
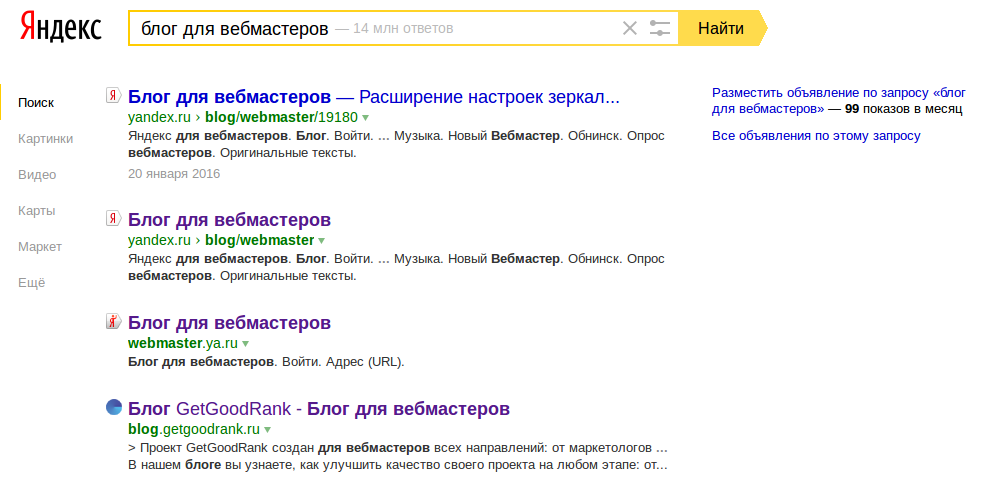
обновления Яндекса и Google, о которых нужно помнить в новом году — CMS Magazine
Поисковые системы продолжают уверенно двигаться в сторону улучшения пользовательского опыта, а их главный тренд — скорость и качество предоставляемого контента. В 2021 году Яндекс и Google выпустили много крупных обновлений своих поисковых алгоритмов. Что нужно брать на вооружение уже сейчас, чтобы в 2022-м ранжироваться выше — разбираем в этой статье.
ЯндексБольшое обновление ПоискаЛетом Яндекс презентовал обновленную версию поиска, главная цель которого — максимально сократить путь от вопроса до ответа для пользователя. В течение года в поисковик внедрялись более двух тысяч улучшений, главными из которых для вебмастеров стали:
-
Быстрые ответы в поисковой выдаче. Если на странице есть ответ за запрос пользователя, Яндекс выберет его для показа прямо над результатами поиска в выдаче.
-
Поиск внутри видео.
 Видеоролик может запуститься прямо с того момента, где начинается ответ на запрос.
Видеоролик может запуститься прямо с того момента, где начинается ответ на запрос. -
Оценка по отзывам. Алгоритмы Яндекса теперь сами анализируют тысячи запросов по разным параметрам и показывают сводную оценку компании.
-
Умная камера. В мобильном приложении Яндекса теперь можно навести камеру на предмет, чтобы найти его в интернет-магазине и узнать стоимость.
 Видеоролик может запуститься прямо с того момента, где начинается ответ на запрос.
Видеоролик может запуститься прямо с того момента, где начинается ответ на запрос.В октябре Яндекс запустил новый алгоритм, учитывающий сигналы о недобросовестности организаций при ранжировании их сайтов. Опираясь на множество факторов и используя совокупность сигналов, алгоритм может определить, если сайт или бизнес действует недобросовестно по отношению к клиентам. Например, алгоритм узнает, если компания уклоняется от предоставления уже оплаченных клиентом услуг или исполняет их в ненадлежащем виде.
Не стоит переживать, что теперь за любое недовольство (тем более необоснованное) сайт будут понижать в выдаче. Человеческий фактор никто не отменял и Яндекс не станет наказывать организации за форс-мажоры и недопонимание с клиентами. Отслеживайте отзывы, отвечайте на них и отрабатывайте негатив.
Человеческий фактор никто не отменял и Яндекс не станет наказывать организации за форс-мажоры и недопонимание с клиентами. Отслеживайте отзывы, отвечайте на них и отрабатывайте негатив.
Мгновенное индексирование — мечта любого SEO-специалиста. В октябре Microsoft Bing и Яндекс представили IndexNow — протокол, позволяющий автоматически сообщать поисковым системам об изменениях на сайте, включая появление новых страниц, обновление или удаление текущих.
Об эффективности нового протокола пока мнений не много и все они противоречивы. Исследование, проведенное SEO-аналитиком Сергеем Кокшаровым (Devaka) показало, что IndexNow работает нестабильно и пока менее эффективно аналогичного инструмента Яндекса (Переобход страниц), но может быть полезен для больших сайтов, когда требуется быстрое сканирование большого количества новых страниц.
Протокол поддерживается Яндексом и Microsoft Bing. В ноябре представитель Google Барри Шварц подтвердил, что компания будет также тестировать новый протокол.
Больше не нужно искать и обзванивать каждое диджитал-агентство
Создайте конкурс на workspace.ru – получите предложения от участников CMS Magazine по цене и срокам. Это бесплатно и займет 5 минут. В каталоге 15 617 диджитал-агентств, готовых вам помочь – выберите и сэкономьте до 30%.
Создать конкурс →
Passage Indexing, или ранжирование фрагментов — технология, используемая алгоритмом Google, которая позволит ранжировать отдельные фрагменты текста на странице по разным запросам, охватывающим одну тему.
Работает это так: например, вы пишете на сайте большую статью о постраничном SEO, включающую в себя отрывки по разным параметрам. Новый алгоритм может ранжировать отдельные куски текста, которые релевантны поисковому запросу.
Технология использует искусственный интеллект для индексации не только страниц сайта, но и отдельных отрывков (абзацев, предложений) с этих страниц. Суть алгоритма в том, чтобы быстрее ответить на запрос пользователя без необходимости прочесывать всю страницу в поиске ответа.
Обновление алгоритма MUMМногозадачная унифицированная модель (MUM) — это модель естественного языка, представленная на конференции Google I/O 2021.
MUM — это инструмент на базе искусственного интеллекта, который использует контекстную информацию из разных источников, чтобы дать исчерпывающие ответы на сложные вопросы пользователей.
MUM понимает информацию из текста и изображений, и Google планирует расширить свои возможности, включив также видео и аудио.
Появление новой технологии не означает, что следует начинать писать контент, отвечающий на сложные вопросы.
