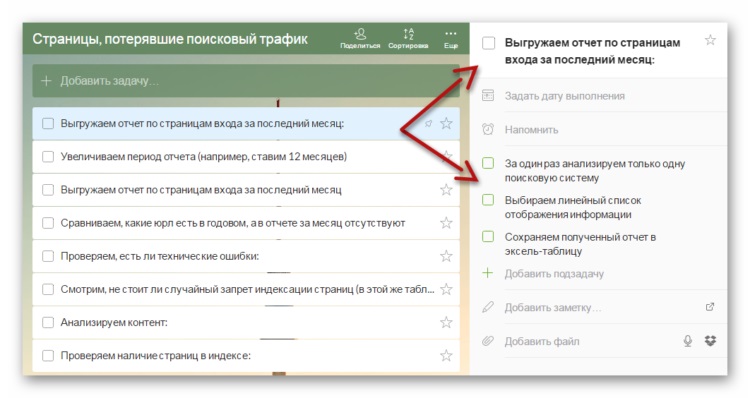
▷ Какие страницы закрыть от индексации: запрет индексации страниц
32411
| How-to | – Читать 14 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Инструкцию одобрил
Tech Head of SEO в TRINET.Group
Рамазан Миндубаев
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Содержание:
- Причины запретить индексацию страницы
- Какие страницы не индекстровать
- Как закрыть страницы от индексации
3.1. Как закрыть сайт от индексации Google - Как проверить, сколько страниц закрыто от индексации
- Заключение
FAQ
Причины запретить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта (корзина, страница оплаты, результатов поиска, авторизация и т.д.), данные с персональной информацией, наборы фильтров каталога товара в электронной коммерции (множественный выбор фильтров по цене, цвету, фактуре и другое).
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое периодически сканирует поисковая система. Для всех сайтов это значение количества страниц разное и не постоянное и в том числе зависит от типа сайта и частоты его обновления. В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
Схема сканирования, индексирования и ранжирования сайта
Хотите прямо сейчас проверить, какие страницы вашего сайта индексируются и находятся в топе поисковой выдачи? А по каким фразам ранжируется ваш конкурент? Попробуйте Serpstat (нужно зарегистрироваться и после вы получите доступ к бесплатным инструментам). Если хотите доминировать на своем рынке — используйте Serpstat и достигайте большей эффективности в онлайн.
Какие закрыть страницы от индексации
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковых систем. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
Закрыть сайт от индексации в robots.txt можно следующим содержимым (первая директива — означает обращение ко всем краулерам, вторая директива — запрещает сканировать все URL сайта):
User-agent: *
Disallow: /
Эти две строчки запретят доступ к сайту всем роботам поисковых систем.
Если нужно при этом разрешить сканировать конкретные URL, нужно добавить директиву Allow: /namepage$ где /namepage URL страницы разрешенной к сканированию. Директива разрешения сканирования доминирует над запретом (для конкретного URL), а значек $ отменяет применение по умолчанию не выводимывого символа «*». То есть если не поставить $ — мы разрешим сканировать вложенные URL относительно родителя, такие как /namepage/indexpage.html и т.д.
Запрет индексации для сайта на сервере NGINX осуществляется с помощью добавления кода add_header X-Robots-Tag «noindex, nofollow»; в файл .conf.
Копии сайта
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в роботс закрыть от индексации все страницы печати.
Ненужные документы
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Пример индексации pdf-файла на сайте
Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические данные сайта
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Форма авторизации в админку OpenCart
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.
Страницы сортировки
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Страницы пагинации
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
- Как провести анализ индексации сайта
- SEO-аудит сайта с помощью Serpstat: обзор инструмента
- Как автоматизировать поиск ошибок на сайте: Аудит сайта теперь доступен в API Serpstat
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Чтобы закрыть страницу от индексации, используйте атрибут noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Это позволяет полностью закрыть страницу, оставив роботам возможность переходить по размещенным на странице ссылкам. Если это не нужно, замените follow на nofollow:
<meta name=»robots» content=»noindex, nofollow»/>
При использовании данных методов страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Как закрыть сайт от индексации Google
Вы можете также закрыть доступ к сайту только ботам Google. Добавьте для этой цели данный метатег внутри <head> </head> всех страниц ресурса:
<meta name=»googlebot» content=»noindex, nofollow»/>
Через robots доступ к сайту ботам Google закрывается так:
User-agent: googlebot
Disallow: /
Еще можно запретить доступ к каким-либо статьям сайта роботам Google Новостей, тогда они не появятся в Google News:
<meta name=»Googlebot-News» content=»noindex, nofollow»>.
