ТОП-10 самых популярных запросов жителей Литвы в разных категориях
Продолжая традицию, которая длится уже 22 года, Google обнародовал результаты поисковых запросов за минувший год. В уходящем году в центре внимания жителей Литвы была война России в Украине, текущие события, связанные с пандемией COVID-19. Наши сограждане интересовались также баскетболом и футболом, выбирали независимого поставщика электроэнергии.
Google опубликовал ТОП-10 самых популярных запросов жителей Литвы в разных категориях
«Тенденции поисковых запросов Google за год отражают, чем отличались последние 12 месяцев, чем мы все жили — какие события, новости, личности, фильмы, сериалы и другие вещи были действительно важны для людей», — говорит Витаутас Кубилюс, глава Google в странах Балтии.
Война в Украине, несомненно, была одной из самых горячих тем 2022 года, а слово «Украина» заняло третье место в списке поисковых запросов. Люди искали информацию как о президенте России Владимире Путине, так и о президенте Украины Владимире Зеленском.
Немало внимания в этом году уделялось и отступающей пандемии. Жителей Литвы, особенно в первом полугодии, интересовали «паспорт возможностей», горячая линия 1808, вакцинирование и т.д.
Еще одной важной темой был выбор независимого поставщика электроэнергии: люди спрашивали у Google, как это сделать, а также искали и самих поставщиков — Elektrum, Enefit и др.
Список событий и мероприятий года возглавили Чемпионат Европы по баскетболу, «Евровидение» и Чемпионат мира по футболу. Однако в конце этого списка можно найти и сюрприз — Вильнюсскую ель, получившую как никогда много внимания. Правда, несмотря на бушующие дискуссии, ее все же обогнали традиционные праздники — Пасха, Масленица и Йонинес.
Статистика Google позволяет узнать, какие фильмы и сериалы чаще всего интересовали жителей нашей страны в интернете. Показывает, что интернет-пользователи грустили из-за смерти королевы Великобритании Елизаветы II и покинувших этот мир знаменитых жителей Литвы.
Ниже можно увидеть, какие поисковые запросы жителей Литвы были самыми популярными в Google в уходящем году.
ТОП года
- EuroBasket 2022
- Galimybių pasas
- Ukraina
- World Cup 2022
- 1808
- Vakcinos nuo COVID-19
- CNN
- Forum cinemas
- Elektrum
- BBC News
Люди
- Vladimiras Putinas
- Monika Liu
- Mika
- Dua Lipa
- Amber Heard
- Simonas Levievas
- Volodymyras Zelenskis
- Andrew Tate’as
- Benas Aleksandravičius
- Luka Dončičius
Фильмы и сериалы
- Stranger Things
- (Ne)Viskas įskaičiuota
- The Tinder Swindler
- Monster: The Jeffrey Dahmer Story
- Don’t Look Up
- Rimti reikalai 4
- Euphoria
- Tautos tarnas
- Purple Hearts
- Kas juoksis paskutinis?
Торговые знаки
- CNN
- Forum cinemas
- Elektrum
- BBC News
- Enefit
- UNIAN
- NEXTA
- Zalando
- Flightradar24
- Apollo Kinas
Люди, которые покинули этот мир
- Karalienė Elžbieta II
- Technoblade
- Viktoras Malinauskas
- Mantas Kvedaravičius
- Gintaras Reklaitis
- Regimantas Adomaitis
- Betty White
- Irena Marozienė
- Jurijus Šatunovas
- Vladimiras Žirinovskis
Запросы со словом «как»
- Kaip gauti galimybių pasą? (Как получить «паспорт возможностей»?)
- Kaip pasirinkti elektros tiekėją? (Как выбрать поставщика электричества?)
- Kaip atsisakyti pensijos kaupimo? (Как отказаться от накопления пенсии?)
- Kaip užsiregistruoti PGR testui? (Как зарегистрироваться на ПЦР-тест?)
- Kaip įdiegti programą „Google Chats“? (Как проинсталлировать програму Google Chats?)
- Kaip deklaruoti pajamas? (Как декларировать доходы?)
- Kaip pakelti spaudimą? (Как повысить давление?)
- Kaip užsidirbti pinigų? (Как заработать деньги?)
- Kaip raugti kopūstus? (Как квасить капусту?)
- Kaip ištraukti erkę? (Как вытащить клеща?)
События 2022 года
- EuroBasket (Europos krepšinio čempionatas)
- Eurovizija
- World Cup (Pasaulio futbolo čempionatas)
- Dakaro ralis
- Velykos
- Užgavėnės
- Jūros šventė
- Joninės
- Vilniaus eglė
- Boso diena
Источник
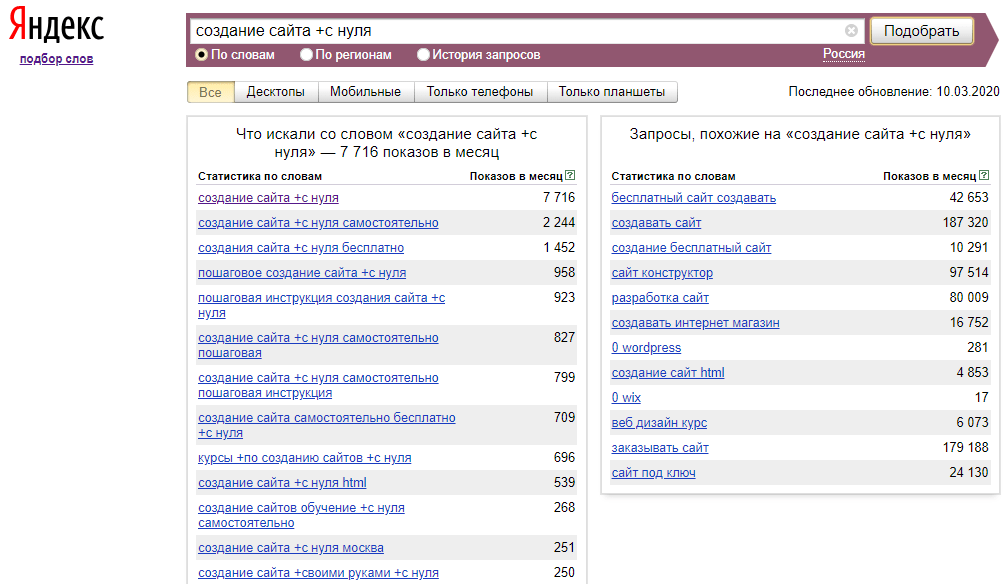
Статистика поисковых запросов в выдаче Гугла – как посмотреть и узнать точное количество слов, анализ ссылок
Создавая очередной сайт, автор проекта в первую очередь рассчитывает на привлечение новых пользователей — популярность сервиса позволяет зарабатывать различными способами, а также способствует дальнейшему развитию.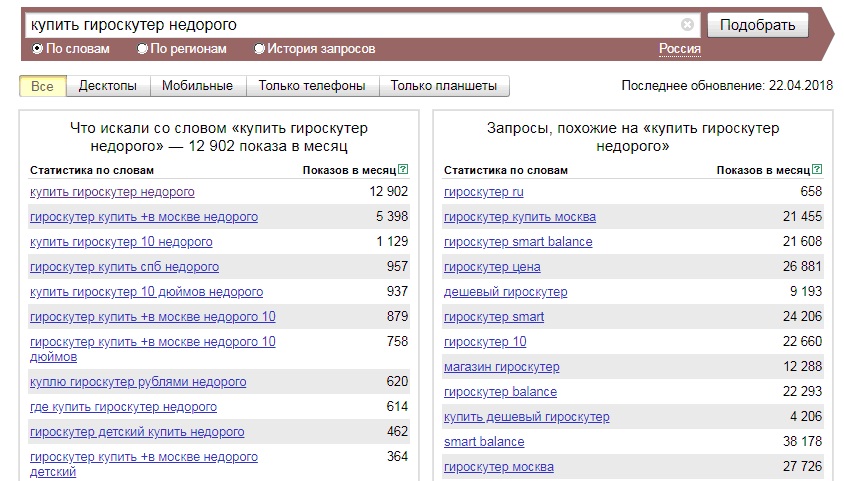 Интерес целевой аудитории важен во всех сферах, будь то ведение блога или страницы в социальной сети, управление онлайн-магазином, выпуск творческого контента или повышение спроса на оказываемые услуги. Для достижения желаемого результата важно учитывать множество нюансов (начиная со специфики выбранного региона и заканчивая особенностями конкретного направления), а также использовать актуальные инструменты, помогающие анализировать данные и отслеживать значимые показатели. Где посмотреть статистику поисковых запросов в Гугле, как узнать точное количество и частотность по словам, и почему анализ метрики выдачи и посещений — ключевой фактор успешного продвижения? Давайте разбираться.
