
от исправления ошибок до discovery-запросов / Хабр
Люди не всегда точно формулируют свои запросы, поэтому поисковые системы должны помогать им в этом. Меня зовут Сергей Юдин, я руковожу группой аналитики функциональности поиска в Яндексе. Мы каждый день улучшаем что-то с помощью машинного обучения. Последний год мы разрабатываем технологию, которая предугадывает интересы человека.
Со специалистом из моей команды Анастасией Гайдашенко avgaydashenko я расскажу читателям Хабра, как работает эта технология, опишу архитектуру и применяемые алгоритмы. А ещё вы узнаете, чем предсказание следующего запроса отличается от предсказания будущих интересов человека.
Что хочет пользователь?
Рассмотрим, как технологии Яндекса помогают в решении задач, на примере воображаемого пользователя. Допустим, он печатает в поисковой строке «копить билет». Что он хочет найти? Узнать про накопление билетов или всё же просто ошибся?
Да, он опечатался. Он хочет не копить, а купить билет. Яндекс его понял, в этом ему помог опечаточник — система, которая исправляет некорректно введённые запросы. Математически эта система максимизирует вероятность корректно введённого запроса при условии введённого текста пользователем. Эта задача уже больше десяти лет решается в Яндексе. И не только в поиске.
Он хочет не копить, а купить билет. Яндекс его понял, в этом ему помог опечаточник — система, которая исправляет некорректно введённые запросы. Математически эта система максимизирует вероятность корректно введённого запроса при условии введённого текста пользователем. Эта задача уже больше десяти лет решается в Яндексе. И не только в поиске.
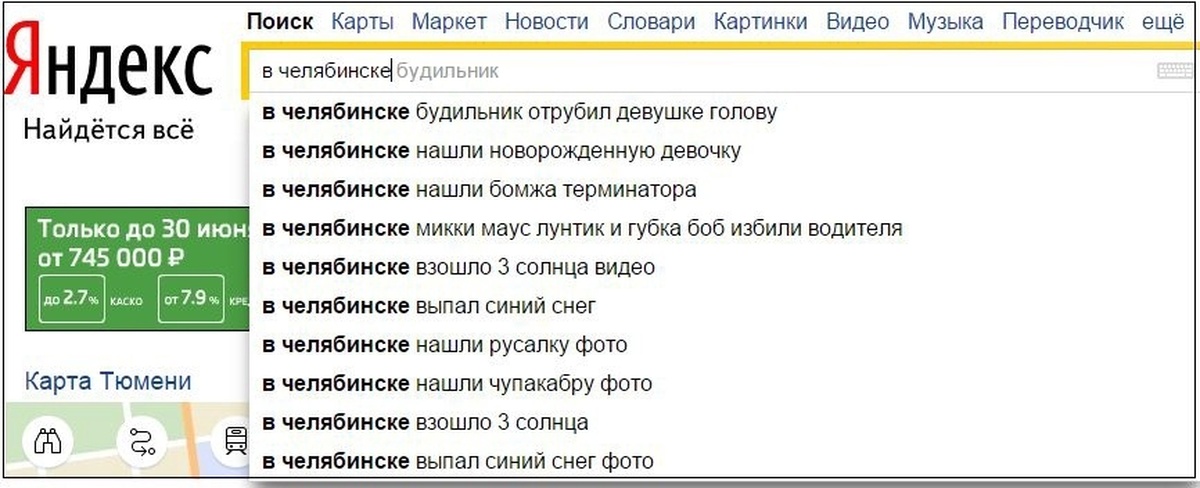
Итак, наш воображаемый пользователь ввёл запрос «купить билет». На этом этапе в игру вступает саджест (или поисковые подсказки). Саджест помогает пользователю доформулировать запрос, правильно его завершить.
Наш саджест прошёл большой путь. Пару лет назад мы усложнили задачу. Хотелось показывать не просто самое логичное завершение запроса, но и предсказывать, какой запрос в итоге введёт именно этот пользователь, и начать его пререндер ещё до клика. Если вам интересно, как это работает, то можно посмотреть на Хабре.
Наш воображаемый пользователь выбирает окончание запроса из ряда подсказок: оказывается, что он искал билеты в Третьяковскую галерею. Таким образом, система рекомендаций выполнила первую свою задачу — помогла пользователю сформулировать запрос.
Таким образом, система рекомендаций выполнила первую свою задачу — помогла пользователю сформулировать запрос.
Эта задача выполнена, но у пользователя ещё остались вопросы. Что он будет искать дальше? Может быть, он хочет узнать, как ему добраться в галерею? Да, он печатает «Лаврушинский пер, 10», чтобы проверить адрес.
Можем ли мы предугадать этот запрос? Да. И мы это делаем довольно давно. Есть такой блок — «Также спрашивают» в конце выдачи. В нём показываются запросы, которые люди обычно задают после введённого в поле поиска. Именно в нём мы увидим наш запрос с адресом Третьяковской галереи.
Мы максимизируем вероятность запроса при условии предыдущего запроса пользователя. Система выполнила вторую задачу — предсказала следующий запрос.
А вот дальше происходит кое-что очень интересное. Пользователь печатает запрос «когда можно посетить Третьяковскую галерею бесплатно». Этот запрос отличается от остальных, идёт вразрез с пользовательской задачей, решает некоторую ортогональную задачу.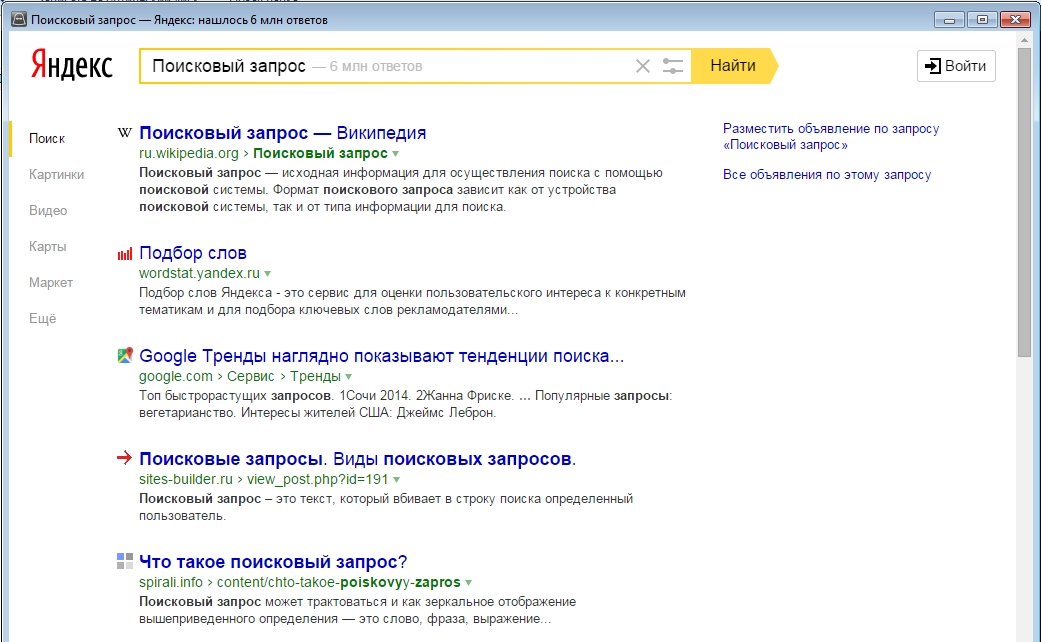
Но давайте подумаем: если бы мы искали билеты в галерею, что бы мы сами хотели увидеть в качестве рекомендации? Огромное количество людей хотели бы узнать, что билет, может быть, и не нужно покупать. Это третья, самая сложная и интересная часть задачи — порекомендовать пользователю что-то новое и полезное. Что-то, о чём он сам ещё не подумал.