Файл robots.txt
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
User-agent: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthType Basic AuthName "Password Protected Area" AuthUserFile путь к файлу с паролем Require valid-user
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления. Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Удаление URL-адресов из индекса в Search Console
Как проверить, сколько страниц закрыто от индексации
С помощью Аудита сайта Serpstat можно быстро проверить сайт на наличие технических ошибок и узнать, сколько страниц не проиндексировано.
Для того, чтобы это сделать нужно всего лишь нажать на кнопку ниже, и у вас будет возможность создать проект для сайта ↓
В появившихся настройках можно указать имя домена и количество страниц, которые нужно просканировать краулеру:
Запуск аудита в Serpstat
Выбор типа сканирования и указание лимита страниц
Когда сканирование будет закончено, на графике в Суммарном отчете можно проверить, какое количество страниц из указанных не проиндексировано:
Проверка индексации страниц в Аудите Serpstat
Хотите узнать, как с помощью Serpstat найти и исправить технические ошибки на сайте?
Оставьте заявку и наши специалисты проконсультируют вас по продвижению вашего проекта, поделятся учебными материалами и инсайтами рынка!
| Заказать бесплатную консультацию |
Error get alias
Заключение
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
Как запретить индексацию сайта?
Запретить доступ ботов поисковых систем к сайту можно с помощью нескольких способов: добавления метатега robots со значением noindex в html-код; указания директивы Disallow в файле robots.txt; установки пароля для доступа к сайту в конфигурационном файле .htaccess. Также можно блокировать доступ к отдельным каталогам и документам.
Как временно закрыть сайт от индексации
Чтобы закрыть сайт от индексации, добавьте метатег name=»robots» content=»noindex, nofollow» в раздел всех веб-страниц или добавьте директиву User-agent: * Disallow: / в файл robots.txt.
Как закрыть сайт от индексации WordPress
Чтобы закрыть сайт WordPress от индексации, зайдите в админку CMS, выберите раздел «Настройки» → «Чтение». Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Задавайте вопросы в комментариях или пишите в техподдержку.:) А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Оцените статью по 5-бальной шкале
4.11 из 5 на основе 45 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как включить HTTP/2 для сайта
How-to
Анастасия Сотула
Как проверить посещаемость сайта в системах аналитики и без счетчика
How-to
Анастасия Сотула
Что такое SEO продвижение сайтов: SEO оптимизация сайта пошагово
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Как запретить индексацию страниц/сайта — все доступные методы
Анализ индексируемости страниц в Linkbox.Pro
Информация обновлена 14 феврая 2023 года
Запрет индексации в Гугл и других поисковых системах прописывают в том случае, если определенная страница или сайт не должны попасть в индекс поисковой системы. Это может понадобиться по нескольким причинам:
- Страница создавалась как техническая, не имеет ценности для поисковой системы и не должна ранжироваться.
- Страница/сайт временно не готовы и пока не должны попадать в индекс.

- Страница является копией, низкокачественной, с плохим контентом.
- Страница предназначена для зарегистрированных и авторизованных пользователей, индексирование и сканирование ее ботом не должно осуществляться.

Ниже я представлю несколько способов запрета индексации страницы и опишу методы их реализации. Также в статье вы узнаете о том, как проверить запрет индексации страницы на своем сайте или запрет индексации на внешних сайтах, например проверка возможности индексации бэклинков.
Способы запрета индексации
#1 — noindex
Директива noindex — это специальное правило, запрещающее Google и других поисковым системам индексировать страницу. Данное правило не запрещает при этом страницу сканировать (читайте подробнее про разницу между индексированием и сканированием в словаре).
Реализация правила noindex возможна двумя способами — с помощью специального тега noindex (#1.1), который нужно поместить в <head>, или же с помощью http-ответа (#1.
#1.1 Использование тега является более простым вариантом. Код выглядит следующим образом
a) запрет индексирования для всех ботов поисковых систем
<meta name="robots" content="noindex" />
б) запрет индексирования для Гуглбота:
<meta name="googlebot" content="noindex" />
Можно запретить индексирование любому боту, для этого нужно просто узнать название бота в справке поисковой системы или краулера.
