
статистика ключевых слов – подробное описание на S1
Мы уже много раз упоминали в статьях сервис Яндекс Вордстат для подбора ключевых слов. Но подробно его ни разу не описывали. С одной стороны, сам по себе сервис очень простой и понятный интуитивно, а о его дополнительных возможностях мы говорили в разных статьях. Но, как видим по вопросам наших клиентов и подписчиков, все же общая обзорная статья об этом инструменте не помешает.
Итак, что же представляет собой статистика ключевых слов Яндекс Вордстат, и чем она может быть полезной оптимизаторам, копирайтерам, директологам и владельцам различных сайтов?
Что такое Яндекс Вордстат
Содержание статьи
- 1 Что такое Яндекс Вордстат
- 2 Первые шаги в Вордстат
- 3 Как пользоваться статистикой ключевых фраз Яндекс Вордстат
- 4 Дополнительные возможности анализа ключевых слов Яндекса
- 5 Подборка ключевых слов Яндекс Вордстат для отдельных регионов
- 6 История запросов в статистике Вордстат и сезонные колебания
- 7 Подборка ключевых слов Яндекс при помощи специальных операторов
- 8 Бонусный совет: как избавиться от капчи в Вордстат
Создавался сервис Вордстат для того, чтобы пользователям было проще производить подбор ключевых фраз Яндекс для объявлений контекстной рекламы. Маркетологи с помощью этого инструмента подбирали наиболее релевантные запросы и создавали рекламные объявления в Яндекс.Директ. В принципе, здесь и сегодня ничего не изменилось. Но благодаря простоте и удобству, сервис статистики поисковых слов давно уже используется намного шире.
Маркетологи с помощью этого инструмента подбирали наиболее релевантные запросы и создавали рекламные объявления в Яндекс.Директ. В принципе, здесь и сегодня ничего не изменилось. Но благодаря простоте и удобству, сервис статистики поисковых слов давно уже используется намного шире.
Статистика Вордстат позволяет:
- Подобрать необходимые запросы для составления сео-ядра сайта;
- Проверить «ключевые слова» при написании статей, необходимых для продвижения проектов;
- Узнать интересы посетителей из определенных регионов;
- Выявить сезонные колебания запросов (интересов) пользователей Яндекс;
- Определить дополнительные фразы пользователей, не учтенные при составлении первоначального сео-ядра;
- Спрогнозировать поисковый трафик по тому или иному ключевому слову в разные периоды (месяцы, дни недели и даже временные промежутки).
Инструмент очень мощный, гибкий и одновременно очень простой. По этой причине статистика ключевых слов Яндекс Вордстат пользуется особой популярностью. А если учесть, что более чем на 90% результаты Вордстата подходят и для продвижения в Google (а там статистика спрятана глубже, и пользоваться ей сложнее), то причины популярности становятся еще более очевидны.
А если учесть, что более чем на 90% результаты Вордстата подходят и для продвижения в Google (а там статистика спрятана глубже, и пользоваться ей сложнее), то причины популярности становятся еще более очевидны.
Давайте подробно и последовательно разберемся, как пользоваться всеми возможностями этого мощнейшего инструмента.
Первые шаги в Вордстат
Для того, чтобы воспользоваться статистикой ключевых запросов Яндекс Вордстат, необходимо пройти регистрацию или авторизоваться под общим логином и паролем Яндекс. На этом этапе обычно проблем не возникает. Регистрация ничем не отличается от любой подобной, при этом вы получаете доступ к электронной почте, Яндекс Диску и многим другим возможностям.
Если вы уже зарегистрированный пользователь Яндекса, то авторизацию пройти можно прямо на страничке сервиса https://wordstat.yandex.ru/
Как пользоваться статистикой ключевых фраз Яндекс Вордстат
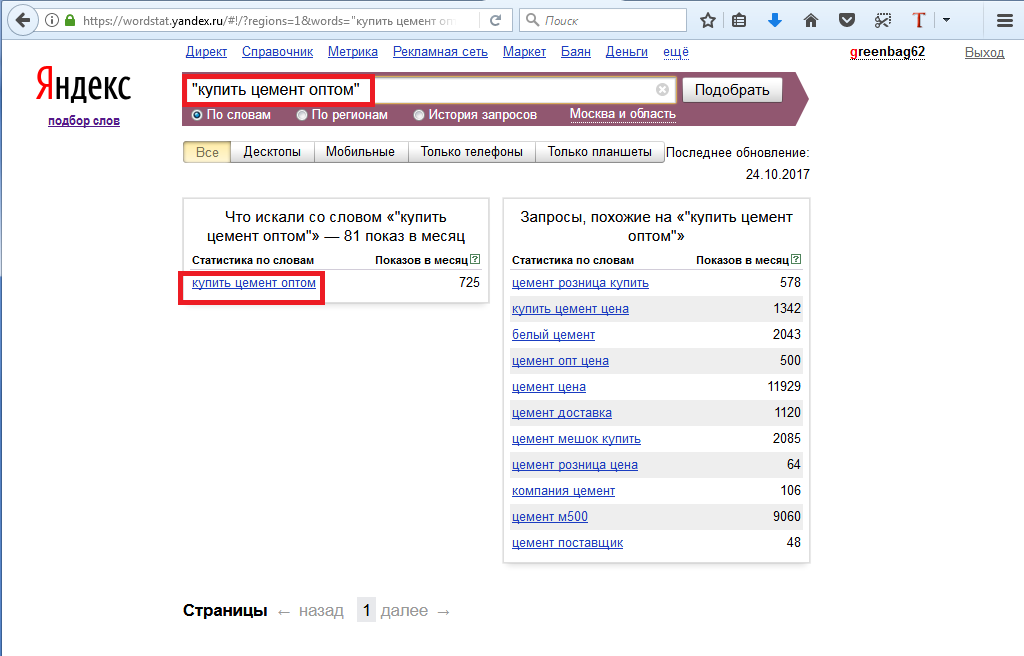
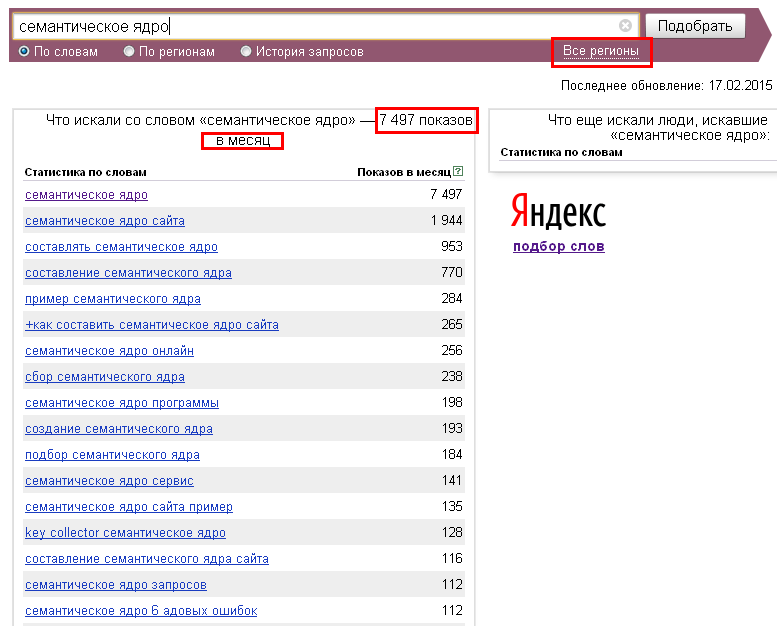
