
Что такое XML выдача Яндекса?
С появлением бесплатного сервиса Яндекс.XML появилась возможность отправлять неограниченное количество запросов к поиску без заполнения captcha (автоматически генерируемый тест-проверка) и без риска быть «забаненным». Полученные результаты подаются в формате XML.
Используя потенциал Яндекс.XML, web-разработчики создают на сайте поиск в Сети с публикацией ответов в соответствии с индивидуальным дизайном, проводят анализ поисковой оптимизации ресурса, разрабатывают новые web-приложения.
Нагрузку на собственного сервера Яндекс регулирует при помощи XML-лимитов, поэтому минимальное количество запросов обрабатывается в дневное время, а максимальное – в нерабочие часы. Формула для расчета количества лимитов основана на расчетах трастовости искомого сайта.
Получение доступа
- Для начала работы с сервисом необходимо пройти стандартную процедуру регистрации;
- Рекомендуется указывать действительный телефонный номер для получения СМС доступа, иначе минимальное количество запросов в течении 24-х часов ограничится десятью.
 Продвижение ресурсов, разработанных профессионально выполняется через систему размещения контекстной рекламы Яндекса, поэтому для них это условие не обязательно;
Продвижение ресурсов, разработанных профессионально выполняется через систему размещения контекстной рекламы Яндекса, поэтому для них это условие не обязательно; - Обязательна регистрация одного или нескольких IP-адресов. Если на протяжении трех месяцев с данного адреса не будет отправлен ни один запрос, действие учетной записи будет приостановлено или произойдет удаление аккаунта;
- Чтобы засвидетельствовать авторство Яндекса, на странице отображения результатов поиска необходимо размещать ссылку на домашнюю страницу Яндекс.XML, в виде одного из стандартных логотипов.
 Продвижение ресурсов, разработанных профессионально выполняется через систему размещения контекстной рекламы Яндекса, поэтому для них это условие не обязательно;
Продвижение ресурсов, разработанных профессионально выполняется через систему размещения контекстной рекламы Яндекса, поэтому для них это условие не обязательно;Для построения запросов, требующихся для оценки продвижения ресурса в Яндексе, можно применить для написания интерфейс, предоставленный сервисом или создать программу своими силами.
Параметры
Яндекс.XML отличается простым и доступным интерфейсом. При отправке запросов необходимо указывать следующие параметры:
Имя пользователя, указанное при авторизации и автоматически сгенерированный системой, индивидуальный для каждого IP-адреса.
Поисковый запрос в текстовом формате, для которого существуют некоторые количественные ограничения. При обработке следует учитывать отличительные черты информационно-поискового языка Яндекса.
Заданный режим фильтрации и сортировки на странице результатов поиска. Применяются значения по релевантности «rlv» и по времени изменения документа «tm». Если вводные не заданы, результаты автоматически распределяются по степени релевантности.
Максимальное число фрагментов обнаруженного документа, содержащих информативные слова, входящие в запрос (пассажей). Возможные значения от 1 до 5. Применяются для формирования текстовых аннотаций к документу.
Список параметров, определяющих порядок группировки результатов. По умолчанию производится «плоский поиск», когда каждая группа включает только один документ;
Номер web-страницы, сгенерированной поисковой системой в ответ на пользовательский запрос. Расстановка нумерации начинается со значения «0». Если параметр не прописан, возвращается первая страница поисковой выдачи.
В зависимости от качества сайта, подтвержденного в сервисе Яндекс. Вебмастер, поисковая система может выделить соответствующее количество лимитов – ограничений на количество запросов к своей базе. Если разрешение на управление ресурсом было подтверждено для нескольких пользователей, лимиты может получить только первый владелец.
Яндекс XML лимиты — за что дают?
Как Яндекс XML начисляет баллы для возможности пользования своим API? Какие факторы на это влияют?
Считается, что баллы Яндекс XML начисляются по количеству страниц в индексе поисковой системы. Чем больше страниц проиндексировал поисковый робот, тем больше баллов появится у администратора сайта (передаст он их кому-нибудь или оставит себе — это уже другой вопрос).
А может быть что-то ещё добавляет баллы? — подумали мы и проверили, как на «XML баллы» влияют:
- количество проиндексированных страниц (чтобы лишний раз убедиться, что это так),
- возраста домена,
- индекс цитирования (тИЦ),
- присутствие в Яндекс. Каталоге.
 Каталоге.
