
Техническая характеристика поисковой системы яндекс. Принцип работы яндекса. Краткая характеристика поисковика Google
Браузер — это окно в интернет. Многие держат его открытым целыми днями: мимо него бежит лента новостей, в нём мы наблюдаем за жизнью наших друзей, к нему обращаемся, когда хотим что-то найти. Но интернет не всегда выглядел так, как мы привыкли. Вернее, долгое время он вообще никак не выглядел.
В браузере мы видим не интернет, а Всемирную паутину, или веб. Сам интернет — это инфраструктура, комплекс сетей, в которые объединены компьютеры по всему миру. А веб — способ наглядно представить хранящуюся на них информацию в виде связанных между собой страниц. На этих страницах могут быть текст, картинки, видеоролики, разнообразные кнопки, ссылки и многое другое. Чтобы все эти элементы работали и отображались корректно, страницу нужно открыть в специальной программе. Эта программа и есть браузер.
Немного истории
Прообраз современного веба и, соответственно, первый браузер появились в 1991 году в ЦЕРН — европейской организации по ядерным исследованиям. Один из её сотрудников, Тим Бернерс-Ли, придумал провязать научные документы гиперссылками и решить таким образом проблему поиска информации в огромном архиве института. Первый браузер назывался WorldWideWeb и выглядел примерно вот так.
Браузер WorldWideWeb в 1993 году. Источник — страница Тима Бернерса-Ли на w3.org
Там же, в ЦЕРН, появилась и первая веб-камера . Учёные, у которых была одна кофе-машина на несколько этажей, поставили рядом с ней камеру, которая несколько раз в минуту отправляла фотографии на их компьютеры — всё для того, чтобы можно было, не отрываясь от работы, узнать, есть ли в машине кофе.
В начале 90-х появились не только веб и первые браузеры — тогда же начинали работать первые коммерческие интернет-провайдеры. До этого интернет финансировался правительством и доступ в него был только в больших университетских центрах и военных организациях. Теперь же в сеть мог выйти любой человек с домашнего компьютера.
Интернет стал публичным, а с появлением веба и сравнительно простых в освоении браузеров вроде Mosaic и Netscape Navigator — ещё и наглядным. Из инструмента научного сообщества он постепенно стал превращаться в средство массовой коммуникации, а затем, с ростом аудитории, и в глобальную торгово-развлекательную площадку.Последняя версия браузера Mosaic, выпущена в 1997 году. Источник — Википедия.
Сегодня сотни миллионов людей ежедневно ищут в сети информацию и новости, слушают музыку и смотрят фильмы, играют, общаются, покупают. Чтобы всё это стало возможным, браузерам пришлось многому научиться. Простейший пример — отображение нескольких страниц в одном окне. Вкладки стали появляться в популярных браузерах только в первой половине 2000-х — теперь же навигацию в сети без них трудно представить.
Из чего сделан Яндекс.Браузер
Первая версия Яндекс.Браузера была выпущена в 2012 году. Создавая его, мы использовали уже существующие наработки. Например, «движок» для нашего браузера мы выбрали такой же, как у Safari и Google Chrome — называется он WebKit. Чтобы объяснить, почему мы выбрали именно его, надо хотя бы в двух словах рассказать, что вообще делает движок.
Если коротко, то он собирает сайты по инструкции — примерно так же, как мы собираем мебель, которая приехала из магазина в нескольких коробках. Страницы сайтов становятся такими, какими мы привыкли их видеть, только на экране компьютера. Пока вы не смотрите на них через браузер, они существуют в виде документов со ссылками на «детали» (например, картинки, которые используются для фона и кнопок) и кодом, который определяет, как их надо соединить..
Это только маленькая часть кода страницы сайт — целиком он длиннее, чем вся эта статья.
У каждого движка есть свои особенности — именно поэтому один и тот же сайт может немного по-разному выглядеть в разных браузерах. Если создатель сайта не учитывает эти особенности, то какой-нибудь браузер может неправильно понять его инструкции и собрать что-то некрасивое или вообще неработающее. Мы не стали придумывать собственный «движок», чтобы разработчикам сайтов не приходилось адаптировать свои сайты ещё и под него. Вместо этого был выбран популярный WebKit, на который уже ориентируются большинство веб-разработчиков.
