
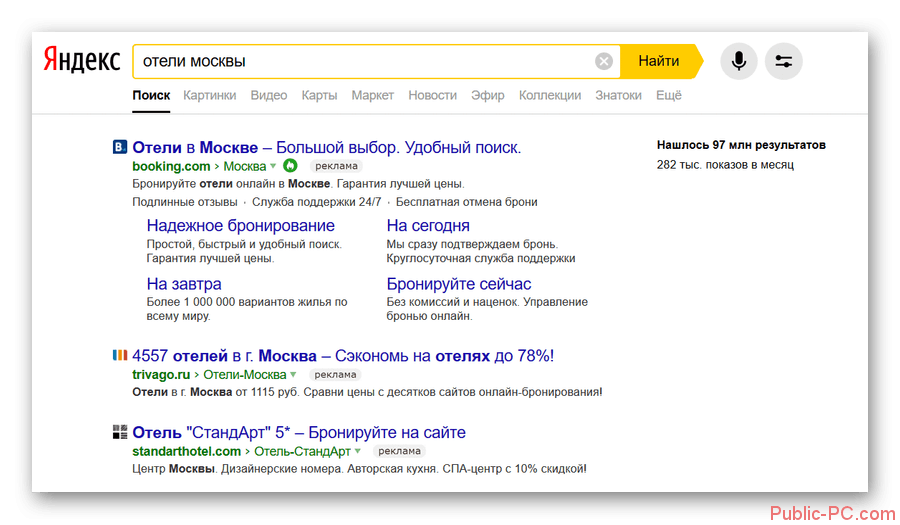
Компания Яндекс — Технологии — Индексирование интернета
Поисковая машина Яндекса отвечает на вопросы пользователей, находя нужные документы в интернете. А размеры современного интернета исчисляются в эксабайтах, то есть в миллиардах миллиардов байтов. Конечно же, Яндекс не обходит весь интернет каждый раз, когда ему задают вопрос. Поисковая система, так сказать, делает домашнее задание.
Поиск в интернете состоит из двух частей. Первая — поисковик обходит интернет, создавая его слепок на своих серверах. Вторая — пользователь задаёт запрос и получает ответ с серверов поисковика.
Яндекс ищет по поисковому индексу — базе данных, где для всех слов, которые есть на известных поиску сайтах, указано их местонахождение — адрес страницы и место на ней. Индекс можно сравнить с предметным указателем в книге или адресным справочником. В отличие от обычного предметного указателя, индекс содержит не только термины, а вообще все слова. А в отличие от адресного справочника, у каждого слова-адресата есть не одно, а очень много «мест прописки».
Подготовка данных, по которым ищет поисковая машина, называется индексированием. Специальная компьютерная система — поисковый робот — регулярно обходит интернет, выкачивает документы и обрабатывает их. Создается своего рода слепок интернета, который хранится на серверах поисковика и обновляется при каждом новом обходе.
У Яндекса два поисковых робота — основной и быстрый (он называется Orange). Основной робот индексирует интернет в целом, а Orange отвечает за то, чтобы в поиске можно было найти самые свежие документы, которые появились минуты или даже секунды назад. У каждого робота есть список адресов документов, которые нужно проиндексировать.
Когда при обходе робот видит на уже известных сайтах новые ссылки, он добавляет их в свой список, увеличивая количество индексируемых страниц. Впрочем, владелец сайта сам может помочь основному роботу Яндекса найти свой ресурс и подсказать, например, как часто обновляются его страницы — через сервис Яндекс.Вебмастер.
