
Частотность поисковых запросов — сервис для определения частотности
Частота ключевых слов и SEO
Если вы пытаетесь занять место по ключевому слову органически , важно знать частоту ваших ключевых слов. Если частота ваших ключевых слов слишком низкая, у вас возникнут проблемы с рейтингом по этому ключевому слову, если только уровень конкуренции не будет очень низким. Поисковые системы, такие как Google, должны видеть «доказательство» в виде ключевых слов, что ваш контент действительно соответствует запросу.
Однако, если частота вашего ключевого слова слишком высока, это посылает негативный сигнал поисковым системам. Избегайте черных методов, известного как «наполнение ключевыми словами», когда частота ваших ключевых слов неестественно высока и отвлекает пользователей.
Как определить частотность
Веб-мастер и SEO-специалист определяет частотность запроса при помощи специализированных сервисов. Например, в Яндексе это Вордстат (читайте, как это сделать в нашей статье). Если воспользоваться кавычками, перед запросом и после него, то в итоге система выдает данные о частоте, учитывая необходимую последовательность слов. Для получения точных данных по частоте с имеющейся морфологией, перед словом следует ставить «!».
Если воспользоваться кавычками, перед запросом и после него, то в итоге система выдает данные о частоте, учитывая необходимую последовательность слов. Для получения точных данных по частоте с имеющейся морфологией, перед словом следует ставить «!».
Какая частота ключевых слов считается хорошей?
Новички в SEO и платном поиске часто спрашивают, какая частота ключевых слов «хорошая» или какие рекомендации им следует соблюдать, когда дело доходит до определения правильной плотности ключевых слов. К сожалению, как и в случае со многими элементами SEO и интернет-рекламы, существует несколько настоящих «правил» относительно частоты ключевых слов. Однако есть некоторые общепринятые передовые методы, которым вы, возможно, захотите следовать.
Вообще говоря, многие профессионалы SEO согласны с тем, что ключевое слово не должно появляться чаще одного раза на 200 слов текста. Это означает, что из каждых 200 слов текста на веб-странице данное ключевое слово не должно появляться более одного раза.
Сюда входят близкие варианты ключевого слова. Например, «подержанные автомобили» — это вариант ключевого слова «подержанные автомобили». Хотя эти два термина различны, они тесно связаны семантически; их значения идентичны, и только их формулировка отличает их друг от друга. Это означает, что вам следует попытаться разделить варианты ключевых слов, как если бы вы использовали несколько экземпляров одного и того же ключевого слова.
Насколько важна частота ключевых слов?
Хотя частота ключевых слов может повлиять на степень обнаружения сайта или веб-страницы, это лишь один из многих таких факторов.
В прошлом многие сайты обходились без «наполнения ключевыми словами» — практики запихивания как можно большего количества ключевых слов и вариантов на одной веб-странице в попытке манипулировать рейтингом страницы. Однако сегодня алгоритмы поиска значительно сложнее, что делает такие методы в значительной степени бесполезными и потенциально даже вредными.
Частота ключевых слов и пользовательский опыт
Возможно, было бы более эффективно думать о частоте ключевых слов не в контексте внутреннего SEO, а скорее в контексте пользовательского опыта.
Независимо от того, какой тип контента содержит веб-страница — список продуктов, сообщение в блоге, целевая страница, страница с благодарностью — всегда учитывайте взаимодействие с пользователем. Все тексты должны читаться легко и естественно, а включение вынужденных, неудобных ключевых слов — один из самых быстрых способов испортить впечатление вашей аудитории.
Заблуждения, связанные с частотностью
Миф первый. Частотность по Wordstat соответствует частоте запросов в поисковой системе Яндекс
Число, которое размещенное напротив определенного запроса, является только предварительным прогнозным значением показов в течение месяца. Точная информация может быть получена исключительно по факту. Для этого необходимо выбрать запрос как ключ и проверить статистику на основании отчетного промежутка времени.
Для получения более точного прогнозного значения необходимо помнить о специализированных операторах – восклицательный знак и кавычки. Также можно указывать регион и использовать прочий инструментарий, предлагаемый сервисом.
Миф второй. Трафик можно предсказывать с помощью информации из Wordstat Результаты экспериментов, которые проводили оптимизаторы, продемонстрировали, что если сайт находится в ТОП-10 по высокочастотному запросу, то это не гарантирует ему трафик.
