
Как закрыть сайт от индексации в robots.txt
Поисковые роботы сканируют всю информацию в интернете, но владельцы сайтов могут ограничить или запретить доступ к своему ресурсу. Для этого нужно закрыть сайт от индексации через служебный файл robots.txt.
Если закрывать сайт полностью не требуется, запрещайте индексацию отдельных страниц. Пользователям не следует видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря. Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Как закрыть сайт полностью
Обычно ресурс закрывают полностью от индексации во время разработки или редизайна.
Запретить индексацию сайта можно для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
| Запрет для всех |
User-agent: * Disallow: / |
| Запрет для отдельного робота |
User-agent: YandexImages Disallow: / |
| Запрет для всех, кроме одного робота |
User-agent: * Disallow: / User-agent: Yandex Allow: / |
Как закрыть отдельные страницы
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:
Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:
- административная панель;
- служебные каталоги;
- личный кабинет;
- формы регистрации;
- формы заказа;
- сравнение товаров;
- избранное;
- корзина;
- каптча;
- всплывающие окна и баннеры;
- поиск на сайте;
- идентификаторы сессий.
Желательно запрещать индексацию т.н. мусорных страниц. Это старые новости, акции и спецпредложения, события и мероприятия в календаре. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
| Отдельной страницы |
User-agent: * Disallow: /contact. 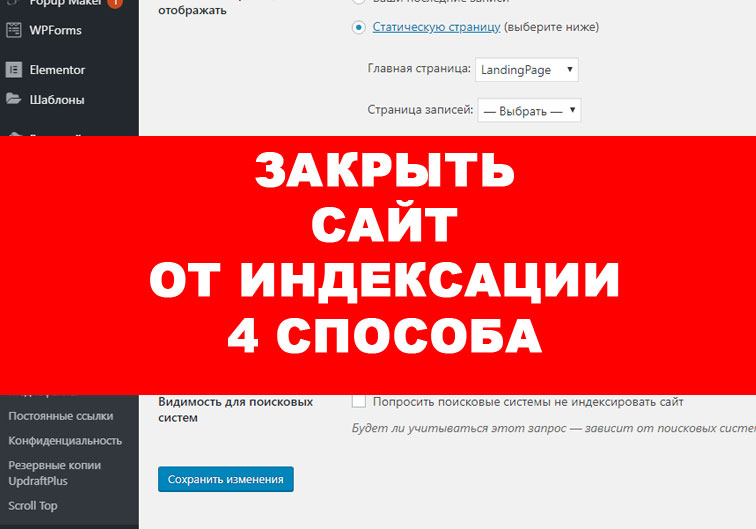 html html
|
| Раздела |
User-agent: * Disallow: /catalog/ |
| Всего сайта, кроме одного раздела |
User-agent: * Disallow: / Allow: /catalog |
| Всего раздела, кроме одного подраздела |
User-agent: * Disallow: /product Allow: /product/auto |
| Поиска на сайте |
User-agent: * Disallow: /search |
| Административной панели |
User-agent: * Disallow: /admin |
Как закрыть другую информацию
Файл robots. txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
Запрет индексации
|
User-agent: * Disallow: /*.jpg |
|
| Папки |
User-agent: * Disallow: /images/ |
| Папку, кроме одного файла |
User-agent: * Disallow: /images/ Allow: file.jpg |
| Скриптов |
User-agent: * Disallow: /plugins/*.js |
| utm-меток |
User-agent: * Disallow: *utm= |
| utm-меток для Яндекса | Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт через мета-теги
Альтернативой файлу robots. txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 1.
txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 1.Вариант 2.
<meta name=”robots” content=”none”/>
Атрибут “content” имеет следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
 На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений.
На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений. Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические — когда правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в инструментах Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксические — когда неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.

Шпаргалка
-
Для запрета на индексацию сайта используйте два варианта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех краулеров. Другой вариант — пропишите запрет через мета-тег robots в файле index.html внутри тега .
-
Закрывайте служебные информацию, устаревающие данные, скрипты, сессии и utm-метки. Для каждого запрета создавайте отдельное правило. Запрещайте всем поисковым роботам через * или указывайте название конкретного краулера. Если вы хотите разрешить только одному роботу, прописывайте правило через disallow.
-
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверяйте файл через инструменты Яндекс.
Вебмастер и Google Robots Testing Tool.
 Вебмастер и Google Robots Testing Tool.
Вебмастер и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льорентэ.
Как закрыть сайт или его страницы от индексации: подробная инструкция
Что нужно закрывать от индексации
Важно, чтобы в поисковой выдаче были исключительно целевые страницы, соответствующие запросам пользователей. Поэтому от индексации в обязательном порядке нужно закрывать:1. Бесполезные для посетителей страницы или контент, который не нужно индексировать. В зависимости от CMS, это могут быть:
- страницы административной части сайта;
- страницы с личной информацией пользователей, например, аккаунты в блогах и на форумах;
- дубли страниц;
- формы регистрации, заказа, страница корзины;
- страницы с неактуальной информацией;
- версии страниц для печати;
- RSS-лента;
- медиа-контент;
- страницы поиска и т. д.
 д.
д.2. Страницы с нерелевантным контентом на сайте, который находится в процессе разработки.
3. Страницы с информацией, предназначенной для определенного круга лиц, например, корпоративные ресурсы для взаимодействий между сотрудниками одной компании.
4. Сайты-аффилиаты.
Если вы закроете эти страницы, процесс индексации других, наиболее важных для продвижения страниц сайта ускорится.
Способы закрытия сайта от индексации
Закрыть сайт или страницы сайта от поисковых краулеров можно следующими способами:
- С помощью файла robots.txt и специальных директив.
- Добавив метатеги в HTML-код отдельной страницы.
- С помощью специального кода, который нужно добавить в файл .htaccess.
- Воспользовавшись специальными плагинами (если сайт сделан на популярной CMS).
Далее рассмотрим каждый из этих способов.
С помощью robots.txt
Robots.txt — текстовый файл, который поисковые краулеры посещают в первую очередь. Здесь для них прописываются указания — так называемые директивы.
Этот файл должен соответствовать следующим требованиям:
- название файла прописано в нижнем регистре;
- он имеет формат .txt;
- его размер не превышает 500 КБ;
- находится в корне сайте;
- файл доступен по адресу URL сайта/robots.txt, а при его запросе сервер отправляет в ответ код 200 ОК.
В robots.txt прописываются такие директивы:
- User-agent. Показывает, для каких именно роботов предназначены директивы.
- Disallow. Указывает роботу на то, что некоторое действие (например, индексация) запрещено.
- Allow. Напротив, разрешает совершать действие.
- Sitemap. Указывает на прямой URL-адрес карты сайта.
- Clean-param. Помогает роботу Яндекса правильно определять страницу для индексации.
Полный запрет сайта на индексацию в robots.txt
Вы можете запретить индексировать сайт как всем роботам поисковой системы, так и отдельно взятым. Например, чтобы закрыть весь сайт от робота Яндекса, который сканирует изображения, нужно прописать в файле следующее:
User-agent: YandexImages Disallow: /
Чтобы закрыть для всех роботов:
User-agent: * Disallow: /
Чтобы закрыть для всех, кроме указанного:
User-agent: * Disallow: / User-agent: Yandex Allow: /
В данном случае, как видите, индексация доступна для роботов Яндекса.
Запрет на индексацию отдельных страниц и разделов сайта
Для запрета на индексацию одной страницы достаточно прописать ее URL-адрес (домен не указывается) в директиве файла:
User-agent: * Disallow: /registration.
 html
htmlЧтобы закрыть раздел или категорию:
User-agent: * Disallow: /category/
Чтобы закрыть все, кроме указанной категории:
User-agent: * Disallow: / Allow: /category
Чтобы закрыть все категории, кроме указанной подкатегории:
User-agent: * Disallow: /uslugi Allow: /uslugi/main
В качестве подкатегории здесь выступает «main».
