
Файл robots.txt — как правильно | Примеры
Что такое robots.txt? Robots.txt – это
текстовый файл, находящийся в корневом каталоге
сайта, содержащий директивы, следуя которым
поисковая
система может понять стратегию
индексирования вашего сайта. Файл robots.txt предназначен для указания
всем поисковым роботам (spiders) индексировать информационные
сервера так, как определено в этом файле, т.е. только те директории
и файлы сервера, которые не описаны в robots.txt.
Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Файл
robots.txt
ограничивает доступ роботов, сканирующих Интернет для
поисковых
систем, к вашему сайту. Перед обращением к страницам сайта эти
роботы автоматически ищут файл robots.
Файл robots.txt должен
находиться только в корневой директории сайта, только тогда он будет
учитываться поисковыми системами.
Правописание — robots.txt,
Структура robots.txt. Файл robots.txt состоит из полей. Структура полей такова: сначала идёт информация о том, какой поисковик должен следовать указаниям в директиве (строка содержит User-Agent поискового бота или *, как рекомендация для всех поисковых систем), далее идёт поле Disallow, в котором указывается название объекта, который необходимо скрыть от индексирования.

Раздел рекомендаций robots.txt между инструкциями для одной поисковой системы распознаётся от раздела рекомендаций для другой поисковой системы пустой строкой, а раздел, в свою очередь, формируется полем User-Agent. В одном разделе может быть сразу несколько полей User-Agent, начинающихся с новой строки.
Стандарт robots.txt поддерживает комментарии. Всё, что начинается от символа # до конца строки, является комментарием.
Строки robots.txt являются регистрозависимыми (primer.html и Primer.html — разные файлы).
Следует отметить любопытный факт
, что файл robots.txt создавался и создаётся с основной целью – запрета индексации, следовательно, и все поля, в нём прописанные, явно указываютПримеры robots.txt
Пример
robots.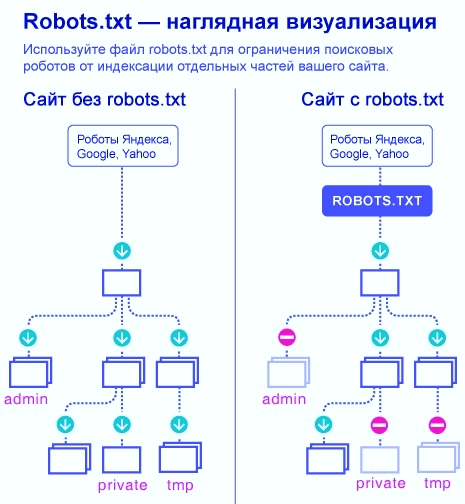 txt:
txt:
Disallow: /cgi-bin/#комментарий
Пример robots.txt, разрешающего всем роботам индексирование всего сайта:
User-agent: *
Disallow:
Host: www.site.ru
Пример robots.txt, запрещающего всем роботам индексирование сайта:
User-agent: *
Disallow: /
Host: www.site.ru
Пример robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
User-agent: *
Disallow: /abc
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в
директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся
символами «dir» (/dir/, /direct/, dir. htm, direction.htm, и т. д.) и
находящиеся в корневом каталоге сайта.
htm, direction.htm, и т. д.) и
находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
Disallow: /dir
Host: www.site.ru
Запомните простые комбинации директив robots.txt:
Disallow: — разрешение
индексировать всё содержимое сайта,
Disallow: / — запрет на индексацию всего сайта.
Disallow: /name – запрет на индексацию любых файлов и директорий,
которые называются или имеют в своём названии name.
Disallow: /*.gif$ — запрет на индексацию всех файлов, имеющих расширение .gif.
Disallow: /name.php – запрет на индексацию файла name.php.
Disallow: /name.php?action=print – запрет индексации переменной, например, страниц для печати.
Allow: / — всё наоборот (разрешается индексировать), синтаксис такой же, как и с Disallow
# — при помощи решётки в robots.txt можно писать комментарии: они не учитываются роботами поисковых систем и носят сугубо информативный характер.

Поле Sitemap используется для указания поисковой системе, где находится сгенерированная для поисковых систем карта сайта.(Sitemap: http://www.site.ru/sitemap.xml). Применяется в Google, Ask, Yahoo, Bing и «Яндекс»
.Директива Sitemap.
