
Как закрыть сайт от индексации в robots.txt — Сollaborator
В данной инструкции разберемся с 2 основными вопросами: зачем закрывать сайт от индексации и как это сделать с помощью файла robots.txt.
Зачем закрывать сайт или страницу от индексацииВ каких ещё ситуациях нужен запрет на индексацию:
1. Открытие сайта для пользователей, когда он еще не оптимизирован. После релиза сайта его страницы сканируются роботами при первом обходе. Однако если дизайн и контент страниц пока ещё не оптимизированы для продвижения, рекомендуется на время доработок закрыть
2. Тестирование сайта на другом домене. Если вы создали аналог основного сайта и проводите на нём тестовые работы, поисковые роботы могут воспринять страницы сайтов как дубликаты. В результате основной сайт может потерять позиции.
3. Смена дизайна, параметров, контента. На время работ по улучшению интерфейса и юзабилити закройте страницы сайта от индексации полностью или частично.
Запрет на сканирование — часто временное явление. После окончания технических работ вы сможете вернуть сайт в прежнее состояние. Такой шаг помогает сохранить позиции в выдаче.
Как закрыть сайт от индексации через robots.txtФайл robots.txt позволяет запретить индексацию страниц, разделов или всего сайта. Используйте директиву Disallow в качестве команды для поисковых роботов.
1. Если нужно закрыть весь сайт от всех роботов, пропишите в файле robots.txt:
User-agent: * Disallow: /
2. Если нужно закрыть сайт от Яндекс, пропишите в robots.txt:
User-agent: Yandex Disallow: /
Обратите внимание. Для обращения к конкретному роботу вместо «*» используйте его название.
3. Если требуется закрыть от индексации определённые разделы, укажите их после директивы Disallow. Для каждого типа контента используйте отдельную директиву.
Пример:
User-agent: * Disallow: /catalogs Disallow: /news
Если страница закрыта от индекса в robots.txt, но это не указано в панели вебмастеров, скорее всего, Google-бот продолжит индексировать эту страницу.
Для проверки в Яндекс.Вебмастер перейдите в раздел «Индексирование» → Проверить статус URL.
Если директива Disallow в robots.txt не помогает закрыть страницу от индексации, то нужно использовать другие методы.
При проведении технических работ желательно временно закрыть сайт от индексации. Так вы сможете работать над дизайном и юзабилити без ущерба для поисковой оптимизации.
Похожие вопросы
- Как настроить файл robots.txt: полное руководство
Ольга Горбенко
Практикующий SEO-специалист
Как закрыть индексацию сайта через robots, htaccess, метатеги
Пошаговая инструкция как закрыть сайт на wordpress (и другие) от индексации.
Приятного чтения!
Закажите создание сайта, или продвижение, или контекстную рекламу у нас
Есть несколько вариантов:
I. Через файл robots.txt;
II. Через файл .htaccess;
III. Через метатеги noindex, nofollow;
IV. Через панель администратора wordpress;
Закрываем индексацию сайта через файл robots.txt:1.1 Для начала проверим есть ли такой файл. Для этого зайдем на сервере в папку с файлами сайта, обычна она называется также как доменное имя:
1.2 Если такого файла нет:
1.2.1 На рабочем столе компьютера нажимаем правой кнопкой мыши, в выпавшем меню выбираем «Создать», далее выбираем «Текстовый документ»:
1.2.2 Новому файлу даем имя robots
Внимание! Не пишите «robots. Parser» search_bot
Order Allow,Deny
Allow from all
Deny from env=search_bot
Parser» search_bot
Order Allow,Deny
Allow from all
Deny from env=search_bot
Так как у меня сайт на CMS WordPress, то мой файл будет выглядеть вот так:
2.3 Сохраняем файл .htaccess и закачиваем его обратно в корневую папку сайта, замещая старый файл;
Запрещаем индексацию через метатеги noindex, nofollow
Для этого нужно знать, в каком из файлов лежит шаблон header для страниц вашего сайта. Ниже я опишу вариант для WordPress
