
Noindex что это — как использовать, скрыть ссылку от Яндекса
Бывают ситуации, когда необходимо разместить на сайте ссылку на сторонний ресурс, но при этом совсем не радует такой факт, что со страницы будет утекать вес.
Или другая проблема: надо закрыть от индексации какую-либо часть текста. Что делать в таком случае?
Как закрыть внешние ссылки
Оказывается, есть выход. Введенный Яндексом парный тег <noindex></noindex> запрещает поисковому роботу индексировать часть кода, заключенного внутри.
Данный тег является командой для ботов Яндекса и Рамблера, но для Google он ничего не значит.
Отсюда вывод, что если мы закроем часть кода noindex, то Яндекс его не будет индексировать, а Гугл будет.
Рассмотрим, к примеру: <noindex><a href=http://seitostroenie.ru>Создание и раскрутка сайта</noindex>.
Данный пример показывает, что мы закрыли от индексации анкор «Создание и раскрутка сайта», но саму ссылку поисковик будет учитывать и по ней будет утекать вес.
Валидность кода
Необходимо учесть такой факт, что закрыв от бота участок текста тегом <noindex>, приведет к тому, что:
- будет нарушена валидность кода. Причина в том, что такой код, кроме Яндекса и Рамблера другие системы не понимают;
- некоторые визуальные редакторы его не воспринимают и даже удаляют, например wordpress.
Чтобы исключить ошибки валидатора, связанные с тегом, можно текст закомментировать следующим образом: <!—noindex—><!—/noindex—>. Данный вариант устроит все поисковые системы, его распознает Яндекс, а валидатор не будет выдавать ошибку. К сожалению Google не понимает его и не придумал ничего аналогичного.
Польза тега noindex
Тег может быть незаменим в следующих случаях:
- если на сайте есть какой-то текст, который нужно спрятать от глаз поисковых роботов;
- чтобы спрятать от индексации код счетчика;
- при наличии неуникального контента, чтобы поисковик его не индексировал.

Напомню, что это правило действует только для Яндекса.
Если надо закрыть от индексации всю страницу
Если прописать мета-тег <meta name=»robots» content=»noindex»>, то вся страница не будет проиндексирована и роботы не смогут переходить по ссылкам. Запретить индексацию и переход по линкам можно также в файле robots.txt.
Как закрыть индексацию контента от Гугла
Атрибут rel=”nofollow” работает со всеми поисковиками и полностью является валидным.
Использование данного атрибута позволяет:
- закрыть ссылку от индексации;
- повлиять на перераспределение веса между всеми линками, которые есть на странице;
- закрыть ссылки в комментариях.
Атрибут rel=”nofollow” можно использовать в файле robots.txt, когда нужно запретить индексацию страницы и переходы по ссылкам.
Если одна ссылка оформлена тегами nofollow и noindex, то такое сочетание позволяет удержать вес страницы и спрятать анкор от Яндекса.
Noindex – это | Что такое Noindex
Что такое Noindex?
Noindex — имя тега, предназначенного для включения в него текста, который не должен быть проиндексирован поисковыми системами (Яндекс и Rambler).
Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Часто у тех, кто использует этот тег, существует убеждение, что если поместить часть какого-либо текста между открывающимся и закрывающимся тегом noindex, то робот Яндекса не станет читать и анализировать этот текст. Но это не так. Этот тег запрещает помещение содержимого в индексную базу, а его содержимое будет прочитано и проанализировано роботом в любом случае.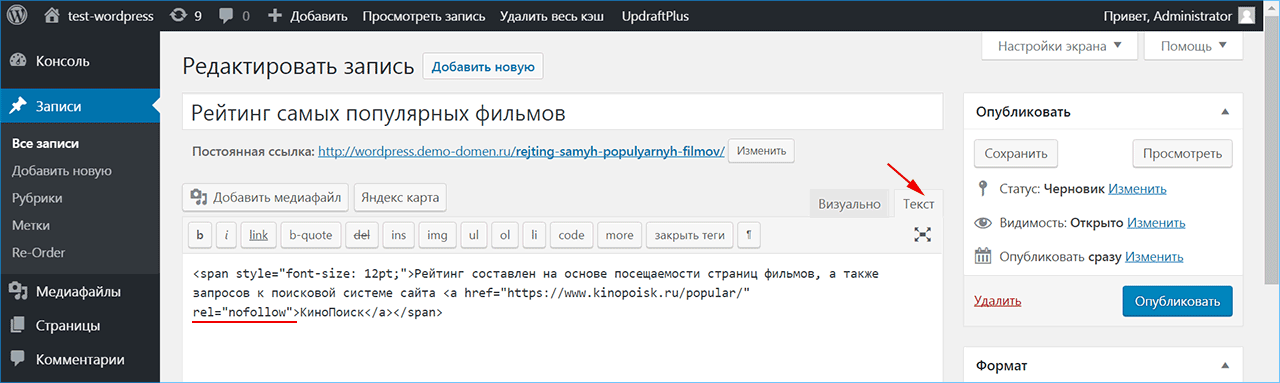
В чем отличие между noindex и nofollow
Существенное отличие их в том, что первый был введен ранее для Google, а второй — только для Яндекс и Rambler. В настоящее время Яндекс также научился распознавать Nofollow, который работает только для ссылок. А Noindex — для любого кода сайта.