Интерес целевой аудитории важен во всех сферах, будь то ведение блога или страницы в социальной сети, управление онлайн-магазином, выпуск творческого контента или повышение спроса на оказываемые услуги. Для достижения желаемого результата важно учитывать множество нюансов (начиная со специфики выбранного региона и заканчивая особенностями конкретного направления), а также использовать актуальные инструменты, помогающие анализировать данные и отслеживать значимые показатели. Где посмотреть статистику поисковых запросов в Гугле, как узнать точное количество и частотность по словам, и почему анализ метрики выдачи и посещений — ключевой фактор успешного продвижения? Давайте разбираться.
- Общее представление
- Search Console
- Google Реклама
- Вспомогательные каналы
- Запросы из внутреннего поиска
- Что дает анализ Google Trends
- Откуда берется статистика
- Как повысить точность поиска
- В чем разница между Trends и Keyword Planner
- Механика представления данных
- Увеличение объема обработки
- Динамический просмотр данных
- Актуальные сервисы для изучения статистики
- Rush Analytics
- Keyword Tool
- Key Collector
- SemRush
- SpyWords
- Serpstat
- Just-Magic
- Заключение
Общее представление
Информация о ключах, предоставляемая Google Analytics, позволяет определить наиболее релевантные формулировки, повышающие фактическую конверсию. Алгоритмы сервиса демонстрируют, как именно потенциальные клиенты ищут те или иные товары, услуги или сведения, благодаря чему можно адаптировать собственный контент и увеличить объем привлекаемого трафика. Для получения актуальной базы рекомендуется использование сразу нескольких источников, дополняющих друг друга и делающих результаты более точными.
Алгоритмы сервиса демонстрируют, как именно потенциальные клиенты ищут те или иные товары, услуги или сведения, благодаря чему можно адаптировать собственный контент и увеличить объем привлекаемого трафика. Для получения актуальной базы рекомендуется использование сразу нескольких источников, дополняющих друг друга и делающих результаты более точными.
Search Console
Связь Гугл Аналитики и Консоли открывает доступ к системе отчетов. В разделе «Источники» доступна сводная статистика ключевых слов, кликов и показов, их соотношения (Click Through Rate, или CTR) и средней позиции. Данные обновляются каждые 2-3 дня, что обусловливает небольшую задержку, однако в целом инструмент позволяет сформировать общую картину по заданным критериям.
Google Реклама
Механика для изучения перечня поисковых запросов, через которые пользователи переходили на сайт. Отчетом можно пользоваться после того, как будет завершена интеграция рекламного профиля и счетчика Analytics. Алгоритм демонстрирует не только основные ключевые слова, но и издержки в пересчете на один клик.
Вспомогательные каналы
При использовании дополнительных источников продвижения, например, сервисов Яндекса, для аналитического исследования необходимо импортировать данные о расходах. Нужная кампания выбирается после загрузки в соответствующем меню, после чего система автоматически выдаст запрашиваемую таблицу, содержащую следующие сведения:
- CTR (кликабельности баннеров и текстовых вставок).
- CPC (средней стоимости взаимодействия).
- CPL (затратам в пересчете на одного лида).
- CPO (расходам на оформление заявки).
- CPA (критерию цены целевого действия).
- ROI (рентабельности инвестиций).
Запросы из внутреннего поиска
Отчет, представленный в разделе «Поведение», позволяет отслеживать формулировки и словосочетания, которые пользователи ресурса используют для перехода к интересующим их разделам.
Что дает анализ Google Trends
Перечень функциональных возможностей, предоставляемых сервисом, доступен для изучения на главной странице, где каждый из блоков интерфейса соответствует конкретному набору задач. В левом верхнем углу экрана расположено выпадающее меню по категориям («Популярные запросы», «Подписки», «Год в поиске» и др.), а также ссылки на разделы справки и обратной связи. В правой части — выбор региона и стандартная форма для переключения между инструментами Гугла.
В левом верхнем углу экрана расположено выпадающее меню по категориям («Популярные запросы», «Подписки», «Год в поиске» и др.), а также ссылки на разделы справки и обратной связи. В правой части — выбор региона и стандартная форма для переключения между инструментами Гугла.
Центральный элемент — поисковая строка, в которую можно ввести интересующую тему. Система автоматически переадресует пользователя в аналитический раздел, где представлена динамика популярности за последние 12 месяцев, распределение по регионам, а также другие сведения. Наконец, внизу шаблоны отчетности и блоки с актуальными темами, позволяющие быстро сориентироваться в трендах.