3.1 Для вордпресса вы должны зайти на сервере по директории /ДОМЕННОЕ ИМЯ ВАШЕГО САЙТА/wp-content/themes/ВАША ТЕМА. Ниже приведен пример для сайта frez.by с используемой темой astra:
3.2 Находим файл «header.php»:
3.3 Скачиваем это файл себе на компьютер с сервера и открываем в текстовом редакторе. После чего находим тег «<head>», после которого сразу вставляет метагег:
<meta name="robots" content="noindex, nofollow">
3.4 Сохраняем файл и не забываем закачать обратно на сервер;
Как закрыть сайт от индексации wordpress через панель управления
4. 1 Заходим в административную панель сайта, в боков меню ищем раздел «Настроки» (4.1), далее выбираем подраздел «Чтение» (4.2), далее в низу страницы находим предложение «Попросить поисковые системы не индексировать сайт» и ставим галочку (4.3) и не забываем сохранить (4.4):
1 Заходим в административную панель сайта, в боков меню ищем раздел «Настроки» (4.1), далее выбираем подраздел «Чтение» (4.2), далее в низу страницы находим предложение «Попросить поисковые системы не индексировать сайт» и ставим галочку (4.3) и не забываем сохранить (4.4):
Все, готово!
Теперь вы знаете как закрыть сайт от индексации.
Надеюсь статья была вам полезна.
Если есть вопросы — задавайте в комментариях
Закажите создание сайта, или продвижение, или контекстную рекламу у нас
Похожие
- Как перенести сайт на OpenCart с локального сервера на хостинг
- Лучшие плагины фильтров товаров woocommerce
- Расширения браузера Google Chrome для Seo-анализа сайтов
6 распространенных проблем с файлом robots.
 txt и способы их устранения
txt и способы их устраненияRobots.txt — это полезный и относительно мощный инструмент для указания поисковым роботам того, как вы хотите, чтобы они сканировали ваш веб-сайт.
Он не всемогущ (по словам самого Google, «это не механизм для защиты веб-страницы от Google»), но он может помочь предотвратить перегрузку вашего сайта или сервера запросами сканера.
Если на вашем сайте установлена эта блокировка сканирования, вы должны быть уверены, что она используется правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этом руководстве мы рассмотрим некоторые из наиболее распространенных проблем с файлом robots.txt, их влияние на ваш веб-сайт и ваше присутствие в поиске, а также способы устранения этих проблем, если вы считаете, что они возникли.
Но сначала давайте кратко рассмотрим файл robots.txt и его альтернативы.
Что такое robots.
 txt?
txt?Robots.txt использует формат простого текстового файла и размещается в корневом каталоге вашего веб-сайта.
Он должен находиться в самом верхнем каталоге вашего сайта; если вы поместите его в подкаталог, поисковые системы просто проигнорируют его.
Несмотря на свои огромные возможности, robots.txt часто представляет собой относительно простой документ, и простой файл robots.txt можно создать за считанные секунды с помощью редактора, например Блокнота.
Существуют и другие способы достижения тех же целей, для которых обычно используется файл robots.txt.
Отдельные страницы могут включать метатег robots в самом коде страницы.
Вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы повлиять на то, как (и будет ли) отображаться контент в результатах поиска.
Что может robots.txt?
Robots.txt может дать различные результаты для различных типов содержимого:
Веб-страницы могут быть заблокированы от сканирования .
Они могут по-прежнему появляться в результатах поиска, но не будут иметь текстового описания. Содержимое страницы, отличное от HTML, также не будет сканироваться.
Можно заблокировать отображение медиафайлов в результатах поиска Google.
Сюда входят изображения, видео и аудиофайлы.
Если файл является общедоступным, он по-прежнему будет «существовать» в сети, и его можно будет просмотреть и связать с ним, но этот частный контент не будет отображаться в результатах поиска Google.
