
Закрытие сайта от индексации | PRIME
Разные причины побуждают вебмастеров закрыть свой ресурс от поисковых роботов. Процедуру защиты от индексации или добавления страниц сайта в базы данных поисковиков, применяют, когда требуется:
- скрывать секретные сведения от общего ознакомления;
- создавать релевантный контент для улучшения позиций, большое количество информации заглушает тематику текста, которую нужно предоставить пользователю;
- закрывать, дублирующий информационный ресурс;
- делать невидимыми устаревшие материалы, мусорные страницы введут в заблуждение поисковую систему.
Содержание
- Запрет индексации поддомена
- Запрет индексации отдельного блока
- Запрет индексации страниц
- Запрет индексации изображений
- Запрет индексации дублей
- Запрет индексации раздела
- Запрет индексации папки
- Запрет индексации ссылок
- Запрет индексации через robots.
 txt
txt - Запрет индексации через .htaccess
 txt
txtЗапрет индексации поддомена
Каждый поддомен для поисковика — это обособленный адрес в интернете. Поэтому скрыть портал можно любым методом, разработанным для веб-страниц.
Запрет индексации отдельного блока
Часто обстоятельства требуют закрыть от индексации разные данные:
- счетчик;
- меню;
- код;
- текст.
В пик популярности Яндекса, когда в Google сайты выводилась на передние позиции сами по себе, для скрытия какой-то информации применяли тег <noindex>.
Однако со временем Яндекс перестал реагировать на применение таких технических мер, а Google вообще не понимал подобных приемов. Поэтому пришлось разрабатывать и внедрять другой механизм. Закрывать информацию от индексации стали при помощи JavaScript. Схема проста: нужный элемент кодируют, используя язык программирования JavaScript, после чего сам скрипт закрывают от индексации через robots. txt.
txt.
Для реализации схемы понадобится набор инструментов:
- HTML-код.
- Файо robots.txt.
- Jquery.
- SEOhide.js.
- Файл BASE64.js
Сам код выглядит так.
- seoContent — переменная, в которую записывается html-код.
- seoHrefs — переменная, в которую записывают ссылки.
- de96dd3df7c0a4db1f8d5612546acdbb — идентификатор для замены.
- 0JHQu9C+0LMgU0VPINC80LDRgNC60LXRgtC+0LvQvtCz0LAgLSDQn9Cw0LLQu9CwINCc0LDQu9GM0YbQtdCy0LAu – html-код для идентификатора.
Содержание HTML:
В конце важно не забыть скрыть SEOhide.js в файле robots.txt
Запрет индексации страниц
Есть несколько вариантов, чтобы закрыть страницу от индексации:
- При помощи файла robots.txt.
- С использованием на нужной странице метатегов.
Совмещенный вариант:
- Запрет индексации через настройку ответа сервера. Например, «ErrorDocument 404 http://site.ru/404» — выдаст ошибку страницы. Если вписать код 410 — что страница удалена,
 Если вписать код 410 — что страница удалена,
Если вписать код 410 — что страница удалена,Данный способ не совсем «белый» и применяется только в крайних случаях
Запрет индексации изображений
Когда контент содержит не уникальные картинки, существует угроза негативной реакции со стороны поисковых систем. В данном случае код элемента будет выглядеть так:
Обработает элемент следующий скрипт:
Запрет индексации дублей
Существует 5 способов, как сделать невидимыми страницы с одинаковым контентом:
- Самый правильный способ — сразу удалить всю лишнюю информацию, чтобы остались только оригинальные источники. На остальные сервер будет отвечать ошибкой 404.
- При помощи файла robots.txt — самый простой способ.
- Метатеги для каждой дублирующей страницы.
- Сделать 301 редирект в файле .htaccess с дублей на оригиналы.
- Тег rel=»canonical» — второй по правильности способ. Во-первых, этот тег запрещает поисковикам индексировать дубли, во-вторых, он передаст вес на оригиналы с дублей.

Запрет индексации раздела
Вообще самый распространенный вариант — при помощи файла robots.txt. Но это не гарантирует 100% результата. В некоторых случаях поисковые системы игнорируют запреты. В robots.txt прописывают следующие строки:
Также можно применять способы, подходящие для запрета индексации страницы, но с единственной оговоркой, что они должны применяться для всех страниц раздела. Предпочтительнее использовать вариант с метатегами на страницах-дублях или настроить код ответа сервера для всех страниц в разделе.
