
Что такое XML? – Описание расширяемого языка разметки (XML) – AWS
Что такое XML?
Расширяемый язык разметки (XML) позволяет определять и хранить данные совместно используемым способом. XML поддерживает обмен информацией между компьютерными системами, такими как веб-сайты, базы данных и сторонние приложения. Предопределенные правила упрощают передачу данных в виде XML-файлов по любой сети, поскольку получатель может использовать эти правила для точного и эффективного чтения данных.
Почему XML важен?
Расширяемый язык разметки (XML) – это язык разметки, который предоставляет правила для определения любых данных. В отличие от других языков программирования, XML не может выполнять вычислительные операции сам по себе. Вместо этого для управления структурированными данными можно использовать любой язык программирования или программное обеспечение.
Например, рассмотрим текстовый документ с комментариями к нему. В комментариях могут содержаться такие предложения:
- Сделайте заголовок жирным
- Это предложение является заголовком
- Это слово автор
Такие комментарии повышают удобство использования документа, не затрагивая его содержание. Точно так же XML использует символы разметки для предоставления дополнительной информации о любых данных. Другие программы, такие как браузеры и приложения для обработки данных, используют эту информацию для более эффективной обработки структурированных данных.
Точно так же XML использует символы разметки для предоставления дополнительной информации о любых данных. Другие программы, такие как браузеры и приложения для обработки данных, используют эту информацию для более эффективной обработки структурированных данных.
Для определения данных используются символы разметки, называемые тегами в XML. Например, для представления данных для книжного магазина можно создать такие теги, как <book>, <title> и <author>. Ваш XML-документ для одной книги будет содержать указанное ниже.
<book>
<title> Изучение Amazon Web Services </title>
<author> Марк Уилкинс </author>
</book>
Теги обеспечивают сложное кодирование данных для интеграции информационных потоков между различными системами.
В чем преимущества использования XML?
Поддержка межделовых транзакцийКогда компания продает товар или сервис другой компании, им необходимо обмениваться такой информацией, как стоимость, спецификации и графики поставок. С помощью расширяемого языка разметки (XML) они могут обмениваться всей необходимой информацией в электронном виде и автоматически закрывать сложные сделки без вмешательства человека.
С помощью расширяемого языка разметки (XML) они могут обмениваться всей необходимой информацией в электронном виде и автоматически закрывать сложные сделки без вмешательства человека.
XML позволяет передавать данные вместе с описанием данных, предотвращая потерю целостности данных. Эту описательную информацию можно использовать для выполнения указанных ниже действий.
- Проверьте точность данных
- Автоматическая настройка представления данных для разных пользователей
- Согласованное хранение данных на нескольких платформах
Компьютерные программы, такие как поисковые системы, могут сортировать и классифицировать XML-файлы более эффективно и точно, чем другие типы документов. Например, слово туши может быть существительным или глаголом. На основе тегов XML поисковые системы могут точно классифицировать метки для релевантных результатов поиска. Таким образом, XML помогает компьютерам более эффективно интерпретировать естественный язык.
Таким образом, XML помогает компьютерам более эффективно интерпретировать естественный язык.
С помощью XML можно удобно обновлять или изменять дизайн приложения. Многие технологии, особенно новые, имеют встроенную поддержку XML. Они могут автоматически читать и обрабатывать файлы данных XML, чтобы вы могли вносить изменения без необходимости переформатирования всей базы данных.
Каковы области применения XML?
Расширяемый язык разметки (XML) является базовой технологией тысяч приложений, начиная от обычных инструментов повышения производительности, таких как обработка текстов, и заканчивая программным обеспечением для публикации книг и даже сложными системами настройки приложений.
Передача данныхМожно использовать XML для передачи данных между двумя системами, в которых одни и те же данные хранятся в разных форматах. Например, на вашем веб-сайте даты хранятся в формате ММ/ДД/ГГГГ, а в бухгалтерской системе даты хранятся в формате ДД/ММ/ГГГГ. Вы можете перенести данные с веб-сайта в систему бухгалтерского учета с помощью XML. Ваши разработчики могут писать код, который автоматически преобразует указанное ниже.