Сначала программа-планировщик выстраивает маршрут — очередность обхода документов.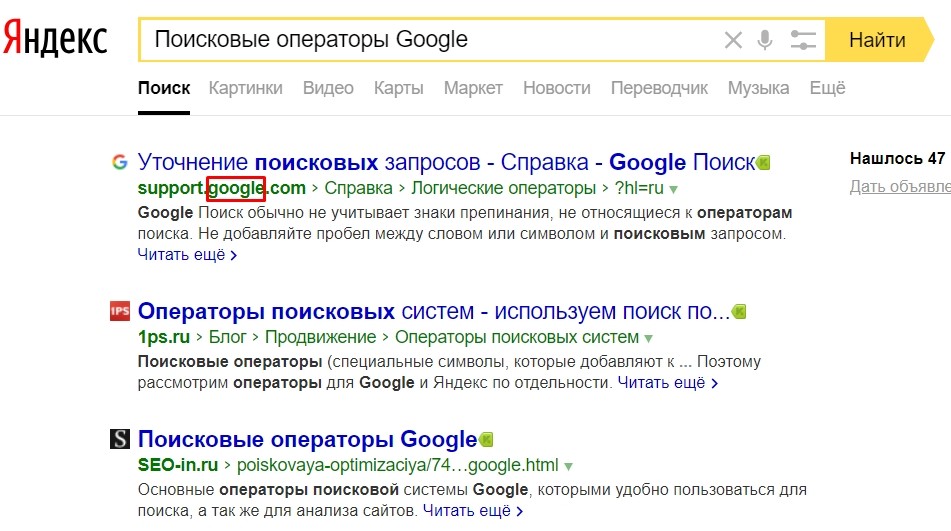 При этом планировщик учитывает важные для поисковой системы характеристики сайтов, такие как, например, цитируемость или частота обновления документов. После создания маршрута планировщик отдаёт его другой части поискового робота — «пауку». Паук регулярно обходит документы по заданному маршруту. Если сайт на месте, то есть работает и доступен, паук выкачивает запланированные в маршруте документы. Он определяет тип скачанного документа (html, pdf, swf и т.п.), кодировку и язык, а затем отправляет данные в хранилище.
При этом планировщик учитывает важные для поисковой системы характеристики сайтов, такие как, например, цитируемость или частота обновления документов. После создания маршрута планировщик отдаёт его другой части поискового робота — «пауку». Паук регулярно обходит документы по заданному маршруту. Если сайт на месте, то есть работает и доступен, паук выкачивает запланированные в маршруте документы. Он определяет тип скачанного документа (html, pdf, swf и т.п.), кодировку и язык, а затем отправляет данные в хранилище.
Там программа разбирает документ по кирпичику: очищает от html-разметки, оставляя чистый текст, выделяет данные о местоположении каждого слова и добавляет их в индекс. Сам документ в исходном виде также остается в хранилище до следующего обхода. Благодаря этому пользователи могут найти в Яндексе и посмотреть документы, даже если сайт временно недоступен. Если сайт закрылся или документ был удалён или обновлён, Яндекс удалит копию со своих серверов или заменит её на новую.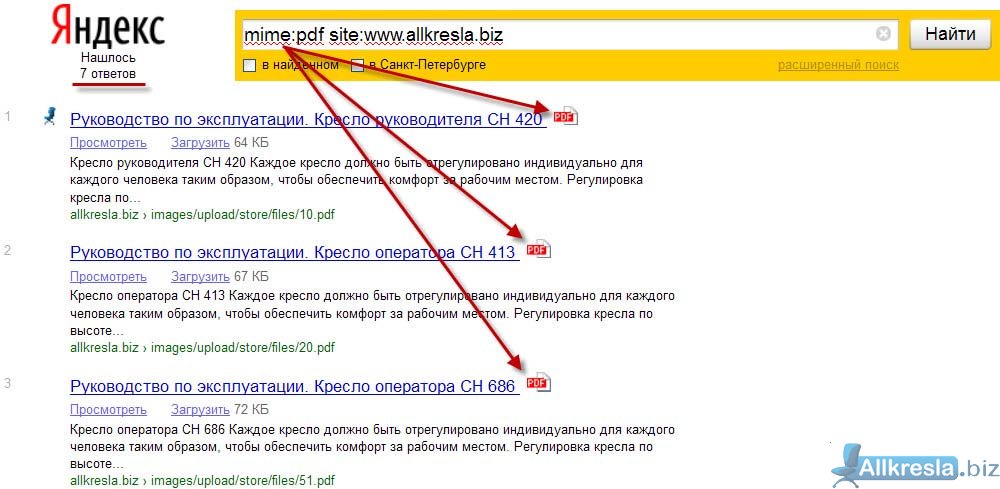
Поисковый индекс, данные о типе документов, кодировке, языке и сохраненные копии документов вместе составляют поисковую базу. Она обновляется постоянно, но, чтобы это обновление стало доступно пользователям, её нужно перенести на «базовый поиск». Базовый поиск — сервера, которые отвечают пользователям на запросы. Туда переносится не вся поисковая база, а только её полезная часть — без спама, дубликатов сайтов (зеркал) и других ненужных документов.
