
5 способов закрытия сайта от индексации поисковиков
Довольно часто возникает необходимость в запрете на включение ресурса в индекс поисковиков, например, когда он разрабатывается и есть риск индексирования информации, которую не хотелось бы разглашать, а также во многих других случаях. Рассмотрим, как закрыть свой сайт от индексации всеми доступными способами.
Закрытие сайта от индексации
Как закрыть сайт от индексации
Причины для запрета индексирования
Интернет-ресурсы скрывают от поисковых роботов в разных ситуациях, но чаще всего эта процедура проводится по одной из таких причин.
- При создании сайта. Допустим, вы на начальном этапе разработки и наполнения своей площадки контентом, меняете навигацию, интерфейс и других параметры. Как только начинается работа над сайтом, он и его наполнение еще не соответствуют всем вашим ожиданиям. Поэтому до окончательной доработки стоит скрыть свой ресурс от просмотра Google и «Яндексом», чтобы не индексировать неполноценные страницы.
 Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере.
Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере. - Когда веб-ресурс копируется. В некоторых случаях у разработчиков возникает необходимость в дублировании сайта, например, для тестирования на втором экземпляре доработок. И стоит сделать так, чтобы этот дубликат не индексировался. Иначе может пострадать оригинальный проект, и поисковики будут введены в заблуждение.
 Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере.
Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере.Способы закрытия индексации
Для решения этой задачи используются такие основные технологии:
- изменение настроек в WordPress;
- внесение команды в файл robots.txt;
- использование специального мета-тега;
- прописывание кода в настройках сервера;
- использование HTTP заголовка X-Robots-Tag.
1-й способ – Запрет на индексирование через WordPress
Для сайтов, созданных на базе этой системы, есть такой быстрый и несложный алгоритм действий для закрытия от роботов.
- В «Панели управления» находим пункт меню «Настройки».
- Заходим в раздел «Чтение».
- Здесь в пункте «Видимость для поисковых систем» ставим галочку возле надписи о рекомендации роботам не проводить индексацию.
- Сохраняем изменения.
В ответ на эти действия происходит автоматическое изменение файла robots.txt, корректируются правила, и таким образом отключается индексирование. При этом поисковая система оставляет за собой право решить, отключить робота или нет, даже несмотря на решение разработчика сайта. Опыт показывает, что от «Яндекса» можно не ждать таких решений, а Google иногда продолжает индексацию.
2-й способ – Изменение файла robots.txt
Если сайт построен не на WordPress, или невозможно закрыть доступ в этой системе по другим причинам, можно провести ручное удаление из поисковых систем. Сделать это также довольно просто. Создаем стандартный текстовый документ robots с расширением txt. Дальше вставляем его в корневую папку сайта, чтобы была возможность открывать его по адресу sait. com (ru, рф и т. п.)/robots.txt, где sait.com – url вашего ресурса. Файл пока пустой, и предстоит его заполнить необходимыми командами, при помощи которых можно полностью запретить доступ к сайту или закрыть только некоторые его участки. Есть несколько вариантов этой операции, каждый из которых мы рассмотрим дальше.
com (ru, рф и т. п.)/robots.txt, где sait.com – url вашего ресурса. Файл пока пустой, и предстоит его заполнить необходимыми командами, при помощи которых можно полностью запретить доступ к сайту или закрыть только некоторые его участки. Есть несколько вариантов этой операции, каждый из которых мы рассмотрим дальше.
Полное закрытие для всех поисковиков
С этой целью прописываем в роботс такие строки:
Usеr-аgеnt: *
Dіsаllоw: /
После сохранения файла robots.txt сайт будет полностью закрыт для индексации ботами всех поисковых систем, и они не смогут ни обрабатывать информацию, размещенную на вашем ресурсе, ни вносить ее в свою базу данных. Для проверки результата, как уже упоминалось, можно ввести в браузере такую строку: sait.com (адрес вашего сайта)/robots.txt. При правильном выполнении задачи на странице появится содержащаяся в файле информация. Если же появится ошибка 404, это в большинстве случаев говорит о том, что файл скопирован не туда.