Миф третий. Информация о частоте запросов из Вордстат позволяет составить семантическое ядро
Информация, предлагаемая данным сервисом, не может считаться полноценным источником формирования семантического ядра для продвижения. Конкурентным и целевым может считаться менее частотный запрос. С помощью таких запросов удается увеличить не только прирост трафика, но и увеличение продаж. Даже если напротив запроса указана цифра 9, то это еще не значит, что данный запрос никто не вводит в строку поиска. Высокочастотный запрос иногда не имеет соответствующего частоте трафикового потенциала.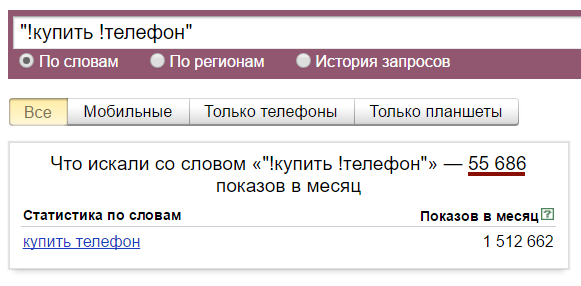 Анализ рынка и опыт специалиста является залогом успеха.
Анализ рынка и опыт специалиста является залогом успеха.
Характеристики поисковых запросов
На первоначальном этапе в вашем списке окажутся десятки и сотни тысяч (а может и миллионы) запросов. Но большая их часть не будет представлять интереса в плане продвижения, поэтому вы неизбежно столкнетесь с задачей анализа и фильтрации полученного списка.
Эту работу надо выполнить в три этапа:
- понять, какие характеристики запросов важны;
- собрать данные по нужным характеристикам;
- отобрать целевые запросы.
Рассмотрим важнейшие характеристики ключевых слов , а также определим взаимосвязи между характеристиками и целесообразностью продвижения сайта по конкретному запросу.
Навигационные, коммерческие и информационные запросы
Запрос относят:
- к навигационным, если пользователю нужна конкретная информация: адрес, время работы, место, сайт;
- коммерческим (трансакционным), если пользователю нужно что-то купить (запрос подразумевает проведение финансовой трансакции трансакции),
- информационным, если нужна общая информация, не подразумевающая конкретного действия.