У WebKit есть несколько реализаций — наш браузер работает на той, что развивается в проекте Chromium. Им занимаются сразу несколько крупных компаний — причём ко всеобщей выгоде. Если одна компания придумывает какое-то техническое улучшение, от этого выигрывают все (если интересно, например, о том, как разработчики Яндекс.Браузера помогли значительно ускорить все программы на основе Chromium). Кроме того, это позволяет совместно продвигать современные веб-стандарты, то есть делать интернет удобнее и безопаснее.
Что делает Яндекс.Браузер особенным
Самый очевидный ответ — это дизайн. С самого начала мы старались сделать так, чтобы интерфейс не был громоздким. Наш идеал браузера — это не просто окно, а «панорамное окно» в интернет: во весь экран и с минимум деталей. Какое-то время мы вообще пробовали сделать прозрачный браузер — этот проект назывался Кусто. Тестирование показало, что далеко не все пользователи готовы к таким переменам, зато некоторые нововведения, вроде анимированных фонов и умной поисковой строки, многим пришлись по душе. В той версии Яндекс.Браузера, над которой м
статья о поисковой системе Рунета
Яндекс – самая популярная в русскоязычном сегменте Интернета поисковая система. Сервисы Яндекса наиболее посещаемые и востребованные из всех известных на сегодняшний день специализированных сервисов. Поисковой системой Яндекс пользуются миллионы людей во всем мире.
История создания поисковой системы Яндекс
История существования поисковой системы Яндекс берет свое начало в 1996 году. Официально поисковик начал свой тернистый путь 23 сентября 1997 года, однако этому предшествовал труд множества специалистов и бесконечное число тестирований.
На момент запуска Яндекс был всего лишь поисковой системой и не имел такого количества сервисов, как сегодня. Почему поисковая система получила такое название, доподлинно неизвестно. Существует несколько версий. Одна из наиболее реалистичных – происхождение названия от слова «index», в сети Интернет обозначающего индексацию сайтов.
В конце 90-х годов создание поисковой системы с русской морфологией было стратегической задачей для инженеров и веб-разработчиков. Нужна была система, которая могла бы максимально точно классифицировать результаты поиска, соответствовала бы постоянно растущим требованиям и пожеланиям пользователей. Как мы видим, цель была достигнута: сегодня поисковая система Яндекс и ее сервисы пользуются огромной популярностью у русскоязычных пользователей.
Согласно данным независимых исследований в прошлом году на долю Яндекса приходилось более 60% аудитории. Второе место заняла поисковая система Google, а на долю всех остальных поисковиков осталось около 10% пользователей.
Название поисковика пережило несколько изменений. Изначально поисковая система имела англоязычное название Yandex, что означало «Yet Another iNDEXer».
Однако стратегия продвижения поисковой системы, направленная на русскоязычных пользователей, вынудила ее разработчиков поменять сначала первую букву на русскую «Я» (получилось «Яndex»), а потом и вовсе русифицировать название, поменяв «Яndex» на «Яндекс». Окончательное название поисковая система получила в 2008 году.
Преимущества и возможности
Почти за двадцать лет своего существования Яндекс стал самой популярной поисковой системой, опередив в Рунете такого гиганта, как Google. По сравнению с американской поисковой системой, Яндекс обладает рядом преимуществ и отвечает самым строгим требованиям поиска на русском языке. Это продвинутый поисковик, алгоритмы работы которого регулярно обновляются и постоянно совершенствуются.
Основное преимущество Яндекса – большое количество специальных приложений и полезных сервисов.
В Яндексе можно:
- Искать необходимую информацию и изображения.
- Выбирать товары и услуги.
- Сравнивать цены и условия.
- Уточнять расписание движения поездов.
- Узнавать погоду и делать многое другое.
В системе Yandex существует множество корпоративных решений, вплоть до создания собственных сайтов на площадке Народ.ру (на данный момент продано компании Ucoz). Особой популярностью пользуется сервис Яндекс.Вебмастер (статья Как добавить сайт в Яндекс Вебмастер), где предоставляются широкие возможности для профессиональной работы с собственными сайтами и клиентскими проектами.
Самые популярные сервисы Яндекса:
- «Яндекс.Почта» – почтовый сервис, позволяющий любому пользователю создать свой собственный электронный ящик или обзавестись любым их количеством. Почте от Яндекса отдает предпочтение более 29 млн. пользователей в неделю.
- «Яндекс.Вебмастер» – полезный для веб-мастеров и оптимизаторов сервис, обладающий широкими функциональными возможностями, облегчающий работу по созданию и продвижению интернет-ресурсов.