Вы можете перенести данные с веб-сайта в систему бухгалтерского учета с помощью XML. Ваши разработчики могут писать код, который автоматически преобразует указанное ниже.
- Данные веб-сайта в формате XML
- Данные XML к данным системы бухгалтерского учета
- Данные системы бухгалтерского учета возвращаются в формат XML
- XML-данные возвращаются к данным веб-сайта
XML обеспечивает структуру данных, которые вы видите на веб-страницах. Другие технологии веб-сайта, такие как HTML, работают с XML для представления посетителям веб-сайта согласованных и релевантных данных. Например, рассмотрим веб-сайт электронной коммерции, на котором продается одежда. Вместо того, чтобы показывать всю одежду всем посетителям, веб-сайт использует XML для создания настраиваемых веб-страниц на основе предпочтений пользователя. Он показывает товары определенных брендов, выполняя фильтрацию по тегу <brand>.
Можно использовать XML для указания структурной информации любого технического документа. Другие программы затем обрабатывают структуру документа для ее гибкого представления. Например, существуют теги XML для абзаца, элемента в нумерованном списке и заголовка. Используя эти теги, другие типы программного обеспечения автоматически подготавливают документ к использованию, например, к печати и публикации на веб-странице.
Тип данныхМногие языки программирования поддерживают XML в качестве типа данных. Благодаря этой поддержке вы можете легко писать программы на других языках, которые работают непосредственно с файлами XML.
Из каких компонентов состоит XML-файл?
Файл расширяемого языка разметки (XML) – это текстовый документ, который можно сохранить с расширением.xml. Можно писать XML аналогично другим текстовым файлам. Для создания или редактирования XML-файла можно использовать любое из указанных ниже действий.
- Текстовые редакторы, такие как Блокнот или Блокнот+
- Онлайн редакторы XML
- Веб-браузеры
Любой XML-файл включает указанные ниже компоненты.
XML-документТеги <xml></xml> используются для обозначения начала и конца XML-файла. Содержимое этих тегов также называется XML-документом. Это первый тег, который будет искать любое программное обеспечение для обработки XML-кода.
Декларация XMLXML-документ начинается с информации о самом XML. Например, в нем может быть указана следующая версия XML. Это открытие называется объявлением XML. Вот пример.
<?xml version=»1.0″ encoding=»UTF-8″?>
Элементы XML- Текст
- Атрибуты
- Другие элементы
Все XML-документы начинаются с первичного тега, который называется корневым элементом.
Например, рассмотрим приведенный ниже XML-файл.
<InvitationList>
<family>
<aunt>
<name>Кристин</name>
<name>Стефани</name>
</aunt>
</family>
</InvitationList>
<InvitationList> – корневой элемент; family и aunt – другие названия элементов.
Атрибуты XMLЭлементы XML могут иметь другие дескрипторы, называемые атрибутами. Вы можете определить собственные имена атрибутов и записать значения атрибутов в кавычки, как показано ниже.
<person age=“22”>
Содержимое XMLДанные в XML-файлах также называются содержимым XML. Например, в XML-файле вы можете увидеть такие данные.
<friend>
<name>Чарли</name>
<name>Стив</name>
</friend>
Значения данных Чарли и Стив являются содержанием.
Что такое схема XML?
Схема расширяемого языка разметки (XML) – это документ, в котором описываются некоторые правила или ограничения структуры XML-файла. Эти ограничения можно описать несколькими способами, например:
- Грамматические правила для определения порядка элементов
- Условия «Да» или «Нет», которым должен удовлетворять контент
- Типы данных для содержимого XML-файлов
- Ограничения целостности данных
Например, схема XML для книжных магазинов может налагать такие ограничения:
- Элемент книги будет иметь атрибуты title и author.
- Элемент book будет вложен в элемент category с именем атрибута.
- Цена книги будет отдельным элементом, вложенным в книгу.
Чтобы выполнить эти ограничения, мы напишем XML-файл, как показано ниже.
