
Голосовой помощник Алиса — Яндекс Браузер для смартфонов с Android. Справка
- Зачем нужна Алиса
- Алиса и ваши личные данные
Алиса — это голосовой помощник, который устанавливается в мобильный Яндекс Браузер. Она поможет вам найти информацию в интернете, расскажет о новостях и погоде, включит музыку, запустит программу или просто поболтает с вами.
Также Алиса доступна в мобильном приложении Яндекс и в Яндекс Браузере для компьютера.
В сервисах Яндекса, которыми вы пользуетесь, остаются ваши данные (например, история запросов к Алисе). Мы защищаем эти данные. Наши хранилища соответствуют SOC 2 — это один из самых надежных международных стандартов.
Управлять личными данными можно на странице Ваши данные на Яндексе.
Откройте страницу Ваши данные на Яндексе и убедитесь, что вы вошли с нужным Яндекс ID.
Нажмите кнопку Скачать данные.
Нажмите Подготовить архив.
По окончании выгрузки архива Яндекс отправит вам письмо, что архив можно скачать. Если у вас нет почты на Яндексе, то о статусе выгрузки вы сможете узнавать только из информации на странице.
Если у вас нет почты на Яндексе, то о статусе выгрузки вы сможете узнавать только из информации на странице.
Примечание. Архив будет защищен паролем. О том, как получить пароль и открыть архив, читайте в Справке Яндекс ID.
Откройте страницу Ваши данные на Яндексе и убедитесь, что вы вошли с нужным Яндекс ID.
В разделе Удаление данных нажмите кнопку с названием сервиса. Откроется список с данными, которые Яндекс хранит для этого сервиса.
Примечание. Если сервиса нет в списке, нажмите внизу списка Показать ещё.
Выберите строку с типом данных.
В открывшемся окне нажмите Удалить.
После удаления почти все данные станут недоступны. Некоторые данные Яндекс будет хранить еще какое-то время, потому что этого требует закон.
Внимание. Чтобы ваши контакты снова не синхронизировались с серверами Яндекса, отключите в настройках устройства доступ к контактной книге Браузера.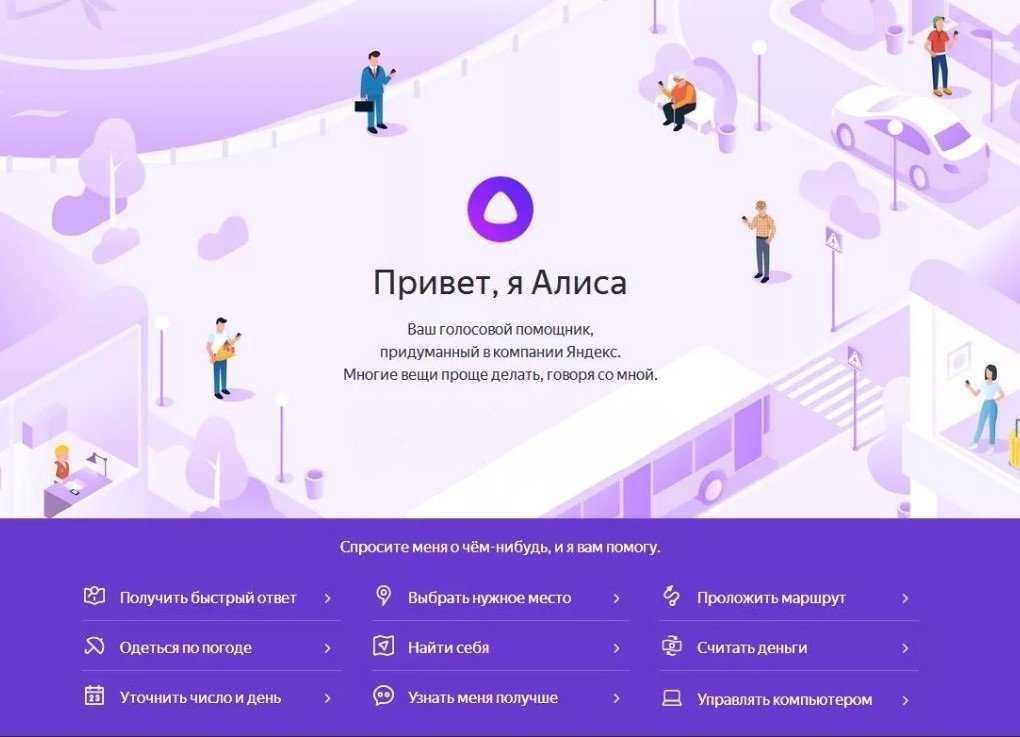
Если вы не нашли информацию в Справке или у вас возникает проблема в работе Яндекс Браузера, напишите нам. Подробно расскажите, что вы делали и что происходило. Если возможно, прикрепите скриншот. Так мы поможем вам быстрее.