Запрет на индексацию прочих данных
Чтобы скрыть директории, в файле нужно указать:
User-agent: * Disallow: /portfolio/
Чтобы скрыть всю директорию, за исключением указанного файла:
User-agent: * Disallow: /portfolio/ Allow: avatar.png
Чтобы скрыть UTM-метки:
User-agent: * Disallow: *utm=
Чтобы скрыть скриптовые файлы, нужно указать следующее:
User-agent: * Disallow: /scripts/*.ajax
По такому же принципу скрываются файлы определенного формата:
User-agent: * Disallow: /*.
 png
pngВместо .png подставьте любой другой формат.
Через HTML-код
Запретить индексировать страницу можно также с помощью метатегов в блоке <head> в HTML-коде.
Атрибут «content» здесь может содержать следующие значения:
- index. Разрешено индексировать все содержимое страницы;
- noindex. Весь контент страницы, кроме ссылок, закрыт от индексации;
- follow. Разрешено индексировать ссылки;
- nofollow. Разрешено сканировать контент, но ссылки при этом закрыты от индексации;
- all. Все содержимое страницы подлежит индексации.
Открывать и закрывать страницу и ее контент можно для краулеров определенной ПС. Для этого в атрибуте «name» нужно указать название робота:
- yandex — обозначает роботов Яндекса:
- googlebot — аналогично для Google.
 Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.
Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.Так выглядит фрагмент кода, запрещающий индексировать страницу:
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>...</body>
</html>Чтобы запретить индексировать страницу краулерам Google, нужно ввести:
<meta name="googlebot" content="noindex, nofollow"/>
Чтобы сделать то же самое в Яндексе:
<meta name="yandex" content="none"/>
На уровне сервера
В некоторых случаях поисковики игнорируют запреты и продолжают индексировать все данные. Чтобы этого не происходило, рекомендуем попробовать ограничить возможность посещения страницы для отдельных краулеров на уровне сервера. Для этого в файл .htaccess в корневой папке сайта нужно добавить специальный код. Yandex» search_bot
На WordPress
В процессе создания сайта на готовой CMS нужно закрывать его от индексации. Здесь мы разберем, как сделать это в популярной CMS WordPress.
Закрываем весь сайт
Закрыть весь сайт от краулеров можно в панели администратора: «Настройки» => «Чтение». Выберите пункт «Попросить поисковые системы не индексировать сайт». Далее система сама отредактирует файл robots.txt нужным образом.
Закрытие сайта от индексации через панель администратора в WordPress
Закрываем отдельные страницы с помощью плагина Yoast SEO
Чтобы закрыть от индексации как весь сайт, так и его отдельные страницы или файлы, установите плагин Yoast SEO.
Для запрета на индексацию вам нужно:
- Открыть страницу для редактирования и пролистать ее вниз до окна плагина.
- Настроить режим индексации на вкладке «Дополнительно».
Закрытие от индексации с помощью плагина Yoast SEO
Настройка режима индексации
Запретить индексацию сайта на WordPress можно также через файл robots. txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
Как узнать, закрыт ли сайт от индексации
Есть несколько способов, которыми вы можете воспользоваться, чтобы проверить, закрыт ли ваш сайт или его отдельная страница от индексации или нет. Ниже рассмотрим самые простые и удобные из них.
В Яндекс.Вебмастере
Для проверки вам нужно пройти верификацию в Яндексе, зайти в Вебмастер, в правом верхнем углу найти кнопку «Инструменты», нажать и выбрать «Проверка ответа сервера».
Проверка возможности индексации страницы в Яндекс.Вебмастере
В специальное поле на открывшейся странице вставляем URL интересующей страницы. Если страница закрыта от индексации, то появится соответствующее уведомление.
Так выглядит уведомление о запрете на индексацию страницы
Таким образом можно проверить корректность работы файла robots.txt или плагина для CMS.
В Google Search Console
Зайдите в Google Search Console, выберите «Проверка URL» и вставьте адрес вашего сайта или отдельной страницы.
Проверка возможности индексации в Google Search Console
С помощью поискового оператора
Введите в поисковую строку следующее: site:https:// + URL интересующего сайта/страницы. В результатах вы увидите количество проиндексированных страниц и так поймете, индексируется ли сайт поисковой системой или нет.
Проверка индексации сайта в Яндексе с помощью специального оператора
Проверка индексации отдельной страницы
С помощью такого же оператора проверить индексацию можно и в Google.
С помощью плагинов для браузера
Мы рекомендуем использовать RDS Bar. Он позволяет увидеть множество SEO-показателей сайта, в том числе статус индексации страницы в основных поисковых системах.
Плагин RDS Bar
Итак, теперь вы знаете, когда сайт или его отдельные страницы/элементы нужно закрывать от индексации, как именно это можно сделать и как проводить проверку, и можете смело применять новые знания на практике.
Как закрыть сайт от индексации — Офтоп на vc.ru
Существует несколько способов закрыть сайт от индексации.
2672 просмотров
Запрет в файле robots.txt
Файл robots.txt отвечает за индексацию сайта поисковыми роботами. Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
Остальные правила должны быть удалены.
Этот метод самый простой для скрытия сайта от индексации.
С помощью мета-тега robots
Прописав в шаблоне страниц сайта в теге <head> следующее правило
<meta name=»robots» content=»noindex, nofollow»/>
<meta name=»robots» content=»none»/>
вы запретите его индексацию.
Как закрыть зеркало сайта от индексации
Зеркало — точная копия сайта, доступная по другому домену. То есть два разных домена настроены на одну и ту же папку с сайтом. Цели создания зеркал могут быть разные, но в любом случае мы получаем полную копию сайта, которую рекомендуется закрыть от индексации.
Сделать это стандартными способами невозможно — по адресам domen1.ru/robots.txt и domen2.ru/robots.txt открывается один и тот же файл robots.txt с одинаковым содержанием. В таком случае необходимо провести специальные настройки на сервере, которые позволят одному из доменов отдавать запрещающий robots. txt.
txt.
Ждите новые заметки в блоге или ищите на нашем сайте.
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots.txt
- Проверка корректности закрытия сайта от индексации
- Альтернативные способы закрыть сайт от поисковых систем
youtube.com/embed/HfSJlKnGZ6o» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Оглавление
Процесс индексации
Индексация сайта – это процесс добавления данных вашего ресурса в индексную базу поисковых систем. Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.Если сайта нет в индексной базе поисковой системе = тогда сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы находитесь в стадии разработки (или доработки) ресурса. В таком случае его лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.txt
Обращение к Вашему сайту поисковой системой начинается с прочтения содержимого файла robots.txt. Это служебный файл со специальными правилами для поисковых роботов.
Подробнее о директивах robots.txt:
Самый простой и быстрый способ это при первом обращении к
вашему ресурсу со стороны поисковых систем (к файлу robots. txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем способам подключения к хостингу или серверу, укажем самый простой способ на наш взгляд.
Файл robots.txt всегда находится в корне Вашего сайта. Например, robots.txt сайта iqad.ru будет находится по адресу:
https://iqad.ru/robots.txt
Для подключения к сайту, мы должны в административной панели
нашего хостинг провайдера получить FTP (специальный протокол передачи файлов
по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
В описании раздела или в разделе помощь, необходимо найти и сохранить необходимую информацию для подключения по FTP к серверу, на котором размещены файлы Вашего сайта. Данные отражают информацию, которую нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно воспользоваться бесплатной программой filezilla (https://filezilla.ru/). Вводим данные в соответствующие поля и нажимаем подключиться.
FTP-клиент filezilla интуитивно прост и понятен: вводим cервер (host) + логин (имя пользователя) + пароль + порт и кнопка {быстрое соединение}. В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt необходимо убедится в том, что все сделано верно. Для этого открываем файл robots.txt на вашем сайте.