<category name=“Technology”>
<book title=“Изучение Amazon Web Services”, автор=“Марк Вилкинс”>
<price>20 USD</price>
</book>
</category>
Схемы XML обеспечивают согласованность в создании и использовании XML-файлов различными программными приложениями. Некоторые отрасли внедряют схемы XML, специфичные для их операций, чтобы упростить написание XML-кода для межделовой передачи данных. Например, Scalable Vector Graphics (SVG) – это спецификация XML для описания данных, связанных с компьютерной графикой. Разработчики программного обеспечения пишут XML-файлы, чтобы они соответствовали отраслевым спецификациям.
Некоторые отрасли внедряют схемы XML, специфичные для их операций, чтобы упростить написание XML-кода для межделовой передачи данных. Например, Scalable Vector Graphics (SVG) – это спецификация XML для описания данных, связанных с компьютерной графикой. Разработчики программного обеспечения пишут XML-файлы, чтобы они соответствовали отраслевым спецификациям.
Что такое синтаксический анализатор XML?
Анализатор расширяемого языка разметки (XML) – это программное обеспечение, которое может обрабатывать или читать XML-документы для извлечения данных из них. Синтаксические анализаторы XML также проверяют синтаксис или правила XML-файла и могут проверять его на соответствие определенной схеме XML. Поскольку XML является строгим языком разметки, синтаксические анализаторы не будут обрабатывать файл, если есть какие-либо ошибки проверки или синтаксиса. Например, синтаксический анализатор XML выдаст ошибки, если выполняется одно из указанных ниже условий.
- Отсутствует закрывающий или конечный тег
- Значения атрибутов не содержат кавычек
- Не выполнено условие схемы
Программные приложения используют синтаксические анализаторы XML для преобразования XML-файлов в собственные типы данных. Таким образом, они могут сосредоточиться на логике приложения, не вдаваясь в детали самого XML.
Таким образом, они могут сосредоточиться на логике приложения, не вдаваясь в детали самого XML.
Чем XML отличается от HTML?
Язык гипертекстовой разметки (HTML) – это язык, используемый на большинстве веб-страниц. Веб-браузер обрабатывает HTML-документы и отображает их в виде мультимедийной страницы. Консорциум World Wide Web (W3C) – это международное сообщество, которое разрабатывает протоколы и руководящие принципы для обеспечения долгосрочного роста Интернета. Компания W3C установила стандарты HTML и расширяемого языка разметки (XML), которые разработчики веб-сайтов внедряют для обеспечения согласованности и качества.
XML и HTMLХотя файлы HTML и XML выглядят очень похоже, у них есть ключевые отличия.
ЦельЦелью HTML является представление и отображение данных. Однако XML хранит и передает данные.
МеткиHTML имеет предопределенные теги, но пользователи могут создавать и определять свои собственные теги в XML.
Есть несколько незначительных, но важных различий между синтаксисом HTML и XML. Например, XML чувствителен к регистру, а HTML – нет. Синтаксические анализаторы XML выдадут ошибки, если вы напишете тег <Book> вместо <book>.
Как сервисы AWS поддерживают XML?
Все сервисы интеграции данных AWS могут обрабатывать файлы языка расширяемой разметки (XML). Ниже мы приведем несколько примеров.
AWS Glue – это бессерверная служба интеграции данных, упрощающая поиск, подготовку и объединение данных для анализа, машинного обучения и разработки приложений. AWS Glue DataBrew – это инструмент визуальной подготовки данных, который можно использовать для подготовки данных с помощью интерактивного визуального интерфейса без написания кода. DataBrew может вводить все типы форматов файлов, включая XML.
Простой сервис очередей Amazon (SQS) – это полностью управляемый сервис очереди сообщений, который можно использовать для отправки, хранения и получения сообщений между программными компонентами на любом томе. Сообщения Amazon SQS могут содержать до 256 КБ текстовых данных, включая форматы XML, JSON и неформатированный текст.
Сообщения Amazon SQS могут содержать до 256 КБ текстовых данных, включая форматы XML, JSON и неформатированный текст.
