
ускоряем парсинг ключевых слов без блокировки аккаунта
Приветствую всех пользователей программы Key Collector!
В сегодняшней статье я расскажу вам о способах ускорения такого процесса, как парсинг ключевых слов. Помимо этого, раскрою одну из самых частых проблем при работе с программой – блокировка аккаунтов и прокси серверов. Почему Key Collector их блокирует? Как избежать блокировки личного IP?
Все это вы узнаете из статьи.
Способы ускорения программы Key Collector
Лично я столкнулся с проблемой медленного парсинга слов, когда мне поступил срочный заказ. Необходимо было собрать семантику для информационного сайта. Заказчик не мог ждать – сроки были четко обозначены. Как известно, ключи собираются в течение суток. Я не располагал таким временем.
Тогда я решил действовать. Я уже несколько раз слышал об удобстве использования прокси серверов, но до того момента у меня не было нужды ими пользоваться. Я решил проверить, действительно ли прокси сервера ускоряют сбор ключевых слов в Key Collector. Все равно ведь попытка не пытка!
Все равно ведь попытка не пытка!
Я купил:
Поначалу у меня не получалось правильно настроить работу прокси и аккаунтов, поскольку я в этом деле новичок. Но благодаря службе поддержки, которая была отзывчивой и терпеливой, у меня все получилось! Прокси сервера действительно ускорили процесс сборки ключевых слов, и я смог сдать заказ вовремя.
Несколько советов по настройке прокси и аккаунтов
Чтобы вам не пришлось мучиться, как мне, набивая шишки при загрузке прокси и аккаунтов, ознакомьтесь с моими рекомендациями по работе.
Полезные советы:
Аккаунты загружайте вместе с прокси серверами.
Ставьте в два раза меньше потоков, чем аккаунтов и прокси. Так как у меня было 20 прокси и столько же аккаунтов, я выставил 10 потоков.
Совета всего два, но зато сколько пользы они принесут! Я убедился в этом на личном опыте. Мне не пришлось ждать сутки для сборки ключевых слов – я все сделал за пару часов.
Причины блокировки личного IP
Проблема, с которой часто сталкиваются пользователи программы Key Collector. Почему это происходит?
Почему это происходит?
Дело в том, что ключевые слова в основном собираются через Яндекс Вордстат. И если вы часто будете парсить слова с одного аккаунта, Яндекс воспримет это как подозрительное действие. В результате ваш аккаунт улетит в бан. Конечно, потом IP разблокируют. Но согласитесь, неприятно попадать в бан и нарушать ритм работы. Ведь блокировка может длиться как пару часов, так и пару дней. Все зависит от объема вашей работы и частоты использования аккаунта. В общем, блокировка – это зло.
Как избежать блокировки IP в Key Collector
Чтобы избежать блокировки, нужно работать с нескольких аккаунтов и активно пользоваться прокси серверами. Вот и весь секрет! Когда поступают запросы с разных IP, Яндекс сортирует их между собой. Бот Яндекса не замечает подозрительной активности, следовательно, работать можно без волнений и переживаний по поводу блокировки. С прокси она вам не страшна!
Моя статья подходит к концу. Давайте подведем итоги:
Для ускорения парсинга ключевых слов необходимо использовать прокси.

При настройках прокси серверов загружать их нужно вместе с аккаунтами.
Потоков должно быть в два раза больше, чем прокси.
Использование нескольких аккаунтов и прокси для кей коллектора убережет ваш IP от блокировки.

Надеюсь, материал был вам полезен! Прощаюсь с вами и желаю удачной работы в Key Collector!
Статью прислал Александр Бойко (Клиент нашего сервиса).
Как защититься от парсинга и не угробить SEO. Читайте на Cossa.ru
Контент крадут у всех. Это закон интернета. Тот, кто думает иначе и уверен в неприкосновенности содержимого своего сайта — текстов, оригинальных картинок, кода и прочего, — либо ошибается, либо сайт ещё молодой и пока (!) не интересует копипастеров. Данные всегда парсили и будут парсить. Защититься от этого на 100% невозможно.
Лучшее противодействие воровству контента — осведомлённость. Вы должны знать, во-первых, что и как парсят. Во-вторых, своевременно замечать, когда украденные данные начинают вредить сайту, прежде всего — когда проседают позиции в поиске. В-третьих, важно научиться играть на опережение и защищать свои данные. И, наконец, когда ваш контент украден, нужно уметь грамотно решать эту проблему. При всех сложностях противодействовать копипастерам — вполне реально. Теперь обо всём этом по порядку.
Что такое парсинг

Поисковые роботы Google и Яндекса — это тоже своего рода парсеры. Принцип их работы аналогичен: периодически совершают обход сайта, собирают информацию и индексируют новые документы. Этим объясняется главная сложность противодействия парсингу: защищаясь от ботов-шпионов, легко заблокировать содержимое сайта для краулеров Google и Яндекса. А это — прощай, SEO и трафик из поиска, за счёт которого живут все нормальные сайты.
Со стороны сервера запросы пользователей и роботов выглядят одинаково. Из этого вытекает, что если живые люди могут получить доступ к сайту, то его содержимое доступно и ботам. Соответственно, большинство автоматизированных средств против парсинга в той или иной мере работает и против пользователей. На практике это выливается в то, что антипарсинговые решения существенно ухудшают опыт пользования сайтом и просаживают поведенческие факторы, что не лучшим образом сказывается на SEO.
Не ботами едиными
Говоря о парсинге и краже данных, не следует забывать, что, помимо использования скриптов, контент не менее успешно копипастят руками. Как правило, это касается копирования текстов и фото. Формально копипаст не подпадает под определение парсинга, но последствия для SEO от такого заимствования аналогичны.
Как правило, это касается копирования текстов и фото. Формально копипаст не подпадает под определение парсинга, но последствия для SEO от такого заимствования аналогичны.
Что парсят чаще всего
Текстовый контент
Это то, что интересует большую часть злоумышленников — тексты были и остаются основой поискового продвижения. Формально, даже если вашу статью украли, Google и Яндекс умеют определять сайт-первоисточник и отдавать ему преимущество в ранжировании. Но так бывает далеко не всегда. Например, если трастовые ресурсы крадут контент у молодых сайтов, последние могут остаться в пролёте.
Статьи иногда перехватывают и публикуют на сторонних ресурсах до того, как они попадают в индекс. Такой перехват зачастую реализуют при помощи специальных скриптов. При подобном сценарии сайт, который украл текст, и вовсе выглядит для поисковиков, как первоисточник. Доказать своё право на контент в этом случае — практически нереально.
До недавнего времени ощущение безопасности веб-мастерам обеспечивал инструмент «Оригинальные тексты» в панели Яндекс.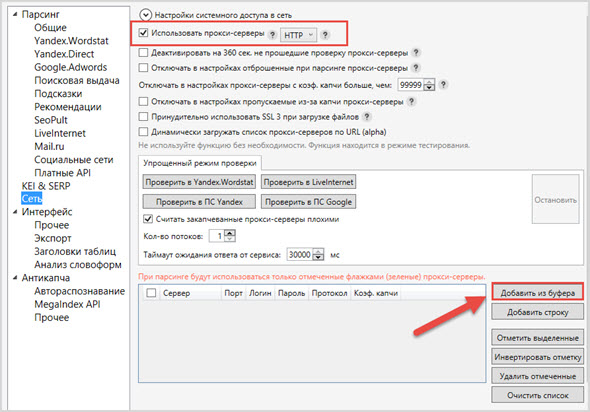 Вебмастера. Предполагалось, что если загружать в него статьи перед публикацией, в случае кражи поисковик будет на вашей стороне. Но с недавнего времени Яндекс отключил и этот инструмент, предложив использовать «Переобход страниц» или «Обход по счётчикам Метрики». Эффективность этих механизмов по-прежнему вызывает много вопросов.
Вебмастера. Предполагалось, что если загружать в него статьи перед публикацией, в случае кражи поисковик будет на вашей стороне. Но с недавнего времени Яндекс отключил и этот инструмент, предложив использовать «Переобход страниц» или «Обход по счётчикам Метрики». Эффективность этих механизмов по-прежнему вызывает много вопросов.
Метатеги и заголовки
Грамотная оптимизация <title>, <description>, заголовков <h2>–<h6> во многом определяет высокие позиции в выдаче. Можно тщательно прорабатывать эти атрибуты, экспериментировать с семантикой и нащупывать самый эффективный вариант, а можно в несколько кликов спарсить метаданные из топа выдачи. Причём для этого не нужен какой-то уникальный софт: парсить эти атрибуты умеют все более или менее серьёзные SEO-анализаторы.
Семантика
Когда страницы сайта оказываются в топе, конкурентов начинает интересовать, как именно они туда попали. Их задача: узнать, под какие ключи оптимизированы статьи, какова их плотность, характер вхождения — всё это также легко узнать.
Цены и товары
Это отдельная ecommerce-уловка, с помощью которой магазины конкурируют друг с другом. Как правило, такой скрапинг осуществляют на постоянной основе, отслеживая обновления каталога и цен.
Дизайн или отдельные элементы кода
Спарсить могут весь сайт или его конкретные элементы, например, какую-то оригинальную функцию. Обычно поисковики жёстко пресекают такие финты, и у недоброжелателя нет шансов обойти вас в выдаче с клонированным ресурсом.
Кто и зачем парсит сайты
Первый и самый очевидный ответ — конкуренты, которым не даёт покоя ваше пребывание в топе. Но ими дело не ограничивается. Парсинг сайтов находит применение для очень широкого спектра задач. Естественно, в 90% случаев — это чёрное SEO. Куда обычно уходит ворованный контент:
-
Наполнение дорвеев.
-
Генерация контента под глобальные PBN-сети. Что такое PBN — читайте здесь.
-
Парсинг текстов для создания Web 2.0.
-
Скрапинг контента для сайтов, на 100% продвигающихся за счёт генерации трафика. В топ такие ресурсы вывести сложно, но они могут вполне нормально ранжироваться и иметь позиции в выдаче. По крайней мере, такое часто встречается в русскоязычном поиске Google.