Такие запросы мы называем discovery. Мы учимся их определять в наших поисковых логах, сохранять и рекомендовать в конце выдачи. И это как раз та новая и революционная задача, которой мы активно сейчас занимаемся. Человеку, покупающему скандинавские палки, Яндекс может порекомендовать запрос о том, как подобрать их по росту. Если человек часто путешествует, то, возможно, ему будет интересен поисковый запрос «куда поехать без визы». И так далее.
Математическая постановка задачи в этом случае будет выглядеть следующим образом: мы максимизируем не вероятность следующего запроса, а вероятность клика по запросу, который мы рекомендуем пользователю на основе его предыдущей сессии.
Как это работает?
Давайте посмотрим на то, как реализована наша система рекомендаций, какая архитектура за этим спрятана. Но для начала определимся, что мы вообще хотим получить от рекомендательной системы.
1. Полезные рекомендации! Конечно, мы хотим, чтобы те запросы, которые мы рекомендуем пользователю, соответствовали его интересам. Они должны быть полезными и релевантными.
2. Масштабируемость. Мы надеемся, что система будет хорошей: пользователей будет всё больше и больше, а количество запросов будет увеличиваться. И мы хотим увеличивать покрытие тем, по которым мы можем делать рекомендации.
3. Простота реализации. Мы предполагаем, что наша система всё-таки будет работать, и мы не хотим её много раз переписывать. Система должна быть проста в реализации, чтобы мы потом могли её улучшать, не запуская новую версию, а улучшая текущую.
Определившись с нашими пожеланиями, давайте посмотрим, как можно воплотить их в жизнь.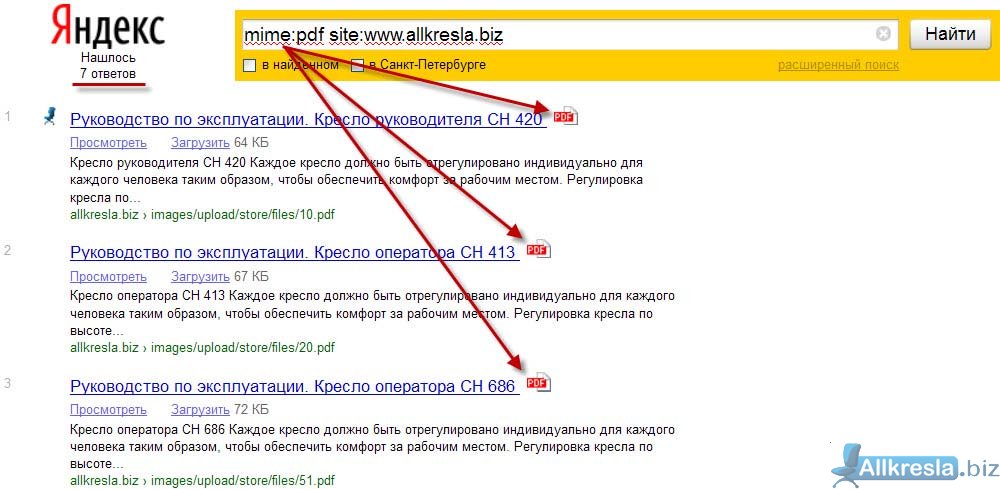
У нас есть некоторая discovery-база — база запросов, которые могут показаться интересными и полезными нашим пользователям. Но если мы начнем ранжировать всю эту базу, нам не хватит вычислительных мощностей. У пользователей много запросов, они разноплановые, поэтому сначала нам нужно эту базу отфильтровать.
Фильтрацию можно осуществлять разными методами. В Яндексе мы используем для этого kNN (k-nearest neighbors) — базовый алгоритм классификации в машинном обучении, известный как «поиск ближайших соседей». С помощью этого алгоритма мы хотим отфильтровать базу: выбрать максимально близкие запросы к тому, что может заинтересовать пользователя. Для этого мы хотим в векторном пространстве сравнить запрос пользователя и те запросы, которые мы готовы порекомендовать.
Но чтобы привести эти запросы в одно векторное пространство, нам тоже нужно что-то придумать. Например, можно использовать DSSM (Deep Structured Semantic Model) — этакий чёрный ящик, который умеет разные сущности переводить в одно векторное пространство.
Следующий этап — это ранжирование. Когда у нас есть список запросов, близких к тому, что, возможно, заинтересует пользователя, мы хотим понять, что ему будет более интересно, а что менее.
Например, мы выбрали 100 запросов. Вряд ли пользователь будет скроллить все 100. Нужно выбрать топ-5 и порекомендовать. Чтобы это сделать, мы присваиваем нашим запросам оценки. Эти оценки мы получаем, исходя из вероятности клика по запросу, который мы рекомендуем пользователю на основе его предыдущей сессии.
Как же мы получаем вероятность следующего клика? Наша система уже запущена и работает, поэтому мы просто собираем фидбек от пользователей — и тем самым постепенно улучшаем нашу рекомендательную систему.
Теперь, когда мы рассмотрели все этапы отдельно, давайте вернёмся к началу и соберём всё вместе. Итого: пользователь приходит к нам с некоторым запросом, а у нас есть какая-то база рекомендаций. Мы берём эту базу и фильтруем, получая запросы, которые мы хотим отранжировать и порекомендовать пользователю.
Теперь вспомним о том, что мы вообще формулировали пожелания к нашей рекомендательной системе. И посмотрим, как мы можем их реализовать в полученной архитектуре.
Например, мы хотели масштабируемость в терминах улучшения базы. У нашего способа реализации есть все необходимые для такого масштабирования свойства. Мы не должны держать всю базу в памяти: как только база расширится настолько, что она не будет помещаться на один кластер, мы можем разбить её на два. И если раньше по одному кластеру мы проходили с kNN и выбирали топ-100, которые будем ранжировать, сейчас мы можем пройтись по двум кластерам отдельно и выбрать в каждом, например, топ-50. Или, вообще, разбить кластеры по тематикам и проходиться с kNN только по нужной тематике.
Чтобы масштабировать количество пользователей, можно просто добавить дополнительных вычислительных мощностей и каждого обрабатывать отдельно, потому что в нашей архитектуре нет мест, где нам пришлось бы держать всех юзеров в памяти одновременно.
В некоторых других подходах такие места есть, которые фильтруют, например, при разложении матрицы. Разложение матрицы — это другой подход, который используется в рекомендациях. На самом деле, Яндекс его тоже использует, но при этом не для фильтрации, а в качестве дополнительных фичей для обучения, потому что там всё ещё много информации, которую полезно анализировать.
Дополнительные фичи, новые алгоритмы и другие методы можно применять в остальной части архитектуры. Когда система запущена и работает, мы можем начинать это улучшать.
Где это работает?
Такая архитектура уже внедрена в Яндексе, и в сравнении с обычными переформулировками, когда мы пытались пользователю посоветовать узнать адрес Третьяковской галереи, мы уже можем советовать, как попасть в Третьяковку без очереди или вообще бесплатно.
