
как пользоваться статистикой запросов Яндекса – Блог iSEO
Чтобы привлечь пользователей на сайт, нужно знать, чем же их туда завлечь? Что вообще интересно людям и что они ищут в интернете, какие запросы вводят в поисковую строку миллионы людей каждый день.
Один из самых простых способов узнать это — воспользоваться инструментом Яндекс Wordstat — основным источником данных по запросам в Яндексе, их частоте и сезонности. В этой статье мы расскажем, что такое Яндекс Wordstat: какие задачи решает и как им пользоваться.
Содержание
- Какие задачи решает Яндекс Wordstat
- Полезные операторы
- Виды частоты запросов
- Как прогнозировать трафик по частоте запросов
- Ограничения сервиса
- Как собрать из Wordstat больше 2 000 запросов
- Расширения к браузерам для упрощения работы
Какие задачи решает Яндекс Wordstat
Изначально статистика запросов Яндекса предназначена для специалистов, занимающихся контекстной и поисковой рекламой. Она позволяет понять:
Она позволяет понять:
- Какие запросы вводят пользователи Яндекса?
- Как часто они их вводят (или насколько популярен тот или иной запрос)?
- Как запросы распределены по разным типам устройств, географии и сезонности?
Поскольку основное направление деятельности нашего агентства — это продвижение сайтов в поиске (SEO), то в этой статье мы рассмотрим, чем сервис полезен именно для решения SEO-задач. Также эта информация может быть полезна маркетологам и менеджерам, кому необходимо анализировать структуру и динамику спроса.
Итак, сервис позволяет вбить ключевой запрос или фразу и получить информацию по трем срезам: по словам, по регионам и по времени (история запросов). Далее рассмотрим каждый.
1. Данные по словам
В срезе «по словам» мы получаем информацию по фразам, которые искали в Яндексе с нашим ключевым словом (левая колонка) или какие похожие, по мнению сервиса, слова и фразы искали за последние 30 дней (правая колонка). Похожие слова нужны для сбора синонимов и понимания, как еще ваш товар или услугу могут искать люди в интернете.
Похожие слова нужны для сбора синонимов и понимания, как еще ваш товар или услугу могут искать люди в интернете.
Введя запрос, вы получите список фраз, напротив которых будет отражена информация о показах в месяц. Число рядом с каждым запросом обозначает прогнозируемое количество показов в месяц, которое вы можете получить, выбрав этот запрос в качестве ключевой фразы для поисковой рекламы в Яндексе. Например, число показов для слова «ремонт» будет включать в себя показы по всем запросам со словом «ремонт» — «ремонт квартир», «капитальный ремонт», «ремонт своими руками» и так далее. При составлении прогноза система использует данные о поисковых запросах за последние 30 дней до даты обновления статистики. Можно добавить дополнительные параметры, выбрав нужные типы устройств и регион поиска.
2. Данные по регионам
В данном срезе добавляется еще один показатель — «Региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион:
- Если региональная популярность больше 100% — в этом регионе повышенный интерес к ключевому слову.

- Если она меньше 100% — интерес в данном регионе пониженный.
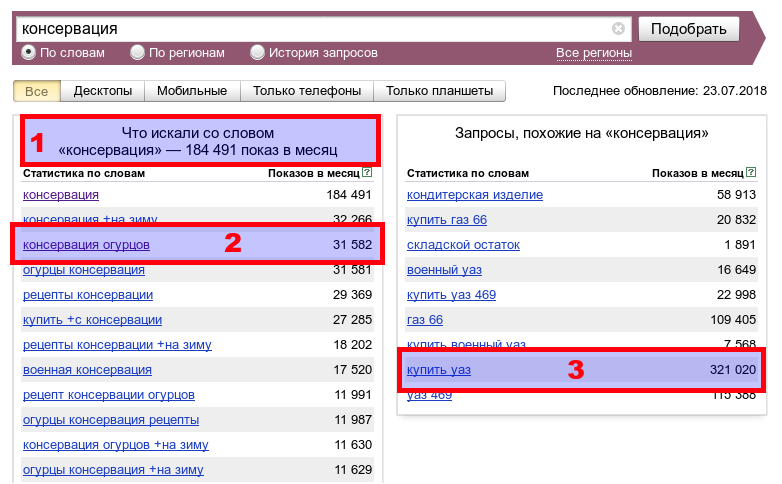
Можно смотреть данные по регионам и странам или сузить до городов. Данный срез подходит, например, если ваш целевой регион — целая страна, и вам интересно посмотреть спрос детально по каждому городу. В других же случаях регион лучше использовать как фильтр в других срезах.
3. История запросов
На данной вкладке вы можете получить информацию в разрезе:
- Месяцев или недель.
- Типов устройств.
- Настроить фильтр по конкретным регионам.
Благодаря этой информации можно оценить сезонность и динамику спроса по ключевому слову. Данные отображаются с учетом всех запросов, в которые входит это ключевое слово. Например, для ключевой фразы «продвижение сайтов» будут показаны данные с учетом запросов «seo продвижение сайтов», «поисковое продвижение сайта», «создание и продвижение сайтов» и так далее.