-
Парсинг описаний для товаров. Может, для кого-то это станет откровением, но карточки с неуникальными описаниями очень хорошо ранжируются поисковиками. Вполне вероятен сценарий, что вас обойдут в выдаче, используя ваши же уникальные тексты для товаров.
Как видно, переживать за сохранность своих данных нужно всем: даже если вы продвигаетесь в нише без конкурентов (чего не бывает) или они белые и пушистые (тоже нонсенс). Примерно 2/3 всего парсинга в сети — это полностью автоматизированный процесс. То есть вас не будут искать и копипастить данные вручную — всё это сделает скрипт, как только ваши страницы попадут в топ или станут более или менее заметными.
Примерно 2/3 всего парсинга в сети — это полностью автоматизированный процесс. То есть вас не будут искать и копипастить данные вручную — всё это сделает скрипт, как только ваши страницы попадут в топ или станут более или менее заметными.
В зоне риска прежде всего оказываются тексты — они представляют наибольший интерес для парсеров и на их защите следует сосредотачиваться в первую очередь.
Как защитить сайт от кражи текстов
Итак, кража статей — это данность. И если не сейчас, то в будущем с этим обязательно столкнётся каждый веб-мастер. Контент нужно защищать, причём не ждать, пока ваш ресурс станет популярным и с него начнут активно копипастить. Молодые сайты находятся в особенно уязвимой ситуации — когда у них заимствуют контент более трастовые площадки, поисковые системы могут приписать право первоисточника им.
Теперь — о способах защиты: эффективных и не очень.
Что работает, но слабо
Запрет на выделение текста
Вы можете создать отдельный CSS-стиль, запрещающий выделение текста. Речь идёт о небольшом микрокоде, с которым легко разобраться самому или поручить эту задачу программисту.
Речь идёт о небольшом микрокоде, с которым легко разобраться самому или поручить эту задачу программисту.
Такое решение нельзя назвать полноценной защитой, поскольку текст можно извлечь из HTML-кода. Это лишь немного усложнит жизнь копипастеру, и то не всегда. Не забываем, что руками копируют очень редко, а этот способ не создаёт никаких преград для парсинга. Даже если кто-то не слишком опытный захочет забрать ваш текст, он погуглит, как это сделать через код (спойлер: совсем несложно).
Запрет на копирование в буфер обмена
Механизм этой защиты несколько иной. На сайт добавляют небольшой скрипт, который разрешает копирование текста, но не позволяет вставить его в буфер обмена. В остальном эффективность этой защиты такая же низкая, как и в первом случае. Она не защищает от парсинга и может обезопасить только от неумелых копипастеров, которым лень сходить в поисковик и узнать, как извлечь текст через код.
Подключение reCAPTCHA
Сервис reCAPTCHA и всевозможные аналоги дают крайне низкую эффективность при защите от парсинга и спама. В профессиональных кругах их упоминание успело стать моветоном. Решений по обходу капч очень много. Если не вдаваться в детали, работают они следующим образом: когда защита запрашивает проверку, капча автоматически перенаправляется на сторонний сервис, где её распознаёт реальный человек и отдаёт обратно на сервер.
В профессиональных кругах их упоминание успело стать моветоном. Решений по обходу капч очень много. Если не вдаваться в детали, работают они следующим образом: когда защита запрашивает проверку, капча автоматически перенаправляется на сторонний сервис, где её распознаёт реальный человек и отдаёт обратно на сервер.
Услуги по обходу капч стоят в прямом смысле копейки (можете сами посмотреть тарифы на 2Captcha или ruCAPTCHA). Поэтому те, кто пишет парсеры, даже не рассматривают капчи как какую-то проблему. А вот для реальных пользователей — это зло. Закрывая контент капчами, будьте готовы к возможным лагам с индексацией и гарантированной просадке поведенческих. Всё это нанесёт неизбежный удар по SEO.
Чтобы смягчить негативный эффект от капч, можно использовать скоринг и задействовать чёрные списки. Это несколько улучшит пользовательский опыт, но не решит главную проблему — при желании на вашем сайте спарсят всё, что нужно.
Использование DMCA protected
Речь идёт о платном сервисе мониторинга контента. Подключившись к вашему сайту, он периодически совершает обход и проверяет страницы на предмет появления копий. Если данные кто-то украл, на почту придёт уведомление. За дополнительную плату представители сайта готовы писать жалобы (abuse), чтобы Google удалил скопированный текст из выдачи. Вплоть до судебных разбирательств. Сайт, находящийся под защитой этого сервиса, получает сертификат и специальную плашку, которая в теории должна отпугивать копипастеров. У нас DMCA protected вспоминают нечасто, но на западе он пользуется довольно большой популярностью.
Подключившись к вашему сайту, он периодически совершает обход и проверяет страницы на предмет появления копий. Если данные кто-то украл, на почту придёт уведомление. За дополнительную плату представители сайта готовы писать жалобы (abuse), чтобы Google удалил скопированный текст из выдачи. Вплоть до судебных разбирательств. Сайт, находящийся под защитой этого сервиса, получает сертификат и специальную плашку, которая в теории должна отпугивать копипастеров. У нас DMCA protected вспоминают нечасто, но на западе он пользуется довольно большой популярностью.
На практике эффективность такой защиты вызывает много вопросов. Начнём с того, что сервис DMCA protected — это не официальный представитель органов американской юстиции. Звучное название сайта dmca.com многих вводит в заблуждение, так как ассоциируется с законом DMCA, контролирующим авторское право в интернете. Но сервис официально никак не связан с органами американской юстиции. А думать, что плашка в футере будет отпугивать воров — наивно. Если более или менее опытный злоумышленник захочет по-тихому увести контент или другие данные, он просто удалит на сайте фрагмент защитного кода и возьмёт то, что нужно.
Если более или менее опытный злоумышленник захочет по-тихому увести контент или другие данные, он просто удалит на сайте фрагмент защитного кода и возьмёт то, что нужно.
Что работает лучше
Блокировка ботов по IP
Это один из способов противодействия парсингу, когда данные крадут постоянно и, как правило, в большом объёме. Речь идёт уже не только о текстах, но и других сведениях, представляющих стратегический интерес для конкурентов. Блокировка IP-адресов ботов, которые скрапят ваши страницы — один из самых распространённых механизмов защиты. Но здесь важно понимать: если вам дорого трафик из поиска, вы вступаете на тонкий лёд. Угробить SEO в этом случае — проще простого.
Хорошо написанный парсер весьма убедительно имитирует активность живого пользователя. Благодаря рандомизации заголовков, постоянной смене прокси (поддельных IP-адресов) и другим техническим уловкам отличить бота-шпиона от реального пользователя очень трудно. Конечно, сервисы для защиты от парсинга тоже становятся более прокачанными, но их основной механизм остаётся неизменным — это блокировка вредоносных запросов по IP. Продолжается своего рода вечная игра в кошки-мышки между ботами и антипарсерами.
Продолжается своего рода вечная игра в кошки-мышки между ботами и антипарсерами.
Защищаясь от парсинга, сайт может оказаться заблокированным для краулеров Google и Яндекса, которые являются такими же ботами, но со своими «белыми» задачами. К слову, обычно боты-шпионы представляются на сервере именно краулерами поисковиков. Последствия такого провала очевидны: сайт частично или полностью вылетит из индекса. Прощай, органический трафик. Об этом важно помнить, самостоятельно закрывая сайт от ботов, устанавливая скрипты от парсинга или заказывая самописную защиту.
Добавление ссылки при копировании текста
Этот весьма простой способ защиты может принести немало пользы. На сайт внедряют небольшой скрипт, который автоматом привязывает к скопированному тексту ссылку на источник. Обычно она располагается внизу. Как ни странно, но такие ссылки убирают не всегда: иногда сознательно, иногда по недосмотру.
Стандартный скрипт лучше допилить и сделать так, чтобы ссылка добавлялась внутри текста. В этом случае вероятность, что её не заметят, увеличивается в несколько раз. Это способ хорош как для защиты от ручного копирования, так и от скрапинга. Он хоть и не препятствует фактической краже, но позволяет узнать, кто скопипастил текст без прогонки статей через антиплагиатчик. Для этого достаточно посмотреть обратные ссылки на свой сайт.
В этом случае вероятность, что её не заметят, увеличивается в несколько раз. Это способ хорош как для защиты от ручного копирования, так и от скрапинга. Он хоть и не препятствует фактической краже, но позволяет узнать, кто скопипастил текст без прогонки статей через антиплагиатчик. Для этого достаточно посмотреть обратные ссылки на свой сайт.
Использование скрипта автозамены символов
Весьма эффективный способ противостоять краже текстов. Его суть состоит в интеграции специального java-скрипта, который при копировании заменяет часть кириллических символов на латиницу — текст становится нечитаемым. Чтобы пофиксить это на уровне кода, нужны специальные навыки, и далеко не каждый копипастер будет возиться. Этот лайфхак защищает главным образом от ручного копирования. Ботам же всё равно: обычно они парсят для автонаполняемых сайтов, где тексты никто не проверяет.
Брендирование контента
Это своего рода аналоговый способ защиты текстов. Его суть проста: статьи нужно делать более персонализированными, писать от лица бренда и чаще упоминать его название, причём делать это так, чтобы бегло подчистить текст было как можно сложнее. Такой контент отсеет часть копипастеров: конечно, наиболее переборчивых и тех, кто ворует вручную. Если вас парсят боты, им это не помещает. Но и здесь у вас будет преимущество: можно узнать о перепубликации контента при помощи Google Alerts, настроив оповещение на бренд.
Его суть проста: статьи нужно делать более персонализированными, писать от лица бренда и чаще упоминать его название, причём делать это так, чтобы бегло подчистить текст было как можно сложнее. Такой контент отсеет часть копипастеров: конечно, наиболее переборчивых и тех, кто ворует вручную. Если вас парсят боты, им это не помещает. Но и здесь у вас будет преимущество: можно узнать о перепубликации контента при помощи Google Alerts, настроив оповещение на бренд.