Если вы используете описание структуры вашего сайта в формате sitemaps.xml, и хотите, чтобы робот узнал о ней, укажите путь к sitemaps.xml в файле robots.txt, в качестве параметра директивы ‘Sitemap’ (если файлов несколько, укажите все), примеры:
User-agent: Yandex
Allow: /
Sitemap: http://mysite.ru/site_structure/my_sitemaps1.xml
Sitemap: http://mysite.ru/site_structure/my_sitemaps2.xmlили
User-agent: Yandex
Allow: /
User-agent: *
Disallow: /
Sitemap: http://mysite.ru/site_structure/my_sitemaps1.xml
Sitemap: http://mysite.ru/site_structure/my_sitemaps2.xmlРобот запомнит пути к sitemaps. xml,
обработает файлы и будет использовать результаты при последующем
формировании сессий закачки.
xml,
обработает файлы и будет использовать результаты при последующем
формировании сессий закачки.
# В случае, когда на сайте используется несколько файлов Sitemap, то их желательно перечислить в файле robots.txt
Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно robots.txt:
User-agent: *
Disallow: Yandex
Правильно robots.txt:
User-agent: Yandex
Disallow: *
Запись «Disallow» содержит несколько директив.
Неправильно robots.txt:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно robots.txt:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Ошибка
при копировании файла.
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записи «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно robots.txt:
User-agent: *
Disallow: /CGI-BIN/
Правильно robots.txt:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты в
robots. txt при
закрытии директории от индексирования.
txt при
закрытии директории от индексирования.
Неправильно robots.txt:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.html
Правильно robots.txt:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.html
Файл robots.txt — как правильно | Примеры | Запрет индексации сайта
Запрет индексации в файле robots.txt
Перейти к содержанию
В этой статье мы разберем файл «Robots.txt», для чего он необходим, и как ним работать.
Robots.txt это файл в формате «.txt», который содержит директивы для индексации определенного сайта. Другими словами, этот файл указывает поисковым системам, какие страницы веб-ресурса нужно проиндексировать, а какие запретить к индексации.
Веб-индексирование — это добавления данных о сайте ботом, системы поиска, в базу данных, которая в дальнейшем используется для поиска информации на проиндексированных сайтах.
Сведенья о сайте это — ключевые слова , статьи, ссылки, документы, изображения, аудио файлы и т. д.
Использование «robots.txt» и карты сайта( «Sitemap xml») позволяют управлять индексацией Вашего сайта и скрыть, страницы, которые не относятся к основной направленности сайта, например: служебные страницы, дубликаты, информацию для печати и т.п..
Содержание
- Как управлять индексированием
- Ошибки
- Длительность индексации
Как управлять индексированием
Файл «robots» находится в коревой папке сайта, просмотреть его можно по адресу: http://vash_site.com/robots.txt.
Если Вам потребовалось закрыть от индексации в Google страницу , например http:// vash_site.com /page-for-robots/. Для этого нужно применить директиву Disallow :
User-agent: GoogleDisallow: /page-for-robots/Host: vash_site. com
com
Если же нужно скрыть от индексации весь сайт кроме определенного раздела, например http:// vash_site.com /category/case/, нужно сделать следующим образом:
User-agent: Google
Disallow: /
Allow: /category/case/
Host: vash_site.com
Если же нужно скрыть от индексации весь сайт кроме определенного раздела, например, http:// vash_site.com /category/case/, нужно сделать следующим образом:
User-agent: Google
Disallow: /
Allow: /category/case/
Host: vash_site.com
Как вы уже поняли, директива «Allow» указывает какую страницу/ раздел/ файл нужно проиндексировать.
Еще один способ скрыть страницу или сайт – мета – тег NAME=»ROBOTS» #.
Для закрытия от индексации внутри тегов <head> </head> документа прописывается такой код:
<meta name="robots" content="noindex, nofollow"/>
Или<meta name="robots" content="none"/>
Так же можно вместо name=»robots» использовать имя конкретного робота, например:
Для паука Google: <meta name="googlebot" content="noindex, nofollow"/>
Или для Яндекса: <meta name="yandex" content="none"/>
Директива «User-agent» содержит название поискового робота. При помощи нее в файле «robots.txt» можно настроить индексацию сайта для каждого конкретной поисковой системы.
При помощи нее в файле «robots.txt» можно настроить индексацию сайта для каждого конкретной поисковой системы.
