
Как закрыть ссылки и страницы от индексации?
С какой целью порой может использоваться закрытие веб-сайта или каких-то его разделов, страниц от индексации поисковыми системами? Вариантов с ответами имеются несколько:
- Следует убрать от всеобщего обзора ту или иную информацию, в которой могут находиться секретные данные.
- Если нужно сформировать подходящий релевантный контент: случаются варианты, если очень сильно возникает желание сообщить пользователям Интернете больший поток информации, однако которая делает туманной релевантность по тексту.
- Закрыть от роботов дублирующий контекст.
- Спрятать информацию, которая не представляет интереса для пользователей, и которую так не любят поисковые роботы, считая ее спамом в медиа-контенте.
Например, это могут быть портфолио, материалы сайта с устаревшим смыслом, какие-то расписания в справочниках.
Запрет на индексацию сайта или каких-то частей с помощью файла robots.txt
Для начала нужно создать текстовый файл с названием robots.
Способ второй
Для страницы, которую необходимо закрыть, можно в файле .htaccess прописать любой из следующих ответов сервера:
1 403 «Доступ к ресурсу запрещен», т.е. код 403 Forbidden
2 410 «Ресурс недоступен», т.е. окончательно удален
Способ третий
Можно закрыть индексацию к сайту с помощью доступа только по паролю:
В этом случае, в файле .htaccess, вставляем следующий код:
1 AuthType Basic
2 AuthName «Password Protected Area»
3 AuthUserFile /home/user/www-pass/.htpasswd
4 Require valid-user
Значит в корне сайта создаем — home/user/www-pass/.htpasswd
где .htpasswd — файл с паролем, который создаем сами в файле.
Но затем следует добавить пользователя в файл паролей htpasswd — /home/user/www-pass/.htpasswd USERNAME
где USERNAME — это имя пользователя для авторизации.
Здесь можно прописать свой вариант.
Как закрыть отдельный блог от индексации?
Зачастую бывает, что необходимо закрыть от поисковой индексации не весь сайт целиком, а только конкретный источник: список, счетчик, запись, страницу либо какой-нибудь код.
В одно время, достаточно было использовать тег «noindex», но это больше подходило для роботов Яндекса, а для Google были достаточны обычные действия.
<noindex>Здесь может быть любой текст, ссылки или код</noindex>
Но затем роботы Яндекс стали меньше обращать внимания на такую техническую «уловку», а роботы Google вообще перестали понимать данную комбинацию. В результате, технические специалисты сайтов, стали применять иной вариант с целью закрытия индексации части текста на какой-либо странице, используя скрипты javascript, либо соответствующие плагины или модули.
Часть текста шифруется с помощью javascript. Но следует помнить, что затем непосредственно сам скрипт нужно будет закрыть от индексации в robots.txt.
Универсальный способ закрытия изображений (медиафайлов) от индексации
Многие сайты используют картинки, которые в основном берутся из Интернета, я значит никак не могу считаться уникальными. В результате таких действий, появляется боязнь, то, что роботы поисковиков отнесутся к таким сайтам негативно, а именно будут блокировать продвижение и повышение в рейтингах.
В этом случае следует на странице сделать следующую запись в коде:
<span class=»hidden-link» data-link=»https://goo.gl»><img src=»…»></span>
Скрипт, который будет обрабатывать элемент:
<script>$(‘.hidden-link’).replaceWith(function(){return'<a href=»‘+$(this).data(‘link’)+’»>’+$(this).html()+'</a>’;})</script>
Как закрыть от индексации внешние либо внутренние ссылки?
Такие действия нужно только в том случае, если нужно закрыть от индексации входящие ссылки от сайтов находящиеся под санкциями поисковых систем, а так же скрыть исходящие ссылки на сторонние ресурсы, чтобы предотвратить уменьшение веса сайта, а именно ТИЦ сайта донора.
Для этого нужно создать файл transfers.js
После этого нижеуказанную часть кода вставляем в файл transfers.js:
function goPage(sPage) {
window.location.href = sPage;
}
После этого данный файл уже размещаем в соответствующей папке сайта и на странице в head добавляем код:
<script type=»text/javascript» src=»/js/transfers. js»></script>
js»></script>
И теперь прописываем необходимую ссылку, которую нужно скрыть от индексации поисковых систем:
<a href=»javascript:goPage(‘http://указываем URL/’)»></a>
Как закрыть от индексации роботов отдельную страницу на сайте?
Первый метод — через файл robots.txt
</pre>
Disallow: /URL-страницы сайта
<pre>
Второй метод — закрытие с помощью метатегов
<meta name=»robots» content=»noindex, nofollow» />
Третий метод — в Вебмастере Яндекса, в разделе «Инструменты» с помощью «Удалить URL» можно отдельно по каждой ссылке сделать запрет на индексацию от роботов Яндекса.
Четвертый метод — сделать запрет на индексацию через ответ сервера:
404 — ошибка страницы
410 — страница удалена
И сделать добавление в файле .htaccess:
ErrorDocument 404 https://URL-сайта/404
Однако, данным метод используется весьма редко.
Как закрыть от индексации сразу весь раздел или категорию на сайте?
Лучший способ — реализовать это с помощью файла robots.
User-agent: *
Disallow: /название раздела или категории
Дополнительные варианты:
Кроме указанных выше способов, также могут подойти способы, которые применяются для сокрытия страницы сайта целиком, либо какого-то раздела, — правда, если подобные действия могут быть сделаны автоматически:
- соответствующий ответ сервера для определенных страниц раздела сайта
- применение мета-тегов к определенным страницам
Все эти без исключения методы, возможно, осуществить программно, а никак не в «ручном» режиме назначать к любой страничке или части текста запрет на индексацию – весьма дороги трудовые затраты.
Конечно, ведь легче в целом сделать соответствующее запрещение в файле robots.txt, однако практика показывает, то что это не может гарантировать на 100% запрет на индексацию.
В этом случае на закрытие пойдет непосредственно папка, а не раздел. Ведь нам нужно закрыть папку с файлами, которые не должны видеть поисковые роботы, а это могут быть какие-то разработки, документы, картинки и многое другое.
Ведь нам нужно закрыть папку с файлами, которые не должны видеть поисковые роботы, а это могут быть какие-то разработки, документы, картинки и многое другое.
User-agent: *
Disallow: /folder/
Пять способов закрытия на сайте дублей от поисковой индексации
Первый способ — и наиболее верный, для того, чтобы их действительно не существовало — необходимо на физическом уровне освободиться от них, т.е. в любом варианте при открытии страницы, кроме оригинальной, должна демонстрироваться страница 404 — ответ сервера.
Второй способ — применять атрибут rel=»canonical», который как раз и является наиболее правильным решением. Таким образом, равно как атрибут не позволяет роботам индексировать дублирующиеся страницы, так перенаправляет вес с дублей на оригиналы.
Только на странице дубля в коде следует прописать:
<link rel=»canonical» href=»https://URL оригинальной страницы сайта»/>
Posted in ПОЛЕЗНОЕ, SEO оптимизация and tagged robots, ссылки, индексация, мета-теги, noindex, nofollow.
Сколько внешних ссылок разрешено размещать на странице сайта
11634 22
| How-to | – Читать 13 минут |
Прочитать позже
АУДИТ САЙТА — ССЫЛКИ
Инструкцию одобрил
генеральный директор Интоп-Медиа
Евгений Глущенко
Веб-мастеру необходимо проводить анализ внешних ссылок, поскольку их излишнее количество может привести к некорректному распределению ссылочного веса и санкциям поисковых систем. Чтобы избежать таких проблем, следует закрывать внешние ссылки от индексации.
Содержание:
- Как проверить внешние ссылки на странице
- Проверка количества внешних ссылок
- Как закрыть внешние ссылки от индексации
- Как проверить внешние ссылки на сайт
- Как найти внешние ссылки в системах аналитики
- Поиск внешних ссылок с помощью Serpstat
Заключение
Как проверить внешние ссылки на странице
Слишком большое количество исходящих ссылок на другие сайты может стать причиной санкций поисковых систем, поскольку они трактуют это как разновидность поискового спама. В настоящее время поисковики достаточно строго относятся к размещению платных ссылок. Поэтому при подозрении на то, что сайт используется в качестве донора с целью продвижения других ресурсов, он может попасть под фильтры.
В настоящее время поисковики достаточно строго относятся к размещению платных ссылок. Поэтому при подозрении на то, что сайт используется в качестве донора с целью продвижения других ресурсов, он может попасть под фильтры.
В этом случае позиции сайта понижаются, либо он исключается из результатов выдачи. Такие последствия использования платных ссылок описаны в лицензии на использование Яндекса и рекомендациях для веб-мастеров Google.
Чтобы избежать подобных рисков, необходимо размещать ссылки с атрибутом dofollow только на качественные ресурсы сходной тематики. Однако стоит помнить, что в этом случае страница-донор теряет ссылочный вес, так как робот, обнаруживший данную ссылку, перестает сканировать исходную страницу и переходит на указанный сайт.
Чтобы избежать потери ссылочного веса и санкций поисковых систем за большое количество исходящих ссылок, рекомендуется добавлять в тег <a> атрибут rel= «nofollow», который указывает роботам на то, что им не нужно переходить по данной ссылке.
Проверить внешние ссылки на странице на наличие атрибута nofollow можно с помощью расширения NoFollow в Chrome:
После установки расширения ссылки, содержащие атрибут nofollow, будут обводиться в красную пунктирную рамочку:
Если запрет индексации ссылок прописан в meta-robots, то отобразится соответствующее сообщение:
Почему позиции сайта не растут: чек-лист по анализу внешних факторов ранжирования от SAPE
| Читать |
Проверка количества внешних ссылок
Максимально допустимое количество внешних ссылок на странице не прописано в справках поисковых систем. При наличии одной-двух тематических ссылок в статье риск попасть под санкции минимален. Однако при пяти и более ссылках, никак не связанных с основным текстом страницы и расположенных в подвале либо специальных блоках, шансы на негативную реакцию поисковых систем существенно повышаются.
Если ваш сайт ссылается строго по теме и по делу на сторонние ресурсы, санкций поисковых систем можно не бояться. Наоборот, сайт даже может получить определенную степень доверия от поисковых систем. Все будет зависеть от того, насколько качественно подобраны внешние ссылки на странице.
Наоборот, сайт даже может получить определенную степень доверия от поисковых систем. Все будет зависеть от того, насколько качественно подобраны внешние ссылки на странице.
Проверку внешних ссылок можно осуществить с помощью инструмента Megaindex. Для этого нужно указать адрес домена и выбрать «Показать»:
Сервис отобразит соотношение естественных и SEO-ccылок, укажет их общее количество и URL-адреса:
Как Serpstat помогает составить ссылочную стратегию — опыт LinkParty
| Читать |
Как закрыть внешние ссылки от индексации
После того, как на проекте обнаружены все ненужные исходящие ссылки, необходимо закрыть их от индексации. Сделать это можно такими способами:
Добавить в тег ссылки атрибут nofollow. Например, код с ссылками на различные варианты доставки будет таким:
<p><a href="https://novaposhta.ua/delivery" target="_blank" rel=”nofollow”>«Новая почта»</a>.</p> <p><a href="https://www.intime.ua/calc" target="_blank" rel=”nofollow”>«Интайм»</a></p>

Запретить в мета-теге robots переход по всем ссылкам, размещенным на странице. Для этого используют такой синтаксис:
<meta name="robots" content="nofollow" />
Данный код размещают в заголовке <head> нужной страницы. Однако так делать не рекомендуется: вместо этого лучше вручную закрывать каждую ссылку отдельно;
Переадресовать ссылку на промежуточную страницу. При этом запретить индексацию данной страницы в файле robots.txt.
