
Закрыть сайт от индексации: robots.txt, .htaccess – Seopapa
С понятием «индексация» сталкиваются все вебмастера. Чтобы сайт увидели поисковые системы, он должен попасть в базу данных. Для этого поисковые роботы просматривают содержимое страниц и передают данные в индекс. Ресурс проверяется по ряду параметров и определяется его место в выдаче. Но есть случаи, когда необходимо скрыть сайт от индексации.
Примеры, когда сайт нужно закрывать от индексации
Строгие алгоритмы краулеров не могут учитывать частные моменты. Факторы времени, обстоятельств, творческие противоречия, оригинальность замысла вебмастера. Запретить роботам прийти на страницы, когда вы не готовы, нельзя, а вот написать запрет на просмотр файлов можно. Вот причины, чтобы отключить индексацию сайта, отдельных страниц, блоков:
- Сайт в работе. Есть пустые страницы, меняется дизайн, ссылки не работают или отсутствуют. Вы не хотите, чтобы ваш проект люди увидели таким.
- Есть два варианта ресурса.
 Один основной, а дубликат – для тестирования нововведений. Краулеры такое совпадение посчитают плагиатом, что повлияет на ранжирование в поисковой выдаче.
Один основной, а дубликат – для тестирования нововведений. Краулеры такое совпадение посчитают плагиатом, что повлияет на ранжирование в поисковой выдаче. - Информация личная или служебная. Например, корзина клиента, его адрес, телефон. Может быть, секретные данные, которые нельзя делать общедоступными по закону или в целях безопасности.
- Есть информация, которую невозможно сделать уникальной: законы, инструкции, календари, цитаты и т.д.
 Один основной, а дубликат – для тестирования нововведений. Краулеры такое совпадение посчитают плагиатом, что повлияет на ранжирование в поисковой выдаче.
Один основной, а дубликат – для тестирования нововведений. Краулеры такое совпадение посчитают плагиатом, что повлияет на ранжирование в поисковой выдаче.Возможны другие причины закрыть сканирование роботами. Процесс смены домена или сайт только для друзей. Ссылки, оставляемые в комментариях, тоже не желательно индексировать.
Способы запрета индексирования сайта или страницы
Вариантов много. Попробуем их структурировать.
| Инструмент / Что нужно скрыть | Текстовый файл robots.txt | Метатег robots | В базовых настройках WordPress | Служебный файл .htaccess | При помощи javascript |
| Весь сайт | |||||
| Страницу | |||||
| Тип файлов | |||||
| Файл | |||||
| Текст | |||||
| Часть текста | |||||
| Ссылку |
Запрет индексирования сайта, раздела или страницы
Итак, есть необходимость не допустить роботов на сайт. Смотрим таблицу и выбираем подходящий способ. Выбор зависит от задачи и возможностей инструмента. Начнем со случая, когда цель не меньше страницы.
Смотрим таблицу и выбираем подходящий способ. Выбор зависит от задачи и возможностей инструмента. Начнем со случая, когда цель не меньше страницы.
Инструмент robots.txt
В программе блокнот создаем файл с названием robots и расширением .txt. Чтобы закрыть сайт от индексации с помощью robots.txt, вводим в этом файле обращение ко всем поисковым роботам User-agent: * и команду Disallow: /. Сохраняем и загружаем файл на сервер в корневую папку через файловый менеджер или админпанель. Этот простой алгоритм поможет запретить индексацию сайта целиком.
- User-agent: *
Disallow: /
Если надо закрыть доступ к сайту определенным поисковым системам, то в обращении вместо User-agent: * нужно поставить имя поисковых роботов данной системы. Например: User-agent: Yandex. И для каждого нежелательного поисковика делать свое обращение отдельной строкой.
Для скрытия раздела по этому алгоритму, после команды Disallow: / пишется razdel. Если нужно спрятать от роботов одну страницу, то после Disallow: / вставляем ее url-адрес.
Важно не увлекаться. Максимальное количество файлов robots.txt — 1024. Но большое количество запретов, приведет к их игнорированию.
Закрыть страницу и сайт с помощью метатега robots
Если у вас есть доступ к редактированию исходного кода, то мета-тег robots, прописанный в head перед <title> ,тоже может сообщить поисковикам о нежелательности индексации. В метатеге используют команды:
- noindex, скрывает главную страницу, или при дополнении, поможет не индексировать содержимое страницы. Она не появится в результатах поиска;
- nofollow – это для ссылок. Команда показывает роботу, что переходить по ним не надо. Но ссылки могут попасть в индексацию, если информация о них есть в других источниках;
- none – заменяет обе предыдущие команды вместе. То есть none = nofollow + noindex.
