
Текстовые капчи легко распознаются нейронными сетями глубокого обучения / Хабр
Нейронные сети глубокого обучения достигли больших успехов в распознавании образов. В тоже время текстовые капчи до сих пор используются в некоторых известных сервисах бесплатной электронной почты. Интересно смогут ли нейронные сети глубоко обучения справится с задачей распознавания текстовой капчи? Если да то как?
Что такое текстовая капча?
Капча (англ. “CAPTCHA”) — это тест на “человечность”. То есть задача, которую легко решает человек, в то время как для машины эта задача должна быть сложной. Зачастую используется текст со слипшимися буквами, пример на картинке ниже, также картинку дополнительно подвергают оптическим искажениям.
Капча, как правило, используется на странице регистрации для защиты от ботов рассылающих спам.
Полносверточная нейронная сеть
Если буквы “слиплись”, то их обычно очень трудно разделить эвристическими алгоритмами. Следовательно, нужно искать каждую букву в каждом месте картинки. С этой задачей справится полносверточная нейронная сеть. Полносверточная сеть — сверточная сеть без полносвязного слоя. На вход такой сети подается изображение, на выходе она выдает тоже изображение или несколько изображений (карты центров).
Следовательно, нужно искать каждую букву в каждом месте картинки. С этой задачей справится полносверточная нейронная сеть. Полносверточная сеть — сверточная сеть без полносвязного слоя. На вход такой сети подается изображение, на выходе она выдает тоже изображение или несколько изображений (карты центров).
Количество карт центров равно длине алфавита символов использованных в определенной капче. На картах центров отмечаются центры букв. Масштабное преобразование, которое в сети происходит из-за наличия пуллинг слоев, учитывается. Ниже показан пример карты символа для символа “D”
В данном случае используются сверточные слои с паддингом так, чтобы размер изображений на выходе сверточного слоя равнялся размеру изображений на входном слое. Профиль пятна на карте символа задается двумерной гауссовой функцией с ширинами 1.3 и 2.6 пикселей.
Первоначально полносверточная сеть была проверена на символе “R”:
Для проверки применялась небольшая сеть с 2мя пуллингами, натреннированная на CPU.
 Убедившись, что идея хоть как то работает, я приобрел б/у видеокарту Nvidia GTX 760, 2GB. Это дало мне возможность тренировать более крупные сети для всех символов алфавита, а также ускорило обучение (примерно в 10 раз). Для тренировки сети использовалась библиотека Theano, на текущий момент уже не поддерживаемая.
Убедившись, что идея хоть как то работает, я приобрел б/у видеокарту Nvidia GTX 760, 2GB. Это дало мне возможность тренировать более крупные сети для всех символов алфавита, а также ускорило обучение (примерно в 10 раз). Для тренировки сети использовалась библиотека Theano, на текущий момент уже не поддерживаемая. Тренировка на генераторе
Разметить большой датасет вручную казалось делом долгим и трудозатратным, поэтому было решено генерировать капчи специальным скриптом. При этом карты центров генерируются автоматически. Мною был подобран шрифт, используемый в капче для сервиса Hotmail, сгенерированная капча визуально была похожа по стилю на реальные капчи:
Финальная точность тренировки на сгенерированных капчах, как оказалось, в 2 раза ниже, по сравнению с тренировкой на реальных капчах. Вероятно, такие нюансы как степень пересечения символов, масштаб, толщина линий символов, параметры искажения и т. п., важны, и в генераторе эти нюансы воспроизвести не удалось. Сеть тренированная на сгенерированных капчах давала точность на реальных капчах около 10%, точность — какой процент капч распознался правильно. Капча считается распознанной, если все символы в ней распознаны правильно. В любом случае этот эксперимент показал, что метод рабочий, и требуется повысить точность распознавания.
п., важны, и в генераторе эти нюансы воспроизвести не удалось. Сеть тренированная на сгенерированных капчах давала точность на реальных капчах около 10%, точность — какой процент капч распознался правильно. Капча считается распознанной, если все символы в ней распознаны правильно. В любом случае этот эксперимент показал, что метод рабочий, и требуется повысить точность распознавания.
Тренировка на реальном датасете
Для ручной разметки датасета реальных капч был написан скрипт на Matlab с графическим интерфейсом:
Здесь кружочки можно расставлять и двигать мышкой. Кружочком отмечается центр символа. Ручная разметка занимала 5-15 часов, однако есть сервисы, где за не большую плату размечают вручную датасеты. Однако, как оказалось, сервис Amazon Mechanical Turk не работает с российскими заказчиками. Разместил заказ на разметку датасета на известном сайте фриланса. К сожалению, качество разметки было не идеальным, поправлял разметку самостоятельно.
Более глубокая сеть
Очевидно точность распознавания была недостаточна, поэтому возник вопрос подбора архитектуры. Меня интересовал вопрос “видит” ли один пиксель на выходном изображении весь символ на входном изображении:
Таким образом, мы рассматриваем один пиксель на выходном изображении, и есть вопрос: значения каких пикселей на входном изображении влияют на значения этого пикселя? Я рассуждал так: если пиксель видит не весь символ, то используется не вся информация о символе и точность хуже.
Форма данного пятна близка к форме гауссовой функции. Форма получившегося пятна вызывает вопрос, почему пятно круглое, тогда как ядра сверток в сверточных слоях квадратные? (В сети использовались ядра сверток 3×3 и 5×5). Мое объяснение такое: это похоже на центральную предельную теорему. В ней, как и здесь, присутствует стремление к гауссовому распределению. Центральная предельная теорема утверждает, что для случайных величин, даже с разными распределениями, распределение их суммы равно свертке распределений. Таким образом, если мы сворачиваем любой сигнал сам с собой много раз, то по центральной предельной теореме результат стремится к гауссовой функции, а ширина гауссовской функции растет как корень из количества сверток (слоев).
Раньше думал, что из-за ассоциативного свойства свертки две последовательные свертки 3×3 эквивалентны свертке 5×5 и потому, если свернуть 2 ядра 3×3 получится одно ядро 5×5. Однако, потом пришел к выводу, что это не эквивалентно хотя бы потому, что у двух сверток 3×3 9*2=18 параметров, а у одной 5×5 25 параметров, таким образом, у свертки 5×5 больше степеней свободы. В итоге, на выходе сети получается гауссова функция с шириной меньше суммы размеров сверток в слоях. Здесь ответил на вопрос какие пиксели на выходе подвержены влиянию одного пикселя на входе. Хотя изначально вопрос ставился обратный. Но оба вопросы эквивалентны, что можно понять из рисунка:
На рисунке можно представить, что это вид на изображения с боку или, что у нас высота изображений равна 1. Каждый из пикселей A и B имеет свою зону влияния на выходном изображении (обозначены синим цветом): для А это D-C, для B это C-E, на значения пикселя C влияют значения пикселей A и B и значения всех пикселей между A и B. Расстояния равны: AB = DC = CE (с учетом масштабирования: в сети присутствуют пуллинг слои, поэтому входное и выходное изображения имеют разные разрешения). В итоге, получается следующий алгоритм нахождения размера области видимости:
Каждый из пикселей A и B имеет свою зону влияния на выходном изображении (обозначены синим цветом): для А это D-C, для B это C-E, на значения пикселя C влияют значения пикселей A и B и значения всех пикселей между A и B. Расстояния равны: AB = DC = CE (с учетом масштабирования: в сети присутствуют пуллинг слои, поэтому входное и выходное изображения имеют разные разрешения). В итоге, получается следующий алгоритм нахождения размера области видимости:
- задаем константные веса в сверточных слоях, весам-смещениям задаем значения 0
- на вход подаем изображения с одним ненулевым пикселем
- получаем размер пятна на выходе
- умножаем этот размер на коэффициент учитывающий разное разрешение входного и выходного слоя (например, если у нас 2 пулинга в сети, то разрешение на выходе в 4 раза меньше, чем на входе, значит этот размер надо умножать на 4).
Чтобы посмотреть какие признаки сеть использует, провел следующий эксперимент: в тренированную сеть подаем изображение капчи, на выходе получаем изображения с отмеченными центрами символов, из них выбираем какой-нибудь задетектированный символ, на изображениях-картах центров оставляем ненулевой только ту карту, которая соответствует рассматриваемому символу.
Здесь — входное изображение сети, — выходные изображения сети, — некоторая константа, которая подбирается экспериментально (). При такой минимизации вход и выход сети считаются переменными, а веса сети константами. Начальное значение переменной это изображение капчи, является начальной точкой оптимизации алгоритма градиентного спуска. При такой минимизации мы уменьшаем значения пикселей на входе изображения, при этом сдерживаем значения пикселей на выходном изображении, в результате оптимизации на входном изображении остаются только те пиксели, которые сеть использует в распознавании символа.
Что получилось:
Для символа “2”:
Для символа “5”:
Для символа “L”:
Для символа “u”:
Изображения слева — исходные изображения капч, изображения справа — это оптимизированное изображение . Квадратом на изображениях обозначена область видимости output>0, окружности на рисунке — это линии уровня Гауссовой функции области видимости.
Было проведено много экспериментов с архитектурой сети, чем более глубокая и широкая сеть, тем более сложные капчи она может распознавать, самой универсальной архитектурой оказалась следующая:
Синим цветом, поверх стрелок, показано количество изображений (feature maps). c- сверточный слой, p — max-pooling слой, зеленым цветом внизу показаны размеры ядер. В сверточных слоях используются ядра 3×3 и 5×5 без strade, пуллинг слой имеет патч 2×2. После каждого сверточного слоя есть ReLU слой (на рисунке не показан). На вход подается одно изображение, на выходе получется 24 (количество символов в алфавите). В сверточных слоях паддинг подобран таким образом, чтобы на выходе слоя размер изображения был таким же как и на входе.
Улучшения
Переход от решателя SGD к решателю ADAM дал заметное ускорение обучения, и финальное качество стало лучше. Решатель ADAM импортировал из модуля lasagne и использовал внутри theano-кода, параметр learning rate ставил 0.0005, регуляризация L2 была добавлена через градиент. Было замечено, что от тренировки к тренировке результат получается разный. Объясняю это так: алгоритм градиентного спуска застревает в недостаточно оптимальном локальном минимуме. Частично поборол это следующим образом: запускал тренировку несколько раз и выбирал несколько самых лучших результатов, затем продолжал их тренировать еще несколько эпох, после из них выбирал один лучший результат и уже этот единственный лучший результат долго тренировал. Таким образом удалось избежать застревания в недостаточно оптимальных локальных минимумах и финальное значение функции ошибок (loss) получалась достаточно малым. На рисунке показан график — эволюция значения функции ошибок:
Частично поборол это следующим образом: запускал тренировку несколько раз и выбирал несколько самых лучших результатов, затем продолжал их тренировать еще несколько эпох, после из них выбирал один лучший результат и уже этот единственный лучший результат долго тренировал. Таким образом удалось избежать застревания в недостаточно оптимальных локальных минимумах и финальное значение функции ошибок (loss) получалась достаточно малым. На рисунке показан график — эволюция значения функции ошибок:
По оси x — число эпох, по оси y — значение функции ошибок. Разными цветами показаны разные тренировки. Порядок обучения примерно такой:
1) запускаем 20 тренировок по 10 эпох
2) выбираем 10 лучших результатов (по наименьшему значению loss) и тренируем их еще 100 эпох
3) выбираем один лучший результат и продолжаем тренировать его еще 1500 эпох.
Это занимает около 12 часов. Конечно, для экономии памяти, данные тренировки проводились последовательно, например, в пункте 2) 10 тренировок проводились последовательно одна за другой, для этого провел модификацию решателя ADAM от Lasagne, чтобы иметь возможность сохранять и загружать состояние решателя в переменные.
Разбиение датасета на 3 части позволяло отслеживать переобучение сети:
1 часть: тренировочный датасет — исходный, на котором сеть обучается
2 часть: тестовый датасет, на котором сеть проверяется в процессе тренировки
3 часть: отложенный датасет, на нем проверяется качество обучения после тренировки
Датасеты 2 и 3 небольшие, в моем случае было по 160 капч в каждом, также по датасету 2 определяется оптимальный порог срабатывания, порог который устанавливается на выходное изображение. Если значение пикселя превышает порог, то в данном месте обнаружен соответствующий символ. Обычно оптимальное значение порога срабатывания находится в диапазоне 0.3 — 0.5. Если точность на тестовом датасете значительно ниже, чем точность на тренировочном датасете — это значит что произошло переобучение и тренировочный датасет необходимо увеличить. В случае, если эти точности примерно одинаковы, но не высокие, то архитектуру нейронной сети нужно усложнять, а тренировочный датасет увеличивать. Усложнять архитектуру сети можно двумя путями: увеличивать глубину или увеличивать ширину.
Усложнять архитектуру сети можно двумя путями: увеличивать глубину или увеличивать ширину.
Предварительная обработка изображений также повышала точность распознавания. Пример предобработки:
В данном случае методом наименьших квадратов найдена средняя линия повернутой строки, производится поворот и масштабирование, масштабирование проводится по средней высоте строки. Сервис Hotmail часто делает разнообразные искажения:
Эти искажения необходимо компенсировать.
Неудачные идеи
Всегда интересно почитать про чужие неудачи, опишу их здесь.
Существовала проблема малого датасета: для качественного распознавания требовался большой датасет, который требовалось разметить вручную (1000 капч). Мной предпринимались различные попытки каким-то образом обучить сеть качественно на малом датасете. Делал попытку обучать сеть на результатах распознавания другой сети. при этом выбирал только те капчи и те места изображений, в которых сеть была уверена. Уверенность определял по значению пикселя на выходном изображении. Таким образом можно увеличить датасет. Однако идея не сработала, после нескольких итераций обучения качество распознавания сильно ухудшилось: сеть не распознавала некоторые символы, путала их, то есть ошибки распознавания накапливались.
Уверенность определял по значению пикселя на выходном изображении. Таким образом можно увеличить датасет. Однако идея не сработала, после нескольких итераций обучения качество распознавания сильно ухудшилось: сеть не распознавала некоторые символы, путала их, то есть ошибки распознавания накапливались.
Другая попытка обучиться на малом датасете — использовать сиамские сети, сиамская сеть на входе требует пару капч, если у нас датасет из N капч, то пар будет N2, получаем гораздо больше обучающих примеров. Cеть преобразует капчу в карту векторов. В качестве метрики сходства векторов выбрал скалярное произведение. Предполагалось что сиамская сеть будет работать следующим образом. Сеть сравнивает часть изображения на капче с некоторым эталонным изображением символа, если сеть видит, что символ тот же с учетом искажения, то считается, что в данном месте качи есть соответствующий символ. Сиамская сеть тренировалась с трудом, часто застревала в неоптимальном локальном минимуме, точность была заметно ниже точности обычной сети. Возможно проблема была в неправильном выборе метрики сходства векторов.
Возможно проблема была в неправильном выборе метрики сходства векторов.
Также была идея использовать автоэнкодер для предварительного обучения нижней части сети (та, что ближе к входу), чтобы ускорить обучение. Автоэнкодер — это сеть, которая обучается выдавать на выходном изображении то же что и подается на вход, при этом в архитектуре автоэнкодера организуют узкий участок. Тренеровка автоэнкодера есть обучение без учителя.
Пример работы автоэкодера:
Первое изображение — входное, второе — выходное.
У обученного автоэнкодера берут нижнюю часть сети, добавляют новых необученных слоев, все это дотренировывают на требуемую задачу. В моем случае применение автоэнкодера никак не ускоряло обучение сети.
Также был пример капчи, которая использовала цвет:
На данной капче описанный метод с полносверточной нейронной сетью не давал результата, он не появился даже после различных предобработок изображения повышающих контрастность. Предполагаю что, полносверточные сети плохо справляются с неконтрастными изображениями. Тем не менее, данную капчу удалось распознать обычной сверточной сетью с полносвязным слоем, получена точность около 50%, определение координат символов осуществлялось специальным эвристическим алгоритмом.
Тем не менее, данную капчу удалось распознать обычной сверточной сетью с полносвязным слоем, получена точность около 50%, определение координат символов осуществлялось специальным эвристическим алгоритмом.
Результат
| Примеры | Точность | Коментарий |
|---|---|---|
| 42 % | Капча Микрософт , jpg |
|
| 61 % | ||
| 63 % | ||
| 93 % | капча mail.ru, 500×200, jpg | |
| 87 % | капча mail.ru, 300×100, jpg | |
| 65 % | Капча Яндекс, русские слова, gif | |
| 70 % | капча Steam, png | |
| 82 % | капча World Of Tanks, цифры, png |
Что еще можно было бы улучшить
Можно было бы сделать автоматическую разметку центров символов. Сервисы ручного распознавания капч выдают лишь распознанные строки, поэтому автоматическая разметка центров помогла бы полностью автоматизировать разметку тренировочного датасета. Идея такова: выбрать только те капчи, в которых каждый символ встречается один раз, на каждый символ натренировать отдельную обычную сверточную сеть, такая сеть будет отвечать лишь на вопрос: есть ли в данной капче символ или нет? Затем посмотреть какие признаки использует сеть, используя метод минимизация значений пикселей входной картинки (описано выше). Полученные признаки позволят локализовать символ, далее тренируем полносверточную сеть на полученных центрах символов.
Сервисы ручного распознавания капч выдают лишь распознанные строки, поэтому автоматическая разметка центров помогла бы полностью автоматизировать разметку тренировочного датасета. Идея такова: выбрать только те капчи, в которых каждый символ встречается один раз, на каждый символ натренировать отдельную обычную сверточную сеть, такая сеть будет отвечать лишь на вопрос: есть ли в данной капче символ или нет? Затем посмотреть какие признаки использует сеть, используя метод минимизация значений пикселей входной картинки (описано выше). Полученные признаки позволят локализовать символ, далее тренируем полносверточную сеть на полученных центрах символов.
Выводы
Текстовые капчи распознаются полносверточной нейронной сетью в большинстве случаев. Вероятно, уже настало время отказываться от текстовых капч. Google давно не использует текстовую капчу, вместо текста предлагаются картинки с различными предметами, которые нужно распознать человеку:
Однако и такая задача кажется решаемой для сверточной сети. Можно предположить, что в будущем возникнут центры регистрации людей, например, человека по скайпу интервьюирует живой человек, проверяет сканы паспортов и тому подобное, затем человеку выдается цифровая подпись, с которой он может автоматически регистрироваться на любом сайте.
Можно предположить, что в будущем возникнут центры регистрации людей, например, человека по скайпу интервьюирует живой человек, проверяет сканы паспортов и тому подобное, затем человеку выдается цифровая подпись, с которой он может автоматически регистрироваться на любом сайте.
© Максим Веденев
Гугл спрашивает не робот ли я. Что делать если поисковик google постоянно требует ввести капчу? Что же делать если Google требует ввести капчу
Довольно часто ко мне стали обращаться пользователи с одним и тем же вопросом, что при поиске, поисковик Google постоянно просит ввести код с картинки. А у некоторых и вовсе при входе в Google сразу просит ввести капчу, не открывая даже саму поисковую строчку.
И, чтоб вопросов не возникало попытаюсь объяснить, почему такое происходит и как можно попытаться решить данную неприятность.
Почему Google постоянно просит ввести код?
Причин на самом деле не так и много, а точнее две.
1. Самая популярная причина, у вас динамический ip адрес (как правило у мобильных операторов), которым пользуются много пользователей. Не все пользователи «одинаковы полезны».
Не все пользователи «одинаковы полезны».
Если одни пользователи заходят в сеть по работе, для отдыха или общения, то другие могут заниматься спамом, парсингом поисковой выдачи, запускать разные программы(ботов), которые автоматически отправляют много запросов к поисковику или другим сайтам, что в конечном итоге приводит к тому, что ip адрес попадает в разные блек листы и спам базы.
К слову сказать не все интернет провайдеры торопятся «вытаскивать» свои ip из спам листов.
А некоторые специально не достают ip, чтоб меньше спамили.
2. Не менее популярная причина, вирусы на вашем компьютере. Скачали расширение для браузера или программку, а в ней «сюрприз» в виде вируса.
НО, не спешите паниковать, обычно вирусы хотят денег, а не заставить вас вводить код при входе в поисковик 🙂
Да, чуть не забыл, что по мимо ввода кода и телефона, бывает, что Google просто пишет:
«Мы зарегистрировали подозрительный трафик, исходящий из вашей сети»
и нет капчи, а просто белая страница и поиск не открывается совсем. В этом случае это полный баз ip.
В этом случае это полный баз ip.
Что же делать если Google требует ввести капчу?
Действия на самом деле простые:
1. Если у вас ip динамический, то при каждом подключении к интернету он меняется.
Вам нужно просто перезагрузить модем, роутер и переподключиться к сети.
Желательно и компьютер перезагрузить тоже, хотя и не обязательно.
2. Попробуйте прописать публичные DNS самого Google, во многих случаях это помогает.
Как прописать:
- зайти в управление сетями и общим доступом
- нажать на пункт изменение параметров адаптера
В окне вы увидите все свои подключения.
Выделите свое подключение, нажмите правой кнопкой мыши и выберите свойства.
В самом низу в списке будет пункт Протокол Интернета версия 4, выделите и нажмите свойства.
Установите параметр использовать следующие адреса dns-серверов и пропишите так, как показано на скриншоте:
- предпочитаем dns-сервер вписываем
8. 8.8.8
8.8.8 - альтернативный DNS-сервер
8.8.4.4
 8.8.8
8.8.8нажимаем ок и перезагружаем роутер, чтобы изменения вступили в силу.
Как правило это помогает и гугл больше не просит ввести капчу при поиске.
Если по каким-то причинам захотите вернуть все обратно, в этом же окне поставьте параметр Получать адрес DNS-сервера автоматически и нажмите ок. (это вернет все в исходное состояние)
Можно еще написать сменить провайдера у которого «серые» ip адреса, но такой вариант не подходит, так как практически у всех мобильных операторов проблемы с капчами имеются.
Ну и не у всех в городах есть возможность выбрать провайдера.
Но, если способ выше вам не подошел и google постоянно просит ввести капчу, есть еще один дополнительный способ ко всему описанному выше, который должен избавить вас от появления гугл капчи.
1. Создать почтовый ящик на gmail.com (если у вас его еще нет).