В данном примере после клика на внешнюю ссылку отображается страница с предупреждением о том, что пользователь совершает переход на другой ресурс.
Но и этот способ находится «на грани». Поисковые системы могут трактовать его как поисковый спам или заподозрить другую не совсем честную схему.
Какими должны быть ссылающиеся сайты: список требований
| Читать |
Как проверить внешние ссылки на сайт
Помимо внимательного отношения к исходящим гиперссылкам, необходимо проводить регулярный анализ внешних ссылок на сайт. Данные ссылки оказывают существенное влияние на SEO-продвижение сайта, однако в некоторых случаях могут также вызвать санкции поисковых систем.
Данные ссылки оказывают существенное влияние на SEO-продвижение сайта, однако в некоторых случаях могут также вызвать санкции поисковых систем.
Для избежания фильтров поисковиков необходимо соблюдать следующие правила:
наращивать ссылочную массу постепенно;
получать ссылки с трастовых ресурсов схожей тематики, которые не занимаются активной продажей ссылок;
использовать разнообразные не спамные анкорные тексты;
добавлять как dofollow, так и nofollow ссылки;
следить, чтобы было больше безанкорных ссылок, примерная пропорция — 40/60%, однако конкретных и жестких требований здесь нет. Во всем нужна мера. Также руководствуйтесь логикой и здравым смыслом;
стремиться к тому, чтобы большинство ссылок были получены естественным путем.
Как правильно наращивать ссылочную массу сайта
| Читать |
Как найти внешние ссылки в системах аналитики
Найти внешние ссылки на сайт можно с помощью систем аналитики поисковых систем. В Search Console эта информация размещается в разделе «Ссылки»:
В Search Console эта информация размещается в разделе «Ссылки»:
В Яндекс.Вебмастере также доступен отчет о внешних ссылках, демонстрирующий график их изменения:
Как проанализировать внешние ссылки на наличие трафика с помощью Google Analytics
| Читать |
Поиск внешних ссылок с помощью Serpstat
Будет отображен график появления новых ссылающихся доменов, их количество и общее число ссылающихся страниц. В отчете видно соотношение follow и nofollow ссылок, а также их анкорные тексты.
Для наглядности на дополнительных диаграммах отображается соотношения новых и потерянных ссылок и история изменений уникальных гиперссылок:
Анализ ссылок: как мы сделали наш модуль эффективнее
| Читать |
Хотите узнать, как улучшить ссылочную массу с помощью Serpstat?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
Error get alias
Заключение
Чтобы избежать санкций поисковых систем, нужно проводить анализ исходящих и входящих ссылок на сайт.
На страницах сайта не должно быть большого количества индексируемых ссылок на другие ресурсы.
Чтобы запретить поисковым роботам переходить на другой сайт по ссылке, можно добавлять атрибут rel=»nofollow» в конкретный тег <a> либо прописывать такой запрет для всей страницы в мета-теге <meta-robots>.
Внешние ссылки положительно влияют на продвижение сайта в случае, если они добавляются на качественные ресурсы по определенным правилам, снижающим риски фильтров поисковых систем.
Проверить исходящие и входящие ссылки, узнать их количество, атрибуты и якорные тексты можно с помощью сервисов аналитики поисковых систем и специальных инструментов, включая Serpstat.
Аудит всего сайта или аудит отдельной страницы в один клик. Полный список ошибок, отсортированный по критичности, пути их устранения и рекомендации. Любая периодичность проверки и автоматическая рассылка отчетов на почту.
| Запустить аудит сайта |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4. 78 из 5 на основе 8 оценок
78 из 5 на основе 8 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Какими должны быть ссылающиеся сайты: список требований
How-to
Анастасия Сотула
Как проанализировать внешние ссылки на наличие трафика с помощью Google Analytics
How-to
Анастасия Сотула
Как провести анализ сниппетов в поисковой выдаче
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Как закрыть ссылки и страницы сайта от индексации?
С какой целью порой может использоваться закрытие веб-сайта или каких-то его разделов, страниц от индексации поисковыми системами? Вариантов с ответами имеются несколько:
- Следует убрать от всеобщего обзора ту или иную информацию, в которой могут находиться секретные данные.
- Если нужно сформировать подходящий релевантный контент: случаются варианты, если очень сильно возникает желание сообщить пользователям Интернете больший поток информации, однако которая делает туманной релевантность по тексту.
- Закрыть от роботов дублирующий контекст.
- Спрятать информацию, которая не представляет интереса для пользователей, и которую так не любят поисковые роботы, считая ее спамом в медиа-контенте.
Например, это могут быть портфолио, материалы сайта с устаревшим смыслом, какие-то расписания в справочниках. php» search_bot
php» search_bot
Способ второй
Для страницы, которую необходимо закрыть, можно в файле .htaccess прописать любой из следующих ответов сервера:
1 403 «Доступ к ресурсу запрещен», т.е. код 403 Forbidden
2 410 «Ресурс недоступен», т.е. окончательно удален
Способ третий
Можно закрыть индексацию к сайту с помощью доступа только по паролю:
В этом случае, в файле .htaccess, вставляем следующий код:
1 AuthType Basic
2 AuthName «Password Protected Area»
3 AuthUserFile /home/user/www-pass/.htpasswd
4 Require valid-user
Значит в корне сайта создаем — home/user/www-pass/.htpasswd
где .htpasswd — файл с паролем, который создаем сами в файле.
Но затем следует добавить пользователя в файл паролей htpasswd — /home/user/www-pass/.htpasswd USERNAME
где USERNAME — это имя пользователя для авторизации.
Здесь можно прописать свой вариант.
Как закрыть отдельный блог от индексации?
Зачастую бывает, что необходимо закрыть от поисковой индексации не весь сайт целиком, а только конкретный источник: список, счетчик, запись, страницу либо какой-нибудь код.
В одно время, достаточно было использовать тег «noindex», но это больше подходило для роботов Яндекса, а для Google были достаточны обычные действия.
Здесь может быть любой текст, ссылки или код
Но затем роботы Яндекс стали меньше обращать внимания на такую техническую «уловку», а роботы Google вообще перестали понимать данную комбинацию. В результате, технические специалисты сайтов, стали применять иной вариант с целью закрытия индексации части текста на какой-либо странице, используя скрипты javascript, либо соответствующие плагины или модули.
Часть текста шифруется с помощью javascript. Но следует помнить, что затем непосредственно сам скрипт нужно будет закрыть от индексации в robots.txt.
Универсальный способ закрытия изображений (медиафайлов) от индексации
Многие сайты используют картинки, которые в основном берутся из Интернета, я значит никак не могу считаться уникальными. В результате таких действий, появляется боязнь, то, что роботы поисковиков отнесутся к таким сайтам негативно, а именно будут блокировать продвижение и повышение в рейтингах.
В этом случае следует на странице сделать следующую запись в коде:
Скрипт, который будет обрабатывать элемент:
Как закрыть от индексации внешние либо внутренние ссылки?
Такие действия нужно только в том случае, если нужно закрыть от индексации входящие ссылки от сайтов находящиеся под санкциями поисковых систем, а так же скрыть исходящие ссылки на сторонние ресурсы, чтобы предотвратить уменьшение веса сайта, а именно ТИЦ сайта донора.
Для этого нужно создать файл transfers.js
После этого нижеуказанную часть кода вставляем в файл transfers.js:
function goPage(sPage) {
window.location.href = sPage;
}
После этого данный файл уже размещаем в соответствующей папке сайта и на странице в head добавляем код:
И теперь прописываем необходимую ссылку, которую нужно скрыть от индексации поисковых систем:
Как закрыть от индексации роботов отдельную страницу на сайте?
Первый метод — через файл robots.txt
Disallow: /URL-страницы сайта
Второй метод — закрытие с помощью метатегов
Третий метод — в Вебмастере Яндекса, в разделе «Инструменты» с помощью «Удалить URL» можно отдельно по каждой ссылке сделать запрет на индексацию от роботов Яндекса.

Четвертый метод — сделать запрет на индексацию через ответ сервера:
404 — ошибка страницы
410 — страница удалена
И сделать добавление в файле .htaccess:
ErrorDocument 404 https://URL-сайта/404
Однако, данным метод используется весьма редко.
Как закрыть от индексации сразу весь раздел или категорию на сайте?
Лучший способ — реализовать это с помощью файла robots.txt, где внутри прописать:
User-agent: *
Disallow: /название раздела или категории
Дополнительные варианты:
Кроме указанных выше способов, также могут подойти способы, которые применяются для сокрытия страницы сайта целиком, либо какого-то раздела, — правда, если подобные действия могут быть сделаны автоматически:
- соответствующий ответ сервера для определенных страниц раздела сайта
- применение мета-тегов к определенным страницам
Все эти без исключения методы, возможно, осуществить программно, а никак не в «ручном» режиме назначать к любой страничке или части текста запрет на индексацию — весьма дороги трудовые затраты.
Конечно, ведь легче в целом сделать соответствующее запрещение в файле robots.txt, однако практика показывает, то что это не может гарантировать на 100% запрет на индексацию.
Как закрыть от индексации целиком папку?
В этом случае на закрытие пойдет непосредственно папка, а не раздел. Ведь нам нужно закрыть папку с файлами, которые не должны видеть поисковые роботы, а это могут быть какие-то разработки, документы, картинки и многое другое.
User-agent: *
Disallow: /folder/
Пять способов закрытия на сайте дублей от поисковой индексации
Первый способ — и наиболее верный, для того, чтобы их действительно не существовало — необходимо на физическом уровне освободиться от них, т.е. в любом варианте при открытии страницы, кроме оригинальной, должна демонстрироваться страница 404 — ответ сервера.
Второй способ — применять атрибут rel="canonical", который как раз и является наиболее правильным решением. Таким образом, равно как атрибут не позволяет роботам индексировать дублирующиеся страницы, так перенаправляет вес с дублей на оригиналы.
Только на странице дубля в коде следует прописать:


Как закрыть сайт от поисковой системы Google или Яндекс [Блон MSystem RU]
В своем блоге мы постоянно рассказываем о том, как привлечь внимание поисковиков, быстро попадать в индекс и хорошо ранжироваться в поиске. Вы в это время решили закрыть сайт от индексации полностью или частично. Понимаем, для этого может много причин: редизайн, глобальная смена контента, другие технические работы. Кроме того, страницы админки, служебные и прочие “непользовательские” страницы в принципе не должны попадать в индекс. Как их скрыть и, что не менее важно, убедиться в том, что они точно скрыты — расскажем ниже.
В каких ситуациях мы скрываем страницы от индексации
Давайте еще раз рассмотрим частые причины и ситуации, в которых страницы сайта следует скрыть:
- Если после запуска сайта дизайн некоторые его страницы или контент на них пока не оптимизированы, мы рекомендуем закрывать их от поисковых ботов на время доработок. В каких ещё ситуациях нужен запрет на индексацию:
- В то время как на отдельном домене создаются мобильная версия сайта могут создаваться дубли страницы. Чтобы поисковики их не зафиксировали и сайт не потерял позиции выдаче, нужно закрыть сайт.
- По той же причине следует закрывать страницы, тогда, когда вы тестируете сайт на другом домене.
