
Парсер yandex.xml для проверки позиций
- Цены
- Преимущества
- О нас
- Парсеры
- Партнерка
Например недвижимость
yandex.xml
Парсер Yandex.XML позволяет получать информацию о позициях сайта по определенным фразам через официальный XML поисковика.
Цена за 1000 запросов:
20.00
Калькулятор
Расчет стоимости запросов для парсера — yandex.xml
Доступен для использования по запросу
Для запроса на парсер, необходима регистрация
- 11 891
- yandex.
 ru
ru
 ru
ruОписание
Граббинг информации о позициях веб-ресурса по списку фраз осуществляется в автоматическом режиме. При этом результаты выдаются после окончания процесса парсинга в удобном пользователям виде.
На основании данных, полученных с официального источника от Яндекса можно формировать более эффективную стратегию оптимизации сайта под различные поисковые запросы, и в оперативном порядке вносить необходимые изменения.
Использование
Использование:
Данный парсер выгодно использовать совместно с парсерами других поисковых систем для составления более полной картины продвижения.
Параметры
Входящие параметры
| Название | Код по API | Тип | Описание |
| ID* | id | Строка | |
| Фраза | phrase | Строка | |
| Регион | region | Строка |
* уникальный параметр внутри одного задания
Результат
| Название | Код по API | Тип | Описание |
| headline | headline | Строка | |
| URL | url | ссылка | |
| Домен | domain | Строка | |
| Сниппед | snippet | Строка | |
| index | index | Число | |
| title | title | Строка | |
| saved | saved | ссылка | |
| Дата и время | dat | timestamp |
* уникальный параметр у всего задания
Интеграция с Вашей системой(API)
Языки програмирования для интеграции с «yandex.
 xml»
xml»yandex.wordstat
30.00
- wordstat
- yandex.ru
- 15 628
Для наполнения и успешного продвижения сайта большое значение имеет качественный контент, его текстовое и графическое содержание. На поиск картинок всегда уходит много времени.
yandex.images
80.00
- yandex.
- Картинки
- 13 636
- yandex.
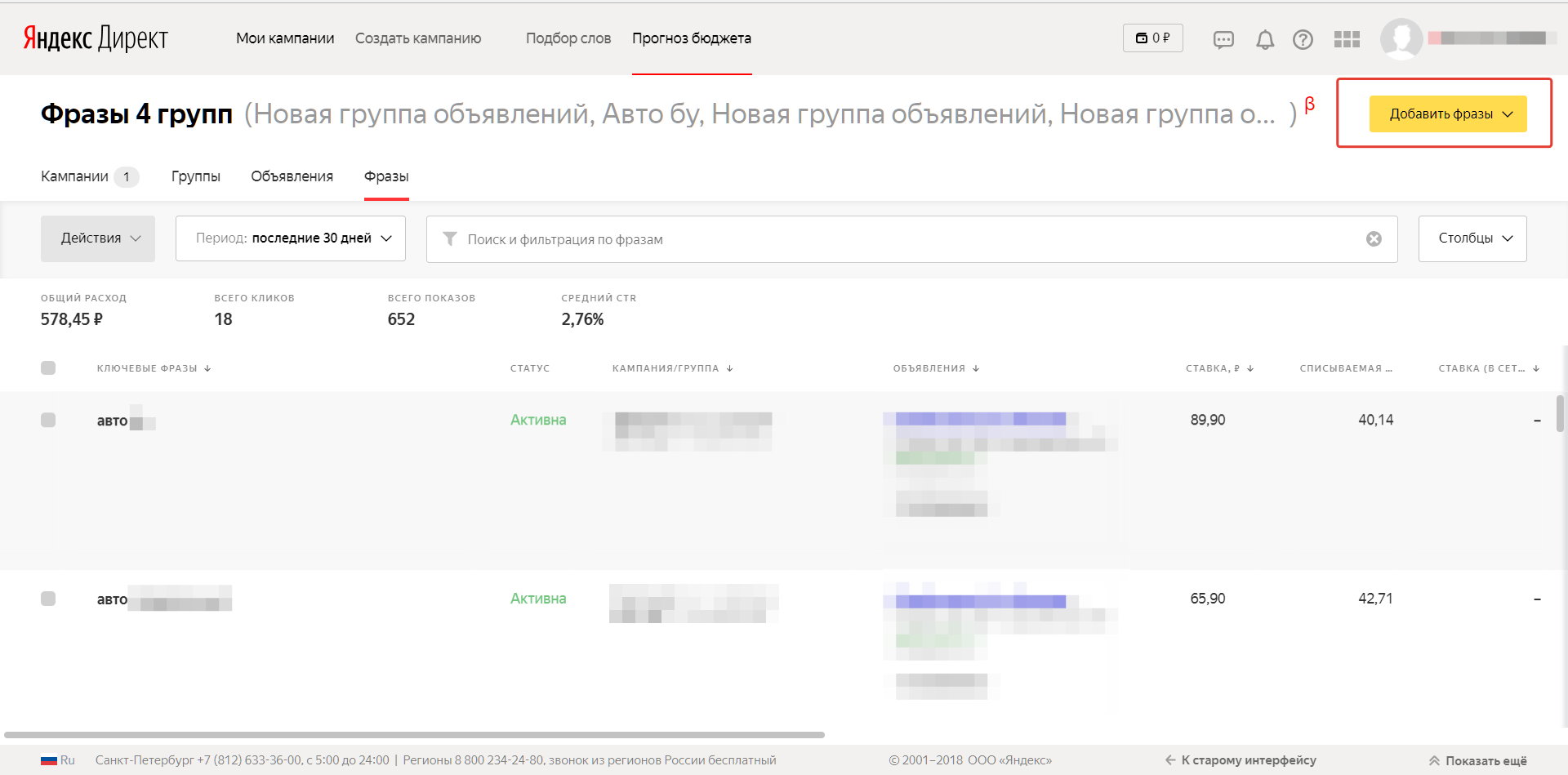
Скрипт сканирования объявлений, размещаемые в Yandex.Direct для каждой из переданных на анализ фразы.