Четких инструкций, как оптимизировать сайт под алгоритм MUM нет. Качественные тексты, написанные простым и естественным языком и точно отвечающие на запрос пользователя — универсальная рекомендация почти для любого алгоритма поисковых систем и MUM — не исключение.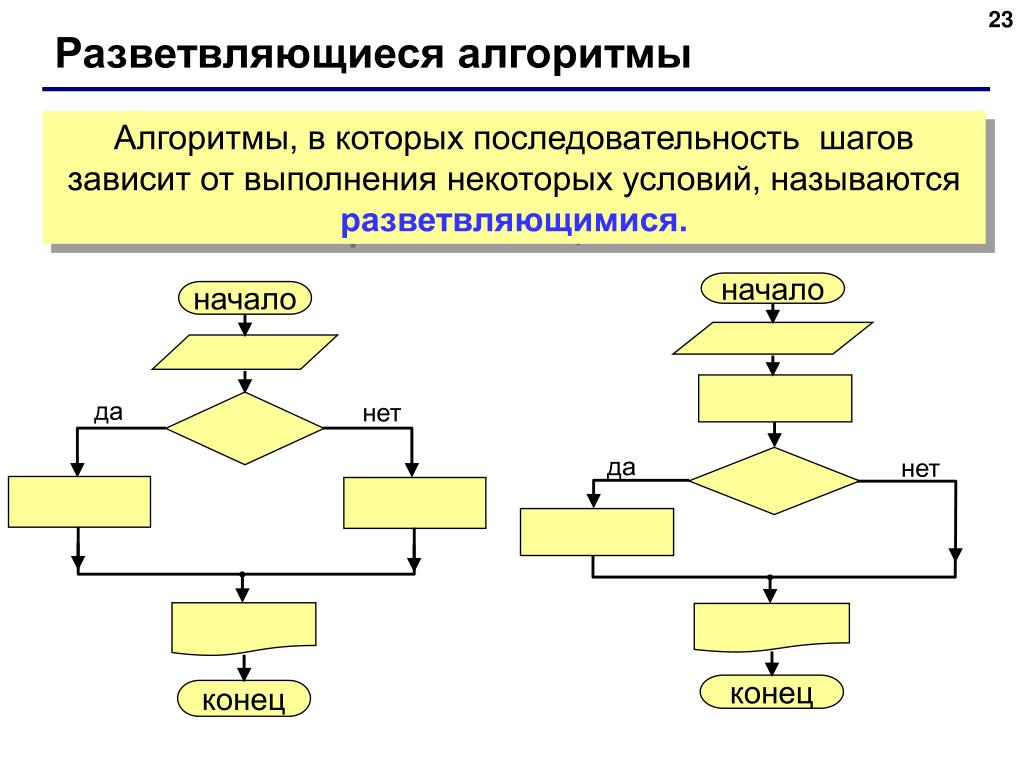
С июня 2021 года алгоритмы Google начал учитывать удобство страниц при их ранжировании, но пока это происходит не в полной мере. Начиная с февраля 2022 года, Google начнет развертывание обновления Page Experience для результатов поиска на десктопах, и завершит к концу марта. Будут приниматься во внимание данные об удобстве страниц для мобильных устройств, используемые с августа 2021 г.
Page Experience — алгоритм ранжирования, предназначенный для оценки веб-страниц на основе того, как пользователи воспринимают взаимодействие с веб-страницей.
При оценке учитываются:
-
Core Web Vitals: набор показателей, которые измеряют производительность страницы с точки зрения UX — скорость загрузки основного контента (Largest Contentful Paint), время ожидания до первого взаимодействия с контентом (First Input Delay), стабильность верстки и элементов, не препятствующих взаимодействию с контентом (Cumulative Layout Shift).
-
Удобство использования на мобильных устройствах. На странице не должно быть ошибок, связанных с удобством использования мобильных устройств.
-
Проблемы безопасности. Любые проблемы с безопасностью сайта лишают все страницы сайта статуса «Хорошо».
-
Использование HTTPS: страница должна открываться по протоколу HTTPS, чтобы иметь право на статус «Хорошо».
-
Работа с рекламой: сайт не должен использовать рекламные форматы, которые отвлекают, мешают или иным образом не способствуют хорошему взаимодействию с пользователем.

Из нового:
-
если публикуете видео, следите за тем, чтобы ролик содержал понятную и полезную инструкцию, а также используйте разметку, чтобы передавать в поиск данные о видеороликах;
-
размещая товары на сайте, следите, чтобы у них всех были качественные иллюстрации и не забывайте добавлять семантическую товарную разметку.
В остальном обновления алгоритмов не требуют от вебмастеров чего-то сверх того, что было и в прошлые годы. Поэтому продолжайте и дальше:
-
создавать подробный и качественный контент по теме, который точно и понятно ответит на запрос пользователя;
-
правильно структурировать содержимое статьи, используя подзаголовки, абзацы, списки;
-
отслеживать отзывы о компании и работать с негативом;
-
делать упор на ключевых словах с длинным хвостом;
-
внедрять микроразметку данных на страницах сайта.
Успешного вам продвижения в новом году!
Сложно разобраться? Заказывайте SEO на тендерной площадке Workspace. Выбирайте среди 3500+ агентств комплексного продвижения сайтов.
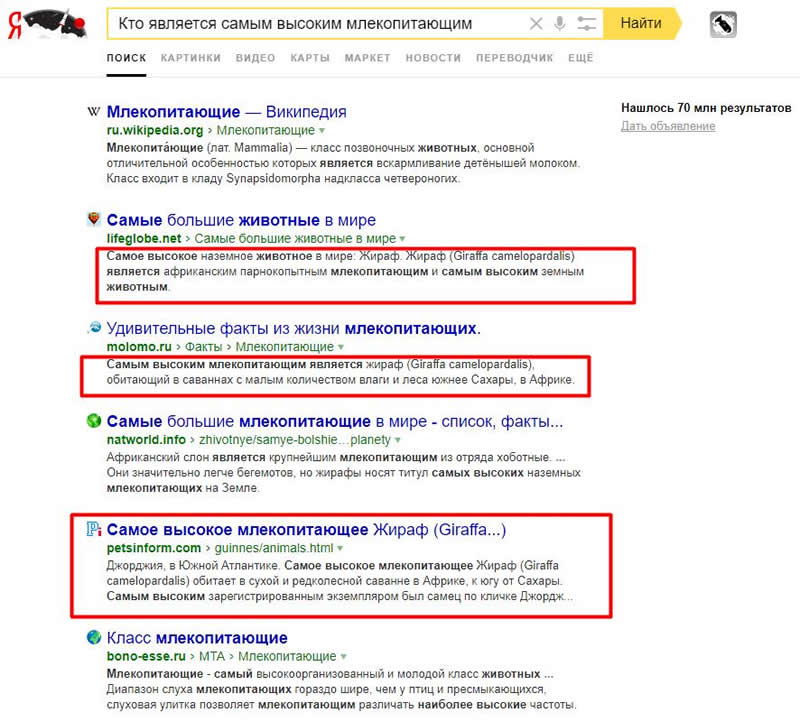
Как будет работать поиск в 2021? YATI – новый алгоритм ранжирования Яндекс — SEO на vc.
 ru
ruВ конце минувшего года Яндекс запустил новый алгоритм поискового ранжирования YATI, действие которого основано на нейросетях-трансформерах. Эта нейросетевая архитектура опирается на смысловую составляющую, обеспечивая совершенно новый подход, который устанавливает наилучшее семантическое единение между намерением пользователя, запросом и документом.
19 259 просмотров
YATI (Yet Another Transformer with Improvements) в переводе означает «Ещё один трансформер с улучшениями»
По заверениям специалистов по машинному обучению в Яндекс – внедрение YATI рекордным образом улучшило ранжирование и стало наиболее значимым событием для отечественного поисковика за последние 10 лет, со времен внедрения Матрикснета.
Совместный эффект Палеха и Королёва оказали меньшее влияние на поиск, чем новая модель на трансформерах. Вместе с тем, следует понимать, что нейросети не отменяют тысячи ранее заложенных правил в общую поисковою формулу.
Как было раньше?
Система поиска всегда определяла релевантность выдачи путем сопоставления множества разнообразных факторов, намекающих на семантическую связь между поисковым запросом и материалом, изложенном на отдельной веб-странице. То есть, в упрощенном представлении, если статья и запрос имели множество одинаковых слов, то роботом данная страница воспринималась наиболее приоритетной. Разумеется, учитывался и расчет количества фраз, объем материала, поведенческие факторы, поисковая история пользователей и многое другое, но робот при этом никогда не понимал сути документа.