- Редизайн и обновление контента.
- Сайт во время разработки.
 В каких ещё ситуациях нужен запрет на индексацию:
В каких ещё ситуациях нужен запрет на индексацию:В таких случаях нужно запретить индексацию сайта на время проведения работ.
Однако, есть также страницы, которые должны быть скрыты от сканирования всегда. К таким относятся:
- Копии сайта
Или так называемое “зеркало” сайта. - Страницы печати
Страница печати, технически — это копия её основной версии. Открытая для сканирования страница может посчитаться поисковым роботом, как приоритетная и более релевантная. - Ненужные документы
На просторах ресурса, наряду с ключевым контентом, могут находиться различные файлы PDF, DOC, XLS, доступные для чтения и загрузки. Заголовки этих файлов, попавших в индекс, в таком случае могут попасть в результаты поиска и конкурировать с нужными html-страницами. - Пользовательские формы и элементы
Это могут быть формы оформления заявок и регистрации, корзина, личный кабинет клиента. - Технические данные ресурса
Страницы, предназначенные исключительно для служебного использования админом. - Персональные данные клиентов
Эта информация должна быть надежно защищена от просмотра. - Страницы сортировки и пагинации
Во избежания генерации дублей.
 Заголовки этих файлов, попавших в индекс, в таком случае могут попасть в результаты поиска и конкурировать с нужными html-страницами.
Заголовки этих файлов, попавших в индекс, в таком случае могут попасть в результаты поиска и конкурировать с нужными html-страницами.Почему так важно закрывать эти страницы от сканирования? В одних случаях их контент не несет в себе смысловой нагрузки ни для пользователей, ни для поисковиков. В других, наличие открытых страниц создает иллюзию дублированного контента, что чревато пессимизацией всего ресурса.
Также это приводит к нерациональному использованию краулингового бюджета. В то время как индексация — это сканирование и обработка содержания веб-страниц для хранения в базе данных поисковика, краулинговый бюджет — это количество страниц, которые поисковик может просканировать за один сеанс на сайте. Т.е., если для индексирования открыты ненужные страницы, это не только приводит к тому, что они могут попасть в выдачу и “портить всю картину”, но и к тому, что нужные страницы в индекс вовремя не попадают. Ведь краулинговый бюджет расходуется еще до того, как робот дойдет до них.
Т.е., если для индексирования открыты ненужные страницы, это не только приводит к тому, что они могут попасть в выдачу и “портить всю картину”, но и к тому, что нужные страницы в индекс вовремя не попадают. Ведь краулинговый бюджет расходуется еще до того, как робот дойдет до них.
Как полностью или частично закрыть сайт от сканирования
Рассмотрим, как отключить индексацию веб-ресурса целиком или выборочно.
Robots.txt
Файл robots.txt, размещаемый в корневой директиве веб-ресурса, позволяет отключить сканирование для отдельных каталогов, страниц, папок, файлов, скриптов, utm-меток на сайте. Полностью или частично. Можно закрыть отдельные разделы или весь сайт, от определенного поисковика, или от всех.
Итак, как закрыть сайт от индексации в robots txt: прилагаем краткую инструкцию.
В тексте документа в формате txt прописываются команды для поисковых роботов. Для индексирования используется директива Disallow со значением » / «.
User-agent: название поисковой системы
Disallow: /
Если нужно закрыть сайт от всех поисковиков в значении для User-agent пропишите «*». Для обращения к конкретному роботу вместо, используйте его название. Например, User-agent: Yandex
Для обращения к конкретному роботу вместо, используйте его название. Например, User-agent: Yandex
Если во время доработок, скажем, одного раздела, его требуется скрыть от сканирования, после Disallow нужно прописать его частичный или полный URL.
Отметим: разделы или страницы, которые вы собираетесь закрыть, нужно не перечислять списком после директивы, а прописывать их по принципу — одна директива — один раздел.
Например:
User-agent:
Disallow: /catalogs
Disallow: /blog
Как проверить?
Проблема одна: бывает, что Google-боты не берут во внимание директиву Disallow и продолжает сканировать все страницы веб-ресурса. Но это легко проверить в панели для вебмастеров
Если в Google Search Console не указывается, что в Роботс закрыты определенные страницы, значит, у нас проблемы и стоит попробовать закрыть их другими методами, которые мы рассмотрим ниже.
“Чекнуть” Яндекс можно в соответствующей панели для вебмастеров в разделе «Индексирование».
Метатег Robots
Еще один способ закрыть страницу от индексации и даже отдельный ее контент — метатег Robots.
Что делаем:
- Если нужно запретить от индексации весь контент, добавляем в раздел <head> страницы строку кода:
<meta name=»robots» content=»noindex, nofollow»/>
или:
<meta name=»robots» content=»none»/> - Если нужно скрыть только часть контента (например, текст или его фрагмент), в тело тега <head> добавляем строку:
<noindex> фрагмент текста </noindex> - Чтоб запретить ботам переходить по ссылке, т.е. скрыть ее от сканирования,используйте nofollow:
<a href=»url» rel=»nofollow»>текст ссылки</a>
Этот метод не гарантирует полное закрытие веб-ресурса от сканирования. После своих действий проверьте число просканированных страниц в консолях вебмастера.
Если ни таким методом ни в robots. txt запретить индексацию не получилось, используйте метод заголовка сервера, который мы опишем далее.
txt запретить индексацию не получилось, используйте метод заголовка сервера, который мы опишем далее.
X-Robots-Tag
Этот метод основывается на указании заголовка HTTP на уровне сервера. С его помощью можно скрыть от ботов определенный контент.
На практике это реализуется несколькими методами, но мы рекомендуем самый удобный — редактирование кода в .htaccess.
Что делаем?
Открываем файл .htaccess и вбиваем в конце документа такие строчки:
<FilesMatch «\.html$»>
Header set X-Robots-Tag «noindex,nofollow»
</FilesMatch>
Таким образом мы, используя директиву FilesMatch закрываем все файлы в формате html. При желании, можно тем же способом скрыть от попадания в индекс файлы другого формата. Например, изображения в .jpeg. Как и другой медиаконтент, файлы и скрипты.
Для этого нужно подставить значение их формата после директивы FilesMatch в верхней строке заголовка, там где в нашем примере указан html.
Можно подставлять директивы, которые, в большинстве своем, совпадают с директивами Robots.
В конце проверьте результативность своих действий: работоспособен ли серверный заголовок. Для этого существуют сервисы типа Askapache. Введите нужную страницу и запустите проверку.
Подключённый заголовок выглядит так:
Заключение
Управление индексацией — важный пул работ. Для результативного продвижения в поиске следует не только оптимизировать полезные этом страницы, но и не забывать скрывать тот контент, продвижение которого не несет никакой пользы или может ему навредить.
Оцените статью
Средняя оценка 0 / 5. Количество оценок: 0
Количество оценок: 0
Оценок пока нет. Поставьте оценку первым.
Личный помощник
Ведет дела в рамках услуги поисковая рекламаПогружается в специфику работы, но при этом умеет донести информацию доступным способомСвязывается с заказчиком минимум раз в неделю для передачи отчетов, обсуждения результатов
Обсудить проект
Особенности индексации сайтов – robots.txt, мета-тег robots и внутренние ссылки
Привет, ребята. Как и обещал, сегодня пойдет речь про тонкости и особенности индексации сайтов в поисковых системах. Мысли к написанию данного поста мне навеяло развязное поведение роботов Google – наверное, многие заметили, что Гугл индексирует все, что ему только вздумается, не смотря на различные запреты, например, в robots.txt.
Но ведь все мы хотим сделать своим сайтам «красиво», чтобы количество полезных существующих (загруженных) роботом страниц равнялось количеству проиндексированных поисковиком, а количество страниц из дополнительного индекса Google (supplemental) сводилось к минимуму.
Так вот из-за «произвола» роботов и начинают, откуда ни возьмись появляться дубли страниц, вылезать различные проблемы и все такое. Ну и начал я копать и изучать подробнее.
Блокировка и удаление страниц с помощью файла robots.txt
Предлагаю начать с разговора о файле robots.txt, как о самом популярном способе запрета индексации страниц сайта.
Сразу приведу несколько выдержек из справки для вебмастеров от Google:
Файл robots.txt ограничивает доступ роботов, сканирующих Интернет для поисковых систем, к вашему сайту. Перед обращением к страницам сайта эти роботы автоматически ищут файл robots.txt, который запрещает им доступ к определенным страницам.
Файл robots.txt необходим только в том случае, если на вашем сайте есть содержание, которое не следует включать в индекс поисковых систем. Если вы хотите, чтобы поисковые системы включали в свои индексы все содержание вашего сайта, файл robots.txt (даже пустой) не требуется.

Хотя Google не сканирует и не индексирует содержание страниц, заблокированных в файле robots.txt, URL-адреса, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие общедоступные сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project (www.dmoz.org), могут появиться в результатах поиска Google.
Вот, последняя выдержка самая интересная, из которой понятно, что Google может игнорировать директивы из файла robots.txt. И, как показывает практика, в индекс очень часто попадают адреса страниц, запрещенные в robots.txt, даже при условии отсутствия на них внешних/внутренних ссылок.
Кстати, в руководство Гугла стоило бы добавить, что не только «URL-адреса, обнаруженные на других страницах в Интернете», но и внутренние ссылки приводят к индексации запрещенных страниц, но об этом чуть позже.
На удивление, информация обо всех адресах хранится в Гугле, наверное, веками. У меня есть сайт, на котором уже лет 5 назад сменилась CMS, а вметсе с ней и все url, и старых адресов уже нигде нет, но Гугл помнит эти адреса если пошерстить доп. индекс 🙂
У меня есть сайт, на котором уже лет 5 назад сменилась CMS, а вметсе с ней и все url, и старых адресов уже нигде нет, но Гугл помнит эти адреса если пошерстить доп. индекс 🙂
В Яндексе с этим дела получше, все страницы, закрытые через роботс, НЕ попадают в основной индекс Яндекса, однако роботом просматриваются и загружаются, это наглядно видно в панели вебмастера, где, например, можно наблюдать такое: Загружено роботом — 178046 / Страниц в поиске — 72437. Разумеется, причина такого расхождения аж в 100к страниц не полностью следствие запрещения страниц через robots.txt, здесь есть и 404 ошибки, например, и другие неполадки сайта, которые могут случаться по различным причинам.
Но это не страшно, вот выдержка из руководства для вебмастеров от Яндекса:
В разделе «Исключённые страницы» отображаются страницы, к которым обращался робот, но по тем или иным причинам принял решение не индексировать их. В том числе, это могут быть уже несуществующие страницы, если ранее они были известны роботу.
Наличие и количество исключенных страниц не влияет на ранжирование сайта в поиске по запросам.
 Информация об причинах исключения из индекса хранится в течение некоторого времени, пока робот продолжает их проверять. После этого, если страницы по-прежнему недоступны для индексирования и на них не ведут ссылки с других страниц, информация о них автоматически удаляется из раздела «Исключённые страницы».
Информация об причинах исключения из индекса хранится в течение некоторого времени, пока робот продолжает их проверять. После этого, если страницы по-прежнему недоступны для индексирования и на них не ведут ссылки с других страниц, информация о них автоматически удаляется из раздела «Исключённые страницы».По аналогии с Гуглом тут имеет место быть влияние внешних/внутренних ссылок.