Файлы ресурсов, такие как неважные внешние скрипты, могут быть заблокированы .
Но это означает, что если Google просканирует страницу, для загрузки которой требуется этот ресурс, робот Googlebot «увидит» версию страницы, как если бы этот ресурс не существовал, что может повлиять на индексацию.
Вы не можете использовать robots.txt, чтобы полностью заблокировать появление веб-страницы в результатах поиска Google.
Чтобы добиться этого, вы должны использовать альтернативный метод, такой как добавление метатега noindex в заголовок страницы.
Насколько опасны ошибки robots.txt?
Ошибка в robots.txt может иметь непредвиденные последствия, но зачастую это не конец света.
Хорошая новость заключается в том, что, исправив файл robots.txt, вы сможете быстро и (как правило) полностью восстановиться после любых ошибок.
В руководстве Google для веб-разработчиков говорится об ошибках robots.txt:
«Веб-сканеры, как правило, очень гибкие и обычно не реагируют на незначительные ошибки в файле robots.txt. В общем, худшее, что может случиться, это то, что некорректные [или] неподдерживаемые директивы будут проигнорированы.
Имейте в виду, что Google не может читать мысли при интерпретации файла robots.txt; мы должны интерпретировать полученный нами файл robots.txt. Тем не менее, если вы знаете о проблемах в файле robots.txt, их обычно легко исправить».
6 Распространенные ошибки в файле robots.txt
- Robots.txt не находится в корневом каталоге.

- Неправильное использование подстановочных знаков.
- Нет индекса в файле robots.txt.
- Заблокированные скрипты и таблицы стилей.
- Нет URL-адреса карты сайта.
- Доступ к сайтам разработки.

Если ваш веб-сайт ведет себя странно в результатах поиска, ваш файл robots.txt — это хорошее место для поиска любых ошибок, синтаксических ошибок и превышения правил.
Давайте рассмотрим каждую из вышеперечисленных ошибок более подробно и посмотрим, как убедиться, что у вас есть действительный файл robots.txt.
1. Robots.txt не находится в корневом каталоге
Поисковые роботы могут обнаружить файл только в том случае, если он находится в корневом каталоге.
Вот почему между .com (или эквивалентным доменом) вашего веб-сайта и именем файла robots.txt в URL-адресе вашего файла robots.txt должна быть только косая черта.
Если там есть подпапка, ваш файл robots.txt, вероятно, не виден поисковым роботам, и ваш сайт, вероятно, ведет себя так, как будто файла robots. txt вообще нет.
txt вообще нет.
Чтобы решить эту проблему, переместите файл robots.txt в корневой каталог.
Стоит отметить, что для этого вам потребуется root-доступ к вашему серверу.
Некоторые системы управления контентом по умолчанию загружают файлы в подкаталог «media» (или что-то подобное), поэтому вам может потребоваться обойти это, чтобы получить файл robots.txt в нужном месте.
2. Неправильное использование подстановочных знаков
Robots.txt поддерживает два подстановочных знака:
- Звездочка * , который представляет любые экземпляры допустимого символа, например Джокера в колоде карт.
- Знак доллара $ , обозначающий конец URL-адреса, что позволяет применять правила только к последней части URL-адреса, например к расширению типа файла.
Разумно использовать минималистский подход к использованию подстановочных знаков, поскольку они могут налагать ограничения на гораздо более широкую часть вашего веб-сайта.
Также относительно легко заблокировать доступ роботов со всего вашего сайта с помощью неудачно расположенной звездочки.
Чтобы решить проблему с подстановочными знаками, вам нужно найти неправильный подстановочный знак и переместить или удалить его, чтобы файл robots.txt работал должным образом.
3. Noindex In Robots.txt
Это чаще встречается на веб-сайтах, которым больше нескольких лет.
Компания Google перестала соблюдать правила noindex в файлах robots.txt с 1 сентября 2019 г. результаты поиска.
Решение этой проблемы заключается в реализации альтернативного метода noindex.