Включить вывод тега noindex в определенных CMS обычно можно благодаря специальным настройкам в интерфейсе системы или же благодаря плагинам. Например, в WordPress с подключенным Yoast нужно перейти на админ-страницу записи, проскроллить к блоку Yoast Seo Premium, открыть блок дополнительно и выбрать вариант «Нет» в вопросе «Разрешить поисковым системам показывать Страница в результатах поиска?».
#1.2. Заголовок HTTP-ответа
Noindex как правило запрета индексирования страницы можно также прописать в HTTP-ответе.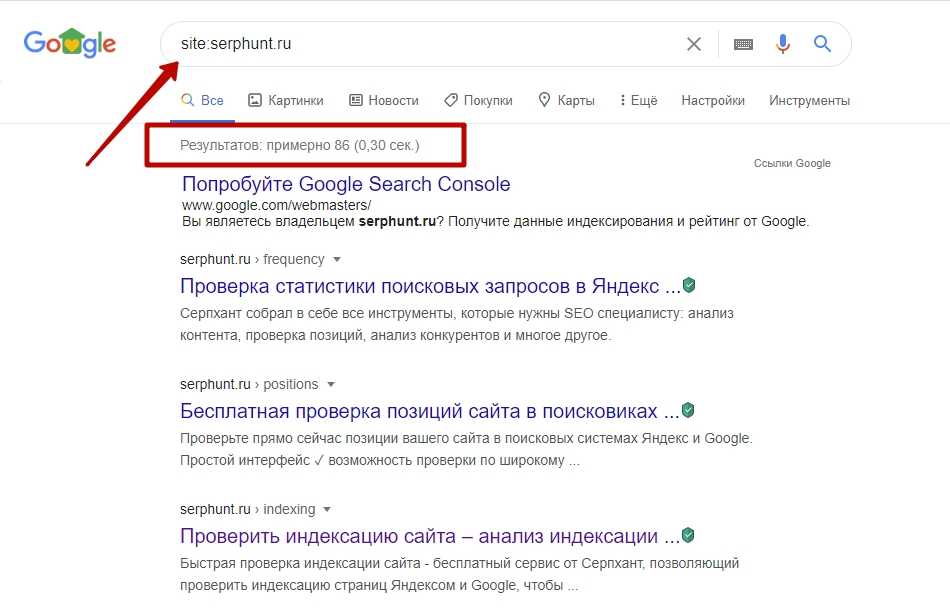 Выглядит это следующим образом:
Выглядит это следующим образом:
HTTP/1.1 200 OK
(...)
X-Robots-Tag: noindex
(...)Данный метод подойдет для тех, кто умеет работать с конфигурациями на сервере, поскольку ответ сервера можно редактировать именно там.
Метод с ноиндексом идеально подходит в тех случаях, когда вам надо навсегда запретить индексирование технической страницы, или не индексировать страницы, предназначенных только для зарегистрированных и авторизованных пользователей. Читайте подробнее в справке.
#2 Запрет доступа ботам (403 ответ сервера)
С помощью специальных правил на сервере или на CDN, можно запретить Гуглботу или любому другому боту сканировать и индексировать сайт/страницу. Если правильно прописать правило, боты будут получать 403 ответ сервера (запрет доступа).
Вот так например выглядит запрет сканирования (и как результат — страница не попадет в индекс) на cloudflare в разделе Firewall для Гуглбота. Подобное правило можно создать в конфигурациях на сервере.
При проверке url, для которого стоит такой запрет, вы увидите 403 ответ сервера (то есть отсутствие доступа на просмотр страницы).
Данный способ запрета индексации подойдет для новых сайтов, которые только разрабатываются, и пока не должны сканироваться или индексироваться. Обратите внимание! Запрет доступа ботам не дает странице не только не попасть в индекс, но также и просканироваться. Подобным образом действует и запрет на сканирование в файле robots.txt но с той разницей, что урлы в robots.txt все равно могут попасть в выдачу, если, например, на них стоит много ссылок с других источников. С новыми сайтами, полностью закрытыми от ботов на сервере или CDN, обычно такого не происходит.
#3 Запрет на сканирование в Robots.txt (не рекомендуемый способ!)