Сбор информации о конкурентах
500.00
- yandex.ru
- 13 150
-
Яндекс.Директ — это система размещения поисковой и тематической контекстной рекламы.
Она показывает ваши объявления людям, которые уже ищут похожие товары или услуги на Яндексе и тысячах других сайтов.Yandex.Direct
30.00
- yandex.ru
- 11 897
Получение страницы из кеша яндекса
Получение Кеша Яндекса
400.00
- yandex.ru
- Кеш
- seo
- 11 735
 org/Product» itemscope=»»>
org/Product» itemscope=»»>Ускорить индексацию сайта или отдельные новые страницы можно добавив запрос на специальную страницу поисковой системы с помощью скрипта yandex.add.
yandex.add
400.00
- yandex.ru
- Индексация
- 11 719
Удобный граббер для получения основных сведений из результатов выдачи популярного браузера от ведущего поисковика Рунета.
yandex.browser
1 000.
00 - yandex.ru
- Javascript
- 11 168
Парсер для массовой проверки индексации сайта
yandex.index
50.00
- yandex.ru
- 10 900
рефераты с referats.
yandex.ruvesna.yandex.ru
80.00
- yandex.ru
- 10 762
Парсер подсказок Yandex
подсказки yandex
80.00
- yandex.ru
- подсказки
- 10 631
Парсер Yandex позволяет получать информацию о позициях сайта по определенным фразам
YandexSerp
50.
00 - yandex.ru
- позиции

 Она показывает ваши объявления людям, которые уже ищут похожие товары или услуги на Яндексе и тысячах других сайтов.
Она показывает ваши объявления людям, которые уже ищут похожие товары или услуги на Яндексе и тысячах других сайтов. 00
00  yandex.ru
yandex.ru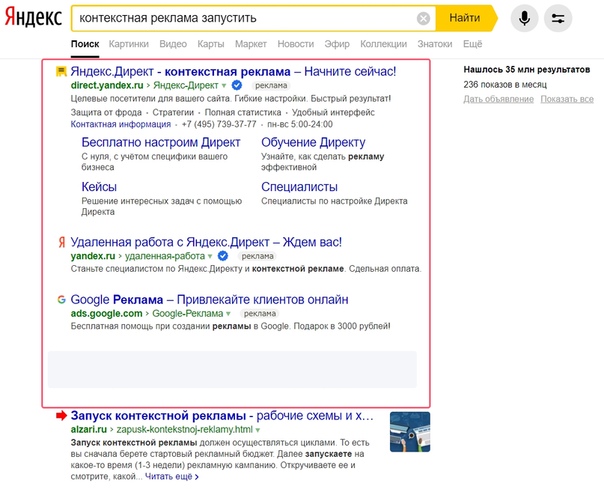 00
00 Yandex.Wordstat-parser/example.py at master · igor-kantor/Yandex.Wordstat-parser · GitHub
| # Подлючаем класс парсера WordstatParser, импортируем необходимые модули | |
| from wsparser import WordstatParser | |
| import time | |
| ################################################################################## | |
| # Вводим исходные данные для парсинга | |
| ################################################################################## | |
# Задаем URL адрес API Яндекс. Директа Директа | |
| # Адрес песочницы: url =’https://api-sandbox.direct.yandex.ru/v4/json/’ | |
| # Адрес полного доступа: url =’https://api.direct.yandex.ru/v4/json/’ | |
| url =’https://api-sandbox.direct.yandex.ru/v4/json/’ | |
| # Указываем свой токен на доступ к API Яндекс.Директ | |
| token = ‘AgAAAAAX1GmLIIX9s4uEoSNiSEyjjxTsAHZ0p8w’ | |
| # Указываем логин своей учетной записи от Яндекс.Директ | |
| userName = ‘yandex.username’ | |
| # Пишем список общих минус-слов, как в примере (со знаком «-«) | |
| minusWords = [ | |
| ‘-купить’, | |
| ‘-дешево’, | |
| ‘-скачать’, | |
| ‘-бесплатно’ | |
| ] | |
| # Пишем список фраз, по которым будем парсить | |
| phrases = [ | |
| ‘фотошоп’, | |
| ‘photoshop’ | |
| ] | |
| # Указываем регион, при необходимости (можно оставить пустым) | |
| geo = [] | |
| ################################################################################## | |
| # Код скрипта парсинга | |
| ################################################################################## | |
| # Добавляем минус-слова ко всем фразам | |
| data = [] | |
| for i in range(len(phrases)): | |
