
Язык запросов Яндекса: что это такое
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ABCDEFGHIJKLMNOPQRSTUVWXYZ0-9
Отправка запроса Яндексу осуществляется посредством расширенного поиска или с помощью возможностей языка поисковой системы, который применяется при поисковой оптимизации сайта.
Пользователи могут указывать требования к встречаемости запросов относительно друг друга:
- точное совпадение, т.е. слова в тексте расположены подряд в точной словоформе. По запросу “монтаж пластиковых окон” будут найдены страницы только с таким словосочетанием. Ресурсы, в контенте которых встречается “монтаже пластикового окна”, “монтажу пластиковых окон” и т.д., в результаты выдачи не попадут. С помощью кавычек также можно задать пропуск одного или нескольких слов, поставив вместо них звездочки через пробел, например, (“старый * год”).
- совместная встречаемость. Если элементы запроса соединены символом & через пробел, то будут найдены страницы, где данные слова расположены в одном предложении (например, продвижение сайтов & Москва).

- исключение слов. Чтобы исключить из результатов страницы, в которых помимо запроса, встречаются конкретные слова (или одно слово), их указывают справа через ~~. Например, запрос раскрутка сайтов ~~ Киев позволит исключить из выдачи предложения киевские SEO компании.
- расстояние между словами внутри предложения регулируется оператором / и числом. Чтобы задать количество предложений между словами запроса, перед / ставят оператор &&.
- порядок слов. Если известен порядок слов запроса, между / и числом указывают + или – для прямого или обратного порядка слов. Например, по запросу Петр /+2 Сидоров будут показаны страницы, где между именем и фамилией встречается отчество.
- выбор из слов. При перечислении нескольких слов в запросе через символ | Яндекс найдет документы, в которых встречается одно или несколько из указанных слов.
- морфология. По умолчанию Яндекс ищет указанные слова во всех морфологических формах. С помощью оператора ! можно задать поиск слова только в одной словоформе (например, !музыка).


Все перечисленные варианты запросов могут быть скомбинированы. Сложные конструкции отделяются круглыми скобками.
Другие термины на букву «Я»
AdSenseAJAXAllSubmitterAltApacheAPIBegunBlogunCAPTCHACMSCookieCopylancerCPACPCCPLCPMCPOCPSCPVCRMCS YazzleCSSCTR, CTB, CTI, VTRDescriptionDigital-агентствоDigital-маркетингDMOZDoS и DDoS атакиEmailFaviconFeedBurnerFTPGoGetLinksGoogle AdWordsGoogle AnalyticsGoogle ChromeGoogle MapsGoogle webmasters toolsGoogle Мой бизнесhCardhProducthRecipehreflanghtaccessHTTP-заголовкиHTTP-протоколHTTPS-протоколInternet ExplorerIP-адресJavaScriptJoomlaKeywordsKPILanding PageLiexLiveinternetLTVMash-upMiralinksMozilla FirefoxMSNNofollow и noindexOperaPageRank и тИЦPerformance MarketingPHPPinterestPPAPPCPush-уведомленияRobots.txtROI (ROMI)RookeeRotapostRSSSafariSapeSEO-продвижениеSEO-трафикSeoPultSeozavrSERPSidebarSitemap.

Все термины SEO-Википедии
Теги термина
ЯндексРанжирование
(Рейтинг: 5, Голосов: 5) |
Находи клиентов. Быстрее!
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Приложи файл или ТЗ
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
наверх
«Яндекс» раскрыл число запросов от властей на данные пользователей — РБК
«Яндекс» впервые раскрыл число запросов госорганов о раскрытии пользовательских данных: в первом полугодии компания отказала в 16% случаев. Google, опубликовавшая такие данные во втором полугодии 2019-го, отказала по 77% запросов
Google, опубликовавшая такие данные во втором полугодии 2019-го, отказала по 77% запросов
Фото: Артем Голощапов для РБК
За первое полугодие 2020 года «Яндекс» получил от органов государственной власти более 15 тыс. запросов на раскрытие пользовательских данных. В большинстве случаев они были удовлетворены, количество отказов составило 2468, или 16%, сообщается на сайте компании. Как пояснил представитель компании, это первый подобный отчет, в дальнейшем он будет выходить каждые полгода.
Речь идет об органах власти не только России, но и других стран, в которых работает «Яндекс».