Алгоритмы Яндекс на 2015 год
Так происходило вплоть до 2016 года, пока не появились такие алгоритмы как Палех и Королев. Тогда Яндекс впервые публично заявил о применении нейросетей, обозначив, меж тем, что дальнейшее развитие поиска им видится в том, чтобы в финале получить модель, которая сможет всякий раз понимать любые запросы на уровне, сопоставимом с человеческим. Технология YATI являет собой еще один значительный шаг к этому, а Палех и Королев являлись важнейшими вехами развития поиска на пути к YATI.
Тогда Яндекс впервые публично заявил о применении нейросетей, обозначив, меж тем, что дальнейшее развитие поиска им видится в том, чтобы в финале получить модель, которая сможет всякий раз понимать любые запросы на уровне, сопоставимом с человеческим. Технология YATI являет собой еще один значительный шаг к этому, а Палех и Королев являлись важнейшими вехами развития поиска на пути к YATI.
Палех
Палех обеспечил возможность понимания сложных запросов пользователей. То есть поиск стал проводиться не строго по словам, которые написал пользователь, но также по смыслу запроса и заголовка страницы. Так, Яндекс научился находить требуемые ответы даже при отсутствии ключевых слов.
Выдача при Палехе стала формироваться по смыслу, а не по точным вхождениям
С этого момента точное вхождение ключевых запросов стало менее значимым фактором при ранжировании и акцент при SEO-продвижении стал смещаться в сторону смысловой и технической уникальности текста, мотивируя к созданию более полезного и содержательного контента.
Королев
Более совершенной вариацией Палеха стал Королев. Он еще лучше научился обрабатывать сложные и многозначные запросы, ориентируясь при этом не только на сопоставление заголовков, но и на содержимое страницы в целом. Алгоритм также стал учитывать поисковую статистику, мнение ассесоров и толокеров, а также оценки самих пользователей.
Например, пользователь вводит запрос «фильм, в котором нельзя шуметь». В этом случае Яндекс сразу выведет название фильма, при этом ключевых фраз в Title и Description не будет.
Работа Королева при сложном запросе
Таким образом, стало возможным задавать поисковой системе сложные вопросы в формате разговорной речи и получать на это корректные ответы.
Существенным преимуществом Королева также стала возможность его применения к существенно большему количеству страниц без ущерба ко времени выдачи результатов по запросу. Палех был относительно тяжелым алгоритмом и использовался исключительно на поздних стадиях ранжирования, приблизительно к 150 лучшим страницам из отфильтрованного по старым правилам списка.
О трансформерах
Палех и Королев позволили Яндексу не просто находить совпадения, а понимать суть вопроса, значительно улучшили процесс ранжирования, но всё же справлялись с этим неидеально. Лишь с момента ввода YATI факторы смысла стали превосходить факторы вхождений по мНЧ-фразам.
Путь Яндекса к YATI
Прежде, чем мы начнем подробнее говорить о YATI, следует отдельно пояснить что такое трансформеры.
Говоря простыми словами, трансформерами в данном случае называют сверхбольшие и сверхсложные нейросети, способные легко справляться с разнообразными задачами в сфере обработки естественного языка, будь то перевод или создание текста.
Скрываются за этим огромные вычислительные мощности. Причем стремительно нарастающие. Так, до применения трансформеров, используемая в Яндексе нейросеть, обучалась только на одном графическом ускорителе Tesla v100. Уходило на такое обучение не более одного часа. А вот обучение нейросети-трансформера на таком ускорителе заняло бы около 10 лет. Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
То есть переход на новый алгоритм YATI был довольно сложной задачей с инженерной точки зрения. Множество ускорителей объединили в кластеры, связали в сеть и разработали для получившихся серверов мощную систему охлаждения. Но даже с такими мощностями на обучение модели сейчас уходит около месяца.
Классическая техника обучения трансформеров предполагает демонстрацию им неструктурированных текстов. То есть берется текст, в нем маскируется определенный процент слов, а перед трансформером ставится задача угадывать данные слова. Для YATI задача была усложнена: ему показывался не просто текст отдельного документа, а действительные запросы и тексты документов, которые видели пользователи. YATI угадывал, какой из документов понравился пользователям, а какой нет. Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
После этого Яндекс брал массив полученных данных и дообучал трансформер угадывать экспертную оценку, обучаясь, таким образом, ранжировать. В результате поисковой алгоритм был существенно улучшен и Яндекс вышел на рекордный уровень в качестве поиска.
Преимущества YATI и трансформеров
В отличие от предшествующих нейросетевых алгоритмов Яндекса Палех и Королёв, YATI умеет предсказывать не клик пользователя, а экспертную оценку, что являет собой фундаментальную разницу.
Кроме этого, преимущества трансформеров заключаются в следующем:
- поиск работает не только с запросами и заголовками, но и способен оценивать длинные тексты;
- присутствует «механизм внимания», выделяющий в тексте наиболее значимые фрагменты;
- учитывается порядок слов и контекст, то есть влияние слов друг на друга.
Теперь, к примеру, когда вы будете искать билеты на самолет из Екатеринбурга в Москву, поисковик поймет, что вам нужно именно из Екатеринбурга в Москву, а не наоборот. Помимо того, Яндекс стал лучше распознавать опечатки.
YATI намного лучше предшественников работает со смыслом запроса, алгоритм направлен на более глубокий анализ текста, понимание его сути. Это значит, что поисковик будет точнее понимать, какая информация является наиболее релевантной запросу пользователя.
Говоря о ранжировании, можно спрогнозировать, что смысловая нагрузка контента возымеет более значимую роль. То есть экспертные тексты, полностью раскрывающие ответ на запрос пользователя, будут всё больше и чаще попадать в ТОП.
Особенности YATI:
1. Переформулирование запросов и «пред-обучение на клик». Яндекс имеет базу из 1 млрд. переформулированных запросов: [1 формулировка] → без клика → [2 формулировка]. Так, модель учится предсказывать вероятность клика.
2. Оценки на Яндекс.Толоке. Использование оценок толокеров.
3. Оценки асессоров. Использование экспертных оценок релевантности.
4. Данные, которые подаются на вход:
- текст запроса;
- расширение запроса;
- «хорошие» фрагменты документа;
- стримы для документа: анкор-лист, запросный индекс для документа.
YATI и Google Bert
Одним из последних обновлений главного конкурента в области поиска Яндекса Google стало внедрение алгоритма BERT. Эта нейронная сеть также, как и YATI, решает задачу анализа поисковых запросов и их контекста, а не отдельный анализ ключевых запросов. То есть BERT анализирует предложение целиком.
И YATI, и BERT ориентированы на лучшее понимание смысла поискового запроса. Однако, как утверждают специалисты Яндекс, алгоритм YATI лучше справляется со своими задачами, поскольку кроме текста запроса анализирует еще и тексты документов, а также учится предсказывать клики.
Ниже в таблице представлено сравнение качества алгоритмов, основанных на нейронных сетях, в задаче ранжирования, где “% NDCG” – нормированное значение метрики качества DCG по отношению к идеальному ранжированию на датасете Яндекс. 100% здесь означает, что модель располагает документы в порядке убывания их настоящих офлайн-оценок.
Вместе с тем, требуется отметить, что BERT решает существенно большее количество задач, среди которых распознавание «смысла» текста лишь одна из множества других. На BERT базируется большое семейство языковых моделей:
С точки же зрения компьютерной лингвистики, BERT и YATI – довольно похожие алгоритмы.