Резюмируя вышесказанное:
Для Яндекса robots.txt запрещает индексацию (в данном случае под этим словом подразумеваем отображение в результатах поиска) закрытых страницы, но не запрещает их загрузку роботами. Такие страницы видны только владельцу сайта в панели вебмастера в разделе «Исключенные страницы».
Для Google robots.txt частично запрещает индексацию страниц, робот их загружает и может отображать в дополнительном индексе, закрытые страницы не отображаются в основном индексе, но все они доступны при изучении дополнительной выдачи (supplemental). Насколько это плохо или хорошо — не известно — в мануалах Гугла такой информации не нашлось. Надеюсь, что это никак не влияет на ранжирование в плохую сторону.
Насколько это плохо или хорошо — не известно — в мануалах Гугла такой информации не нашлось. Надеюсь, что это никак не влияет на ранжирование в плохую сторону.
Рекомендую к прочтению:
- Мануал Яндекса «Использование robots.txt»
- Мануал Google «Блокировка и удаление страниц с помощью файла robots.txt»
Плавно переходим к следующему пункту про метатег robots.
Использование метатега robots для блокирования доступа к сайту
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Чтобы полностью исключить вероятность появления контента страницы в индексе Google, даже если на нее ссылаются другие сайты, используйте метатег noindex. Если робот Googlebot начнет сканировать страницу, то обнаружит метатег noindex и не станет отображать ее в индексе.
Внушает оптимизм, не правда ли? И еще:
Обратите внимание: чтобы увидеть тег noindex, мы должны просканировать вашу страницу, поэтому существует небольшая вероятность, что поисковый робот Googlebot не увидит метатег noindex и не отреагирует на него. Кроме того, если вы заблокировали эту страницу с помощью файла robots.txt, мы также не сможем увидеть этот тег.
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег <meta name="robots" content="noindex">.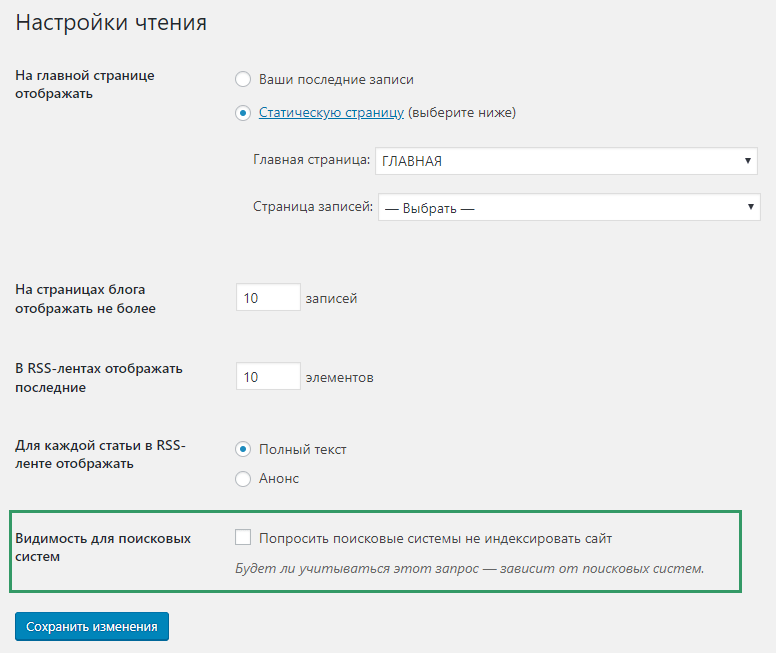 Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег <meta name="robots" content="noindex,nofollow">.
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега <head> </head>), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Однажды я задавал службе поддержки Яндекса следующий вопрос:
1. Играет ли пробел роль в коде <meta name=»robots» content=»noindex, nofollow»/>. То есть, есть ли разница как писать noindex, nofollow или noindex,nofollow — в первом случае после запятой идет пробел, во втором случае директивы без пробела.
2. И второй вопрос. Если, допустим, на странице по какой-то причине указаны два метатега robots, например, в такой последовательности:
<meta name=»robots» content=»all»/>
<meta name=»robots» content=»noindex, follow»/>
Какие правила применит робот в этом случае?И получил следюущий ответ:
1. Пробел роли не играет.
2. Последовательность роли не играет. При наличии одновременно запрещающего и разрешающего мета-тега будет учтен разрешающий.
 Важно ли это или нет?
Важно ли это или нет?Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots. txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉
Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.
Итоги — или что сделать, чтобы стало все круто?
Наконец-то я могу подвести итог сегодняшнего огромного поста, и он будет кратким.
Чтобы улучшить качество индексации сайта, необходимо:
- Скрыть от гостей (к ним относятся и роботы) ссылки, которые им не нужны или не предназначены.
- Ссылки, которые нельзя удалить или спрятать от живых посетителей, стоит скрыть и выводить через JavaScript.
- Если ничего из перечисленного невозможно или не получается, то хотя бы необходимо закрыть ссылки на ненужные страницы атрибутом rel=”nofollow”. Хоть польза от этого и сомнительная, но все же…
- Страницы, которые не должны быть проиндексированы и не должны попасть в индекс поисковых систем, стоит запрещать при помощи метатега robots и параметра noindex:
<meta name="robots" content="noindex"> - Страницы, содержащие тег robots не должны быть запрещены к индексации через robots.txt
 Хоть польза от этого и сомнительная, но все же…
Хоть польза от этого и сомнительная, но все же…Что даст нам весь этот «улучшайзинг»:
- Во-первых, чистота индекса сайта, что в наше время очень редко и почти не встречается.
- Во-вторых, быстрота индексации/переиндексации сайта увеличится за счет того, что робот не будет загружать страницы, которые закрыты для него.
- В-третьих, сохранится какая-то часть статического веса сайта, которая раньше утекала по ссылкам на закрытые страницы, а это может положительно отразится на ранжировании сайта.
- В-четвертых, это просто круто и говорит об уровне профессионализма вебмастера.
Фуф, два дня (а точнее — две ночи) писал этот пост и никак не мог дописать, но я это сделал! Потому жду ваших отзывов и комментариев.
Если у кого-то есть практический опыт по теме, обязательно поделитесь им со мной и другими читателями, это будет очень интересно и полезно.
Всем спасибо за внимание и до скорой встречи!
Закрыть сайт от индексации: 5 простых способов
Автор Svitlana Stetsko Просмотров 325 Опубликовано Обновлено
Сегодня разберёмся что такое индекс, как в него попасть, а когда лучше закрыть сайт от индексации. Я расскажу о 5 простых способах, с которыми справится даже новичок. Познакомимся поближе с поисковыми роботами и научимся общаться с ними.
Оглавление
- Индексация простыми словами
- Нужно ли индексировать новый сайт
- Как запретить индексирование
- С помощью robots.txt
- С помощью мета-тега robots
- В админ-панели WP
- Через файл .htaccess
- Установить пароль на весь сайт
- Как проверить какие страницы попали в поиск
- Как удалить страницу из поиска
Индексация простыми словами
Чтобы пользователи интернета смогли найти проект по какому-то запросу в поиске, он должен предварительно попасть в общую базу данных (индекс). Этот процесс добавления страницы в базу называется индексацией и производится роботами (автоматизированными программами) поисковой машины.
Этот процесс добавления страницы в базу называется индексацией и производится роботами (автоматизированными программами) поисковой машины.
Роботы (они же веб-пауки, краулеры, боты) заходят на ресурс и сканируют доступные страницы, изображения, видео и другие файлы. Полученные данные собираются в поисковый индекс, а затем из этой базы берутся результаты для выдачи информации пользователям.
Также краулеры собирают ссылки с вашего проекта для дальнейшей их обработки. Из этого следует, что оставляя ссылки на свой ресурс в других сервисах (сайтах, форумах, социальных сетях), вы привлекаете поисковых ботов на свой сайт и ускоряете процесс индексации.
Веб-краулеры разных поисковых систем работают по-разному. Кроме того, алгоритмы сканирования (краулинга) и обработки данных совершенствуются с каждым годом.
Максимально работайте над уникальностью контента, структурностью, полезностью ресурса. Если веб-паук не нашёл интересной новой информации, то страница может и не проиндексироваться. Другими словами, статья была просканирована, но в индекс (а значит и в поисковую выдачу) не попала.
Другими словами, статья была просканирована, но в индекс (а значит и в поисковую выдачу) не попала.
За раз краулер сканирует только несколько страниц, чтобы не создавать нагрузку на сервер своими запросами. На новостные порталы, которые постоянно обновляются, боты заходят очень часто и наоборот: если сайт заброшен, то и «гости» заходят редко.
Очень важно вести работу системно, обновляя периодически старые записи. Очень помогают в этом смысле комментарии, которые оставляют читатели. Проект, на котором ведутся дискуссии, привлекает внимание поисковых роботов, он становится более интересным и лучше продвигается.
Нужно ли индексировать новый сайт
Представим себе начинающего вебмастера, который создаёт свой первый проект. Хорошо, если у него есть наставник, который быстро научит всем тонкостям этого процесса. Как правило, это входит в платный пакет обучения. В реальности большинство «учеников» разбираются самостоятельно, а это потеря времени, ошибки, переделки.
А теперь представьте, что робот пришёл на новоиспечённый сайт, проиндексировал его. Владелец же каждый день усовершенствуете своё детище: улучшаете структуру, работает над заголовками, меняет ключевые слова… Вдруг пользователь находит и кликает ссылку в поиске, а данная страница уже не существует… Клиент расстроится и возможно в следующий раз выберет сайт конкурента.
Владелец же каждый день усовершенствуете своё детище: улучшаете структуру, работает над заголовками, меняет ключевые слова… Вдруг пользователь находит и кликает ссылку в поиске, а данная страница уже не существует… Клиент расстроится и возможно в следующий раз выберет сайт конкурента.
Поисковые системы (ПС) тоже с недоверием относятся к ресурсам, в которых много битых (несуществующих) ссылок. Это так называемая ошибка 404 (Not Found, «не найдено»).
Разумнее на период экспериментов и разработки закрыть сайт от индексации, чтобы не путать людей и ботов а также не засорять интернет мёртвыми ссылками. Или нужно делать редиректы, хотя вряд ли новичок будет во всё это вникать на первых этапах.
Как запретить индексирование
Причины, по которым лучше закрыть сайт от индексации, могут быть разными:
- ресурс не готов к показу, например, находится на стадии создания или кардинальных изменений;
- проект предназначен для ограниченного круга лиц;
- содержит платный материал;
- архивы (устаревшая информация) могут быть вынесены на отдельный поддомен и не ранжироваться в поиске.
Есть несколько способов попробовать «договориться с краулерами» и закрыть сайт от индексации. Давайте разберёмся с ними, но помните, что одновременное применение нескольких вариантов может привести к конфликту. Поэтому сначала изучите, а потом примените подходящий способ.
С помощью robots.txt
Каждый современный сайт должен содержать специальный текстовый файл robots.txt с набором инструкций для ПС. Краулеры сначала скачивают и анализируют его, получают указания, что можно сканировать, а что — нет.
Для начала нужно проверить, возможно он уже есть а также убедиться в его общедоступности. Для этого введите в поиск в режиме инкогнито подобный адрес:
https://sitefromzero.info/robots.txt
Если такого файла не оказалось, то создайте его в текстовом редакторе (лучше Notepad++), точно указав название (обязательно с маленькой буквы). Теперь добавьте правило для поисковых ботов в виде кода:
User-agent: * Disallow: /
Сохраните файл в кодировке UTF-8 в корневую папку сайта, иначе роботы его просто не поймут или не найдут.
