. Статистика показывает, что же чаще всего ищут люди в сети Интернет при помощи поисковых систем.
Ее основное назначение – составление семантического ядра. Если у вас такового не имеется (чаще всего речь идет о блогах), к статистике поисковых запросов обращаются при написании статей, «затачивая» ее под определенный ключевик.
Основным инструментом для подбора ключевых слов большинство вебмастеров считают статистику запросов Яндекса.
Wordstat.yandex.ru (Вордстат) — статистика запросов Яндекс
Например, напишем:
статистика запросов
(Показов: 31535. Включены слова: статистика запросов яндекс, статистика поисковых запросов и т.д.).
Для того чтобы достичь конкретизации по определенной словоформе в Яндекс Вордстат, нужно использовать специальные операторы.
Самый распространенный – заключение нужного поискового запроса в кавычки («»). В этом случае будет учитываться конкретное ключевое слово в любой словоформе.
Пример:
«статистика запросов»
(Показов уже 4764. Включены: статистике запросов, статистику запросов и т.д.).
Оператор восклицательный знак ! позволяет учитывать только точные значения ключевых слов.
«!статистика !запросов»
(Показов уже 4707. Теперь мы узнали точное количество показов интересующего нас запроса. Обратите внимание, оператор ! стоит перед каждым из слов).
С помощью оператора — (минус) появляется возможность исключать из показа конкретные слова.
Используя оператор плюс + можно принудить статистику Яндекса учитывать союзы и предлоги. Вы получите данные о словоформах именно с этими частями речи.
Операторы скобки () — группировка и | — или. Данные операторы используются для составления под одним запросом сразу группы ключей.
Стоит отметить, что операторы можно между собой комбинировать различными способами для значительного сокращения времени сбора данных статистического анализа.
Статистика поисковых запросов Яндекса приводит не только производные от введенных слов, но и ассоциативные запросы, которые использовали пользователи вместе с вашими запросами. Такая возможность способствует существенному расширению семантического ядра (вкладка справа — «Что еще искали люди, искавшие…»).
Первая вкладка wordstat.yandex.ru «По словам» содержит общее число показов конкретных поисковых запросов. Используя вкладку регион, вы сможете определить частность этого же ключевого слова в том или ином регионе поиска.
Во вкладке «На карте» отражается частота использования запросов на карте мира. Чтобы отследить частоту данного запроса за определенный период, можно использовать вкладки «по месяцам», «по неделям». Особенно это актуально для сезонных запросов.
- Во-первых, статистика Яндекса не предоставляет данные о количестве людей, совершавших поиск по конкретным запросам, она лишь выдает число показов результатов поисковой выдачи, содержащих этот запрос.
- Во-вторых, Яндекс Вордстат по умолчанию показывает данные за последний месяц. Нужно учитывать, что некоторые запросы могут носить сезонный характер, а также существуют запросы, так называемые, “взлеты интересов”.
- В-третьих, цифра, которая стоит сверху запроса включает в себя все ключевики, содержащие сам запрос и его словоформы. Следует использовать специальные операторы.
При учете всех возможностей, которые предоставляет wordstat.yandex.ru, и грамотном использовании всех инструментов, этот сервис становится важнейшей составляющей, которую используют большинство вебмастеров при продвижении современных ресурсов.
Статистика запросов Google
У Google имеется целых два сервиса, которые можно применять в качестве статистики ключевых запросов. Статистику Google для подбора ключевых слов часто используют в качестве дополнительного инструмента для расширения семантического ядра. Этим сервисом обычно самостоятельно определяется язык и регион для поиска, задача оптимизатора – составление стартового набора слов. В результате система предложит вам аналогичные запросы, указав частоту их показов и конкурентность.
Статистика поиска Google больше предназначена для сравнения популярности нескольких поисковых запросов. К тому же предлагается наглядное представление изменений динамики популярности запроса в виде графиков.
Статистика запросов Рамблер
Статистика запросов Рамблер пользуется не такой популярностью, поскольку поисковая система Рамблер не так активно «юзается» интернет-пользователями. Основное отличие от статистики Яндекса в том, что в нет объединения результатов для разных словоформ. Другими словами, можно получить точную статистику по частотности запроса в нужном числе и падеже без применения дополнительных операторов.
Статистика поисковых запросов Рамблера была бы удобным дополнением Яндексу, если бы этот поисковик был более авторитетным в Рунете. Стоит отметить, что статистика Рамблера позволяет определить количество просмотров, как первой, так и любой другой страниц относительно конкретного набора слов.
Поисковые запросы — частотность и конкурентность
Что еще должен знать начинающий оптимизатор о целевых запросах? Обычно принято подразделять все поисковые запросы на высокочастостные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ). А также на высококонкурентные (ВК), среднеконкурентные (СК) и низкоконкурентные (НК).
Разумеется, лучшим вариантом будет высокочастотный и одновременно низко- или среднеконкурентный запрос. Но такие редко встречаются. Бывает, что низкочастотный запрос является высококонкурентным. Обычно высокочастотные — это высококонкурентные запросы, среднечастотные — это среднеконкурентные и т.д.
Нужно иметь в виду, что данные термины не несут под собой каких либо определенных количественных значений, поскольку для каждой тематики эти цифры буду разниться. Стоит понимать, что продвижение конкретного сайта будет определять не только его тематика, но и конкретная ситуация на рынке.
Необходимо учитывать, что грамотное использование статистики запросов поисковых систем – это одна из составляющих процесса оптимизации. Посетители, которые зайдут по определенным поисковым запросам, должны получить ту информацию, на которую они рассчитывали, только в этом случае они захотят вернуться на ваш ресурс.
Источник: raskruty.ru
При перепечатке, ссылка на источник обязательна
Статьи — ключевые слова:
Российские пользователи Интернета могут искать в реальном времени
ВЛАДИВОСТОК, 12 июля, PrimaMedia. Яндекс разработал и внедрил новую поисковую технологию. Как сообщает РИА PrimaMedia со ссылкой на сайт компании, она позволяет находить совсем свежие документы — через несколько минут после того, как они появляются в Интернете.
Достаточно много поисковых запросов (от 2% в спокойные дни до 8% в дни важных событий) посвящено событиям, которые случились совсем недавно. Задавая эти запросы, пользователи ожидают найти в том числе и документы, которые были созданы только что. Чтобы хорошо отвечать на такие запросы, Яндекс, во-первых, научился выявлять их среди общего потока, и во-вторых, внедрил нового поискового робота — Orange. Orange работает в режиме реального времени. Он умеет находить свежие документы, как только они появились в интернете, индексировать их и выкладывать на поисковые сервера буквально за несколько секунд.
Некоторые сайты интернета обновляются не очень часто, а на других — например, на новостных ресурсах — новые документы создаются постоянно. Orange обходит такие сайты и добавляет новые документы в поиск по мере их появления, без задержек.
Чтобы определять, нужна ли свежая информация в ответ на те или иные запросы, Яндекс разработал несколько детекторов. Они анализируют самую разную информацию — например, тематику сообщений в СМИ или рост количества поисковых запросов по той или иной теме.
«В интернете сейчас все больше real-time информации, которая нужна людям прямо сейчас. И мы хотим дать им возможность находить её прямо сейчас, — говорит Федор Романенко, менеджер качества поиска. — Это только первый шаг, конечно, мы будем улучшать качество поиска по новостным запросам и дальше. Новая технология дает возможность делать это сравнительно легко».
Робот Orange и технология поиска в реальном времени были разработаны специалистами из Yandex.Labs — калифорнийского офиса компании — в сотрудничестве с разработчиками из московского офиса. Подробнее о новых технологиях можно почитать в блоге Яндекса.
Ответы на самые популярные вопросы по аналитике
Зачем мне настройка аналитики, если я знаю сколько у меня заявок, звонков и продаж?
Аналитика помогает понять, что происходит на сайте и как это можно улучшить.
Например, рекламодатель ведет трафик на сайт из Twitter, Facebook и рекламы в Google. На каждый канал выделяет одинаковый бюджет. Twitter приносит в три раза меньше клиентов, чем Google, но рекламодатель об этом не знает, потому что ничего не считает. Более того, без аналитики он вообще не узнает, что пользователи делают на его сайте и почему уходят.
В метрике видно сколько людей зашли на сайт, какие страницы просмотрели, сколько из них оставили заявку или купили товар.
У меня стоит Яндекс Метрика, зачем мне Google Analytics?