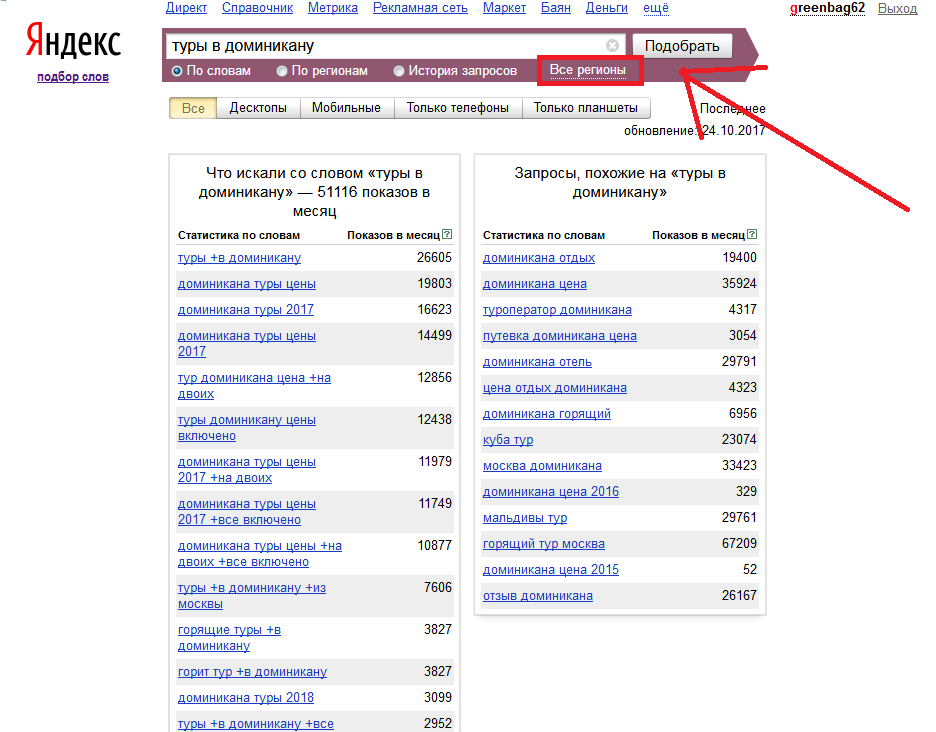
Как вам помогут рекомендованные запросы от Яндекса
В январе 2018 года Яндекс вывел из беты новую функциональность Вебмастера — Рекомендованные запросы. Разбираемся, как с ними работать и какую пользу для продвижения сайта они могут принести. Как получить рекомендованные запросы Рекомендованные запросы доступны владельцу сайта с подтвержденными правами в Яндекс. Вебмастере. Для того, чтобы сформировать отчет, просто зайдите в подраздел Рекомендованные запросы раздела Поисковые запросы: Нажмите кнопку Получить рекомендованные запросы: Срок формирования отчета — около недели. Данные появятся в этом же подразделе в виде таблицы с фильтрами. Если сайт…
Вебмастере. Для того, чтобы сформировать отчет, просто зайдите в подраздел Рекомендованные запросы раздела Поисковые запросы: Нажмите кнопку Получить рекомендованные запросы: Срок формирования отчета — около недели. Данные появятся в этом же подразделе в виде таблицы с фильтрами. Если сайт…
Откуда берется статистика
Trends собирает данные по количеству поисковых запросов Google, соблюдая анонимность пользователей, распределяя их по тематическим категориям и объединяя в группы. Сервис предоставляет возможность просмотра выборки по всем странам и городам в виде отношения общего числа использований конкретного слова за определенный временной промежуток, переведенного в значение по 100-балльной шкале. Информация доступна как за последнюю неделю, так и за весь период существования поисковика без учета последних 36 часов. Стоит отметить, что статистическая модель Трендов не учитывает редкие формулировки, спам от одних и тех же пользователей, а также нестандартные фразы, в которых присутствуют специальные символы.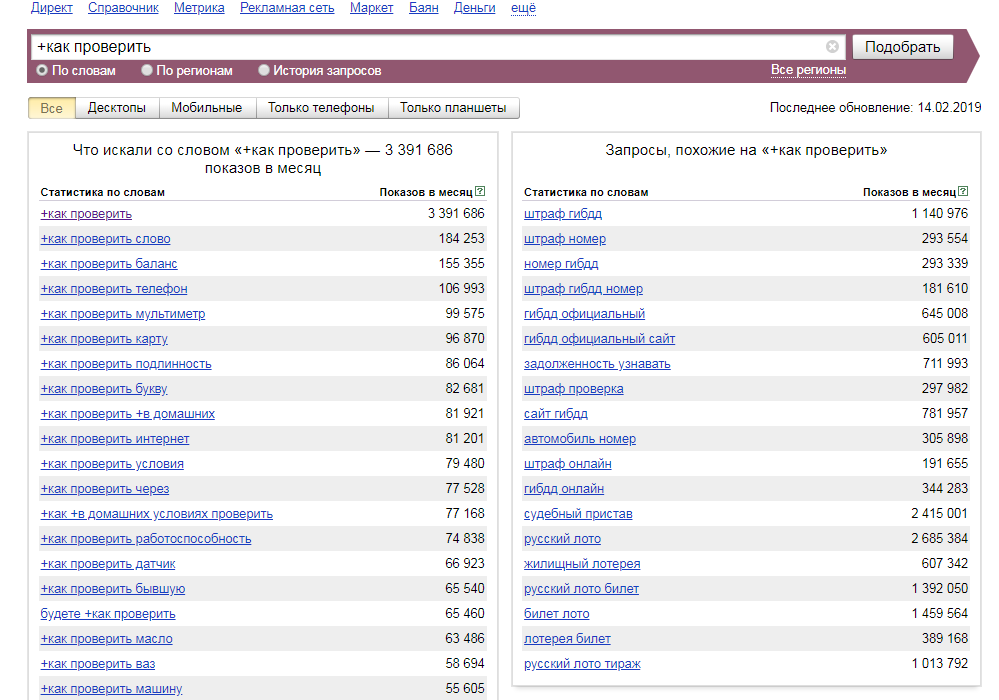
Как повысить точность поиска
Проверка частотности запросов в Google Trends может выявить некоторые расхождения, для устранения которых стоит воспользоваться следующими рекомендациями:
- Использование операторов. На статистику влияют формулировки, содержащие схожие слова — так, в перечень по словосочетанию «купить куртку» также попадут вводные с уточнениями «красную», «зимнюю», «детскую», «модную» и т. д., но при этом не войдут синонимы и сочетания, написанные с орфографическими ошибками. Вспомогательные знаки — кавычки, плюс, минус — помогают исключить отдельные словоформы, зафиксировать последовательность и объединить несколько вариантов написания.