С помощью Amazon Kinesis можно просто собирать, обрабатывать и анализировать потоковые данные в режиме реального времени, чтобы своевременно получать аналитические результаты и быстро реагировать на новую информацию. Благодаря ключевым возможностям Kinesis вы можете экономично обрабатывать потоковые данные в любом масштабе. Кроме того, вы получаете возможность выбирать инструменты, соответствующие требованиям вашего приложения. Транслируйте, преобразуйте и анализируйте данные XML в реальном времени с помощью Kinesis.
Начните интеграцию данных, создав аккаунт AWS уже сегодня.
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);


Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- 1.
- Итого
 Есть корневой элемент
Есть корневой элементКак устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда.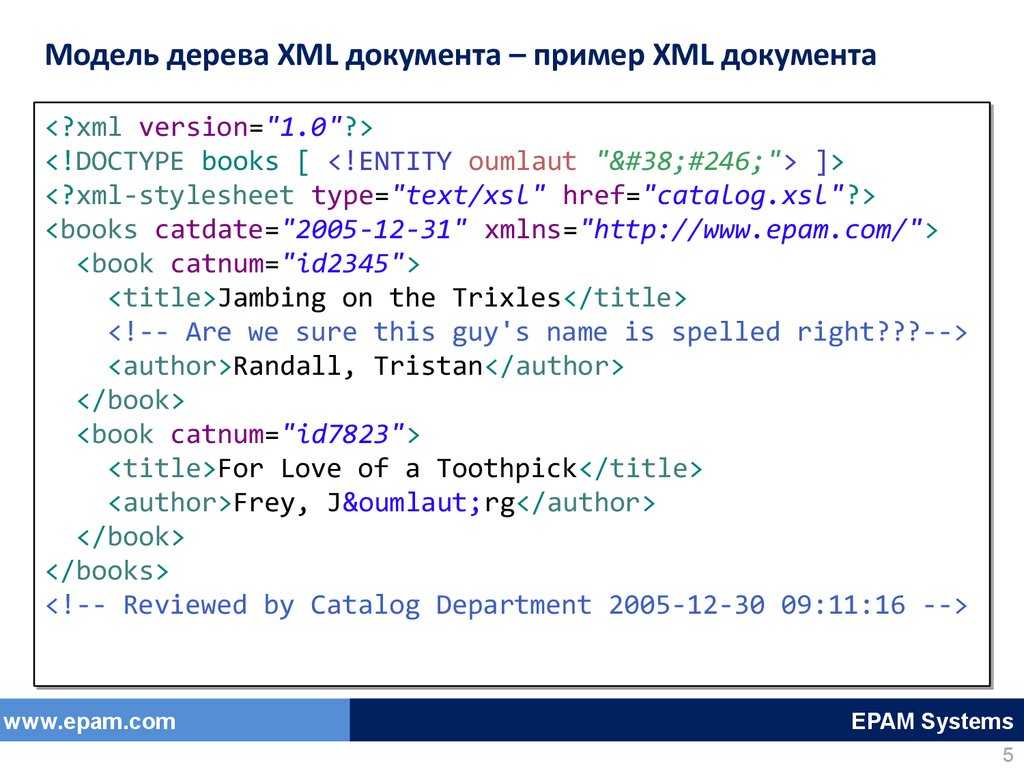 Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
безкавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»
Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
Давайте разберем эту запись. У нас есть основной элемент party.