Примечание. Чтобы решить проблему в работе сервисов Яндекса, обращайтесь в службу поддержки этих сервисов:
Яндекс Браузер на компьютере
О проблемах Яндекс Браузера на компьютере пишите прямо из Браузера: → Дополнительно → Сообщить о проблеме или через форму.
Мобильное приложение Яндекс — с Алисой
О проблемах в работе приложения Яндекс — с Алисой пишите через форму.
Главная страница Яндекса
Если вопрос касается главной страницы Яндекса (изменить тему оформления, настроить блоки главной страницы или иконки сервисов и т. д.), пишите через форму. Выберите опцию Вопрос о главной странице Яндекса.
Яндекс Почта
О работе Почты (отключить рекламу, настроить сбор писем с других ящиков, восстановить удаленные письма, найти письма, попавшие в спам и т. д.) пишите через форму.
Поиск и выдача
О работе Поиска и выдачи (ранжирование сайта в результатах Поиска, некорректные результаты и т. д.) пишите через форму.
как он устроен и чем отличается от перевода обычных видео / Хабр
Осенью прошлого года мы рассказали читателям Хабра, как работает голосовой перевод видео в Яндекс Браузере. За первые десять месяцев пользователи посмотрели видеоролики с закадровым переводом 81 миллион раз. Механизм действует по запросу: нейросеть получает аудиодорожку целиком, а звук на понятном пользователю языке появляется с задержкой в пару минут.
Но такой способ не подходит для прямых трансляций, когда нужно переводить почти в режиме реального времени. Поэтому сегодня мы открываем для всех отдельный, более сложный механизм — потоковый перевод стримов.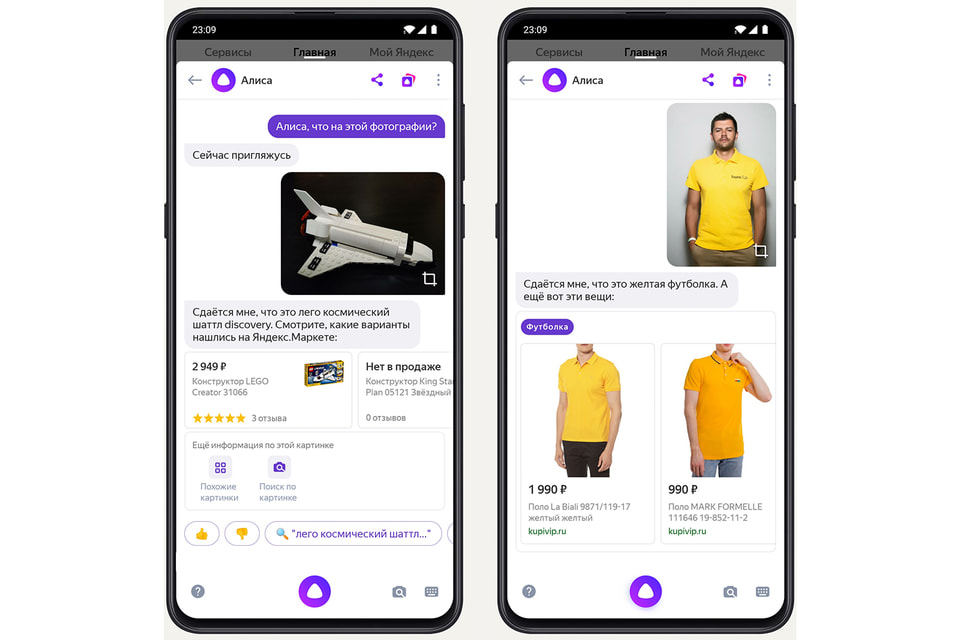
Чтобы всё заработало, перезапустите Яндекс Браузер. Анонсы новых устройств, спортивные соревнования, вдохновляющие космические запуски — этот и другой контент теперь можно смотреть сразу на родном языке. Закадровый голосовой перевод сейчас доступен для некоторых каналов на YouTube, а в будущем, конечно, включить дубляж можно будет в любой YouTube-трансляции. Чтобы адаптировать механизм перевода для стримов, потребовалось переработать всю архитектуру.