Пояснения к коду:
- User-agent — так мы обращаемся к поисковому роботу (агенту пользователя). Звёздочка означает, что мы обращаемся сразу ко всем поисковикам. Если хотите пообщаться с кем-то конкретно, то укажите имя бота, например
User-agent: Googlebot или User-agent: Yandex
Googlebot и Yandex — это основные роботы-индексаторы от Google и Яндекса.
- Disallow: — директива (правило), указывающая какие пути не должны сканироваться.
- Allow: — директива, указывающая какие пути можно сканировать.
По умолчанию роботу разрешено сканировать всё, что не запрещено директивой Disallow:. Строка обязательно должна начинаться с косой линии. Обратите внимание, упустив лишь один символ, вы откроете проект для индексации:
User-agent: * Disallow:
Нужно понимать, что robots.txt не запрещает, а лишь указывает поисковикам какую информацию обрабатывать, а какую — нет. Большинство ботов следуют установленным директивам, однако некоторые пауки могут проигнорировать правила.
Большинство ботов следуют установленным директивам, однако некоторые пауки могут проигнорировать правила.
Если у вас новенький проект на CMS WordPress, то такой файл уже есть, правда он виртуальный. В корневой папке вы его не найдёте.
Но он работает, открывается по нужному адресу и выглядит так.
Отредактировать этот файл можно с помощью популярных плагинов: Clearfy, ClearfyPro, Rank Math, Yoast SEO. А лучше создать фактический robots.txt и разместить его в корневую папку сайта. Роботам без разницы реальный он или виртуальный, выбор только за вами.
На сайте должен быть только один robots.txt.
С помощью мета-тега robots
Более строгий вариант закрыть сайт от индексации: прописать мета-тег в исходный код, а именно в файле index.html в контейнере <head>:
<meta name="robots" content="noindex, nofollow"/>
или
<meta name="robots" content="none"/>
Давайте разберёмся что это значит:
- robots — обращаемся ко всем ботам;
- noindex — запрет на индексацию контента;
- nofollow — запрет на индексацию ссылок;
- none — запрет на индексацию контента и ссылок.

Если сайт создан на WordPress, то этот шаг делайте только после установки шаблона, поскольку <head> находится непосредственно в папке «Themes» и нужно выбрать header.php именно вашей темы. Путь к данному файлу выглядит так.
Ваш сайт/public_html/wp-content/themes/Ваша тема
Покажу на примере стандартной WP-темы TwentyTwenty.
Правой мышкой выберите режим Просмотр / Правка.
В открывшемся файле вверху находим <head> и вставляем код.
Все правки кода рекомендуется делать в дочерней теме, поскольку при обновлении родительской изменения пропадут.
В админ-панели WP
Попросить поисковые системы не индексировать сайт можно прямо с админ-панели WordPress. Для этого зайдите в Настройки / Чтение и поставьте галочку в пункте «Видимость для поисковых систем».
При этом автоматически прописывается мета-тег robots, в чём легко убедиться нажав Ctrl+U. Parser» search_bot
Parser» search_bot
Это достаточно жёсткий метод блокировки, используемый опытными вебмастерами.
Установить пароль на весь сайт
Самый надёжный способ закрыть сайт от индексации — установить пароль. Есть несколько плагинов WordPress, наиболее простой и популярный — Password Protected.
Администратор и зарегистрированные пользователи могут входить без пароля.
Как проверить какие страницы попали в поиск
Иногда так случается, что несмотря на запрет нежелательный контент попал в выдачу. Для проверки индексации всего проекта можно воспользоваться поисковым оператором [site:]. Этот способ наиболее простой, но не очень точный.
В строку поиска Google и Яндекса нужно ввести такой запрос: site:domain.info
При запросе в Яндексе я получила 31 результат.
При аналогичном запросе в Google получила гораздо больше проиндексированных страниц. Среди них оказались удалённые страницы, например первая пробная статья «Привет, мир!», которая шла вместе с загрузкой WordPress.
Как видите, Yandex достаточно послушен и придерживается правил, чего не скажешь о Googlebot. Так что не думайте, что проект никто не найдёт. Если вы открыли его в браузере, этого уже достаточно, чтобы «засветиться».
Как удалить страницу из поиска
Если проект только создан и там нет важной информации в виде персональных данных, то можно ничего не делать, а просто подождать пока краулеры сами выявят несуществующие страницы и удалят их из поиска.
Сам Google просит не создавать срочных запросов на удаление URL, если лишние страницы возникли в результате изменения структуры сайта.
Если необходимо срочно удалить URL, то воспользуйтесь специальными инструментами в кабинетах Вебмастера от Google и Яндекс. Как это сделать, я подробно опишу в новом обзоре.
Итак, теперь вы знаете несколько простых способов как закрыть сайт от индексации, главное не забудьте потом открыть доступ. Советую дополнительно изучить рекомендации от Google и Яндекс.
В некоторых случаях требуется запретить индексацию не всего проекта, а только его отдельные страницы или элементы. Об этом мы поговорим в другой раз. Подписывайтесь на обновления, чтобы не пропустить новые публикации.
Об этом мы поговорим в другой раз. Подписывайтесь на обновления, чтобы не пропустить новые публикации.
НЕ УПУСТИ
Будь первым, кто узнает о новых обзорах и акциях на SiteFromZero
Ваше имя
Ваш email *
Мы не спамим! Прочтите нашу политику конфиденциальности, чтобы узнать больше.
macos — Spotlight сообщает «Индексирование и поиск отключены» в Lion
Lion продолжает «терять след» информации Spotlight. Каталоги и приложения исчезают, полнотекстовый поиск перестает работать и т. д. Кажется, мне нужно переиндексировать его раз в неделю или около того.
Однако теперь он вообще не работает.
Работает
sudo mdutil -i вкл/
из Терминала я получаю сообщение
"Индексирование и поиск отключены".
Я пытался очистить файлы настроек, удалить всю папку V100, восстановить разрешения и т. д., но Spotlight по-прежнему считает, что индексирование отключено для всего моего тома (Да, я добавил/удалил весь диск из настроек конфиденциальности Spotlight).
В консоли у меня довольно много ошибок, которые выглядят так:
mds: (Ошибка) Сервер: Отключено хранилище, зарегистрированное для области «/ Приложения»
Однако я не знаю, как сказать ему снова включить эту область, поскольку mdutil выдает ошибку при попытке включить индексирование и выдает ошибку при попытке удалить индекс
РЕДАКТИРОВАТЬ: я переустановил Lion. Это не решило проблему (ы) 🙁
- macos
- прожектор
8
У меня была точно такая же проблема, и все приведенные выше решения не сработали одинаково. Затем я еще раз просмотрел список каталогов для / и нашел скрытый файл .metadata_never_index в корневом каталоге. Я удалил этот файл и смог снова включить прожектор с помощью mdutil -i на /.
mds сейчас переиндексирует жесткий диск, пока все выглядит хорошо.
4
sudo mdutil -i выкл / sudo rm -rf /.
 Прожектор*
sudo mdutil -i вкл/
судо mdutil -E /
Прожектор*
sudo mdutil -i вкл/
судо mdutil -E /
1 — отключить индексирование
2 — удалить папку Spotlight
3 — включить индексирование
4 — восстановить
Помогает ли это?
Также кажется, что вы могли бы использовать эти команды:
sudo mdutil -a -i off sudo mdutil -a -i на
7
Другие решения у меня не сработали, однако в моем случае виновником было следующее.
Убедитесь, что ваш корневой/основной жесткий диск не находится в настройках «конфиденциальности» для внимания. По какой-то причине у меня был весь жесткий диск в списке «Запретить прожектору индексировать следующие местоположения».
Вы можете получить доступ к этому разделу из Системных настроек -> Spotlight -> Конфиденциальность
4
sudo mdutil -i выкл / sudo rm -rf /.Прожектор* sudo rm -rf /.metadata_never_index sudo mdutil -i вкл/ судо mdutil -E /
У меня сработало сочетание вышеперечисленного. Шаг 3 был большим. Избавился от «Индексирование и поиск отключены». сообщение. Затем шаги 4 и 5 сработали, как и ожидалось.
Шаг 3 был большим. Избавился от «Индексирование и поиск отключены». сообщение. Затем шаги 4 и 5 сработали, как и ожидалось.
- индексация поворота выключена
- удалить папку Spotlight
- удалить файл метаданных
- индексация поворота на
- восстановить
1
После всех первоначальных шагов по устранению неполадок:
- Перестроить индекс
- Попытка входа в другую учетную запись пользователя
- Сбросить префы/кеш и начать заново
Я обнаружил, что проблема заключается в том, что было включено/выключено. В терминале я запустил «mdutil -sa» и получил:
/:
Индексация включена.
/Группы:
Индексация отключена.
/Общие элементы/Общедоступно:
Индексация отключена.
/Пользователи:
Индексация отключена.
/Пользователи/сара/Документы:
Индексация включена.
Я заметил «/Пользователи: индексирование отключено». Вот в чем проблема. Исправление: «sudo mdutil -i on/Users». После этого он переиндексировал /Users, что заняло значительно больше времени, чем раньше, и до того, как он был завершен, он искал мою почту!
Вот в чем проблема. Исправление: «sudo mdutil -i on/Users». После этого он переиндексировал /Users, что заняло значительно больше времени, чем раньше, и до того, как он был завершен, он искал мою почту!
Это также может быть вызвано зависанием в безопасном режиме. Чтобы это исправить, вам нужно сбросить NVRAM, удерживая клавиши Command ⌘ , Option ⌥ , P и R сразу после перезагрузки (до появления серого экрана).
Я заметил эту проблему после того, как на мой компьютер iMac было установлено обновление программного обеспечения 10.7.4 . Большинство предлагаемых командных строк выдают «Индексирование и поиск отключены» 9.0034 . sudo mdutil -pEsav дал мне «публикация хранилища данных не реализована».
Ниже приведено решение, которое сработало:
редактировать/etc/hostconfigдобавьте строкуSPOTLIGHT=-YES-внизу (эта строка отсутствовала)перезагрузка
(после перезагрузки сварите суп, пока ваша машина готовит индекс)
У меня работала только комбинация -E и -i на :
sudo mdutil -E -i в /Volumes/blah
Это сработало для меня: повторно включить индексирование Spotlight
sudo launchctl load -w /System/Library/LaunchDaemons/com.
 apple.metadata.mds.plist
apple.metadata.mds.plist
2
В течение нескольких дней я пробовал каждое решение для Big Sur, и комбинация этих шагов, похоже, решила его для меня. Поверьте мне, я тоже не хотел отключать целостность системы, но это единственное, что сработало:
Отключить целостность системы (перезагрузить -> удерживать cmd + r -> выбрать терминал утилит -> csrutil отключить -> перезапустить снова)запустить
sudo РМ /Система/Тома/Данные/.metadata_never_index
запуск
sudo launchctl unload -w /System/Library/LaunchDaemons/com.apple.metadata.mds.plist
запуск
sudo launchctl load -w /System/Library/LaunchDaemons/com.apple.metadata.mds.plist
Повторно включите целостность системыcsrutil enable, выполнив шаги шага №1
В частности, проблема заключалась в том, что я не мог искать приложения. Как вы можете видеть на изображении, теперь я вижу приложение, и оно успешно его открывает.
Также обратите внимание на индикатор загрузки индекса:
Как вы можете видеть на изображении, теперь я вижу приложение, и оно успешно его открывает.