Отключение индексации одной папки
В команде дополнительно указываем ее название:
Usеr-аgеnt: *
DіsаІІоw: /fоІdеr/
Этот способ позволяет полностью скрыть файлы, размещенные в определенной папке.
Блокировка индексирования «Яндексом»
В первой строке меняем «*» на название бота поисковика:
Usеr-аgеnt: Yаndех
DіsаІІоw: /
Убедиться в том, что сайт удален из индекса «Яндекса», можно путем его добавления в «Вебмастер». После этого нужно перейти в раздел «роботс» по адресу https://webmaster-yandex.ru/tools/robotstxt/. Ссылки на несколько документов сайта вставляем в поле для url и кликаем «Проверить». Подтверждением успешного запрета индексации является появление надписи «Запрещено правилом /*?*».
Закрытие сайта от бота Google
Принцип построения команды тот же. Только меняется название бота:
Usеr-аgеnt: GооgІеbоt
DіsаІІоw: /
При проверке используется тот же прием, что и для «Яндекса».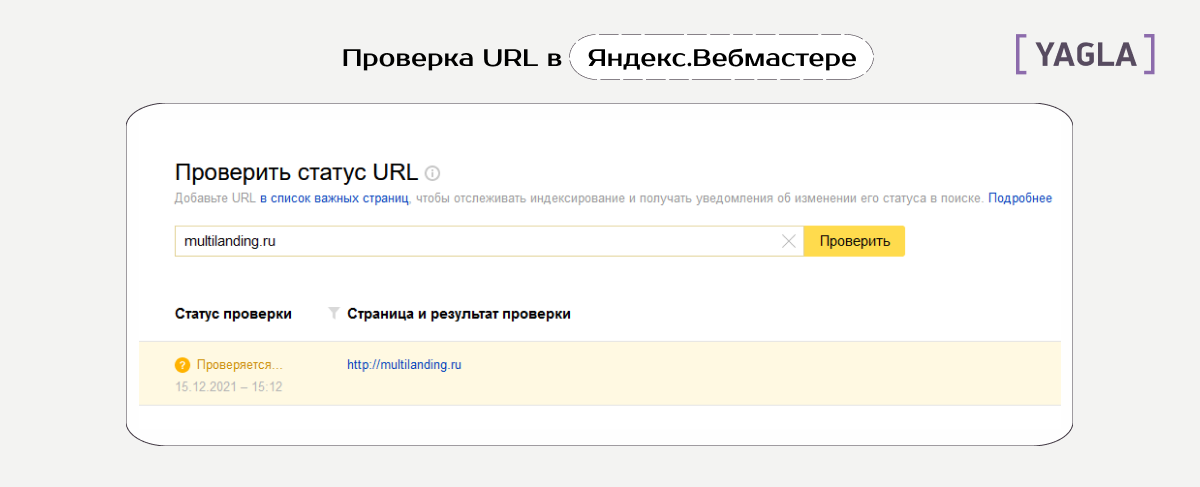 На панели инструментов Google Search Console должны появиться надпись «Заблокировано по строке» напротив соответствующей ссылки и команда, запрещающая ботам индексацию сайта. Но велика вероятность получить ответ «Разрешено», который говорит о вашей ошибке или о том, что поисковик разрешил индексацию страниц, для которых в robots прописан запрет. Как уже упоминалось выше, поисковые роботы воспринимают содержимое этого файла не как руководство к действию, а как набор рекомендаций, поэтому они оставляют за собой право решать, индексировать сайт или нет.
На панели инструментов Google Search Console должны появиться надпись «Заблокировано по строке» напротив соответствующей ссылки и команда, запрещающая ботам индексацию сайта. Но велика вероятность получить ответ «Разрешено», который говорит о вашей ошибке или о том, что поисковик разрешил индексацию страниц, для которых в robots прописан запрет. Как уже упоминалось выше, поисковые роботы воспринимают содержимое этого файла не как руководство к действию, а как набор рекомендаций, поэтому они оставляют за собой право решать, индексировать сайт или нет.
Запрет индексации другими поисковыми системами
У каждого поисковика свои боты с оригинальными именами, что позволяет веб-мастерам прописывать для них персональные команды в robots.txt. О «Яндексе» и Google мы уже писали. Вот еще три робота популярных поисковиков:
- МSNВоt – бот поисковой системы Віng;
- SputnіkВоt – «Спутника»;
- Slurр – Yаhоо.