В каждой системе поиска бот имеет свое название, ниже мы приведем список роботов самых популярных поисковиков:
Google http://www.google.com Googlebot
Yahoo! http://www.yahoo.com Slurp (или Yahoo! Slurp)
AOL http://www.aol.com Slurp
MSN http://www.msn.com MSNBot
Live http://www.live.com MSNBot
Ask http://www.ask.com Teoma
AltaVista http://www.altavista.com Scooter
Alexa http://www.alexa.com ia_archiver
Lycos http://www.lycos.com Lycos
Яндекс http://www.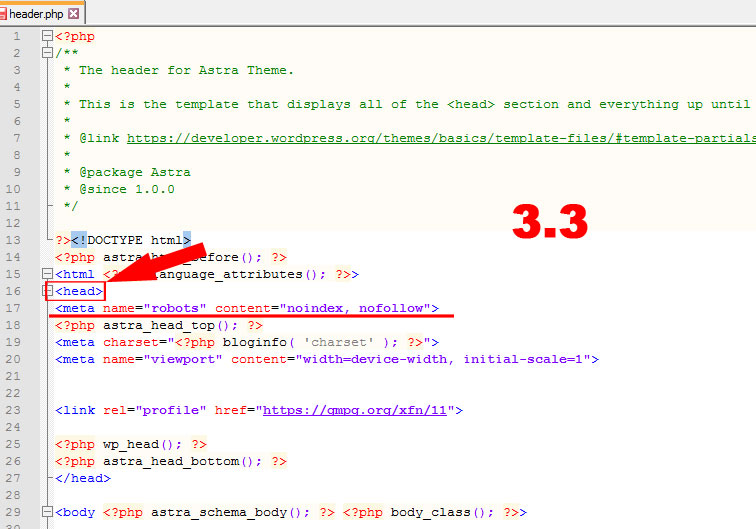 ya.ru Yandex
ya.ru Yandex
Рамблер http://www.rambler.ru StackRambler
Мэйл.ру http://mail.ru Mail.Ru
Aport http://www.aport.ru Aport
Вебальта http://www.webalta.ru WebAlta (WebAlta Crawler/2.0)
Можно написать универсальные правила индексации, которые будут применимы ко всем поисковикам, используя « User-agent: *»
User-agent: *
Disallow: /
Allow: /category/case/
Host: vash_site.com
Одной из важных считается директива Host, в ней нужно прописать основное зеркало сайта. Что бы это сделать, нужно выяснить какое зеркало является основным.
Для этого нужно ввести в поисковик адрес Вашего сайта, навести курсор на URL в выдаче и внизу слева будет прописан домен с «www» или без него.
Например:
После того как Вы определили главное зеркало сайта, его нужно прописать в Robots.txt:
Host: vash_site.com.
Ошибки
Даже если веб-мастер хорошо разбирается в командах, это не означает, что он застрахован от ошибок. У неопытных разработчиков сайтов прослеживается целый ряд типичных ошибок. Многие часто путают значения директив, так как не понимают их значений. К примеру, не там ставят знак «/» или вписывают имя робота после директивы Disallow.
Зачастую перечисляют запрещенные страницы друг за другом, тогда директиву к каждой странице следует писать отдельно. Множество ошибок связано с именем файла. Его следует писать маленькими буквами, без заглавных букв.
Длительность индексации
Файлы robots индексирует ресурсы согласно информации. Срок проведения процедуры может составлять от одной до двух, трех недель, особенно на сайте Яндекса. На сегодняшний день самым медленным считается поисковик Гугл, который еще не так давно (2012 г) занимал первое место.
Если сайт размещен, однако постоянно изменяется, корректируется и на нем видна свежая информация, индексации страниц ускоряется.
Виды поисковых роботов
Варианты поисковых роботов меняются в зависимости от предопределения программы.
- «Зеркальными», так как работают на схожих сайтах;
- Мобильными — для мобильных вариаций интернета;
- Ультрадействующими — быстро рассматривают новую информацию;
- Ссылочными, рассматривают и подсчитывают ссылки;
- «Шпионскими» — так как отыскивают страницы, не отображающие в ПС;
- «Дятлами» — это те, кто время от времени заходят на сайты для проверки;
- Национальными — контролируют только веб-ресурсы одной страны, например,
- Глобальными — рассматривают ресурсы всей паутины, всего мира.