Инструменты iqadВ арсенале команды IQAD есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
СамостоятельноОткрыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www.site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.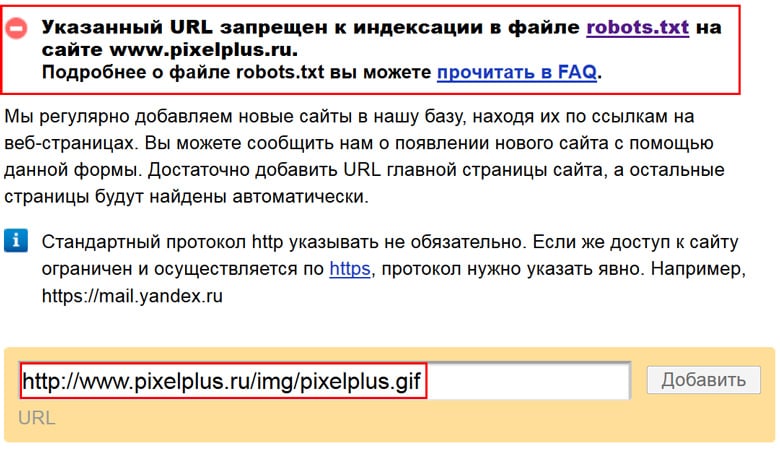
Бесплатный сервис Я.ВЕБМАСТЕР – анализ robots.txt.
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.Альтернативные способы закрыть сайт от поисковых систем
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков.
- Вы можете отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не гарантирует 100% исключения сайта из индекса. Какое-то время робот может хранить копию Ваших страниц и отдавать именно их.
- С помощью специального meta тега: <meta name=”robots”>
<meta name=”robots” content=”noindex, nofollow”>
Но
так как метатег размещается и его действие относиться только к 1 странице, то
для полного закрытия сайта от индексации Вам придется разместить такой тег на
каждой странице Вашего сайта.
Недостатком этого может быть несовершенство поисковых систем и проблемы с индексацией ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться много времени, иногда несколько месяцев, часть страниц будет присутствовать в поиске.
- Использование технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет увидеть контент сайта. При этом по названию сайта или по открытой части в индексе поисковиков может что-то хранится. Более того, уже завра новое обновление поисковых роботов может научится индексировать такой контент.
- Скрыть все данные Вашего сайта за регистрационной формой. При этом стартовая страница в любом случае будет доступна поисковым роботам.
Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
«robots.txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Как закрыть сайт от индексации в robots.txt
Автор wbooster На чтение 3 мин Просмотров 1530 Опубликовано
В процессе проведения редизайна или же разработки ресурса нередко бывают ситуации, когда требуется предотвратить посещение поисковых роботов и по сути, закрыть ресурс от индексации. Сделать это можно посредством закрытия сайта в коне сайта. в данном случае используется текстовый файл robots.txt.
Файл находится на файловом хранилище Вашего сайта, найти его можно с помощью файловых менеджеров, через хостинг (файловый менеджер на хостинге) или через админку сайта (доступно не во всех CMS).
kak-zakryt-sajt-v-robots-txt.img
Данные строки закроют сайт от индексации поисковым роботом Google:
User-agent: Google
Disallow: /
А с помощью данных строк, мы закроем сайт для всех поисковых систем.
User-agent: *
Disallow: /
Закрытие отдельной папки
Также существует возможность в указанном файле осуществить процесс закрытия конкретной папки. Посредством таких действий осуществляется закрытие всех файлов, которые присутствуют в указанной папке. Прописывается следующее:
User-agent: *
Disallow: /papka/
Можно будет в такой ситуации отдельно указать на те файлы в папке, которые могут быть открыты для дальнейшей индексации.
Если же вы хотите закрыть не только конкретную папку, а также все вложенные внутри папки, то используйте звездочку на конце папке:
User-agent: *
Disallow: /papka/*
Если же у вас 2 правила, которые могут конфликтовать между собой, то в данном случае поисковые роботы выставят приоритет по наиболее длинной строчке. То есть, для роботов, нет последовательности строчек.
Цифрами мы обозначили, по какому приоритету будет идти строчки:
То есть, в данном случае папка /papka/kartinki/logotip/ будет закрыта, однако остальные файлы и папки в /papka/kartinki/ будут открыты.
Закрытие отдельного файла
Тут все производится в том же формате, как и при закрытии папки, но в процессе указания конкретных данных, нужно четко определить файл, который вы хотели бы скрыть от поисковой системы.
User-agent: *
Disallow: /papka/kartinka.jpg
Если же вы хотите закрыть папку, однако открыть доступ к файлу, то используйте директиву Allow:
User-agent: *
Allow: /papka/kartinka.jpg
Disallow: /papka/
Проверка индекса документа
Чтобы осуществить проверку нужно воспользоваться специализированным сервисом Яндекс.Вебмастер.
Скрытие картинок
Чтобы картинки, расположенные на страницах вашего интернет ресурса, не попали в индекс, рекомендуется в robots.txt, ввести команду – Disallow, а также указать четкий формат картинок, которые не должны посещаться поисковым роботом.
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
Можно ли закрыть поддомен?
Опять же используется директория Disallow, при этом указания на закрытие должно осуществляться исключительно в файле robots.txt конкретного поддомена. Дубли на поддоменне при использовании CDN могут стать определенной проблемой. В данном случае обязательно нужно использовать запрещающий файл с указанием четко определенных дублей, чтобы они не появлялись в индексе и не влияли на продвижение интернет ресурса.
Чтобы осуществить блокировку других поисковых систем вместо Yandex, нужно будет указать данные поискового робота. Для этого можно воспользоваться специализированными программами, чтобы иметь четкие назначения роботов той или же иной системы.
Закрытие сайта или же страницы при помощи мета-тега
Можно процесс закрытия осуществить посредством применения мета-тега robots. В определенных ситуациях данный вариант закрытия считается более предпочтительным, так как он влияет на различные поисковые системы и требует введение определенного кода (в коде обязательно прописываются данные конкретного поискового робота).
Как правило, данную строку пишут в теге <head> или </footer>:
<meta name=”robots” content=”noindex, nofollow”/>
Или
<meta name=”robots” content=”none”/>
Также, мы можем написать отдельное правило для каждого поискового паука:
Google:
<meta name=”googlebot” content=”noindex, nofollow”/>
Яндекс:
<meta name=”yandex” content=”none”/>
Как Закрыть Сайт от Индексации Поисковых Машин в WordPress
ВведениеНеобычная тема, правда? Когда вы только начинаете свой блог, все чего вы хотите, это трафик на ваш сайт и появление страниц вашего сайта в Google. Тогда зачем кому-то пытаться закрыть сайт от индексации поисковых машин?
Для чего может понадобится закрыть сайт для индексации поисковых машин?
К примеру, вы только начали создание сайта и начинаете вносить изменения на нем напрямую. На этом этапе ваш сайт и контент на нем не такой, который вы хотели бы показывать другим. Следовательно, вы захотите закрыть сайт от индексации Google до тех пор, пока сайт не будет полностью готов для посетителей.
Вы могли подумать, что только начали работу над сайтом и не предоставили необходимые ссылки для работы поисковых машин, однако, вы ошибаетесь. Поисковые системы работают не только по ссылкам, которые вы предоставляете для индексации, они также работают на основе контента вашего сайта. Но не беспокойтесь, закрыть ваш сайт от индексации очень легко.
Так как же это сделать? Есть несколько советов для достижения этой цели. Ознакомьтесь с данным руководством, чтобы узнать, как закрыть сайт от индексации на WordPress.