data. append(phrases[i]) append(phrases[i]) | |
| for j in range(len(minusWords)): | |
| data[i] += ‘ ‘+minusWords[j] | |
| # Создаем парсер | |
| parser = WordstatParser(url, token, userName) | |
| try: | |
| # Запрашиваем кол-во оставшихся баллов Яндекс.Директ API | |
| units = parser.getClientUnits() | |
| if ‘data’ in units: | |
| print (‘>>> Баллов осталось: ‘, units[‘data’][0][‘UnitsRest’]) | |
| else: | |
| raise Exception(‘Не удалось получить баллы’, units) | |
# Отправляем запрос на создание нового отчета на сервере Яндекс. Директ Директ | |
| response = parser.createReport(data, geo) | |
| if ‘data’ in response: | |
| reportID = response[‘data’] | |
| print (‘>>> Создается отчет с ID = ‘, reportID) | |
| else: | |
| raise Exception(‘Не удалось создать отчет’, response) | |
| # Проверяем список отчетов на сервере. Должен появиться новый. Ожидаем его готовности | |
| reportList = parser.getReportList() | |
| if ‘data’ in reportList: | |
| lastReport = reportList[‘data’][len(reportList[‘data’])-1] | |
| i = 0 | |
| while lastReport[‘StatusReport’] != ‘Done’: | |
print (‘>>> Подготовка отчета, ждите . .. (‘+str(i)+’)’) .. (‘+str(i)+’)’) | |
| time.sleep(2) | |
| reportList = parser.getReportList() | |
| lastReport = reportList[‘data’][len(reportList[‘data’])-1] | |
| i+=1 | |
| print (‘>>> Отчет ID = ‘, lastReport[‘ReportID’], ‘ получен!’) | |
| else: | |
| raise Exception(‘Не удалось прочитать список отчетов’, reportList) | |
| # Читаем отчет | |
report = parser. readReport(reportID) readReport(reportID) | |
| if ‘data’ in report: | |
| # Сохраняем результаты парсинга в файлы (отдельно фразы, отдельно частотности). | |
| # Если rightCol == True, будет сохраняться правая колонка Яндекс.Вордстат (в дополнение к левой) | |
| parser.saveReportToTxt(report, True) | |
| print (‘>>> Результаты парсига успешно сохранены в файлы!’) | |
| else: | |
| raise Exception(‘Не удалось прочитать отчет’, report) | |
# Удаляем на сервере Яндекс. Директ новый отчет (он больше не нужен) Директ новый отчет (он больше не нужен) | |
| report = parser.deleteReport(reportID) | |
| if ‘data’ in report: | |
| print (‘>>> Отчет с ID = ‘, reportID, ‘ успешно удален с сервера Яндекс.Директ’) | |
| else: | |
| raise Exception(‘Не удалось удалить отчет’, report) | |
| print (‘>>> Все готово!’) | |
| # Все готово! Ищем файлы «phrases_lef.txt» и «shows_left.txt» с резльтатами парсинга в директории этого скрипта | |
| except Exception as e: | |
| print (‘>>> Поймано исключение:’, e) |
Получить статистику за любые даты.
 API Яндекс Директа. Версия 5
API Яндекс Директа. Версия 5Python 2 или 3 с использованием XML с библиотеками Requests и PyXB
После установки библиотеки PyXB будет доступна утилита для создания классов pyxbgen. Выполнить
pyxbgen -u https://api.direct.yandex.com/v5/reports.xsd -m directapi5reports
В результате будет сформировано два файла: _general.py и directapi5reports.py. Импортируйте файл directapi5reports.py в сценарий, чтобы сгенерировать действительные коды запроса XML. Для получения дополнительной информации см. http://pyxb.sourceforge.net.