Как изменится ранжирование в условиях действия Яндекс YATI
Владельцев ресурсов, а также всех, кто занимается продвижением сайта, очевидно, должен интересовать вопрос, как YATI повлияет на способы оптимизации. Если исходить из утверждения, что новый алгоритм обеспечивает более 50% вклада в ранжирование, то можно предположить, что «смысл» окончательно победил возможности SEO-специалистов в проработке текстов, а значит оптимизировать ничего не нужно. А также можно решить, что такие факторы, как «точное вхождение», «Title» и «добавить ключей» больше не имеют влияния.
А также можно решить, что такие факторы, как «точное вхождение», «Title» и «добавить ключей» больше не имеют влияния.
Данные суждения будут поспешны и ошибочны. Новый алгоритм не отменяет старые факторы ранжирования, а лишь дополняет их более качественным анализом текстов. Дело в том, что изначально для улучшения распределения, поиск Яндекс обучался на редких запросах, где документов и без того недостаточно. И когда речь идет о 50%-ом вкладе в ранжирование, то имеются ввиду именно редкие запросы. Борьба между «смыслом» и «вхождением», где «смысл» начал побеждать, видна именно на них.
А вот ситуация по ВЧ-запросам, по средне- и низкочастотным не претерпела значительных изменений. Это означает, что техническую оптимизацию, привлечение естественных ссылок и улучшение поведенческих факторов как на поиске, так и на сайте – забрасывать не нужно.
Исследования независимых специалистов показывают, что значимость фактора «точное вхождение в тексте» по НЧ-запросам после запуска YATI ничуть не ослабла, а, напротив, увеличила свою значимость. А вот тут ситуация с точным вхождением поменялась – явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
А вот тут ситуация с точным вхождением поменялась – явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
Среднее значение ключевого фактора ТОП-10 и вне его:
Среднее значение фактора здесь находится в районе единицы. То есть, если имеется одно вхождение, значит этого вполне достаточно.
Фактор «наличие всех слов из запроса в тексте» также не потерял своего значения. Выборка коммерческих запросов в Яндексе демонстрирует, что существенной разницы между НЧ и СЧ+ВЧ запросами нет. Тем не менее, наблюдается взаимосвязь между попаданием в ТОП и наличием всех слов запроса в документе. Значение этого фактора составляет 0.8, то есть, работает это для 80% сайтов.
Проверка фактора «слова в Title» после YATI показывает рост среднего значения этого фактора. То есть в выдаче стали чаще встречаться документы, Title которых содержит все слова в запросе, но вместе с тем, здесь наблюдается заметное понижение взаимосвязи с позицией.
Практические советы
Итак, перейдем к конкретным рекомендациям по оптимизации сайта в условиях работы алгоритма YATI:
- Адаптируйтесь под YATI. Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
- Расставляйте акценты в тексте и форматируйте его. В текстах свыше 12-14 предложений обязательно требуется использовать заголовки, выносить в них и в выделенные фрагменты тематические и ключевые слова.
- Выполняйте анализ и оптимизацию запросного индекса и для документов, и для сайта в целом в Яндекс.Вебмастере. Проверяйте релевантность запросов, по которым были как переходы на заданный URL, так и только показы без переходов. Данные всего сайта, как и прежде, также сказываются на факторах для заданной страницы. Поэтому проверки имеют смысл в разрезе всего сайта, а не только URL.
- Расширяйте семантическое ядро для продвижения в сторону НЧ-запросов. Синонимичные и, так называемые, вложенные запросы помогают в продвижении по более общим и близким по смыслу.
- Выполняйте конкурентный анализ. Анализируйте показы страниц конкурентов по запросам. Изучайте чужие тексты: какие тематические слова и фразы в них используются, какова структура и т.п.
- Проводите классическую оптимизацию: текст, точные вхождения, слова в Title.
 Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
Заключение
Трансформеры значительно улучшили качество поиска в Яндексе и вывели его на новый рекордный уровень. Применение тяжелых моделей, основанных на работе нейронных сетей, способных приближать структуру естественного языка и лучше учитывать семантические связи между словами в тексте, помогает пользователям все чаще встречаться с эффектом «поиска по смыслу», а не по словам.
Тем не менее несмотря на то, что YATI преподносится и по праву считается прорывной технологией, принципы работы поиска в Яндексе всегда формируются эволюционным, а не революционным образом. То есть, его обновление выполняется путем последовательного добавления новых факторов ранжирования к старым, а не радикальной сменой всех основ. Это означает, что поисковая оптимизация с приходом YATI не потеряла своей актуальности, а лишь требует некоторых корректировок ряда своих методов.
Это означает, что поисковая оптимизация с приходом YATI не потеряла своей актуальности, а лишь требует некоторых корректировок ряда своих методов.
Управляющий директор группы компаний Яндекс Тигран Худавердян о внедрение алгоритма YATI в интервью на конференции YaС 2020
YATI безусловно изменит поисковую выдачу Яндекса, но поскольку система требует обучения, то для этого потребуется время. Поэтому сейчас у вас есть хорошая возможность внести необходимые изменения на сайте и доработать SEO-тексты устаревшего формата, сохранив тем самым свои позиции и улучшив их к тому моменту, когда поиск окончательно перестроится на новый формат. С оптимизацией вам могут помочь советы, изложенные в этой статье, а также наша компания ADVIANA.
Заметим, что мы никогда не гнались за некачественными и серыми методами оптимизации и всегда много внимания уделяли описаниям на сайте, а также всем видам текста. Для наших проектов переход на новый алгоритм не был болезненным, так как все они уже соответствовали новым требованиям. Кроме того, мы постоянно следим за изменениями в мире digital-маркетинга в целом и SEO-оптимизации в частности, что позволяет нам использовать в своей работе только актуальные методы продвижения по понятной цене и с прогнозируемым результатом.
Кроме того, мы постоянно следим за изменениями в мире digital-маркетинга в целом и SEO-оптимизации в частности, что позволяет нам использовать в своей работе только актуальные методы продвижения по понятной цене и с прогнозируемым результатом.
Желаем всем высоких позиций в поиске!
В статье используются графические иллюстрации из вебинара Дмитрия Севальнева («Пиксель Тулс»).
Примеры задач по алгоритму
Примеры задач по алгоритму
A. Время сквозь стекло
Решить эту задачу на Яндекс.Конкурсе
Постановка| 1 секунда | |
| Ограничение памяти | 512Mb |
| Ввод | стандартный ввод или ввод.txt |
| Вывод | стандартный вывод или вывод.txt |
Бомбослав работает в хорошем и красивом офисе. Весь офис украшен стильными дизайнерскими часами. Их лицо представляет собой стандартную окружность с 60 равноудаленными отметками вдоль нее, которые обозначают минуты. 12 из этих 60 отметок больше остальных (начиная с самой верхней, равноудаленные с шагом в пять отметок), эти отметки обозначают часы. Часы стильные тем, что на них вообще не написаны цифры, автор полагал, что всем известно их местонахождение и какая отметка соответствует какому значению.
12 из этих 60 отметок больше остальных (начиная с самой верхней, равноудаленные с шагом в пять отметок), эти отметки обозначают часы. Часы стильные тем, что на них вообще не написаны цифры, автор полагал, что всем известно их местонахождение и какая отметка соответствует какому значению.
Сегодня кто-то повесил эти часы над рабочим местом Бомбослава. Он проверил их несколько раз и заметил, что их поведение какое-то странное. Приглядевшись, он понял, что на самом деле смотрит в зеркало, в котором отражаются часы, расположенные позади него. Это означает, что циферблат часов отражается вдоль вертикальной линии, проходящей через центр циферблата. Теперь он хочет иметь возможность определять текущее время, зная время в зеркальной версии часов.