- «Яндекс.Деньги» – уникальная система электронных платежей с дружественным функционалом и удобным интерфейсом. Доступна для пользователей из России и других стран.
- «Яндекс.Директ» – платный сервис контекстной рекламы, представляющий собой эффективный инструмент продвижения товаров и услуг в сети Интернет, имеющий простые настройки и интуитивно понятный функционал.
- «Яндекс.Карты» – популярный информационный сервис, с помощью которого можно проложить любой маршрут и найти любой, даже малозначимый объект.
- «Яндекс.Метрика» – самый популярный сервис по сбору статистики в Рунете, позволяющий проводить аудит ресурсов, отслеживать поведение пользователей на сайте, его посещаемость и другие события, важные для успешного продвижения.
- «Яндекс.Диск» – облачный сервис, позволяющий хранить неограниченный объем данных на удаленном сервере и передавать их любому пользователю.
В настоящее время поисковая система Яндекс доступна на русском, украинском, белорусском, казахском, татарском, английском, французском и немецком языках. Поиск данных осуществляется по морфологическим и некоторым другим признакам поисковых слов и фраз.
Работа системы постоянно совершенствуется, предъявляются все более высокие требования к качеству сайтов, что избавляет Интернет от низкосортных неинформативных сайтов и прочего веб-мусора.
Основателями Яндекса являются И. В. Сегалович и А. Ю. Волож. Изначально это был скромный проект, который сегодня вырос в крупную корпорацию с офисами в разных городах России, ближнего и дальнего зарубежья, с тысячами сотрудников и далеко идущими планами.
Для тех интернет-агентств, которые занимаются продвижением WEB-сайтов в русскоязычном сегменте сети, наилучшим показателем качественной работы является достижение лидирующих позиций в поисковой выдаче Яндекс.
Поисковая система Яндекс настроена таким образом, что быстрое продвижение сайтов в ней невозможно.
Особое влияние на показатели продвижения оказывают ключевые запросы. Если эти запросы отличаются низкой конкурентностью, хорошего результата можно будет достигнуть быстрее, если в сегменте, с которым работает вебмастер, большая конкуренция, раскрутить сайт будет намного труднее. Не следует забывать, что каждый сайт – уникальный проект, который имеет массу особенностей и индивидуальные сроки продвижения сайта в ТОП Яндекса.
Продвижение сайта быстро пройти не сможет, особенно, если это молодой домен (наша статья о продвижении молодых сайтов и кейс).
В таком случае средний срок продвижения сайта в Яндексе, будет составлять около 9-12 месяцев. На временной показатель срока продвижения оказывает влияние конкурентность ключевых запросов.
Читайте также:
Как работает поисковик Яндекс — схемы и описания алгоритмов работы
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы-пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
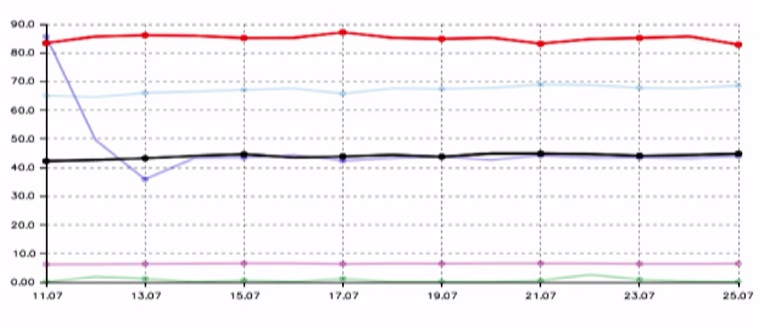
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
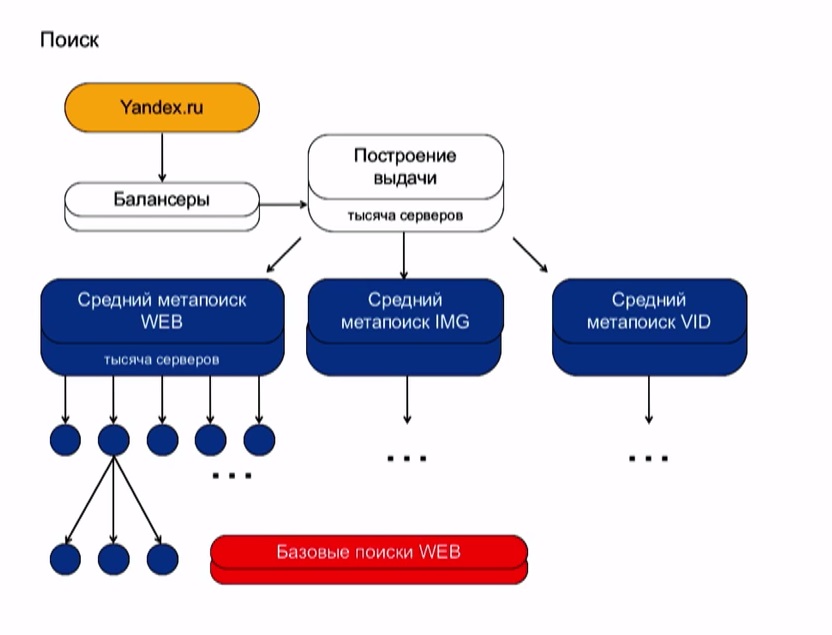
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую-самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где-то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент-трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
Обзор функционала современных поисковых систем
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО
ОБРАЗОВАНИЯ «МОРДОВСКИЙ ГОСУДАРСТВЕННЫЙ
ПЕДАГОГИЧЕСКИЙ ИНСТИТУТ
ИМЕНИ М.Е. ЕВСЕВЬЕВА»
Физико-математический факультет
Кафедра информатики и вычислительной техники