У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.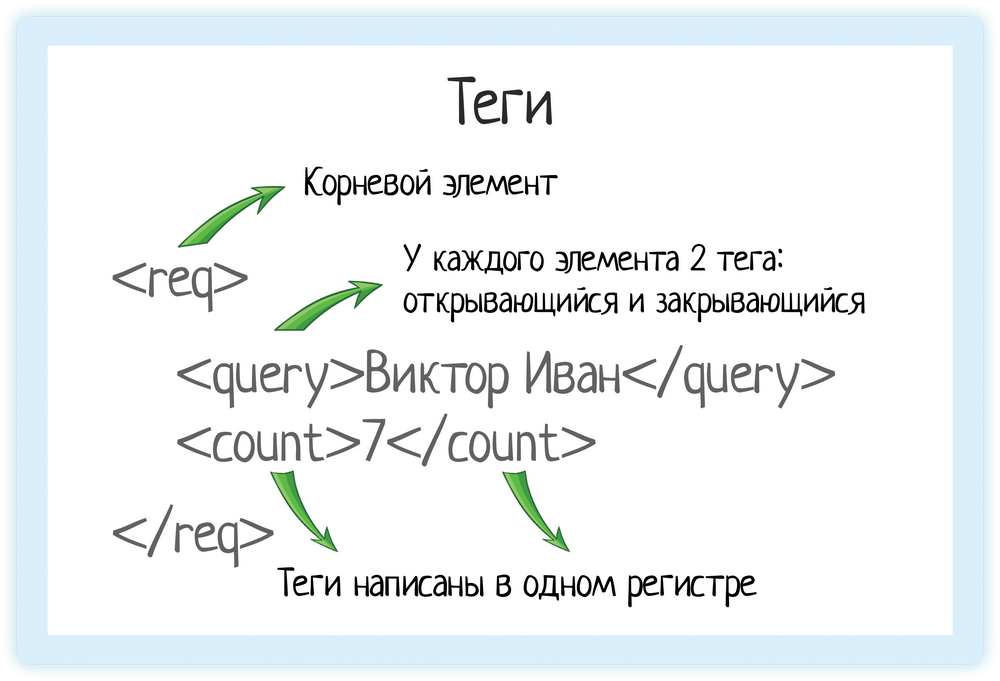
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение
<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.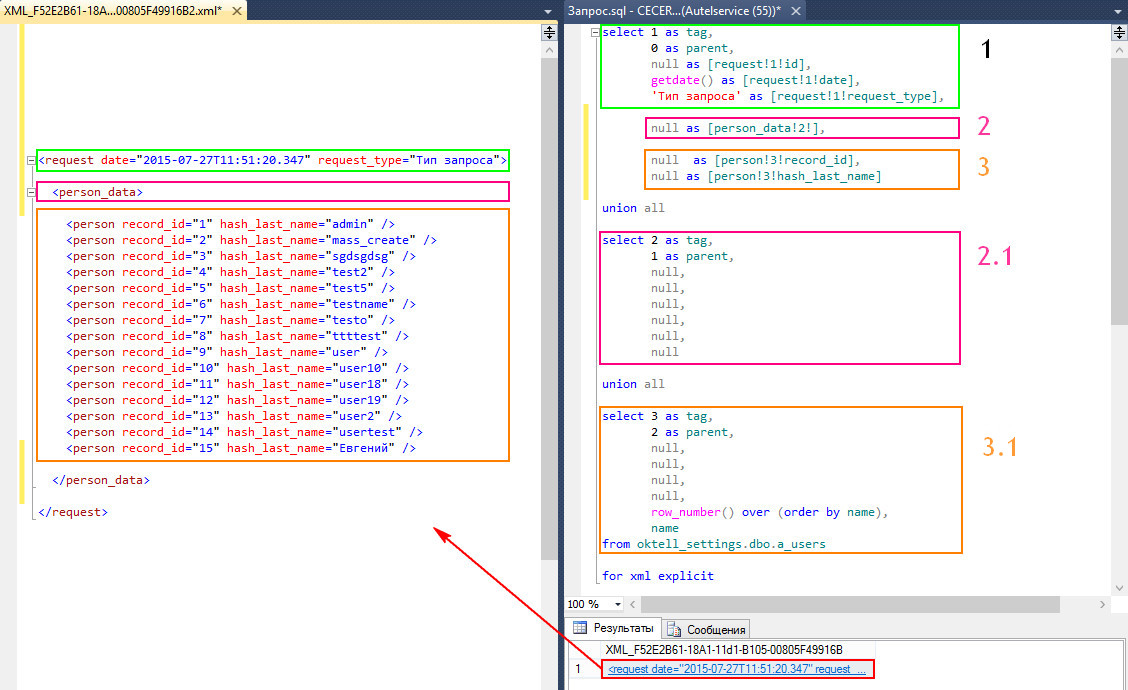
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
Для чего используется XML?