Что делать при краже контента
Обращение к копипастеру напрямую
Первым делом свяжитесь с админами площадки и попросите удалить контент. Запугивание судами в рунете воспринимают несерьёзно. Поэтому просто напишите, что у вас есть очевидные доказательства принадлежности текста вам, и когда вы подадите жалобу в DMCA — она будет рассмотрена в вашу пользу. Часто это работает. Но лишь в тех случаях, когда вас обокрал худо-бедно белый или серый сайт. Если вас спарсили дорвеи, порносайты или другие треш-ресурсы из 100% чёрной ниши, надеяться, что отреагируют — не имеет особого смысла.
Уведомление в службу поддержки поисковиков
Второй шаг — написать в саппорт Яндекс.Вебмастера и Google Search Console. Это особенно актуально, если у вас спарсили весь сайт или копипастер обошёл вас в выдаче с вашим же контентом. Сразу скажем, что на быстрый и результативный отклик рассчитывать не приходится. Особенно тяжёлой на подъём является служба поддержки Google. Но связываться с саппортом в таких случаях нужно обязательно.
Жалоба в DMCA
На международном уровне наиболее действенный механизм правовой защиты контента — закон DMCA (Digital Millennium Copyright Act). Он работает в США и распространяется на все американские компании, в том числе поисковики Google, Bing, Ask. По понятным причинам всех в первую очередь интересует Google. Если вы докажете факт нарушения авторских прав, страницы копипастера удалят из выдачи. Подать жалобу на украденный контент могут в том числе нерезиденты США.
Как это работает на практике? Владелец сайта подаёт заявку о нарушении авторских прав.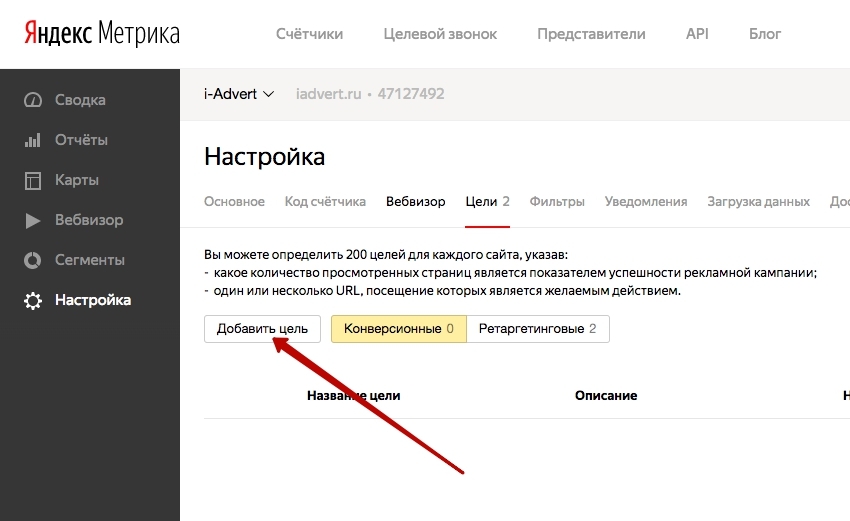 В отличие от техподдержки, Google реагирует довольно быстро: присылает ответ и обычно сразу скрывает из выдачи страницы с украденным контентом. Администраторам сайта, на который написана жалоба, высылается соответствующее уведомление.
В отличие от техподдержки, Google реагирует довольно быстро: присылает ответ и обычно сразу скрывает из выдачи страницы с украденным контентом. Администраторам сайта, на который написана жалоба, высылается соответствующее уведомление.
Это идеальный сценарий. Но им обычно всё не заканчивается. За владельцем сайта, которого обвиняют в плагиате, остаётся право подать встречное уведомление. И этой возможностью, как правило, никто не пренебрегает. Тогда доступ к удалённым страницам восстанавливается и начинается долгая волокита. В теории она предполагает судебные тяжбы, но на практике чаще всего заканчивается ничем.
Жалоба в DMCA отлично работает, когда ваши материалы спарсили дорвейщики. Такие страницы Google обычно блокирует без колебаний. Больше шансов, если контент украл порносайт, автонаполняемый статейник или другой сомнительный ресурс. В остальных случаях вашу жалобу будут парировать встречным уведомлением, прекрасно понимая, что реальное судебное разбирательство, скорее всего, не грозит.
Жалоба хостерам
Это ещё один весьма действенный способ решить проблему, связанную с кражей данных. Конечно, за спорную статью вряд ли кто-то накажет копипастера, но если речь идёт о систематическом копировании контента, хостер, дорожащий своей репутацией, может забанить такой домен. Другое дело, что большинство откровенно мутных сайтов, типа дорвеев или автонаполняемых PBN-сетей, специально разворачивают на «абузоустойчивых» хостингах. Достучаться с жалобой до провайдера в этом случае — нереально.
Если речь идёт о крупном воровстве данных, можно проявить настойчивость и пойти ещё дальше, написав жалобу в ICANN. Это всемирная корпорация, которая координирует систему присвоения доменных имён. Формально она не управляет содержимым в сети, но через неё можно подать жалобу на домен, если сайт занимается противозаконной деятельностью или злоупотреблениями.
Добиться блокировки домена этим способом реально, если вам досаждают откровенно «чёрные» сайты, которые уже многократно приводились в пример. Но и в этом случае подача жалобы предполагает множество нюансов, разобраться с которыми не так-то просто. Как вариант, можно воспользоваться услугами специальных компаний-посредников, специализирующихся на написании жалоб в ICANN.
Но и в этом случае подача жалобы предполагает множество нюансов, разобраться с которыми не так-то просто. Как вариант, можно воспользоваться услугами специальных компаний-посредников, специализирующихся на написании жалоб в ICANN.
Тексты не удаляют, а позиции просели. Что делать?
Решение контентных споров может затянуться надолго и с большой долей вероятности закончиться ничем. Это не лучший сценарий для тех, кто из-за копипастеров потерял позиции в выдаче и несёт убытки. В таких случаях куда эффективнее — попробовать вернуть утраченные позиции.
-
Актуализируйте статью: допишите 1–2 тысячи знаков, обновите дату публикации и отправьте документ на переиндексацию.
-
Сделайте посев ссылками в соцсетях и поставьте 1–2 беклинка на сторонних (тематически близких) сайтах. Актуализируя статью, следите за тем, чтобы новый текст не размывал релевантности старой семантики.
Это должно дать результат. Особенно хорошо такой финт работает в Google. Некоторые веб-мастеры даже стараются держать под рукой запасной контент, чтобы максимально быстро реагировать на просевшие позиции в подобных ситуациях. Это особенно актуально в конкурентных нишах, где кража контента является очень распространённой практикой. Естественно, всё это предполагает постоянный контроль позиций и автомониторинг страниц сайта на плагиат.
Особенно хорошо такой финт работает в Google. Некоторые веб-мастеры даже стараются держать под рукой запасной контент, чтобы максимально быстро реагировать на просевшие позиции в подобных ситуациях. Это особенно актуально в конкурентных нишах, где кража контента является очень распространённой практикой. Естественно, всё это предполагает постоянный контроль позиций и автомониторинг страниц сайта на плагиат.
Партнёрская публикация
Источник фото на тизере: скриншот The Gentlemen, Miramax Films
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
Яндекс подкручивает гайки seo-сервисам, меняя лимиты парсинга Яндекс.XML. Кому от этого станет лучше?
9788 просмотров
На днях в официальном блоге Яндекса для вебмастеров появилась новость об изменении правил использования сервиса Яндекс. XML. Если раньше при подтверждении телефона для аккаунта предоставлялся лимит в 1000 запросов в сутки, то теперь суточный лимит парсинга рассчитывается на основе популярности подтвержденных в Яндекс.Вебмастере сайтов. Аккаунты с отсутствующими подтвержденными сайтами не имеют теперь возможности использовать сервис.
XML. Если раньше при подтверждении телефона для аккаунта предоставлялся лимит в 1000 запросов в сутки, то теперь суточный лимит парсинга рассчитывается на основе популярности подтвержденных в Яндекс.Вебмастере сайтов. Аккаунты с отсутствующими подтвержденными сайтами не имеют теперь возможности использовать сервис.
С одной стороны понятно желание Яндекса снизить нагрузку на свой сервис и дать возможность использовать его больше по назначению. Однако, Яндекс.XML был единственным легальным способом снимать позиции в поиске, не затрагивая при этом поисковую выдачу, не нагружая её и не влияя на данные показателей Wordstat. На данный момент работают также старые лимиты, но через 3 месяца останутся лишь те, которые обозначены новыми правилами Яндекс.XML.
Взвесил ли Яндекс все плюсы и минусы данного нововведения или отделы Яндекс.XML работают, не согласуя изменения с отделом веб-поиска?
Видимые плюсы
— Разгрузка нескольких веб-серверов
Как указал автор новости, лимиты вводились в целях более оптимального использования ресурсов сервиса вебмастерами.
Видимые минусы
— Увеличение нагрузки на прямую выдачу Яндекса
Крупные компании и аналитические сервисы, использующие Яндекс.XML для съема позиций, переориентируются на парсинг основной выдачи Яндекса, таким образом, нагружая её вместо xml.yandex.ru.
— Влияние на показатели Яндекс.Wordstat
В вордстате появится большее количество накрученных запросов, что исказит данные не только для оптимизаторов, но и для рекламодателей. Изменение правил Яндекс.XML косвенно повлияет на цены рекламы в Яндекс.Директе.
— Влияние на поведенческий фактор
CTR выдачи по ряду коммерческих запросов значительно снизится, так как многие из них будут автоматическими. Это может затронуть и ранжирующую формулу, влияя на качество поисковой выдачи.
— Рынок проксей и антикапч увеличится
Своим нововведением Яндекс порождает увеличение рынка проксей и антикапч, вместо создания легальных платных инструментов для съема важных аналитических данных.