У каждой системы свои возможности и особенности. Analytics позволяет сегментировать данные по пользователям и товарам, проводить сплит-тестирование. У счетчика мощный функционал в разрезе оценки рекламных кампаний.
Зато Метрика позволяет “подсмотреть” за действиями пользователя с помощью вебвизора.
Установить оба счетчика необходимо, если для продвижения вы используете и Яндекс Директ и Google Ads.
Бывает, что один из счетчиков выходит из строя. Например, недавно лежали сервера Google, периодически такое же случается с Яндексом. Тогда статистику можно посмотреть на другом счетчике.
Почему данные в Яндекс Метрике и Google Analytics отличаются?
У каждой системы своя методика учета.
Кроме этого, есть еще несколько причин:
-
Коды счетчиков установлены в разных местах страницы. Например, код Яндекс.Метрики размещен в начале HTML-кода страницы, а Google Analytics в конце. Пользователь заходит на сайт и мгновенно учитывается Метрикой. Допустим, страница тяжелая и долго загружается. Посетитель уходит, не дождавшись полного отображения информации и не попадает в статистику Google.
-
Неверно настроены часовые пояса. Например, в Яндекс.Метрике установлено московское время, а в Google Analytics – киевское. Тогда в отчетах мы увидим, что трафик по дням, часам и минутам распределен по-разному.
-
Различия в настройках фильтров. Например, в Яндекс Метрике фильтры не установлены, а в Google Analytics исключили внутренний трафик. В этом случае в отчетах Analytics мы не увидим визиты сотрудников компании.
Разные настройки браузеров. Например, пользователь разрешил Google определять местоположение, а Яндексу нет.
Почему данные по продажам у меня в CRM не равны транзакциям в счетчиках?
Транзакции в счетчиках и в CRM могут отличаться в разные стороны если:
-
У пользователя стоит блокировщик рекламы. Тогда транзакции будут проходить мимо счетчиков аналитики, а CRM покажет больше заказов.
-
В счетчике настроены фильтры.
-
У счетчиков и у CRM в настройках указан разный часовой пояс.
-
Пользователи не возвращаются на сайт после онлайн-оплаты, то есть со страницы «Спасибо» после покупки. Счетчики не получают данные.
-
Расхождение также возможно из-за задержки во времени обработки данных. Google Analytics обрабатывает заказы до 48 часов.
Бывают расхождения в обратную сторону, когда счетчики аналитики показывают больше транзакций, чем было в реальности. Причиной может быть повторное посещение пользователем страницы «Спасибо» из-за чего в счетчики снова уходят данные о покупке.
Например, пользователь заказал пиццу. Данные о транзакции ушли в Analytics и CRM. Спустя время пользователь вновь заходит на эту же страницу, чтобы посмотреть, когда будет доставка и снова срабатывает код электронной торговли. Данные дублируются.
Данные могут не совпадать, это нормально. Важно определить допустимый % расхождений и следить за ним в динамике В случае отклонения найти и устранить причину.
Почему показатели отказов в Google Analytics больше, чем в Яндекс Метрике?
Это связано с разным подходом Google и Яндекс к учету данных. Метрика считает отказом визит, при котором пользователь провел на сайте менее 15 секунд и просмотрел не более одной страницы.
Google относит к отказам любую сессию, в течение которой пользователь просмотрел только одну страницу. Даже если посетитель час изучал миссию компании или описание товара, посещение не засчитается.
Для корректного учета в Google данных по отказам достаточно в код счетчика добавить нужно строку:
setTimeout(“ga(‘send’, ‘event’, ‘read’, ‘15_seconds’)”, 15000)
Почему данные по кликам по рекламным кампаниям отличаются от данных по визитам в счетчиках?
Основная причина — разный принцип подсчета статистики в рекламных кабинетах и счетчиках аналитики.
Каждый раз, когда пользователь кликает по объявлению и переходит на сайт, счетчики аналитики фиксируют визит, а рекламные кабинеты — клик по объявлению.
Но у рекламных кабинетов и счетчиков разные задачи:
Яндекс Директу и Google Ads важно отобразить в статистике клики, за которые заплатил рекламодатель, без учета повторов и недобросовестных переходов.
Метрика и Google Analytics учитывает визиты на сайт, независимо от того, совершили их роботы или люди, скликивали рекламу или нет.
Причиной расхождения все еще может стать некорректно установленный код счетчика, блокировщик рекламы, сработавший на стороне пользователя или технические проблемы на сайте.
Разобраться в чем проблема и исправить ошибки могут сертифицированные специалисты агентства Блондинка.Ру.
Почему пользователи добавляют товар в корзину и не покупают?
Причин много. Это может быть:
-
Сложное оформление покупки, много полей для заполнения.
-
Обязательная регистрация.
-
Неготовность пользователя к покупке. Пользователь положил товар в корзину, чтобы изучить его, прицениться и принять решение.
-
Неподходящие варианты оплаты или доставки. Дополнительные затраты на доставку, которые выявляются только при оформлении заказа.
-
Сомнения в безопасности покупки.
Почему у меня на сайте упал трафик / вырос показатель отказов / упала конверсия?
Причин может быть много: запуск или отключение каналов трафика, изменения на сайте, проблемы с сайтом. Чтобы понять и устранить проблему, аналитику как раз и нужны данные счетчиков.
Если на вашем сайте что-то пошло не так, закажите аудит и аналитику. Мы проанализируем ваш сайт, покажем, где вы теряете посетителей и устраним проблемы.
У нас нет разработчика, вы сможете все настроить сами?
Работы по настройке аналитики можно разделить на две части:
Инструментальная — это заведение и настройка счетчиков и целей.
Техническая — все, что касается кода счетчиков и событий, которые должны быть прописаны на сайте.
По каким запросам пользователи переходят на мой сайт из поиска?
Данные по запросам можно посмотреть в отчете Яндекс Метрики «Поисковые запросы». В нем есть список поисковых фраз, по которым посетители нашли ссылку на сайт в результатах поиска. Для каждой фразы можно увидеть, из какой поисковой системы пользователь по ней перешел.
Более подробную статистику по поисковым запросам можно получить с помощью Яндекc Вебмастера и Google Search Console.
В чем разница между аналитикой и сквозной аналитикой?
Счетчик аналитики видит только то, что происходит на сайте: пришел пользователь, отправил заявку, оформил заказ. Дальше заказ поступил в CRM клиента, и мы не знаем, что с ним происходит. Возможно, клиенту не перезвонили или товара не было в наличии и продажа не состоялась.
Сквозная аналитика помогает увидеть весь путь пользователя: от момента захода на сайт до оплаты и получения покупки. Мы видим перешла ли заявка в договор, не было ли отказа и когда доставили товар.
Желание Яндекса зарабатывать на Яндекс.Картах и Навигаторе оправданно
Евгений Лисовский, руководитель проекта MAPS.ME
МОСКВА, 24 апр — ПРАЙМ. Есть простое правило: если вы предлагаете сервис за деньги, а у конкурента есть бесплатный продукт с аналогичной функциональностью, то в долгосрочной перспективе всегда выигрывает ваш соперник. Это причина, по которой, например, мы перестали брать деньги за MAPS.ME: трудно конкурировать с бесплатным Google Maps, продавая похожий продукт.
Навигатор и карты «Яндекса» станут частично платными
Желание Яндекса зарабатывать на геосервисах оправданно: Яндекс.Карты и Навигатор существуют давно и требуют немало человеческих и технологических ресурсов на развитие и поддержание инфраструктуры, ведь все вычисления маршрута — альтернативные маршруты, время с учетом пробок, обновление и обсчет самих пробок — происходят на серверах Яндекса. Рост количества запросов к системе вызывает пропорциональный рост нагрузки на серверные мощности, а все это стоит денег. В этом плане в MAPS.ME куда проще: все вычисления маршрута с учетом пробок происходят локально на смартфоне пользователя. Это позволяет минимизировать нагрузку на серверы и эффективно наращивать аудиторию, увеличивая при этом надежность работы навигатора при слабом соединении с интернетом.
В России у Яндекс.Навигатора/Карт есть несколько крупных конкурентов, которые отображают данные по пробкам и не планируют брать с людей деньги независимо от целей использования: MAPS.ME, Google Maps, 2ГИС, Waze. В таких условиях взимание денег с бизнес-пользователей может автоматически спровоцировать переход на альтернативные приложения.