- Уточнение региона и временного периода. Конкретизация помогает понять, что интересует целевую аудиторию в текущий момент — этот аспект особенно важен для тех, кто специализируется на продажах или оказании услуг.
- Применение категорий. Рекомендуется в тех случаях, когда составляющие поисковое обращение фразы имеют несколько трактовок, относящихся к различным тематическим кластерам.
 Для выбора нужного раздела достаточно воспользоваться выпадающим меню.
Для выбора нужного раздела достаточно воспользоваться выпадающим меню.
 Для выбора нужного раздела достаточно воспользоваться выпадающим меню.
Для выбора нужного раздела достаточно воспользоваться выпадающим меню.В чем разница между Trends и Keyword Planner
Планировщик слов — инструмент, применяемый при составлении семантического ядра, на основе которого разрабатывается контекстная реклама. В нем точно так же имеется счетчик, показывающий, сколько запросов в Гугл было выполнено в отдельно взятом регионе. Однако есть и определенные отличия от Трендов.
Механика представления данных
Алгоритм Планера построен на усредненных значениях, характеризующих частоту обращений за определенный период. При этом объем отражается в конкретных числах, а не в баллах по условной шкале. Так, в Trends статистика по двум разным регионам с равнозначным количеством может отличаться, поскольку сумма по всем ключам будет разной. А вот Keyword Planner в аналогичной ситуации покажет одинаковые цифры.
Увеличение объема обработки
Планировщик предоставляет возможность импорта списка ключевых фраз, практически моментально выводя результат по всем заявленным позициям.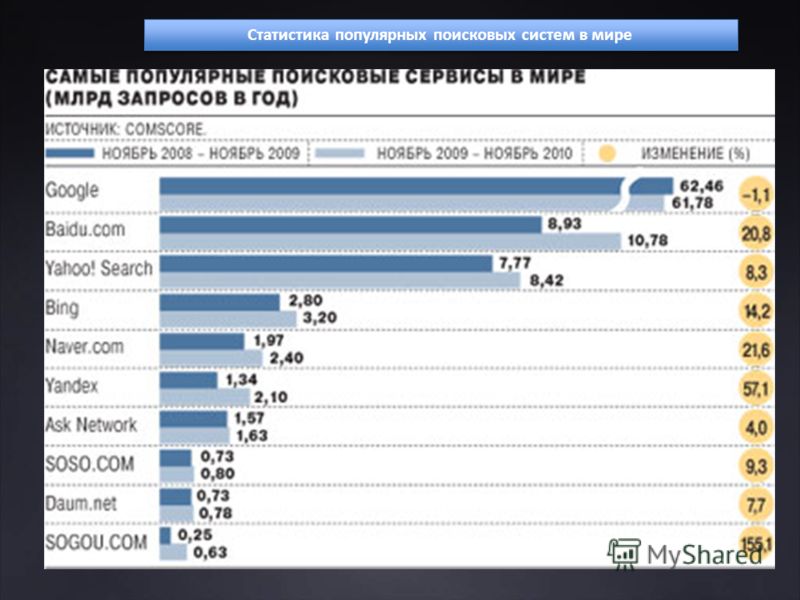 Тренды, в свою очередь, позволяют сравнивать не более пяти ключей, что ограничивает полноценный анализ больших массивов.
Тренды, в свою очередь, позволяют сравнивать не более пяти ключей, что ограничивает полноценный анализ больших массивов.
Динамический просмотр данных
Функционал Google trending topics предлагает следить за изменением популярности конкретного запроса в онлайн-режиме: какие темы пользуются спросом, а что уже начало терять первоначальный интерес аудитории. Keyword Planner ограничивается обобщением сведений относительно ежемесячной частоты.
Актуальные сервисы для изучения статистики
Современные алгоритмы помогают решить множество задач: они анализируют базы данных поисковиков, формируют статистические отчеты, характеризующие релевантность значений, и делают это максимально быстро. Разработчики создают эффективные инструменты, отличающиеся как функционалом, так и способами представления информации. В качестве дополнения, а иногда и альтернативы рассмотренным выше системам, можно рассматривать следующие варианты.
Rush Analytics
Платформа, предназначенная для сбора ключей и формирования семантической структуры, применение которой заметно экономит время SEO-оптимизации. Возможности сервиса позволяют как проверить частотность запросов в Гугл, так и собрать статистику по ссылкам — для анализа индексации и подсказок, подбора актуальных маркеров и получения рекомендаций по улучшению рекламного контента.
Возможности сервиса позволяют как проверить частотность запросов в Гугл, так и собрать статистику по ссылкам — для анализа индексации и подсказок, подбора актуальных маркеров и получения рекомендаций по улучшению рекламного контента.