«В ответ на запрос компания предоставляет ровно столько информации, сколько необходимо для ответа. А если запрос не соответствует требованиям закона, «Яндекс» его отклоняет. Запросы, пришедшие по неофициальным каналам, например по электронной почте или по телефону, не получают ответа и не учитываются в статистике», — сообщили в компании.
adv.rbc.ru
adv.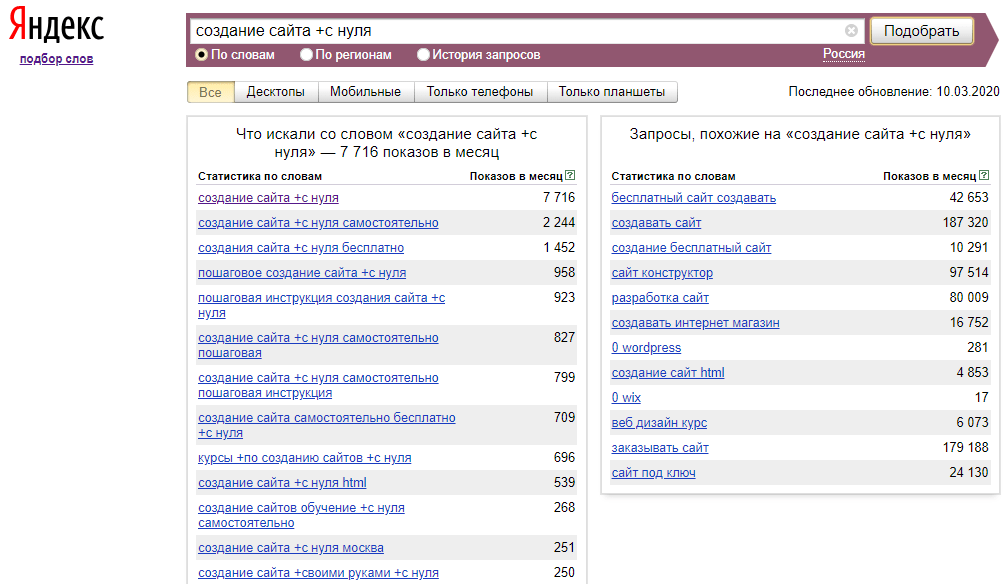 rbc.ru
rbc.ru
В «Яндексе» также пояснили, что законы стран, в которых работает компания, позволяют госорганам запрашивать данные пользователей. В России это имеют право делать МВД, Следственный комитет, прокуратура, ФАС, ФТС, суды и некоторые другие органы.
«Яндекс» обязан отвечать на все запросы, оформленные в соответствии с требованиями действующего законодательства. Если запрос приходит на бумаге, он должен быть оформлен на официальном бланке ведомства, содержать контакты и собственноручную подпись уполномоченного лица, а в ряде случаев еще и должен быть заверен оригинальным оттиском печати. Запрос в электронной форме считается обязательным для предоставления ответа только в том случае, если он заверен усиленной квалифицированной электронной подписью», — говорится в сообщении.
Наибольшее количество запросов приходит по пользователям сервиса «Яндекс.Паспорт», поскольку в нем хранятся основные регистрационные данные пользователей. Сервис получил 8,8 тыс. запросов за полгода. «Яндекс.Такси» получил 5280 запросов, «Яндекс.Драйв» — 706.
«Яндекс.Такси» получил 5280 запросов, «Яндекс.Драйв» — 706.
Один из основных конкурентов «Яндекса» в направлении поиска, электронной почты и ряда других сервисов в России — компания Google — уже несколько лет регулярно выпускает отчет под названием Transparency Report, в котором раскрывает количество запросов от властей разных стран и сколько из них было удовлетворено. Google пока не публиковала статистику о запросах пользовательских данных в России в первом полугодии 2020 года. Но с июля по декабрь 2019-го компания получила 258 запросов на раскрытие пользовательских данных от органов государственной власти страны. Из них только в 23% случаев Google предоставила «некоторые данные» государственным органам.