Одним из вариантов является метатег robots, который можно добавить в заголовок любой веб-страницы, которую вы хотите предотвратить от индексации Google.
4. Заблокированные сценарии и таблицы стилей
Может показаться логичным заблокировать доступ сканера к внешним сценариям JavaScript и каскадным таблицам стилей (CSS).
Однако помните, что роботу Googlebot требуется доступ к файлам CSS и JS, чтобы правильно «видеть» ваши HTML- и PHP-страницы.
Если ваши страницы странно отображаются в результатах Google или кажется, что Google не видит их правильно, проверьте, не блокируете ли вы доступ сканера к необходимым внешним файлам.
Простое решение этой проблемы — удалить из файла robots.txt строку, блокирующую доступ.
Или, если у вас есть файлы, которые нужно заблокировать, вставьте исключение, которое восстанавливает доступ к необходимым CSS и JavaScript.
5. Нет URL карты сайта
Это больше касается SEO, чем что-либо еще.
Вы можете включить URL-адрес вашей карты сайта в файл robots.txt.
Поскольку это первое, на что обращает внимание робот Googlebot при сканировании вашего веб-сайта, это дает ему преимущество в знании структуры и основных страниц вашего сайта.
Хотя это не является строго ошибкой, так как отсутствие карты сайта не должно отрицательно влиять на фактическую основную функциональность и внешний вид вашего веб-сайта в результатах поиска, все же стоит добавить URL-адрес вашей карты сайта в robots.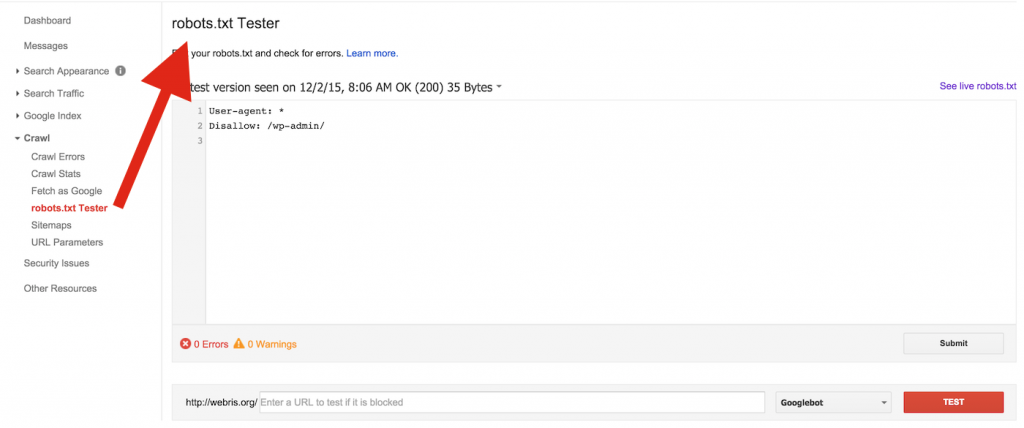 txt, если вы хотите дать свой SEO усилие.
txt, если вы хотите дать свой SEO усилие.
6. Доступ к сайтам разработки
Блокировать поисковые роботы на вашем действующем веб-сайте нельзя, как и разрешать им сканировать и индексировать ваши страницы, которые все еще находятся в стадии разработки.
Рекомендуется добавить инструкцию о запрете в файл robots.txt веб-сайта, находящегося в стадии разработки, чтобы широкая публика не увидела его, пока он не будет завершен.
Точно так же очень важно удалить команду запрета при запуске готового веб-сайта.
Забыть удалить эту строку из robots.txt — одна из самых распространенных ошибок среди веб-разработчиков, которая может помешать правильному сканированию и индексированию всего вашего веб-сайта.