Блокировка картинок
Для запрета индексации изображений в зависимости от их формата прописываются такие команды:
Usеr-Аgеnt: *
DіsаІІоw: *. jрg (*.gіf или *.рng)
jрg (*.gіf или *.рng)
Закрытие поддомена
В этом случае нужно учитывать один важный нюанс. У каждого поддомена свой файл robots.txt, находящийся, как правило, в его корневой папке. В нем нужно прописать стандартную команду блокировки:
Usеr-аgеnt: *
Dіsаllоw: /
При отсутствии такого документа его необходимо создать.
3-й способ – Использование специального мета-тега name=”robots”
Этот способ закрытия сайта или его отдельных элементов от поисковых роботов считается одним из лучших. Он заключается в прописывании с тегами <head> и </head> такого кода:
<mеtа nаmе=”rоbоts” соntеnt=”nоnе”/>
или такого:
<mеtа nаmе=”rоbоts” соntеnt=”nоіndех, nоfоІІоw”/>
Место размещения кода значения не имеет.
4-й способ – Прописывание кода в настройках сервера
Веб-мастера выбирают этот вариант запрета индексации, когда боты не реагируют на другие действия. Если такое происходит, для решения проблемы можно прописать в файле . Googlebot» search_bot
Googlebot» search_bot
Она заблокирует доступ для бота Google. Дальше нужно повторить операцию и прописать такие же строки для других поисковиков, но с названиями их ботов: Yаndех, msnbоt, MаіІ, Yаhоо, Rоbоt, Snарbоt, Раrsеr, WоrdРrеss, рhр, ВІоgPuІsеLіvе, bоt, Ароrt, іgdеSрydеr и sріdеr. Всего должно получиться 15 команд.
5-й способ – Использование X-Robots-Tag
В этом случае также настраивается блокировка через .htaccess, но при этом меняется заголовок НТТР X-Robots-Tag, который дает поисковикам указания, для понимания которых не нужно загружать сам документ. Такие инструкции авторитетнее, так как не нужно тратить ресурсы на изучение содержимого. Кроме того, этот метод подходит для любых видов контента.
Он используется с такими же директивами, как и Meta Robots: nоnе, nоіndех, nоаrсhіvе, nоfоІІоw и т. д. Есть два способа применения X-Robots-Tag. Первый – при помощи РНР, а второй – через настройку файла .htaccess.
Проверка индексирования сайта и отдельных страниц
Чтобы определить, индексируется сайт (страница, отдельный материал) в поисковике или нет, можно использовать один из таких четырех способов.
- Через панель инструментов «Вебмастера». Это самый популярный вариант. Находим в меню раздел индексирования сайта и проверяем, какие страницы попали в поиск.
- С использованием операторов поисковиков. Если указать команду «site: url сайта» в строке поиска Google или «Яндекса», можно определить, какое примерное количество страниц попало в индекс.
- При помощи расширений и плагинов. Можно провести автоматическую проверку индексирования через специальные приложения. Лидер по популярности среди таких плагинов – RDS bar.
- Посредством специальных сторонних сервисов. Они наглядно демонстрируют, что попало в индекс, а каких страниц там нет. Есть и платные, и бесплатные варианты таких инструментов.
Подведем итоги
Независимо от причины, по которой поисковым роботам закрывается доступ к ресурсу в целом, определенным страницам или материалам, можно использовать любой из описанных выше способов блокировки. Их несложно реализовать, и для этого не требуется большое количество времени. Вам вполне под силу самостоятельно скрыть от поисковых ботов определенную информацию, но следует помнить, что не каждый из методов дает 100-процентный результат.
Вам вполне под силу самостоятельно скрыть от поисковых ботов определенную информацию, но следует помнить, что не каждый из методов дает 100-процентный результат.
ЧИТАЙ ТАКЖЕ
Как за час вывести в топ статью на «Яндекс.Дзене»
301 редирект на URL без префикса WWW через файл .htaccess
Что такое 301-й редирект. Подробная инструкция по настройке
5 способов закрыть сайт от индексации в Google и Яндекс
Очень часто требуется закрыть сайт от индексации, например при его разработке, чтобы ненужная информация не попала в индекс поисковых систем или по другим причинам. При этом есть множество способов, как это можно сделать, все их мы и рассмотрим в этой статье.
