
Как запретить индексирование сайта или страниц
Иногда нужно, чтобы страницы сайта или размещенные на них ссылки не появлялись в результатах поиска. Скрыть содержимое сайта от индексирования можно с помощью файла robots.txt, HTML-разметки или авторизации на сайте.
- Запретить индексирование сайта, раздела или страницы
- Запретить индексирование части текста страницы
- Скрыть от индексирования ссылку на странице
Если какие-то страницы или разделы сайта не должны индексироваться (например, со служебной или конфиденциальной информацией), ограничьте доступ к ним следующими способами:
В файле robots.txt укажите директиву Disallow.
В HTML-коде страниц сайта укажите метатег robots с директивой noindex или none. Подробнее см. в разделе Метатег robots и HTTP-заголовок X-Robots-Tag.
Используйте авторизацию на сайте. Рекомендуем этот способ, чтобы скрыть от индексирования главную страницу сайта. Если главная страница запрещена в файле robots.


Скрыть от индексирования часть текста можно несколькими способами:
В HTML-код страницы добавьте элемент noindex. Например:
<noindex>текст, индексирование которого нужно запретить</noindex>
Элемент не чувствителен к вложенности — может находиться в любом месте HTML-кода страницы. Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.
При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex-->
В HTML-код страницы добавьте элемент noscript. Например:
<noscript>текст, индексирование которого нужно запретить</noscript>
Элемент noscript, как и noindex, запрещает индексирование, но при этом скрывает содержимое сайта от пользователя, если его браузер поддерживает технологию JavaScript.
Примечание. JavaScript поддерживают все популярные браузеры, если эта функция не отключена пользователем специально.
Посмотреть отчет о наличии JavaScript можно в Яндекс Метрике .

Рекомендуем использовать атрибут rel. Разные значения атрибута указывают на тип ссылки, что помогает поисковой системе лучше распознавать содержимое сайта.
rel=»ugc». Используйте, если на вашем сайте есть форум или возможность оставить отзыв и вы не уверены в качестве ссылок, которые оставляют посетители.
rel=»sponsored». Используйте, если ссылка носит рекламный характер, указывает на рекламное место или размещение в рамках партнерской программы с другим сайтом.
rel=»nofollow». Указывайте, чтобы робот не проходил по ссылке, не зависимо от ее типа.
Можно комбинировать несколько значений. Пример:
<a href="url" rel="nofollow,sponsored">текст ссылки</a> или <a href="url" rel="nofollow sponsored">текст ссылки</a>
Значения атрибута rel воспринимаются роботом как рекомендация не принимать ссылку во внимание.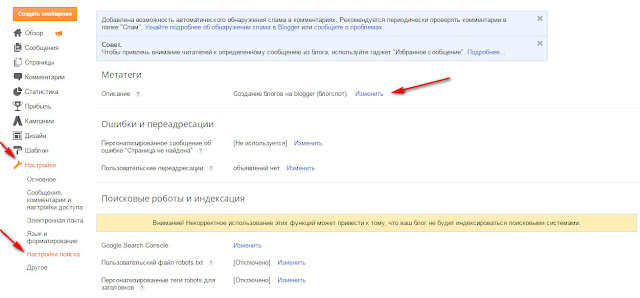
Чтобы скрыть от индексирования все ссылки на странице, укажите в HTML-коде страницы метатег robots с директивой nofollow. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.
При использовании любого из перечисленных указаний ссылка может быть обработана роботом и отобразиться в Вебмастере как внутренняя или внешняя. Само отображение или отсутствие ссылки в Вебмастере не указывает на то, что поисковые алгоритмы учитывают ее.
Как закрыть страницу сайта, поддомен, фильтр или текст от индексации в Яндекс и Google с помощью файла robots.txt или meta-тега
Январь 31, 2018
Основы SEO Инструкции к Labrika Алгоритмы
Что такое индексация?
Индексация — это процесс анализа страниц сайта поисковыми системами и внесение информации о них в Базу Данных (индекс) для последующего использования ее в ранжировании web-ресурсов и формирования поисковой выдачи.
Зачем нужны запреты от индексации?
Как правило, от поисковых систем закрывают информацию, которая не должна отображаться в поисковой выдаче — это разного рода техническая, служебная и конфиденциальная информация, страницы с непригодным для продвижения контентом. Чаще всего оптимизаторы запрещают для индекса дубли страниц, корзину, результаты поиска на сайте, личный кабинет пользователя.