Это новый уровень взаимодействия поисковой системы с пользователями. Мы не просто исправляем ошибки и дополняем запросы, а учимся предсказывать интересы человека и предлагать ему что-то новое. Возможно, именно таким будет поиск будущего. А что думаете вы?
Операторы языка поисковых запросов в Google и Яндекс
Поисковые системы стали неотъемлемой часть жизни каждого современного человека. Но объем информации в каждой системе настолько огромен, что пользователь не всегда получает на первой странице выдачи именно то, что ему нужно. В данной ситуации приходится потратить больше времени. Как же упростить этот процесс – учимся использовать особые команды поиска для Гугл и Яндекс.
- Уточнение и расширение запроса
- Поиск по сайту или конкретным страницам
- Задаем дату, тип файла и язык
- Основные команды
- Актуальные операторы для выполнения SEO-задач
- Повседневные действия
Как уточнить поиск: поисковые операторы – что это и для чего?
Для быстрого и четкого поиска данных в сети существуют специальные поисковые операторы, которые действуют в каждой системе. Они выглядят как набор специальных символов. Основная цель использования операторов – сужение выборки по определенным критериям, чтобы быстрее найти релевантную информацию. Использовать операторы поисковых запросов можно по-разному – самостоятельно или же сочетать между собой сразу несколько.
Они выглядят как набор специальных символов. Основная цель использования операторов – сужение выборки по определенным критериям, чтобы быстрее найти релевантную информацию. Использовать операторы поисковых запросов можно по-разному – самостоятельно или же сочетать между собой сразу несколько.
Представленные инструменты предназначены не только для простых пользователей, но также их применяют специалисты для внешней и внутренней оптимизации ресурса. Поисковые команды упрощают выбор сайтов для размещения внешних ссылок, позволяют исправить допущенные ошибки индексации и выполнять другие разнообразные действия.
Если вы хотите освоить операторы поиска, то сперва необходимо ознакомиться с популярными рабочими вариантами для каждой популярной системы – Гугл и Яндекс, а также примерами их использования на практике.
Операторы расширенного поиска Яндекс
Команды Яндекс позволяют конкретизировать, дополнить либо же отфильтровать поисковые запросы. С помощью данного ручного управления поисковой системой информация будет находиться намного прозе и быстрее. Чтобы вам было проще сориентироваться в командах, мы поделили все операторы на несколько групп, в зависимости от цели:
Чтобы вам было проще сориентироваться в командах, мы поделили все операторы на несколько групп, в зависимости от цели:
Уточнение и расширение запроса
«» — поиск точной фразы
С помощью кавычек можно найти фразу или же полностью предложение в прямом вхождении – именно в заданном порядке слов. Например, оператор с фразой «Красота в глазах смотрящего» отберет именно те ресурсы, которые ее содержат.
! – ищем определенную словоформу
Если вам важен определенный падеж и число, то просто поставьте ! именно перед этим словом (не после).
+ — находим страницы с конкретным словом
Если написать команду купить +лекарства, то в выдаче появятся именно те страницы, где присутствует слово «лекарства». При этом поиск осуществляется везде как на странице, так и в самом ее заголовке.
— (минус) – удаляем слово из поискового результата
Этот оператор работает как прошлый вариант (плюс), но с точностью до наоборот. К примеру, если вы напишите запрос купить дерево -саженцы, то вы найдете страницы, где можно купить дерево, но будут исключены все варианты с саженцами.
К примеру, если вы напишите запрос купить дерево -саженцы, то вы найдете страницы, где можно купить дерево, но будут исключены все варианты с саженцами.
* — выдача всех вариантов с подставленным словом
Если вы хотите найти какое-либо упущенное слово во фразе, просмотреть похожие запросы на поисковую фразу, то данный оператор отлично подойдет. В практическом примере далее использовалось несколько команд: «заказать *аудит» –бухгалтерский. При помощи данного запроса удастся узнать, какие фразы могут использоваться со словом аудит.
Обратите внимание, что с «» (кавычками) оператор работает лучше.
Поиск по сайту или конкретным страницам
Url – поиск нескольких страниц на одном сайте
• введите адрес сайта целиком: url:«ru.wikipedia.org/wiki/Лингвистика” – поиск выдает конкретную веб-страницу;
• укажите только одну категорию, но со всеми возможными схожими страницами: лингвистика url:ru.wikipedia.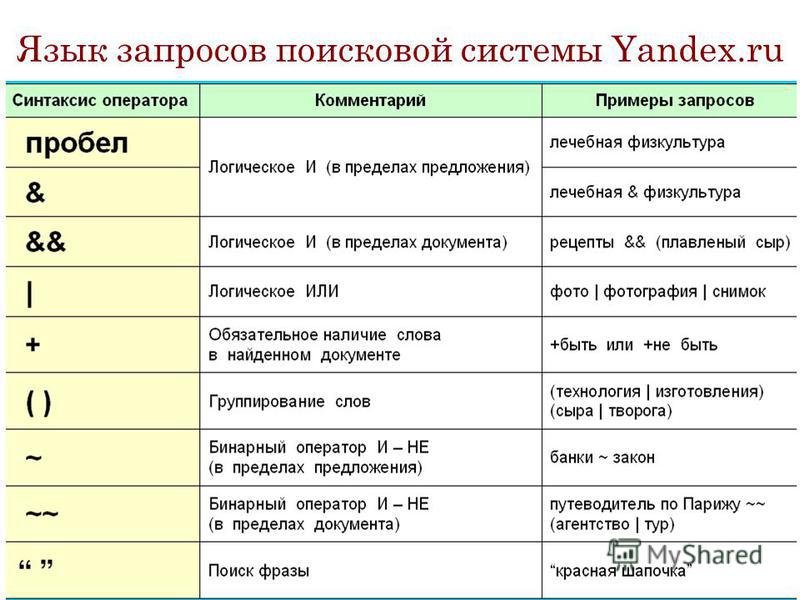 org/wiki/* — поисковая система выдаст любые страницы с введенного сайта, где есть слово лингвистика.
org/wiki/* — поисковая система выдаст любые страницы с введенного сайта, где есть слово лингвистика.
Inurl – ищем в URL ключевые фразы
Поисковая система Яндекс ищет ключевые слова не только в самом тексте страницы, но и прочих ее элементах, в частности, сюда также входит URL. Например, если задать в поисковик команду: SEO inurl:unisender.com, то будут отобраны все веб-страницы, где в URL присутствует SEO.
Site – ищем только на одном сайте
Если стоит задача искать на сайте (только одном) что-то определенное, то данный инструмент отлично для этого подходит.
Например, в поисковой строке задается команда: индексация site:xmlriver.com, то будут выданы все страницы данного сайта, где присутствует слово индексация.
Host – ищем страницы с определенным словом на хосте
Это оператор несколько похож на прошлые, но он работает несколько иначе. Простыми словами, хост прописывается как простой адрес ресурса.
К примеру, вам интересны услуги по парсингу wordstat на конкретном сайте xmlriver.com, то запрос будет следующим: wordstat host:xmlriver.com
Domain – выборка ресурсов с конкретным доменом
Если вы ищете сайты конкретной доменной зоны, а также региона, то можно ввести следующий поисковый запрос: программа для кластеризации domain:com
Задаем дату, тип файла и язык
Mime – ищем конкретные файлы
Если вам необходимы файлы конкретного формата, то данный оператор легко поможет справиться с этой задачей. К примеру: инструкция стиральной машины самсунг mime:pdf
Оператор поддерживает разные форматы: pdf, xls, doc и прочие.