Операторы Яндекс Wordstat
1. Исключение слов
Оператор минус «-» — исключает из выборки фразы с «заминусованным» словом.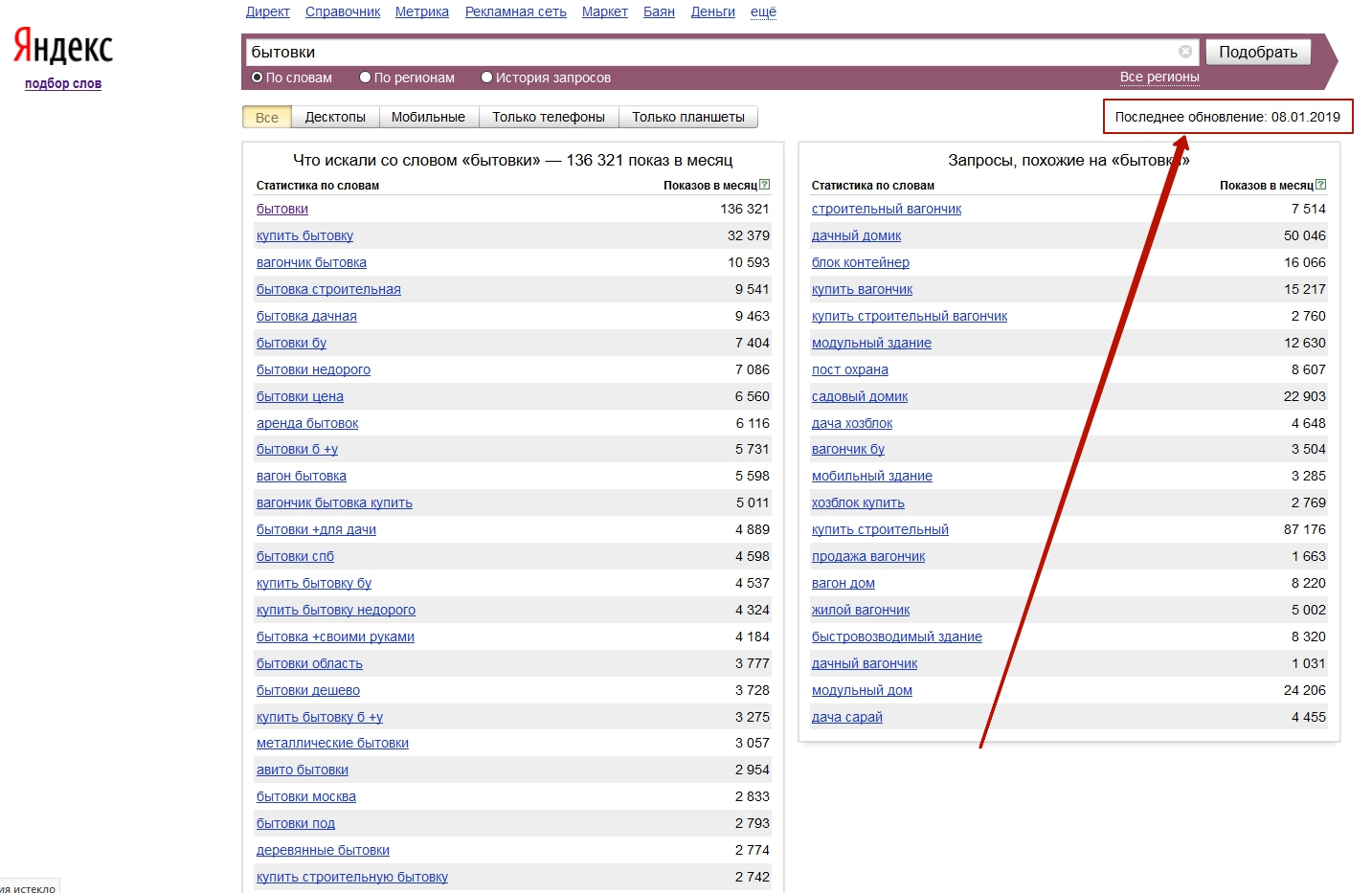 Пример:
Пример:
туфли -коричневые
Wordstat соберет и покажет фразы, в которых не будет встречаться слово «коричневые».
2. Добавление слов
Оператор плюс «+» — будут показаны фразы строго с «заплюсованным» словом. По умолчанию Wordstat исключает служебные слова и местоимения, а также слова, которые, по его мнению, не несут смысловой нагрузки. Поэтому такие слова можно включить в запрос принудительно. Пример:
+один +в поле +не воин
Если убрать плюсы, то мы получим данные по всем запросам со словами «поле» и «воин» (слова «один», «в» и «не» будут проигнорированы).
3. Фиксация фразы
Оператор кавычки «»»» — фиксирует количество и сами слова, данные по которым мы хотим получить. Пример:
"купить автомобиль"
Будут показаны данные по запросам, включающим в себя слова в кавычках (с учетом словоформ). При этом запросы с дополнительными словами (например, «купить автомобиль kia») показаны и учтены не будут.
4. Фиксация словоформы
Оператор восклицательный знак «!» — используем, если текущая словоформа значительно влияет на смысл запроса. Пример:
перелет из !москвы в !иркутск
Фиксирование словоформ в данном случае исключает возможность показать нам информацию по запросу «перелет из иркутска в москву».
5. Фиксация порядка слов во фразе
Оператор квадратные скобки «[]» — когда от перемен мест слагаемых сумма меняется. Пример:
[дома на воде]
Получим данные без запросов «вода на дом».
6. Оператор «или»
Операторы скобки и вертикальная черта «(|)» — позволяют задать несколько вариантов поисковой фразы, по которой хотите получить данные. Пример:
(айфон|iphone) (10|11) (купить|заказать|доставка|цена)
Получим данные с учетом всего многообразия вариантов, заданного в запросе: «айфон 10 заказать», «айфон 11 купить», «iphone 11 цена» и так далее.
Виды частоты запросов в Яндекс Wordstat
Частота — это количество показов результатов поиска по ключевому слову в месяц. Она бывает разной, в зависимости от того, насколько конкретные данные мы хотим получить.
Она бывает разной, в зависимости от того, насколько конкретные данные мы хотим получить.
1. Общая (или базовая) — WS
Частота всех запросов, содержащих данный запрос.
Что нужно знать про общую частоту:
- Не отражает спрос по конкретному запросу без учета других слов. Например, общая частота по запросу «туфли», будет учитывать этот запрос вместе со всеми запросами со словом «туфли», такими как «коричневые туфли», «туфли лодочки», «туфли для танцев» и так далее.
