
Яндекс Wordstat (Вордстат) | Синапс
Зачем нужен вордстатВордстат это — “Статистика показов заданного пользователем слова или словосочетания, а также запросов, которые делали искавшие его люди. Возможность уточнить регион или посмотреть помесячный и понедельный срезы.” (с) Яндекс.
Что это значит?Яндекс хранит всю информацию о том, что спрашивают люди в интернете и любой человек может бесплатно получить доступ к этой информации с помощью сервиса https://wordstat.yandex.ru/
Например мы компания, которая продает кирпич и нам интересно посмотреть сколько человек в нашем регионе ищет в интернете кирпич, чтобы понять стоит ли вообще этим заниматься.
Открываем сервис (для этого необходимо авторизоваться в яндексе или создать учетку если у вас ее еще нет и вводим для начала максимально общую фразу “кирпич”.
Левая колонка вордстатЧто это значит? Мы видим сколько человек по всему миру в яндексе искали какие-либо фразы и словосочетания с использованием слова “кирпич” или производных к нему (например “кирпича”). Всего этих запросов было 1 921 241. Впечатляет, не правда ли?
Всего этих запросов было 1 921 241. Впечатляет, не правда ли?
А ниже в списке мы видим наиболее популярные запросы с этим словом, например “купить кирпич”, “под кирпич” и т.д, То есть из 1 921 241 запроса было 172 572 запроса с использованием не просто “кирпич”, а “купить кирпич”.
Эти цифры называются Базовой частотностью и являются достаточно общим показателем. Есть более точные показатели, например “точная частотность”.
Если мы поставим слово “кирпич” в кавычки, то получим другие цифры — 18 706. Это показатель того сколько раз в поиске была фраза “кирпич” без дополнений, но в разных формах, например “кирпича” или “кирпичей”.
Чтобы исключить словоформы мы добавляем перед словом восклицательный знак и получаем тот самый показатель точной частотности. Он показывает сколько раз вбивали именно это слово в этом виде.
Правая колонка вордстат
Правая колонка является подсказкой для вас какие запросы похожие на ваш вводили люди. Например “кирпичный завод” или “кирпичный дом”. Это нужно для того, чтобы вы не упустили те запросы, которые вводят пользователи, но вы бы никогда так не подумали написать 🙂