Зачем сайт закрывают для индекса?
Какие есть способы запрета индексации сайта?
1. Закрытие индексации через WordPress
2. Посредством файла robots. txt
txt
Закрыть сайта полностью для всех поисковых систем
Отдельную папку
Только в Яндексе
Только для Google
Для других поисковиков
Скрыть изображения
Закрыть поддомен
3. С применением тега name=”robots”
4. В настройках сервера
5. С помощью HTTP заголовка X-Robots-Tag
Как проверить индексацию сайта и страниц?
Заключение
Зачем сайт закрывают для индекса?
Есть несколько причин, которые заставляют вебмастеров скрывать свои проекты от поисковых роботов. Зачастую к такой процедуре они прибегают в двух случаях:
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Не думайте, что если ваш ресурс только появился на свет и вы не отправили поисковикам ссылки для его индексации, то они его не заметят. Роботы помимо ссылок учитывают еще и ваши посещения через браузер.
- Иногда разработчикам требуется поставить вторую версию сайта, аналог основной на которой они тестируют доработки, эту версию с дубликатом сайта лучше тоже закрывать от индексации, чтобы она не смогла навредить основному проекту и не ввести поисковые системы в заблуждение.
 Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.Какие есть способы запрета индексации сайта?
- Панель инструментов в WordPress.
- Изменения в файле robots.txt.
- Посредством мета-тега name=“robots”
- Написание кода в настройках сервера.
1. Закрытие индексации через WordPress
Если сайт создан на базе WordPress, это ваш вариант. Скрыть проект от ботов таким образом проще и быстрее всего:
- Перейдите в «Панель управления».
- Затем в «Настройки».
- А после – в «Чтение».
- Отыщите меню «Видимость для поисковиков».
- Возле строки «Рекомендовать поисковым роботам не индексировать сайт» поставьте галочку.
- Сохраните изменения.

Благодаря встроенной функции, движок автоматически изменит robots.txt, откорректировав правила и отключив тем самым индексацию ресурса.
На заметку. Следует отметить, что окончательное решение, включать сайт в индекс или нет, остается за поисковиками, и ниже можно увидеть это предупреждение. Как показывает практика, с Яндексом проблем не возникает, а вот Google может продолжить индексировать документы.
2. Посредством файла robots.txt
Если у вас нет возможности проделать эту операцию в WordPress или у вас стоит другой движок сайта, удалить веб-сайт из поисковиков можно вручную. Это также реализуется несложно. Создайте обычный текстовый документ, разумеется, в формате txt, и назовите его robots.
Затем скиньте его в корневую папку своего портала, чтобы этот файл мог открываться по такому пути site. ru/robots.txt
ru/robots.txt
Но сейчас он у вас пустой, поэтому в нем потребуется прописать соответствующие команды, которые позволят закрыть сайт от индексации полностью или только определенные его элементы. Рассмотрим все варианты, которые вам могут пригодиться.
Закрыть сайта полностью для всех поисковых систем
Укажите в robots.txt команду:
User-agent: * Disallow: /
Это позволит запретить ботам всех поисковиков обрабатывать и вносить в базу данных всю информацию, находящуюся на вашем веб-ресурсе. Проверить документ robots.txt, как мы уже говорили, можно, введя в адресной строке браузера: Название__вашего_домена.ru/robots.txt. Если вы все сделали правильно, то увидите все, что указано в файле. Но если, перейдя по указанному адресу, вам выдаст ошибку 404, то, скорее всего, вы скинули файл не туда.
Отдельную папку
User-agent: * Disallow: /folder/
Так вы скроете все файлы, находящиеся в указанной папке.
Только в Яндексе
User-agent: Yandex Disallow: /
Чтобы перепроверить, получилось ли у вас удалить свой блог из Яндекса, добавьте его в Яндекс. Вебмастер, после чего зайдите в соответствующий раздел по ссылке https://webmaster.yandex.ru/tools/robotstxt/. В поле для проверки URL вставьте несколько ссылок на документы ресурса, и нажмите «Проверить». Если они скрыты от ботов, напротив них в результатах будет написано «Запрещено правилом /*?*».