Lang – ищем страницы на конкретном языке
Может быть, вам интересно посмотреть англоязычные сайты, где упоминается определенный термин. Например, можно ввести запрос: SEO lang:en
Date – ищем страницы по определенной дате
В данной ситуации предложено несколько вариантов поиска:
• введите определенную дату: к примеру, вам нужны все события за 11 мая 2023 года, то нужно ввести соответствующий запрос: мероприятие date: 20230511
• можно задать определенные рамки (после определенной даты или же до нее), используя знаки , к примеру: кинофестиваль date: >20200105
• задайте конкретную дату, используя «…», к примеру: юридический форум date: 20230612…20230517
Операторы расширенного поиска Google
Современные команды Google подразумевают несколько десятков вариантов. Их можно применять самостоятельно или же комбинировать между собой – вариантов множество. Все работающие на данный момент операторы Google можно поделить на несколько групп, в зависимости от целей:
Их можно применять самостоятельно или же комбинировать между собой – вариантов множество. Все работающие на данный момент операторы Google можно поделить на несколько групп, в зависимости от целей:
Основные команды
OR | (или) – выдача сразу по 2-м запросам
В выдаче появляются результаты по 2-м фразам, как в той ситуации, если бы они искались п отдельности. Результаты выдаются вместе.
К примеру, пифагор OR оракул
OR всегда нужно писать заглавными буквами. Также представленный вариант поиска превосходно срабатывает со знаком |
() – группировка выдачи
Отдельно скобки никоим образом не работают, но их непременно стоит использовать с прочими операторами.
К примеру, вы можете ввести: (живопись OR эпоха) возрождение
Актуальные операторы для выполнения SEO-задач
Нижеперечисленные операторы зачастую применяются SEO-специалистами, в то же время некоторые из них превосходно подходят для выполнения прочих задач (анализ конкурентов и других).
site: — поиск на конкретном сайте
Оператор site позволяет отобрать в выдачу страницы определенного сайта. Кроме того, также можно ограничить выдачу конкретным поддоменом. К примеру, запрос может выглядеть следующим образом: site://ru.wikipedia.org/wiki/ Лев Толстой
cache: — отображает кэш
Представленный оператор не используется обычными пользователями, поскольку он предназначен для того, чтобы проанализировать, увидел ли поисковый робот те изменения, которые были сделаны. Если же она не прошла индексацию, то эта команда не будет работать вовсе, поскольку поисковой робот ее не видел вообще.
Как практический пример использования: cache://ru.wikipedia.org/wiki/
related: — оператор, позволяющий найти похожие сайты
Применим в той ситуации, если необходимо отобрать разные веб-страницы со схожей тематикой. Стоит отметить, что представленный инструмент выдает результат не всегда так как надо, поскольку невозможно прогнозировать выдачу, по какому принципу система отберет похожие сайты.
Пример использования: related:skyeng.ru
filetype: — отбор по заданному файловому формату
Схожий оператор «Mime» использовался и в Яндексе, но в Гугл он называется по-другому.
Пример использования: искусство filetype:pdf
intext: — поиск по конкретному слову в тексте на странице
Использовать данный оператор можно отдельно, чтобы выдались разнообразные сайты (отлично подходит для просмотра конкурентов) либо же можно сузить выдачу, воспользовавшись еще одним инструментом для поиска на конкретном ресурсе. К примеру, вы можете ввести: site:xmlriver.com intext:google
intitle: — находим слово по заголовкам страниц
В данной ситуации принцип похож на прошлый вариант, только поисковая система проводит анализ исключительно заголовков страниц. Как пример использования оператора: site:ru.wikipedia.org intitle:литература
inurl: поиск страниц с конкретным словом в url
Данный оператор позволяет анализировать только url-адрес. Выдача будет корректной только в том случае, если слово отделить знаками препинания. При этом слово непременно нужно писать правильно, поскольку похожие варианты не учитываются.
Выдача будет корректной только в том случае, если слово отделить знаками препинания. При этом слово непременно нужно писать правильно, поскольку похожие варианты не учитываются.
Например, можно ввести: site:ru.wikipedia.org inurl:фильм
Повседневные действия
При помощи особых команд получится активировать конкретные виджеты Гугл.
weather – узнаем погоду
С его помощью можно найти погоду в определенном регионе. Его легко использовать: погода Москва
map – ориентируемся по картам
Чтобы найти конкретное место на Google Maps, достаточно ввести запрос: карта черемушки
source – открываем новостную ленту
Обратите внимание, что данный виджет не всегда работает корректно. К примеру, можно ввести: новости евро.
movie – какие фильмы сейчас в прокате
Представленный виджет активируется при вводе слова «киноафиша». К примеру, киноафиша москва. Если ввести просто киноафиша без города, то премьеры будут отобраны в зависимости от вашего местоположения.
К примеру, киноафиша москва. Если ввести просто киноафиша без города, то премьеры будут отобраны в зависимости от вашего местоположения.
IN (в) – конвертация валют
Чтобы узнать актуальный курс, то нужно ввести валюту. Например, можно ввести: 200 евро в долларах.
Узнаем значение слова
Источником слов всегда выбирается Оксфордский словарь. Например, чтобы узнать, достаточно ввести команду: значение слова аутсайдер.
Stocks – биржевые данные
Если вам интересна актуальная информации с биржи, то достаточно ввести: акции эпл.
Выводы
Совсем не нужно запоминать сразу все поисковые операторы, они легко находятся в поиске, например, в этой статье. Главное знать о возможностях расширенного поиска Яндекса и Google.
Анализ факторов ранжирования в поиске Яндекса
TLDR
Как обстоят дела с факторами ранжирования в Яндексе? Узнайте больше о том, что такое факторы ранжирования.
 ..
..Сообщество поискового маркетинга пытается разобраться в просочившемся репозитории Яндекса, который содержит файлы со списком факторов ранжирования поиска.
Некоторые могут искать действенные советы по SEO, но вряд ли это истинная ценность.
Принято считать, что это будет полезно для общего понимания того, как работают поисковые системы.
Есть что открыть
Райан Джонс (@RyanJones) считает эту утечку важной.
Он уже протестировал некоторые модели машинного обучения Яндекса на своей машине.
Райан убежден, что есть чему поучиться, но для этого потребуется гораздо больше, чем просто просмотр списка факторов ранжирования.
Райан уточняет:
«Хотя Яндекс — это не Google, мы можем многому научиться из этого с точки зрения сходства.
Яндекс активно использует технологии, разработанные Google. Среди прочего, они особо упоминают PageRank, а также Map Reduce и BERT.
Факторы, очевидно, будут различаться, как и присваиваемые им веса, но методы информатики, используемые для анализа релевантности текста, связывания текста и выполнения вычислений, будут очень похожи в разных поисковых системах.
Я считаю, что факторы ранжирования могут дать ценную информацию, но недостаточно просто взглянуть на просочившийся список.
При просмотре весов по умолчанию (до ML) есть некоторые отрицательные веса, которые SEO-специалисты считают положительными, и наоборот.
Существует также НАМНОГО больше факторов ранжирования, рассчитанных в коде, чем то, что было указано в списках факторов ранжирования, которые были распространены.
Этот список, по-видимому, содержит только статические факторы, без упоминания о том, как они вычисляют релевантность запроса, или о многих динамических факторах, связанных с набором результатов для этого запроса».