Часы сделаны таким образом, что движение обеих стрелок дискретно , т.е. часовая стрелка всегда указывает на одну из 12 больших отметок, показывающих текущий час, а минутная стрелка всегда указывает на одну из 60 отметок, показывающих текущий час. минута.
минута.
Формат ввода
Единственная строка входных данных содержит два целых числа h и m(0≤h≤11, 0≤m≤59) — текущее положение часовой стрелки и текущее положение минутной стрелки в отраженной версии часов. ч=0 означает, что часовая стрелка указывает вверх, ч=3 обозначает позицию, указывающую вправо, ч=6 — вниз и ч=9- Слева. То же самое относится к минутной стрелке и значениям м=0, м=15, м=30 и м=45
Формат вывода
Выведите два целых числа x и y(0≤x≤11, 0≤y≤59) — фактическое время, отображаемое на часах.
Образец 1
Образец 2
Примечания
На рисунке ниже показан первый образец. Левые часы показывают то, что видит Бомбослав, а правые часы обозначают исходное положение стрелок часов. Часовая стрелка красная, а минутная — синяя.
РешениеРешение
Рассмотрим движение «реальной» и «отраженной» рук. Если «настоящая» рука поворачивается на некоторый угол, то «отраженная» рука проходит точно такой же угол в другом направлении. Таким образом, сумма углов двух стрелок всегда равна 360 градусам. Для каждой руки мы найдем ее результирующую позицию независимо. Для часовой стрелки это 12 минус текущая позиция, а для минутной стрелки 60 минус текущая позиция. В обоих случаях мы не должны забывать заменить 12 или 60 на 0,9.0009
Таким образом, сумма углов двух стрелок всегда равна 360 градусам. Для каждой руки мы найдем ее результирующую позицию независимо. Для часовой стрелки это 12 минус текущая позиция, а для минутной стрелки 60 минус текущая позиция. В обоих случаях мы не должны забывать заменить 12 или 60 на 0,9.0009
B. Палиндромная функция
Решить эту задачу на Яндекс.Конкурсе
Постановка| Ограничение по времени | 1 секунда | Лимит памяти | 512Mb |
| Ввод | стандартный ввод или ввод .txt |
| Вывод | стандартный вывод или output.txt |
Аркадий очень любит машинное обучение, он пытается применять его в каждой задаче, над которой работает. Он верит в невероятную магическую силу этой популярной молодой части компьютерных наук. Вот почему Аркадий всегда изобретает новые функции машинного обучения, чтобы вычислять их для своих любимых объектов.
Напомним, что строка называется палиндром , если она читается одинаково с начала до конца и наоборот, с конца в начало. Для каждой строки в своей базе данных Аркадий хочет вычислить ее кратчайшую подстроку , состоящую как минимум из двух символов и являющуюся палиндромом. Если таких строк несколько, Arkday хочет выбрать лексикографически наименьшую из них.
Формат ввода
Единственная строка входных данных содержит единственную строку из базы данных Аркадия, то есть непустую последовательность строчных латинских букв. Длина этой строки не менее 2 и не превышает 200 000 символов.
Формат вывода
Выведите кратчайшую подстроку входной строки, состоящую не менее чем из двух символов и являющуюся палиндромом. Не забывайте, что Аркадий хочет найти лексикографически наименьшую возможную такую строку.
Образец 1
Образец 2
Примечания
Мы говорим, что строка а=а1а2 … ан) лексикографически меньше, чем строка b=b1b2 . .. bm) если верно одно из следующих утверждений:
.. bm) если верно одно из следующих утверждений:
- если nm и a1=b1, a2=b2, …, an=bn, то есть первая строка является префиксом второй строки.
- такая позиция существует 1≤i≤min(n,m), что a1=b1, a2=b2 …, ai-1=bi-1 и ai=bi, то есть первая строка имеет меньший символ в первой позиции, где строки отличаются.
Раствор
Рассмотрим некоторую подстроку заданной строки, являющуюся палиндромом. Мы можем удалить ее первый символ и ее последний символ, и строка останется палиндромом. Продолжайте этот процесс, пока длина строки не станет равной двум или трем (в зависимости от четности).
Количество подстрок длины два или три линейно, как и их общая длина. Таким образом, мы можем применить наивный алгоритм для выбора оптимального палиндрома. Если нет палинромной подстроки длины два или три, выведите -1.
C. Разделить их всех
Решить эту задачу на Яндекс.Конкурсе
Постановка| Лимит времени | 1 секунда | Ограничение памяти | 512 Мб |
| Ввод | стандартный ввод или ввод.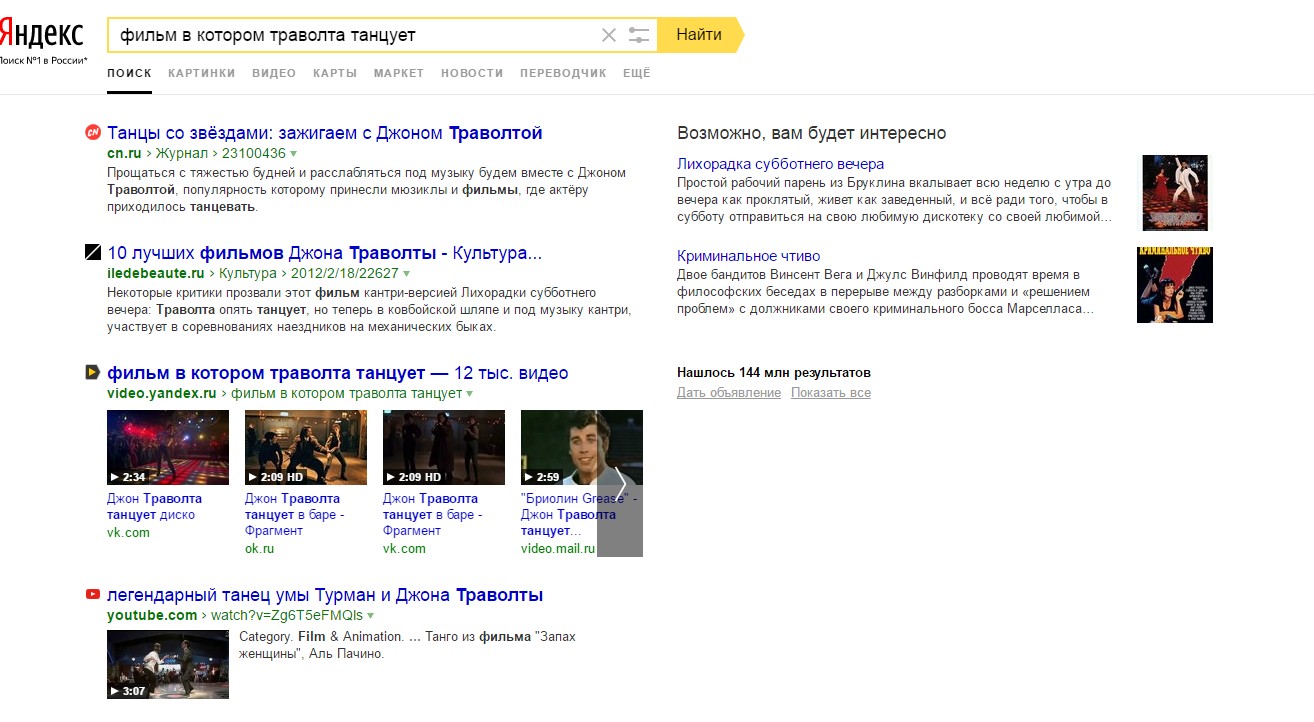 txt txt |
| Вывод | стандартный вывод или вывод.txt |
После тяжелого рабочего дня Оля и Толя решили сходить на стрельбище. Они уже прослушали вводный инструктаж, получили в руки винтовки и теперь стоят на огневых позициях. Через них проходит стена, на которой расположены n мишеней. Каждая мишень может рассматриваться как фигура на плоскости и представляет собой либо круг, либо прямоугольник. Цели могут перекрываться и пересекаться любым образом.