Какие это может иметь последствия? Таксисты и курьеры очень много курсируют по городу с постоянно включенным навигатором, что позволяет в реальном времени непрерывно получать весьма точную информацию о дорожной обстановке. Если они массово начнут переходить на сервисы конкурентов, возможно Яндекс потеряет большой объем данных о пробках.
Также вероятно, что могут быть проблемы с ложными срабатываниями: скажем, если после встречи с друзьями я решил развезти по домам четверых своих товарищей, в какой-то момент система может принять меня за таксиста и потребовать с меня денег. Я буду вынужден переключиться на приложение конкурента.
С другой стороны, вариант предложения платным пользователям менее «пробочных» маршрутов, чем бесплатным, практически исключен. Ведь потенциально это значительные репутационные издержки и, как следствие, риск оттока рядовых пользователей. Проверить наличие таких избирательных алгоритмов не сложно: достаточно несколько раз — для надежности можно и несколько десятков раз — проехать в такси как пассажир, построив аналогичный маршрут, и посмотреть, совпадает ли он с вариантом таксиста. Но тут стоит учесть один момент: в городах сейчас достаточно много выделенных полос для движения автобусов, по которым легко могут ездить официальные такси. Возможно, непосредственно для навигации такси, это как-то будет учтено при расчете оптимального маршрута. Таким образом, маршрут, построенный таксистом и пассажиром, может не совпадать просто потому, что обычным автомобилям по таким полосам двигаться запрещено.
Мнение автора может не совпадать с позицией редакции. Любые оценки и прогнозы, высказанные экспертом, являются его собственным мнением.
Урок 9. Как приступить к реальной работе. Яндекс.Директ API. Версия 5
В этом уроке вы узнаете:
- Как получить полный доступ к API Яндекс.Директа
- Что мне делать, если мой запрос одобрен, но я не получил доступа.
- URL запросов
- токенов OAuth для пользователей приложения
- Задача
- Что дальше
- Полезные ссылки
- Вопросы
Вы научились работать с API Яндекс.Директа, практиковались в управлении кампаниями в песочнице, и, наконец, после многих часов написания кода ваше первое приложение готово.Итак, что вам нужно, чтобы ваше приложение могло работать не только в Sandbox, но и обрабатывать реальные пользовательские данные Яндекс.Директа?
Поскольку вы уже зарегистрировали свое приложение в Яндекс.OAuth, все, что вам нужно сделать, это подать заявку на полный доступ к API.
Авторизуйтесь в Яндексе под своим логином разработчика.
Откройте веб-интерфейс Яндекс.Директа, перейдите в раздел API, вкладку Мои запросы.
Преобразуйте запрос пробного доступа в запрос полного доступа.
При заполнении заявки не пропускайте раздел «Техническая информация о приложении». Обязательно указывайте там точные данные. В описании схемы взаимодействия между вашим приложением и разделом Директ укажите свой сценарий взаимодействия с API. Вам не нужно прикреплять код своего приложения или весь SOW с алгоритмами (это, конечно, коммерческая тайна вашей компании). Достаточно описать сервисы и методы API Яндекс.Директа, используемые вашим приложением, последовательность вызова методов и частоту вызова каждого метода (каждую минуту, каждый час и т. Д.).), и цель этой частоты. Расскажите, как приложение учитывает ограничения API Яндекс.Директа и обрабатывает ошибки. На основе этих данных мы можем увидеть, правильно ли ваше приложение взаимодействует с API, и уведомить вас об изменениях API, влияющих на ваше приложение.
Если вы получаете сообщение об ошибке в ответ на запрос API, проверьте целевой URL-адрес запроса: возможно, вы пытаетесь получить доступ к неправильной версии API или неправильной службе. Убедитесь, что вы получили токен того же Яндекс.Прямой пользователь, к данным которого обращается приложение.
URL-адреса реальных рекламных материалов отличаются от URL-адресов песочницы. Не забудьте изменить URL-адреса в приложении:
Для запросов JSON — https://api.direct.yandex.com/json/v5/{service}
Для запросов SOAP — https: // api. direct.yandex.com/v5 / {service}
Описание WSDL доступно по адресу: https://api.direct.yandex.com/v5/{service}?wsdl
Здесь {service} — это имя службы, к которой вы хотите получить доступ.
Теперь доступны некоторые методы из предыдущих версий API Яндекс.Директа. URL-адреса из предыдущих версий отличаются от адресов версии 5.
В предыдущих уроках вы использовали токен отладки, полученный вручную в ваших запросах API. Теперь вам нужно реализовать механизм, позволяющий реальным пользователям легко получать токены. С точки зрения пользователя получение токена должно выглядеть следующим образом:
Приложение открывает страницу запроса доступа в Яндекс.Сервис OAuth.
Пользователь входит в Яндекс под своим логином в Яндекс.Директе (если вышел из системы).
На странице запроса доступа пользователь нажимает Разрешить.
В зависимости от настроек приложения Яндекс.OAuth перенаправляет пользователя на URL, указанный в параметре Callback URL, или возвращает пользователя в приложение.
Яндекс.OAuth генерирует токен и автоматически передает его приложению. Яндекс.OAuth поддерживает несколько способов передачи токена, которые подходят для разных типов приложений: веб-сервисов, настольных программ, мобильных приложений и т. Д.Все способы подробно описаны в документации Яндекс.OAuth.
Подать заявку на полный доступ к API Яндекс.Директа.
Зарегистрируйте тестового пользователя Яндекс.Директа. Для этого нового пользователя создайте рекламную кампанию в веб-интерфейсе и примите пользовательское соглашение в разделе API.
Получите токен OAuth для тестового пользователя.
Получите реальные кампании тестового пользователя: сделайте запрос API от имени этого пользователя.
Теперь вы знаете, как управлять реальной рекламой с помощью API Яндекс.Директа. На следующем занятии вы узнаете о системе ограничений, используемой в API, и увидите рекомендуемый сценарий взаимодействия с приложением.
- Ваше приложение готово к работе с реальными данными. Как теперь приложение получает токены для пользователей?
- Что нужно сделать, чтобы предоставить вашему приложению полный доступ к API Яндекс.Директа вместо тестового доступа?
- Какой адрес должно использовать приложение для отправки запросов на реальный доступ к данным?
Урок 6.Как сделать запрос к API. Яндекс.Директ API. Версия 5
В этом уроке вы узнаете:
- Что нужно для запроса API
- Какие форматы для взаимодействия с API Яндекс.Директа?
- Куда отправлять запросы
- Какие заголовки HTTP используются
- Что использовать для выполнения запросов
- Сделать первый запрос
- Что дальше
- Полезные ссылки
- Вопросы
В этом уроке вы увидите форматы взаимодействия с Яндекс.Direct API и узнайте, как сделать свой первый запрос.
Пройдя предыдущие уроки, вы уже выполнили все условия для возможности делать запросы API:
У вас есть аккаунт Яндекс.Директа и вы приняли пользовательское соглашение в разделе API в сети Яндекс.Директ интерфейс.
Вы зарегистрировали свое приложение в Яндекс.OAuth.
Вы запросили доступ к API, и ваш запрос был одобрен.
У вас есть токен OAuth.
- Вы включили Песочницу.
Внимание. Поскольку вы запросили пробный доступ, вы можете работать только с тестовыми данными и песочницей.
Приложение обращается к серверу API Яндекс.Директа по сетевому протоколу HTTPS, отправляя POST-запросы. Каждый запрос POST должен соответствовать определенному формату. Сервер API вернет ответ в том же формате.
API Яндекс.Директа поддерживает два формата:
URL для отправки запросов в Sandbox зависит от выбранного формата:
Для запросов JSON —
https: // api-sandbox.direct.yandex.com/json/v5/{service}Для запросов SOAP —
https://api-sandbox.direct.yandex.com/v5/{service}Описание WSDL доступен по адресу:
https://api-sandbox.direct.yandex.com/v5/{service}?wsdl
Здесь {service} — это имя службы, к которой вы хотите получить доступ. Каждая служба предназначена для использования с определенным классом объектов. Например, для управления рекламными кампаниями вы можете использовать службу Campaigns, отправляя запросы к этой службе по следующим URL-адресам:
URL-адрес, используемый в запросах, чувствителен к регистру: вы должны указать все символы в нижнем регистре, включая имя service, иначе произойдет ошибка.
Внимание. URL-адреса для доступа к реальным данным рекламы отличаются от URL-адресов песочницы: они начинаются с https://api.direct.yandex.com.