- В связи с тем, что учитываются все возможные поисковые фразы с этим запросом, у вас могут возникнуть неверные представления о потенциале трафика по такому запросу. Например, вы продаете только женские туфли для офиса. Если вы будете смотреть спрос по общей частоте, то туда попадут данные по туфлям для детей, для танцев и так далее.
- Можно использовать для грубой оценки спроса в тематике (особенно в сочетании со стоп-словами).
2. Фразовая — «WS»
Частота всех запросов, содержащих данный запрос, но без дополнительных слов.
Что нужно знать про фразовую частоту:
- Включает в себя все запросы с данными словами в любом порядке и в любой форме (то есть с разными окончаниями).
- Более полезна для SEO, чем общая частота WS.
- Не используйте эту частоту, если при изменении словоформ в ваших запросах может сильно поменяться смысл. Например, у запросов «карта мир» (банковская) и «карта мира» (географическая) фразовая частота будет одинаковая. В таких случаях лучше точная частота.
- Обращайте внимание на запросы, где фразовая частота «WS» сильно больше точной «!WS» — это могут быть мусорные запросы.
3. Точная — «!WS»
Частота всех запросов, содержащих данные слова именно в такой форме. Используются операторы восклицательный знак и кавычки — «!WS»
Оптимальный вариант для SEO в большинстве случаев:
- Обеспечивает баланс между точностью и скоростью сбора данных, если вы используете Key Collector и парсите Яндекс Директ.
- Объединяет данные по всем вариантам запроса с разным порядок слов. Зачастую нет смысла добавлять в семантическое ядро такие вариации запросов. Позиции сайта, как правило, не сильно зависят от порядка слов в запросе.
- Позволяет лучше фильтровать мусорные запросы, чем фразовая «WS».

4. Порядковая — «[!WS]»
Частота всех запросов, содержащих данные слова именно в такой форме и в том же порядке. Используются операторы: квадратные скобки, восклицательный знак и кавычки.
Что нужно знать про порядковую частоту:
- Обычно нет необходимости в использовании такой частоты. Особенно, если в качестве источника данных о запросах вы использовали только сам Wordstat. Он показывает лишь один вариант запроса (один порядок слов) и не показывает все возможные варианты с перестановкой слов местами.
- Используйте этот тип частоты, если в запросах есть повторы слов. Фразовая и точная частоты дадут вам искаженные данные для таких запросов. С добавлением повтора слова частота будет расти, а не падать, поскольку Wordstat интерпретирует повтор слова внутри кавычек не как «еще одно такое же слово», а как «еще одно любое слово». Пример: «!фильм» — 810 тысяч показов в месяц, «!фильм !фильм» — 10 миллионов, «!фильм !фильм !фильм» — 24 миллиона. При этом «[!фильм !фильм !фильм]» — всего 1 398 показов.
- Можно использовать для фильтрации неявных дублей, когда в списке есть запросы из одних и тех же слов в разном порядке. В частности, если в качестве источника запросов вы использовали парсинг поисковых подсказок. Потому что из подсказок вы можете получить запросы из одних и тех же слов в разном порядке.
 Пример: «!фильм» — 810 тысяч показов в месяц, «!фильм !фильм» — 10 миллионов, «!фильм !фильм !фильм» — 24 миллиона. При этом «[!фильм !фильм !фильм]» — всего 1 398 показов.
Пример: «!фильм» — 810 тысяч показов в месяц, «!фильм !фильм» — 10 миллионов, «!фильм !фильм !фильм» — 24 миллиона. При этом «[!фильм !фильм !фильм]» — всего 1 398 показов.Как спрогнозировать органический трафик на сайт на основе данных о частоте из Яндекс Wordstat
Как мы уже разобрали выше, показы в Wordstat — это НЕ переходы (трафик).
Чтобы спрогнозировать трафик на основе показов вам нужно знать примерный CTR (click-through rate, отношение кликов к показам). Посмотреть CTR в поиске по своему сайту (по разным типам запросов и страниц) вы можете для Яндекса в Яндекс Вебмастере, а для Google — в Google Search Console.
Если же ваш сайт еще не ранжируется ни по каким запросам, тогда можете взять «средний по больнице» CTR, например, из исследования компании Advanced Web Ranking:
Предположим, для запроса «кредит наличными» Wordstat выдает точную частоту 24 000 показов по России в месяц. Если мы рассчитываем попасть по этому запросу в ТОП-10, то можем получить ~7% от этого количества (1 700 переходов на сайт с Яндекса в месяц). Но если нам удастся пробиться в ТОП-3, то можем рассчитывать на ~17% (4 000 переходов). Чтобы учесть не только Яндекс, но и Google — можете умножить прогноз еще на два.
Если мы рассчитываем попасть по этому запросу в ТОП-10, то можем получить ~7% от этого количества (1 700 переходов на сайт с Яндекса в месяц). Но если нам удастся пробиться в ТОП-3, то можем рассчитывать на ~17% (4 000 переходов). Чтобы учесть не только Яндекс, но и Google — можете умножить прогноз еще на два.
Ограничения Яндекс Wordstat
Конечно, при всем многообразии возможностей сервиса, есть и ложка дегтя в виде некоторых ограничений:
- Операторы не работают в «Истории запросов». Историческая частота всегда только общая.
- Показывает максимум 2 000 фраз по вашему запросу. О способах это обойти — расскажем далее.
- Не показывает запросы длиннее 7 слов. Более длинные запросы можно собрать из поисковых подсказок.
- Учитывают все запросы к выдаче без фильтрации ботов (могут быть «накрученные» запросы).
Как собрать из Wordstat больше 2 000 запросов
Есть как минимум четыре способа.