Если вы новый разработчик, вы, вероятно, сталкивались с термином XML и задавались вопросом, что он означает и как он используется. Дело в том, что независимо от того, какой язык программирования вы изучаете, вам может понадобиться знать XML, но это не сам язык программирования. Давайте посмотрим, что такое XML, почему он полезен и для чего именно он используется.
Что такое XML и почему он важен?
XML означает расширяемый язык разметки. Это язык, который используется для описания данных. Данные, хранящиеся в XML, известны как «самоопределяющиеся». Это означает, что структура данных встроена в сами данные.
Большая часть информации, доступ к которой вы получаете на компьютерах, не сохраняется в виде конечного результата, который вы видите в веб-браузере, мобильном приложении или настольном приложении. Вместо этого он существует в текстовом формате.
Использование текста для хранения данных останется, но без стандартной структуры этих данных трудно обмениваться ими между приложениями. Без стандартов данных пришлось бы писать пользовательский код для их анализа для каждого приложения, обращающегося к этим данным, и для каждого нового набора данных требовался бы собственный пользовательский код.
Без стандартов данных пришлось бы писать пользовательский код для их анализа для каждого приложения, обращающегося к этим данным, и для каждого нового набора данных требовался бы собственный пользовательский код.
Вот пример правильного XML:
Bob Janice Напоминание Не забудьте вынести мусор !
Приведенный выше XML-код действителен, поскольку тег окружает каждую часть данных, описывающую, что это такое. Это позволяет разработчикам хранить контекст вместе со своими данными в стандартном структурированном формате.
Поскольку XML имеет стандарты, его можно анализировать и интерпретировать всеми типами языков программирования и приложениями без ошибок или неверных конфигураций. Приведенный выше пример XML можно использовать между различными приложениями для обмена сообщениями, которые знают его структуру.
Для чего используется XML?
XML — это формат для хранения данных вместе с их структурой. Эта функция делает его полезным для многих вещей, включая передачу данных, форматирование документов, создание макетов и многое другое. Давайте подробнее рассмотрим, для чего используется XML.
Эта функция делает его полезным для многих вещей, включая передачу данных, форматирование документов, создание макетов и многое другое. Давайте подробнее рассмотрим, для чего используется XML.
Передача данных
Практически каждое приложение нуждается в некотором способе хранения и извлечения данных. Обычно это происходит через Интернет с использованием API (интерфейс прикладного программирования). Back-End Engineers создают API, которые работают на веб-серверах.
Один и тот же API может использоваться многими приложениями, включая веб-приложения, настольные приложения и мобильные приложения, для сохранения и доступа к данным в базе данных. Стандартный формат этих данных делает это возможным.
XML — это один из форматов, который программисты используют для передачи данных в виде структуры, которую можно анализировать всеми этими разнообразными приложениями, и он обычно используется для создания API. SOAP и XML-RPC — это два типа XML API, используемых в веб-службах. Любое приложение, которое подключается к любому из этих API, должно знать только формат для использования содержащихся в нем данных.
Любое приложение, которое подключается к любому из этих API, должно знать только формат для использования содержащихся в нем данных.
Форматирование документов
Веб-страницы представляют собой HTML-документы, а HTML очень похож на XML. HTML обрабатывается веб-браузером, который затем представляет его в визуально приятном формате. Теги в HTML-документе определяют определенные типы элементов, например заголовки, абзацы, изображения и т. д. Браузер знает, как отображать эти элементы на основе этих тегов.
HTML также хранит контекстную информацию о содержащихся в нем данных в виде атрибутов, включающих идентификатор и класс. CSS работает с HTML, чтобы применять определенные стили на основе этих атрибутов, например делать заголовок красным или устанавливать шрифт для абзаца.