Вы можете разработать приложение для запросов API на любом языке программирования. В учебных целях вы можете использовать любую программу для отправки запросов POST: например, вы можете использовать плагин для браузера или утилиту командной строки cURL.
Примеры, показанные здесь и ниже, подходят для утилиты cURL. Вы можете адаптировать предложенный код к своему приложению, написанному на любом языке программирования.
Формат примеров для Windows отличается: код JSON заключен в двойные кавычки, а все двойные кавычки в коде экранированы. Например:
-d "{\" method \ ": \" get \ ", \" params \ "... Внимание. Не забудьте заменить идентификаторы токена и объекта, используемые в примере. код со своими данными.
Давайте посмотрим, какие тестовые кампании были созданы в Sandbox. Обратите внимание на ключевые параметры запроса:
- cURL
curl -k -H "Авторизация: Bearer TOKEN" -d '{" method ":" get "," params ": {" SelectionCriteria ": {}," FieldNames ": [" Id "," Name "]}} 'https: // api-sandbox.direct.yandex.com/json/v5/campaigns- cURL для Windows
curl -k -H "Авторизация: токен на предъявителя" -d "{\" метод \ ": \" получить \ ", \ "params \": {\ "SelectionCriteria \": {}, \ "FieldNames \": [\ "Id \", \ "Name \"]}} "https://api-sandbox.direct.yandex.com / json / v5 / campaign- Запрос
POST / json / v5 / campaign / HTTP / 1.1 Хост: api-sandbox.direct.yandex.com Авторизация: ТОКЕН на предъявителя Accept-Language: ru Вход для клиентов: CLIENT_LOGIN Тип содержимого: приложение / json; charset = utf-8 { "метод": "получить", "params": { "Критерий отбора": {}, "FieldNames": ["Id", "Name"] } }- Ответ
HTTP / 1.1 200 ОК Подключение: закрыть Тип содержимого: приложение / json Дата: пт, 28 июня 2016 г., 17:07:02 GMT RequestId: 1111111111111111112 Единиц: 10/20828/64000 Сервер: nginx Кодирование передачи: фрагментированное { "результат": { "Кампании": [{ "Name": "Кампания тестовой среды API 1", «Id»: 1234567 }, { "Name": "Кампания тестовой среды API 2", «Id»: 1234578 }, { "Name": "Кампания тестовой среды API 3", «Id»: 1234589 }] } }
Итак, вы сделали свой первый запрос в Яндекс.Прямой API. В следующем уроке вы узнаете больше о принципах доступа к данным через API и увидите несколько более сложные примеры кода.
- Как приложение может взаимодействовать с API Яндекс.Директа?
- Какой HTTP-заголовок требуется при запросе к API-серверу Яндекс.Директа?
- Как сервер API Яндекс.Директа отличает запросы тестовых данных от запросов реальных данных?
как подать заявку.Яндекс.Директ API. Версия 5
В этом уроке вы узнаете:
- Как отправить запрос на доступ
- Как узнать результат рассмотрения вашего запроса
- Сроки рассмотрения запроса
- Что дальше
- Полезные ссылки
- Вопросы
В этом уроке мы обсудим второй шаг, позволяющий вашему приложению получить доступ к API Яндекс.Директа: отправка запроса.
После регистрации вашего приложения в Яндекс.OAuth, ваш следующий шаг — отправить запрос на доступ к API Яндекс.Директа. Для выполнения запросов API требуется одобренный запрос. Получив ваш запрос, мы добавим ваше приложение в реестр приложений, обращающихся к Яндекс.Директу, и свяжемся с вами как с его разработчиком, чтобы уведомить вас о важных новостях, попросить настроить работу вашего приложения и т. Д.
Их два типы доступа к API Яндекс.Директа:
Пробный доступ ограничен Яндекс.Прямой API; он позволяет запускать ваше приложение в тестовой среде (песочнице), изолированной от реальных пользовательских данных.
Полный доступ к API Яндекс.Директа; это позволяет вашему приложению работать как в тестовой среде, так и управлять реальными рекламными кампаниями.
Поскольку вы учитесь работать с API Яндекс.Директа, запросите пробный доступ к вашему приложению прямо сейчас. Вы можете сделать запрос, даже если вы еще не создали свое приложение. Вы можете преобразовать этот запрос в запрос полного доступа в любое время позже.
Внимание.Только разработчик может подать заявку на доступ к приложению (а также зарегистрировать приложение в Яндекс.OAuth).
Пользователям вашего приложения это не нужно.
Создайте по одному запросу для каждого из ваших приложений, зарегистрированных на Яндекс.OAuth: один идентификатор приложения — один запрос на доступ. После утверждения запроса любое количество пользователей может запустить приложение.
Авторизуйтесь на Яндексе под своим логином разработчика, т.е.д., имя пользователя, которое вы использовали для регистрации своего приложения в Яндекс.OAuth.
- В веб-интерфейсе Яндекс.Директа перейдите в раздел API, чтобы увидеть настройки доступа к API.
При первом посещении этого раздела примите пользовательское соглашение.
- Перейдите на вкладку Мои запросы.
Щелкните кнопку Новый запрос. В открывшемся меню выберите тип запроса «Пробный доступ».
- В форме создания запроса:
- Выберите идентификатор приложения, полученный при регистрации в Яндекс.OAuth из списка на предыдущем уроке.
Введите адрес электронной почты, который вы используете в настоящее время. Мы будем использовать его, чтобы связаться с вами в случае необходимости.
Введите данные своего приложения в другие поля.
Подтвердите соблюдение вами условий пользовательского соглашения разработчика.
Щелкните кнопку Отправить.
- Выберите идентификатор приложения, полученный при регистрации в Яндекс.OAuth из списка на предыдущем уроке.
Посмотреть свои запросы можно в веб-интерфейсе Яндекс.Директа: перейдите в раздел API, вкладку Мои запросы.Во вкладке вы можете:
отслеживать статус рассмотрения вашего запроса; если он отклонен, вы можете увидеть причины здесь
запросы на добавление, редактирование и удаление.
Запросы на доступ рассматриваются с 10 до 19 часов. в рабочие дни (кроме праздников в России). Рассмотрение запроса может занять от одного часа до трех рабочих дней (в периоды пиковой нагрузки это может занять до семи дней).
Итак, вы создали заявку на доступ к Яндекс.Прямой API. На следующем уроке вы узнаете, как получить токен OAuth, а затем создать и настроить песочницу. Вы можете продолжить этот курс, не дожидаясь завершения рассмотрения вашего запроса: одобренный запрос вам понадобится только позже, когда вы начнете делать запросы API.
- Какие существуют типы доступа к API Яндекс.Директа?
- Кому следует подавать заявку на доступ приложения к API Яндекс.Директа?
- Сколько запросов лучше отправить на одно приложение?
Яндекс.Taxi Graph Technologies: идеальный поиск без маршрутизации запросов к API | от Яндекс.Такси: Под капотом
Артем Бондаренко и Сергей Воронцов, Яндекс.Такси Торговая площадка Эффективность
Когда вы заказываете поездку, ваша служба каршеринга постарается найти водителя, который сможет добраться до вас быстрее всех, чтобы вы тратят меньше времени на ожидание, и они тратят меньше времени на бесплатную поездку. Как правило, служба совместного использования автомобилей использует API маршрутизации, предоставляемый Google Maps и т. Д., Чтобы проверить ожидаемое время прибытия, сравнить их и выбрать лучший автомобиль для вас.Но этот простой поиск является очень дорогостоящим и неэффективным при масштабировании. В Яндекс.Такси нашли изящное решение этой проблемы. Наш новый алгоритм на основе графов каждый раз находит самый быстрый автомобиль, устраняя при этом дорогостоящие вызовы API.
Пятнадцать лет назад, когда мы еще жили в мире без агрегаторов такси, время посадки могло достигать получаса и более. Диспетчеры вручную выбирали ближайший автомобиль из относительно небольшого пула. С появлением агрегаторов количество доступных автомобилей резко возросло, а поиск ближайших водителей был автоматизирован.Но сегодня эффективность этого процесса оставляет желать лучшего.
Когда дело касается крупных игроков рынка, этот процесс необходимо оптимизировать вместе с необходимыми вычислительными ресурсами. Это как раз та задача, которую мы любим решать в Яндекс.Такси. В этом посте мы расскажем, как мы разработали алгоритм, который элегантно решает эту проблему.
Начнем со «старого» прямого подхода.