Например “кирпичный завод” или “кирпичный дом”. Это нужно для того, чтобы вы не упустили те запросы, которые вводят пользователи, но вы бы никогда так не подумали написать 🙂
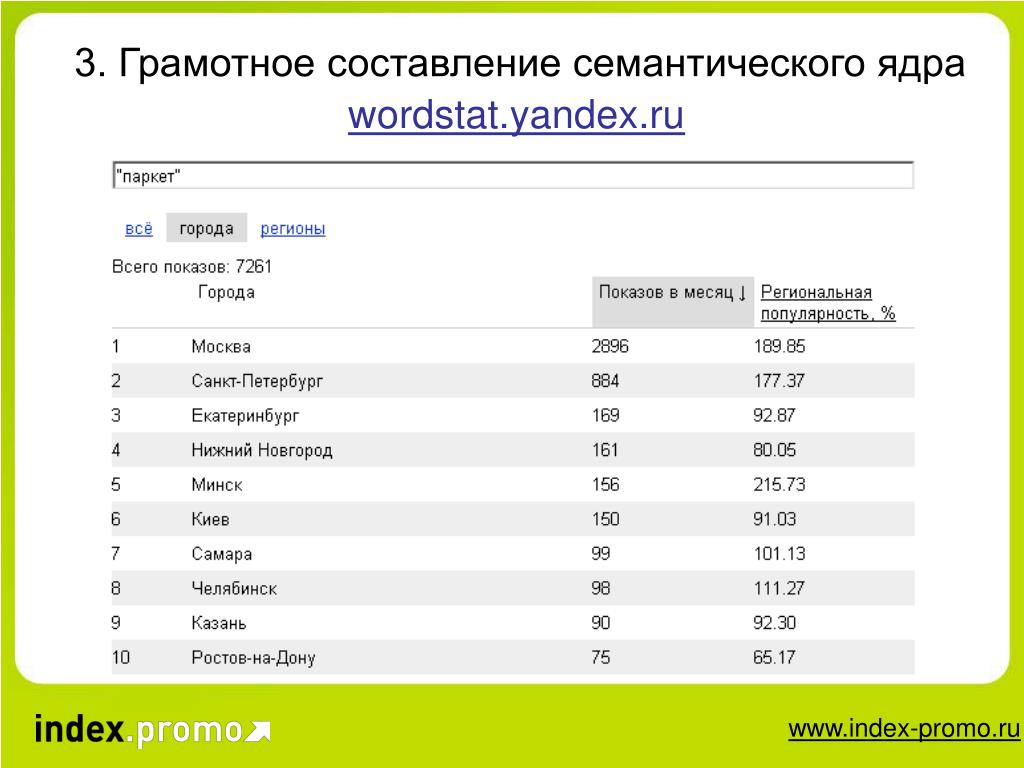
Те цифры которые мы получили показывают данные за последний месяц и по всему миру. Но мы же продаем кирпич по нашей области, поэтому нам интересно узнать сколько пользователей ищет кирпич только, например, в Вологодской области.
Для этого под поисковой строкой справа мы нажимаем на “Все регионы” и выбираем нужный нам регион.
И видим, что по общему запросу содержащему “кирпич” данные уже намного ниже — 12 612 запросов.
И так как этот запрос слишком общий и может содержать “дом из кирпича” и прочее, то мы будем ориентироваться на более целевой запрос, например “купить кирпич”. Чтобы продолжить собирать статистику по нему, необходимо просто кликнуть на этот запрос.
870 запросов в месяц тоже не так мало, но сейчас февраль, данные собираются за январь, а мы знаем, что этот месяц не самый ходовой для кирпича, поэтому нам будет интересно посмотреть сезонность и изменение этого показателя по месяцам. Для этого под поисковой строкой мы можем переключится на вкладку “История запросов” и увидеть данные в динамике.
Мы видим, что в пиковые месяцы количество запросов превышает 1400, а это почти в 2 раза больше чем в январе.
Есть еще одна возможность — оценить спрос по регионам. Если бы мы, например, выбрали район где нам стоит открывать филиал в первую очередь, то мы могли бы оценить перспективу.
Эти данные там можно посмотреть как на карте, так и списком.
Лидирует конечно же Москва и Спб, а за ними идут Краснодарский край и Самарская область.
Вывод
Это лишь простой пример получения информации из вордстата.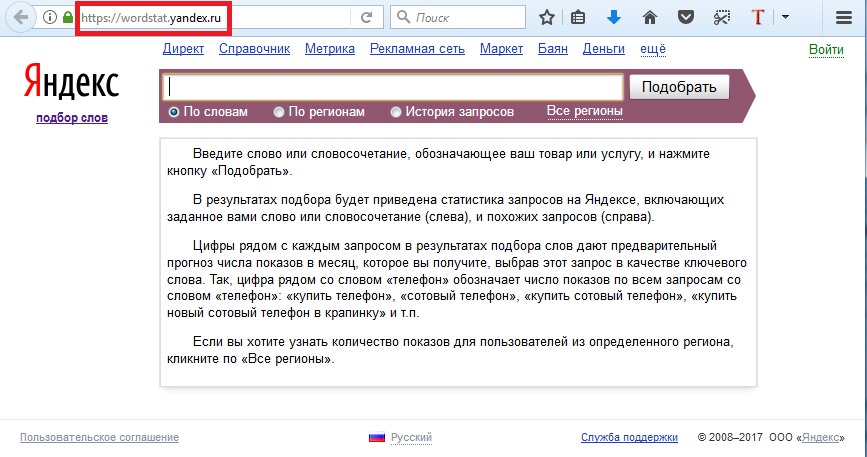 Этим сервисом пользуются не только для того, чтобы оценить такие общие данные, но и собрать конкретные фразы в тематике для создания страниц по ним и дальнейшего SEO продвижения по ним. Чтобы люди вводя эти запросы видели именно наш сайт и становились нашими клиентами.