Также обратите внимание на индикатор загрузки индекса:
big sur - Spotlight Индексирование файлового потока Google Диска отключено при перезапуске
Вот пошаговое решение для Google Диска v49 (может не работать в будущих версиях):
Выйти из Google Диска (щелкнуть значок Google Диска в строке меню, затем нажать на шестеренку, затем нажать «Выход»).Save this file somewhere aschange_gdrive_smb_port.py(ex:curl -LO https://gist.githubusercontent.com/emersonford/85cc74f7f90c81d1b75c3c246124591d/raw/442834222e2aaa2be61badb6e84f53183ee10624/change_gdrive_smb_port.py).Прочтите сценарий самостоятельно, чтобы убедиться, что его безопасно запускать.Запустите этот скрипт сpython3 change_gdrive_smb_port.py. Он даст вам несколько подсказок, когда найдет учетную запись и на какой порт изменить порт SMB этой учетной записи. Эти порты должны быть неиспользуемыми в вашей системе.Перезапустите Google Диск.Запустите командуmdutil -i on, которую выдает сценарий.Дайте Spotlight немного времени, чтобы проиндексировать все на Google Диске. Теперь он должен оставаться включенным!
 Эти порты должны быть неиспользуемыми в вашей системе.
Эти порты должны быть неиспользуемыми в вашей системе. Если мой сценарий нарушит работу Google Диска или если вы захотите сбросить это изменение, все, что вам нужно сделать, это удалить core_feature_config из ~/Library/Application Support/Google/DriveFS/ и перезапустите Google Диск.
РЕДАКТИРОВАТЬ: Это не так постоянно, как я думал. Похоже, что Google может удаленно вносить изменения в файл «feature_config», что они делают раз в день, судя по всему. Когда они вносят изменения, они перезаписывают изменения, внесенные моим скриптом в core_feature_config ...
Как минимум, вы всегда можете повторно запустить скрипт и перезапустить Google Диск (связать его вместе с pkill "Google Drive" && sleep 5 && echo "yes\n[PORT_NUM]" | python3 change_gdrive_smb_port. ). Это не очень хорошо, но сохраняет базу данных индексов Spotlight, поэтому вам не нужно каждый раз ждать/тратить циклы ЦП на переиндексацию.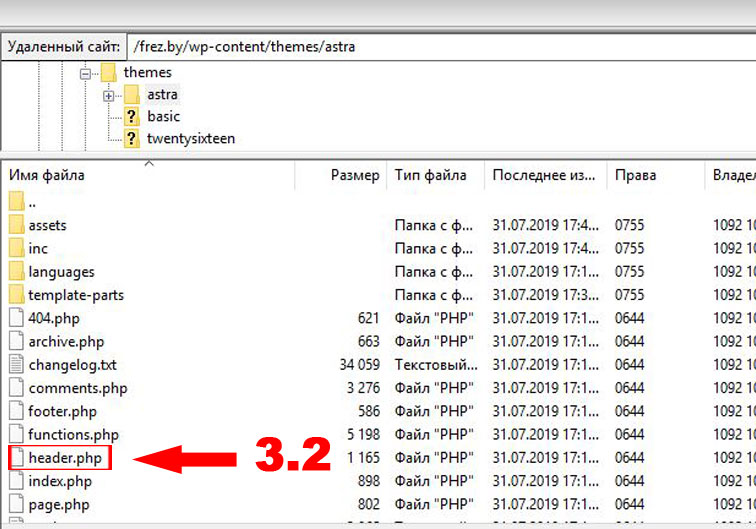 py && откройте /Applications/Google\ Drive.app
py && откройте /Applications/Google\ Drive.app
Я обновлю это снова, если найду обходной путь!
Google Диск использовал пользовательскую реализацию FUSE под названием DriveFS на macOS, которая, по-видимому, имела встроенную поддержку индексации Spotlight. Похоже — и это все мои предположения, поскольку я не сотрудник Google — они было много проблем с переносом этого на новые M1 Mac на основе этой статьи. Даже без этого реализации FUSE, как правило, очень сложны в обслуживании, поэтому я бы не стал винить их за желание отойти от него.
Я предполагаю, что в рамках своего развертывания потоковой передачи Google Диска для всех они хотели убедиться, что каждый может запускать Google Диск без испорченных расширений ядра, поэтому они, похоже, перенесли файловую систему Google Диска на реализацию сервера Samba, а затем смонтируйте это с помощью встроенного в macOS клиента Samba (поэтому вы теперь видите «localhost», смонтированный в сети). Вид умный, если вы спросите меня!
Вид умный, если вы спросите меня!
Проблема с этим для Spotlight двоякая. Во-первых, Apple теперь по умолчанию отключает Spotlight на сетевых дисках (вероятно, не без оснований), поэтому теперь вам нужно вручную включать Spotlight на Google Диске.
Во-вторых, Google Диск устанавливает привязку порта сервера Samba к -1, что означает, что ОС выбирает для вас случайный доступный порт. Я не уверен, когда это изменилось, но Spotlight больше не размещает свой индекс в корневой папке с именем Spotlight-V100 . Все индексы Spotlight теперь хранятся в /var/db/Spotlight-V100 ; кроме того, для сетевых дисков этот индекс называется примерно так: smb%3A%2F%2FDRIVE@localhost%3A59999%2FGoogle%2520Drive . Если присмотреться, номер порта сетевого диска является частью имени индекса Spotlight. Вот почему индексация Spotlight, кажется, отключается через некоторое время. Когда Google Диск перемонтирует FS (иногда случайным образом, иногда при отключении сети), скорее всего, он получил новый порт от ОС для привязки.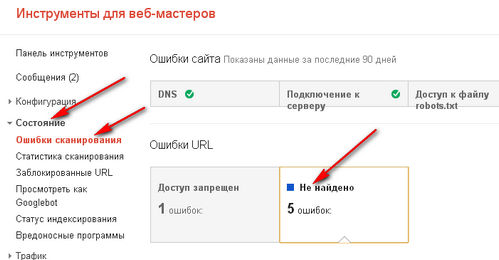 Таким образом, для Spotlight это выглядит как совершенно другой сетевой диск, на котором вы не включили индексирование Spotlight, поэтому вам нужно не только повторно включить индексирование, но и подождать, пока Spotlight снова все проиндексирует.
Таким образом, для Spotlight это выглядит как совершенно другой сетевой диск, на котором вы не включили индексирование Spotlight, поэтому вам нужно не только повторно включить индексирование, но и подождать, пока Spotlight снова все проиндексирует.
Я копался в журналах (в ~/Library/Application Support/Google/DriveFS/Logs ) и заметил это в разделе запуска:
2021-07-22T18:12:33.759ZI [6139763:CrBrowserMain] global_features_manager.cc:266:CompositeAll Составные глобальные функции *БЕЗ* переопределений: drive_dot: true
...
mac_smb_port: -1
...
, поэтому кажется, что изменение порта SMB на статический порт является предпочтительным, просто нужно выяснить, где. Мне потребовалось немного времени, чтобы найти это, так как это не настройка plist, а использование strings , я смог сделать вывод, что это core_feature_config , который, как я обнаружил, является двоичным файлом в формате protobuf. Так что просто нужно было найти нужное поле и заменить значение mac_smb_port на то, что я хотел (с правильной кодировкой protobuf). Как только я понял это с помощью правильного скрипта, Spotlight стал для меня стабильным!
Как только я понял это с помощью правильного скрипта, Spotlight стал для меня стабильным!
Не думайте, что это будет проблемой еще долго, поэтому, если вам неудобно пользоваться моим скриптом и вы готовы подождать, я думаю, вы можете сидеть смирно. Либо сотрудники Google Диска добавят статический номер порта (или параметр), чтобы решить эту проблему, либо перейдут на использование встроенного API поставщика файлов (который, как я обнаружил, вы можете включить прямо сейчас, изменив другой флаг в core_feature_config ), который, вероятно, будет иметь лучшую встроенную поддержку Spotlight.
Как отключить индексирование в Windows 10 и нужно ли это делать? — Блог Auslogics
Продолжается обсуждение того, следует ли отключить индексирование поиска Windows или оставить его включенным. Microsoft ввела службу индексирования в Windows 2000 и не думала об отказе от нее.
Хотя в Windows 2000 ее нужно было включить, теперь она включена по умолчанию.
Так что, если вы один из тех, кто против сервиса, вам придется его отключить. К счастью, в этой статье показано, как это сделать.
К счастью, в этой статье показано, как это сделать.
Однако, если вам интересно, следует ли вам отключить индексирование или нет, вы также находитесь в нужном месте. Мы объясним концепцию индексации поиска Windows и расскажем, когда лучше оставить или отключить эту функцию.
Что такое индексирование поиска Windows?
Индексация поиска Windows позволяет вашему компьютеру быстрее получать результаты поиска.
Когда Windows создает индекс, она регистрирует информацию для сообщений электронной почты, файлов, документов и другого содержимого на вашем ПК. Информация, которую он каталогизирует для индекса, включает такие вещи, как метаданные и слова.
После этого ваш компьютер обращается к индексу всякий раз, когда вы выполняете поиск. Так, например, если вы ищете файл, Windows проверяет его проиндексированную информацию и извлекает ее вместо того, чтобы просматривать ваш жесткий диск.
Должен ли я отключить индексирование поиска Windows в Windows 10?
Windows пытается отслеживать все изменения на вашем компьютере, чтобы поддерживать актуальность каталога индексов. Таким образом, всякий раз, когда вы создаете или удаляете файл, служба индексирования отмечает изменения. То же самое касается новых загрузок, установки и удаления приложений.
Таким образом, всякий раз, когда вы создаете или удаляете файл, служба индексирования отмечает изменения. То же самое касается новых загрузок, установки и удаления приложений.
Постоянное индексирование может потреблять вычислительную мощность и замедлять работу компьютера. Кроме того, в зависимости от типа, количества и размера файлов на вашем компьютере индексация может занимать значительную часть вашего жесткого диска.
Тем не менее, вам все еще может понадобиться индексирование, если вы всегда полагаетесь на поиск Windows для поиска файлов и документов. Вы также должны учитывать, что у индексации есть и другие применения.
Например, Outlook использует проиндексированные данные для поиска в электронной почте. Microsoft Edge использует его для отображения результатов истории браузера при вводе текста в адресной строке. Кроме того, приложение «Настройки» зависит от него, чтобы отображать актуальные результаты.
Более того, некоторые приложения, которые вы загружаете через магазин Microsoft, используют индексированные данные для поиска ваших файлов и другого содержимого ПК.
Отключение индексации увеличит время, необходимое Windows и другим приложениям для возврата результатов поиска.
Итак, если у вас быстрый процессор и стандартный жесткий диск, вы можете продолжать индексирование. Поскольку жесткие диски читаются медленно, Windows будет дольше искать файлы без проиндексированных данных. А с быстрым процессором вам не придется беспокоиться о непрерывном фоновом индексировании.
Однако, если вы не слишком полагаетесь на поиск, используете медленный процессор и SSD, было бы неплохо отключить индексирование.
Windows может быстро искать файлы на SSD, так как эти диски быстрые.
Поисковое индексирование использует вашу оперативную память и ЦП, поэтому вам необходимо отключить эту функцию, если у вас недостаточно оперативной памяти и процессор работает медленно.