В реальном мире автомобили передвигаются по дорогам.Но в электронном мире агрегаторы знают только свои координаты на плоскости. Они не имеют ни малейшего представления о том, на какой улице движется транспортное средство и по какому пути следует подобрать водителя. Легко понять, почему знание дорожной сети и трафика имеет решающее значение для определения того, какой автомобиль доберется до места быстрее всего. Здесь на помощь приходят сервисы маршрутизации.
Приложения для совместного использования позволяют рассчитать время прибытия в пункт выдачи для каждой доступной машины. Традиционно они используют службу маршрутизации для нанесения на карту маршрутов для каждого транспортного средства на основе текущего трафика.
Но вот в чем проблема: запросы на маршрутизацию стоят денег. Невозможно каждый раз спрашивать у маршрутной службы о каждой машине в городе, не обанкротившись. Предположим, есть город с 100 000 запросов в день и 1 000 доступных автомобилей в любой момент времени. Оценка времени прибытия каждой машины в город может стоить десятки или даже сотни тысяч долларов в день, что непомерно дорого.
Для нашего метода мы использовали сервисы маршрутизации нашей материнской компании, предоставляемые Яндекс-картами.Наличие собственной службы маршрутизации — огромное преимущество, но каждый дополнительный запрос маршрутизации по-прежнему не был бесплатным, поскольку увеличивал нагрузку на наш сервер.
Значит, по-прежнему нужно было как-то ограничивать количество проверяемых автомобилей. Но поскольку все, что вы знаете об автомобилях, — это их координаты, вы можете выбрать только ближайшие автомобили по геометрическому расстоянию (то есть по кругу). Действительно, проверять водителей на другом конце города бессмысленно.
К сожалению, бывают случаи, когда кружок вокруг места посадки, который обычно работает нормально, не включает ближайшую машину.Представьте себе всадника, ожидающего на одной стороне реки, а несколько водителей ждут на другой стороне без каких-либо близлежащих мостов. Этот случай может показаться редким, но по мере того, как ваше приложение масштабируется и начинает обслуживать миллионы людей, вы обнаруживаете, что теряете оптимальные совпадения в значительном количестве случаев. Это означает, что по мере того как вы ограничиваете запросы услуг маршрутизации меньшим кругом вокруг пункта посадки, вы увеличиваете риск того, что вы не найдете автомобиль, который может быстро забрать водителя.
Это приводит к следующему компромиссу:
● Сэкономьте на количестве путей, запрашиваемых службой маршрутизации, но рискуете не найти самый быстрый автомобиль
● Или всегда находите водителя с самым быстрым временем посадки, но платите через зубы в оплате услуг маршрутизации.
Новый алгоритм, который мы разработали, исключает компромисс между эффективностью и ценой: он гарантирует, что самый быстрый автомобиль будет найден каждый раз, и делает ненужными запросы к дорогостоящим службам маршрутизации. Это может показаться волшебством, но за этим стоит тяжелая работа. Нам пришлось разобрать весь процесс сопоставления и собрать новый с новыми структурами данных и новыми алгоритмами, оптимизированными для каждой задачи.
Мы начали с изучения сервисов технической маршрутизации, которые используются для обработки запросов от приложений для совместного использования.Обычно он основан на данных городской дорожной сети и трафика, включая расположение улиц, их взаимосвязи, направления движения на этих улицах и скорость движения. Служба маршрутизации находит самый быстрый маршрут из одной точки в другую и прогнозирует время, которое потребуется автомобилю, чтобы проехать по нему. Затем приложение для совместного использования сравнивает ожидаемое время прибытия всех доступных водителей в определенной близости, чтобы выбрать самого быстрого. Поэтому приложения для совместного использования поездок полагаются на внешние службы маршрутизации, чтобы знать, как быстро водители могут добраться до места отправления.
Легко видеть, что если бы у нас были все эти знания на нашей стороне, мы могли бы каждый раз правильно находить самую быструю машину. Вот почему мы решили интегрировать структуру дорожных сетей в наши системы. Мы построили структуру данных графа с ребрами, представляющими улицы, узлами, представляющими перекрестки, и всеми характеристиками, необходимыми для расчета оптимального маршрута и времени прибытия, включая ограничения движения и скорость движения на каждом краю. Теперь Яндекс.Такси видит автомобили не как массу точек на поверхности, а как места на структуре данных графа.
Имея такую структуру, мы используем один из наших алгоритмов «обхода графа» для поиска на графе и нахождения водителя, который первым достигнет точки сбора. Более того, алгоритм может найти любое указанное количество автомобилей в порядке ожидаемого времени прибытия.
Обратите внимание, что без данных о трафике в реальном времени было бы невозможно правильно предсказать время прибытия автомобилей. Недостаточно знать дорожную систему, потому что текущие условия движения сильно влияют на то, сколько времени потребуется, чтобы добраться из пункта А в пункт Б.
Как уже упоминалось выше , Яндекс.Такси имеет огромное преимущество перед другими компаниями, занимающимися вызовом такси, когда дело касается картографии и навигации в реальном времени. У нас есть доступ к картам и совершенно точным, регулярно обновляемым данным о дорожной инфраструктуре из собственных геосервисов Яндекс, нашей материнской компании. Кроме того, мы полагаемся на геосервисы Яндекса для получения данных о дорожной обстановке в режиме реального времени, что очень важно для точной оценки времени прибытия. Яндекс.Такси использует эти тесные отношения для создания лучших в своем классе технологий и услуг.
Две части — график и данные о дорожном движении в реальном времени — взаимодействуют в гармонии, создавая совершенно новый способ подбора гонщиков и водителей. Мы избавились от необходимости запрашивать время прибытия для каждой машины поблизости от службы маршрутизации. Используя дорожную инфраструктуру и данные о дорожном движении в режиме реального времени, мы создали алгоритм, который выполняет поиск по дорожной диаграмме и находит автомобили строго по времени посадки. Другими словами, мы решили проблему «ближайшей машины» максимально точно, без необходимости многократных запросов маршрутизации.И вишенка на вершине: наш подход также определяет произвольное количество ближайших автомобилей с максимальной эффективностью.
Созданная нами новая технология решает раз и навсегда компромисс между качеством поиска и стоимостью запросов маршрутизации:
1. Миллионы запросов API маршрутизации в день в алгоритмах поиска были полностью исключены.
2. Снижены средние сроки подачи, в том числе до 15% в регионах со сложной дорожной структурой: вблизи многоуровневых развязок, железных дорог и рек.
3. Мы заложили основу для переосмысления всей группы плоских алгоритмов на графах. Скачкообразное ценообразование — один из таких алгоритмов — он может более эффективно работать в графической инфраструктуре. Например, он может распознавать различный баланс спроса и предложения на противоположных сторонах дороги. Иногда это происходит из-за асимметрии доступных автомобилей, вызванной пробками и ограничениями на разворот.