Этим сервисом пользуются не только для того, чтобы оценить такие общие данные, но и собрать конкретные фразы в тематике для создания страниц по ним и дальнейшего SEO продвижения по ним. Чтобы люди вводя эти запросы видели именно наш сайт и становились нашими клиентами.
как пользоваться сервисом для сбора семантического ядра – SML Marketing
Блог про интернет-маркетинг » Контекстная реклама » Подбор ключевых слов в Яндекс.Вордстат: как пользоваться сервисом для сбора семантического ядра
Контекстная реклама
Автор Марюс Салангинас На чтение 2 мин. Просмотров 2k. Опубликовано
Заходите в мой
Telegram-канал
Яндекс.Wordstat – это сервис для оценки спроса по поисковым фразам в Яндексе.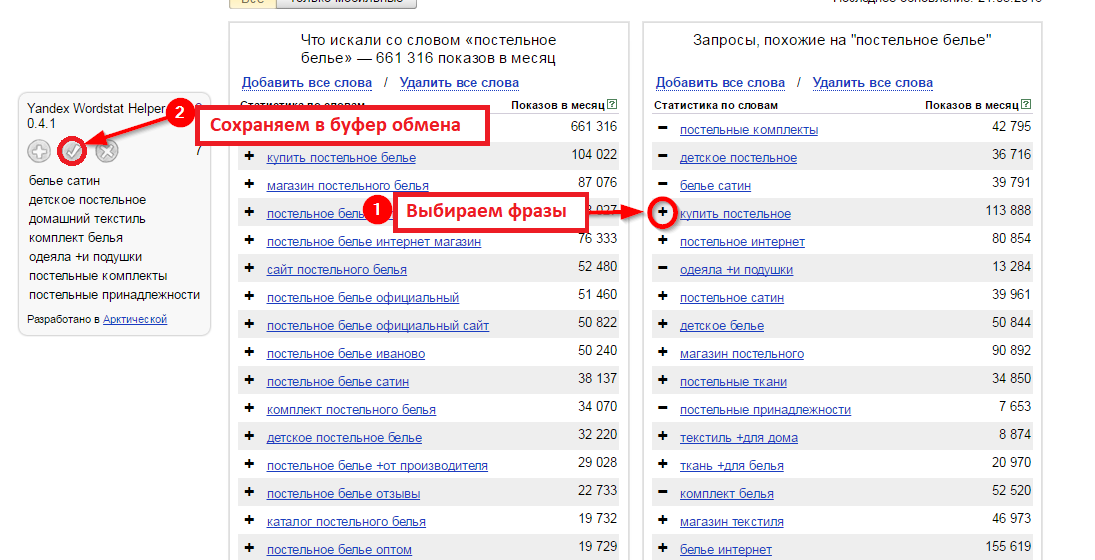
В вордстате можно анализировать любые запросы, которые пользователи вводят в поисковую строку Яндекса, и смотреть статистику по ним: количество запросов, региональную популярность, популярность запросов в зависимости от устройства и т.д.
В этой статье я расскажу, как можно быстро собрать семантическое ядро для контекстной рекламы (Яндекс.Директ или Google Ads) или для SEO-продвижения сайта.
Содержание
- Установка расширения для Google Chrome
- Парсинг ключевых слов
- Итог
Установка расширения для Google Chrome
Для продуктивной работы с Вордстатом я рекомендую установить расширение Wordstater (кликабельно), которое сильно упрощает работу с сервисом. С его помощью собрать семантику получится в 2-3 раза быстрее, чем без него.
После установки, при переходе в Яндекс Вордстат, у вас будет отображаться вот такое окно:
Если оно появилось – вы все сделали правильно. Если нет – возможно расширение не активировано, проверьте настройки в браузере:
Кстати!
Я оказываю услуги по интернет-маркетингу.
Если интересно – кликайте по нужной кнопке снизу. Или пишите напрямую в мессенджеры. 😉
Telegram
Парсинг ключевых слов
Переходим к сбору ключевиков. Первым шагом вводим запрос, который хотим спарсить в глубину, и нажимаем “Подобрать” или Enter.