Кроме личной информации госорганы отправляют Google запросы на удаление контента. За истекшее первое полугодие компания получила 12,7 тыс. запросов от органов власти на удаление данных. Из них 44% было связано с нарушением авторских прав, 18% касалось вопросов национальной безопасности, 13% — товаров и услуг, подпадающих под действие специальных законов.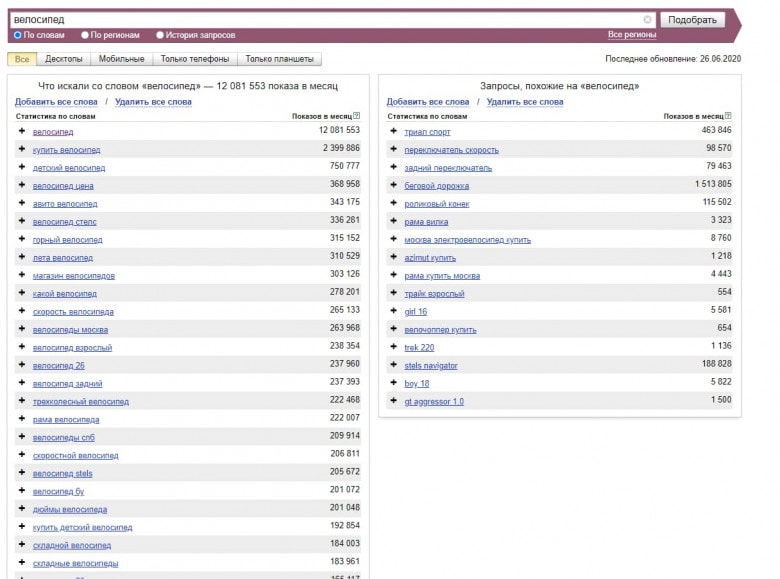 При этом около 16% от всех запросов Google отклонила. В частности, компания может отказать в удалении данных, если запрос не содержит точной информации, что именно государственные органы требуют удалить (например, может быть не указан URL), не все распоряжения суда, которые присылаются в запросах, требуют от Google конкретных действий и т.д., отмечается в отчете.
При этом около 16% от всех запросов Google отклонила. В частности, компания может отказать в удалении данных, если запрос не содержит точной информации, что именно государственные органы требуют удалить (например, может быть не указан URL), не все распоряжения суда, которые присылаются в запросах, требуют от Google конкретных действий и т.д., отмечается в отчете.
Кроме того, Google рассказывает о запросах государственных органов, которые вызывают общественный интерес. Так, в первой половине 2020 года Роскомнадзор потребовал, чтобы Google удалила из результатов поиска четыре ссылки, где пользователям предлагалось купить пропуск для выхода из дома во время режима самоизоляции. Компания частично удалила запрос: исключила три ссылки из поиска в России. По четвертой ссылке меры не приняли — она не индексировалась в поисковой системе Google.
Представитель «Яндекса» сообщил, что компания не планирует публиковать отчеты о запросах властей на удаление контента.
Как с «Яндекса» спрашивают о данных пользователей
В 2017 году Служба безопасности Украины обвинила «Яндекс» в передаче данных украинских пользователей российским спецслужбам, в подразделениях компании в Киеве и Одессе прошли обыски.
«Ни у сотрудников «Яндекс.Украина», ни у руководства украинского подразделения не было доступа к персональным данным пользователей «Яндекса». Защита персональных данных наших пользователей во всех странах, где мы предоставляем сервисы, является наивысшим приоритетом. В частности, для обеспечения этого данные о пользователях обезличены и анонимны», — ответили в компании.
В «Яндексе» тогда уточнили, что для раскрытия тех или иных данных о пользователях правоохранительным органам разработчику необходимо убедиться в обоснованности такого требования со стороны властей, а также получить соответствующее решение суда.
Тогда же, в мае 2017 года, президент Украины Петр Порошенко подписал указ, который запретил работу в стране «Яндекса», а также социальных сетей «Одноклассники», «ВКонтакте» и ряда других российских сервисов.
airflow.providers.yandex.
 operators.yandexcloud_dataproc — apache-airflow-providers-yandex Документация
operators.yandexcloud_dataproc — apache-airflow-providers-yandex Документация- Главная
-
airflow.providers.yandex -
airflow.провайдеры.яндекс.операторы -
airflow.providers.yandex.operators.yandexcloud_dataproc
Классы
| Данные для действия инициализации, которое должно выполняться при запуске кластера DataProc. |
| Создает кластер Yandex.Cloud Data Proc. |
| Базовый класс для операторов DataProc, работающих с данным кластером. |
| Удаляет кластер Yandex. |
| Запускает задание Hive в кластере Data Proc. |
| Запускает задание Mapreduce в кластере Data Proc. |
| Запускает задание Spark в кластере Data Proc. |
| Запускает задание Pyspark в кластере Data Proc. |
 Cloud Data Proc.
