
Справочник по ошибкам анализа robots.txt
- Ошибки
- Предупреждения
- Ошибки проверки URL
Перечень ошибок, возникающих при анализе файла robots.txt.
| Ошибка | Расширение Яндекса | Описание |
|---|---|---|
| Правило начинается не с символа / и не с символа * | Да | Правило может начинаться только с символа / или *. |
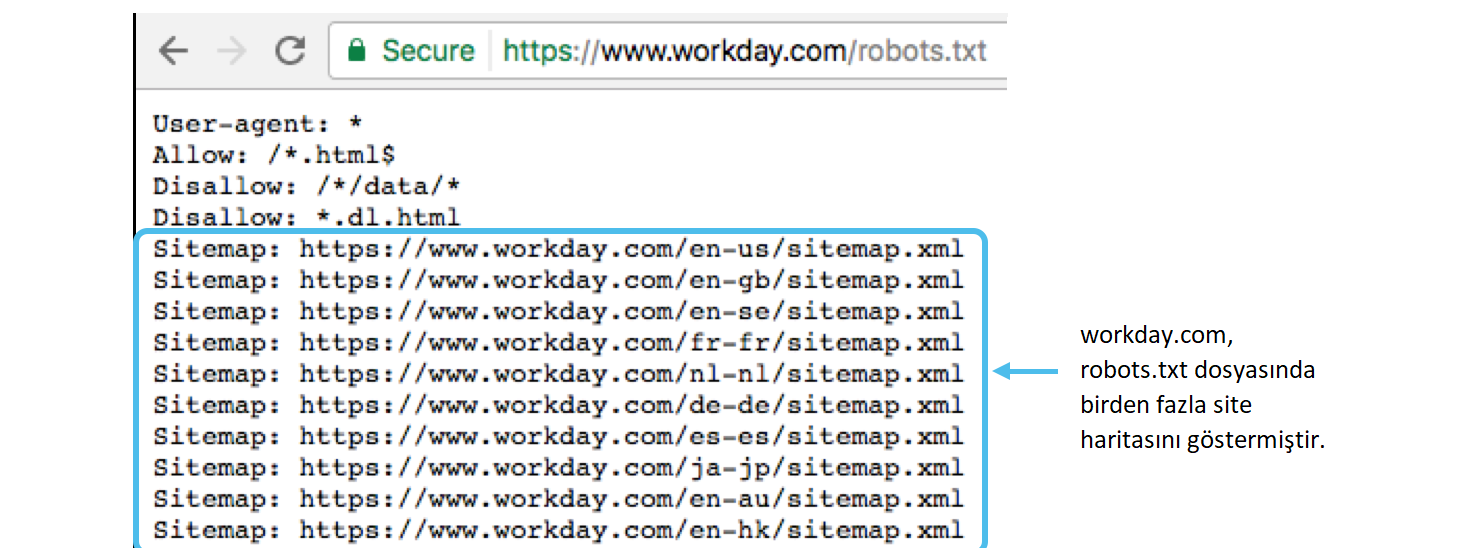
| Найдено несколько правил вида User-agent: * | Нет | Допускается только одно правило такого типа. |
| Превышен допустимый размер robots.txt | Да | Количество правил в файле превышает 2048. |
Перед правилом нет директивы User-agent. | Нет | Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent. |
| Слишком длинное правило | Да | Правило превышает допустимую длину (1024 символа). |
| Некорректный формат URL файла Sitemap | Да | В качестве URL файла Sitemap должен быть указан полный адрес, включая протокол. Например, https://www.example.com/sitemap.xml |
| Некорректный формат директивы Clean-param | Да | В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом. |

Перечень предупреждений, возникающих при анализе файла robots.txt.
| Предупреждение | Расширение Яндекса | Описание |
|---|---|---|
| Возможно, был использован недопустимый символ | Да | Обнаружен спецсимвол, отличный от * и $. |
| Обнаружена неизвестная директива | Да | Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем. |
| Синтаксическая ошибка | Да | Строка не может быть интерпретирована как директива robots.txt. |
| Неизвестная ошибка | Да | При анализе файла возникла неизвестная ошибка. Обратитесь в службу поддержки. |

Перечень ошибок проверки URL в инструменте Анализ robots.txt.