Перед тем как собирать запросы я рекомендую собрать минус-слова, чтобы исключить все нецелевые запросы.
Предположим, что нам нужно собрать семантику по запросу “купить iphone 10”. Вводим эту фразу в Вордстат и получаем выдачу, в которой нам нужно отметить все минус-слова, делается это кликом по слову.
После сбора всех минус-слов они попадают в отдельную вкладку, откуда вы можете скопировать их и вставить в рекламную кампанию.
Далее мы переходим к сбору всех слов. Во первых исключаем все ключевые фразы, содержащие минус-слова, путем клика по кнопке “исключить минус-слова”, после этого кликаем на “+ столбец” для сбора всех ключевых фраз в этом столбце.
После этого внизу страницы переходим на следующую, собираем там, и так далее, пока не пройдем по всем страницам.
Все собранные фразы попадают во вкладку “Ключевые фразы”, откуда вы можете забрать их в рекламную кампанию или Excel для дальнейшей обработки.
Пример переноса слов в группу объявлений в Яндекс.Директ.
Итог
Как видите, ничего сложного в сборе семантического ядра нет. Если вы хотите собрать семантику по одной или нескольким услугам, то это вполне можно сделать с помощью данного алгоритма. Для сбора ядер, содержащих десятки тысяч ключевых слов нужно использовать автоматизацию, например Key Collector, об этом поговорим в другой статье.
Если остались вопросы – задавайте в комментариях)
Оцените автора
Корень слова: стат (корень) | Мембрана
стойки
Краткий обзор
Латинский корень stat и его вариант stit означают «стоять». Этот латинский корень является источником большого количества слов английского словаря, в том числе stat e, stat ue, con stit ution и super stit ion.
«Стат» наготове!
Латинский корень stat и вариант stit означают «стоять». Сегодня мы приведем вас в готовность stat e, что позволит вам «стоять» подготовленными, когда появятся корни stat и stit !
Каков ваш стат ион в жизни, то есть где вы «стоите»? твой stat нас или «стояние» в обществе высокое, низкое или среднее? Таков ли ваш физический рост ure, что вы «стоите» высоко над другими? Является ли ваше социальное «стояние» настолько высоким, что однажды будет создано stat
ue, или изображение, которое «стоит» прямо, чтобы другие могли помнить, что вы когда-то «стояли» так высоко? Представьте себе такой постоянный статус мент того, как у вас «стоят» дела!Каков ваш текущий стат е здоровья, то есть где он «стоит»? Вы настолько здоровы, что вам ec stat ic, «стоять» вне нормальных чувств, чтобы быть очень счастливым? Или вы вынуждены оставаться стат ионными, неспособными двигаться, а только «стоять» на месте? Если ваше здоровье не так хорошо, надеюсь, врач не слишком ди стант или «стоят» далеко, чтобы позаботиться о вас!
Вариантом корня stat является stit , сформированный таким образом , потому что слово с stit иногда легче произнести , чем слово с stat .
Super stit ion — это «стояние» над верой в нормальные, повседневные, осязаемые вещи, а вместо этого вера в реальность сверхъестественных сил, а не в основу хорошего правительства.Теперь, когда мы в stit объединили корни stat и stit как часть ваших знаний о корнях, вы больше не будете путать stit e значения слов с этими корнями в них!
- станция : «стояние» или место, где «стоят»
- статус : «положение» в обществе
- рост : какой рост у человека «стоит» или его социальное «положение»
- статуя : «стоящее» изображение
- заявление : сказать, как что-то «стоит»
- состояние : где что-то «стоит»
- в экстазе : «стояние» вне нормальных чувств
- стационарный : «стоячий» неподвижный
- далекий : «стоящий» далекий от
- конституция : состояние того, как что-то «стоит» вместе
- конституция : документ, определяющий, как нация будет «стоять» в отношении ее структуры и законов
- обездоленный : «положение» от финансового здоровья
- суеверие : «стояние» над верой в повседневные вещи
- институт : сделать «стойку»
- искажение : неправильно сказать, как что-то «стоит»
Связанные руткасты
Увлекательные части слов
Морфология — это изучение того, как слова составляются с помощью морфем, которые включают префиксы, корни и суффиксы.