Cloud Data Proc.- класс airflow.providers.yandex.operators.yandexcloud_dataproc.InitializationAction[источник]
Данные для действия инициализации, которое должно выполняться при запуске кластера DataProc.
- uri : стр [источник]
- аргументы : Последовательность [str] [источник]
- таймаут : int [источник]
- class airflow. providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_, 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник]
Базы:
airflow. models.BaseOperator Создает кластер Yandex.Cloud Data Proc.
- Параметры
folder_id ( str | None ) — ID папки, в которой должен быть создан кластер.
имя_кластера ( str | Нет ) — имя кластера. Должен быть уникальным внутри папки.
cluster_description ( str | Нет ) — Описание кластера.
cluster_image_version ( str | None ) — версия образа кластера. Использовать по умолчанию.
SSH_PUBLIC_KEYS ( STR | IEERABLE [ STR ] | .
subnet_id ( str | None ) – идентификатор подсети. Все узлы кластера Data Proc будут использовать одну подсеть.
services ( Iterable [ str ] ) — список служб, которые будут установлены в кластер. Возможные варианты: HDFS, ПРЯЖА, MAPREDUCE, HIVE, TEZ, ZOOKEEPER, HBASE, SQOOP, FLUME, SPARK, SPARK, ZEPPELIN, OOZIE
s3_bucket ( str | None ) — корзина Yandex.Cloud S3 для хранения логов кластера. Задания не будут работать, если ведро не указано.
zone ( str ) — Зона доступности для создания кластера. В настоящее время существуют ru-central1-a, ru-central1-b и ru-central1-c.
service_account_id ( str | None ) — идентификатор учетной записи службы для кластера.
Учетная запись службы может быть создана внутри папки.masternode_resource_preset ( str | Нет ) — Предустановка ресурсов (конфигурация CPU+RAM) для основного узла кластера.
masternode_disk_size ( int | None ) — размер хранилища Мастерноды в ГиБ.
masternode_disk_type ( str | Нет ) — Тип хранилища Мастерноды. Возможные варианты: сеть-ssd, сеть-hdd.
datanode_resource_preset ( str | Нет ) — Предустановка ресурсов (конфигурация CPU+RAM) для узлов данных кластера.
datanode_disk_size ( int | None ) — размер хранилища Datanodes в ГиБ.
datanode_disk_type ( str | None ) — Тип хранилища Datanodes.
Возможные варианты: сеть-ssd, сеть-hdd.Computenode_resource_preset ( str | Нет ) — Предустановка ресурсов (конфигурация CPU+RAM) для вычислительных узлов кластера.
Computenode_disk_size ( int | None ) — размер хранилища вычислительных узлов в ГиБ.
Computenode_disk_type ( str | None ) — тип хранилища вычислительных узлов. Возможные варианты: сеть-ssd, сеть-hdd.
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
Computenode_max_count — максимальное количество узлов подкластера автоматического масштабирования вычислений.
Computenode_warmup_duration ( int | None ) — время прогрева экземпляра в секундах.
В течение этого времени,
трафик отправляется на инстанс,
но метрики экземпляра не собираются. В секундах.вычисление_стабилизации_длительности ( целое число | Нет ) – Минимальное время в секундах для мониторинга до Группы экземпляров могут уменьшить количество экземпляров в группе. За это время размер группы не уменьшается, даже если новые значения метрик указывают на то, что это необходимо. В секундах.
calculatenode_preemptible ( bool ) — Выгружаемые экземпляры останавливаются не реже одного раза в 24 часа, и могут быть остановлены в любое время, если их ресурсы потребуются вычислительным ресурсам.
Computenode_cpu_utilization_target ( int | None ) — определяет правило автомасштабирования на основе средней загрузки ЦП группы экземпляров. в процентах. 10-100. По умолчанию не задано и используется стратегия автомасштабирования по умолчанию.