Запрет на индексацию сайта robots работает для страниц, текста, ссылок. Но если вам нужно закрыть сайт от индексации целиком, то лучше воспользоваться инструментом robots.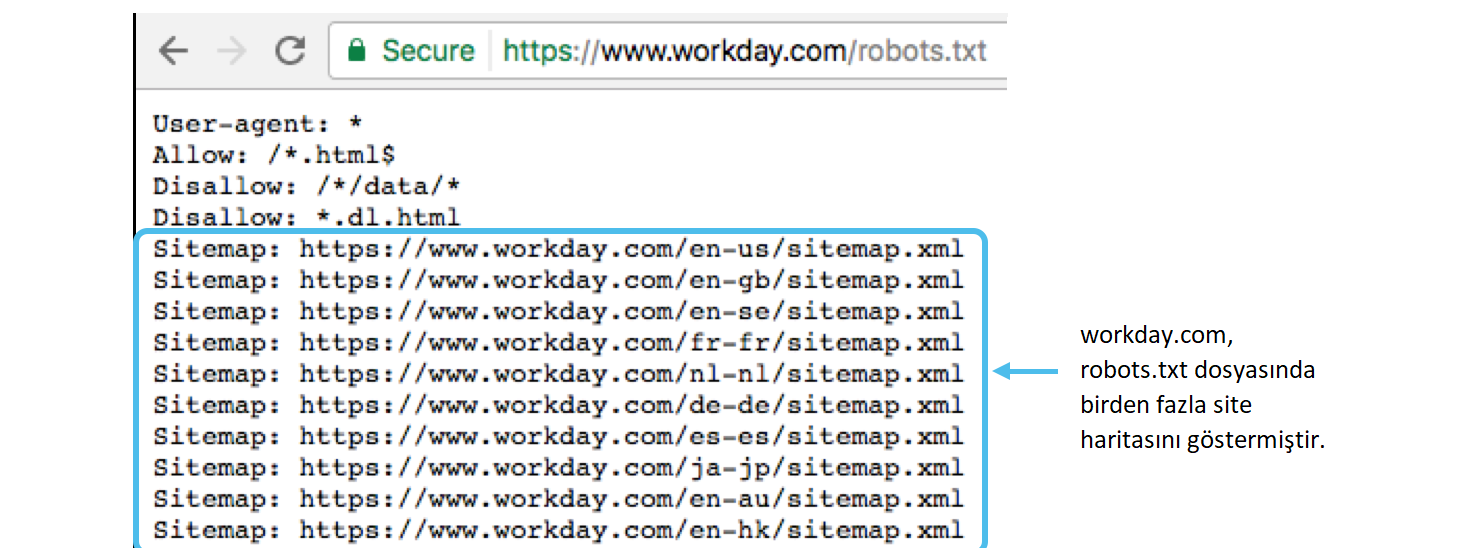
Второй вариант запрета индексации сайта htaccess – прописывается код доступа по паролю.
И еще можно в .htaccess сделать так, чтобы при обращении к странице поисковиком, появлялось уведомление об ошибке 403 или 410. 1ErrorDocument 404 http://site.ru/404
Запрет индексирования контента страницы
На страницах могут содержаться блоки, картинки, текст и другие элементы. Скрыть их помогут уже названные инструменты.
- Файл robots.txt с командой Disallow: /, после которой прописывается, что нужно скрыть.
- Мета-тег robots с исполнительными командами noindex, nofollow, none.
- На WordPress есть возможность скрыть элемент контента или страницу функцией редактора «Видимость». Последовательно нажимаем: «Изменить», «Защищено паролем», «Ок».
- Еще применяется технология SEO Hide с помощью языка JavaScript. Текст пишется на этом языке, а скрипт прячется через robots.txt .
Заключение
Возможностей для скрытия контента от поисковиков достаточно. Каждая из них имеет свои плюсы и особенности. Применяя любой способ, связанный с написанием кода, важно делать это внимательно. Допущенные ошибки могут дать результат обратный ожидаемому. Многие проблемы можно решить без запрета. Например, закрывать ли фильтры на сайте от индексации? Не обязательно – грамотные скрипты оставят на странице только один параметр, а остальные будут появляться по клику. К каждому вопросу оптимизации надо подойти индивидуально, особенно пока опыта еще нет.