Подбор слов в Яндекс статистике предлагаем разобрать на примере ключевого слова «копирайтер». Для этого выполняем следующие действия:
Для этого выполняем следующие действия:
- Вводим слово или фразу в окно поиска;
- Нажимаем кнопку «Подобрать».
Через 1-2 секунды статистика Вордстат покажет вам результаты.
Что показывает подбор запросов Яндекс Вордстат:
- Строка сразу под окном поиска: популярность искомого слова или фразы за последний месяц;
- Левый столбец – поисковые запросы, включающие слово или фразу из окна поиска, а также число их показов в течение месяца;
- Правый столбец статистики Вордстат – похожие по смыслу фразы, но состоящие из других слов. Эта статистика очень полезна, так как позволяет расширить семантическое ядро и помогает не пропустить важные словосочетания.
По умолчанию в результатах открыта вкладка «Все». Но при желании вы можете посмотреть выдачу с учетом устройства, с которого пользователи выходили в Яндекс поиск: декстопы, мобильные устройства (телефоны и планшеты), а также отдельно – планшеты и телефоны.
Дополнительные возможности анализа ключевых слов Яндекса
В сервисе вам доступен не только подбор слов, но и Яндекс статистика с разных точек зрения:
- По странам, городам или списку регионов;
- История популярности запроса с разной детализацией: еженедельно или помесячно;
- Возможность сузить перечень возможных запросов при помощи операторов уточнения или исключения (минус-слова).


Давайте с каждой из возможностей статистики Вордстат разберемся немного подробнее.
Подборка ключевых слов Яндекс Вордстат для отдельных регионов
Если вы создаете сайт, который предназначен для пользователей из любой точки мира, дополнительные настройки при выборе ключевых слов вам не понадобятся. Но что делать, если вы создаете интернет-магазин, обслуживающий людей только в определенном городе или области? Или если ваш сайт ориентирован на пользователей из определенной страны? Не имеет смысла тратить лишние силы и средства на достижения ТОПа по всему Рунету. Лучше сосредоточиться на выбранных регионах, в том числе, при подборе необходимых слов.
Для этого нужно:
- справа под строкой поиска (в цветном блоке) найти фразу «Все регионы»;
- по клику на эту фразу открывается окно с картой и списком возможных регионов;
- отмечайте «галочками» на карте или в списке нужные вам города, области или страны;
- после выбора сохраните настройки.

Все, теперь статистика Вордстат будет ограничена выбранными вами регионами.
Кроме того, вы можете посмотреть популярность вашего запроса на карте. Наведите курсор мыши на нужный регион, и вы увидите, насколько ваши фразы популярны в том или ином городе. Если цифра будет меньше 100%, значит, интерес к вашему запросу здесь ниже среднего, если выше – соответственно, интерес повышен. Если цифра стремится к нулю, в этом регионе ваша тематика не востребована вообще.
История запросов в статистике Вордстат и сезонные колебания
Проверка ключевых слов в Яндекс Вордстат возможна также с учетом сезонных колебаний. Для того, чтобы посмотреть, когда ваши запросы оказываются на пике популярности, а когда стоит ожидать спада, воспользуйтесь функцией «История запросов».
Статистика выглядит в виде двух графиков:
- Абсолютное значение – показатель фактического числа запросов в указанный период;
- Относительное значение – пропорции между заданной ключевой фразой и общим количеством поисковых запросов в сети.
По идее, эти графики должны быть очень близкими друг к другу. Такой подход является дополнительным подтверждением корректности собранной статистики Яндекс Вордстат.
Ниже под графиками видны цифровые значения. Но чтобы не искать, можно просто навести курсор мыши на заинтересовавший фрагмент графика, и вы увидите соответствующие цифры.