Запрет индексации папки
В папке может находиться разная информация – текстовые документы, фотографии, графические изображения и другие файлы, которые нуждаются в закрытии от поисковиков. Здесь может помочь только файл robots.txt.
Запрет индексации ссылок
Может потребоваться, чтобы уменьшить вес конкретной страницы сайта или чтобы не передавать вес сторонним ресурсам. Для закрытия страницы от индексации необходимо создать файл с названием «transfers. js» и добавить в него следующие строки:
js» и добавить в него следующие строки:
Затем поместить данный файл в заранее созданную папку, и подключить скрипт в head на странице, где нужно скрыть ссылку от индексации:
Так выглядит ссылка, которую скрывают от индексации:
Запрет индексации сайта через robots.txt
В файле robots.txt прописываются следующие строки:
Если нужно закрыть только от Яндекса:
Если нужно закрыть только от Гугла:
Запрет индексации сайта через .htaccess
- Способ №1. Прописать в файле .htaccess следующие строки, каждая из которых отвечает за отдельную поисковую систему:
- Способ №2. В файле .htaccess прописать ответ сервера 403 (доступ к контенту запрещен) при обращении к какой-то конкретной странице.
- Способ №3. Прописать ответ сервера 410 (информация окончательно удалена).
- Способ №4. Запретить индексацию, предоставив доступ к сайту только при помощи пароля. для этого в файл .htaccess добавляют следующие строки:
После добавления этих строк авторизация появится на сайте, но для того, чтобы она работала, в файл пароля необходимо добавить пользователя.
Вместо Username нужно указать собственное значение — это имя пользователя для авторизации на сайте
Как закрыть от индексации страницу, сайт, ссылки, текст. Что нужно запрещать индексировать в robots.txt
Наш аналитик Александр Явтушенко недавно поделился со мной наблюдением, что у многих сайтов, которые приходят к нам на аудит, часто встречаются одни и те же ошибки. Причем эти ошибки не всегда можно назвать тривиальными – их допускают даже продвинутые веб-мастера. Так возникла идея написать серию статей с инструкциями по отслеживанию и исправлению подобных ошибок. Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Для хорошей индексации сайта и лучшего ранжирования страниц нужно, чтобы поисковик обходил ключевые продвигаемые страницы сайта, а на самих страницах мог точно выделить основной контент, не запутавшись в обилие служебной и вспомогательной информации.
У сайтов, приходящих к нам на анализ, встречаются ошибки двух типов:
1. При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
2. Наоборот, владельцы чересчур рьяно взялись за чистку сайта. Вместе с ненужной информацией могут прятаться и важные для продвижения и оценки страниц данные.
Сегодня мы хотим рассмотреть, что же действительно стоит прятать от поисковых роботов и как это лучше делать. Начнём с контента страниц.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
– скрываются от индексации фильтры, форма поиска, сортировка.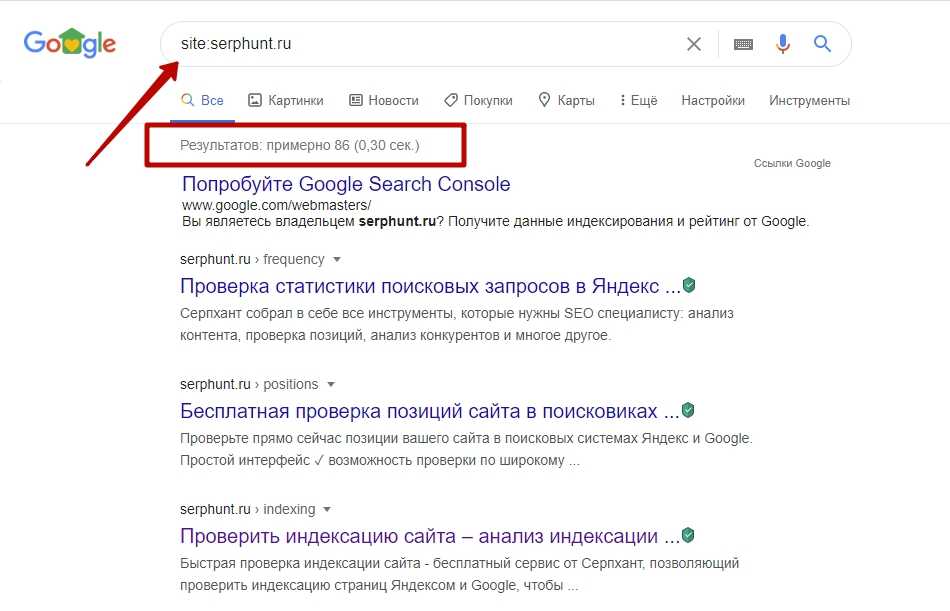 Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
– прячется информация об оплате и доставке. Это делают, чтобы повысить уникальность на товарных карточках. А ведь это тоже информация, которая должна быть на качественной товарной карточке.