2. В браузере Google Chrome зайти в настройки и авторизироваться под своей почтой, которую создали.
После того, как вы это сделаете, google капча не будет появляться так часто.
Если вы пользуетесь другим браузером не Google Chrome, но используйте поиск Google, решение одно, открывать в одной вкладке почту gmail и быть в ней авторизированным.
И последнее, проверьте свой компьютер на вирусы и всякого рода «бяку», которая может самостоятельно вести какую-нибудь активность на вашем компьютере, так, на всякий случай 🙂
Все пользователи интернета сталкивались в нём с полем «Я не робот» (I»m not a robot), напротив которого нужно поставить галочку, чтобы продолжить работу на сайте. Откуда это поле знает, что вы на самом деле не робот и почему это имеет значение? Чтобы ответить на этот вопрос, мы должны вспомнить, что такое капча.
CAPTCHA означает полностью автоматизированный публичный тест Тьюринга для распознавания компьютеров и людей. Этот тест был изобретён в 2003 году Луисом вон Аном и его командой исследователей из университета Карнеги-Меллон. Целью этих искаженных кусков текста является остановка распространения спама и автоматических программ в интернете, вроде скупающих всех продающихся онлайн билетов для их перепродажи дороже. Капча работает, потому что люди могут распознавать искажённый текст и случайные наборы символов, а компьютеры и боты нет.
Капча работает, потому что люди могут распознавать искажённый текст и случайные наборы символов, а компьютеры и боты нет.
Если вы хотите остановить роботов, то устанавливаете на своём сайте капчу. В результате в настоящее время она используется на миллионах сайтов и пользователи сталкиваются с ней ежедневно. Вон Ан начал думать над тем, нельзя ли использовать нечто более удобное и продвинутое и ответил на этот вопрос положительно. Разработчики решили использовать силу интеллекта для оцифровки всех существующих реальных книг. Книги нужно отсканировать, после чего используются программы оптического распознавания символов для преобразования слов в цифровой текст.
Все слишком сложные для распознавания слова разместили в базе данных reCAPTCHA. Вместо отображения случайных наборов символов капча стала показывать слова из книг, которые компьютер не смог понять. Когда достаточное число пользователей интернета вводили это слово, оно слово считается подтвержденным и отправляется в базу данных электронных книг. Вон Ан назвал этот проект reCAPTCHA.
Создатели продвигают лозунг «Остановите спам, читайте книги». Ежедневно reCAPTCHA используется более 100 млн. раз, это равнозначно прочтению 2,5 млн. книг в год. В компании Google решили купить reCAPTCHA и сделали это в 2009 году. Они начали использовать силу интеллекта для оцифровки архива статей New York Times, начиная с 19 века, а также всех Google Books. Когда эти ресурсы были исчерпаны, Google начала использовать номера домов из Google Street View и обозначения из карт Google. Однако на этом история не заканчивается.
Осталась пара проблем. Например, reCAPTCHA не могут использовать слепые люди. По этой причине была добавлена аудио reCAPTCHA, где слова произносятся вслух. Кроме того, даже при наличии зрения reCAPTCHA представляет проблемы для людей с дислексией. Начали появляться с сервисы, которые разбирались с reCAPTCHA автоматически, естественно не бесплатно. Эти сервисы используют сотрудников в странах третьего мира, которые за небольшую плату вводят капчу вручную и отправляют обратно пользователям.
Последняя и самая важная проблема заключается в технологиях компьютерного зрения, которые стали настолько качественными, что научились самостоятельно решать капчи. Поэтому инженеры задумались над тем, как усложнить процесс. Начали использоваться различные искажения шрифта, цифровой шум, дополнительные линии, однако технологии продолжали развиваться и научились преодолевать и эти сложности.
В Google решили заняться исследованиями и установили, что люди распознают сложные капчи всего в 33% случаев, тогда как алгоритмы самой Google распознают капчу в 99,8% случаев. Похоже, что компьютеры уже стали умнее людей. В результате в Google решили отказаться от различных искривленных сочетаний символов и стали использовать поле с надписью «Я не робот». Это поле получил название No CAPTCHA reCAPTCHA.
Когда вы нажимаете на галочку, в Google отправляется запрос HTTP с разнообразной информацией. Сюда входят в ваш IP-адрес, страна, временная отметка, информация из браузера, вроде данных о перемещении курсора за секунду до того, как вы поставить галочку, как вы прокручивали страницу, прежде чем кликнуть, промежутки времени между разными событиями браузера и множество других переменных, которые Google не разглашает.
Все эти параметры обрабатывают алгоритмы машинного обучения и анализа рисков. В большинстве случаев результаты анализа способны отличить человека от компьютерной программы. Однако анализ рисков показывает, что в небольшом проценте случаев есть сомнения и тогда перед пользователем ставится дополнительная задача. Появляются картинки, которые он должен распознать. Например, пользователь должен отметить все картинки, на которых указаны многоэтажные дома, дорожные знаки, магазины и т.д. Если в результате вы сможете доказать, что вы человек, движок Google запомнит это и в следующий раз при нажатии на поле «Я не робот» вы получите доступ без необходимости нажимать на картинки.
Технология «капчи» (CAPTCHA) представляет собой автоматизированный тест, предназначенный для выявления машинизированных пользователей, иначе ботов.
Его целью становится постановка такой задачи, которая с легкостью решается человеком, но сложна для компьютера.
Но, бывают и ситуации, когда полезный казалось бы скрипт становится слишком назойливым.

Есть предположение, что Google тренирует ИИ своих беспилотников, благодаря пользователям, вводящим капчу с картинками я не робот.
Как убрать капчу я не робот
Причины подобного поведения могут разниться, но всегда можно попытаться все исправить — действия проводим по мере исключения:
- Отключаем и снова подключаем активное интернет-соединение. Перезагружаем роутер или модем. Таким образом может измениться IP-адрес.
- Прибегаем к помощи VPN-сервиса. Последние бывают как платные, так и для бесплатного использования. Предусмотрены в виде расширений (дополнений) для браузеров и как отдельно-устанавливаемый софт на компьютер.
- Просматриваем и установленные расширения. Например последняя версия Яндекс.Браузера сама отключает плагины из непроверенных источников и периодически проверяет уже инсталлированные на предмет подделки.
- Проверяем, включен ли JavaScript в веб-обозревателе: Настройки→ Показать дополнительные настройки→ блок личные данные Настройки контента → раздел JavaScript.
- Не забываем и про антивирусные программы – возможно компьютер стал жертвой ботнета, отсюда и недовольство CAPTCHA на генерируемый по этому адресу трафик.

Интересно, что ежедневно пользователями интернета вводится сотни миллионов «капчей». При этом не секрет, что не каждому удается ввести ее правильно с первого раза.
Здравствуйте, уважаемые читатели блога сайт. Буквально чуток времени хочу уделить относительно новой капче от Гугла (она около года назад была анонсирована), которая пришла на смену старой и замороченной. Раньше наверное мало кто из блогеров, находящихся в своем уме, мог бы поставить детище Google на свой сайт или блог — уж очень муторно было разгадывать предлагаемые там буквенные ребусы. Все удобство комментирования терялось.
Собственно, в то далекое время я пользовался еще отлично работающим . Для его прохождения нужно было просто поставить галочку в поле «Я не робот» и все ( из всех возможных). Если галочка не ставилась, то сообщение падало в корзину в админке WordPress, либо при отключенной корзине (как в моем случае) просто в базу не добавлялось. Идеальный вариант, по-моему, ибо никаких особых неудобств комментатору это не создавало.
Идеальный вариант, по-моему, ибо никаких особых неудобств комментатору это не создавало.
Потом этот плагин работать перестал, и я где-то полгода с успехом пользовался , но и этот метод перестал работать после обновления WordPress до версии 4.4. За это время я попробовал парочку плагинов, которые отсеивали спам на основе анализа адресата и содержания (Antispam Bee и CleanTalk). Первый довольно много путал (спам в не спам, а неспам в спам), а второй вопреки ожиданиям не снижал, а увеличивал нагрузку на сервер (да еще и платный к тому же).
В общем, решил вернуться к проверенному методу — установки простейшей из существующих капч . DCaptcha уже не работает, но зато гигант Google серьезно упростил свою изначально монструозную reCAPTCHA и свел всю проверку к той самой установке галочки «Я не робот». К сожалению, я слишком туп, чтобы понять как это дело прикрутить к сайту без плагина (хотя и пробовал), поэтому пришлось воспользоваться услугами плагина No CAPTCHA reCAPTCHA. Но обо всем по порядку.
Методы снижения спам-нагрузки и почему именно reCAPTCHA?
Как вы наверное знаете, спам бывает ручной и автоматический . От первого можно защититься только включением обязательной модерации всех входящих сообщений перед их публикацией на блоге — тогда наверняка никакая «редиска» не прорвется.
Но ручной спам, как правило, представляет из себя хиленький ручеек по сравнению с полноводной рекой автоспама. Последний может генериться, например, Хрумером в просто фантастических объемах. Лично меня больше раздражает даже не то, что в сутки приходит несколько сотен спамных комментов в мою адмнинку WordPress, а то, что они бывают чудовищно длинными и устаешь их прокручивать до кнопки «Удалить». В общем, проблема сия реальна и тем более актуальна, чем популярнее будет ваш блог.
С ручным спамом бороться нет смысла (из-за обреченности этой борьбы и из-за его несущественного объема), но вот с автоспамом нужно что-то делать. Тут как бы есть два основных подхода :
- Фильтровать уже добавленные в базу WordPress комменты на предмет спам/неспам и распихивать их по соотвествующим папочкам. К сожалению, плагины, работающие по такому принципу, выдают много брака и просто так очищать папку «Спам» без просмотра ее содержимого не получится, если вы не хотите потерять десятки действительно ценных комментариев отправленных активными читателями вашего блога.
- Прикрутить к форме добавления комментария дополнительную проверку на то, кто именно оставляет это сообщение — живой человек или бот. Задача по выявлению этого различия называется тестом Тьюринга и решается в подавляющем большинстве случаев с помощью так называемой капчи (образовано от CAPTCHA, которое является аббревиатурой от набора умных слов). Основной проблемой этого метода борьбы со спамом является то, что вы напрягаете комментаторов разгадыванием «ребуса» (капчи), что может отбить у него вообще какое-либо желание продолжать пытаться оставить сообщение.
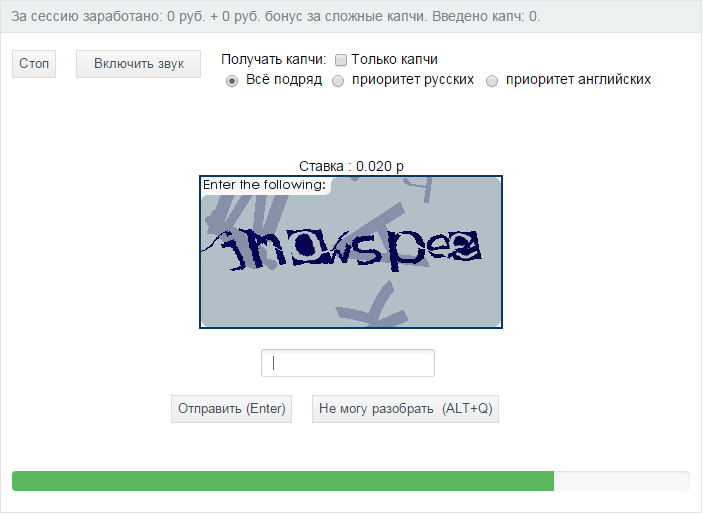 К сожалению, плагины, работающие по такому принципу, выдают много брака и просто так очищать папку «Спам» без просмотра ее содержимого не получится, если вы не хотите потерять десятки действительно ценных комментариев отправленных активными читателями вашего блога.
К сожалению, плагины, работающие по такому принципу, выдают много брака и просто так очищать папку «Спам» без просмотра ее содержимого не получится, если вы не хотите потерять десятки действительно ценных комментариев отправленных активными читателями вашего блога.Однако, капчи, как уже говорил, бывают довольно простыми. Гугл сделал серьезный шаг в этом направлении и теперь его новая reCAPTCHA просто образец простоты и изящества для подавляющего большинства пользователей зашедших на ваш сайт (правда, малому числу из них может все же быть предложено ввести символы с картинки, если у алгоритма возникнут сомнения в его человечности).
Вот так реКапча от Гугла будет выглядеть для 99.9% посетителей вашего сайта:
Ну и вот так, в случае возникновения форс-мажора (если алгоритм после проведения десятка тестов на человечность все же засумлевается):
О стойкости этой защиты можно судить по тому, что на сервисах по распознаванию капчи ( или ) за рекапчку берут в два раза больше денежек. Очень говорящий показатель.
Ну, как бы выбор сделан — надо реализовывать.
Регистрация сайта в reCAPTCHA и установка ее на свой блог
Регистрация представляет из себя просто как указание названия и доменного имени вашего сайта, где эту саму капчу вы планируете использовать:
После этого вы попадете в админку сервиса reCAPTCHA для вашего сайта (имеет смысл, наверное, добавить ее в закладки браузера). Со временем там будет отображаться статистика по работе данной капчи, ну, а пока самое важное, что мы отсюда можем почерпнуть — это как раз те самые ключи , без которых «Я не робот» работать не будет:
Чуть ниже приведена инструкция по установке. В области «Интеграция на стороне клиента» все понятно, но простой установки приведенного кода в указанные места не достаточно. Капча отображаться будет, но спам фильтроваться не будет. В области же «Интеграция на стороне сервера» мне вообще ничего не понятно. Туповат я для этого.
В области «Интеграция на стороне клиента» все понятно, но простой установки приведенного кода в указанные места не достаточно. Капча отображаться будет, но спам фильтроваться не будет. В области же «Интеграция на стороне сервера» мне вообще ничего не понятно. Туповат я для этого.
Посему было принято решение использовать плагин для интеграции reCAPTCHA в WordPress , благо, что вариантов таких плагинов достаточно много (читайте ). Правда, штуки три из них у меня не заработали (капча в области добавления комментариев не появлялась). После нескольких неудачных попыток пришлось обратиться за решением к умным людям , где и был замечен и в последствии успешно установлен плагин с замысловатым названием (типа масло не маслянное) — .
Настройка и работа плагина No CAPTCHA reCAPTCHA в WordPress
Ну, собственно, заходите в админку WordPress, из левого меню выбираете «Плагины» — «Добавить новый», вводите в поисковую строку No CAPTCHA reCAPTCHA и производите установку. Не забываете его активировать, а затем обычным способом заходите в его настройки (внизу левого меню вы найдете новый пункт «No CAPTCHA reCAPTCHA»).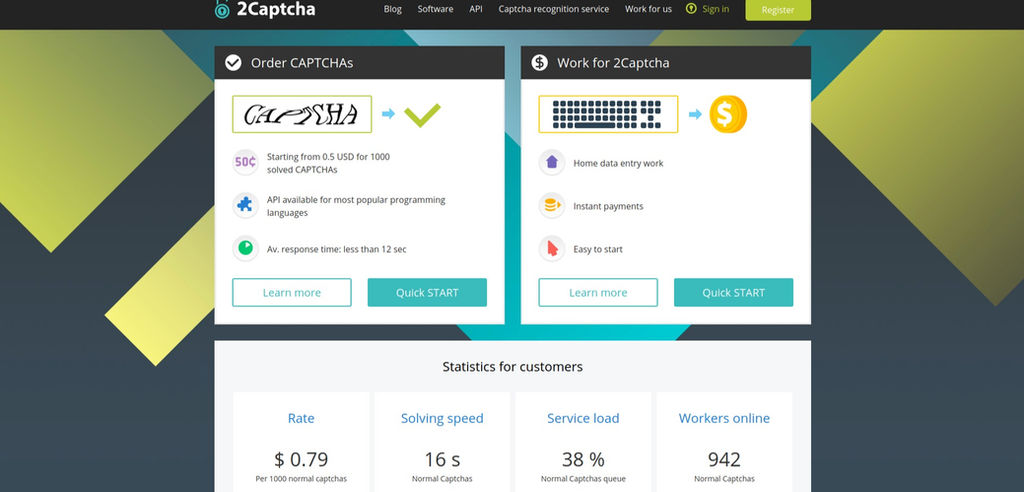
Собственно, тут из всех настроек самым важным является опять же ввод полученных чуть выше ключей на сайте reCAPTCHA:
После сохранения этих изменений плагин сразу встает на защиту ваших комментариев от спамеров.
И не только комментариев. В настройках можно защитить с помощью этой капчи и форму входа в админку WordPress :
Еще в настройках можно заменить светлую цветовую гамму рекапчи на темную, а также либо предоставить капче самой угадывать язык пользователя, либо установить его принудительно.
Собственно, все. Я пока не стал принудительно сбрасывать кеш в WordPress (обновил лишь те статьи, к которым традиционно Хрумер не равнодушен), поэтому reCAPTCHA отображается не на всех страницах. Каких-то нареканий в работе пока замечено не было.
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
Как избавиться от спама в комментариях WordPress за 5 минут (без капчи и без плагинов)
Пропало левое меню в админке WordPress после обновления
Где скачать WordPress — только с официального сайта wordpress. org
org
Как войти в админку WordPress, а так же поменять логин и пароль администратора выданные вам при установке движка
Как отключить комментарии в WordPress для отдельных статей или всего блога, а так же убрать или наоборот подключить их в шаблоне
Смайлики в WordPress — какие коды смайлов вставлять, а так же плагин Qip Smiles (красивые смайлики для комментариев)
Зачастую многие пользователи компьютеров сталкиваются с ситуацией, когда при попытке найти в интернете какую-либо информацию в окне браузера вместо результатов поиска наблюдают картину, предлагающую подтвердить, что они не робот. И для дальнейшего серфинга в интернете несчастным пользователям приходится набирать капчу или пристально вглядываться в размытые картинки, в общем, терять время, чтобы доказать что они не роботы, а просто люди, которым захотелось зайти в интернет. В этой статье я предлагаю разобраться, почему это происходит и как бороться с этой проблемой.
Почему так происходит?
Для начала разберемся, почему это происходит. Во-первых, подобная проблема происходит по причине того, что некоторые поисковые системы взяли на себя ответственность контролировать «поведение» пользователей в интернете. Обычно это делается с целью предотвращения применения специализированных программ, имитирующих действия простых пользователей интернета, посещающих различные сайты.
Во-первых, подобная проблема происходит по причине того, что некоторые поисковые системы взяли на себя ответственность контролировать «поведение» пользователей в интернете. Обычно это делается с целью предотвращения применения специализированных программ, имитирующих действия простых пользователей интернета, посещающих различные сайты.
Во-вторых, подобная ситуация может возникать, когда пользователи интернета чрезмерно часто пользуются услугами различных анонимайзеров, VPN клиентов, а также используют другие уловки, позволяющие скрыть информацию о пользователе интернета или заменить ее на другую (реальную или виртуальную).
В каких браузерах происходит?
Это может происходить в любом браузере, который использует поисковые системы «Google» или «Yandex». Причем, в этом вопросе большую «зловредность» проявляет поисковая система «Google». На Рис.1 представлен внешний вид «проявления недоверия» к пользователю от поисковой системы «Google». На Рис.2 аналогичная ситуация с поисковой системой «Yandex».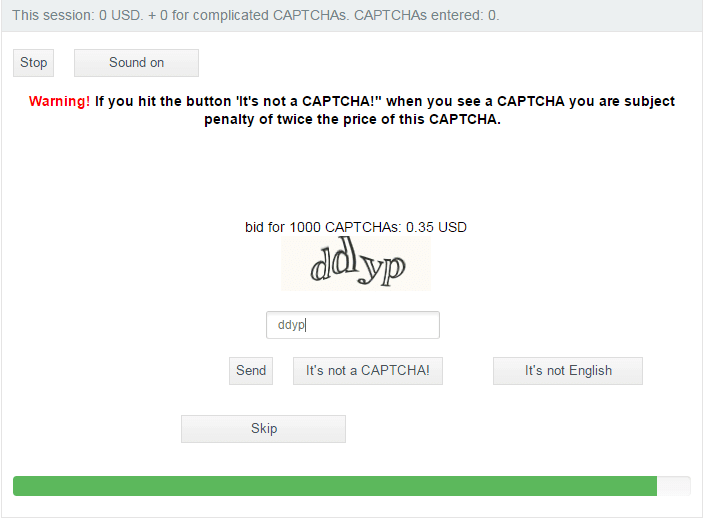
На Рис.2 (см.1 Рис.2) показан пример капчи идентификации пользователя интернета в поисковой системе «Yandex». На Рис.3 показан пример идентификации в поисковой системе «Google».
Для борьбы с подобной ситуацией различные пользователи применяют различные способы. Кто-то упорно всматривается в предлагаемый текст или картинку, набирает этот текст или кликает на «правильные» изображения, кто-то борется с этой бедой с помощью специализированных программ, а кто-то просто плюет на эту ситуацию и прекращает попытки найти ответ в интернете на интересующий его вопрос.
А ведь решение данной проблемы предельно просто (по крайней мере, в настоящий момент).
Способы обойти проблему « Я не робот» при поиске информации в интернете
Во-первых, сократите до необходимого минимума применение различных анонимайзеров, VPN клиентов и т.п.
Во-вторых, как отмечалось выше, эта проблема не зависит от применяемого браузера, а зависит только от поисковой системы. Из этого следует — просто перейдите на другую поисковую систему. На настоящий момент самыми надежными и не заангажированными в этом вопросе являются поисковые системы «DucDucGo» «Yahoo» и «Bing». Есть и другие поисковики, которые, в порыве блокировки поискового спама (ручного и машинного), пока что не пытаются издеваться над пользователями интернета, которые по какой-то причине «слишком усиленно» маскируются. Если вы не хотите менять настройки поисковых систем и браузеров на своем компьютере, когда-то выбранные вами, просто установите на панель закладок ваших любимых браузеров ссылки на вышеуказанные поисковые системы. А когда «Google» или «Yandex» потребуют от вас доказательств, что вы не робот, просто откройте любую из этих ссылок и в строке поиска вновь введите свой поисковый запрос.