Перед началом стрельбы Оля и Толя решили провести линию, которая разделит самолет со всеми мишенями на две части, чтобы можно было идентифицировать выстрелы. Однако для справедливости они хотят, чтобы эта линия делила каждую из мишеней на две равные части. То есть для каждого круга и каждого прямоугольника линия должна делить эту фигуру на две равные по площади части.
Оля и Толя долго спорили, чтобы придумать этот план разделения. Однако они не уверены, что такая линия вообще существует, и просят вас проверить, возможно ли желаемое деление или нет.
Формат ввода
Первая строка ввода содержит одно целое число n(1≤n≤100 000) количество целей. Каждая из следующих n строк начинается с целого числа ти(0≤ти≤1), которые определяют тип этой цели. ти=0, означает, что эта цель представляет собой круг и еще три целых числа ри, xi и yi, следовать (1≤ri≤1000, −10 000≤xi, yi≤10 000) . Они определяют радиус и координаты центра окружности соответственно. Если ти=1, то эта цель представляет собой прямоугольник и определяется еще восемью целыми числами x1,i, y1,i, x2,i, y2,i, x3,i, y3,i, x4,i, y4,i — координаты его вершин в порядке обхода по или против часовой стрелки (−10 000≤xj,i, yj,i≤10 000). Гарантируется, что данные четыре точки образуют прямоугольник положительной площади.
Формат вывода
Если существует линия, которая делит каждую из целей на две части равной площади, выведите «Да» . в единственной строке вывода. В противном случае напечатайте «Нет» .
Образец 1
Образец 2
Образец 3
РешениеРешение
Для решения этой задачи воспользуемся простым геометрическим фактом, что линия делит круг на две части равной площади тогда и только тогда, когда эта линия проходит через центр круга. Точно так же прямая делит прямоугольник на две части равной площади тогда и только тогда, когда она проходит через точку пересечения его диагоналей. В обоих случаях достаточность следует из точечной симметрии, а необходимость можно показать, рассмотрев прямую, проходящую через центр и параллельную данной.
Точно так же прямая делит прямоугольник на две части равной площади тогда и только тогда, когда она проходит через точку пересечения его диагоналей. В обоих случаях достаточность следует из точечной симметрии, а необходимость можно показать, рассмотрев прямую, проходящую через центр и параллельную данной.
Теперь нам нужно только проверить, существует ли линия, содержащая все центры. Ради простоты мы будем работать с удвоенными координатами, чтобы они оставались целыми. Это позволяет нам получить центр прямоугольника, вычислив сумму координат двух противоположных вершин.
Если среди множества всех центров не более двух различных точек, то ответ однозначно положительный. В противном случае рассмотрите любую пару различных точек и убедитесь, что каждый центр принадлежит линии, которую они определяют. Чтобы проверить, являются ли три точки а, б и в (а≠б) принадлежат одной прямой, мы можем вычислить векторное произведение векторов б-а и с-а. Общая сложность этого решения На).
D. Задание на собеседование
Решить эту задачу на Яндекс.Конкурсе
Заявление| Лимит времени | 3 секунды |
| Лимит памяти | 512Mb |
| Ввод | стандартный ввод или ввод .txt |
| Вывод | стандартный вывод или output.txt |
Алексей очень опытный интервьюер. Несмотря на то, что он дал несколько сотен собеседований на стажировку, он чувствует, что пора что-то менять. Кандидаты теперь легко решают все замечательные задачи, которыми он успешно пользовался все эти годы.
Выбора нет, поэтому Алексей придумал новое задание. Вам дана последовательность целых чисел, которая на первом шаге состоит из двух целых чисел 1. На каждом шаге вы вставляете новый элемент между любыми двумя соседними элементами последовательности, и значение нового элемента равно их сумме. После нескольких первых шагов последовательность выглядит следующим образом:
• 1 1
• 1 2 1
• 1 3 2 3 1
• 1 4 3 5 2 5 3 4 1
Во время собеседования Алексей планирует попросить кандидата написать программу, которая по заданному целочисленному значению n будет вычислять, сколько раз значение n встречается в последовательности на шаге n. Хотя Алексей понятия не имеет, как решить эту задачу, он слышал, что следующий кандидат — опытный участник соревнований по программированию, поэтому он должен придумать решение.
Хотя Алексей понятия не имеет, как решить эту задачу, он слышал, что следующий кандидат — опытный участник соревнований по программированию, поэтому он должен придумать решение.
Формат ввода
Ввод состоит из одного целого числа n(1≤n≤1013).
Формат вывода
Выведите одно целое число, сколько раз целое число n встречается в последовательности на шаге n.
Образец 1
Образец 2
РешениеРешение
Мы хотели бы начать с некоторых лемм.
Лемма 1 . Любые два соседних целых числа взаимно просты на любом шаге.
Используйте математическую индукцию. Базовый случай тривиален, так как 1 и 1 взаимно просты. Предположим, что утверждение верно для первых n шагов. Затем любое целое число, полученное на шаге п+1 представляет собой сумму двух взаимно простых чисел. Однако, НОД(а+b, b)=НОД(a, b), таким образом, любые два соседа по-прежнему взаимно просты.
Лемма 2 . Каждая упорядоченная пара целых чисел (а, б) появляется в качестве соседей ровно один раз (и только на одном шаге).
Каждая упорядоченная пара целых чисел (а, б) появляется в качестве соседей ровно один раз (и только на одном шаге).
Доказательство от противного. Пусть k — первый шаг, при котором некоторая упорядоченная пара появилась во второй раз. Обозначим эту пару как (р, q) и я≤к это шаг другого появления этой пары. Без ограничения общности пусть р>q , то p было получено как сумма p-q и q, таким образом, на шагах я-1 и к-1 также имело место повторение какой-либо пары, порождающее противоречие.
Лемма 3 . Любая упорядоченная пара взаимно простых чисел встретится на каком-то шаге.
Пусть p и q соседи на каком-то шаге. Тогда, если
р>q он был получен как сумма
p-q и q, значит, они были соседями на предыдущем шаге. В двух шагах позади нас было либо
р-2q
и q, или
p-q
и
2q-p
(в зависимости от того, что больше,
p-q или q) и так далее. Процесс аналогичен алгоритму Евклида и продолжается, пока у нас нет 1 и x. Наконец, пары (1, х) и (х, 1) всегда появляются на шаге x$. Двигаясь по действиям в обратном направлении, приходим к выводу, что любая из промежуточных пар должна появиться в процессе, таким образом, пара (р, q) также появляется.
Двигаясь по действиям в обратном направлении, приходим к выводу, что любая из промежуточных пар должна появиться в процессе, таким образом, пара (р, q) также появляется.
Вычисление функции Эйлера — хорошо изученная задача. Это известно, что это мультипликативная функция, поэтому n=p1k1·p2k2· … ·pnkn , количество взаимно простых целых чисел равно (p1k1-p1k1-1)·(p2k2-p2k2-1)· … (pnkn-pnkn-1) Факторизация n может быть выполнена в На) время.