1. Используйте минус-слова
Посмотрите список запросов в Wordstat по основным вашим запросам. Добавьте в список стоп-слов явный мусор, который вам точно не нужен. Например, это могут быть бренды конкурентов, сайты-агрегаторы, слова «бесплатно», «своими руками», «домашних условиях» и тому подобное.
Добавьте в список стоп-слов явный мусор, который вам точно не нужен. Например, это могут быть бренды конкурентов, сайты-агрегаторы, слова «бесплатно», «своими руками», «домашних условиях» и тому подобное.
2. Добавляйте уточняющие слова
Подумайте, какие слова в запросах являются наиболее целевыми для вашего сайта/бизнеса. Расширьте список запросов для парсинга Wordstat, добавив в него запросы с уточняющими словами (например, «купить», «цена» и так далее).
3. Перебирайте форму слова
С помощью оператора «!» (восклицательный знак) сформируйте по отдельному запросу для каждой формы слова. Например, вместо того чтобы парсить запросы по фразе «кредит наличными», можно спарсить все запросы по таким маскам:
!кредит наличными !кредиты наличными !кредитов наличными !кредита наличными !кредите наличными !кредиту наличными !кредитом наличными !кредитам наличными !кредитами наличными !кредитах наличными
4. Соберите запросы с нужным числом слов
Для каждого основного запроса (маски или маркера):
- Поместите его целиком в кавычки.
- Повторяйте любое из слов в запросе до тех пор, пока всего слов не станет 7.

Пример. Маски, чтобы собрать запросы со словами «кредит наличными», состоящие из 3, 4, 5, 6 и 7 слов:
"кредит наличными кредит" "кредит наличными кредит кредит" "кредит наличными кредит кредит кредит" "кредит наличными кредит кредит кредит кредит" "кредит наличными кредит кредит кредит кредит кредит"
Недостаток такого метода — вы можете получить на выходе много мусора («кривых» запросов, которые редко спрашивают). Но большая его часть, скорее всего, отфильтруется на этапе сбора точной частоты.
Расширения к браузерам для упрощения работы с Яндекс Wordstat
Для браузера Chrome есть два похожих по функционалу расширения:
- Yandex Wordstat Assistant
- Yandex Wordstat Helper
Оба позволяют:
- Добавлять подходящие вам фразы из Wordstat в свой отдельный список.
- Добавлять целые страницы фраз (до 50 запросов сразу) в свой список.
- Копировать составленный список в буфер обмена, например, для дальнейшей обработки в Excel.
Если вы анализируете запросы для сбора семантического ядра или разработки стратегии продвижения сайта, вы всегда можете обратиться за помощью к профессиональной команде iSEO. Вам не придется разбираться с сервисами и заниматься ручным сбором данных. Все работы мы возьмем на себя.
Виктория Бруякина
Руководитель отдела по работе с клиентами
Яндекс Wordstat: Большой Гайд 🗝️
Сбор ключевых слов и минус-слов
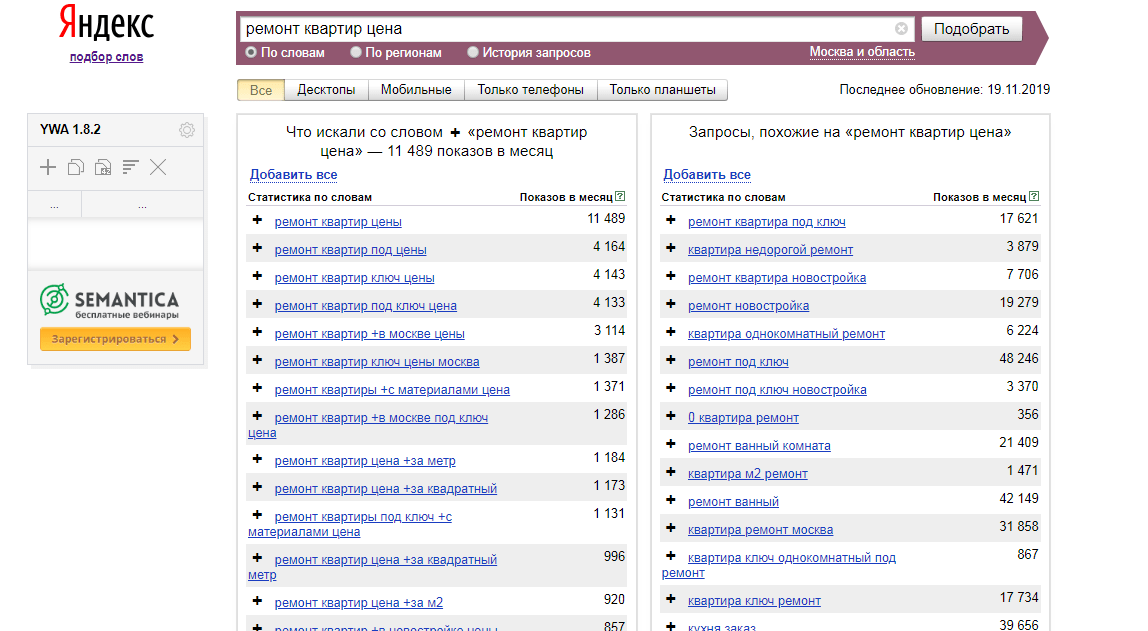
Теперь разбираемся непосредственно со сбором ключевых слов.
Выбираем необходимый регион, вводим интересующий нас запрос, и нажимаем на кнопку «Подобрать».
Далее начинаем двигаться по списку всех запросов, входящих в наш, которые выдала нам система. Рядом с теми запросами, которые нам подходит нажимаем на значок плюса «+». После нажатия запрос станет тусклее и автоматически добавится в поле Yandex Wordstat Assistant, которое находится в левой части экрана.