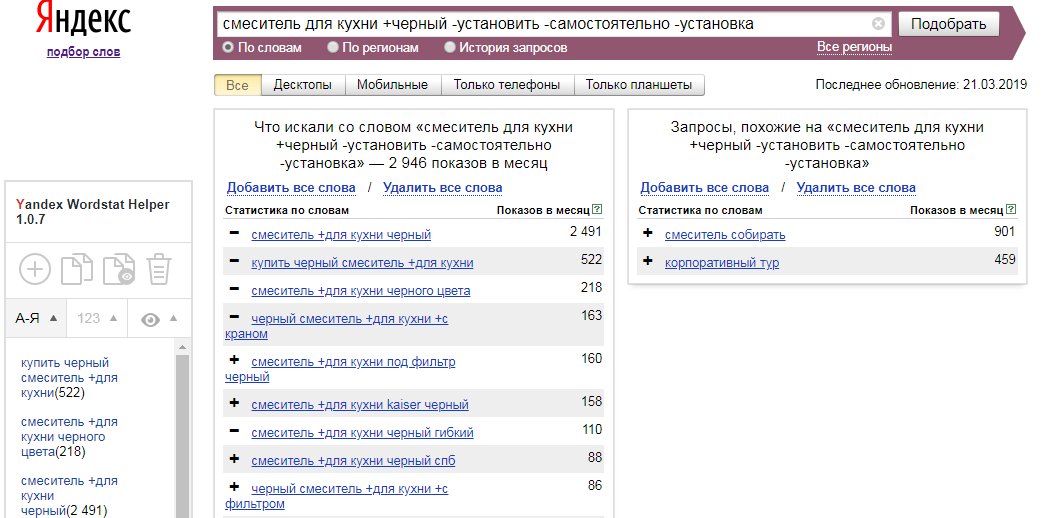
Подборка ключевых слов Яндекс при помощи специальных операторов
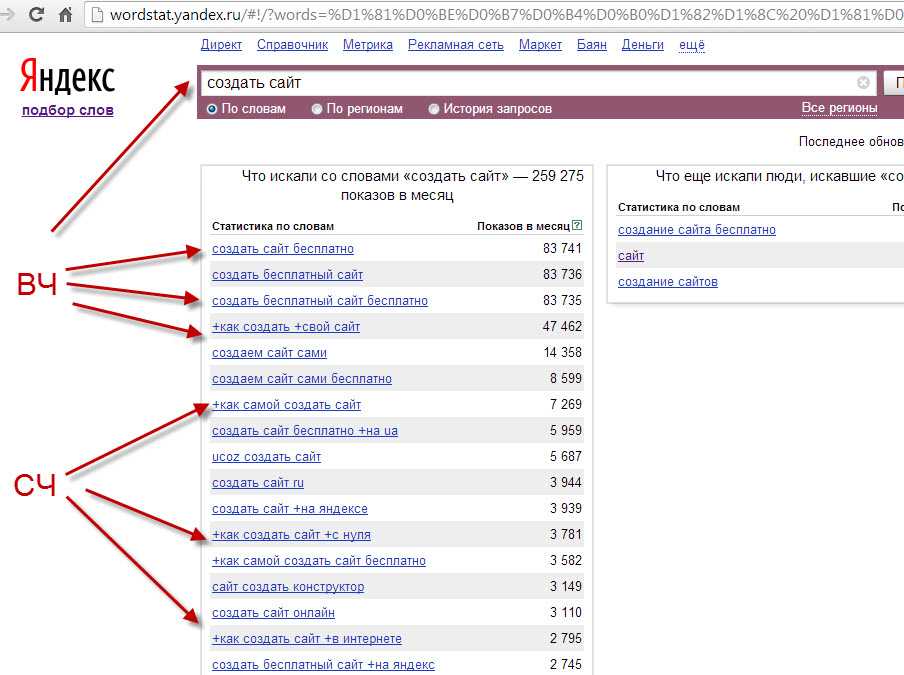
Запросы по ключевым словам Яндекс Вордстат всегда можно уточнить, и тогда полученная статистика будет ограничена нужными вам параметрами. Обычно это требуется, если основное слово или фраза очень популярны, и статистика Вордстат занимает не одну страницу.
Простые операторы помогут сократить эти списки возможных ключевых слов, исключив из их числа заведомо неподходящие. Либо, как вариант, всегда можно вместо одного многостраничного списка собрать несколько, но каждый из них будет выборкой с учетом разных вариантов детализации. С такими списками работать намного удобнее, чем вручную отсеивать все неподходящие «ключевики».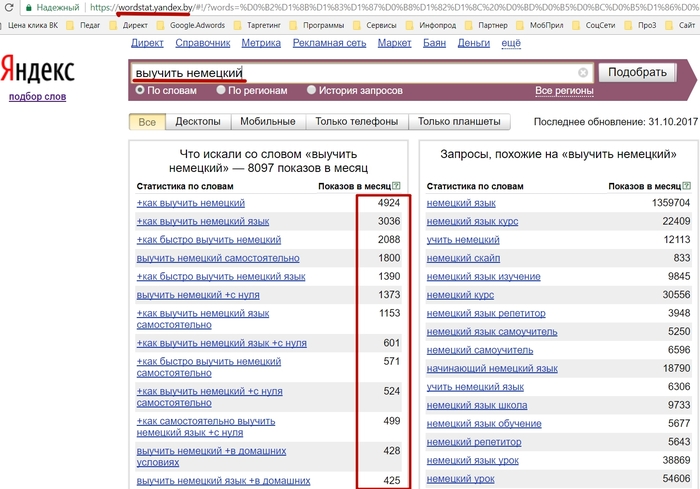
Ниже представлены 5 таких операторов поиска:
- Знак «». Помогает ограничить выдачу поисковой статистики только нужным количеством слов. Избавляет от слишком длинных дополнительных «хвостов». Вернемся к примеру со словом копирайтер. Если вы хотите, чтобы выдача ограничивалась фразами не более чем из 3 слов, можно написать «копирайтер копирайтер копирайтер». И тогда вы получите все варианты ключевых запросов из трех слов, одно из которых – обязательно «копирайтер». Но если вы решите указать фразу без повторяющихся слов, например «купить автомобиль», то выдача будет содержать только эти слова в разных словоформах и последовательности (слова будут меняться местами).