Между процессами сканирования и индексирования есть разница, однако первый процесс всегда является предшественником второго. Поэтому теоретически запрет сканирования исключает возможность попадания в выдачу, ведь бот не может просканировать страницу и понять, о чем она.
Запрет на сканирование в Robots.txt осуществляется путем прописывания в файле Robots.txt запрета на сканирование страницы/сайта/подпапки(директории)/типов файлов следующим способом:
User-agent: *
Disallow: /user/*
Disallow: /news/*Данное правило запрещает сканирование всем ботам каталогов (подпапок) /user/ и /news/ и любых файлов в этих каталогах.
На самом деле данный метод не рабочий в плане запрета индексации. «Файл robots.txt не предназначен для того, чтобы запрещать показ ваших материалов в результатах поиска Google.» — прямая цитата из справки Гугл. Другими словами, если страница, закрытая от сканирования, будет обнаружена другими методами, например на нее ведут внешние ссылки, она все равно может попасть в индекс (и в моей практике такое не раз случалось).
Еще одна цитата для подтверждения:
Если доступ к странице запрещен в файле robots.txt, она все равно может быть проиндексирована по ссылкам с других сайтов.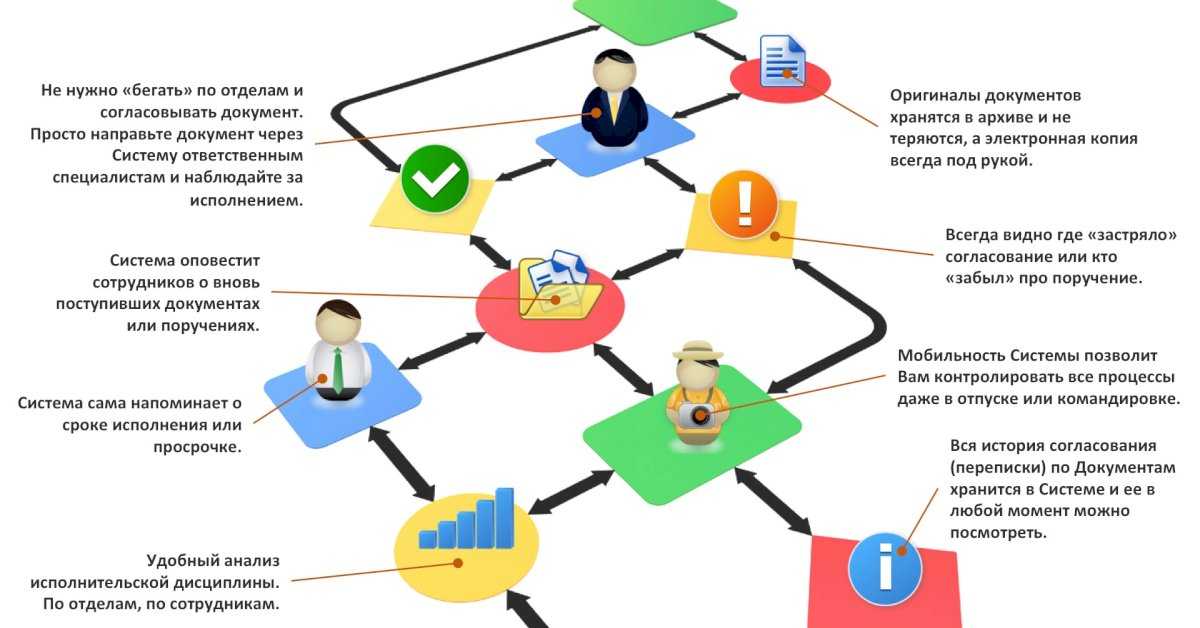 Google не будет напрямую сканировать и индексировать контент, который заблокирован в файле robots.txt. Однако если на такой URL ссылаются другие сайты, то он все равно может быть найден и добавлен в индекс. После этого страница может появиться в результатах поиска (во многих случаях вместе с текстом ссылки, которая на нее ведет). Если вас это не устраивает, рекомендуем защитить файлы на сервере паролем или использовать директиву noindex в теге meta или HTTP-заголовке ответа. Альтернативное решение – полностью удалить страницу.
Google не будет напрямую сканировать и индексировать контент, который заблокирован в файле robots.txt. Однако если на такой URL ссылаются другие сайты, то он все равно может быть найден и добавлен в индекс. После этого страница может появиться в результатах поиска (во многих случаях вместе с текстом ссылки, которая на нее ведет). Если вас это не устраивает, рекомендуем защитить файлы на сервере паролем или использовать директиву noindex в теге meta или HTTP-заголовке ответа. Альтернативное решение – полностью удалить страницу.