Хотя такие поисковые системы как Гугл и Яндекс являются лидерами, существуют множество систем, имеющих своих роботов. На деле весь процесс запрета или исключения достаточно прост, но если нет уверенности в своих силах, лучше оставить все на индексацию, система сама выберет то, что посчитает важным.
Go to Top
Как и почему предотвратить сканирование вашего сайта ботами
По большей части боты и пауки относительно безвредны.
Например, вы хотите, чтобы бот Google просканировал и проиндексировал ваш веб-сайт.
Однако боты и поисковые роботы иногда могут создавать проблемы и создавать нежелательный трафик.
Нежелательный трафик такого типа может привести к:
- Запутыванию источника трафика.
- Запутанные и трудные для понимания отчеты.
- Неверная атрибуция в Google Analytics.
- Увеличение стоимости полосы пропускания, за которую вы платите.
- Другие неприятности.
Есть хорошие боты и плохие боты.
Хорошие боты работают в фоновом режиме, редко атакуя другого пользователя или веб-сайт.
Плохие боты нарушают безопасность веб-сайта или используются в качестве обширной крупномасштабной ботнета для проведения DDOS-атак на крупную организацию (что-то, что не может устранить одна машина).
Вот что вам следует знать о ботах и о том, как предотвратить сканирование вашего сайта злоумышленниками.
Что такое бот?
Точное понимание того, что такое бот, может помочь понять, почему нам нужно его заблокировать и не допустить сканирования нашего сайта.
Бот, сокращение от «робот», представляет собой программное приложение, предназначенное для многократного повторения определенной задачи.
Для многих SEO-специалистов использование ботов связано с масштабированием SEO-кампании.
«Масштабирование» означает, что вы максимально автоматизируете работу, чтобы быстрее получать лучшие результаты.
Распространенные заблуждения о ботах
Возможно, вы столкнулись с неправильным представлением о том, что все боты — зло, и их нужно однозначно запретить на вашем сайте.
Но это далеко не так.
Google — бот.
Если вы заблокируете Google, можете ли вы предположить, что произойдет с вашим рейтингом в поисковых системах?
Некоторые боты могут быть вредоносными, созданными для создания поддельного контента или выдающими себя за законные веб-сайты для кражи ваших данных.
Однако боты не всегда являются вредоносными скриптами, запускаемыми злоумышленниками.
Некоторые из них могут быть отличными инструментами, облегчающими работу специалистам по поисковой оптимизации, например, автоматизация повторяющихся задач или извлечение полезной информации из поисковых систем.
Некоторыми распространенными ботами, которые используют SEO-специалисты, являются Semrush и Ahrefs.
Эти боты извлекают полезные данные из поисковых систем, помогают специалистам по поисковой оптимизации автоматизировать и выполнять задачи, а также могут облегчить вашу работу, когда речь идет о задачах SEO.
Зачем нужно блокировать доступ ботов к вашему сайту?
Хотя есть много хороших ботов, есть и плохие.
Плохие боты могут помочь украсть ваши личные данные или вывести из строя работающий веб-сайт.
Мы хотим заблокировать всех плохих ботов, которых сможем обнаружить.
Нелегко обнаружить каждого бота, который может сканировать ваш сайт, но немного покопавшись, вы можете найти вредоносных ботов, которым вы больше не хотите посещать свой сайт.
Так зачем вам блокировать ботов от сканирования вашего сайта?
Некоторые распространенные причины, по которым вы можете захотеть заблокировать сканирование вашего сайта ботами, могут включать:
Защита ваших ценных данных
Возможно, вы обнаружили, что подключаемый модуль привлекает ряд вредоносных ботов, которые хотят украсть ваши ценные потребительские данные.
Или вы обнаружили, что бот воспользовался уязвимостью системы безопасности, чтобы добавить плохие ссылки на весь ваш сайт.
Или кто-то пытается спамить вашу контактную форму с помощью бота.
Здесь вам нужно предпринять определенные шаги, чтобы защитить ваши ценные данные от компрометации ботом.
Превышение пропускной способности
Если вы получите приток бот-трафика, скорее всего, ваша пропускная способность также резко возрастет, что приведет к непредвиденным перерасходам и расходам, которых вы предпочли бы не иметь.
В этих случаях вы обязательно должны заблокировать ботов-нарушителей от сканирования вашего сайта.
Вам не нужна ситуация, когда вы платите тысячи долларов за пропускную способность, за которую не заслуживаете оплаты.
Какая пропускная способность?