- Знак !. Помогает жестко задать форму слова определенного слова. Например, если вы напишете запрос «копирайтер в !Москве», то слово «копирайтер» будет встречаться в любых возможных падежах, а вот Москва будет только в варианте «в Москве». Это особенно удобно при подборе фраз под анкоры или заголовки объявлений.
- Знак +. Позволяет проводить поиск ключевых слов в Яндекс Вордстат без использования предлогов и других ничего не значащих слов. Например, вы хотите собрать разные варианты слов и словосочетаний, связанных с поиском работы для программистов. Если вы напишете просто «работа для программиста», то предлог «для» будет учитываться в процессе сбора статистики. А ведь ваши целевые запросы могут и не содержать этого предлога, например, «работа программисту» или «программист поиск работы». Конструкция «работа + программист» поможет обойти это ограничение и получить выборку по всем возможных фразам, содержащим слова, объединенные оператором «+». Причем, эти слова будут располагаться в любом порядке и между ними могут находиться любые предлоги и другие конструкции.
- Знак –. Предназначен для удаления из списка рейтинга ключевых слов Яндекс Вордстат, так называемых, «минус слов». Т.е. в этом случае слова после знака «минус» будут исключаться из выдачи. Очень удобно, если вы хотите исключить неподходящие слова. Например, вы хотите собрать сео ядро для продажи программного продукта. Оператор поможет избавиться от многочисленных фраз «скачать», «скачать бесплатно» и т.д.
- Знак () и |. Его называют оператором перебора. В этом случае вы можете объединить несколько запросов в один общий список. Например, вам нужно подобрать подходящие слова для двух сходных между собой словосочетаний: «купить автомобиль» и «купить машину». Составляете такую конструкцию: купить (автомобиль|машину). И получаете объединенный список для двух вариантов второго слова. Это помогает сэкономить много времени.
 Очень удобно, если вы хотите исключить неподходящие слова. Например, вы хотите собрать сео ядро для продажи программного продукта. Оператор поможет избавиться от многочисленных фраз «скачать», «скачать бесплатно» и т.д.
Очень удобно, если вы хотите исключить неподходящие слова. Например, вы хотите собрать сео ядро для продажи программного продукта. Оператор поможет избавиться от многочисленных фраз «скачать», «скачать бесплатно» и т.д.При выборе ключевых фраз Yandex обязательно обращайте внимание на количество запросов в месяц. Минимальное их количество каждый определяет для себя сам, с учетом тематики и потребностей. Если число фраз небольшое, то вы увидите их все на одной странице. При работе с высокочастотниками, когда список фраз очень большой, статистика ключевых слов Вордстат ограничивает их 40 страницами. Полный перечень вариантов вы можете увидеть, если будете использовать специализированные программы парсинга (Key Collector, SlovoEB и др.).
Полный перечень вариантов вы можете увидеть, если будете использовать специализированные программы парсинга (Key Collector, SlovoEB и др.).
Бонусный совет: как избавиться от капчи в Вордстат
И напоследок, поделимся с вами полезным советом, как быстро избавиться от вечного «убийцы» вашего времени – капчи от Яндекс Вордстат. При единичных случаях использования сервиса ключевых слов Яндекс она редко всплывает. Но если вы всерьез собираете сео-ядро в режиме онлайн, после 2-3 проверок ключевиков вас ждут постоянные просьбы ввести какие-то фразы по-русски или по-английски. Это не только раздражает, но и замедляет сбор статистики.
Во-первых, отключите в своем браузере блокировщик рекламы Adblock Plus (ABP) или его аналог, которым вы пользуетесь. При неработающем блокировщике Яндекс Вордстат, скорей всего, перестанет к вам «приставать» с постоянной просьбой «доказать, что вы не бот».
Другой вариант решения этого вопроса – пользуйтесь сервисом по ссылке direct.yandex.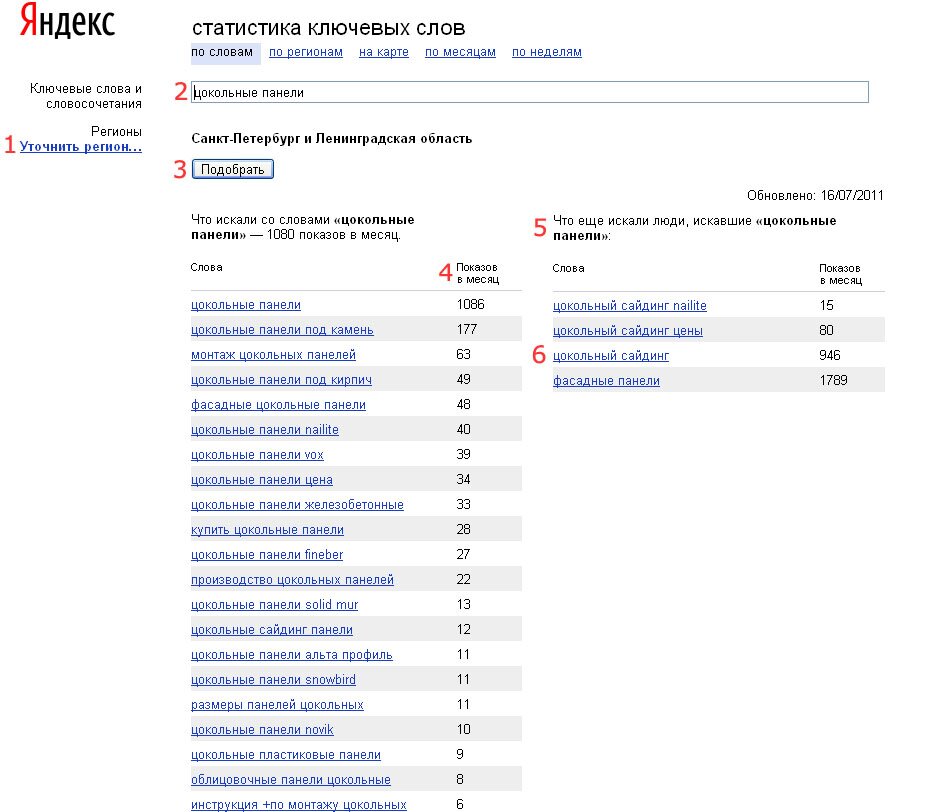 ru. Он предназначен для работы с контекстной рекламой. Но уже на основной странице вы увидите ссылку на сервис «Прогноз бюджета». Здесь у вас есть возможность работать одновременно с целым списком ключевых фраз, пользоваться отдельным «всплывающим окном» для ввода минус слов и т.д.
ru. Он предназначен для работы с контекстной рекламой. Но уже на основной странице вы увидите ссылку на сервис «Прогноз бюджета». Здесь у вас есть возможность работать одновременно с целым списком ключевых фраз, пользоваться отдельным «всплывающим окном» для ввода минус слов и т.д.
