
Полный запрет индексации страниц со строкой запроса ?add-to-cart= ⋆ Speed+
Speed+ВордПресс
Сегодня рассмотрим интересную задачу: как Запретить индексацию add-to-cart, то есть URL со строкой запроса, параметрами ?add-to-cart= в WooCommerce, и решим ее двумя способами.
Описание задачи
Плагин WooCommerce может генерировать огромное количество ссылок вида https://site.com/?add-to-cart=111, причем после site.com/ может быть название категории или тега. Такие ссылки находят боты поисковых систем, индексируют их, после чего вы получаете ошибку, например, в Search Console о дублях страниц, неканонических страницах и т. д.
Почему так происходит?
Ссылки /?add-to-cart=111 размещаются в виде кнопок «Добавить в корзину» или «Купить» на страницах архивов, а также в виджетах:
- категории товаров
- метки товаров
- виджет «Похожие товары»
- блок «Вас также может заинтересовать»
- виджет «Ранее просмотренные товары»
- любые другие виджеты или блоки Вукомерса, где отображается миниатюра товара и кнопка для добавления его в Корзину.


При нажатии на такую кнопку осуществляется перевод по ссылке, товар добавляется в корзину, но открывается та же самая страница. То есть реальной страницы по ссылке с /?add-to-cart=111 не существует. Таким образом, поисковый бот индексирует дубль страницы.
Решение задачи
Запрет индексации ссылок формата /?add-to-cart можно осуществить двумя путями: в файле robots.txt и в файле .htaccess. Мы рекомендуем комбинировать эти способы, чтобы добиться 100% гарантии результата.
Запрещаем индексацию в robots.txt
Файл robots.txt находится в корневой папке вашего сайта и доступен по ссылке вида https://site.com/robots.txt. При отсутствии в папке физического файла ВордПресс формирует виртуальный файл robots.txt.
Если у вас такой файл есть, то проверьте наличие в нем такой строки, запрещающей поисковикам сканировать ссылки с параметром add-to-cart:
Disallow: *?add-to-cart*
В случае отсутствия такой строки, добавьте ее вручную (воспользуйтесь FTP-клиентом).
А когда в корневой папке вообще нет файла robots.txt, рекомендуем воспользоваться плагином SpeedPlus OptiMini, который автоматически создает правильный файл robots.txt.
Между тем, добавление такого правила не является полной гарантией того, что поисковик послушается. Боты нередко своевольничают и после этого в СерчКонсоли появляются сообщения «Просканировано, несмотря на запрет…». И вот тогда мы используем дополнительный способ.
Запретить индексацию add-to-cart в файле .htaccess
Файл .htaccess находится тоже в корневой папке сайта. Это самый главный файл на всем сайте, так как он загружается первым и указывает браузеру, в частности, как открывать ссылки. Файл можно редактировать исключительно в прямом доступе, например, с помощью FTP-клиента. И не забудьте сделать резервную копию файла.
Для запрета индексации ссылок со строкой запроса ?add-to-cart= вам следует добавить в .htaccess такой код:
# Disable indexing of "?add-to-cart=" pages by Speedplus.
 com.ua
<IfModule mod_rewrite.c>RewriteCond %{QUERY_STRING} add-to-cart= [NC]
RewriteRule .* - [E=NOINDEXME:1]
Header set X-Robots-Tag "noindex, nofollow" env=NOINDEXME
</IfModule>
com.ua
<IfModule mod_rewrite.c>RewriteCond %{QUERY_STRING} add-to-cart= [NC]
RewriteRule .* - [E=NOINDEXME:1]
Header set X-Robots-Tag "noindex, nofollow" env=NOINDEXME
</IfModule>После добавления этого кода страницам с параметром ?add-to-cart= будет присвоен HTTP-заголовок X-Robots-Tag, который, хоть и не отображается в исходном коде страницы, находится в файле конфигурации сервера. Такая настройка сообщает ботам поисковых систем о запрете индексации страницы даже без загрузки содержимого страницы. Фантастика, да?
Проверить, добавляется ли HTTP-заголовок на страницах вашего сайта, вы можете с помощью бесплатного сервиса. Для пущей уверенности в корректности работы кода, введите в текстовый блок запроса сразу два адреса страницы вашего сайта: со строкой запроса и без нее.
https://site.com/ https://site.com/?add-to-cart=111
Успешные результаты анализа второго адреса (с параметрами) должны содержать строку:
X-Robots-Tag: noindex, nofollow
Таким образом, теперь вы вдвойне запретили индексацию страниц-дублей с ?add-to-cart= в адресной строке.