Вебмастер, после чего зайдите в соответствующий раздел по ссылке https://webmaster.yandex.ru/tools/robotstxt/. В поле для проверки URL вставьте несколько ссылок на документы ресурса, и нажмите «Проверить». Если они скрыты от ботов, напротив них в результатах будет написано «Запрещено правилом /*?*».
Только для Google
User-agent: Googlebot Disallow: /
Проверить, получилось ли сделать запрет, или нет, можно аналогичным способом, что и для Яндекса, только вам нужно будет посетить панель вебмастера Google Search Console. Если документ закрыт от поисковика, то напротив ссылки будет написано «Заблокировано по строке», и вы увидите ту самую строку, которая дала команду ботам не индексировать его.
Для других поисковиков
Все поисковики имеют собственных ботов с уникальными именами, чтобы вебмастера могли прописывать их в robots.txt и задавать для них команды. Представляем вашему вниманию самые распространенные (кроме Яндекса и Google):
- Поисковик Yahoo. Имя робота – Slurp.
- Спутник. Имя робота – SputnikBot.
- Bing. Имя робота – MSNBot.
Список имен всех ботов вы с легкостью найдете в интернете.
Скрыть изображения
Чтобы поисковики не могли индексировать картинки, пропишите такие команды (будут зависеть от формата изображения):
User-Agent: * Disallow: *.png Disallow: *.jpg Disallow: *.gif
Закрыть поддомен
Любой поддомен содержит собственный robots.txt. Как правило, он находится в корневой для поддомена папке. Откройте документ, и непосредственно там укажите:
User-agent: * Disallow: /
Если такого текстового документа в папке поддомена нет, создайте его самостоятельно.
5. С помощью HTTP заголовка X-Robots-Tag
Это тоже своего рода настройка сервера с помощью файла .htaccess, но этот способ работает на уровне заголовков. Это один из самых авторитетных способов закрытия сайта от индексации, потому что он настраивается на уровне сервера.
Мы подробно расписали как этот способ настроить и использовать в нашей статье.
Как проверить индексацию сайта и страниц?
Если вы не знаете как это сделать, то мы расписали подробно, всевозможные способы в нашей статье — все способы проверки индексации сайта.
Заключение
Вне зависимости от того, по какой причине вы хотите закрыть сайт, отдельные его страницы или материалы от индексации, можете воспользоваться любым из перечисленных способов. Они простые в реализации, и на их настройку не потребуется много времени. Вы самостоятельно сможете скрыть нужную информацию от роботов, однако стоит учесть, что не все методы помогут на 100%.
5 способов подготовиться к закрытию сайта
Вы планируете закрыть свой сайт на день или дольше? Согласно совету Джона Мюллера, эксперта по поиску Google, вот пять способов подготовиться.
Мюллер делится этим советом в твиттере, ссылаясь на соответствующие страницы справки Google.
Внимание, спойлер — нет хорошего способа временно закрыть сайт. Вам следует избегать этого, если это вообще возможно.
Однако есть вещи, которые вы можете сделать, чтобы свести негативное воздействие к минимуму.
Рекомендации Мюллера включают:
- Использовать код состояния HTTP 503
- Поддерживать HTTP 503 не более суток
- Изменить файл robots.txt, чтобы он возвращал код состояния 200
- Будьте готовы к последствиям, если сайт не работает более суток
- Ожидайте сокращения сканирования от Googlebot
Дополнительные сведения об этих рекомендациях и о том, как бороться с негативными последствиями перевода сайта в автономный режим, объясняются в следующих разделах.
1. Код состояния HTTP 503
При переводе веб-сайта в автономный режим убедитесь, что он передает поисковым роботам код состояния HTTP 503.
Когда поисковые роботы, такие как Googlebot, обнаруживают код состояния 503, они понимают, что сайт недоступен, и могут стать доступными позже.
С кодом 503 сканеры знают, что нужно снова проверить сайт, а не удалить его из поискового индекса Google.