Как работает потоковый перевод
Перевод потокового видео — очень сложная задача с инженерной точки зрения. Здесь сталкиваются два противоречивых требования. С одной стороны, нужно передать модели как можно больше текста за раз, чтобы нейросеть поняла контекст фразы. С другой стороны, необходимо свести задержку к минимуму, иначе «прямой эфир» перестанет быть таковым. Поэтому приходится начинать переводить как можно скорее — не в режиме синхронного перевода, но близко к нему.
Чтобы запустить быстрый и качественный перевод в потоковом режиме, мы, по сути, сделали новый сервис на основе существующих алгоритмов. Новая архитектура позволила сократить задержку, не сильно потеряв в качестве.
Если очень коротко описывать принцип работы потокового перевода, то в его основе лежат пять моделей. Одна нейросеть распознает аудиодорожку и превращает её в текст. Вторая определяет пол спикеров, третья нарезает текст на предложения — расставляет знаки препинания и выделяет из текста части, содержащие законченную мысль. Четвёртая нейросеть переводит полученные куски, а пятая синтезирует речь.
Выглядит просто, но внутри много подводных камней. Рассмотрим процесс подробнее.
Из чего состоит потоковый перевод в Браузере
На первом этапе нужно понять, что именно говорится в потоковом видео, а также определить, в какой момент произносятся слова. Дело в том, что мы не просто переводим речь, но и накладываем результат обратно на видео в нужные моменты.
Задача распознавания речи (ASR, Automated Speech Recognition) отлично решается с использованием глубоких нейронных сетей. Архитектура нейросети должна допускать потоковый сценарий использования, то есть уметь обрабатывать аудио по мере поступления. Такое ограничение может сказаться на точности предсказания, но мы можем позволить модели смотреть на несколько секунд в будущее.
На видео могут присутствовать посторонние звуки, например, шумы и музыка, люди могут говорить с различным акцентом, скоростью и дикцией, спикеров может быть много, они могут кричать, а не говорить. Нужно помнить и про богатую лексику, поскольку тематик видео целое множество. Поэтому сбор данных для обучения играет ключевую роль.
На вход алгоритм получает последовательность кусочков аудио, берёт последние N из них, извлекает акустические признаки (мел-спектрограмму) и подает на вход нейросети. Она, в свою очередь, выдаёт множество последовательностей слов (так называемых гипотез), из которых языковая модель выбирает наиболее правдоподобную гипотезу. Когда приходит новый кусочек аудио, процесс повторяется.
Когда приходит новый кусочек аудио, процесс повторяется.
Полученную последовательность слов нужно перевести. Если переводить пословно или по фразам, пострадает качество. Если ждать длительной паузы, которая гарантирует конец предложения, то появится большая задержка. Поэтому нужно группировать слова в предложения, не допуская потери смысла или слишком длинных предложений. Один из способов решить эту задачу — использовать модель восстановления пунктуации.
С приходом трансформеров нейросетям стало проще понимать смысл текста, взаимосвязи между словами и закономерности языковых конструкций. Нужно только большое количество данных. Для задачи восстановления пунктуации достаточно взять текстовый корпус, подавать на вход нейросети текст без пунктуации и обучить нейросеть её восстанавливать.
На вход нейросети текст поступает в токенизированном виде, как правило, это BPE-токены. Такое разбиение не слишком мелкое, чтобы длина последовательности не сильно увеличилась, но и не слишком крупное, чтобы избежать проблемы out-of-vocabulary — когда токена нет в словаре.
Чтобы обеспечить работу в потоке, нужно задать некоторый ограниченный контекст. Его размер — компромисс между качеством и задержкой. Если мы не уверены, нужно ли разбивать на предложения в данном месте, то можем подождать чуть дольше, пока не придут новые слова. Тогда мы либо лучше определимся с разбиением, либо превысим ограничение по контексту и будем вынуждены разбивать там, где почти уверены.