Если кажется, что ваш сайт разработки получает реальный трафик или ваш недавно запущенный веб-сайт совсем не работает в поиске, найдите универсальное правило запрета пользовательского агента в файле robots.txt:
User-Agent : *
Disallow: /
Если вы видите это, когда не должны (или не видите, когда должны), внесите необходимые изменения в файл robots. txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
Как исправить ошибку robots.txt
Если ошибка в robots.txt оказывает нежелательное влияние на внешний вид вашего веб-сайта в результатах поиска, самым важным первым шагом является исправление файла robots.txt и проверка того, что новые правила имеют желаемое значение. эффект.
В этом могут помочь некоторые инструменты SEO-сканирования, поэтому вам не нужно ждать, пока поисковые системы снова просканируют ваш сайт.
Если вы уверены, что robots.txt ведет себя должным образом, вы можете попытаться повторно просканировать свой сайт как можно скорее.
Могут помочь такие платформы, как Google Search Console и Bing Webmaster Tools.
Отправьте обновленную карту сайта и запросите повторное сканирование любых страниц, которые были неправомерно удалены из списка.
К сожалению, вы попали в прихоть робота Google – нет никаких гарантий относительно того, сколько времени потребуется, чтобы отсутствующие страницы снова появились в поисковом индексе Google.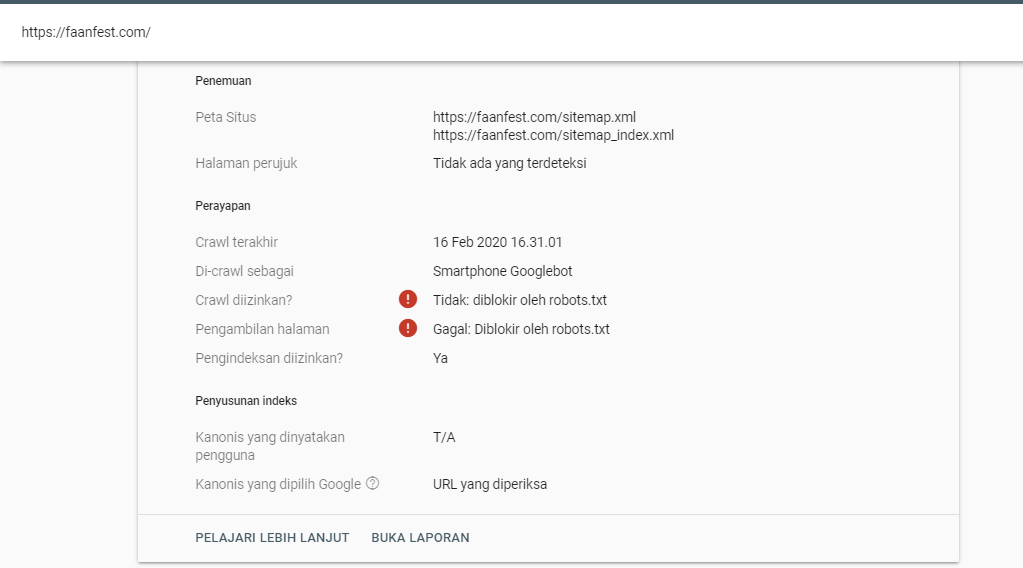
Все, что вы можете сделать, это предпринять правильные действия, чтобы максимально сократить это время, и продолжать проверять, пока робот Googlebot не внедрит исправленный файл robots.txt.
Заключительные мысли
Когда речь идет об ошибках robots.txt, их предотвращение определенно лучше, чем их устранение.
На крупном доходном веб-сайте случайный подстановочный знак, который удаляет весь ваш веб-сайт из Google, может немедленно повлиять на доход.
Изменения в robots.txt должны вноситься опытными разработчиками с осторожностью, дважды проверяться и, при необходимости, с учетом второго мнения.
Если возможно, протестируйте в редакторе песочницы перед запуском на реальный сервер, чтобы избежать непреднамеренного возникновения проблем с доступностью.
Помните, когда случается самое худшее, важно не паниковать.