E. Резервная копия
Решить эту задачу на Яндекс.Конкурсе
Заявление| Ограничение по времени | 5 секунд |
| 512Mb | |
| Ввод | стандартный ввод или ввод. txt txt |
| Вывод | стандартный вывод или output.txt |
Чтобы пользовательские данные были в безопасности и не были потеряны при аварии, Аркадий постоянно придумывает и тестирует новые способы организации резервного копирования. На этот раз он перечислил все компьютеры, которыми он владеет, от 1 до n и для каждого компьютера с индексом от 1 до п-1 идентифицированный резервный компьютер Пи Он следовал правилу, согласно которому индекс резервного компьютера всегда должен быть больше индекса самого компьютера, т.е. пи > я . Из-за этого правила нет резервной копии для компьютера n.
Во время текущего эксперимента Аркадий выбрал некоторую конфигурацию значений Пи , и теперь планирует выключать компьютеры в определенном порядке, по одному компьютеру в секунду. Эксперимент заканчивается, когда компьютер с индексом n выключается. Изначально каждый компьютер имеет блок данных размера 1. Когда компьютер x выключается, его блок данных размера 1 копируется на компьютер. пикс. . В случае, если на компьютере x были какие-то другие блоки (которые были получены в качестве резервной копии с других компьютеров) и они не копируются и считаются потерянными. Более того, если компьютер пикс. уже выключен, блок данных с компьютера x никуда не копируется и также считается утерянным.
пикс. . В случае, если на компьютере x были какие-то другие блоки (которые были получены в качестве резервной копии с других компьютеров) и они не копируются и считаются потерянными. Более того, если компьютер пикс. уже выключен, блок данных с компьютера x никуда не копируется и также считается утерянным.
Акради хочет, чтобы его эксперимент длился как можно дольше. Однако он должен следовать еще одному правилу: если в течение какой-то секунды количество блоков данных, собранных на какой-то машине, равно k, то эта машина должна быть выключена в течение следующей секунды для обеспечения аппаратной безопасности. Обратите внимание, что последняя секунда (когда компьютер n выключен) не учитывается.
Формат ввода
Первая строка ввода содержит одно целое число т(1≤т≤20) — количество тестов.
Затем следуйте t описаниям отдельных тестов. Каждое описание начинается с двух целых чисел n и k(1≤n≤100 000, 2≤k≤10). — количество компьютеров, участвующих в этом эксперименте, и максимально возможная загрузка одного компьютера. Следующая строка содержит
п-1 целые числа p1, p2, … pn-1(i+1≤pi≤n) .
Следующая строка содержит
п-1 целые числа p1, p2, … pn-1(i+1≤pi≤n) .
Формат вывода
Для каждого из t тестов выведите одно целое число, равное максимально возможному количеству секунд, прежде чем Аркадию придется выключить машину номер n.
Образец
РешениеРешение
В этой задаче нам дано корневое дерево. За один шаг удаляется один узел. Если узел удаляется, а его непосредственный предок все еще присутствует, значение в этом предке увеличивается на 1 (изначально все значения равны 1). Если значение некоторого узла равно k, его следует удалить на следующем шаге. Цель состоит в том, чтобы максимизировать количество шагов при удалении корня.
Обратите внимание, что если корень имеет только к-1 потомок, мы можем удалить все дерево, прежде чем коснуться узла n. В противном случае потомки должны быть разделены на три множества: полностью удаленные поддеревья, поддеревья с оставшимся корнем и одно поддерево, у которого в конце удаляется корень, вызывающий узел n. также подлежат удалению. Запустите поиск в глубину, чтобы вычислить следующее значение динамического программирования:
также подлежат удалению. Запустите поиск в глубину, чтобы вычислить следующее значение динамического программирования:
средний) это количество узлов, которые мы можем удалить в поддереве v, если нам разрешено удалить v в любой точке. Можно показать, что средний) равно общему количеству узлов в поддереве.
б(в) это количество узлов, которые мы можем удалить в поддереве v, если нам не разрешено касаться узла v. Если их меньше к-1 потомки, б(в) равно а(в)-1 . В противном случае мы должны выбрать к-2 потомок использовать значение а(у) , а для других мы используем б(у) . Этот к-2 потомки выбираются по максимальному значению а(и)-б(и) .
резюме) равно количеству узлов, которые мы можем удалить, если нам разрешено удалить узел v, но это нужно сделать в самом конце. Значение
с (н)
это окончательный ответ. Мы должны выбрать некоторые
к-2
потомки использовать а(у) , один для использования с(и) а для других берем б(у) . Попробуйте каждого потомка как кандидата на с(и) и для другого использования жадный алгоритм, чтобы выбрать лучший
а(и)-б(и) . Предварительно вычислить отсортированный массив всех потомков и вычислить сумму к-2 лучший. Если потомок x будет использоваться с
с(х)
среди них
к-2
использовать к-1
(должно быть как минимум к-1
потомков, иначе уничтожаем все поддерево).
Предварительно вычислить отсортированный массив всех потомков и вычислить сумму к-2 лучший. Если потомок x будет использоваться с
с(х)
среди них
к-2
использовать к-1
(должно быть как минимум к-1
потомков, иначе уничтожаем все поддерево).
Общая сложность О(n log n)
F. Лежащие процессоры
Решить эту задачу на Яндекс.Конкурсе
Постановка| Лимит времени | 3 секунды | Лимит памяти | 512Mb |
| Ввод | стандартный ввод или ввод .txt |
| Вывод | стандартный вывод или output.txt |
Для тестирования последних достижений в области алгоритмов машинного обучения Евгений использует
н·м процессоры, расположенные в элементарных ячейках п×м доска. Таким образом, процессоры занимают n рядов, по m штук в каждом. Два процессора называются соседними, если они расположены в соседних ячейках одной строки или на одинаковых позициях в соседних строках.
В результате неудачного эксперимента с новым алгоритмом некоторые процессоры научились врать Евгению. Однако, благодаря базовой версии используемого алгоритма, все обработчики, которые научились лгать, делают это каждый раз, когда что-то сообщают Евгению, так что результат их работы по-прежнему легко интерпретировать.
Сейчас Евгений работает над тем, чтобы определить, какие из процессоров всегда лгут, но для начала он хочет понять возможный размер проблемы. Для этого он спросил у каждого из процессоров, правда ли, что среди его соседей есть процессоры, которые работают правильно, и процессоры, которые всегда возвращают ложь? К его удивлению, каждый из процессоров ответил положительно. Теперь Евгений задается вопросом, какое минимально возможное количество лежащих процессоров на плате может привести к таким ответам?
Формат ввода
Единственная строка входных данных содержит два целых числа n и m(1≤n≤7, 1≤m≤100) — количество рядов на плате и количество процессоров в каждом из рядов соответственно.
Формат вывода
Выведите одно целое число — минимально возможное количество лжецов среди процессоров на доске, при котором каждый из процессоров сообщил, что среди его соседей есть как правильные, так и лживые процессоры.
Образец 1
Образец 2
Примечания
Одно из возможных решений в первом примере (лжецы отмечены единицами): 1):
100
001
Решение
Мы будем использовать тот факт, что п≤7 и вычислить профиль динамического программирования. Если мы уже заполнили первые i столбцов таблицы и для первого все верно я-1 столбцы, нам нужно знать только состояние последних столбцов, чтобы иметь возможность продолжить.