В принципе, сервис сравнительно прост, также интуитивно понятен. А его подробное описание можно посмотреть в статьях, посвященных настройке контекстной рекламы Яндекс. С одной стороны, он не столь нагляден, в нем нет некоторых полезных функций (например, истории запросов), с другой – подбор ключевых фраз Яндекс Вордстат здесь работает по тем же алгоритмам, а капчи в сервисе не предусмотрено.
Мы надеемся, что статья помогла вам разобраться, как искать ключевые слова в Яндексе и пользоваться статистикой Вордстат для подбора ключевых слов. А если у вас, не смотря на все наши статьи и советы, все равно остаются вопросы или просто нет времени на долгие часы ручной обработки статистических данных для правильного отбора наиболее подходящих «ключей», вы всегда можете заказать услугу составления сео-ядра профессионалам.
Остались вопросы?
наш телефон:
+7 (499) 340 64 04
Статистика слов по Яндекс
Статистика слов по Яндекс| Поисковый запрос | Позиция наша на Яндекс по всем регионам | Позиция наша на Яндекс по Беларуси | Статистика ключевых слов | |||||||||
| Запчасти для стиральных машин | До 7 страницы нету | 48 | запчасти +для стиральных машин — 20678 запчасти +к стиральным машинам — 3636 магазин запчастей +для стиральных машин — 1478 купить запчасти +для стиральной машины — 1458 | |||||||||
| Запчасти для СВЧ | 14 | 15 | запчасти +для свч — 35 свч печь запчасти – 18 запчасти +для свч печей — 14 | |||||||||
| Запчасти к микроволновым печам | 26 | 23 | запчасти микроволновая печь – 54 запчасти +к микроволновым печам – 24 купить запчасти +для микроволновых печей — 4 | |||||||||
| Запчасти для холодильников | До 7 страницы нету | До 7 страницы нету | ||||||||||
| Запчасти к кофеваркам | 49 | 23 | запчасти +для кофеварки — 4 | |||||||||
| Ремень к стиральной машине | 3 | 3 | ремень +для стиральной машины – 45 ремни +к стиральным машинам – 13 ремень привода стиральной машины — 6 | |||||||||
| Тэн для стиральной машины | До 7 страницы нету | 29 | тэн +для стиральной машины – 203 купить тэн +для стиральной машины – 71 тэн +для стиральной машины lg – 49 | |||||||||
| Сальники для стиральных машин | До 7 страницы нету | 54 | сальник +для стиральной машины – 18 сальники +к стиральным машинам — 11 | |||||||||
| Подшипники для стиральных машин | 42 | 20 | замена подшипника +в стиральных машинах – 110 подшипники +для стиральных машин – 75 купить подшипник стиральной машины — 17 | |||||||||
| Слюда к СВЧ печам | 15 | 2 | Нет запросов | |||||||||
| Слюда к микроволновым печам | 7 | 2 | микроволновая печь слюда – 4 слюда +для микроволновой печи – 3 купить слюду +для микроволновой печи — 3 | |||||||||
| Запчасти к мясорубке Braun | 4 | 3 | мясорубки braun запчасти — 27 | |||||||||
| Запчасти к мясорубке Мулинекс | 6 | 6 | мулинекс мясорубка запчасти – 9 купить запчасти +для мясорубки мулинекс — 4 | |||||||||
| Магнетрон купить | 22 | 13 | куплю магнетрон – 58 магнетрон купить – 58 купить магнетрон +в минске – 12 магнетрон +для свч купить — 8 | |||||||||
| Портативный усилитель звука | 5 | 5 | портативный усилитель звука — 12 | |||||||||
| Клипса от храпа | 3 | — | клипса +от храпа – 21 клипса +от храпа купить — 7 | |||||||||
| Двигатель тарелки СВЧ | 2 | 2 | Двигатель тарелки СВЧ — 7 | |||||||||
| Двигатель стола СВЧ | 6 | 2 | Нет запросов | |||||||||
| Вспениватель молока | нету | нету | вспениватель молока – 16 ручной вспениватель молока – 7 вспениватель молока купить – 6 купить ручной вспениватель молока -5 | |||||||||
Проведя анализ по товарам, которые мы реализуем через интернет-магазин, и которые являются популярными, где мы находимся в поисковиках и на каких позициях, а также проанализировав Яндексом наиболее популярные запросы и их формулировки, пришла к формулировкам фраз, которые необходимо продвигать через контекстную рекламу.
Общедоступные наборы данных
Логотип TolokaПолучить бесплатную демоверсию
Войти
С тысячами аннотаторов, ежедневно выполняющих миллионы оценок в сотнях задач, Толока является основным источником
обучающих данных, помеченных человеком. Toloka поддерживает академические исследования и инновации, обмениваясь большими объемами
точных данных, применимых к машинному обучению в различных областях.
Обратите внимание: эти общедоступные наборы данных доступны только для некоммерческого использования с четкой ссылкой на Толоку как на источник данных.
Если вы планируете использовать какой-либо из этих наборов данных в коммерческих целях, свяжитесь с нами для получения нашего согласия.