Мюллер объясняет, как проверить код состояния 503 с помощью Chrome:
1. Они должны использовать HTTP 503 для «закрытых» страниц. Вы можете проверить это в Chrome, щелкнув правой кнопкой мыши: «Проверить», выберите «Сеть» вверху, затем обновите страницу. Проверьте верхнюю запись, она должна быть красной и показывать статус 503. pic.twitter.com/dkH7VE7OTb
— 🌽〈link href=//johnmu.com rel=canonical 〉🌽 (@JohnMu) 19 сентября 2022 г.
столкнувшись с 503, но он не будет возвращаться навсегда.
Если робот Googlebot видит код 503 день за днем, он в конечном итоге начнет удалять страницы из индекса.
Мюллер говорит, что в идеале вы должны хранить код состояния 503 не более суток.
«Сохранять статус 503 — в идеале — максимум сутки. Я знаю, не все ограничивается 1 днем. «Постоянный» 503 может привести к исключению страниц из поиска. Будьте экономны с 503 раза. Не беспокойтесь о настройке «повторить попытку после».
3. Robots.txt — 200 Код состояния
В то время как страницы закрытого веб-сайта должны возвращать код состояния 503, файл robots.txt должен возвращать код состояния 200 или 404.
Robots.txt не должен показывать ошибку 503, говорит Мюллер. Робот Google будет считать, что сканирование сайта полностью заблокировано.
Кроме того, Мюллер рекомендует использовать Chrome DevTools для проверки файла robots.txt вашего веб-сайта:
2. Файл robots.txt должен возвращать либо 200 + правильный файл robots.txt, либо 404. Он должен *не* возвращать 503. Никогда не верьте, если на странице отображается «404», это все еще может быть 503 — проверьте Это.
pic.twitter.com/nxN2kCeyWm — 🌽〈link href=//johnmu.com rel=canonical 〉🌽 (@JohnMu) 19 сентября 2022 г.

перевести сайт в автономный режим и избежать всех негативных последствий.
Если ваш веб-сайт будет отключен более суток, подготовьтесь соответствующим образом.
Мюллер говорит, что страницы, скорее всего, выпадут из результатов поиска независимо от кода состояния 503:
«Хм… Что, если сайт хочет закрыться более чем на 1 день? Независимо от того, какой вариант вы выберете (503, заблокировано, без индекса, 404, 403), будут негативные последствия — страницы, скорее всего, выпадут из результатов поиска».
Когда вы снова «откроете» свой веб-сайт, проверьте, индексируются ли важные страницы. Если нет, отправьте их на индексацию.
5. Ожидайте сокращения сканирования
Неизбежным побочным эффектом обслуживания кода 503 является сокращение сканирования, независимо от того, как долго оно длится.
Мюллер пишет в Твиттере:
«Побочным эффектом даже одного дня 503-х является то, что Googlebot (примечание: все это с объективом Google, я не знаю других поисковых систем) замедляет сканирование. Это маленький сайт? Это не имеет значения. Это гигант? Ключевое слово — «краулинговый бюджет».
Сокращение сканирования может повлиять на сайт несколькими способами. Главное, о чем следует помнить, это то, что для индексации новых страниц может потребоваться больше времени, а для отображения обновлений существующих страниц в результатах поиска может потребоваться больше времени.
Как только робот Googlebot обнаружит, что ваш сайт снова в сети и вы активно его обновляете, скорость сканирования, скорее всего, вернется к норме.
Источник : @JohnMu в Твиттере
Избранное изображение: BUNDITINAY/Shutterstock
Категория Новости SEO
Закрытие районов выращивания в штате Мэн: инвентаризация районов выращивания моллюсков с юридическими уведомлениями и картами
- Рыболовство
- Коммерческая рыбалка
- Развлекательный
- Моллюски
- Закрытия
- Карта закрытия моллюсков и аренды аквакультуры
- Бюро программ общественного здравоохранения
- Информационные бюллетени программы общественного здравоохранения DMR
- Мэн DMR Vibrio Образование
- Идентификация моллюсков
- Напоминание о безопасном потреблении моллюсков
- Морское рыболовство
Контактная информация
- В обычные рабочие часы : Координатор программы по моллюскам, телефон: 207-633-9515
- Ночью/выходными/праздничными днями : Казармы государственной полиции свяжут вас с Морским патрулем:
- От границы Нью-Гэмпшира до Брансуика , казармы 1-800-228-0857
- От Cushing/Boothbay до Lincolnville/Belfast area , казармы 1-800-452-4664
- Из Белфаста до границы с Канадой , казармы 1-800-432-7381
См. внизу этой страницы предупреждения, заявление об отказе от ответственности и дату последнего обновления.