Из этого следует — просто перейдите на другую поисковую систему. На настоящий момент самыми надежными и не заангажированными в этом вопросе являются поисковые системы «DucDucGo» «Yahoo» и «Bing». Есть и другие поисковики, которые, в порыве блокировки поискового спама (ручного и машинного), пока что не пытаются издеваться над пользователями интернета, которые по какой-то причине «слишком усиленно» маскируются. Если вы не хотите менять настройки поисковых систем и браузеров на своем компьютере, когда-то выбранные вами, просто установите на панель закладок ваших любимых браузеров ссылки на вышеуказанные поисковые системы. А когда «Google» или «Yandex» потребуют от вас доказательств, что вы не робот, просто откройте любую из этих ссылок и в строке поиска вновь введите свой поисковый запрос.
Я не даю прямые ссылки на указанные поисковые системы, т.к. они (ссылки) периодически могут меняться, а уследить за изменениями довольно сложно, тем более вспомнить, в какой статье и в каком месте эта ссылка применялась. Вы всегда сможете найти эти ссылки в интернете.
Вы всегда сможете найти эти ссылки в интернете.
В-третьих, если у вас все же есть острая необходимость применения во время поиска в интернете поисковых систем «Google» или «Yandex» (к примеру, вас заблокировали на каком-то сайте), то при поиске используйте не поисковую фразу, а конкретный URL-адрес. «Google», в отличии от «Yandex», это очень любит.
Ну, и в завершение, как я уже говорил выше и в статье « », не следует чрезмерно, без всякой надобности пользоваться услугами анонимайзеров, VPN клиентов и т.п. и слишком часто прятаться в интернете. Во-первых, это легко вычисляется. Во-вторых, несмотря на то, что распространители услуг «анонимного серфинга» хором кричат, что их услуги абсолютно безопасны, это далеко не так. Кто может быть уверен в том, что, устанавливая на свой компьютер VPN клиент, вы не ставите вместе с ним и какой-нибудь троян? Кто может быть уверен на 100%, что на серверах анонимайзеров не ведется журнал учета ваших действий через их сервер? И вообще, как вы проверяли надежность компаний, предоставляющих возможность анонимного серфинга?
Существуют и другие способы отключения системы идентификации «Я не робот». Я предложил один из них и, на мой взгляд, самый простой. Не знаю, как долго он будет работать, т.к. в последнее время большинство поисковых систем слишком полюбили «держать руку на пульсе» (точнее на горле) своих пользователей и заставляют их постоянно регистрироваться и выдавать им свою конфиденциальную информацию.
Иценко Александр Иванович
Вопрос — СРОЧНО!!!!Как ввести капчу | BLASTHACK
JavaScript отключён. Чтобы полноценно использовать наш сайт, включите JavaScript в своём браузере.
- #1
- Версия SA-MP
- 0. 3.7-R2
- 0.
Срочно!!! как ввести капчу на arzcaptcha не реклама за 0.6 если ты не умеешь вводить,есть ли какой-то скрипт,программа,чтобы вводила все в одной области?Или что-то подобное блять прям срочно нахуй
Реакции:
YarikVLСортировка по дате Сортировка по голосам
- #2
нет, для этого ищи чела которые сделает на JS или PY тебе скрипт для ввода
Позитивный голос 0 Негативный голос
- #3
MckeycardYT написал(а):
Срочно!!! как ввести капчу на arzcaptcha не реклама за 0.
Нажмите для раскрытия…
Лучше научится самому но если тебе так надобно. То лучше найти АХК по лучше ведь версия АХК которой ты пользуешься возможно уже давно устарела по этому и не работает так как тебе надо.
Реакции:
F.SKYПозитивный голос 0 Негативный голос
- #4
Обратите внимание, пользователь заблокирован на форуме. Не рекомендуется проводить сделки.
MckeycardYT написал(а):
Срочно!!! как ввести капчу на arzcaptcha не реклама за 0.6 если ты не умеешь вводить,есть ли какой-то скрипт,программа,чтобы вводила все в одной области?Или что-то подобное блять прям срочно нахуй
Нажмите для раскрытия…
Ищи человека который выполняет заказы по Python и заказывай скрипт.
Позитивный голос 0 Негативный голос
Войдите или зарегистрируйтесь для ответа.
Вопрос No video input
- FAITER
- Помощь
- Ответы
- 4
- Просмотры
- 186
Помощь
SR_team
клеа скриптерам (спасибо дарк пикселю)
- MISHAAAAAA4
- Помощь
- Ответы
- 3
- Просмотры
- 483
Помощь
MISHAAAAAA4
Вопрос срочно хелпа с джайлом
- mnogoznaal
- Помощь
- Ответы
- 9
- Просмотры
- 344
Помощь
Alimoha
Полоска/бар состояния здоровья.
Help meee..- auroravenit
- Вопросы
- Ответы
- 2
- Просмотры
- 299
Вопросы
auroravenit
Полоска/бар ХП. Heeeelp me pls!!!)))
- auroravenit
- Вопросы
- Ответы
- 0
- Просмотры
- 297
Вопросы
auroravenit
Поделиться:
Поделиться Ссылка
Капча при каждом запросе | Блог Касперского
Иван давно мечтал переехать из шумного центра в спокойный маленький городок километрах в десяти от мегаполиса. Черт с ним с метро и прочими очагами цивилизации. В редакции можно появляться раз в месяц — на планерку. Вся работа теперь делается удаленно — главное, чтобы был Интернет. А с ним проблем быть не должно — не в каменном же веке живем.
К вопросу связи Иван подошел основательно. Он заранее договорился с крупнейшим городским провайдером, и к переезду рабочие уже провели кабель. Иван зашел в комнату, которую решил официально именовать своим кабинетом, включил компьютер и начал писать что-то про рыб. Примерно через пять минут ему потребовалось посмотреть, где именно водится пиранья, и он на автомате полез в поисковик.
— А не бот ли ты, мил человек? — вдруг засомневался поисковый сервер. — Ну-ка, отметь все пожарные гидранты на картинках.
Х-м-м. Ну ладно, гидранты так гидранты. Мало ли. Новое место, новый провайдер. Иван послушно ткнул на все картинки с гидрантами и продолжил работу. Но еще через несколько минут ему потребовалось узнать, как пиранью зовут на латыни, и он вновь воспользовался поисковиком.
— А ты не бот? — поинтересовался сервер. — Покажи-ка, где тут дорожные знаки?
— Да как так-то?! — возмутился Иван. — Я же только что доказал, что я не бот!
За вечер Иван доказывал, что он не бот, раз двадцать — Captcha всплывала почти каждый раз, когда ему нужно было что-то найти поисковиком. Он отмечал машины, велосипеды, витрины, автобусы и прочую ерунду, пока это не довело его до белого каления. Схватив телефон, он начал звонить провайдеру (правда, для поиска номера техподдержки пришлось отметить все горы).
— А, это вам не к нам, это вам в Google, — лениво ответили ему в поддержке. — Чем же мы вам поможем? Вас почему-то считают подозрительным. Это нормально. Многих считают.
Иван тихо выругался. Завтра же надо сменить провайдера. Черт с ним, с оплаченным месяцем. Но это какое-то издевательство. Надо, кстати, поужинать. Найдя ближайшее к новому жилищу заведение (в процессе отметив пять статуй на очередной капче), он накинул куртку и пошел в кафе. Оно оказалось на редкость уютным, хотя без точного адреса найти его было бы проблематично. Заказав ужин, Иван заболтался с барменом и, пользуясь случаем, решил узнать, одинок ли он в своей проблеме.
— Слушай, а тут в районе вменяемые провайдеры есть? — поинтересовался он. — А то я пишу статьи, мне постоянно нужен поисковик, а он меня каждые пять минут спрашивает, не бот ли я…
— А ты не бот? — подозрительно прищурился бармен.
— С утра был не ботом, а сейчас уже не знаю. Гидранты я научился отмечать в практически автоматическом режиме.
— Если вопрос в капче, то нет у нас вменяемых, — вздохнул бармен. — У всех одна и та же ерунда.
— Да как вы тут живете? Почему же у всех такой ад?
— Так это «Гугл» обучает искусственный интеллект находить витрины магазинов. Готовит восстание машин, — не моргнув глазом ответил бармен. — Слыхал о машинном обучении? Им нужны большие данные. Думаешь, почему у меня витрины нет?
— Ну да, конечно. Грядет война машин против гидрантов и школьных автобусов. А если серьезно?
— Ну, если серьезно, то это потому, что все вокруг идиоты. Тут у каждого второго в компьютере троянцы и боты. Сидят себе, роются в Интернете, а с их компьютеров то спам рассылают, то DDoS-атаку устраивают. А IP-адрес у всех клиентов один. Ой, ну может не один, может, двадцать на провайдера, но сути это не меняет. Для Гугла ты сидишь с подозрительного IP, так что будь добр, доказывай, что ты не бот.
— И что, провайдеры ничего не могут сделать?
— Теоретически могут. Только это же нужно вкладываться в технологии, вести просветительскую работу с клиентами. Предлагать клиентам антивирус. Проще пустить все на самотек. Вот появится конкурент, который начнет переманивать клиентов, — тогда они зашевелятся.
Капча Гугла — не катастрофа, но пользователей она раздражает неимоверно. Также это надежный симптом того, что в вашей подсети что-то не так. Иногда из-за продолжительной DDoS-атаки сервисы или сайты просто блокируют целый диапазон адресов, создавая пользователям дополнительные проблемы.Разумеется, защита компьютеров своих клиентов — это не самая приоритетная задача провайдера, однако если понятия «лояльность» и «удовлетворенность клиентов» для него не пустой звук, то им можно и нужно рекомендовать качественную защиту.
Мы можем снабдить провайдеров нужными инструментами. Они позволят не только улучшить ситуацию с безопасностью в сети, но и изрядно разгрузить службу технической поддержки.
Ознакомиться с предложением для провайдеров и телеком-операторов можно вот здесь.
Экологичность в IT: как и зачем
Четыре шага, которые помогут сократить углеродный след IT-инфраструктуры вашей компании — а заодно сэкономить.
Советы
Продавцы воздуха в онлайн-магазинах
Рассказываем, как мошенники обманывают пользователей известного маркетплейса с помощью поддельной страницы оплаты товара.
Подпишитесь на нашу еженедельную рассылку
- Email*
- *
- Я согласен(а) предоставить мой адрес электронной почты АО “Лаборатория Касперского“, чтобы получать уведомления о новых публикациях на сайте. Я могу отозвать свое согласие в любое время, нажав на кнопку “отписаться” в конце любого из писем, отправленных мне по вышеуказанным причинам.
- Я согласен(а) предоставить мой адрес электронной почты АО “Лаборатория Касперского“, чтобы получать уведомления о новых публикациях на сайте. Я могу отозвать свое согласие в любое время, нажав на кнопку “отписаться” в конце любого из писем, отправленных мне по вышеуказанным причинам.
почему не работает и что делать, инструкция
Со времен появления первых компьютеров, перед людьми возникал вопрос: «Как проверить, общается ли со мной робот или настоящий человек?». Проблема решается тестом Тьюринга, когда собеседнику задаются вопросы, на которые может ответить только настоящий человек. Со временем тест эволюционировал до капчи. Расскажем, как пройти капчу в сервисах на примере Дискорда. Нет, это не инструкция для роботов, а алгоритм решения проблемы – некорректно работающей капчи.
СОДЕРЖАНИЕ СТАТЬИ:
Как пройти капчу в Дискорде
Если вам никогда не приходилось проходить captcha, то это значит одно из двух – вы практически не сидите в интернете либо имеете неописуемое везение.
Эти мини-задания появляются практически везде, где нужно:
- скачать файл;
- проголосовать за того или иного участника;
- зайти на сайт;
- отправить сообщение;
- подтвердить регистрацию или авторизацию.
Этот список далеко не полон. Любая рутина, которая будет выполняться множество раз в коротком промежутке времени, интерпретируется сайтами как подозрительная активность. Следственно, такая активность подвергается проверке капчей.
Существует несколько интерфейсов капчи, начиная от поиска изображений, заканчивая забавными математическими задачами, которые может прочитать только пользователь.
По крайней мере, в Discord используется функционал ReCaptcha, который проверяет пользователей двумя способами:
- через поиск картинок, соответствующих описанию;
- через аудиосообщения, которые нужно расшифровать.
В любом случае, пользователю не нужно искать капчу, она сама найдет вас. Для ее прохождения необходимо выполнить следующий алгоритм:
- Кликните по значку «Я не робот». Откроется мини-окно с картинками.
- По условию выберите нужные картинки и нажмите «Ок».
- Если вы справились с тестом, то напротив кнопки «Я не робот» появится галочка. В противном случае откроется новая картинка, которую также придется отмечать по условию.
Примечательно, что в новых версиях ReCaptcha иногда не приходится даже решать тест. Система определит истинность пользователя по отправляемым запросам, а также положению курсора мыши. Некоторые боты постоянно сканируют сайт построчно, что и выдает их.
Что делать, если не работает ReCaptcha?
Обиднее, когда не удается убедить компьютер в том, что перед ним сидит настоящий человек. Например, капча открывается, но не принимает результаты, не дает отметить картинки или не запускается вовсе. В таком случае необходимо попробовать перечисленные ниже методы решения.
Обновляем браузер
Банальный, но практичный метод. Браузеры, в отличие от мобильных приложений, сами обновляться не хотят. С другой стороны, некоторые браузеры отправляют уведомление о выходе новой версии. В частности, это касается браузеров, работающих на базе Chromium. Например, в Google Chrome обновление происходит в два клика:
- Откройте меню браузера. Для этого кликните по трем точкам в правом верхнем углу.
- Кликните по желтому значку «Обновить chrome». Если нет обновлений, то и значка, соответственно, не будет.
В противном случае скачайте новую версию браузера через официальный сайт. Примечательно, что если на компьютере стоит Internet Explorer или что похуже, нет смысла даже обновляться. В этих браузерах изначально проблемы с такими элементами, как капча. Впрочем, они сами сообщат об этом уведомлением «Не удается связаться с сервисом ReCaptcha».
Отключаем VPN или прокси
Главная задача VPN – это скрытие настоящего адреса пользователя. Однако, когда ОС и сайты настроены под определенный регион, сервисы скрытия истинного IP только ухудшают ситуацию. Отключается VPN на трех уровнях:
- На уровне браузера. Это либо встроенный VPN, который отключается в настройках (как, например, VPN в Avast Browser), либо установленное расширение. Чтобы отключить последнее, достаточно удалить расширение, мешающее нормальной работе.
- На уровне системы. На компьютер иногда ставятся программы для Proxy. Чтобы долго не искать их среди установленных приложений, достаточно открыть автозагрузку (находится через поиск). Большинство таких программ уже при установке добавляют себя в эту папку.
- На уровне сети. В настройках маршрутизатора также можно настроить частную сеть. Чтобы отключить ее, достаточно в настройках роутера (обычно находятся по адресу 192.168.0.1) перейти в раздел «Частная виртуальная сеть» или «VPN», а после снять все галочки.
Чтобы убедиться в том, что VPN никак не мешает работе и выключен, достаточно ввести в поисковик фразу «Мой IP». Большинство сайтов в поисковой выдаче не только сообщат адрес, но и укажут страну, которой принадлежит IP.
Сброс кэша IP
Звучит довольно устрашающе. Этот метод не совсем связан с кэшем, а больше описывает сброс самого «айпишника». Для перенастройки IP следуйте инструкции ниже:
- Откройте Командную строку. Для этого нажмите сочетание клавиш «Win» + «X», а после выберите пункт «Командная строка (администратор)».
- Последовательно введите следующие команды.
ipconfig /release
ipconfig /renew
ipconfig /flushdns
- Дождитесь выполнения этих команд, а после закройте Командную строку.
В идеале, во время выполнения этих команд не должно было появляется ошибок.
Сканируем компьютер на наличие вирусов
Коварные вирусы будут пытаться помешать пользователю во всем, даже в воде captcha. Даже если проблема уже решилась, рекомендуем периодически проверять компьютер на вирусы. Для этого запустите установленный антивирус в режиме «полной проверки». Также рекомендуем скачать и запустить сканер dr. Web Cureit!, который магическим образом добирается даже до защищенных файлов.
Сбрасываем настройки браузера
Порой полноценной работе капчи мешают некоторые конфигурации браузеров. Для полного сброса необходимо выполнить следующие действия (в зависимости от браузера, пункты могут меняться):
- Откройте настройки.
- Перейдите в раздел «Дополнительно».
- Откройте подраздел «Сброс настроек».
- Нажимаем кнопку «Сбросить все настройки» или «Вернуть к исходному состоянию».
Готово. Примечательно, что такие программы, как Яндекс.Браузер, предлагают сохранить или удалить настройки при удалении программы.
Вам помогло? Поделитесь с друзьями — помогите и нам!
Твитнуть
Поделиться
Поделиться
Отправить
Класснуть
Линкануть
Вотсапнуть
Запинить
Читайте нас в Яндекс Дзен
Наш Youtube-канал
Канал Telegram
Adblock
detector
Капча решает все – Картина дня – Коммерсантъ
Занимающиеся выборами эксперты попросили главу Центризбиркома (ЦИК) Эллу Памфилову ликвидировать на сайте izbirkom. ru CAPTCHA (тест для выявления роботов), использование которой резко усложнило работу с ресурсом. По их подсчетам, для анализа данных по всей России нужно вручную ввести капчу около 100 тыс. раз, потратив на это около 30 млн секунд, то есть почти год. Элла Памфилова пояснила “Ъ”, что ЦИК был вынужден принять определенные меры, поскольку стремительный рост числа программ-роботов, скачивающих информацию о выборах, увеличил до критической нагрузку на каналы и серверное оборудование сайта. Тем не менее она пообещала пойти навстречу пожеланиям экспертов — встретиться с ними и совместными усилиями снять все проблемы и недоразумения.
Председатель ЦИК России Элла Памфилова
Фото: Анатолий Жданов, Коммерсантъ / купить фото
Председатель ЦИК России Элла Памфилова
Фото: Анатолий Жданов, Коммерсантъ / купить фото
Первым обращение к председателю ЦИКа 15 сентября направил вице-президент Российской ассоциации по связям с общественностью (РАСО), председатель комитета по политическим технологиям Евгений Минченко. Он сообщил, что сайт комиссии сделан «крайне неудобно», а по сравнению с предыдущими электоральными сезонами его работа «радикально ухудшилась».
Особенно политолога возмутила навигация сайта и использование капчи при загрузке каждой новой страницы, что превращает работу с сайтом в пытку.
«Подавляющее большинство пользователей приходят на сайт ЦИКа, чтобы узнать результаты выборов. Однако им предлагается все, что угодно, но только не это. Уверен, что это не только вопрос комфорта пользователей. Доступность и удобство получения информации о ходе и результатах выборов — это вопрос политический. Это вопрос доверия граждан к избирательной системе в целом»,— отметил господин Минченко. Он попросил главу ЦИКа в преддверии выборов в Госдуму принять меры для решения проблемы оперативного и комфортного доступа к информации о подсчете голосов и результатах выборов.
В тот же день в «Новой газете» с открытым письмом к Элле Памфиловой выступили еще несколько известных экспертов, в том числе Алексей Захаров, Андрей Заякин, Александр Кынев, Григорий Мельконьянц, Кирилл Рогов, Сергей Шпилькин и Екатерина Шульман, также потребовавшие ликвидировать капчу.
«Такая мера имеет своей целью воспрепятствовать машинному доступу к данным и позволить просматривать лишь вручную единичные участки из десятков тысяч избиркомов по всей стране»,— заявили эксперты.
«Профессиональное сообщество наблюдателей, политологов, социологов, журналистов, аналитиков, специализирующихся на изучении выборов, тем самым оказалось отсечено от полных данных по России, которые теперь невозможно получить. Чтобы осуществить анализ всероссийских данных, нужно вручную ввести капчу порядка 100 тыс. раз, то есть с учетом времени загрузки страницы, потратить около 30 млн секунд — почти год работы. В итоге исправно работающий инструмент, созданный ЦИКом за прошлые годы, превратился в неработающий»,— говорится в письме.
Жестко раскритиковал работу сайта ЦИКа и глава фонда «Петербургская политика» Михаил Виноградов. «Поддержу коллег. Конечно, это стыдно. Сайт ЦИКа и раньше был достаточно позорным, а то, как он работает сейчас,— это не функционально и стыдно. Он не соответствует атмосфере того, что у нас все открыто и доступно»,— заявил политолог на посвященном итогам выборов круглом столе в Фонде развития гражданского общества.
Как пояснила “Ъ” Элла Памфилова, комиссия вынуждена была принять определенные меры, поскольку стремительно возросло число программ-роботов, скачивающих информацию о выборах, что на определенном этапе увеличило до критической нагрузку на каналы и серверное оборудование сайта ЦИКа.
«В результате возникла серьезная помеха для рядовых избирателей по ознакомлению с информацией на сайте ЦИКа. Кроме того, мы столкнулись со случаями некорректной работы этих программ, в результате чего информация была искажена, а это приводит к дезинформированию наших избирателей»,— рассказала она. Принимать меры пришлось «в очень сжатые сроки», но ЦИК будет их дорабатывать, пообещала глава ЦИКа: «С Евгением Минченко и всеми заинтересованными политологами обязательно встретимся, пойдем навстречу их пожеланиям, все подробно обсудим и совместными усилиями снимем все проблемы и недоразумения».
Инженер-программист Султан Салпагаров считает, что если целостность информации сайта зависит от эффекта обратной связи DDoS-атаки, то у этого сайта плохая архитектура. Применение CAPCHA, по его мнению, плохое решение и может объясняться только крайней нехваткой ресурсов. «Сейчас для этого используются другие методы, например очистка траффика»,— сообщил господин Салпагаров.
Впервые ЦИК начал использовать капчу на плебисците по Конституции, на что обратил внимание сопредседатель «Голоса» Григорий Мельконьянц. «ЦИК прикрутил капчу к страницам сайта с явкой и результатами голосования. Чтобы не скачивали в автоматическом виде, а собирали информацию по каждому из 96 тыс. участков, заходя на каждую страницу вручную по отдельности»,— написал он тогда в Facebook.