Computenode_decommission_timeout ( int | Нет ) — тайм-аут для корректного вывода узлов из эксплуатации во время уменьшения масштаба. В секундах
свойства ( dict [ str , str ] | Свойства переданы основному узлу. Документы: https://cloud.yandex.com/docs/data-proc/concepts/settings-list
enable_ui_proxy ( bool ) — включить функцию UI Proxy для перенаправления веб-интерфейсов компонентов Hadoop. Документы: https://cloud.yandex.com/docs/data-proc/concepts/ui-proxy
host_group_ids ( Iterable [ str ] | None ) — выделенные группы хостов для размещения виртуальных машин кластера. Документы: https://cloud.yandex.com/docs/compute/concepts/dedicated-host
security_group_ids ( Iterable [ str ] | None ) — группы безопасности пользователей.
Документы: https://cloud.yandex.com/docs/data-proc/concepts/network#security-groupslog_group_id ( str | None ) — идентификатор группы журналов для записи журналов. По умолчанию журналы будут отправлены в группу журналов по умолчанию. Чтобы отключить отправку облачного журнала, установите свойство кластера dataproc:disable_cloud_logging = true Документы: https://cloud.yandex.com/docs/data-proc/concepts/logs
initialization_actions ( Iterable [ InitializationAction ] | Нет ) — Набор инициализирующих действий, выполняемых при запуске кластера. Документы: https://cloud.yandex.com/docs/data-proc/concepts/init-action
- свойство cluster_id[источник]
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.Дополнительные сведения см. в get_template_context.
 providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_, 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник]
providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , folder_id=None , cluster_name=None , cluster_description=» version_, 0127, ssh_public_keys=Нет , subnet_id=Нет , services=(‘HDFS’, ‘YARN’, ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket=Нет 6, ru-central1-b’ , service_account_id=None , masternode_resource_preset=None , masternode_disk_size=None , masternode_disk_type=None , datanode_resource_preset=None , datanode_disk_size=None , datanode_disk_type=None , datanode_count=1 , computenode_resource_preset=None , computenode_disk_size=None , computenode_disk_type=None , computenode_count=0 , computenode_max_hosts_count=None , computenode_measurement_duration=None , computenode_warmup_duration=None , computenode_stabilization_duration = Нет , Computenode_preemptible = Ложь , Computenode_cpu_utilization_target = Нет , computenode_decommission_timeout=None , connection_id=None , properties=None , enable_ui_proxy=False , host_group_ids=None , security_group_ids=None , log_group_id=None , initialization_actions=None , * *kwargs )[источник] models.BaseOperator
models.BaseOperator 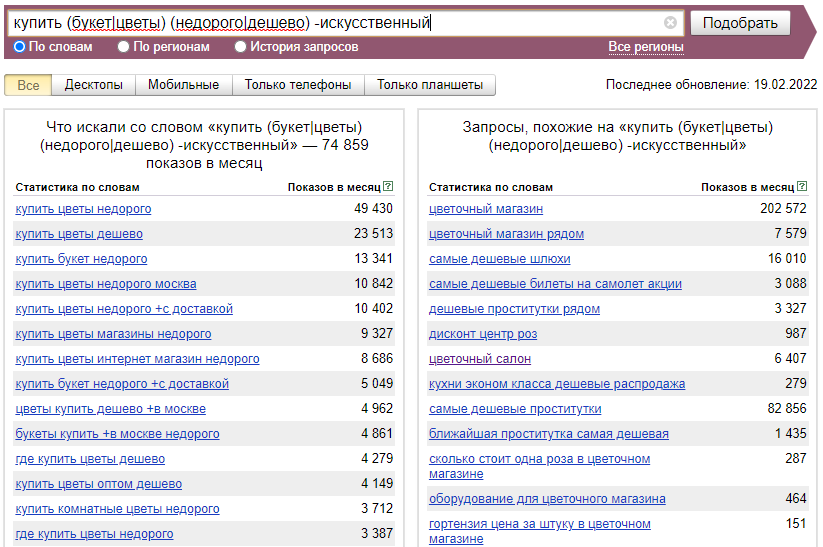
 Учетная запись службы может быть создана внутри папки.
Учетная запись службы может быть создана внутри папки. Возможные варианты: сеть-ssd, сеть-hdd.
Возможные варианты: сеть-ssd, сеть-hdd. В течение этого времени,
трафик отправляется на инстанс,
но метрики экземпляра не собираются. В секундах.
В течение этого времени,
трафик отправляется на инстанс,
но метрики экземпляра не собираются. В секундах.