Спектральные запросы: что это такое и как использовать их для продвижения
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA Что такое технология «Спектр» в Яндексе и как она работает В интернете можно найти практически любую информацию. Но поисковикам не всегда удается понять, что вы спрашиваете и какой ответ хотите получить. В нашей статье мы уже рассматривали язык запросов – прочитайте, если хотите всегда получать те сведения, которые вам нужны. Неоднозначные вопросы задают часто, поэтому поисковики вынуждены подстраиваться и совершенствовать алгоритмы. В выдаче Яндекса с 2010 года работает функция «Спектр».…
Keyword Tool
Инструмент, охватывающий широкий спектр источников. Помимо основных поисковых систем, он также учитывает популярные социальные сети и видеохостинги.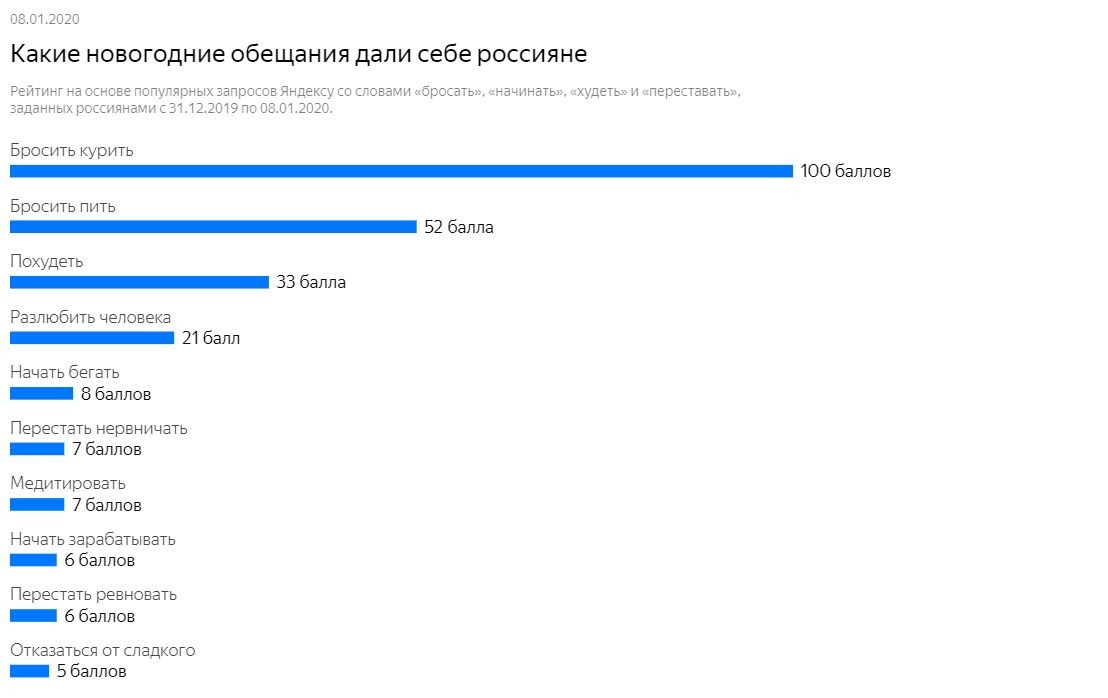 Ключевые слова подбираются исходя из заданной тематики с уточнением домена, языка и региона. Дополнением к рекомендациям служат дифференцированная статистика в формате вопросов и хэштегов, перечень минус-слов и функция просмотра стоимости одного клика в рекламных сервисах.
Ключевые слова подбираются исходя из заданной тематики с уточнением домена, языка и региона. Дополнением к рекомендациям служат дифференцированная статистика в формате вопросов и хэштегов, перечень минус-слов и функция просмотра стоимости одного клика в рекламных сервисах.
Key Collector
Сервис для работы с семантическим ядром и контекстной рекламой, автоматически подбирающий лучшие варианты на основе анализа более чем 30 источников. Функционал предусматривает возможность применения фильтров, поиска дублей и минусовых словоформ, а также визуализации структуры для последующего редактирования.
SemRush
Система, определяющая объем поисковых запросов для каждого ключа, и составляющая на основе полученных данных прогноз будущей динамики. Предлагает рекомендации по подбору, которые должны способствовать привлечению дополнительного трафика и повышению конверсии.
SpyWords
Платформа для сбора ключевых слов под рекламные кампании, анализирующая опубликованные конкурентами объявления, и выделяющая основные маркеры. Преимущество — возможность прямого сравнения доменов и расчета маркетингового бюджета по дням.
Преимущество — возможность прямого сравнения доменов и расчета маркетингового бюджета по дням.
Serpstat
Аналитический сервис, оценивающий структуру созданного сайта, и показывающий, какие именно потенциально эффективные запросы могли быть упущены при подготовке семантического ядра. Удобен с точки зрения оптимизации, предоставляет статистику распределения совокупного трафика.
Just-Magic
Набор инструментов, вполне достаточный для быстрого формирования семантики, анализа публикуемого контента и кластеризации по категориям. Дополнительный плюс — функция составления технического задания для написания SEO-оптимизированных статей.
Заключение
Разнообразие доступных сервисов заметно облегчает решение задач, связанных с продвижением в Сети. Грамотное использование современных разработок позволяет без особого труда рассчитать бюджет рекламной кампании, проанализировать качество и кол-во запросов в Google, а также спрогнозировать посещаемость сайта в ближайшей перспективе.
CVE.report — clickhouse
Ниже перечислены 10 новейших известных уязвимостей, связанных с «Clickhouse» от «Яндекса».
Эти CVE извлекаются на основе точных совпадений в указанной информации о программном обеспечении, оборудовании и поставщике (данные CPE), а также на основе поиска по ключевым словам, чтобы обеспечить отображение новейших уязвимостей без официально указанной информации о программном обеспечении.
Данные об известных уязвимых версиях также отображаются на основе информации от известных CPE
| CVE | Сокращенное описание | Серьезность | Дата публикации | Последнее изменение |
|---|---|---|---|---|
| CVE-2021-43305 | Переполнение буфера кучи в кодеке сжатия Clickhouse LZ4 при анализе вредоносного запроса. Нет подтверждения, что… | 8.8 — ВЫСОКИЙ | 2022-03-14 | 08.12.2022 |
| CVE-2021-43304 | Переполнение буфера кучи в кодеке сжатия Clickhouse LZ4 при анализе вредоносного запроса. Нет подтверждения, что… Нет подтверждения, что… | 8.8 — ВЫСОКИЙ | 2022-03-14 | 08.12.2022 |
| CVE-2021-42391 | Деление на ноль в кодеке сжатия Clickhouse Gorilla при анализе вредоносного запроса. Первый байт сжатого буфера… | 6,5 — СРЕДНЯЯ | 2022-03-14 | 2022-03-22 |