Запрос может также быть нечетким, а поисковая выдача по нему — смешанной, так как у поисковика нет возможности точно определить намерение пользователя. Например, по запросу «стул» поисковики будут показывать и интернет-магазины стульев, и информационные статьи про стулья.
Необходимо проанализировать каждый запрос и понять, стоит ли его брать в работу. Для продвижения контентных проектов нужно ориентироваться на информационные запросы, для интернет-магазинов и корпоративных сайтов — на коммерческие. Однако разделение это условное: интернет-магазин может привлекать дополнительный трафик на информационные статьи в блоге, а информационный портал предлагать полезный каталог с выбором товаров и последующей его покупкой на сайтах-партнерах.
Характеристики частотности и конкурентности
По частотности (количеству запросов в месяц) можно разделить ключевые слова на высоко-, средне- и низкочастотные, а по уровню конкуренции — на высоко-, средне- и низкоконкурентные.
Определить частотность запроса не всегда просто, так как здесь нужно учесть много факторов: базовую частотность, влияние сезонности и моды, всплески актуальности запроса в соц. сетях и прочее.
Однако для практических задач высокая точность не нужна. Поэтому проще всего воспользоваться следующим алгоритмом.
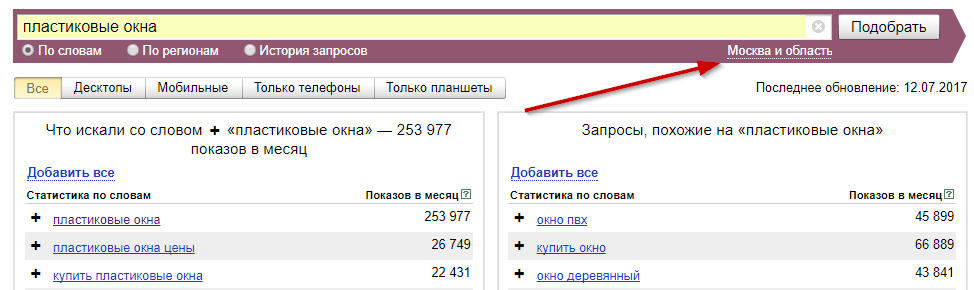
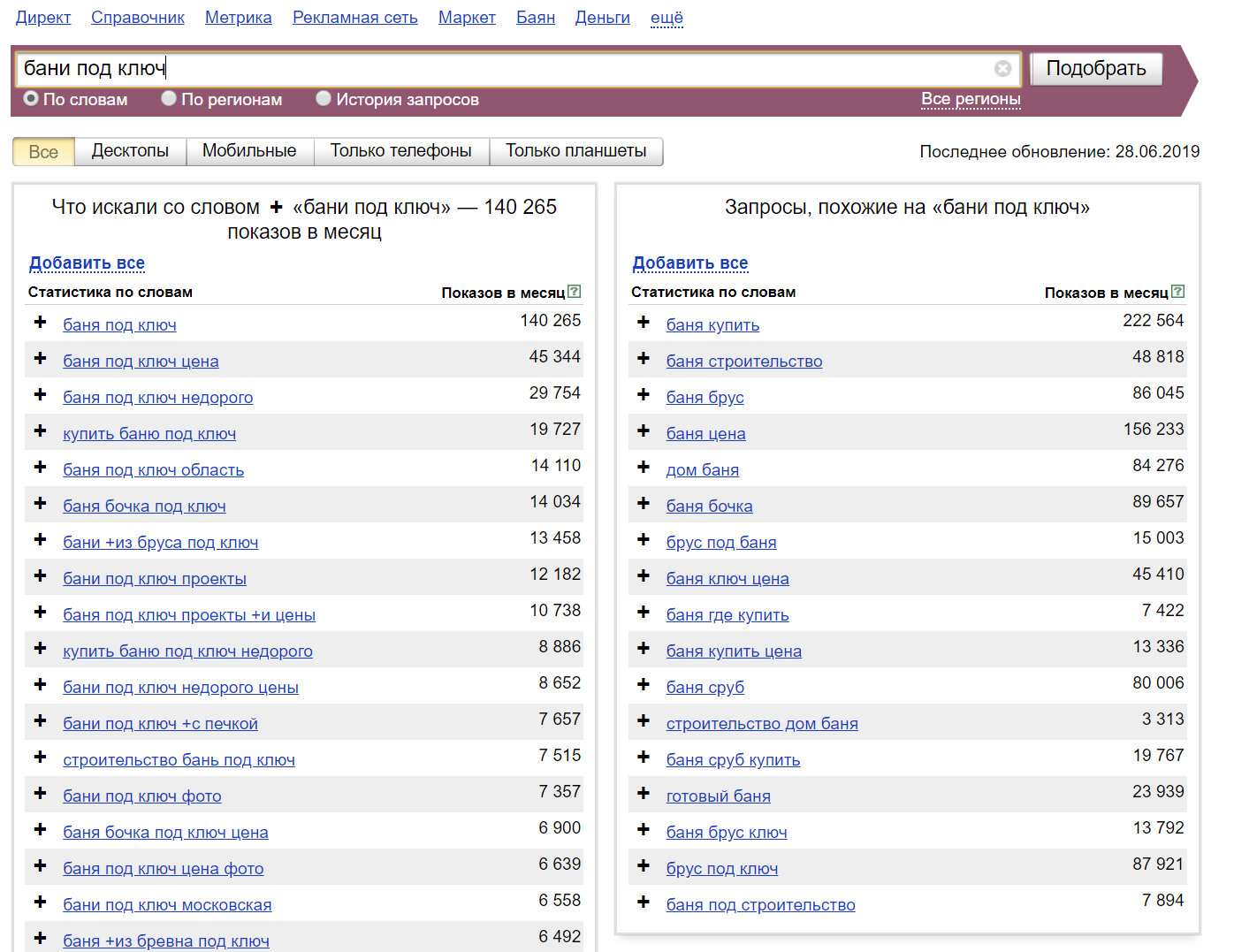
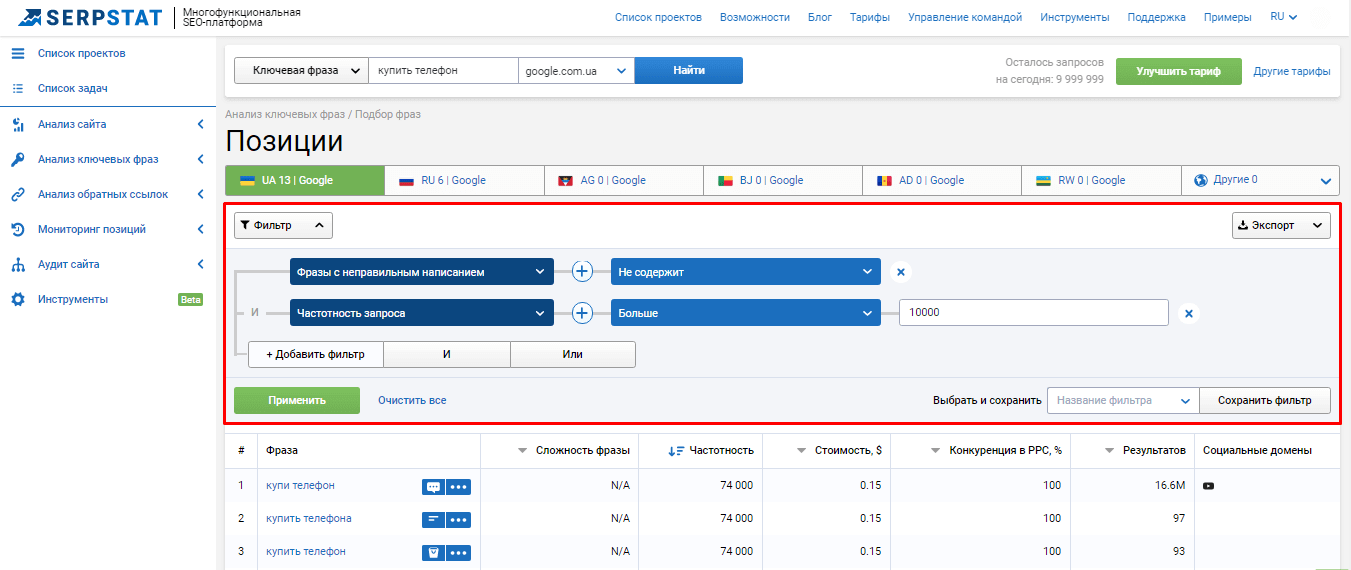
Идем в сервис Яндекс.Вордстат. Вводим туда целевой запрос (например, «велосипед») и получаем базовую частотность (4 092 821 показ в месяц). Базовая частотность показывает количество всех запросов, содержащих целевой запрос, которое пользователи запрашивали в Яндексе в последний месяц. Например, для «велосипеда» это «велосипеды», «купить велосипед», «детский велосипед» и далее по списку.
Можно уточнить цифры, введя в сервисе Вордстат целевой запрос в кавычках («велосипед»). Так мы получим фразовую частотность (59 993 показа в месяц), которая показывает, сколько раз пользователи вводили в поисковик запросы, содержащие только слова из нашего целевого запроса (в нашем случае это «велосипед» и «велосипеды»).