Диагностируйте проблему, внесите необходимые исправления в файл robots.txt и повторно отправьте карту сайта для нового сканирования.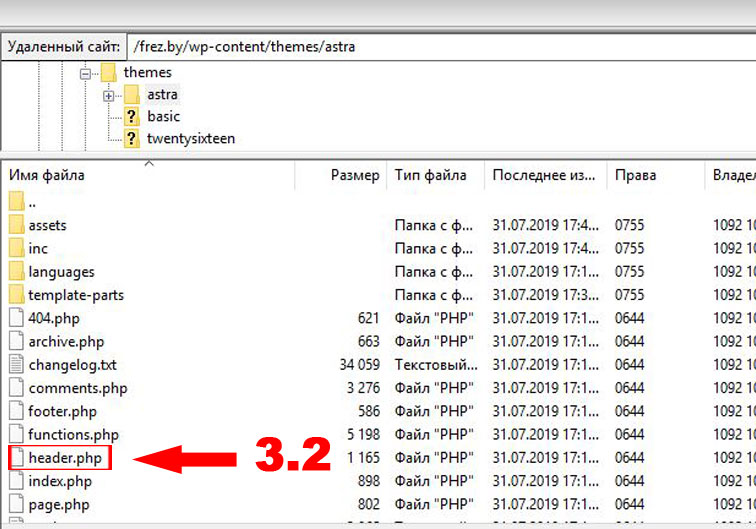
Мы надеемся, что ваше место в поисковом рейтинге будет восстановлено в течение нескольких дней.
Дополнительные ресурсы:
- Возникла ли у Google проблема с файлами Big Robots.txt?
- 7 предупреждений и ошибок инструмента сканирования SEO, которые вы можете безопасно игнорировать
- Продвинутое техническое SEO: полное руководство
Рекомендуемое изображение: M-SUR/Shutterstock
Категория SEO
Как запретить индексацию сайта или страниц?
Иногда необходимо, чтобы страницы сайта или размещенные на них ссылки не отображались в результатах поиска. Вы можете использовать файл robots.txt, HTML-разметку или авторизацию на сайте, чтобы скрыть содержимое сайта от индексации,
Если некоторые страницы или разделы сайта не должны индексироваться (например, те, которые содержат технические или конфиденциальные информации), для ограничения доступа к ним используйте следующие способы:
В файле robots.
txt укажите директиву Disallow.Укажите метатег robots директивой noindex или none в HTML-коде страниц сайта. Дополнительные сведения см. в разделе Метатег Robots и заголовок HTTP X-Robots-Tag.
Воспользоваться авторизацией на сайте. Мы рекомендуем этот метод, чтобы скрыть домашнюю страницу от индексации. Если главная страница запрещена в файле robots.txt или метатегом noindex, но есть ссылки, ведущие на нее, страница может быть включена в результаты поиска.
 txt укажите директиву Disallow.
txt укажите директиву Disallow.- Скрыть часть текста страницы от индексации
Добавить элемент noindex в HTML-код страницы. Примеры:
Элемент не чувствителен к вложенности — может располагаться в любом месте HTML-кода страницы. Если на странице нет закрывающего тега, все содержимое страницы считается скрытым. Не создавайте несколько вложенных тегов noindex, потому что разметка будет игнорировать все, что находится после первого закрывающего тега.
Вы можете использовать тег в следующем формате, если необходимо сделать код сайта действительным:
текст, который не должен индексироваться
Добавьте элемент noscript в HTML-код страницы. Примеры:
Элемент noscript, как и noindex, запрещает индексацию, но скрывает содержимое сайта от пользователя, если его браузер поддерживает JavaScript.
Примечание. JavaScript поддерживается всеми популярными браузерами, если эта функция специально не отключена пользователем.
Вы можете просмотреть отчет о поддержке JavaScript в Яндекс.Метрике.
- Скрыть ссылку на странице от индексации
Чтобы скрыть все ссылки на странице от индексации, в HTML-коде страницы укажите метатег robots с директивой nofollow. Робот не будет переходить по ссылкам при сканировании сайта, но может узнать о них из других источников.

