
Как пользоваться Wordstat — как работать с операторами Яндекс Вордстат и статистикой поисковых запросов
Как пользоваться Яндекс Вордстат, работать с операторами и статистикой поисковых запросов. Подробное руководство по работе с сервисом.
В этой статье мы расскажем:
- как работать со статистикой поисковых запросов Яндекса с самых азов;
- рассмотрим на примерах основные и дополнительные операторы;
- научимся определять сезонность спроса;
- дадим полезные советы по использованию софта, облегчающего работу.
Яндекс Вордстат – это бесплатный сервис компании Yandex, призванный помочь оптимизаторам и владельцам сайтов узнать, как люди ищут товары или услуги и собрать ключевые слова для продвижения сайтов.
Помимо этого, сервис позволит:
- узнать частотность;
- определить сезонность по каждому продвигаемому запросу;
- определить спрос по конкретным регионам;
- определить долю популярности фраз по устройствам (смартфон, десктоп, планшет).


Вы сможете собрать полное семантическое ядро и разработать структуру проекта. Сделать это проще с помощью специализированного софта, но вернемся к этому позже.
Начало работы
Для доступа к статистике сначала необходимо зарегистрироваться в Яндексе.
- заведите почтовый ящик на Яндекс и авторизуйтесь;
- откройте инструмент по ссылке https://wordstat.yandex.ru/.
Готово, можно приступать к работе.
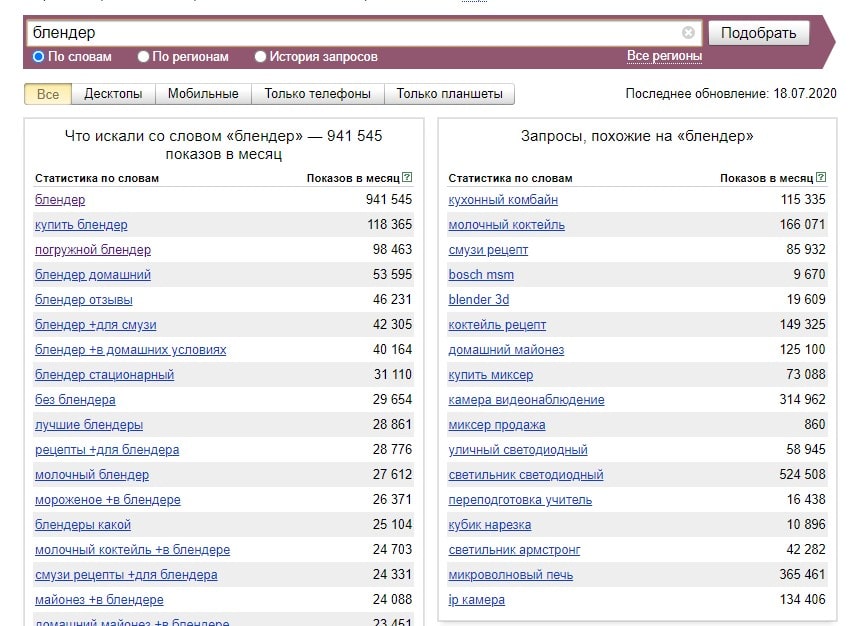
Поиск по словам
Осуществляется поиск запросов, в которых присутствует введенная фраза (в левой колонке), а также всех похожих (в правой колонке). В колонке «Показов в месяц» выводится базовая частотность за последний месяц (суммарная частотность фраз из левой колонки).
Частота по регионам
Отражает частотность запроса в отдельности по регионам, во второй и третьей колонках отражена популярность в числовом и процентном соотношении.
История запросов — сезонность запроса
С помощью этого инструмента можно проанализировать сезонность спроса по товару или услуге. Показывает популярность поискового запроса по месяцам или неделям. По скриншоту ниже видим, что спрос на услугу по «созданию сайтов» имеет значительный рост популярности в период с апреля по июнь.
Регион отображаемой статистики
Выбираем регион, статистика по которому нас интересует. При продвижении, скажем, по Москве – выбираем «Москва и область».
Инструмент позволяет сделать выгрузку по всей России, а также СНГ, Европе, Азии, Африке, Северной и Южной Америке, Австралии и Океании.
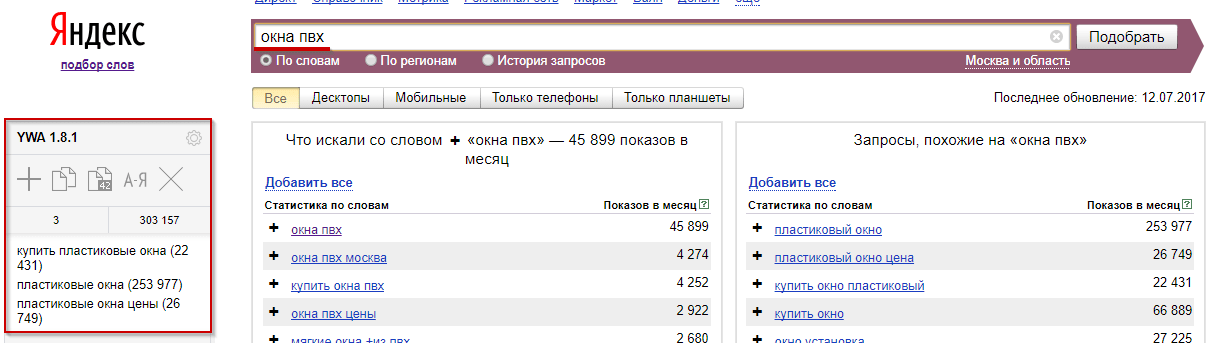
Статистика по устройствам
Вкладки «десктоп, мобильные, только телефон, только планшеты» содержат информацию с каких конкретно устройств наиболее часто вводят поисковый запрос.
Операторы Wordstat
Операторы необходимы для уточнения формулировки запроса и точного определения частотности ключевых фраз. Если ввести интересующие слова без применения специальных символов, то получим их базовую частотность, то есть – суммарную частоту поисковых запросов пользователей Яндекс с применением данной фразы.