+ корень vent + суффикс -ion , от которого образовано существительное «изобретение». Анализ различных морфем в слове показывает значение и часть речи. Например, слово «изобретение» включает в себя префикс 9.0009 изобретение
Анализ различных морфем в слове показывает значение и часть речи. Например, слово «изобретение» включает в себя префикс 9.0009 изобретение Этимология: происхождение слова
Этимология — это часть языкознания, изучающая происхождение слов. Английские словарные слова образованы из множества различных источников, особенно латинского и греческого. Определив происхождение морфем в английских словах, можно лучше запомнить и определить словарные определения слов.
 Анализ различных морфем в слове показывает значение и часть речи. Например, слово «изобретение» включает в себя префикс 9.0009 изобретение
Анализ различных морфем в слове показывает значение и часть речи. Например, слово «изобретение» включает в себя префикс 9.0009 изобретение Применение
установленный законом
Нечто stat utory, например власть, данная губернатору или президенту, создается, устанавливается и контролируется правилами и законами; следовательно, за ним стоит вся сила закона, и ему необходимо следовать.
отступник
Апо со статусом e отказался от своей религиозной веры, политической партии или религиозного дела.
восторженный
Когда вы ec stat ic о чем-то, вы вне себя от радости или чрезвычайно счастливы по этому поводу.
восстановить
Когда вы обуздываете кого-то stat e, вы возвращаете его работу или положение, которое он потерял; это слово также относится к восстановлению для использования чего-то, что больше не использовалось.
стоял
Если вы уравновешены, вы твердо стоите на своем; следовательно, вы уравновешены, серьезны, законопослушны, консервативны и традиционны — и, возможно, даже немного скучны.
рост
положение человека в обществе его положение в обществе; этот уровень значимости определяется их положением в жизни или характером.
препятствие
Препятствие — это то, что мешает вам что-то сделать или мешает вам.
стационарный
Ионный объект stat неподвижен, неподвижен или вообще не движется.
замена
Заменитель занимает место кого-то или чего-то на короткое время.
контраст
Контраст между двумя вещами показывает, насколько эти вещи отличаются друг от друга.
состояние
stat e чего-либо — это то, как оно стоит, в какой форме находится или каково оно сейчас.
выписка
stat ement — это то, что кто-то говорит или пишет, часто для того, чтобы выдать информацию.
нестабильный
Что-то нестабильное, например, здание или правительство, непрочно и имеет проблемы; следовательно, он может внезапно измениться к худшему или как-то потерпеть неудачу.
универсал
все, что у тебя есть
штат
Устанавливать, размещать или устанавливать, например, в ранге, должности или состоянии; установить; инвестировать; как, в stat e человек в величии или в милости.