Pro Tip
Возможно, вы рассматриваете возможность отключения индексации поиска, поскольку считаете, что это является причиной низкой производительности вашей системы. Хотя это может быть правдой, это не всегда так. Ваш компьютер может работать медленно по многим другим причинам.
Хотя это может быть правдой, это не всегда так. Ваш компьютер может работать медленно по многим другим причинам.
Например, накопление ненужных файлов может привести к засорению жесткого диска, ненужные фоновые приложения могут увеличить нагрузку на ЦП и ОЗУ, а оставшиеся или неисправные ключи реестра могут вызвать сбои.
К счастью, для решения этих проблем можно использовать оптимизатор, например Auslogics BoostSpeed. Таким образом, вам не обязательно отключать индексирование. Программа удаляет ненужные и неверные ключи реестра и защищает ваш жесткий диск от шпионских программ.
РЕКОМЕНДУЕТСЯ
Решение проблем с ПК с помощью Auslogics BoostSpeed
Помимо очистки и оптимизации вашего ПК, BoostSpeed защищает конфиденциальность, диагностирует проблемы с оборудованием, предлагает советы по повышению скорости и предоставляет более 20 инструментов для удовлетворения большинства потребностей в обслуживании ПК.
Auslogics BoostSpeed — это продукт компании Auslogics, сертифицированного Microsoft® Silver Application Developer
БЕСПЛАТНАЯ ЗАГРУЗКА
Итак, как же отключить поисковое индексирование? Давайте перейдем к делу.
Как отключить индексирование в Windows 10
Существуют различные способы управления поисковым индексированием. Если вы полагаетесь на него, вы можете ограничить количество используемых системных ресурсов. Например, вы можете отключить поисковое индексирование для определенных папок и дисков или разделов.
Мы покажем различные способы отключения и изменения индексации поиска.
Отключить поиск Windows
Если вам не нужен поиск Windows, вы можете отключить его. Однако после отключения вы больше не сможете использовать функции поиска в ОС. Эти области включают приложение «Настройки», магазин Microsoft, Cortana и меню «Пуск». Это также означает, что Windows больше не будет выполнять операции индексирования в фоновом режиме.
Итак, выполните следующие действия, чтобы отключить службу:
Перейдите в меню «Пуск» и введите «службы».Щелкните значок приложения «Службы», когда панель поиска откроет его.После открытия приложения «Службы» прокрутите вниз до записи поиска Windows и дважды щелкните ее.

Откроется окно свойств поиска Windows.На вкладке «Общие» выберите «Отключено» в раскрывающемся списке «Тип запуска».Нажмите кнопку «Стоп».Нажмите OK.
Перезагрузите компьютер.
Использование командной строки
Вы можете ввести код в командной строке, чтобы отключить службу поиска Windows и предотвратить ее запуск при запуске.
Этот метод быстрее, чем через приложение «Службы». Однако, если вам неудобно использовать командную строку, выполните описанные выше действия. Вы также можете перейти к следующему решению, чтобы найти другой метод.
Выполните следующие действия:
Откройте диалоговое окно «Выполнить» с помощью комбинации Win + R.После того, как откроется окно «Выполнить», введите CMD и нажмите CTRL + Shift + Enter на клавиатуре.Нажмите Да во всплывающем окне.Теперь введите следующую строку в окно «Администратор: Командная строка» и нажмите клавишу «Ввод».
sc stop «wsearch» && sc config «wsearch» start=disabled
Вы можете снова включить поиск Windows, используя эту строку:
sc config «wsearch» start=delayed-auto && sc start «wsearch»
Вот и все.
Отключить индексирование для определенных областей
Windows предоставляет возможность отключить индексирование для определенных папок. Итак, если есть области, где вы не пользуетесь поиском, вы можете отключить для них индексацию. С другой стороны, вы можете оставить эту функцию для часто используемых папок.
Этот параметр позволяет экономить ресурсы ЦП и ОЗУ, не избавляясь полностью от индексации. Кроме того, поскольку размер индексируемых данных зависит от количества и размера файлов, индексируемых Windows, этот параметр уменьшит нагрузку на хранилище.
Итак, выполните следующие действия:
Откройте меню «Пуск» и введите «индексирование».Нажмите «Индексирование» в параметрах поиска.

Вы также можете открыть диалоговое окно «Параметры индексирования» через панель управления. Нажмите Win + R, чтобы открыть «Выполнить», затем введите «панель управления» в диалоговом окне «Выполнить» и нажмите Enter. После открытия панели управления перейдите в правый верхний угол и выберите «Крупные значки» в раскрывающемся списке «Просмотр». Нажмите «Параметры индексирования».
Нажмите «Изменить» в диалоговом окне «Параметры индексирования».
Теперь будут отображаться ваши места индексации. Нажмите «Показать местоположения», если вы не видите свой жесткий диск.Теперь разверните жесткий диск, щелкнув стрелку рядом с ним.
Примечание. Если установить флажок рядом с диском, Windows проиндексирует весь диск.
После расширения диска перейдите к папкам, которые Windows не должна индексировать, и установите флажки рядом с ними.После завершения упражнения нажмите кнопку OK.Вы увидите Включенные и Исключенные местоположения в нижнем сегменте диалогового окна Индексированные местоположения.

Отключить индексирование Windows по жесткому диску
Вы можете отключить индексирование на определенном жестком диске или разделе, если вы не выполняете поиск файлов на нем. Это существенно снижает ресурсы, которые индексация требует от вашего процессора и оперативной памяти.
Выполните следующие действия:
Используйте комбинацию Win + E, чтобы открыть Проводник.Когда появится проводник, перейдите на левую панель и нажмите «Этот компьютер».Теперь щелкните жесткий диск, для которого вы хотите отключить индексирование, и щелкните его правой кнопкой мыши.Щелкните Свойства.На вкладке «Общие» снимите флажок «Разрешить контекстную индексацию файлов на этом диске» и нажмите кнопку «ОК».
Windows спросит, хотите ли вы, чтобы изменения применялись только к корневому каталогу или ко всем подпапкам на диске. Выберите свой вариант и нажмите ОК.
 Выберите свой вариант и нажмите ОК.
Выберите свой вариант и нажмите ОК. Отключить индексирование для Microsoft Outlook
Как мы уже упоминали, Microsoft Outlook использует индексированные данные для поиска сообщений электронной почты. Если вы этого не хотите, вы можете отключить эту функцию для программы. А поскольку Outlook не отображается в диалоговом окне «Индексированные местоположения», вам придется внести изменения в приложение.
Вот как отключить индексирование Outlook:
Запустите Outlook.Нажмите «Файл» и выберите «Параметры».Когда вы перейдете к экрану «Параметры», перейдите на левую панель и выберите «Поиск».Теперь перейдите на главную страницу и нажмите «Параметры индексирования».Теперь появится диалоговое окно «Параметры индексирования», а Outlook включен в список.Затем щелкните Outlook и нажмите кнопку «Изменить».После появления окна «Индексированные местоположения» снимите флажок рядом с Outlook и нажмите кнопку «ОК».

Перестройте свой индекс
Если вы регулярно пользуетесь поиском, но по-прежнему получаете медленные результаты, значит, что-то не так с вашим поисковым индексом. Проблема может быть связана с поврежденным или неисправным индексом. В этом случае вам нужно перестроить индекс.
Следуйте этому руководству:
Откройте меню «Пуск» и введите «индексирование».Нажмите «Параметры индексирования» в результатах поиска.Вы также можете пройти через панель управления, чтобы открыть диалоговое окно «Параметры индексирования», если поиск неисправен. Нажмите Win + R, чтобы открыть «Выполнить», затем введите «панель управления» в диалоговом окне «Выполнить» и нажмите Enter. После открытия панели управления перейдите в правый верхний угол и выберите «Крупные значки» в раскрывающемся списке «Просмотр». Нажмите «Параметры индексирования».Нажмите «Дополнительно» в диалоговом окне «Параметры индексирования».Нажмите кнопку «Перестроить» и выберите «ОК».
Заключение
Помните, что вы всегда можете отменить изменения, если вам не нравится, как работает ваш поиск. В конце концов, что имеет значение, зависит от вас. Если вы не против подождать еще несколько секунд или минут, прежде чем появятся результаты поиска, вы можете обойтись без индексации Windows.
Сайт отображается в Google, хотя индексирование отключено - SEO - Форум
Mark_Mo_Lerner
(Марк Мо Лернер)
#1
image1226×162 18,8 КБ
image1290×208 34,7 КБ
Это испортит мою поисковую оптимизацию, когда я переведу страницу на фактический URL?? Как запретить Google находить мой сайт
Brando
(Брэндон Роше)
#2
Привет, @Mark_Mo_Lerner.
Если промежуточный сайт был опубликован до отключения индексации поддоменов Webflow, поисковые системы, такие как Google, скорее всего, все еще проиндексировали эти страницы.
Теперь, когда этот параметр включен, Google не будет переиндексировать ваши страницы в дальнейшем. Другими словами, этот параметр не имеет обратной силы.
Вы можете узнать, как удалить уже проиндексированные страницы из результатов Google. Вам могут быть полезны следующие ресурсы: Удаление страниц из Google: подробное руководство для владельцев контента
Марк_Мо_Лернер
(Марк Мо Лернер)
#3
Спасибо! По иронии судьбы, эта страница имеет номер 404
. 1 Нравится
Брандо
(Брэндон Роше)
#4
О нет! Спасибо, что сообщили мне, что я обновил его
Justin_c
(Джастин)
#5
@Mark_Mo_Lerner похоже, что результатом является не сам промежуточный сайт, а фактическая страница-витрина в конце Webflow. Например, это URL-адрес, который отображается как проиндексированный в Google: https://webflow.com/website/marks-fantabulous-project-8bb5d7
Мне всегда казалось странным, что Webflow индексирует эти страницы, поскольку он может навредить SEO на реальном сайте (поскольку эти страницы-витрины, как правило, занимают высокие позиции в Google).
Я полагаю, что единственный способ удалить это — избавиться от страницы витрины и/или обратиться в службу поддержки Webflow за помощью вручную.
Марк_Мо_Лернер
(Марк Мо Лернер)
#6
изображение 2426×180 23,6 КБ
Будет ли это работать?
justin_c
(Джастин)
#7
@Mark_Mo_Lerner Я так не думаю, эта ссылка для вашего промежуточного сайта, маркировка-fantabulous{}.webflow.io… Обратите внимание, что она находится в домене webflow. io. Ссылка, которая индексируется Google, не имеет ничего общего с этим промежуточным доменом. Ссылка, проиндексированная Google:
https://webflow.com/website/marks-fantabulous-project-8bb5d7
Здесь вы можете видеть, что ссылка находится в домене webflow.com, а не в домене webflow.io. Это ссылка на фактическую страницу витрины в конце Webflow. Чтобы избавиться от этой страницы, вы можете отключить витрину. Для этого ознакомьтесь с этой статьей, а именно с заголовком «Отключить демонстрацию» внизу: Демонстрация сайта | Университет Вебфлоу
Эта страница будет удалена, но, как упоминалось ранее, Google может по-прежнему хранить ее в своих индексных архивах. Возможно, вам придется обратиться в службу поддержки Webflow, чтобы попытаться исправить это для вас.
Марк_Мо_Лернер
(Марк Мо Лернер)
#8
Я отказался от страницы-витрины и обратился в службу поддержки Webflow. Какой-то облом — надеюсь, это не так уж плохо для моего SEO, когда я запущу.