| CVE-2021-42390 | Деление на ноль в кодеке сжатия Clickhouse DeltaDouble при анализе вредоносного запроса. Первый байт сжатого… | 6,5 — СРЕДНЯЯ | 2022-03-14 | 2022-03-22 |
| CVE-2021-42389 | Деление на ноль в кодеке сжатия Delta компании Clickhouse при анализе вредоносного запроса. Первый байт сжатого буфера… | 6,5 — СРЕДНЯЯ | 2022-03-14 | 2022-03-22 |
| CVE-2021-42388 | Heap out-of-bounds считан кодеком сжатия Clickhouse LZ4 при анализе вредоносного запроса. Как часть LZ4::decompressI.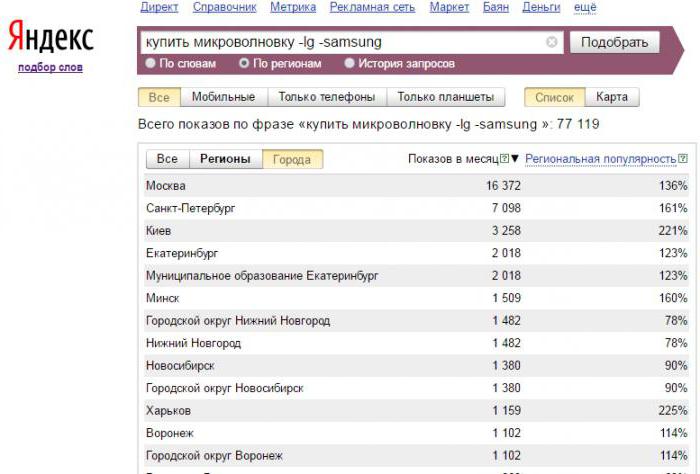 .. .. | 8.1 — ВЫСОКИЙ | 2022-03-14 | 08.12.2022 |
| CVE-2021-42387 | Heap out-of-bounds считан кодеком сжатия Clickhouse LZ4 при анализе вредоносного запроса. Как часть LZ4::decompressI… | 8.1 — ВЫСОКИЙ | 2022-03-14 | 03.12.2022 |
| CVE-2021-25263 | Уязвимость локальных привилегий в Яндекс.Браузере для Windows до версии 21.9.0.390 позволяет локальному злоумышленнику с низкими привилегиями… | 7,8 — ВЫСОКИЙ | 2021-08-17 | 2023-02-10 |
| CVE-2019-16535 | Во всех версиях ClickHouse до 19.14 чтение OOB, запись OOB и потеря значимости целочисленного значения в алгоритмах декомпрессии могут… | 9.8 — КРИТИЧЕСКИЙ | 2019-12-30 | 03.01.2020 |
| CVE-2019-15024 | Во всех версиях ClickHouse до 19.14.3 злоумышленник, имеющий доступ на запись к ZooKeeper и способный запустить пользовательскую се. .. | 6,5 — СРЕДНЯЯ | 2019-12-30 | 2020-08-24 |
Известные затрагиваемые конфигурации (CPE V2.3)
| Тип | Поставщик | Продукт | Версия | Обновление | Издание | Язык |
|---|---|---|---|---|---|---|
| Приложение | Яндекс | Clickhouse | 20.1.1.2042 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 20.1.1.2039 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.9.5.36 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.9.4.34 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.9.3.31 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19. 9.2.4 9.2.4 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.8.3.8 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.7.5.29 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.7.5.27 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.7.3.9 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.6.3.18 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.6.2.11 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.5.4.22 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19. 5.3.8 5.3.8 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.5.2.6 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.4.5.35 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.4.4.33 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.4.3.11 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.4.2.7 | Все | Все | Все |
| Приложение | Яндекс | Clickhouse | 19.4.1.3 | Все | Все | Все |
Популярные запросы для Clickhouse
Clickhouse
Немногие слышали о Clickhouse, в том числе и я до недавнего времени.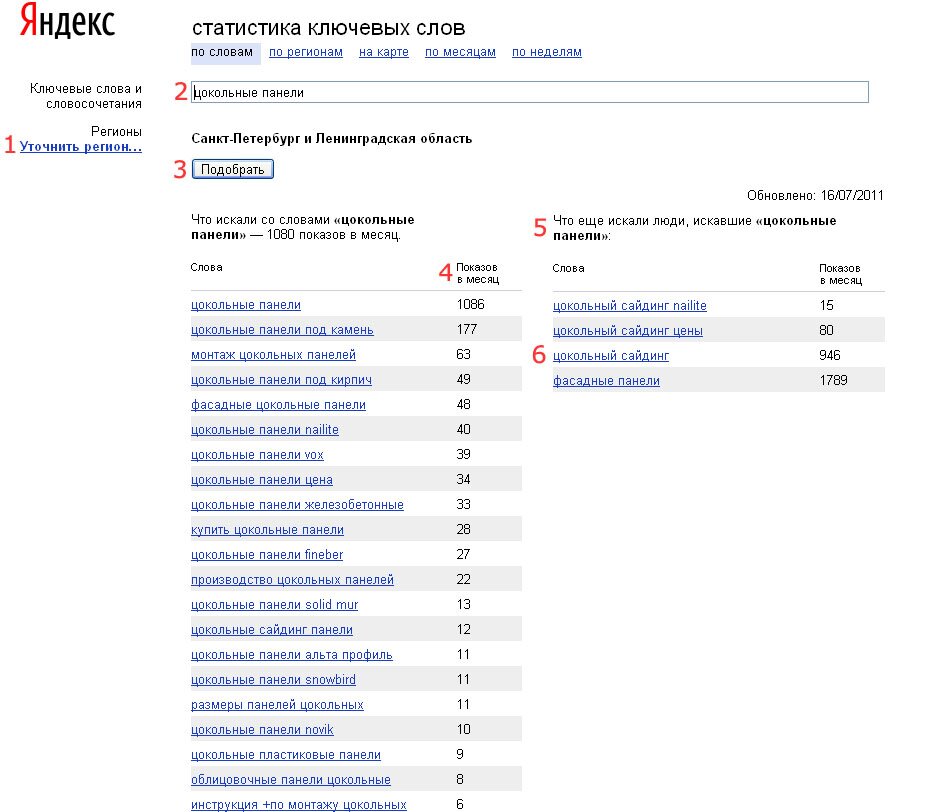 У него странное имя, которое на самом деле не дает вам никакого представления о том, что это такое или что оно делает, но это большинство названий приложений в наши дни (обязательная ссылка на «Покемон или большие данные?»).
У него странное имя, которое на самом деле не дает вам никакого представления о том, что это такое или что оно делает, но это большинство названий приложений в наши дни (обязательная ссылка на «Покемон или большие данные?»).
Так что же это такое и откуда взялось? Это СУБД OLAP с открытым исходным кодом, основанная на столбцах, изначально созданная Яндексом (российский эквивалент Google) для выполнения веб-аналитики, отсюда и часть клика Clickhouse. Он может справиться с абсолютно чудовищных томов данных; На момент написания этой статьи Яндекс использовал Clickhouse для хранения около 90 497 13 триллионов 90 498 записей с 90 497 20 миллиардами 90 498 ежедневных событий. Это безумие.
Я не буду пересказывать подробную историю, но вы можете найти ее здесь, если хотите почитать. Они должны были назвать это Clickmonster, Click-cluthulu (Clickthulu?) или что-то в этом роде.
Время игры
Я не собираюсь создавать какие-то супер-причудливые бенчмарки. Другие люди уже сделали это, и сделали гораздо лучше, чем я. Все, что я собираюсь сделать здесь, это получить некоторые данные и передать их в Clickhouse, чтобы я мог выполнить несколько основных запросов, просто чтобы почувствовать это. Я также проведу быстрое сравнение этих же запросов в Postgres, просто чтобы проиллюстрировать разницу в производительности между столбцовыми СУБД OLAP и OLTP на основе строк.