Если ввести интересующие слова без применения специальных символов, то получим их базовую частотность, то есть – суммарную частоту поисковых запросов пользователей Яндекс с применением данной фразы.
Пример:
Частотность всех ключей со словом «велосипед» – купить велосипед, детский велосипед, трехколесный велосипед и т.д.
Ниже предлагаем рассмотреть основные операторы.
“Кавычки”
Фразы, зафиксированные оператором “кавычки”, например «создание сайтов», отобразят частотность только данного словосочетания без хвостов, во всех возможных формах и в любом порядке.
Сбор статистики запросов определенной длины
С помощью оператора “кавычки” можно вывести на экран статистику запросов, состоящих из заданного количества слов – из 2, 3, 4 и так далее.
Например, чтобы получить список ключей из 2 слов по фразе «велосипед», введите в Wordstat следующую конструкцию – “велосипед велосипед”.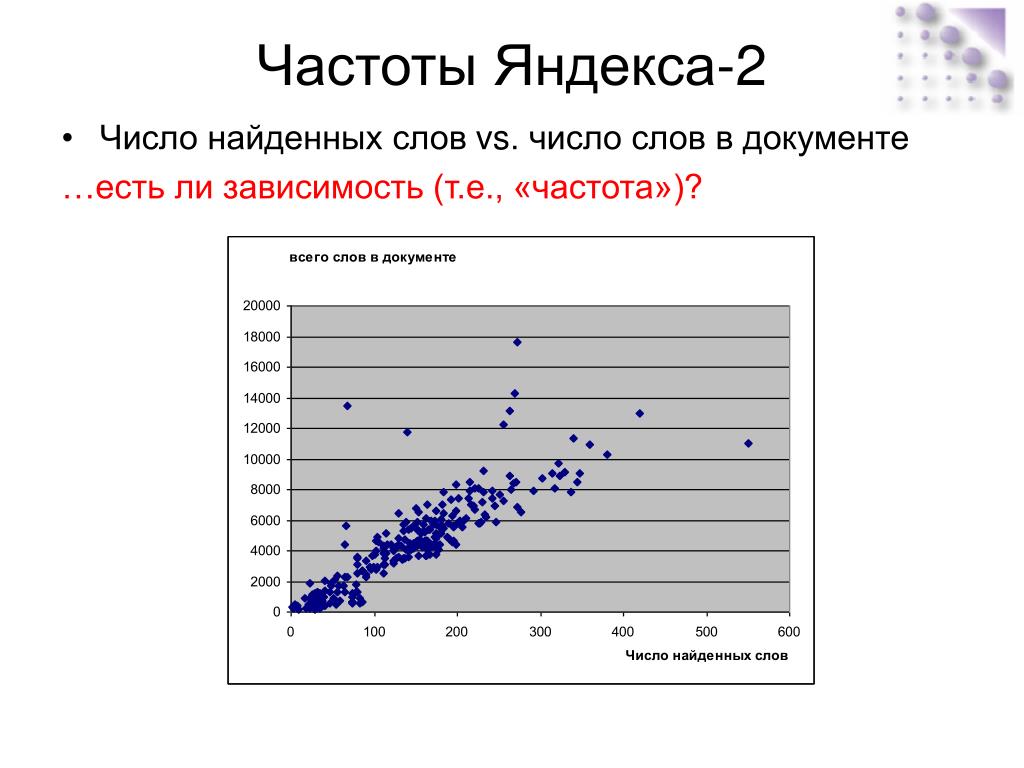
В итоге получаем ключевые слова и базовую частотность по всем запросам из двух слов с заданной фразой. Данная конструкция применима для произвольного количества слов в запросе и любых тематик.
!Восклицательный !знак
Если перед введенными фразами применить оператор «восклицательный знак», то получите частотность по всем фразам с их присутствием именно в том виде и с тем окончанием, как вы ввели.
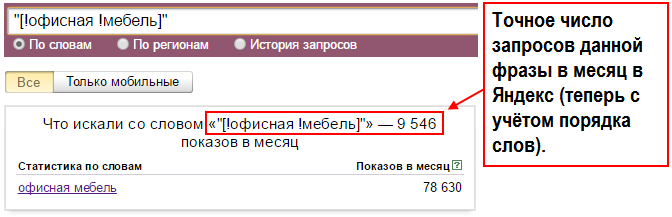
“!Кавычки !с !восклицательным !знаком”
Если совместить использование операторов Яндекс Вордстат “кавычки” и !восклицательный !знак, сервис покажет частотность четко по заданной фразе слово в слово, без учета порядка.
Дополнительные операторы
Операторы, предназначенные для более сложной сортировки данных при работе со статистикой запросов Wordstat.
[Квадратные скобки]
С помощью данной конструкции фиксируется порядок слов в запросе.
Пример – [стол для обеда]
Абсолютно точная частота запроса с учетом порядка, состава слов и окончаний.
Для получения точной частотности, используйте конструкцию вида – «[!стол !для !обеда]».
(Или|Или)
Вводится с применением вертикального разделителя “|” между словами и заключением их в круглые скобки. Чаще всего применяется, когда необходимо сравнить статистику по двум одинаковым по смыслу запросам, но с разным написанием.
Пример –
(Iphone|айфон), (сайт|вебсайт), (раскрутка|продвижение).
Таким образом, Вордстат показывает все ключи и число их показов сразу по обеим фразам – “iphone” и “айфон”.
Оператор “+”
Если перед любым словом указать символ «плюс», то оно становится обязательным для программы. Также его использование очень полезно для выделения предлогов, так как сам Вордстат их не учитывает.
Пример #1. Вводим поисковый запрос с предлогом
Как мы видим, инструмент проигнорировал наличие предлога и мы не получили статистику в том виде, в каком хотели.
Пример #2. Указываем перед предлогом «+»
Теперь видим, что в левой колонке все запросы содержат нужное нам слово.
С помощью данной конструкции удобно готовить контент-план для публикаций в блоге. Для этого используйте вместе с основным запросом вопросительные плюс-фразы: «как, зачем, почему, своими руками» и так далее.