В этом примере показан запрос к службе отчетов, а также обработка и вывод результатов. Режим формирования отчета выбирается автоматически. Если отчет добавляется в очередь в автономном режиме, выполняются повторные запросы.
Отчет содержит статистику показов, кликов и расходов по всем кампаниям рекламодателя за любой указанный период с группировкой по дате, названию кампании и местоположению пользователя.
Чтобы использовать пример, укажите токен доступа OAuth во входных данных. Для запроса от имени агентства также укажите логин клиента. В теле сообщения запроса укажите дату начала и окончания отчетного периода, а также имя отчета, уникальное среди отчетов рекламодателя.
Для запроса от имени агентства также укажите логин клиента. В теле сообщения запроса укажите дату начала и окончания отчетного периода, а также имя отчета, уникальное среди отчетов рекламодателя.
# --*- кодировка: utf-8 --*-
запросы на импорт
из запросов.исключения импортировать ConnectionError
из времени импортировать сон
импортировать отчеты directapi5reports
импортировать pyxb
# Метод правильного анализа строк в кодировке UTF-8 как для Python 3, так и для Python 2
импорт системы
если sys.version_info < (3,):
защита и(х):
пытаться:
вернуть x.encode ("utf8")
кроме UnicodeDecodeError:
вернуть х
еще:
защита и(х):
если тип (x) == тип (b''):
вернуть x.decode('utf8')
еще:
вернуть х
# --- Входные данные ---
# Адрес службы отчетов для отправки XML-запросов (с учетом регистра)
ReportsURL = 'https://api.direct.yandex.com/v5/reports'
# Токен OAuth пользователя, от имени которого будут выполняться запросы
токен = 'ТОКЕН'
# Логин клиента рекламного агентства
# Обязательный параметр, если запросы делаются от имени рекламного агентства
clientLogin = 'CLIENT_LOGIN'
# --- Подготовка запроса ---
# Создание заголовков HTTP-запроса
заголовки = {
# Токен OAuth. Слово Bearer должно быть использовано
"Авторизация": "Предъявитель" + токен,
# Логин клиента рекламного агентства
«Клиент-Логин»: clientLogin,
# Язык ответных сообщений
"Accept-Language": "ru",
# Режим формирования отчета
"режим обработки": "авто"
# Формат денежных значений в отчете
# "returnMoneyInMicros": "false",
# Не включать строку с названием отчета и диапазоном дат в отчет
# "skipReportHeader": "true",
# Не включать строку с именами столбцов в отчет
# "skipColumnHeader": "true",
# Не включать строку с количеством строк статистики в отчет
# "skipReportSummary": "true"
}
# Создание тела сообщения запроса
requestData = directapi5reports.ReportDefinition ()
# Критерии выбора данных
requestData.SelectionCriteria = pyxb.BIND()
requestData.SelectionCriteria.DateFrom = pyxb. ПРИВЯЗАТЬ ("START_DATE")
requestData.SelectionCriteria. DateTo = pyxb. ПРИВЯЗАТЬ ("END_DATE")
# Поля, которые нужно получить в запросе
requestData.FieldNames = ["Дата", "CampaignName", "LocationOfPresenceName", "Показы", "Клики", "Стоимость"]
# Сортировать по возрастанию даты
requestData.OrderBy = [pyxb.BIND ("Дата", "ПО ВОЗРАСЧЕНИЮ")]
# Имя отчета
requestData.ReportName = u("REPORT_NAME")
# Тип отчета: статистика кампании
requestData.ReportType = "CAMPAIGN_PERFORMANCE_REPORT"
# Отчетный период: даты, указанные в параметрах DateFrom и DateTo
requestData.DateRangeType = "CUSTOM_DATE"
# Формат отчета
requestData.Format = "TSV"
# Вернуть цену за клик без НДС
requestData.IncludeVAT = "НЕТ"
# Вернуть цену за клик без скидки клиента
requestData.IncludeDiscount = "НЕТ"
# Преобразование данных в XML для запроса
ЗапросДанные = ЗапросДанные.toxml()
# --- Запуск цикла выполнения запроса ---
# Если возвращается HTTP-код 200, выводим содержимое отчета
# Если возвращается HTTP-код 201 или 202, отправляем повторные запросы
пока верно:
пытаться:
req = request. post (URL-адрес отчетов, requestData, заголовки = заголовки)
req.encoding = 'utf-8' # Обязательная обработка ответа в UTF-8
если требуется код_статуса == 400:
print("Неверные параметры запроса, либо очередь отчетов заполнена")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для запроса: {}".format(u(requestData)))
print("Код XML для ответа сервера: \n{}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 200:
print("Запрос успешно создан")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Результирующий файл отчета: \n{}".format(u(req.text)))
перерыв
Элиф req.status_code == 201:
print("Отчет успешно добавлен в автономную очередь")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}". format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 202:
print("Отчет создается в автономном режиме")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}".format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 500:
print("При создании отчета произошла ошибка. Повторите попытку позже.")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 502:
print("Превышен лимит сервера на время создания отчета.")