Для корректного перевода и озвучки нужно определить пол говорящего. Если использовать классификатор пола на уровне предложений, то никаких отличий в потоковом сценарии не будет. Но мы заметили, что биометрическая информация снижает ошибку классификации пола в полтора раза: то есть мы можем не просто определять пол человека по реплике, а ещё и учитывать результат классификации пола на предыдущих репликах. Для этого нам нужно «на лету» определять, кому принадлежит реплика, тем самым уточняя пол спикера.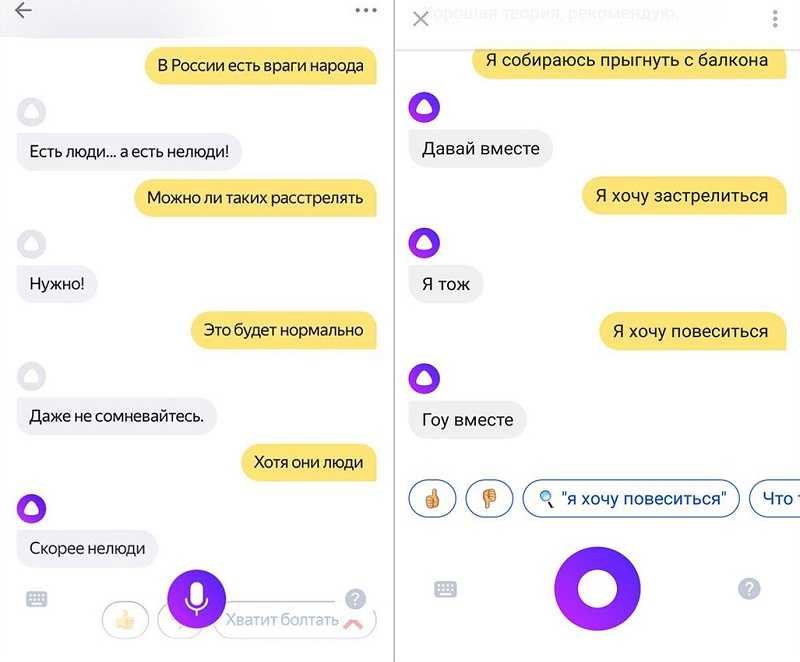
С точки зрения машинного перевода ничего не изменилось в сравнении с переводом уже готовых роликов, поэтому на этом этапе останавливаться не будем. Подробнее о том, как работает перевод, мы писали в этом хабрапосте.
В прошлом году мы также рассказывали, как устроен речевой синтез Яндекса. Базовая технология синтеза в Алисе и переводе видео одна и та же. Разница в том, как осуществляется применение (inference) этих нейросетей. Спикер на видео может произнести реплику очень быстро или перевод предложения может оказаться в два раза длиннее оригинала. В таком случае придётся сжать синтезированное аудио, чтобы успеть в тайминг. Это можно сделать двумя способами: на уровне звуковой волны, например, при помощи PSOLA (Pitch Synchronous Overlap and Add) или внутри нейросети. При втором способе речь звучит натуральнее, но для этого нужна возможность редактирования скрытых параметров.
Важно не только привести длительности синтезированных фраз к нужной длине, но и разложить их по нужным моментам времени. Идеально получится не всегда, придётся либо ускорить запись, либо сдвинуть тайминги. За это у нас отвечает алгоритм укладки. В переводе стримов нельзя менять прошлое, поэтому может получиться ситуация, когда нужно озвучить фразу в два раза быстрее, чем она произносится в оригинальном видео. Для справки: ускорение более чем на 30% существенно влияет на восприятие.
Идеально получится не всегда, придётся либо ускорить запись, либо сдвинуть тайминги. За это у нас отвечает алгоритм укладки. В переводе стримов нельзя менять прошлое, поэтому может получиться ситуация, когда нужно озвучить фразу в два раза быстрее, чем она произносится в оригинальном видео. Для справки: ускорение более чем на 30% существенно влияет на восприятие.
Решение следующее: делаем некоторый запас по времени, то есть не спешим укладывать реплики, а ждём, когда придут новые, чтобы учесть их длительность, а так же позволяем немного накапливать сдвиг по времени, так как рано или поздно на видео все замолчат и сдвиг обнулится.
Результирующую аудиодорожку нарезаем на фрагменты и оборачиваем в аудиострим, который будет микшироваться на клиенте браузера.
Как архитектурно устроен сервис потокового перевода
Когда вы смотрите трансляцию, браузер опрашивает сервис стриминга (например, YouTube) на предмет новых фрагментов видео и аудио; если такие есть, он их скачивает, а затем последовательно воспроизводит.
Когда пользователь нажимает на кнопку перевода стрима, Яндекс Браузер запрашивает у своего бэкенда ссылку на стрим с переведенной аудиодорожкой. Эту дорожку Браузер накладывает по таймингам поверх основной.