ClickHouse — быстрая СУБД OLAP с открытым исходным кодом
sudo apt-get install apt-transport-https ca-Certificates dirmngr
sudo apt-key adv --keyserver hkp: // сервер ключей.ubuntu.com:80 --recv E0C56BD4
echo "deb https://repo.clickhouse.tech/deb/stable/ main /" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y кликхаус-сервер кликхаус-клиент
запуск службы sudo clickhouse-server
clickhouse-client sudo yum установить yum-utils sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo sudo yum установить clickhouse-server clickhouse-client sudo / etc / init.d / clickhouse-server start clickhouse-client
export LATEST_VERSION = $ (curl -s https://repo.clickhouse.tech/tgz/stable/ | \
grep -Eo '[0-9] + \. [0-9] + \. [0-9] + \. [0-9] +' | sort -V -r | голова -n 1)
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-common-static-$LATEST_VERSION.tgz
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-common-static-dbg-$LATEST_VERSION.tgz
curl -O https://repo.clickhouse.tech/tgz/stable/clickhouse-server-$LATEST_VERSION.tgz
curl -O https: // репо.clickhouse.tech/tgz/stable/clickhouse-client-$LATEST_VERSION.tgz
tar -xzvf clickhouse-common-static- $ LATEST_VERSION.tgz
sudo clickhouse-common-static- $ LATEST_VERSION / install / doinst.sh
tar -xzvf clickhouse-common-static-dbg- $ LATEST_VERSION.tgz
sudo clickhouse-common-static-dbg- $ LATEST_VERSION / install / doinst.sh
tar -xzvf clickhouse-server- $ LATEST_VERSION.tgz
sudo clickhouse-server- $ LATEST_VERSION / install / doinst.sh
sudo /etc/init.d/clickhouse-server start
tar -xzvf clickhouse-client- $ LATEST_VERSION.тгз
sudo clickhouse-client- $ LATEST_VERSION / install / doinst.sh # Сборка ARM (AArch64) работает на машинах Amazon Graviton, Oracle Cloud, Huawei Cloud ARM. # Поддержка AArch64 подготовлена к производству. wget 'https://builds.clickhouse.tech/master/aarch64/clickhouse' chmod a + x ./clickhouse sudo ./clickhouse установить
wget 'https://builds.clickhouse.tech/master/macos/clickhouse' chmod a + x ./clickhouse ./clickhouse
wget 'https://builds.clickhouse.tech/master/macos-aarch64/clickhouse' chmod a + x./ clickhouse ./clickhouse
wget 'https://builds.clickhouse.tech/master/freebsd/clickhouse' chmod a + x ./clickhouse sudo ./clickhouse install
Российские технологии: будь большим и оставайся дома — Executive Search
Яндекс — ведущая поисковая система в России, опережающая Google и занимающая более половины поискового рынка страны (54% по состоянию на август 2017 года) и 61% интернет-рекламы. Его фирменные веб-сайты привлекают более 60 миллионов посетителей в месяц. И все же, несмотря на то, что Яндекс является одной из крупнейших интернет-компаний в мире, он имеет относительно небольшое глобальное присутствие.92% его доходов поступает из России, где находится самая большая в Европе база пользователей Интернета, насчитывающая около 87 миллионов человек.
Яндекс быстро завоевал лидирующие позиции в Интернете, разумно предлагая технологии, адаптированные к местным потребностям. Например, поисковый алгоритм Яндекса значительно лучше справлялся с запросами на русском языке, чем у международных конкурентов. Картографическая программа, предоставляющая информацию о дорожном движении в реальном времени, особенно понравилась водителям на забитых московских дорогах, которые Яндекс хорошо знал.
Быть «местным» продолжает оставаться важной частью стратегии компании. Как выразился соучредитель Аркадий Волож: «Вы либо выходите на мировой рынок в рамках одной услуги, которая вам нравится, либо вы сосредотачиваетесь на одном рынке и делаете это очень хорошо». Соответственно, расширяющийся ассортимент продуктов и услуг Яндекса, от такси, покупок и платежей до образования, удовлетворяет особые потребности российских пользователей. В настоящее время Яндекс наращивает свои транспортные возможности и возможности электронной коммерции для поддержки своих услуг на местах.
Признаки успешной диверсификации привели к росту акций Яндекса примерно на 50% за последний год. Согласно The Economist, «инвесторы особенно оптимистично относятся к таксомоторному бизнесу». После дорогостоящей ценовой войны в июле Яндекс согласился на слияние с Uber за 3,7 миллиарда долларов, что помешало последнему стремиться к доминированию. Обе компании объединят свой бизнес по вызову автомобилей на местном рынке в рамках новой, пока не названной компании. Яндекс получит контрольный пакет акций в размере 59,3%, а Тигран Худавердян, генеральный директор Яндекс.Такси будет исполнять обязанности генерального директора.
Яндекс также создает совместное предприятие с государственной компанией, предоставляющей банковские и финансовые услуги, Сбербанк, чтобы превратить свою платформу сравнения цен в полноценный бизнес электронной коммерции. Другие инициативы, такие как виртуальный помощник на русском языке, выстраиваются в очередь, чтобы поддержать видение Яндекса себя центром цифровой экономики России.
На фоне всего этого успеха и расширения у Яндекса долгое время была проблема: политическая критика.Его мобильные платежи и новостные сервисы, среди прочего, вызвали раздражение у государственных чиновников, поскольку они действуют в значительной степени вне контроля государства. Эти двое продолжают враждовать. Но, учитывая реалии ведения бизнеса в России, Яндекс в последнее время пошел на некоторые уступки, например, указав на своих картах Крым как часть России. И хотя потребовались некоторые корректировки, чтобы смягчить свободную и открытую среду технологической компании по этому случаю, президент Владимир Путин 21 сентября нанес дружеский визит по случаю своего 20-летия.
Эволюция структур данных в Яндекс.Метрике
Яндекс.Метрика — вторая по величине система веб-аналитики в мире. Метрика принимает поток данных, представляющих события, которые произошли на сайтах или в приложениях. Наша задача — обработать эти данные и представить их в анализируемой форме.
Обработка данных сама по себе не проблема. Настоящая трудность заключается в попытке определить, в какой форме следует сохранять обработанные результаты, чтобы с ними было легко работать.В процессе разработки нам несколько раз приходилось полностью менять подход к организации хранения данных. Мы начали с таблиц MyISAM, затем использовали LSM-деревья и в итоге пришли к базе данных, ориентированной на столбцы, ClickHouse. В этой статье я объясню, что заставило нас остановиться на последнем варианте.
Яндекс.Метрика была запущена в 2008 году и работает уже более девяти лет. Каждый раз, когда мы меняли подход к хранению данных в прошлом, это происходило из-за того, что конкретное решение оказалось неэффективным: либо был недостаточный резерв производительности, либо решение было ненадежным, либо оно использовало слишком много вычислительных ресурсов, либо просто не позволяло нам реализовать то, что нам нужно.
Старая Яндекс.Метрика для веб-сайтов имеет более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов аналитики на странице (например, карты кликов), Webvisor (который позволяет изучать действия отдельных пользователей в большая деталь), а также отдельный конструктор отчетов.
С новыми Metrica и Appmetrica вы можете настраивать каждый отчет вместо того, чтобы иметь дело с «фиксированными» типами. Вы можете добавлять новые параметры (например, в отчете по поисковым запросам вы можете разбить данные по целевым страницам), сегментировать и сравнивать (например, между источниками трафика для всех посетителей ипосетителей из Сан-Франциско), измените свой набор показателей и т. д. Новая система, таким образом, требует совершенно другого подхода к хранению данных, чем тот, который мы использовали ранее.
MyISAM
Изначально Метрика была разработана как ответвление Яндекс.Директ, службы поисковой рекламы. Таблицы MySQL с движком MyISAM использовались в Direct для хранения статистики, и именно с этого мы начали в Метрике. Мы использовали MyISAM для хранения «фиксированных» отчетов с 2008 по 2011 годы.
Позвольте мне немного пояснить, какую структуру следует использовать в таблицах отчетов, например, при работе с географией.Отчет составляется по конкретному сайту (точнее, конкретному идентификатору счетчика Метрики). Это означает, что первичный ключ должен содержать CounterID. Пользователь может выбрать произвольный отчетный период. Хранить данные для каждой пары дат не имеет смысла, поэтому данные сохраняются для каждой даты, а затем накапливаются по запросу для выбранного интервала. Следовательно, первичный ключ содержит дату.
Данные в отчете отображаются для регионов либо в виде списка, либо в виде дерева, состоящего из стран, регионов и городов.Таким образом, имеет смысл поместить RegionID в первичный ключ таблицы и собрать данные в дерево на стороне кода приложения, а не на стороне базы данных.
Допустим, мы также хотим учитывать среднюю продолжительность сеанса. Это означает, что столбцы таблицы должны содержать количество сеансов и общую продолжительность сеанса.
Итак, итоговая таблица будет иметь следующую структуру: CounterID, Date, RegionID -> Visits, SumVisitTime,… Теперь посмотрим, что происходит, когда мы запрашиваем отчет.Запрос SELECT выполняется с условиями WHERE CounterID = AND Date BETWEEN min_date AND max_date. Другими словами, считывается диапазон первичного ключа.
Как данные на самом деле хранятся на диске?
Таблица MyISAM состоит из файла данных и индексного файла. Если ничего не было удалено из таблицы и строки не изменились по длине во время обновления, файл данных будет состоять из сериализованных строк, расположенных последовательно в том порядке, в котором они были вставлены. Индекс (включая первичный ключ) представляет собой B-дерево, где листья содержат смещения в файле данных.Когда мы читаем данные диапазона индекса, набор смещений в файле данных извлекается из индекса. Затем файл данных считывается этим набором смещений.
Давайте посмотрим на реальную ситуацию, когда индекс находится в ОЗУ (ключевой кеш в MySQL или кеш системных страниц), но данные в нем не кэшируются. Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от количества операций поиска, которые необходимо выполнить. Количество поисков определяется местонахождением данных на диске.