Пусть дп(я, м1, м2) , где i варьируется от 1 до m, м1 и
м2 битовые маски в диапазоне от 0 до 2н-1
означает минимальное количество процессоров, необходимое для заполнения первых i столбцов, чтобы сделать первый я-1
столбцы правильные, а последние два столбца должны быть заполнены как м1 и
м2 соответственно. Количество различных состояний равно О(м·22n) . Наконец, чтобы вычислить релаксации, мы пробуем все возможные маски.
м3
для нового государства дп(я+1, м2, м3) .
Количество различных состояний равно О(м·22n) . Наконец, чтобы вычислить релаксации, мы пробуем все возможные маски.
м3
для нового государства дп(я+1, м2, м3) .
Применяя битовые операции и некоторые предварительные вычисления получаем О(м·23n) Продолжительность. Мы можем значительно ускорить его, предварительно вычислив все допустимые значения. м3 за пару (м1, м2) .
Упражнение: придумай О(нм22н) решение.
Как работает алгоритм Яндекса?
Яндекс — российская поисковая система, созданная в 1997 году Аркадием Воложем, Ильей Сегаловичем и Аркадием Борковским. Это популярная поисковая система в России с долей рынка более 60%, которая также используется в Беларуси, Казахстане и Турции. Алгоритм Яндекса работает на основе определения релевантности и рейтинга веб-страниц в его результатах поиска.
В этой статье мы подробно рассмотрим, как работает алгоритм Яндекса.
Как работает алгоритм Яндекса?
Вот запущенный процесс алгоритма Яндекса.
1. Анализ запроса
Когда пользователь вводит поисковый запрос в Яндекс, поисковая система анализирует запрос, чтобы определить намерение пользователя. Яндекс учитывает такие факторы, как язык запроса, местоположение пользователя и историю поиска пользователя, чтобы определить наиболее релевантные результаты.
Например, если пользователь из Москвы введет запрос «доставка пиццы», алгоритм Яндекса, скорее всего, выдаст результаты для служб доставки пиццы в Москве.
2. Индексирование документов
После анализа запроса алгоритм Яндекса просматривает свой индекс веб-страниц, чтобы найти наиболее релевантные результаты. Индекс Яндекса постоянно обновляется и содержит миллиарды веб-страниц. Поисковик использует поисковый робот Яндекс.
Бот для обнаружения и индексации новых страниц. Яндекс. Бот похож на поисковый робот Google, Googlebot, в том, что он переходит по ссылкам с одной страницы на другую, чтобы обнаружить новые страницы для добавления в индекс.
3. Рейтинг релевантности
После того как алгоритм Яндекса определил наиболее релевантные веб-страницы для данного запроса, он использует собственный алгоритм для ранжирования этих страниц в порядке релевантности. Алгоритм ранжирования Яндекса учитывает сотни факторов, в том числе:
4. Релевантность ключевого слова
Яндекс ищет страницы, содержащие ключевые слова, используемые в поисковом запросе, на видном месте, такие как заголовок страницы, заголовки и основной текст.
5. Качество контента
Яндекс оценивает общее качество контента на странице. Страницы с качественным информативным и полезным для пользователей контентом имеют больше шансов получить более высокий рейтинг.
6. Возраст домена
Алгоритм Яндекса учитывает возраст домена при ранжировании страниц. Старые домены обычно считаются более надежными и авторитетными.
7. Входящие ссылки
Яндекс смотрит на количество и качество ссылок, ведущих на страницу. Страницы с большим количеством качественных внешних ссылок с большей вероятностью будут иметь более высокий рейтинг.
Страницы с большим количеством качественных внешних ссылок с большей вероятностью будут иметь более высокий рейтинг.
8. Поведение пользователей
Алгоритм Яндекса учитывает сигналы поведения пользователей, такие как рейтинг кликов и показатель отказов, при ранжировании страниц. Страницы, на которые кликают чаще и с более низким показателем отказов, считаются более релевантными и с большей вероятностью занимают более высокие позиции.
9. Персонализация
Яндекс также учитывает историю поиска пользователя и личные предпочтения при ранжировании результатов поиска. Яндекс использует технологию MatrixNet для персонализации результатов поиска.
MatrixNet — это алгоритм машинного обучения, который использует данные об истории поиска пользователя, местоположении и устройстве, чтобы предсказать, какие результаты поиска, скорее всего, будут релевантны пользователю.
10. Вертикальный поиск
Помимо общих результатов поиска, Яндекс также предлагает результаты вертикального поиска для определенных типов контента, таких как изображения, видео, новости и карты. Результаты вертикального поиска Яндекса ранжируются по другому алгоритму, чем его общие результаты поиска.
Результаты вертикального поиска Яндекса ранжируются по другому алгоритму, чем его общие результаты поиска.
Например, результаты поиска изображений Яндекса ранжируются на основе таких факторов, как разрешение изображения, размер изображения и релевантность поисковому запросу.
11. Обнаружение спама
В Яндексе есть команда инженеров и аналитиков, которые работают над выявлением и наказанием веб-сайтов, используя тактику рассылки спама для повышения их поискового рейтинга. Алгоритм обнаружения спама Яндекса ищет шаблоны поведения, которые обычно ассоциируются со спамом, такие как наполнение ключевыми словами, маскировка и схемы ссылок.
Веб-сайты, уличенные в рассылке спама, могут быть оштрафованы снижением позиций в поиске или даже удалены из индекса Яндекса.
Для обнаружения спама Яндекс использует комбинацию ручной проверки и автоматических алгоритмов. Ручные проверки проводятся аналитиками, которые оценивают веб-сайты на наличие признаков рассылки спама. Автоматизированные алгоритмы используют машинное обучение для выявления моделей поведения, которые обычно ассоциируются со спамом.
Автоматизированные алгоритмы используют машинное обучение для выявления моделей поведения, которые обычно ассоциируются со спамом.
Как алгоритм Яндекса обнаруживает спам?
Некоторые из факторов, которые принимает во внимание алгоритм обнаружения спама Яндекса, включают:
1.
Наполнение ключевыми словамиАлгоритм Яндекса ищет страницы, которые используют высокую плотность ключевых слов, пытаясь манипулировать поисковым рейтингом.
2. МаскировкаАлгоритм Яндекса ищет страницы, содержание которых для сканеров поисковых систем отличается от содержания, которое они показывают пользователям-людям.
3. Схемы ссылокАлгоритм Яндекса ищет страницы, которые используют манипулятивные схемы ссылок, такие как покупка или продажа ссылок, в попытке манипулировать поисковым рейтингом.
4.
Дублированный контент Алгоритм Яндекса ищет страницы, содержащие дублирующийся контент или скопированные из других источников.
Если алгоритм Яндекса обнаружит спам-поведение на сайте, сайт может быть оштрафован понижением позиций в поиске или вообще удален из индекса Яндекса.
В Яндексе также есть система, с помощью которой веб-мастера могут сообщать о спам-поведении, что позволяет поисковой системе быстро выявлять и наказывать веб-сайты, использующие тактику рассылки спама.
Заключение
Алгоритм Яндекса работает, анализируя запросы пользователей, индексируя веб-страницы, ранжируя результаты поиска на основе релевантности и персонализации, предоставляя результаты вертикального поиска для определенных типов контента и обнаруживая наказывающие веб-сайты, которые используют спам или манипулятивную тактику.
Алгоритм ранжирования Яндекса учитывает сотни факторов, включая релевантность ключевых слов, качество контента, возраст домена, входящие ссылки и поведение пользователей, а его технология персонализации MatrixNet использует данные об истории поиска пользователя, местоположении и устройстве для прогнозирования какие результаты поиска, скорее всего, будут релевантны пользователю.