Каждая из них имеет свои плюсы и особенности. Применяя любой способ, связанный с написанием кода, важно делать это внимательно. Допущенные ошибки могут дать результат обратный ожидаемому. Многие проблемы можно решить без запрета. Например, закрывать ли фильтры на сайте от индексации? Не обязательно – грамотные скрипты оставят на странице только один параметр, а остальные будут появляться по клику. К каждому вопросу оптимизации надо подойти индивидуально, особенно пока опыта еще нет.
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Запрет индексации сайта поисковыми системами.
20.08.2019
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots. txt
- Проверка корректности закрытия сайта от индексации
- Альтернативные способы закрыть сайт от поисковых систем
 txt
txtОглавление
- Процесс индексации
- Зачем закрывать сайт от индексации
- Закрываем сайт от индексации в robots.txt
- Инструкция по изменению файла robots.txt
- Проверка корректности закрытия сайта от индексации
- Альтернативные способы закрыть сайт от поисковых систем
- Заключение
Процесс индексации
Индексация сайта – это процесс добавления данных вашего ресурса в индексную базу поисковых систем. Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.
Если сайта нет в индексной базе поисковой системе = тогда сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров. Давайте выделим самые основные объективные причины, когда закрытие сайта от индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы находитесь в стадии разработки (или доработки) ресурса. В таком случае его лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.
 txt
txtОбращение к Вашему сайту поисковой системой начинается с прочтения содержимого файла robots.txt. Это служебный файл со специальными правилами для поисковых роботов.
Подробнее о директивах robots.txt:
- Вебмастер.Яндекс
- Справка.Google
Самый простой и быстрый способ это при первом обращении к вашему ресурсу со стороны поисковых систем (к файлу robots.txt) сообщить поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем
способам подключения к хостингу или серверу, укажем самый простой способ на наш
взгляд.
Файл robots.txt всегда находится в корне Вашего сайта. Например, robots.txt сайта agency.sape.ru будет находится по адресу:
https://agency.sape.ru/robots.txt
Для подключения к сайту, мы должны в административной панели нашего хостинг провайдера получить FTP (специальный протокол передачи файлов по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
Авторизуемся в панели управления вашим хостингом и\или сервером, находим раздел FTP и создаем ( получаем ) уникальную пару логин \ пароль.В описании раздела или в разделе помощь, необходимо найти и сохранить необходимую информацию для подключения по FTP к серверу, на котором размещены файлы Вашего сайта. Данные отражают информацию, которую нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно
воспользоваться бесплатной программой filezilla (https://filezilla.
После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt необходимо убедится в том, что все сделано верно. Для этого открываем файл robots.txt на вашем сайте.
Инструменты Sape AgencyВ арсенале команды Sape Agency есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
СамостоятельноОткрыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www. site.ru/robots.txt
site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.
Сервис Я.ВЕБМАСТЕРБесплатный сервис Я.ВЕБМАСТЕР – анализ robots.txt.
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.Альтернативные способы закрыть сайт от поисковых систем
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков.
- Вы можете отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не гарантирует 100% исключения сайта из индекса. Какое-то время робот может хранить копию Ваших страниц и отдавать именно их.
- С помощью специального meta тега: <meta name=”robots”>
<meta name=”robots” content=”noindex, nofollow”>
Но
так как метатег размещается и его действие относиться только к 1 странице, то
для полного закрытия сайта от индексации Вам придется разместить такой тег на
каждой странице Вашего сайта.
Недостатком этого может быть несовершенство поисковых систем и проблемы с индексацией ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться много времени, иногда несколько месяцев, часть страниц будет присутствовать в поиске.
- Использование технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет увидеть контент сайта. При этом по названию сайта или по открытой части в индексе поисковиков может что-то хранится. Более того, уже завра новое обновление поисковых роботов может научится индексировать такой контент.
- Скрыть все данные Вашего сайта за регистрационной формой. При этом стартовая страница в любом случае будет доступна поисковым роботам.
Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
«robots. txt» это служебный файл со специальными правилами для поисковых роботов.
txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
поисковый робот — запретить роботам индексировать субдомен с ограниченным доступом
спросил
Изменено 7 лет, 3 месяца назад
Просмотрено 927 раз
У меня есть настройка поддомена, для которой я возвращаю 403 для всех IP-адресов, кроме одного. Я также хочу, чтобы сайт не индексировался поисковыми системами, поэтому я добавил robots.txt в корень своего поддомена.