между штатами
вовлекающие и относящиеся к взаимным отношениям stat es особенно Соединенных Штатов
искажение
a stat ment, который содержит ошибку
завышено
представлено как большее, чем истинное или разумное
величественность
сложная манера делать что-либо
величественный
впечатляющий внешний вид
статический
не находится в физическом движении
станция
присваивается stat ion
канцелярские товары
бумага, обрезанная до подходящего размера для письма
статистик
математик, специализирующийся на статистике статистике
статистика
раздел прикладной математики, связанный со сбором и интерпретацией количественных данных и использованием теории вероятностей для оценки параметров населения
статуя
скульптура, изображающая человека или животное
статный
размера и достоинства, наводящие на размышления о stat ue
статус
относительное положение или положение вещей или особенно лиц в обществе
закон
принят законодательным органом
термостат
контроль температуры с помощью термометра stat

.jpg)
Назад к корням
Дифференцированный словарный запас для ваших учеников всего за один клик.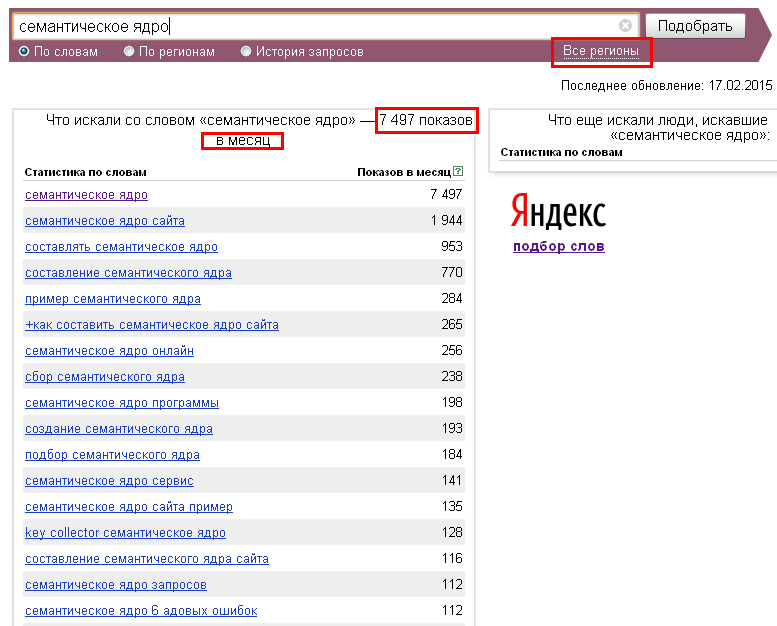
SDAS — WordStat
Передовое программное обеспечение для анализа контента и извлечения текста с непревзойденными возможностями анализа.
Загрузите бесплатную пробную версиюНужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. Полная интеграция WordStat с SimStat — нашим инструментом статистического анализа данных — QDA Miner — нашим программным обеспечением для качественного анализа данных — и Stata — комплексным статистическим программным обеспечением от StataCorp, дает вам беспрецедентную гибкость для анализа текста и сопоставления его содержимого со структурированной информацией, включая числовую. и категориальные данные.
WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и анализа текста используется для:
- Контент-анализа открытых ответов, стенограмм интервью или фокус-групп
- Бизнес-аналитика и анализ конкурентных веб-сайтов
- Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
- Контент-анализ новостей или научной литературы
- Автоматическая маркировка и классификация документов
- Обнаружение мошенничества, установление авторства, патентный анализ
- Разработка и проверка таксономии
Изучение содержимого документа с помощью анализа текста
Анализ больших объемов неструктурированной информации с помощью WordStat. Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