Оператор “-”
Добавление символа “минус” перед словом поможет исключить все ключи с его участием. Можно добавлять неограниченное количество минус-фраз.
Например, вы хотите создать сайт веб-студии и ваш основной запрос «Создание сайтов». Вам необходимо оценить количество коммерческих запросов и их частотность для понимания целесообразности продвижения в данной тематике.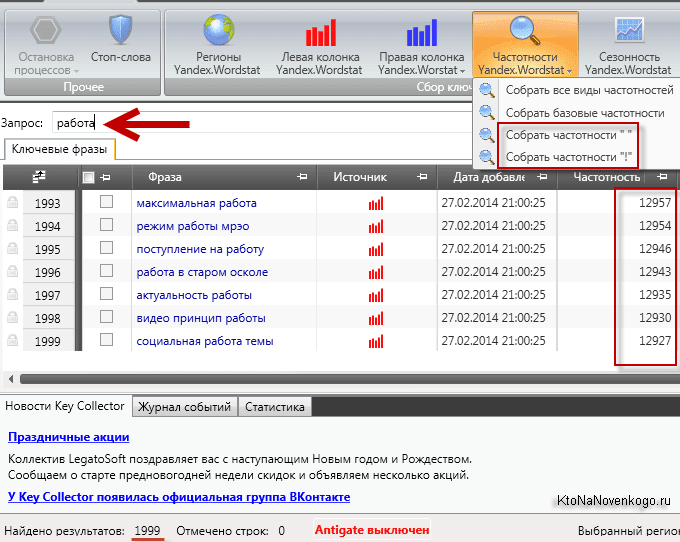
Для этого соберите список всех минус-фраз, либо найдите в интернете (существует множество готовых списков почти под любую тематику) и введите их все по данной конструкции: создание сайтов -бесплатно -самостоятельно -обучение -курсы и так далее.
Группировка запросов с использованием различных операторов
Пример конструкции:
В данному случае, мы сгруппировали фразы «seo, сео, поисковое, поисковая система, поисковик, яндекс, google» с фразами «продвижение, раскрутка, оптимизация» и убрали ключевые слова с вхождениями «бесплатно, самостоятельно, самому, инструкция».
Как автоматизировать работу со статистикой Вордстат?
Сбор семантического ядра через Вордстат для крупного ресурса или интернет-магазина – очень трудоемкий процесс. Его можно автоматизировать с помощью дополнительного программного обеспечения, сильно сэкономив свое время. Существует большое количество различного ПО для подбора, расширения семантики, анализа видимости конкурентов. Ниже перечислим самые основные и популярные.
Ниже перечислим самые основные и популярные.
1. Yandex Wordstat Helper – бесплатное расширение для браузера Chrome, с помощью которого вы сможете добавлять выбранные запросы в отдельное поле (нажатием на «+»), а потом копировать вместе с частотами одним нажатием кнопки.
Скачать его можно здесь
2. KeyCollector — инструмент для автоматического парсинга статистики с Wordstat. Использование КейКоллектор исключает необходимость ручного сбора и копирования. Для формирования полного семантического ядра вам понадобится только список базовых запросов:
- вносите их в инструмент;
- выбираете регион сбора статистики;
- запускаете процесс.
Программе понадобится от нескольких часов до нескольких дней, в зависимости от количества ключевых слов в вашей тематике. После окончания сбора ядра необходимо произвести чистку от ненужных фраз и кластеризацию.
2. Just Magic – содержит модуль парсинга статистики из левой колонки Wordstat с функцией поддержки всех операторов.
3. Букварикс – готовая онлайн база ключевых слов. Для моментальной выгрузки достаточно ввести базовые запросы и инструмент предоставит полный список необходимых вам фраз.
4. SpyWords – позволяет выгрузить видимость сайта конкурента в Яндекс и Google, определив по каким запросам его находят в поиске.
Итог
Надеемся, наша инструкция по Яндекс Вордстат помогла вам разобраться с сервисом. В этой статье мы рассказали о функциях и возможностях программы, а также упомянули инструменты, помогающие упростить и автоматизировать работу.
Еще мы помогаем с продвижением сайтов. Делаем полный анализ тематики вашей деятельности, составляем стратегию, оптимизируем ресурс для выхода в ТОП поисковых систем.
Какую частотность Wordstat (Вордстат) использовать для продвижения сайта?
Чем собрать частотность запросов всем известно, а вот вопрос какую частотность использовать — остается открытым. На этот счет существует множество мнений: кто то считает, что нужно оставлять запросы с частотностью не ниже 50 по «! «, а кто то работает с запросами частотностью от 1 по «! «. В данном руководстве мы подробно ответим на все вопросы, касающиеся данной темы.
Пожалуй стоит начать с того, частотность каких запросов мы оцениваем. Прежде всего, это подсказки и запросы, полученные из «левой колонки» Wordstat. Разница в том, что в подсказках гораздо более «свежие» и «живые» запросы пользователей, в то время как в «левой колонке» Wordstat гораздо большее количество «накрученных» оптимизаторами и различным сервисами (например сервисами сбора позиций) запросов. Плюс Wordstat отдает данные на месяц назад от даты съема частотности.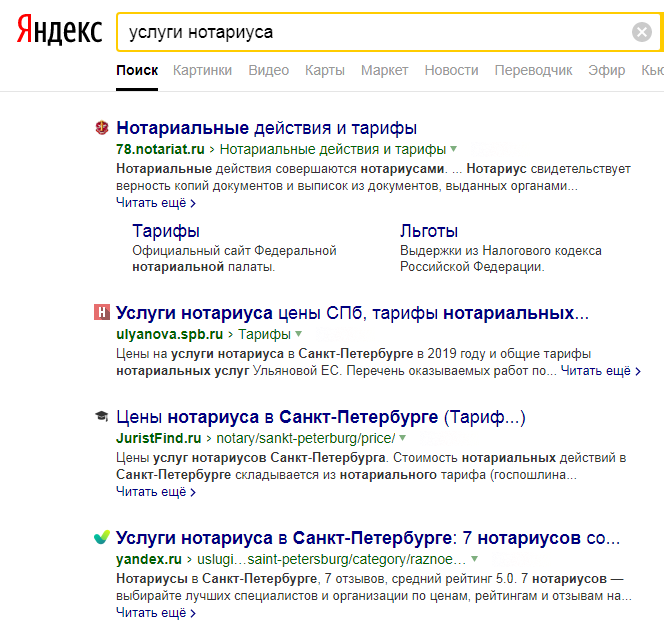 Подробнее о нашем парсере Wordstat>>
Подробнее о нашем парсере Wordstat>>
При сборе подсказок Яндекса существует проблема так называемых «фантомных» подсказок — подсказки которые Яндекс автоматические генерирует на основе персонализации или других данных. Наши алгоритмы эффективно находят такие подсказки и вырезают их, позволяя вам экономить множество времени и денег.