Шаг 1 — Закрытие сайта от индексации поисковых систем в WordPressСамый легкий способ для закрытия сайта от индексации, это предотвращение его сканирования:
Метод 1 — Как закрыть сайт от индексации при помощи функций на сайте WordPressУдалить WordPress сайт из поисковых систем довольно легко, все что вам нужно сделать, это использовать встроенную функцию WordPress для предотвращения сканирования сайта:
- Войдите в вашу панель управления администратора, нажмите Настройки и выберите Чтение.
- Здесь вы найдете опцию под названием Видимость для поисковых систем. Поставьте галочку напротив Попросить поисковые системы не индексировать сайт. После ее включения, WordPress отредактирует файл robots.txt с новыми правилами предотвращающими сканирование и индексацию вашего сайта.
- Нажмите кнопку Сохранить изменения для применения изменений.
Если вы предпочитаете делать все вручную, вы можете добиться аналогичного результата отредактировав данный файл:
- Используйте Файловый Менеджер или FTP-клиент для доступа к файлам вашего сайта.
- Найдите файл robots.txt. Он должен быть расположен в той же папке, что и сам WordPress (обычно в папке public_html), если вы не можете найти его, создайте пустой файл.
- Введите следующий синтаксис, чтобы закрыть сайт от индексации поисковых систем:
User-agent: * Disallow: /
Код сверху используется для предотвращения одновременно и сканирования, и индексации вашего сайта. Данный код в файле robots.txt является сигналом для поисковых систем о запрете сканирования сайта.
Шаг 2 — Защита вашего сайта WordPress паролемПоисковые системы и поисковые роботы не имеют доступа к файлам защищенных паролем. Защитить свои файлы паролем можно следующими методами:
Метод 1 — Защита паролем вашего сайта с помощью контрольной панели вашего хостингаЕсли вы являетесь клиентом Hostinger, функция защиты паролем может быть легко включена с помощью инструмента под названием Защита Папок Паролем:
- Войдите в контрольную панель Hostinger и нажмите иконку Защита Папок Паролем.
- В левой части выберите каталоги, которые хотите защитить. В нашем случае WordPress установлен в public_html.
- После выбора каталога, введите имя пользователя и пароль в правой панели и нажмите кнопку Защитить.
Если вы используете cPanel, процесс довольно схож:
- Войдите в вашу учетную запись cPanel и нажмите Конфиденциальность каталога.
- Выберите папку в которой установлен WordPress. Обычно это public_html.
- Затем выберите опцию Защитить этот каталог паролем. Далее введите имя каталога, который хотите защитить. Нажмите кнопку Сохранить. Используя форму, создайте учетную запись пользователя для доступа к защищенным каталогам. После завершения нажмите кнопку Сохранить.
Вы также можете установить плагины для достижения такого же результата. Существуют различные плагины, которые могут вам в этом помочь. Среди них можно назвать: Password Protected Plugin, WordFence и множество других. Выберите самый свежий плагин и установите его, как только он будет установлен, перейдите в настройки плагина и установите пароль для сайта. Когда ваш сайт станет защищен паролем, поисковые системы не смогут получить к нему доступ и следовательно проиндексировать его.
Шаг 3 — Удаление уже индексированных страниц из GoogleДаже если ваш сайт уже был проиндексирован, вы все равно можете попытаться удалить его из Google следуя данным шагам:
- Настройте Google Search Console на вашем сайте.
- Войдите в Search Console, выберите только что добавленный сайт и нажмите на Индекс Google → Удалить URL-адреса.
- В новом окне выберите Временно скрыть, далее впишите адрес страницы и нажмите Продолжить.
Google временно удалит URL из результатов поиска. Убедитесь в том, что выполнили действия из Шага 1 и закрыли сайт WordPress от повторной индексации Google.
ЗаключениеКакая бы ни была у вас причина для контроля поисковых систем, закончив данное руководство вы узнали, как закрыть сайт от индексации поисковыми системами. Несмотря на то, что некоторые из способов не приносят 100% гарантии, они непременно послужат цели.
Как запретить индексацию страницы с помощью robots.txt?
От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/ |
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееЕстественно, указываем настоящие url-адреса. Если же вам необходимо не индексировать страничку //blog.ru/about-me, то в robots.txt нужно прописать так:
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
<meta name = «robots» content = «noindex,nofollow»>
<meta name = «robots» content = «noindex,nofollow»> |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.
Запрещается использовать более двух значений. Например:
<meta name = «robots» content = «noindex,nofollow, follow»>
<meta name = «robots» content = «noindex,nofollow, follow»> |
И любые другие. В этом случае мы видим противоречие.
Итог
Наиболее удобным способом закрытия страницы для поискового робота я вижу использование мета-тега. В таком случае вам не нужно будет постоянно, сотни раз редактировать файл robots.txt, чтобы открыть или закрыть очередной url, а это решение принимается непосредственно при создании новых страниц.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееХотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
СмотретьВременно приостановить или отключить веб-сайт
Если вы не можете выполнять заказы или многие из ваших товаров отсутствуют на складе, вы можете подумать о временное закрытие вашего онлайн-бизнеса. Если ситуация временная, то есть вы ожидаете иметь возможность продавать товары в ближайшие недели или месяцы, мы рекомендуем вам принять меры, которые максимально сохраняет позицию вашего сайта в поиске. Это руководство объясняет, как вы можно безопасно приостановить свой онлайн-бизнес.
Ограничьте функциональность вашего сайта (рекомендуется)
Если ваша ситуация временная и вы планируете возобновить свой бизнес в Интернете, мы рекомендуем вы держите свой сайт в сети и ограничиваете его функциональность. Это рекомендуемый подход, поскольку он сводит к минимуму любое негативное влияние на присутствие вашего сайта в Поиске. Люди все еще могут найти ваш продукты, читать обзоры или добавлять списки желаний, чтобы они могли приобрести их позже. Мы рекомендуем делать следующий:
- Отключить функцию тележки : Отключение функции тележки простейший подход и ничего не меняет для видимости вашего сайта в Поиске.
- Показать баннер или всплывающее окно : Баннер или всплывающее окно div на всех страницах, включая
целевая страница быстро проясняет статус для пользователей. Укажите любые известные и необычные задержки,
время доставки, варианты получения или доставки, чтобы пользователи могли
ожидания.
Чтобы содержимое баннера или всплывающего окна не отображалось во фрагменте в результатах поиска,
используйте HTML-атрибут
data-nosnippet. Обязательно следуйте нашим методические рекомендации во всплывающих окнах и баннерах. - Обновите структурированные данные : Если на вашем сайте используются структурированные данные (например,
Товар,Книга, г.Event), обязательно отрегулируйте его соответствующим образом. (отражает текущую доступность продукта или меняет события на отмененные). Если у вашего бизнеса есть физическая витрина, обновить местный бизнес структурированные данные, отражающие текущие часы работы. - Проверьте свой фид Merchant Center. : Если вы используете Merchant Center, следуйте лучшие практики для атрибут доступности.
- Сообщите Google о своих обновлениях : попросить Google повторно сканировать ограниченное количество страниц (например, домашняя страница), используйте Search Console. Для большего количества страниц (например, весь ваш продукт страниц), используйте карты сайта.
Не рекомендуется: отключить весь веб-сайт
Предупреждение : Системы Google спроектированы так, чтобы быть надежными и чтобы помочь веб-сайтам восстановиться после временных проблем. Однако полное удаление сайта из Индекс Google — это существенное изменение, восстановление которого может занять некоторое время.Есть нет фиксированного времени для восстановления после полного удаления, и нет механизма, чтобы ускорить это вверх. Вот почему мы настоятельно рекомендуем ограничить функциональность вместо того, чтобы удалять сайт из Поиск.Вы можете решить отключить весь сайт. Это крайняя мера, которую следует принимать в течение очень короткого периода времени (максимум несколько дней), так как в противном случае значительно влияет на на веб-сайте в поиске, даже если он реализован правильно.
Убедитесь, что вы учитываете следующие побочные эффекты отключения всего сайта:
- Ваши клиенты не будут знать, что происходит с вашим бизнес, если они вообще не могут найти ваш бизнес в Интернете.