– со страниц «вырезается» меню, ухудшая оценку удобства навигации по сайту.
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!
У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен. Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Это видно из самого описания тега в справке Яндекса.
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
«Не до конца понятна механика действия и влияние на ранжирование тега <noindex>текст</noindex>. Далее поясню, почему так озадачены. А сейчас — есть 2 гипотезы, хотелось бы найти истину.
№1 Noindex не влияет на ранжирование / релевантность страницы вообще
При этом предположении: единственное, что он делает — закрывает часть контента от появления в поисковой выдаче. При этом вся страница рассматривается целиком, включая закрытые блоки, релевантность и сопряженные параметры (уникальность; соответствие и т. п.) для нее вычисляется согласно всему имеющему в коде контенту, даже закрытому.
№2 Noindex влияет на ранжирование и релевантность, так как закрытый в тег контент не оценивается вообще. Соответственно, все наоборот. Страница будет ранжироваться в соответствии с открытым для роботов контентом.»

Ответ:
В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение.
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:
Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:
Рекомендации Google.
Рекомендации Яндекса.
Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.
Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.
Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.
Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно в блоге Siteclinic.
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Рекомендации Яндекса.
Рекомендации Google.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:
В Google Search Console «Удалить URL-адрес»:
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Тег noindex
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.
Он распространяется только на текст.
Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:
Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Заключение
Удаление со страницы объёмных сквозных блоков действительно может давать положительный эффект для ранжирования. Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Убирая со страницы часть контента, не забывайте, что для ранжирования важны не только текстовые критерии, но и полнота информации, коммерческие факторы.
Примерно аналогичная ситуация и с внутренними ссылками. Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Со страницами сайта всё более однозначно. Важно следить за тем, чтобы мусорные, малополезные страницы не попадали в индекс. Для этого есть много методов, которые мы собрали и описали в этой статье.
Вы всегда можете взять у нас консультацию по техническим аспектам оптимизации, или заказать продвижение под ключ, куда входит ежемесячный seo-аудит.
ОТПРАВИТЬ ЗАЯВКУ
Автор: Александр, SEO аналитик SiteClinic.ru
5 способов подготовиться к закрытию сайта
Вы планируете закрыть свой сайт на день или дольше? Согласно совету Джона Мюллера, эксперта Google по поиску, вот пять способов подготовиться.
Мюллер делится этим советом в твиттере, ссылаясь на соответствующие страницы справки Google.
Внимание, спойлер — нет хорошего способа временно закрыть сайт. Вам следует избегать этого, если это вообще возможно.
Однако есть вещи, которые вы можете сделать, чтобы свести негативное воздействие к минимуму.
Рекомендации Мюллера включают:
- Использовать код состояния HTTP 503
- Поддерживать HTTP 503 не более суток
- Изменить файл robots.txt, чтобы он возвращал код состояния 200
- Будьте готовы к последствиям, если сайт не работает более суток
- Ожидайте сокращения сканирования от Googlebot
Дополнительные сведения об этих рекомендациях и о том, как бороться с негативными последствиями перевода сайта в автономный режим, объясняются в следующих разделах.
1. Код состояния HTTP 503
При переводе веб-сайта в автономный режим убедитесь, что он передает поисковым роботам код состояния HTTP 503.
Когда поисковые роботы, такие как Googlebot, обнаруживают код состояния 503, они понимают, что сайт недоступен, и могут стать доступными позже.
С кодом 503 сканеры знают, что нужно снова проверить сайт, а не удалить его из поискового индекса Google.