Если нужна еще более точная информация, поставьте перед каждым или некоторым словами целевого запроса восклицательный знак («!велосипед» — не забудьте кавычки). Так вы получите точную частотность (29 634 показа в месяц), которая покажет, сколько раз пользователи Яндекса запрашивали именно такие слова за последний месяц.
Чтобы прикинуть общую частотность по всем поисковикам, нужно полученные цифры умножить в соответствии с долей Яндекса на поисковом рынке (информацию о ней легко найти в сети).
Разделение по частотности условное: на одном рынке высокочастотный ключевик будет иметь десятки тысяч («пластиковые окна»), а на другом — всего сотни запросов в месяц («ледяная рыба купить»).
Понятно, что продвижение по более частотным запросам может привлечь больше трафика, но тут не все так просто. За хорошие места по высокочастотным запросам борются многие сайты, поэтому бюджет продвижения по высокочастотникам выше.
На практике это часто означает, что лучше взять в работу менее частотные, но более простые в продвижении запросы.
Для расчета конкурентности существуют разные методы, но суть их одна: надо проанализировать поисковую выдачу по целевому запросу и составляющие ее сайты. Основные параметры:
— количество оптимизированных главных страниц,
— количеству оптимизированных страниц,
— возрасту сайтов,
— количеству рекламы по запросу,
— оптимизированность каждого отдельного сайта и т.д.
Всю эту информацию обычно сводят к показателю KEI (Keyword Effectiveness Index, придуман Самантой Рой), чтобы было удобно сравнивать запросы между собой. Классическая формула этого показателя:
KEI = F2/Q,
где F — это частотность за последние 60 дней, а Q — это количество сайтов в выдаче, оптимизированных под данный ключевик. Как правило, чем выше KEI, тем выше частотность и конкурентность запроса.