Реферат
ОБЗОР ФУНКЦИОНАЛА СОВРЕМЕННЫХ ПОИСКОВЫХ СИСТЕМ
Автор: Е. В. Шукшин, группа МДФ-112 |
Преподаватель: Т. В. Кормилицына
|
Саранск 2017
Содержание
Введение 3
1. Понятие и функции поисковой системы 3
2. Основные характеристики поисковой системы 5
3. Краткая история развития поисковых систем 7
4. Состав и принципы работы поисковой системы 8
Заключение 12
Список использованных источников 14
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто. Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»)
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Рис. 1. – Результаты поиска по запросу
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
Опишем основные характеристики поисковых систем:
- Полнота
- Полнота — одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
- Точность — еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
- Актуальность
- Актуальность — не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
- Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
- Наглядность
- Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска. Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google — самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
В России основной поисковой системой является «Яндекс», далее — Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе.
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Рис. 2 – Обработка поискового запроса в системе «Рамблер»
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим — с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Теперь подытожим все вышесказанное. Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
- Гусев, В.С. Google. Эффективный поиск – Москва: Диалектика, 2010г., 231с.
- Егоров, А.Б. Поиск в Интернете — Санкт — Петербург.: НиТ, 2010г. 119с.
- Несколько слов о том, как работают роботы поисковых машин // Citforum URL: http://www.citforum.ru/internet/search/art_1. shtm (дата обращения: 01.03.2017).
- Поиск и навигация в Internet // Открытые системы URL: http://www.osp.ru/cw/1996/20/31.htm (дата обращения: 01.03.2017).
- Рассел, С. Интеллектуальные системы – М.: Вильямс, 2007. – 1408 с.
- Экслер, А.Б. Самоучитель работы в Интернете — Москва.: NT Press, 2010г. 542с.
самые популярные сервисы и статистика
Здравствуйте, уважаемые пользователи, подписчики и просто читатели моего блога! Интернет в значительной степени облегчил жизнь каждого из нас, на страницах его сайтов содержится самая различная информация, и не существует таких фактов, теорий и домыслов, о которых не знает всемогущая Сеть.
Первый помощник в море информации – поисковая система. Чем пользоваться – дело вкуса и привычки, но мы сегодня проведем сравнительный анализ трех самых лучших распространенных поисковиков, отметив достоинства и недостатки каждой из них.
Наглядное сравнение поисковых систем google yandex и rambler поможет вам сориентироваться и выбрать наиболее удобную систему для постоянного пользования.
OK, Google
Google можно по праву назвать самой популярной поисковой системой в мире. Созданное в Америке и адаптированное, в первую очередь, под американцев и англоязычное население, системное обеспечение Google постепенно перестраивается, покоряя и русскоязычную аудиторию.
Его можно смело назвать прямым и самым активным конкурентом Яндекса. Кроме того, этот поисковик- одна из самых дорогих компаний в мире. Можно представить, какими активами владеет ее руководство, если по оборотам за прошлый год они обошли даже Apple!