Более 200 факторов ранжирования
Согласно просочившейся информации, Яндекс использует 1923 фактора ранжирования (некоторые говорят, что меньше).
По словам Кристофа Цемпера (профиль LinkedIn), основателя Link Research Tools, существует гораздо больше факторов ранжирования.
Кристоф упомянул:
«Друзья были свидетелями:
- Существует 275 факторов персонализации.

- Существует 220 факторов «свежести в Интернете».
- 3186 переменных поиска изображений
- Существует 2314 факторов поиска видео.
- Еще многое предстоит открыть.

Тот факт, что у Яндекса есть сотни факторов для ссылок, наверное, больше всего удивляет многих».
Дело в том, что это намного больше, чем 200+ факторов ранжирования, заявленных Google.
Даже Джон Мюллер из Google заявил, что компания отошла от 200 с лишним факторов ранжирования.
Так что, возможно, это поможет индустрии поиска перестать думать об алгоритме Google в этих терминах.
Никто не знает весь алгоритм Google?
Что поражает в утечке данных, так это то, как легко были собраны и организованы факторы ранжирования.
Утечка ставит под сомнение идею о том, что алгоритм Google тщательно охраняется и что никто, включая сотрудников Google, не знает всего алгоритма.
Возможно ли, что у Google есть таблица с более чем тысячей факторов ранжирования?
Кристоф Цемпер оспаривает представление о том, что никто не знает алгоритма Google.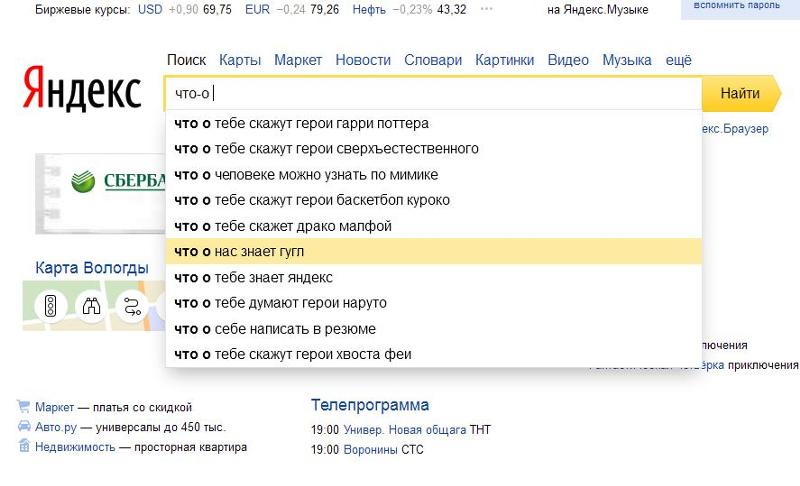
Кристоф сделал следующий комментарий для Search Engine Journal:
«В LinkedIn кто-то прокомментировал, что он не может представить, чтобы Google «документировал» факторы ранжирования таким образом.
Эта информация была получена от надежного инсайдера.
У Google также есть код, который может быть слит.
Людей, владеющих всей информацией, будет очень мало.
Но это должно быть в коде, потому что именно код управляет поисковой системой.»
Какие функции Яндекса похожи на Google?
Утекшие файлы Яндекса намекают на то, как работают поисковые системы.
Данные соответствуют не демонстрирует, как работает Google. Тем не менее, он позволяет вам увидеть часть того, как поисковая система (Яндекс) оценивает результаты поиска.
То, что содержится в данных, не следует путать с тем, что Google может с ними делать.0003
Тем не менее, есть некоторые интересные параллели между двумя поисковыми системами.
MatrixNet — это не то же самое, что RankBrain
Одно из интригующих открытий связано с нейронной сетью Яндекса под названием MatrixNet.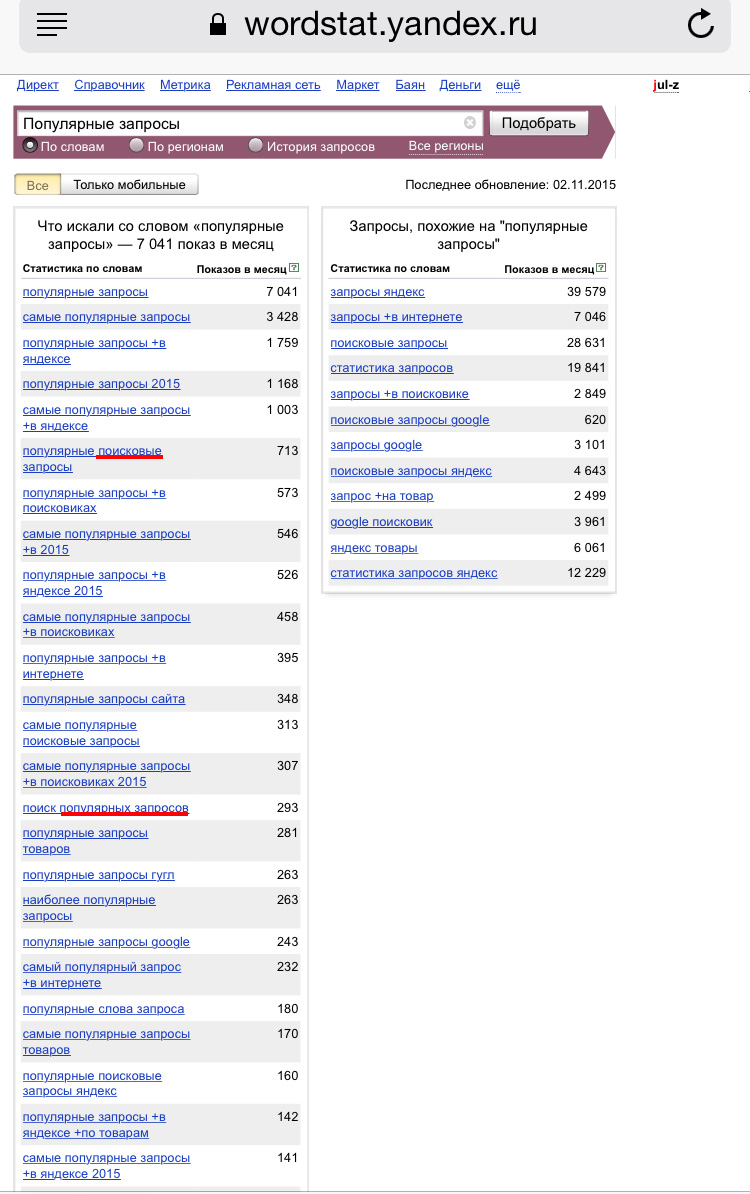
MatrixNet — более старая технология, впервые представленная в 2009 г. (ссылка на объявление на сайте archive.org).
Вопреки распространенному мнению, MatrixNet не является эквивалентом Google RankBrain от Яндекса.
Google RankBrain — это ограниченный алгоритм, который фокусируется на понимании 15% поисковых запросов, которые Google никогда раньше не видел.
Согласно статье Bloomberg, назначение RankBrain ограничено:
«Если RankBrain встречает незнакомое ей слово или фразу, машина может угадать, какие слова или фразы могут иметь сходное значение, и соответствующим образом отфильтровать результат, делая он более эффективен при обработке невиданных ранее поисковых запросов».
MatrixNet, с другой стороны, представляет собой многоцелевой алгоритм машинного обучения.
Он классифицирует поисковые запросы, а затем применяет к этим запросам соответствующие алгоритмы ранжирования.