Если вы встречаете запрос, в котором употребляется некое слово, из-за которого вся фраза становится для вас нецелевой, то такое слово вы можете добавить в минус-слова. Например, в нашем случае, мы производим всю мебель под заказ, кроме детской. В таком случае слово «детская» нам необходимо добавить после запроса в поисковой строке, поставив пробел и знак минуса (тире). Смотрите скриншот ниже.
После этого необходимо нажать кнопку «Подобрать» и из нашей выдачи пропадет не только этот запрос за словом «детская», но и все запросы, которые могли бы встретиться дальше с этим словом.
Важно знать, что Яндекс умеет различать все формы слов. Таким образом, отминусовав слово «детская», пропадут и все запросы с другими возможными вариантами этого слова, например: «детскую», «детской» и т.д. Более того, Яндекс прекрасно понимает слова, который во множественном и единственном значении имеют совершенно разные корни. Например, если вы отминусуете слово «ребенок», то также будут отминусованы и все запросы со словом «дети», поскольку это множественное число слова «ребенок». Как минусовать слова только в конкретной форме мы расскажем чуть позже. Такая возможность есть и необходимость периодически возникает.
Как минусовать слова только в конкретной форме мы расскажем чуть позже. Такая возможность есть и необходимость периодически возникает.
Далее, например, мы не производим также мягкую мебель. Соответственно слово «мягкая» мы также добавляем в минус слова после слова «детская», нажимаем кнопку «Подобрать», и все запросы с этим словом и его формами также исчезнут из выдачи.
Отметим, что необязательно после каждого добавленного минус-слова нажимать кнопку «Подобрать». Вы можете добавить в поисковую строку все необходимые минус-слова по странице и затем нажать кнопку «Подобрать», все запросы этими словами пропадут сразу.
ВАЖНО: обязательно нажимайте кнопку «Подобрать» перед тем, как перейти на следующую страницу поисковой выдачи, иначе все минус-слова, внесенные в поисковую строку, исчезнут, и вам придется собирать их заново.
Таким образом, добавляя в поле Yandex Wordstat Assistant все необходимы слова и в поисковую строку все минус-слова вы можете пройтись по всем страницам, чтобы собрать необходимое вам количество ключевых слов и минус-слов для контекстной рекламы или семантического ядра вашего сайта.
Теперь давайте рассмотрим все элементы управления Yandex Wordstat Assistant, чтобы понять, как экспортировать собранные ключевые слова.
Итак, элементы управления слева направо:
Значок «+» – добавить ключевые слова
Кнопка с двумя файлами позволяет скопировать все собранные ключевые слова для дальнейшего их использования.
Кнопка с двумя файлами и цифрами позволяет скопировать все собранные ключевые слова вместе с количеством показов по данным Яндекс Вордстат.
Кнопка «А-Я» – отсортировать ключевые слова по алфавиту.
Крестик – очистить все собранные ключевые слова.
Также, напротив каждого ключевого слова есть знак «-», нажав на который можно удалить соответствующий запрос.
Организационное развитие в Яндексе (ведущий поставщик услуг в России) (12-страничный документ Word)
Торговая площадка
Business Best Practices
Искать в…
Название документа
Описание документа
Автор:
Тип файла:
PowerPoint
Excel
Word
Bundle
Библиотека:
Marketplace
FlevyPro [?]
Другое:
Исключить документы У меня уже есть
Автор: Arbalest Partners
Тип файла: 12-страничный документ Word
$40..png) 00
00Все сборы включены. Мгновенная загрузка при покупке.
Добавить в корзину
ОПИСАНИЕ ДОКУМЕНТА
Этот продукт (Организационное развитие в Яндексе [Ведущий поставщик услуг в России]) представляет собой 12-страничный документ Word, который вы можете скачать сразу после покупки.
Яндекс — один из ведущих интернет-провайдеров в России, а поисковая система Яндекса в настоящее время является крупнейшей русскоязычной. Это также самая популярная поисковая система в России, так как в августе 2012 года она привлекла более 60% трафика и насчитывает около 49 миллионов пользователей (Яндекс, 2012). С момента своего создания в 1990 году Яндекс быстро рос, и в 2009 году его рыночная доля составила 56% по сравнению с 23% доли Google в России (Schenker, 2007). Следуя своей цели — обеспечить простой доступ к онлайн-информации для русскоязычных людей, Яндекс вошел в несколько других сегментов услуг, таких как онлайн-новости, информация о рынке, мониторинг трафика, социальные сети, онлайн-платежи и другие. Более того, не вступая в область создания контента, а просто перенаправляя пользователей на несколько страниц информации в Интернете, компания поддерживает гармоничные отношения со своими партнерами.
Более того, не вступая в область создания контента, а просто перенаправляя пользователей на несколько страниц информации в Интернете, компания поддерживает гармоничные отношения со своими партнерами.
Одной из ключевых причин быстрого роста Яндекса является его кадровая политика и инвестиции в человеческий капитал. Благодаря открытому общению, инновациям и творческой атмосфере Яндекс смог привить чувство командного духа всем своим сотрудникам (Latuha, 2010). Кадровую стратегию Яндекса можно охарактеризовать как парадоксальную, поскольку, с одной стороны, Яндекс — это структурированная компания, работающая с западными инвесторами и расширяющаяся по всему миру, но в то же время структуры команд очень слабо определены, и решения могут быть оспорены, изменены или отменены после открытых обсуждений. . По словам американского исследователя Д. Хока, философию Яндекса можно охарактеризовать как «хаордическое лидерство», где хаос и порядок переплетаются в базовой корпоративной культуре (Latuha, 2010).
Есть вопрос по товару? Напишите нам по адресу [email protected] или спросите автора напрямую, используя форму «Задать вопрос автору». Если вы не можете просмотреть предварительный просмотр над этим описанием документа, перейдите сюда, чтобы вместо этого просмотреть большой предварительный просмотр.