CVNLPcrowdsourcing
Наборы данных рукописного текста
Этот набор данных содержит более 7000 изображений рукописного текста от более чем 100 уникальных авторов на 3 языках: испанском, французском и арабском. Набор данных хорошо подходит для обучения и тестирования моделей распознавания рукописного текста. Изображения содержат текст со знаками препинания и уникальными для каждого языка символами, которых нет в латинском алфавите, что усложняет задачу распознавания по сравнению с другими эталонными наборами данных с открытым исходным кодом, доступными для распознавания текста.
Скачать
Архив ZIP, 10,8 ГБ
Метки: тексты. информационные знаки, снятые в Российской Федерации, с нанесенными на них кодами ИНН (ИНН) и ОГРН (ОГРН). Толока использовалась как для фотосъемки, так и для распознавания кодов ИНН и ОГРН.
 Набор данных хорошо подходит для обучения и тестирования моделей распознавания рукописного текста. Изображения содержат текст со знаками препинания и уникальными для каждого языка символами, которых нет в латинском алфавите, что усложняет задачу распознавания по сравнению с другими эталонными наборами данных с открытым исходным кодом, доступными для распознавания текста.
Набор данных хорошо подходит для обучения и тестирования моделей распознавания рукописного текста. Изображения содержат текст со знаками препинания и уникальными для каждого языка символами, которых нет в латинском алфавите, что усложняет задачу распознавания по сравнению с другими эталонными наборами данных с открытым исходным кодом, доступными для распознавания текста.Скачать
Zip Archive, 19,5 ГБ
Метки: Data.tsv
Фотографии: Фотографии/
Toloka Watermeters
Этот наход, собранной Roman Kucev от TrainingData. и счетчиков холодной воды, а также их показания и координаты дисплеев, отображающих эти показания. Каждое изображение содержит ровно один счетчик воды. В архив также включены фотографии результатов сегментации с масками и коллажами. Толока использовалась для фотосъемки, сегментации и распознавания показаний.
 Каждое изображение содержит ровно один счетчик воды. В архив также включены фотографии результатов сегментации с масками и коллажами. Толока использовалась для фотосъемки, сегментации и распознавания показаний.
Каждое изображение содержит ровно один счетчик воды. В архив также включены фотографии результатов сегментации с масками и коллажами. Толока использовалась для фотосъемки, сегментации и распознавания показаний.Скачать
Архив почтового индекса, 981 МБ
Фотографии: изображения/
Маски: Маски/
коллажи: коллаж/
Оценка человеческих данных. Написание сюжета из предварительно обученных языковых моделей», этот набор данных оценивает сгенерированные истории на основе различных базовых показателей по нескольким аспектам: естественность, интересность, связность и окончание истории. Отдельные оценочные задания выполнялись для каждого аспекта естественности, интересности и связности в 50 сгенерированных историях. Дополнительное задание оценивало концовки историй в 50 случайно выбранных парах (история, концовка) как попарные сравнения.
Подробнее
Необработанные данные: general-new. tsv
tsv
В каждой папке:
Метки: full-annotation-result-new.tsv
Демонстрационные примеры с
ожидаемыми метками: train.csv
- 6
RuBQ 2.0: Инновационный набор данных ответов на вопросы в России
RuBQ 2.0 — вторая версия RuBQ. Он содержит 2910 вопросов, а также ответы и запросы SPARQL. Набор данных можно использовать для оценки KBQA и понимания машинного чтения, поиска абзацев, сквозных ответов на открытые вопросы и экспериментов в гибридном QA, где KBQA и текстовый QA могут обогащать и дополнять друг друга.
6
Учить больше
Набор разработки: rubq_2.0_dev.json
Тестовый набор: rubq_2.0_test.json
Параграфы: rubq_2.0_paragraphs.json
. Викиданные
RuBQ 1.0 (русские вопросы базы знаний, произносится [рубик]) — это первый русский набор данных для ответов на вопросы базы знаний (KBQA). Он состоит из 1500 вопросов различной сложности вместе с их английскими машинными переводами, соответствующими SPARQL-запросами, ответами и подмножеством Викиданных, охватывающих объекты с русскими метками. Предполагается, что набор данных будет использоваться в качестве наборов для разработки и тестирования при межъязыковом переносе, обучении за несколько шагов или обучении с использованием сценариев синтетических данных.
 Предполагается, что набор данных будет использоваться в качестве наборов для разработки и тестирования при межъязыковом переносе, обучении за несколько шагов или обучении с использованием сценариев синтетических данных.
Предполагается, что набор данных будет использоваться в качестве наборов для разработки и тестирования при межъязыковом переносе, обучении за несколько шагов или обучении с использованием сценариев синтетических данных.Learn Dire Dore
Набор разработки:
RUBQ_1.0_DEV.JSON
Тестовый набор: RUBQ_1.0_TEST.JSON
TOLOKA Persona CHAT RUS
. Лаборатория нейронных сетей и глубокого обучения МФТИ для исследования разговорного ИИ. Набор данных содержит профили воображаемых личностей с описаниями и диалогами между участниками, которым дают случайный профиль и просят имитировать описанную личность.
Скачать
Архив почтового индекса, 8,19 МБ
Профили: Profile.tsv
Диалоги: Диалоги.tsv
Российский нежелательный лекарственный корпус из Twects (Ruadrect)
Созданный в российском нежелательном лекарств. Общие задачи Mining for Health Applications (#SMM4H ’20), этот набор данных состоит из 9515 твитов, описывающих проблемы со здоровьем. Каждый твит помечен на предмет того, содержит ли он информацию о неблагоприятном побочном эффекте, возникшем при приеме препарата. Набор данных был создан совместно с Центром UPenn HLP и Исследовательской лабораторией хемоинформатики и молекулярного моделирования Казанского федерального университета.