print("Пожалуйста, попробуйте изменить параметры запроса: уменьшите период времени и объем запрашиваемых данных.")
print("Код XML для запроса: {}". format(requestData))
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
еще:
print("Непредвиденная ошибка")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Код XML для запроса: {}".format(requestData))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
# Обработка ошибок, если не было установлено соединение с API-сервером Яндекс Директ.
кроме ConnectionError:
# В этом случае мы рекомендуем повторить запрос позже
print("Ошибка подключения к серверу API Яндекс Директ")
# Принудительный выход из цикла
перерыв
# Если произошла какая-либо другая ошибка
кроме:
# В этом случае следует проанализировать действия приложения
print("Непредвиденная ошибка")
# Принудительный выход из цикла
перерыв  Слово Bearer должно быть использовано
"Авторизация": "Предъявитель" + токен,
# Логин клиента рекламного агентства
«Клиент-Логин»: clientLogin,
# Язык ответных сообщений
"Accept-Language": "ru",
# Режим формирования отчета
"режим обработки": "авто"
# Формат денежных значений в отчете
# "returnMoneyInMicros": "false",
# Не включать строку с названием отчета и диапазоном дат в отчет
# "skipReportHeader": "true",
# Не включать строку с именами столбцов в отчет
# "skipColumnHeader": "true",
# Не включать строку с количеством строк статистики в отчет
# "skipReportSummary": "true"
}
# Создание тела сообщения запроса
requestData = directapi5reports.ReportDefinition ()
# Критерии выбора данных
requestData.SelectionCriteria = pyxb.BIND()
requestData.SelectionCriteria.DateFrom = pyxb. ПРИВЯЗАТЬ ("START_DATE")
requestData.SelectionCriteria.
Слово Bearer должно быть использовано
"Авторизация": "Предъявитель" + токен,
# Логин клиента рекламного агентства
«Клиент-Логин»: clientLogin,
# Язык ответных сообщений
"Accept-Language": "ru",
# Режим формирования отчета
"режим обработки": "авто"
# Формат денежных значений в отчете
# "returnMoneyInMicros": "false",
# Не включать строку с названием отчета и диапазоном дат в отчет
# "skipReportHeader": "true",
# Не включать строку с именами столбцов в отчет
# "skipColumnHeader": "true",
# Не включать строку с количеством строк статистики в отчет
# "skipReportSummary": "true"
}
# Создание тела сообщения запроса
requestData = directapi5reports.ReportDefinition ()
# Критерии выбора данных
requestData.SelectionCriteria = pyxb.BIND()
requestData.SelectionCriteria.DateFrom = pyxb. ПРИВЯЗАТЬ ("START_DATE")
requestData.SelectionCriteria. DateTo = pyxb. ПРИВЯЗАТЬ ("END_DATE")
# Поля, которые нужно получить в запросе
requestData.FieldNames = ["Дата", "CampaignName", "LocationOfPresenceName", "Показы", "Клики", "Стоимость"]
# Сортировать по возрастанию даты
requestData.OrderBy = [pyxb.BIND ("Дата", "ПО ВОЗРАСЧЕНИЮ")]
# Имя отчета
requestData.ReportName = u("REPORT_NAME")
# Тип отчета: статистика кампании
requestData.ReportType = "CAMPAIGN_PERFORMANCE_REPORT"
# Отчетный период: даты, указанные в параметрах DateFrom и DateTo
requestData.DateRangeType = "CUSTOM_DATE"
# Формат отчета
requestData.Format = "TSV"
# Вернуть цену за клик без НДС
requestData.IncludeVAT = "НЕТ"
# Вернуть цену за клик без скидки клиента
requestData.IncludeDiscount = "НЕТ"
# Преобразование данных в XML для запроса
ЗапросДанные = ЗапросДанные.toxml()
# --- Запуск цикла выполнения запроса ---
# Если возвращается HTTP-код 200, выводим содержимое отчета
# Если возвращается HTTP-код 201 или 202, отправляем повторные запросы
пока верно:
пытаться:
req = request.