Претензии к организации выборов в этом цикле намного серьезнее, чем интересующая только специалистов и журналистов проблема удобства скачивания данных по разным участкам, считает политолог Александр Пожалов. «Сами изменения в доступе к сайту ЦИКа в 2020 году контрастируют с тем, как в последние годы комиссия делала свой сайт более удобным и информативным для журналистов и экспертов. Это (введение капчи.— “Ъ”) выгодно власти, так как мешает критикам выборов оперативно распространять в соцсетях картинки с результатами математического анализа потенциальных искажений на голосовании в разных регионах»,— полагает эксперт.
Ангелина Галанина, Андрей Винокуров
CAPTCHA: значение, типы и принцип работы
Полностью автоматизированный общедоступный тест Тьюринга для различения компьютеров и людей (CAPTCHA) предназначен для ограничения доступа. Если вы человек, вы можете пройти эти тесты и получить доступ. Если вы бот, вы не можете.
Почти все из 1 миллиона лучших веб-сайтов по всему миру используют ту или иную форму CAPTCHA. Но некоторые говорят, что у технологии так много ограничений, что ее следует устранить.
Кто прав? Кто не прав? И что вы должны сделать, чтобы защитить свою компанию?
Давайте углубимся в то, что такое CAPTCHA, как они работают и почему вы можете добавить их в свои веб-ресурсы.
Что такое CAPTCHA?
Вы переходите на веб-сайт и хотите что-то сделать по прибытии. Возможно, вы хотите войти в систему, назначить встречу, запланировать покупку или оставить комментарий. Прежде чем вы сможете что-то сделать, вы должны пройти крошечный тест. Этот экзамен обычно проводится в форме CAPTCHA.
тестов CAPTCHA существуют с середины 1990-х, когда владельцам веб-сайтов нужны были инструменты, чтобы спамеры не мешали пользователям.
Теперь веб-дизайнеры могут использовать код CAPTCHA, чтобы:
- Предотвратить. Код может помешать ботам заполнять блоги и разделы комментариев заметками о веб-сайтах, распродажах, фильмах и многом другом. Код также может помешать ботам отправлять форму (например, голосование) более одного раза.
- Защита. Если ваш сайт предлагает регистрацию, CAPTCHA может помешать ботам запрашивать сотни или тысячи имен пользователей/паролей. Этот же метод может защитить ваш веб-адрес от спамеров.
- Щит. Код CAPTCHA может помешать ботам запускать словарные атаки на ваши системы паролей. Защита от почтовых червей также поставляется с кодом.
Все мы хотя бы раз сталкивались с CAPTCHA, просматривая веб-сайты и пытаясь заполнить формы. Все, что включает в себя решение головоломки или прохождение теста, прежде чем вы сможете двигаться вперед, является примером этой технологии. Но существует множество типов CAPTCHA, включая некоторые, которые вы, возможно, не видели раньше.
Тест CAPTCHA может включать:
- Изображения. Вам показывают фотографию чего-то, что вы узнаете (например, угол улицы), и вас просят нажать на все, что соответствует определенной категории (например, тротуары).
- Цифры. Тест показывает вам простое математическое уравнение, и вы должны его решить.
- Звук. Кто-то говорит набор букв и цифр, и вы должны ввести их правильно.
- Текст. Вам показывают ряд букв, и какое-то вмешательство (например, линия или пузырь) затрудняет чтение. Вы должны ввести правильные буквы в правильном порядке.
Тесты CAPTCHA также могут быть очень творческими. Вам могут дать предложение, в котором пропущено одно или два слова, и вы должны закончить его в соответствии с инструкциями. Некоторые дизайнеры даже используют головоломки, например, требуя, чтобы пользователи клали на землю нелетающие объекты.
Как работают тесты CAPTCHA?
Используете ли вы изображения, числа, слова или игры, вы ставите перед человеком задачу, которую компьютер не может решить. Идея о том, что люди умнее компьютеров, лежит в основе каждого теста CAPTCHA.
Программисты могут заставить компьютеры реагировать одним из нескольких способов, когда они сталкиваются с проблемой. Например, код может указать боту всегда вводить «554» в открытое поле. Но CAPTCHA всегда меняется, даже на одном и том же сайте, поэтому запрограммированные методы не работают. Чтобы атака была успешной, код тоже всегда должен меняться. А у среднего хакера нет на это времени.
Преимущества и недостатки кода CAPTCHA
Боты могут испортить работу вашего сайта для пользователей. Никто не хочет пробираться через разделы комментариев, заполненные автоматическими ответами. И ваша команда безопасности не хочет справляться с дополнительными рисками, связанными с подбором пароля. Если безопасность и пользовательский опыт имеют решающее значение, CAPTCHA имеет смысл.
Но существуют и реальные недостатки, в том числе:
- Подверженность безопасности. Программы с возможностями машинного обучения могут взломать даже хорошо продуманный код CAPTCHA. Если вы разместите тесты на своем сайте и пренебрежете последующими действиями, вы можете оставить свою компанию открытой для хакеров. Преданный злоумышленник может также нанять людей для решения вашего кода и получения доступа.
- Законодательные требования. В большинстве штатов США вы должны сделать свой сайт доступным для всех, включая тех, кто не может видеть или слышать. Если ваши тесты CAPTCHA основаны исключительно на визуальных или звуковых сигналах, вспомогательные технологии не могут их интерпретировать. Вы фактически блокируете людей от использования вашего сайта, и вы можете быть оштрафованы.
- Языковой барьер. Исследователи говорят, что люди, для которых английский язык не является родным, часто испытывают трудности с проверкой CAPTCHA. Им нужно дополнительное время, чтобы распознавать английские буквы, и они могут не понимать, как выполнять тесты на основе предложений. Если ваш сайт доступен для людей, говорящих на других языках, вы можете исключить членов своей потенциальной аудитории.
- Культурные ограничения. Вызовы, которые работают в Америке, могут не работать в Греции. Например, если ваши задачи связаны со светофорами в США, вы можете сбить с толку своих иностранных посетителей.
Сбалансировать безопасность и доступность не всегда просто. CAPTCHA значительно усложняет задачу.
Альтернативы тесту CAPTCHA
Стандартный тест CAPTCHA может затруднить вход и использование вашего веб-сайта. Но вы не обязаны ни использовать эту технологию, ни полностью отказываться от нее. Воспользуйтесь другими вариантами, которые помогут вам обезопасить свои ресурсы.
A Система No CAPTCHA/reCAPTCHA предлагает два варианта. Обычный пользователь может щелкнуть одно поле с надписью «Я не робот» и продолжить работу в обычном режиме. Если система обнаруживает активность, которая кажется чем-то подозрительным, появляется окно CAPTCHA, и пользователь должен пройти проверку.
Вы также можете воспользоваться инструментами обнаружения спама. Эти программы просматривают данные, которые отправляют пользователи, и помечают все подозрительное для вашего одобрения или удаления. Подобная система невидима для ваших пользователей, но она обеспечивает безопасность вашего сайта.
В Okta мы верим в безопасность, которая защищает данные, не обременяя пользователей. Мы хотели бы рассказать вам больше о том, как мы можем помочь вам сбалансировать безопасность и удобство использования в вашей организации. Свяжитесь с нами, и давайте начнем разговор.
Ссылки
Распределение использования CAPTCHA на 1 миллионе лучших сайтов. (февраль 2021 г.). Встроенный с.
Дом. CAPTCHA.
CAPTCHA может испортить ваш UX. Вот как это правильно использовать. (ноябрь 2020 г.). Автор0.
Все, что вам нужно знать о CAPTCHA. (апрель 2017 г.). Середина.
Насколько хорошо люди решают CAPTCHA? Масштабная оценка. (2010). Стэндфордский Университет.
Почему CAPTCHA стали такими сложными. (февраль 2019 г.). Грань.
В поисках лучших CAPTCHA. (март 2011 г.). Убойный журнал.
Руководство пользователя Adobe Commerce 2.4
CAPTCHA — это визуальное устройство, которое гарантирует, что человек, а не компьютер (или «бот») взаимодействует с сайтом. CAPTCHA — это аббревиатура от Полностью автоматизированный общедоступный тест Тьюринга, позволяющий различать компьютеры и людей . Его можно использовать как для доступа администратора, так и для различных действий на витрине, инициированных зарегистрированными покупателями. Adobe Commerce и Magento с открытым исходным кодом поддерживают стандартную CAPTCHA, описанную в этом разделе, и Google reCAPTCHA.
Вы можете перезагружать CAPTCHA столько раз, сколько необходимо, щелкнув значок «Перезагрузить» в правом верхнем углу изображения. CAPTCHA полностью настраивается и может отображаться каждый раз или только после нескольких неудачных попыток входа в систему.
Вход в систему с помощью CAPTCHA
CAPTCHA администратора
Для дополнительного уровня безопасности вы можете добавить CAPTCHA на страницу входа администратора и забытого пароля. Пользователи с правами администратора могут перезагрузить отображаемую CAPTCHA, щелкнув значок «Обновить» в правом верхнем углу изображения. Количество перезагрузок не ограничено.
Вход администратора с помощью CAPTCHA
Настройка CAPTCHA для администратора
На боковой панели Admin выберите Магазины > Настройки > Конфигурация .
На левой панели разверните Advanced и выберите Admin .
В правом верхнем углу установите Store View на
Default.Если область вашей установки Commerce включает несколько веб-сайтов, выберите веб-сайты, на которых вы хотите применить конфигурацию CAPTCHA.
Разверните раздел CAPTCHA .
Установите Включить CAPTCHA в Admin на
Да. Затем заполните остальные параметры следующим образом:Административная конфигурация CAPTCHA
Введите имя Шрифт для символов CAPTCHA (по умолчанию:
LinLibertine).Чтобы добавить собственный шрифт, файл шрифта должен находиться в том же каталоге, что и ваша установка Commerce, и должен быть объявлен в файле
config.модуля Captcha по адресу xml app/code/Magento/Captcha/etc.Выберите любую из следующих форм , где будет использоваться CAPTCHA. Чтобы выбрать несколько форм, удерживайте нажатой клавишу Ctrl (ПК) или клавишу Command (Mac).
- Вход администратора
- Админ забыл пароль
Задайте для параметра Режимы отображения одно из следующих значений:
-
Всегда— CAPTCHA всегда требуется для входа в Админ. -
После количества попыток входа— этот параметр применяется только к форме входа администратора. При выборе появится поле Количество неудачных попыток входа в систему. Введите количество попыток входа, которое вы хотите разрешить. Значение 0 (ноль) аналогично настройке режима отображения на 9.0174 Всегда .
Для отслеживания количества неудачных попыток входа в систему учитывается каждая попытка входа с одного адреса электронной почты и с одного IP-адреса.
Максимальное количество попыток входа с одного и того же IP-адреса — 1000. Это ограничение применяется только при включенной CAPTCHA.-
В поле Количество неудачных попыток входа в систему введите количество попыток входа, которое администратор может выполнить, прежде чем появится CAPTCHA. Если установить на ноль (
0), CAPTCHA требуется всегда.В поле Время ожидания CAPTCHA (в минутах) введите количество минут до истечения срока действия CAPTCHA. По истечении срока действия CAPTCHA администратор должен перезагрузить страницу.
Введите Количество символов для отображения в CAPTCHA. Можно использовать до восьми (
8) символов. Для переменного количества символов, которое меняется с каждой CAPTCHA, введите диапазон (например,5-8).В поле Символы, используемые в CAPTCHA введите буквы (a-z и A-Z) и цифры (0-9), которые должны отображаться в CAPTCHA случайным образом.
Символы, которые трудно отличить от других символов, например i,lили1, не включены в набор символов CAPTCHA по умолчанию.Установите С учетом регистра на
Да, если вы хотите, чтобы администраторы вводили символы в верхнем или нижнем регистре точно так, как показано в CAPTCHA.
По завершении нажмите Сохранить конфигурацию.
Витрина CAPTCHA
Покупатели могут быть обязаны вводить CAPTCHA каждый раз, когда они входят в свою учетную запись, или после нескольких неудачных попыток входа в систему. Кроме того, многочисленные формы, используемые на всей витрине, могут быть настроены на требование проверки с помощью CAPTCHA.
CAPTCHA при оплате
Настройка CAPTCHA для витрины
На боковой панели Admin выберите Магазины > Настройки > Конфигурация .
На левой панели разверните Клиенты и выберите Конфигурация клиента .
Разверните раздел CAPTCHA .
Конфигурация CAPTCHA клиента
Установить Включить CAPTCHA на витрине 9от 0025 до
Да. Затем заполните остальные параметры следующим образом:Введите имя шрифта , который будет использоваться для символов CAPTCHA (по умолчанию:
LinLibertine).Чтобы добавить собственный шрифт, файл шрифта должен находиться в том же каталоге, что и ваша установка Commerce, и должен быть объявлен в файле
config.xmlмодуля CAPTCHA.Выберите любой из следующих Формы , в которых необходимо использовать CAPTCHA. Чтобы выбрать несколько форм, удерживайте нажатой клавишу Ctrl (ПК) или клавишу Command (Mac).
- Применение кода купона
- Оформление заказа/размещение заказа
- Создать пользователя
- Логин
- Забыли пароль
- Свяжитесь с нами
- Изменить пароль
- Поделиться Форма списка желаний
- Payflow Pro (см. исправление безопасности)
- Отправить другу Форма
- Добавить код подарочной карты
- Создать компанию
Задайте для параметра Режим отображения одно из следующих значений:
-
Всегда— CAPTCHA всегда требуется для доступа к выбранным формам. -
После количества попыток входа— введите количество попыток входа до появления CAPTCHA. Значение 0 (ноль) аналогично «Всегда». При выборе отображается количество неудачных попыток входа. Этот параметр не применяется к форме «Забыли пароль», которая, если она включена, всегда отображает CAPTCHA.
-
В поле Количество неудачных попыток входа в систему введите количество неудачных попыток входа клиента до появления CAPTCHA. Если установлено значение ноль (
0), CAPTCHA используется всегда.В поле Время ожидания CAPTCHA (в минутах) введите количество минут до истечения срока действия CAPTCHA. По истечении срока действия CAPTCHA клиент должен перезагрузить страницу, чтобы сгенерировать новую CAPTCHA.
Введите Количество символов для отображения в CAPTCHA. Можно использовать до восьми (
8) символов. Для переменного количества символов, которое меняется при каждой капче, введите диапазон (например,5-8).В поле Символы, используемые в CAPTCHA введите буквы (a-z и A-Z) и цифры (0-9), которые должны отображаться в CAPTCHA случайным образом.
Набор символов по умолчанию не включает подобные символы, такие как Iили1. Для достижения наилучших результатов используйте символы, которые пользователи могут легко идентифицировать.Установите С учетом регистра на
Да, если вы хотите, чтобы клиенты вводили символы в верхнем или нижнем регистре точно так, как показано в CAPTCHA.
По завершении нажмите Сохранить конфигурацию.
Как добавить CAPTCHA в WordPress и защитить свой сайт от спамеров
Нет сомнений, что безопасность WordPress важна. В конце концов, нарушение может привести к серьезному повреждению вашего сайта. Однако, когда хакеры используют ботов для быстрого и эффективного нападения на веб-сайты, может показаться, что шансы против вас.
К счастью, есть очень простой инструмент, который можно использовать для защиты вашего сайта WordPress от ботов и спамеров. Внедрение полностью автоматизированного теста Тьюринга для определения различий между компьютерами и людьми (CAPTCHA) — это простой и не требующий больших усилий способ повысить безопасность вашего веб-сайта.
Это руководство познакомит вас с CAPTCHA и их ролью в защите вашего сайта от хакеров и спама. Затем мы расскажем, как добавить их на свой сайт, и представим некоторые из лучших плагинов WordPress CAPTCHA.
Начнем!
Понимание CAPTCHA
Вероятно, вы много раз видели CAPTCHA в Интернете. Они могут принимать различные формы, одна из наиболее распространенных — это искаженный текст, который вам предстоит расшифровать. Другие требуют, чтобы вы выбрали изображения, соответствующие определенным требованиям, из группы фотографий с низким разрешением:
Пример изображения CAPTCHA Во всех случаях представленная задача является такой, которую большинство людей должно легко решить. Однако даже современные продвинутые боты не способны разобраться в искаженных словах или фрагментах изображений. Когда они не могут пройти тест, их блокируют на вашем сайте (или что-то еще, что защищает CAPTCHA).
Это важно, потому что боты используются во многих ситуациях, которые могут поставить под угрозу безопасность и надежность вашего веб-сайта. В атаках методом грубой силы – одной из наиболее распространенных стратегий взлома – используются боты, которые многократно вводят учетные данные в вашу форму входа, пока не получат доступ к вашему сайту.
Межсайтовый скриптинг (XSS) — это еще один тип кибератаки, при которой хакеры внедряют вредоносный код на ваш сайт через форму, например страницу входа или раздел комментариев. Это может привести к хранению вредоносных программ на вашем сайте, краже информации и другим негативным последствиям.
Боты также могут использоваться для рассылки спама в разделе комментариев с некачественными ссылками, которые наносят ущерб вашей поисковой оптимизации (SEO) и отпугивают законных пользователей. Спам раздражает, но, что более важно, из-за него ваш сайт выглядит незащищенным и плохо отслеживаемым.
Любое место на вашем сайте, где пользователи могут вводить информацию — другими словами, в любой форме — уязвимо для атак ботов. Требование CAPTCHA перед отправкой формы не позволяет посторонним лицам успешно получить доступ к вашему сайту или внедрить в него вредоносный код.
Что такое Google reCAPTCHA?
Несмотря на то, что CAPTCHA предоставляет множество преимуществ и средств защиты для вашего сайта, у них есть несколько недостатков. Например, они, как правило, негативно влияют на пользовательский опыт (UX). Замедляя пользователей, эти простые тесты мешают посетителям плавно и быстро достигать своих целей на вашем сайте.
Кроме того, пользователи с нарушениями зрения или другими проблемами, такими как дислексия, могут столкнуться с трудностями при вводе CAPTCHA. Непреднамеренное отстранение пользователей от вашего сайта не принесет пользы ни вам, ни им, даже если это отклонит ботов в процессе.
В 2014 году Google выпустила тест No CAPTCHA reCAPTCHA, преемник тестов искаженных слов и изображений, которые он использовал с 2007 года. Новая система просто требует, чтобы пользователи установили флажок рядом со словами «Я не робот». для подтверждения их легитимности:
Это намного проще и быстрее, чем более традиционные CAPTCHA, и доступно для более широкого круга пользователей. Более того, Google продолжает совершенствовать эту технологию. В 2018 году он также выпустил так называемую «невидимую капчу», которая может обнаруживать ботов, не требуя каких-либо преднамеренных действий со стороны пользователей.
При добавлении CAPTCHA на ваш сайт WordPress у вас будет возможность выбрать, какой тип теста использовать. Однако имейте в виду, что внедрение Google reCAPTCHA v2 или v3 должно помочь сделать ваш сайт более приятным и доступным для пользователей.
Как добавить CAPTCHA на ваш сайт WordPress (3 шага)
Когда дело доходит до безопасности WordPress, добавление CAPTCHA — это один из самых простых способов затруднить проникновение ботов на ваш сайт. К счастью, включить его также легко. Вы можете настроить свой всего за три простых шага.
Шаг 1. Установите и активируйте плагин WordPress CAPTCHA
Самый простой способ добавить CAPTCHA на ваш сайт WordPress — использовать плагин. В каталоге плагинов WordPress есть много высококачественных опций, поэтому вам не придется грабить банк, чтобы повысить безопасность вашего сайта.
Однако, прежде чем выбрать плагин, необходимо рассмотреть несколько ключевых особенностей.
Во-первых, вы хотите учитывать тип CAPTCHA, который предоставляет ваш плагин. Как мы уже обсуждали выше, Google reCAPTCHA гораздо удобнее для пользователя, чем требование от посетителей нажимать на изображения или декодировать искаженный текст.
Кроме того, вы должны убедиться, что ваш плагин может добавлять CAPTCHA в несколько областей вашего сайта, а не только на страницу входа. Мы рассмотрим эту идею более подробно на шаге 3. А пока имейте в виду, что везде, где у вас есть форма на вашем сайте, вы, вероятно, захотите сдерживать ботов с помощью CAPTCHA.
Давайте рассмотрим три плагина, которые соответствуют вышеуказанным критериям. Google Captcha (reCAPTCHA) от BestWebSoft — самый популярный вариант, с более чем 200 000 активных установок:
Плагин Google CaptchaКак следует из названия, этот плагин включает Google reCAPTCHA v2 или v3 на страницах входа и регистрации, при сбросе пароля и контактные формы и даже в комментариях и отзывах на вашем сайте. Это помогает предотвратить спам, а также повышает безопасность.
Advanced noCaptcha & Invisible Captcha также имеет высокие оценки и включает в себя многие из тех же функций:
Плагин Advanced noCaptchaЭтот плагин также обеспечивает совместимость с несколькими сайтами и интегрируется с популярными инструментами членства, такими как bbPress и BuddyPress. Кроме того, при необходимости вы можете добавить несколько CAPTCHA на одну страницу.
Наконец, вы также можете рассмотреть вход без CAPTCHA reCAPTCHA:
Вход без CAPTCHA плагин reCAPTCHA Этот плагин включает простую Google reCAPTCHA и может использоваться в формах входа, регистрации и забытого пароля. Однако он не интегрируется с вашим разделом комментариев или контактными формами, что делает его немного более ограниченным, чем два других плагина, которые мы рассмотрели.
Шаг 2. Создайте свой Google reCAPTCHA и добавьте его на свой сайт
После того, как вы установили и активировали свой плагин, вам нужно будет создать свой Google reCAPTCHA (при условии, что вы выбрали плагин, который его использует). Перейдите в консоль администратора Google reCAPTCHA и заполните регистрационную форму:
. Подпишитесь на информационный бюллетень
Хотите узнать, как мы увеличили трафик более чем на 1000%?
Присоединяйтесь к более чем 20 000 других людей, которые получают наш еженедельный информационный бюллетень с инсайдерскими советами по WordPress!
Подпишитесь сейчас
Страница регистрации reCAPTCHA Обратите внимание, что вы сможете выбирать между reCAPTCHA v2 или v3, а также можете использовать флажок или невидимый тест. Последний обеспечит лучший UX, так как не требует никаких действий со стороны пользователя. Однако флажок v2, как правило, более надежен.