Что думают аналитики и владельцы аналитических сервисов по поводу действий Яндекса?
Мнения экспертов
Станислав Ставский, экс-менеджер антиробота в Яндексе
Я думаю, что главной целью Яндекса в данном случае является решение внутренней проблемы “снижение роботной нагрузки в часы пик”. То, что заодно со снижением нагрузки можно доставить неприятности сервисам парсинга – лишь один из плюсов принятого решения. Но, в принципе, не удивлюсь, если одновременно с анонсированным запуском ужесточится алгоритм фильтрования роботов на выдаче и капча станет показываться роботам чаще. Ведь задача “удорожания парсинга” напрямую связана с задачей “снижение нагрузки”.
Все равно, конечно, будут парсить – через прокси, антикапчу, добавлять в вебмастерские аккаунты “левые” сайты, но я допускаю, что в самое ближайшее время можно ожидать повышения цен на услуги сервисов, парсящих выдачу Яндекса.
Любопытно отметить, что за последние несколько месяцев Гугл также сильно усложнил жизнь подобным сервисам, усложнив парсинг своей выдачи. Вполне допускаю сотрудничество двух поисковиков по данному вопросу и обмен информацией о роботах. И на месте менеджеров поисковиков, отвечающих за роботов, стремился бы к этому.
Вполне допускаю сотрудничество двух поисковиков по данному вопросу и обмен информацией о роботах. И на месте менеджеров поисковиков, отвечающих за роботов, стремился бы к этому.
Евгений Пошибалов, руководитель биржи ссылок Sape.ru
Очевидно, что к текущей схеме работы интернет-сервисы и seo-компании (как основные потребители) уже давно адаптировались и создали себе аккаунты по 1000 запросов. Новые правила “игры” практически повторяют эту достаточно “унылую” схему, только с другого ракурса. Лично я считаю как эту, так и предыдущую идею в корне неверной. О чем даже пару раз беседовал с А.Садовским 2-3 года назад.
Самый оптимальный для Яндекса путь решения этого вопроса или отключить вообще эту историю, так как части вебмастеров это просто не нужно, а второй части выделенного объема точно не хватит, или же сделать это в цивилизованной форме, причем с финансовой выгодой для Яндекса. Это очень просто, берется технологическая компания – например это может быть любой более менее крупный сервис с наработанной репутацией – как Sape. ru и заканчивая Драйвлинком и другими небольшими сервисами. Далее эта компания получает прямой канал к XML, обеспечивает создание удобных инструментов для работы с ним и предоставляет их в публичный доступ вебмастерам и сервисам – определенный объем – бесплатно, при превышении – платно (но очень недорого), с агрегированной передачей денег Яндексу за вычетом %.
ru и заканчивая Драйвлинком и другими небольшими сервисами. Далее эта компания получает прямой канал к XML, обеспечивает создание удобных инструментов для работы с ним и предоставляет их в публичный доступ вебмастерам и сервисам – определенный объем – бесплатно, при превышении – платно (но очень недорого), с агрегированной передачей денег Яндексу за вычетом %.
В данном случае компании будет выгодно следить за тем, чтоб не было “халявщиков” с сотнями аккаунтов, а с Яндекса снимается головная боль по управлению этим бардаком и обеспечивается дополнительный доход, который я бы оценил в 1-3 млн. долл в год. Что-то типа ЦОП XML. Ну либо закрывать эту историю, так как ни к чему хорошему оно снова не приведет. К сожалению руководство Яндекса пока игнорирует эту возможность как заработать, так и снять с себя ворох определенных проблем, таких как парсинг естественной выдачи и так далее.
Михаил Сливинский, руководитель отдела поисковой аналитики компании Wikimart
К сожалению, пока не видно расширения возможностей для веб-мастеров и оптимизаторов. Жаль. Довольно очевидно, что оптимизаторы очень разные и далеко не все стремятся заработать свой кусок хлеба, ухудшая экосистему спамными ссылками или бредотекстами.
Жаль. Довольно очевидно, что оптимизаторы очень разные и далеко не все стремятся заработать свой кусок хлеба, ухудшая экосистему спамными ссылками или бредотекстами.
При этом рынку крайне нужна маркетинговая информация и аналитика. В частности, это и результаты поиска, и статистика запросов, и позапросная конверсионность и многое другое. Понятно, какой-то фильтр в любом случае нужен. Но почему этот фильтр реализуется через попытки запрета парсинга, а не через коммерческую продажу доступа к сервисам – мне не вполне понятно.
Станислав Поломарь, руководитель направления поискового продвижения и аналитики компании webit
Если рассматривать данное изменение с точки зрения вебмастера, у которого один или несколько сайтов, то в среднем его это не сильно заденет. Исходя из статистики в несколько сотен сайтов – средний корпоративный сайт, который обладает определенной ссылочной массой и трафиком, получает лимит 490. Сайты с большим индексом при прочих равных могут получить 1000. А крупные проекты 2900. Таким образом при наличии 1-2 подобных сайтов тот же лимит в 1000 запросов сохранится.
А крупные проекты 2900. Таким образом при наличии 1-2 подобных сайтов тот же лимит в 1000 запросов сохранится.
А вот агентства или компании, работа которых связана с поисковой оптимизацией, – явно проиграют. Тут потребности значительно выше, так как компания банально сильно бОльше вебмастера занимается аналитикой (видимость своих проектов и их конкурентов, индексация и прочее).
К примеру, сейчас наша компания использует только XML для работы с выдачей Яндекса, но при данных изменениях мы вынуждены будем использовать парсинг выдачи напрямую. Зачем компании подталкивать к этому непонятно, так как (будь такая возможность) мы могли бы вполне пользоваться платным тарифом (с разумным ценообразованием конечно ;))
На подопечных проектах были замечены следующие значение лимитов: 10-34-150-490-1000-2900. Из приятных «плюшек» – поддомены крупных проектов дают вклад 2900 наравне с основным. Не известно правда насколько это долго не прикроют ;))
Александр Люстик, руководитель проекта Key Collector (LegatoSoft). Ведущий блога SEOM.info
Ведущий блога SEOM.info
Новые лимиты явно очередная затяжка узла на удавке, примитивных методах съема данных. Все давным давно покупали активированные аккаунты, даже не утруждая себя покупкой сим-карт, как это было ранее. Увеличивали лимиты. Покупались десятки тысяч аккаунтов, с увеличенными лимитами в XML. Яндексу это надоело 🙂 видимо. Новый виток. С одной стороны “законопослушным”, отчасти, лимитов хватит. Хотя для более или менее профессиональных задач их окажется маловато. Для “домохозяек” пойдет.
“Дрочево” пойдет в выдачу. Больше банов проксей, больше затрат на массовые и промышленные объемы. Пока так, дальше опять все будет хорошо и будет очередной узелок на удавке 🙂 Я думаю такие репрессии делают рынок более узким, те кто не могут адаптироваться будут “прогибаться” под больших игроков. В целом это хорошо, клиенты тоже будут платить чуть больше 🙂
Юрий Кушнеров, руководитель сервиса SeoLib.ru
Как нам кажется, на рынок в целом это никак не повлияет. Нововведения затронут лишь сегмент SEO-сервисов, которые активно используют XML для парсинга выдачи Яндекса. В этой нише, возможно, будет передел рынка, так как многим небольшим компаниям, действительно, «перекроют кислород».
Нововведения затронут лишь сегмент SEO-сервисов, которые активно используют XML для парсинга выдачи Яндекса. В этой нише, возможно, будет передел рынка, так как многим небольшим компаниям, действительно, «перекроют кислород».
Позиция Яндекса в данном случае ясна (и они ее не скрывают). Это не «еще один камень в оптимизаторов», а оптимизация собственных ресурсов (именно поэтому в разное время суток количество запросов будет меняться. Когда Яндекс свободен — парсите на здоровье. Когда нет — извините). Кстати, такая ситуация наблюдается уже давно. В пиковые часы, порой, отдаются пустые страницы.
Что же касается простых веб-мастеров, то для своих собственных нужд того количества запросов, что выдается, должно хватать. Но судя по тому, что мы наблюдаем в панели вебмастера xml.yandex.ru – система еще не доработана и тестируется, цифры не совсем адекватные. Пока будем ждать. Паниковать причин не видим.
Евгений Трофименко, аналитик, владелец сервиса tools.promosite. ru
ru
До этого, очевидно, довели покупатели симок для парсинга ХМЛ. Ну ничего – сейчас будут создавать сайты не только под продажу ссылок, но и под получение лимитов ХМЛ. Кстати, я на tools.promosite.ru попрошу людей делегировать не очень нужные им лимиты на меня (просто так или в обмен на какие-то сервисы, в противном случае придется ограничивать доступ – у меня ХМЛ используется часто). Например, можно взамен этого доступа давать аналитику по установленным ссылкам, я тут скачал все сайты-доноры и установленные ссылки.
А что вы думаете по поводу данной новости?
Как быстро собрать поисковые подсказки из Яндекса, Google и YouTube
Вы собрали семантику для рекламной кампании. Но есть вероятность, что в нее не попали самые трендовые запросы, по которым можно получить максимум переходов. Собрать их поможет парсер поисковых подсказок Click.ru.
Разбираемся, как работает этот инструмент и чем он полезен.
Инструмент парсинга поисковых подсказок от Click. ru
ru
Что такое поисковые подсказки и зачем они нужны
Как пользоваться парсером поисковых подсказок
Шаг 1. Добавление ключевых слов
Шаг 2. Выбор поисковых систем и регионов
Шаг 3. Выбор способов сбора подсказок
Шаг 4. Настройка глубины сбора
Шаг 5. Получение результата
Сколько стоит инструмент
Что делать с подсказками дальше
Инструмент парсинга поисковых подсказок от Click.ru
Собирать поисковые подсказки вручную долго. Для решения этой задачи в Click.ru есть инструмент сбора поисковых подсказок. Он парсит поисковые подсказки из Яндекса, Google и YouTube.