Короче, этот способ я могу порекомендовать использовать в последнюю очередь только в том случае, если вы не можете отредактировать тег роботс в head, прописать ответ сервера или настроить файерволл.
#4 Защита файлов паролем
Способ подобный к способу #2 — он будет возвращать ботам 403 ответ сервера (запрет доступа). Идеально подходит для страниц, предназначенных только для пользователей/пользователей по подписке.
Для защиты страниц паролем вы можете использовать плагин ограничения контента (для WordPress это, например, Password Protected). Установите и активируйте его, затем перейдите в «Настройки» > «Защищено паролем» и включите «Статус защиты паролем». Это дает более тонкий контроль, позволяя занести в белый список определенные IP-адреса.
Установите и активируйте его, затем перейдите в «Настройки» > «Защищено паролем» и включите «Статус защиты паролем». Это дает более тонкий контроль, позволяя занести в белый список определенные IP-адреса.
5 Ручное удаление из индекса
Это способ срочно (примерно в течении часа) удалить из индекса страницы. Для подтвержденного в консоли сайта инструмент удаления находится по адресу https://search.google.com/u/0/search-console/removals. Там можно запросить удаление целого сайта или каталога.
Данный способ не запрещает индексацию, а просто временно удаляет страницы из индекса.
Для удаления проиндексированного контента не своего сайта воспользуйтесь справкой https://support.google.com/websearch/answer/6349986 (там будет ссылка на инструмент). Чтобы избежать манипуляциям сеошников, проверка заявок на удаления контента с чужого сайта осуществляется по определенным критериям и чаще всего не одобряется. Также в основном удаляется не страница из индекса, а именно устаревший контент (скидывается кеш).
Как проверить, разрешена ли индексация страницы
#1 Страницы своего сайта можно проверить в Search Console с помощью инструмента Test live Url. Он показывает,
#1.1 если страница закрыта от индексации с помощью тега или ответа сервера noindex:
#1.2 если у Гуглбота нет доступа к странице из-за защиты паролем или файервола (403 ответ сервера):
#1.3 если страница не может быть просканирована из-за ограничений в файле robots.txt (однако еще раз повторю: такая страница все равно может попасть в индекс):
#2 Массово проверить страницы на возможность индексации (например, проверить свои бэклинки) можно в специальных сервисах, например Linkbox.Pro, а также с помощью краулера ScreamingFrog SEO Spider (желательно с лицензией).
Быстрые ответы
Самый простой способ закрыть страницу от индексации?
Самый простой и правильный (рекомендуемый Google) способ — прописать в секции head тег Noindex.
Какой синтаксис тега Noindex?
<meta name=»robots» content=»noindex» />
Какой самый простой способ массово проверить индексируемость страниц?
Самый простой способ проверить индексирумость массово — использовать сервис ЛинкбоксПро.
Почему disallow в Robots.txt не помогает запретить индексацию?
Disallow в Robots.txt не запрещает индексацию страницы. Если Гугл находит ее в других источниках (внешних ссылках), она может все равно попасть в индекс.
Можно ли использовать noindex и disallow в robots.txt для лучшего эффекта?
Нет. В процессах оценки страницы сначала идёт сканирование, потом индексирование. Запрет сканирования в robots.txt не даст Гуглу учесть тот факт, что на странице noindex, и она может попасть в индекс все равно. Чтобы noindex работал, страница должна нормально сканироваться.
Поддержите Украину!🇺🇦
Мы боремся за нашу независимость прямо сейчас. Поддержите нас финансово. Даже пожертвование в 1 доллар важно.
Проверка есть ли у сайта бан от гугла. Как защитить и восстановить?
Как проверить?
Бан в поисковых системах может наступить по разным причинам, в основном из-за попыток манипулирования поиском и использования запрещенных методов для продвижения вашего сайта.
Для того, чтобы проверить бан на гугл, нужно просто ввести в строку поиска это:
сайт: имя_сайта.com
Вместо sitename.com подставьте название своего сайта. Если вам показывают не 10-12 страниц запросов, а всего 5-10 запросов, то сайт под санкциями. Но то, что сайт не индексируется в поисковых системах, не означает, что именно ваш сайт забанен, вы также должны проверить, не закрыт ли ваш сайт от индексации.