 Документы: https://cloud.yandex.com/docs/data-proc/concepts/network#security-groups
Документы: https://cloud.yandex.com/docs/data-proc/concepts/network#security-groups Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.- класс airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocBaseOperator( * , yandex_conn_id=Нет , cluster_id=Нет , **kwargs )[8] 900
Базы:
airflow.models.BaseOperatorБазовый класс для операторов DataProc, работающих с данным кластером.
- Параметры
- template_fields : Последовательность [str] = (‘cluster_id’,) [источник]
- абстрактный выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
- класс airflow. providers.yandex.operators.yandexcloud_dataproc.DataprocDeleteClusterOperator( * , connection_id=нет , cluster_id=нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorУдаляет кластер Yandex.Cloud Data Proc.
- Параметры
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 providers.yandex.operators.yandexcloud_dataproc.DataprocDeleteClusterOperator( * , connection_id=нет , cluster_id=нет , **kwargs )[источник]
providers.yandex.operators.yandexcloud_dataproc.DataprocDeleteClusterOperator( * , connection_id=нет , cluster_id=нет , **kwargs )[источник]- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateHiveJobOperator( * , query=None , query_file_uri=None , script_variables=None , continue_on_failure=False , properties=None , name=’Hive job’ , cluster_id=None , connection_id=None , **kwargs )[источник]
Оснований:
DataprocBaseOperatorЗапускает задание Hive в кластере Data Proc.
- Параметры
запрос ( str | Нет ) — запрос Hive.
query_file_uri ( str | None ) — URI скрипта, содержащего запросы Hive. Можно разместить в HDFS или S3.
свойств ( dict [ стр , стр ] | Нет ) — сопоставление имен свойств со значениями, используемое для настройки Hive.
Script_Variables ( DICT [ STR , STR ] | 7777777777777777 гг.
continue_on_failure ( bool ) — продолжать ли выполнение запросов в случае сбоя запроса.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание.
Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)- класс airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateMapReduceJobOperator( * , main_class=Нет , main_jar_file_uri=Нет , jar_file_uris = none , archive_uris = none , file_uris = none , args = none , . Нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Mapreduce в кластере Data Proc.
- Параметры
main_jar_file_uri ( str | Нет ) — URI jar-файла с заданием. Можно разместить в HDFS или S3. Можно указать вместо main_class.
main_class ( str | None ) — Имя основного класса задания. Можно указать вместо main_jar_file_uri.
file_uris ( Iterable [ str ] | Нет ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | None ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | None ) — URI файлов JAR, используемых в задании.
Можно разместить в HDFS или S3.свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.Дополнительные сведения см. в get_template_context.

 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateSparkJobOperator( * , main_class=None , main_jar_file_uri=None , jar_file_uris=None , archive_uris=None , file_uris=None , args=None , properties=None , name=’Spark job’ , cluster_id=None , connection_id=Нет , пакетов=Нет , репозиториев=Нет , exclude_packages=Нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Spark в кластере Data Proc.
- Параметры
main_jar_file_uri ( str | None ) — URI файла jar с заданием.
Можно разместить в HDFS или S3.main_class ( str | None ) — Имя основного класса задания.
file_uris ( Iterable [ str ] | None ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | Нет ) – URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | None ) — URI файлов JAR, используемых в задании. Можно разместить в HDFS или S3.
свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
packages ( Iterable [ str ] | None ) — список maven-координат классов jar для включения в драйвер и исполнитель.
репозитории ( Iterable [ стр ] | Нет ) — Список дополнительных удаленных репозиториев для поиска координат maven дается с —packages.
exclude_packages ( Iterable [ str ] | None ) — Список groupId:artifactId, чтобы исключить зависимости при разрешении зависимостей предоставляется в –packages, чтобы избежать конфликтов зависимостей.
- выполнить( контекст )[источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.

- class airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreatePysparkJobOperator( * , main_python_file_uri=Нет , python_file_uris=Нет , jar_file_uris = none , archive_uris = none , file_uris = none , args = none , . , пакетов = нет , репозиториев = нет , exclude_packages = нет , **kwargs )[источник]
Базы:
DataprocBaseOperatorЗапускает задание Pyspark в кластере Data Proc.
- Параметры
main_python_file_uri ( str | Нет ) — URI файла Python с заданием.