Это только один пример использования XML для форматирования. Файлы PDF, файлы PostScript, документы Microsoft Word, документы PowerPoint и текстовые файлы RTF также хранятся в формате XML. Когда вы открываете эти файлы в приложении по умолчанию, оно анализирует этот XML, форматирует его и придает ему стиль, который вы видите на экране своего компьютера.
Когда вы открываете эти файлы в приложении по умолчанию, оно анализирует этот XML, форматирует его и придает ему стиль, который вы видите на экране своего компьютера.
Веб-поиск
Поисковые системы развивались годами. Первоначально они не делали ничего большего, чем определяли, содержит ли веб-страница искомую фразу. Теперь они используют теги HTML (XML), чтобы сделать поиск более точным.
Примером может служить поиск книги вашего любимого автора. Скажем, вы искали Марка Твена. Анализируя тег на HTML-страницах, поисковая система может ограничить результаты поиска только теми, где в этом теге присутствует Марк Твен, а не всеми страницами, содержащими его имя.
Создание макетов
Каждый макет в мобильном приложении Android создается в формате XML. Эти макеты определяют, где данные должны отображаться на экране телефона. Общие макеты Android включают линейный макет, который указывает приложению выравнивать содержимое на экране по горизонтали или вертикали, макет кадра, который предназначен для динамического размещения других макетов, и макет списка, который отображает элементы, которые вы можете прокручивать.
Хранение данных конфигурации
XML также хранит данные, используемые для настройки приложения. В Microsoft Excel XML содержит всю информацию, содержащуюся в электронной таблице. Не только данные, но и определения столбцов, формат полей, любые вычисления, которые они используют, и многое другое. Приложения для Android используют XML не только для макетов, но и для хранения цветов, стилей и размеров, которые будут использоваться приложением.
Где узнать больше о XML
XML — относительно простой язык для изучения. Вы можете изучать XML сам по себе, но гораздо лучше изучать его в тандеме с языком программирования для обработки и использования данных, которые он хранит.
XML часто используется в интерфейсной веб-разработке. Он также используется в серверной веб-разработке, поскольку некоторые API используют его для передачи данных в стандартном формате. Посетите наши курсы веб-разработки, чтобы узнать больше.
Приложения для Android также сильно зависят от XML для создания макетов и хранения конфигураций, поэтому вам следует изучить XML, если вы заинтересованы в разработке мобильных приложений.
Каждый язык программирования, о котором вы только можете подумать, имеет встроенные способы использования XML или сторонние библиотеки, которые делают это возможным, поэтому, когда вы выбираете язык программирования из нашего каталога курсов, есть большая вероятность, что вы столкнетесь с некоторыми XML.
XML Введение
❮ Предыдущий Далее ❯
XML — это независимый от программного и аппаратного обеспечения инструмент для хранения и передачи данных.
Что такое XML?
- XML означает расширяемый язык разметки
- XML — это язык разметки, очень похожий на HTML .
- XML был разработан для хранения и передачи данных
- XML был разработан, чтобы быть самоописательным
- XML — это рекомендация W3C .
XML ничего не делает
Возможно, это немного сложно понять, но XML ничего не делает.
Это записка для Туве от Джани, сохраненная в формате XML:
<заметка>
Приведенный выше XML-код говорит сам за себя:
- Он содержит информацию об отправителе
- Имеет информацию о приемнике
- Он имеет заголовок .
- Имеет тело сообщения

Тем не менее, приведенный выше XML ничего не делает. XML — это просто информация, заключенная в теги.
Кто-то должен написать программу для отправки, получения, хранения или отображения:
Примечание
Кому: Туве
От: Яни
Напоминание
Не забудьте меня в эти выходные!
Разница между XML и HTML
XML и HTML были разработаны с разными целями:
- XML был разработан для переноса данных с упором на то, что представляют собой данные
- HTML был разработан для отображения данных с упором на то, как данные выглядят
- Теги XML не предопределены, как теги HTML
XML не использует предопределенные теги
Язык XML не имеет предопределенных тегов.
Теги в приведенном выше примере (например,
HTML работает с предопределенными тегами, такими как
,
 д.
д. 09.2015 08:30
09.2015 08:30