Если у вас есть вопросы, задавайте их в комментариях к этой статье. Если вам необходима доработка этого кода или кастомная разработка, обращайтесь к нам напрямую (контакты).
Статьи по теме
Стоит ли запрещать индексацию страниц категорий и архивов
В этой статье поговорим о том, стоит ли запрещать индексацию страниц категорий и архивов и о влиянии запрета на SEO продвижение сайта.
Запрет индексации страниц категорий и архивов — делать или нет
Оглавление статьи
- 1 Запрет индексации страниц категорий и архивов — делать или нет
- 2 Robots.txt
- 3 Метатег robots noindex
- 4 Ошибки 404 и Soft 404
- 5 Следует ли использовать метатег noindex на страницах категорий
- 6 Чего не стоит делать
- 7 Итог
- 8 Вместо заключения
- 9 SEO продвижение сайта по России:
Итак, начнем с того, что ответ, вероятно, нет. Большинство веб-сайтов не должны волноваться о том, что Google обойдет некоторые страницы, в которых нет никакой полезной информации.
Страницы с тегами, страницы категорий и страницы с результатами поиска, которые входят в стандартный пакет популярных систем управления контентом, таких как Drupal и WordPress, как правило, недостаточно широко распространены, чтобы иметь большое значение. Если Google видит в них ценность, сканирование и индексирование будут проводиться.
Если у вас есть большой сайт продаж через интернет с сотнями тысяч продуктов, это может стать более серьезной проблемой, потому что вы хотите, чтобы поисковики Google сосредоточились на страницах, которые имеют значение, и хотите удалить те вещи, которые не имеют никакого значения.
Чтобы полностью решить данную проблему, вы также должны понять разницу между элементами robots.txt и метатегом noindex, а также ошибками 404 и soft 404.
Robots.txt
Если вы размещаете команду в файле robots.txt, чтобы заблокировать доступ Google (и других поисковиков) к страницам, вы фактически не позволяете им попасть на эти страницы.
Если Google попадается страница, которая заблокирована в robots.txt, данный поисковик не будет выполнять команду «извлечь» или «прочитать», чтобы получить доступ к заголовку страницы. Это означает, что если позже вы решите, что не хотите, чтобы на этой странице был запрет на индексацию, или хотите, чтобы у нее был другой статус (например, перенаправление или ошибка 404), Google не сможет увидеть это изменение.
Команды robots.txt должны быть ограничены страницами, которые Google не увидит другими способами (т. е. люди не перейдут на них по ссылке, на вашем сайте нет ссылок на них, и они, вероятно, защищены паролем).
Функционал администратора, входа в систему или корзины является хорошим примером страниц, которые вы можете заблокировать в файле robots.txt. Никогда не следует блокировать файлы JavaScript или CSS, необходимые для правильной визуализации страниц.
Метатег robots noindex
Метатег robots = noindex отличается от robots.txt, но многие SEO-оптимизаторы считают его таким же. Самыми большими отличиями тега noindex являются:
Самыми большими отличиями тега noindex являются:
- Это также директива по работе с роботами, но она менее ограничена, чем robots.txt. Google и другие поисковые системы могут прочитать страницу, заголовки и все остальное.
- Он делает именно то, что заложено в названии. Он предписывает Google не индексировать, то есть не добавлять страницу в качестве подходящей для результатов поиска. Google по-прежнему будет собирать все данные на странице и следовать всем ссылкам, если вы не используете тег nofollow. Тег nofollow не является официальной директивой, но Google и другие поисковые системы уважают его.
- Если вы используете тег noindex, а затем решите сделать перенаправление или ошибку 404, Google сможет получить доступ к этому изменению статуса и соответствующим образом обновить свои данные.
Ошибки 404 и Soft 404
Страница с ошибкой 404 указывает на то, что страница не найдена, и это веб-стандарт, который соблюдают все поисковики. Если роботы Google и Яндекс обнаружат страницу с ошибкой 404, они удаляют ее из индекса, но хранят ее в своем планировщике обхода контента, чтобы периодически перепроверять… просто чтобы убедиться, что она не изменилась.