Что мы имеем в итоге:
- более частотные, но, часто накрученные, запросы из «левой колонки» Wordstat
- нетипичные для русского языка, накрученные запросы вроде «коляска детская москва купить»
- менее частотные, но реальные, живые запросы пользователей из поисковых подсказок
- *поисковые запросы из Яндекс Метрики и Google Analytics
* Такие запросы могут быть выгружены за большой период времени и в момент сбора частотности могут иметь нулевую частотность из-за сезонности или неактуальности запроса в момент сбора частотности.
Я собрал подсказки, но многие из них имеют небольшую частотность «!ws», стоит ли их использовать?
Безусловно стоит. Наш сервис призван найти как можно больше целевых ключевых слов, которые можно использовать и о которых не знают конкуренты. Большинство таких ключевых слов — низкочастотные и они приносят до 70% поискового трафика на веб-сайты в любой стране мира. Плюс, как уже было сказано выше, это живые запросы пользователей, которые актуальны в данный момент времени и могут (часто так и происходит) достаточно быстро набирать популярность, создавая новые семантические тренды и срезы.
Наш сервис призван найти как можно больше целевых ключевых слов, которые можно использовать и о которых не знают конкуренты. Большинство таких ключевых слов — низкочастотные и они приносят до 70% поискового трафика на веб-сайты в любой стране мира. Плюс, как уже было сказано выше, это живые запросы пользователей, которые актуальны в данный момент времени и могут (часто так и происходит) достаточно быстро набирать популярность, создавая новые семантические тренды и срезы.
Ключевые слова ниже какой частотности отбрасывать?
Здесь все зависит от тематики вашего сайта:
В тематиках, где поисковый спрос узкий (как пример — ремонт телефонов Vertu) — целесообразно использовать даже ключевые слова с частотностью «!» = 1 т.к. здесь важен каждый пользователь из поисковых систем — их в принципе немного.
Для электронной коммерции, например магазинов электроники/подарков/одежды, где очень большой поисковый спрос — можно отбрасывать все ключевые слова с частотностью менее «!» = 5, сконцентрировав усилия на более частотных запросах, а к совсем непопулярным НЧ вернуться позже, при второй итерации.
Для информационных сайтов, таких, как сайты рецептов, сайты кино-тематики, сайты рефератов, автомобильные порталы и для других аналогичных сайтов — можно отбрасывать все ключевые слова с частотностью менее «!» = 50 т.к. спрос в этих нишах просто огромный и физически нереально работать над всем семантическим ядром. Идите от самых популярных потребностей пользователей, к менее популярным. Работайте итерациями.
Как не потерять нужные запросы и не выкинуть лишнее?
Бывают такие ситуации и тематики, в которых:
- поискового спроса очень мало в принципе
- преобладают многословные запросы в различных словоформах и переформулировках
а) Первый вариант — оставлять запросы с частотностью от «!» = 1, как было сказано выше. Но не везде это возможно, в некоторых тематиках такие запросы или слишком конкретные (не имеют общих URL в SERP с другими запросами и не кластеризуются) и продвигать их нецелесообразно (нет смысла создавать отдельную страницу под такой низкий спрос) или не совсем целевые.
б) Второй вариант — использовать » «, вместо «!». Этот способ работает, когда в вашей семантике преобладают многословные запросы в различных словоформах и переформулировках. Дело в том, что «!» закрепляет конкретную словоформу, а так как многословный запрос может иметь огромное множество переформулировок, а «!» учитывает только одну конкретную, все остальные вы потеряете. Этот метод целесообразно использовать в том случае, если вы видите устойчивый тренд резкого падения частотности от » » к «!» — падение на 70% и более.
Не забываем про сезонность
Так же необходимо учитывать сезонность для некоторых запросов. Ее можно просмотреть в Яндекс Wordstat, если выбрать «История запросов» после ввода ключевого слова.
Так, например запросы связанные с Новогодними праздниками начинают увеличиваться в частотности с сентября, а с середины декабря уже падают.
Так же очень важно учитывать то, что Яндекс показывает данные за прошлый месяц. И если у вас новый запрос, такой, что только что появился, данных о нем может и не быть, либо будет низкая частотность.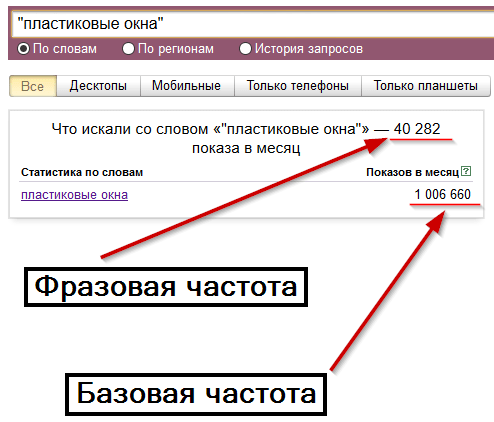 Или, возможен вариант, что вы снимаете частотность в «низкий сезон». Если вы имеете примерное представление о популярности запросов, но частотности по ним получились сильно меньше, чем вы ожидали, проверьте сезонность и не спешите отказываться от этих запросов! Начиная продвигать запросы в «низкий сезон», вы получите преимущество перед конкурентами, которые начнут продвигать те же запросы в «высокий сезон».