| Ошибка | Описание |
|---|---|
| Синтаксическая ошибка | Ошибка синтаксиса URL. |
| Этот URL не принадлежит вашему домену | Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена. |
Создаем правильный robots.txt для wordpress для Яндекса и Google
Автор Антонио с WPbiz. ru На чтение 3 мин Просмотров 61 Обновлено
ru На чтение 3 мин Просмотров 61 Обновлено
Привет, Веб-мастер! Сегодня создадим на 100% правильный robots.txt для вордпресс. Он учитывает все нюансы CMS, так же разграничивает Яндекс и Google — они получают каждый свой фрагмент.
Содержание
- Скачать идеальный robots.txt для WordPress
- Содержание файла robots.txt
- Как проверить правильность robots.txt в Яндексе и Google
Скачать идеальный robots.txt для WordPress
Собственно сам файл
Скачать robots.txt
Не забудьте заменить URL в host на свой домен!
Содержание файла robots.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc. |
 php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.svg
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.
php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.svg
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.
Директива host убрана, как давно неработающая ни в Яндексе, ни в Гугле.
Как проверить правильность robots.txt в Яндексе и Google
Для проверки рекомендую использовать встроенные инструменты в вебмастере (в разделе «инструменты» — «Анализ robots. txt«) и в google console: https://www.google.com/webmasters/tools/robots-testing-tool.
txt«) и в google console: https://www.google.com/webmasters/tools/robots-testing-tool.
Антонио с WPbiz.ru
Манимейкер в сети с 2008 года
Подпишись
Не уверен, что нужно описывать каждую строчку. Пишите в комментариях — если нужно будет добавлю!
А если у вас остались вопросы — задавайте, с радостью отвечу!
Удачи!
Robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL-адрес
- Как отслеживать изменения файла
- FAQ
Инструмент анализа Robots.txt поможет вам проверить, сканирует ли robots. txt файл правильный. Вы можете ввести содержимое файла, проверить его, а затем скопировать в robots.txt.
Этот инструмент также поможет вам отслеживать изменения в файле и загружать его конкретную версию.
- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL
- Как отслеживать изменения файла
- FAQ
- Если сайт был добавлен в Яндекс.
 Вебмастер и были права на управление сайтом Verified
Вебмастер и были права на управление сайтом Verified Содержимое файла появится на странице анализа Инструменты → Robots.txt, как только будут подтверждены права на управление сайтом.
Если содержимое отображается на странице анализа Robots.txt, щелкните Проверить.
- Если сайт не добавлен в Яндекс.Вебмастер
Перейти на страницу анализа robots.txt.
В поле Проверяемый сайт введите адрес вашего сайта. Например, https://example.com.
- Щелкните значок. Содержимое файла robots.txt и результаты анализа будут показаны ниже.
 Вебмастер и были права на управление сайтом Verified
Вебмастер и были права на управление сайтом VerifiedВ разделах, предназначенных для робота Яндекса (User-agent: Яндекс или User-agent: *), валидатор проверяет директивы, используя условия использования robots.txt. Остальные разделы проверяются на соответствие стандарту.
После проверки вы можете увидеть:Предупреждения. Они сообщают об отклонении от правил, которое может быть исправлено самим инструментом.
Предупреждения также указывают на потенциальную проблему с опечатками или неточностями в директивах.Ошибки в файле. Это означает, что инструмент не может обработать строку, раздел или весь файл из-за серьезных синтаксических ошибок в директивах.
 Предупреждения также указывают на потенциальную проблему с опечатками или неточностями в директивах.
Предупреждения также указывают на потенциальную проблему с опечатками или неточностями в директивах.При загрузке файла robots.txt в Яндекс.Вебмастер на странице анализа Robots.txt отображается блок Проверить, разрешены ли ссылки.