Если роботы Google и Яндекс обнаружат страницу с ошибкой 404, они удаляют ее из индекса, но хранят ее в своем планировщике обхода контента, чтобы периодически перепроверять… просто чтобы убедиться, что она не изменилась.
Ошибка soft 404 является неофициальным обозначением, которое поисковик размещает на страницах, которые могут получить статус 200 (найдено), но которые не предоставляют никакого контента. Страницы с нулевыми результатами внутреннего поиска являются одним из примеров.
Если роботы Google и Яндекс определят страницу как имеющую ошибку soft 404, они обрабатывают ее так же, как страницу с ошибкой 404. Как и в случае с ошибкой 404, они будут периодически проверять ее, чтобы убедиться, что она не меняется.
Следует ли использовать метатег noindex на страницах категорий
Возвращаемся к нашему вопросу — является ли метатег noindex правильной стратегией для страниц категорий, которые имеют небольшую ценность для вашего сайта или вообще не имеют таковой?
Ответ заключается в том, что если вы чувствуете, что страницы ничего не добавляют вашему сайту, вы, вероятно, должны полностью удалить их и присвоить им статус ошибки 404. Если страницы важны для перемещения по сайту пользователей и являются «необходимым злом» для наличия блога, то они должны иметь метатег noindex.
Если страницы важны для перемещения по сайту пользователей и являются «необходимым злом» для наличия блога, то они должны иметь метатег noindex.
Если вы используете метатег noindex на страницах, компания Google заявила, что будет рассматривать эти страницы как имеющие ошибку soft 404. Это означает, что никакие ссылки, указывающие на эти страницы, не будут учитываться при определении рейтинга.
Почему это имеет значение? В конечном счете, вероятно, не имеет.
Если ссылки указывают на страницы, которые, по вашему мнению, не имеют никакой ценности, то поисковые системы и пользователи, вероятно, не находят в них никакой ценности для себя.
Чего не стоит делать
Необязательно вставлять все категории и теги страниц к корневой странице блога. Такое неправильное использование Google будет игнорировать.
Не помещайте эти страницы в файл robots.txt. Если вы заблокируете их, Google не сможет увидеть, когда вы обновите или измените их, но они останутся в результатах поиска.
Итог
Убедитесь, что вы и ваша команда разработчиков знаете разницу между командами robots.txt и метатегом robots noindex. Используйте их соответствующим образом, и вы будете на шаг впереди конкурентов.
Если у вас есть страницы, которые не предоставляют никакой ценности для поисковиков в качестве целевой страницы, но они необходимы для навигации, вы должны либо переосмыслить свою навигационную стратегию (возможно, более информативная страница категории с уникальным контентом будет уместна?), либо использовать метатег noindex на страницах.
Если у вас есть всего несколько таких страниц или вы не думаете, что они важны для вашего сайта, просто оставьте их такими, какие они есть. Google достаточно умен, чтобы понять это.
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Записаться на SEO обучение
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс.
Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
Заказать SEO продвижение сайта
SEO продвижение сайта по России:
Как удалить URL-адрес моего веб-сайта из индекса Google?
Редактор: Steve Paine
Изменено: 16. 11.2022
11.2022
Чтобы удалить URL-адрес (веб-страницу) с вашего собственного сайта из поискового индекса Google, оставив его активным на вашем сайте, доступны два варианта. В одном используется метатег robots, в другом — быстрый метод с использованием Google Search Console
Contents
Contents
Лили Рэй об удалении URL из Google
Лили Рэй — член группы журналистики данных SISTRIX.Вариант №1: Используйте метатег robots с NOINDEX
Добавьте метатег robots в исходный код страницы, которая не должна отображаться в индексе, и установите значение NOINDEX.
При добавлении следующего URL-адрес будет удален из индекса:
Вы должны добавить метатег в область конкретного страница:
строка 6: метаэлемент robots со значением NOINDEX в исходном коде Если на странице уже есть метаэлемент robots со значением INDEX, вы можете просто заменить его на NOINDEX.
Готово. Теперь вам просто нужно дождаться, пока нужный URL-адрес будет удален из индекса Google. В зависимости от сайта это может занять несколько дней.
При использовании значения мета-роботов NOINDEX URL также будет удален из индекса поисковой системы Microsoft Bing и других поисковых систем, которые реагируют на тег noindex.
Могу ли я использовать WordPress для установки NOINDEX для URL-адреса?