Или, возможен вариант, что вы снимаете частотность в «низкий сезон». Если вы имеете примерное представление о популярности запросов, но частотности по ним получились сильно меньше, чем вы ожидали, проверьте сезонность и не спешите отказываться от этих запросов! Начиная продвигать запросы в «низкий сезон», вы получите преимущество перед конкурентами, которые начнут продвигать те же запросы в «высокий сезон».
Руководство по сбору Wordstat + видео
Была ли статья полезной?
14
0
Частота— Об Adfox. Об Adfox
- Общие настройки
- Настройки показов
- Настройки кликов
При таргетинге по частоте вы можете установить ограничения для кампании или баннера на основе показов и кликов для конкретного пользователя.
Например, не показывать баннер чаще двух раз в день или приостанавливать показы, если пользователь уже переходил по ссылке на баннере.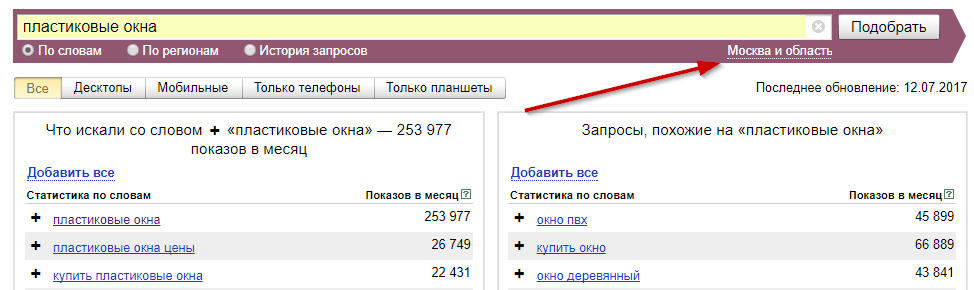
Настройки меняются на вкладке Таргетинг → Частота.
- Максимальное количество показов пользователю
- Любой уникальный браузер увидит баннеры этой кампании не более указанного количества раз, пока она не прекратит работу. Это при условии, что не исчерпан лимит параметра Максимальное количество кликов на одного пользователя.
- Максимальное количество кликов на одного пользователя
- Количество кликов, которые пользователь может сделать за все время активности кампании.
- Дата начала периода
- Значение станет активным, если в настройках показов или кликов используется период 14 дней и более.
- Период частоты показов
- Выберите период и установите ограничения на количество показов для уникального пользователя в этот период.
- Специальный период показа (часы:минуты)
- Если <другой период> выбран в качестве периода частоты показов, укажите этот временной интервал в формате чч:мм .
- Количество показов за период
- Укажите лимит показов за указанный период.
- Минимальный период между показами (часы:минуты:секунды)
- Чтобы установить интервал времени между первым показом баннера для пользователя и следующим показом, укажите в этом параметре время в формате чч:мм:сс .

- Период частоты кликов
- Выберите период и установите ограничения на количество кликов для уникального пользователя в этот период.
- Специальный период кликов (часы:минуты)
- Если <другой период> 9В качестве Периода кликов выбрано 0039, укажите этот временной интервал в формате чч:мм .
- Количество кликов за период
- Укажите лимит кликов за указанный период.
- Минимальный период между кликами (часы:минуты:секунды)
- Чтобы установить временной интервал между кликом с баннера и показом следующего баннера, укажите в этом параметре время в формате чч:мм:сс .
Например, на сайте есть три раздела. Существует ограничение на всю кампанию: максимальное количество показов = 10, максимальное количество кликов = 6,9.0011
Таргетинг по частоте не был переопределен для сайта.
Для раздела 1 5 показов и 3 клика.
Для раздела 2 5 показов и 3 клика.
Для раздела 3: без переопределения.
В результате этих настроек получаем всего 20 показов и 12 кликов. Это связано с тем, что в разделах 1 и 2 кампания будет работать так, как было переопределено для этих разделов. Но есть еще раздел 3, который унаследует лимиты кампании (10/6).
«Вепрь», обученный Яндексом Масштабная утечка данных свидетельствует об использовании искусственного интеллекта в интернет-слежке и подавлении протестов в России получил доступ к более чем двум терабайтам документов и сообщений, которыми обменивались сотрудники неизвестной структуры в рамках более крупной структуры российского регулятора СМИ, Роскомнадзора. Так называемый Главный радиочастотный центр (ГРЧЦ), или (по-русски) «ФГУП ГРЧЦ», оказался местом российской интернет-слежки и главным двигателем репрессий против россиян, критикующих путинский режим или протестующих против войны.
 в Украине. Киберпартизаны поделились своими данными с журналистами в нескольких независимых изданиях, что привело к осознанию того, что малоизвестное агентство играет центральную роль в построении государства слежки нового поколения в России. Просочившиеся сообщения также свидетельствуют о тесном сотрудничестве MRFC с «Яндексом»: разделенный I.T. Российская сторона гиганта, по-видимому, глубоко вовлечена в подготовку следующего поколения ИИ. приложения, предназначенные для тотальной слежки и подавления политической оппозиции и протеста в зачаточном состоянии. «Медуза» подводит итоги подробного анализа утечки, опубликованного «Настоящим временем» совместно с «Радио Свободная Европа». Война с пацифистами
в Украине. Киберпартизаны поделились своими данными с журналистами в нескольких независимых изданиях, что привело к осознанию того, что малоизвестное агентство играет центральную роль в построении государства слежки нового поколения в России. Просочившиеся сообщения также свидетельствуют о тесном сотрудничестве MRFC с «Яндексом»: разделенный I.T. Российская сторона гиганта, по-видимому, глубоко вовлечена в подготовку следующего поколения ИИ. приложения, предназначенные для тотальной слежки и подавления политической оппозиции и протеста в зачаточном состоянии. «Медуза» подводит итоги подробного анализа утечки, опубликованного «Настоящим временем» совместно с «Радио Свободная Европа». Война с пацифистами Главный радиочастотный центр (ФГУП ГРЧЦ) был создан как подразделение федерального регулятора связи Госсвязьнадзора в 2000 году. Дмитрий Медведев. В мае 2014 года перед MRFC была поставлена задача «контролировать соблюдение установленных требований Роскомнадзора». В восьми филиалах центра работает около 5000 человек; его бюджет на 2022 год составил 20,5 млрд рублей (или чуть более 280,6 млн долларов).