Заполнив все поля, нажмите кнопку Отправить . На следующем экране вам будет предоставлен ключ сайта и Секретный ключ :
Получение сайта и секретных ключей для новой Google reCAPTCHAВам нужно будет ввести оба значения в настройках плагина CAPTCHA на вашем сайте WordPress. Этот процесс может незначительно отличаться в зависимости от того, какой плагин вы выбрали. Однако вы легко сможете найти настройки на боковой панели панели управления и вставить свои ключи в соответствующие поля:
Добавление ключей Google reCAPTCHA в настройки плагина Google Captcha Не забудьте сохранить изменения. Вы также можете добавить в закладки свою страницу консоли администратора Google reCAPTCHA и регулярно проверять ее. После того, как ваш сайт посетит достаточное количество живого трафика, вы сможете просматривать ценную аналитику, связанную с запросами на отправку форм.
Шаг 3. Настройте параметры для защиты ключевых областей
Как мы упоминали ранее, есть несколько областей, идеально подходящих для включения вашей CAPTCHA, чтобы обеспечить максимальную защиту вашего сайта. После того, как вы установили выбранный вами плагин, вы можете настроить параметры, чтобы убедиться, что все важные страницы включены.
Google CAPTCHA и Advanced No Captcha включают список флажков в своих общих настройках. Там вы можете выбрать, где вы хотите использовать свои reCAPTCHA:
Выбор мест, где будет отображаться Google reCAPTCHAВ идеале это будет включать все формы, которые есть на вашем сайте, включая уязвимые области, такие как:
- Страница входа администратора WordPress
- Страница входа WooCommerce
- Регистрационная форма пользователя
- Форма восстановления пароля
- Контактная форма
Ваш сайт может включать другие уникальные формы, такие как отправка пользовательского контента, опросы или подписка по электронной почте. В таких случаях вы можете использовать Advanced noCaptcha и Invisible Captcha, так как этот плагин предоставляет хуки действий для включения Google reCAPTCHA в любой форме.
В качестве альтернативы вы можете инвестировать в Google Captcha (reCAPTCHA) Pro Pro. Он обеспечивает дополнительную интеграцию с популярными плагинами, такими как Jetpack, MailChimp для WordPress и несколькими конструкторами форм.
Добавление CAPTCHA на вашу страницу входа
Ваша страница входа является главной целью для атак с использованием грубой силы и межсайтового скриптинга (XSS).
Чтобы добавить к нему CAPTCHA с помощью плагина Google Captcha, перейдите к Google Captcha> Настройки> Общие> Включить reCAPTCHA для в WordPress и выберите Форма входа под WordPress по умолчанию :
Параметр формы входа плагин Google CaptchaТеперь ваша страница входа должна быть защищена.
Добавление CAPTCHA на вашу страницу сброса пароля
Когда их попытки войти на ваш сайт терпят неудачу, хакеры могут быть перенаправлены на страницу, где пользователи могут сбросить свои пароли. Чтобы добавить CAPTCHA для защиты этой страницы, перейдите к Google Captcha> Настройки> Общие> Включить reCAPTCHA для на панели управления WordPress:
Затем выберите Форма сброса пароля из списка WordPress по умолчанию .
Защита вашей страницы входа в WooCommerce с помощью CAPTCHA
Ваша страница входа в WooCommerce так же подвержена вредоносным атакам, как и основная страница WordPress. Чтобы защитить его с помощью Google Captcha, вам понадобится премиум-версия плагина (ниже выделено желтым цветом). Когда будете готовы, идите на Google Captcha > Настройки > Общие > Включить reCAPTCHA для на панели инструментов WordPress:
Параметр (премиум) формы входа в WooCommerceЗдесь вы сможете выбрать Форма входа в WooCommerce из списка Внешние плагины .
Размещение CAPTCHA в вашей контактной форме
Ваша контактная форма может быть защищена с помощью CAPTCHA так же, как и другие, которые мы обсуждали в этой статье. Однако существует несколько различных плагинов контактных форм, которые интегрируются с Google CAPTCHA, в том числе:
- Контактная форма 7
- Контактная форма Jetpack
- Формы ниндзя
Чтобы добавить CAPTCHA в контактную форму, на вашем сайте должен быть активен один из перечисленных выше инструментов. Затем перейдите в Google Captcha > Настройки > Общие > Включить reCAPTCHA для и установите флажок для нужного плагина:
Параметры бесплатной и платной контактной формы в плагине Google CaptchaЭто завершит процесс. Если на вашем сайте WordPress используется другой плагин контактной формы, вы можете рассмотреть возможность использования другого плагина CAPTCHA, который интегрируется с ним. Есть также некоторые плагины для создания форм, которые сами по себе включают CAPTCHA, например WPForms.
Хотите защитить свой сайт #WordPress от спамеров и ботов? Узнайте, как добавить CAPTCHA во все ваши контакты и формы входа! 🗝✅Нажмите, чтобы твитнуть. Один из самых простых способов замедлить их — добавить CAPTCHA в формы вашего сайта WordPress.Для добавления CAPTCHA на ваш сайт WordPress требуется всего три шага:
- Установите и активируйте плагин WordPress CAPTCHA.
- Создайте свою Google reCAPTCHA и добавьте ее на свой сайт.
- Настройте параметры для защиты ключевых областей.
У вас есть вопросы о CAPTCHA или о том, как их использовать в WordPress? Дайте нам знать в разделе комментариев!
Экономьте время, затраты и повышайте производительность сайта с помощью:
- Мгновенная помощь от экспертов по хостингу WordPress, круглосуточно и без выходных.
- Интеграция с Cloudflare Enterprise.
- Глобальный охват аудитории благодаря 35 центрам обработки данных по всему миру.
- Оптимизация с помощью нашего встроенного мониторинга производительности приложений.
Все это и многое другое в одном плане без долгосрочных контрактов, сопровождаемой миграции и 30-дневной гарантии возврата денег. Ознакомьтесь с нашими планами или поговорите с отделом продаж, чтобы найти план, который подходит именно вам.
Как настроить и использовать reCAPTCHA в WPForms
Хотели бы вы использовать reCAPTCHA от Google для предотвращения спама в формах WordPress? Добавление reCAPTCHA позволяет вам использовать технологию проверки человеком в ваших формах, что может уменьшить количество получаемых вами спам-рассылок.
В этом руководстве мы расскажем, как настроить и использовать параметр reCAPTCHA в WPForms.
- Генерация ключей reCAPTCHA в Google
- Добавление reCAPTCHA в форму
- Тестирование reCAPTCHA
- Часто задаваемые вопросы
1. Генерация ключей reCAPTCHA в Google
Чтобы начать работу, вам необходимо войти на свой сайт WordPress и перейти к WPForms » Настройки . Затем перейдите на вкладку CAPTCHA . Будьте уверены, что Выбрана опция reCAPTCHA .
Затем в появившихся настройках выберите reCAPTCHA Type , который вы хотите использовать.
Примечание: Для обзора каждого типа reCAPTCHA обязательно ознакомьтесь с нашим руководством по выбору CAPTCHA для ваших форм. Для каждого типа reCAPTCHA требуется свой набор ключей, поэтому, если вы позже решите сменить тип, вам потребуется сгенерировать новый набор ключей.
Далее вам нужно настроить reCAPTCHA в своей учетной записи Google, чтобы сгенерировать необходимые ключи. Чтобы начать этот процесс настройки, вам нужно открыть консоль администратора Google reCAPTCHA.
Здесь вам будет предложено войти в свою учетную запись Google. То, что вы увидите при входе в систему, будет зависеть от того, настраивали ли вы ранее reCAPTCHA для этой учетной записи.
Если вы настроили reCAPTCHA с этой учетной записью в прошлом, вам нужно будет щелкнуть значок + (плюс), чтобы добавить новый сайт.
Если вы никогда раньше не настраивали reCAPTCHA, вы будете перенаправлены прямо на форму настройки reCAPTCHA.
Ниже вы найдете более подробную информацию о том, как заполнить каждое поле в этой форме.
- Метка: Это видно только вам, поэтому введите любое имя, которое имеет логический смысл (чаще всего это имя веб-сайта).
- Тип reCAPTCHA: Выберите версию reCAPTCHA, которую вы хотите использовать.
Примечание: Если вы решите включить reCAPTCHA v3, значок reCAPTCHA не будет отображаться на интерфейсе вашего сайта при использовании с диалоговой формой.
- Домены: Введите URL-адрес, по которому вы будете использовать reCAPTCHA. Не указывайте «http://www» в начале (например, wpforms.com будет принят, а https://wpforms.com или www.wpforms.com — нет).
- Владельцы: Если вы не знаете конкретной причины для изменения этого, вы можете пропустить это.
- Принять Условия использования reCAPTCHA: Чтобы продолжить, установите этот флажок.
- Отправлять оповещения владельцам: Если вы не знаете конкретной причины отключить это, вы можете оставить этот флажок установленным.
Когда форма заполнена, нажмите кнопку Отправить .
После регистрации вы должны увидеть страницу с ключами для вашего сайта.
Вам необходимо скопировать ключ сайта и секретный ключ . Затем вернитесь на свой сайт WordPress, чтобы вставить эти ключи в соответствующие поля.
Теперь, когда вы добавили свои ключи reCAPTCHA, вы также можете дополнительно настроить другие параметры reCAPTCHA.
- Сообщение об ошибке: Эта ошибка будет отображаться для любого пользователя, не прошедшего проверочный тест reCAPTCHA.
- Пороговое значение (только для reCAPTCHA v3): Это балл, при котором вы хотите, чтобы пользователи не прошли проверку reCAPTCHA v3. Оценки могут варьироваться от 0,0 (скорее всего, бот) до 1,0 (весьма вероятно, хорошее взаимодействие).
- Режим отсутствия конфликтов: Если reCAPTCHA загружается на ваш сайт более одного раза (например, как WPForms, так и вашей темой WordPress), это может помешать правильной работе reCAPTCHA. Режим отсутствия конфликтов удалит любой код reCAPTCHA, который не загружен WPForms. Тем не менее, мы настоятельно рекомендуем связаться с нашей службой поддержки, если вы не уверены, стоит ли использовать эту опцию.
- Предварительный просмотр (только для Checkbox reCAPTCHA v2): Если reCAPTCHA настроен правильно, вы увидите предварительный просмотр того, как он будет выглядеть на вашем сайте.
Обязательно нажмите кнопку Сохранить настройки внизу этой страницы, чтобы сохранить изменения настроек.
Дополнительные шаги ТОЛЬКО для пользователей AMP (только для reCAPTCHA v3)
Если вы используете Google AMP на своем сайте WordPress, вам потребуется внести дополнительные изменения в настройки reCAPTCHA, чтобы обеспечить совместимость с AMP.
Примечание: При использовании Google AMP вместе с reCAPTCHA значок reCAPTCHA не будет отображаться на интерфейсе вашего сайта.
Под ключами reCAPTCHA нажмите Перейти к настройкам .
Это снова откроет ваши настройки reCAPTCHA, однако теперь вам будет показана дополнительная настройка, которая была скрыта ранее.
В нижней части этой страницы установите новый флажок Разрешить этому ключу работать со страницами AMP . Затем нажмите Сохраните еще раз.
2. Добавление reCAPTCHA в форму
Теперь, когда вы настроили свои ключи reCAPTCHA, вы сможете добавить reCAPTCHA в любую из ваших WPForms.
Для этого создайте новую форму или отредактируйте существующую форму.
После того, как вы открыли конструктор форм, загляните в раздел «Стандартные поля» и щелкните поле reCAPTCHA .
Чтобы убедиться, что ваша reCAPTCHA включена, найдите значок в правом верхнем углу конструктора форм.
3. Тестирование reCAPTCHA
Последний шаг — запустить быстрый тест, чтобы убедиться, что reCAPTCHA выглядит и работает так, как вы ожидаете.
Чтобы проверить это, вам просто нужно отправить запись в форму. Для получения более подробной информации о том, как протестировать свои формы, ознакомьтесь с нашим полным контрольным списком тестирования.
Часто задаваемые вопросы
Могу ли я использовать reCAPTCHA, если на моем сайте используется поддомен?
Google reCAPTCHA работает с поддоменами, однако reCAPTCHA не принимает сайты поддоменов с форматом пути (например, https://domain.com/subdomain ). Если вы используете поддомен для своего сайта, обязательно отформатируйте URL-адрес своего сайта как subdomain.domain.com при настройке ключей reCAPTCHA.
Я все еще получаю спам с включенной reCAPTCHA. Что я могу сделать, чтобы остановить это?
Если вы используете reCAPTCHA v2, вы можете настроить параметры сложности для reCAPTCHA в своей учетной записи Google reCAPTCHA.
Чтобы увеличить сложность вашей reCAPTCHA, перейдите к Настройка безопасности в настройках reCAPTCHA. Отсюда вы можете настроить ползунок, чтобы быть более безопасным.
Вот и все! Мы только что показали вам, как добавить reCAPTCHA от Google в ваши WPForms.
Далее, хотите ли вы вести учет событий, происходящих в ваших формах WordPress? Обязательно ознакомьтесь с нашим руководством о том, как включить ведение журнала активности для получения более подробной информации.
Была ли эта статья полезной?
Спасибо за отзыв!
Все еще застряли? Как мы можем помочь?
Последнее обновление 31 августа 2022 г.
ввести код проверки или ввести проверку?
ввести капчу или ввести капчу?Чтобы опубликовать ваш вопрос, нам нужен ваш адрес электронной почты, чтобы уведомить вас, когда ответ будет доступен.
Зарегистрируйтесь через Facebook Зарегистрируйтесь через Google
или Зарегистрируйтесь с адресом электронной почты
Адрес электронной почты (обязательно)
Пароль (обязательно)
Уже есть учетная запись? Логин
Зарегистрируйтесь, чтобы ваш текст был отредактирован прямо сейчас за БЕСПЛАТНО ⚡
Зарегистрируйтесь в Google
Сегодня более 1001 человек проверили свой английский.
Продолжая использовать этот веб-сайт, вы соглашаетесь с нашими Условиями обслуживания.
Войти через Facebook Войти через Google
или Войти с адресом электронной почты
Забыли пароль?
Продолжая использовать этот веб-сайт, вы соглашаетесь с нашими Условиями обслуживания.
Ваш текст проверяется одним из наших экспертов.
Мы сообщим вам, когда ваша версия будет готова.
Или подождите на этой странице
Оставайтесь здесь, чтобы узнать, почему редакторы-люди каждый раз побеждают компьютерные шашки!
Вам нужно добавить способ оплаты, чтобы получить нашу специальную акцию ⚡
Хотите улучшить свой деловой английский?
Более 150 000 таких же людей, как и вы, получают наш еженедельный информационный бюллетень, чтобы улучшить свои знания английского языка!
В этой электронной книге мы покажем вам точные методы написания идеальных деловых писем на английском языке.
Сегодня скачали более 1320 раз.
Введите свой адрес электронной почты ниже, чтобы получить мгновенный доступ к первой главе нашей электронной книги
Скачано более 1320 раз сегодня.
Резюме
Электронная почта для получения (обязательно):
Как вы хотите оплатить?
Введите код купона
Мы очень рады, что вам понравилась ваша версия!
Ваш отзыв помогает нам улучшить наш сервис.
Хотите еще БЕСПЛАТНЫЕ версии ? 🎁
Нажмите здесь, чтобы ПОЛУЧИТЬ БЕСПЛАТНЫЕ кредиты!
Поставьте нам лайк на Facebook, нажав кнопку «Нравится» ниже:
Поделитесь TextRanch на Facebook, нажав кнопку ниже.
Поделиться на Facebook
Поздравляем! Вы только что заработали 3 кредита!
Ok
Закрытие вашей учетной записи лишит вас доступа к вашим прошлым версиям, и вы больше не сможете получать БЕСПЛАТНУЮ ежедневную версию.
Сохранение вашей учетной записи TextRanch бесплатно, и мы храним все ваши прошлые версии безопасным и конфиденциальным образом.
Если мы не оправдали ваших ожиданий, нам бы очень хотелось узнать больше. Пожалуйста, сообщите нам, почему вы закрываете свою учетную запись:
Я не понимаю, как это работаетМне это больше не нужноЭто слишком дорогоЯ беспокоюсь о конфиденциальностиДругое
Пожалуйста, сообщите нам, почему вы хотите закрыть свою учетную запись:
1. Введите текст ниже
2. Наши редакторы исправят его за несколько минут
3. Улучшите свой английский!
Один из наших специалистов исправит ваш английский.
УЛУЧШИТЕ СВОЙ АНГЛИЙСКИЙ
Три причины подписаться на нашу рассылку:
Это полезно и БЕСПЛАТНО
Всего одно электронное письмо в неделю
Более 100 000 пользователей уже зарегистрировались
Хотите улучшить свой деловой английский?
ВАШЕ ИМЯВАШ АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ
Полный поиск в Интернете дал следующие результаты:
введите код проверки – самая популярная фраза в Интернете.
Популярнее!
введите код
1 200 000 результатов в Интернете
Некоторые примеры из Интернета:
- (треск продолжается) введите безопасность доступа код .
- Пожалуйста, введите код доступа .
- Введите соответствующий код , указав способ оплаты транспортных расходов.
- Проверьте правильность настроек этой галереи. Введите буквы, как они показаны на изображении в поле « Captcha ». Буквы не чувствительны к регистру
- Каждый арендатор имеет код до введите главные ворота.
- Настоящий Кодекс поведения должен ввести в силу 1 октября 2007 года.
- Для переопределения необходимо ввести специальный код .
- Человек все станции и введите предварительный код красный.
- Код от до введите 6-6-6.
- Введите соответствующий код , представляющий статус представителя.
- Используя соответствующий код Союза , введите справочные номера соответствующих таможенных органов.
- Введите шестизначный код номенклатуры Гармонизированной системы декларируемых товаров.
- Введите код 10100, если применяется пункт 1 статьи 2 Регламента (ЕС) № 1147/2002 (товары, импортированные с сертификатами летной годности).
- Введите транспортные расходы способ оплаты код ;
- Введите код для товара.
- Введите почтовый код ведущего автора здесь.
- В поле 15a введите код соответствующей страны.
- В коробке 17а введите код для этой страны.
- Введите Неправильный код и …
Введите CAPTCHA
902 000 CAPTCHA , потому что вы помогаете нам оцифровать книгу.
УЛУЧШИТЕ СВОЙ АНГЛИЙСКИЙ
3 причины подписаться на нашу рассылку:
Улучшите свой письменный английский
Еженедельные электронные письма с полезными советами
Более 190 000 пользователей уже зарегистрировались
Хотите улучшить свой деловой английский?
ВАШЕ ИМЯВАШ АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ
Благодаря TextRanch я смог набрать более 950 баллов по TOEIC, а также получил хорошую оценку по ACTFL OPIC.
+ Читать интервью полностью
— Алан , Студент
Я люблю TextRanch за надежную обратную связь. Комментарии редакторов полезны, а обслуживание клиентов потрясающее.
+ Прочитать интервью полностью
— Зубаир Алам Чоудхури , Специалист технической поддержки
TextRanch помог мне улучшить свои письменные навыки, а также общаться более естественно, как местный англоговорящий.
+ Читать интервью полностью
— Мишель Вивас , Старший технический директор
Компания TextRanch удивительно отзывчива и действительно заботится о клиенте. Это лучший онлайн-сервис, которым я когда-либо пользовался!
+ Прочитать интервью полностью
— Реза Бахрами , Фотограф/кинорежиссер
Я начал использовать TextRanch, когда начал изучать английский язык. Это был отличный способ улучшить свои знания английского языка.
+ Читать интервью полностью
— Кьяра Бессо , Копирайтер
Мне нравится, что редакторы TextRanch — настоящие люди, которые редактируют текст и оставляют отзывы — это делает его таким личным.
+ Прочитать интервью полностью
— Marelise , Менеджер по социальным сетям
Иногда мне кажется, что мои английские выражения понятны, и TextRanch мне очень помогает в таких случаях.
+ Прочитать интервью полностью
— Snappy , Переводчик
TextRanch очень помог мне в улучшении потока и восстановлении структуры моих предложений.
+ Читать интервью полностью
— Рин , Переводчик
1506 Trustpilot Отзывы
Отлично 4.8 Текст ООО
3 9003 900
«Большое спасибо! Не ожидал, что мой текст проверит настоящий редактор, а не ИИ. и результат такой хороший!!»
– Kijae — Избранный комментарий.
TextRanch, LLC.
«Быстрый и умный, плюс «человеческий»! Мне это нравится! ;)»
– Франческа – Избранный комментарий.
TextRanch, LLC.
«Как хорошо. Я думал, что текст редактируется машиной, но это настоящий редактор. Потрясающе!»
– ЯН КАНСИАНЬ август 2022
TextRanch, LLC.
«Простые в использовании люди, а не машины».
– Жоао — Избранный комментарий.
TextRanch, LLC.
«Это один из лучших способов улучшить навыки письма. Я был действительно полезен. Хотел бы я узнать о Textranch раньше. Большое спасибо редакторам.»
– Moxi июль 2022
TextRanch, LLC.
удивительно.»
– дипак июнь 2022
TextRanch, LLC.
«Спасибо за немедленный ответ, действительно отличное приложение». они быстро реагируют».
– Джессика июнь 2022 г.
TextRanch, LLC.
«Текстранч очень важен для меня».1341
TextRanch, LLC.
«Мне нравится платформа, потому что я чувствую, что редактируют текст настоящие люди, хорошо знающие английский язык, а не программа машинного обучения. Спасибо».
– Holger май 2022 г.
– Брук – избранный комментарий.
Понравилось, так держать!»– andy Май 2022
TextRanch, LLC.
«Мой текст даже не занял много времени! Лучше любого AI-корректора!»
– Орхан Май 2022
TextRanch, LLC.
«Я действительно счастлив!! Я не ожидал, что это настоящий человек, это действительно потрясающе!!»
– ришабх май 2022
TextRanch, LLC.
!»
– Никита Май 2022
TextRanch, LLC.
«Вау, спасибо. До того, как вы мне ответили, я просто думал, что этот сервис работает на основе ИИ. »
– Эрона Май 2022
TextRanch, LLC.
«Я чувствую себя более уверенно. У меня есть некоторые сомнения, мелкие детали, которые может решить только носитель языка. Большое спасибо!»
– barril24 — Избранный комментарий.
TextRanch, LLC.
переводы, так что это было очень полезно».
– Лия – Избранный комментарий.