Всегда необходимо выявить причины, по которым это произошло, устранить баги и вернуть сайт обратно в поиск. Если сайт не будет индексироваться, и не будет присутствовать в поиске, сео продвижение сайта бесполезно.
Что нужно сделать, чтобы вернуться:
Конечно, чтобы вернуться, вы должны отправить запрос на повторное включение. Да, вы должны проглотить свою гордость и просить милостыню на коленях в зависимости от того, насколько вы цените свое доменное имя.
По словам SEO-хакеров, вы также можете отправить твит руководителю программы Google Webspam Брайану Уайту: @brianwhite просто сказать: «Привет, мой сайт помещен в песочницу».
Google, вероятно, знает каждую деталь вашего преступления против них. Если вы ничего не скажете им о своем проступке (и, возможно, скажете, что сожалеете о каждом из них и что больше никогда этого не сделаете), вам будет труднее вернуться, если не полностью отвергнуть вас. Команда Google по борьбе со спамом хочет получить полный отчет о том, что вы сделали.
Если это не сработает
Поднимите белый флаг и перейдите к другому домену. Google, вероятно, больше не будет включать вас снова. Все, что мы можем сделать, это надеяться, что Google будет любезен и снова примет нас. К сожалению, Google тоже умеет ловить плохое настроение. Иногда вам нужно решить, что пора двигаться дальше и оставить надежду на то, что ваш сайт снова проиндексируется.
Советы:
Хакеры и спамеры преследуют одни и те же цели, поэтому им нет дела до Google, так как мы, обычные блоггеры или веб-мастера, должны передавать правила Google:
1. Не создавайте сообщения исключительно для того, чтобы давать ссылки на какой-либо веб-сайт(ы).
Не создавайте сообщения исключительно для того, чтобы давать ссылки на какой-либо веб-сайт(ы).
2. Не создавайте искусственных ссылок, не связанных с категорией или темой вашего сайта.
3. Не размещайте ссылки на ваш сайт на нерелевантных сайтах, незаконных сайтах, порносайтах или спам-сайтах, а также в обмене ссылками или в массовых рассылках.
4. Не присоединяйтесь к схеме ссылок. Не размещайте ссылку на свой сайт в этих схемах ссылок.
5. Не принимайте участие в спаме с помощью виджетов или не размещайте на своем сайте виджеты, указывающие на спам-сайты (другими словами, создание спам-ссылок или обмен веб-сайтами) веб-сайты, которые уже обсуждались выше. Размещение ссылок вашего сайта на спам-сайтах Google полностью или частично не доверяет вашему сайту в зависимости от количества ссылок, которые ваш сайт получает с этих спам-сайтов.
7. Не занимайтесь спамом в гостевых книгах, спамом в блогах, отправкой чрезмерных статей, отправкой чрезмерных ссылок с помощью программного обеспечения для отправки ссылок.
8. Не давайте текстовое имя привязки для вашего виджета для определенного ключевого слова или фразы. Google считает это тоже спамом. Если ваш виджет на 100% релевантен, а также ссылается на конкретный веб-сайт в той же категории с более высоким рейтингом страницы, тогда проблем нет. Если ваш виджет ссылается на спам-сайт. Тогда ваш сайт будет оштрафован Google за такую практику.
9. Не давайте ссылки вверх или вниз в одном и том же сообщении слишком часто. Не давайте слишком много ссылок на другую часть вашего веб-сайта (другой пост или другие страницы вашего веб-сайта) и всегда следуйте рекомендациям Google для веб-мастеров.
10. Не одобряйте комментарии читателей, пока вы не прочитаете комментарий полностью, а также убедитесь, что читатели, размещающие URL-адреса, на 100% соответствуют вашей публикации, странице или «нише» вашего веб-сайта. Если ваш читатель попытается разместить спам-ссылки или нерелевантные ссылки в комментарии, вы проиграете. Рейтинг вашей страницы резко упадет, и ваш веб-сайт будет исключен из поискового индекса Google для этой публикации или страницы или всего веб-сайта в целом. Так что остерегайтесь спам-комментариев на вашем сайте.