В восьми филиалах центра работает около 5000 человек; его бюджет на 2022 год составил 20,5 млрд рублей (или чуть более 280,6 млн долларов).
Основным инструментом центра по отслеживанию политически нежелательного интернет-контента является Единая автоматизированная информационная система, также известная как «Единый реестр». Сотрудники MRFC ищут «запрещенный» контент и составляют ссылки на основании решений судов и запросов Генпрокуратуры. Продуктом этого исследования является регистрационная карточка с отметкой о нарушении в Едином реестре, которая затем становится основанием для привлечения к ответственности. Затем автор оскорбительной веб-страницы или сообщения получает письмо с требованием удалить незаконный контент. В случае неудовлетворения письма о прекращении действия цензор блокирует страницу или весь сайт.
Российские власти подвергают цензуре контент, связанный с наркотиками, суицидом, азартными играми и детской порнографией. После вторжения на Украину в феврале 2022 года MRFC начал отслеживать в Интернете «фейки о специальной военной операции» (по сути, любой контент, который противоречит официальной версии о войне и благонамеренных целях России в Украине). Судя по внутреннему отчету Роскомнадзора, за первые 10 месяцев полномасштабной войны было удалено 150 000 публикаций в социальных сетях. Среди обнаруженных агентством нелегальных изданий 169000 «фейков» о вторжении и 40 000 призывов к протесту (тоже незаконных по действующему российскому законодательству).
Судя по внутреннему отчету Роскомнадзора, за первые 10 месяцев полномасштабной войны было удалено 150 000 публикаций в социальных сетях. Среди обнаруженных агентством нелегальных изданий 169000 «фейков» о вторжении и 40 000 призывов к протесту (тоже незаконных по действующему российскому законодательству).
В 2019 году орган государственной цензуры Роскомнадзор поручил одной из своих дочерних компаний разработать безопасный мессенджер для оперативной связи в силовых структурах (МВД, ФСБ, Генпрокуратуре, Росгвардии, нравиться). Получившееся в результате приложение ASKOV похоже на общедоступные мессенджеры — разница в том, что все групповые чаты ASKOV организованы по общим задачам участников. (Приложение также позволяет пользователям обмениваться прямыми сообщениями.)
Какие же темы для чата в ASKOV? В ноябре 2022 года названия включали следующее:
- Protest Moods
- Оперативная дестабилизация
- Терроризм
- Протестный вы можете увидеть подробные ежедневные отчеты о «протестных настроениях в социальных сетях», составленные путем мониторинга 546 «национальных» и 3000 «региональных» аккаунтов. В этих отчетах рассматриваются ключевые ежедневные новости, в том числе любые «горячие точки» публикаций в так называемых «оппозиционных» источниках. В этих отчетах также есть специальная рубрика по содержанию, в которой людям рассказывается, как они могут отправлять деньги «оппозиционным структурам и террористическим или экстремистским организациям». Отчеты завершаются разделом о запланированных митингах протеста со ссылками на информацию о каждом протесте. (Ссылки также пересылаются в Генеральную прокуратуру.)
«Оперативник по дестабилизации» — чат про «антироссийских лидеров общественного мнения». Информация, собранная в чате, также передается в Генеральную прокуратуру. «Экстремизм» — это чат с краткими инструкциями принять к сведению те или иные публичные заявления, вроде призыва Фонда борьбы с коррупцией саботировать мобилизацию всеми способами, «в том числе поджигать военкоматы».
По состоянию на июль 2022 года у АСКОВ было около 1000 зарегистрированных пользователей, работающих в таких местах, как Роскомнадзор и МРСК, МВД, Росгвардия, Генеральная прокуратура, региональные правительства и Офис президента.
«Спецзадание Яндекс Ю» Любопытно, что Федеральную службу безопасности (ФСБ) представляет всего один анонимный пользователь, зарегистрированный как «Сотрудник». Среди пользователей АСКОВ также заместитель Мэра Москвы Наталья Сергунина, московский городской И.Т. глава ведомства Эдуард Лысенко и соратник Рамзана Кадырова Ахмед Дудаев, министр печати Чечни.В копилке документов, полученных киберпартизанами, есть несколько таблиц Excel с пометкой «Спецзадание Яндекс У», а также обмен сообщениями об этом конкретном документе. Один из сотрудников MRFC прислал сообщение с разъяснением характера этого «специального задания» и узнал, что в таблицах отслеживаются ключевые слова, которые необходимо исключить из результатов поиска Яндекса (условно говоря, Яндекс — это «российский Google»). Затем тот же сотрудник запросил проверку: речь шла об обысках типа «Россия бомбит гражданское жилье», «Россия убивает мирных жителей», «Зверства российских военных в Буче», «Необученные новобранцы в Украине», «Огромные потери России на Украине»?
Второй ответ подтвердил, что он все понял правильно.
По данным Роскомнадзора, российские поисковые системы Яндекс и Mail.ru заблокировали более 11 800 различных публикаций о потерях России на Украине, массовой капитуляции российских войск, нападениях России на гражданскую инфраструктуру Украины, убийствах мирных жителей Украины вторгшиеся военные.
«Фейки», «иностранные агенты» и «Путин в образе краба»Определенные сотрудники MRFC проводят мониторинг основных социальных сетей России, каждый из них выявляет 100–300 «фейковых новостей» в день и регистрирует инциденты в специальной таблице Excel. Вновь к «фейковым новостям» относятся сведения об убийствах мирных жителей, нападениях на гражданскую инфраструктуру и артиллерийских ударах по жилым кварталам, а также о российских потерях на Украине, мародерстве со стороны российских военных, российских военнопленных на Украине, мобилизации и политическая нестабильность в самой России. Часть этих выводов выборочно направляется в Генеральную прокуратуру через интерфейс АСКОВ.