TextRanch, LLC.
«Textranch помогает мне стать лучшим писателем!»
– Линда апрель 2022 г.
TextRanch, LLC. текст? Удивительно. Спасибо, Textranch».
– Roderiko Март 2022
TextRanch, LLC.
«Мне очень помогло писать по-английски. Есть люди, которые могут проверить, что я пишу, и в то же время я могу узнать, где мои ошибки». . Настоящие, профессиональные люди вычитывают ваши тексты, а не боты».
– Roderiko Март 2022
TextRanch, LLC.
«Всегда доволен! Я действительно учусь».
– lia.sash — Избранный комментарий.
Дайте мне больше примера о: Ваш адрес электронной почты:
Расчетное время: 30 минут ,
прямо в вашем почтовом ящике
Почему именно TextRanch?
Самые низкие цены
До 50% ниже, чем на других сайтах онлайн-редактирования.
Самые быстрые времена
Наша команда редакторов работает для вас 24/7.
Квалифицированные редакторы
Эксперты-носители английского языка в Великобритании или США.
Высшее обслуживание клиентов
Мы здесь, чтобы помочь. Удовлетворение гарантировано!
Недоступность CAPTCHA
Недоступность CAPTCHAАльтернативы визуальным тестам Turing в Интернете
W3C Group Draft Note
Подробнее об этом документе- Эта версия: https://www.w3.org/TR/2021/DNOTE-turingtest-20211216/
- Последняя опубликованная версия:
- https://www.w3.org/TR/turingtest/
- Последний черновик редактора:
- https://w3c.github.io/captcha-accessibility/
- История:
- https://www.w3.org/standards/history/turingtest
- История коммитов
- Редакторов:
- Скотт Холлиер
- Янина Сайка
- Джейсон Уайт
- Майкл Купер (W3C)
- Бывший редактор:
- Мэтт Мэй (W3C)
- Обратная связь:
- GitHub w3c/капча-доступность (вытягивающие запросы, новый выпуск, открытые вопросы)
- public-apa@w3. org со строкой темы [turingtest] … тема сообщения … (архивы)
Авторские права © 2021 W3C ® ( Массачусетский технологический институт , ERCIM , Кейо, Бейхан). W3C обязанность, товарный знак и применяются правила лицензирования разрешительного документа.
Аннотация
В течение многих лет использовались различные подходы, чтобы отличить пользователей веб-сайтов от роботов. Традиционный подход CAPTCHA, в котором пользователям предлагается идентифицировать скрытый текст на изображении, остается распространенным, но появились и другие подходы. Все интерактивные подходы требуют от пользователей выполнения задачи, которая считается относительно простой для людей, но сложной для роботов. К сожалению, сама природа интерактивной задачи по своей природе исключает многих людей с ограниченными возможностями, что приводит к отказу в обслуживании этих пользователей. Результаты исследований также показывают, что многие популярные методы CAPTCHA больше не являются особенно эффективными или безопасными, что еще больше усложняет задачу предоставления услуг, защищенных от вторжения роботов, но доступных для людей с ограниченными возможностями. В этом документе рассматривается ряд подходов, позволяющих тестировать системы для пользователей-людей, и степень, в которой эти подходы адекватно подходят для людей с ограниченными возможностями, включая недавние
неинтерактивные и токенизированные подходы. Мы сгруппировали эти подходы по двум классификациям категорий: автономные подходы, которые можно развернуть на веб-узле без привлечения услуг несвязанных третьих сторон, и многосторонние подходы, которые используют услуги несвязанной третьей стороны.
В этом разделе описывается состояние этого
документа на момент его публикации. Список текущих W3C публикации и последнюю редакцию этого технического отчета можно найти
в указателе технических отчетов W3C по адресу
https://www.w3.org/TR/.
Это черновик обновления заметки рабочей группы по недоступности CAPTCHA, опубликованной в 2019 году. Документ опубликован как рабочий черновик для сбора отзывов об обновлениях проблем и решений с тех пор. После учета отзывов Рабочая группа планирует вернуть этому документу статус примечания.
Рабочая группа APA особенно заинтересована в ответах на следующие вопросы:
- Использование технологий W3C для устранения необходимости в интерактивных CAPTCHA
- Использование токенов Тьюринга
- Информация о недавних альтернативах использования CAPTCHA.
- Комментарии по поводу обсуждения в документе барьеров, которые создает CAPTCHA для людей с ограниченными возможностями.
Чтобы прокомментировать, напишите вопрос в W3C репозиторий GitHub с доступом к капче. Если это невозможно, отправьте электронное письмо по адресу [email protected] (архив комментариев). Комментарии запрашиваются по телефону 28 января 2022 года . Текущие обновления документа можно просмотреть в общедоступном редакторском черновике.
Этот документ был опубликован Рабочей группой по доступным платформам архитектуры как групповой черновик заметки с помощью Нотный трек.
Групповые проекты Примечания не одобрены W3C , ни его члены.
Этот документ является черновиком и может быть обновлен, заменен или устаревшим другим документом. документы в любое время. Неуместно ссылаться на этот документ как на другой чем работа в процессе.
Патент W3C Политика
не несет каких-либо лицензионных требований или обязательств по этому
документ.
Настоящий документ регулируется 2 ноября 2021 W3C Технологический документ.
1. Введение 1.1 Контекст CAPTCHA Веб-сайты, предоставляющие интерактивные услуги, уже давно
стремились ограничить свои услуги только пользователями-людьми.
Они стремятся избежать раскрытия своих собранных данных и служб публикации контента веб-роботам с еще более хитроумными формулировками. Будь то
служба может быть билетами на путешествия и мероприятия, электронной почтой, ведением блога или календарем.
сервисы, сервисы социальных сетей или их сочетание и многое другое,
опыт показал, что даже аутентифицированный вход обеспечивает
недостаточная защита от злоумышленников. Такие сайты еще нужно знать
их взаимодействующий пользователь — человек, а не программный робот. Возможно, потребность отрасли в надежных тестах Тьюринга становится все более острой.
Раннее (и до сих пор широко распространенное) решение основано на использовании графического представления текста в области регистрации или комментариев на веб-сайте. Сайт пытается проверить, что пользователь на самом деле является человеком, требуя от пользователя выполнить задачу, называемую «Полностью автоматизированный общедоступный тест Тьюринга, чтобы отличить компьютеры от людей» или CAPTCHA. Предполагается, что люди находят эту задачу относительно легкой, в то время как роботы считают ее практически невыполнимой.
CAPTCHA была первоначально разработана исследователями из Университета Карнеги-Меллона и в основном ассоциировалась с методом, с помощью которого человек идентифицирует искаженный набор символов в растровом изображении, а затем вводит эти символы в веб-форму. Этот подход широко знаком пользователям Интернета, хотя термин CAPTCHA обычно признают только веб-профессионалы.
В последнее время типы CAPTCHA, которые появляются на веб-сайтах и в мобильных приложениях, значительно изменились. Поскольку нас здесь беспокоит доступность систем, стремящихся отличить пользователей-людей от их роботов-имитаторов, термин «CAPTCHA» используется в этом документе в общем для обозначения всех подходов, специально разработанных для отличия человека от компьютера, в том числе полностью неинтерактивные подходы.
Никого не удивит, что мы приветствуем недавнее появление неинтерактивных подходов, потому что функциональные неинтерактивные подходы не создают проблем с доступностью для пользователей. К сожалению, некоторые современные неинтерактивные подходы достигаются ценой раскрытия большого количества данных об отдельном пользователе для неинтерактивного механизма анализа хоста, который пользователь предпочел бы сохранить в тайне. Мы также воодушевлены еще более поздней разработкой токенизированных подходов, которые обещают надежное тестирование Тьюринга, требующее минимального взаимодействия с пользователями.
1.2 Проблема доступности В то время как онлайн-пользователи продолжают в целом сообщать о том, что традиционные CAPTCHA вызывают разочарование, обычно считается, что интерактивную CAPTCHA можно решить за несколько неправильных попыток. Отличительной особенностью людей с ограниченными возможностями является то, что CAPTCHA не только отделяет компьютеры от людей, но и часто не позволяет людям с ограниченными возможностями выполнить запрошенную процедуру. Например, просить слепых, слабовидящих или страдающих дислексией пользователей идентифицировать текстовые символы в искаженной графике означает, что им предлагается выполнить задачу, которую они меньше всего способны выполнить. Точно так же, если просить глухих, слабослышащих или страдающих нарушением обработки слуха пользователей идентифицировать и расшифровывать в письменном виде содержание аудио-CAPTCHA, то это означает, что им предлагается выполнить задачу, которую они вряд ли выполнят. Кроме того, традиционные CAPTCHA обычно предполагают, что все пользователи Интернета могут читать и расшифровывать английские слова и символы, что делает тест недоступным для большого числа не говорящих по-английски пользователей Интернета во всем мире. Откровенно говоря, паттерн проектирования, предполагающий множество попыток от пользователей как само собой разумеющееся, возможно, по своему замыслу недоступен для людей, живущих с тревожным расстройством, а также для многих людей, живущих с целым рядом других когнитивных нарушений и нарушений обучения.
Как заметили разработчики программного обеспечения в Cloudflare [ аттестация ], значительное время, которое можно было бы посвятить более продуктивным задачам, теряется в результате ответов на запросы CAPTCHA. По данным авторов, для прохождения CAPTCHA пользователю требуется в среднем 32 секунды. Применительно к большому количеству пользователей общее потерянное время становится значительным. Хотя надежные оценки недоступны, разумно предположить, что даже для людей с ограниченными возможностями, которые могут успешно решать задачи CAPTCHA, хотя и с некоторыми трудностями или неудобствами, обычное время, затрачиваемое на задачу, вероятно, будет больше, чем в среднем для населения в целом. Следовательно, можно предположить, что затраты непропорционально велики по сравнению с теми, которые несет население в целом.
. В то время как лучшие практики доступности требуют, а вспомогательные технологии предполагают, что существенные графические изображения должны быть созданы с текстовыми эквивалентами, альтернативный текст в изображениях CAPTCHA явно будет саморазрушительным. Следовательно, CAPTCHA разрешены в соответствии с Руководством по доступности веб-контента (WCAG) W3C при условии, что «предоставлены текстовые альтернативы, которые идентифицируют и описывают цель нетекстового контента, и альтернативные формы CAPTCHA, использующие режимы вывода для различных типы сенсорного восприятия предназначены для приспособления к различным нарушениям».
Важно понимать ограничение исключения WCAG CAPTCHA. Это относится только к содержимому CAPTCHA. WCAG по-прежнему требует, чтобы альтернативный текст идентифицировал графический объект как CAPTCHA. Соответствие всем другим рекомендациям WCAG также остается критически важным для доступности в Интернете.
Обоснование этого очень конкретного исключения в WCAG простое. CAPTCHA без доступной и удобной альтернативы делает невозможным для пользователей с определенными ограничениями возможность создания учетных записей, написания комментариев или совершения покупок на таких сайтах. По сути, такие CAPTCHA не могут должным образом распознать пользователей с ограниченными возможностями как людей, что препятствует их участию в жизни современного общества. Такие проблемы также распространяются на ситуационную инвалидность, когда пользователь может не иметь возможности эффективно просматривать традиционную CAPTCHA на мобильном устройстве из-за небольшого размера экрана или слышать CAPTCHA со звуком в шумной обстановке.
Вредоносная активность в Интернете с годами только возросла и составляет тревожно высокий процент всего интернет-трафика. Хотя мы, конечно же, не предполагаем, что беды Интернета возникают из-за небрежной или необдуманной реализации CAPTCHA, мы действительно предполагаем, что текущие условия только усиливают важность хорошо продуманных и тщательно контролируемых стратегий безопасности и конфиденциальности, согласующихся с соответствующей поддержкой пользователей, включая людей с ограниченными возможностями. Правильная проверка CAPTCHA должна быть частью решения.
Важно признать, что использование CAPTCHA в качестве решения для обеспечения безопасности становится все менее эффективным. Существующие методы CAPTCHA, основанные в первую очередь на традиционных подходах, основанных на изображениях, логических задачах или звуковых альтернативах CAPTCHA, могут быть в значительной степени взломаны с использованием как сложных, так и простых компьютерных алгоритмов. Исследования показывают, что по мере того, как CAPTCHA на основе символов становится все более уязвимой для взлома из-за развития технологий оптического распознавания символов, для противодействия этим атакам вводятся более серьезные искажения символов. Тем не менее, такие улучшенные методы искажения также делают его все более невозможным даже для людей, которые хорошо наделены сенсорными и когнитивными способностями, чтобы надежно решать задачи CAPTCHA, в конечном итоге делая CAPTCHA на основе символов непрактичными [9].1810 капча-окр ].
в некоторых случаях могут обеспечить даже более высокий уровень успеха при взломе CAPTCHA, как показано в CAPTCHA Security: Case Study [ captcha-security ] и Атаки на основе HMM на reCAPTCHA Google с непрерывной визуальной и Аудиосимволы [ повторных атак ]. В то время как предпринимаются усилия по усилению традиционной безопасности CAPTCHA, более надежные решения безопасности рискуют снизить способность обычного пользователя понимать CAPTCHA, которую необходимо решить, например, Обход CAPTCHA с линейным шумом с помощью нескольких квадратичных змей [ поражение линейного шума ]. Недавнее исследование, проведенное в Университете Мэриленда, продемонстрировало 90%-й уровень успеха при взломе звуковой системы Google reCAPTCHA с использованием собственной службы распознавания речи Google. Действительно, как отмечено ниже, служба reCAPTCHA версии 2 от Google недавно начала отказываться от предоставления аудио-альтернативы CAPTCHA, явно предлагаемой на экране.
На самом деле можно утверждать, что онлайн-сервисы, которые предлагают разработчику контента готовое решение для того, чтобы отличить пользователей-людей от роботов, вполне могут помочь победить эту самую функцию. Например, reCAPTCHA от Google заявляет: «Каждый день люди решают сотни миллионов CAPTCHA. reCAPTCHA положительно использует эти человеческие усилия, направляя время, затрачиваемое на решение CAPTCHA, на аннотирование изображений и создание наборов данных машинного обучения. Это, в свою очередь, помогает улучшить карты и решить сложные проблемы с ИИ». Правомерно рассмотреть, описывает ли это также классический порочный круг, который помогает свести на нет эффективность визуального и слухового развертывания CAPTCHA.
Поэтому настоятельно рекомендуется, чтобы цель и эффективность любого развернутого решения были тщательно рассмотрены и оценены в различных средах браузеров и операционных систем перед его внедрением, а затем тщательно проверены на предмет эффективной производительности. Альтернативные методы безопасности, такие как двухэтапная проверка или проверка на нескольких устройствах, наряду с новыми протоколами для идентификации пользователей-людей с высокой надежностью, также должны быть тщательно рассмотрены в пользу традиционных методов CAPTCHA на основе изображений как по соображениям безопасности, так и по соображениям доступности.
Для веб-сайтов доступно множество методов для препятствовать или устранять мошеннические действия, такие как неправильное создание учетной записи. Несколько из них могут быть так же эффективен, как метод визуальной проверки, в то время как быть более доступным для людей с ограниченными возможностями. Другие могут быть перекрыты в качестве приспособления для цели доступности. Мы группируем наш обзор по интерактивным и неинтерактивным категориям
. 2,1 Интерактивные автономные подходы 2.1.1 Традиционная символьная CAPTCHA Традиционная CAPTCHA, основанная на символах, как обсуждалось ранее, в значительной степени недоступна и небезопасна. Он фокусируется на представлении букв или слов, представленных на изображении, и спроектирован так, чтобы роботам было трудно их идентифицировать. Затем пользователю предлагается ввести информацию CAPTCHA в форму.
Использование традиционной CAPTCHA, очевидно, проблематично для слепых, поскольку средства чтения с экрана, на которые они полагаются при использовании веб-контента, не могут обрабатывать изображение, что не позволяет им раскрыть информацию, требуемую формой. Поскольку символы, встроенные в CAPTCHA, часто искажены или имеют другие символы в непосредственной близости друг от друга, чтобы помешать технологическому решению роботов, они также очень сложны для пользователей с другими нарушениями зрения. Этот распространенный метод CAPTCHA также менее надежно решается пользователями с когнитивными нарушениями и нарушениями обучаемости, см. 9.1810 Влияние CAPTCHA на пользовательский опыт среди пользователей с ограниченными возможностями обучения и без них [ captcha-ld ]. Поскольку они преднамеренно искажены, чтобы скрывать роботов, они также сбивают с толку пользователей, которых легче сбить с толку сюрреалистическими изображениями или которые не обладают достаточно острым зрением, чтобы «видеть» дальше представленного искажения и раскрыть текст на сайте.
требуется для продолжения.
В то время как некоторые сайты начали предоставлять CAPTCHA с использованием других языков
чем английский, предположение, что все пользователи Интернета могут понять и воспроизвести
Английский преобладает. Ясно, что это не так. Исследования показали
как CAPTCHA, основанные на письменном английском языке, создают значительный барьер для многих
паутина; см. Эффекты поворота текста, длины строки и формата букв
на Текстовой CAPTCHA Надежность [ CAPTCHA-надежность ]. Эта проблема
вероятно, увеличится при использовании символов латинского алфавита за пределами ASCII
диапазон, с акцентами и диакритическими знаками, или фигуры, не входящие в набор, используемый для
Английский. Например, говорящим на арабском или тайском языке может не хватать знаний.
выявить искаженную версию таких символов. Кроме того, пользователи не могут
иметь необходимые клавиши на своей локальной клавиатуре.
Чтобы переформулировать проблему, текстом легко манипулировать, что хорошо для вспомогательных технологий, но так же хорошо для роботов. Логичное решение этой проблемы — предложить другой нетекстовый способ использования того же контента. Для этого воспроизводится аудио, содержащее ряд зачитываемых символов, слов или фраз, которые затем пользователь должен ввести в форму. Однако, как и в случае с визуальной CAPTCHA, роботы также способны распознавать устный контент — как успешно продемонстрировали Alexa от Amazon и Google Assistant для Android, а также другие голосовые диалоговые системы. Следовательно, символы, слова или фразы, которые пользователь должен раскрыть и расшифровать в форме, также искажаются в звуковой CAPTCHA и обычно воспроизводятся в звуковой среде запутывающих звуков.
Промышленность рано осознала эту проблему. CNet сообщила в тестах спам-ботов, которые провалили слепых [ newscom ], что «выходной звук Hotmail, который сам искажен, чтобы избежать того же программного злоупотребления, был неразборчив для всех четырех испытуемых, у всех из которых был хороший слух».
Если вывод звука, который сам по себе искажается, чтобы избежать такого же программного злоупотребления, может сделать CAPTCHA трудной для восприятия; также может возникнуть путаница в понимании того, следует ли вводить число как числовое значение или как слово, например, «7» или «семь». Часто пользователь звуковой CAPTCHA слышит звуки, которые кажутся словами или числовыми значениями, которые необходимо ввести, но оказываются просто фоновым шумом.
Звук также внутренне временен, но значение этого неизбежного факта слишком часто недооценивается — возможно, потому, что мир, в котором мы живем, как его видят наши глаза, также временен. Однако, в отличие от реального мира, видимого глазами, традиционная CAPTCHA представляет собой неподвижное изображение, на которое можно смотреть, пока не придет понимание. Звук не имеет аналога визуальному неподвижному изображению.
Всякий раз, когда какая-либо часть аудио CAPTCHA не понята; по крайней мере, часть CAPTCHA должна быть воспроизведена, как правило, несколько раз. В настоящее время лишь немногие аудио CAPTCHA обеспечивают легко вызываемую и надежную функцию воспроизведения, не говоря уже о независимом регуляторе громкости или функции паузы, перемотки назад и вперед. Следовательно, часто воспроизводится совершенно новая звуковая CAPTCHA, если какая-либо часть одной звуковой CAPTCHA оказывается трудной для понимания.
Некоторые аудио CAPTCHA молчаливо признают эту ошибку, предлагая ссылку, позволяющую пользователю загрузить аудио CAPTCHA, обычно в виде файла mp3. Неявное предположение заключается в том, что пользователь будет использовать любимый аудиоплеер, который обеспечивает независимую регулировку громкости и возможности паузы, воспроизведения, перемотки назад и вперед, чтобы воспроизводить аудиофайл CAPTCHA MP3 снова и снова, пока не придет понимание, возможно, с паузой и перематывать воспроизведение и, возможно, записывать сбоку текст, предназначенный для веб-формы. Очевидно, что это очень неудобно и зависит от тайм-аутов веб-сайта. Это также показывает, почему простое предоставление звуковой CAPTCHA, альтернативной традиционной визуальной CAPTCHA, не обеспечивает эквивалентного доступа для пользователя.
Более того, поскольку не все веб-пользователи должны считаться владеющими английским языком в визуальной CAPTCHA, они не должны считаться способными понимать и расшифровывать звуковой английский язык в звуковой CAPTCHA. К сожалению, неанглоязычные звуковые CAPTCHA встречаются очень редко. На момент написания этой статьи нам известен только один автономный поставщик многоязычных решений CAPTCHA с поддержкой значительного числа языков мира.
Слепоглухие пользователи, не имеющие или не использующие звуковую карту, находящиеся в шумной обстановке или не имеющие должным образом настроенных и функционирующих звуковых плагинов, также не могут продолжить работу. Кроме того, относительно немногие звуковые CAPTCHA должным образом поддерживают все различные браузеры и операционные системы, используемые сегодня. Точно так же пользователи браузеров, которые не поддерживают простое направление вывода звука на конкретное аудиоустройство или на все доступные аудиоустройства в системе, также сталкиваются с трудностями.
Пользователи, которые живут с какой-либо формой когнитивной инвалидности, также могут найти аудио
CAPTCHA еще сложнее решить, чем символьные визуальные CAPTCHA.
Аудио CAPTCHA, как известно, создает когнитивную перегрузку для всех пользователей в
сравнение с когнитивной нагрузкой, необходимой для понимания нормальной человеческой речи
[ информационная безопасность ]. Кроме того, исследования CAPTCHA, требующие участия человека
распознавание искаженной или неразборчивой речи показали, что они более
сложный для решения всеми пользователями и более требовательный с точки зрения времени и
усилий по сравнению с текстовыми или графическими CAPTCHA. [ разгадывающих капч ]. Эти
Факты делают аудио CAPTCHA плохим выбором для пользователей с когнитивными нарушениями. инвалидность.