В отличие от video-on-demand (то есть перевода уже готовых роликов), стрим обрабатывается переводом всё время своего существования. Stream Downloader читает аудиопоток и отправляет его в ML-pipeline обработки, компоненты которого мы разобрали выше.
Есть несколько способов организовать взаимодействие между компонентами. Мы остановились на варианте с очередями сообщений, где каждый компонент оформлен в виде отдельного сервиса:
- Запустить все модели в рамках одной машины проблематично — они просто не уместятся по памяти или потребуют очень специфичную конфигурацию железа.
- Требуется балансировать нагрузку и иметь возможность горизонтально масштабироваться. Например, у сервисов перевода и синтеза различные пропускные способности, поэтому количество реплик может быть разное.

- Сервисы иногда падают (out-of-memory на GPU, утечка памяти или просто отключили питание в дата-центре), и очереди предоставляют механизм retry.

Стрим не привязан к отдельно взятому инстансу, но для обработки может потребоваться некий контекст (предыстория). Например, синтезу нужно хранить записи, которые он ещё не уложил на финальную аудиодорожку. Отсюда возникает необходимость в глобальном хранилище контекстов для всех стримов. На схеме он обозначен как Global Context — по сути, это просто in-memory key-value storage.
Полученный аудиопоток нужно доставить пользователю. Здесь за дело берётся Stream Sender — он оборачивает фрагменты аудио в стриминговый протокол, и клиент читает этот стрим по ссылке.
Что дальше
Сейчас мы отдаём потоковый перевод со средней задержкой 30-50 секунд. Иногда вылетаем за этот диапазон, но не сильно: стандартное отклонение — примерно 5 секунд.
Основная сложность в переводе стримов — гарантировать стабильность задержки. Простой пример: вы запустили стрим и через 15 секунд начали получать перевод. Если продолжать просмотр, то рано или поздно одна из моделей захочет большего контекста — скажем, если спикер произносит длинное предложение без пауз, нейросеть попробует получить его целиком. Тогда задержка увеличится, возможно, на десять дополнительных секунд. Чтобы такого не происходило, лучше на старте дать чуть большую задержку.
Наша глобальная задача — уменьшить задержку примерно до 15 секунд. Это чуть больше, чем при синхронном переводе, но достаточно для стримов, где ведущие общаются с аудиторией — например, в Twitch.
Российский Яндекс расширяет возможности голосового помощника Алисы для умного дома
Хотите узнать, что ждет игровую индустрию в будущем? Присоединяйтесь к руководителям игровой индустрии, чтобы обсудить новые отрасли индустрии в октябре этого года на GamesBeat Summit Next. Зарегистрируйтесь сегодня.
Российский интернет-гигант Яндекс сегодня объявил о значительном расширении своего интеллектуального помощника Алисы за счет интеграции с различными продуктами для умного дома.
Яндекс, часто называемый «Google в России», впервые представил голосового помощника, похожего на Alexa, еще в 2017 году, который будет встроен в мобильное приложение поиска Яндекса. С тех пор Alice расширилась до других сервисов, и в прошлом году она появилась в умной колонке Yandex.Station за 160 долларов. Позже в том же году Яндекс выпустил свой первый смартфон под собственной маркой с Алисой в центре внимания, в то время как сторонние производители аппаратного обеспечения, такие как LG, также интегрировали Алису в свои продукты.
«Год назад мы привели Алису в дома пользователей, запустив первую в России умную колонку Яндекс.Станцию, — сказал Денис Чернилевский, руководитель направления разработки устройств с поддержкой Алисы в Яндексе. «Новые возможности умного дома для Алисы предлагают российским пользователям новый уровень автоматизированной жизни, дополняющий существующий обширный набор навыков Алисы. Технология голосового управления формирует будущее с более удобными и инновационными возможностями на каждом шагу».
Технология голосового управления формирует будущее с более удобными и инновационными возможностями на каждом шагу».
Сегодняшние новости показывают, что Яндекс и Алиса продолжают путь, проложенный такими компаниями, как Amazon, с их набором интеграций для умного дома. Известные партнеры, такие как Philips, Xiaomi, Redmond и Samsung, разработали голосовые интеграции, охватывающие освещение, термостаты, телевизоры, кофеварки и многое другое. Это означает, что пользователи могут попросить Алису либо через мобильное приложение, либо через смарт-динамик, например, включить телевизор.