Мюллер объясняет, как проверить код состояния 503 с помощью Chrome:
1. Они должны использовать HTTP 503 для «закрытых» страниц. Вы можете проверить это в Chrome, щелкнув правой кнопкой мыши: «Проверить», выберите «Сеть» вверху, затем обновите страницу. Проверьте верхнюю запись, она должна быть красной и показывать статус 503. pic.twitter.com/dkH7VE7OTb
— 🌽〈link href=//johnmu.com rel=canonical 〉🌽 (@JohnMu) 19 сентября 2022 г.
столкнувшись с 503, но он не будет возвращаться навсегда.
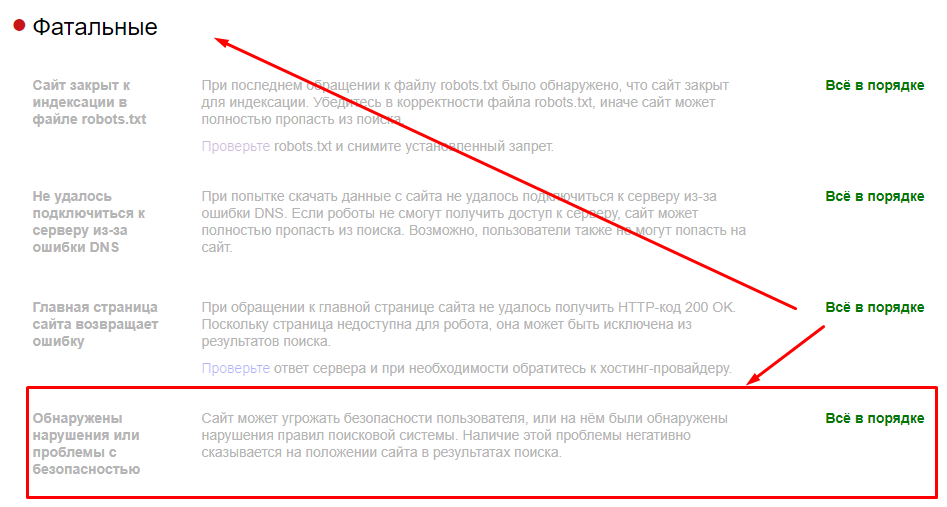
Если робот Googlebot видит код 503 день за днем, он в конечном итоге начнет удалять страницы из индекса.
Мюллер говорит, что в идеале вы должны хранить код состояния 503 не более суток.
«Сохранять статус 503 — в идеале — максимум сутки. Я знаю, не все ограничивается 1 днем. «Постоянный» 503 может привести к исключению страниц из поиска. Будьте экономны с 503 раза. Не беспокойтесь о настройке «повторить попытку после».
3. Robots.txt — 200 Код состояния
В то время как страницы закрытого веб-сайта должны возвращать код состояния 503, файл robots.txt должен возвращать код состояния 200 или 404.
Robots.txt не должен показывать ошибку 503, говорит Мюллер. Робот Google будет считать, что сканирование сайта полностью заблокировано.
Кроме того, Мюллер рекомендует использовать Chrome DevTools для проверки файла robots.txt вашего веб-сайта:
2.
— 🌽〈link href=//johnmu.com rel=canonical 〉🌽 (@JohnMu) 19 сентября 2022 г.
 Файл robots.txt должен возвращать либо 200 + правильный файл robots.txt, либо 404. Он должен *не* возвращать 503. Никогда не верьте, если на странице отображается «404», это все еще может быть 503 — проверьте это. pic.twitter.com/nxN2kCeyWm
Файл robots.txt должен возвращать либо 200 + правильный файл robots.txt, либо 404. Он должен *не* возвращать 503. Никогда не верьте, если на странице отображается «404», это все еще может быть 503 — проверьте это. pic.twitter.com/nxN2kCeyWmперевести сайт в автономный режим и избежать всех негативных последствий.
Если ваш веб-сайт будет отключен более суток, подготовьтесь соответствующим образом.
Мюллер говорит, что страницы, скорее всего, выпадут из результатов поиска независимо от кода состояния 503:
«Хм… Что, если сайт хочет закрыться более чем на 1 день? Независимо от того, какой вариант вы выберете (503, заблокировано, без индекса, 404, 403), будут негативные последствия — страницы, скорее всего, выпадут из результатов поиска».