Специальный отдел MRFC осуществляет мониторинг СМИ. С октября 2020 года он выдвигал потенциальных «иностранных агентов» в своих регулярных отчетах, которые информировали об официальных назначениях Министерства юстиции. Такие издания, как «Проект», «Холод», «Колокол», «Открытые медиа», «Редакция» и многие другие, прошли через этот процесс сообщения MRFC, а затем были объявлены «иностранными агентами». Когда «Медуза» получила «рекомендательное письмо» от MRFC, всего через два дня она присоединилась к другим «иностранным агентам» в реестре Минюста. Агентство публикует аналогичные отчеты о лицах, особенно о фигурах СМИ. Всего было составлено 804 рекомендации о признании физического или юридического лица «иностранным агентом» (полный список с возможностью поиска доступен здесь).
Чиновники также отслеживают негативную информацию о президенте, в частности упоминания о «критическом состоянии здоровья» Путина или другие негативные высказывания о его здоровье. Эта категория уступает «фейковым новостям» по количеству заблокированных и удаленных публикаций.
Контент, связанный с Путиным, собирается автоматически с помощью разработанной в России системы Brand Analytics.Подпишитесь на The Beet
Заниженные истории. Свежие взгляды. Из Будапешта в Бишкек.
Подписаться
MRFC классифицирует сообщения о Путине по источнику и его «национальному», «региональному» или «иностранному» статусу. С сентября 2022 года он снизил частоту своих репортажей с ежедневной до еженедельной после того, как большинство источников, публикующих антипутинский контент, были заблокированы внутри России.
В 2021 году Роскомнадзор заявил, что разрабатывает Oculus (не путать с калифорнийской компанией виртуальной реальности) — новую систему для выявления нелегальных фото и видео. Ожидалось, что Oculus будет анализировать 200 000 изображений в день.
Утечка данных MRFC содержит систему классификации, используемую для обучения Oculus обнаружению нежелательных изображений Путина. В этой «классификации графических объектов» выделяются два основных типа контента: «оскорбительные изображения президента» и «сравнения президента с отрицательными персонажами».
Эти рубрики дополнены такими тегами, как «Путин в образе краба», «президент в образе мотылька», «президент в мусорном баке», «президент в образе Гитлера» и «президент в образе вампира. ” Oculus также обучают классифицировать контент как «экстремизм», «призывы к хулиганству», «пропаганду ЛГБТ» и «самоубийство». Он может искать «призывы к хулиганству» по фотографиям Алексея Навального, членов его команды, сине-бело-голубым альтернативным российским флагам, отфотошопленным изображениям горящего Кремля и фотографиям различных прошлых протестов как в России, так и на Украине. .
Во внутренней презентации 2022 года утверждается, что при запуске Oculus сможет идентифицировать лица и определять их возраст «с учетом наличия бороды или маски». Но предполагаемая дата запуска приложения пока неизвестна.
Высвобождение «Кабана»Летом 2022 года MRFC начал поиск подрядчика для разработки системы искусственного интеллекта «Вепрь» («Вепрь»), инструмента для выявления в сети «информационных точек напряжения».
». Эта фраза означает «случаи распространения общественно значимой информации под видом достоверных фактов, создавая при этом угрозу общественной безопасности».«Опасность общественной безопасности» якобы представляют публикации, оказывающие «негативное информационно-психологическое воздействие», «дестабилизирующие общественно-политическую ситуацию», «манипулирующие общественным мнением», «дискредитирующие традиционные ценности» или просто «дезинформировать» (как бы это ни интерпретировалось). А.И. приложение, в свою очередь, должно обнаруживать следующее:
- Протестные настроения и факты социальной дестабилизации в связи с территориальной целостностью, межнациональными конфликтами и миграционной политикой
- Негатив и «фейковые новости» в отношении главы государства, его руководителей и самого государства
- Манипулирование или поляризация общественного мнения (по таким темам, как прививки, несистематическая оппозиция или санкции)
- Профанация или дискредитация традиционных ценностей
Вепрь А.
И. должен быть запущен в июле 2023 года. Журналисты обратили внимание на дублирование между двумя A.I. продукты, Oculus и Vepr, функциональные возможности которых во многом совпадают. Оба приложения изначально были разработаны Московским физико-техническим институтом («МФТИ») и, вероятно, станут частью более крупного проекта «Чистый Интернет», работа над которым ведется с лета 2020 года. в мае 2023 года «Чистый Интернет» будет проверять не только онлайн-тексты, но и мультимедийный контент, выявляя следующие категории нарушений:- Несанкционированные массовые мероприятия
- Вовлечение несовершеннолетних в политику
- Оскорбление президента
- Обвинение президента в экстремизме
- «Фейки» о президенте и государстве
- ЛГБТ «пропаганда моя не может» 90,3 данных без сотрудничества с поисковыми системами. Судя по просочившимся документам, MRFC полагается на API Яндекса для поддержки своих усилий по наблюдению. Сама компания увеличила ежедневный лимит поисковых запросов федерального регулятора до 300 000 и предоставила доступ к своему сервису обучения ИИ «Толока».
 В этих отчетах рассматриваются ключевые ежедневные новости, в том числе любые «горячие точки» публикаций в так называемых «оппозиционных» источниках. В этих отчетах также есть специальная рубрика по содержанию, в которой людям рассказывается, как они могут отправлять деньги «оппозиционным структурам и террористическим или экстремистским организациям». Отчеты завершаются разделом о запланированных митингах протеста со ссылками на информацию о каждом протесте. (Ссылки также пересылаются в Генеральную прокуратуру.)