- Ваши клиенты не могут найти или прочитать информацию из первых рук о вашем бизнесе и его примере, обзоры, спецификации, руководства по ремонту или руководства не будут можно найти. Сторонняя информация может быть не такой точной или исчерпывающей, как вы. предоставлять.Это часто также влияет на решения о будущих покупках.
- Панели знаний могут потерять информацию, например контакт номера телефонов и логотип вашего сайта.
- Search Console не пройдет проверку, и вы потеряете полный доступ к информации о вашей компании в Поиске. Сводные отчеты в Search Console потеряет данные, как страницы выпал из индекса.
- Восстановление скорости после продолжительного периода времени будет значительно сложнее, если ваш сайт нужно сначала переиндексировать.Кроме того, это не уверены, сколько времени это займет, и будет ли сайт так же отображаться в Поиске после.
Если вы решили, что вам нужно это сделать (опять же, не рекомендуется ), вот некоторые варианты:
- Если нужно срочно отключить сайт на 1-2 дня, то верните информационный страница с ошибкой 503 Код результата HTTP вместо всего содержимого. Обязательно следуйте рекомендации по отключению сайта.
- Если вам нужно отключить сайт на более длительное время, укажите индексируемую домашнюю страницу как заполнитель, который пользователи могут найти в поиске с помощью кода состояния HTTP 200.
- Если вам нужно быстро скрыть свой сайт в поиске, пока вы рассматриваете варианты, вы можете временно удалить веб-сайт из поиска.
Рекомендации по отключению сайта
Предупреждение : имейте в виду, что это невозможно для Системы Google для обновления заголовков, описаний, метаданных или структурированных данных, включенных в веб-сайт, если страница возвращает код результата HTTP 503.Хотя мы не рекомендуем отключать ваш сайт, вот несколько рекомендаций, если вы решите сделать это это:
FAQs
Что, если я закрою сайт всего на несколько недель?
Полное закрытие сайта даже на несколько недель может иметь негативные последствия для Индексирование вашего сайта Google. Рекомендуем ограничить сайт вместо этого функциональность.Имейте в виду, что пользователи также могут захотеть найти информацию о ваших продуктах, услугах и вашей компании, даже если вы в настоящее время не продавать что угодно.
Что, если я хочу исключить все второстепенные продукты?
Могу ли я попросить Google меньше сканировать, пока мой сайт временно закрыт?
Да, вы можете уменьшить Googlebot скорость сканирования, хотя в большинстве случаев это не рекомендуется.Это может иметь некоторое влияние о свежести ваших результатов в Поиске. Например, поиск может занять больше времени. чтобы отразить, что все ваши продукты в настоящее время недоступны. С другой стороны, если сканирование робота Google вызывает критические проблемы с ресурсами сервера, это допустимый подход. Мы рекомендуем установить для себя напоминание о необходимости сбросить скорость сканирования один раз. вы готовы вернуться в бизнес.
Как мне быстро проиндексировать или обновить страницу?
Чтобы попросить Google повторно сканировать ограниченное количество страниц (например, домашнюю страницу), используйте Search Console.Для большего количества страниц (например, всех страниц вашего продукта), использовать карты сайта.
Что, если я заблокирую доступ к моему сайту для определенного региона?
Гугл вообще сканирует из США. Если вы заблокируете США, Google Search не сможет чтобы вообще получить доступ к вашему сайту. Мы не рекомендуем вам блокировать весь регион от временный доступ к вашему сайту; вместо этого мы рекомендуем ограничить функциональность сайта для этого региона.
Стоит ли использовать инструмент удаления убрать товары, которых нет в наличии?
Нет. Если вы это сделаете, клиенты не смогут найти информацию о вашем продукты в Поиске, но информация о продукте может быть сторонней. это может быть неправильным или неполным. Лучше все же разрешить эту страницу и пометить ее нет на складе.Таким образом, люди все еще могут понять, что происходит, даже если они не могут купить товар. Если вы удалите продукт из поиска, люди не поймут, почему он исчез.
Как правильно закрыть сайт на день
Джон Мюллер из Google написал в блоге Webmaster Central статью с советами о том, как правильно закрыть сайт на день. Эти советы описывают правильный способ временного закрытия сайта, не влияя на его поисковое присутствие.
Блокировка функций тележки для покупок
Если сайту электронной коммерции просто необходимо запретить людям совершать покупки, то рекомендация Мюллера — просто отключить функцию корзины для покупок. Помимо сообщения клиентам о завершении работы, также рекомендуется заблокировать сканирование страницы корзины покупок с помощью файла robots.txt или заблокировать ее от индексации с помощью метатега robots.
Используйте межстраничное или всплывающее окно
Если необходимо заблокировать весь сайт от посетителей, Мюллер рекомендует использовать межстраничное или всплывающее окно, чтобы сообщить, что сайт временно недоступен.Кроме того, сервер должен возвращать код результата HTTP 503 («Служба недоступна»), чтобы Google не индексировал временный контент. Можно безопасно использовать 503 до недели — через неделю Google может полностью исключить контент из результатов поиска.
Выключить весь веб-сайт
Выключить весь сервер — еще один безопасный вариант, если у вас есть второй временный сервер с кодом результата 503 HTTP для всех URL-адресов. Кроме того, в это время рекомендуется переключить ваш DNS так, чтобы он указывал на этот сервер.
Объявление
Продолжить чтение ниже
Мюллер объясняет, как это сделать, шаг за шагом:
- Установите низкое время TTL для DNS (например, 5 минут) за несколько дней.
- Измените DNS на временный IP-адрес сервера.
- Переведите основной сервер в автономный режим после того, как все запросы будут отправлены на временный сервер.
- … ваш сервер отключен от сети…
- Когда все будет готово, снова подключите главный сервер.
- Снова переключите DNS на IP-адрес основного сервера.
- Верните значение TTL DNS в нормальное состояние.
Если вы владеете местным бизнесом, который будет закрыт в течение того же времени, в течение которого ваш сайт не будет работать, рекомендуется изменить часы работы в местных списках, чтобы отразить закрытие.
Реклама
Продолжить чтение ниже
Правильный способ предотвращения индексации вашего сайта • Yoast
Йост де ВалкЙост де Валк — основатель и директор по продуктам Yoast.Он интернет-предприниматель, который незадолго до основания Yoast инвестировал и консультировал несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Мы уже говорили это когда-то, но повторим еще раз: нас удивляет, что до сих пор есть люди, использующие только файла robots.txt для предотвращения индексации своего сайта в Google или Bing. В результате их сайт все равно появляется в поисковых системах. Вы знаете, почему это нас удивляет? Потому что robots.txt на самом деле не выполняет последнего, хотя и предотвращает индексацию вашего сайта. Позвольте мне объяснить, как это работает, в этом посте.
Чтобы узнать больше о robots.txt, прочтите robots.txt: полное руководство. Или найдите лучшие методы работы с robots.txt в WordPress.
Есть разница между индексированием и включением в Google
Прежде чем мы продолжим объяснять вещи, нам нужно сначала рассмотреть некоторые термины:
- Индексирование / индексирование
Процесс загрузки сайта или содержимого страницы на сервер поисковой системы, тем самым добавляя его в свой «индекс».” - Рейтинг / Листинг / Отображение
Отображение сайта на страницах результатов поиска (также известных как SERP).
Итак, хотя наиболее распространенный процесс идет от индексирования к листингу, сайт не обязательно должен быть проиндексирован , чтобы быть внесенным в список. Если ссылка указывает на страницу, домен или другое место, Google перейдет по этой ссылке. Если файл robots.txt в этом домене препятствует индексации этой страницы поисковой системой, он все равно будет показывать URL в результатах, если он может быть получен из других переменных, на которые, возможно, стоит обратить внимание.
Раньше это мог быть DMOZ или каталог Yahoo, но я могу представить, что Google использует, например, данные о вашем бизнесе в наши дни или старые данные из этих проектов. Больше сайтов резюмируют ваш сайт, верно.
Теперь, если приведенное выше объяснение не имеет смысла, взгляните на это видеообъяснение бывшего сотрудника Google Мэтта Каттса из 2009 г .:
Если у вас есть причины для предотвращения индексации вашего веб-сайта, добавление этого запроса на конкретную страницу, которую вы хотите заблокировать, как говорит Мэтт, по-прежнему является правильным способом.
Но вам нужно сообщить Google об этом метатеге robots. Итак, если вы хотите эффективно скрыть страницы от поисковых систем, вам нужно , чтобы проиндексировали эти страницы. Хотя это может показаться противоречивым. Это можно сделать двумя способами.
Предотвратить листинг вашей страницы, добавив метатег роботов
Первый способ предотвратить размещение вашей страницы в списке — использовать метатеги robots. У нас есть подробное руководство по метатегам роботов, которое более обширно, но в основном оно сводится к добавлению этого тега на вашу страницу:
Если вы используете Yoast SEO, это очень просто! Самостоятельно добавлять код не нужно.Узнайте, как добавить тег noindex с помощью Yoast SEO здесь.
Проблема с таким тегом в том, что его нужно добавлять на каждую страницу.
Управление метатегами роботов упрощено в Yoast SEO Чтобы упростить процесс добавления метатега robots на каждую страницу вашего сайта, поисковые системы разработали HTTP-заголовок X-Robots-Tag. Это позволяет вам указать HTTP-заголовок с именем X-Robots-Tag и установить значение так же, как и значение мета-тегов robots.Самое замечательное в этом то, что вы можете сделать это для всего сайта. Если ваш сайт работает на Apache и включен mod_headers (обычно это так), вы можете добавить следующую строку в свой файл .htaccess :
Заголовочный набор X-Robots-Tag "noindex, nofollow"
И это приведет к тому, что весь сайт может быть проиндексирован . Но никогда не будет отображаться в результатах поиска.
Итак, избавьтесь от этого файла robots.txt с помощью Disallow: / в it.Используйте вместо этого X-Robots-Tag или этот метатег robots!
Подробнее: Полное руководство по мета-тегу robots »
Вот что происходит, когда вы случайно деиндексируете свой сайт в Google
Взгляды автора полностью принадлежат ему (за исключением маловероятного случая гипноза) и могут не всегда отражать взгляды Moz.
Приводит ли чтение этого заголовка к приступу мини-паники?
Пройдя в точности так, как следует из названия, я могу гарантировать, что ваше беспокойство полностью обосновано.
Если вы хотите пережить вместе со мной мой кошмар — возможно, как катарсис в равной степени и исследование SEO — мы пройдемся по событиям в хронологическом порядке.
Вы готовы?
4 августа 2019 года
Было воскресное утро. Я пил кофе и возился с нашими инструментами SEO, как обычно, ни черта не ожидал. Тогда… БАМ!
Что. Файл. Ад?
Как специалисты по оптимизации, мы все привыкли видеть естественные колебания в рейтинге. Колебания, а не исчезновения.
Шаг 1: Отказ
Я сразу же вспоминаю одно: это ошибка. Итак, я перешел к другим инструментам, чтобы проверить, теряет ли Ahrefs рассудок.
Google Analytics также показал соответствующее падение трафика, подтверждая, что что-то определенно произошло. Поэтому, как оптимизатор, я, естественно, предполагал худшее…
Шаг 2: Паника алгоритма
Обновление алгоритма. Пожалуйста, не позволяйте этому быть обновлением алгоритма.
Я запрыгнул в инструмент Barracuda Panguin Tool, чтобы проверить, совпала ли наша проблема с подтвержденным обновлением.
Нет обновлений. Уф.
Шаг 3: Диагностика
Никто никогда не думает ясно, когда задействован мозг рептилий. Вы паникуете, думаете нерационально и принимаете неверные решения. Без холода.
Наконец-то я собрался с духом, чтобы ясно подумать о том, что произошло: совершенно необычно, чтобы рейтинг ключевых слов полностью исчез. Это должно быть техническое.
Должна быть индексация.
Быстрый поиск в Google страниц, потерявших рейтинг по ключевым словам, подтвердил, что эти страницы действительно исчезли.Search Console сообщила то же самое:
Обратите внимание на предупреждение внизу:
Нет: в метатеге robots обнаружено «noindex»
Итак, мы кое-что получили. Затем пришло время подтвердить этот вывод в исходном коде.
Наши страницы были помечены для деиндексации. Но сколько страниц было деиндексировано на данный момент?
Шаг 4: Исследование повреждений
Все. Отправив несколько бешеных заметок нашему разработчику, он подтвердил, что спринт, развернутый в четверг вечером (1 августа 2019 г.), почти за три дня до этого, случайно разместил код на каждой странице.
Но был ли деиндексирован весь сайт?
Это маловероятно, потому что для этого Google пришлось бы сканировать каждую страницу сайта в течение трех дней, чтобы найти разметку «noindex». Search Console в этом отношении не поможет, поскольку его данные всегда будут отставать и могут никогда не получить изменения, пока они не будут исправлены.
Даже сейчас, оглядываясь назад, мы видим, что Search Console обнаружила максимум 249 затронутых страниц из более 8000 проиндексированных.Что невозможно, учитывая, что наши поисковые запросы сократились на треть за всю неделю после того, как инцидент был устранен.
Примечание: Я никогда не буду уверен, сколько страниц было полностью деиндексировано в Google, но я точно знаю, что КАЖДАЯ страница имела разметку noindex, и я смутно помню, как гуглил «site: brafton.com» и видно, что проиндексирована примерно одна восьмая наших страниц. Конечно, хотелось бы иметь скриншот. Простите.
Шаг 1. Устранение проблемы
Как только проблема была обнаружена, наш разработчик откатил обновление и запустил сайт, как это было до разметки «noindex».Затем возникла проблема переиндексации нашего контента.
Шаг 2. Выполните повторное сканирование сайта как можно скорее.
Я удалил старую карту сайта, построил новую и повторно загрузил ее в Search Console. Я также захватил большинство наших основных целевых страниц продуктов и вручную запросил повторное индексирование (что, как я не верю, дает что-либо с момента последнего обновления SC).
Шаг 3: Подождите
На этом этапе мы ничего не могли сделать, кроме как ждать. Было так много вопросов:
- Будут ли страницы ранжироваться по тем же ключевым словам, что и раньше?
- Будут ли они занимать одинаковые позиции?
- Будет ли Google каким-либо образом «наказывать» страницы за кратковременное исчезновение?
Только время покажет.
8 августа 2019 г. (одна неделя) — снижение присутствия в поиске на 33%
При оценке ущерба я собираюсь использовать дату, когда код ошибки был полностью развернут и заполнен на действующих страницах (2 августа) как нулевой точки. Таким образом, первое измерение будет выполнено в течение семи дней, со 2 по 8 августа.
Search Console, вероятно, даст мне лучшее представление о том, насколько сильно пострадали наши поисковые запросы.
Мы потеряли около 33,2% поискового трафика.Ой.
К счастью, это будет пиковый уровень ущерба, который мы испытали за все время испытания.
15 августа 2019 г. (две недели) — падение трафика на 23%
В этот период я следил за двумя вещами: поисковым трафиком и проиндексированными страницами. Несмотря на повторную отправку моей карты сайта и ручное извлечение страниц в Search Console, многие страницы все еще не индексировались, даже основные целевые страницы. Это станет темой на протяжении всей временной шкалы.
В результате того, что у нас оставались неиндексированные страницы, наш трафик все еще страдал.
Спустя две недели после инцидента, мы все еще упали на 8%, а наши приносящие доход конверсии упали вместе с трафиком (несмотря на увеличение коэффициента конверсии).