В поле списка URL введите адрес страницы, которую хотите проверить. Вы можете указать URL полностью или относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите Проверить.
Если URL-адрес разрешен для индексации ботами Яндекса, рядом с ним появится значок . В противном случае адрес будет выделен красным цветом.
Примечание. Доступна полугодовая история изменений. Максимальное количество сохраняемых версий — 100.
Чтобы оперативно узнавать об изменениях в файле robots.txt, настройте уведомления.
Яндекс.Вебмастер регулярно проверяет файл на наличие обновлений и сохраняет версии вместе с датой и временем изменения. Чтобы просмотреть их, перейдите в Инструменты → Анализ Robots.txt.
Список версий отображается при соблюдении всех следующих условий:Вы добавили сайт в Яндекс.Вебмастер и подтвердили право на управление сайтом.
Яндекс.Вебмастер хранит информацию об изменениях в robots.txt.
- Просмотреть текущую и предыдущую версии файла
В списке версий robots.txt выберите версию файла. Поле ниже показывает файл robots.txt вместе с результатами синтаксического анализа.
- Скачать выбранную версию файла
В списке версий robots.txt выберите версию файла.
Нажмите кнопку «Загрузить». Файл будет сохранен на вашем устройстве в формате TXT.

- Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, вы включили зеркало в список URL вашего сайта. Например, http://example.com вместо http://www.example.com (технически это два разных URL-адреса). Технически это два разных URL. URL-адреса в списке должны принадлежать сайту, для которого проверяется файл robots.txt.
Укажите инструмент, в котором вы обнаружили ошибку, максимально подробно опишите ситуацию и, если необходимо, прикрепите скриншот, иллюстрирующий ее.
Как заблокировать самые популярные поисковые роботы через robots.txt?
Задавать вопрос
спросил
Изменено 7 лет, 6 месяцев назад
Просмотрено 884 раза
Я хочу запретить индексацию моего веб-сайта через robots.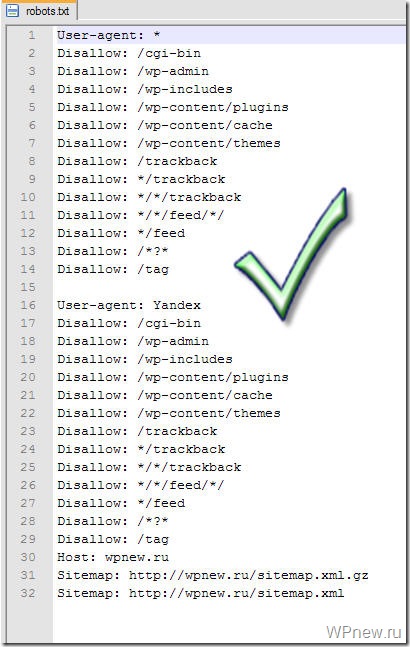 txt роботами-пауками MSN/Bing, Yahoo, Ask Jeeves, Baidu и Yandex.
txt роботами-пауками MSN/Bing, Yahoo, Ask Jeeves, Baidu и Yandex.
Я хочу запретить поисковым роботам контента и мультимедиа (изображений, видео).
Причина этого в том, что мой сайт предназначен только для рынка Google и США и расположен на хостинге с ограниченными ресурсами.
Я нашел разные правила, пока гуглил и объединил все вместе:
# Заблокировать Bing Агент пользователя: bingbot Запретить: / Агент пользователя: msnbot Запретить: / # Заблокировать Yahoo Агент пользователя: slurp Агент пользователя: yahoo Запретить: / # Заблокировать запрос Агент пользователя: jeeves Агент пользователя: teoma Запретить: / # Заблокировать Байду Агент пользователя: baidu Запретить: / # Заблокировать Яндекс Агент пользователя: yandex Запретить: /
Верны ли эти правила?
Или я что-то пропустил?
А может я что-то лишнее добавил?
Существуют ли официальные правила robots.txt для каждого поискового робота?
- поисковые роботы
- robots.