Justin_c
(Джастин)
#9
@Mark_Mo_Lerner Я тебя слышу. Пожалуйста, дайте мне знать их ответ, если можете. В прошлом у меня был клиент, который задавался вопросом, почему версия их сайта Webflow Showcase отображается в результатах Google (и сбивает с толку их клиентов). С тех пор я никогда не выставлял сайты по этой причине.
система
(система)
закрыто
#10
Эта тема была автоматически закрыта через 60 дней после последнего ответа. Новые ответы больше не допускаются.
Google Search Console временно приостановила функцию индексации запросов.
Всякий раз, когда веб-мастер публикует статью, он следит за тем, чтобы содержание было видно в Google, правильно. Для этого он использует инструмент проверки URL в Google Search Console, который является важным элементом SEO . Если вы управляете веб-сайтом, вы должны знать, что «Запрос индексирования» — это функция инструмента проверки URL-адресов, с помощью которой вы просите Google проиндексировать контент вашего сайта. После индексации ваш контент становится видимым в поисковой выдаче Google. Это довольно важный процесс, которому должен следовать каждый веб-мастер и SEO, чтобы их сайт занял место в Google. Но шокирующие новости пришли от Google об индексации. Вы знаете, что это? Недавно Google объявил, что временно отключил функцию «Индексирование запросов» в Google Search Console. Шокирует нет?
Изображение предоставлено Google Я знаю, вам было бы интересно узнать больше об этой новости, верно. В этой статье я расскажу о функции «Запросить индексацию» и о том, когда она снова станет доступной для веб-мастеров.
Давайте перейдем к делу.
Несколько дней назад в мире Интернета стали известны новости от Google об отключении функции «индексирования запроса» инструмента проверки URL в Google Search Console . Об этой новости веб-мастера узнали из Твиттера, где Google написал: «Мы отключили функцию «Индексирование запросов» в инструменте проверки URL, чтобы внести некоторые изменения в инфраструктуру. Мы ожидаем, что он вернется в ближайшие недели. Мы продолжаем находить и индексировать контент с помощью наших обычных методов, описанных здесь».
Вопрос, почему Google отключает функцию индексации запросов? Из заявления Google становится ясно, что Google приостанавливает работу этой функции из-за внесения некоторых изменений в инфраструктуру.
Какова цель функции индексации запросов в Google Search Console? Функция запроса индексации в инструменте проверки URL-адресов в Google Search Console поможет вам отображать ваши страницы на страницах результатов поиска Google (SERP), а также поможет вам занять место в Google. Поэтому, когда вы запрашиваете Search Console для индексации вашей страницы, она будет показывать ваши страницы в Google, но такой гарантии нет. Кроме того, он используется для запроса сканирования отдельных URL-адресов.
При правильном индексировании вы управляете содержанием своего сайта в Google, а также помогаете Google обнаруживать ваш контент. Это первый процесс индексации контента.
Давайте продвинемся немного дальше и узнаем причину отключения функции индексации.
Почему Google отключает функцию индексирования в Search Console? Причина отключения функции индексирования заключается в том, что от SEO-специалистов и веб-мастеров поступило много жалоб на проблемы с индексацией. Кроме того, Google не индексирует контент должным образом. Из-за чего многие SEO-специалисты очень недовольны состоянием поиска Google и процесса индексации. Похоже, что в Search Console возникла проблема с ошибкой, но это также еще не подтверждено Google. Много проблем увеличилось с результатами поиска Google.
Таким образом, изменения инфраструктуры Google приведут к некоторым улучшениям для SEO-специалистов и веб-мастеров. Вот почему Google приостанавливает функцию индексации на следующие несколько недель.
Если вы в настоящее время отправляете URL своего сайта для индексации, будет ли он принят? Ребята, если вы в настоящее время используете функцию индексации запросов, она не будет индексировать URL вашего сайта на данный момент. Однако Google заявил, что продолжит индексировать ваш сайт посредством обычного сканирования и индексации. Позвольте мне также сказать вам, что даже если функция работает, она не гарантирует немедленной индексации. В некоторых случаях Google предпочитает индексировать URL вашего сайта, а не вообще.
На странице справки Search Console компания заявляет: «Запрос сканирования не гарантирует, что включение произойдет мгновенно или вообще произойдет. Наши системы отдают приоритет быстрому добавлению высококачественного и полезного контента».
Так что да, оптимизаторы и владельцы сайтов могут позволить себе временно обходиться без функции индексации запросов, не так ли?
Есть ли альтернатива, которую Google предлагает для функции индексации запросов? Как вы думаете, предлагает ли Google альтернативу функции индексации запросов? Если вы так думаете, то вы правы. Вот три метода, которые вы можете использовать на данный момент для индексации URL вашего сайта. Прочитайте их один за другим ниже.
1.
Использовать пассивный подход Итак, консоль поиска Google говорит, что если у вас есть веб-сайт без карты сайта, система автоматически попытается найти и проиндексировать ваш сайт, если вы не заблокируете свой контент от сканера. Единственное, что вам нужно сделать здесь, это производить качественный контент. Этот метод отлично подходит для тех, у кого простой веб-сайт и нет своевременного обнаружения контента в Search Console.
2.
Активно управляйте своими URL-адресами В этом методе вы предоставляете список URL-адресов вашего контента, который называется картой сайта. Это помогает и ускоряет систему для обнаружения вашего контента. Вам просто нужно разместить карту сайта в своем домене в месте, доступном для робота Googlebot. Такой подход повысит эффективность ваших расширенных результатов в Поиске. Более того, этот метод также во многих отношениях устранит препятствие для быстрого обслуживания вашего контента Google.
3.
Вы также можете отправлять новые и обновленные URL-адреса в Google Последний вариант, который у вас есть, — отправить новые и обновленные URL-адреса в Google. Здесь вам нужно только предоставить уведомления о новых URL-адресах или существующих URL-адресах с измененным содержанием. Отправка новых URL-адресов на карте сайта поможет быстро их обнаружить. Для существующих URL-адресов вы можете предоставить карту сайта в формате XML, чтобы система знала, что ваш измененный контент готов к переиндексации.
Когда Google включит функцию индексации запросов? Позвольте мне сказать вам, что команда веб-мастеров Google четко заявила, что приостановка функции индексации запросов является временной. И в ближайшие недели он снова возобновится. До тех пор команда веб-мастеров Google будет индексировать контент обычными способами.
Окончательный вариант Индексация сайта — одна из важнейших частей SEO в мире цифрового маркетинга. Отсутствие индексации сайта означает отсутствие видимости или рейтинга сайта в Google. Но то, что Google сделал, отключив функцию индексации запросов, вносит в нее изменения инфраструктуры. Есть несколько альтернатив, которые Google предложил вам использовать до тех пор, пока функция индексации запросов не вступит в силу.
А пока продолжайте читать наши недавно опубликованные статьи и не забывайте подпишитесь на наш сайт.
безопасность - Как отключить индексацию каталогов из apache2 при переходе в корень сервера?
спросил
Изменено
2 года назад
Просмотрено
81к раз
Мне нужно отключить эту индексацию, когда я вхожу в свой корневой каталог на сервере apache2, какие-нибудь советы?
- безопасность
- apache
- индексирование
- веб-сервер
Отредактируйте файл конфигурации apache2, который обычно находится в каталоге: "/etc/apache2/httpd. conf".
Добавьте следующее или отредактируйте, если у вас уже есть некоторые конфигурации для каталога веб-сервера по умолчанию (/var/www):
<Каталог /var/www>
Параметры - Индексы
Разрешить переопределить все
Порядок разрешить, запретить
Разрешить от всех
Это отключит индексацию всех общедоступных каталогов.
2
Обычно делается так:
Опции -Индексы
Минус означает "нет"...
2
Если вы хотите защитить только один каталог от просмотра содержимого, вы также можете просто добавить index.html или index.php, которые будут отображаться всякий раз, когда кто-то просматривает этот каталог.
0
sudo nano /etc/apache2/apache2.conf
Находится в этом разделе <Каталог /var/www/> в файле
Добавить минус к индексам (отказано)
Добавить плюс к FollowSymLinks
Результат : <Каталог /var/www/> Опции -Индексы +FollowSymLinks
Аллововеррайд
Требовать все предоставленные
Работает в Raspbian
Вы получите сообщение: «У вас нет разрешения на доступ к «Каталогу» на этом сервере».
1
Если в вашем дистрибутиве есть утилита a2dismod , вы можете полностью удалить модуль, если вам вообще не нужны индексы каталогов:
sudo a2dismod --force autoindex
Используйте флаг --force или -f , чтобы избежать появления следующего предупреждения:
ПРЕДУПРЕЖДЕНИЕ. Следующий важный модуль будет отключен.
Это может привести к неожиданному поведению и НЕ ДОЛЖНО делаться.
если вы точно не знаете, что делаете!
автоиндекс
Чтобы продолжить, введите фразу «Да, делай, как я говорю!» или повторите попытку, передав '-f': Да, делайте, как я говорю!
Автоиндекс модуля отключен.
Чтобы активировать новую конфигурацию, вам нужно запустить:
systemctl перезапустить apache2
Вот документы для mod_autoindex
1
Убедитесь, что вы также добавили -Indexes в файлы конфигурации в вашем каталоге с включенными сайтами (или доступными сайтами, как это было в моем случае), обычно они находятся в каталоге «/etc/apache2/».
 1 Нравится
1 Нравится
 io. Ссылка, которая индексируется Google, не имеет ничего общего с этим промежуточным доменом. Ссылка, проиндексированная Google:
io. Ссылка, которая индексируется Google, не имеет ничего общего с этим промежуточным доменом. Ссылка, проиндексированная Google: Какой-то облом — надеюсь, это не так уж плохо для моего SEO, когда я запущу.
Какой-то облом — надеюсь, это не так уж плохо для моего SEO, когда я запущу. Новые ответы больше не допускаются.
Новые ответы больше не допускаются. В этой статье я расскажу о функции «Запросить индексацию» и о том, когда она снова станет доступной для веб-мастеров.
В этой статье я расскажу о функции «Запросить индексацию» и о том, когда она снова станет доступной для веб-мастеров. Поэтому, когда вы запрашиваете Search Console для индексации вашей страницы, она будет показывать ваши страницы в Google, но такой гарантии нет. Кроме того, он используется для запроса сканирования отдельных URL-адресов.
Поэтому, когда вы запрашиваете Search Console для индексации вашей страницы, она будет показывать ваши страницы в Google, но такой гарантии нет. Кроме того, он используется для запроса сканирования отдельных URL-адресов. Много проблем увеличилось с результатами поиска Google.
Много проблем увеличилось с результатами поиска Google.
 Это помогает и ускоряет систему для обнаружения вашего контента. Вам просто нужно разместить карту сайта в своем домене в месте, доступном для робота Googlebot. Такой подход повысит эффективность ваших расширенных результатов в Поиске. Более того, этот метод также во многих отношениях устранит препятствие для быстрого обслуживания вашего контента Google.
Это помогает и ускоряет систему для обнаружения вашего контента. Вам просто нужно разместить карту сайта в своем домене в месте, доступном для робота Googlebot. Такой подход повысит эффективность ваших расширенных результатов в Поиске. Более того, этот метод также во многих отношениях устранит препятствие для быстрого обслуживания вашего контента Google. И в ближайшие недели он снова возобновится. До тех пор команда веб-мастеров Google будет индексировать контент обычными способами.
И в ближайшие недели он снова возобновится. До тех пор команда веб-мастеров Google будет индексировать контент обычными способами. conf".
conf".