Достоинства использования поисковой системы Google:
- Специализированные роботы сканируют и оценивают содержание страниц для поискового индекса;
- Главный плюс – очень короткое время отклика системы на запрос;
- Поиск информации по запросу в PDF-файлах;
- Google организует поиск на десяти различных языках – это максимальный результат;
- Поисковик показывает наиболее высокие результаты по чистоте, релевантности и точности поиска;
- Поисковая система имеет собственную почту, облачное хранилище, браузер, карты и прочие сервисы;
Недостатки всемогущего Google:
- Постоянное усовершенствование систем и добавление различных фильтров в значительной мере усложняет работу и затрудняет продвижение сайтов;
- Обширная информационная база препятствует точному поиску, засоряя «эфир» огромным количеством несоответствующих запросу ссылок.
Что скажет Yandex?
Список самых популярных систем для поиска информации в Сети продолжает Яндекс. О его востребованности и народной любви к нему свидетельствуют многочисленные социологические опросы пользователей.
Вы знаете, как звучит девиз компании? «Найдется все», скромно заявляют разработчики этого интернет — поисковика и прилагают максимум усилий, чтобы воплотить свое заявление в жизнь.
Штат компании состоит более, чем из полутора тысяч сотрудников, а сеть дата-центов и серверов – самая широкая в России.
Плюсы Yandex:
- Огромное количество сервисов системы, самые популярные из которых – почта, маркет, карты, диск, браузер и другие, значительно превосходящие основных конкурентов;
- Создание виджетов (блоков новостей) на главной странице Yandex;
- Высокая информативность Яндекса;
- Удобное и компактное расположение результатов поиска;
- База поисковой системы – индекс –которую формирует поисковый робот. Он анализирует и собирает информацию в Сети с определенной периодичностью. При выдаче информации пользователю робот учитывает язык пользователя, его местоположение, прошлую активность и историю запросов. Каждый результат создается индивидуально! Такого подхода не встретишь ни у одного другого поисковика;
- Необходимо добавить, что Yandex обладает еще одной очень ценной характеристикой: он исправляет орфографические ошибки и предлагает возможные варианты. Это крайне удобно, если вы ищете информацию по термину, в написании которого вы не уверены. Google в этом отношении не надежен и запросто может предложить несколько десятков страниц результатов на неверный запрос. Так что плюсы пользования системой Yandex очевидны;
- Ну, и по мелочи: удобный и красивый интерфейс, надежный хостинг, отсутствие спама в поиске и нераздражающее количество коммерческой информации;
- Удобный поиск по сервисам: картинки, каталог, новости, маркет, энциклопедия.
Минусы Yandex:
- Постоянно появляющаяся CAPTCHA отнимает время и раздражает пользователей;
- Для тех, кто сайты «делает» и продвигает очень сложно раскрутить новый ресурс именно на Яндексе, система крайне подозрительно воспринимает «юные» сайты;
- Сбои в поиске порою приводят к тому, что в топе оказываются откровенно никчемные сайты, а популярные еще вчера площадки стремительно скатываются в рейтинге. Впрочем, так же неожиданно они возвращаются на ранее занимаемые места.
Rambler: особенности поиска
Согласно данным статистики, Рамблер предпочитают люди зрелого возраста, с высшим образованием и жизненным опытом. Эта поисковая система не похожа на прочие.
Положительные стороны Rambler:
- Большой опыт работы;
- Новая технология анализирует поведение пользователя и определяет его пол и возраст;
Отрицательные стороны Rambler:
- Поисковик морально устарел, не выдержав конкуренции со стороны отечественных и западных поисковых систем;
- Тестирование Рамблера указывает на низкое индексирование динамических сайтов.
Подводя итоги.
Опросы пользователей показывают, что предпочтения у всех разные. Можно составлять сколь угодно много сводных таблиц, сопоставляя результаты работы различных поисковиков (а ведь их куда как больше трех!), но, так или иначе каждый сам делает свой выбор. Привлекает скорость – Google к вашим услугам, нужна точность и широкая вариативность запросов – к вам на помощь придет Yandex, а Rambler для тех, кто хочет отойти от шаблона.
Я прощаюсь с вами, ищите, спрашивайте, будьте пытливы, и вы найдете ответы на все вопросы. Подписывайтесь на обновления и оставляйте свои комментарии. Пока-пока.
С уважением, Роман Чуешов
Загрузка…Прочитано: 1167 раз