Обновление поисковой базы из хранилища основного робота попадает в поиск «пакетами» — раз в несколько дней. Этот процесс создаёт дополнительную нагрузку на сервера, поэтому производится ночью, когда к Яндексу обращаются на порядок меньше пользователей. Сначала новые части базы помещаются рядом с такими же частями из прошлого обхода. Затем они проверяются по целому ряду факторов, чтобы обновление не ухудшило качество поиска. Если проверка прошла успешно, новая часть базы заменяет собой старую.
Робот Orange предназначен для поиска в реальном времени. Его планировщик и паук настроены так, чтобы находить новые документы и выбирать из огромного их количества все, хоть сколько-нибудь интересные. Каждый такой документ Orange сразу обрабатывает и выкладывает на базовый поиск. Срочных документов не очень много по сравнению с общим объемом интернета, поэтому обновление базы в реальном времени можно делать и при дневных нагрузках на сервера.
Его планировщик и паук настроены так, чтобы находить новые документы и выбирать из огромного их количества все, хоть сколько-нибудь интересные. Каждый такой документ Orange сразу обрабатывает и выкладывает на базовый поиск. Срочных документов не очень много по сравнению с общим объемом интернета, поэтому обновление базы в реальном времени можно делать и при дневных нагрузках на сервера.
Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
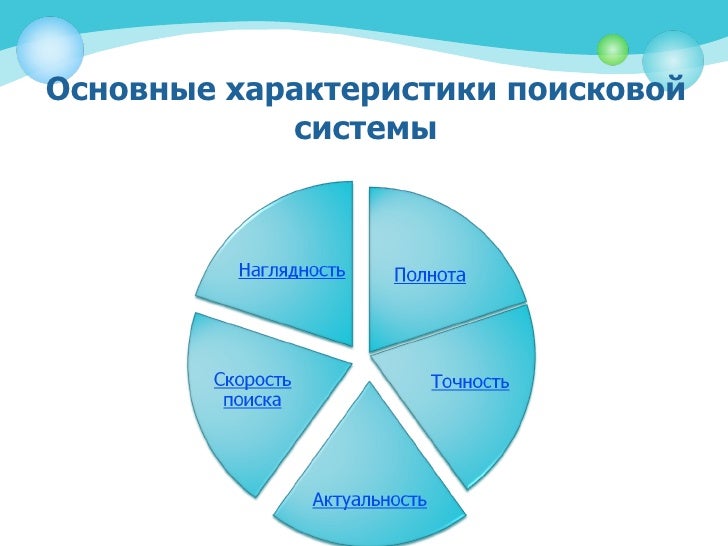
3. Основные характеристики поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.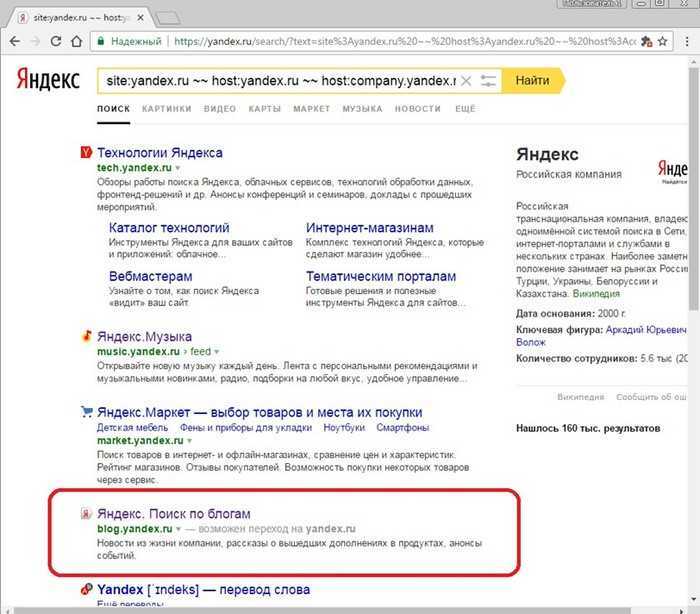
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный материал призван дать ответ на вопрос о том, как работают поисковые системы. Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам
2. Понятие и функции поисковой системы
Поисковая система – это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».

Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5).
 Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу. - Актуальность
Актуальность – не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам.
- Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.
Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http:\/\/help\.yandex\.ru\/search\/?id=481937.
 Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу.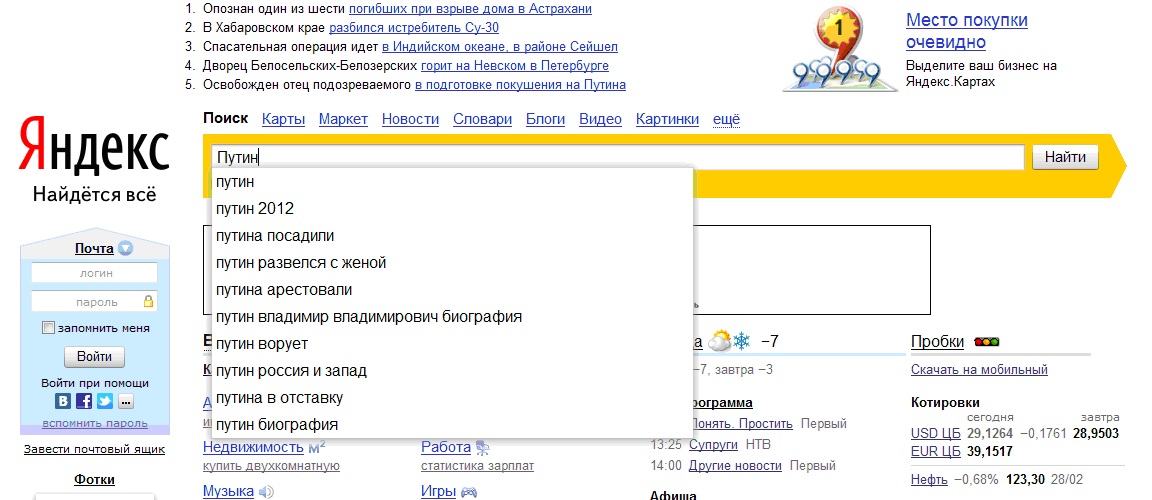
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google –самая популярная поисковая система в мире!
В настоящий момент Google –самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.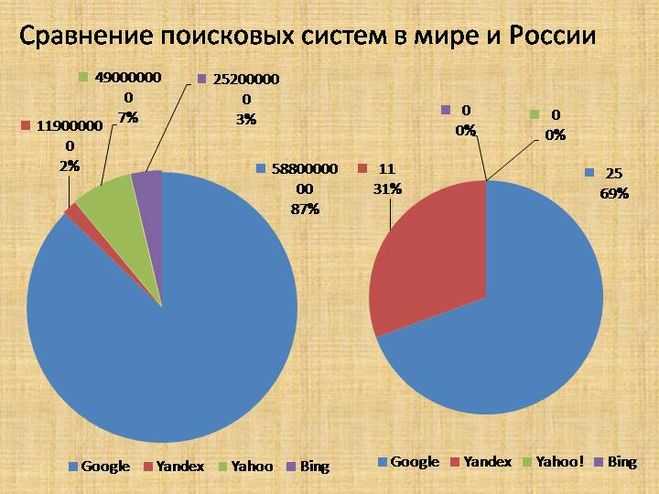 1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш материал позволит вам поближе познакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.
Преимущества и недостатки поисковой системы Яндекса
Популярность Яндекса в течение многих лет среди других поисковых систем, таких как Google и Bing, росла. Вопрос в том, сможет ли она сохранить свои позиции? Яндекс — российская компания, основанная в 2000 году и предлагающая интернет-услуги, включая электронную почту, хранилище фотографий, хостинг веб-сайтов, такси, карты и многое другое. Он также имеет поисковую систему, которая предоставляет пользователям список результатов на основе их запросов. В приведенных ниже статьях рассматриваются как преимущества, так и недостатки использования этой службы.
Содержание
Модули Яндекса
Модули ЯндексаЯндекс имеет четыре основных жизненно важных модуля:
1. Агент, 2. Паук, 3. Краулер, 4. Индексатор.