 Общие задачи Mining for Health Applications (#SMM4H ’20), этот набор данных состоит из 9515 твитов, описывающих проблемы со здоровьем. Каждый твит помечен на предмет того, содержит ли он информацию о неблагоприятном побочном эффекте, возникшем при приеме препарата. Набор данных был создан совместно с Центром UPenn HLP и Исследовательской лабораторией хемоинформатики и молекулярного моделирования Казанского федерального университета.
Общие задачи Mining for Health Applications (#SMM4H ’20), этот набор данных состоит из 9515 твитов, описывающих проблемы со здоровьем. Каждый твит помечен на предмет того, содержит ли он информацию о неблагоприятном побочном эффекте, возникшем при приеме препарата. Набор данных был создан совместно с Центром UPenn HLP и Исследовательской лабораторией хемоинформатики и молекулярного моделирования Казанского федерального университета.Скачать
ZIP архив, 95,6 КБ
Данные для обучения: task2_ru_train.tsv
Данные для валидации: task2_ru_validation.tsv
Данные для тестирования: task2_ru_test.tsv
Скрипт для скачивания твитов: Readmepy script: Инструкция и
md
Лексические отношения от мудрости толпы (LRWC)
Этот набор данных, собранный Дмитрием Усталовым в 2017 году для метода Watlink, содержит мнения носителей русского языка о связи между родовым термином (гиперонимом) ) и конкретный экземпляр этого термина (гипоним) в 10 600 пар слов. В его основу положены существительные из Национального корпуса русского языка и отношения из лексических онтологий RuThes и RuWordNet.
 В его основу положены существительные из Национального корпуса русского языка и отношения из лексических онтологий RuThes и RuWordNet.
В его основу положены существительные из Национального корпуса русского языка и отношения из лексических онтологий RuThes и RuWordNet.Скачать
ZIP-архив, 2,01 МБ
Входные данные: lrwc-1.1-assignments.tsv
Тренировочные задания: toloka-isa-50-skip-300-train-hit.tsv
Сводные результаты: lrwc-1.1- совокупность.tsv
Характеристики агрегации Толока
Этот набор данных содержит около 60 000 краудсорсинговых меток, собранных на Толоке для 1000 задач, и метки истинности почти для всех из них. Задача состояла в том, чтобы классифицировать веб-сайты по пяти категориям в зависимости от наличия контента для взрослых. Кроме того, каждая задача имеет 52 функции с действительными значениями, которые можно использовать для прогнозирования категории.
Скачать
Архив почтового индекса, 0,45 МБ
Наземная правда: Golden_labels.tsv
Особенности: особенности.
Шуф Этот набор данных, собранный Дмитрием Усталовым в 2017 году, содержит аннотированные человеком смысловые идентификаторы для 2562 контекстов из 20 слов, использованных в общем задании RUSSE’2018 по индуцированию смысла слов и устранению неоднозначности для русского языка. После маркировки каждый контекст дополнительно проверялся и курировался организаторами общего задания.
Загрузить
ZIP-архив, 2,23 МБ Метки толпы:
Assignments_01-12-2017.tsv
Основная правда: report-curated.tsv.xz
Сводные результаты: bts-rnc-crowd.tsv 900 6 152399
CrowdSpeech
Этот набор данных, полученный на Толоке, содержит транскрипции аудиозаписей из LibriSpeech, полученные на Толоке. Этот процесс описан в документе NeurIPS ’21 Datasets and Benchmarks, озаглавленном «CrowdSpeech и VoxDIY: контрольные наборы данных для краудсорсинговой транскрипции аудио».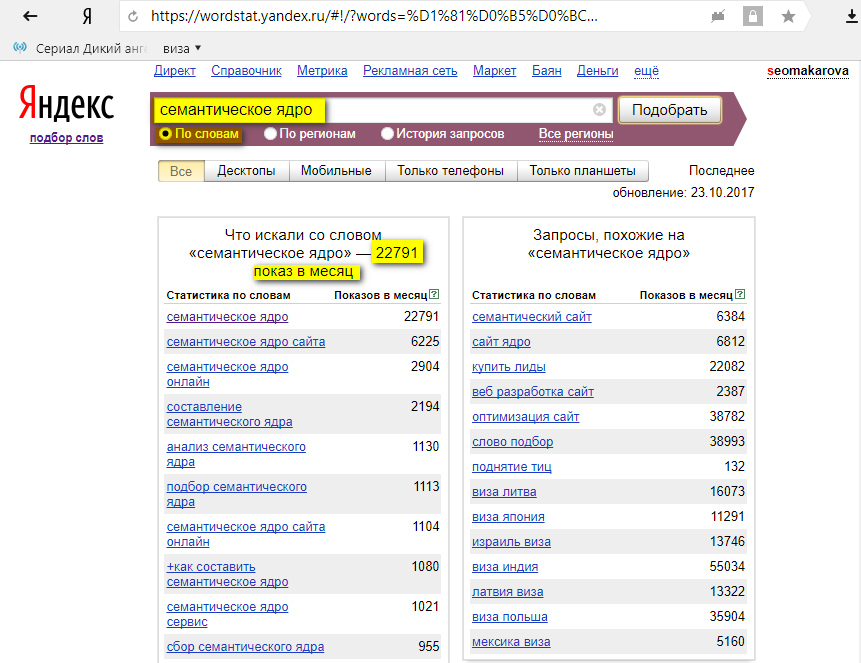
Скачать
ZIP-архив, 2,6 МБ : gt.csv
crowdspeech-test-clean:
Ярлыки толпы: crowd_labels.csv
Основная правда: gt.csv
crowdspeech-test-other:
Ярлыки толпы: crowd_labels.csv
Основная правда: gt.csv
- 16
Толока Агрегация Релевантность 2
Этот набор данных, предназначенный для оценки методов агрегирования ответов в краудсорсинге, содержит около 0,5 млн анонимных краудсорсинговых ярлыков, собранных в рамках проекта «Актуальность 2 Градации» в 2016 году в Яндексе. В этом проекте парам запрос-документ присваиваются бинарные метки: релевантные или нерелевантные. Набор данных также содержит золотые метки для сравнения методов агрегирования.