Для решения каких задач подходит этот инструмент:
- Сбор дополнительной семантики для рекламной кампании.
- Сбор семантики для расширения семантического ядра сайта.
- Определение интересов аудитории.
- Формирование тегов для роликов в YouTube.
- Поиск новых тем для написания контента и съемки видео.
Основные возможности парсера Click.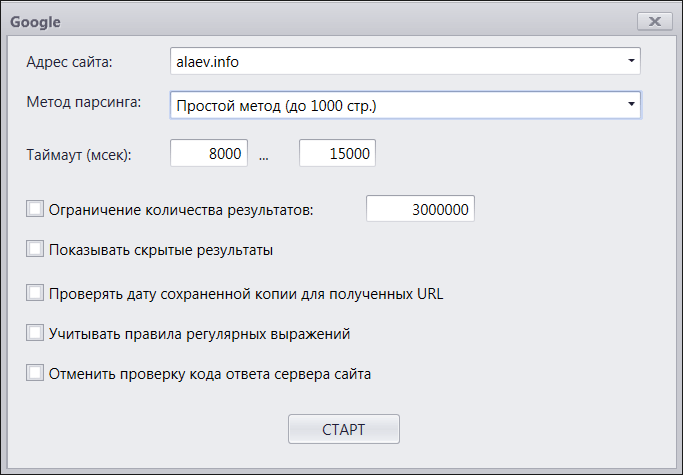 ru:
ru:
- Загрузка исходных ключевых фраз: списком или с помощью XLSX-файла.
- Доступные поисковые системы: Яндекс, Google, YouTube.
- Управление региональностью: доступны все регионы поисковых систем.
- Способы сбора фраз: по заданным фразам, по исходным фразам с добавлением через пробел букв кириллического алфавита [А-Я], латинского алфавита [A-Z], цифр [0-9];
- Глубина парсинга: 1-3.
Преимущества инструмента:
- Самая низкая цена на рынке — в 3-5 раз ниже, чем у конкурентов.
- Инструмент работает «в облаке» — не нужно скачивать и устанавливать софт;
- Парсинг осуществляется в фоновом режиме, не нужно держать браузер открытым;
- Нет необходимости создавать фейковые аккаунты в поисковиках и вводить капчу;
- Результаты парсинга хранятся на удаленном сервере и доступны для скачивания в формате XLSX в любое время.
Что такое поисковые подсказки и зачем они нужны
Поисковые подсказки — это фразы, которые появляются в виде списка автозаполнения, как только пользователь начинает вводить искомую фразу в поисковой строке.
Поисковые подсказки в Google:
Поисковые подсказки в Яндексе:
Поисковые подсказки в YouTube:
По одной и той же фразе поисковики выдают разные подсказки. Дело в том, что каждый поисковик формирует подсказки по собственным алгоритмам. Но есть ряд общих факторов, которые объединяют все поисковые системы.
Что учитывают поисковые системы при подборе поисковых подсказок:
- Популярность поискового запроса в данный момент времени (актуальные и трендовые запросы вроде «что такое инаугурация» или «что такое криптовалюта» выводятся в первую очередь).
- История пользовательского поиска (каждый пользователь склонен просматривать страницы определенных тематик чаще других, и поисковики формируют подсказки в зависимости от интересов).
- Местоположение пользователя (учитывается актуальность запросов для конкретного региона).
- Фактор разнообразия (поисковые системы «подмешивают» варианты подсказок из разных тематик, чтобы повысить вероятность того, что пользователь воспользуется автоподстановкой).

Подсказки обновляются не реже одного раза в день, в отличие от баз Вордстата и Keyword Planner. Поэтому они более актуальны на данный момент времени, отражают текущие тренды и потребности аудитории.
Фразы из подсказок значительно расширяют и дополняют базовую семантику (в том числе LSI-фразами), позволяют поймать «горячий» и сезонный трафик. Среди них вы наверняка найдете ключи, которых не выдаст ни Вордстат, ни Keyword Planner.
Допустим, перед вами стоит задача оптимизировать страницу каталога интернет-магазина под запрос «газонокосилки Bosch». Вводите запрос в поисковую строку Яндекса и получаете список подсказок:
В итоге у вас целый перечень дополнительных LSI-фраз (названия популярных моделей газонокосилок Bosch и комплектующих), которые стоит упомянуть в тексте.
Как пользоваться парсером поисковых подсказок
Шаг 1. Добавление ключевых слов
Для использования парсера поисковых подсказок зарегистрируйтесь в Click.ru.
Войдите в свой аккаунт. В меню выберите «Cемантика» — «Cбор поисковых подсказок»:
В меню выберите «Cемантика» — «Cбор поисковых подсказок»:
Кликните на «+», чтобы добавить задачу.
Загрузите запросы одним из двух способов:
1. Загрузите XLSX-файл. Click.ru учитывает все фразы из первого листа файла. Содержимое одной ячейки система идентифицирует как одну ключевую фразу. Поэтому убедитесь, что в ячейках нет вспомогательной информации — пометок, заголовков столбцов, нумерации строк и т. п.
2. Добавьте ключевые фразы списком в соответствующее поле. Каждая новая фраза должна идти с новой строки.
Если в списке фразы дублируются, система их объединяет в одну. То есть перерасхода бюджета не будет.
Перед загрузкой списка ключевых слов учтите ряд рекомендаций:
1. Используйте ключевые фразы в разных падежах, во множественном и единственном числе. Например, по фразам «смартфон samsung» и «смартфоны samsung» подсказки отличаются. В первом случае поисковик предлагает преимущественно конкретные модели, а во втором — запросы, по которым можно перейти в каталог.
2. Используйте разные варианты написания брендов — латиницей и кириллицей. Подсказки в зависимости от способа написания будут отличаться.
3. Добавьте синонимы и схожие по смыслу слова («установка кондиционера» + «монтаж кондиционера»; «станок для бритья» + «бритва» + «бритвенный станок»; «автоюрист» + «автоадвокат» + «адвокат по ДТП» и т. п.).
4. Если у вас интернет-магазин, не указывайте только названия брендов (например, «Siemens» или «Bosch»), поскольку вариантов подсказок будет много, и часть из них может не подойти вашей тематике. Лучше конкретизировать («холодильники Siemens», «дрели Bosch» и т. д.). Этот совет касается не только названий брендов, но и прочих высокочастотных фраз, когда до конца не ясен интент пользователя.
5. При сборе семантики информационной направленности будьте особо внимательны при формировании списка исходных запросов, иначе есть риск собрать массив нецелевых коммерческих ключей. В этом случае лучше конкретизировать запросы с помощью информационных маркеров («как…», «когда…», «почему…», «ТОП-10…», «…своими руками» и т. п.).
п.).
Исключите из результатов парсинга слова, которые не относятся к целевым запросам. Сделать это просто — внесите список фраз в соответствующее поле («Исключить слова»). В качестве этих фраз можно использовать список минус-слов (вот гайд по работе с минус-словами в контекстной рекламе).
Допустим, вы рекламируете женскую кожаную обувь. Исключите из сбора такие слова, как «искусственная кожа», «кожзаменитель», «кожзам», «мужская», «для мужчин».
По умолчанию инструмент исключит из результатов введенные слова в любой словоформе (отмечен чекбокс «Все словоформы»). Например, если вы ввели фразу «для мужчин», то из результатов будут исключены слова «обувь для мужчин», «туфли для мужчин», «кроссовки для мужчин». То есть исключенные фразы выступают в роли минус-слов.
Шаг 2. Выбор поисковых систем и регионов
Инструмент собирает подсказки из трех систем: Яндекс, Google и YouTube. Какие именно системы выбрать, зависит от поставленных задач:
- Если вы планируете продвигаться в России и/или Беларуси, то выбирайте Яндекс и Google.
- Для Украины, Казахстана и стран Запада актуален Google.
- Если вы хотите собрать фразы для оптимизации собственного канала на YouTube, выбирайте эту систему.

Советуем внимательно отнестись к сбору подсказок одновременно в трех системах. Дело в том, что набор исходных ключевых запросов для оптимизации YouTube-роликов зачастую будет отличаться от набора запросов для оптимизации сайта под Яндекс и Google. Ключи для продвижения на YouTube будут преимущественно информационного характера. Поэтому советуем собрать подсказки отдельно для Яндекса и/или Google, а потом (с учетом отсеивания неподходящих запросов) — для YouTube.
Настройте региональность:
- Для Яндекса и Google доступны все регионы России и соседних стран. Если вы хотите собрать поисковые подсказки по целевому запросу для Москвы или Санкт-Петербурга, то вы легко сможете это сделать.
- Для YouTube — только страны. Настройки позволяют указать любую страну и собрать поисковые подсказки по России, Казахстану, США, Великобритании и т. д.
 д.
д.Регионы выбирайте в зависимости от того, где живет целевая аудитория и где будет продвигаться сайт.
Шаг 3. Выбор способов сбора подсказок
По умолчанию система собирает подсказки только по заданным фразам. Но можно активировать опции:
- Фраза [А-Я]. К каждой указанной фразе система добавляет пробел и поочередно 29 букв русского алфавита (не учитывается «Ь», «Ъ», «Ё», «Ы»).
- Фраза [A-Z]. К каждой фразе система добавляет пробел и поочередно все 26 букв латинского алфавита.
- Фраза [0-9]. К каждой фразе система добавляет пробел и поочередно 10 цифр — от 0 до 9.
Пример. Допустим, вы собираете подсказки по фразе «купить палатку». Если не активировать дополнительные способы сбора фраз, то в Яндексе вы получите 10 подсказок:
Если же активировать опции, то система сама расширит семантику дополнительными подсказками:
Если вам нужно быстро «прикинуть» семантику по заданному набору фраз, посмотреть, по каким правилам есть смысл парсить подсказки, то следует собирать их только по исходным фразам, без расширения. Так вы поймете, подходят ли фразы для сбора подсказок (может, их нужно конкретизировать, изменить словоформы и т. п.).