Другие люди уже сделали это, и сделали гораздо лучше, чем я. Все, что я собираюсь сделать здесь, это получить некоторые данные и передать их в Clickhouse, чтобы я мог выполнить несколько основных запросов, просто чтобы почувствовать это. Я также проведу быстрое сравнение этих же запросов в Postgres, просто чтобы проиллюстрировать разницу в производительности между столбцовыми СУБД OLAP и OLTP на основе строк.
Я не собираюсь использовать какие-либо модные облачные платформы для этого. Я знаю, что у многих из них есть инструменты и продукты, предназначенные для выполнения всего этого, либо путем «укажи и щелкни», либо путем записи больших файлов YAML. Это не сексуально, но не всегда весело и бесплатно. Я снова буду использовать инструменты командной строки GNU.
Данные
Я решил использовать S.M.A.R.T. данные с жестких дисков в центре обработки данных BackBlaze. Я скачал данные за 2014-2018 годы и разархивировал их, чтобы каждый год был в своей директории.
Теперь проблема с данными заключается в том, что каждый файл содержит разное количество столбцов, поэтому первое, что я собираюсь сделать, это унифицировать формат файла перед загрузкой. Назовите меня странным, но я нахожу это немного забавным.
Назовите меня странным, но я нахожу это немного забавным.
Исправление данных
Первоначально, когда я начал это, я не знал, что каждый год может иметь разное расположение столбцов. Если я хотел загрузить какие-либо из этих данных в базу данных, мне нужно было обеспечить, чтобы все данные были в одном и том же формате.
Я хотел создать единый формат файла для всех данных, то есть мне нужно было создать новый формат, содержащий все столбцы из всех файлов. Итак, первое, что я сделал, это извлек все строки заголовков из файлов данных.
$ за год в {2014..2018}; do head -q -n1 ${год}/* | sort -u > header_${год}; сделанный
$ найти . -name 'заголовок*'
./header_2016
./header_2018
./header_2017
./header_2015
./header_2014
Следующим шагом было создание нового файла, содержащего все столбцы из всех заголовков — единый унифицированный формат заголовка или UBER HEADER! Для начала я объединил все заголовки в один файл, с именами каждого столбца в новой строке.
$ за год в {2014..2018}; делать \
кошка header_${год} | tr -t ',' '\n' > header_${year}_rows; \
сделанный
$ голова ./header_2017_rows
дата
серийный номер
модель
емкость_байт
отказ
умный_1_нормализованный
smart_1_raw
smart_2_normalized
smart_2_raw
smart_3_normalized
Ну вот, имена столбцов на новой строке.
Чтобы создать UBER HEADER , мне нужно было объединить каждый из этих отдельных файлов заголовков вместе, дедуплицировать их, преобразовать их в TSV-файл, разделенный табуляцией, и вывести в новый файл с именем uber_header_flat .
$ cat header_201[45678]_rows | сортировать -у | сортировать -n | tr -t '\n' '\t' | tr -d '\r' > uber_header_flat $ кошка -A uber_header_flat | голова -с 60 вместимость_байтов модель сбоя даты серийный_номер smart_10_nor%
Это дает мне файл TSV со всеми столбцами, доступными во всех файлах. Это мой UBER HEADER , но что дальше? Данные должны были соответствовать этому новому формату, прежде чем их можно было загрузить куда угодно.
Мне нужно было изменить все файлы данных, которые у меня были, чтобы они имели один и тот же унифицированный формат. Звучит как боль в заднице? Правильный! Но именно здесь пригодится awk . Мои данные были организованы в такие каталоги:
$ дерево -d . ├── 2014 ├── 2015 ├── 2016 ├── 2017 └── 2018
Каждый каталог содержит данные за годы — сотни файлов, и я не собирался переделывать их вручную, поэтому я создал скрипт awk для их переформатирования (с именем transform.awk ).
Сценарий ожидает следующие входные данные:
- Необязательный список исходных входных столбцов, разделенный табуляцией, в противном случае считывается строка заголовка входного файла.
- Разделенный табуляцией список выходных столбцов назначения.
- Файл для работы
Сопоставляет входные столбцы с выходными столбцами, выводя пустое поле, если сопоставление не удается для любого из входных столбцов. Предполагается, что все входные файлы имеют строки заголовков.
Предполагается, что все входные файлы имеют строки заголовков.
Вот пример того, что делает этот зверь. Учитывая эти входные данные:
имя, фамилия, д.б. Джейми, Скипворт, 01.01.2000
Если вы запустите на этих данных следующее:
awk -F, -f трансформер.awk -v output_cols=фамилия,имя,доб my_test_file.csv
Результат будет выглядеть следующим образом, что позволит вам переформатировать файл любым удобным для вас способом:
фамилия, имя, д.б. Скипуорт, Джейми, 01 января 2000 г.
Все файлы данных необходимо преобразовать в единый унифицированный формат, как указано в ЗАГОЛОВКЕ UBER . Скрипт у меня был, но данных много, поэтому я распараллелил работу с помощью xargs .
$ mkdir all_data/ $ find 201[45678] -name '*.csv' | \ xargs -t -P8 -I _FILE_ bash -c \ 'awk -F, -f трансформатор.awk \ -v output_cols="$(cat uber_header_flat)" \ -v РС='"'\r\n'"' \ -v ОФС=\\t \ -v null_value="\\\N" _FILE_ > all_data/$(базовое имя _FILE_)'
Это позволит найти все файлы данных CSV, которые у меня есть, и преобразовать их в желаемое расположение столбцов. Используя
Используя xargs , я запускаю 8 из этих процессов параллельно, чтобы немного ускорить его. В итоге я получу 1278 файлов в каталоге all_data .
Запуск Clickhouse и загрузка данных
Пока что этот пост в блоге не имеет ничего общего с Clickhouse, все, что я делал, это возился с данными! Я знаю, но мы сейчас здесь.
Пришло время раскрутить ClickHouse и создать таблицу, соответствующую формату UBER HEADER . Я использовал образ докера ClickHouse и следовал инструкциям здесь.