Источник: Организационное развитие в Яндексе (ведущий поставщик услуг в России) Документ Word (DOCX), Arbalest Partners
АВТОР: ARBALEST PARTNERS
Arbalest Partners опубликовал 32 дополнительных документа о Флеви.
Все сборы включены. Мгновенная загрузка при покупке.
Добавить в корзину
ДЕТАЛИ ДОКУМЕНТА
Размер файла: 138 КБ
Количество страниц: 12
Немедленная цифровая загрузка при покупке.
Пожизненные обновления документов входят в комплект поставки.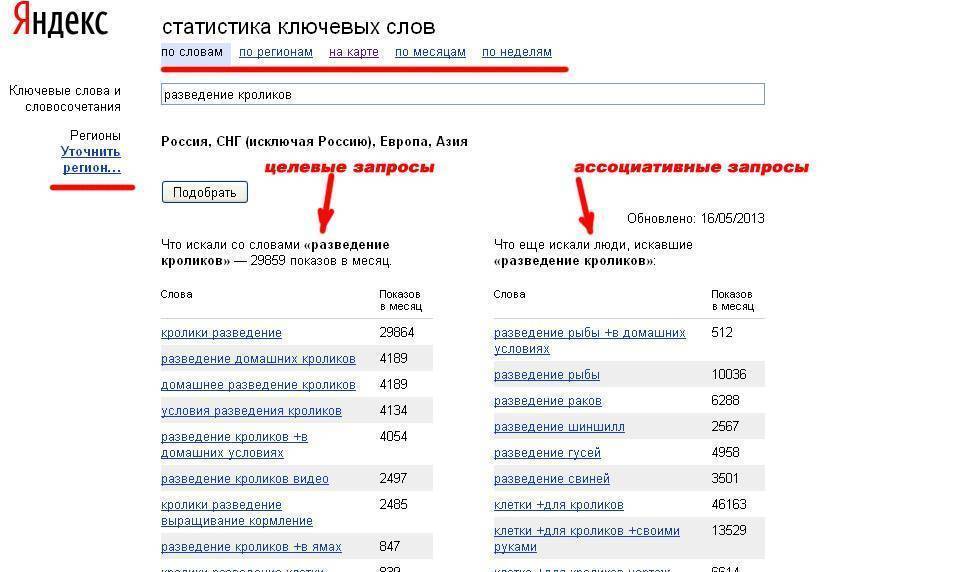
Полностью редактируемый и настраиваемый документ DOCX .
Дата первоначальной загрузки (первая версия): 4 февраля 2014 г. 4 Подписавшись на этот бесценный сайт с множеством тем, которые являются ключевыми и важными для консалтинга, я смог превзойти ожидания и предоставить качественные советы и решения своим клиентам. Качество и опыт авторов являются образцовыми и вселяют в меня большую уверенность в том, что я могу использовать их как часть своих предложений услуг. Я настоятельно рекомендую эту компанию всем консультантам, желающим применять передовые международные стандарты в своих предложениях услуг. » – Ниши Сингх, стратег и управляющий директор NSP Consultants – Дебби Саффо, президент The NiKhar Group – Юлия Т., владелец консалтинговой фирмы (бывший менеджер Deloitte и Capgemini) — Майкл Эванс, управляющий директор Newport LLC — Джим Шон, директор FRC Group – Роберто Фуэнтес Мартинес, старший исполнительный директор компании Technology Transformation Advisory Я опытный топ-менеджер в сфере международного гостеприимства, который работал и жил в течение последних 35 лет в 23 странах на 5 континентах, и я могу смиренно сказать, что знаю, что такое обслуживание клиентов, поверьте мне. Помимо отличного и профессионального обслуживания, предоставляемого командой Flevy, их широкий выбор материалов высочайшего качества, профессионально составлен и актуален. Молодец, Флеви, продолжай в том же духе, и я с нетерпением жду возможности продолжить сотрудничество с тобой в будущем и порекомендовать тебя своим коллегам по всему миру». – Роберто Пелличча, старший исполнительный директор International Hospitality – Крис Макканн, основатель Resilient.World «Как молодой консалтинговой фирме, запросы на ввод данных от клиентов различаются, и иногда невозможно предоставить экспертные решения по широкому спектру требований. Это было до того, как я открыл для себя Flevy.com. «Если вы ищете отличные ресурсы, чтобы сэкономить время на ваших бизнес-презентациях, Flevy — это действительно ресурс с добавленной стоимостью. 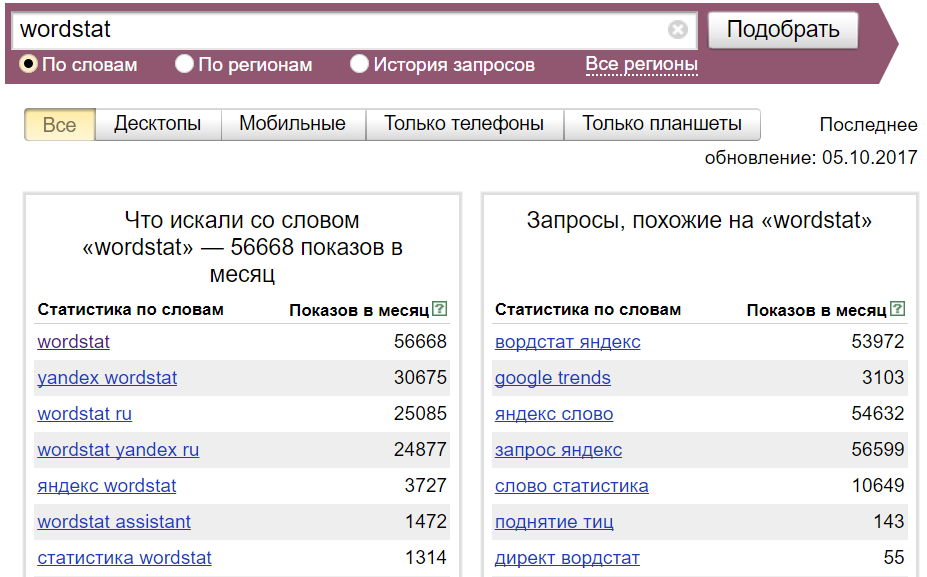 Flevy сделал всю работу за вас, и мы будем продолжать использовать Flevy в качестве источника для извлечения актуальных информацию и данные для наших виртуальных и выездных презентаций!»