Каталоге.Мы проводили исследование на 103 сайтах. Для начала давайте поглядим, что же из себя представляет выборка, которую мы подготовили. Получились такие графики:
Что мы видим:
- Подтверждается зависимость количества баллов Яндекс.XML от количества страниц в индексе.
- Возраст сайта не на количество баллов Яндекс.XML (на количество страниц — тоже).
- С тИЦ и Яндекс.Каталогом — как-то не очень понятно
Обратите внимание, мы здесь использовали логарифмическую шкалу (10-100-1000, а не 10-20-30).
Регрессионная модель
Мы с 10-й попытки смогли найти нужные символы, чтобы составить эту красивую модель:
\[\hat{Score} = \hat{\beta_0} + \hat{\beta_1}Age + \hat{\beta_2}YandexCatalog + \hat{\beta_3}YandexIndex + \hat{\beta_5}YandexCitation\]
А ещё Евгений Летов долго требовал поиграть в ней шрифтами.
Какие переменные значимы?
На 5% уровне значимы:
- Количество страниц в индексе. Каждая проиндексированная страничка дает примерно 0,3 XML-балла.
- тИЦ. Каждый дополнительный балл тИЦ добавляет 0,6 XML-балла.

Возраст сайта и присутствие в Яндекс.Каталоге роли не сыграли.
«Ха! Всё равно вы что-нибудь да пропустили!»
Да, мы могли что-то пропустить. Поэтому провели RESET-тест Рамсея, который создан как раз для таких случаев.
На нашей выборке p-value составил 0.95 — поэтому на данной выборке нет оснований полагать, что мы действительно что-то упустили.
Итог (Что делать?)
Приоритетные направления деятельности любителей Яндекс.XML:
- Увеличивать тИЦ ваших ресурсов.
- Загонять индекс побольше страниц.
P.S. 103 сайта — это довольно маленькая выборка. Кто его знает, может быть всё совсем не так — ведь мы «игрались» только с опекаемыми нами сайтами, в которых реальное количество страниц примерно соответствует количеству проиндексированных.
Если вы хотите помочь нашему исследованию стать точнее, можете отправлять списки вида «сайт» — «количество баллов» на почту letov@promoexpert. pro.
pro.
P.P.S. При подготовке материала ни один SEO’шник не пострадал (разве что от скуки).
Соавтор статьи
квот | ClickHouse Docs
Квоты позволяют ограничить использование ресурсов в течение определенного периода времени или отслеживать использование ресурсов. Квоты настраиваются в конфигурации пользователя, обычно это «users.xml».
В системе также есть функция ограничения сложности одного запроса. См. раздел Ограничения на сложность запроса.
В отличие от ограничений сложности запросов, квоты:
- Накладывают ограничения на набор запросов, которые могут выполняться в течение определенного периода времени, вместо ограничения одного запроса.
- Учет ресурсов, израсходованных на всех удаленных серверах для распределенной обработки запросов.
Давайте посмотрим на раздел файла «users.xml», который определяет квоты.
<квоты>
<по умолчанию>
<интервал>
<длительность>3600
0
0
0
0
0
< read_rows>0
0
По умолчанию квота отслеживает потребление ресурсов каждый час без ограничения использования. Потребление ресурсов, рассчитанное для каждого интервала, выводится в журнал сервера после каждого запроса.
<интервал>
3600
1000
100
100
100
< result_rows>1000000000
100000000000
900
86400
10000
10000
10000
1000
5000000000
500000000000
7200
Для квоты ‘statbox’ ограничения устанавливаются на каждый час и на каждые 24 часа (86 400 секунд). Интервал времени отсчитывается, начиная с фиксированного момента времени, определенного реализацией. Другими словами, 24-часовой интервал не обязательно начинается в полночь.
Интервал времени отсчитывается, начиная с фиксированного момента времени, определенного реализацией. Другими словами, 24-часовой интервал не обязательно начинается в полночь.
Вот суммы, которые могут быть ограничены:
запросов — Общее количество запросов.
query_selects — общее количество запросов на выборку.
query_inserts — общее количество запросов на вставку.
ошибок — количество запросов, вызвавших исключение.
result_rows – Общее количество строк, полученных в результате.
read_rows — общее количество исходных строк, прочитанных из таблиц для выполнения запроса на всех удаленных серверах.
время выполнения — общее время выполнения запроса в секундах (время стены).