Так вы поймете, подходят ли фразы для сбора подсказок (может, их нужно конкретизировать, изменить словоформы и т. п.).
Дополнительные опции стоит активировать, если перед вами стоит задача собрать максимально широкую семантику. Вот сколько дополнительных фраз можно получить при сборе по 1 исходной фразе в Яндексе и Google:
- Обычный парсинг — max 20 подсказок (по 10 в каждом поисковике).
- Фраза [А-Я] — max 580 подсказок.
- Фраза [A-Z] — max 520 подсказок.
- Фраза [0-9] — max 200 подсказок.
- все способы — max 1320 подсказок.
Таким образом, всего одна фраза теоретически может дать нам 1320 подсказок. Конечно, на практике количество фраз будет меньшим, поскольку не по всем буквам и цифрам будут подсказки (а если и будут, то их может быть меньше 10). Тем не менее это простой и быстрый способ перебрать все возможные варианты ключевых запросов и ничего не упустить.
Шаг 4. Настройка глубины сбора
Выбор глубины парсинга зависит от поставленных задач:
Первая — сбор подсказок только по тем фразам, которые указаны в исходном списке + по фразам, которые образованы в результате автоподстановок [А-Я], [A-Z], [0-9] (если эти опции активированы).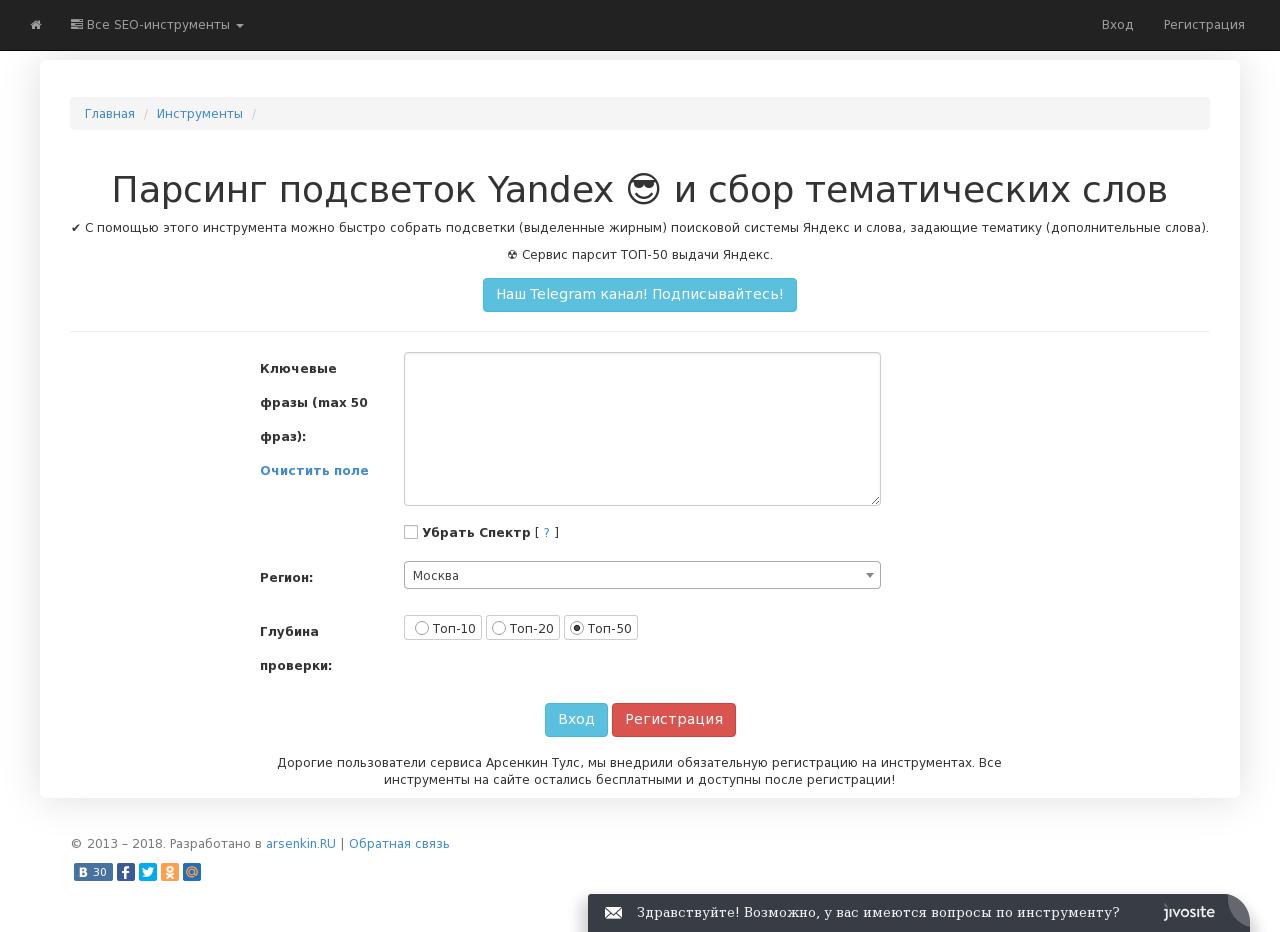 Такая глубина парсинга подходит для сбора наиболее трендовых фраз.
Такая глубина парсинга подходит для сбора наиболее трендовых фраз.
Вторая — подсказки собираются не только по исходным, но и по фразам, полученным в результате парсинга первого уровня. Семантика становится намного более широкой, появляется масса средне- и низкочастотных ключей.
Третья — самый глубокий уровень, подходит для максимального охвата тематики. Во многих ситуациях нет смысла вкладываться в парсинг третьего уровня, поскольку в результате у вас на руках будут десятки тысяч фраз, которые еще нужно обработать (в частности, найти и удалить немало «мусора») и под которые нужно написать контент. Но крупным сайтам, с широким охватом, особенно в тематиках с запредельной конкуренцией (вроде кредитования или продвижения сайтов) такой парсинг подходит. Кроме того, он подходит, если вы хотите углубиться в семантику по ограниченному кругу конкурентных запросов.
Шаг 5. Получение результата
Сбор подсказок осуществляется в фоновом режиме — при необходимости вы можете закрыть браузер. Результат доступен в интерфейсе Click.ru по окончании парсинга.
Результат доступен в интерфейсе Click.ru по окончании парсинга.
Отчет доступен в формате HTML и XLSX в разделе «Список задач». Здесь указана дата запуска задачи и ее завершения, исходные настройки и список полученных подсказок.
В XLSX-файле ключи разбиты по столбцам, каждый из которых соответствует определенной поисковой системе и конкретному региону:
Сколько стоит инструмент
Стоимость проверки рассчитывается исходя из количества ТЗ.
1 ТЗ — это сбор подсказок в 1 поисковой системе в 1 регионе по 1 фразе.
Первые 50 запросов — бесплатно.
Важно! Не путайте ТЗ с количеством подсказок. В рамках 1 ТЗ может быть собрано и 10 подсказок, и 5, и 2 (в зависимости от популярности запроса). Стоимость 1 ТЗ (то есть обращения к поисковой системе) при этом не меняется.
Приведем несколько примеров расчета стоимости сбора подсказок.
* — окончательная стоимость проверки известна только после завершения сбора подсказок, поскольку если по фразе не было подсказок, то средства не списываются;
** — реальное количество будет меньшим, поскольку при углублении парсинга увеличивается количество низкочастотных запросов, по которым подсказок меньше 10 или вовсе нет.
Итак, чем больше объем парсинга, тем ниже стоимость одной подсказки. В итоге можно вполне выйти на цену, равную 1/10 копейки за подсказку. Это в 2-3 дешевле, чем в конкурентных сервисах. Кроме того, доступно 50 бесплатных ТЗ для пробного использования инструмента.
Как запустить рекламу в Яндекс.Директ и Google Ads через Click.ru [пошаговая инструкция]
Что делать с подсказками дальше
Итак, вы получили файл с поисковыми подсказками. Ваши дальнейшие действия:
- Пройдитесь по списку и удалите нерелевантные фразы.
- Оставшиеся запросы объедините с исходными фразами на одном листе в файле XLSX.
- Загрузите этот файл в инструмент кластеризации, и вы получите готовое семантическое ядро.
Если вы решите предварительно собрать частотности полученных из подсказок ключей, чтобы отсечь «нули», советуем быть внимательными: статистика Wordstat не поспевает за актуальными трендами, поэтому вы можете случайно удалить запросы с низкой конкуренцией и высоким спросом (просто они еще не попали в базу Wordstat).
Click.ru предлагает не только набор профессиональных инструментов, но и партнерскую программу для агентств и фрилансеров. Регистрируйтесь в системе, подключайте аккаунты своих клиентов и получайте до 12% от их расходов на контекстную и до 18% — на таргетированную рекламу.
Шаблоны Zennoposter | Zenno.pro
Опубликовано: 23.05.2017
Шаблон так же продается в комплекте с Шаблонами для поиска клиентов. Использовать шаблон вы можете…
Опубликовано: 04.05.2017
Шаблон работает через браузер через полную версию mail.ru Два варианта использование proxy из файла или ProxyChecker’a. Пауза между…
Опубликовано: 05.11.2016
К сожалению Advse банит IP за постоянный парсинг поэтому рекомендую использовать хорошие прокси для работы. Шаблон так…
Шаблон так…
Опубликовано: 05.10.2016
Шаблон проверяет возможность отправки писем на список мыл mail.ru UPD 16.08.2017 Обновлена авторизация и парсинг. …
Опубликовано: 05.10.2016
Шаблон для парсинга id пользователей vk.com с группы или поиска Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox….
Опубликовано: 05.10.2016
Шаблон для добавления друзей по списку id vk.com Шаблон работает через мобильную версию. Ввод подтверждения номера когда этого требует вк….
Опубликовано: 03.10.2016
Простой парсер ссылок с yandex.ru Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a. Можно получить…
Можно получить…
Опубликовано: 03.10.2016
Простой регер аккаунтов mail.ru Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a. Можно получить бесплатно…
Опубликовано: 03.10.2016
Простой регер аккаунтов Фотострана.ру Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a. Подтверждение мыла…
Опубликовано: 28.09.2016
Шаблон для добавления ссылок в Bing.com Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a….