Рассчитать параметры конкуренции для большого количества запросов в ручном режиме нереально, поэтому процесс надо автоматизировать с помощью специальных сервисов и программ (например, Key Collector).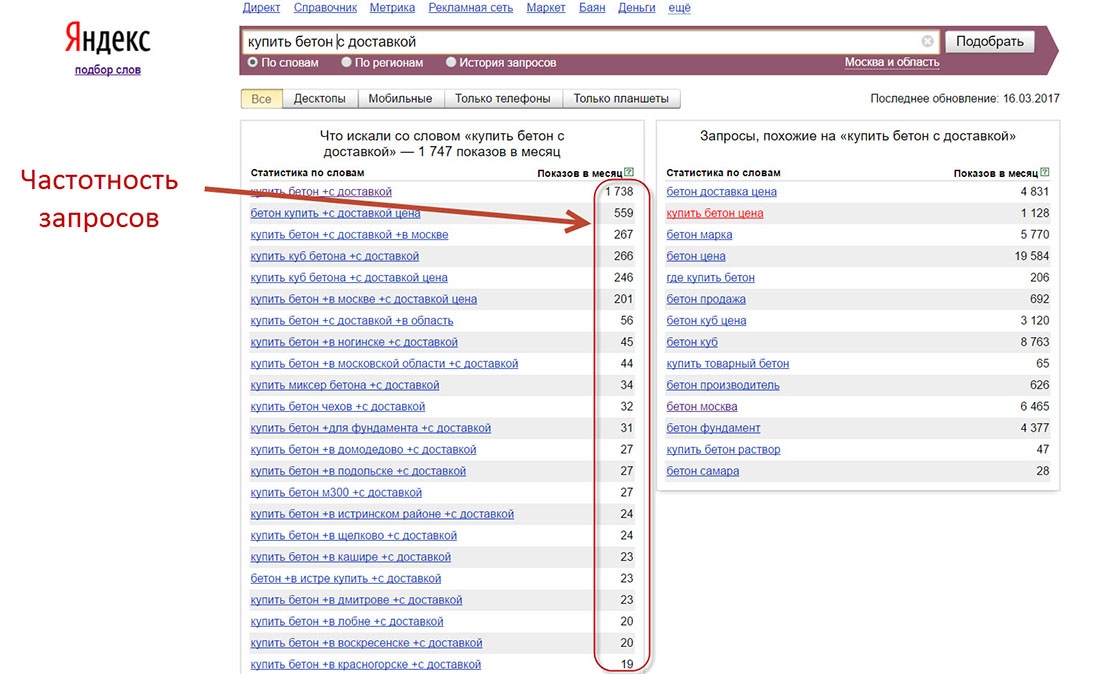
Можно использовать другие методы. Например, сравнить ставки контекстной рекламы: у более конкурентных запросов они будут выше. Или проверить запросы в сервисах так называемого «автоматического» продвижения: чем выше бюджет — тем сильнее конкуренция по запросу.
При этом надо понимать, что любые полученные цифры будут условными. Но они помогут принять правильное решение и выстроить стратегию продвижения, при которой в работу в первую очередь надо брать запросы с высокими показателями частотности и умеренной конкуренцией.
Геозависимость
Если поисковая выдача меняется в зависимости от региона, то запрос является геозависимым, если нет — геонезависимым.
Для понимания того, какие запросы являются геозависимыми, можно воспользоваться специальными сервисами в интернете или вбить запрос в поисковую систему два-три раза, при этой не забывая менять регион.
Учитывать геозависимость запросов необходимо для того, чтобы понимать специфику поисковой выдачи. Если вы продвигаетесь в конкретном регионе, приоритет стоит отдать геозависимым запросам — так у вас будет больше шансов в сравнении с федеральными брендами.
Если же продвижение идет на федеральном уровне, то лучше сосредоточиться на геонезависимых запросах, так как вам может быть сложно конкурировать с региональными игроками без дополнительных расходов (например, открытия филиала).
В такой ситуации может помочь лайфхак. Попробуйте договориться с региональной компанией о представительстве в регионе — это повысит ваши шансы в гонке, даже если «представительство» будет номинальным.
Главное — указать на продвигаемом сайте физический адрес представительства и его контактные данные в нужном регионе.
Zero-click запросы
Согласно свежим данным более половины мобильных и около трети десктопных поисковых сессий в Гугле заканчиваются без перехода на контент других сайтов. То есть на многие запросы поисковики стараются дать ответ уже на странице поисковой выдачи.
Это касается информации об отдельных фактах, таблицах, расписаниях и других запросах, ответ на который легко «упаковать» в специальный формат на странице выдачи.
Со временем таких специальных форматов будет становиться все больше, а конкурировать за трафик станет сложнее.

С zero-click запросами можно и нужно работать, но они явно не будут в приоритете при планировании стратегии продвижения.
Витальные запросы
Витальные запросы — поисковые запросы, состоящие строго из названия сайта, компании или бренда. В выдаче по ним на первых местах будут исключительно соответствующие ресурсы — официальный сайт компании, его популярные страницы или поддомены.
Обратите внимание: витальными являются запросы без уточняющих слов. Например, запрос «купить samsung» не витальный, а коммерческий, а запрос «как перепрошить самсунг гелакси 2» — информационный.
Категорийные или товарные запросы
Данная характеристика важна для проектирования структуры сайта. Запрос считается категорийным, если в выдаче по нему большую часть позиций занимают категории товаров (листинги). Если же большую часть выдачи занимают страницы конкретных товаров, запрос считается товарным.
Больше информации:
- продвижение сайтов
- создание продающих сайтов
Подсчет частот в списке с использованием словаря в Python
Посмотрите на формат ввода-вывода, чтобы лучше понять.
Ввод: [‘а’, ‘а’, ‘а’, ‘б’, ‘б’]
Вывод: {‘а’: 3, ‘б’: 2}
Чтобы решить эту проблему, мы можем использовать следующие подходы:
- по , повторяя по списку и подсчитывая частоту
- с использованием метода list.count()
- с использованием метода dict. get()
 get()
get() Подход 1: Итеративный подход
Мы определим функцию, которая принимает список в качестве параметра. Затем мы создадим словарь, где элемент списка является ключом, а его частота будет значением. Чтобы получить частоту, мы пройдемся по списку и проверим, присутствует ли элемент уже в словаре или нет, и будем соответственно вести подсчет.
Алгоритм
Следуйте алгоритму, чтобы лучше понять подход.
Шаг 1 — Определите функцию, которая будет подсчитывать частоту элементов в списке
Шаг 2 — Создание пустого словаря
Шаг 3 — Запустите цикл для обхода элементов списка
Шаг 4 — Чтобы подсчитать частоту, проверьте, существует ли элемент в словаре
Шаг 5 — Если да, то увеличьте значение, присутствующее в ключе элемента, на 1,
Шаг 6- иначе добавьте этот элемент в качестве ключа и установите его значение 1
Шаг 7- Распечатать словарь как результат
Программа Python 1
Посмотрите на программу, чтобы понять реализацию вышеупомянутого подхода. Чтобы проверить, присутствует ли элемент списка в словаре или нет, мы использовали условный оператор if вместе с оператором in.
Чтобы проверить, присутствует ли элемент списка в словаре или нет, мы использовали условный оператор if вместе с оператором in.
по определению CountFreq(li):
частота = {}
для элемента в ли:
если (элемент в частоте):
частота [элемент] += 1
еще:
частота [элемент] = 1
печать (частота)
ли = [1, 1, 3, 2, 6, 5, 3, 1, 3, 3, 1, 4, 6, 4, 4, 2, 2, 2, 2]
CountFreq(li)
{1:4, 3:4, 2:5, 6:2, 5:1, 4:3}
Подход 2: использование list.count()
Метод list.count() возвращает общее количество переданного в него элемента. Используя этот метод, мы сохраним счетчик как значение, а символ как ключ в словаре.
Алгоритм
Следуйте алгоритму, чтобы лучше понять подход.
Шаг 1 — Определите функцию, которая будет подсчитывать частоту элементов в списке
Шаг 2 — Создание пустого словаря
Шаг 3 — Запустите цикл для обхода элементов списка
Шаг 4 — Используйте count, чтобы получить частоту элементов и сохранить их в словаре
Шаг 5 — Распечатать словарь как результат
Шаг 6- Объявить список и передать список в функцию
Программа Python 2
Посмотрите на программу, чтобы понять реализацию вышеупомянутого подхода. Используя цикл for, мы будем хранить значение, возвращаемое
Используя цикл for, мы будем хранить значение, возвращаемое count() метод в словаре.
по определению CountFreq(li):
частота = {}
для элементов в ли:
freq[элементы] = li.count(элементы)
печать (частота)
li = ['а', 'с', 'а', 'с', 'с', 'с', 'с', 'б']
CountFreq(li)
{‘a’: 2, ‘s’: 2, ‘c’: 3, ‘b’: 1}
Подход 1: использование dict.get()
Метод dict.get() класса словаря возвращает значение указанного ключа, если ключи взяты из словаря. Мы можем использовать этот метод вместо использования условия if-else, которое обсуждалось в первом подходе, чтобы получить частоту элементов списка.
Алгоритм
Следуйте алгоритму, чтобы лучше понять подход.
Шаг 1 - Определите функцию, которая будет подсчитывать частоту элементов в списке
Шаг 2 - Создание пустого словаря
Шаг 3 - Запустите цикл для обхода элементов списка
Шаг 4 - Используйте get() и передайте в него элементы списка, чтобы получить частоту
Шаг 5 - Распечатать словарь как результат
Шаг 6- Объявить список и передать список в функцию
Программа Python 2
Посмотрите на программу, чтобы понять реализацию вышеупомянутого подхода. Мы создали пустой словарь и сохранили элементы списка как ключи, а их частоту — как значения.