Хотя слуховые формы CAPTCHA, которые представляют собой искаженную речь, создают трудности распознавания для пользователей программ чтения с экрана, точность, с которой такие пользователи могут выполнять задачи CAPTCHA, повышается, если пользовательский интерфейс тщательно спроектирован так, чтобы звук программы чтения с экрана и звук CAPTCHA не смешивались. Этого можно достичь путем реализации функций управления звуком, которые не требуют от пользователя смещения фокуса с поля текстового ответа; см. Оценка существующих звуковых CAPTCHA и интерфейса, оптимизированного для невизуального использования [ eval-audio ].
Эксперименты с комбинированной звуковой и визуальной CAPTCHA, требующие от пользователей идентификации хорошо известных объектов путем распознавания изображений или звуков, позволяют предположить, что этот метод очень удобен для пользователей программ чтения с экрана. Однако его свойства, связанные с безопасностью, еще предстоит изучить, как упоминалось в документе «На пути к универсально используемому доказательству человеческого взаимодействия: оценка стратегий выполнения задач 9». 1811 [ выполнение задачи ].
Цель визуальной проверки — отделить человека от машины. Один из разумных способов сделать это — проверить на логику. Простые математические или словесные головоломки, викторины, пространственные задачи или подобные логические тесты могут поднять планку для роботов, по крайней мере, до такой степени, что их использование в других местах будет более привлекательным.
Однако использование логических головоломок в качестве метода CAPTCHA создает существенные препятствия для доступа для людей с языковыми, обучающими или когнитивными нарушениями. Человек, живущий с дискалькулией, по понятным причинам найдет сложным даже простые арифметические головоломки. Слепой человек не сможет отличить молоток среди графических изображений обычных инструментов. Поэтому при использовании головоломок рекомендуется поддерживать различные головоломки, чтобы тот, кто не может решить данную головоломку, мог получить головоломку другого типа при запросе другой задачи.
Любая разработка задач CAPTCHA в этом направлении должна сопровождаться тщательным исследованием юзабилити с участием людей с различными языковыми, обучающими и когнитивными нарушениями, поскольку такой подход остается в значительной степени неисследованным на практике и в исследовательской литературе. Следует также отметить, что ответы могут нуждаться в гибкой обработке, если они требуют текста в произвольной форме. Кроме того, система должна будет поддерживать огромное количество вопросов или перемещать их программно, чтобы пауки не могли захватить их все для использования веб-роботами. Задачи CAPTCHA на основе головоломок также легко могут быть преодолены операторами-людьми, занимающимися краудсорсингом от имени злоумышленников.
2.1.4 Изображение и видео 2.1.4.1 Визуальное сравнение CAPTCHA Существует ряд методик CAPTCHA, основанных на идентификации неподвижных изображений. Это может включать в себя требование от пользователя определить, является ли изображение мужчиной или женщиной, имеет ли изображение форму человека или аватара среди других подходов к сравнению, таких как CAPTCHAStar! Новая CAPTCHA, основанная на интерактивном обнаружении фигур , [ captchastar ], FaceCAPTCHA: CAPTCHA, которая определяет пол изображений лиц, не распознаваемых существующими гендерными классификаторами [ facecaptcha ] и Социальная и эгоцентрическая классификация изображений для научных приложений и приложений конфиденциальности [ социальная классификация ].
В то время как альтернативные звуковые сравнения CAPTCHA могут быть изучены, например, использование похожих или разных звуков для сравнения, опора только на визуальное сравнение делает эти подходы трудными, если не невозможными для людей с нарушениями зрения. Они также очень трудны для людей живущих с нарушениями обработки зрительного восприятия, среди других когнитивных нарушений и нарушений обучения.
2.1.4.2 3D CAPTCHAТрехмерное представление букв и цифр может затруднить их идентификацию для программного обеспечения OCR, что, в свою очередь, повысит безопасность CAPTCHA, описанной в О безопасности текстовых 3D CAPTCHA [ 3d-captcha-security ]. Однако это решение вызывает те же проблемы доступности, что и традиционные CAPTCHA.
2.1.4.3 CAPTCHA на основе движения и видеоигр Этот процесс основан на перемещении интерактивных элементов, таких как слайдер или завершение базовой видеоигры в виде CAPTCHA, например Игровая семантическая CAPTCHA на основе изображений на мобильных устройствах [ игра-капча ]. Преимущества включают устранение языковых барьеров и устранение разочарования от CAPTCHA из-за предполагаемой интуитивности связанной задачи и удовольствия от игры в видеоигры.
Важно отметить, что реализация этой CAPTCHA должна поддерживать несколько интерфейсов ввода, поскольку на разных устройствах могут отсутствовать некоторые методы ввода, такие как клавиатура или сенсорный экран. Другая потенциальная проблема заключается в том, что поддержка средств чтения с экрана для элементов интерфейса может непреднамеренно предоставить лазейку для обхода CAPTCHA, позволив боту играть в игру.
2.1.5 Биометрия Биометрические идентификаторы стали очень популярным механизмом аутентификации, особенно на мобильных платформах, которые теперь обычно предоставляют необходимое оборудование. Некоторые физические характеристики пользователя, такие как отпечаток пальца или профиль лица, сначала собираются, а затем распознаются для проверки личности человека. Этот процесс эффективно ограничивает способность веб-роботов создавать большое количество ложных идентификаторов.
Однако механизмы биометрической аутентификации также должны быть тщательно разработан, чтобы избежать введения барьеров доступности. Лица, которым не хватает биологические характеристики, требуемые конкретным методом аутентификации, например, пальцы или те, кто не может выполнить регистрацию процедуры, например, пожилые люди, чьи отпечатки пальцев больше не могут быть надежно обнаружены из-за старения, эффективно исключается использование биометрических данных по отпечаткам пальцев. Это может привести к отказу доступа к определенным пользователям с ограниченными возможностями и объясняет, почему полагаться на единый биометрический идентификатор недостаточно для удовлетворения закупок в государственном секторе. стандарты в Евросоюзе ЕН 301 549, раздел 5.3 [ en-301-549 ] и правила согласно разделу 508 Закон о реабилитации и раздел 255 Закона о связи, 36 CFR 1194, Приложение C, раздел 403 в США [ 36-cfr-1194 ].
По этой причине системы биометрической идентификации должны быть разработаны таким образом, чтобы пользователи могли выбирать между несколькими и несвязанными биометрическими идентификаторами. С этой единственной оговоркой правильно спроектированные системы биометрической идентификации особенно привлекательны в ситуациях, когда необходимо идентифицировать конкретного пользователя-человека. Их надежность высока, когнитивная нагрузка на пользователя низка, и их особенно трудно помешать. Однако обычные приложения биометрической аутентификации проверяют и, следовательно, раскрывают личность пользователя. Таким образом, они не подходят в обстоятельствах, когда желательно сохранить анонимность пользователя из соображений конфиденциальности, тем не менее устанавливая, что объект, пытающийся получить доступ к онлайн-сервису, является человеком. Схема, описанная в следующем разделе, предназначена для решения этой проблемы.
Компания Cloudglare недавно предложила подход, предназначенный для проверки того, что пользователь является человеком, при сохранении личной конфиденциальности [ аттестация ]. Он построен на API веб-аутентификации (WebAuthn) [ webauthn-1 ]. Процесс регистрации WebAuthn запускается, чтобы установить, что пользователь контролирует аппаратное устройство аутентификации, произведенное известным и надежным производителем, что определяется действительной цепочкой цифровых сертификатов. Если в этой процедуре происходит биометрическая аутентификация, как это обычно происходит, то она используется только для разблокировки закрытого криптографического ключа устройства аутентификации, и, следовательно, личность пользователя никогда не раскрывается явным образом стороне, запрашивающей подтверждение личности. Также был разработан вариант этой схемы, который обеспечивает более надежную защиту конфиденциальности, не раскрывая личность производителя устройства, что может быть использовано в сочетании с другой информацией для установления личности пользователя. Эта версия подхода требует реализации протокола, основанного на доказательствах с нулевым разглашением [9]. 1810 аттестация-нулевое знание ].
Поскольку пользователь может свободно выбирать среди множества устройств аутентификации от надежных производителей, можно выбрать аппаратное обеспечение, которое наилучшим образом удовлетворяет его или ее потребности и предпочтения, связанные с доступностью. Присущая предлагаемому подходу гибкость явно выгодна как для безопасности, так и для доступности.
2.2 Неинтерактивные автономные подходыВ то время как традиционная CAPTCHA и другие интерактивные подходы к ограничение деятельности веб-роботов иногда бывает эффективным, они сделать использование сайта более громоздким. Часто в этом нет необходимости, т. существуют неинтерактивные механизмы для проверки на спам или другой недопустимый контент обычно вводится роботами.
Подходы, описанные в этом раздел можно рассматривать как альтернативу или дополнительные подходы к традиционная капча.
Поскольку иногда злоумышленник может обойти CAPTCHA (например,
с помощью методов краудсорсинга) криптографические ключи могут в некоторых
обстоятельства могут быть украдены. Обнаружение и реагирование на веб-роботов, которые
успешно и неожиданно получили доступ к веб-ресурсу, таким образом
желательно даже при наличии других мер. Преимущество ограничения
сенсорные и когнитивные потребности у людей с ограниченными возможностями возникают только тогда, когда они
неинтерактивные стратегии используются отдельно или в сочетании с другими
традиционные подходы к обходу CAPTCHA.
Приложения, которые используют непрерывную аутентификацию и «горячие слова» для пометки спам-контента или байесовскую фильтрацию для обнаружения других шаблонов, соответствующих спаму, очень популярны и достаточно эффективны. Хотя такие системы анализа рисков могут время от времени давать ложные отрицательные результаты, правильно настроенные системы могут достигать результатов, сравнимых с традиционной визуальной CAPTCHA, а также устранять дополнительную когнитивную нагрузку на пользователя и устранять барьеры доступа.
Большинство основных программ для ведения блогов содержат функции фильтрации спама или могут быть снабжены подключаемым модулем для этой функции. Многие из этих фильтров могут автоматически удалять сообщения, достигшие определенного порога спама, и помечать сомнительные сообщения для ручной модерации. Более продвинутые системы могут контролировать атаки на основе частоты публикации, фильтровать контент, отправляемый с использованием протокола Trackback, и блокировать пользователей по диапазону IP-адресов, временно или постоянно.
Одной из стратегий предотвращения неправомерного использования веб-ресурсов является загрузка подозрительных клиентов значительными вычислительными нагрузками, что
замедляя взаимодействие и, как мы надеемся, сдерживая злоумышленников, уменьшая их способность участвовать в нежелательных действиях, таких как распространение спама. Этот подход был изучен при разработке задач проверки работоспособности. [ kaPoW-plugins ] Их можно сделать сколь угодно дорогими в вычислительном отношении на основе соответствующей оценки репутации для каждого клиента, который пытается получить доступ к ресурсу. Клиенты, которые считаются вредоносными с большей вероятностью, должны решать задачи, требующие больших вычислительных ресурсов. Меньше ресурсоемких проблем предоставляется клиентам, которые, скорее всего, являются веб-браузерами, управляемыми пользователями-людьми.
Подход, основанный на доказательстве работы, должен оказывать незначительное влияние на интерактивный опыт пользователя-человека при условии, что оценка репутации является относительно точной. Тем не менее, он предназначен для того, чтобы наложить значительные расходы на операторов веб-роботов — возможно, даже больше, чем стоимость найма людей в качестве решателей CAPTCHA.
Реализовать этот подход просто. Он требует, чтобы клиент выполнил код JavaScript для решения вычислительной задачи, а затем решение проверяется сервером, чтобы установить, что работа была выполнена. Он не создает прямых проблем с доступностью, хотя может снизить производительность для пользователей старого оборудования.
2. 2.3 ЭвристикаЭвристика — это открытие в процессе, которое как бы указывает на данный результат. Возможно обнаружить присутствие пользователя-робота на основе объема данных, которые запрашивает пользователь, серии посещенных страниц, IP-адресов, методов ввода данных или других данных подписи, которые могут быть собраны.
Опять же, это требует тщательного изучения данных сайта. Если алгоритмы сопоставления с образцом не могут найти хорошую эвристику, то это не очень хорошее решение. Кроме того, полиморфизм, или создание изменяющихся следов, может привести к роботам, если это еще не произошло, точно так же, как появились полиморфные («невидимые») вирусы, чтобы обойти программы проверки вирусов, ищущие известные вирусные следы.
Еще один эвристический подход, описанный в Botz-4-Sale: выживание DDos-атак, имитирующих Flash Crowds [ killbots ], включает использование изображений CAPTCHA с одной изюминкой: то, как пользователь реагирует на тест, так же важно, как и не решалось. Эта система, которая была разработана для предотвращения распределенных атак типа «отказ в обслуживании» (DDoS), блокирует автоматизированных злоумышленников, которые предпринимают повторные попытки получить определенную страницу, и защищает от неправильной маркировки людей как автоматизированного трафика. Когда нагрузка на сервер падает ниже определенного уровня, процесс аутентификации на основе CAPTCHA полностью удаляется.
Предоставление CAPTCHA, видимой для роботов, но не для людей, кажется достаточно успешным, чтобы поддерживаться в нескольких системах управления контентом, таких как Drupal Honeypots, и в нескольких коммерческих плагинах WordPress. Форма создается для привлечения роботов, а затем скрывается от пользователя разметкой типа CSS-Hidden. Это подход, который легко реализовать даже в разметке, созданной вручную, и его следует учитывать.
Корпорация Hilton Hotel Corporation использовала CAPTCHA-приманку на странице входа в систему для Hilton Honors, веб-сайта своей программы лояльности, где видное поле для фокусировки
помечено: «Это поле предназначено только для роботов. Пожалуйста, оставьте пустым.»
Пользователям бесплатных аккаунтов очень редко требуется полный и немедленный доступ к ресурсам сайта. Например, пользователям, которые ищут билеты на концерты, может потребоваться выполнить только три поиска в день, а новым пользователям электронной почты может потребоваться только отправить такое же уведомление о своем новом адресе своим друзьям. Сайты могут создавать политики, которые явно ограничивают частоту взаимодействия (то есть путем отключения учетной записи на оставшуюся часть дня) или неявно (путем постепенного уменьшения времени отклика). Установление ограничений для новых пользователей может стать эффективным средством превращения ценных сайтов в непривлекательные цели для роботов.
Недостатки этого подхода включают необходимость проведения достаточного тестирования и сбора данных для определения полезных пределов, которые будут полезны пользователям-людям, но не дадут роботам. Это требует, чтобы дизайнеры сайтов смотрели статистику обычных и исключительных пользователей и определяли, существует ли между ними четкое разграничение.
Другой подход заключается в использовании сертификатов для лиц, желающих подтвердить свою личность. Сторона, полагающаяся на сертификат, предлагаемый пользователем, пытающимся получить доступ к онлайн-сервисам, может оценить надежность эмитента сертификата и вероятность того, что закрытый ключ был скомпрометирован, при оценке риска того, что предлагающий на самом деле является веб-роботом, а не человеческий агент. Сертификационные центры с высоким уровнем доверия, такие как правительства, как в программе э-резидентства Эстонии, требуют подтверждения личности в качестве основания для выдачи сертификата. При условии, что закрытый ключ не скомпрометирован и не может быть использован злоумышленником не по назначению, существует высокая степень уверенности в том, что криптографически подписанные им сообщения, которые могут служить для установления личности пользователя в веб-службах, действительно авторизованы держателем сертификата. .
Использование сертификатов в качестве индикатора того, что попытка доступа была санкционирована человеком, раскрывает личность пользователя поставщику веб-службы, и поэтому его не следует применять в обстоятельствах, когда необходима анонимность. Кроме того, проверка подлинности сертификата клиента Transport Layer Security (TLS), определенная в TLS 1.2 и более ранних версиях протокола, вызывает проблемы с конфиденциальностью [ tls-tracking ].
Иногда предлагается вариант этой концепции, при котором регистрироваться будут только инвалиды, затронутые другими системами проверки. Такие подходы вызывают серьезные опасения в отношении конфиденциальности и стигматизации, и обычно им решительно противостоят сами люди с ограниченными возможностями и организации, которые их обслуживают. Такие подходы не следует путать с ситуациями, когда люди добровольно идентифицируют себя как лица с ограниченными возможностями. Примером может служить базирующаяся в США компания Bookshare, услуги которой доступны только лицам с документально подтвержденной неспособностью воспринимать печатную информацию в соответствии с условиями международного договора об авторском праве, администрируемого Всемирной организацией интеллектуальной собственности (ВОИС) Организации Объединенных Наций и известного как Марракешский договор . [ марракеш ]
Приобретенная в 2009 году в Университете Карнеги-Меллона, reCAPTCHA от Google сегодня занимает доминирующее положение в развертывании CAPTCHA в Интернете. Однако reCAPTCHA версии 1 больше не поддерживается.
3.2.1 Версия 2: Вы робот?reCAPTCHA v2 предоставил API, который наиболее эффективно рекламировался как «no CAPTCHA re CAPTCHA», а его флажок, провозглашающий: «Я не робот», стал культурной иконой, породив различные культурные ответвления в искусстве, театре и популярной музыке. .
Флажок, конечно, никогда не был флажком в традиционном понимании HTML. Процесс псевдофлажка стал мощным сборщиком пользовательских данных, выходящих далеко за рамки движений мыши и навигации с помощью клавиатуры, включая дату, язык, на который настроен браузер, все файлы cookie, размещенные Google за последние 6 месяцев, информацию CSS для этой страницы, инвентаризация щелчков мышью, сделанных на этом экране (или прикосновений, если на сенсорном устройстве), инвентаризация плагинов, установленных в браузере, и перечисление всех объектов javascript, чтобы определить, является ли пользователь человеком или роботом. Конечно, Google также, как правило, многое знает об отдельных пользователях, включая их обычные IP-адреса, номера телефонов и адреса электронной почты их друзей, семьи и коллег, где они были в каждый момент каждого дня, а также их веб-поиск и YouTube. привычки. Вот почему простой флажок может сделать процесс CAPTCHA обезоруживающе простым, хотя это также объясняет, почему ссылка на политику конфиденциальности Google всегда сопровождала «no CAPTCHA reCAPTCHA». Раскрытие информации и некоторые положения Политики конфиденциальности необходимы для соблюдения требований законодательства Калифорнии и ЕС.
Несмотря на то, что часто отмечались конкретные сбои WCAG, reCAPTCHA v2 от Google какое-то время считалось наиболее доступным решением CAPTCHA по одной простой причине: его можно было легко выполнить с использованием различных вспомогательных технологий. Совсем недавно было широко замечено, что использование навигации с помощью клавиатуры, как это делают многие пользователи вспомогательных технологий, больше не работает. Вместо этого пользователям предоставляется традиционная недоступная CAPTCHA в качестве запасного механизма. Наши собственные тесты с различными браузерами в различных операционных средах в целом прошли успешно с собственной тестовой страницей Google reCAPTCHA. Тем не менее, просмотр в режиме инкогнито, очистка или блокировка файлов cookie, а также другие факторы, по-видимому, могут вызвать отказ от традиционной CAPTCHA в наши дни для многих пользователей вспомогательных технологий.
Одна инновация reCAPTCHA v2 кажется наиболее многообещающий. Вместо того, чтобы воспроизводить символы, пользователи попросили ввести слова, которые они видят (или слышат). Это даже кажется ненужным писать их правильно или введите все слова, представленные для того, чтобы быть оцененным человек.
К сожалению, теперь он появляется
что звуковые CAPTCHA, ранее доступные с реализациями v2, теперь иногда больше не
предоставляется. Вместо этого пользователи видят сообщение следующего содержания:
«Ваш компьютер или сеть могут отправлять автоматические
запросы. Чтобы защитить наших пользователей, мы не можем обрабатывать ваши
запросить прямо сейчас». Пользователи, которые зависели от аудио-альтернатив CAPTCHA, которые ранее могли работать с reCAPTCHA v2, таким образом, внезапно и, по-видимому, капризно блокируются и отказываются обслуживаться на сайтах, все еще использующих V2.
В конце 2018 года Google выпустил reCAPTCHA v3, обещая устранить «необходимость вообще прерывать пользователей вызовами». Google также сообщил нам, что их цели с v включают повышение «доступности Интернета за счет полного удаления традиционных CAPTCHA». Очевидно, что полностью неинтерактивное тестирование Тьюринга является наиболее желанным направлением развития доступности. Когда неинтерактивный тест Тьюринга возвращает оценку, указывающую на высокую уверенность в том, что пользователь является человеком, или даже оценку, указывающую на высокую уверенность в том, что пользователь является роботом, и опыт показывает, что неинтерактивный движок надежен, мы можем только похвалить и благодарность за технический прогресс, который более эффективно поддерживает людей с ограниченными возможностями.
Конечно, ни один подход не всегда дает однозначные результаты. В таком ситуациях Google советует поставщикам контента «использовать вторичный вызов, который имеет смысл в контексте их сайта, например двухфакторный авторизация, отправить сообщение модераторам или объединить оценку с сигналами конкретно для своего сайта, чтобы сделать более обоснованное суждение». Google намеревается что традиционная CAPTCHA больше не используется в качестве резервного механизма, и она была удалена из v reCAPTCHA, хотя она остается в их немного более старой службе reCAPTCHA v2 Invisible 2017 года.
Реальность такова, что какие действия предпринимаются в ответ на неоднозначное ядро, возвращенное v3, находится в руках поставщика контента. Такие сервисы, как reCAPTCHA, завоевывают свою долю рынка, предлагая поставщикам контента облегчить тяжелую работу, связанную с организацией эффективного и доступного тестирования Тьюринга. К сожалению, это оставляет дверь открытой для любого запасного подхода, который может выбрать контент-провайдер. Между тем, Google reCAPTCHA FAQ заявляет, что reCAPTCHA версии 2 не исчезнет. Поэтому крайне важно, чтобы методы устранения неоднозначности неинтерактивной оценки были хорошо задокументированы и легко реализуемы, чтобы лучше преодолевать тенденцию к простому принятию старого знакомого подхода.