Это часть объявления алгоритма 2009 года на английском языке 2016 года:
«MatrixNet может генерировать очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций.
Еще одна полезная функция MatrixNet: возможность адаптировать формулу ранжирования к определенному классу поисковых запросов
Кроме того, настройка алгоритма ранжирования, скажем, для поиска музыки не ухудшит качество ранжирования для других типов запросов.
Алгоритм ранжирования аналогичен сложному механизму с десятками кнопок, переключателей, рычагов и датчиков. В большинстве случаев поворот одного переключателя в механизме вызывает глобальные изменения во всей машине.
MatrixNet, с другой стороны, позволяет настраивать определенные параметры для определенных классов запросов, не требуя капитального ремонта всей системы.
MatrixNet также может автоматически выбирать чувствительность для определенных диапазонов факторов ранжирования.»
MatrixNet делает гораздо больше, чем RankBrain; они явно не одинаковы.
Что хорошо в MatrixNet, так это то, что его факторы ранжирования являются динамическими в том смысле, что он классифицирует поисковые запросы и применяет к ним различные факторы.
MatrixNet упоминается в нескольких документах по факторам ранжирования, поэтому важно поместить MatrixNet в надлежащий контекст, чтобы факторы ранжирования имели смысл.
Чтобы разобраться в утечке Яндекса, может быть полезно узнать больше об алгоритме Яндекса.
Некоторые факторы Яндекса соответствуют практикам SEO.
У Доминика Вудмана (@domwoodman) есть несколько проницательных комментариев по поводу утечки.
Алекс Буракс (@alex buraks) опубликовал обширную ветку Twitter на эту тему, которая содержит отголоски практики SEO.
Одним из таких факторов, о котором упоминает Алекс, является оптимизация внутренних ссылок для уменьшения глубины сканирования важных страниц.
Джон Мюллер из Google уже давно призывает издателей размещать на видном месте ссылки на важные страницы.
Мюллер советует не хоронить важные страницы глубоко в архитектуре сайта.
В 2020 году Джон Мюллер заявил:
«Что произойдет, так это то, что мы увидим, что домашняя страница очень важна, и что ссылки на главной странице также очень важны.
А потом… поскольку он удаляется от главной страницы, мы, вероятно, будем думать, что это менее важно».
Крайне важно располагать важные страницы рядом с главными страницами, на которые заходят посетители сайта.
Таким образом, если ссылки ведут на домашнюю страницу, страницы, на которые есть ссылки с домашней страницы, считаются более важными.
Глубина сканирования не упоминалась Джоном Мюллером в качестве фактора ранжирования. Он просто заявил, что информирует Google о том, какие страницы важны.
Алекс цитирует правило Яндекса, которое использует глубину сканирования с главной страницы в качестве фактора ранжирования.
Имеет смысл рассматривать домашнюю страницу в качестве отправной точки важности, а затем вычислять меньшую важность по мере того, как пользователь переходит вглубь сайта, удаляясь от нее.
Аналогичные идеи можно найти в исследовательских работах Google (Reasonable Surfer Model, Random Surfer Model), в которых рассчитывалась вероятность того, что случайный посетитель окажется на данной веб-странице, просто перейдя по ссылкам.
В течение многих лет эмпирическим правилом SEO было размещение важного контента в нескольких кликах от главной страницы (или от внутренних страниц, которые привлекают внешние ссылки).
Обновление Яндекса Веги… Что касается экспертизы и авторитета?
Поисковик Яндекса обновился в 2019 годус обновлением Веги. В обновлении Яндекс Веги появились нейронные сети, обученные с профильными экспертами.
Целью этого обновления 2019 года было включение экспертных и авторитетных страниц в результаты поиска. Тем не менее, поисковые маркетологи, просматривающие документы, еще не обнаружили ничего, что коррелировало бы с такими вещами, как биографии авторов, которые, по мнению некоторых, связаны с опытом и авторитетом, которые ищет Google.
Hocalwire CMS включает в себя фантастические функции автоматизации, которые помогают сосредоточить трафик из различных источников на вашем веб-сайте. Вы можете значительно увеличить свой трафик с помощью Google Analytics и потенциальных возможностей Hocalwire. Чтобы узнать больше о безграничном потенциале Hocalwire CMS, запланируйте демонстрацию.
Чтобы узнать больше о безграничном потенциале Hocalwire CMS, запланируйте демонстрацию.
Next Story
Визуальные интерфейсы от сторонних разработчиков
Open-Source
Tabix
Веб-интерфейс для ClickHouse в проекте Tabix.
Особенности:
- Работает с ClickHouse прямо из браузера, без необходимости установки дополнительного ПО.
- Редактор запросов с подсветкой синтаксиса.
- Автодополнение команд.
- Средства графического анализа выполнения запросов.
- Варианты цветовой схемы.
Документация Tabix.
HouseOps
HouseOps — это UI/IDE для OSX, Linux и Windows.
Особенности:
- Построитель запросов с подсветкой синтаксиса. Просмотрите ответ в виде таблицы или JSON.
- Экспорт результатов запроса в формате CSV или JSON.
- Список процессов с описаниями. Режим записи. Возможность остановить (
KILL) процесс. - График базы данных. Показывает все таблицы и их столбцы с дополнительной информацией.
- Быстрый просмотр размера столбца.
- Конфигурация сервера.
 Показывает все таблицы и их столбцы с дополнительной информацией.
Показывает все таблицы и их столбцы с дополнительной информацией.Планируется разработка следующих функций:
- Управление базой данных.
- Управление пользователями.
- Анализ данных в реальном времени.
- Мониторинг кластера.
- Управление кластером.
- Мониторинг реплицированных таблиц и таблиц Kafka.
LightHouse
LightHouse — это легкий веб-интерфейс для ClickHouse.
Характеристики:
- Список таблиц с фильтрацией и метаданными.
- Предварительный просмотр таблицы с фильтрацией и сортировкой.
- Выполнение запросов только для чтения.
Redash
Redash — платформа для визуализации данных.
Поддерживает несколько источников данных, включая ClickHouse, Redash может объединять результаты запросов из разных источников данных в один окончательный набор данных.
Особенности:
- Мощный редактор запросов.
- Проводник базы данных.
- Средства визуализации, позволяющие представлять данные в различных формах.
Grafana
Grafana — платформа для мониторинга и визуализации.
«Grafana позволяет вам запрашивать, визуализировать, предупреждать и понимать ваши показатели независимо от того, где они хранятся. Создавайте, исследуйте и делитесь информационными панелями с вашей командой и развивайте культуру, основанную на данных. Пользуйтесь доверием и любовью сообщества» — grafana .ком.
Плагин источника данных ClickHouse обеспечивает поддержку ClickHouse в качестве серверной базы данных.
qryn (#qryn)
qryn — это многоязычный, высокопроизводительный стек наблюдения для ClickHouse (ранее cLoki) с собственной интеграцией Grafana, позволяющий пользователям получать и анализировать журналы, метрики и трассировки телеметрии от любого агента, поддерживающего Loki/ LogQL, Prometheus/PromQL, OTLP/Tempo, Elastic, InfluxDB и многие другие.
Особенности:
- Встроенный интерфейс Explore UI и интерфейс командной строки LogQL для запроса, извлечения и визуализации данных
- Встроенные API-интерфейсы Grafana для запросов, обработки, приема, отслеживания и оповещения без подключаемых модулей
- Мощный конвейер для динамического поиска, фильтрации и извлечения данных из журналов, событий, трассировок и т. д.