DateTo = pyxb. ПРИВЯЗАТЬ ("END_DATE")
# Поля, которые нужно получить в запросе
requestData.FieldNames = ["Дата", "CampaignName", "LocationOfPresenceName", "Показы", "Клики", "Стоимость"]
# Сортировать по возрастанию даты
requestData.OrderBy = [pyxb.BIND ("Дата", "ПО ВОЗРАСЧЕНИЮ")]
# Имя отчета
requestData.ReportName = u("REPORT_NAME")
# Тип отчета: статистика кампании
requestData.ReportType = "CAMPAIGN_PERFORMANCE_REPORT"
# Отчетный период: даты, указанные в параметрах DateFrom и DateTo
requestData.DateRangeType = "CUSTOM_DATE"
# Формат отчета
requestData.Format = "TSV"
# Вернуть цену за клик без НДС
requestData.IncludeVAT = "НЕТ"
# Вернуть цену за клик без скидки клиента
requestData.IncludeDiscount = "НЕТ"
# Преобразование данных в XML для запроса
ЗапросДанные = ЗапросДанные.toxml()
# --- Запуск цикла выполнения запроса ---
# Если возвращается HTTP-код 200, выводим содержимое отчета
# Если возвращается HTTP-код 201 или 202, отправляем повторные запросы
пока верно:
пытаться:
req = request.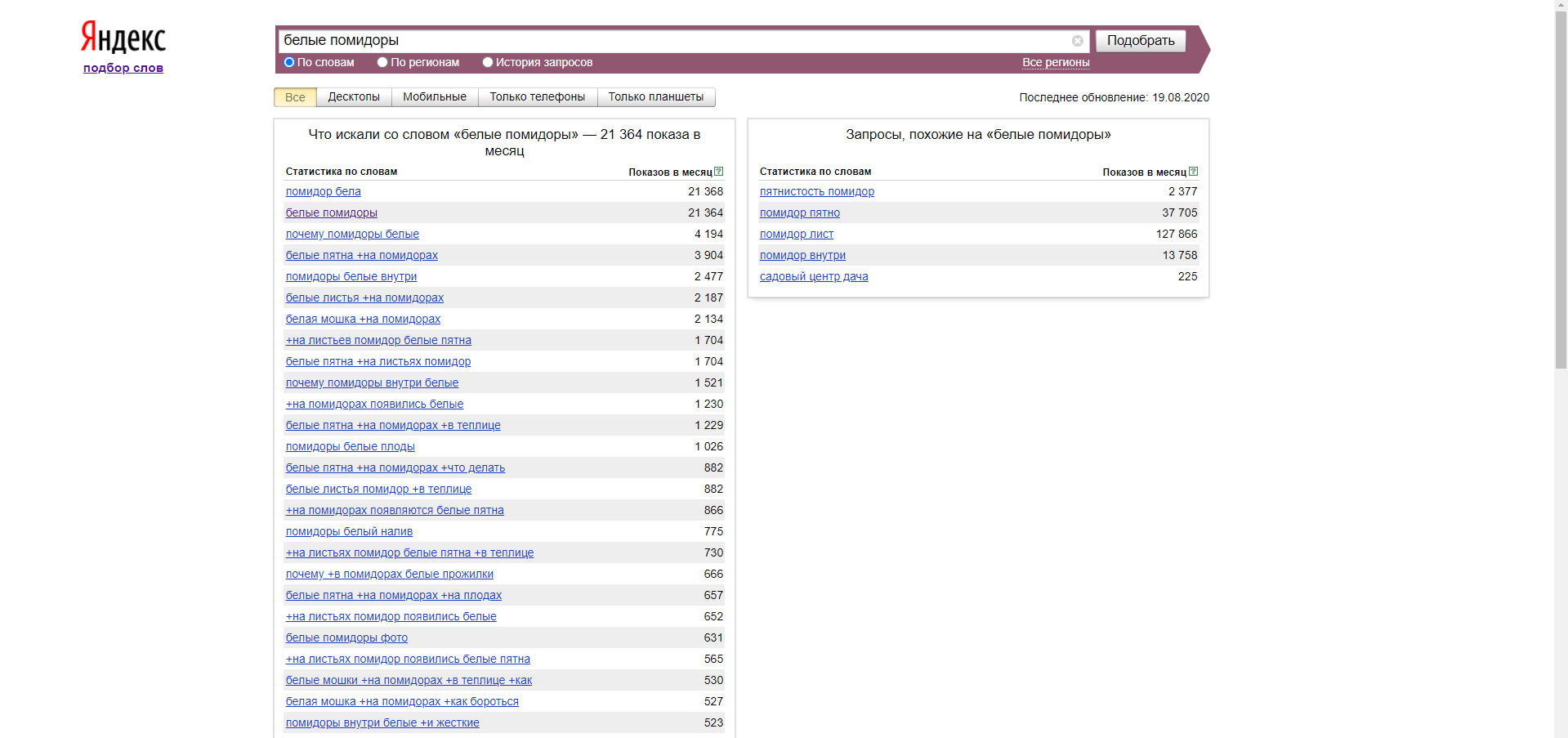 post (URL-адрес отчетов, requestData, заголовки = заголовки)
req.encoding = 'utf-8' # Обязательная обработка ответа в UTF-8
если требуется код_статуса == 400:
print("Неверные параметры запроса, либо очередь отчетов заполнена")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для запроса: {}".format(u(requestData)))
print("Код XML для ответа сервера: \n{}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 200:
print("Запрос успешно создан")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Результирующий файл отчета: \n{}".format(u(req.text)))
перерыв
Элиф req.status_code == 201:
print("Отчет успешно добавлен в автономную очередь")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}".