Опубликовано: 01.06.2016
В видео по поиску клиентов Влад рассказывал о шаблонах для парсинга Advse , парсинга email и рассылки…
Опубликовано: 01.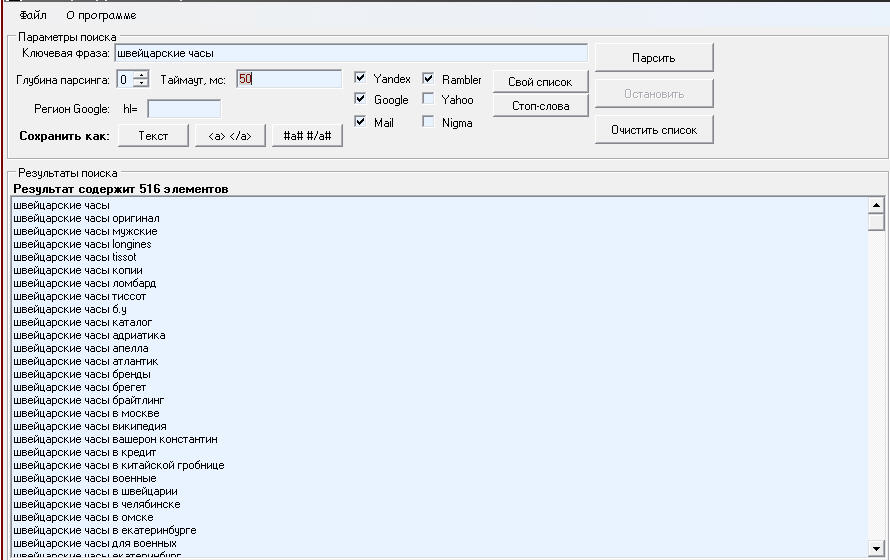 06.2016
06.2016
Шаблон входит в аккаунт mail.ru. Берет из файла нужное кол-во email адресов, берет текст и заголовок с рандомизацией,…
Опубликовано: 01.06.2016
Шаблон входит в аккаунт mail.ru. В настройках акканута включаем переадресацию , вводит указанный email (gmail.com) и подтверждает переадресацию. Входит…
Опубликовано: 08.04.2016
Шаблон переходит на главную сайт и парсит ссылки на активные страницы (исключая скрытые) и ищет там контактный email адрес….
Опубликовано: 19.06.2015
Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у вас нет Zennoposter’a вы можете использовать Zennobox…
Опубликовано: 18.06.2015
Шаблон для парсинга id групп vk. com Критерии поиска Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если…
com Критерии поиска Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если…
Опубликовано: 17.06.2015
Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у вас нет Zennoposter’a вы можете использовать Zennobox…
Опубликовано: 17.06.2015
Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у вас нет Zennoposter’a вы можете использовать…
Опубликовано: 17.06.2015
Шаблон для добавления друзей по списку id vk.com Шаблон работает через api. 2 формата аккаунтов, login:pass и access_token. Ввод подтверждения…
Опубликовано: 16.06.2015
Шаблон для парсинга id пользователей vk. com с обходом лимита в 1000 пользователей Критерии поиска Использовать шаблон вы можете только на…
com с обходом лимита в 1000 пользователей Критерии поиска Использовать шаблон вы можете только на…
Опубликовано: 16.06.2015
Шаблон проверяет список групп Vk.com на наличие открытых альбомов в которые можно загрузить фотографии. Шаблон работает через Api Vk.com …
Опубликовано: 15.06.2015
Шаблон для автоматической регистрации аккаунтов Vk.com Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у вас нет…
Опубликовано: 14.06.2015
Шаблон для автоматической регистрации аккаунтов Ok.ru Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у…
Опубликовано: 14.06.2015
Шаблон для автоматической регистрации аккаунтов Badoo. com Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у…
com Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если у…
Опубликовано: 13.06.2015
Шаблон для автоматической регистрации аккаунтов и 1freehosting.com Использовать шаблон вы можете только на вашей лицензии Zennoposter или ZennoBox. Если…
Опубликовано: 06.06.2015
Шаблон для автоматической регистрации аккаунтов и редиректов на Ucoz.com Использовать шаблон вы можете только на вашей лицензии Zennoposter…
Опубликовано: 09.03.2015
Шаблон для регистрации почтовых аккаунтов Mail.russia.ru Не актуально в связи с закрытием почтового сервиса ! Настройки POP3: Сервер pop3.russia.ru Порт 110…
Опубликовано: 08.03.2015
Шаблон для регистрации почтовых аккаунтов Safe-mail. net Настройки POP3: Сервер pop.safe-mail.net Порт 110 Использовать шаблон вы можете только на вашей лицензии Zennoposter…
net Настройки POP3: Сервер pop.safe-mail.net Порт 110 Использовать шаблон вы можете только на вашей лицензии Zennoposter…
Опубликовано: 08.03.2015
Шаблон для автоматической регистрации аккаунтов и блогов WordPress.com Автоподтверждения аккаунтов по почте (mail.ru) Выбор модуля распознавания капчи в настройках. Два…
Опубликовано: 08.03.2015
Шаблон для постинга на WordPress.com Шаблон добавляет посты из заранее сгенерированных html файлов, в сети достаточно как платных так и…
Опубликовано: 08.03.2015
Шаблон для регистрации почтовых аккаунтов Mail.ngs.ru Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или…
Опубликовано: 08.03.2015
Шаблон для постинга в аккаунты Jujuju. ru Постинг ссылок из файла. Возможность добавления случайных сообщений из файла. Настройка количества постов с одного аккаунта. Два…
ru Постинг ссылок из файла. Возможность добавления случайных сообщений из файла. Настройка количества постов с одного аккаунта. Два…
Опубликовано: 03.03.2015
Шаблон постинга в аккаунты Friendfeed.com (Не актуально с 09.05.15. Friendfeed закрылся) Постинг ссылок из файла. Возможность постинга случайных сообщений из файла….
Опубликовано: 02.03.2015
Шаблон для регистрации почтовых аккаунтов Rambler.ru Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a. Активация…
Опубликовано: 28.02.2015
Шаблон для автоматической регистрации аккаунтов Liveinternet.ru Автоподтверждения аккаунтов по почте (mail.ru) Автоматическое распознавание капчи через сервис Antigate.com. Два варианта использование proxy…
Опубликовано: 27. 02.2015
02.2015
Шаблон для регистрации аккаунтов Pinterest.com Автоподтверждения аккаунтов по почте (mail.ru) Автоматическое распознавание капчи через сервис Antigate.com. Два варианта использование proxy из…
Опубликовано: 24.02.2015
Шаблон для регистрации аккаунтов Friendfeed.com (Не актуально с 09.05.15. Friendfeed закрылся) Автоподтверждения аккаунтов по почте (mail.ru/yandex.ru) Автоматическое распознавание капчи через сервис Antigate.com….
Опубликовано: 23.02.2015
Шаблон для регистрации почтовых аккаунтов Meta.ua Выбор модуля распознавания капчи в настройках. Два варианта использование proxy из файла или ProxyChecker’a….
Опубликовано: 23.02.2015
Автоматическое распознавание капчи через сервис Antigate.com. Два варианта использование proxy из файла или ProxyChecker’a. Активация POP3 после регистрации. Настройки POP3: Сервер…
Активация POP3 после регистрации. Настройки POP3: Сервер…
Опубликовано: 17.02.2015
Шаблон для регистрации аккаунтов Jujuju.ru Не требует подтверждения по почте. Почта генерируется на реальных доменах (600+). Автоматическое распознавание капчи через сервис…
Опубликовано: 17.02.2015
Шаблон для регистрации аккаунтов фрихостинга hostinger.ru Временно не актуально в связи с новой recaptcha Подтверждение аккаунтов по почте (по умолчанию…
Автообработка писем (парсинг) и Неразобранное — НЕРАЗОБРАННОЕ И ИСТОЧНИКИ
Автопочта, или парсер email’ов (парсинг) — это обработчик входящей почты. Является источником заявок.
Если пользователю на почту присылаются типовые, шаблонные письма, то с помощью обработчика можно настроить, какое
слово письма в какое поле в
карточке клиента попадет.
Для настройки обработчика нужно зайти в настройки «Digital Воронку» (раздел «Сделки» — «Настроить воронку») и выбрать в источниках «Автообработка писем».
Для подключения источника нужно пройти 4 этапа:
- В зависимости от «Службы электронной почты» (Gmail, Yandex и прочие), вам предоставляется инструкция для настройки пересылки шаблонных писем с вашего ящика и он не обязательно должен быть подключен в amoCRM. На этом этапе система создает специальный ящик для обработки шаблонных писем, который автоматически подключается в аккаунте;
- После настроек в своем почтовом ящике, нажмите кнопку «Далее» и перейдите на следующий этап настройки. Здесь вам на почту приходит письмо со ссылкой, перейдя по которой вы подтверждаете пересылку писем на специальный ящик, созданный системой;
- На следующем этапе вам будет предложено выбрать типовое письмо, по которому и будет происходить обработка почты;
- В тексте письма выделяем значения, которые хотим занести в поля карточек сделки, контакта или компании. Нужные
поля должны быть заранее
добавлены в карточку в ее настройках. При выделении какого-либо слова в тексте письма, появляется список полей
карточки. Выбираем нужные поля.
Также имеется возможность добавить нужные теги, статус, в который должны попадать письма и ответственного за
сделку. Здесь же можно включить
создание задачи при создании сделки.
 Нужные
поля должны быть заранее
добавлены в карточку в ее настройках. При выделении какого-либо слова в тексте письма, появляется список полей
карточки. Выбираем нужные поля.
Также имеется возможность добавить нужные теги, статус, в который должны попадать письма и ответственного за
сделку. Здесь же можно включить
создание задачи при создании сделки.