- API-интерфейсы Ingestion и PUSH, прозрачно совместимые с LogQL, PromQL, InfluxDB, Elastic и многими другими Grafana-Agent, Vector, Logstash, Telegraf и многие другие
DBeaver
DBeaver — универсальный настольный клиент базы данных с поддержкой ClickHouse.
Особенности:
- Разработка запросов с подсветкой синтаксиса и автодополнением.
- Список таблиц с фильтрами и поиском по метаданным.
- Предварительный просмотр данных таблицы.
- Полнотекстовый поиск.
По умолчанию DBeaver не подключается с использованием сеанса (например, CLI). Если вам требуется поддержка сеанса (например, для установки параметров сеанса), отредактируйте свойства подключения драйвера и задайте для
Если вам требуется поддержка сеанса (например, для установки параметров сеанса), отредактируйте свойства подключения драйвера и задайте для session_id случайную строку (под капотом используется http-соединение). Затем вы можете использовать любую настройку из окна запроса.
clickhouse-кли
clickhouse-cli — это альтернативный клиент командной строки для ClickHouse, написанный на Python 3.
Особенности:
- Автодополнение.
- Подсветка синтаксиса для запросов и вывода данных.
- Поддержка пейджера для вывода данных.
- Пользовательские команды, подобные PostgreSQL.
clickhouse-flamegraph
clickhouse-flamegraph — это специализированный инструмент для визуализации system.trace_log в виде flamegraph.
clickhouse-plantuml
cickhouse-plantuml — это скрипт для создания диаграммы PlantUML схем таблиц.
xeus-clickhouse
xeus-clickhouse — это ядро Jupyter для ClickHouse, которое поддерживает запросы данных CH с использованием SQL в Jupyter.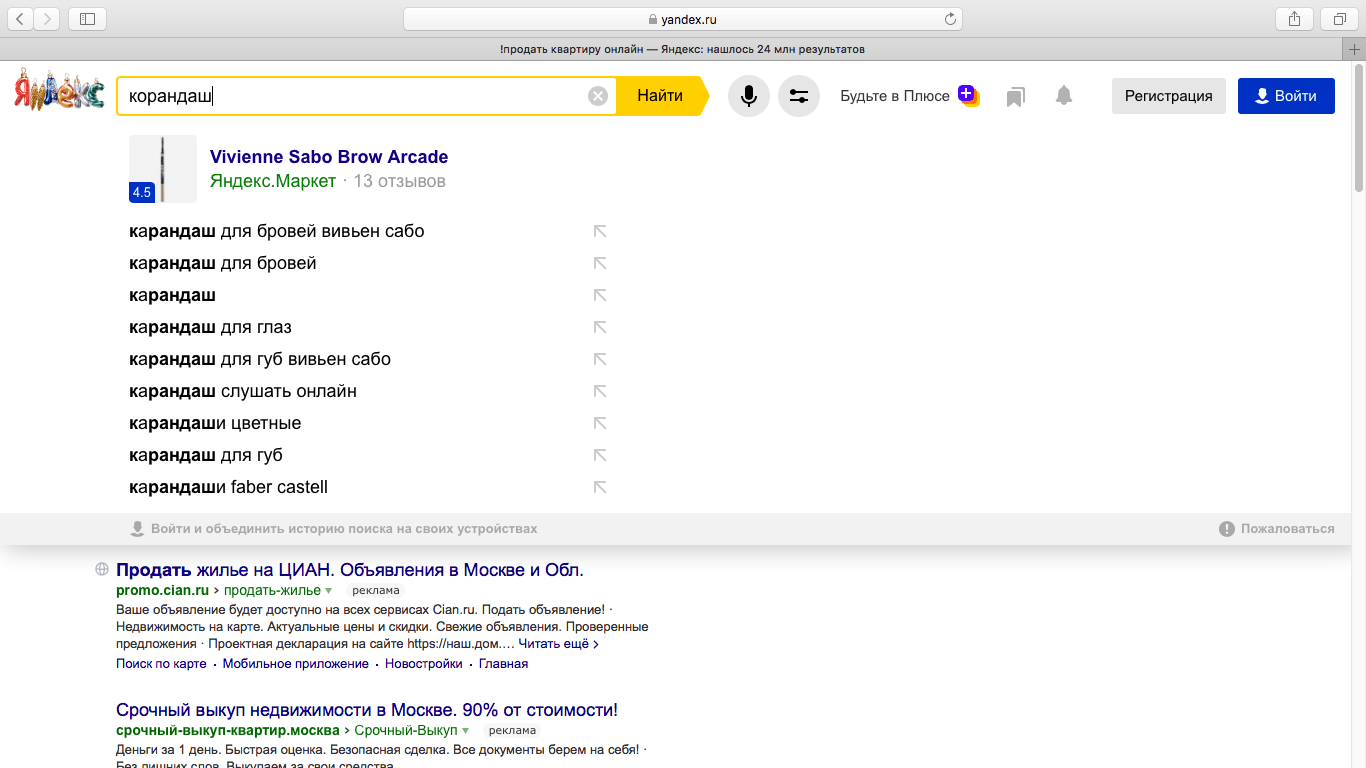
MindsDB Studio
MindsDB — это уровень искусственного интеллекта с открытым исходным кодом для баз данных, включая ClickHouse, который позволяет без особых усилий разрабатывать, обучать и развертывать современные модели машинного обучения. MindsDB Studio (GUI) позволяет обучать новые модели из базы данных, интерпретировать прогнозы, сделанные моделью, выявлять потенциальные смещения данных, а также оценивать и визуализировать точность модели с помощью функции объяснимого ИИ для более быстрой адаптации и настройки моделей машинного обучения.
DBM
DBM DBM — это визуальный инструмент управления для ClickHouse!
Особенности:
- Поддержка истории запросов (разбиение на страницы, очистка всего и т. д.)
- Поддержка выбранных предложений sql запроса
- Поддержка завершающего запроса
- Поддержка управления таблицами (метаданные, удаление, предварительный просмотр)
- Поддержка управления базой данных ( удалить , создать)
- Поддержка пользовательского запроса
- Поддержка управления несколькими источниками данных (проверка соединения, мониторинг)
- Монитор поддержки (процессор, соединение, запрос)
- Поддержка переноса данных
Bytebase
Bytebase – это веб-инструмент для изменения схемы и контроля версий с открытым исходным кодом для команд.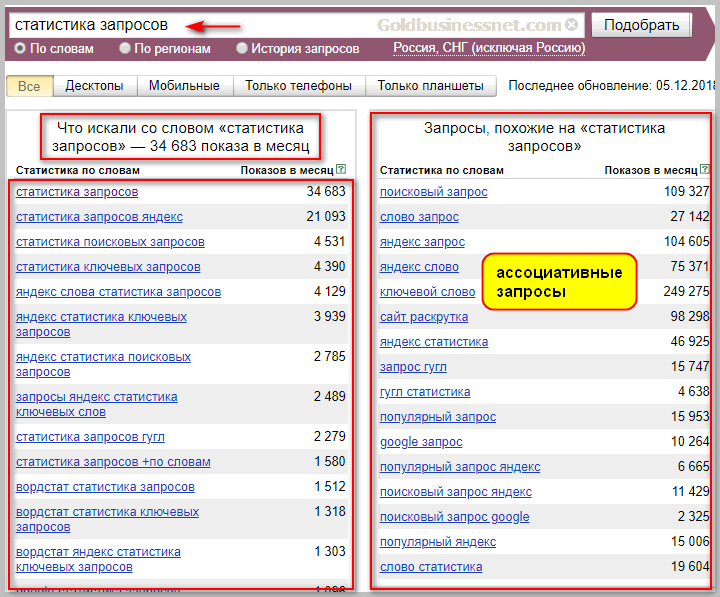 Он поддерживает различные базы данных, включая ClickHouse.