$ docker run -d --name clickhouse_db_test --ulimit nofile=262144:262144 --volume /Users/jamieskipworth/clickhouse_db_test:/var/lib/clickhouse yandex/clickhouse-server $ docker run -it --rm --link clickhouse_db_test:clickhouse-server yandex/clickhouse-client --host clickhouse-server --query="СОЗДАТЬ БАЗУ ДАННЫХ так;"
Это запускает сервер ClickHouse и создает новую базу данных. Затем я создал новую таблицу, соответствующую формату UBER HEADER .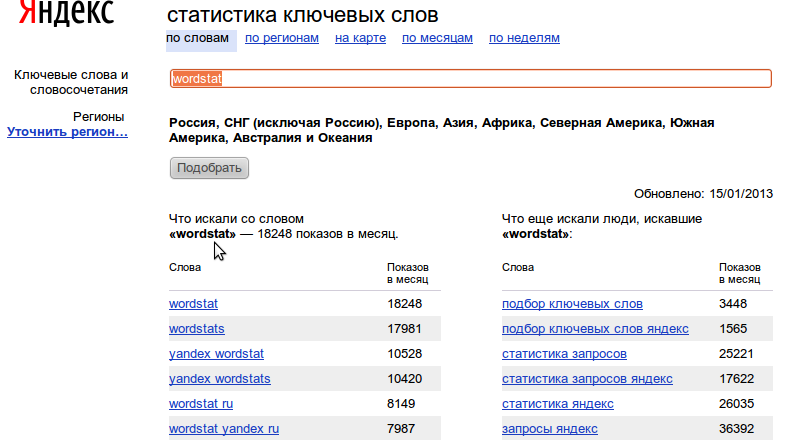
Я могу выполнить этот SQL (хранящийся в create_table.sql ), выполнив следующее:
$ docker run -it --rm --link clickhouse_db_test:clickhouse-server yandex/clickhouse-client --host clickhouse-server --query="$(cat create_table.sql)"
Теперь загрузим данные. Помните, что из приведенных выше шагов у меня должен быть новый каталог с именем all_data , содержащий переформатированные файлы. Чтобы загрузить их, я могу использовать tail с опцией -n +2 , чтобы пропустить строки заголовков в каждом из файлов.
$ tail -q -n +2 all_data/* | \ docker run -i --rm --link clickhouse_db_test:clickhouse-server yandex/clickhouse-client --host clickhouse-server --query="ВСТАВИТЬ В SO.data_all ФОРМАТ TabSeparated"
Давайте просто перепроверим все загруженные данные.
$ docker run -it --rm \ --link clickhouse_db_test:clickhouse-сервер яндекс/clickhouse-клиент \ --host clickhouse-сервер Клиент ClickHouse версии 19.
 14.3.3 (официальная сборка).
Подключение к clickhouse-server:9000 по умолчанию.
Подключен к серверу ClickHouse версии 19.14.3 ревизии 54425.
09e25071240a :) выберите count(1) из so.data_all;
ВЫБЕРИТЕ количество(1)
ОТ так.data_all
┌─количество(1)─┐
│ 77280092 │
└──────────┘
1 ряд в наборе. Прошедшее: 0,364 сек. Обработано 77,28 млн строк, 154,56 МБ (212,11 млн строк/с, 424,21 МБ/с).
09e25071240a :)
14.3.3 (официальная сборка).
Подключение к clickhouse-server:9000 по умолчанию.
Подключен к серверу ClickHouse версии 19.14.3 ревизии 54425.
09e25071240a :) выберите count(1) из so.data_all;
ВЫБЕРИТЕ количество(1)
ОТ так.data_all
┌─количество(1)─┐
│ 77280092 │
└──────────┘
1 ряд в наборе. Прошедшее: 0,364 сек. Обработано 77,28 млн строк, 154,56 МБ (212,11 млн строк/с, 424,21 МБ/с).
09e25071240a :)
Похоже, все 77 млн строк загружены. Давайте запустим несколько SQL-запросов! Кстати, вы заметили, как быстро этот счет побежал?
Запрос данных
Итак, я собрал несколько очень простых запросов, которые буду запускать как в Clickhouse, так и в Postgres, просто чтобы дать вам представление о разнице в производительности. Я чувствую себя немного виноватым, потому что на самом деле это какое-то несправедливое сравнение, но какого черта.
Запрос : При какой температуре отказало большинство дисков?
выбрать
smart_194_raw
, сумма(неудача)
от
так. data_all
где smart_194_raw не равно нулю
группа по smart_194_raw
упорядочить по smart_194_raw по возрастанию;
 data_all
где smart_194_raw не равно нулю
группа по smart_194_raw
упорядочить по smart_194_raw по возрастанию;
data_all
где smart_194_raw не равно нулю
группа по smart_194_raw
упорядочить по smart_194_raw по возрастанию;
Результаты
Кликхаус =========== В наборе 52 ряда. Прошедшее: 1.140 сек. Обработано 77,28 млн строк, 1,39 ГБ (67,80 млн строк/с, 1,22 ГБ/с). PostgreSQL =========== 0,00 с пользователь 0,01 с система 0% ЦП 1:23,28 всего
Запрос : Какие модели приводов самые популярные по кварталам?
выбрать
модель
, toStartOfQuarter(дата) как qtr
, считать (1) как число
от
так.data_all
группировка по модели, кв.
заказать по кварталу
Результаты
Кликхаус =========== В наборе 911 рядов. Прошедшее: 1,443 сек. Обработано 77,28 млн строк, 2,01 ГБ (53,54 млн строк/с, 1,39 ГБ/с). PostgreSQL =========== 0,01 с пользователь 0,01 с система 0% ЦП 1:50,28 всего
Запрос : Каково среднее время работы привода до отказа?
выбрать
Avg((smart_9_raw / 24)) как время безотказной работы
от
так. data_all
где smart_9_raw не равно нулю
и отказ > 0
упорядочить по времени безотказной работы по возрастанию;
 data_all
где smart_9_raw не равно нулю
и отказ > 0
упорядочить по времени безотказной работы по возрастанию;
data_all
где smart_9_raw не равно нулю
и отказ > 0
упорядочить по времени безотказной работы по возрастанию;
Результаты
Кликхаус =========== 1 ряд в наборе. Прошедшее: 0,653 сек. Обработано 77,28 млн строк, 835,12 МБ (118,37 млн строк/с, 1,28 ГБ/с). PostgreSQL =========== 0,00 с пользователь 0,01 с система 0% ЦП 1:25,28 всего
Запрос : Какая модель диска имеет в среднем самое продолжительное время безотказной работы?
выбрать
Avg((smart_9_raw / 24)) как время безотказной работы
, модель
от
так.data_all
где smart_9_raw не равно нулю
и отказ > 0
группировать по модели
упорядочить по времени безотказной работы по возрастанию;
Результаты
Кликхаус =========== В наборе 76 рядов. Прошедшее: 0,845 сек. Обработано 77,28 млн строк, 1,21 ГБ (91,41 млн строк/с, 1,43 ГБ/с). PostgreSQL =========== 0.00s пользователь 0.00s система 0% процессор 1:23.66 всего
Посмотрите на эту статистику.