22 августа 2019 г. (три недели) — падение трафика на 13%
Наши страницы по-прежнему индексировались медленно. Уж больно медленно, пока я смотрел, как мои коммерческие цели падают через пол.
По крайней мере, было ясно, что наше присутствие в поиске восстанавливается. Но особый интерес для меня представлял , как восстанавливается.
Были ли повторно проиндексированы все страницы, но с уменьшенным присутствием в поиске?
Была ли переиндексирована только часть страниц с полностью восстановленным присутствием в поиске?
Чтобы ответить на этот вопрос, я рассмотрел страницы, которые были деиндексированы и повторно проиндексированы по отдельности. Вот пример одной из этих страниц:
Вот пример страницы, которая была деиндексирована на гораздо более короткий период времени:
В каждом случае, который я мог найти, каждая страница была полностью восстановлена до исходного состояния поиска. .Так что вопрос не в том, восстановятся ли страницы или нет, вопрос в том, когда страницы будут переиндексированы.
Кстати, в Search Console появилась новая функция, в которой она будет «проверять» страницы с ошибками. Я начал этот процесс 26 августа. После этого SC медленно повторно просматривал (я полагаю) эти страницы в количестве примерно 10 страниц в неделю. Это даже быстрее, чем обычное сканирование по расписанию? Эти инструменты в СЦ вообще хоть что-то делают?
Что я знал наверняка, так это то, что по прошествии трех недель был деиндексирован ряд страниц, в том числе коммерческие целевые страницы, на которые я рассчитывал для привлечения трафика.Подробнее об этом позже.
29 августа 2019 г. (четыре недели) — падение трафика на 9%
В этот момент я очень расстраивался, потому что оставалось всего около 150 страниц для повторного индексирования, и независимо от того, сколько раз я проверял и запросил новую индексацию в Search Console, это не сработает.
Эти страницы можно было полностью проиндексировать (по данным проверки URL-адреса SC), но они не были просканированы. В результате почти через месяц мы все еще были на 9% ниже базового уровня.
Одна конкретная страница просто отказалась переиндексировать. Это была страница продукта с высокой коммерческой ценностью, и я рассчитывал на конверсию.
В своих попытках принудительно переиндексировать я попробовал:
- Проверка URL и запрос индексации (15 раз в месяц).
- Обновление даты публикации с последующим запросом индексации.
- Обновление содержимого и даты публикации, затем запрос индексации.
- Повторная отправка карты сайта в SC.
Ничего не заработало.Эта страница не будет повторно индексироваться. Та же история и с более чем сотней других менее значимых с коммерческой точки зрения URL-адресов.
Примечание: Эта страница не будет повторно проиндексирована до 1 октября, то есть через два полных месяца после деиндексации.
Кстати, вот как выглядел наш общий прогресс восстановления через четыре недели:
5 сентября 2019 г. (пять недель) — падение трафика на 10,4%
Великолепное плато. К этому моменту мы переиндексировали все наши страницы, за исключением примерно 150, предположительно «проверенных».
Их не было. И их тоже не перекраивали.
Казалось, что мы, скорее всего, полностью выздоровеем, но время было в руках Google, и я ничего не мог сделать, чтобы повлиять на это.
12 сентября 2019 г. (шесть недель) — прирост трафика на 5,3%
Прошло около шести недель, прежде чем мы полностью восстановили наш трафик.
Но по правде говоря, мы все еще не полностью восстановили наш трафик, поскольку некоторый контент работал с перебоями и чрезмерно компенсировал количество страниц, которые еще не были проиндексированы.Примечательно, что страница нашего продукта не будет индексироваться еще ~ 2,5 недели.
В итоге, наши поисковые запросы восстановились через шесть недель. Но наш контент был полностью переиндексирован только через восемь с лишним недель после устранения проблемы.
Заключение
Для начала, определенно не деиндексируйте свой сайт случайно, в эксперименте или по любой другой причине. Это ужалит. По моим оценкам, мы удалили около 12% всего органического трафика, что в равной степени привело к снижению коммерческих конверсий.
Что мы узнали ??
После повторной индексации страниц они были полностью восстановлены с точки зрения видимости при поиске. Самая большая проблема заключалась в их повторной индексации.
Некоторые основные вопросы, на которые мы ответили с помощью этого случайного эксперимента:
Выздоровели?
Да, мы полностью восстановились, и все URL-адреса, похоже, обеспечивают одинаковую видимость в поиске.
Сколько времени это заняло?
Видимость поиска вернулась к исходному уровню через шесть недель. Все страницы повторно индексируются примерно через восемь-девять недель.
iis — Как удалить / деиндексировать страницу из Google?
Во-первых, зарегистрируйте учетную запись Google Webmaster Tools. Это позволит вам просматривать статистику Google о том, как они сканируют ваш сайт, и позволяет запрашивать удаление страниц из индекса (подробнее об этом позже).
Затем настройте файл robots.txt для своего сайта. Вам не нужно блокировать весь свой сайт от Google, чтобы использовать robots.txt . Все поисковые системы следуют за robots.txt , поэтому это также предотвратит индексацию этих страниц такими сайтами, как Bing или Yahoo.
Чтобы настроить это, создайте robots.txt как простой текстовый файл в корневом каталоге вашего сайта (например, http://www.example.com/robots.txt ). Синтаксис очень прост: вы указываете пользовательский агент, к которому это должно применяться, используя * в качестве подстановочного знака для всех роботов, и вы указываете, куда роботы не должны сканировать. Обратите внимание, что вы не должны включать какие-либо страницы, которые вы хотите быть полностью «секретными», так как это общедоступный файл. Синтаксис robots.txt выглядит следующим образом:
User-agent: имя пользовательского агента
Disallow: имя каталога
Запретить: другой каталог
Запретить: (и т. Д.)
Если вы хотите запретить любым поисковым системам индексировать данные в подкаталоге вашего каталога изображений, вы можете сделать что-то вроде этого:
Агент пользователя: *
Запретить: / images / foo / bar /
Запретить: / images / foo / baz /
Вы даже можете запретить только определенный файл:
Агент пользователя: *
Запретить: / images / foo / bar / qux.jpg
Настройка robots.txt предотвратит индексацию указанных каталогов и файлов в будущем. Со временем эти страницы будут удалены из поискового индекса, но не сразу. Чтобы ускорить этот процесс, используйте свою учетную запись инструментов для веб-мастеров, чтобы отправить запрос на удаление URL-адреса из индекса. Щелкните учетную запись веб-сайта, URL-адрес которой вы хотите удалить, затем откройте «Конфигурация сайта» слева. Нажмите «Доступ для сканера», затем откройте вкладку «Удалить URL».Нажмите «Новый запрос на удаление» и введите URL-адрес, который нужно удалить. Затем нажмите Enter. Страница должна попросить вас подтвердить, что вы уже заблокировали URL через robots.txt (что вы только что сделали). Нажмите ОК, и он должен отправить запрос. Обычно на обработку запроса у них уходит 1-3 дня. Вы можете проверить статус запроса, войдя в свою учетную запись инструментов для веб-мастеров в любое время.
API закрытия индекса | Elasticsearch Guide [7.13]
Закрывает индекс.
Для закрытия открытых индексов используется API закрытия индексов.
Закрытый индекс заблокирован для операций чтения / записи и не позволяет все операции, которые позволяют открывать индексы. Невозможно проиндексировать документы или для поиска документов в закрытом индексе. Это позволяет закрытые индексы, чтобы не поддерживать внутренние структуры данных для индексирование или поиск документов, что снижает накладные расходы на кластер.
При открытии или закрытии индекса мастер отвечает за перезапуск осколков индекса, чтобы отразить новое состояние индекса.Затем осколки пройдут обычный процесс восстановления. В данные открытых / закрытых индексов автоматически реплицируются кластер, чтобы обеспечить безопасное хранение достаточного количества копий осколков всегда.