Flevy сделал всю работу за вас, и мы будем продолжать использовать Flevy в качестве источника для извлечения актуальных информацию и данные для наших виртуальных и выездных презентаций!» «Широкий выбор фреймворков очень полезен для меня как для независимого консультанта. Фактически, он конкурирует с тем, что я имел в своем распоряжении в консалтинговых фирмах Большой четверки, с точки зрения эффективности и организации». «Как консалтинговая фирма мы создавали тематические учебные материалы для наших сотрудников и нашли отличные материалы по Flevy, что сэкономило нам 100 часов воссоздания того, что уже существует на купленных нами материалах Flevy». 
«Как независимый консультант по управлению, я считаю Flevy очень ценным источником лучших практик, шаблонов и информации о новых тенденциях. Flevy созрел, качество и количество библиотеки превосходны. беспроигрышная ценность для клиента, Флеви и различных авторов. Это действительно услуга, которая приносит пользу консалтинговой отрасли и связанным с ней клиентам. Спасибо за предоставление этой услуги «. «Мне нравится ваш продукт. Я часто разрабатываю презентации PowerPoint для своей компании, и ваш продукт дал мне так много отличных идей по использованию диаграмм, макетов, инструментов и фреймворков. Я действительно думаю, что шаблоны являются ценным активом для работа.  »
» «Я пользуюсь услугами Flevy уже несколько лет и ни разу не разочаровался. На самом деле, Дэвид и его команда продолжают время от времени удивлять меня своей готовностью помочь и настоящим смыслом На самом деле я пришел к выводу, что это вовсе не просто хранилище документов/ресурсов, но то, как Дэвид и его команда управляют фирмой, похоже на общение с консультантами, всегда готовыми помочь, посоветовать и направить вас к то, что вам действительно нужно, и они всегда делают это правильно. 
«Flevy — это наш доступный источник управленческих материалов по доступной цене. Библиотека Flevy обширна и содержательна, и, как правило, обеспечивает нам прекрасную основу для дальнейшего развития и адаптации нашего собственного предложения услуг».
ВЫБЕРИТЕ КЛИЕНТЫ
С 2012 года мы предоставили лучшие практики более чем 10 000 предприятий и организаций всех размеров по всему миру — в более чем 130 странах.
Ниже приведена лишь небольшая часть нашей клиентской базы.
Знаете ли вы?
Средняя дневная ставка консультанта McKinsey составляет 6 625 долларов США (не включая расходы). Средняя цена документа Флеви составляет 65 долларов.
РЕКОМЕНДАЦИИ У НАС ЕСТЬ ДЛЯ ВАС
СВЯЗАННЫЕ ТЕМЫ
ТОП-10 ТЕМЫ
Загрузите наши БЕСПЛАТНЫЕ шаблоны стратегии и трансформации
Получите наш БЕСПЛАТНЫЙ продукт.
Загрузите нашу бесплатную подборку из 50+ слайдов и шаблонов по стратегии и трансформации. Среди фреймворков — Стратегическая модель McKinsey 7-S, Сбалансированная система показателей, Подрывные инновации, Кривая опыта BCG и многие другие.
Нет, спасибо, сейчас мне это не нужно.
Что мы можем узнать о Google из утечки Яндекса
Утечка исходного кода Яндекса, так что теперь мы знаем о наиболее важных сигналах ранжирования для этой поисковой системы. Я не буду связывать эти документы здесь, но быстрый поиск в Google или социальных сетях должен помочь вам быстро их найти.
Я не буду связывать эти документы здесь, но быстрый поиск в Google или социальных сетях должен помочь вам быстро их найти.
Даже если вам наплевать на Яндекс (используется в основном в России), эта новость значима. Это прямое понимание внутренней работы полноценного конкурента Google.
Давайте посмотрим, что мы можем узнать из этой утечки о том, как улучшить SEO. Я расскажу о некоторых из самых интересных переменных, которые я обнаружил, и о том, как они могут влиять на наши представления о поиске.
Яндекс собирает информацию о пользователях
Задача поисковой системы, такой как Google, Yandex или Bing, заключается в том, чтобы отвечать на запрос пользователя.
Но чтобы ответить на этот вопрос, его нужно понять. И конкретное намерение пользователя должно быть выведено из всего, что поисковая система знает о пользователе.
Вот почему поисковые системы собирают как можно больше информации о пользователях, например о предыдущих поисках, местоположении или устройстве.
Яндекс ничем не отличается, и мы находим тому подтверждение в утечке данных. Например, Яндекс собирает переменную FI_REQUEST_IS_FROM_IOS, которая проверяет, находится ли данный пользователь на устройстве iOS.
Яндекс собирает тонны данных веб-сайтов
Яндекс, так же как Google и Bing, имеет индекс страниц, которые потенциально могут удовлетворить потребности своих пользователей. Но чтобы найти страницы, наиболее подходящие для помощи своим пользователям, они должны тщательно их проанализировать.
Утечка выявила массу переменных, связанных со страницей и доменом, которые Яндекс использует в качестве сигналов ранжирования.