post (URL-адрес отчетов, requestData, заголовки = заголовки)
req.encoding = 'utf-8' # Обязательная обработка ответа в UTF-8
если требуется код_статуса == 400:
print("Неверные параметры запроса, либо очередь отчетов заполнена")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для запроса: {}".format(u(requestData)))
print("Код XML для ответа сервера: \n{}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 200:
print("Запрос успешно создан")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Результирующий файл отчета: \n{}".format(u(req.text)))
перерыв
Элиф req.status_code == 201:
print("Отчет успешно добавлен в автономную очередь")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}".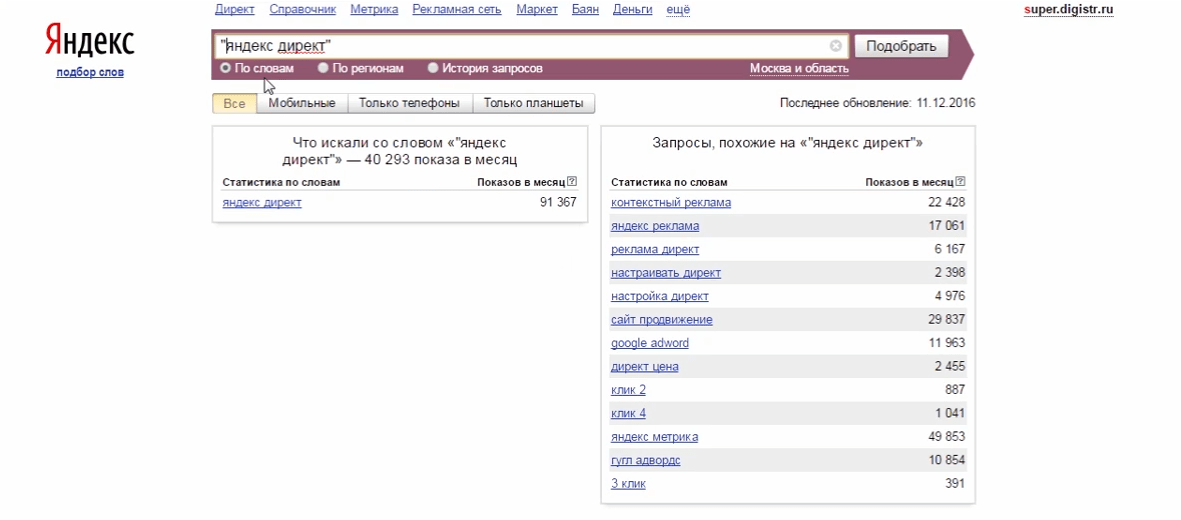 format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 202:
print("Отчет создается в автономном режиме")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}".format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 500:
print("При создании отчета произошла ошибка. Повторите попытку позже.")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 502:
print("Превышен лимит сервера на время создания отчета.")
print("Пожалуйста, попробуйте изменить параметры запроса: уменьшите период времени и объем запрашиваемых данных.")
print("Код XML для запроса: {}".
format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 202:
print("Отчет создается в автономном режиме")
retryIn = int(req.headers.get("retryIn", 60))
print("Запрос будет отправлен повторно через {} секунд".format(retryIn))
print("RequestId: {}".format(req.headers.get("RequestId", False)))
спать (повторить попытку)
Элиф req.status_code == 500:
print("При создании отчета произошла ошибка. Повторите попытку позже.")