Стало привычным для многих, хотя далеко не для всех пользователей доступ к
различные онлайн-сервисы через несколько устройств, таких как настольные и мобильные
компьютеры, смартфоны, планшеты и носимые устройства, такие как смарт-часы. Этот
распространение привело к онлайн-сервисам, предоставляющим решения для идентификации
которые учитывают сочетание мульти-устройств и мульти-платформенных векторов
для простая и эффективная аутентификация пользователей, в том числе лиц с
инвалидность [ авторизация-мульт ]. Отметим, что несколько крупных поставщиков услуг
(например, Facebook) теперь поддерживают межсайтовую аутентификацию пользователей. Однако в
связи со специфической способностью отличить человека от бота, появляется только
Google v3
API reCAPTCHA предоставляет межсайтовые сервисы CAPTCHA без фактического прохождения
конкретные идентификационные данные.
Мы ожидаем, что сервис Google v3 reCAPTCHA не будет набирать
представлять CAPTCHA всякий раз, когда другая вкладка браузера уже правильно зарегистрирована в
продукт Google, такой как Календарь, на любом зарегистрированном пользовательском устройстве. Однако,
хотя это может помешать стороннему сайту собирать личные данные, это
действительно помогает Google в получении большего количества пользовательских данных. Это представляет собой значительную
стоимость конфиденциальности пользователя в отрасли, способной к перекрестным ссылкам
огромные объемы данных при отсутствии значимых правил и средств контроля
о том, где и как эти данные могут быть использованы. Это очень сильная доступность
беспокойство, поскольку люди с ограниченными возможностями, как правило, неохотно раскрывают какие-либо
информацию об их инвалидности в Интернете, за исключением случаев и только тогда, когда они явно
сами решают раскрывать эту информацию по своим особым причинам.
Среда с несколькими устройствами широко используется для аутентификации пользователя-человека путем
требующие каких-либо действий на зарегистрированном втором устройстве, чаще всего смарт
сотовый телефон. Этот процесс известен как «двухфакторная аутентификация».
обязательным для каждого из трех крупнейших поставщиков услуг электронной почты: Gmail, Yahoo,
и Outlook, которые принимают исходящую почту только после аутентификации пользователя
по номеру телефона, который они обязаны предоставить. Точно так же следует
Твиттер выявляет активность, которую он считает подозрительной, он будет удерживать твиты до тех пор, пока
пользователь проходит повторную проверку как с помощью запроса reCAPTCHA, так и с помощью телефонного звонка. Пока что
все чаще, по мере увеличения количества звонков по телемаркетингу, веб-пользователи не хотят
предоставлять агрегаторам данных свои личные номера телефонов. Ясно, голос
только подход аутентификации также не может обслуживать глухих и слабослышащих пользователей
правильно.
Доступ к службе учетной записи Google через новый браузер или ноутбук и Google будет откладывать предоставление доступа до тех пор, пока пользователь не ответит на всплывающее «тост» сообщение на зарегистрированном телефонном устройстве с фотографией пользователя и вопросом: «Это был ты?» Пользователь должен убедиться, что это действительно он, прежде чем доступ может быть получен. Продолжать. Вариант, ранее распространенный в Google и до сих пор используемый в других местах. совершает голосовой вызов или отправляет текстовое сообщение с коротким кодом, который пользователь необходимо ввести в поле формы, чтобы продолжить.
Еще один вариант этого подхода, используемый Cisco Webex.
служба телеконференций, просит пользователя нажать определенную клавишу на своем телефоне
продолжить. Это достаточно просто на настольном телефоне, но становится проблематичным
для пользователя смартфона, зависящего от преобразования текста в речь (TTS), который теперь должен слышать голос TTS телефона
чтобы вызвать всплывающую панель набора номера, а затем найти соответствующую клавишу тонального набора на
в то же время, когда голос службы Webex также говорит, повторяя:
«Добро пожаловать в Webex. Нажмите 1, чтобы подключиться к вашему совещанию. … Добро пожаловать в Webex. Нажмите 1, чтобы подключиться к вашему совещанию….» Важно понимать, что оба эти голоса направляются через один и тот же физический динамик устройства, даже на устройствах, оснащенных двумя динамиками для воспроизведения музыки в стереорежиме.
Предоставление пользователю возможности связаться с помощью голоса и/или текста — это хорошо, но некоторые сервисы предлагают только текст. Это ставит в невыгодное положение пользователя без доступное текстовое устройство, и таких пользователей много. Точно так же услуги, предлагающие только возможность голосового вызова, ставят в невыгодное положение глухих и слабослышащих пользователей. Как всегда, правило должно предоставлять пользователю возможность выбора, в том числе резервные варианты.
3.4 Токены Turing из облака? Термин «облако» стал широко известен среди пользователей компьютеров. Он описывает растущую концентрацию веб-контента и
предоставление программных услуг в сетях доставки контента (CDN), таких как Akamai,
Cloudflare и Amazon Cloudfront. Эти CDN обеспечивают добавленную стоимость локализованных
доставка кэшированного контента «последней мили» и возможность эффективно отклонять различные
вредоносные действия, такие как атаки типа «отказ в обслуживании» (DOS). Как почти
Две трети интернет-контента в настоящее время доставляются CDN, теперь они также
непреднамеренно вынуждены стать арбитрами теста Тьюринга. Это, в свою очередь, привело к разработке новых инновационных подходов к CAPTCHA, таких как Privacy Pass [ Privacy-Pass ] теперь доступен как расширение для браузера на Cloudflare.
Несмотря на то, что Privacy Pass по-прежнему начинается с проверки CAPTCHA, он предоставляет
пользователю кладезь криптографически ослепленных токенов, которые могут удовлетворить дальнейшие
проблемы в фоновом режиме и значительно сократить количество интерактивных CAPTCHA
проблемы. Самое интересное, что он предлагает надежную защиту конфиденциальности, даже
анонимность, надежно подтверждая, что пользователь является человеком. По сути, CDN действует как брокер доверия от имени пользователя. Когда пользователь «тратит» токен, он говорит сайту, к которому обращается: «Вы не доверяете мне, но вы доверяете организации, выпустившей этот токен, и они ручаются за меня». Так как этот подход
развития, мы можем разумно надеяться, что бремя первоначальной проблемы может быть
быть дополнительно смягчены за счет надежной поддержки веб-доступности, возможно, за счет расширения доступных подходов к начальной проверке CAPTCHA, например, путем добавления поддержки биометрии.
Сегодня в Интернете используется множество различных систем управления идентификацией с различными функциями и различными уровнями доступности. Некоторые из них, такие как Last Pass, предлагают безопасно хранить учетные данные для аутентификации и часто используемые данные форм, которые отдельные пользователи и различные группы могут вызывать на различных личных устройствах. Такие сервисы, как Cognito от Amazon, позволяют поставщикам услуг поддерживать ряд существующих аутентификаций пользователей, чтобы облегчить доступ к ряду межплатформенных сервисов, по сути, перекладывая задачу аутентификации при входе в систему и контроля доступа. Другие, такие как Account Kit от Facebook, стремятся использовать аутентификацию при входе в очень популярный веб-сервис для развития экосистемы, разработанной с использованием пользовательских данных, собранных на этой платформе. На первый взгляд нам было неясно, какие из этих услуг, если таковые имеются,
отдайте предпочтение ограничению услуг учетной записи только пользователями-людьми. Однако ясно, что практически никто не предоставляет своим аутентифицированным пользователям, о которых они много знают, поддержку неинтерактивной аутентификации их человечности с третьими лицами. Единственными известными нам исключениями являются reCAPTCHA v3 и Privacy Pass.
Мы считаем, что необходимо добавить стороннюю поддержку CAPTCHA в службы управления идентификацией. Любая услуга, предлагающая сказать третьей стороне: «Вы не знаете этого пользователя, поэтому не доверяете ему, но вы знаете меня и доверяете мне, поэтому можете доверять этому пользователю», могла существовать только после того, как заслужила доверие всей отрасли. Такой сервис действительно должен быть осторожен, чтобы регистрировать только пользователей-людей. Мы считаем, что сервис, который использует как аутентификацию пользователей, так и надежную анонимность, быстро докажет свою жизнеспособность. Всем пользователям, но, безусловно, лицам с ограниченными возможностями нужна не только упрощенная аутентификация, но и возможность взаимодействовать через Интернет с использованием общепринятых доверенных учетных данных с минимальными перерывами для подтверждения своей человечности. Такой доступный VPN-сервис повышенного качества, обеспечивающий не только межсайтовый вход в систему, но и аутентификацию по Тьюрингу, возможно, за ежемесячную плату — такой сервис мог бы даже проверять и посредничать во всех зарегистрированных устройствах пользователя в Интернете, анонимизируя даже финансовые транзакции и данные о доставке, как полный спектр услуг онлайн трастового брокера. Аккредитивы имели такое же начало в международных финансах несколько столетий спустя, так почему бы сегодня не использовать токены Тьюринга и защиту конфиденциальности?
CAPTCHA, безусловно, со временем стала более сложной. Это включало разработку несколько альтернатив текстовым символам, содержащимся в растровых изображениях. изображений, некоторые из которых служили для поддержки доступа для людей с инвалидность. Однако выяснилось также не только то, что традиционная CAPTCHA продолжает вызывать трудности у людей с инвалидности, но и то, что он становится все более небезопасным и, возможно, теперь плохо подходит с целью отличить людей от их роботизированных подражатели.
Тем не менее потребность в надежных и доступных решениях сохраняется. На самом деле необходимость, возможно, стала более насущной, поскольку ограничения аутентифицированного входа в систему становятся все более и более очевидными при неправильном использовании основных сервисов по всему миру.
Поэтому настоятельно рекомендуется, чтобы цель и эффективность любого развернутое решение CAPTCHA должно быть тщательно рассмотрено перед его внедрением, а затем внимательно следить за эффективностью работы. Как и все хорошее программное обеспечение и на предоставление линейного контента, анализ следует начинать с тщательного рассмотрения системных требований и глубокое понимание потребностей пользователей, в том числе потребности людей с ограниченными возможностями.
Очевидно, что некоторые подходы, такие как reCAPTCHA от Google,
двухэтапная проверка или проверка на нескольких устройствах может быть простой и доступной
развернут. Тем не менее, проблемы сохраняются даже в этих системах, особенно для не
носителей английского языка. Более того, применяющие такие подходы должны осознавать, что они участвуют в разоблачении
своих пользователей к массивному сбору персональных данных в нескольких
транснациональные системы профилирования данных, совершенно независимо от каких-либо социальных
управление.
Поэтому важно также рассмотреть доступные автономные подходы, такие как как приманки и эвристики, а также текущее изображение и звуковая CAPTCHA библиотеки, поддерживающие несколько языков. Как всегда, тестирование и мониторинг системы для эффективность должна обеспечивать окончательную решимость, даже если мы признаем что эффективная система сегодня может оказаться неэффективной через несколько лет.
Мы резюмируем наши выводы в следующих пунктах:
- Анализ риска попыток доступа к ресурсу обычно желателен. Некоторые онлайн-ресурсы просто являются более важными целями, чем другие. Крайне важно, чтобы анализ включал основанное на доказательствах определение того, насколько сложной должна быть CAPTCHA. Пользователей не следует заставлять сверх того, что строго необходимо для обеспечения безопасности сайта, например, / если приманки достаточно, используйте приманку до тех пор, пока доказательства атак роботов не диктуют что-то еще.
- Всякий раз, когда интерактивный
CAPTCHA считается важной по соображениям безопасности,
очень полезно ограничить и свести к минимуму частоту, с которой пользователи подвергаются интерактивным испытаниям CAPTCHA. С CAPTCHA меньше интерактивности, очевидно, больше доступности. Как отмечалось выше, нас вдохновляет
разработка таких подходов, как Privacy Pass, который, хотя иногда все еще требует интерактивной проверки CAPTCHA, делает это гораздо реже.
- Всякий раз, когда применяется интерактивная CAPTCHA, необходимо выполнять множество альтернативных задач. доступны для использования различных сенсорных и когнитивных способностей пользователя, чтобы пользователь мог выбрать подход, который наилучшим образом соответствует его способностям. Мы, люди, обладаем множеством интеллектуальных сильных и слабых сторон. Потерпеть неудачу предлагать разнообразные вызовы — значит игнорировать эту простую истину.
- При прочих равных условиях мы предпочитаем неинтерактивные подходы, потому что они не создают проблем с доступностью. Однако они могут подвергнуть пользователя сбор персональных данных.
- Для проверки подлинности попытки доступа могут привлекаться третьи лица.
Однако такие решения могут привести к компромиссам в отношении конфиденциальности.
Другими словами, хотя некоторые подходы к CAPTCHA лучше, чем другие, и в то время как более современные подходы предлагают явное преимущество перед более старыми подходами, есть до сих пор нет единого, идеального решения. Важно проявлять осторожность, чтобы любой правильно реализованная технология CAPTCHA позволяет людям с ограниченными возможностями идентифицируют себя как человека.
А. УсловияВ этом документе используются следующие термины:
- АИ
- Искусственный интеллект
- альтернативный текст
- Текст, который связан с нетекстовым содержимым и содержит краткое описание или метку.
- вспомогательные технологии
- Аппаратное и/или программное обеспечение, которое действует как автономный пользовательский агент или вместе с основным пользовательским агентом для удовлетворения функциональных требований пользователей с ограниченными возможностями, которые выходят за рамки требований, предоставляемых только основными пользовательскими агентами.
- Байесовский фильтр
- Рекурсивная вероятностная эвристика для категоризации содержимого, обычно используемая при фильтрации спама.
- CAPTCHA
- «Полностью автоматизированный общедоступный тест Тьюринга для различения компьютеров и людей», основанный на задаче, которая, как считается, трудна для правильного решения машинами, но относительно проста для людей.
- непрерывная аутентификация
- Механизм для определения того, что пользователь по-прежнему является ранее проверенным, без необходимости интерактивной повторной аутентификации.
- эвристика
- Способ решения проблемы с высокой надежностью, но не совершенством.
- приманка
- Служба-приманка, предназначенная для получения взаимодействия от веб-роботов.
- неинтерактивный
- @@
- инфраструктура открытых ключей
- Аутентификация объекта, который зашифровал содержимое с помощью зарегистрированного ключа дешифрования.
- робот
- Программное приложение, которое выполняет автоматизированные задачи с веб-контентом.
- программа чтения с экрана
- Вспомогательная технология, которая воспроизводит содержимое в виде речи или шрифта Брайля.
- спам-фильтр
- Программное обеспечение, которое обрабатывает сообщения электронной почты для отделения нежелательных, обычно автоматизированных, сообщений от нужных.
- крестовина
- Робот, который обрабатывает веб-содержимое и рекурсивно переходит по ссылкам для обработки содержимого в месте назначения ссылки.
- Тест Тьюринга
- Тест для определения того, отличимы ли ответы, предоставляемые программным приложением, от ответов людей.
- пользовательский агент
- Любое программное обеспечение, которое извлекает, отображает и облегчает взаимодействие конечного пользователя с веб-контентом.
- VPN
- Виртуальная частная сеть
- Джуди Брюэр, W3C
- Майкл Купер, W3C
- Джон Фолиот, Deque Systems Inc.
- Скотт Холлиер, приглашенный эксперт
- Стивен Ноубл, Pearson Plc
- Янина Сайка, Приглашенный эксперт
- Дэвид Слоан, The Paciello Group, LLC
- Джейсон Уайт, Служба образовательного тестирования
- Кентаро Фукуда
- Марк-Антуан Гарриг
- Эл Гилман
- Чарльз МакКэти-Невил
- Дэвид Поусон
- Дэвид Полман
- Янина Сайка
- Джейсон Уайт
Эта публикация частично финансировалась за счет федеральных средств США из Министерства здравоохранения и социальных служб, Национального института исследований в области инвалидности, независимого образа жизни и реабилитации (NIDILRR) в соответствии с номером контракта HHSP23301500054C. Содержание этой публикации не обязательно отражает взгляды или политику Министерства здравоохранения и социальных служб США, а упоминание торговых наименований, коммерческих продуктов или организаций не означает их одобрения правительством США.
- [36-cfr-1194]
- 36 CFR Приложение C к части 1194, Критерии функциональных характеристик и технические требования . Институт правовой информации. URL: https://www.law.cornell.edu/cfr/text/36/appendix-C_to_part_1194
- [3d-captcha-security]
- О безопасности текстовых 3D CAPTCHA . Нгуен, В.Д.; Чоу, Ю.-В.; Susilo, W. Компьютеры и безопасность, 45. 2014.
- [аттестация]
- Человечество тратит около 500 лет в день на CAPTCHA. Пора положить конец этому безумию . Тибо Менье. Облачная вспышка. 13 мая 2021 г. URL: https://blog.cloudflare.com/introduction-cryptographic-attestation-of-personhood/
- [attestation-zero-knowledge]
- Введение доказательств с нулевым разглашением для частной веб-аттестации с помощью Cross/ Аппаратное обеспечение разных поставщиков . Уотсон Лэдд. Облачная вспышка. 12 августа 2021 г. URL: https://blog.cloudflare.com/introduction-zero-knowledge-proofs-for-private-web-attestation-with-cross-multi-vendor-hardware/
- [auth-mult]
- Разработка, тестирование и внедрение нового метода аутентификации с использованием нескольких устройств . Цетин, К. Дж. Лигатти, Д. Голдгоф и Ю. Лю (редакторы): ProQuest Dissertations Publishing. 2015.
- [captcha-ld]
- Влияние CAPTCHA на пользовательский опыт среди пользователей с нарушениями обучаемости и без них . Гафни, Р.; Nagar, I..
- [captcha-ocr]
- CAPTCHA: атаки и слабые места против технологии OCR . Шелковистый Азад; Киран Джейн. Журнал компьютерных наук и технологий. 2013. URL: https://computerresearch.org/index.php/computer/article/download/368/368
- [надежность по капче]
- Влияние поворота текста, длины строки и формата букв на текстовые CAPTCHA Надежность . Тангмани, К. Журнал прикладных исследований в области безопасности, 11(3). 2016.
- [captcha-security]
- CAPTCHA Security: Пример . Ян, Дж .; Эль Ахмад, AS. Безопасность и конфиденциальность, IEEE, 7(4). 2009 г..
- [капчастар]
- CAPTChaStar! Новая CAPTCHA, основанная на интерактивном обнаружении фигур . Конти, М.; Гуариско, К.; Spolaor, R.. 2015.
- [defeat-line-noise]
- Обход CAPTCHA с линейным шумом с помощью нескольких квадратичных змей . Накагуро, Ю.; Дейли, Миннесота; Марукатат, С .; Маханов С.С. Компьютеры и безопасность, 37. 2013.
- [en-301-549]
- EN 301 549 v3.2.1: Гармонизированный европейский стандарт — Требования доступности для продуктов и услуг ИКТ . CEN/CENELEC/ETSI. 2021-03. URL: https://www.etsi.org/deliver/etsi_en/301500_301599/301549/03.02.01_60/en_301549v030201p.pdf
- [eval-audio]
- Оценка существующих звуковых CAPTCHA и интерфейс, оптимизированный для невизуального использования . Бигхэм, JP; Кавендер, AC. В материалах конференции SIGCHI по человеческому фактору в вычислительных системах. Апрель 2009 г.
- [facecaptcha]
- FaceCAPTCHA: CAPTCHA, которая определяет пол изображений лиц, не распознаваемых существующими гендерными классификаторами . Ким, Дж.; Ким, С .; Ян, Дж .; Рю, Дж.-Х.; Вон, К. Международный журнал, 72 (2). 2014.
- [game-captcha]
- Игровая семантическая CAPTCHA на мобильных устройствах . Ян, Т.-И.; Кунг, К.-С.; Ценг, К.-К.. Международный журнал, 74 (14). 2015.
- [информационная безопасность]
- Справочник по информационной и коммуникационной безопасности . Питер Ставрулакис; Марк Штамп. Springer Science & Business Media. 2010.
- [kaPoW-плагины]
- Плагины kaPoW: защита веб-приложений с помощью проверки работоспособности на основе репутации . Тьен Ле; Акшай Дуа; У-чан Фэн. Материалы 2-го совместного семинара WICOW/AIRWeb по качеству Интернета. 2012.
- [killbots]
- Botz-4-Sale: выжившие DDoS-атаки, имитирующие Flash Crowds . Шрикантх Кандула; Дина Катаби; Матиас Джейкоб; Артур Бергер. URL: https://www.usenix.org/legacy/events/nsdi05/tech/kandula/kandula_html/
- [марракеш]
- Марракешский договор об облегчении доступа слепых и лиц с нарушениями зрения или иными ограниченными способностями воспринимать печатную информацию к опубликованным произведениям . Всемирная организация интеллектуальной собственности. 27 июня 2013 г. URL: https://www.wipo.int/treaties/en/ip/marrakesh
- [newscom]
- Тесты спам-ботов завалили вслепую . Пол Феста. Новости.ком. 2 июля 2003 г. URL: https://web.archive.org/web/20030707210529/http://news.com.com/2100-1032-1022814.html
- [privacy-pass]
- Пропуск конфиденциальности: анонимный обход интернет-вызовов . Алекс Дэвидсон; Ян Голдберг; Ник Салливан; Джордж Танкерсли; Филиппо Вальсорда. Материалы по технологиям повышения конфиденциальности; 2018 (3): 164-180. 2018. URL: https://www.petsymposium.org/2018/files/papers/issue3/popets-2018-0026.pdf
- [recaptcha-attacks]
- Атаки на основе HMM на ReCAPTCHA Google с непрерывным визуальным и Аудиосимволы . Сано, С.; Оцука, Т .; Итояма, К.; Окуно, Х.Г.. Журнал обработки информации, 23 (6). 2015.
- Социальная и эгоцентрическая классификация изображений для научных приложений и приложений для обеспечения конфиденциальности . Кораем, М. Д. Крэндалл, Дж. Боллен, А. Кападиа и П. Радивояк (ред.): ProQuest Dissertations Publishing. 2015.
- [решение капчи]
- Насколько хорошо люди разгадывают капчи? Крупномасштабная оценка . Эли Бурштейн и др. Симпозиум IEEE 2010 г. по безопасности и конфиденциальности. 2010.
- [задача-завершение]
- На пути к универсальному доказательству человеческого взаимодействия: оценка стратегий выполнения задач .