Пропускная способность — это передача данных с вашего сервера на клиентскую сторону (веб-браузер).
Каждый раз, когда данные отправляются через попытку подключения, вы используете пропускную способность.
Когда боты получают доступ к вашему сайту и вы тратите пропускную способность впустую, с вас может взиматься плата за перерасход из-за превышения выделенной вам ежемесячной пропускной способности.
При подписке на пакет хостинга вы должны были получить хотя бы некоторую подробную информацию от вашего хоста.
Ограничение нежелательного поведения
Если вредоносный бот каким-то образом начал нацеливаться на ваш сайт, было бы уместно принять меры для контроля над этим.
Например, вы хотите убедиться, что этот бот не сможет получить доступ к вашим контактным формам. Вы хотите убедиться, что бот не может получить доступ к вашему сайту.
Сделайте это до того, как бот сможет взломать ваши самые важные файлы.
Убедившись, что ваш сайт правильно заблокирован и защищен, можно заблокировать этих ботов, чтобы они не причиняли слишком большого ущерба.
Как эффективно заблокировать ботов на вашем сайте
Вы можете использовать два метода, чтобы эффективно заблокировать ботов на вашем сайте.
Первый — через robots.txt.
Это файл, который находится в корневом каталоге вашего веб-сервера. Обычно у вас его может не быть по умолчанию, и вам придется его создать.
Вот несколько очень полезных кодов robots.txt, которые можно использовать для блокировки большинства поисковых роботов и ботов на вашем сайте:
Запретить доступ робота Googlebot с вашего сервера
Если по какой-то причине вы хотите запретить роботу Googlebot сканировать ваш сервер вообще, следующий код — это код, который вы бы использовали:
User-agent: Googlebot
Disallow: /
Вы хотите использовать этот код только для того, чтобы ваш сайт вообще не индексировался.
Не используйте это по прихоти!
Имейте конкретную причину, по которой вы вообще не хотите, чтобы боты сканировали ваш сайт.
Например, часто возникает проблема, когда вы хотите, чтобы ваш промежуточный сайт не попал в индекс.
Вы не хотите, чтобы Google сканировал промежуточный сайт и ваш настоящий сайт, потому что вы удваиваете свой контент и в результате создаете проблемы с повторяющимся контентом.
Запрет всех ботов на вашем сервере
Если вы хотите, чтобы все боты вообще не сканировали ваш сайт, используйте следующий код:
User-agent: *
Disallow: /
Это это код для запрета всех ботов. Помните наш пример промежуточного сайта выше?
Возможно, вы хотите исключить промежуточный сайт из всех ботов, прежде чем полностью развернуть свой сайт для них всех.
Или, возможно, вы хотите, чтобы ваш сайт некоторое время оставался приватным, прежде чем запускать его для всего мира.
В любом случае, это скроет ваш сайт от посторонних глаз.
Не позволять ботам сканировать определенную папку
Если по какой-то причине вы хотите запретить ботам сканировать определенную папку, которую вы хотите указать, вы также можете это сделать.
Ниже приведен код, который вы могли бы использовать:
User-agent: *
Disallow: /folder-name/
Есть много причин, по которым кто-то хотел бы исключить ботов из папки. Возможно, вы хотите, чтобы определенный контент на вашем сайте не индексировался.
Или, может быть, эта конкретная папка будет вызывать определенные типы проблем с дублированием содержимого, и вы хотите полностью исключить ее из сканирования.
В любом случае это поможет вам в этом.
Распространенные ошибки при работе с robots.txt
Есть несколько ошибок, которые SEO-специалисты допускают при работе с robots.txt. К наиболее распространенным ошибкам относятся:
- Использование disallow в robots.txt и noindex.
- Использование косой черты / (все папки от корня), когда вы действительно имеете в виду конкретный URL-адрес.

- Не включая правильный путь.
- Не проверяется файл robots.txt.
- Не зная правильного имени пользовательского агента, который вы хотите заблокировать.

Использование Disallow в robots.txt и Noindex на странице
Джон Мюллер из Google заявил, что вы не должны использовать одновременно Disallow в robots.txt и noindex на самой странице.
Если вы сделаете и то, и другое, Google не сможет просканировать страницу, чтобы увидеть noindex, поэтому потенциально он все равно может проиндексировать страницу.
Вот почему вы должны использовать только один или другой, а не оба.