Я также хочу, чтобы сайт не индексировался поисковыми системами, поэтому я добавил robots.txt в корень своего поддомена.
Однако, поскольку я возвращаю ошибку 403 при каждом запросе к этому поддомену, поисковый робот также получит ошибку 403 при запросе файла robots.txt.
По данным Google, если robots.txt возвращает ошибку 403, он все равно попытается просканировать сайт.
Есть ли что-нибудь вокруг этого? Рад услышать ваши мысли.
- индексирование
- поисковый робот
- поддомен
- http-status-code-403
- robots.txt
С robots.txt вы можете запретить сканирует , а не индексирует .
Вы можете запретить индексирование (но не сканирование) с помощью HTML meta — robots или соответствующего HTTP-заголовка X-Robots-Tag .
Итак, у вас есть три варианта:
Белый список
/robots.txt, чтобы он ответил 200. Соответствующие боты не будут сканировать что-либо на вашем хосте (кроме robots.txt), но они могут индексировать URL-адреса, если они их каким-то образом находят (например, если они связаны с другого сайта).Агент пользователя: * Запретить: /
Добавьте элемент
meta—robotsна каждую страницу. Соответствующие боты могут сканировать, но не индексировать. Но это работает только для документов HTML.Отправьте заголовок
X-Robots-Tagдля каждого документа. Соответствующие боты могут сканировать, но не индексировать.X-Robots-Tag: noindex
 Соответствующие боты не будут сканировать что-либо на вашем хосте (кроме robots.txt), но они могут индексировать URL-адреса, если они их каким-то образом находят (например, если они связаны с другого сайта).
Соответствующие боты не будут сканировать что-либо на вашем хосте (кроме robots.txt), но они могут индексировать URL-адреса, если они их каким-то образом находят (например, если они связаны с другого сайта).(Отправка 403 для каждого запроса сама по себе может быть сильным сигналом о том, что там нет ничего интересного, но что с этим делать, конечно, зависит от бота.)
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Теги роботов: секрет правильного индексирования вашего контента Google
Итак, теги роботов на самом деле не секрет… но их часто упускают из виду или, что еще хуже, неправильно используют. В январе Google выпустил новый тег «Роботы», специально для производителей медиа, , поэтому, если в вашем служении есть подкаст, аудиопроповеди и т. д., вы можете присмотреться к нему поближе. Учитывая, что есть новый тег, мы потратим несколько минут, чтобы дать вам краткое изложение, а также несколько других простых способов использования тегов robots и устранения неполадок.
В январе Google выпустил новый тег «Роботы», специально для производителей медиа, , поэтому, если в вашем служении есть подкаст, аудиопроповеди и т. д., вы можете присмотреться к нему поближе. Учитывая, что есть новый тег, мы потратим несколько минут, чтобы дать вам краткое изложение, а также несколько других простых способов использования тегов robots и устранения неполадок.
Давайте начнем с того, что нового, в конце концов, кто не любит новые блестящие ярлыки роботов. Новый тег «indexifembedded», да, это точно. Это немного более читабельно как «индексировать, если он встроен», и он делает именно то, что звучит. Это позволяет Google сканировать и индексировать контент в iframe, встроенный в другой контент.
Где это может пригодиться.
Одна довольно распространенная проблема, с которой производители медиа сталкиваются с точки зрения SEO, заключается в том, что медиаконтент часто размещается в одном месте, а затем встраивается в другое место.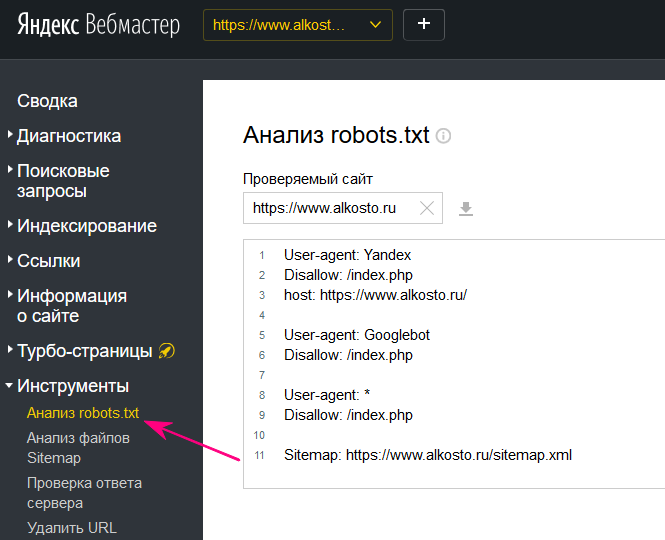 Именно так работает большинство хостингов подкастов (когда вы добавляете эпизод на свою страницу с помощью кода для встраивания, это, скорее всего, делается через iframe). Раньше у вас было два варианта при этом: первый вариант — не индексировать исходный контент, а затем он также не будет индексироваться при встраивании в страницу, или сделать его индексируемым и надеяться, что это не вызовет проблем с дублированием контента (поскольку Google индексировать как исходный контент, так и страницу, в которую он встроен).