Применение
Пример 1:
<noindex>Текст, запрещенный к индексированию</noindex>
Яндекс не индексирует текст, но читает его
Пример 2:
<noindex><a href=»http:// … .ru/»>Текст ссылки</a>
Яндекс не индексирует анкор, но учитывает ссылку на сайт и передает по ней вес
При работе с Noindex существует вероятность того, что снизится валидность кода, так как данный тег знает только российский поисковик. Некоторые HTML-редакторы не воспринимают его, поскольку он не является валидным. К примеру, визуальный редактор в WordPress его попросту удаляет.
<!—Noindex—> Весь текст, который надо скрыть <!—/Noindex—>.
При этом другие поисковые системы просто его пропустят, а валидность кода останется неизменной.
Не стоит путать тег Noindex с метатегом, имеющим такое же название. Последний прописывают в начале страницы. Они служат для разных целей. Если взять метатег <meta name=»robots» content=»noindex,nofollow»>, то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt — и такие страницы поисковыми роботами учтены не будут.
Категории
SEO (search engine marketing)
Внутренняя оптимизация
Метатеги
Title
Description
Альт теги
Микроразметка
Теги-заголовки
Nofollow
Noindex
Контент
Копирайтинг
Robots.
 txt
txtСемантическое ядро сайта
Внешняя оптимизация
Биржа ссылок
Miralinks
Аудит сайта
Яндекс.Вебмастер
См. также
Хлебные крошки на сайте
Зеркало сайта
XML карта
Как запретить индексацию сайта или страниц?
Иногда необходимо, чтобы страницы сайта или размещенные на них ссылки не отображались в результатах поиска. Вы можете использовать файл robots.txt, HTML-разметку или авторизацию на сайте, чтобы скрыть содержимое сайта от индексации,
Если некоторые страницы или разделы сайта не должны индексироваться (например, те, которые содержат технические или конфиденциальные информации), для ограничения доступа к ним используйте следующие способы:
В файле robots.txt укажите директиву Disallow.
Укажите метатег robots с директивой noindex или none в HTML-коде страниц сайта.
Дополнительные сведения см. в разделе Метатег Robots и заголовок HTTP X-Robots-Tag.Воспользоваться авторизацией на сайте. Мы рекомендуем этот метод, чтобы скрыть домашнюю страницу от индексации. Если главная страница запрещена в файле robots.txt или метатегом noindex, но есть ссылки, ведущие на нее, страница может быть включена в результаты поиска.
 Дополнительные сведения см. в разделе Метатег Robots и заголовок HTTP X-Robots-Tag.
Дополнительные сведения см. в разделе Метатег Robots и заголовок HTTP X-Robots-Tag.- Скрыть часть текста страницы от индексации
Добавить элемент noindex в HTML-код страницы. Примеры:
Элемент не чувствителен к вложенности — может располагаться в любом месте HTML-кода страницы. Если на странице нет закрывающего тега, все содержимое страницы считается скрытым. Не создавайте несколько вложенных тегов noindex, потому что разметка будет игнорировать все, что находится после первого закрывающего тега.
Вы можете использовать тег в следующем формате, если необходимо сделать код сайта действительным:
текст, который не должен индексироваться
Добавьте элемент noscript в HTML-код страницы.
Примеры:Элемент noscript, как и noindex, запрещает индексацию, но скрывает содержимое сайта от пользователя, если его браузер поддерживает JavaScript.
Примечание. JavaScript поддерживается всеми популярными браузерами, если эта функция специально не отключена пользователем.
Вы можете просмотреть отчет о поддержке JavaScript в Яндекс.Метрике.
- Скрыть ссылку на странице от индексации
Чтобы скрыть все ссылки на странице от индексации, в HTML-коде страницы укажите метатег robots с директивой nofollow. Робот не будет переходить по ссылкам при сканировании сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.
Вы также можете добавить к ссылке атрибут rel=»nofollow». Примеры:
текст ссылки
Атрибут rel=»nofollow» воспринимается роботом как рекомендация игнорировать ссылку.
При использовании любой из перечисленных инструкций ссылка может быть обработана роботом и отображаться в Яндекс.Вебмастере как внутренняя или внешняя. Отображение или отсутствие ссылки в Яндекс.Вебмастере не означает, что поисковые алгоритмы ее никак не учитывают.
 Примеры:
Примеры:
Может ли категория noindex запретить индексацию других страниц на Яндексе?
спросил
Изменено 6 лет, 4 месяца назад
Просмотрено 97 раз
На моем веб-сайте я помещаю noindex на страницы своих категорий, но не на страницы под ним. Несмотря на то, что прошло две недели, единственная проиндексированная страница — это моя домашняя страница, которая не входит ни в одну из категорий.
Когда я смотрю на yandex webmasters, в разделе индексация>статистика>исключенные страницы я вижу как www. example.com/category
example.com/category
www.example.com/category/. Интересно, означает ли www.example.com/category/ (косая черта в конце) «Я не индексирую никакие страницы под ним», а www.example.com/category означает, что я не индексирую категорию.- поисковая-индексация
- noindex
- yandex
- yandex-webmaster-tools
1
страницы индексируются, если:
- их нет
noindex, - у них есть входящие ссылки (внутренние и/или внешние),
- входящие ссылки на них не являются
nofollow. - бот имеет непрерывный URL-адрес от точки входа до страницы, которая должна быть проиндексирована, например: URL-адрес входа ссылается на url1 (нет
nofollow) -> url1 ссылается на url2 (нетnofollow) -> url2 ссылки на url должны быть проиндексированы (нетnofollow) -> url, который должен быть проиндексирован (
0
Бот не может понять, какой каталог является каталогом, а какой нет, из-за множества конфигураций на стороне сервера, позволяющих использовать конечную косую черту или нет, по желанию веб-мастера.