В этих отчетах рассматриваются ключевые ежедневные новости, в том числе любые «горячие точки» публикаций в так называемых «оппозиционных» источниках. В этих отчетах также есть специальная рубрика по содержанию, в которой людям рассказывается, как они могут отправлять деньги «оппозиционным структурам и террористическим или экстремистским организациям». Отчеты завершаются разделом о запланированных митингах протеста со ссылками на информацию о каждом протесте. (Ссылки также пересылаются в Генеральную прокуратуру.)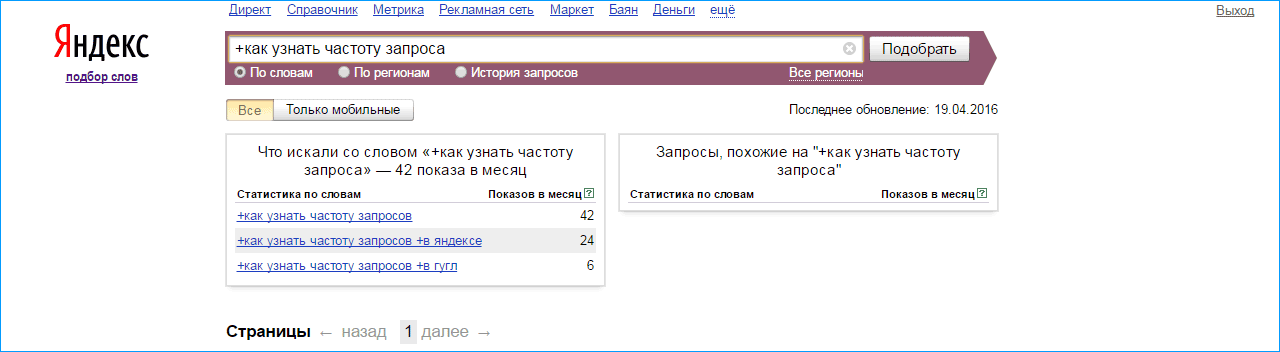 Любопытно, что Федеральную службу безопасности (ФСБ) представляет всего один анонимный пользователь, зарегистрированный как «Сотрудник». Среди пользователей АСКОВ также заместитель Мэра Москвы Наталья Сергунина, московский городской И.Т. глава ведомства Эдуард Лысенко и соратник Рамзана Кадырова Ахмед Дудаев, министр печати Чечни.
Любопытно, что Федеральную службу безопасности (ФСБ) представляет всего один анонимный пользователь, зарегистрированный как «Сотрудник». Среди пользователей АСКОВ также заместитель Мэра Москвы Наталья Сергунина, московский городской И.Т. глава ведомства Эдуард Лысенко и соратник Рамзана Кадырова Ахмед Дудаев, министр печати Чечни.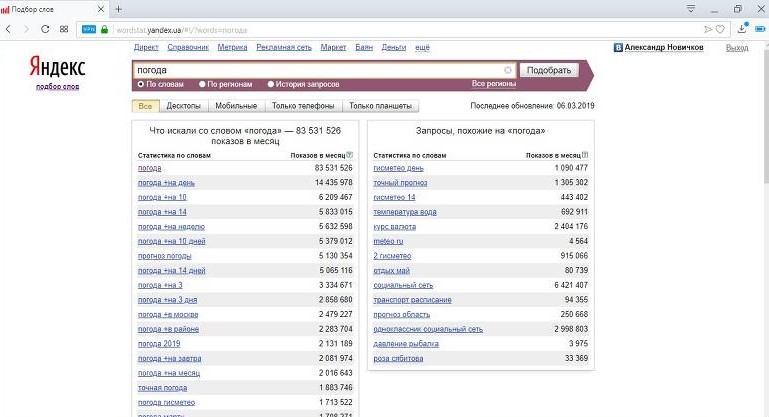
 Контент, связанный с Путиным, собирается автоматически с помощью разработанной в России системы Brand Analytics.
Контент, связанный с Путиным, собирается автоматически с помощью разработанной в России системы Brand Analytics.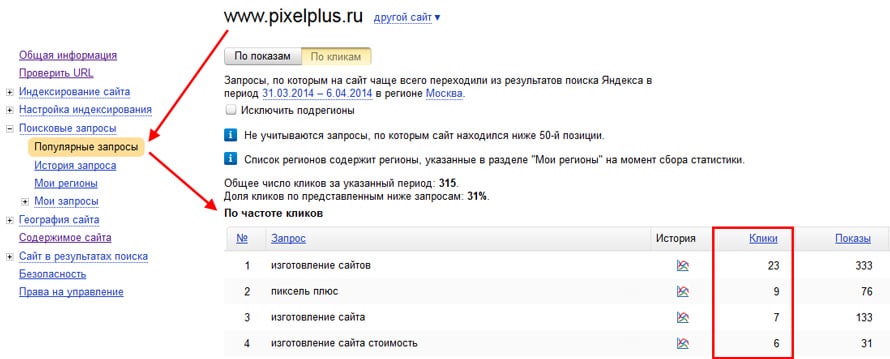 Эти рубрики дополнены такими тегами, как «Путин в образе краба», «президент в образе мотылька», «президент в мусорном баке», «президент в образе Гитлера» и «президент в образе вампира. ”
Эти рубрики дополнены такими тегами, как «Путин в образе краба», «президент в образе мотылька», «президент в мусорном баке», «президент в образе Гитлера» и «президент в образе вампира. ”  ». Эта фраза означает «случаи распространения общественно значимой информации под видом достоверных фактов, создавая при этом угрозу общественной безопасности».
». Эта фраза означает «случаи распространения общественно значимой информации под видом достоверных фактов, создавая при этом угрозу общественной безопасности». И. должен быть запущен в июле 2023 года. Журналисты обратили внимание на дублирование между двумя A.I. продукты, Oculus и Vepr, функциональные возможности которых во многом совпадают. Оба приложения изначально были разработаны Московским физико-техническим институтом («МФТИ») и, вероятно, станут частью более крупного проекта «Чистый Интернет», работа над которым ведется с лета 2020 года. в мае 2023 года «Чистый Интернет» будет проверять не только онлайн-тексты, но и мультимедийный контент, выявляя следующие категории нарушений:
И. должен быть запущен в июле 2023 года. Журналисты обратили внимание на дублирование между двумя A.I. продукты, Oculus и Vepr, функциональные возможности которых во многом совпадают. Оба приложения изначально были разработаны Московским физико-техническим институтом («МФТИ») и, вероятно, станут частью более крупного проекта «Чистый Интернет», работа над которым ведется с лета 2020 года. в мае 2023 года «Чистый Интернет» будет проверять не только онлайн-тексты, но и мультимедийный контент, выявляя следующие категории нарушений: