
301-й редирект полностью заменил директиву Host — Блог Яндекса для вебмастеров
20 марта 2018, 12:51
Как мы писали ранее, мы отказываемся от директивы Host. Теперь эту директиву можно удалять из robots.txt, но важно, чтобы на всех не главных зеркалах вашего сайта теперь стоял 301-й постраничный редирект. Вебмастерам, которые, по нашим данным, ещё не установили перенаправление, мы отправили соответствующее уведомление.
Кроме того, за прошедшее с анонса время мы собрали наиболее распространенные ситуации, и хотим рассказать о них подробнее.
I Мне нужно переехать на новый домен или протокол, переезд я еще только планирую
- поставьте постраничный 301-й редирект
- зайдите в Вебмастер в инструмент «Переезд сайта», укажите новое главное зеркало
- подождите, обычно переезд занимает несколько дней
II Мне нужно переехать на новый домен или протокол, переезд я уже начал
Аналогично I пункту:
- поставьте постраничный 301-й редирект
- зайдите в Вебмастер в инструмент «Переезд сайта», укажите новое главное зеркало: если вы сделали это ранее — данный пункт можно пропустить
- подождите, обычно переезд занимает несколько дней
III Мне нужно переехать на новый домен или протокол, но я не могу использовать 301-й редирект
- добавьте новый сайт в Вебмастер
- используйте «Переезд сайта»
- подождите, в таком случае переезд может занимать несколько недель
IV Мне не нужно никуда переезжать, нужно ли мне что-то менять, редирект я поставить могу
- проверьте, чтобы на всех неглавных зеркалах вашего сайта стояли постраничные редиректы на главные, это позволит прямо указать роботу на нужный вам адрес в поиске
V Мне не нужно никуда переезжать, нужно ли мне что-то менять, редирект я поставить не могу
- нужно понимать, что главное зеркало в таком случае может быть выбрано на усмотрение робота: в случае смены главного зеркала воспользуйтесь «Переездом сайта»
VI Нужно ли ставить редирект для мобильных версий сайтов
- как и ранее, ставить редирект для мобильных версий сайтов не обязательно: мобильная версия может быть или доступна для основного робота, или осуществлять редирект на основную версию сайта
VII Что делать, если мои зеркала все-таки изменились из-за того, что не был установлен 301-й редирект
Совершите переезд аналогично I пункту:
- поставьте постраничный 301-й редирект на нужный адрес
- зайдите в Вебмастер в инструмент «Переезд сайта», укажите новое главное зеркало
- подождите, обычно переезд занимает несколько дней
VIII Что делать с директивой Host
- её можно удалить из robots.
 txt или оставить, робот её просто игнорирует
txt или оставить, робот её просто игнорирует
 txt или оставить, робот её просто игнорирует
txt или оставить, робот её просто игнорируетКоманда Поиска
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
YouTube
Канал для владельцев сайтов в Яндекс.Дзене
Внутренняя SEO оптимизация сайта в 2020 по шагам.
Внутренняя оптимизация — это целый комплекс работ, которые проводятся для улучшения качества сайта с целью лучшего ранжирования в поисковых системах.
При проведении оптимизации необходимо смотреть на сайт не только глазами пользователя, но и «глазами» роботов поисковых систем.
Чек-лист внутренней seo оптимизации:
1. Техническая оптимизация сайта 2. Оптимизация для продвижения 3. Коммерческие факторыТехническая оптимизация сайта
Техническая оптимизация – один из самых важных шагов в комплексной оптимизации сайта, отвечающий за настройку индексирования, быструю загрузку и корректное отображение сайта на разных устройствах.
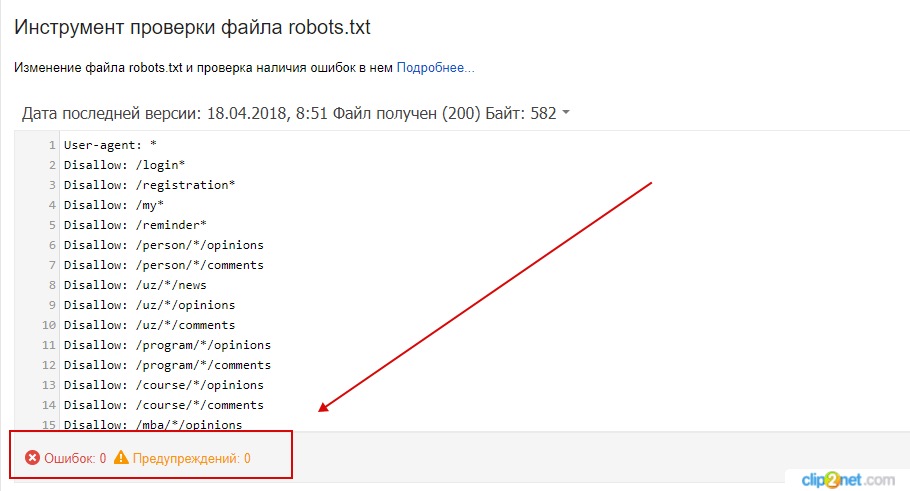
Robots.txt
Задать конкретные параметры сканирования сайта как для всех роботов сразу, так и для каждой поисковой системы (ПС) по отдельности. Для этого в файле robots.txt, который лежит в корневой директории сайта, с помощью директив указываются файлы или разделы, которые не нужно посещать роботу (директива Disallow), либо же наоборот – те, которые надо посетить (директива Allow).
Кроме этих директив в файле можно указать:
- Sitemap: — указывает адрес, по которому расположена XML карта сайта;
- Clean-param: — указывает поисковому роботу, что URL адрес содержит параметры, которые необходимо не учитывать при индексации, например UTM-метки;
- Crawl-delay: — задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Пример файла robots.txt (источник https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html)
Sitemap. xml
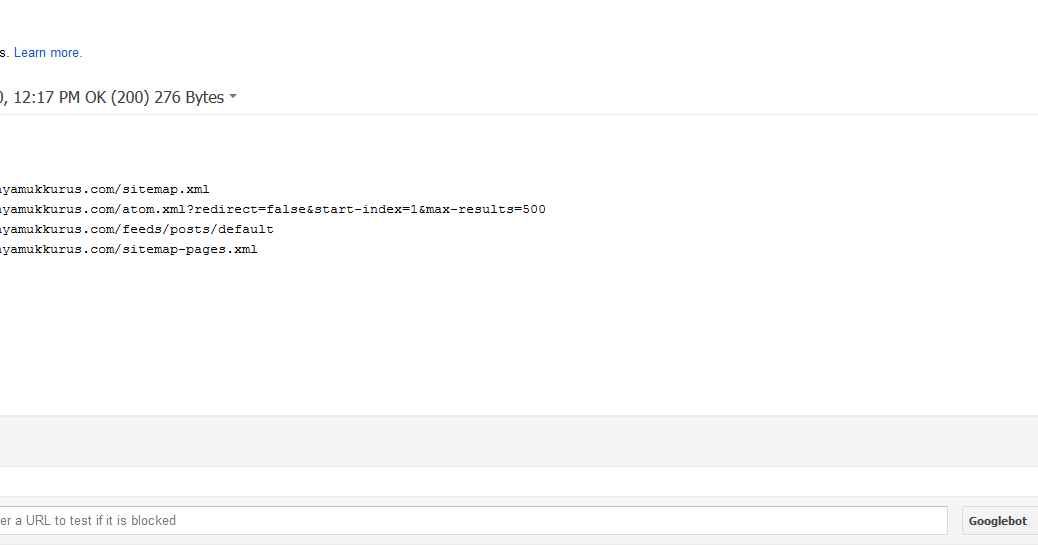 xml
xmlИли просто карта сайта – дает информацию поисковому роботу о всех страницах на сайте. Для каждой страницы необходимо указывать значимость – тег <priority>, дату последнего обновления – тег <lastmod> и частоту, с которой обновляется страница — <changefreq>.
Пример файла sitemap.xml (источник https://kokoc.com/sitemap-files.xml)
Создать sitemap.xml можно разными способами:
- вручную, добавляя все url сайта и соблюдая синтаксис, однако, это довольно трудозатратный процесс и не подойдет для больших сайтов;
- в некоторых CMS карта сайта может быть сгенерирована автоматически – самый оптимальный вариант;
- с помощью онлайн сервисов, или специальных программ – ScreamingFrogSEOSpider или Netpeak Spider.
Несуществующие страницы
Несуществующие страницы сайта:
- ранее существовавшие и удаленные;
- страницы, в адресе которых допущена ошибка;
Сайт должен корректно обрабатывать несуществующие страницы чтобы избежать их попадания в индекс поисковых систем.
Страницу 404 ошибки рекомендуется оформить в стиле сайта и разместить на ней переходы на главную и основные страницы сайта.
Пример страницы с 404 ошибкой (источник https://kokoc.com/)
Структура формирования URL
Еще один пункт внутренней оптимизации – настройка ЧПУ и структуры url.
ЧПУ – это человеко-понятные URL адреса – их лучше понимают и поисковые системы, и пользователи. Для русскоязычных сайтов лучше использовать транслитерацию, но подойдут и английские переводы.
Важно соблюдать правильную вложенность страниц при построении url адресов – она должна отражать структуру сайта и важность страницы. Для поисковых систем больший вес в ранжировании имеют страницы с наименьшим уровнем вложенности в url адресе.
Главную страницу поисковая система считает страницей 1 уровня. Страницы, которые находятся после первого слеша – страницы второго уровня вложенности url адреса. Страница, которая следует за вторым слешем, будет считаться страницей третьего уровня вложенности url адреса и так далее.
Страница, которая следует за вторым слешем, будет считаться страницей третьего уровня вложенности url адреса и так далее.
Несколько советов по настройке адресов страниц:
- в url страницы следует добавить 1-3 ключевых слова, по которым продвигается страница;
- нужно соблюдать иерархию в построении адреса;
- не стоит делать адрес слишком длинным;
- все url должны быть уникальными;
- структура адреса должна соответствовать названию в меню и в «хлебных крошках».
Пример корректного адреса на сайте (источник https://kokoc.com/)
Дубликаты страниц
Наличие на сайте дубликатов страниц негативно сказывается на ранжировании сайта. Если в индексе поисковой системы есть дубликат страницы – он может создавать сложности поисковой системе при выборе релевантной страницы.
Найти такие страницы можно с помощью панелей GoogleWebmaster и Яндекс.Вебмастер или специализированных программ – ScreamingFrogSEOSpider, Netpeak Spider, Xenu.
Наиболее распространенные причины появления дублей, и пути их устранения:
- сайт доступен сразу по двум адресам – с www и без, и по двум протоколам – http и https. Для верной индексации поисковыми системами страница должна быть доступна только с одного зеркала и иметь ответ сервера 200 ОК. Со всех остальных зеркал должен быть настроен редирект с ответом сервера 301 Moved Permanently.
- Страницы сайта могут быть доступны со слешем «/» в конце и без. Для устранения дубликатов, необходимо определиться с типом url адресов и настроить переадресацию с ответом 301 на основной вид страниц.
- Главная страница доступна сразу по нескольким адресам — site.ru/index.html, site.ru/index.php, site.ru/index, site.ru/main/ и т.д. Со всех таких url настраиваем 301 редирект на главную – site.ru.
- Доступны страницы с символами в адресе в разных регистрах — site.ru/pAgE/ и site.ru/page/. Такие дубли устраняем 301 редиректом с любых адресов верхнего регистра на нижний.
- На сайте используются UTM-метки рекламных кампаний и реферальные ссылки. Для таких страниц с помощью тега link с атрибутом rel=»canonical» необходимо указать «чистый» урл страницы – ту, которую нужно индексировать. Либо запретить индексацию меток в файле robots.txt при помощи директивы Disallow или Clean-param.

Дублирование заголовков и мета-тегов.
Помимо дублей страниц одна из частых проблем – дублирование заголовков и мета-тегов. Обычно эта проблема встречается на новых, еще не оптимизированных сайтах или появляться при автоматическом заполнении, например, у товаров интернет-магазина. Обнаружить дублирование можно с помощью seo-программ. Для их устранения в шаблон заполнения необходимо включить дополнительные параметры, уникализирующие страницу – цвет, размер, номер, артикул – любую особенность.
301 редирект и битые ссылки
Если при внутренней оптимизации сайта появилась необходимость изменить url-адрес страницы, то со старого url-адреса необходимо настроить переадресацию на новый с ответом сервера 301 Moved Permanently. В таком случае поисковик проиндексирует новый адрес страницы и заменит в выдаче страницу на новую.
В таком случае поисковик проиндексирует новый адрес страницы и заменит в выдаче страницу на новую.
Редирект следует настроить в случае:
- Смены домена.
- Переноса сайта на другую CMS.
- Необходимости настроить ЧПУ.
- Устранения дублей на сайте.
- Изменения адреса страницы.
В первом и втором случаях необходимо сохранить при возможности url такими же как они были на старом домене. Это позволит минимизировать потери трафика при «переезде».
Важный момент — при настройке 301 редиректа не создавать цепочки редиректов – когда с исходного адреса настроена переадресация на другой url, а затем – еще на один. Редирект должен иметь только одно перенаправление, это позволит снизить потери при передаче исходного веса и накопленных метрик на новую страницу.
Если при удалении страницы, файла или изображения, на которые остались ссылки на стайте, не настроить переадресацию 301, это приведет к появлению ссылок, ведущих на страницы 404 Not Found. Наличие на сайте таких ссылок негативно воспринимается пользователями, как следствие и поисковыми системами при ранжировании.
В рамках оптимизации сайта все обнаруженные «битые ссылки» необходимо скорректировать, удалив на них ссылки, либо настроив переадресацию на работающую страницу сайта.
Навигация
Хлебные крошки
Навигационные цепочки или «хлебные крошки» — важный элемент навигации по сайту.
По примеру известной сказки братьев Гримм – они помогают понять, где посетитель находится в данный момент, как он сюда дошел и куда он сможет вернуться.
По цепочке, находящейся, как правило, в верхней части, отображается путь от главной страницы до той, на которой находится пользователь, учитывая все разделы сайта, которые ему понадобилось пройти.
Пример реализации хлебных крошек
Кроме удобства для пользователя, а, следовательно, улучшения юзабилити сайта и поведенческих факторов, хлебные крошки участвуют во внутренней перелинковке сайта и распределении ссылочного веса.
Правильная перелинковка и улучшение поведенческих факторов положительно влияют на ранжирование сайта в поисковой выдаче.
При наличии правильной разметки навигационные цепочки появляются в сниппетах выдачи Яндекса и Гугла. Благодаря такому сниппету пользователи прямо из выдачи могут перейти в любой раздел сайта.
Пример хлебных крошек в выдаче Яндекса.
Навигационное меню сайта.
Яндекс оценивает вложенность страницы по количеству кликов с главной.
Вложенность — важный параметр ранжирования запросов на странице. Поэтому важно, чтобы с главной страницы сайта все категории и подкатегории, были доступны в минимальное количество кликов как человеку, так и поисковому роботу. Основным инструментом для уменьшения вложенности является навигационное меню.
Пример навигационного меню, которое содержит основные категории и подкатегорий и образует физическую вложенность второго уровня для поисковых систем.
В ходе внутренней оптимизации сайта необходимо проверить:
- Все ли нужные пункты меню доступны с главной страницы с нужными анкорами. Для этого стоит посмотреть еще и текстовую копию страниц.
- Также, в html коде страницы необходимо проверить – не дублируется ли меню из-за адаптивной версии или просто из-за ошибки.
Внутренняя перелинковка
С помощью внутренних ссылок связываются между собой отдельные страницы сайта.
Перелинковка необходима для распределения ссылочного веса и повышения релевантности страниц «в глазах» поисковых систем, а также, для удобства посетителей.
Есть несколько видов внутренней перелинковки на сайте:
- Сквозная – это ссылки на основные страницы, расположенные в шапке сайта и футере.
- Контекстная – ссылки, размещенные в тексте.
- Навигационная – это содержание страницы – помогает быстро перейти к нужному разделу страницы.
- Полезные ссылки – размещенные в конце основного контента страницы. Для сайта интернет-магазина – это блок рекомендуемых или похожих товаров, для информационных сайтов – это ссылки на похожие статьи.

Размещать внутренние ссылки можно как вручную, так и автоматически.
Пример реализации навигационной перелинковки (Источник https://ru.wikipedia.org/)
Микроразметка
Семантическая разметка данных структурирует содержимое страницы и помогает поисковым системам обрабатывать информацию для удобного её предоставления в выдаче. Данные размечаются в коде страницы с помощью специальных атрибутов.
Основные виды микроразметок – это:
- Schema.org — стандарт семантической разметки для поисковых систем;
- Open Graph — микроразметка Facebook для правильного отображения публикаций.
С помощью микроразметки можно описать всевозможные сущности и их свойства. Размечаются хлебные крошки, контактные данные, товары и их свойства – название, цена и т.д., описания, изображения, вопросы и ответы и многое другое.
Размечаются хлебные крошки, контактные данные, товары и их свойства – название, цена и т.д., описания, изображения, вопросы и ответы и многое другое.
Наличие микроразметки увеличивает занимаемое место в выдаче, показывает больший объем информации о ресурсе и повышает количество разделов сайта, на которые можно перейти сразу из поиска.
Проверить наличие разметки и ошибки в ней можно с помощью сервисов «Валидатор микроразметки» от Яндекса — https://webmaster.yandex.ru/tools/microtest/ и «Проверка структурированных данных» от Google — https://search.google.com/structured-data/testing-tool/u/0/.
Пример микроразметки сайта в выдаче Яндекса
Адаптивная версия сайта
Адаптивный дизайн позволяет оптимизировать отображение сайта на различных устройствах, например, на смартфонах и планшетах, не создавая отдельную версию на поддомене.
Мобильная версия является важным фактором в ранжировании сайта в поисковых системах – и Яндекс, и Google ставят в приоритет мобильную версию сайта, оценивая ее наличие в том числе, как удобство для посетителя в использовании сайта на разных устройствах.
Проверить оптимизацию сайта для мобильных устройств можно с помощью браузера, в панели Яндекс.Вебмастера, с помощью сервиса проверки Google https://search.google.com/test/mobile-friendly
Сайты, не имеющие мобильной версии сайта, могут воспользоваться инструментом Яндекс Турбо (https://yandex.ru/dev/turbo/), для создания облегченных версий страниц вашего сайта.
Скорость загрузки страниц
Еще одна важная составляющая внутренней оптимизации сайта – скорость загрузки ресурса. Она зависит от многих факторов, таких как: корректная настройка сервера, близость дата-центров хостинга к местоположению основной аудитории, правильная оптимизация CMS и кода сайта, и прочего.
Быстрая загрузка сайта позволяет поисковым системам лучше его индексировать и создает положительный опыт взаимодействия с посетителями, что, в свою очередь, влияет на ранжирование в выдаче.
Проверить скорость загрузки можно с помощью сервисов:
Регистрация сайта в панелях вебмастеров
Для мониторинга и анализа сайта нужно добавить его в панели для вебмастеров Яндекс-Вебмастер и Google Search Console.
Панели вебмастеров укажут на ошибки и санкции на сайте, дадут рекомендации по улучшению индексации, покажут количество страниц в индексе, а также обладают обширным набором инструментов.
Для детального изучения эффективности трафика с различных источников, а так же для изучения поведенческих факторов необходимо установить на сайте счетчики Яндекс Метрика и Google Analytics.
Для появления организации на картах, а также для присвоения региона продвижения сайта, нужно создать карточку организации в Яндекс.Справочнике и в сервисе Google Мой Бизнес. Заполнить карточки организаций желательно максимально подробно – это поможет поисковой системе лучше ранжировать сайт в локальном поиске и среди сайтов определенной тематики.
Оптимизация сайта для продвижения
После того, как ваш сайт стал идеален с технической точки зрения, можно приступать к оптимизации страниц сайта под поисковые системы. Этот раздел расскажет, как грамотно собрать семантику, подготовить контент и сделать базовую оптимизацию тегов.
Ключевые слова (семантика)
Семантическое ядро (СЯ) — это полный список запросов сайта из набора слов с морфологическими формами, наиболее точно описывающие вид деятельности, тематику, услуги и/или товары, предлагаемые сайтом. В целом – это список слов, по которым сайт должен быть на 1-10 месте выдачи поисковых систем.
Все запросы делятся на высокочастотные (ВЧ), среднечастотные (СЧ), низкочастотные (НЧ). Для разных тематик значения частотности запросов могут быть разные – для одних сайтов ВЧ будут начинаться со 100 запросов в месяц, для других – с 1000. В целом распределение выглядит так: СЧ имеют частоту в 3-10 раз ниже, чем ВЧ, а НЧ в 3-10 ниже, чем СЧ.
Для определения частотности запросов используется сервис Яндекса по подбору слов — https://wordstat.yandex.ru/.
При составлении СЯ с помощью этого сервиса важно учитывать регион и виды частотности.
- Базовая частотность – частота запроса при вводе запроса без какого-либо синтаксиса. Она содержит в сумму частотностей всех фраз, содержащих слова из запроса в любых формах и в любом порядке.
- «Частотность в кавычках» – частота запроса без других слов, но с учетом словоформ и перестановок.
- «!Точная» (в кавычках с восклицательным знаком) – содержит частотность слова в таком виде, в котором оно написано.
- » [!Точная !частотность]» – будет показывать количество запросов в месяц фразы с учетом порядка слов и форму слова, которая задана.
 Она содержит в сумму частотностей всех фраз, содержащих слова из запроса в любых формах и в любом порядке.
Она содержит в сумму частотностей всех фраз, содержащих слова из запроса в любых формах и в любом порядке.При составлении семантического ядра, если в него входят запросы, содержащие перестановки или являющиеся неявными дубликами, важно выбрать именно последний вид частотности запросов для более точной оценки спроса и планирования трафика и посетителей.
Сбор ядра сайта происходит в несколько этапов:
- Собираем все подходящие слова с помощью сервисов Яндекс.Вордстат и Google Adwords;
- Дополнить семантику можно словами конкурентов – для этого подойдут сервисы https://spywords. ru или https://www.keys.so/ru;
- Расширение запросами из систем статистики Яндекс Метрика и Google Analytics, Вебмастера и сбором подсказок по целевым запросам;
- Из полученного списка удаляем нецелевые запросы и запросы с нулевой частотностью;
- Кластеризуем запросы – распределяем запрос или группу запросов на соответствующие для продвижения страницы сайта.
 ru или https://www.keys.so/ru;
ru или https://www.keys.so/ru;Контент согласно семантике
После составления СЯ необходимо оптимизировать контент сайта в соответствии с выбранными ключевыми словами.
Ключевым словам должны соответствовать анкоры в меню, названия ссылок при внутренней перелинковке, url страниц.
Так же ключевые слова должны также содержаться в текстах. SEO-рекомендации к тексту можно описать так:
- Количество вхождений запросов необходимо подбирать, анализируя конкурентов. Важно избегать частых и неоправданных повторений.
- Текст должен быть уникальным.
- Текст должен быть полезным и понятным, в полной мере отвечающим на запрос пользователя.
- Текст должен быть разбит на абзацы и структурирован, содержать маркированные и нумерованные списки.

Оптимизация тегов на странице
Один из самых важных пунктов внутренней оптимизации сайта – грамотно заполненные seo-теги страниц — title, description, заголовки уровня h2-h6.
Мета-теги title и description в первую очередь важны для поисковой системы, при этом их цель – привлечь пользователя из выдачи ПС именно на наш сайт.
Title
Title – самый важный тег, содержащий в себе основную информацию о содержании страницы. В поисковой выдаче отображается как заголовок страницы, содержащий ссылку на сайт.
При написании тега Title должны быть учтены все основные ключевые слова страницы, самый ВЧ запрос должен стоять первым. Заголовок должен быть коротким и логичным, а также уникальным для каждой страницы сайта.
Description
Description – краткое описание. Тут важно детальнее рассказать о содержимом странице. Описание должно содержать ключевые слова и быть уникальным для каждой страницы.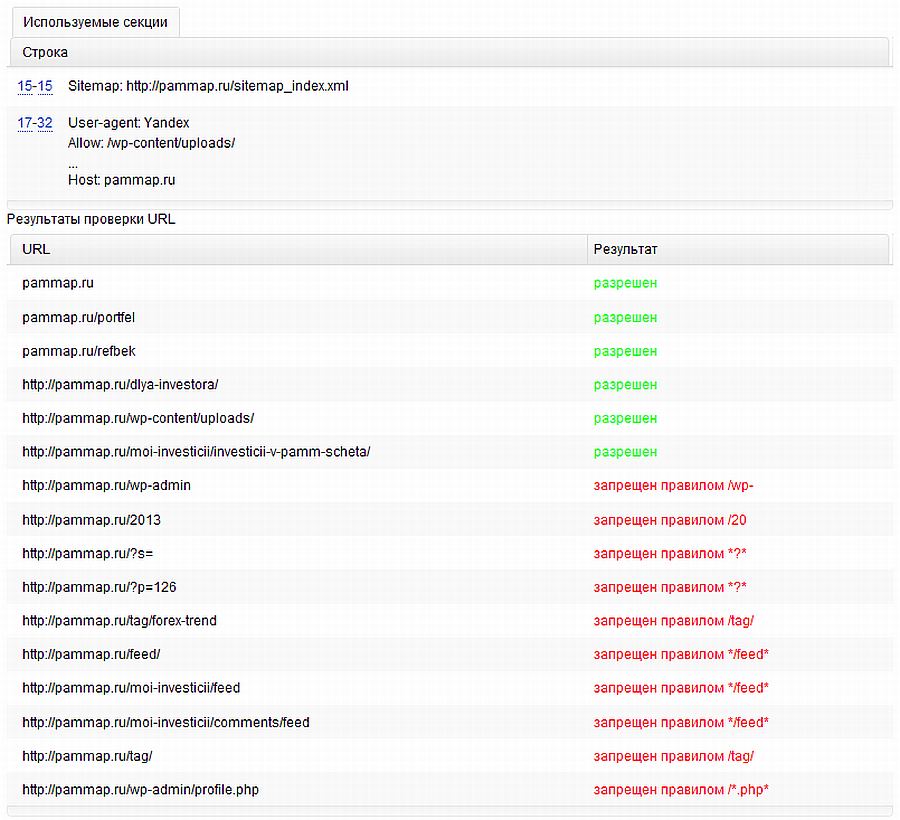
Пример мета-тегов title и description из выдачи Яндекса по запросу «робот пылесос».
Заголовок h2
Заголовок h2 — самый главный заголовок в контентной части страницы как для поисковика, так и для посетителя. Должен содержать самый частотный запрос на продвигаемой странице, однако, во избежание заспамленности не рекомендуется в заголовке h2 полностью дублировать title.
Важно соблюдать иерархию заголовков в тексте: h2, затем h3, h4 и так далее.
Коммерческие факторы
Коммерческие факторы учитываются поисковыми системами при ранжировании и напрямую влияют на конверсию посетителей сайта. Это те элементы сайта, которые показывают пользователю и поисковой системе, что сайт что-то продает и что на сайте указана вся необходимая информация для совершения покупки.
Для продвижения сайта в коммерческой тематике при проведении внутренней оптимизации следует обратить внимание на следующие коммерческие факторы:
- Наличие нескольких видов связи – телефоны, электронная почта, мессенджеры, скайп.
- Наличие нескольких телефонов, телефонов разных профильных сотрудников с их фото, номер 8-800.
- Наличие форм обратной связи и обратно звонка, онлайн консультант и социальные сети.
- Наличие адреса и времени работы.
- На странице контактов кроме номеров и адреса важно указать схему или карту проезда, реквизиты компании, фото помещений.
- Наличие раздела «О компании». В нем важно предоставить миссию компании, историю, вакансии, сертификаты свидетельства, дипломы, подтверждающие официальную деятельность компании.
- Наличие фильтров, сортировок, акционных и специальных предложений в каталогах товаров.
- Наличие отзывов о товарах и их рейтинга.

В данной статье описаны основные моменты внутренней оптимизации сайта. Каждый из пунктов можно развернуть в отдельное руководство по поиску и решению конкретной проблемы. Работа seo-специалиста по внутренней оптимизации – это не разовая проверка, а задача, к которой необходимо возвращаться постоянно. Результаты проделанной работы положительно скажутся не только на ранжировании сайта и его позициях, они так же сделают сайт удобным и приятным для посетителя, а значит — улучшат поведенческие факторы и повысят доверие к ресурсу.
Результаты проделанной работы положительно скажутся не только на ранжировании сайта и его позициях, они так же сделают сайт удобным и приятным для посетителя, а значит — улучшат поведенческие факторы и повысят доверие к ресурсу.
Robots.txt — определение термина. SEO-википедия
Определение
Файл robots.txt по своей сути – это сборник инструкций для роботов, составленный консилиумом W3C зимой 1994 г. Почти все роботы-поисковики на добровольных началах внедрили в работу инструкции robots.txt.
В документе перечисляются стандарты, которые определяют индексацию некоторых документов, каталогов, разделов или страниц на любом онлайн-ресурсе.
Как используется robots
Robots.txt для ресурса является важным элементом оптимизации поиска. Например, в рамках SEO-продвижения данный файл используется для того чтобы вычленить из индексации ресурсы, на которых отсутствует полезный для пользователей контент. Маленькие сайты также могут пользоваться отдельными его блоками, все зависит от целей, поставленных перед программистом.
Настройка robots.txt
Программист должен грамотно настроить файл под каждый сайт, что в будущем исключит попадание персональных данных в результаты выдачи поисковиков. Роботы проверенных систем, таких как Гугл, Яндекс и Рамблер, в своей деятельности учитывают принятые стандарты. Остальные поисковики могут игнорировать их, что снижает качество поисковой выдачи.
Директива User-agent дает указание конкретной поисковой системы. Сразу после нее формируется сама команда, прописывающая условия для определенного робота. Пример выполнения перевода строки представлен ниже.
User-agent: Yandex
Disallow: /*utm_
Allow: /*id=
Можно заметить, что тут была применения запрещающая команда Disallow (присвоено значение «/*utm_»). Благодаря этой процедуре производится закрытие страниц, на которых расположены метки UTM. Также можно наблюдать, что указания формируются блоками, которые содержат информацию для определенного робота или для всех сразу («*»).
Настраивая robots. txt,
важно учесть порядок и сортировку указаний, особенно при одновременном
использовании нескольких команд, таких как «Disallow» и «Allow». Последняя
директива является разрешающей и, соответственно, полной противоположностью «Disallow»,
накладывающей запрет.
Приведем пример применения нескольких директив в одном документе.
User-agent: *
Allow: /blog/page
Disallow: /blog
Выше поисковику запрещается индексация ресурсов, которые начинаются с /blog. При этом одновременно допустима индексация тех, которые начинаются с /blog/page.
Что такое синтаксис robots.txt
Для того чтобы грамотно работать с robots.txt, следует посмотреть порядок формирования его синтаксиса. Ниже приводится список классических правил.
- Любая директива всегда начинается с отдельной строки.
- В рамках строки должна находиться только одна команда.
- Пробел не может стоять в начале строчки.
- Параметр команды также должен быть указан в одной строке.
- Параметры директив нельзя брать в кавычки, не
следует применять и закрывающие знаки (точка с запятой).
- Команда в файле должна быть указана в стандартном формате.
- Пустой перевод строки воспринимается как завершение команды User-agent.
- В файле могут быть сделаны комментарии, но предварительно проставляется знак решетка.
- Команда «Disallow: », если содержит пустое значение, то приравнивается к разрешающей команде «Allow: /».
- В перечисленных выше директивах можно прописывать только один параметр.
- В самом названии файла с инструкциями не используются строчные буквы. Например, распространенное написание Robots и ROBOTS некорректно по правилам составления синтаксиса.
- Названия команд и параметров строчными буквами некорректные. Изначально robots.txt нечувствителен к определенному регистру, но чувствительными могут оставаться названия директорий и других документов.
- Если параметр команды является директорией, то в его имени перед названием необходимо проставить знак «слеш» (Disallow: /category).
- Если перечислены директивы «User-agent», но
при этом пустой перевод не выполнен, то все команды кроме первой могут
игнорироваться поисковиками.
- Файлы с инстуркциями от 32 Кб по умолчанию считаются разрешающими и приравниваются к команде «Disallow: ».
- Запрещено применение знаков национальных алфавитов.
- Если robots.txt недоступен по любой причине, то по умолчанию считается полностью разрешающим.
- Пустой robots.txt считается по умолчанию разрешающим.
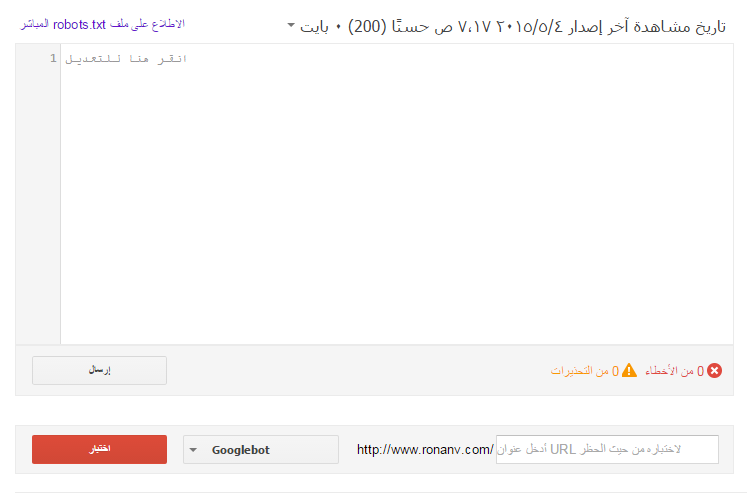

Проверка синтаксиса
Для того чтобы оценить корректность работы, построение и синтаксис можно использовать онлайн-ресурсы. Некоторые крупные поисковики, такие как Гугл и Яндекс, реализовали собственные сервисы, которые позволяют комплексно проанализировать сайт по всем веб-параметрам. В проверку обязательно входит и анализ инструкций.
Так, проверку этого файла можно запустить в Яндекс.Вебмастере и аналогичном сервисе в Google по ссылке https: // www.google.com/webmasters/tools/siteoverview?hl=ru.
Дополнительно в интернете представлены различные онлайн-валидаторы.
Запрет индексации: Disallow
Вышеуказанная команда применяется в robots.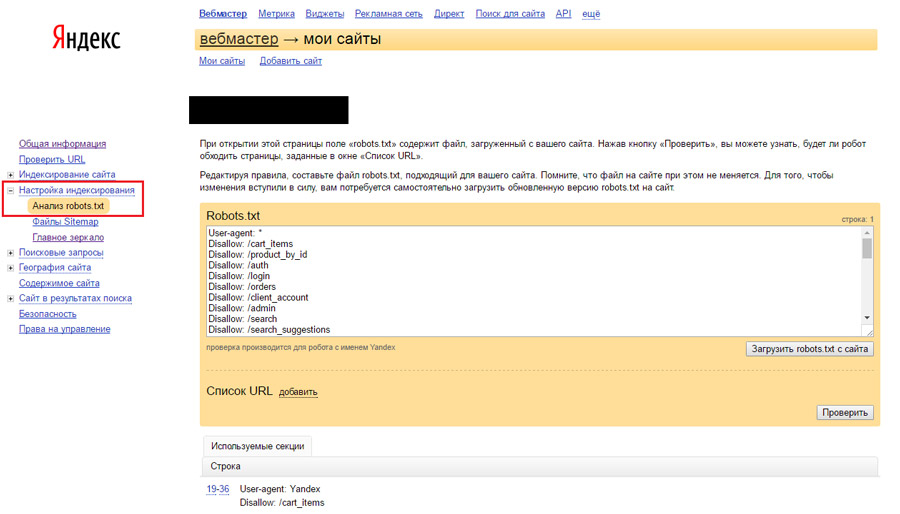 txt наиболее
часто. Ее функцией является запрет индексации любого ресурса, учитывая
параметры, который был прописаны в этой команды.
txt наиболее
часто. Ее функцией является запрет индексации любого ресурса, учитывая
параметры, который был прописаны в этой команды.
User-agent: *
Disallow: /
Выше видим пример участка кода, задающего запрет индексации сайта для любого робота-поисковика.
Разрешение индексации: Allow
Указанная разрешающая команда является антагонистом директивы Disallow. Тем не менее, она имеет с ней очень схожий синтаксис.
Ниже приведен участок кода, запрещающий индексацию, но при этом делается исключение для определенных страниц.
User-agent: *
Disallow: /
Allow: /page
Как вы можете наблюдать, индексация в примере разрешена для страниц, в начале которых размещается фраза /page. То есть любые другие ресурсы без выполнения этого условия проиндексированы не будут.
Учтите, что указывая одну лишь директиву allow: / в роботсе, т.е. по-логике разрешая индексировать весь сайт, вы можете очень сильно ухудшить индексацию вашего сайта.
Главное зеркало ресурса: Host
С помощью команды поисковик Яндекса разглядит главное
зеркало любого портала. Интересно, что из всех распространенных поисковиков Host
«понимает» только Яндекс.
Интересно, что из всех распространенных поисковиков Host
«понимает» только Яндекс.
Директива применяется в случае, когда ресурс размещается на нескольких доменах, например: newsite.ru и newsite.com. Также она позволяет определить приоритет между такими именами сайта: newsite.ru и www. newsite.ru.
Директива Host входит в блок другой директивы «User-agent: Yandex». При этом предпочтительный или основной адрес сайта необходимо прописывать без «http://».
Поисковику Яндекса можно показать главное зеркало, что позволит оптимизировать выдачу страниц пользователям.
Карта сайта: sitemap
Благодаря команде в robots.txt можно задать конкретное место хранения файла карты сайта (именуется как sitemap.xml).
Рассмотрим пример участка кода, где задан адрес карты ресурса.
User-agent: *
Disallow: /page
Sitemap: http:// www.newsite.ru/sitemap.xml
Поисковик использует указанный, чтобы начать индексацию страницы или ресурса в целом.
Выводы
Файл robots.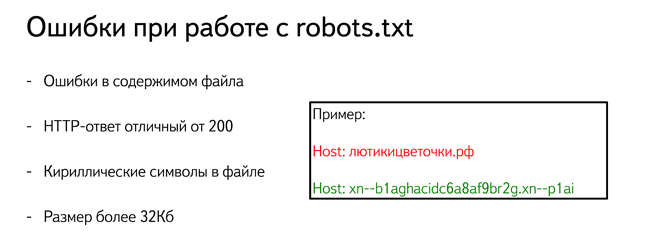 txt является эффективным инструментом, который
позволяет взаимодействовать с поисковыми системами и оптимизировать SEO-продвижение.
txt является эффективным инструментом, который
позволяет взаимодействовать с поисковыми системами и оптимизировать SEO-продвижение.
Что проверяет поисковик. Оптимизация сайта для поиска.
Ранее, мы подробно рассмотрели все возможные виды оптимизации для поискового продвижения сайта. О методах продвижения сайта и seo оптимизации.
Что в первую очередь проверяют роботы поисковых систем и что наиболее важно?
Наличие фатальных ошибок, в результате которых — сайт не индексируется или недоступен. Взлом сайта
- Роботам запрещена индексация сайта. Сайт закрыт к индексации в файле robots.txt При последнем обращении к файлу robots.txt было обнаружено, что сайт закрыт для индексации. Убедитесь в корректности файла robots.txt, иначе сайт может полностью пропасть из поиска.Проверьте robots.txt и снимите установленный запрет.
- Роботы не могут получить доступ к содержимому сайта. Не удалось подключиться к серверу из-за ошибки DNS При попытке скачать данные с сайта не удалось подключиться к серверу из-за ошибки DNS. Если роботы не смогут получить доступ к серверу, сайт может полностью пропасть из поиска. Возможно, пользователи также не могут попасть на сайт.
- Главная страница недоступна или возвращает ошибку. Главная страница сайта всегда должна быть доступна! При обращении к главной странице сайта не удалось получить HTTP-код 200 OK. Поскольку страница недоступна для робота, она может быть исключена из результатов поиска.Проверьте ответ сервера и при необходимости обратитесь к хостинг-провайдеру.
- Сайт взломан или на нем размещены запрещенные материалы. Сайт может угрожать безопасности пользователя, или на нём были обнаружены нарушения правил поисковой системы. Наличие этой проблемы негативно сказывается на положении сайта в результатах поиска.
 Если роботы не смогут получить доступ к серверу, сайт может полностью пропасть из поиска. Возможно, пользователи также не могут попасть на сайт.
Если роботы не смогут получить доступ к серверу, сайт может полностью пропасть из поиска. Возможно, пользователи также не могут попасть на сайт.Наличие критичных ошибок. При таких ошибках сайт доступен, но его индексирование затруднено.
С точки зрения продвижения, ранжирование такого сайта может идти только на убыль.- Ошибки ссылочной массы. Накопленные или же ошибки автоматизации. Большое количество неработающих внутренних ссылок На сайте не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.Ознакомьтесь с примерами и исправьте ошибки.
- Сайт «тормозит». Долгий ответ сервера При обращении к серверу среднее время ответа превышает 3 секунды. Долгая загрузка страниц затрудняет работу с сайтом.Проверьте ответ сервера и при необходимости свяжитесь с хостинг-провайдером.
 Большое количество неработающих внутренних ссылок На сайте не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.Ознакомьтесь с примерами и исправьте ошибки.
Большое количество неработающих внутренних ссылок На сайте не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.Ознакомьтесь с примерами и исправьте ошибки.Сайт доступен, ранжируется в поиске, но оптимизирован не полностью и нет продвижения в топ.
Также нет продвижения в топ низкочастотных ключевых слов с низкой конкуренцией (проверочные, длинные ключевые фразы).- Проверьте наличие xml карты сайта. Нет используемых роботом файлов Sitemap Робот не использует ни одного файла Sitemap. Это может негативно сказаться на скорости индексирования новых страниц сайта. Если корректные файлы Sitemap уже добавлены в очередь на обработку, сообщение автоматически исчезнет с началом их использования. Обратите внимание на раздел «Файлы Sitemap» в webmastere поисковика.
- Роботом обнаружены ошибки в файлах Sitemap. В одном или нескольких файлах Sitemap обнаружены ошибки, которые могут повлиять на обработку файлов индексирующим роботом.Проверьте файлы Sitemap и внесите необходимые исправления.
- При запросе роботом несуществующих файлов и страниц получен неверный ответ сервера. Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 Not Found, что может негативно сказаться на индексировании сайта роботом. Настройте возврат кода 404 на запрос несуществующих страниц.
- Поисковой робот обнаружил ошибки в файле robots.txt. Это может привести к некорректному обходу и индексированию сайта.Проверьте файл robots.txt, внесите исправления.
- При обращении к сайту идет перенаправление на другой, внешний ресурс. Главная страница перенаправляет на другой сайт При обращении к главной странице робот получает перенаправление на другой сайт, что делает невозможным её индексирование. Проверьте ответ сервера.
- При обращении к разным страницам, робот получает одинаковый html код или одинаковое содержимое. Большое количество страниц-дублей На сайте обнаружено большое количество одинаковых страниц, это усложняет индексирование сайта. Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt.
- В файле robots.txt критическая ошибка или он недоступен.Робот не смог получить доступ к файлу robots.txt при последнем обращении. Из-за отсутствия параметров индексирования и инструкций в поиск могут попасть нежелательные страницы.Внесите исправления или добавьте файл robots.txt.
- При ранжировании неправильно определяется зеркало. В файле robots.txt не задана директива Host Для корректного определения главного зеркала сайта рекомендуется задать соответствующую директиву Host в файлах robots.txt всех зеркал сайта. В случае ее отсутствия главное зеркало может быть выбрано автоматически.Добавьте директиву Host в файл robots.txt.
- Ошибка при задании директива Host в файле robots. txt Возможно в директиве Host указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы указания директивы Host были учтены, идентичные директивы должны присутствовать в файлах robots.txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.
- Ошибка заголовка страниц сайта. Отсутствуют теги «title» Значительная часть страниц не содержит тег «title», или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.
- Ошибка заполнения мета тегов страниц сайта. Отсутствуют мета-теги «description» Значительная часть страниц сайта не содержит мета-тег «description», или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.
- В течении длительного времени робот получает один и тот же sitemap. Возможно файлы Sitemap давно не обновлялись или сайт «брошен» и на нем не ведутся никакие работы по наполнению и изменению. Проверьте, не нужно ли обновить файлы Sitemap. Методично работайте над содержимым сайта. Отслеживайте текущие тенденции в SEO продвижении. Не забывайте, что правильная структура сайта, удобство для посетителя в поиске информации — это увеличение конверсии и увеличение дохода от ресурса.
 Обратите внимание на раздел «Файлы Sitemap» в webmastere поисковика.
Обратите внимание на раздел «Файлы Sitemap» в webmastere поисковика. Проверьте ответ сервера.
Проверьте ответ сервера. txt Возможно в директиве Host указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы указания директивы Host были учтены, идентичные директивы должны присутствовать в файлах robots.txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.
txt Возможно в директиве Host указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы указания директивы Host были учтены, идентичные директивы должны присутствовать в файлах robots.txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.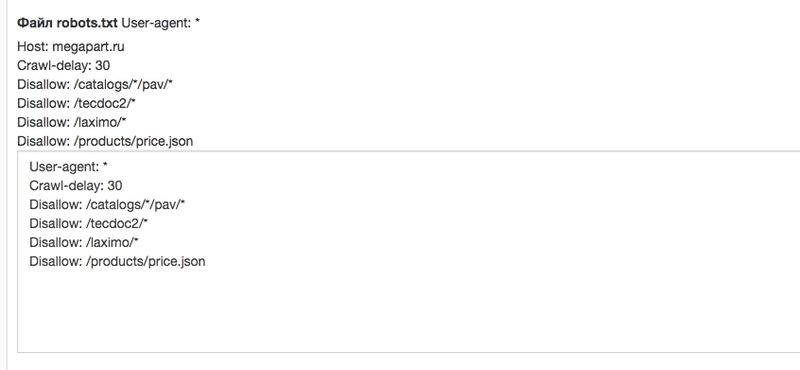 Методично работайте над содержимым сайта. Отслеживайте текущие тенденции в SEO продвижении. Не забывайте, что правильная структура сайта, удобство для посетителя в поиске информации — это увеличение конверсии и увеличение дохода от ресурса.
Методично работайте над содержимым сайта. Отслеживайте текущие тенденции в SEO продвижении. Не забывайте, что правильная структура сайта, удобство для посетителя в поиске информации — это увеличение конверсии и увеличение дохода от ресурса.Дополнительные рекомендации по оптимизации сайта
- Задайте региональность сайта в вебмастере поисковиков или укажите на сайте явно (в контактах и в шапке сайта) региональную принадлежность.Помните, что региональные сайты ранжируются в поиске выше сайтов у которых более общая региональность (Россия или весь мир).
- Зарегистрируйте сайт в Яндекс.Справочнике и Гугл справочнике. Если у вас есть офисы или филиалы, добавьте их в справочник, чтобы улучшить внешний вид сайта в поиске и региональное ранжирование. Если офисов и филиалов нет, явно укажите «Нет региона» в подразделе «Вебмастер» раздела настройки региональности.Обратите внимание на раздел «Региональность».Помните, что указание адреса офиса или торговой точки увеличивает доверие к сайту.
- Для поисковика Яндекс!Отсутствует файл favicon на сайте Не найден файл с изображением, которое должно отображаться во вкладке браузера и может быть показано возле названия сайта в поиске.
- Оптимизируйте сайт для для мобильных устройств. Это может быть вызвано несколькими причинами — например, на страницах сайта не указан тег , контент не помещается на экран по ширине, присутствуют Flash-элементы, плагины Silverlight или Java-апплеты.Помните, что отсутствие оптимизации сайта для мобильных устройств может привести к полному отсутствию сайта в поиске при просмотре через мобильные устройства и планшеты.

Рекомендации яндекса по оптимизации сайта
После того как сайт создан, первым делом его необходимо добавить в инструменты поисковых систем. В Яндексе таким инструментом является Вебмастер. Как добавить сайт в Яндекс Вебмастер мы объяснили здесь.
В Яндекс Вебмастере можно увидеть много профессиональных показателей и рекомендаций по оптимизации сайта. Найти рекомендации Яндекса для оптимизации сайта довольно просто — критичные ошибки сразу же появляются на панели, остальные можно посмотреть перейдя по ссылке «посмотреть рекомендации».
Найти рекомендации Яндекса для оптимизации сайта довольно просто — критичные ошибки сразу же появляются на панели, остальные можно посмотреть перейдя по ссылке «посмотреть рекомендации».
Какие же рекомендации по оптимизации сайта даёт Яндекс в Вебмастере:
Рекомендации по фатальным ошибкам — раздел на который при оптимизации сайта необходимо обратить очень серьёзное внимание. Если в этом разделе имеются какие-либо ошибки, то скорее всего ваш сайт вообще не появился в выдаче поисковых систем. Исправление фатальных ошибок крайне важно не столько для оптимизации сайта в Яндексе, сколько для его индексации.
Раздел фатальных ошибок содержит следующие пункты:
- Запрет индексации сайта файлом robots.txt
- Ошибка подключения к сайту при помощи dns
- Ошибка главной страницы
- Проблемы с безопасностью сайта
Раздел критичных ошибок содержит всего два пункта — большое количество неработающих ссылок и долгий ответ сервера. Однако эти пункты крайне важны для внутренней оптимизации и по рекомендациям Яндекса на них тоже нужно обратить очень пристальное внимание.
Раздел возможных проблем в Яндекс Вебмастере наиболее обширен и затрагивает множество сторон оптимизации сайта. Основная работа всех вебмастеров по оптимизации сайта в поисковой системе Яндекс заключаются в исправлении ошибок и правильному функционированию именно этого раздела рекомендаций.
Возможные проблемы содержат следующие пункты:
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Некорректно настроено отображение несуществующих файлов и страниц
- Ошибки в файле robots.txt
- Главная страница перенаправляет на другой сайт
- Большое количество страниц-дублей
- Не найден файл robots.txt
- В файле robots.txt не задана директива Host
- В файле robots.txt задана противоречивая директива Host
- Отсутствуют теги <title>
- Отсутствуют мета-теги <description>
- Файлы Sitemap давно не обновлялись
Выполнение рекомендаций Яндекса при оптимизации сайта по этим пунктам многократно улучшает индексацию и позволяет ранжировать ресурс в поисковой выдаче гораздо выше.
И наконец, завершающим разделом рекомендаций Яндекса по оптимизации сайтов является раздел, который так и называется — рекомендации. В данном разделе содержатся пункты, которые позволят настроить сайт на работу в конкретном регионе или же улучшить его представление в поисковой выдаче.
Раздел рекомендаций состоит из следующих пунктов:
- Не задана региональная принадлежность сайта
- Сайт не зарегистрирован в Яндекс.Справочнике
- Отсутствуют быстрые ссылки
- Отсутствует файл favicon на сайте
- Сайт не оптимизирован для мобильных устройств
В дальнейших разборах мы более подробно рассмотрим оптимизацию сайта по рекомендациям Яндекса и дадим конкретные советы как при исправлении ошибок повышать качество и релевантность ресурса для поисковой выдачи.
Диагностика сайта и Страницы в поиске. Разбор ошибок в Яндекс.Вебмастер
Доброго дня, читатели блога SEO-Дилетанта. Я всегда получаю много вопросов от вебмастеров, владельцев сайтов и блогеров об ошибках и сообщениях, которые появляются в Яндекс. Вебмастер. Многих такие сообщения пугают.
Вебмастер. Многих такие сообщения пугают.
Но, хочу сказать, не все сообщения бывают критичны для сайта. И в ближайших статьях я постараюсь максимально полно охватить все возможные вопросы, которые могут возникать у вебмастеров. В данной статье пойдет речь о разделах:
- Диагностика — Диагностика сайта
- Индексирование — Страницы в поиске
О том, что такое Яндекс.Вебмастр и зачем он нужен, я писала ещё несколько назад. Если вы не знакомы с данным инструментом, ознакомьтесь сначала со статьей по ссылке.
Диагностика сайта
Возможные проблемы
1. В файле robots.txt не задана директива Host
Данное замечание Яндекс примечательно тем, что директива Host не является стандартизированной директивой, ее поддерживает только поисковая система Яндекс. Нужна она в том случае, если Яндекс неправильно определяет зеркало сайта.
Как правило, зеркало сайта определяется Яндексом автоматически на основе URL, которые формирует сама CMS, и на основе внешних ссылок, которые ведут на сайт. Чтобы указать главное зеркало сайта, не обязательно указывать это в файле robots.txt. Основной способ — использовать 301 редирект, который либо настроен автоматически в CMS, либо необходимый код вносится в файл .htachess.
Чтобы указать главное зеркало сайта, не обязательно указывать это в файле robots.txt. Основной способ — использовать 301 редирект, который либо настроен автоматически в CMS, либо необходимый код вносится в файл .htachess.
Обращаю внимание, что указывать директиву в файле robots.txt нужно в тех случаях, когда Яндекс неправильно определяет главное зеркало сайта, и вы не можете повлиять на это никаким другим способом.
CMS, с которыми мне приходилось работать в последнее время, WordPress, Joomla, ModX, по умолчанию редиректят адрес с www на без, если в настройках системы указан адрес сайта без приставки. Уверена, все современные CMS обладают такой возможностью. Даже любимый мной Blogger правильно редиректит адрес блога, расположенного на собственном домене.
2. Отсутствуют мета-теги
Проблема не критичная, пугаться ее не нужно, но, если есть возможность, то лучше ее исправить, чем не обращать внимание. Если в вашей CMS по умолчанию не предусмотрено создание мета-тегов, то начните искать плагин, дополнение, расширение или как это называется в вашей CMS, чтобы иметь возможность вручную задавать описание страницы, либо, чтобы описание формировалось автоматически из первых слов статьи.
3. Нет используемых роботом файлов Sitemap
Конечно, лучше эту ошибку исправить. Но обратите внимание, что проблема может возникать и в тех случаях, когда файл sitemap.xml есть, так и в тех, когда его действительно нет. Если файл у вас есть, но Яндекс его не видит, просто перейдите в раздел Индексирование — Файлы Sitemap. И вручную добавьте файл в Яндекс.Вебмастер. Если такого файла у вас вообще нет, то в зависимости от используемой CMS, ищите варианты решения.
Файл sitemap.xml находится по адресу http://vash-domen.ru/sitemap.xml
4. Не найден файл robots.txt
Все же этот файл должен быть, и если у вас есть возможность его подключить, лучше это сделать. И обратите внимание на пункт с директивой Host.
Файл robots.txt находится по адресу http://vash-domen.ru/robots.txt
На этом фонтан ошибок на вкладке Диагностика сайта у меня иссяк.
Вкладку Безопасность и нарушения я пропускаю. К счастью, на нескольких десятках сайтов у меня ни разу не было сообщений в этом разделе. Поделиться нечем.
Поделиться нечем.
Индексирование
Страницы в поиске
Начнем именно с этого пункта. Так будет легче структурировать информацию.
Выделяем в фильтре «Все страницы»
Опускаемся ниже, справа на странице «Скачать таблицу» Выбираем XLS и открываем файл в Excel.
Получаем список страниц, которые находятся в поиске, т.е. Яндекс о них знает, ранжирует, показывает пользователям.
Смотрим, сколько записей в таблице. У меня получилось 289 страниц.
А как понять, сколько должно быть? Каждый сайт уникален и только вы можете знать, сколько страниц вы опубликовали. Я покажу на примере своего блога на WordPress.
В блоге на момент написания статьи имеется:
- Записи — 228
- Страницы — 17
- Рубрики — 4
- Метки — 41
- + главная страница сайта
В сумме имеем 290 страниц, которые должны быть в индексе. В сравнении с данными таблицы разница всего в 1 страницу. Смело можно считать это очень хорошим показателем. Но и радоваться рано. Бывает так, что математически все совпадает, а начинаешь анализировать, появляются нестыковки.
Но и радоваться рано. Бывает так, что математически все совпадает, а начинаешь анализировать, появляются нестыковки.
Есть два пути, чтобы найти ту одну страницу, которой нет в поиске. Рассмотрим оба.
Способ первый. В той же таблице, которую я скачала, я разделила поиск на несколько этапов. Сначала отобрала страницы Рубрик. У меня всего 4 рубрики. Для оптимизации работы пользуйтесь текстовыми фильтрами в Excel.
Затем Метки, исключила из поиска Страницы, в результате в таблице остались одни статьи. И тут, сколько бы статей не было, придется просмотреть каждую, чтобы найти ту, которой нет в индексе.
Опять же, если на примере WordPress, обратите внимание, какие разделы сайта у вас индексируются, а какие закрыты. Здесь могут быть и страницы Архива по месяцам и годам, страницы Автора, пейджинг страниц. У меня все эти разделы закрыты настройками мета тега robots. У вас может быть иначе, поэтому считайте все, что у вас не запрещено для индексации.
Если взять для примера Blogger, то владельцам блогов нужно считать только опубликованные Сообщения, Страницы и главную. Все остальные страницы архивов и тегов закрыты для индексации настройками.
Все остальные страницы архивов и тегов закрыты для индексации настройками.
Способ второй. Возвращаемся в Вебмастер, в фильтре выбираем «Исключенные страницы».
Теперь мы получили список страниц, которые исключены из поиска. Список может быть большой, намного больше, чем со страницами, включенными в поиск. Не нужно бояться, что что-то не так с сайтом.
При написании статьи я пыталась работать в интерфейсе Вебмастера, но не получила желаемого функционала, возможно, это временное явление. Поэтому, как и в предыдущем варианте, буду работать с табличными данными, скачать таблицу можно также внизу страницы.
Опять же, на примере своего блога на WordPress я рассмотрю типичные причины исключения.
В полученной таблице нам в первую очередь важна колонка D — «httpCode». Кто не знает, что такое ответы сервера, прочитайте в википедии. Так вам будет легче понять дальнейший материал.
Начнем с кода 200. Если вы можете попасть на какую-то страницу в интернете без авторизации, то такая страница будет со статусом 200. Все такие страницы могут быть исключены из поиска по следующим причинам:
Все такие страницы могут быть исключены из поиска по следующим причинам:
- Запрещены мета тегом robots
- Запрещены к индексации в файле robots.txt
- Являются неканоническими, установлен мета тег canonical
Вы, как владелец сайта, должны знать, какие страницы какие настройки имеют. Поэтому разобраться в списке исключенных страниц должно быть не сложно.
Настраиваем фильтры, выбираем в колонке D — 200
Теперь нас интересует колонка E — «status», сортируем.
Статус BAD_QUALITY — Недостаточно качественная. Самый неприятный из всех статус. Давайте разберем его.
У меня в таблице оказалось всего 8 URL со статусом Недостаточно качественная. Я их пронумеровала в правой колонке.
URL 1, 5, 7 — Страницы фида, 2,3,4,5,8 — служебные страницы в директории сайта wp-json. Все эти страницы не являются HTML документами и в принципе не должны быть в этом списке.
Недостаточно качественной может являться только HTML страница с информацией для пользователя. Здесь же на лицо программная ошибка, которую, не нужно бояться.
Здесь же на лицо программная ошибка, которую, не нужно бояться.
Поэтому внимательно просмотрите свой список страниц и выделите только HTML страницы.
Статус META_NO_INDEX. Из индекса исключены страницы пейджинга, страница автора, из-за настроек мета тега robots
Но есть в этом списке страница, которой не должно быть. Я выделила url голубым цветом.
Статус NOT_CANONICAL. Название говорит само за себя. Неканоническая страница. На любую страницу сайта можно установить мета тег canonical, в котором указать канонический URL.
Это очень полезная настройка, когда CMS создает много дублей одной страницы, когда на сайте много страниц пейджинга.
На этом пока заканчиваю. Остальные разделы будут подробно разобраны в следующих постах блога. Подписывайтесь на обновления блога.
Если у вас в Вебмастере есть ошибки из описанных в этой статье разделов, которые я не разобрала, пишите в комментариях, будем разбираться вместе.
что это и как спользовать
Важно! В марте 2018 года поисковая система Яндекс отказалась от использования директивы Host. Правило можно удалить из robots.txt, но на всех главных зеркалах веб-ресурса вместо него нужно поставить 301-й постраничный редирект читать полную инструкцию.
Возможно вам захочется узнать, как раньше использовалась эта директива host для Яндекса.
Host – это директива файла robots.txt, указывающая роботам поисковых систем главное зеркало сайта. Из всех директив, Host распознается исключительно ботами Яндекса. Ее актуально применять для сайтов, доступных по нескольким доменам. К примеру:
Также с помощью Host можно указать предпочтительный URL:
- site.ru
- www.site.ru
Правило указывают в блоке User-agent: Yandex, а в качестве параметра прописывают приоритетный УРЛ-адрес без указания http://.
Примеры файла Robots с директивой Host
User-agent: Yandex
Disallow: /page
Host: site. ru ru
ruВ данном случае главным зеркалом указывают домен site.ru без www. Благодаря этому в поисковую выдачу попадет именно такой URL-адрес.
А если прописать данную инструкцию:
User-agent: Yandex
Disallow: /page
Host: www.site.ruГлавным зеркалом будет домен www.site.ru.
На заметку. Правило Host в Robots можно прописать лишь один раз. Если указать директиву два и больше раза, поисковый робот учтет только первую, игнорируя все последующие.
Если в Яндексе не сообщить главное зеркало в robots.txt, Яндекс оповестит вас об этом:
Не зная главное зеркало сайта, его легко определить, указав в поисковой строке Яндекса домен. Какой URL-адрес отобразит поисковая выдача, тот и является основным зеркалом.
А если веб-сайт еще не был проиндексирован, тогда перейдите в Яндекс.Вебмастер в меню Переезд сайта. Можно самому указать главное зеркало.
Указать главное зеркало роботам поисковой системы Google можно в Google Search Console.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Что проверяет поисковик. Оптимизация сайта для поиска.
Ранее мы подробно рассмотрели все возможные виды оптимизации для поискового продвижения сайта. О методах продвижения сайта и поисковой оптимизации.
Что в первую очередь проверяют роботы поисковых систем и что наиболее важно?
Наличие фатальных ошибок, в результате которых — сайт не индексируется или недоступен. Взлом сайта
- Роботам запрещена индексация сайта. Сайт закрыт к индексции в файле robots.txt При последнем обращении к файлу robots.txt было обнаружено, что сайт закрыт для индексации. Убедитесь в корректности файла robots.txt, иначе сайт может полностью пропасть из поиска.Проверьте robots.txt и снимите установленный запрет.
- Роботы не могут получить доступ к содержимому сайта. Не удалось подключиться к серверу из-за ошибки DNS При попытке скачать данные с сайта не удалось подключиться к серверу из-за ошибки DNS. Если роботы не получить доступ к серверу, сайт может полностью пропасть из поиска.Возможно, пользователи также не могут попасть на сайт.
- Главная страница недоступна или возвращает ошибку. Главная страница сайта всегда должна быть доступна! При обращении к главной странице сайта не удалось получить HTTP-код 200 ОК. Проверьте ответ сервера и при необходимости обратитесь к хостинг-провайдеру.
- Сайт взломан или на нем размещены запрещенные материалы. Сайт может угрожать безопасности пользователя, или на нём были обнаружены нарушения правил поисковой системы.Наличие этой проблемы негативно сказывается на положении сайта в результатах поиска.

Наличие критичных ошибок. При таких ошибках сайт доступна, но его индексирование затруднено.
С точки зрения продвижения, ранжирование такого сайта может идти только на убыль.
- Ошибки ссылочной массы. Накопленные или же ошибки автоматики. Большое количество неработающих внутренних ссылок на сайт не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.Ознакомьтесь с примерами и исправьте ошибки.
- Сайт «тормозит». Долгий ответ сервера При обращении к серверу среднее время ответа больше 3 секунды. Долгая загрузка затрудняет работу с сайтом.Проверьте ответ сервера и при необходимости с хостинг-провайдером.
Сайт доступен, ранжируется в поиске, но оптимизирован не полностью и нет продвижения в топ.
Также нет продвижения в топ низкочастотных ключевых слов с низкой конкуренцией (проверочные, длинные фразы).- Проверьте наличие xml карты сайта. Нет используемого роботом файлов Карта сайта Робот не использует ни одного файла Карта сайта. Это может негативно сказаться на скорости индексирования новых страниц сайта. Если файлы Sitemap уже добавлены в очередь на обработку, сообщение автоматически исчезнет с началом их использования. Обратите внимание на раздел «Файлы Sitemap» в веб-мастере поисковика.
- Роботом обнаружены ошибки в файлах Sitemap. В одном или нескольких файлах Sitemap обнаружены ошибки, которые могут повлиять на обработку файлов индексирующим роботом.Проверьте файлы Sitemap и внесите необходимые исправления.
- При запросе роботом несуществующих файлов и страниц получен неверный ответ сервера. Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 Not Found, что может негативно сказаться на индексировании сайта роботом. Настройте возврат кода 404 на запрос несуществующих страниц.
- Поисковой робот обнаружил ошибки в файле robots.txt. Это может быть к некорректному обходу и индексированию сайта.txt, внесите исправления.
- При обращении к сайту идет перенаправление на другой, внешний ресурс. Главная страница перенаправляет на другой сайт При обращении к главной странице робот получает перенаправление на другой сайт, что делает невозможным ее индексирование.
- При обращении к разным страницам, робот одинаковый html код или одинаковое содержимое. Большое количество страниц-дублей На сайте обнаружено большое количество одинаковых страниц, это усложнение индексирование сайта.Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt.
- В файле robots.txt критическая ошибка или он недоступен.Робот не смог получить доступ к файлу robots.txt при последнем обращении. Из-за отсутствия параметров индексирования и инструкций по поиску ошибочные страницы.
- При ранжировании неправильно определяется зеркало. В файле robots.txt не задана директива Host Для корректного определения главного зеркала сайта рекомендуется установить соответствующий директиву Host в файлах robots.txt всех зеркал сайта. В случае ее отсутствия главное зеркало может быть выбрано автоматически.Добавьте директиву в файл robots.txt.
- Ошибка при задании директива Хост в файле robots.txt Возможно в директиве Хост указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы директивы хоста были учтены, идентичные директивы присутствовать в файлах robots. txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.
- Ошибка заголовка страниц сайта.Отсутствуют теги «title» Значительная часть страниц не содержит тег «title», или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.
- Ошибка заполнения мета тегов страниц сайта. Отсутствуют мета-теги «description» Значительная часть страниц сайта не содержит мета-тег «description», или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.
- В длительного времени робот один получает и тот же карту сайта.Возможно файлы Sitemap давно не обновлялись или сайт «брошен» и на нем не ведутся никакие работы по наполнению и изменению. Проверьте, не нужно ли обновить файлы Карта сайта.Методично работайте над содержимым сайта. Отслеживайте текущие тенденции в SEO-продвижении. Не забывайте, что правильная структура сайта, удобство для посетителя в поиске информации — это увеличение конверсии и увеличение дохода от ресурса.
 Обратите внимание на раздел «Файлы Sitemap» в веб-мастере поисковика.
Обратите внимание на раздел «Файлы Sitemap» в веб-мастере поисковика. Большое количество страниц-дублей На сайте обнаружено большое количество одинаковых страниц, это усложнение индексирование сайта.Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt.
Большое количество страниц-дублей На сайте обнаружено большое количество одинаковых страниц, это усложнение индексирование сайта.Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt. txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.
txt всех зеркал сайта.Проверьте файл robots.txt и устраните противоречия.
Дополнительные рекомендации по оптимизации сайта
- Задайте региональность сайта в вебмастере поисковиков или укажите на сайте явно (в контактах и в шапке сайта) региональную принадлежность.Помните, что региональные сайты ранжируются в поиске выше сайтов у которых общая региональность (Россия или весь мир).
- Зарегистрируйтесь на сайте в Яндекс.Справочнике и Гугл справочнике. Если у вас есть офисы или филиалы, добавьте их в справочник, чтобы улучшить внешний вид сайта в поиске и региональное ранжирование. Если офисов и филиалов нет, укажите «Нет региона» в «Вебмастер» настройки раздела региональности.Обратите внимание на раздел «Региональность» .Помните, что указание адреса офиса или торговой точки увеличивает доверие к сайту.
- Для поисковика Яндекс! Отсутствует файл значка на сайте Не найден файл с изображением, которое должно быть показано возле названия сайта в поиске.
- Оптимизируйте сайт для мобильных устройств. Отсутствие оптимизации сайта для мобильных устройств может привести к полному отсутствию элементов, размещенных на экране по ширине, присутствуют элементы Flash, плагины Silverlight или Java-аппиду. сайта в поиске при просмотре через мобильные устройства и планшеты.
 сайта в поиске при просмотре через мобильные устройства и планшеты.
сайта в поиске при просмотре через мобильные устройства и планшеты.301-й редирект полностью заменил директиву Host — Блог Яндекса для вебмастеров
20 марта 2018, 12:51
Как мы писали ранее, мы отказываемся от директивы Host. Теперь эту директиву можно удалить из robots.txt, но важно, чтобы на всех не главных зеркалах вашего сайта теперь стоял 301-й постраничный редирект. Вебмастерам, которые по нашим данным, ещё не установили перенаправление.
Кроме того, мы собрали наиболее распространенные ситуации, и хотим рассказать о них подробнее.
Мне нужно переехать на новый домен или протокол, переезд я еще планирую
- поставьте постраничный 301-й редирект
- зайдите в Вебмастер в инструмент «Переезд сайта», новое главное зеркало
- подождите, обычно переезд занимает несколько дней
II Мне нужно переехать на новый домен или протокол, переезд я уже начал
Аналогично I пункту:
- поставьте постраничный 301-й редирект
- зайдите в Вебмастер в инструмент «Переезд сайта», укажите новое главное зеркало: если вы сделали это ранее — данный пункт можно пропустить
- подождите, переезд занимает несколько дней
III Мне нужно переехать на обычно новый домен или протокол, но я не могу использовать 301-й редирект
- добавить новый сайт в Вебмастер
- використовуйте «Переезд сайта»
- подождите, в таком случае переезд може т занимать несколько недель
IV Мне не нужно никуда переезжать, нужно ли мне что-то менять, редирект я поставить могу
- проверить, чтобы на всех неглавных зеркалах вашего сайта стояли постраничные редиректы на главные, это позволит прямо указать роботу на нужный вам адрес в поиске
V Мне не нужно никуда переезжать, нужно ли мне что-то менять, редирект я поставить не могу
- нужно понимать, что главное зеркало в таком случае может быть выбрано на усмотрение робота : В случае смены главного зеркала воспользуйтесь возможностью «Переездом сайта»
VI Нужно ли ставить редирект для мобильных версий сайтов
- как и ранее, ставить редирект для мобильных версий сайтов не обязательно: мобильная версия может быть или доступна для основного робота , или редирект на основную версию сайта
VII Что делать, если мои зеркала все-та ки изменились из-за того, что не был установлен 301-й редирект
Совершите переезд аналогично I:
- поставьте постраничный 301-й редирект на нужный адрес
- за переход в Вебмастер в инструмент «Переезд сайта», укажите новое главное зеркало
- подождите, обычно переезд занимает несколько дней
VIII Что делать с директивой Host
- её можно удалить из robots. txt или оставить, робот её просто игнорирует
 txt или оставить, робот её просто игнорирует
txt или оставить, робот её просто игнорируетКоманда Поиска
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
YouTube
Канал для владельцев сайтов в Яндекс.Дзене
Robots.txt определение — термина. SEO-википедия
Определение
Файл robots.txt по своей сути — это сборник инструкций для роботов, составленный консилиумом W3C зимой 1994 г. Почти все роботы-поисковики на добровольных началах внедрили в работу инструкции robots.текст.
В документе перечисляются стандарты, которые определяют индексцию некоторых документов, каталогов, разделов или страниц на любом документе онлайн-ресурс.
Как используется robots
Robots.txt для ресурса является важным элементом оптимизации поиска. Например, в рамках SEO-продвижения данный файл используется для того, чтобы вычленить из индексации ресурсы, на которых отсутствует полезный для пользователей контент. Маленькие сайты также могут пользоваться отдельными блоками, все зависит от целей, поставленных перед программистом.
Настройка robots.txt
Программист должен грамотно настроить файл под сайт, что в будущем исключит каждый попадание данных в результаты выдачи поисковиков. Роботы проверенных систем, таких как Гугл, Яндекс и Рамблер, в своей деятельности принимают принятые стандарты. Остальные поисковики могут игнорировать их, что снижает качество поисковой выдачи.
Директива User-agent дает указание поисковой системы. Сразу после нее формируется сама команда, прописывающая условия для определенного робота.Пример выполнения представлен представлен ниже.
User-agent: Яндекс
Disallow: / * utm_
Allow: / * id =
Можно заметить, что тут была применение запрещающая команда Disallow (присвоено значение «/ * utm_»). Благодаря этой процедуре создается закрытие страниц, на которых размещены метки UTM. Также можно вести, что указания формируются блоками, которые содержат информацию для определенного робота или для всех сразу («*»).
Настраивая robots. текст,
важно учесть порядок и сортировку указаний, особенно при одновременном
использования нескольких команд, таких как «Запретить» и «Разрешить». Последняя
директива является разрешающей и, соответственно, полной противоположностью «Disallow»,
накладывающей запрет.
текст,
важно учесть порядок и сортировку указаний, особенно при одновременном
использования нескольких команд, таких как «Запретить» и «Разрешить». Последняя
директива является разрешающей и, соответственно, полной противоположностью «Disallow»,
накладывающей запрет.
Приведем пример применения нескольких директив в одном документ.
User-agent: *
Разрешить: / blog / page
Disallow: / blog
Выше поисковику запрещается индекс ресурсов, которые начинаются с / blog.При этом одновременно допустимый индекс тех, которые начинаются с / blog / page.
Что такое синтаксис robots.txt
Для того, чтобы грамотно работать с robots.txt, следует посмотреть порядок формирования его синтаксиса. Ниже представлен список классических правил.
- Любая директива всегда начинается с отдельной строки.
- В строки должна быть только одна команда.
- Пробел не может стоять в начале строчки.
- Параметр команды также должен быть указан в
одной строке.
- Параметры директив нельзя брать в кавычки, не следует применять и закрывающие знаки (точка с запятой).
- Команда в файле должна быть указана в стандартном формате.
- Пустой перевод строки воспринимается как завершение команды User-agent.
- В файле могут быть сделаны комментарии, но Предпоставляется знак решетка.
- Команда «Disallow:», если содержит пустое , то приравнивается к разрешающей команде «Разрешить: /».
- В перечисленных выше директивах можно прописывать только один параметр.
- В самом названии файла с инструкциями не используются строчные буквы. Например, распространенное написание Роботы и РОБОТЫ некорректно по правилам составления синтаксиса.
- Названия команд и параметров строчных буквами некорректные. Изначально robots.txt нечувствителен к определенному регистру, но чувствительными могут оставаться названия директорий и других документов.
- Если параметр команды является директорией,
то в его имени перед названием необходимо проставить знак «слеш» (Disallow:
/ категория).
- Если файл директивы «User-agent», но при этом пустой перевод не выполнен, то все команды кроме первой игнорироваться поисковиками.
- Файлы с инстуркциями от 32 Кб по умолчанию считаются разрешающими и приравниваются к команде «Disallow:».
- Запрещено применение знаков национальных алфавитов.
- Если robots.txt недоступен по любой причине, то по умолчанию считается полностью разрешающим.
- Пустой robots.txt считается по умолчанию разрешающим.


Проверка синтаксиса
Чтобы проверить корректность работы, построение и синтаксис можно использовать онлайн-ресурсы. Некоторые крупные поисковики, такие как Гугл и Яндекс, реализовали собственные сервисы, позволяющие комплексно проанализировать сайт по всем веб-параметрам. В Проверка обязательно входит и анализ инструкций.
Так, Проверка этого файла можно запустить в
Яндекс.Вебмастере и аналогичном сервисе в Google по ссылке https:
// www.google.com/webmasters/tools/siteoverview?hl=ru.
Дополнительно в интернете представленные онлайн-валидаторы.
Запрет индексции: Disallow
Вышеуказанная команда в robots.txt наиболее часто. Ее функция является запретом индекса любого ресурса, учитывая параметры, который был прописаны в этой команде.
User-agent: *
Disallow: /
Выше видимый пример участка кода, задающего запрет индексации сайта для любого робота-поисковика.
Разрешение индексции: Разрешить
Указанная разрешающая команда является антагонистом директивы Запретить. Тем не менее, она имеет с ней очень схожий синтаксис.
Ниже приведен участок кода, запрещающий индексцию, но при это делается исключение для определенных страниц.
User-agent: *
Disallow: /
Allow: / page
Как вы можете наблюдать индекс в примере разрешена для страниц, в начале размещается фраза / page.То есть любые другие без выполнения этих условий проиндексированы ресурсы не будут.
Учтите, что есть одну лишь директиву allow: / в роботсе, т. е. по-рейтингу индексировать весь сайт.
е. по-рейтингу индексировать весь сайт.
Главное зеркало ресурса: Host
С помощью команды поисковик Яндекса разглядит главное зеркало любого портала. Интересно, что из всех распространенных поисковиков Host «Понимает» только Яндекс.
Директива применяется в случае, когда ресурс размещается на нескольких доменах, например: newsite.ru и newsite.com. Также она позволяет определить приоритет между такими именами сайта: newsite.ru и www. newsite.ru.
Директива Host входит в блок другой директивы «User-agent: Яндекс ». При этом предпочтительный или основной адрес сайта необходимо прописывать без «http: //».
Поисковику Яндекса можно главное показать зеркало, что позволит оптимизировать выдачу страниц пользователям.
Карта сайта: карта сайта
Благодаря команде в команде robots.txt можно указать конкретное место хранение файла карты сайта (именуется как карта сайта.xml).
Рассмотрим пример участка кода, где задан адрес карты
ресурс.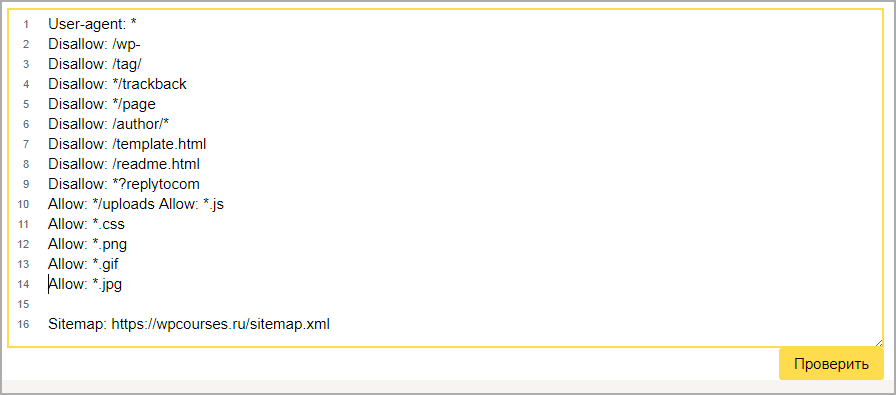
User-agent: *
Disallow: / page
Карта сайта: http: // www.newsite.ru/sitemap.xml
Поисковик использует инструмент, чтобы начать индексцию страницы или ресурса в целом.
Выводы
Файл robots.txt является эффективным инструментом, который позволяет взаимодействовать с поисковыми системами и оптимизировать SEO-продвижение.
Диагностика сайта и Страницы в поиске.Разбор ошибок в Яндекс.Вебмастер
Доброго дня, читатели блога SEO-Дилетанта. Я всегда получаю много вопросов от вебмастеров, владельцев сайтов и блогеров об ошибках и сообщениях, которые появляются в Яндекс.Вебмастер. Многих такие сообщения пугают.
Но, хочу сказать, не все сообщения бывают критичны для сайта. И в ближайших статьях я постараюсь максимально полно охватить все возможные вопросы, которые могут быть включены у вебмастеров. В данной статье пойдет речь о разделах:
- Диагностика — Диагностика сайта
- Индексирование — Страницы в поиске
О том, что такое Яндекс. Вебмастр и зачем он нужен, я писала ещё несколько назад. Если вы не знакомы с данным инструментом, ознакомьтесь сначала со статьей по ссылке.
Вебмастр и зачем он нужен, я писала ещё несколько назад. Если вы не знакомы с данным инструментом, ознакомьтесь сначала со статьей по ссылке.
Диагностика сайта
Возможные проблемы
1. В файле robots.txt не задана директива Host
Стандартное замечание Яндекс примечательно, что директива Host не является стандартизированной директивой, ее поддерживает только поисковая система Яндекс. Нужна она в том случае, если Яндекс неправильно определить зеркало сайта.
Как правило, зеркало сайта определяется Яндексом автоматически на основе URL-адресов, которые формируют сама CMS, и на основе внешних ссылок, которые ведут на сайт. Чтобы указать главное зеркало сайта, не обязательно указывать это в файле robots.txt. Основной способ — использовать 301 редирект, который либо настроен автоматически в CMS, либо необходимый код вносится в файл .htachess.
Обращаю внимание, что указывать директиву в файле robots.txt нужно в тех случаях, когда Яндекс неправильно указать главное зеркало сайта, и вы не можете повлиять на это никаким другим способом.
CMS, с которой мне приходилось работать в последнее время, WordPress, Joomla, ModX, по умолчанию редиректят адрес с www на без, если в настройках системы указан адрес сайта без приставки. Уверена, все современные CMS обладают таким. Даже любимый мной Blogger правильно редиректит адрес блога, расположенного на собственном домене.
2. Отсутствуют мета-теги
Проблема не критичная, пугаться ее не нужно, но, если есть возможность, то лучше ее исправить, чем не обращать внимание.Если в вашей CMS по умолчанию не предусмотрено создание мета-тегов, то начните искать плагин, расширение или это называется в вашей CMS, чтобы иметь возможность вручную задавать описание страницы, либо чтобы описание сформировалось автоматически из первых слов статьи.
3. Нет используемым роботом файлов Карта сайта
Конечно, лучше эту ошибку исправить. Но обратите внимание, что проблема может возникнуть и в тех случаях, когда файл sitemap.xml есть, так и в тех, когда его действительно нет.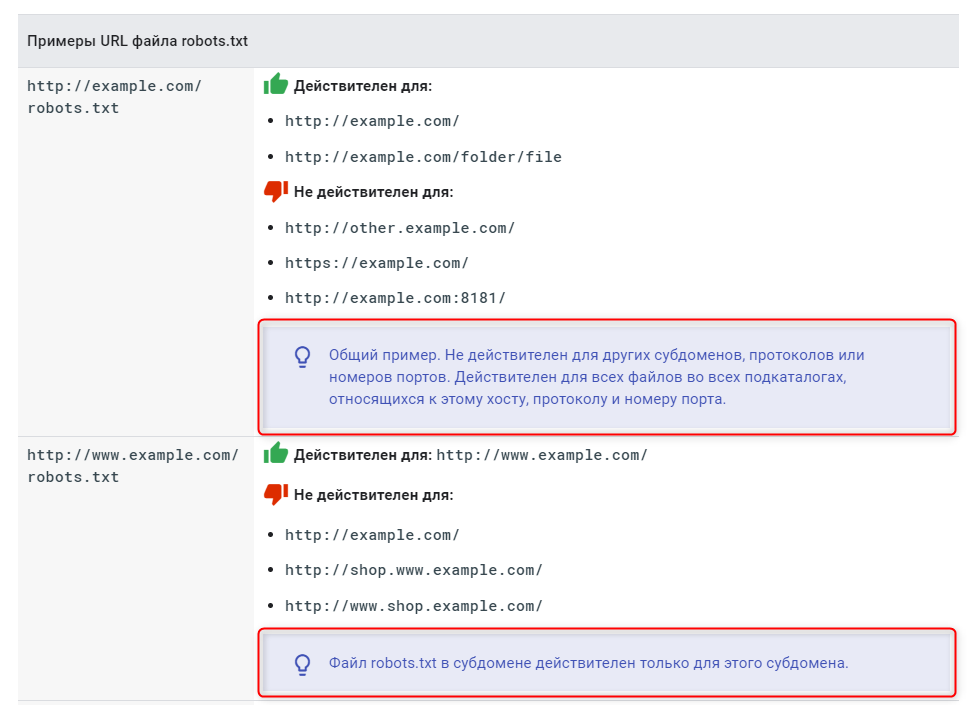 Если файл у вас есть, но Яндекс его не видит, просто ведет в раздел Индексирование — Файлы Sitemap. И вручную добавить файл в Яндекс.Вебмастер. Если такого файла у вас вообще нет, то в зависимости от используемой CMS, ищите варианты решения.
Если файл у вас есть, но Яндекс его не видит, просто ведет в раздел Индексирование — Файлы Sitemap. И вручную добавить файл в Яндекс.Вебмастер. Если такого файла у вас вообще нет, то в зависимости от используемой CMS, ищите варианты решения.
Файл sitemap.xml находится по адресу http://vash-domen.ru/sitemap.xml
4. Не найден файл robots.txt
Все же этот файл должен быть, и если у вас есть возможность его подключить, лучше это сделать. И обратите внимание на пункт с директивой Host.
Файл robots.txt находится по адресу http://vash-domen.ru/robots.txt
На этом фонтан ошибок на вкладке Диагностика сайта у меня иссяк.
Вкладку Безопасность и нарушения я пропускаю. К счастью, на нескольких десятках сайтов у меня ни разу не было сообщений в этом разделе. Поделиться нечем.
Индексирование
Страницы в поиске
Начнем именно с этого пункта. Так будет легче структурировать информацию.
Выделяем в фильтре «Все страницы»
Опускаемся ниже, справа на странице «Скачать таблицу» Выбираем XLS и открываем файл в Excel.
Получаем список страниц, которые находятся в поиске, т.е. Яндекс о них знает, ранжирует, показывает пользователей.
Смотрим, сколько записей в таблице. У меня получилось 289 страниц.
А как понять, сколько должно быть? Каждый сайт уникален и только вы знаете, сколько страниц вы опубликовали. Я покажу на примере своего блога на WordPress.
В блоге на момент написания статьи имеется:
- записей — 228
- Страницы — 17
- Рубрики — 4
- Метки — 41
- + главная страница сайта
В сумме имеем 290 страниц, которые должны быть в индексе.В сравнении с таблицей разница всего в 1 страницу. Смело можно считать это очень хорошим показателем. Но и радоваться рано. Бывает так, что математически все совпадает, а начинаешь анализировать появляются, нестыковки.
Есть два пути, чтобы найти ту одну страницу, которой нет в поиске. Рассмотрим оба.
Способ первый. В той же таблице, которую я скачала, я разделила поиск на несколько этапов. Сначала отобрала страницы Рубрик. У меня всего 4 рубрики. Для оптимизации работы пользуйтесь текстовыми фильтрами в Excel.
Сначала отобрала страницы Рубрик. У меня всего 4 рубрики. Для оптимизации работы пользуйтесь текстовыми фильтрами в Excel.
Затем Метки, исключила из поиска Страницы, в результате в таблице остались одни статьи. И тут, сколько бы статей не было, посмотрите каждую, чтобы найти ту, которую нет в индексе.
Опять же, если на примере WordPress, обратите внимание, какие разделы сайта у вас индексируются, а какие закрыты. Здесь могут быть и страницы Архива по месяцам и годам, страницы Автора, пейджинг страниц. У меня все эти разделы закрыты настройками мета тега robots. У вас может быть иначе, поэтому считайте все, что у вас не для индексции.
Если взять для примера Blogger, то владельцам блогов нужно считать только опубликованные Сообщения, Страницы и главную. Все остальные страницы архивов и тегов закрытые для индексации настройками.
Способ второй. Возвращаемся в Вебмастер, в фильтре выбираем «Исключенные страницы».
Теперь мы получили список страниц, которые исключены из поиска. Список может быть большой, намного больше, чем со страницами, включенными в поиск. Не нужно бояться, что-то не так с сайтом.
Список может быть большой, намного больше, чем со страницами, включенными в поиск. Не нужно бояться, что-то не так с сайтом.
При написании статьи я пыталась работать в интерфейсе Вебмастера, но не получила желаемого функционала, возможно, это временное явление. Как и в предыдущем варианте, буду работать с табличными данными, скачать таблицу можно также внизу страницы.
Опять же, на примере своего блога на WordPress я рассмотрю типичные причины исключения.
В полученной таблице нам в первую очередь важна колонка D — «httpCode». Кто не знает, что такое ответы сервера, прочитайте википедии.Так вам будет легче понять дальнейший материал.
Начнем с кода 200. Если вы попадете на какую-то страницу в интернете без авторизации, то такая страница будет со статусом 200. Все такие страницы могут быть исключены из поиска по следующим причинам:
- Запрещены мета тегом роботы
- Запрещены к индексции в файле robots.txt
- Являются неканоническими, установлен мета тег canonical
Вы, как владелец сайта, должны знать, какие страницы какие настройки имеют.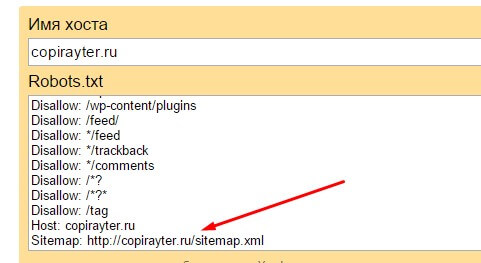 Поэтому разобраться в списке исключенных страниц быть не сложно.
Поэтому разобраться в списке исключенных страниц быть не сложно.
Настраиваем фильтры, выбираем в колонке D — 200
Теперь нас интересует колонка E — «status», сортируем.
Статус BAD_QUALITY — Недостаточно качественная. Самый неприятный из всех статус. Давайте разберем его.
У меня в таблице оказалось всего 8 URL со статусом Недостаточно качественная. Я их пронумеровала в правой колонке.
URL 1, 5, 7 — Страницы фида, 2,3,4,5,8 — служебные страницы в директории сайта wp-json.Все эти страницы не являются HTML-документами и в принципе не должны быть в этом списке.
Недостаточно качественной может являться только HTML страница с информацией для пользователя. Здесь же на лицо программная ошибка, которую, не нужно бояться.
Поэтому внимательно просмотрите свой список страниц и выделите только HTML страницы.
Статус META_NO_INDEX. Из определить исключены страницы пейджинга, страница автора, из-за настроек мета тега robots
Но есть в этом списке страницы, которой не должно быть. Я выделила url голубым цветом.
Я выделила url голубым цветом.
Статус NOT_CANONICAL. Название говорит само за себя. Неканоническая страница. На любую страницу можно установить мета тег canonical, в котором указать канонический URL.
Это очень полезная настройка, когда CMS создает много дублей одной страницы, когда на сайте много страниц пейджинга.
На этом пока заканчиваю. Остальные разделы будут подробно разобраны в следующих постах блога. Подписывайтесь на обновления блога.
Если у вас в Вебмастере есть ошибки из описанных в этой статье разделов, которые я не разобрала, пишите в комментариях, будем разбираться вместе.
Рекомендации яндекса по оптимизации сайта
создан, первым делом его необходимо добавить в инструменты после поисковых систем. В Яндексе инструментом является Вебмастер. Как добавить сайт в Яндекс Вебмастер мы объяснили здесь.
В Яндекс Вебмастере можно увидеть много профессиональных показателей и рекомендаций по оптимизации сайта. Найти рекомендации Яндекса для оптимизации сайта довольно просто — критичные ошибки сразу же появляются на панели, остальные можно посмотреть перейдя по ссылке «посмотреть рекомендации».
Найти рекомендации Яндекса для оптимизации сайта довольно просто — критичные ошибки сразу же появляются на панели, остальные можно посмотреть перейдя по ссылке «посмотреть рекомендации».
Какие же рекомендации по оптимизации сайта даёт Яндекс в Вебмастере:
Рекомендации по фатальным ошибкам — раздел для оптимизации сайта необходимо обратить очень серьёзное внимание. В этом разделе имеются какие-либо ошибки, скорее всего, ваш сайт вообще не в выдаче поисковых систем.Исправление фатальных ошибок крайне важно не столько для оптимизации сайта в Яндексе, сколько для его индексации.
Раздел фатальных содержит следующие области:
- Запрет индексации сайта файла robots.txt
- Ошибка подключения к сайту при помощи dns
- Ошибка главной страницы
- Проблемы с безопасностью сайта
Раздел критичных ошибок содержит всего два пункта — большое количество неработающих ссылок и долгий ответ сервера.Однако эти крайне важны для внутренней оптимизации и рекомендаций Яндекса на них тоже нужно обратить очень пристальное внимание.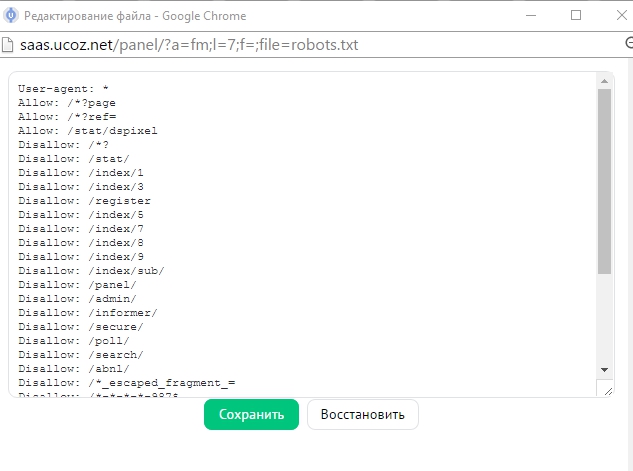
Раздел проблем в Яндекс Вебмастере обширный ресурс оптимизации сайта. Основная работа всех вебмастеров по оптимизации сайта в поисковой системе Яндекс заключаются в исправлении ошибок и правильном функционировании этого раздела рекомендаций.
Возможные проблемы следующие области:
- Нет используемых роботом файлов Карта сайта
- Обнаружены ошибки в файле Карта сайта
- Некорректно настроено отображение несуществующих файлов и страниц
- в файле robots.txt
- Главная страница перенаправляет на другой сайт
- Большое количество страниц-дублей
- Не найден файл robots.txt
- В файле robots.txt не задана директива Host
- В файле robots.txt задана противоречивая директива Host
- Отсутствуют теги
</li><li> Отсутствуют мета-теги <description></li><li> Файлы Sitemap не обновлялись</li></ul><p> Выполнение рекомендаций Яндекса при оптимизации сайта по этим пунктам многократно улучшают индексцию и позволяет ранжировать ресурс в поисковой выдаче гораздо выше.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/www.wordpress-abc.ru/wp-content/uploads/2019/09/search-console-%E2%80%93-instrument-proverki-fajla-robots.txt.jpg' style='float: right;' /><noscript><img src='/800/600/https/www.wordpress-abc.ru/wp-content/uploads/2019/09/search-console-%E2%80%93-instrument-proverki-fajla-robots.txt.jpg' style='float: right;' /></noscript></p><p> И наконец, завершающим разделом Яндекса по оптимизации сайтов является раздел, который так и называется — рекомендации. В данном разделе возможностей, которые позволяют настроить сайт на работу в конкретном регионе или улучшить его представление в поисковой выдаче.</p><h4><span class="ez-toc-section" id="i-56"> Раздел рекомендаций состоит из следующих пунктов: </span></h4><ul><li> Не задана региональная принадлежность сайта</li><li> Сайт не зарегистрирован в Яндекс.Справочнике</li><li> Отсутствуют быстрые ссылки</li><li> Отсутствует значок на сайте</li><li> не оптимизирован для мобильных устройств</li></ul><p> В дальнейших разборах мы более подробно рассмотрим оптимизацию сайта по критериям Яндекса и дадим рассмотрим как при исправлении ошибок повышать качество и релевантность ресурса для поисковой выдачи.</p> <br/><h2><span class="ez-toc-section" id="i-57"> что это и как спользовать </span></h2><p> <strong> Важно! </strong> В марте 2018 года поисковая система Яндекс отказалась от использования директивы Host. Правило можно удалить из robots.txt, но на всех главных зеркалах веб-ресурса вместо него нужно поставить 301-й постраничный редирект читать полную инструкцию.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/allyslide.com/thumbs_2/32d430caf2faeeac71e9659271b5a155/img14.jpg' style='float: right;' /><noscript><img src='/800/600/https/allyslide.com/thumbs_2/32d430caf2faeeac71e9659271b5a155/img14.jpg' style='float: right;' /></noscript></p><p> Возможно вам захочется узнать, как раньше использовалась эта директива host для Яндекса.</p><p> <strong> Host </strong> — это директива файла robots.txt, указывающая роботам поисковых систем главное зеркало сайта. Из всех директив, Host распознается исключительно ботами Яндекса. Ее актуально применять для сайтов, доступных по нескольким доменам. К примеру:</p><p> Также с помощью Host можно указать предпочтительный URL:</p><ol><li> site.ru</li><li> www.site.ru</li></ol><p> Правило указать в блоке User-agent: Яндекс, а в качестве прописывают приоритетный УРЛ-адрес без указания http: //.</p><h3><span class="ez-toc-section" id="_Robots_Host-2"> Примеры файла Robots с директивой Host </span></h3><pre> <code> Пользовательский агент: Яндекс Запретить: / страница Хост: сайт.ru </code> </pre><p> В данном случае зеркалом указывает домен site.ru без www. Благодаря этому в поиск выдачу попадет именно такой URL-адрес.</p><p> А если прописать инструкцию:</p><pre> <code> Пользовательский агент: Яндекс Запретить: / страница Хост: www.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/2.bp.blogspot.com/-Fhz93Cna9qA/XKBfEQAsoXI/AAAAAAAACgE/CCaWG7e_TOs597DyVt_TzK2M0Zyx3BWsACLcBGAs/s1600/Untitled2.jpg' style='float: right;' /><noscript><img src='/800/600/https/2.bp.blogspot.com/-Fhz93Cna9qA/XKBfEQAsoXI/AAAAAAAACgE/CCaWG7e_TOs597DyVt_TzK2M0Zyx3BWsACLcBGAs/s1600/Untitled2.jpg' style='float: right;' /></noscript> site.ru </code> </pre><p> Главным зеркалом будет домен www.site.ru.</p><p> <strong> На заметку. </strong> Правило Хост в Роботов можно прописать лишь один раз. Если указать директиву два и больше раза, поисковый робот учтет только первую, игнорируя все последующие.</p><p> Если в Яндексе не сообщите главное зеркало в robots.txt, Яндекс оповестит вас об этом:</p><p> Не зная главное зеркало сайта, его легко определить, указав в поисковой строке Яндекса домен. Какой URL-адрес указит поисковая выдача, тот и является основным зеркалом.</p><p> А если веб-сайт еще не был проиндексирован, тогда перейти в Яндекс.Вебмастер в меню Переезд сайта. Можно самому указать главное зеркало.</p><p> Указать главное зеркало роботам поисковой системы Google можно в Google Search Console.</p><p> Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите <em> Ctrl + Enter </em>.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/yula-group.ru/foto2-robots-txt-domeny-rf.jpg' style='float: right;' /><noscript><img src='/800/600/https/yula-group.ru/foto2-robots-txt-domeny-rf.jpg' style='float: right;' /></noscript></p><h2><span class="ez-toc-section" id="_robotstxt_Google"> Файл robots.txt для поисковых систем Яндекса и Google </span></h2><p></p><h3><span class="ez-toc-section" id="i-58"> <strong> Что это за файл и зачем он нужен? </strong> </span></h3><p> Если вы заходили на ftp-сервер, где находится ваш сайт, то наверняка задавались вопросы, какие функции работают разные файлы, зачем они нужны и как они работают.</p><p> В этой статье мы рассмотрим robots.txt и ответим на эти вопросы о нем.</p><p> Прежде всего поисковые роботы проверяют наличие файла robots.txt, который находится в папке, а затем уже происходит обращение ботов к страницам сайта, блога или форума.</p><p> При этом роботы читают инструкции, которые прописаны специально для них в этом файле, в основном там прописано, что из страниц и даже целых разделов сайта разрешено, а что — запрещено индексировать и разглашать всему миру.</p><p></p><p> Запрет не означает, что на сайте есть секретные материалы, просто мы помогаем поисковым системам делать их работу на «отлично». Хорошему вебмастеру лишние страницы в индексе мешают и он лучше знает, какие из них вспомогательные функции и несут полезные нагрузки ни роботам ни людям.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/mbahwp.com/wp-content/uploads/2019/02/robot-yoast2.jpg' style='float: right;' /><noscript><img src='/800/600/https/mbahwp.com/wp-content/uploads/2019/02/robot-yoast2.jpg' style='float: right;' /></noscript> Поэтому важно, как правильно составить и настроить robots.txt.</p><p> Примеры страниц, которые рекомендуется исключить из индекса: версия для печати, страница регистрации, логина, RSS, архивы сайта и других подобных.</p><p> Кроме запретов и разрешений robots.txt может предоставлять пользу, — например, указывать расположение карты сайта, задавать главное сайта (домен с www или без), уменьшать нагрузку зеркало поисковых ботов на хостинг, задаваемые интервалы посещения и т.д.</p><p> <strong> Итак, файл robots.txt нужен для правильной обработки сайта поисковыми ботами. </strong></p><p> <strong> </strong></p><h4/><span class="ez-toc-section" id="_robotstxt_robotstxt_robotstxt_9000_robotstxt_Notepad_AkelPad_http_robotstxt_httpyandexrurobotstxt_Google_httpwwwgooglecomrobotstxt_robotstxt_robotstxt_sitemap_http-_Punycode_User-agent_-_txt_User-agent_Googlebot_robotstxt_User_agent_StackRambler_Slurp_Yahoo_Slurp_Yahoo_SearchMonkey_Bing_User-agent_txt"><h3> <strong> Как правильно настроить robots.txt? </strong></h3><p> В одних системах управления контентом файл robots.txt может генерироваться автоматически, в других — его нужно создавать вручную. Этот файл всегда нужно проверять, в большинстве случаев и редактировать.</p><p> Следует учитывать, что нет универсального файла robots.txt даже для одинаковых систем управления контентом, у каждого проекта есть свои особенности, которые отражаются на реализации всех технических деталей.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/i2.wp.com/lexium.ru/images/2017/10/smr2.png' style='float: right;' /><noscript><img src='/800/600/https/i2.wp.com/lexium.ru/images/2017/10/smr2.png' style='float: right;' /></noscript> Даже по мере развития вашего проекта придется менять многое, в том числе и файл роботс.</p><p> Итак, когда мы знаем, зачем нам нужен этот файл, мы можем углубиться в технические подробности.</p> 9000 Горючее — это обычный текстовый файл с названием robots.txt, который можно создать в любом блокноте (системном, Notepad ++, AkelPad или другом) и загрузить в корневую папку сайта на сервере.</p><p> После загрузки можно просмотреть все содержимое этого файла по адресу: http: // <имя сайта> /robots.txt. Это работает для всех сайтов, у которых есть этот файл. А вот роботс самого Яндекса http://yandex.ru/robots.txt</p><p></p><p> и Google http://www.google.com/robots.txt</p><p></p><h3> Изучим основы синтаксиса robots.txt и самые распространенные директивы</h3><p> Прежде всего нужно знать, что использование кириллицы в файлах robots.txt, файлах sitemap и http-заголовках сервера. Вместо нее нужно использовать специальный Punycode.</p><p> <strong> Поисковые агенты (</strong> <strong> User-agent </strong> <strong>) </strong></p><p> В первой строке, которая не закомментирована знаком <strong> # </strong>, обычно указывается поисковый агент (робот поисковой или группы ботов), которым предназначены последующие правила.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/kostyakhmelev.ru/wp-content/uploads/2014/12/direktiva-host.jpg' style='float: right;' /><noscript><img src='/800/600/https/kostyakhmelev.ru/wp-content/uploads/2014/12/direktiva-host.jpg' style='float: right;' /></noscript> Будьте внимательны — Пользователь-агент не должен быть пустым! То есть вот такая строка и последующие не сработают:</p><p> <strong> Пользователь </strong> <strong> — </strong> <strong> агент </strong> <strong>: </strong></p><p> Последующие директивы не обрабатываются, так как задан пустой поисковый агент.</p><p> А вот так правильно:</p><p> <strong> # </strong> <strong> роботов </strong> <strong>. </strong> <strong> txt </strong> <strong> комментарий </strong></p><p> <strong> User-agent: </strong> <strong> * </strong></p><p> # со знака решетки начинается комментарий, который игнорируется поисковыми ботами.Для улучшения читаемости и соблюдения правил стиля комментарий лучше писать с новой строки, а продолжать ту, в которой уже прописаны директивы.</p><p> <strong> * </strong> звездочка означает последовательность любых символов, то есть любой агент должен выполнять дальнейшие инструкции.</p><p> <strong> Агент пользователя: Яндекс </strong></p><p> — означает, что следущие правила написаны для ботов Яндекса.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/wp-system.ru/wm/wp-content/uploads/2016/03/urok-bonus-22.jpg' style='float: right;' /><noscript><img src='/800/600/https/wp-system.ru/wm/wp-content/uploads/2016/03/urok-bonus-22.jpg' style='float: right;' /></noscript></p><p> <strong> Пользователь </strong> <strong> — </strong> <strong> агент </strong> <strong>: </strong> <strong> Googlebot </strong></p><p> <strong> — </strong> соответственно для ботов Гугла.</p><p> В старых версиях robots.txt можно встретить устаревшие инструкции:</p><p> <strong> User </strong> <strong> — </strong> <strong> agent </strong> <strong>: </strong> <strong> StackRambler </strong></p><p> — устарел, так как Рамблер перешел к использованию технологий Яндекса.