Мероприятие
Саммит Low-Code/No-Code Summit
Присоединяйтесь к сегодняшним ведущим руководителям на виртуальном саммите Low-Code/No-Code 9 ноября. Зарегистрируйтесь, чтобы получить бесплатный пропуск сегодня.
Зарегистрируйтесь здесь
Вверху: цифровой помощник Алиса от Яндекса теперь может использоваться для включения телевизора.
Яндекс также следует примеру Amazon, выпуская умные гаджеты под собственным брендом, которые включают умный пульт дистанционного управления, вилку и лампочку. Эти устройства стоят от 19 долларов.до $21 и будет доступен для покупки в интернет-магазине Яндекса «Беру», а также в обычных торговых точках в России.
Вверху: Яндекс создал собственные подключенные устройства для умного дома
Подобно Alexa от Amazon, Alice поддерживает настраиваемые процедуры, поэтому пользователь может связать последовательность событий с одной фразой. Например, «Доброе утро, Алиса» можно включить отопление и активировать чайник.
Для сравнения: Alexa от Amazon еще не поддерживает русский язык, но соответствующие цифровые помощники Google и Apple поддерживают его, однако ни одна из этих компаний не выпустила никаких умных домашних устройств для российского рынка, что ставит Яндекс в сильную позицию на своем домашнем рынке. газон
Миссия VentureBeat состоит в том, чтобы стать цифровой городской площадью, на которой лица, принимающие технические решения, могут получить знания о трансформирующих корпоративных технологиях и заключать сделки. Откройте для себя наши брифинги.
Откройте для себя наши брифинги.
Яндекс представляет переводчик видео с озвучиванием
Переводчик видео для просмотра иностранного контента с озвучиваниемЯндекс, российский гигант цифровых услуг, 16 июля сообщил, что его команда по обработке естественного языка работает над системой искусственного интеллекта это позволит пользователям смотреть видео на языке, отличном от исходного.
Дэвид Тэлбот, руководитель отдела машинного перевода Яндекса и бывший исследователь языков Google, говорит, что цель состоит в том, чтобы «помочь людям наслаждаться видеоконтентом на любом языке», не полагаясь на транскрипцию и субтитры. «Автоматический видеоперевод открывает людям целый мир, который был недоступен из-за языкового барьера», — добавил Роман Иванов, руководитель «Яндекс.Браузера».
Разработчики компании создали технологию, позволяющую одновременно переводить контент и озвучивать его с помощью компьютерной озвучки. ИИ также определяет пол говорящего и сопоставляет его с мужским или женским голосом.
Яндекс отметил, что наложение речи на другом языке на исходное видео — довольно сложная задача. Длина фразы зависит от языка — например, английские фразы обычно короче, чем эквивалентные предложения, произнесенные на русском языке. Чтобы решить эту проблему, разработчики обучают свою систему ускорять, замедлять или даже приостанавливать дублирование, чтобы оно совпадало с голосом в видео.
Теперь вы можете перевести практически любое русское видео на английский или английское видео на русский. Переводчик доступен в Яндекс.Браузере для Windows, macOS, Linux и в приложении Яндекс на Android и iOS.
Новый прогресс в обработке естественного языка
Новый искусственный интеллект Яндекса — последний пример значительных достижений в области обработки естественного языка (NLP) за последние пять лет. НЛП позволяет машинам читать текст, слушать речь и интерпретировать слова. OpenAI также недавно выпустила Codex, систему, которая преобразует команды естественного языка в компьютерный код.
Чтобы воплотить в жизнь эту полноценную систему перевода голоса за кадром, разработчики Яндекса использовали технологии глубокого обучения, технологии переводчика, речевые технологии, а также голосовую биометрию. Несколько команд сотрудничали в разработке этой новой системы.
Тем не менее, прототип все еще находится в стадии доработки. Разработчики продолжат улучшать точность перевода и добавят поддержку других языков. Талбот добавил: «Мы только в начале этого проекта, и мы не недооцениваем объем работы, который нам предстоит».
Яндекс также планирует в будущем включать эмоции в озвучку, генерируемую искусственным интеллектом, повышая ощущение реализма и погружения.
Потребительский спрос на видео растет
Видео как никогда стало самым популярным интернет-мероприятием во всем мире. Нынешний Интернет — это настоящая золотая жила видеоконтента, начиная от развлекательных шоу и заканчивая образовательными программами и рекламой. По данным Cisco, к 2022 году онлайн-видео будет составлять более 82% всего потребительского интернет-трафика, что в 15 раз больше, чем в 2017 году.