Рейтинг вашей страницы резко упадет, и ваш веб-сайт будет исключен из поискового индекса Google для этой публикации или страницы или всего веб-сайта в целом. Так что остерегайтесь спам-комментариев на вашем сайте.
Google объясняет, как скрыть веб-сайт из результатов поиска
Google утверждает, что лучший способ скрыть веб-сайт из результатов поиска — использовать пароль, но есть и другие варианты, которые вы можете рассмотреть.
Эта тема освещена в последнем выпуске серии видеороликов Ask Googlebot на YouTube.
Джон Мюллер из Google отвечает на вопрос о том, как предотвратить индексацию контента в поиске и разрешено ли это делать веб-сайтам.
«Короче говоря, да, можете, — говорит Мюллер.
Есть три способа скрыть сайт из результатов поиска:
- Использовать пароль
- Обход блока
- Индексация блока
Веб-сайты могут либо вообще отказаться от индексации, либо проиндексироваться и скрыть контент от робота Googlebot с помощью пароля.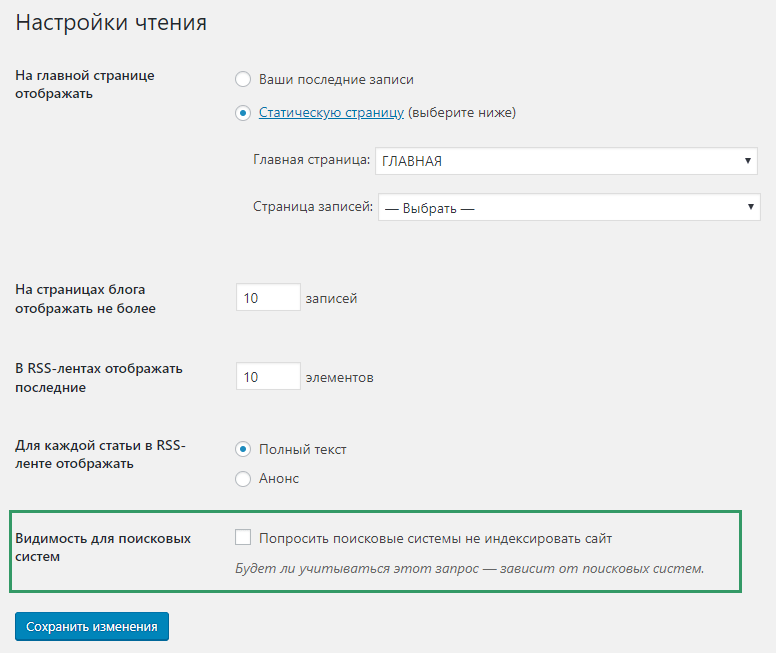
Блокировка контента от Googlebot не противоречит правилам веб-мастера, если он одновременно заблокирован для пользователей.
Например, если сайт защищен паролем при сканировании роботом Googlebot, он также должен быть защищен паролем для пользователей.
В качестве альтернативы сайт должен иметь директивы, запрещающие роботу Googlebot сканировать или индексировать сайт.
У вас могут возникнуть проблемы, если ваш веб-сайт предоставляет другой контент для робота Googlebot, чем для пользователей.
Это называется «маскировкой» и противоречит рекомендациям Google.
С учетом этого различия, вот правильные способы скрытия контента от поисковых систем.
1. Защита паролем
Блокировка веб-сайта паролем часто является лучшим подходом, если вы хотите сохранить конфиденциальность своего сайта.
Пароль гарантирует, что ни поисковые системы, ни случайные пользователи сети не смогут увидеть ваш контент.
Это обычная практика для веб-сайтов в разработке. Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
2. Заблокировать сканирование
Еще один способ запретить роботу Googlebot доступ к вашему сайту — заблокировать сканирование. Это делается с помощью файла robots.txt.
С помощью этого метода люди могут получить доступ к вашему сайту по прямой ссылке, но она не будет обнаружена «благоразумными» поисковыми системами.
По словам Мюллера, это не лучший вариант, потому что поисковые системы могут индексировать адрес веб-сайта без доступа к его содержимому.
Такое случается редко, но о такой возможности вам следует знать.
3. Заблокировать индексирование
Третий и последний вариант — заблокировать индексирование вашего веб-сайта.
Для этого вы добавляете на свои страницы метатег noindex robots.
Тег noindex указывает поисковым системам не индексировать эту страницу до тех пор, пока после они не просканируют ее.