Когда вы снова «откроете» свой веб-сайт, проверьте, индексируются ли важные страницы. Если нет, отправьте их на индексацию.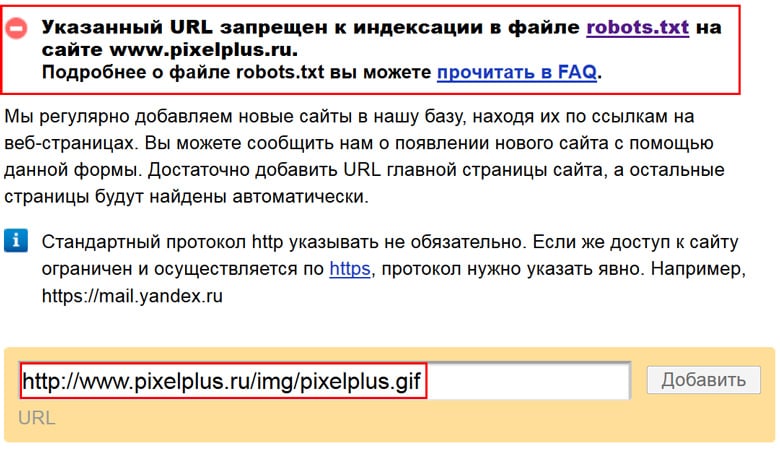
5. Ожидайте сокращения сканирования
Неизбежным побочным эффектом обслуживания кода 503 является сокращение сканирования, независимо от того, как долго оно длится.
Мюллер пишет в Твиттере:
«Побочным эффектом даже одного дня 503-х является то, что Googlebot (примечание: все это с объективом Google, я не знаю других поисковых систем) замедляет сканирование. Это маленький сайт? Это не имеет значения. Это гигант? Ключевое слово — «краулинговый бюджет».
Сокращение сканирования может повлиять на сайт несколькими способами. Главное, о чем следует помнить, это то, что для индексации новых страниц может потребоваться больше времени, а для отображения обновлений существующих страниц в результатах поиска может потребоваться больше времени.
Когда робот Googlebot обнаружит, что ваш сайт снова в сети и вы активно его обновляете, скорость сканирования, скорее всего, вернется к норме.
Источник : @JohnMu в Твиттере
Избранное изображение: BUNDITINAY/Shutterstock
Категория Новости SEO
Как не допустить, чтобы ваш промежуточный или разрабатываемый сайт попал в индекс
Как правило, вы не хотите, чтобы ваш промежуточный сайт появлялся в результатах поиска, так как же вы можете запретить Google индексировать этот контент? Обозреватель Патрик Стокс предлагает несколько советов.

Патрик Стокс 22 ноября 2017 г., 11:45 | Время чтения: 5 минут
Одной из наиболее распространенных технических проблем SEO, с которыми я сталкиваюсь, является непреднамеренная индексация серверов разработки, промежуточных сайтов, рабочих серверов или любых других названий, которые вы используете.
Это происходит по ряду причин: от людей, которые думают, что никто никогда не будет связываться с этими областями, до технических недоразумений. Эти части веб-сайта обычно носят конфиденциальный характер, и их включение в индекс поисковой системы может привести к раскрытию запланированных кампаний, бизнес-аналитики или личных данных.
Как определить, индексируется ли ваш сервер разработки
Вы можете использовать поиск Google, чтобы определить, индексируется ли ваш промежуточный сайт. Например, чтобы найти промежуточный сайт, вы можете выполнить поиск в Google по запросу site:domain.com и просмотреть результаты или добавить такие операторы, как -inurl:www, чтобы удалить все URL-адреса www. domain.com. Вы также можете использовать сторонние инструменты, такие как SimilarWeb или SEMrush, для поиска субдоменов.
domain.com. Вы также можете использовать сторонние инструменты, такие как SimilarWeb или SEMrush, для поиска субдоменов.
Могут быть и другие конфиденциальные области, содержащие порталы входа или информацию, не предназначенную для публичного использования. В дополнение к различным операторам поиска Google (также известным как Google Dorking), веб-сайты, как правило, блокируют эти области в своих файлах robots.txt, сообщая вам, где именно вам не следует искать. Что может быть не так, если вы сообщите людям, где найти информацию, которую вы не хотите, чтобы они видели?
Существует множество действий, которые можно предпринять, чтобы не допустить посетителей и поисковых систем к серверам разработки и другим конфиденциальным областям сайта. Вот варианты:
Хорошо: HTTP-аутентификация
Все, что вы хотите убрать из индекса, должно включать аутентификацию на стороне сервера. Требование аутентификации для доступа является предпочтительным методом защиты от пользователей и поисковых систем.