внизу этой страницы предупреждения, заявление об отказе от ответственности и дату последнего обновления.
По телефону горячей линии по борьбе с биотоксинами и моллюсками звоните по телефону 1-800-232-4733 или 207-624-7727.
Убедитесь, что настройки вашего интернет-браузера очищают кэшированные файлы при закрытии веб-сайтов, иначе вы не сможете просмотреть самую последнюю версию уведомления о закрытии. Удерживая нажатой клавишу Ctrl (Shift для Mac) при нажатии кнопки обновления/перезагрузки страницы в браузере, вы также обеспечите отображение самого последнего юридического уведомления.
| Имя | Описание | Дата |
|---|---|---|
| Условная область | Условные области WG(CA2-4), WI (CR3, CA1-CA2), WJ (CA1, CA6), WN (CA1, CA2), WS(CA1-CA2), WU (CA1-CA2), WV (CA1 ) и WZ (CA1) из-за более чем одного дюйма осадков за 24-часовой период. Зоны условного астрономического прилива WU (CA1-CA2) закрыты В 00:01 ЧАСА, 24 ноября 2022 г. | 12.11.2022 |
| Аварийное закрытие | Вступление В СИЛУ 00:01 ЧАСА 13 НОЯБРЯ 2022 ГОДА : Верхний залив Пенобскот к северу от Линкольнвилля и Кастина, Юнион-Ривер и Мачайспорт до Катлера. | 12.11.2022 |
| Затворы для аквакультуры | Закрытие отдельных участков аквакультуры в связи с эстафетной деятельностью | 22.10.2022 |
| Борьба с загрязнением | Область EF (R.3) и WU (CR.1) | 17.08.2022 |
| Морские гребешки | Зона № 1000 | 22.09.2022 |
| Плотоядные улитки | Зона № 1001 | 06. |
| Красное дерево/океанские куахоги | Граница ME/NH до мыса Скудик (Зимняя гавань) 164-A | 03.06.2016 |
| Красное дерево/океанские куахоги | Калф-Пойнт (Рок-Блаффс) и Грейт-Хед (Катлер) 164-B | 31.08.2022 |
| Консервационные крышки | Закрытие городского заповедника стр. | Н/Д |
 Зоны WG(CA2-CA4), WI (CR3, CA1-CA2), WJ (CA1, CA6), WN (CA1) и WV (CA1) ВНОВЬ ОТКРЫВАЮТСЯ В 00:01 ЧАСА 25 ноября 2022 г. Зоны WN (CA2) , WS (CA1-CA2), WU (CA1-CA2) и WZ (CA1) ВНОВЬ ОТКРЫВАЮТСЯ В 00:01 ЧАСОВ 20 ноября 2022 г.
Зоны WG(CA2-CA4), WI (CR3, CA1-CA2), WJ (CA1, CA6), WN (CA1) и WV (CA1) ВНОВЬ ОТКРЫВАЮТСЯ В 00:01 ЧАСА 25 ноября 2022 г. Зоны WN (CA2) , WS (CA1-CA2), WU (CA1-CA2) и WZ (CA1) ВНОВЬ ОТКРЫВАЮТСЯ В 00:01 ЧАСОВ 20 ноября 2022 г. 12.2017
12.2017- Некоторые зоны выращивания содержат условную классификацию площадей. Эти области открываются и закрываются в зависимости от различных условий, влияющих на уровень загрязнения, таких как очистные сооружения, очистные сооружения, пристани, осадки или время года. Вы также можете проверить горячую линию по телефону 1-800-232-4733 , чтобы узнать, открыта ли зона или закрыта. Имейте в виду, что лучшая информация поступает от вашего местного офицера морского патруля, местного инспектора по моллюскам или местного офиса морского патруля.