Мы создали пустой словарь и сохранили элементы списка как ключи, а их частоту — как значения.
по определению CountFreq(li):
частота = {}
для элементов в ли:
freq[items] = freq.get(items,0)+1
печать (частота)
li = ['а', 'а', 1, 1, 1, 'б', 'б', 'б', 2, 2, 2]
CountFreq(li)
{'а': 2, 1: 3, 'б': 3, 2: 3}
Заключение
В этом уроке мы рассмотрели три разных подхода к вычислению и нахождению частоты элементов списка с использованием словаря в Python. Мы использовали итеративный подход, метод list.count() и метод dict.get() для решения этой проблемы.
Справка NVivo для Mac — запуск запроса частоты слов
Для получения списка наиболее часто встречающиеся слова в ваших источниках.
В этой теме
- Посмотреть видеоинструкцию
- Понять Частотные запросы слов
- Создать запрос частоты слова
- Понять результаты
- Что слова подсчитываются в запросе Word Frequency?
- Исключить определенные слова при выполнении запросов Word Frequency
- Выполнить запрос текстового поиска для слова, показанного в результатах запроса
Посмотреть обучающее видео
 youtube.com/embed/Pm2sgWuGvTI?list=PLNjHMRgHS4FfTN-GoztTaPLshavAb0NxR?iv_load_policy=3" frameborder="0" allowfullscreen="">
youtube.com/embed/Pm2sgWuGvTI?list=PLNjHMRgHS4FfTN-GoztTaPLshavAb0NxR?iv_load_policy=3" frameborder="0" allowfullscreen="">
Верх стр.
Понять Запросы Word Frequency
Используйте запросы Word Frequency для получения списка наиболее часто встречающиеся слова в ваших источниках. Вы можете выбрать исходный контент, который вы хотите искать, выбирая источники, узлы, наборы или папки.
Вы можете использовать запрос Word Frequency для
Определите возможные темы, особенно на ранних стадиях проекта.
Анализировать наиболее часто используемые слова в определенной демографической группе. Например, проанализируйте наиболее общие слова, используемые фермерами при обсуждении изменения климата. Ты мог бы выполнить запрос кодирования, чтобы собрать весь контент, закодированный в климате change и в узлах case с атрибутом farmer — затем выберите узел результата в качестве критерия для запроса Частота слов.
Вы можете искать точные слова или включать слова с той же основой. Например, если вы поищите наиболее часто встречающиеся слова в наборе интервью, вы можете найти ту воду, здоровье, и вредны наиболее часто встречающиеся слова. Однако если включить слова с тем же стеблем, вы можете обнаружить, что загрязнение (включая загрязняющие вещества, загрязнение, загрязняется и загрязняется) встречается наиболее часто.
Перед выполнением запроса Word Frequency убедитесь, что язык текстового содержимого установлен на языке ваших исходных материалов — см. установить язык содержимого текста и стоп-слова для получения дополнительной информации.
Верх Страница
Создать запрос частоты слова
По запросу на вкладке "Создать" нажмите "Частота слов".
Выберите, где вы хотите для поиска подходящего текста:
Все источники — поиск контента во всех источниках вашего проекта, включая внешние документы и памятки
Выбрано Элементы — ограничьте поиск выбранными элементами (например, комплект с расшифровками интервью)
шт.
в выбранных папках — ограничить поиск содержимым в выбранных
папки (например, папка стенограмм интервью)
 в выбранных папках — ограничить поиск содержимым в выбранных
папки (например, папка стенограмм интервью)
в выбранных папках — ограничить поиск содержимым в выбранных
папки (например, папка стенограмм интервью)(необязательно) Выберите «Включить слова с основами», если вы хотите включить слова с той же основой (например, ищите «говорить», а также находите «говорить») при поиске совпадений. По умолчанию, Выбирается только точное совпадение.
(необязательно) Вы можете выберите для отображения:
Все чтобы включить все слова, найденные в выбранных элементах проекта.
<номер> чаще всего включать определенное количество слов, например, вы можете отобразить 100 наиболее часто встречающихся слов.
(Необязательно) Введите Минимальная длина, исключающая короткие слова. из результатов — например, введите 7 для отображения только слов с семью или более буквами.
Нажмите кнопку "Выполнить" Кнопка запроса в верхней части подробного представления.

ПРИМЕЧАНИЕ
См. Выбор элементы проекта для получения информации о том, как выбирать источники, узлы или другие элементы проекта, в которых вы хотите выполнить поиск.