Общая система управления веб-сайтом WordPress не имеет стандартного метода для управления индексом на уровне URL, но есть дополнительные плагины, которые можно добавить, которые предоставят вам эту функцию. Yoast — это распространенный SEO-плагин, который можно использовать для добавления кода NOINDEX. Некоторые темы могут включать шаблон страницы, тег или категорию, включающую код NOINDEX.
Вариант № 2: Используйте Google Search Console
Используя настройку в Google Search Console, вы можете удалить URL-адрес из индекса Google.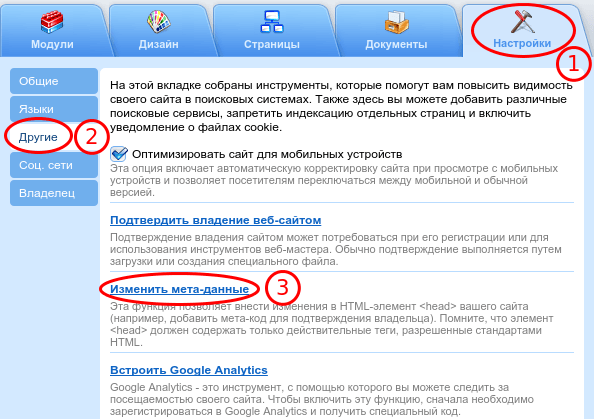 Это быстро, но временный метод . Для окончательного удаления URL-адреса вам необходимо добавить функцию NOINDEX, как описано выше, или удалить саму страницу с вашего веб-сайта в дополнение к выполнению опции временного удаления.
Это быстро, но временный метод . Для окончательного удаления URL-адреса вам необходимо добавить функцию NOINDEX, как описано выше, или удалить саму страницу с вашего веб-сайта в дополнение к выполнению опции временного удаления.
Если вы еще не используете Google Search Console (GSC), вам следует активировать свой сайт для бесплатной статистики и контроля. Как подключиться к ГСК.
Удаление URL из индекса с помощью Google Search Console
- Войдите в Google Search Console и выберите нужный веб-сайт. В нашем примере мы выбрали asite.com
- Нажмите на вкладку «Временное удаление» в верхней части основного окна
- Нажмите «НОВЫЙ ЗАПРОС» в основном окне. (Красная кнопка)
- Теперь вам будет предложено ввести URL-адрес страницы, которую вы хотите удалить, и подтвердить свой выбор, нажав «Далее». Если вы хотите удалить набор страниц, вы можете ввести префикс.
После удаления URL-адреса через Search Console вам придется подождать до 24 часов, пока нужный URL-адрес не будет удален из индекса Google.
Удаление URL-адреса из индекса Bing
Поисковая система Bing также предоставляет собственные инструменты для веб-мастеров, которые можно использовать для удаления URL-адресов из индекса.
Инструмент Bing для веб-мастеров позволяет блокировать URL-адрес от индексации (http://www.bing.com/toolbox/webmaster)Редактор: Steve Paine
Изменено: 16.11.2022
Простой способ запретить индексирование нескольких страниц — поддержка
r0berts
1
Привет, я использую тему Hugo и Academic. Спасибо за отличный софт! Я не профессиональный веб-дизайнер — я врач, который ведет небольшой информационный сайт для стажеров.
Я так понимаю есть два типа индексации — поисковиками и самим сайтом (теги, таксономии и т.д.). Я хочу иметь возможность сделать одну или две страницы доступными только по ссылке, которой я делюсь. Защита паролем не обязательна, я просто не хочу, чтобы страницы были доступны через поиск (google) или через внутренние механизмы индексации Hugo с главной страницы сайта или индекса блога. Каким будет самый простой механизм для достижения обеих целей?
Защита паролем не обязательна, я просто не хочу, чтобы страницы были доступны через поиск (google) или через внутренние механизмы индексации Hugo с главной страницы сайта или индекса блога. Каким будет самый простой механизм для достижения обеих целей?
Большое спасибо,
Роберт
Хришикеш
2
Вы можете добавить новую переменную фронтматера:
--- индекс: ложь ---
и в свои шаблоны можно добавить следующее:
- Чтобы отключить поисковые системы, в
{{- если не .Params.Index -}}
<мета-имя = "роботы" content = "noindex">
{{- конец -}}
- Чтобы отключить страницу из списков, вам нужно найти файл, отвечающий за создание страниц списка, и он может иметь что-то вроде
{{- range .