Извлечение смысла с помощью режима проводника
Быстро и легко извлекайте смысл из больших объемов текстовых данных с помощью режима проводника, специально разработанного для тех, у кого мало опыта анализа текста. Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
Связь текста со структурированными данными
Исследование отношений между неструктурированным текстом и структурированными данными, такими как даты, числа или категориальные данные, для определения временных тенденций или различий между подгруппами или для оценки отношений с рейтингом или другими видами категориальных или числовых данных с помощью статистические и графические инструменты.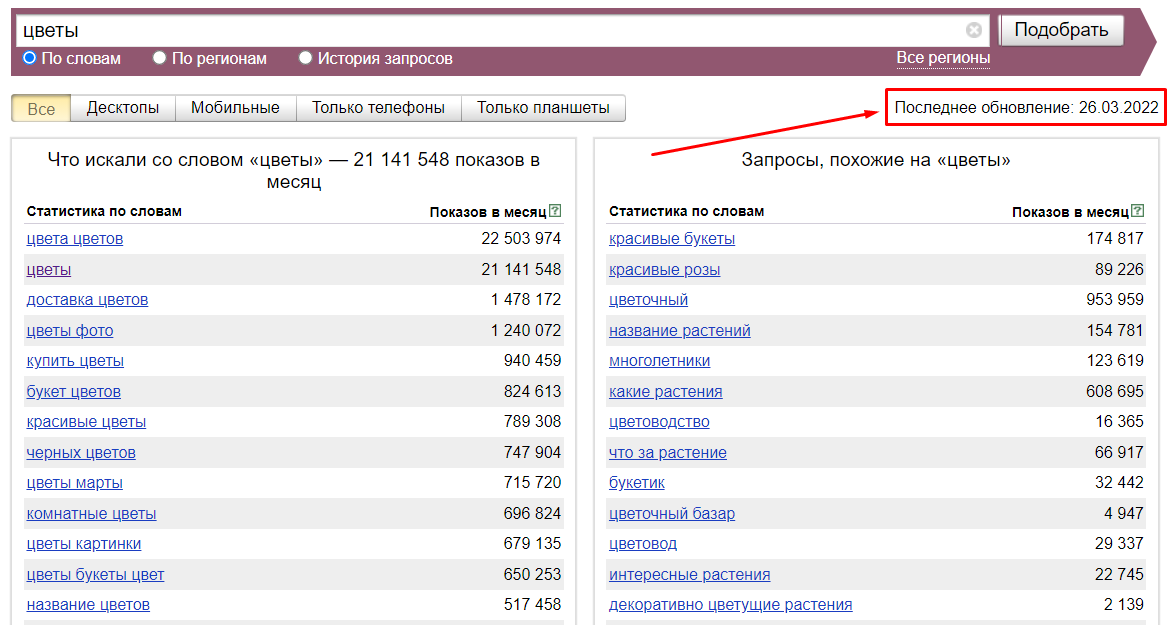
Основные темы
Получите краткий обзор наиболее важных тем из больших текстовых коллекций с помощью современных методов автоматического извлечения тем.
Исследуйте связи
Исследуйте связи между словами или понятиями и извлекайте текстовые сегменты, связанные с определенными связями.
Импорт
Импорт Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDF-файлов, а также изображений. Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
Категоризация текстовых данных с помощью словарей
Добейтесь автоматизации полнотекстового анализа с помощью существующих словарей или создайте собственную модель категоризации со словами, фразами, правилами близости и т. д.
Уникальная помощь при создании словаря
Создавайте свой словарь быстрее с помощью инструментов для извлечения общих фраз и технических терминов, а также для быстрого выявления в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и родственных слов.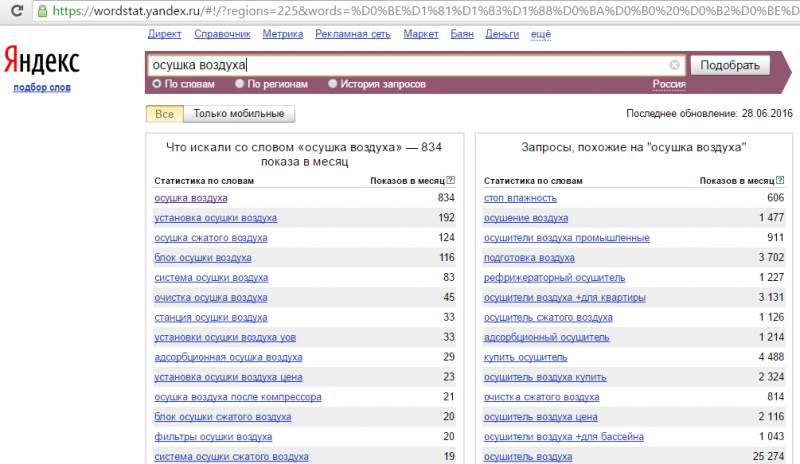
Картография ГИС
Связывайте неструктурированные текстовые данные с географической информацией и создавайте интерактивные графики точек данных, тематических карт и тепловых карт, а также веб-службу геокодирования для преобразования названий местоположений, почтовых индексов и IP-адресов в широту и долготу.
Экспорт
Легко экспортируйте результаты анализа текста в распространенные отраслевые форматы файлов, такие как Excel, SPSS, ASCII, HTML, XML, MS Word, и графики, такие как PNG, BMP и JPEG.
Качественное кодирование
Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо.
Категоризация текстовых данных с помощью машинного обучения
Разработка и оптимизация моделей автоматической классификации документов с использованием наивного байесовского метода и метода K-ближайших соседей.