Использование косой черты, когда вы действительно имеете в виду конкретный URL-адрес
Косая черта после Disallow означает «от этой корневой папки вниз, полностью и целиком навечно».
Каждая страница вашего сайта будет заблокирована навсегда, пока вы ее не измените.
Одна из наиболее распространенных проблем, которые я обнаруживаю при аудите веб-сайтов, заключается в том, что кто-то случайно добавил косую черту к «Запретить:» и заблокировал Google от сканирования всего своего сайта.
Не включая правильный путь
Мы поняли. Иногда кодирование файла robots.txt может быть сложной задачей.
Изначально вы не могли вспомнить точный правильный путь, поэтому вы прошлись по файлу и пролистали его.
Проблема в том, что все эти похожие пути приводят к ошибке 404, потому что они отличаются на один символ.
Вот почему важно всегда перепроверять пути, которые вы используете для определенных URL-адресов.
Вы не хотите рисковать добавлением URL-адреса в robots.txt, который не будет работать в robots.txt.
Не зная правильного имени пользовательского агента
Если вы хотите заблокировать определенный пользовательский агент, но не знаете имя этого пользовательского агента, это проблема.
Вместо того, чтобы использовать имя, которое, как вам кажется, вы помните, проведите небольшое исследование и выясните точное имя нужного вам пользовательского агента.
Если вы пытаетесь заблокировать определенных ботов, то это имя становится чрезвычайно важным в ваших усилиях.
Зачем еще блокировать ботов и пауков?
Есть и другие причины, по которым SEO-специалисты хотели бы заблокировать ботов от сканирования их сайта.
Возможно, они глубоко увлечены серыми (или черными) PBN и хотят скрыть свою частную сеть блогов от посторонних глаз (особенно от своих конкурентов).
Они могут сделать это, используя robots.txt, чтобы заблокировать обычных ботов, которые SEO-специалисты используют для оценки своих конкурентов.
Например, Semrush и Ahrefs.
Если вы хотите заблокировать Ahrefs, вот код для этого:
User-agent: AhrefsBot
Disallow: /
Это заблокирует сканирование всего сайта AhrefsBot.
Если вы хотите заблокировать Semrush, используйте этот код.
Здесь есть и другие инструкции.
Необходимо добавить много строк кода, поэтому будьте осторожны при добавлении следующих:
Чтобы запретить SemrushBot сканировать ваш сайт на предмет различных SEO и технических проблем:
Агент пользователя: SiteAuditBot
Запретить: /Чтобы запретить SemrushBot сканировать ваш сайт для инструмента аудита обратных ссылок:
User-agent: SemrushBot-BA
Disallow: /Чтобы запретить SemrushBot сканировать ваш сайт для инструмента On Page SEO Checker и аналогичных инструментов:
Агент пользователя: SemrushBot-SI
Запретить: /Чтобы запретить SemrushBot проверять URL-адреса на вашем сайте для инструмента SWA:
Агент пользователя: SemrushBot-SWA
Запретить: /Чтобы запретить SemrushBot сканировать ваш сайт для инструментов Content Analyzer и Post Tracking:
Агент пользователя: SemrushBot-CT
Запретить: /Чтобы запретить SemrushBot сканировать ваш сайт для мониторинга брендов:
Агент пользователя: SemrushBot-BM
Запретить: /Чтобы запретить SplitSignalBot сканировать ваш сайт для инструмента SplitSignal:
Агент пользователя: SplitSignalBot
Запретить: /Чтобы запретить SemrushBot-COUB сканировать ваш сайт для инструмента Content Outline Builder:
User-agent: SemrushBot-COUB
Disallow: /
Использование файла HTACCESS для блокировки ботов
Если вы используете веб-сервер APACHE, вы можете использовать файл htaccess своего сайта для блокировки определенных ботов.
Например, вот как можно использовать код в htaccess для блокировки ahrefsbot.
Обратите внимание: будьте осторожны с этим кодом.
Если вы не знаете, что делаете, вы можете вывести из строя свой сервер.
Мы приводим этот код только в качестве примера.
Убедитесь, что вы изучили и попрактиковались самостоятельно, прежде чем добавлять его на рабочий сервер.
Заказать Разрешить, Запретить
Запретить с 51.222.152.133
Запретить с 54.36.148.1
Запретить с 195.154.122
Разрешить со всех
Чтобы эта статья работала должным образом, убедитесь, что вы заблокировали все диапазоны IP-адресов, указанные в статье. в блоге Ahrefs.