Методы блокировок от индексации
На эту тему существует подробная инструкция от Google. Выделим два основных метода запрета индексации страницы:
С помощью robots.txt
Robots.txt — это специальный текстовый файл, в котором содержатся рекомендации для поисковых систем о том, какие страницы можно индексировать, а какие не следует. Яндекс.Помощь дает подробное разъяснение по использованию файла
robots.txt, почитать которое можно здесь.Чтобы заблокировать страницу от индексации поисковых систем в
robots.txt, необходимо воспользоваться директивой Disallow.При помощи тега <meta> robots с атрибутом noindex.
О правилах употребления noindex вы можете прочитать в нашей статье Страницы с тегом <noindex>. Чтобы заблокировать страницу с помощью этого атрибута, необходимо добавить в раздел страницы
<head>следующие строчки:<meta name="robots" content="noindex">— страница будет заблокирована для большинства поисковых роботовТакже можно закрыть страницу от какой-либо конкретной поисковой системы, например:
<meta name="googlebot" content="noindex">
Как обнаружить на сайте заблокированные от индексации страницы?
Иметь информацию о таких страницах необходимо хотя бы потому, что некоторые из них могут быть закрыты случайно, например, из-за ошибки при употреблении директив в robots.txt. К тому же, ссылаться на заблокированные URL не рекомендуется, потому что это нарушает передачу статического веса страниц.
На странице отчета вы можете увидеть следующую информацию:
- Кнопка для обновления данных по сайту. При ее нажатии вы сможете получить свежий SEO-анализ по всем важным параметрам, в том числе — по блокировкам от индексации.
- На этой вкладке содержатся данные обо всех страницах, которые закрыты от индексации.
- Данные исключительно об ошибках в блокировках:
- URL страницы, которая закрыта от индексации.
- Информация о директиве в
robots.txt, если страница заблокирована этим способом. В данном случае, заблокированы все страницы, которые содержат в URL знак «?». - В случае, если блокировка прописана МЕТА-тегом robots, тут будут указываться данные о его содержимом.
Читать дальше подобные статьи
- Тег noindex: запрещенные к индексированию страницы
- Файл robots. txt для WordPress, Modx. Как не закрыть сайт от индексации?
- Исправляем ошибки и правильно настраиваем файл robots.txt
- Ошибки в файле карты сайта sitemap.xml
 txt для WordPress, Modx. Как не закрыть сайт от индексации?
txt для WordPress, Modx. Как не закрыть сайт от индексации?Online SEO-инструменты для продвижения сайтов
Проверьте свой сайт и сайты конкурентов на 205 факторов поисковых систем.
Как закрывать страницы от indexind и когда это нужно
5081
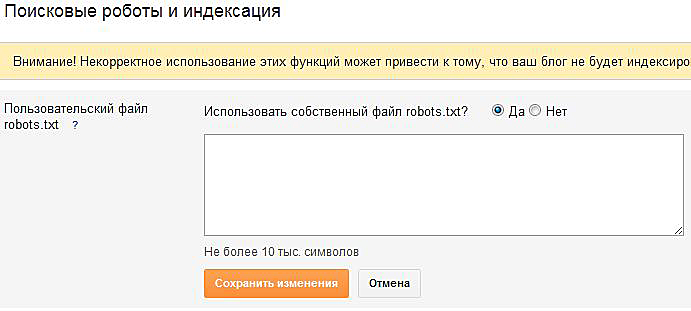
| How-to | – 9 мин чтения и соответствующие страницы должны быть открыты для поискового сканирования. Однако бывают случаи, когда индексация страницы нежелательна и может снизить эффект от оптимизации. Причины закрытия страниц от индексации Владелец сайта желает, чтобы потенциальный клиент нашел его веб-ресурс в результатах поиска, а поисковая система, в свою очередь, готова предоставить пользователю ценную и актуальную информацию. Рассмотрим причины, по которым следует убрать индексацию сайта или отдельных страниц: Контент не несет смысловой нагрузки для поисковой системы и пользователей или вводит их в заблуждение Такой контент может включать технические и административные сайты страницы, а также информацию о личных данных. Кроме того, некоторые страницы могут создавать иллюзию дублирования контента, что является нарушением и может привести к штрафным санкциям на всем ресурсе. Нерациональное использование краулингового бюджета Краулинговый бюджет — это определенное количество страниц сайта, которое может просканировать поисковая система. Мы заинтересованы в том, чтобы тратить ресурсы сервера только на ценные и качественные страницы. Чтобы быстро и эффективно проиндексировать важный контент ресурса, нужно закрыть ненужный контент от сканирования. Какие страницы нужно убрать из индексации Страницы сайта в разработке Если проект еще в разработке, лучше закрыть сайт от поисковых систем. Рекомендуется разрешить доступ для обхода полных и оптимизированных страниц, которые рекомендуется отображать в результатах поиска. При разработке сайта на тестовом сервере следует ограничить доступ к нему с помощью файла robots.txt, без индекса и пароля. Копии сайта При настройке копии сайта важно правильно указать зеркало с помощью 301 редиректа или атрибута rel=»canonical», чтобы сохранить рейтинг существующего ресурса и сообщить