Он поддерживает различные базы данных, включая ClickHouse.
Функции:
- Проверка схемы между разработчиками и администраторами баз данных.
- База данных как код, управление версиями схемы в VCS, например GitLab, и запускает развертывание после фиксации кода.
- Упрощенное развертывание с политикой для каждой среды.
- Полная история миграции.
- Обнаружение дрейфа схемы.
- Резервное копирование и восстановление.
- RBAC.
Zeppelin-Interpreter-for-ClickHouse
Zeppelin-Interpreter-for-ClickHouse — интерпретатор Zeppelin для ClickHouse. По сравнению с интерпретатором JDBC он может обеспечить лучший контроль времени ожидания для длительных запросов.
ClickCat
ClickCat — это удобный пользовательский интерфейс, который позволяет вам искать, исследовать и визуализировать данные ClickHouse.
Особенности:
- Онлайн-редактор SQL, который может запускать ваш код SQL без какой-либо установки.
- Вы можете наблюдать за всеми процессами и мутациями. Для этих незавершенных процессов вы можете убить их в пользовательском интерфейсе.
- Метрики содержат кластерный анализ, анализ данных, анализ запросов.
ClickVisual
ClickVisual ClickVisual — это облегченная платформа для запросов к журналам с открытым исходным кодом, анализа и визуализации сигналов тревоги.
Особенности:
- Поддерживает создание библиотек журналов анализа одним щелчком мыши
- Поддерживает управление конфигурацией коллекции журналов
- Поддерживает пользовательскую настройку индекса
- Поддерживает настройку сигналов тревоги
- Поддержка детализации разрешений для библиотек и настроек разрешений для таблиц
ClickHouse-Mate 9001 5
ClickHouse-Mate — это угловой веб-клиент + пользовательский интерфейс для поиска и изучения данных в ClickHouse.
Возможности:
- Автозаполнение SQL-запросов ClickHouse
- Быстрая навигация по базе данных и дереву таблиц
- Расширенная фильтрация и сортировка результатов
- Встроенная документация ClickHouse SQL
- Предустановки и история запросов
- 100% на основе браузера, без сервера/бэкенда
Клиент доступен для мгновенного использования через github страницы: https://metrico. github.io/clickhouse-mate/
github.io/clickhouse-mate/
Uptrace
Uptrace — это инструмент APM, который обеспечивает распределенную трассировку и метрики на основе OpenTelemetry и ClickHouse.
Функции:
- Трассировка, показатели и журналы OpenTelemetry.
- Уведомления по электронной почте/Slack/PagerDuty с использованием AlertManager.
- SQL-подобный язык запросов для объединения интервалов.
- Язык, подобный Promql, для запроса метрик.
- Готовые панели показателей.
- Несколько пользователей/проектов через конфигурацию YAML.
Коммерческий
DataGrip
DataGrip — это интегрированная среда разработки баз данных от JetBrains со специальной поддержкой ClickHouse. Он также встроен в другие инструменты на базе IntelliJ: PyCharm, IntelliJ IDEA, GoLand, PhpStorm и другие.
Особенности:
- Очень быстрое завершение кода.
- Подсветка синтаксиса ClickHouse.
- Поддержка специфичных для ClickHouse функций, например, вложенных столбцов, табличных движков.
- Редактор данных.
- Рефакторинг.
- Поиск и навигация.

Yandex DataLens
Yandex DataLens — сервис визуализации и аналитики данных.
Особенности:
- Широкий спектр доступных визуализаций, от простых гистограмм до сложных информационных панелей.
- Информационные панели могут быть общедоступными.
- Поддержка нескольких источников данных, включая ClickHouse.
- Хранилище материализованных данных на базе ClickHouse.
DataLens доступен бесплатно для проектов с низкой нагрузкой, даже для коммерческого использования.
- Документация DataLens.
- Учебник по визуализации данных из базы данных ClickHouse.
Программное обеспечение Holistics
Holistics — это полнофункциональная платформа данных и инструмент бизнес-аналитики.
Особенности:
- Автоматизированная электронная почта, Slack и Google Sheet расписания отчетов.
- Редактор SQL с визуализацией, контролем версий, автозавершением, многократно используемыми компонентами запросов и динамическими фильтрами.
- Встроенная аналитика отчетов и дашбордов через iframe.
- Возможности подготовки данных и ETL.
- Поддержка моделирования данных SQL для реляционного отображения данных.

Looker
Looker — это платформа данных и инструмент бизнес-аналитики с поддержкой более 50 диалектов баз данных, включая ClickHouse. Looker доступен как на платформе SaaS, так и на собственном хостинге. Пользователи могут использовать Looker через браузер для изучения данных, создания визуализаций и информационных панелей, планирования отчетов и обмена своими знаниями с коллегами. Looker предоставляет богатый набор инструментов для внедрения этих функций в другие приложения, а также API интегрировать данные с другими приложениями.
Особенности:
- Простая и гибкая разработка с использованием LookML, языка, который поддерживает Моделирование данных для поддержки составителей отчетов и конечных пользователей.
- Мощная интеграция рабочего процесса с помощью Looker’s Data Actions.
Как настроить ClickHouse в Looker.
SeekTable
SeekTable — это инструмент самообслуживания BI для исследования данных и оперативной отчетности. Он доступен как в виде облачного сервиса, так и в виде собственной версии. Отчеты из SeekTable можно встраивать в любое веб-приложение.
Особенности:
- Удобный конструктор отчетов для бизнес-пользователей.
- Мощные параметры отчета для фильтрации SQL и настройки запросов для конкретных отчетов.
- Может подключаться к ClickHouse как с собственной конечной точкой TCP/IP, так и с интерфейсом HTTP(S) (2 разных драйвера).
- Можно использовать всю мощь диалекта ClickHouse SQL в определениях измерений/мер.
- Веб-API для автоматического создания отчетов.
- Поддерживает поток разработки отчетов с резервным копированием/восстановлением данных учетной записи; Конфигурация моделей данных (кубов)/отчетов представляет собой удобочитаемый XML и может храниться в системе контроля версий.
SeekTable бесплатен для личного/индивидуального использования.
Как настроить подключение ClickHouse в SeekTable.
Chadmin
Chadmin — это простой пользовательский интерфейс, в котором вы можете визуализировать ваши текущие запросы в вашем кластере ClickHouse и информацию о них, а также убивать их, если хотите.
TABLUM.IO
TABLUM.IO — онлайн-инструмент запросов и аналитики для ETL и визуализации. Он позволяет подключаться к ClickHouse, запрашивать данные через универсальную консоль SQL, а также загружать данные из статических файлов и сторонних сервисов. TABLUM.IO может визуализировать результаты данных в виде диаграмм и таблиц.
Возможности:
- ETL: загрузка данных из популярных баз данных, локальных и удаленных файлов, вызовы API.
- Универсальная консоль SQL с подсветкой синтаксиса и визуальным конструктором запросов.
- Визуализация данных в виде диаграмм и таблиц.
- Материализация данных и подзапросы.