Если вы хотите получить всестороннее представление о .htaccess, посмотрите это руководство на Apache.org.
Если вам нужна помощь в использовании файла htaccess для блокировки определенных типов ботов, вы можете следовать этому руководству.
Блокирование ботов и пауков может потребовать некоторой работы
Но в конце концов оно того стоит.
Заблокировав доступ ботов и поисковых роботов к вашему сайту, вы не попадете в ту же ловушку, что и другие.
Вы можете быть спокойны, зная, что ваш сайт защищен от определенных автоматизированных процессов.
Когда вы можете контролировать этих конкретных ботов, это делает вашу работу намного лучше для вас, профессионала SEO.
Если вам нужно, всегда следите за тем, чтобы блокировать нужных ботов и пауков от сканирования вашего сайта.
Это приведет к усилению безопасности, улучшению общей онлайн-репутации и улучшению сайта в ближайшие годы.
Дополнительные ресурсы:
- Как провести аудит карты сайта для лучшего индексирования и сканирования с помощью Python
- 7 предупреждений и ошибок SEO-инструмента сканирования, которые вы можете безопасно игнорировать
- Расширенное техническое SEO: полное руководство
Избранное изображение: Роман Самборский/Shutterstock
Блокировка поисковых систем с помощью robots.
 txt
txtБоты поисковых систем (также известные как боты ) — это программы, которые автоматически просматривают веб-сайты. Эти программы используются для сканирования содержимого сайта, которое затем используется для поиска или других действий. На первый взгляд может показаться, что это хорошо, но не все эти программы хороши. Иногда эти программы могут быть вредными. Например, они собирают электронную почту, делают веб-скрапинг и делают другие вещи. Они также могут вызвать нагрузку на ваш сайт, когда сайт посещают либо много разных ботов одновременно, либо тот, который генерирует много запросов одновременно. Однако вы, как владелец сайта, можете создать robots.txt файл, содержащий инструкции (протокол исключения роботов) специально для этих посетителей.
Где я могу найти файл robots.txt?
Вы можете найти файл robots.txt в папке public_html вашего сайта. Войдите в свою cPanel и выберите Файловый менеджер
Войдите в папку public_html
Проверьте, существует ли файл robots. txt . Если это так, щелкните файл правой кнопкой мыши и выберите 9.0329 Редактировать
txt . Если это так, щелкните файл правой кнопкой мыши и выберите 9.0329 Редактировать
Если файл не существует, вы можете создать его, нажав + Файл в левом-правом углу вашего Файлового менеджера
s в правилах робота. txt file
В файле обычно описываются две-три инструкции, которые содержат название робота и его правила. Вы найдете файлы правил, описанные ниже.
Все роботы имеют доступ ко всем частям сайта (также работает, если robots.txt пуст или отсутствует):
Агент пользователя: * Запретить: /
Одному роботу запрещено индексировать сайт, всем остальным разрешено. Обратите внимание, что когда вы вводите несколько инструкций, они разделяются одним пробелом:
User-agent: robot_name Запретить: / Пользовательский агент: * Запретить:
Запросы для одного конкретного робота замедляются до 1 запроса каждые 10 секунд:
Агент пользователя: robot_name Задержка сканирования: 10
Всем роботам запрещен доступ только к двум каталогам:
Агент пользователя: * Запретить: /temp/ Disallow: /include/
Всем роботам не разрешен доступ к одному файлу:
User-agent: * Disallow: /folder/file.
 html
html Пример файла robots.txt может выглядеть следующим образом:
Как определить, какие роботы сканируют мой сайт?
Это можно сделать, проверив журнал Apache вашего сервера. Вы можете найти журнал Apache в файловом менеджере cPanel (/var/home/user/log)
Если вам нужны последние записи, вы можете проверить раздел Raw Access . Используйте поиск в текстовом редакторе (Ctrl+F) и попробуйте найти значение ‘ Bot ’. Поиск даст вам результаты, в которых вы сможете увидеть, какие роботы просканировали ваш сайт.
В этом примере вы можете увидеть записи Google Bot.
Некоторые поисковые системы, такие как Google, также имеют возможность управлять скоростью сканирования Googlebot . Это означает, что вы можете ограничить скорость сканирования напрямую через Google. Дополнительную информацию можно найти на странице ниже:
https://support.