В этом выпуске вы не можете найти совпадения для слов со схожим значением (синонимы, специализации и обобщения). Если вы работаете с NVivo проект, созданный на платформе Windows, вы не можете выполнять запросы которые ищут синонимы, специализации и обобщения.
Верх стр.
Понять результаты
Когда вы запускаете запрос Word Frequency, результаты отображается в подробном представлении. Вы можете просмотреть результаты в виде списка в сводке. панели или как визуализация на панели Word Cloud.
Панель сводки
1 Критерии запроса
оставаться видимым в верхней части подробного представления — если вы хотите больше места для просмотра
результаты запроса, щелкните треугольник раскрытия, чтобы скрыть критерии.
2 Самый часто встречающиеся слова, за исключением любой остановки слова. Если вы решили включить слова с основой, наиболее часто встречающееся слово из группы отображается в этом столбце.
3 Длина — количество букв или символов в слове.
4 Считать — количество раз, когда это слово встречается в искомых элементах проекта. Если вы решили включить слова с основой, это количество является общим для всех слова с одной основой.
5 Взвешенный Процент — частота слова по отношению к общему количеству подсчитанных слов. взвешенный процент присваивает часть частоты слова каждому группировать так, чтобы общая сумма не превышала 100%.
6 Похожие Слова — другие слова, которые были включены в результате выбора включать однокоренные слова, например, загрязняющие вещества, загрязнение, а загрязнение будет быть сгруппированы вместе. Этот столбец недоступен, если вы используете Exact только совпадение'
Панель Word Cloud
1 Критерии запроса
оставаться видимым в верхней части подробного представления — если вы хотите больше места для просмотра
результаты запроса, щелкните треугольник раскрытия, чтобы скрыть критерии.
2 Слово облачная визуализация отображает до 100 слов с разным размером шрифта, где часто встречающиеся слова выделены более крупным шрифтом.
3 Нажмите здесь, чтобы выбрать из галереи стилей.
ПРИМЕЧАНИЕ. Вы можете экспортировать облако слов в виде файла изображения, которое можно включать в отчеты и презентации — см. экспортировать результаты запроса (Экспорт визуализации запроса в виде файла изображения) для Дополнительная информация.
Верх стр.
При определении частотности слов NVivo применяет следующие правила:
Слов, содержащих знаки препинания (например, дефисы, точки и другие символы) разделены на отдельные слова. Например, неполный рабочий день будет считаться как часть и время.
Слова, содержащие апострофы (например, o'clock и d'accord) рассматриваются как одно слово, но если за апострофом следует 's тогда s не включается (том Тома будет считаться Томом).
В аудио- и видеорасшифровках, только слова в поле Transcript (столбец) подсчитываются.
В наборах данных только слова в кодируемых полях (столбцах) подсчитываются любые слова в классифицирующих полях игнорируются.
При поиске текста в выбранные узлы, если слово закодировано для нескольких узлов, оно считается один раз для каждого узла. Точно так же, если слово было закодировано несколькими пользователей на один и тот же узел, он считается один раз для каждого пользователя.
запросов частоты слова не включайте «стоп-слова» — см. «Исключить». определенные слова при выполнении запросов Word Frequency для более информация.
запросов частоты слова не искать текст в изображениях. PDF-файлы, созданные путем сканирования бумажных документов может содержать только изображения — каждая страница представляет собой отдельное изображение. Если вы хотите используйте запросы Word Frequency для изучения текста в этих PDF-файлах, а затем вам следует рассмотреть возможность использования оптического распознавания символов (OCR) для преобразования отсканированные изображения в текст (перед импортом PDF-файлов в NVivo).

Верх стр.
Исключить определенные слова при выполнении запросов Word Frequency
Запросы Word Frequency не включают «стоп-слова» — по по умолчанию это менее значимые слова, такие как союзы или предлоги, это может не иметь значения для вашего анализа. Вы можете просматривать и редактировать список стоп-слов, см. Set язык текстового содержимого и стоп-слова для получения дополнительной информации.
Вы можете добавить слово, отображаемое в результатах вашего запроса к списку стоп-слов — выберите слово, которое хотите исключить из запроса результатов, затем нажмите «Добавить в список стоп-слов», в группе Действия в Запросе вкладка Слова, которые вы добавите в список стоп-слов, будут исключены в следующий раз. время, когда вы запускаете запрос частоты слова или текстовый поиск.
Верх из страницы
Вы можете выполнить запрос текстового поиска для выбранного слова в результатах запроса Word Frequency.
По запросу вкладку, в группе Действия щелкните Другие действия, а затем щелкните Запустите текстовый поисковый запрос.