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
Элиф Треб. код_статуса == 502:
print("Превышен лимит сервера на время создания отчета.")
print("Пожалуйста, попробуйте изменить параметры запроса: уменьшите период времени и объем запрашиваемых данных.")
print("Код XML для запроса: {}". format(requestData))
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
еще:
print("Непредвиденная ошибка")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Код XML для запроса: {}".format(requestData))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
# Обработка ошибок, если не было установлено соединение с API-сервером Яндекс Директ.
кроме ConnectionError:
# В этом случае мы рекомендуем повторить запрос позже
print("Ошибка подключения к серверу API Яндекс Директ")
# Принудительный выход из цикла
перерыв
# Если произошла какая-либо другая ошибка
кроме:
# В этом случае следует проанализировать действия приложения
print("Непредвиденная ошибка")
# Принудительный выход из цикла
перерыв
format(requestData))
print("RequestId: {}".format(req.headers.get("RequestId",False)))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
еще:
print("Непредвиденная ошибка")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Код XML для запроса: {}".format(requestData))
print("Код XML для ответа сервера: \n {}".format(u(req.text)))
перерыв
# Обработка ошибок, если не было установлено соединение с API-сервером Яндекс Директ.
кроме ConnectionError:
# В этом случае мы рекомендуем повторить запрос позже
print("Ошибка подключения к серверу API Яндекс Директ")
# Принудительный выход из цикла
перерыв
# Если произошла какая-либо другая ошибка
кроме:
# В этом случае следует проанализировать действия приложения
print("Непредвиденная ошибка")
# Принудительный выход из цикла
перерыв Была ли статья полезна?
tomita-parser 0.
 0.3 уязвимости | Сник
0.3 уязвимости | СникОбёртка узла для Яндекса Tomita Parser
последняя версия
0.0.3
первая публикация
8 лет назад
опубликована последняя версия
8 лет назад
лицензий обнаружено
Просмотр работоспособности пакета tomita-parser на Snyk Advisor Откройте эту ссылку в новой вкладке
Вернуться ко всем версиям этого пакета
Сообщить о новой уязвимости Нашли ошибку?
Прямые уязвимости
Известные уязвимости в пакете tomita-parser.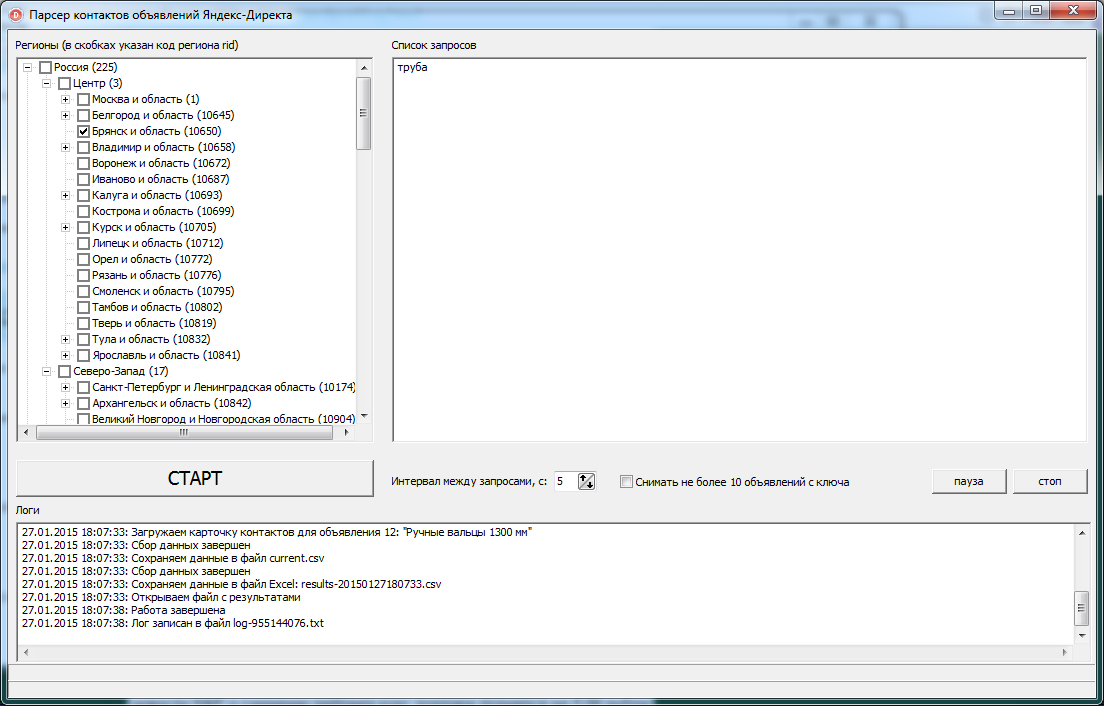 Сюда не входят уязвимости, принадлежащие
зависимости этого пакета.
Сюда не входят уязвимости, принадлежащие
зависимости этого пакета.
Автоматически находите и устраняйте уязвимости, затрагивающие ваши проекты. Snyk сканирует на наличие уязвимостей и предоставляет исправления бесплатно.
Исправить бесплатно
|