Нужные
поля должны быть заранее
добавлены в карточку в ее настройках. При выделении какого-либо слова в тексте письма, появляется список полей
карточки. Выбираем нужные поля.
Также имеется возможность добавить нужные теги, статус, в который должны попадать письма и ответственного за
сделку. Здесь же можно включить
создание задачи при создании сделки.
Авторизация на Яндексе — Яндекс ID. Справка
Для использования личных сервисов Яндекса (Яндекс.Почта, Яндекс.Диск и т. Д.) Войдите в свою учетную запись одним из следующих способов:
- Переключение между учетными записями
- Как войти в Яндекс на безопасное устройство стороннего производителя
- Двухфакторная аутентификация
Если у вас несколько учетных записей Яндекса, вы можете переключаться между ними, не вводя логина и пароля:
Вы также можете выбрать учетную запись, которую вы используете в других сервисах Яндекса, которые это поддерживают функция. Выбранная вами учетная запись будет основной и будет использоваться для входа в службы, которые в настоящее время не позволяют вам переключаться между учетными записями.
Выбранная вами учетная запись будет основной и будет использоваться для входа в службы, которые в настоящее время не позволяют вам переключаться между учетными записями.
В список можно добавить до 15 учетных записей. Чтобы удалить учетную запись из списка, переключитесь на эту учетную запись и нажмите «Выйти». Эта учетная запись исчезнет из списка, и вы автоматически войдете в следующую.
После входа в Яндекс вам нужно будет снова ввести пароль на этом устройстве только в том случае, если вы не входите в сервисы Яндекса в течение трех и более месяцев.Это удобно для персональных или домашних компьютеров, но может быть опасно на общедоступных компьютерах (например, в интернет-кафе): если вы забудете выйти из своей учетной записи, следующий человек с тем же компьютером получит доступ к вашим данным.
Чтобы защитить свою учетную запись на чужом компьютере, используйте режим инкогнито в браузере.
Если на компьютере нет браузера, поддерживающего режим инкогнито:
Отключите параметры автозаполнения и сохранения паролей.
Перед началом работы очистите кеш и удалите куки.
По окончании:
Выйдите из своей учетной записи — щелкните свой портрет в правом верхнем углу и выберите «Выход» в раскрывающемся меню.
Очистите кеш еще раз и удалите файлы cookie.
- Если вы забыли выйти из своей учетной записи на чужом устройстве, перейдите по ссылке «Выход на всех устройствах» на странице управления учетной записью.

Независимо от того, насколько надежен ваш пароль, кто-то все равно может заглянуть вам через плечо или украсть его (например, с помощью вируса). Чтобы защитить свою учетную запись, вы можете использовать исключительно одноразовые пароли.
Подробнее об одноразовых паролях и двухфакторной аутентификации можно узнать в разделе Двухфакторная аутентификация.
sashasochka / yandex-xml-parser: Парсер яндекс-запросов (Используя Яндекс.XML)
GitHub — sashasochka / yandex-xml-parser: Парсер яндекс-запросов (Используя Яндекс. XML)
XML)Файлы
Постоянная ссылка Не удалось загрузить последнюю информацию о фиксации.Тип
Имя
Последнее сообщение фиксации
Время фиксации
Этот инструмент позволяет получить базовую информацию веб-поиска яндекса, проанализированную и сохраненную на локальном компьютере.
Вам нужно:
- Java 7
- Яндекс.XML логин (зарегистрироваться)
- Пароль Яндекс.XML
- Не использовать слишком много — количество запросов ограничено
Характеристики:
- получить основную информацию по запросу, например URL, заголовок, аннотации и яндекс «зеленая линия»
- сохранить все веб-страницы, возвращенные запросом, локально
Использование:
- Для сохранения веб-страниц в КАТАЛОГЕ:
java yandex. Parser «Здесь ваш запрос» yourlogin yourpassword directory
- Для сохранения веб-страниц в каталоге по умолчанию: java яндекс.Парсер «Здесь ваш запрос» yourlogin yourpassword
- Отключить сохранение веб-страниц локально: java yandex.Parser «Здесь ваш запрос» yourlogin yourpassword —nosave
 Parser «Здесь ваш запрос» yourlogin yourpassword directory
Parser «Здесь ваш запрос» yourlogin yourpassword directoryПример:
java яндекс.Парсер "python docs" uid-fhsghafr 03.206015392: 53811c98048d4bb4a046d45678239987 --nosave
Типовая мощность:
Обзор - документация Python v3.3.0
http://docs.python.org/
Установка и использование Python, как использовать Python на разных платформах.Подробные документы Python HOWTO по конкретным темам, документы для других версий. Python 2.7 (стабильный).
docs.python.org
Документация GIMP Python
http://www.gimp.org/docs/python/
В этом документе описываются интерфейсы к GIMP-Python, который представляет собой набор модулей Python, которые действуют как оболочка для libgimp, позволяя писать надстройки для GIMP.
gimp.org
Обзор - документация Python v2.7
Sell docspython.org
Распространение модулей Python, разделяющих модули с другими. Документирующее руководство по Python для авторов документации.Документы для других версий. Python 2.6 (стабильный).
docspython.org
Добро пожаловать на python-docs.net!
http://python-docs.net/
python-docs.net. Экономьте на: доменных именах, веб-хостинге, учетных записях электронной почты, сертификатах SSL, продуктах электронной коммерции И МНОГОЕ ДРУГОЕ!
python-docs.net
Клиентская библиотека Python - Braintree
https://www.braintreepayments.com/docs/python
wget http://pypi.python.org/packages/source/b/braintree/braintree-2.20.0.tar.gz tar zxf braintree-2.20.0.tar.gz cd braintree-2.20.0 python setup.py установить .
Braintreepayments.ком
ADOdb для Python
http://phplens.com/lens/adodb/adodb-py-docs.htm
ADOdb изначально был разработан для PHP и перенесен на Python. Версия Python реализует подмножество версии PHP. Из документации Python DB API.
phplens.com
Блендер
http://www. blender.org/documentation/249PythonDoc/
API игрового движка отделен от API-интерфейса Blender Python, на который ссылается этот документ, и вы можете найти его собственный справочный документ в разделе документации на основных сайтах ниже.
blender.org
PythonDocs - NetBeans Wiki
http: // вики.netbeans.org/PythonDocs
Цель вики-страницы - предоставить централизованное место для планирования документации Python для IDE NetBeans.Web Docs.
wiki.netbeans.org
Python: модуль xbmc и xbmcgui
http://xbmc.sourceforge.net/python-docs/
xbmc.sourceforge.net
Автостопом по Python! - Автостопом по Python
http://docs.python-guide.org/
Добро пожаловать в "Автостопом" по Python. Это руководство в настоящее время находится в стадии активной разработки. Прочтите документацию.
docs.python-guide.org
 gimp.org
Обзор - документация Python v2.7
gimp.org
Обзор - документация Python v2.7
 blender.org/documentation/249PythonDoc/
API игрового движка отделен от API-интерфейса Blender Python, на который ссылается этот документ, и вы можете найти его собственный справочный документ в разделе документации на основных сайтах ниже.
blender.org
PythonDocs - NetBeans Wiki
http: // вики.netbeans.org/PythonDocs
Цель вики-страницы - предоставить централизованное место для планирования документации Python для IDE NetBeans.Web Docs.
wiki.netbeans.org
Python: модуль xbmc и xbmcgui
http://xbmc.sourceforge.net/python-docs/
xbmc.sourceforge.net
Автостопом по Python! - Автостопом по Python
http://docs.python-guide.org/
Добро пожаловать в "Автостопом" по Python. Это руководство в настоящее время находится в стадии активной разработки. Прочтите документацию.
docs.python-guide.org
blender.org/documentation/249PythonDoc/
API игрового движка отделен от API-интерфейса Blender Python, на который ссылается этот документ, и вы можете найти его собственный справочный документ в разделе документации на основных сайтах ниже.
blender.org
PythonDocs - NetBeans Wiki
http: // вики.netbeans.org/PythonDocs
Цель вики-страницы - предоставить централизованное место для планирования документации Python для IDE NetBeans.Web Docs.
wiki.netbeans.org
Python: модуль xbmc и xbmcgui
http://xbmc.sourceforge.net/python-docs/
xbmc.sourceforge.net
Автостопом по Python! - Автостопом по Python
http://docs.python-guide.org/
Добро пожаловать в "Автостопом" по Python. Это руководство в настоящее время находится в стадии активной разработки. Прочтите документацию.
docs.python-guide.org
Около
Парсер яндекс-запросов (с использованием Яндекс.XML)
Ресурсы
Вы не можете выполнить это действие в настоящее время. Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.
Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.уязвимостей безопасности CVE, версии и подробные отчеты
Ленты и виджеты уязвимостейВы можете создать собственный RSS-канал, встраиваемый виджет списка уязвимостей или URL-адрес вызова json API.
(Ленты или виджет будут содержать только уязвимости этого продукта)Выбранные типы уязвимостей объединяются оператором ИЛИ. Если вы не выберете какие-либо критерии, будут возвращены «все» записи CVE.
Тенденции уязвимости с течением времени
| Год | # уязвимостей | DoS | Выполнение кода | Переполнение | Повреждение памяти | SQL-инъекция | XSS | Обход каталогов | Разделение HTTP-ответа | Обойти что-то | Получить информацию | Получите привилегии | CSRF | Включение файла | # эксплойтов |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2018 г. | 1 | 1 | |||||||||||||
| Итого | 1 | 1 | |||||||||||||
| % от всех | 0.0 | 100,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
Предупреждение: Уязвимости с датами публикации до 1999 года не включены в эту таблицу и диаграмму.(Потому что их не так много, и из-за них страница выглядит плохо; и они могут не публиковаться в те годы.)
| 1 | 2018 1 |
| 1 | Выполнить код 1 |
Щелкните названия легенды, чтобы показать / скрыть строки для типов уязвимостей
Если вы не видите диаграммы стилей MS Office выше, пора обновить браузер!
с.