- Модуль агента отвечает за пользовательский интерфейс, результаты поиска, рекламу и другой персонализированный контент.
- Модуль Spider собирает данные с веб-страниц, которые посещает Яндекс.
- Индексатор считывает созданный индекс и сохраняет его на сервере Яндекса.
- Модуль Crawler считывает собранные данные и создает индекс слов и фраз, найденных на веб-страницах.

Процесс индексации поисковой системы Яндекса
Процесс индексации поисковой системы ЯндексаЯндекс имеет собственный процесс индексации. Его алгоритм очень продвинут. Индексация проходит в несколько этапов:
Этап 1 — Индексация по структуре ссылок, которую Яндекс отслеживает на всех уровнях глубины, но без поиска обратных ссылок. Яндекс совершенно другой в этом вопросе, когда другие поисковые системы отдают приоритет обратным ссылкам как фактору индексации и ранжирования.
Этап 2 — Индексирование таких ресурсов, как файловые архивы (которые можно скачать), новостные статьи, форумы и блоги, где происходит регулярная индексация каждый день. Индексация также может происходить по расписанию или при появлении нового контента на этих ресурсах.
Этап 3 — Индексация выполняется роботами, которые анализируют текст страниц. Индексация может производиться двумя способами:
– Автоматически, при загрузке новой страницы и анализе ее текста. Индексация выполняется сразу для всех ресурсов на странице, включая изображения, таблицы стилей и т. д.
— Вручную, когда пользователь поисковой системы отправляет URL-адрес, индексация выполняется только для запрошенной страницы, а не для любых ресурсов, которые она содержит.
После завершения процесса индексации страницы сохраняются в базе данных поисковой системы и становятся доступными для поисковых запросов.
Статья по теме: Ознакомьтесь с 10 ведущими поисковыми системами Великобритании.
Конфиденциальность Яндекса
Яндекс — компания, которая стремится предоставить пользователям наилучшие возможности при использовании ее сервисов. Это означает сбор информации о том, какие поисковые запросы вы выполняете на Яндексе, а также о том, какие продукты этого провайдера наиболее привлекательны для ваших нужд, чтобы убедиться, что все клиенты получают именно те результаты, которые им нужны.
Самый безопасный способ использования поисковой системы Яндекса — настроить меры предосторожности, защищающие ваши данные. Если вы запускаете его через настольный или мобильный браузер, включите режим инкогнито, чтобы автоматически удалять все файлы cookie и историю при закрытии приложения, чтобы исключить риск утечки.
Плюсы Яндекса
- Яндекс — самая популярная поисковая система в России с долей рынка более 45%.
- Компания предлагает широкий спектр интернет-услуг, недоступных на других платформах.
- У Яндекса есть собственный алгоритм индексации, который дает пользователям более релевантные результаты, чем у других поисковых систем.
- Яндекс браузер быстрый, легкий и безопасный.
Минусы Яндекса
- Яндекс недоступен во многих странах мира.
- Некоторые пользователи считают его результаты менее релевантными, чем результаты других поисковых систем.
- Известно, что некоторые результаты поиска блокируются.
- Яндекс не так удобен для пользователя, как другие платформы, такие как Google или Bing.
- Яндекс не имеет приватного режима и хранит данные пользователей до 18 месяцев.

О Яндекс Браузере
Яндекс Браузер — это бесплатный веб-браузер, использующий движок Blink и основанный на проекте с открытым исходным кодом Chromium.
Pros
Яндекс.Браузер имеет мощную функцию обратного поиска картинок. Возможность доступа к веб-сайтам, которые трудно увидеть в традиционных браузерах, является большим преимуществом. Его интерфейс очень удобен для пользователей.
Минусы
Много пользовательских данных может отправлять этот браузер в Яндекс для использования в рекламе и в своих алгоритмах. На мобильных устройствах он намного тяжелее и может занимать много места.
Как Яндекс стал популярнее Google в России?
Когда речь заходит о поисковых системах, большинство людей думают о Google. Однако есть еще одна быстро набирающая популярность поисковая система — Яндекс. В России Яндекс почти догоняет Google по доле рынка. Итак, почему Яндекс становится популярнее Google в России? Есть несколько причин. Во-первых, Яндекс лучше понимает русский язык, чем Google. Во-вторых, Яндекс предлагает больше местного контента, чем Google. Наконец, многие россияне не доверяют Google из-за его связей с правительством США.