При превышении лимита хотя бы для одного временного интервала выбрасывается исключение с текстом о том, какое ограничение было превышено, за какой интервал и когда начинается новый интервал (когда запросы можно отправлять повторно).
Квоты могут использовать функцию «Ключ квоты» для независимого отчета о ресурсах для нескольких ключей. Вот пример:
Квота назначается пользователям в разделе «users» конфигурации. См. раздел «Права доступа».
При распределенной обработке запросов накопленные суммы сохраняются на запрашивающем сервере. Поэтому, если пользователь перейдет на другой сервер, квота там «начнется заново».
Поэтому, если пользователь перейдет на другой сервер, квота там «начнется заново».
При перезапуске сервера квоты сбрасываются.
О дневных квотах запросов и лимитах
Группа поддержки сайта Supermetrics
Дата изменения: ср, 12 октября 2022 г., 13:24
Многие источники данных имеют ограничения на количество запросов, которые учетная запись API может сделать за определенный период времени. Они называются квотами запросов API или лимитами запросов.
Если вы достигли квоты или лимита запросов
Если вы видите это сообщение об ошибке, вы, вероятно, достигли лимита запросов API для вашего источника данных:- Превышена дневная квота [источник данных], повторите попытку позже.

Вы можете отслеживать использование вашей лицензии и запрашивать квоты на сайте группы Supermetrics. Если вы считаете, что достигли предела, вы найдете здесь дополнительную информацию.
Один запрос Supermetrics может привести к множеству запросов к API источника данных, в зависимости от выбранных показателей и измерений. Это означает, что вы можете достичь предела квоты всего за несколько запросов.
Как это исправить
Если какая-либо из ваших квот на источник данных достигает своего предела, уменьшите размер запроса до значения, которое ниже предела вашего источника данных. Мы рекомендуем вам:
- Сокращение диапазонов дат
- Удаление ненужных полей
- Одновременное использование меньшего количества учетных записей
Если вы используете Google Таблицы, вы также можете использовать функцию «Объединить новые результаты со старыми», чтобы создавать более эффективные запросы.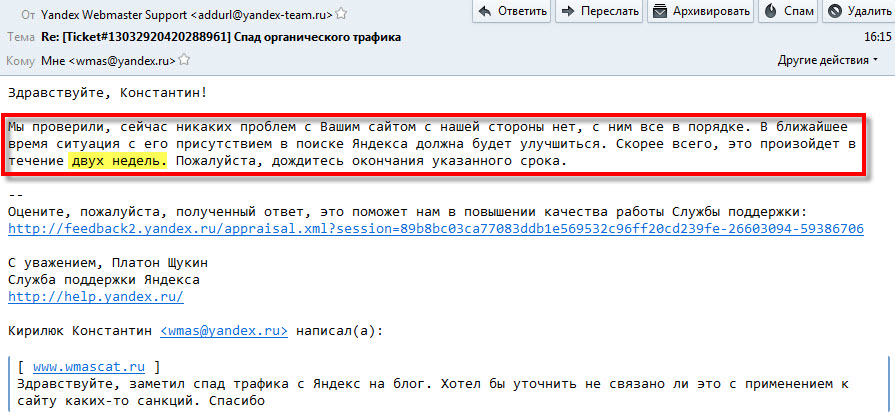
Справочный список: Доступные лимиты запросов к источнику данных
| Источник данных | Лимит запросов | Время сброса |
|---|---|---|
| Adform per day | 9 0017824 часа с момента первого запроса | |
| Adobe Analytics | Лицензии Adobe не имеют стандартного лимита запросов. Свяжитесь с Adobe, чтобы внести изменения. | |
| Adobe Analytics V2 (Reference) | 120 requests per minute per license (enforced as 12 requests every 6 seconds) | |
| Google Campaign Manager 360 | 30,000 requests per user per день Существует квота на 36 одновременных отчетов.  | Midnight, Pacific Standard Time (UTC-8) |
| Google Display & Video 360 | 2000 Запросы в день | |
| 5220 | ||
| 5220 | ||
| 5220 | ||
| 220 | До одного часа | |
| Facebook Insights | 4800 запросов на каждого заинтересованного пользователя в день | 24-часовой скользящий период |
| Google Analytics (ссылка) | 10,000 requests per view (profile) per day | Midnight, Pacific Standard Time (UTC-8) |
| Twitter Ads | 250 requests per 15 minutes | Every 15 minutes |
| Twitter Public Data | Зависит от типа данных | Каждые 15 минут |
Яндекс. |