События Метрики принимаются почти в том же порядке, в котором они действительно имели место. В этом входящем потоке данные с разных счетчиков разбросаны совершенно случайным образом. Другими словами, входящие данные являются локальными по времени, но не локальными по номеру счетчика. При записи в таблицу MyISAM данные с разных счетчиков также размещаются довольно случайно. Это означает, что для чтения отчета с данными вам нужно будет выполнить примерно столько произвольных чтений, сколько строк в таблице нам нужно.
Стандартный жесткий диск со скоростью 7200 об / мин может выполнять от 100 до 200 произвольных операций чтения в секунду. RAID-массив при правильном использовании может пропорционально выполнять гораздо больше. Один SSD-накопитель семилетней давности может выполнять 30 000 произвольных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. В этой системе, если нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
InnoDB намного лучше подходит для чтения диапазонов первичных ключей, поскольку он использует кластеризованный первичный ключ (т.е. данные хранятся упорядоченным образом на первичном ключе). Но InnoDB было невозможно использовать из-за его низкой скорости записи. Если это напоминает вам TokuDB, читайте дальше.
Мы применили несколько приемов, чтобы MyISAM работал быстрее при выборе диапазона первичного ключа.
Стол сортировочный. Поскольку данные должны обновляться постепенно, недостаточно один раз отсортировать таблицу, но сортировать ее каждый раз невозможно. Тем не менее, это можно делать периодически для старых данных.
Разбиение на разделы.Таблица разделена на несколько меньших диапазонов первичных ключей. Это делается в надежде, что данные из одного раздела будут храниться более или менее локально, а запросы для диапазона первичных ключей будут обрабатываться быстрее. Этот метод можно отнести к ручной реализации кластеризованного первичного ключа. Это немного замедляет вставку данных. Однако при выборе количества разделов обычно достигается компромисс между скоростью вставки и скоростью чтения.
Разделение данных по поколениям.При одной схеме разбиения выборки могут сильно замедляться, при другой — скорость вставки. И оба тормозят при использовании промежуточного варианта. Решение этой проблемы — разделить данные на несколько отдельных поколений. Например, первое поколение мы назовем оперативными данными; здесь разбиение либо происходит по мере вставки данных (по времени), либо не происходит вообще. Мы будем называть данные архива второго поколения; здесь происходит разбиение по мере считывания данных (по номеру счетчика).Данные передаются из поколения в поколение с помощью скрипта, но не слишком часто (например, один раз в день) и сразу же считываются из всех поколений. Это помогает, но также создает массу трудностей.
Эти (и другие) уловки какое-то время использовались в Яндекс.Метрике, чтобы все заработало.
Подведем итог недостаткам предыдущей системы:
- расположение данных на диске очень сложно поддерживать
- таблиц заблокированы во время INSERT
- репликация медленная; реплики часто лагают
- Согласованность данных после аппаратного сбоя не гарантируется
- агрегатов, таких как количество уникальных пользователей, очень сложно подсчитать и сохранить
- сжатие данных сложно использовать и работает неэффективно Индексы
- занимают много места и не помещаются в ОЗУ полностью
- данные должны быть сегментированы вручную
- многие вычисления должны выполняться на стороне кода приложения после SELECT
- сложный в обслуживании и эксплуатации
Изображение: расположение данных на диске (художественная визуализация)
В общем, MyISAM было крайне неудобно использовать.Днем серверы работали со 100% загрузкой дисковых массивов (постоянное движение головы). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, восстанавливать RAID-массивы приходилось довольно часто. Иногда реплики отставали настолько, что нам приходилось отбрасывать и воссоздавать их. Переключение мастера репликации действительно неудобно.
Несмотря на его недостатки, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM. Затем все было переконвертировано в Metrage, удалено, и в конце концов освободилось много серверов.
Metrage и OLAPServer
Мы используем Metrage для хранения фиксированных отчетов с 2010 года. Предположим, у вас есть следующий сценарий:
- данные постоянно записываются в базу данных небольшими партиями
- поток записи относительно велик (не менее нескольких сотен тысяч строк в секунду)
- сравнительно мало запросов на чтение (несколько тысяч запросов в секунду)
- все чтения диапазона первичного ключа (до миллионов строк на запрос)
- строк довольно короткие (около 100 байт без сжатия)
Для этого хорошо подходит довольно распространенная структура данных, LSM Tree.Эта структура состоит из сравнительно небольшой группы «блоков» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные изначально помещаются в какую-либо структуру данных RAM (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков в фоновом режиме сжимаются в один более крупный. Таким образом сохраняется относительно небольшой набор фрагментов.
Этот вид структур данных используется в HBase и Cassandra. Среди встроенных структур данных LSM-Tree реализованы LevelDB и RocksDB.Впоследствии RocksDB используется в MyRocks, MongoRocks, TiDB, CockroachDB и многих других.
Metrage также является LSM-деревом. Произвольные структуры данных (фиксированные во время компиляции) могут использоваться в нем как «строки». Каждая строка — это пара ключ-значение. Ключ — это структура с операциями сравнения на равенство и неравенство. Значение представляет собой произвольную структуру с операциями по обновлению (добавлению чего-либо) и слиянию (агрегированию или объединению с другим значением). Короче говоря, это CRDT.
В качестве значений могут использоваться как простые структуры (целочисленные кортежи), так и более сложные (например, хеш-таблицы для расчета количества уникальных посетителей или структуры карты кликов).Используя операции обновления и слияния, инкрементная агрегация данных постоянно выполняется в следующих точках:
- при вставке данных при формировании новых пакетов в RAM
- во время фонового слияния
- во время запросов на чтение
Metrage также содержит нужную нам предметно-ориентированную логику, которая выполняется во время запросов. Например, для отчетов по регионам ключ в таблице будет содержать идентификатор самого низкого региона (город, деревня), и, если нам нужен отчет по стране, данные страны завершат агрегирование на стороне сервера базы данных.
Вот основные преимущества этой структуры данных:
- Данные расположены довольно локально на жестком диске; чтение диапазона первичного ключа происходит быстро.
- Данные сжимаются блоками. Поскольку данные хранятся упорядоченно, сжатие очень хорошо работает при использовании алгоритмов быстрого сжатия (в 2010 году мы использовали QuickLZ, с 2011 года — LZ4).
- Хранение данных, отсортированных по первичному ключу, позволяет нам использовать разреженный индекс. Разреженный индекс — это массив значений первичного ключа для каждой N-й строки (порядка N тысяч).Этот индекс максимально компактен и всегда умещается в оперативной памяти.
Поскольку чтение выполняется не очень часто (даже если при этом читается много строк), увеличение задержки из-за наличия большого количества фрагментов и распаковки блоков данных не имеет значения. Чтение дополнительных строк из-за разреженности индекса также не имеет значения.
Записанные блоки данных не изменяются. Это позволяет читать и писать без блокировки — для чтения берется моментальный снимок данных.Используется простой и единообразный код, но мы можем легко реализовать всю необходимую логику для конкретной предметной области.
Нам пришлось написать Metrage вместо того, чтобы вносить поправки в существующее решение, потому что на самом деле его не было. LevelDB не существовал в 2010 году, и TokuDB в то время был проприетарным.
Все системы, реализующие LSM-Tree, подходили для хранения неструктурированных данных и преобразования BLOB в BLOB с небольшими вариациями. Но адаптация этого типа системы для работы с произвольным CRDT заняла бы гораздо больше времени, чем разработка Metrage.
Преобразование данных из MySQL в Metrage было довольно трудоемким: программа преобразования работала всего за неделю, а основная часть работала около двух месяцев.
После передачи отчетов в Metrage мы сразу увидели увеличение скорости интерфейса Metrica. Мы используем Metrage пять лет, и это оказалось надежным решением. За это время было всего несколько мелких сбоев. Его преимущества заключаются в простоте и эффективности, что сделало его гораздо лучшим выбором для хранения данных, чем MyISAM.
По состоянию на 2015 год мы хранили 3,37 триллиона строк в Metrage и использовали для этого 39 * 2 серверов. Затем мы отошли от хранения данных в Metrage и удалили большую часть таблиц. У системы есть свои недостатки; он действительно эффективно работает только с фиксированными отчетами. Metrage агрегирует данные и сохраняет агрегированные данные. Но для этого вы должны заранее перечислить все способы, которыми вы хотите агрегировать данные. Так что если мы сделаем это 40 различными способами, это означает, что Метрика будет содержать 40 типов отчетов и не более.