поисковой системе: где исходный сайт и где его клон. Скрывать рабочий ресурс от индексации крайне нежелательно. Тем самым вы рискуете сбросить возраст сайта и приобретенную репутацию. Печатные страницы Распечатанные страницы могут быть полезны посетителю. По сути, распечатанная страница является копией своей основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее в качестве приоритетной и посчитать более релевантной. Чтобы правильно оптимизировать веб-сайт с большим количеством страниц, вы должны удалить проиндексированные страницы для печати. Для закрытия ссылки на документ можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега или закрыть все проиндексированные страницы от индексации в robots.txt. Лишние документы Помимо страниц с основным содержанием, на сайте могут быть доступны для чтения и скачивания документы PDF, DOC, XLS. Наряду со страницами в результатах поиска можно увидеть заголовки pdf-файлов. Возможно, содержимое этих файлов не соответствует потребностям целевой аудитории сайта. Либо документы появляются в результатах поиска над html страницами сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt. Пользовательские формы и элементы Сюда входят все страницы, полезные для клиентов, но не несущие информационной ценности для других пользователей и, как следствие, поисковых систем. Это может быть форма регистрации и заявки, корзина, личный кабинет. Доступ к таким страницам должен быть ограничен. Технические данные веб-сайта Технические страницы предназначены только для официального использования администратором. Например, форма входа в панель управления. Личная информация о клиенте Эти данные могут содержать не только имя и фамилию зарегистрированного пользователя, но и контактную и платежную информацию, сохраненную после оформления заказа. Сортировка страниц Структурные особенности этих страниц делают их похожими. Чтобы снизить риск санкций со стороны поисковых систем за дублированный контент, рекомендуем убрать их из индексации. Страницы Хотя эти страницы частично дублируют содержание главной страницы, удалять их из индексации не рекомендуется; вместо этого нужно установить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать, какие параметры разбивают страницы в разделе «URL-параметры» в Google Search Console, или намеренно оптимизировать их. Как закрыть страницы от индексации Метатег robots со значением noindex в html файле Если в html-коде страницы есть атрибут noindex, это сигнал для поисковой системы не индексировать ее в результаты поиска. Чтобы использовать метатеги, вам нужно добавить в заголовок соответствующего html-документа. При использовании этого метода страница будет закрыта для сканирования, даже если на нее есть внешние ссылки. Чтобы закрыть от индексации текст (или отдельный фрагмент текста), а не всю страницу, используйте html-тег: . Файл robots.txt Вы можете заблокировать доступ ко всем выбранным страницам в этом документе или запретить поисковым системам индексировать сайт. Ограничить индексацию страниц через файл robots.txt можно следующим образом: Агент пользователя: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL страницы для закрытия Для эффективного использования этого метода следует проверить наличие внешних ссылок на раздел сайта, который вы хотите скрыть, а также изменить все внутренние ссылки, ведущие на него. Файл конфигурации .htaccess С помощью этого документа вы можете ограничить доступ к сайту с помощью пароля. Тип аутентификации Базовый AuthName "Область, защищенная паролем" AuthUserFile путь к файлу с паролем Require valid-user Удаление URL-адресов через Webmaster Services В Google Search Console вы можете удалить страницу из результатов поиска, указав URL-адрес в специальной форме и указав причину, по которой его необходимо удалить. Эта опция доступна в разделе Google Index. Обработка запроса может занять некоторое время. Вывод Управление индексами — важный этап поисковой оптимизации. Он должен не только оптимизировать эффективность страниц для трафика, но и скрывать контент, который не имеет никакой пользы для индексации. Ограничение доступа к определенным страницам и документам сэкономит ресурсы поисковых систем и ускорит индексацию всего сайта. » title = «Какие страницы следует закрыть от индексации в Google 16261788341697» /> Контрольный список — это готовый список дел, который помогает вести отчеты о ходе работы над конкретным проектом. Инструмент содержит шаблоны с обширным списком параметров разработки проекта, куда вы также можете добавить свои элементы и планы.