В России Яндекс почти догоняет Google по доле рынка. Итак, почему Яндекс становится популярнее Google в России? Есть несколько причин. Во-первых, Яндекс лучше понимает русский язык, чем Google. Во-вторых, Яндекс предлагает больше местного контента, чем Google. Наконец, многие россияне не доверяют Google из-за его связей с правительством США.
Как Яндекс сделал свое самое большое улучшение в поисковой системе с помощью Толоки / Хабра
Введение
Прежде всего, я должен отметить, что современные технологии ML все еще полагаются на человеческую оценку. Люди транскрибируют звук в текст, чтобы настроить алгоритмы распознавания голоса; люди оценивают релевантность справочных документов поисковым запросам, чтобы на них ориентировались формулы ранжирования поиска; люди классифицируют изображения, чтобы, обучившись на этих примерах, нейросеть смогла делать это дальше без людей и лучше людей.
Толока умеет все перечисленное. Итак, пришло время рассказать вам больше о платформе.
Задачи, о которых я говорил выше, обычно решает Яндекс с помощью подготовленных специалистов — асессоров. Оценщики смотрят, насколько результаты поиска соответствуют запросу, находят спам среди найденных веб-страниц, классифицируют его и решают аналогичные проблемы для других сервисов.
Ирония заключается в том, что по мере развития новых технологий растет потребность в человеческой оценке. Недостаточно просто определить релевантность страницы поисковому запросу. Важно понимать, не засорена ли страница вредоносной рекламой? Содержит ли страница контент для взрослых? И если это так, означает ли запрос пользователя, что это именно тот контент, который он искал? Чтобы автоматически учитывать все эти факторы, вам нужно собрать достаточно примеров для обучения поисковой системы. А так как в интернете все постоянно меняется, тренировочные наборы нужно постоянно обновлять и поддерживать в актуальном состоянии. В целом, только для задач поисковых систем потребность в человеческих оценках измеряется миллионами в месяц, и это число только растет с каждым годом.
И не только это, поиск большего количества асессоров в разных странах — сложный процесс. Но, для некоторых задач вам даже не нужна профессиональная подготовка — вот когда мы полагаемся на краудсорсинг .
Толока
В фундаментальной логике любой краудсорсинговой платформы, а Толока в частности, нет ничего сложного. С одной стороны, Толока работает с пользователями, раздает задания, осуществляет платежи, а с другой стороны, Толока помогает клиентам получать результат с минимальными усилиями.
Некоторым компаниям нужны пользователи для классификации изображений, некоторым нужны пользователи для выбора определенного объекта на изображении. Потенциально задачи могут быть чем угодно с точки зрения входных данных, интерфейса и ожидаемых ответов. Например, вы можете проверить этот пост (на русском языке), где автор попросил толокеров (пользователей Толоки) сфотографировать свои счетчики воды, чтобы сделать набор данных для будущей нейронной сети, которая вводит измерения автоматически.
Как заработать с Толокой всем?
На самом деле очень просто! Если вам нужны люди для оценки данных даже с дополнительным обучением, то в Толоке есть множество руководств и готовых решений для постановки ваших задач. Вы можете выбрать любой аспект задачи: цену, качество оценки, рейтинги пользователей и т. д. Но если вы хотите зарабатывать с Толокой — вот вам краткое руководство. Лучше всего то, что вы получаете оплату практически мгновенно и можете легко вывести заработанные деньги.
Как вы обеспечиваете качество оценки?
Этот вопрос является серьезной проблемой для любой краудсорсинговой платформы. В Толоке есть старательные и внимательные люди, а есть ленивые, недобросовестные люди, умеющие писать сценарии. Основная задача — наградить честных людей и забанить пользователей скриптов. Для этого Толока обучена анализировать поведение пользователей. Клиенты теперь имеют возможность автоматически идентифицировать и ограничивать тех толокеров, которые, например, отвечают слишком быстро или чьи ответы не согласуются с ответами других. Также в Толоке есть возможность использовать контрольные задания и обязательное принятие до оплаты. И приемку тоже можно упростить. Выдавайте задания одним пользователям, а оценку их результатов другим.