Чтобы смягчить это, нам пришлось на время сохранить отдельное хранилище для мастера настраиваемых отчетов, называемое OLAPServer. Это простая и очень ограниченная реализация базы данных, ориентированной на столбцы. Он поддерживает только одну таблицу, установленную во время компиляции — сеансовую таблицу. В отличие от Metrage, данные обновляются не в реальном времени, а несколько раз в день. Единственный поддерживаемый тип данных — это числа фиксированной длины от 1 до 8 байтов, поэтому он не подходил для отчетов с другими типами данных, например URL-адресами.
ClickHouse
Используя OLAPServer, мы разработали понимание того, насколько хорошо ориентированные на столбцы СУБД справляются с задачами специальной аналитики с неагрегированными данными.Если вы можете получить какой-либо отчет из неагрегированных данных, тогда возникает вопрос, нужно ли вообще агрегировать данные заранее, как мы это сделали с Metrage.
Изображение: обработка запросов в базе данных, ориентированной на столбцы
С одной стороны, предварительная агрегация данных может уменьшить объем данных, которые используются в момент загрузки страницы отчета. С другой стороны, агрегированные данные не решают всего. Вот причины, почему:
- вам необходимо иметь список отчетов, которые потребуются вашим пользователям заранее
- другими словами, пользователь не может составить собственный отчет
- при агрегировании большого количества ключей объем данных не уменьшается и агрегирование бесполезно
- при большом количестве отчетов слишком много вариантов агрегирования (комбинаторное разнесение)
- при агрегировании ключей с высокой мощностью (например, URL-адресов) объем данных не уменьшается намного (менее чем вдвое)
- из-за этого объем данных может не уменьшаться, а реально расти при агрегации
- пользователей не будут просматривать все отчеты, которые мы для них рассчитываем (другими словами, многие расчеты оказываются бесполезными)
- трудно поддерживать логическую последовательность при хранении большого количества различных агрегатов
Как видите, если ничего не агрегируется и мы работаем с неагрегированными данными, то возможно даже сокращение объема вычислений.Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Итак, если мы агрегируем данные заранее, мы должны делать это постоянно (в реальном времени), но асинхронно по отношению к запросам пользователей. Нам действительно нужно просто агрегировать данные в реальном времени; большая часть получаемого отчета должна состоять из подготовленных данных.
Если данные не агрегированы заранее, вся работа должна выполняться в тот момент, когда пользователь запрашивает их (т.е. пока они ждут загрузки страницы отчета). Это означает, что в ответ на запрос пользователя необходимо обработать многие миллиарды строк; чем быстрее это можно будет сделать, тем лучше.
Для этого вам понадобится хорошая колоночная СУБД. На рынке не было СУБД, ориентированных на столбцы, которые бы достаточно хорошо справлялись с задачами интернет-аналитики в масштабе Рунета (российского Интернета) и не были бы непомерно дорогими для лицензирования.
В последнее время в качестве альтернативы коммерческим СУБД, ориентированной на столбцы, начали появляться решения для эффективной специальной аналитики данных в распределенных вычислительных системах: Cloudera Impala, Spark SQL, Presto и Apache Drill.Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить как бэкэнд для веб-интерфейса аналитической системы, доступной внешним пользователям.
В Яндексе мы разработали, а затем открыли исходный код собственной колоночной СУБД — ClickHouse. Давайте рассмотрим основные требования, которые мы имели в виду, прежде чем приступить к разработке.
Умение работать с большими наборами данных. В нынешней Яндекс.Метрике для веб-сайтов ClickHouse используется для хранения всех данных для отчетов.По состоянию на сентябрь 2017 года база данных состоит из 25,1 трлн строк. Он состоит из неагрегированных данных, которые используются для получения отчетов в режиме реального времени. Каждая строка в самой большой таблице содержит более 500 столбцов.
Система должна масштабироваться линейно. ClickHouse позволяет увеличивать размер кластера, добавляя новые серверы по мере необходимости. Например, основной кластер Яндекс.Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы распределены по разным центрам обработки данных.ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Высокая эффективность. Мы действительно делаем упор на высокую производительность нашей базы данных. По результатам внутренних тестов ClickHouse обрабатывает запросы быстрее, чем любая другая система, которую мы могли бы приобрести. Например, ClickHouse обрабатывает запросы веб-аналитики в среднем в 2,8–3,4 раза быстрее, чем одна из самых эффективных коммерческих СУБД, ориентированных на столбцы (назовем ее DBMS-V).
Функциональности должно хватить для инструментов веб-аналитики.База данных поддерживает диалект языка SQL, подзапросы и СОЕДИНЕНИЯ (локальные и распределенные). Существует множество расширений SQL: функции для веб-аналитики, массивы и вложенные структуры данных, функции высшего порядка, агрегатные функции для приближенных вычислений с использованием эскизов и т. Д.
ClickHouse изначально был разработан командой Яндекс.Метрики. Кроме того, нам удалось сделать систему достаточно гибкой и расширяемой, чтобы ее можно было успешно использовать для решения различных задач. Хотя база данных может работать на больших кластерах, ее можно установить на одном сервере или даже на виртуальной машине.
ClickHouse хорошо оборудован для создания всевозможных аналитических инструментов. Только подумайте: если система справится с задачами Яндекс.Метрики, вы можете быть уверены, что ClickHouse справится с другими задачами с большим запасом производительности.
ClickHouse хорошо работает как база данных временных рядов; в Яндексе он обычно используется как бэкэнд для Graphite вместо Ceres / Whisper. Это позволяет нам работать с более чем триллионом метрик на одном сервере.
ClickHouse используется аналитикой для внутренних задач.Исходя из нашего опыта в Яндексе, ClickHouse работает примерно на три порядка выше, чем древние методы обработки данных (скрипты на MapReduce). Но это не простая количественная разница. Дело в том, что обладая такой высокой скоростью вычислений, вы можете позволить себе использовать радикально другие методы решения задач.
Если аналитик должен составить отчет, и он компетентен в своей работе, он не будет просто строить один отчет. Вместо этого они начнут с поиска десятков других отчетов, чтобы лучше понять природу данных и проверить различные гипотезы.Часто бывает полезно взглянуть на данные с разных сторон, чтобы сформулировать и проверить новые гипотезы, даже если у вас нет четкой цели.
Это возможно только в том случае, если скорость анализа данных позволяет проводить мгновенное исследование. Чем быстрее выполняются запросы, тем больше гипотез вы сможете проверить. Работая с ClickHouse, даже возникает ощущение, что они могут думать быстрее.
В традиционных системах данные, образно говоря, подобны мертвому грузу. Вы можете манипулировать им, но это занимает много времени и неудобно.Однако, если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных сечениях и переходить к отдельным строкам данных.
После года использования открытого исходного кода ClickHouse теперь используется сотнями компаний по всему миру. Например, CloudFlare использует ClickHouse для анализа трафика DNS, обрабатывая около 75 миллиардов событий каждый день. Другой пример — Vertamedia (платформа SSP для видео), которая ежедневно обрабатывает 200 миллиардов событий в ClickHouse со скоростью загрузки около 3 миллионов строк в секунду.
Выводы
Яндекс.Метрика стала второй по величине системой веб-аналитики в мире. Объем данных, которые принимает Метрика, вырос с 200 миллионов событий в день в 2009 году до более 25 миллиардов в 2017 году. Чтобы предоставить пользователям широкий спектр возможностей, при этом не отставая от растущей рабочей нагрузки, нам пришлось постоянно меняем наш подход к хранению данных.
Для нас очень важно эффективное использование оборудования. По нашему опыту, когда у вас большой объем данных, лучше не беспокоиться о том, насколько хорошо масштабируется система, и вместо этого сосредоточиться на том, насколько эффективно используется каждая единица оборудования: каждое ядро процессора, диск и SSD, RAM и сеть.В конце концов, если ваша система уже использует сотни серверов и вам нужно работать в десять раз эффективнее, маловероятно, что вы сможете просто приступить к установке тысяч серверов, независимо от того, насколько масштабируема ваша система.
Чтобы добиться максимальной эффективности, важно настроить решение в соответствии с потребностями конкретного типа рабочей нагрузки. Нет такой структуры данных, которая бы хорошо справлялась с совершенно разными сценариями. Например, очевидно, что базы данных «ключ-значение» не работают для аналитических запросов.