Вы можете открывать и закрывать несколько индексов. Выдается ошибка
если запрос явно ссылается на отсутствующий индекс. Такое поведение может быть
отключено с помощью параметра ignore_unavailable = true .
Все индексы можно открывать или закрывать сразу, используя _all в качестве имени индекса.
или указание шаблонов, которые идентифицируют их все (например,грамм. * ).
Определение индексов с помощью подстановочных знаков или _все можно отключить, установив action.destructive_requires_name в файле конфигурации на true .
Этот параметр также можно изменить через api настроек обновления кластера.
Закрытые индексы занимают значительный объем дискового пространства, что может вызвать
проблемы в управляемых средах. Индексы закрытия можно отключить в настройках кластера.
API, установив cluster.indices.close.enable to false . По умолчанию , правда .
В следующем примере показано, как закрыть индекс:
POST / my-index-000001 / _close
API возвращает следующий ответ:
{
"подтверждено": правда,
"shards_acknowledged": правда,
"индексы": {
"my-index-000001": {
"закрыто": правда
}
}
} Как исправить ошибку «Проиндексировано, но заблокировано файлом robots.txt» в консоли поиска Google
«Проиндексировано, но заблокировано роботами.txt »означает, что Google проиндексировал URL-адреса, даже если они были заблокированы вашим файлом robots.txt.
Google пометил эти URL-адреса как «Действительные с предупреждением», поскольку они не уверены, хотите ли вы проиндексировать эти URL-адреса. В этой статье вы узнаете, как решить эту проблему.
Вот как это выглядит в отчете об индексировании в Google Search Console с указанием количества показов URL:
Перепроверьте уровень URL
Вы можете еще раз проверить это, перейдя на страницу Покрытие > проиндексировано, хотя и заблокировано роботами.txt и проверьте один из перечисленных URL-адресов. Затем под заголовком Crawl он скажет «Нет: заблокировано robots.txt» для поля Crawl разрешено и «Failed: Blocked by robots.txt» для поля Page fetch .
Какую часть вашего контента Google не может сканировать?
Разместите свой сайт и узнайте прямо сейчас!
Так что случилось?
Обычно Google не индексировал бы эти URL-адреса, но, по-видимому, они нашли ссылки на них и сочли их достаточно важными, чтобы их можно было проиндексировать.
Вероятно, что показанные фрагменты неоптимальны, например, например:
Полезные ресурсы
Как исправить ошибку «Проиндексировано, но заблокировано файлом robots.txt»
- Экспортируйте список URL-адресов из Google Search Console и отсортируйте их в алфавитном порядке.
- Просмотрите URL-адреса и проверьте, есть ли в нем URL-адреса…
- То, что вы хотите проиндексировать. В этом случае обновите файл robots.txt, чтобы разрешить Google доступ к этим URL-адресам.
- , к которому вы не хотите, чтобы поисковые системы получали доступ. В этом случае оставьте файл robots.txt как есть, но проверьте, есть ли у вас внутренние ссылки, которые следует удалить.
- Которые поисковые системы имеют доступ, но которые вы не хотите индексировать. В этом случае обновите файл robots.txt, чтобы отразить это, и примените директивы noindex для роботов.
- Это не должно быть доступно никому и никогда. Возьмем, к примеру, постановочную среду. В этом случае выполните действия, описанные в нашей статье «Защита промежуточных сред».
- Если вам не ясно, какая часть вашего robots.txt вызывает блокировку этих URL-адресов, выберите URL-адрес и нажмите кнопку
TEST ROBOTS.TXT BLOCKINGна панели, которая открывается с правой стороны. Откроется новое окно, в котором будет показано, какая строка в вашем файле robots.txt запрещает Google доступ к URL-адресу. - Когда вы закончите вносить изменения, нажмите кнопку
VALIDATE FIX, чтобы запросить у Google повторную оценку вашего файла robots.txt на соответствие вашим URL.
Начните мониторинг своего сайта, прежде чем вносить изменения
Отслеживайте каждое вносимое вами изменение и убедитесь, что файл robots.txt не наносит дальнейшего вреда вашему сайту!
Проиндексировано, но заблокировано исправлением robots.txt для WordPress
Процесс устранения этой проблемы для сайтов WordPress такой же, как описано в шагах выше, но вот несколько указателей, которые помогут быстро найти файл robots.txt в WordPress:
WordPress + Yoast SEO
Если вы используете плагин Yoast SEO, выполните следующие действия, чтобы настроить robots.txt файл:
- Войдите в свой раздел
wp-admin. - На боковой панели перейдите к
Yoast SEO plugin>Tools. - Перейти к
Редактор файлов.
WordPress + Rank Math
Если вы используете плагин Rank Math SEO, выполните следующие действия, чтобы настроить файл robots.txt:
- Войдите в свой раздел
wp-admin. - На боковой панели выберите
Rank Math>Общие настройки. - Перейдите на страницу
Отредактируйте robots.txt.
WordPress + все в одном SEO
Если вы используете плагин All in One SEO, выполните следующие действия, чтобы настроить файл robots.txt:
- Войдите в свой раздел
wp-admin. - На боковой панели перейдите к
All in One SEO>Robots.txt.
Наконечник Pro
Если вы работаете над веб-сайтом WordPress, который еще не запущен, и не можете понять, почему ваш robots.txt содержит следующее:
User-agent: *
Disallow: /
, затем проверьте свои настройки в разделе: Настройки > Чтение и найдите Видимость в поисковой системе .
Если установлен флажок Запретить поисковым системам индексировать этот сайт , WordPress сгенерирует виртуальный файл robots.txt, предотвращающий доступ поисковых систем к сайту.
Проиндексировано, но заблокировано исправлением robots.txt для Shopify
Shopify не позволяет вам управлять своими роботами.txt из их системы, поэтому вы работаете со значением по умолчанию, которое применяется ко всем сайтам.
Возможно, вы видели сообщение «Проиндексировано, но заблокировано файлом robots.txt» в Google Search Console или получили электронное письмо от Google «Обнаружена новая проблема с покрытием индекса». Мы рекомендуем всегда проверять, какие URL-адреса это касается, потому что вы не хотите ничего оставлять на волю случая в SEO.
Просмотрите URL-адреса и посмотрите, не заблокированы ли какие-либо важные URL-адреса. В этом случае у вас есть два варианта, которые требуют некоторой работы, но позволяют вам изменить свои robots.txt в Shopify:
- Настроить обратный прокси (открывается в новой вкладке)
- Использовать Cloudflare Workers (открывается в новой вкладке)
Стоят ли эти варианты для вас, зависит от потенциальной награды. Если он значительный, рассмотрите возможность реализации одного из этих вариантов.
Вы можете использовать тот же подход на платформе Squarespace.
Полезные ресурсы
Часто задаваемые вопросы
🤖 Почему Google показывает эту ошибку для моих страниц?
Google обнаружил ссылки на страницы, недоступные для них из-за роботов.txt запрещают директивы. Когда Google сочтет эти страницы достаточно важными, они их проиндексируют.
🧐 Как исправить эту ошибку?
Если коротко, то убедитесь, что страницы, которые вы хотите проиндексировать Google, должны быть доступны только для поисковых роботов Google. И страницы, которые вы не хотите, чтобы они индексировали, не должны иметь внутренних ссылок. Подробный ответ описан в разделе «Как исправить ошибку« Проиндексировано, но заблокировано файлом robots.txt »» этой статьи.
🧾 Могу ли я редактировать свои файлы robots.txt на WordPress?
Популярные плагины SEO, такие как Yoast, Rank Math и All in one SEO, например, позволяют редактировать файл robots.txt прямо из панели wp-admin.
ContentKing Academy
Прочтите всю статью Академии, чтобы узнать все об отчете о покрытии индекса Google Search Console
.