Хорошо: белый список IP-адресов
Разрешение только известных IP-адресов, например принадлежащих вашей сети, клиентов и т. д., — еще один важный шаг в обеспечении безопасности вашего веб-сайта и гарантии того, что только те пользователи, которым необходимо видеть область веб-сайта, будут видеть это.
Возможно: Noindex в robots.txt
Noindex в robots.txt официально не поддерживается, но может сработать для удаления страниц из индекса. Моя проблема с этим методом заключается в том, что он по-прежнему указывает людям, куда им не следует смотреть, и может не работать вечно или не со всеми поисковыми системами.
Причина, по которой я говорю «может быть», заключается в том, что это может работать и на самом деле может быть объединено с запретом в robots.txt, в отличие от некоторых других методов, которые не работают, если вы запрещаете сканирование (о чем я расскажу позже). в этой статье).
Возможно: Теги Noindex
Тег noindex либо в метатеге robots, либо X-Robots-Tag в заголовке HTTP может помочь предотвратить попадание ваших страниц в результаты поиска.
Одна проблема, которую я вижу в этом, заключается в том, что это означает, что поисковые системы будут сканировать больше страниц, что съедает ваш краулинговый бюджет. Я обычно вижу, что этот тег используется, когда в файле robots.txt также есть запрет. Если вы просите Google не сканировать страницу, они не смогут соблюдать тег noindex, потому что не видят его.
Еще одна распространенная проблема заключается в том, что эти теги могут быть применены к промежуточному сайту, а затем оставлены на странице, когда она будет запущена, эффективно удаляя эту страницу из индекса.
Возможно: Canonical
Если у вас есть канонический набор на промежуточном сервере, который указывает на ваш основной веб-сайт, практически все сигналы должны быть правильно объединены. В содержании могут быть несоответствия, которые могут вызвать некоторые проблемы, и, как и в случае с тегами noindex, Google придется сканировать дополнительные страницы. Веб-мастера также имеют тенденцию добавлять запрет в файл robots. txt, поэтому Google лишний раз не может просканировать страницу и не может соблюдать каноничность, потому что не может ее видеть.
txt, поэтому Google лишний раз не может просканировать страницу и не может соблюдать каноничность, потому что не может ее видеть.
Вы также рискуете, что эти теги не изменятся при переходе с рабочего сервера на рабочий, что может привести к тому, что тот, который вы не хотите показывать, будет канонической версией.
Плохо: Ничего не делать
Ничего не делать для предотвращения индексации промежуточных сайтов, как правило, потому, что кто-то предполагает, что никто никогда не будет ссылаться на эту область, поэтому ничего делать не нужно. Я также слышал, что Google просто «выяснит это», но обычно я не доверяю им свои проблемы с дублирующимся контентом. Не могли бы вы?
Плохо: Запретить в robots.txt
Вероятно, это самый распространенный способ, которым люди пытаются предотвратить индексацию промежуточного сайта. Директивой disallow в robots.txt вы говорите поисковым системам не сканировать страницу, но это не мешает им индексировать страницу. Они знают, что в этом месте существует страница, и все равно будут показывать ее в результатах поиска, даже не зная точно, что там находится. У них есть подсказки из ссылок, например, о типе информации на странице.
Они знают, что в этом месте существует страница, и все равно будут показывать ее в результатах поиска, даже не зная точно, что там находится. У них есть подсказки из ссылок, например, о типе информации на странице.
Когда Google индексирует заблокированную для сканирования страницу, в результатах поиска обычно отображается следующее сообщение: «Описание этого результата недоступно из-за файла robots.txt этого сайта».
Если вы помните, эта директива также запрещает Google видеть другие теги на странице, такие как теги noindex и canonical, потому что она вообще не позволяет им видеть что-либо на странице. Вы также рискуете не забыть удалить этот запрет при запуске веб-сайта, что может помешать сканированию при запуске.
Что делать, если вы случайно проиндексировали что-то?
Сканирование может занять некоторое время в зависимости от важности URL-адреса (вероятно, низкой в случае промежуточного сайта). Повторное сканирование URL-адреса может занять несколько месяцев, поэтому любая блокировка или проблема могут долго не обрабатываться.