Можно разместить в HDFS или S3.python_file_uris ( Iterable [ str ] | None ) — URI файлов python, используемых в задании. Можно разместить в HDFS или S3.
file_uris ( Повторяемый [ стр ] | Нет ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Iterable [ str ] | None ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Iterable [ str ] | Нет ) — URI файлов JAR, используемых в задании. Можно разместить в HDFS или S3.
свойства ( dict [ str , str ] | Свойства для работы.
args ( Iterable [ str ] | None ) — аргументы для передачи в задание.
имя ( стр ) – Название задания. Используется для маркировки.
cluster_id ( str | None ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он указан. (шаблон)
connection_id ( str | None ) — идентификатор подключения Яндекс.Облака Airflow.
packages ( Iterable [ str ] | None ) — список maven-координат jar для включения в пути к классам драйвера и исполнителя.
репозиториев ( Iterable [ str ] | None ) — Список дополнительных удаленных репозиториев для поиска m-координат дается с —packages.
exclude_packages ( Iterable [ str ] | None ) — Список groupId:artifactId, чтобы исключить при разрешении зависимостей предоставляется в –packages, чтобы избежать конфликтов зависимостей.
- выполнить ( контекст ) [источник]
Это основной метод получения при создании оператора. Контекст — это тот же словарь, который используется при рендеринге шаблонов jinja.
Дополнительные сведения см. в get_template_context.
 Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.
Была ли эта запись полезной?
Яндекс
Запросите наши расширения
прокрутка вниз
RDAP-API
Интерфейс API соответствует поведению, указанному в RFC RDAP:
- RFC7480 — Использование HTTP в протоколе доступа к регистрационным данным (RDAP)
- RFC7481 — Службы безопасности для протокола доступа к регистрационным данным (RDAP)
- RFC7482 — формат запроса протокола доступа к регистрационным данным (RDAP)
- RFC7483 — ответы JSON для протокола доступа к регистрационным данным (RDAP)
- RFC7484 — Поиск службы авторитетных регистрационных данных (RDAP)
- RFC8056 — Сопоставление состояния расширяемого протокола инициализации (EPP) и протокола доступа к регистрационным данным (RDAP)
Эта реализация соответствует рабочему профилю RDAP для реестров и регистраторов рДВУ версии 1. 0. Вы можете запрашивать домены, серверы имен и сущности (объекты регистратора). : Запрос объектов Contact не поддерживается.
0. Вы можете запрашивать домены, серверы имен и сущности (объекты регистратора). : Запрос объектов Contact не поддерживается.
Запросы могут выполняться для точного совпадения, когда ресурс указан непосредственно в URL-адресе. Например, чтобы запросить доменные имена, укажите RESTful-клиенту адрес: /rdap/domain/example.com , где example.com — это TLD для запроса.
Запросы также можно выполнять с использованием звездочки в качестве подстановочного знака для соответствия нулю или более завершающим символам. Например, поиск домена по имени: /rdap/domains?name=exam*.com вернет результаты для доменных имен exam.com, exams.com, example.com и т. д.
Единственный тип контента , поддерживаемый в наших ответах, — это application/rdap+json . Если клиент RDAP отправляет заголовок Accept в своем запросе, мы его игнорируем.
Информация WHOIS, представленная на этой странице, была отредактирована в соответствии с Временной спецификацией ICANN для регистрационных данных рДВУ.
Данные в этой записи предоставлены UNR только в информационных целях и не гарантируют их точность. UNR является полномочным органом в отношении информации whois в доменах верхнего уровня, с которыми он работает по контракту с Internet Corporation for Assigned Names and Numbers. Информация Whois из других доменов верхнего уровня предоставляется третьей стороной по лицензии UNR.
Эта служба предназначена только для доступа на основе запросов. Используя эту услугу, вы соглашаетесь с тем, что вы будете использовать любые данные, представленные только в законных целях, и что вы ни при каких обстоятельствах не будете использовать (а) данные, полученные с целью разрешения, включения или иной поддержки передачи по электронной почте, телефон, факс или другой механизм связи для массовой незапрашиваемой коммерческой рекламы или предложений лицам, не являющимся вашими существующими клиентами; или (b) эта услуга для включения большого объема автоматизированных электронных процессов, которые отправляют запросы или данные в системы любого регистратора или любого реестра, за исключением случаев, когда это разумно необходимо для регистрации доменных имен или изменения существующих регистраций доменных имен.