Также в Толоке есть возможность использовать контрольные задания и обязательное принятие до оплаты. И приемку тоже можно упростить. Выдавайте задания одним пользователям, а оценку их результатов другим.
Улучшения
Итак, пришло время рассказать вам об улучшениях в Яндекс.Поиске и о том, как Толока уже помогла многим компаниям сделать их продукт лучше.
С помощью Толоки Яндекс создал новый поисковый алгоритм под названием ЯТИ (Еще один трансформер с улучшениями). В отличие от предыдущих алгоритмов, YATI основан на нейросетях, прошедших серьезную подготовку на реальных ключевых фразах пользователей и открываемых ими страницах. Помимо самообучения, результаты проверяются и дополняются асессорами – специалистами, которые проводят экспертную оценку качества ранжирования текстов. Алгоритм учится делить текстовый документ на зоны, отличающиеся своей значимостью в контексте введенного пользователем запроса. Фрагменты текста из наиболее важных областей также выбираются для ранжирования, в то время как наименее важные области игнорируются и не влияют на позиционирование сайта в результатах поиска. Если страница содержит небольшое количество текста, то все это повлияет на ранжирование документа. По заявлениям представителей Яндекса, YATI изначально «обращает внимание» на заголовки документов — они должны соответствовать определенным запросам пользователей. Только после того, как это будет подтверждено, весь документ начинает участвовать в ранжировании.
Если страница содержит небольшое количество текста, то все это повлияет на ранжирование документа. По заявлениям представителей Яндекса, YATI изначально «обращает внимание» на заголовки документов — они должны соответствовать определенным запросам пользователей. Только после того, как это будет подтверждено, весь документ начинает участвовать в ранжировании.
Что такое трансформатор YATI?
Трансформеры — это сложные и большие нейронные сети, работа которых направлена на решение задач обработки и генерации текста. Это новый виток развития нейронных сетей, открывающий огромные возможности для различных сфер, в частности для построения алгоритмов ранжирования в поисковых системах. Теперь алгоритм поиска может сегментировать текстовые элементы на части по различным признакам и обрабатывать их по отдельности. Элемент представляет собой слово, знаки препинания и другие последовательности символов. Как отмечалось выше, в YATI есть механизм внимания, благодаря которому фрагменты вводимого текста отделяются и обрабатываются отдельно. Например, это позволит понять, какая часть текста действительно важна для пользователей, и включить ее в факторы ранжирования, исключив при этом другие, неважные части. Это позволит значительно очистить результаты поиска от документов с некачественным содержанием.
Например, это позволит понять, какая часть текста действительно важна для пользователей, и включить ее в факторы ранжирования, исключив при этом другие, неважные части. Это позволит значительно очистить результаты поиска от документов с некачественным содержанием.
Последовательность алгоритма обучения
На основе задач и особенностей ранжирования сеть обучается правилам языка по принципу маскированного моделирования языка. Входными данными являются пользовательский запрос и заголовок документа. Цель подхода — научить алгоритм предсказывать вероятность появления документа из результатов поиска по заданному ключевому слову.
Следующий шаг — дообучение алгоритма с помощью асессоров. Сначала данные изучают пользователи сервиса Толока. Как вы понимаете, это некачественная оценка релевантности запроса документу. Для улучшения этих показателей после толокеров данные перепроверяются специалистами самого Яндекса. В результате этих действий данные получают определенные оценки релевантности.
После этого полученная аналитика и сами данные отправляются на обработку, чтобы объединить их в сегменты по определенным признакам. Благодаря сбору итоговых метрик алгоритм оценивает уровень релевантности документа и пользовательского запроса.
Результаты
По данным Яндекса, качество ранжирования значительно повысилось с момента внедрения алгоритма, и YATI стал самым значимым нововведением последнего десятилетия. Алгоритм научился корректно искать не только короткие ключевые фразы, но и целые текстовые фрагменты. Учитывается не только порядок и форма слов, но и контекст введенного запроса, который сопоставляется с изучаемым документом. Такие улучшения позволят алгоритму «понимать» естественность языка, находить смысловые связи между словами и т. д. Поэтому, если смотреть с точки зрения пользователей поисковой системы Яндекс, YATI значительно улучшит качество результатов. Теперь сайты будут ранжироваться с максимальным совпадением по смыслу.