Скачать
ZIP архив, 3,08 МБ0003
Релевантность агрегации Толока 5
Этот набор данных был разработан для оценки методов агрегации ответов в краудсорсинге. Он содержит около 1 млн анонимных краудсорсинговых ярлыков, собранных в рамках проекта «Актуальность 5 градаций» в 2016 году в Яндексе. В этом проекте пары запрос-документ помечены по шкале от 1 до 5. от наиболее релевантных до наименее релевантных. Набор данных также содержит золотые метки для сравнения методов агрегирования.
 Он содержит около 1 млн анонимных краудсорсинговых ярлыков, собранных в рамках проекта «Актуальность 5 градаций» в 2016 году в Яндексе. В этом проекте пары запрос-документ помечены по шкале от 1 до 5. от наиболее релевантных до наименее релевантных. Набор данных также содержит золотые метки для сравнения методов агрегирования.
Он содержит около 1 млн анонимных краудсорсинговых ярлыков, собранных в рамках проекта «Актуальность 5 градаций» в 2016 году в Яндексе. В этом проекте пары запрос-документ помечены по шкале от 1 до 5. от наиболее релевантных до наименее релевантных. Набор данных также содержит золотые метки для сравнения методов агрегирования.Скачать
ZIP архив, 7,17 МБ
Crowd labels: crowd_labels.tsv
Наземная правда: golden_labels.tsv
Забаненные пользователи: bans.tsv Прогноз почасового дохода и времени выполнения на краудсорсинговой платформе», этот набор данных содержит сеансы активности пользователей, зарегистрированные в 18 миллионах задач, выполненных 161 377 пользователями в Толоке за трехмесячный период (сентябрь-ноябрь 2018 года). Он включает временные метки, анонимные идентификаторы проекта и пользователя, информацию о наградах, количество микрозадач, инструкции, описание схемы данных, ответы и различные описательные свойства задач.
Скачать
Архив ZIP, 1,07 ГБ
Завершенные задачи: назначения. Данные проекта
-WIKI-SbS Этот набор данных, как описано в документе NeurIPS ’20 Data-Centric AI Workshop под названием «IMDB-WIKI-SbS: оценочный набор данных для краудсорсинговых парных сравнений», содержит 9 150 изображений, появляющихся в 250 249 парных сравнениях, аннотированных на Толоке. краудсорсинговая платформа. Он имеет сбалансированное распределение по возрасту и полу с использованием известного набора данных IMDB-WIKI в качестве достоверной информации.
Загрузить
ZIP-архив, 9 МБ
Метки толпы: crowd_labels.csv
Основная правда: gt.csv
У вас есть набор данных, которым вы готовы поделиться? Отправьте его для публикации на этой странице.
Соберите и аннотируйте
свой набор данных
Используйте платформу Толока для подготовки набора данных, который соответствует вашим потребностям.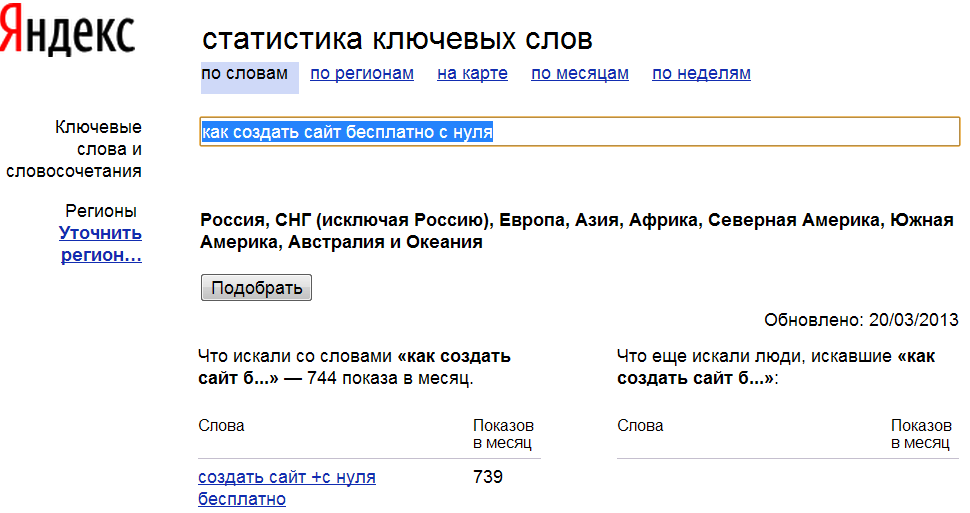
Начать сейчас
Яндекс Метрика — статистика Android SDK
Сделайте свое Android-приложение более популярным Размещайте рекламу в Google Play с продвижением приложений AppBrain Проверьте это
Android-статистика > Android-библиотеки > Яндекс Метрика
Последнее обновление:
Yandex AppMetrica — решение для отслеживания рекламы и аналитики мобильных приложений в режиме реального времени.
Количество приложений
Более 13 тысяч
Общее количество загрузок
Более 34 миллиардов
Теги
Аналитика, #2 в Отчет о сбоях
Веб-сайт
https://tech.yandex.com/metrica-mobile-sdk/
↓ Подробнее о нашей статистике
Статистика
Общая доля рынка
Доля рынка популярных приложений
Доля рынка новых приложений
Связанные библиотеки
Компоненты архитектуры Android· Активность AndroidX · Совместимость с приложением Android Jetpack · Библиотека поддержки Android Async Layout Inflater · Коллекции библиотеки поддержки Android · Адаптер курсора AndroidX · Файл документа библиотеки поддержки Android · AndroidX Legacy: поддержка основного пользовательского интерфейса библиотеки · AndroidX Legacy: поддержка основных утилит библиотеки · Загрузчик AndroidX
Добавьте на свой сайт