Узнайте, как получить максимальную отдачу от SerpstatХотите получить личную демонстрацию, пробный период или множество успешных вариантов использования? Отправьте запрос и наш специалист свяжется с вами 😉 Оцените статью по пятибалльной шкале Статью уже оценили 1 человек в среднем 2 из 5 Нашли ошибку? Выберите его и нажмите Ctrl + Enter, чтобы сообщить нам Рекомендуемые сообщенияHow-to Denys Kondak Как сделать резервную копию вашего сайта и восстановить резервную копию How-to Denys Kondak информация 900 сайт интернет-магазина How-to Денис Кондак Как повысить узнаваемость бренда с помощью Google Ads Кейсы, лайфхаки, исследования и полезные статьи Нет времени следить за новостями? Без проблем! Наш редактор подберет статьи, которые обязательно помогут вам в работе. Нажимая на кнопку, вы соглашаетесь с нашей политикой конфиденциальности. Поделитесь этой статьей с друзьями Вы уверены? Спасибо, мы сохранили ваши новые настройки рассылки. Отчет о ошибке Отмена Удалить контент из индекса GoogleВСЕМ на все уроки Вернуться к библиотеке уроков Все уроки Удалить контент из Google’s Index Библиотека уроков Все уроки Удалить контент. из индекса Google Запретите Google или любой другой поисковой системе индексировать ваш контент с помощью одной строки кода. У этого видео старый интерфейс. Скоро будет обновленная версия! Клонировать этот проект Расшифровка Существует тысяча причин, по которым вы можете не захотеть, чтобы поисковые системы индексировали определенный контент в опубликованном проекте. В этом урокемы собираемся показать вам один из самых распространенных способов запретить Google индексировать ваш контент — используя этот фрагмент кода:
Прежде чем начать
Удаление страницы из индексаЧтобы удалить определенную страницу, добавьте фрагмент кода в код этой страницы.
|
 Только те страницы, которые имеют смысл в результатах поиска, должны быть открыты для индексации.
Только те страницы, которые имеют смысл в результатах поиска, должны быть открыты для индексации.
 Необходимая информация может быть распечатана в адаптированном текстовом формате: статья, информация о продукте, схема расположения компании.
Необходимая информация может быть распечатана в адаптированном текстовом формате: статья, информация о продукте, схема расположения компании.
 Эта информация должна быть защищена от просмотра.
Эта информация должна быть защищена от просмотра.  В файле паролей .htpasswd необходимо указать Username пользователей, которые могут иметь доступ к нужным страницам и документам. Далее укажите путь к этому файлу с помощью специального кода в файле .htaccess.
В файле паролей .htpasswd необходимо указать Username пользователей, которые могут иметь доступ к нужным страницам и документам. Далее укажите путь к этому файлу с помощью специального кода в файле .htaccess.
 Присоединяйтесь к нашему уютному сообществу 🙂
Присоединяйтесь к нашему уютному сообществу 🙂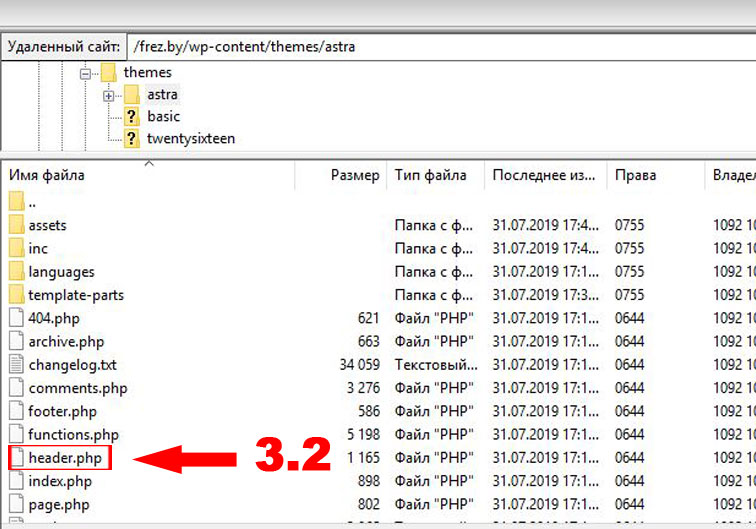 Возможно, вам нужно опубликовать конфиденциальную информацию, но вы не хотите, чтобы Google или любая другая поисковая система отображала эту страницу в результатах поиска.
Возможно, вам нужно опубликовать конфиденциальную информацию, но вы не хотите, чтобы Google или любая другая поисковая система отображала эту страницу в результатах поиска. 8
8 Если они не смогут просканировать вашу страницу, они не смогут прочитать этот код, а это означает, что ваша страница по-прежнему будет проиндексирована и может по-прежнему отображаться в результатах поиска.
Если они не смогут просканировать вашу страницу, они не смогут прочитать этот код, а это означает, что ваша страница по-прежнему будет проиндексирована и может по-прежнему отображаться в результатах поиска.