Ниже приведены некоторые примеры, которые мне показались наиболее захватывающими или удивительными.
- Яндекс проверяет, реализован ли на странице какой-либо картографический сервис ( FI_PAGE_HAS_MAPS_API),
- Яндекс судит о качестве данного по общему качеству хоста – сайта (FI_PAGE_QUALITY_HOST),
- Яндекс проверяет отсутствие контента NSFW, включая текст, изображения и видео,
- Яндекс проверяет наличие в документе отзывов/комментариев пользователей,
- Яндекс оценивает страницу по дате последнего изменения и количеству известных дубликатов,
- Яндекс обращает внимание на публикации в социальных сетях от проверенных аккаунтов, которые ссылаются на данную страницу.

В утечке Яндекса более 18 тысяч различных факторов. Я думаю, что их стоит изучить, но это выходит за рамки этого поста. Я только хочу обратить ваше внимание на широкий спектр анализов, которые Яндекс делает для классификации всех страниц в своем индексе.
Яндекс использует показатели поведения пользователей
Как и Bing, Яндекс использует поведенческие показатели для определения качества страницы.
Время, потраченное на время имеет значение:
- FI_BROWSER_HOST_CNT_DWELL_TIME_LOG проверяет среднее время, проведенное пользователем на определенном веб-сайте — эти данные сегментированы по локализации и стране,
- FI_MORE_90_SEC_VISITS_SHARE проверяет процент посещений продолжительностью более 90 секунд,
- FI_MORE_160_SEC_VISITS_SHARE проверяет процент посещений продолжительностью более 160 секунд.
Яндекс также использует моментальную популярность как фактор ранжирования. Он измеряет среднее количество посещений в течение трех часов.
Они также учитывают, насколько глубоко средний пользователь взаимодействует с веб-сайтом (средняя глубина сеанса).
Это указывает на сходство Яндекса и Bing.
Позвольте мне процитировать документацию Bing:
«Bing также учитывает, как пользователи взаимодействуют с результатами поиска. Чтобы определить вовлеченность пользователей, Bing задает такие вопросы, как: нажимали ли пользователи на результаты поиска по заданному запросу, и если да, то какие результаты? Тратили ли пользователи время на эти результаты поиска, по которым они просматривали, или быстро возвращались в Bing? Пользователь скорректировал или переформулировал свой запрос?»
Утечка также показывает несколько факторов, которые прямо или косвенно соответствуют некоторым механизмам, которые, как мы знаем, использует Google.
- И Google, и Яндекс используют BERT.
- И Google, и Яндекс используют сигналы качества на уровне всего сайта, а не только сигналы на уровне страницы (например, FI_PAGE_QUALITY_HOST ).
- И Google, и Яндекс используют PageRank.
- У Яндекса тоже есть правила для конкретных сайтов. Например, Яндекс по-разному относится к ссылкам из Википедии. У Яндекса также есть правила для отдельных сайтов. Например, есть фактор с именем FI_DSSM_SUNHOME_POPULARITY. Проверяет вероятность того, что sunhome.ru является популярным хостингом по данному запросу.
- И у Google, и у Яндекса есть понятие YMYL-страниц. У Яндекса есть специальный алгоритм определения качества хоста для медицинских сайтов (FI_MEDICAL_HOST_QUALITY_METRIC»). Он также имеет нейронные модели для определения качества контента по финансовым и юридическим темам (FI_FIN_LAW_URL_QUALITY).
- Обе поисковые системы могут аннотировать разные части содержимого (поэтому они понимают макет страницы). Мы знаем, что Google использует центральный механизм аннотаций, чтобы различать основной контент, дополнительный контент и рекламу.
- И у Google, и у Яндекса есть общие базовые факторы ранжирования (например, удобство для мобильных устройств, которое Яндекс измеряет с помощью переменной FI_IS_MOBILE_BEAUTY_HOST).


Когда вы знаете, какие сигналы качества и релевантности использует поисковая система для поиска наилучшего контента, вы можете легко улучшить свой рейтинг.
Сначала вы проверяете, какие факторы ранжирования оказывают наибольшее влияние (не все они имеют одинаковый вес в алгоритме ранжирования). Затем вы выбираете факторы, которые являются действенными для вас и которые легко улучшить с вашей стороны. Сосредоточьтесь на улучшении этих факторов на своем веб-сайте и измерьте влияние.
Я не думаю, что Яндекс будет переписывать свою кодовую базу, чтобы люди не играли с его алгоритмом. Так что, если вы хотите улучшить свой рейтинг в Яндексе, теперь это проще, чем когда-либо — с технической точки зрения.
Но когда дело доходит до Google, все не так просто.
Если вы сравните результаты поиска по одним и тем же запросам в Google, Yandex и Bing, вы быстро заметите существенные различия. Это указывает на тот факт, что даже если они используют схожие сигналы ранжирования, они взвешивают их по-разному или используют для разных типов запросов.
Но утечка информации из Яндекса — это потрясающая возможность реконструировать ход мыслей людей, управляющих одной из самых успешных поисковых систем в мире. Изучите эти документы, чтобы понять, как поисковая система видит ваш бизнес и что вы можете сделать, чтобы улучшить свою видимость в поиске.
SEO-специалисты ведут дискуссию о том, что является фактором ранжирования, а что нет.
Мы должны изменить свое мышление, чтобы понять, что мы живем в эпоху машинного обучения.
Позвольте мне рассмотреть два примера: грамматические ошибки и количество слов. Google официально отрицает, что оба фактора являются факторами ранжирования.
Потому что они не являются факторами ранжирования. Но они, возможно, способствуют вашему успеху в SEO.
Компания Google опубликовала исследование по обнаружению высококачественного контента. Выборка была экстраординарной – 500 млн документов. Описанный алгоритм учитывал такие особенности, как количество слов и правильность грамматики.