Именно так работает большинство хостингов подкастов (когда вы добавляете эпизод на свою страницу с помощью кода для встраивания, это, скорее всего, делается через iframe). Раньше у вас было два варианта при этом: первый вариант — не индексировать исходный контент, а затем он также не будет индексироваться при встраивании в страницу, или сделать его индексируемым и надеяться, что это не вызовет проблем с дублированием контента (поскольку Google индексировать как исходный контент, так и страницу, в которую он встроен).
Как правило, когда вы встраиваете медиафайлы на определенную страницу, это происходит потому, что эта страница предлагает более богатые возможности для ваших пользователей, поэтому вы хотите, чтобы эта страница была проиндексирована и показана вашим пользователям, и поскольку нам нравится иметь все это, вы хотите, чтобы ваш медиаконтент также был проиндексирован на этой странице.
С помощью тега indexifembedded вы можете заблокировать индексацию исходного источника с помощью тега noindex, а затем разрешить его индексацию при встраивании в страницу. Google описывает несколько различных способов реализации этого здесь, , но проще всего добавить к метатегам исходного контента следующее:
Google описывает несколько различных способов реализации этого здесь, , но проще всего добавить к метатегам исходного контента следующее:
пока не так много данных о том, насколько хорошо это работает или есть ли какие-либо «подводные камни» при его реализации. Если вы решите внедрить этот тег, сообщите нам, мы будем рады увидеть, как он работает для вас.
Даже если вы не готовы попробовать это, ниже приведены несколько быстрых советов о тегах роботов и о том, как они вызывают проблемы.
1. Блокировка вашего сайта для разработки или промежуточной версии , после чего вы забыли снять блокировку при публикации сайта в рабочей среде. Мы знаем, что это звучит глупо, но это происходит чаще, чем вы думаете. Если вы недавно внесли изменения в свой веб-сайт и увидели, что ваш трафик увеличился, это первое место, на которое вы должны обратить внимание.
2. Страницы, заблокированные robots.txt, индексируются. Это довольно сложная проблема, которая делает ее одной из самых распространенных. Страница может быть заблокирована Google либо через файл robots.txt, либо с помощью метатега noindex, который мы продемонстрировали выше. Однако, когда вы блокируете страницу с помощью файла robots.txt, это только останавливает Google от индексации страницы с помощью средств, которые он может найти на вашем веб-сайте. Однако, если внешний источник ссылается на эту страницу, Google добавит URL-адрес в свой индекс, но не добавит содержимое страницы. Вы увидите это предупреждение в Search Console. Если вы хотите, чтобы URL-адрес не отображался в поисковом индексе, единственный способ сделать это в настоящее время — заблокировать его с помощью метатега.
Страницы, заблокированные robots.txt, индексируются. Это довольно сложная проблема, которая делает ее одной из самых распространенных. Страница может быть заблокирована Google либо через файл robots.txt, либо с помощью метатега noindex, который мы продемонстрировали выше. Однако, когда вы блокируете страницу с помощью файла robots.txt, это только останавливает Google от индексации страницы с помощью средств, которые он может найти на вашем веб-сайте. Однако, если внешний источник ссылается на эту страницу, Google добавит URL-адрес в свой индекс, но не добавит содержимое страницы. Вы увидите это предупреждение в Search Console. Если вы хотите, чтобы URL-адрес не отображался в поисковом индексе, единственный способ сделать это в настоящее время — заблокировать его с помощью метатега.
3. Добавление заблокированных страниц в вашу карту сайта. Мы всегда рекомендуем иметь очень чистую карту сайта. Google решает, как они хотят находить ваш контент и индексировать ваши страницы.