</p><p> <strong> Пользователь </strong> <strong> — </strong> <strong> агент </strong> <strong>: </strong> <strong> Slurp </strong></p><p> — поисковый робот Yahoo !, имел смачное имя Slurp. Больше не используется, так как компания Yahoo! вместо своей поисковой машины SearchMonkey перешла на использование поисковика Bing от Майкрософт.</p><p> Пустые строки после User-agent означают конец директив (инструкций текущего поисковому агенту), поэтому нужно безопасные строки после ошибочно не оборвали работу агента.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/serpstat.com/img/blog/how-to-detect-which-cms-a-website-is-using-8-easy-ways/1570531562image1.png' style='float: right;' /><noscript><img src='/800/600/https/serpstat.com/img/blog/how-to-detect-which-cms-a-website-is-using-8-easy-ways/1570531562image1.png' style='float: right;' /></noscript></p><p></p><h4> <strong> Директивы </strong> <strong> роботы </strong> <strong>. </strong> <strong> txt </strong> </span></h4><p> <strong> </strong></p><p> Сразу после указания поискового агента должны идти директивы, относящиеся к нему.</p><h5><span class="ez-toc-section" id="Disallow"> <strong> Disallow </strong> </span></h5><p> Обязательная инструкция, даже если мы хотим открыть сайт полностью и ничего не запрещать его просто нужно оставить пустым:</p><p> <strong> Агент пользователя: </strong> <strong> * </strong></p><p> <strong> Disallow: </strong></p><p> Такой роботс ничего не Запрещает работать, но наличие строки запрещает поисковым ботом, она может некорректно обработать директивы.</p><p> Вот так закрываются папки, каждая папка — отдельной отдельной.</p><p> <strong> Disallow </strong> <strong>: / </strong> <strong> css </strong> <strong>/</strong></p><p> <strong> Disallow </strong> <strong>: / </strong> <strong> cgi </strong> <strong> — </strong> <strong> bin </strong> <strong>/</strong></p><p> <strong> Disallow: / images / </strong></p><p> Запись одной строки не только нарушает стандарты robots.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/debgameku.com/wp-content/uploads/2020/01/cara-setting-yoast-seo-robotstxt.png' style='float: right;' /><noscript><img src='/800/600/https/debgameku.com/wp-content/uploads/2020/01/cara-setting-yoast-seo-robotstxt.png' style='float: right;' /></noscript> txt, но и может повлечь непредсказуемую работу разных ботов.</p><p> <strong> Disallow: / css / / cgi-bin / / images / </strong></p><p> Директива распространяется только для текущего поискового агента, то есть такой роботс закроет каталог для всех роботов кроме Яндекса:</p><p> <strong> User-agent: </strong> <strong> * </strong></p><p> <strong> Disallow: / css / </strong></p><p></p><p> <strong> User-agent: Yandex </strong></p><p> <strong> Disallow: </strong></p><p></p><p> Вот так выглядит роботс, полностью закрывающий весь сайт от Децииции:</p><p> <strong> User-agent: * </strong></p><p> <strong> Disallow: / </strong></p><p> <strong> </strong></p><h5><span class="ez-toc-section" id="Allow"> <strong> Allow </strong> </span></h5><p> Эта директива появилась сравнительно недавно, по логическому смыслу — противоположной команде Disallow, но ее понимает только Яндекс.</p><p> <strong> User-agent: Яндекс </strong></p><p> <strong> Allow </strong> <strong>: / </strong></p><p> Такой роботс запрещает доступ к всему сайту для ботов Яндекса, строка</p><p> <strong> Allow </strong> <strong>: </strong></p><p> аналогично</p><p> <strong> Disallow </strong> <strong>: / </strong></p><p> Иногда для ботов Яндекса (но не для других ботов) удобней разрешить несколько каталогов, чем прописывать множество запрещающих строк.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/presentacii.ru/documents_4/99b85f7403f0c2e55ba3e17adf675835/img20.jpg' style='float: right;' /><noscript><img src='/800/600/https/presentacii.ru/documents_4/99b85f7403f0c2e55ba3e17adf675835/img20.jpg' style='float: right;' /></noscript></p><p></p><h5><span class="ez-toc-section" id="i-59"> <strong> Карта сайта </strong> </span></h5><p> Если сайт достаточно большой и содержит тысячи страниц, то ему для индексации потребуется карта сайта.</p><p> Чтобы указать поисковому боту, где находится эта карта, нужно добавить в robots.txt строку, указывающую на эту карту. Кириллица недопустима (см ниже).</p><p> <strong> Карта сайта: http: // <</strong> <strong> имя </strong> <strong> _ </strong> <strong> сайта </strong> <strong>> /sitemap.xml </strong></p><p></p><h5><span class="ez-toc-section" id="i-60"> <strong> Хост </strong> </span></h5><p> Директива host сообщает поисковому боту, какое зеркало главное — с www или без. Поддерживается только Яндексом. Обратите внимание, он указывается без <strong> http </strong> <strong>: // </strong> и без слеша в конце строки <strong>/</strong>.</p><p> Указаниеа не гарантирует, что главным зеркалом сайта будет именно этот хост, однако Яндекс будет его учитывать при определении главного зеркала.</p><p> Для счастливых обладателей кириллических доменов нужно использовать специальный Punycode, а не кириллицу.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/homework-cool.ru/wp-content/uploads/2017/02/shag-3-perevoda-sayta-na-HTTP.jpg' style='float: right;' /><noscript><img src='/800/600/https/homework-cool.ru/wp-content/uploads/2017/02/shag-3-perevoda-sayta-na-HTTP.jpg' style='float: right;' /></noscript></p><p> <strong> Хост: xn — d1acufc.xn — p1ai </strong></p><p> Punycode для своего домена можно с помощью специального сервиса — Punycode-конвертера.</p><h3><span class="ez-toc-section" id="_robotstxt-5"> <strong> Особенности robots.txt для разных систем поисковых запросов </strong> </span></h3><p> Разные поисковые системы имеют свои особенности и поэтому в robots.txt, как уже упоминалось в этой статье, существуют разные директивы для различных поисковых агентов.</p><p> Директивы <strong> Разрешить </strong> и <strong> Хост </strong> обрабатывают только боты <strong> Яндекс </strong> <strong>, </strong> для остальных юзерагентов они не сработают.</p><p> GoogleBot — поддерживает в директивах регулярные выражения.Если нам нужно запретить индексцию файлов по расширм, то можно написать так:</p><p> <strong> User-agent: googlebot </strong></p><p> <strong> Disallow: * .cgi </strong></p><p> Нужно учитывать, что Гугл может игнорировать правила, так как для него это не догма , а рекомендация. Если на страницу есть ссылка, то она может попасть в индекс Гугла.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/pbs.twimg.com/media/Ea0TJdOXYAEbEtb.png' style='float: right;' /><noscript><img src='/800/600/https/pbs.twimg.com/media/Ea0TJdOXYAEbEtb.png' style='float: right;' /></noscript> Поэтому нежелательно закрывать индексции страницу, на которую есть ссылки. У таких страниц плохой сниппет:</p><p></p><p></p><p> В таких случаях для закрытия дублей страниц лучше использовать средства, предоставляющие самую CMS, а уже потом использовать robots.текст.</p><p> Во всех сомнительных ситуациях лучше обращаться к документации, используя поисковые системы для вебмастеров. Тем более, что рассмотренные правила могут обновиться.</p><p> <strong> </strong></p><h3><span class="ez-toc-section" id="_robotstxt-6"> <strong> Советы по работе с robots.txt </strong> </span></h3><p> При разработке сайта нужно закрыть его полностью, чтобы не засорять индекс ненужными страницами</p><ul><li> Закрыть приватные данные, которые не должны попадать в индекс</li><li> Запретить определенным поисковым системам индексировать сайт.Например, если на русскоязычном сайте не нужен трафик с Yahoo! Или наоборот — на русскоязычном нам не нужны посетители с Яндекс.</li><li> Снятие нагрузки на сервер: если сайт часто обновляется, можно умерить их пыл директивой</li></ul><p> <strong> Задержка сканирования: 20 </strong></p><p> Выставили таймаут, чтобы текущий юзерагент сканировал сайт не чаще, чем раз в 20 секунд.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/i0.wp.com/info-effect.ru/wp-content/uploads/2015/08/24-08-2015-14-57-59.jpg' style='float: right;' /><noscript><img src='/800/600/https/i0.wp.com/info-effect.ru/wp-content/uploads/2015/08/24-08-2015-14-57-59.jpg' style='float: right;' /></noscript> При этом нужно убедиться, что этот бот поддерживает директиву.</p><p> <strong> Чего избежать при использовании robots.txt </strong></p><p> <strong> </strong> Закрывать дубли страниц с помощью роботс нужно только в том случае, если исчерпаны средства самой CMS. В остальных случаях используйте 301 редиректом через соответствующую команду в файле .htaccess, тегами robots noindex, rel = canonical, страниц 404.</p><ul><li> Удалить в индексе страницы с помощью robots.txt путь путь не получится</li><li> Закрытие админ панели злоумышленнику узнать к админке сайта, так как robots.txt доступен всем желающим.</li></ul><p> Если закрываете страницы, четко представляйте, что при этом происходит. Например, если мы закроем в WordPress всю папку / wp-content /, то / wp-content / uploads / также закроется. А если у нас сайт с большими увеличениями или уникальными изображениями, то будет обидно, что они не индексируются и по ним мы не получим трафик.</p><p> <strong> Что можно еще почитать по robots.<img class="lazy lazy-hidden" src="//russia-dropshipping.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/1.bp.blogspot.com/-BOg-0oEz49Q/XQNud3L8gyI/AAAAAAAABK0/qe7MaalHjDIFdofoWd4E8xQSIj66P8C4ACLcBGAs/s1600/17.jpg' style='float: right;' /><noscript><img src='/800/600/https/1.bp.blogspot.com/-BOg-0oEz49Q/XQNud3L8gyI/AAAAAAAABK0/qe7MaalHjDIFdofoWd4E8xQSIj66P8C4ACLcBGAs/s1600/17.jpg' style='float: right;' /></noscript></div><footer class="entry-footer"> <span><i class="fa fa-folder"></i> <a href="https://russia-dropshipping.ru/category/raznoe" rel="category tag">Разное</a></span><span><i class="fa fa-link"></i><a href="https://russia-dropshipping.ru/raznoe/v-fajle-robots-txt-ne-zadana-direktiva-host-v-fajle-robots-txt-ne-zadana-direktiva-host-vopros-ot-olga-kosmina.html" rel="bookmark"> permalink</a></span></footer></article><nav class="navigation post-navigation clearfix" role="navigation"><h1 class="screen-reader-text">Post navigation</h1><div class="nav-links"><div class="nav-previous"><a href="https://russia-dropshipping.ru/raznoe/kontekstnaya-reklama-na-rezultat-kontekstnaya-reklama-360-kak-razvivat-biznes-bez-uvelicheniya-byudzheta.html" rel="prev"><i class="fa fa-long-arrow-left"></i> Контекстная реклама на результат: Контекстная реклама 360°: как развивать бизнес без увеличения бюджета</a></div><div class="nav-next"><a href="https://russia-dropshipping.ru/raznoe/chto-eto-event-marketing-sobytijnyj-event-marketing-chto-eto-primery-vidy-instrumenty.html" rel="next">Что это event marketing – Событийный (event) маркетинг — что это, примеры, виды, инструменты <i class="fa fa-long-arrow-right"></i></a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe/v-fajle-robots-txt-ne-zadana-direktiva-host-v-fajle-robots-txt-ne-zadana-direktiva-host-vopros-ot-olga-kosmina.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://russia-dropshipping.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='19849' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main></div><div id="secondary" class="widget-area" role="complementary"><aside id="search-2" class="widget widget_search"><form role="search" method="get" class="search-form" action="https://russia-dropshipping.ru/"> <label> <span class="screen-reader-text">Найти:</span> <input type="search" class="search-field" placeholder="Поиск…" value="" name="s" /> </label> <input type="submit" class="search-submit" value="Поиск" /></form></aside><aside id="categories-3" class="widget widget_categories"><h3 class="widget-title">Рубрики</h3><ul><li class="cat-item cat-item-7"><a href="https://russia-dropshipping.ru/category/seo">Seo</a></li><li class="cat-item cat-item-15"><a href="https://russia-dropshipping.ru/category/instrument-2">Инструмент</a></li><li class="cat-item cat-item-9"><a href="https://russia-dropshipping.ru/category/instrument">Инструменты</a></li><li class="cat-item cat-item-16"><a href="https://russia-dropshipping.ru/category/program-2">Програм</a></li><li class="cat-item cat-item-4"><a href="https://russia-dropshipping.ru/category/program">Программы</a></li><li class="cat-item cat-item-14"><a href="https://russia-dropshipping.ru/category/prodvizh-2">Продвиж</a></li><li class="cat-item cat-item-5"><a href="https://russia-dropshipping.ru/category/prodvizh">Продвижение</a></li><li class="cat-item cat-item-3"><a href="https://russia-dropshipping.ru/category/raznoe">Разное</a></li><li class="cat-item cat-item-13"><a href="https://russia-dropshipping.ru/category/semant-2">Семант</a></li><li class="cat-item cat-item-8"><a href="https://russia-dropshipping.ru/category/semant">Семантика</a></li><li class="cat-item cat-item-17"><a href="https://russia-dropshipping.ru/category/sovet-2">Совет</a></li><li class="cat-item cat-item-11"><a href="https://russia-dropshipping.ru/category/sovet">Советы</a></li><li class="cat-item cat-item-12"><a href="https://russia-dropshipping.ru/category/sozdan-2">Создан</a></li><li class="cat-item cat-item-6"><a href="https://russia-dropshipping.ru/category/sozdan">Создание</a></li><li class="cat-item cat-item-18"><a href="https://russia-dropshipping.ru/category/sxem-2">Схем</a></li><li class="cat-item cat-item-10"><a href="https://russia-dropshipping.ru/category/sxem">Схемы</a></li></ul></aside></div></div><div id="sidebar-footer" class="footer-widget-area clearfix" role="complementary"><div class="container"></div></div><footer id="colophon" class="site-footer" role="contentinfo"><div class="site-info"><div class="container"> Copyright © 2025 <font style="text-align:left;font-size:15px;"><br> Дропшиппинг в России.<br> Сообщество поставщиков дропшипперов и интернет предпринимателей.<br>Все права защищены.<br>ИП Калмыков Семен Алексеевич. ОГРНИП: 313695209500032.<br>Адрес: ООО «Борец», г. Москва, ул. Складочная 6 к.4.<br>E-mail: mail@russia-dropshipping.ru. <span class="phone-none">Телефон: +7 (499) 348-21-17</span></font></div></div></footer></div> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://russia-dropshipping.ru/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --> <script defer src="https://russia-dropshipping.ru/wp-content/cache/autoptimize/js/autoptimize_4cad87507949d1a2750fb90f494c0e55.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="b475e9704200ec4eb0a8a71f-|49" defer></script>